Abstract
We live in the era of large data analysis, where processing vast datasets has become essential for uncovering valuable insights across various domains of our lives. Machine learning (ML) algorithms offer powerful tools for processing and analyzing this abundance of information. However, the considerable time and computational resources needed for training ML models pose significant challenges, especially within cascade schemes, due to the iterative nature of training algorithms, the complexity of feature extraction and transformation processes, and the large sizes of the datasets involved. This paper proposes a modification to the existing ML-based cascade scheme for analyzing large biomedical datasets by incorporating principal component analysis (PCA) at each level of the cascade. We selected the number of principal components to replace the initial inputs so that it ensured 95% variance retention. Furthermore, we enhanced the training and application algorithms and demonstrated the effectiveness of the modified cascade scheme through comparative analysis, which showcased a significant reduction in training time while improving the generalization properties of the method and the accuracy of the large data analysis. The improved enhanced generalization properties of the scheme stemmed from the reduction in nonsignificant independent attributes in the dataset, which further enhanced its performance in intelligent large data analysis.
1. Introduction
In today’s digital age, data have emerged as one of the most valuable types of assets across sectors, research domains, and industries. With the exponential growth of data generation from various sources, such as social media, sensors, and transactions, the ability to extract meaningful insights from large datasets has become paramount. Large data analysis, which is processed by machine learning algorithms, has proven to be instrumental in uncovering latent patterns, predicting future trends, and driving informed decision making [1].
First, large data analysis employed by machine learning algorithms enables organizations to harness the power of big data effectively. Traditional methods of data analysis struggle to cope with the sheer volume, velocity, and variety of data being generated daily. Machine learning algorithms, however, excel in handling large datasets by automatically identifying patterns, correlations, and anomalies that may be imperceptible to human analysts [2]. Through techniques such as supervised learning, unsupervised learning, and deep learning, these algorithms can sift through vast amounts of data to extract actionable insights.
Second, the predictive capabilities of machine learning algorithms are invaluable in various domains. By analyzing historical data, these algorithms can forecast future trends, behaviors, and events with remarkable accuracy. In healthcare, for instance, predictive analytics can help to anticipate disease outbreaks, personalize treatment plans, and improve patient outcomes [3,4]. The ability to anticipate future events based on data-driven insights empowers organizations to make proactive decisions and stay ahead of the curve.
Moreover, large data analysis using machine learning algorithms facilitates personalized experiences and targeted interventions. By analyzing individual preferences, behaviors, and interactions, organizations can tailor products, services, and recommendations to specific users. This level of personalization enhances customer satisfaction, drives engagement, and fosters brand loyalty. In healthcare, personalized medicine leverages patient data to customize treatment plans and improve therapeutic outcomes.
Furthermore, large data analysis with machine learning algorithms contributes to innovation and discovery across various fields [5,6]. By uncovering hidden patterns and relationships within data, researchers can make groundbreaking discoveries, develop novel solutions, and advance scientific knowledge. In drug discovery, for example, machine learning algorithms expedite the process of screening potential drug candidates, leading to the development of new treatments for diseases [7]. The insights gleaned from large data analysis fuel innovation, drive research, and pave the way for transformative breakthroughs.
However, one of the significant challenges faced in large data analysis is the considerable time and computational resources required for training ML models, particularly in cascade schemes, where multiple models are sequentially trained [8,9,10]. In the ever-evolving landscape of machine learning (ML), the utilization of cascade schemes has emerged as a powerful strategy to tackle complex problems and extract deeper insights from data. Cascade schemes involve the sequential application of multiple ML models, with each building upon the outputs of its predecessors to address different aspects of the problem at hand [11]. In domains such as healthcare, finance, and scientific research, where the timely analysis of large datasets can lead to significant discoveries and advancements, accelerating the training of ML models holds immense potential for driving innovation and improving outcomes.
One of the most common approaches to reducing the training time of algorithms during the analysis of large datasets is employing parallel processing [12,13,14]. However, in the case of the ML-based cascade scheme, which operates in series, with each subsequent step depending on the previous one, analyzing in parallel is not feasible [15,16]. An exception could be a cascade scheme where multiple machine learning algorithms are used at each level, as in [17]. And even in this case, parallelizing the algorithm will not significantly speed up the operation of the entire method due to the sequential nature of cascade operations. Thus, deploying parallel computation faces severe limitations in addressing this challenge.
The use of hardware accelerators to further expedite the training process, which involves taking advantage of advancements in technology to push the boundaries of performance and scalability, is not always available or feasible [18]. Implementing the efficient training time of machine learning algorithms essentially boils down to using linear methods [19]. However, the latter does not always lead to a high accuracy.
In [1], the authors addressed the challenge of improving the efficiency of analyzing large datasets, particularly in their classification using PCA. They investigated how PCA, in conjunction with single machine learning algorithms, impacts the classification of large datasets. The study showcased a notable reduction in training time for individual models by reducing the input data dimensionality through PCA. Furthermore, the article explored various existing adaptations of PCA for tackling this issue. Refs. [20,21,22,23] introduce alternative methods for reducing input data dimensionality that could potentially replace PCA and offer quicker transformations. Notably, the non-iterative nature of the neural-like structure discussed in [22] contributes to this capability. However, each approach’s application should be thoroughly examined independently for its effectiveness. Specifically, it should not only aim to decrease the training time but also strive to maintain or enhance the classifier’s accuracy in analysis.
In an effort to provide solutions to the challenge, the authors of [24] developed a new ML-based cascade scheme using linear machine learning methods that demonstrated a significant increase in the accuracy of analyzing biomedical datasets. It is based on the use of linear machine learning algorithms, and the reason for the selection is their high speed. The increase in accuracy was achieved through the utilization of nonlinear input expansion. In [25], this was implemented precisely through the use of Kolmogorov–Gabor polynomials. The advantage of such a step lies in the high approximation properties of the latter. However, the main drawback is the significant increase in the duration of the training procedure. This is explained by the significant increase in the number of input attributes after applying this polynomial to the machine learning algorithm at each level of the cascade. Moreover, since cascade ensembles are hierarchical constructions [26,27] that work in series, the significant depth of the ML-based cascade scheme multiplies the duration of the training procedure. A similar approach is also applied in [25]. The authors of the paper employed one of the fastest linear machine learning methods: stochastic gradient descent. However, the issue of a significant increase in the number of attributes due to the application of the Kolmogorov–Gabor polynomial at each level of the ML-based cascade scheme remained.
In view of further pushing the boundaries of cascade modelling, this study aimed to reduce the duration of the training procedure while maintaining or improving the accuracy of the ML-based cascade scheme during the analysis of large biomedical datasets. This was achieved by reducing the dimensionality of the input data space at each level of the cascade scheme using principal component analysis (PCA). By optimizing the training process in this manner, this study aimed to enhance the efficiency and scalability of data analysis pipelines and improve the generalization properties of the method [28].
The main contributions of this paper are the results of the following actions:
- We modified the existing ML-based cascade scheme, its training, and its application algorithms to enhance the efficiency of analyzing large volumes of biomedical data by using PCA at each level of the cascade. The number of principal components that replace the original inputs of the task was chosen to ensure 95% variance coverage. This approach resulted in a significant reduction in training procedure duration of the modified scheme while preserving, and, in some cases, improved the accuracy of intelligent analysis of biomedical datasets.
- We conducted a comparison of the effectiveness of the modified ML-based cascade scheme with the existing one and found a significant reduction in its training time and a small but non-negligible improvement in the accuracy. The latter can be explained by the increase in the generalization properties of the improved scheme due to the reduction in the number of independent attributes in the large dataset processed by machine learning methods at each level of the cascade.
In the subsequent sections of this paper, we describe the methodologies employed, present experimental results and analysis, and discuss the implications of our findings.
2. Materials and Methods
The proposed modification discussed in this paper was based on a cascade scheme from [25]. The authors of [25] developed a new cascade approximation scheme for large tabular datasets using linear machine learning methods. Given the low accuracy of these methods, the enhancement in their performance in the proposed [25] cascade scheme was attained through the utilization of the Kolmogorov–Gabor polynomial.
The approximation of large datasets in this case is carried out implicitly using high-degree polynomials. This is achieved through the construction of a hierarchical scheme, where at each level of the cascade, a second-degree Kolmogorov–Gabor polynomial is used to model nonlinearity in the given dataset. It should be noted that at each level of the cascade, a unique subset of data is used that is randomly sampled from the overall dataset. According to the method, each subsequent level of the cascade utilizes the result of the previous level as an additional feature to expand the next input data subset. In other words, when the result of the first level is used by the ensemble (approximation by a second-degree polynomial), at the second level of the ensemble, it can implicitly obtain a fourth-order polynomial. Each subsequent level of the cascade scheme, in the case of using the quadratic Kolmogorov–Gabor polynomial, implicitly doubles the order of approximation compared with the previous one. At the same time, the number of independent attributes grows very slowly compared with the use of direct approximation by high-order Kolmogorov–Gabor polynomials [25].
Despite the significant advantages in accuracy, even the use of the quadratic Kolmogorov–Gabor polynomial substantially increases the dimensionality of the problem, especially when a large number of initial inputs of the problem [29] is analyzed. This becomes critical during the analysis of large datasets. This is because, first, the duration of the training procedure significantly increases, and second, increasing the dimensionality of the problem may deteriorate the generalization properties of the selected machine learning method, affecting the practical applicability of the method [30]. Therefore, in this paper, a modification of the cascade scheme [25] is proposed, which is intended to alleviate the aforementioned drawbacks.
The proposed novel modification of the ML-based cascade scheme for large data analysis is based on the utilization of PCA to reduce the number of nonlinearly expanded independent features at each level of the cascade scheme [25]. PCA (principal component analysis) is a dimensionality reduction method used to detect and remove correlations between variables by transforming them into a new set of variables called principal components. The detailed principles of its operation are described in [1], and expanding on these is not in the scope of this paper. The additional use of PCA at each cascade level requires additional computational resources. Moreover, PCA itself is a resource-intensive method [1]. However, in the analysis of high-dimensional datasets of large volumes, with additional application of the Kolmogorov–Gabor polynomial, which significantly increases the data dimensionality and is provided by the existing cascade structure, PCA application can greatly reduce the dimensionality of subsets at each cascade level. Practical experiments showed such a reduction by at least 10 times, even when using PCA that should ensure 95% variance. Therefore, this method provides several important advantages, especially in our case, for reducing the dimensionality of the input data space that is expanded by the aforementioned polynomial to enhance the accuracy of analyzing large datasets with linear machine learning methods. First, PCA allows for selecting principal components that best explain the variance in the data, enabling the reduction in redundancy in the data while retaining the most significant information. Second, after applying PCA, the dimensionality of the data becomes smaller, reducing the computational costs for further analysis, which is particularly relevant during the analysis of large datasets. It is these advantages that formed the basis for using PCA to modify the cascade scheme from [25].
Let us consider the training and application modes algorithms of the modified ML-based cascade scheme for solving the classification task.
2.1. The Training Mode Algorithm
Step 1. Data cleaning and preparation. Data normalization according to the chosen scaler. Split the training dataset of the large dataset into a unique number N of subsets of equal size.
Step 2. Formation of N levels of the cascade corresponding to the number of subsets obtained in the first step.
Step 3. Expansion of subset 1 using a quadratic Kolmogorov–Gabor polynomial. Apply PCA to select the number of principal components that provide 95% of the variance. Train the classifier of the first level of the cascade on the modified subset 1, as described above.
Step 4. Expansion of subset 2 using a quadratic Kolmogorov–Gabor polynomial. Apply PCA to select the number of principal components that provide 95% of the variance. Apply subset 2 to the trained classifiers of the first level of the cascade. Obtain the desired value and add it as a new feature to the current dataset. Expand the already enlarged subset 2 by one attribute using a quadratic Kolmogorov–Gabor polynomial. Apply PCA to select the number of principal components that provide 95% of the variance. Train the classifier of the second level of the cascade on the modified subset 2, as described above.
Step 5. Expansion of subset 3 using a quadratic Kolmogorov–Gabor polynomial. Apply PCA to select the number of principal components that provide 95% of the variance. Apply subset 3 to the trained classifiers of the first level of the cascade. Obtain the desired value and adding it as a new feature to the current dataset. Expand the already enlarged subset 3 by one attribute using a quadratic Kolmogorov–Gabor polynomial. Apply PCA to select the number of principal components that provide 95% of the variance. Apply subset 3 to the trained classifiers of the second level of the cascade. Obtain the desired value and adding it as another new feature to the current dataset. Expand the already enlarged subset 3 by two attributes using a quadratic Kolmogorov–Gabor polynomial. Train the classifier of the third level of the cascade on the modified subset 3 as described above.
Step 6. Perform steps 2–5 with all subsequent N − 1 subsets. Use the last Nth subset of data to synthesize the results of the classifier of the last level of the cascade scheme; this is the criterion for stopping the cascade operation. These values are the sought-after class markers in the method training mode.
A flowchart of the training mode of the modified ML-based cascade scheme for large data analysis is provided in Figure 1.
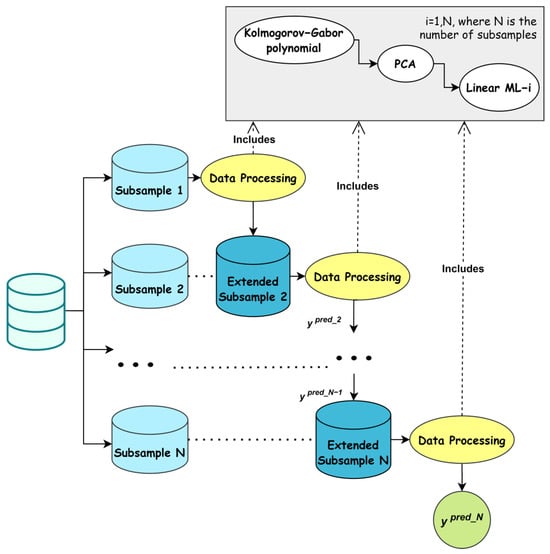
Figure 1.
Flowchart of the modified ML-based cascade scheme for large data analysis by incorporating additional usage of PCA at each cascade level.
2.2. The Application Mode Algorithm
In the application mode of the modified cascade scheme, an observation with a set of independent attributes is inputted, for which the marker of belonging to one of the defined classes must be found. This observation undergoes a series of subsequent procedures until it reaches the last level of the modified ML-based cascade scheme.
Step 1. Expansion of all components of the data vector with unknown output using a quadratic Kolmogorov–Gabor polynomial. Apply PCA to select the number of principal components determined in step 3 of the cascade scheme training algorithm. Apply the current vector to the trained classifier of the first level of the cascade. Obtain the desired value and add it as a new feature to the current vector.
Step 2. Expansion of all components of the extended data vector by one feature with an unknown output using a quadratic Kolmogorov–Gabor polynomial. Apply PCA to select the number of principal components determined in step 4 of the cascade scheme training algorithm. Apply such a vector to the trained classifier of the second level of the cascade. Obtain the desired value and add it as another new feature to the current vector.
…
Step N. Expansion of all components of the extended data vector, which is already expanded by N − 2 features, with unknown output using a quadratic Kolmogorov–Gabor polynomial. Apply PCA to select the number of principal components determined in step 6 of the cascade scheme training algorithm. Apply such a vector to the trained classifier of the Nth level of the cascade. Obtain the desired value, which will be the marker belonging to one of the defined classes of the task.
As a result of performing all the aforementioned steps of the application procedure, at the last level of the cascade, the desired marker belonging to one of the classes defined by the specific task can be obtained. The improvement in accuracy in this case occurs due to refining the class marker at each new level of the cascade scheme. This is achieved through the nonlinear expansion of inputs at each level of the cascade scheme by taking into account the results of the previous level. This is precisely what ensures (as demonstrated in [25]) a significant improvement in the accuracy of operation of linear, i.e., high-speed classifiers, which form the basis of the method’s operation. Additionally, the application procedure proposed in this work, which involves PCA at each level of the cascade, allows for the elimination of redundancy in the data while preserving the most significant information. This should significantly reduce the duration of the training procedure while maintaining, and in some cases even enhancing, the generalization properties and accuracy of the method overall.
3. Results
To model the operation of the modified ML-based cascade scheme, the authors developed custom software in Python version 1.0 [31]. The experimental analysis was conducted on a real large-scale dataset [32]. The research was conducted on the following computer: Intel® Core™ i7-8750H, 2.20 GHz, and 8 GB RAM.
3.1. Dataset Description
Extensive datasets were obtained from the 2021 United States Disease Risk Factor Surveillance System (BRFSS) [31], which was disseminated by the Centers for Disease Control and Prevention in the United States and its surveyed regions. The parameters scrutinized by the BRFSS during the 2021 cycle encompassed health status and duration of wellness, physical exertion, hypertension screening bloc, cholesterol screening bloc, chronic illnesses, arthritic conditions, tobacco consumption, ingestion of fruits and vegetables, and access to medical assistance (principal section). Supplementary thematic modules encompassed informational domains concerning obesity and diabetes, cognitive dysfunction, patient caregiving, and post-cancer rehabilitation.
The primary dataset contained a diverse array of information regarding several aforementioned diseases. Consequently, the final dataset was refined to include only the segment of data relevant to human lifestyle factors. The primary objective was to predict occurrences of cardiovascular diseases (a binary classification task). The obtained dataset comprised 308,854 records, collectively representing 29 attributes.
3.2. Dataset Preprocessing
Data preprocessing consisted of two primary stages: duplicate removal and handling missing values. First, all duplicate entries were identified and eliminated to ensure the uniqueness of each record within the dataset. Subsequently, any entries with missing values within the dataset were removed. Then, the dataset was divided into training and testing subsamples, with 80% allocated to training and 20% to testing.
Following data preprocessing, the next analytical step involved addressing the class imbalance within the training part of the dataset. In the initial dataset, a class distribution ratio of 92% to 8% was observed. Balancing the classes is crucial to ensure the effective and reliable performance of the machine learning model. Class balancing within the training dataset was achieved by applying two principal algorithms in parallel: SMOTE (Synthetic Minority Oversampling Technique) to augment instances of the minority class and NearMiss to reduce instances of the majority class. This process was conducted iteratively by exploring various parameter values to adjust the number of instances [50,000 to 150,000] with a step size of Δ = 25,000 from both classes within the dataset. The accuracy and generalization were the primary criteria for selecting the appropriate balancing scheme. As demonstrated by the experiments, the optimal balancing scheme involved synthesizing 75,000 instances from each class of the original dataset. This approach precisely yielded the optimal accuracy and superior generalization properties for the classifier used.
3.3. Results of the Modified ML-Based Cascade Scheme Based on Its Optimal Parameters
The modified ML-based cascade scheme for large data analysis, like any other machine learning method, is characterized by a set of parameters, the optimal values of which will ensure its highest performance. Since in this study, we modified an existing cascade scheme of linear machine learning methods, one of the main parameters of its operation is the depth level of the cascade. This parameter determines how many parts the large dataset will be divided into, which influences the following:
- The accuracy of the method’s performance.
- The speed of the method’s operation.
- The generalization properties of the method.
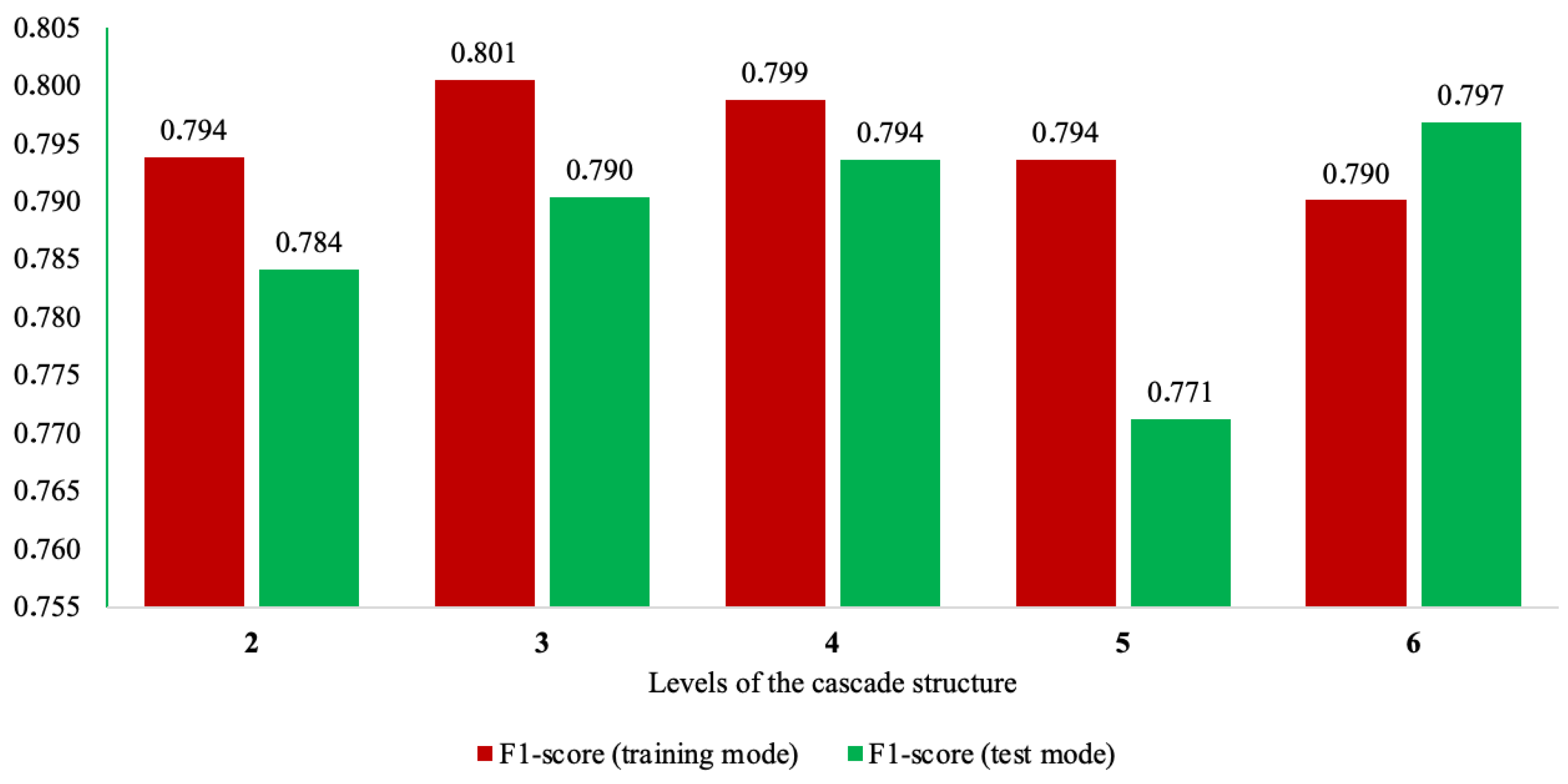
To determine the optimal value of this parameter, experimental modeling of the operation of the modified ML-based cascade scheme was conducted in this study by varying its depth from 1 to 6 levels. The accuracy of the method was evaluated using precision, recall, and F1-score performance indicators. The total accuracy was not considered, as the analysis focused on an unbalanced dataset where this metric would not provide adequate assessment of the method’s effectiveness.
It should be noted that for the modification of the method, the authors used PCA to reduce the dimensionality of the input data space at each level of the cascade, thereby reducing the duration of its training procedure. This process was automated by selecting the number of principal components at each individual level of the cascade scheme, which in sum, accounted for 95% of the variance.
The results of this experiment based on the F1-score are presented in Figure 2.
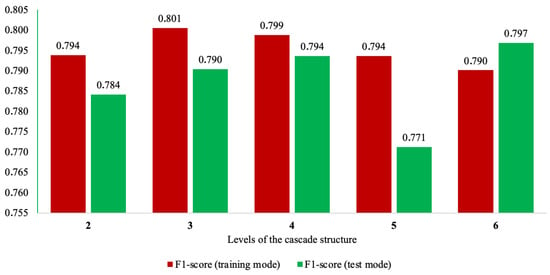
Figure 2.
The investigation of the accuracy and generalization properties of the modified ML-based cascade scheme as its depth varied from 2 to 6 levels.
From Figure 2, the following conclusions can be drawn:
- Increasing the number of levels of the modified ML-based cascade scheme enhanced the accuracy in both modes, but only up to a certain point. Beyond this, the method’s accuracy began to decline.
- The peak accuracy in the application mode was achieved when using a cascade scheme with four levels. However, the training mode’s accuracy for this cascade configuration was not the highest (with the difference being less than 0.02). The latter phenomenon can be explained by the fact that the four-level cascade processed data in smaller increments compared with the three-level cascade, which optimized for higher accuracy during training. While this enhances the method’s generalization properties, it may marginally reduce the training accuracy.
- The modified ML-based cascade scheme with four levels demonstrated the highest generalization properties among all other implementations. This is evident from the smallest difference in the accuracy of the method between the training and application modes.
- The use of a cascade scheme with five levels significantly deteriorated the generalization properties of the method. The application accuracy dropped by almost 3%.
- The use of a cascade scheme with six levels demonstrated overfitting. The application accuracy here surpassed the training accuracy. Therefore, further increasing the number of cascade levels did not seem appropriate.
Taking into account all the aforementioned results and considering that the four-level cascade scheme demonstrated the highest accuracy in the application mode and, most importantly, the highest generalization properties of the method, this variant of the modified ML-based cascade scheme was chosen as the final one.
In Table 1, the performance indicators of the optimized modification of the ML-based cascade scheme are summarized in both the training and application modes.

Table 1.
Results of the modified ML-based cascade scheme.
As seen from Table 1, the modified ML-based cascade scheme demonstrated high generalization across all three investigated metrics. Additionally, the duration of its training procedure, when considering the volume of input data and the four-level cascade construction, which was optimal for this task, was quite low.
The parameters from Table 1 were considered to compare the effectiveness of the modified method with a range of existing ones.
4. Discussion
The basic and modified versions of the ML-based cascade schemes are both based on the use of SGD (stochastic gradient descent). This choice is justified by the high speed of operation of this machine learning algorithm, which is a significant advantage when analyzing large volumes of data. Therefore, the comparison of its performance was conducted using SGD-based methods.
Thus, the effectiveness comparison of the modified ML-based cascade scheme was conducted with a range of such methods:
- Classical SGD [33] using a balanced dataset in this paper;
- Classical SGD using the Kolmogorov–Gabor polynomial [29];
- Initial ML-based cascade scheme [25].
It should be noted that the parameters of the SGD operation for all the mentioned methods above were optimized using the grid search algorithm.
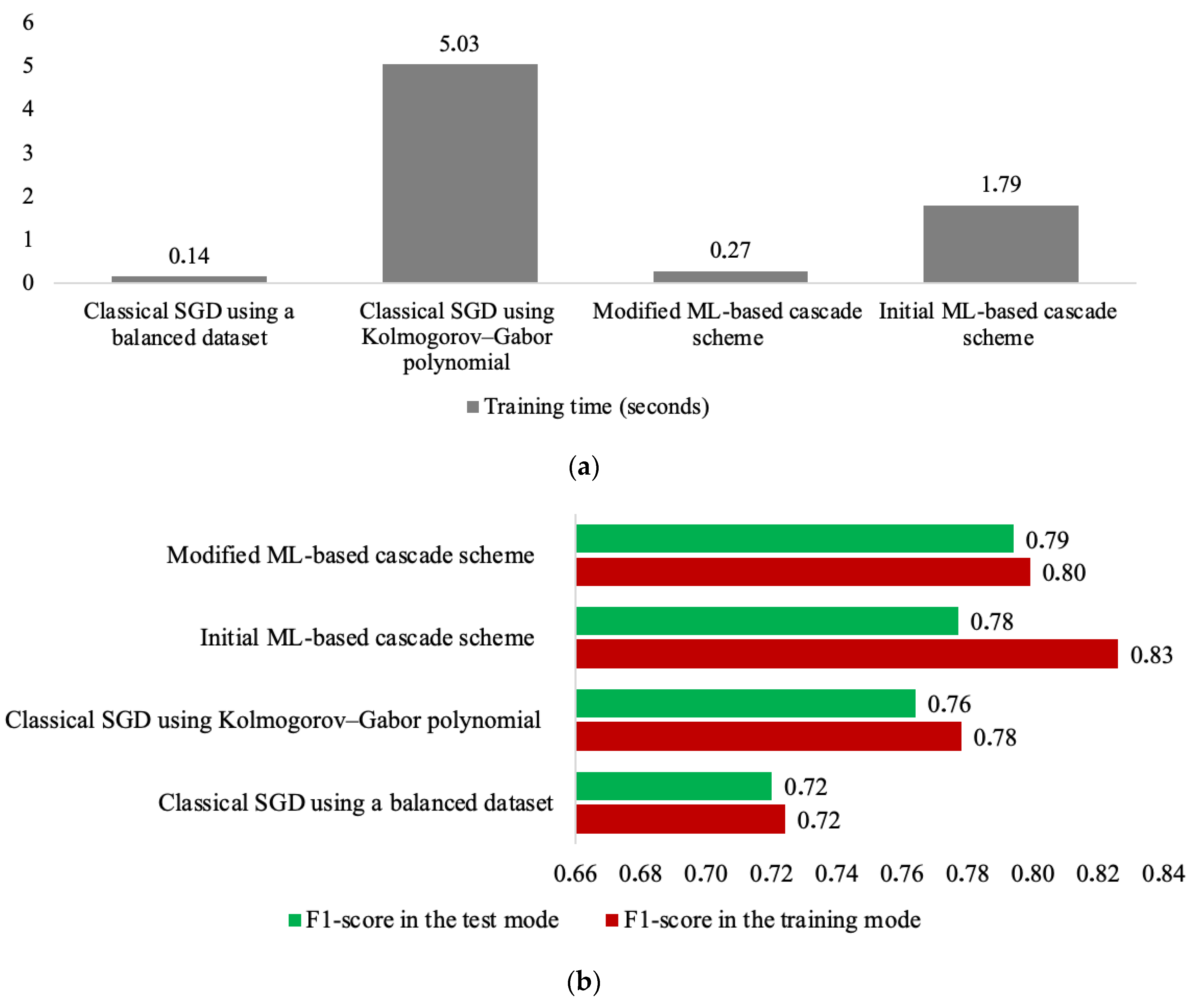
Figure 3 presents the results of comparing all the methods investigated based on SGD using the F1-score and training time in seconds.
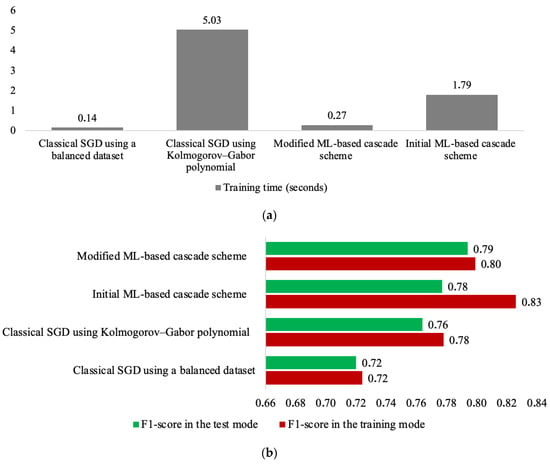
Figure 3.
Comparison of the results for all methods investigated based on (a) F1-score and (b) training time.
The following conclusions can be drawn based on the results of Figure 3:
- The method from [33] (classical SGD using a balanced dataset) required the shortest training time. However, this method was found to have the lowest accuracy in solving the classification task, albeit with satisfactory generalization properties.
- The method from [29] achieved higher accuracy but with poorer generalization. This was because the former employs a nonlinear input expansion based on the Kolmogorov–Gabor polynomial, which, according to Cover’s theorem, enhances the classification accuracy. However, such an algorithm with a significant expansion of inputs entails a considerable increase in the training procedure duration. Specifically, the method from [29] demonstrates an over thirty-five-fold increase in training duration compared with the method from [33].
- The initial ML-based cascade scheme from [25] demonstrated an almost threefold decrease in training duration compared with [29]. This was attributed to the significantly smaller amount of data processed by each cascade classifier. However, due to the substantial increase in the dimensionality of the task, this method showed nearly a 13-fold increase in training time compared with [33]. It is worth noting that in this case, the optimal number of cascade levels from [25] was five.
- Additionally, the method from [25] demonstrated the lowest generalization properties among all the considered methods. The difference between the training and application accuracies reached 5%. This is once again explained by the high dimensionality of the task due to the application of the Kolmogorov–Gabor polynomial at each level of the cascade scheme.
- The modified ML-based cascade scheme demonstrated a significant reduction in the training procedure duration (more than 6.6 times) compared with the base method from [25]. Thus, the goal of this article was achieved.
- Furthermore, due to the significant reduction in dimensionality of the already nonlinear input data (after applying the Kolmogorov–Gabor polynomial) through the use of PCA, it was possible to substantially improve the generalization properties of the investigated cascade scheme. Specifically, the difference between the training and application accuracy was only 1%.
- The dimensionality reduction procedure implemented in this work, which was achieved by selecting the number of principal components that accounted for 95% of the variance, enabled the automated operation of the modified ML-based cascade scheme.
- However, one of the most significant advantages of substantial dimensionality reduction in the task was that it not only preserved but also enhanced the accuracy of the modified scheme compared with the existing one. According to the F1-score, the accuracy of the modified ML-based cascade scheme was increased by 1%. This was made possible by transitioning from a large number of nonlinearly expanded inputs, as in [25], to the space of principal components and discarding more insignificant ones according to the procedure proposed in this paper. Specifically, the average number of independent attributes across all four levels of the cascade scheme after using PCA (which was intended to provide 95% variance) was 42, which were processed by the classifiers at each level. For comparison, the average number of independent variables that reached the classifiers at each level of the initial ML-based cascade scheme from [25] was 435.
Overall, the modification of the initial ML-based cascade scheme from [25] not only provided a significant reduction in training procedure duration (almost sevenfold) but also improved its generalization properties and increased the classification accuracy (by 1%). This opened up a range of advantages for the application of this method in analyzing large datasets across various domains.
In finance [34,35], where timely and accurate data analysis is crucial for decision making, the enhanced efficiency and accuracy of this modified cascade scheme could revolutionize risk assessment, portfolio management, and fraud detection processes. By reducing the training time and improving generalization, financial institutions can better handle large-scale datasets, identify market trends more swiftly, and effectively mitigate risks.
In manufacturing and engineering [36,37], the method’s ability to handle complex datasets could streamline quality control processes and predictive maintenance strategies, leading to cost savings and enhanced operational efficiency. Moreover, in fields like environmental monitoring, the method’s improved accuracy and efficiency could aid in analyzing vast amounts of data collected from sensors and satellites, thus facilitating timely interventions and policy decisions.
The versatility of this modified cascade scheme extends to the social sciences [38], where it could enhance research in areas such as sentiment analysis, demographic studies, and urban planning by providing robust tools for data-driven insights and decision making.
Among the prospects for further research, it is important to highlight efforts aimed at enhancing the accuracy of the modified ML-based cascade scheme, especially in addressing imbalanced classification tasks within the analysis of large datasets. One promising approach to achieve this could involve adopting a different data partitioning strategy, such as bootstrap sampling, for the classifiers at each cascade level. The current scheme utilizes nearly equal-sized subsets at each cascade level. Implementing bootstrap sampling, which involves generating subsets with repetitions and significantly larger volumes, would provide more diverse and informative data to each classifier in the cascade scheme, thereby potentially enhancing method accuracy.
Another research direction involves exploring alternative methods for dimensionality reduction in the input data space [20,21,22,23]. Specifically, by leveraging neural network analogs to PCA with non-iterative training [22], utilizing SGTM neural-like structures could substantially reduce the time and complexity associated with PCA at each cascade level. This enhancement would improve the efficiency of the modified cascade ensemble method in tackling diverse practical challenges.
These avenues of research hold promise for advancing the capabilities of the modified cascade ensemble approach, making it more effective in addressing various real-world applications.
5. Conclusions
Our study demonstrated the modification of an existing ML-based cascade scheme for analyzing large datasets through the integration of principal component analysis (PCA) at each cascade level. This highlights the efficacy of employing dimensionality reduction techniques to bolster the efficiency of cascade schemes in managing extensive data volumes.
In addition to scheme modification, we optimized the training algorithm, which ensured that the enhanced cascade operated at peak efficiency. This comprehensive approach leveraged cutting-edge techniques to derive meaningful insights from complex data.
Through rigorous comparative analysis, we assessed the effectiveness of our modified ML-based cascade scheme against the conventional approach. Our results indicate a substantial reduction in training time (over 6.6 times faster), which was accompanied by a marginal accuracy improvement (1%). These findings underscore the practical advantages of our modifications in tackling the computational complexities associated with large-scale data analysis.
The observed accuracy enhancement can be attributed to the scheme’s improved generalization properties. By reducing the number of independent attributes at each cascade level, we enhanced the scheme’s ability to generalize to unseen data, thereby boosting the overall performance in biomedical data analysis.
Looking ahead, future research will explore avenues to further optimize the cascade scheme efficiency. Specifically, we aim to investigate alternative methods for reducing the input data dimensionality, such as neural network PCA variants with non-iterative machine learning.
Author Contributions
Conceptualization, R.T. and I.I.; methodology, R.M. and I.I.; software, R.M.; validation, S.-A.M., K.Y. and I.D.; formal analysis, I.D.; investigation, R.M.; resources, I.D.; data curation, R.M.; writing—original draft preparation, I.I. and R.M.; writing—review and editing, I.I. and S.-A.M.; visualization, K.Y.; supervision, R.T.; project administration, I.I.; funding acquisition, I.D. All authors have read and agreed to the published version of the manuscript.
Funding
This work is funded by the European Union’s Horizon Europe research and innovation program under grant agreement No. 101138678, project ZEBAI (Innovative Methodologies for the Design of Zero-Emission and Cost-Effective Buildings Enhanced by Artificial Intelligence).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Publicly available datasets were used in this study. This data can be found here [32].
Acknowledgments
Stergios-Aristoteles Mitoulis received funding from the UK Research and Innovation (UKRI) under the UK Government’s Horizon Europe funding guarantee [grant agreement no.: 10062091]. This is the funding guarantee for the European Union HORIZON-MISS-2021-CLIMA-02 [grant agreement no.: 101093939] RISKADAPT—Asset-level modelling of risks in the face of climate-induced extreme events and adaptation. Stergios-Aristoteles Mitoulis would also like to acknowledge funding by the UK Research and Innovation (UKRI) under the UK Government’s Horizon Europe funding guarantee [grant agreement no.: 101086413, EP/Y003586/1, EP/Y00986X/1, EP/X037665/1]. This is the funding guarantee for the European Union HORIZON-MSCA-2021-SE-01 [grant agreement no.: 101086413] ReCharged—Climate-Aware Resilience for Sustainable Critical and Interdependent Infrastructure Systems Enhanced by Emerging Digital Technologies. Ivan Izonin thanks the British Academy’s Researchers at Risk Fellowships Programme, which supported this study.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Mohammed, M.A.; Akawee, M.M.; Saleh, Z.H.; Hasan, R.A.; Ali, A.H.; Sutikno, T. The Effectiveness of Big Data Classification Control Based on Principal Component Analysis. Bull. Electr. Eng. Inform. 2023, 12, 427–434. [Google Scholar] [CrossRef]
- Krak, I.; Barmak, O.; Manziuk, E. Using Visual Analytics to Develop Human and Machine-centric Models: A Review of Approaches and Proposed Information Technology. Comput. Intell. 2022, 38, 921–946. [Google Scholar] [CrossRef]
- Apio, A.L.; Kissi, J.; Achampong, E.K. A Systematic Review of Artificial Intelligence-Based Methods in Healthcare. Int. J. Public Health 2023, 12, 1259. [Google Scholar] [CrossRef]
- Krak, Y.; Barmak, O.V.; Mazurets, O. The Practice Implementation of the Information Technology for Automated Definition of Semantic Terms Sets in the Content of Educational Materials. Probl. Program. 2018, 2139, 245–254. [Google Scholar] [CrossRef]
- Manziuk, E.; Barmak, O.; Krak, I.; Mazurets, O. Formal Model of Trustworthy Artificial Intelligence Based on Standardization. In Proceedings of the IntelITSIS’2021: 2nd International Workshop on Intelligent Information Technologies and Systems of Information Security, Khmelnytskyi, Ukraine, 24–26 March 2021; Volume 2853, pp. 190–197. [Google Scholar]
- Berezsky, O.; Pitsun, O.; Liashchynskyi, P.; Derysh, B.; Batryn, N. Computational Intelligence in Medicine. In Lecture Notes in Data Engineering, Computational Intelligence, and Decision Making; Babichev, S., Lytvynenko, V., Eds.; Lecture Notes on Data Engineering and Communications Technologies; Springer International Publishing: Cham, Switzerland, 2023; Volume 149, pp. 488–510. ISBN 978-3-031-16202-2. [Google Scholar]
- Chumachenko, D.; Piletskiy, P.; Sukhorukova, M.; Chumachenko, T. Predictive Model of Lyme Disease Epidemic Process Using Machine Learning Approach. Appl. Sci. 2022, 12, 4282. [Google Scholar] [CrossRef]
- Liu, W.; Fan, H.; Xia, M. Tree-Based Heterogeneous Cascade Ensemble Model for Credit Scoring. Int. J. Forecast. 2023, 39, 1593–1614. [Google Scholar] [CrossRef]
- Zomchak, L.; Melnychuk, V. Creditworthiness of Individual Borrowers Forecasting with Machine Learning Methods. In Advances in Artificial Systems for Medicine and Education VI; Hu, Z., Ye, Z., He, M., Eds.; Lecture Notes on Data Engineering and Communications Technologies; Springer Nature: Cham, Switzerland, 2023; Volume 159, pp. 553–561. ISBN 978-3-031-24467-4. [Google Scholar]
- Bilski, J.; Smoląg, J.; Kowalczyk, B.; Grzanek, K.; Izonin, I. Fast Computational Approach to the Levenberg-Marquardt Algorithm for Training Feedforward Neural Networks. J. Artif. Intell. Soft Comput. Res. 2023, 13, 45–61. [Google Scholar] [CrossRef]
- Ji, J.; Li, J. Tri-Objective Optimization-Based Cascade Ensemble Pruning for Deep Forest. Pattern Recognit. 2023, 143, 109744. [Google Scholar] [CrossRef]
- Bisikalo, O.V.; Kovtun, V.V.; Kovtun, O.V. Modeling of the Estimation of the Time to Failure of the Information System for Critical Use. In Proceedings of the 2020 10th International Conference on Advanced Computer Information Technologies (ACIT), Deggendorf, Germany, 16–18 September 2020; pp. 140–143. [Google Scholar]
- Mochurad, L.; Shchur, G. Parallelization of Cryptographic Algorithm Based on Different Parallel Computing Technologies. In Proceedings of the IT&AS’2021: Symposium on Information Technologies & Applied Sciences, Bratislava, Slovakia, 5 March 2021; Volume 2824, p. 2029. [Google Scholar]
- Samaan, S.S.; Jeiad, H.A. Feature-Based Real-Time Distributed Denial of Service Detection in SDN Using Machine Learning and Spark. Bull. Electr. Eng. Inform. 2023, 12, 2302–2312. [Google Scholar] [CrossRef]
- Mochurad, L.; Hladun, Y.; Zasoba, Y.; Gregus, M. An Approach for Opening Doors with a Mobile Robot Using Machine Learning Methods. Big Data Cogn. Comput. 2023, 7, 69. [Google Scholar] [CrossRef]
- Ali, A.H.; Alhayali, R.A.I.; Mohammed, M.A.; Sutikno, T. An Effective Classification Approach for Big Data with Parallel Generalized Hebbian Algorithm. Bull. Electr. Eng. Inform. 2021, 10, 3393–3402. [Google Scholar] [CrossRef]
- Xu, S.; Tang, Q.; Jin, L.; Pan, Z. A Cascade Ensemble Learning Model for Human Activity Recognition with Smartphones. Sensors 2019, 19, 2307. [Google Scholar] [CrossRef] [PubMed]
- Ganguli, C.; Shandilya, S.K.; Nehrey, M.; Havryliuk, M. Adaptive Artificial Bee Colony Algorithm for Nature-Inspired Cyber Defense. Systems 2023, 11, 27. [Google Scholar] [CrossRef]
- Nehrey, M.; Hnot, T. Data Science Tools Application for Business Processes Modelling in Aviation: In Advances in Computer and Electrical Engineering; Shmelova, T., Sikirda, Y., Rizun, N., Kucherov, D., Eds.; IGI Global: Hershey, PA, USA, 2019; pp. 176–190. ISBN 978-1-5225-7588-7. [Google Scholar]
- van der Maaten, L.; Hinton, G. Visualizing Data Using T-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- McInnes, L.; Healy, J.; Melville, J. UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction. arXiv 2018, arXiv:1802.03426. [Google Scholar]
- Tkachenko, R.; Izonin, I. Model and Principles for the Implementation of Neural-Like Structures Based on Geometric Data Transformations. In Advances in Computer Science for Engineering and Education; Hu, Z., Petoukhov, S., Dychka, I., He, M., Eds.; Springer International Publishing: Cham, Switzerland, 2019; Volume 754, pp. 578–587. ISBN 978-3-319-91007-9. [Google Scholar]
- Wang, Y.; Zhao, Y. Arbitrary Spatial Trajectory Reconstruction Based on a Single Inertial Sensor. IEEE Sens. J. 2023, 23, 10009–10022. [Google Scholar] [CrossRef]
- Izonin, I.; Tkachenko, R.; Gurbych, O.; Kovac, M.; Rutkowski, L.; Holoven, R. A Non-Linear SVR-Based Cascade Model for Improving Prediction Accuracy of Biomedical Data Analysis. Math. Biosci. Eng. 2023, 20, 13398–13414. [Google Scholar] [CrossRef] [PubMed]
- Izonin, I.; Tkachenko, R.; Holoven, R.; Yemets, K.; Havryliuk, M.; Shandilya, S.K. SGD-Based Cascade Scheme for Higher Degrees Wiener Polynomial Approximation of Large Biomedical Datasets. Mach. Learn. Knowl. Extr. 2022, 4, 1088–1106. [Google Scholar] [CrossRef]
- Mulesa, O.; Snytyuk, V.; Myronyuk, I. Optimal alternative selection models in a multi-stage decision-making process. EUREKA Phys. Eng. 2019, 6, 43–50. [Google Scholar] [CrossRef]
- Mulesa, O.; Geche, F.; Batyuk, A.; Buchok, V. Development of Combined Information Technology for Time Series Prediction. In Advances in Intelligent Systems and Computing II; Shakhovska, N., Stepashko, V., Eds.; Advances in Intelligent Systems and Computing; Springer International Publishing: Cham, Switzerland, 2018; Volume 689, pp. 361–373. ISBN 978-3-319-70580-4. [Google Scholar]
- Syed Ahmad, S.S.; Azmi, E.F.; Kasmin, F.; Othman, Z. Dimentionality Reduction Based on Binary Cooperative Particle Swarm Optimization. Indones. J. Electr. Eng. Comput. Sci. 2019, 15, 1382. [Google Scholar] [CrossRef]
- Izonin, I.; Gregušml, M.; Tkachenko, R.; Logoyda, M.; Mishchuk, O.; Kynash, Y. SGD-Based Wiener Polynomial Approximation for Missing Data Recovery in Air Pollution Monitoring Dataset. In Advances in Computational Intelligence; Rojas, I., Joya, G., Catala, A., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2019; Volume 11506, pp. 781–793. ISBN 978-3-030-20520-1. [Google Scholar]
- Sambir, A.; Yakovyna, V.; Seniv, M. Recruiting Software Architecture Using User Generated Data. In Proceedings of the 2017 XIIIth International Conference on Perspective Technologies and Methods in MEMS Design (MEMSTECH), Lviv, Ukraine, 20–23 April 2017; pp. 161–163. [Google Scholar]
- Yakovyna, V.; Uhrynovskyi, B. User-Perceived Response Metrics in Android OS for Software Aging Detection. In Proceedings of the 2020 IEEE 15th International Conference on Computer Sciences and Information Technologies (CSIT), Zbarazh, Ukraine, 23–26 September 2020; pp. 436–439. [Google Scholar]
- CDC—2021 BRFSS Survey Data and Documentation. Available online: https://www.cdc.gov/brfss/annual_data/annual_2021.html (accessed on 4 March 2024).
- Sklearn.Linear_Model.SGDRegressor—Scikit-Learn 0.20.2 Documentation. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.SGDRegressor.html (accessed on 8 February 2019).
- Kharchuk, V.; Oleksiv, I. The Intellectual Structure of Sustainable Leadership Studies: Bibliometric Analysis. In Advances in Intelligent Systems, Computer Science and Digital Economics IV; Hu, Z., Wang, Y., He, M., Eds.; Lecture Notes on Data Engineering and Communications Technologies; Springer Nature: Cham, Switzerland, 2023; Volume 158, pp. 430–442. ISBN 978-3-031-24474-2. [Google Scholar]
- Wasilczuk, J.; Chukhray, N.; Karyy, O.; Halkiv, L. Entrepreneurial Competencies and Intentions among Students of Technical Universities. Probl. Perspect. Manag. 2021, 19, 10–21. [Google Scholar] [CrossRef]
- Duriagina, Z.A.; Tkachenko, R.O.; Trostianchyn, A.M.; Lemishka, I.A.; Kovalchuk, A.M.; Kulyk, V.V.; Kovbasyuk, T.M. Determination of the Best Microstructureand Titanium Alloy Powders Propertiesusing Neural Network. J. Achiev. Mater. Manuf. Eng. 2018, 1, 25–31. [Google Scholar] [CrossRef]
- Argyroudis, S.A.; Mitoulis, S.A.; Chatzi, E.; Baker, J.W.; Brilakis, I.; Gkoumas, K.; Vousdoukas, M.; Hynes, W.; Carluccio, S.; Keou, O.; et al. Digital Technologies Can Enhance Climate Resilience of Critical Infrastructure. Clim. Risk Manag. 2022, 35, 100387. [Google Scholar] [CrossRef]
- Fedushko, S.; Molodetska, K.; Syerov, Y. Analytical Method to Improve the Decision-Making Criteria Approach in Managing Digital Social Channels. Heliyon 2023, 9, e16828. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).