Abstract
Hierarchical clustering is a widely used data analysis technique. Typically, tools for this method operate on data in its original, readable form, raising privacy concerns when a clustering task involving sensitive data that must remain confidential is outsourced to an external server. To address this issue, we developed a method that integrates Cheon-Kim-Kim-Song homomorphic encryption (HE), allowing the clustering process to be performed without revealing the raw data. In hierarchical clustering, the two nearest clusters are repeatedly merged until the desired number of clusters is reached. The proximity of clusters is evaluated using various metrics. In this study, we considered two well-known metrics: single linkage and complete linkage. Applying HE to these methods involves sorting encrypted distances, which is a resource-intensive operation. Therefore, we propose a cooperative approach in which the data owner aids the sorting process and shares a list of data positions with a computation server. Using this list, the server can determine the clustering of the data points. The proposed approach ensures secure hierarchical clustering using single and complete linkage methods without exposing the original data.
1. Introduction
Clustering, also referred to as cluster analysis, is a key area of study that is particularly significant in fields such as image analysis, pattern recognition, and machine learning [1]. It serves as an exploratory data analysis technique, categorizing data into distinct groups or subsets, where elements within each subset are more similar to each other than to elements in different subsets. A primary application of clustering is assigning labels to previously unlabeled data, especially when there is no prior knowledge of their groupings [2]. Many clustering algorithms have been introduced by researchers and are frequently used in various applications. Among these, partitional and hierarchical clustering are the most popular [3,4]. The partitional approach segments a dataset directly using a specific objective function, whereas hierarchical clustering gradually creates distinct clusters. Hierarchical methods generally follow either an agglomerative path or a divisive approach. Agglomerative clustering begins with individual data points as unique clusters and develops a hierarchical structure by continuously combining these clusters in a bottom-up fashion. In contrast, divisive clustering starts with all data points in one collective cluster and breaks them down gradually [4]. Among the hierarchical techniques, agglomerative hierarchical clustering stands out for its time efficiency and enhanced computational stability [1]. In agglomerative hierarchical clustering, the two nearest clusters are consistently combined until either all points are within a single cluster or the desired number of clusters is reached [5]. The definition of “nearest” may vary. In this study, two primary distance metrics were considered: single and complete linkages. For further details, refer to Equations (1) and (2).
Clustering is a fundamental method in data analysis, but a common challenge is the use of data in its original, unencrypted form, posing risks to sensitive information. In resource-constrained environments like internet of things and sensor data applications, clustering tasks are often outsourced to external servers, necessitating robust data protection measures. Encryption offers a reliable solution to safeguard sensitive data. Particularly, homomorphic encryption (HE) [6] enables computations on encrypted data without decryption, ensuring confidentiality. HE allows mathematical operations to be performed on two ciphertexts, and the decrypted result is identical to that obtained when the operations are performed on plaintexts. The Cheon-Kim-Kim-Song (CKKS) scheme stands out in this field because it allows both addition and multiplication operations on encrypted data using an approximation-based arithmetic approach [7].
This study proposes a method that combines agglomerative hierarchical clustering using single and complete linkages with the benefits of HE. This ensures that data can be grouped appropriately without revealing their original forms. However, sorting encrypted data, a necessary step for both single- and complete-linkage clustering, poses challenges. To address this issue, we introduce a joint approach where the data owner assists in sorting and shares a list indicating the positions of the data points with the server. With this guidance, the server can accurately group data points. This approach integrates privacy preservation measures into hierarchical clustering while ensuring the confidentiality of the data involved.
2. Preliminaries
2.1. Agglomerative Hierarchical Clustering
In this paper, the term “agglomerative hierarchical clustering” will be referred to simply as “hierarchical clustering”. The process of hierarchical clustering is outlined in the following steps.
Step 1: First, each data point is regarded as its own separate cluster, resulting in a total of distinct clusters.
Step 2: As the procedure progresses, the two nearest clusters are combined into one. For instance, given a set of clusters labeled as , when the two closest clusters and are determined, they are merged to create a new cluster, .
Step 3: After merging and they are replaced in the set by , reducing the number of clusters by one.
This merging process (Steps 2 and 3) is repeated until a single comprehensive cluster is formed, yielding a sequence of nested clusters. If necessary, merging can stop once a specified number of clusters is reached.
In Step 2 of the clustering process, the proximity between two clusters can be determined using several methods. In this study, two main distance measurement methods were studied: single linkage and complete linkage.
For two clusters and , the single linkage distance is defined as the shortest Euclidean distance between a point in and a point in . This is expressed as follows:
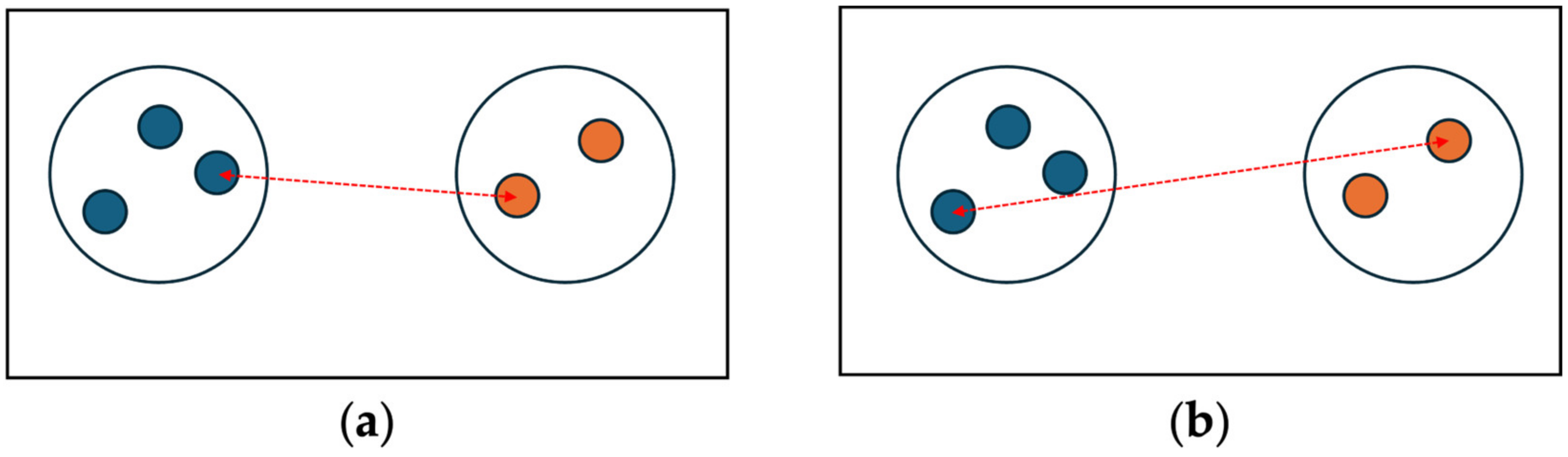
A single linkage distance can be visualized as shown in Figure 1a. On the other hand, the complete linkage distance between two clusters is determined by the longest Euclidean distance among all pairs of points, as shown in
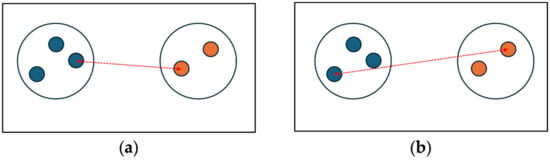
Figure 1.
Distance between two clusters defined by (a) single linkage and (b) complete linkage.
The visualization of the distance between two clusters defined by complete linkage is illustrated in Figure 1b.
In Equations (1) and (2), denotes the Euclidean distance between x and y. These calculated distances are then used to construct a distance matrix, where the element at the th row and th column represents the distance between and . During Step 3, when two clusters merge, the distance matrix is updated by recomputing the distances from the newly combined cluster to the others. While the distances from the merged cluster to the others must be updated with every merge, the distances amongst the other clusters remain unchanged [5].
2.2. Homomorphic Encryption
Homomorphic encryption (HE) [6] preserves the algebraic structure, allowing computations on encrypted data without requiring decryption. Fully homomorphic encryption supports an unlimited number of additions and multiplications, which are core operations for deriving more complex functions [7]. While schemes such as BGV [8,9] and BFV [8,10] primarily support operations on integers, the CKKS scheme broadens this scope to include real and complex numbers [11]. The CKKS scheme supports approximate operations, crucial for statistical analyses and machine learning.
The “Homomorphic Encryption for Arithmetic of Approximate Numbers” (HEaaN) is a specialized library that implements the CKKS scheme, offering features like key generation, encryption, decryption, and homomorphic operations [12]. In the CKKS scheme, data are represented as polynomials, which are divided into components referred to as slots. Each slot can independently hold a number, either complex or real, enabling parallel operations. In this study, we represent a plaintext vector A as once encrypted. Arrays containing multiple elements, whether ciphertexts or plaintexts, are denoted by parentheses. The operation ‘ represents element-wise multiplication between two ciphertexts or between a ciphertext and a plaintext. Similarly, and denote element-wise addition and subtraction, respectively. Additionally, a ciphertext can be shifted either to the left or the right by a specified number of rotations using the ’ and ‘ functions.
2.3. Privacy-Preserving Clustering
Recent advancements in cryptographic methods have spurred the development of privacy-preserving clustering algorithms. Much of this research has focused on centroid-based clustering, employing techniques such as HE, secure multiparty computation, or a combination thereof, to safeguard data privacy during clustering operations [13,14,15,16,17,18,19,20].
Additionally, density-based clustering methods have been adapted for encrypted environments to ensure privacy, enabling data grouping without direct access to raw data [21,22,23].
A smaller subset of studies has investigated hierarchical clustering within privacy-preserving frameworks. Meng et al. [24], for instance, integrated HE and multiparty computation to facilitate hierarchical clustering while maintaining data confidentiality throughout various stages of data processing.
Our research contributes to this field by implementing hierarchical clustering using the CKKS scheme of HE, an approach that has been relatively less widely explored. This methodology allows us to perform hierarchical clustering directly on encrypted data, ensuring privacy throughout the entire data analysis process.
3. Proposed Approach
The goal of this study was to perform hierarchical clustering using HE. The proposed approach closely follows the standard clustering process. However, in Step 3, where distances between initially separate clusters remain unchanged but need updating in the distance matrix, we opted for sorting instead of recomputation.
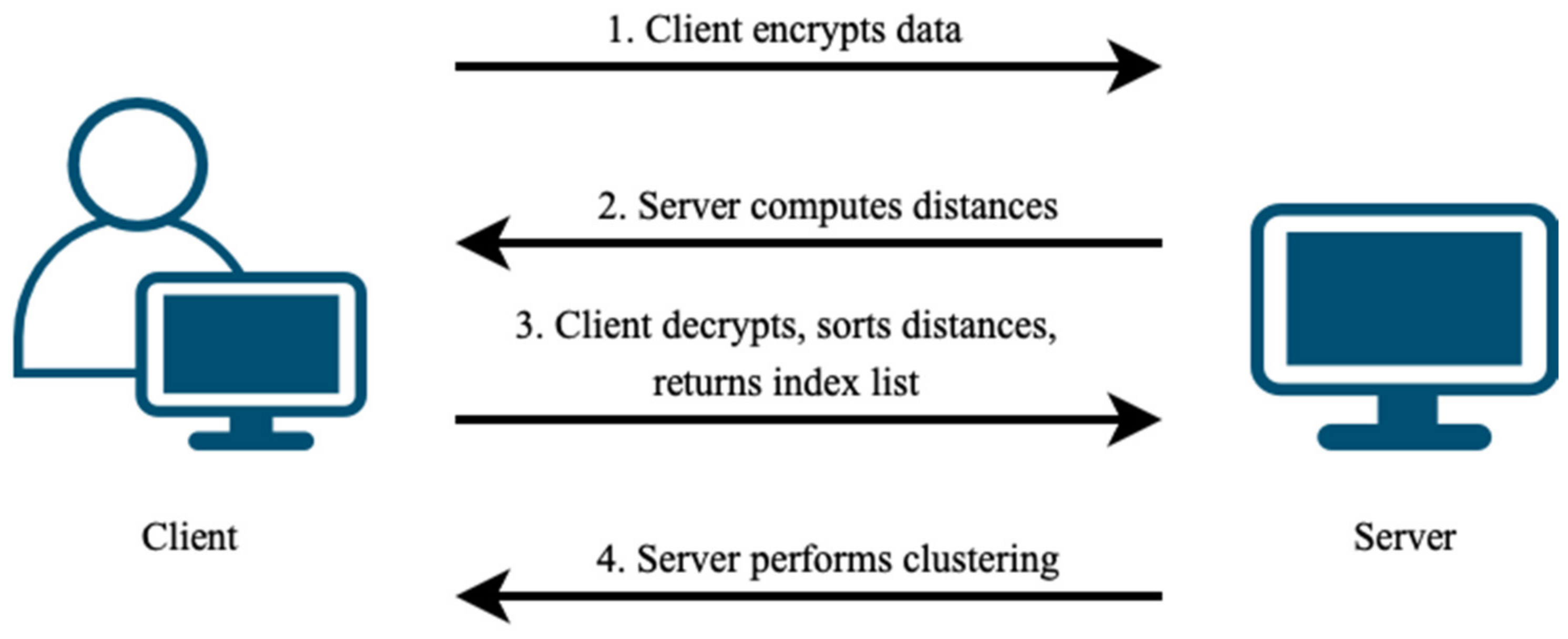
With HE, data are represented as ciphertext blocks. The sorting function in HEaaN, though powerful, is computationally intensive and sorts only the values within ciphertext slots without preserving original index positions. When merging clusters, knowing both the distances and the original cluster indices is crucial. Therefore, we propose a collaborative approach involving the data owner. The data owner assists in sorting distances and provides the original index positions of the initial single clusters (data points). Since sorting alters the original positions, sharing these post-sorted positions does not compromise the confidentiality of encrypted data. The process begins with the client (the data owner) encrypting the data and transmitting it to the server for distance calculation. The server then sends intermediate results back to the client. After decrypting and sorting the distances, the client sends the sorted indices corresponding to these distances back to the server for clustering. The process flow is illustrated in Figure 2.
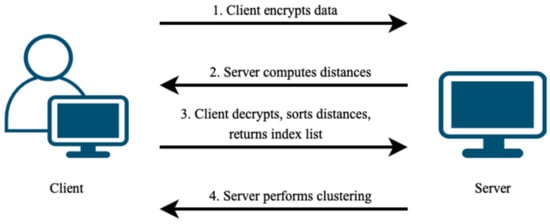
Figure 2.
Client–server process flow for handling and clustering encrypted data.
Suppose we have a ciphertext containing data points, where each data point has N features (assuming and are powers of two for simplicity). The ciphertext is rotated to allow distance computation between all possible combinations of individual data points, as detailed in Algorithm 1. We denote the -th data point as .
| Algorithm 1: Computation of |
| Input: A ciphertext Output: 1: for to do 2: 3: 4: append to 5: end for 6: return |
Algorithm 2 outlines the process of computing the Euclidean distance for each pair of data points. The output of this algorithm is the -dimensional ciphertext vector , where represents the sequence of zeros.
| Algorithm 2: : Computation of Euclidean distance |
| Input: Ciphertext , : the th rotation of Output: Euclidean distance list 1: 2: 3: for to do 4: 5: 6: end for 7: initialize as a plaintext of s with length 8: for to do 9: 10: end for 11: 12: return |
In the computation of Euclidean distance, the result is a list of squared distances, not the distances themselves. Since the actual distance values are unnecessary and squared Euclidean distances increase monotonically with Euclidean distances, the list of squared distances is sufficient for subsequent sorting tasks. After computing , it is forwarded to the data owner for sorting.
The data owner sorts all distances within and provides the server with the corresponding indices that match the sorted distances. Upon receiving these indices, the server begins with the clustering process based on the sorted index list returned by the data owner.
3.1. Single Linkage
Algorithm 3 presents the clustering procedure using single linkage, employing union-find operations to manage disjoint sets (i.e., clusters) of data points. In lines 4–20, the algorithm iteratively processes each pair from the sorted index pairs until the number of clusters reduces to the specified number, . The algorithm begins by examining the first pair representing the two closest data points. The function, defined in lines 28–33, determines the cluster identifier, or the root node of the set tree to which the input element belongs. If two elements in a pair share the same root, indicating that they are already part of the same cluster, the pair is discarded. Conversely, if the roots are different, as checked in line 8, the two elements are combined to form a new cluster. Lines 12 and 13 update the root nodes of the newly formed cluster to reflect the new cluster identifiers. The original clusters that were merged are then cleared, indicating that their elements are part of the new cluster. Following the merging, the processed pair is removed from the list, and the algorithm proceeds to the next closest pair. This procedure is repeated until the desired number of clusters is reached.
| Algorithm 3: : Clustering via single linkage |
| Input: : a list of sorted index pairs, number of data points, : desired number of clusters Output: : a list of clusters 1: 2: 3: 4: while do 5: 6: 7: 8: if then 9: 10: append to 11: 12: 13: 14: empty 15: empty 16: 17: 18: end if 19: 20: end while 21: initialize as an empty list 22: for each in do 23: if is not empty then 24: append to 25: end if 26: end for 27: return 28: function 29: while do 30: 31: end while 32: return 33: end function |
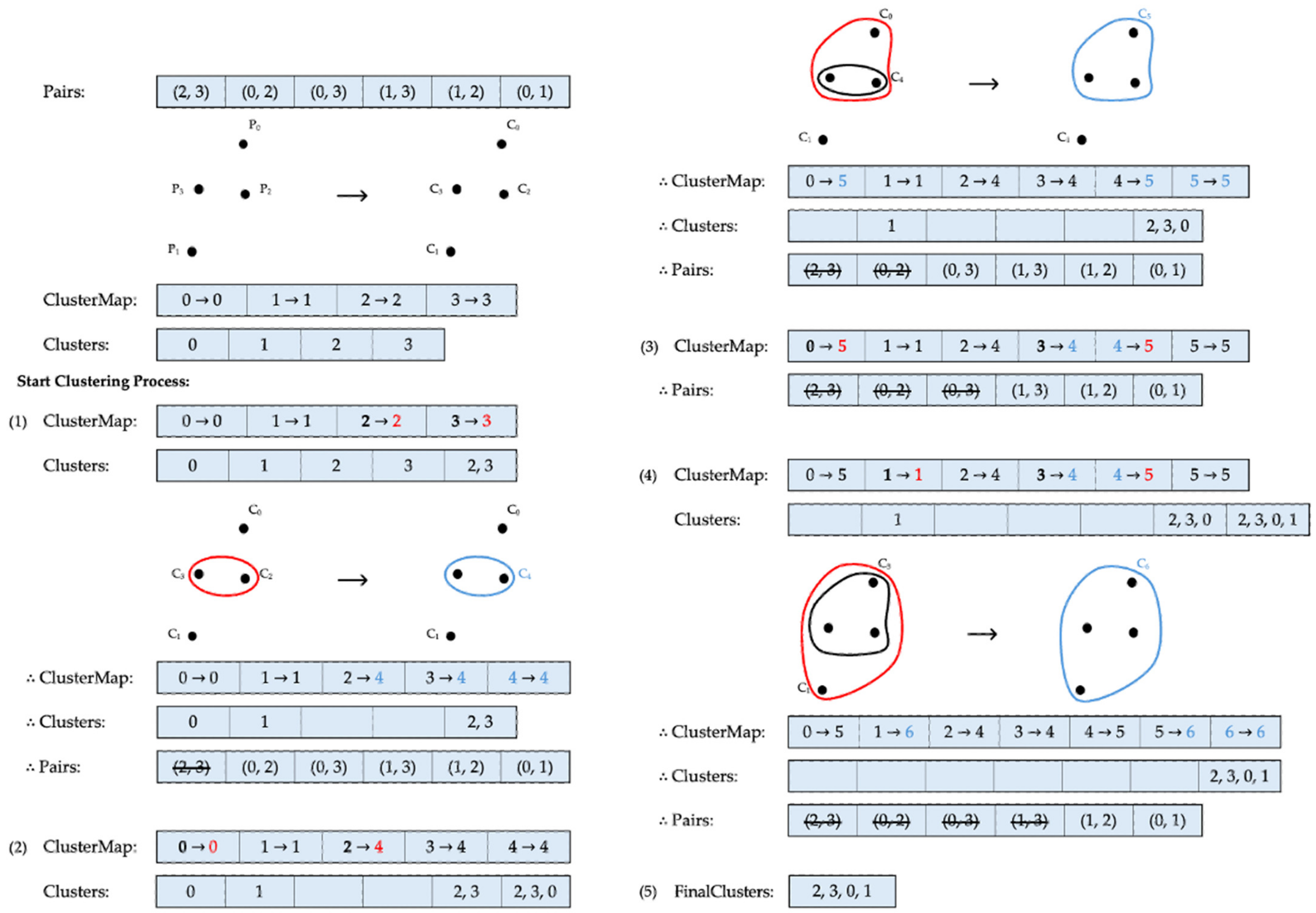
Figure 3 illustrates an example of the clustering process using the single linkage method, where . Starting with four data points, each data point initially forms a separate cluster. The roots of these clusters point to identifiers that match the cluster labels. According to the list provided by the client, the first elements to be processed are and . Because both elements point to different roots, they qualify for merging. This new combination is then added to the existing list, and the roots of and in are updated to a new cluster identifier, . Following this, the elements that have already been merged are cleared from their previous positions in , and the processed pair is completely removed from the index pair list. After this merging process, three clusters remain. The next pair to be considered is and . Although the root of has changed to , the pair still points to different roots, qualifying them for merging. All elements of and are then added to , creating another cluster identifier, , which updates the identifiers of the related clusters accordingly. After merging, the now irrelevant clusters are cleared from the cluster list, and the merged pair is removed. At this stage, two clusters, and , remain. The next elements to be processed are and . However, because of the previous merging, and have already formed one cluster, sharing the same root. Therefore, this pair is skipped, and the algorithm moves on to the next pair, and . This pair can be combined, as they have separate roots, resulting in the creation of as a new cluster identifier. After following similar processing steps as in the previous merges, only two pairs remain in the list. Since these remaining pairs belong to the same cluster and every data point has now become part of one cluster, the procedure concludes. Consequently, all individual clusters, , , and , are merged into one final cluster, as shown in Figure 3.
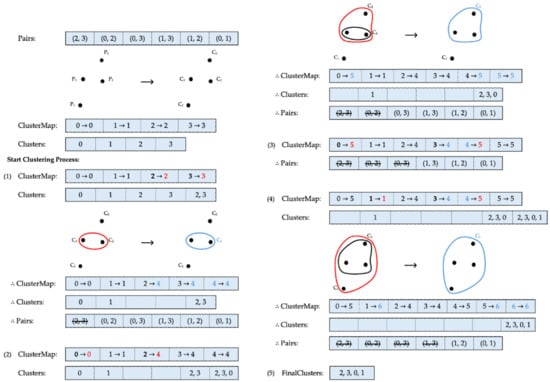
Figure 3.
Clustering via single linkage. Cluster identifiers before and after each update are marked in red and blue, respectively.
3.2. Complete Linkage
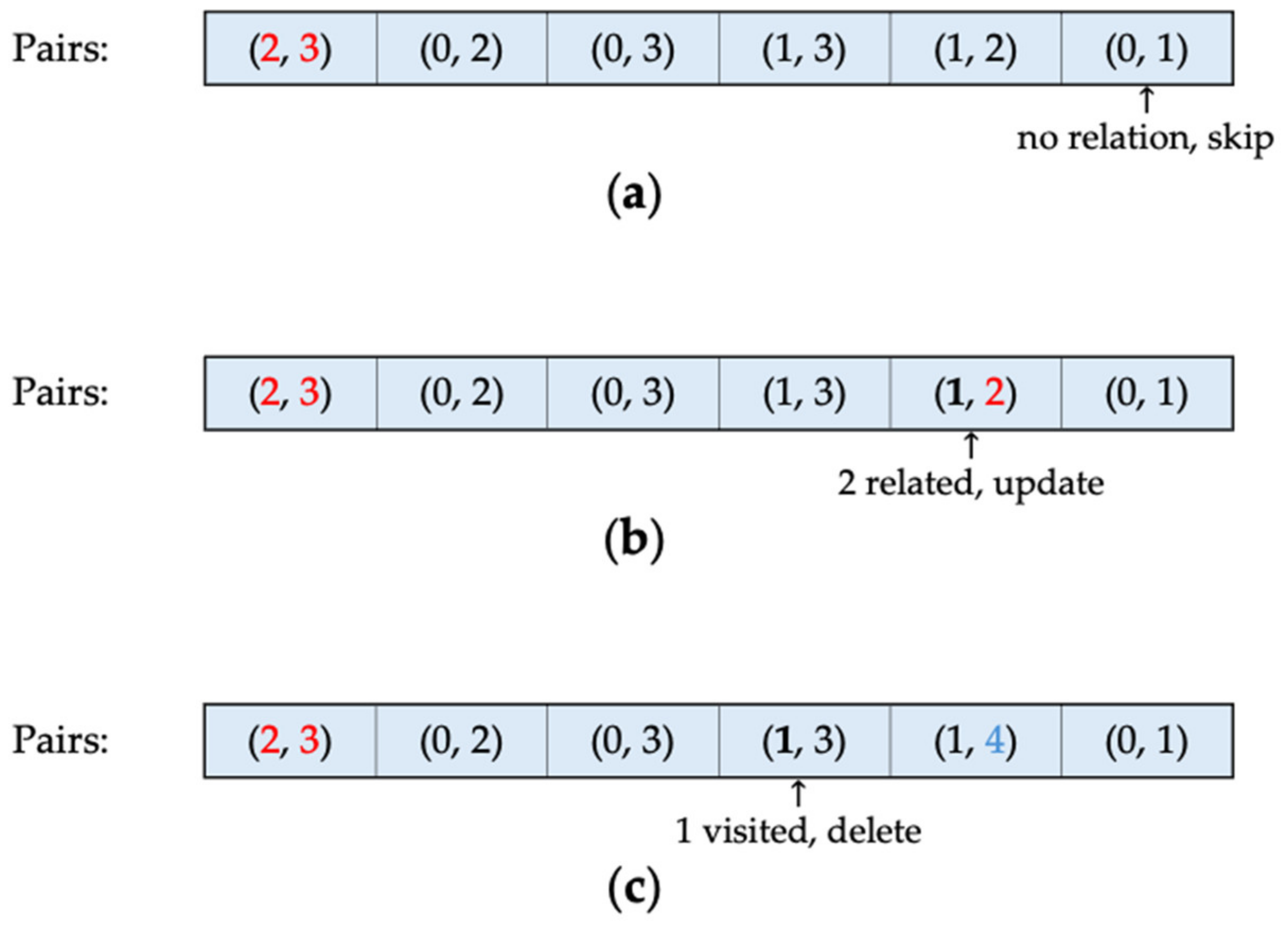
Algorithm 4 demonstrates the clustering procedure using complete linkage. Similar to single linkage, the closest clusters are merged; however, the key difference lies in the distance used to represent the two clusters. The complete linkage distance is defined as the maximum distance between any two points in the clusters, as outlined in Equation (2). The primary objective of Algorithm 4 is to identify the closest clusters with the maximum inter-cluster distance, using a sorted index pair list. The function, defined in lines 21–56, accomplishes this by identifying the pair with the longest distance, removing pairs with shorter distances in the newly formed cluster, and updating the cluster identifiers to reflect the current state of cluster formation. When a list of sorted index pairs is provided, the first pair represents the shortest distance among all combinations of points or single clusters. Consequently, the first pair is combined to form a new cluster, and the cluster identifiers are updated. Figure 4 illustrates various scenarios in which cluster pairs are handled following the function. Initially, when an index list is presented by the client in ascending order according to their distances, the first two cluster identifiers—2 and 3, representing the closest distance—are merged to create a new cluster with a new identifier, 4.
| Algorithm 4: : Clustering via complete linkage |
| Input: : a list of sorted index pairs, number of data points, : desired number of clusters Output: : a list of clusters 1: 2: 3: while do 4: 5: 6: append to 7: empty 8: empty 9: 10: 11: 12: 13: end while 14: initialize as an empty list 15: for each in do 16: if is not empty then 17: append to 18: end if 19: end for 20: return 21: function 22: 23: length of list 24: if then 25: 26: return 27: else 28: initialize as an empty list 29: initialize as a list of s with length 30: for to do 31: 32: if or then 33: if then 34: append to 35: else 36: 37: 38: end if 39: else if or then 40: if then 41: append to 42: else 43: 44: 45: end if 46: end if 47: end for 48: initialize as an empty list 49: for to do 50: if not in then 51: append to 52: end if 53: end for 54: return 55: end if 56: end function |
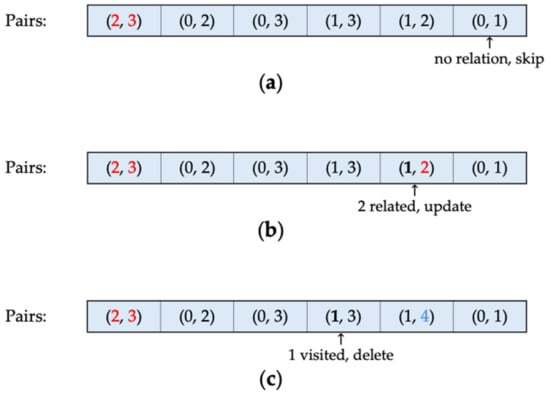
Figure 4.
Case where the pair in focus (a) has no relation to the formed cluster, (b) is related to the formed cluster, and (c) defines a shorter distance between two clusters.
As a non-single cluster now exists, the index pair list must be adjusted; otherwise, the next pair to be merged in ascending order will not represent the maximum distance of the cluster. This adjustment involves searching the list backward to identify pairs related to the newly formed cluster. Starting from the end of the list, if a pair is not related to the formed cluster, this indicates that the pair is outside the cluster and should remain unchanged during the current step. Figure 4a shows the case where the longest distance, indicated by pairs 0 and 1, corresponds to the cluster identifiers that are not connected to the merged identifiers 2 and 3.
Conversely, if a pair is related to the cluster—meaning one of the elements in the pair belongs to the previously formed cluster—the first encounter of such a relation indicates that the pair represents the maximum distance from a single cluster to the formed cluster. Consequently, the cluster identifier is updated, and its counterpart element is marked as visited. In Figure 4b, the second-longest distance corresponds to the distance between clusters 1 and 2, where cluster 2 already belongs to a previously merged cluster. This represents the longest distance between Cluster 1 and Cluster 4. Therefore, Cluster 2, no longer a single cluster but part of Cluster 4, updates its identifiers to four, transforming pair (1, 2) to (1, 4).
As the process advances towards the front of the list, encountering another pair related to the formed cluster where the paired element, initially a single cluster, has been encountered previously, indicates that its distance is not the maximum distance from the formed cluster to the single-clustered element. Consequently, the pair is marked for deletion from the list. In Figure 4c, because the maximum distance between Clusters 1 and 4 has already been identified, any pair representing the distance from Cluster 1 to other elements of Cluster 4 is removed, as it would indicate shorter distances between the two clusters. Once all pairs are processed and the search returns to the list’s front, the remaining pairs are valid, representing the longest distance from the previously formed cluster to every other cluster. The clustering procedure proceeds from the front, followed by another backward search.
In Algorithm 4, the complete linkage clustering begins by sequentially processing each pair of data points or cluster identifiers, starting with the closest. The two clusters are merged into a new cluster, as shown in line 5. The original data points belonging to a cluster are no longer considered single clusters and must be repositioned to reflect their new identifiers. After merging, the cluster identifier and index pair list are updated using the function. This function compiles a new index pair list, excluding those pairs marked for deletion, thereby maintaining an updated and relevant list of pairs for further processing. The initial pair processed for clustering is then removed, and the clustering procedure is repeated until the number of remaining clusters is reduced to . At the end of the process, includes only valid clusters that are not empty.
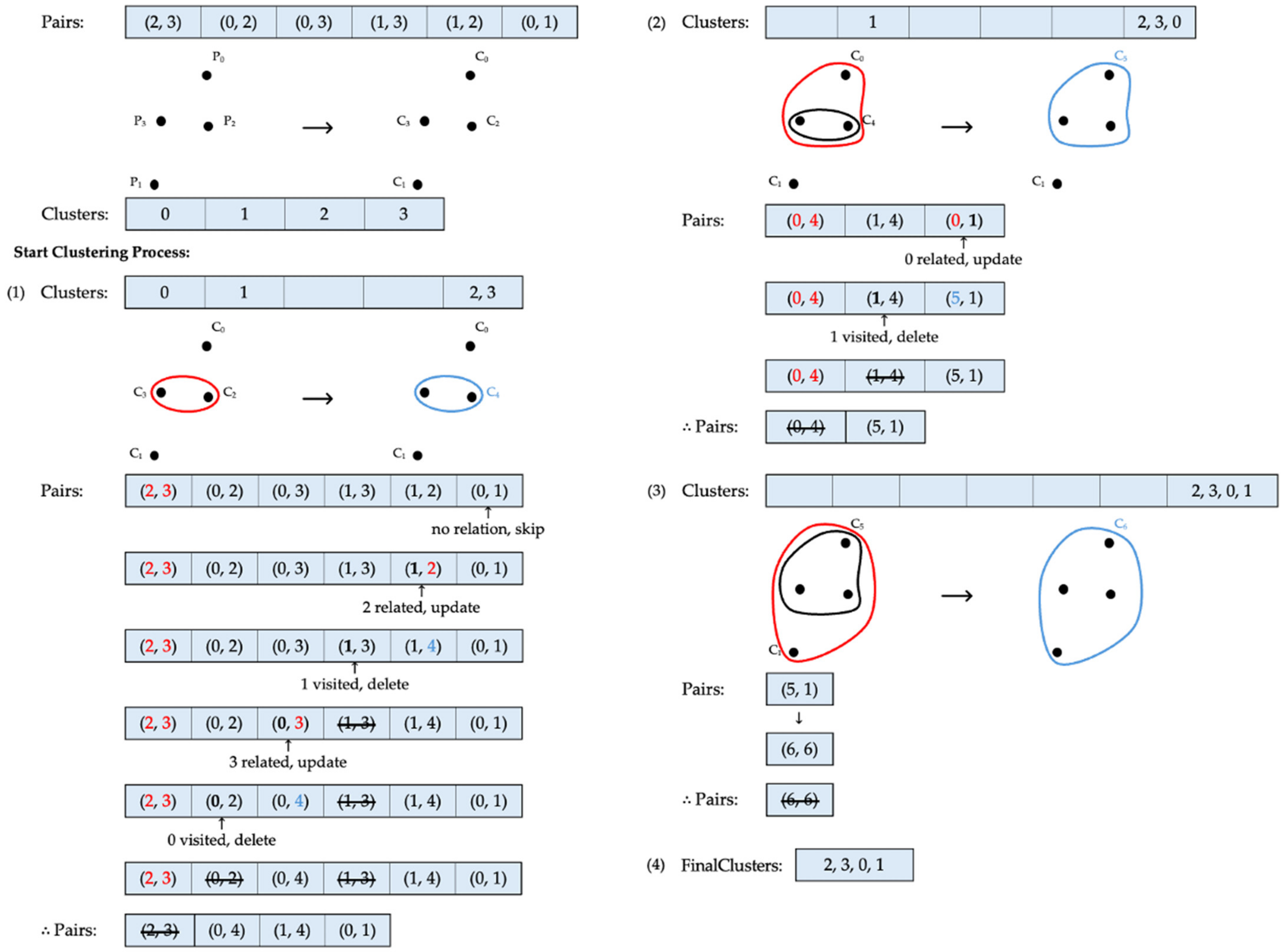
In Figure 5, is a list used to store each cluster as the procedure progresses. The process begins with the list provided by the client. According to this list, and are identified as the closest single clusters to be merged, forming a new cluster, . After merging, the new combination of and is added to , and their previous separate cluster positions are emptied. The list is then scanned backward using the function mentioned in Algorithm 4 to update pairs connected to and , and to remove pairs representing shorter Euclidean distances. Since and have no relation to the newly formed cluster, this pair can be safely skipped. Next, the pair and is considered. Although already belongs to the new cluster, this is the first encounter with . Therefore, the cluster identifier of is updated to its new cluster, , and is marked as visited. This pair represents the maximum distance from to . The next pair to be considered is and . Since belongs to , this pair represents the distance from to another single cluster, which cannot be the maximum distance, given that the list is sorted in ascending order. Thus, the pair and is removed from the list. Following this, and are processed. Similar to the previous case, since is part of and has not been visited before, is updated to its new cluster identifier, , and is marked as visited. For the pair and , since is already part of the formed cluster and has been visited previously, this pair does not represent the maximum distance from to . Therefore, this pair is also removed from the list. Now that all pairs in the list have been processed, the first pair that formed the cluster is omitted from the list. At this stage, three clusters remain after the initial merge. Using the updated list, the next closest pair identified is and , forming a new cluster identifier, . All elements from and are added to the cluster list, and their previous positions are cleared from . Starting the search from the back of the list, and are the first elements to be processed. Since now belongs to the new cluster , and this is the first encounter with , the distance represented by this pair must be the maximum distance between and . Thus, the cluster identifier of is updated to , and is marked as visited. In the next pair, and , since is not a single cluster anymore and has already been visited, this pair is discarded. After this step, the merged pair, and , is removed from , leaving only and . With only one pair left to be combined, after merging, their cluster identifiers are updated to the same identifier. As a result, all four data points now become part of one final cluster.
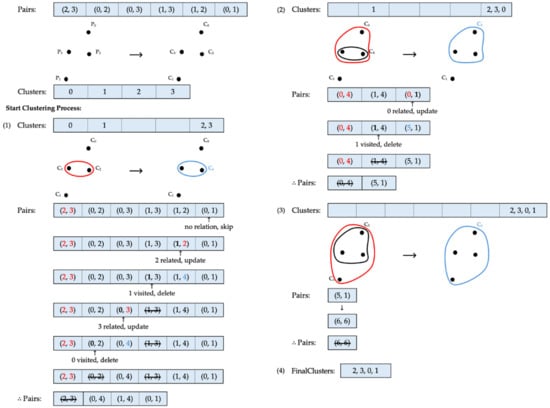
Figure 5.
Clustering via complete linkage. Cluster identifiers before and after each update are marked in red and blue, respectively.
4. Implementation
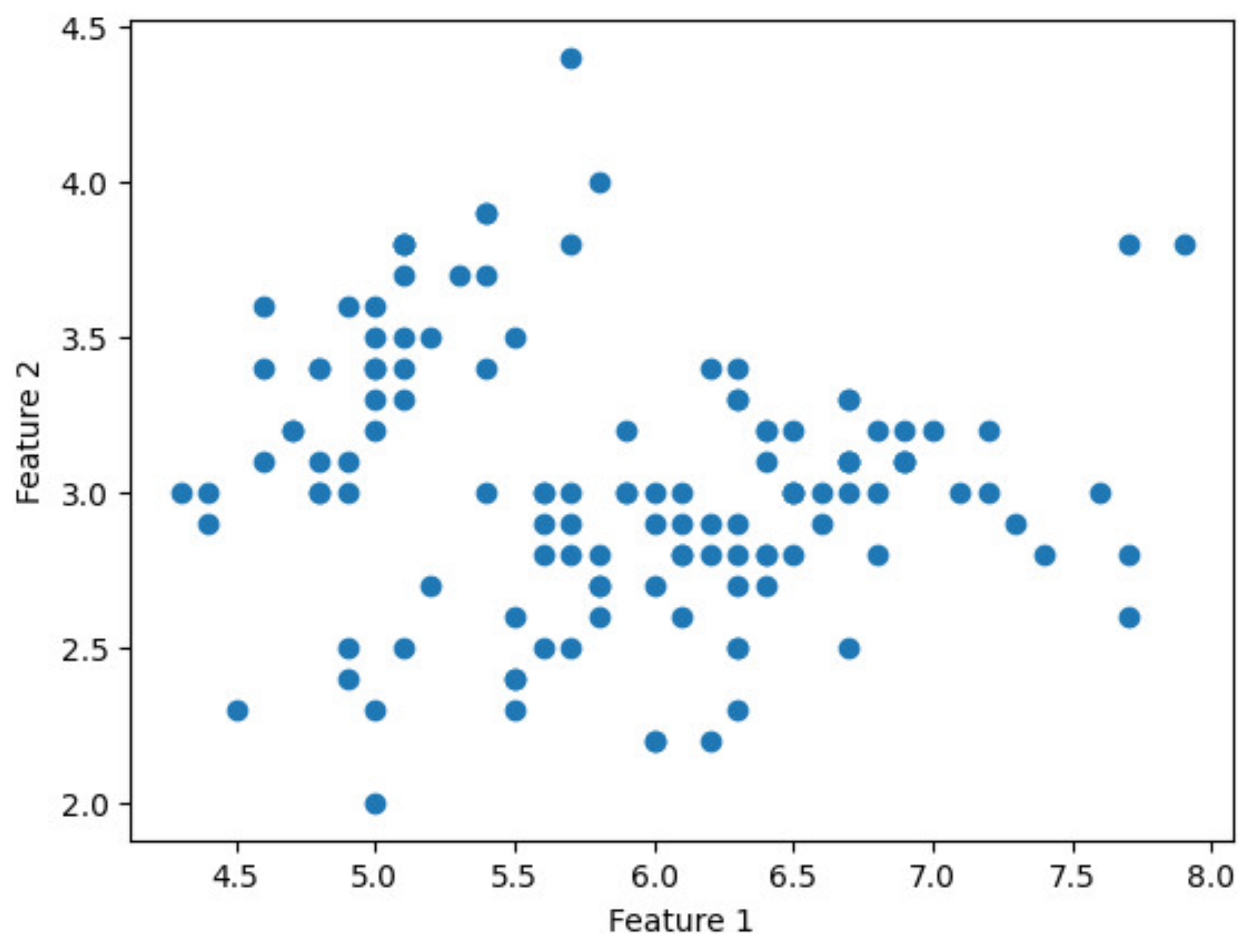
To verify the feasibility of the proposed approach, it was implemented on the Iris dataset [25] using the HEaaN library. The Iris dataset, widely recognized in the fields of machine learning and data analysis, comprises 150 data points, each with four features: sepal length, sepal width, petal length, and petal width. Due to the requirement that ciphertext dimension be a power of two, only 128 data points were used for the implementation. The experiment was conducted using the FGb parameter preset in HEaaN and executed on an NVIDIA TITAN RTX GPU featuring 4608 CUDA cores. The GPU was sourced from NVIDIA Corporation, Santa Clara, CA, USA. The sort function in Python 3.8.16 was employed for client-side sorting. Figure 6 presents a scatter plot illustrating the distribution of the data points in the Iris dataset before clustering, specifically using features 1 (sepal length) and 2 (sepal width).
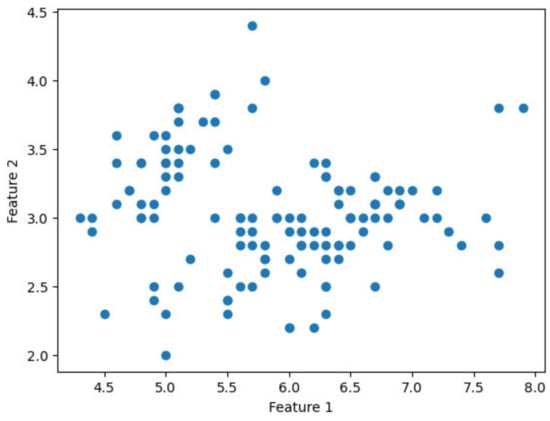
Figure 6.
Scatter plot of feature 1 vs. feature 2 before clustering.
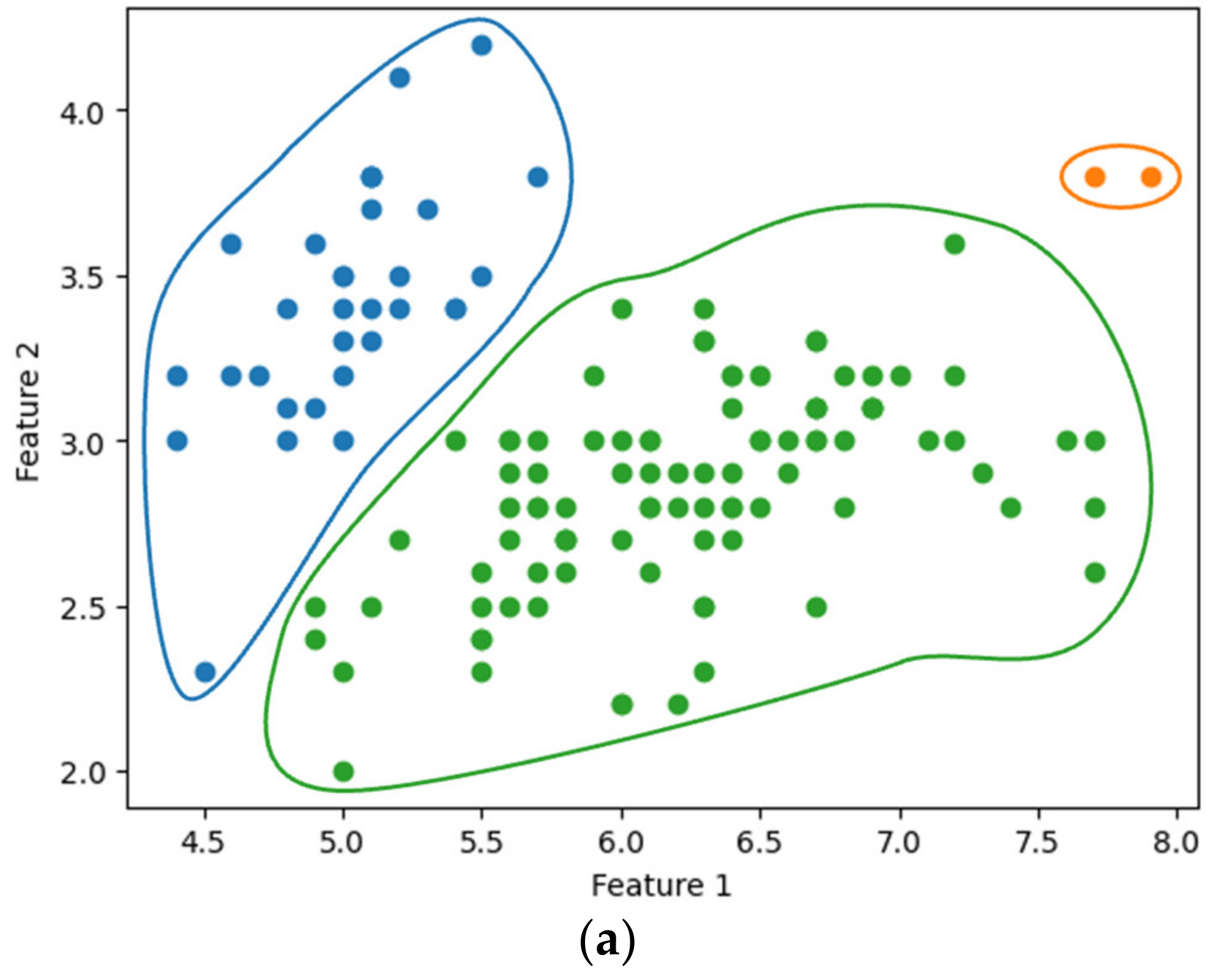
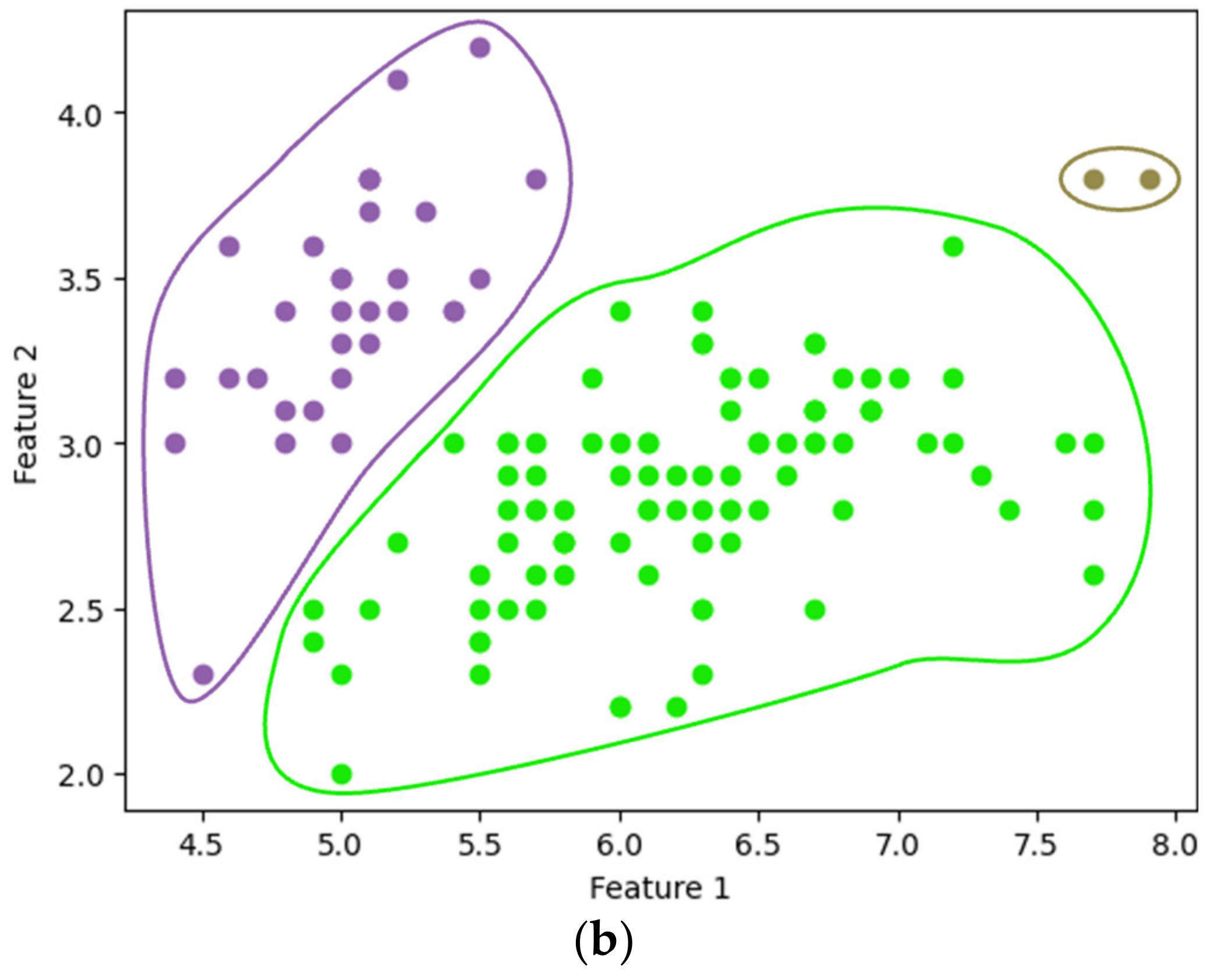
Figure 7a,b show the single-linkage clustering results for three clusters (), obtained using the existing SciPy library and our method, respectively. The entire process of our method, from data encryption to clustering, was completed in approximately 2.085 s. Similarly, Figure 8 compares the results of complete linkage clustering for the three clusters. Figure 8a displays the outcome from the SciPy library, while Figure 8b presents the results obtained using our method, completed in 2.918 s. Our clustering approach yielded results consistent with those produced by the widely used SciPy library.
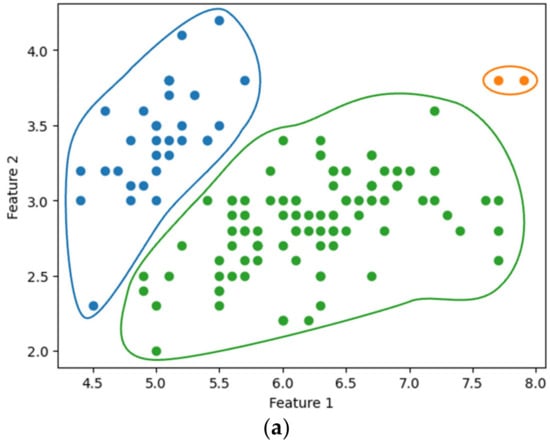
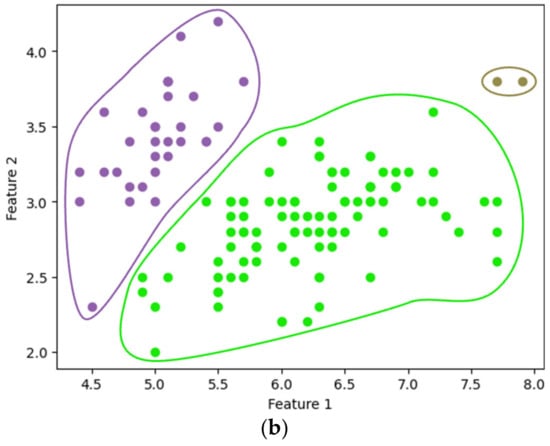
Figure 7.
Single linkage clustering with : using (a) SciPy and (b) the proposed method.
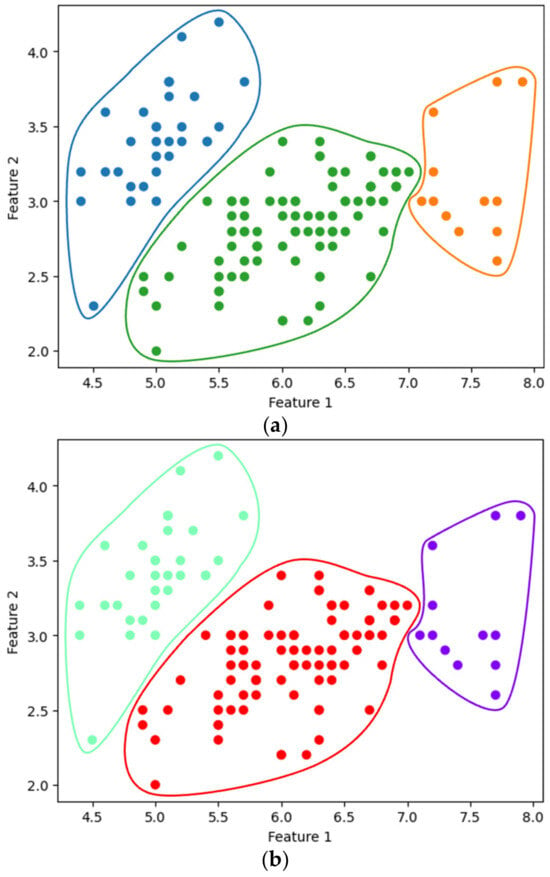
Figure 8.
Complete linkage clustering with : using (a) SciPy and (b) the proposed method.
Further testing of the proposed clustering method was conducted using Scikit-learn to evaluate its performance across various desired numbers of clusters, ranging from 2 to 10 clusters. For each configuration, the method was iterated 10 times with 128 data points randomly sampled from the Iris dataset. The evaluation focused on detecting misassigned points in comparison to clusters generated by the Scikit-learn library. Consistency is defined as the absence of misassigned points across all iterations for each number of clusters. Throughout these tests, no misassigned points were observed in either single or complete linkage clustering, demonstrating the reliability and consistency of the proposed method across different numbers of clusters. This consistency highlights the suitability of our approach for diverse clustering scenarios compared to existing methods.
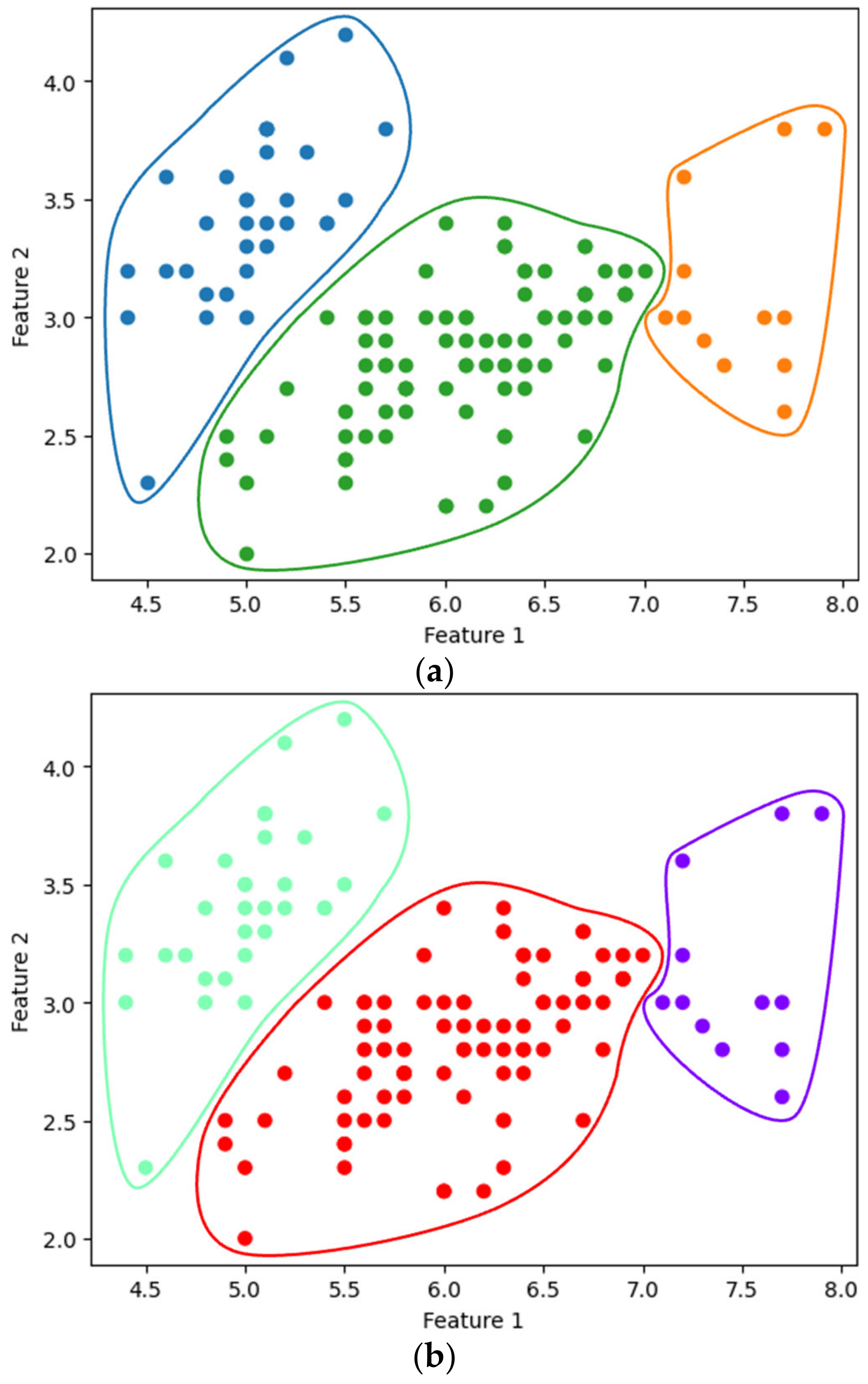
In addition to the Iris dataset, experiments were also conducted on other datasets, varying the numbers of features, data points, and clusters. One such dataset is the Breast Cancer Wisconsin (Diagnostic) dataset, which comprises 569 instances and 30 features [26]. For this experiment, 256 data points with eight features were sampled. Our clustering process, employing both single and complete linkage methods, yielded the following results: for , single linkage took approximately 3.392 s, while complete linkage took an average of 7.875 s. These results are compared in Figure 9, where (a) shows the clustering outcomes using the SciPy library and (b) illustrates the results from our approach. Our method consistently produced results similar to those from SciPy for both linkage methods.
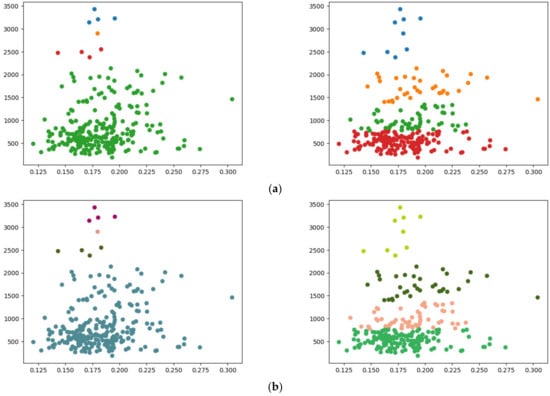
Figure 9.
Comparison of clustering conducted on the Breast Cancer Wisconsin (diagnostic) dataset: (a) SciPy results for single (left) and complete (right) linkage; (b) results from our method for single (left) and complete (right) linkage.
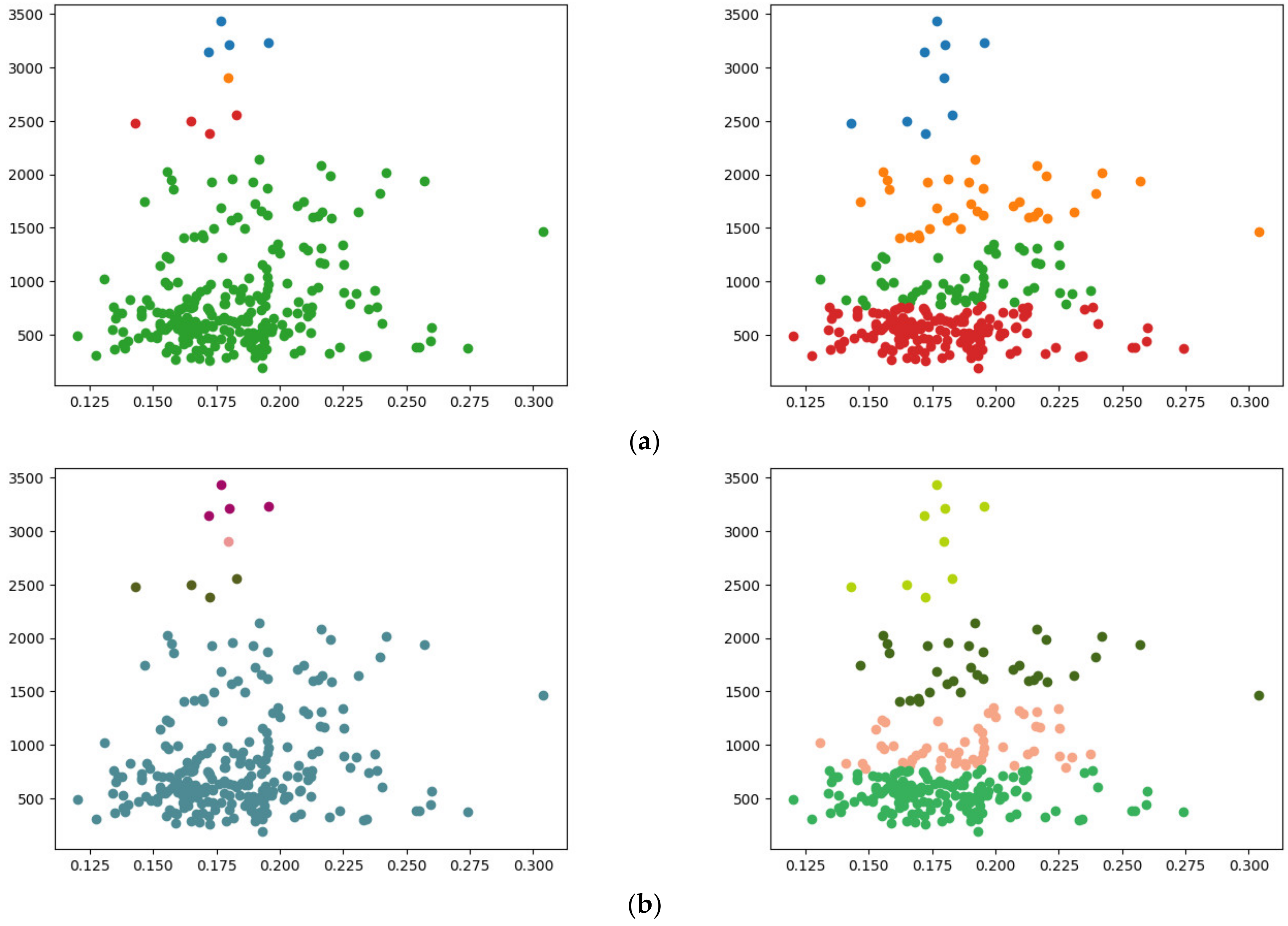
Another set of tests was conducted on the UGRansome dataset [27], a network traffic dataset. We sampled 1024 instances, each with three features. To align with our clustering algorithm’s requirement of ciphertext values being powers of two, we added zero-padding to include a fourth feature. Figure 10 presents the comparison of the clustering results for clusters. Figure 10a displays the results from SciPy version 1.10.1, while Figure 10b shows the results obtained from our method. For our method, single linkage took s, and complete linkage took s.
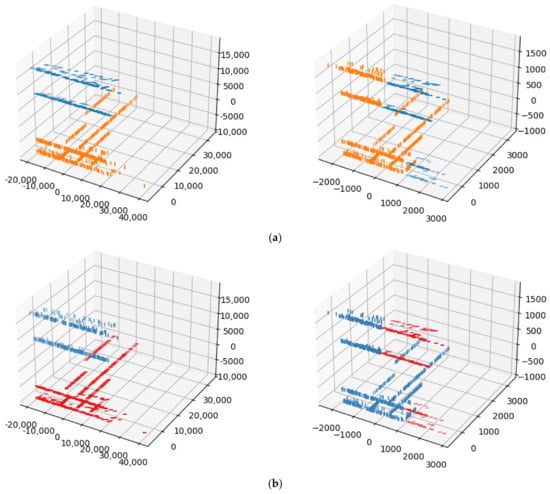
Figure 10.
Comparisons of clustering conducted on the UGRansome dataset: (a) SciPy results for single (left) and complete (right) linkage; (b) results from our method for single (left) and complete (right) linkage.
Notably, a slight difference appeared in the clustering results obtained from the two methods. For instance, in the complete linkage clustering, data points at indexes and were clustered into the second cluster (the orange cluster in Figure 10a), whereas they were assigned to the first cluster using our method (the red cluster in Figure 10b). This discrepancy is discussed further in Section 5.
5. Discussion
Table 1 compares our approach with prior studies on privacy-preserving clustering, outlining the methodologies and privacy-preserving techniques employed in each study [28]. Previous research has predominantly focused on centroid-based clustering, specifically the k-means algorithm [13,14,15,16,17,18,19,20]. Additionally, density-based clustering methods, such as mean shift [21] and DBSCAN [22,23], have been explored. Hierarchical clustering has also been investigated, particularly through the integration of HE and secure multi-party computation (MPC) [24]. In contrast, our study focuses exclusively on enhancing hierarchical clustering via HE.

Table 1.
Comparison of privacy-preserving clustering approaches.
The CKKS scheme is based on approximation, which inherently introduces precision errors [29]. For instance, in our experiments with the UGRansome dataset, these errors led to slight discrepancies in the computed distances, causing some data points to be clustered differently than in SciPy’s implementation. Despite these variations, particularly noticeable at small distance values, our method aligns with the fundamental principles of both single and complete linkage clustering.
6. Conclusions
Traditional hierarchical clustering methods often operate directly on raw data, which can expose sensitive information and compromise data privacy and security. In contrast, the use of HE ensures data privacy and reduces the risk of information leakage, providing a solution for preserving sensitive information during data analysis. By leveraging the HEaaN library, this study demonstrated a methodology for performing agglomerative hierarchical clustering in a privacy-preserving manner using both single and complete linkage methods.
Our experiment with various datasets served as a practical demonstration of the feasibility and effectiveness of the proposed approach. Both the single and complete linkage methods produced results that closely aligned with outcomes derived from widely used libraries that perform computations in plaintext. This alignment underscores the validity and reliability of the proposed clustering approach and its potential for real-world applications.
Author Contributions
Conceptualization, M.-K.L.; Methodology, L.S. and Y.-S.P.; Software, L.S. and Y.-S.P.; Validation, L.S. and Y.-S.P.; Writing—original draft, L.S.; Writing—review & editing, Y.-S.P. and M.-K.L.; Visualization, L.S.; Supervision, M.-K.L. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported in part by the National Research Foundation of Korea (NRF) Grant funded by the Korea Government [Ministry of Science and ICT (MSIT)] under Grant No.RS-2023-00209294, in part by the Institute of Information and Communications Technology Planning and Evaluation (IITP) Grant funded by the Korea Government (MSIT) under Grant No.RS-2022-00155915 and No.2022-0-01047, and in part by an Inha University Research Grant (2023).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data is contained within the article.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Zhou, S.; Xu, Z.; Liu, F. Method for Determining the Optimal Number of Clusters Based on Agglomerative Hierarchical Clustering. IEEE Trans. Neural Netw. Learn. Syst. 2017, 28, 3007–3017. [Google Scholar] [CrossRef] [PubMed]
- Havens, T.C.; Bezdek, J.C.; Palaniswami, M. Scalable Single Linkage Hierarchical Clustering for Big Data. In Proceedings of the IEEE Eight International Conference on Intelligent Sensors, Sensor Networks and Information Processing (ISSNIP), Melbourne, Australia, 2–5 April 2013; pp. 396–401. [Google Scholar]
- Lin, C.-R.; Chen, M.-S. Combining Partitional and Hierarchical Algorithms for Robust and Efficient Data Clustering with Cohesion Self-Merging. IEEE Trans. Knowl. Data Eng. 2005, 17, 145–159. [Google Scholar]
- Zhong, C.; Miao, D.; Fränti, P. Minimum Spanning Tree Based Split-and-Merge: A Hierarchical Clustering Method. Inf. Sci. 2011, 181, 3397–3410. [Google Scholar] [CrossRef]
- Zaki, M.J.; Meira, W., Jr. Data Mining and Machine Learning: Fundamental Concepts and Algorithms, 2nd ed.; Cambridge University Press: Cambridge, UK, 2020. [Google Scholar]
- Gentry, C. Fully Homomorphic Encryption Using Ideal Lattices. In Proceedings of the Symposium on the Theory of Computing, Bethesda, MD, USA, 31 May–2 June 2009; ACM: New York, NY, USA, 2009; pp. 169–178. [Google Scholar]
- Cheon, J.H.; Kim, A.; Kim, M.; Song, Y. Homomorphic Encryption for Arithmetic of Approximate Numbers. In Proceedings of the Advances in Cryptology—ASIACRYPT 2017, Hong Kong, China, 3–7 December 2017; Springer: Cham, Switzerland, 2017; pp. 409–437. [Google Scholar]
- Marcolla, C.; Sucasas, V.; Manzano, M.; Bassoli, R.; Fitzek, F.H.P.; Aaraj, N. Survey on Fully Homomorphic Encryption, Theory, and Applications. Proc. IEEE 2022, 110, 1572–1609. [Google Scholar] [CrossRef]
- Brakerski, Z.; Gentry, C.; Vaikuntanathan, V. (Leveled) Fully Homomorphic Encryption without Bootstrapping. In Proceedings of the Innovations in Theoretical Computer Science Conference, Cambridge, MA, USA, 8–10 January 2012; ACM: New York, NY, USA, 2012; pp. 309–325. [Google Scholar]
- Fan, J.; Vercauteren, F. Somewhat Practical Fully Homomorphic Encryption. IACR Cryptol. ePrint Arch. 2012, 2012, 144. [Google Scholar]
- Cheon, J.H.; Han, K.; Kim, A.; Kim, M.; Song, Y. A Full RNS Variant of Approximate Homomorphic Encryption. In Proceedings of the 25th International Conference on Selected Areas in Cryptography, Calgary, AB, Canada, 15–17 August 2018; LNCS. Springer: Berlin/Heidelberg, Germany, 2018; Volume 11349, pp. 347–368. [Google Scholar]
- CryptoLab HEaaN. Available online: https://www.cryptolab.co.kr/en/products-en/heaan-he/ (accessed on 28 March 2024).
- Almutairi, N.; Coenen, F.; Dures, K. K-Means Clustering Using Homomorphic Encryption and an Updatable Distance Matrix: Secure Third Party Data Clustering with Limited Data Owner Interaction. In Proceedings of the International Conference on Big Data Analytics and Knowledge Discovery, Lyon, France, 28–31 August 2017; pp. 274–285. [Google Scholar]
- Jäschke, A.; Armknecht, F. Unsupervised Machine Learning on Encrypted Data. In Proceedings of the Selected Areas in Cryptography (SAC) 2018, Calgary, AB, Canada, 15–17 August 2018; pp. 453–478. [Google Scholar]
- Samanthula, B.K.; Rao, F.-Y.; Bertino, E.; Yi, X.; Liu, D. Privacy-Preserving and Outsourced Multi-User k-Means Clustering. In Proceedings of the 2015 IEEE Conference on Collaboration and Internet Computing (CIC), Hangzhou, China, 27–30 October 2015; pp. 80–89. [Google Scholar]
- Kim, H.J.; Chang, J.W. A Privacy-Preserving k-Means Clustering Algorithm Using Secure Comparison Protocol and Density-Based Center Point Selection. In Proceedings of the IEEE International Conference on Cloud Computing, CLOUD, San Francisco, CA, USA, 2–7 July 2018; pp. 928–931. [Google Scholar]
- Ramírez, D.H.; Auñón, J.M. Privacy Preserving K-Means Clustering: A Secure Multi-Party Computation Approach. arXiv 2020, arXiv:2009.10453. [Google Scholar]
- Mohassel, P.; Rosulek, M.; Trieu, N. Practical Privacy-Preserving K-Means Clustering. Proc. Priv. Enhancing Technol. 2020, 2020, 414–433. [Google Scholar] [CrossRef]
- Bunn, P.; Ostrovsky, R. Secure Two-Party k-Means Clustering. In Proceedings of the 14th ACM conference on Computer and Communication Security, Alexandria, VA, USA, 2 November–31 October 2007; pp. 486–497. [Google Scholar]
- Jha, S.; Kruger, L.; Mcdaniel, P. Privacy Preserving Clustering. In Proceedings of the European Symposium on Research in Computer Security, Milan, Italy, 12–14 September 2005; pp. 397–417. [Google Scholar]
- Cheon, J.H.; Kim, D.; Park, J.H. Towards a Practical Cluster Analysis over Encrypted Data. In Proceedings of the Selected Areas in Cryptography (SAC) 2019, Waterloo, ON, Canada, 12–16 August 2019. [Google Scholar]
- Bozdemir, B.; Canard, S.; Ermis, O.; Möllering, H.; Önen, M.; Schneider, T. Privacy-Preserving Density-Based Clustering. In Proceedings of the 2021 ACM Asia Conference on Computer and Communications Security, Hong Kong, China, 7–11 June 2021; pp. 658–671. [Google Scholar]
- Zahur, S.; Evans, D. Circuit Structures for Improving Efficiency of Security and Privacy Tools. In Proceedings of the Proceedings—IEEE Symposium on Security and Privacy, Berkeley, CA, USA, 19–22 May 2013; pp. 493–507. [Google Scholar]
- Meng, X.; Papadopoulos, D.; Oprea, A.; Triandopoulos, N. Private Two-Party Cluster Analysis Made Formal & Scalable. arXiv 2019, arXiv:1904.04475. [Google Scholar]
- Lichman, M. Iris Dataset. Available online: https://archive.ics.uci.edu/dataset/53/iris (accessed on 28 March 2024).
- Wolberg, W.; Mangasarian, O.; Street, N.; Street, W. Breast Cancer Wisconsin (Diagnostic). UCI Mach. Learn. Repos. 1995. [Google Scholar] [CrossRef]
- Nkongolo, M.W. UGRansome Dataset. Available online: https://www.kaggle.com/datasets/nkongolo/ugransome-dataset/versions/1 (accessed on 9 July 2024).
- Hegde, A.; Möllering, H.; Schneider, T.; Yalame, H. SoK: Efficient Privacy-Preserving Clustering. Proc. Priv. Enhancing Technol. 2021, 2021, 225–248. [Google Scholar] [CrossRef]
- Costache, A.; Curtis, B.R.; Hales, E.; Murphy, S.; Ogilvie, T.; Player, R. On the Precision Loss in Approximate Homomorphic Encryption. In Proceedings of the International Conference on Selected Areas in Cryptography, Fredericton, NB, Canada, 14–18 August 2023. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).