
Spectral Features Analysis for Print Quality Prediction in Additive Manufacturing: An Acoustics-Based Approach
 and
and 
Abstract
1. Introduction
2. Literature Review
3. Methodology
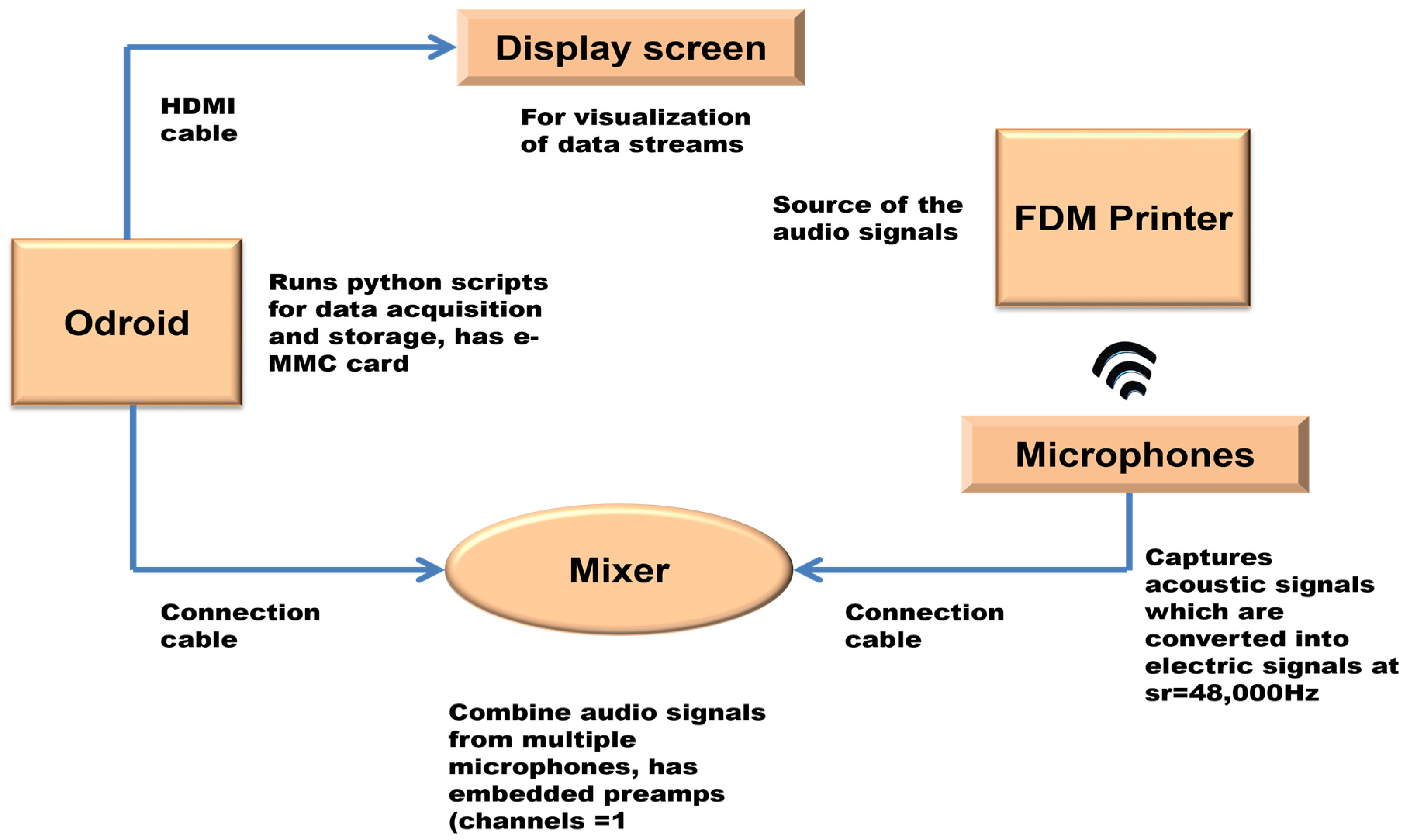
3.1. Experimental Set-Up
3.2. Data Acquisition
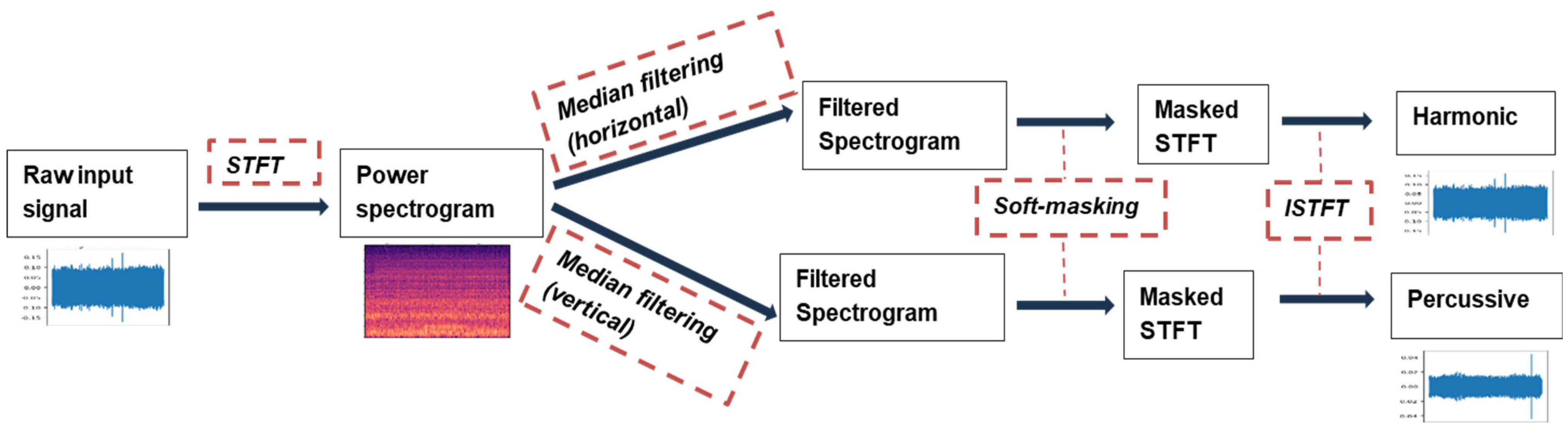
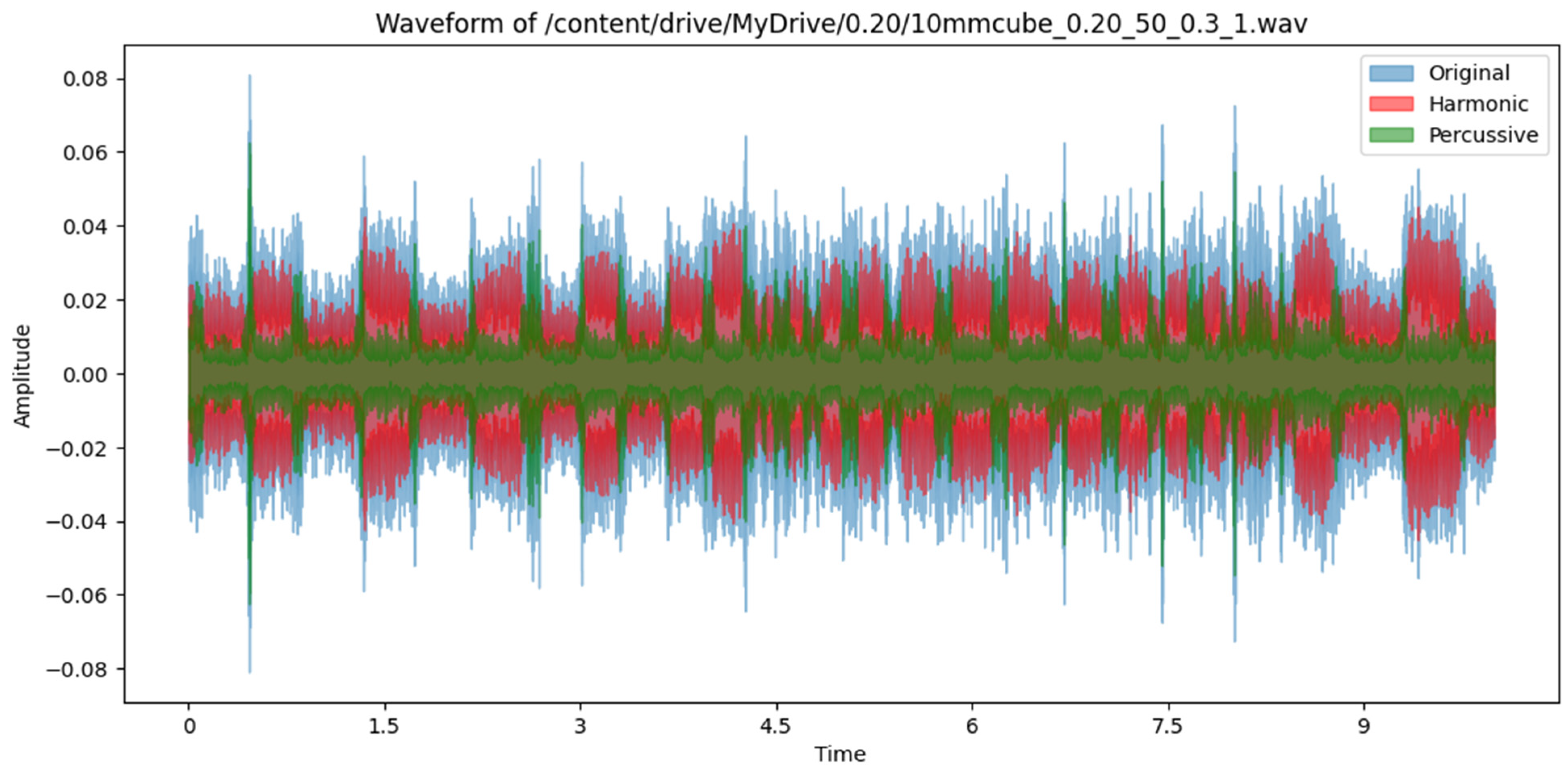
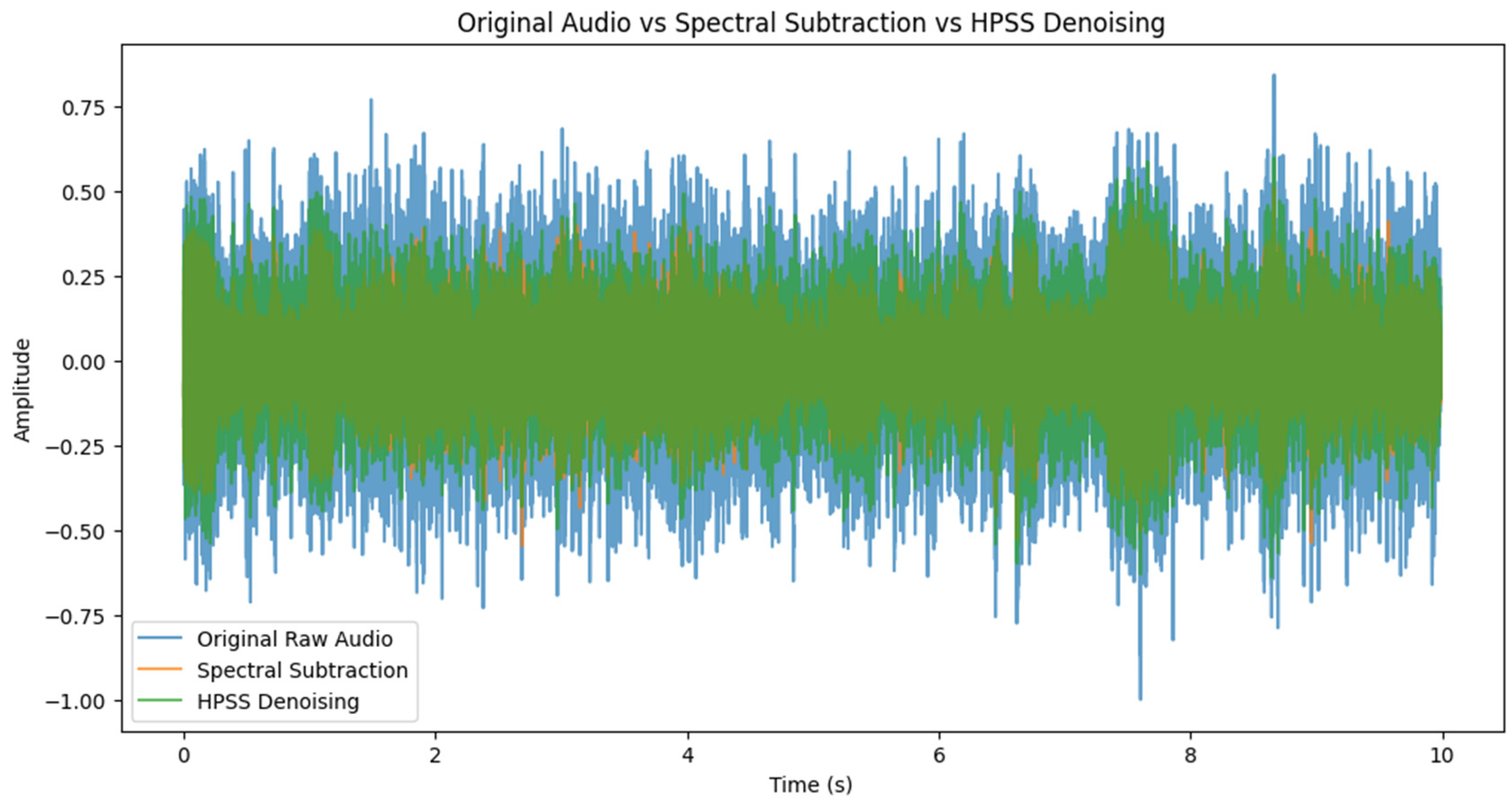
3.3. Data Preprocessing
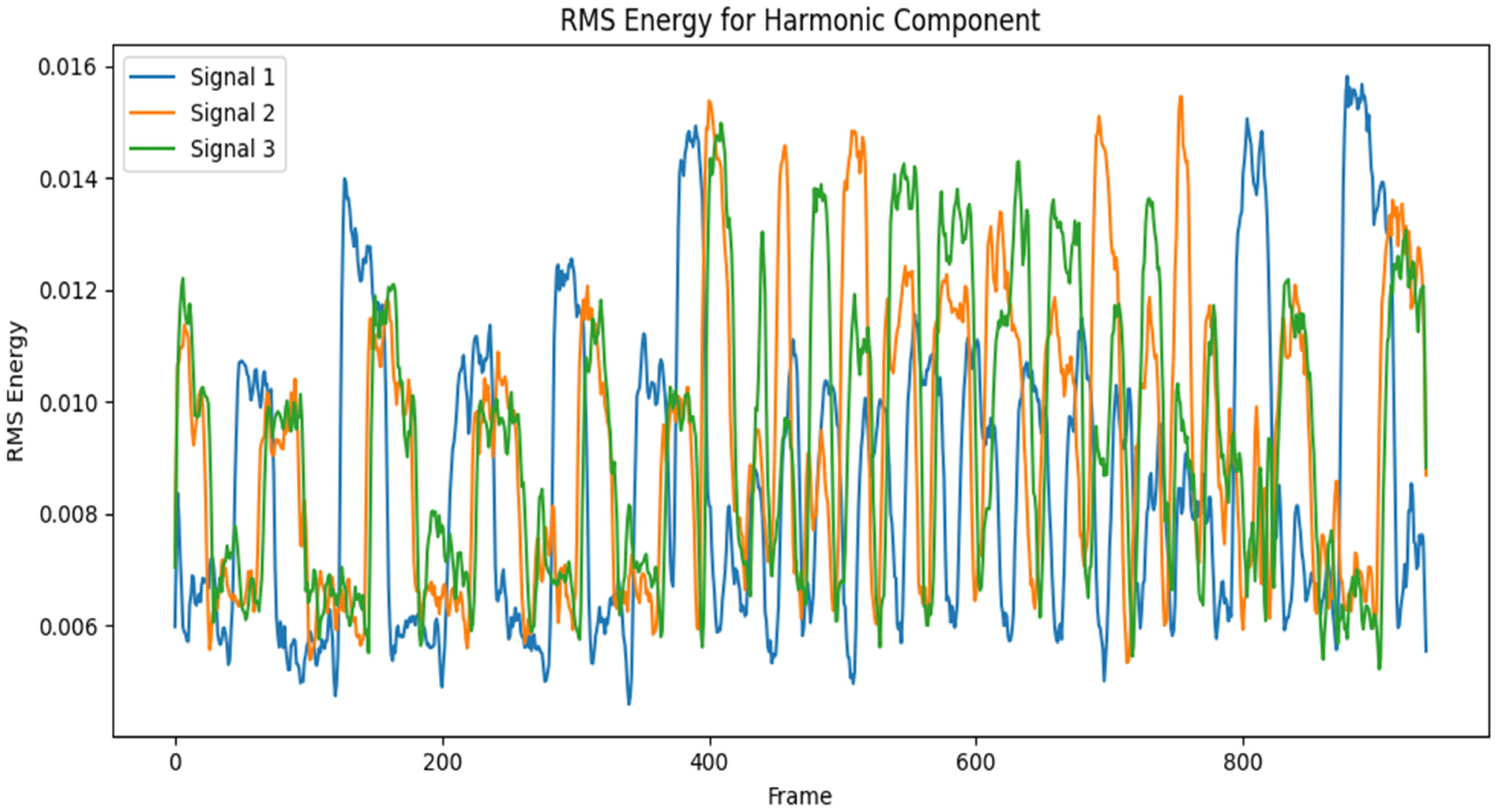
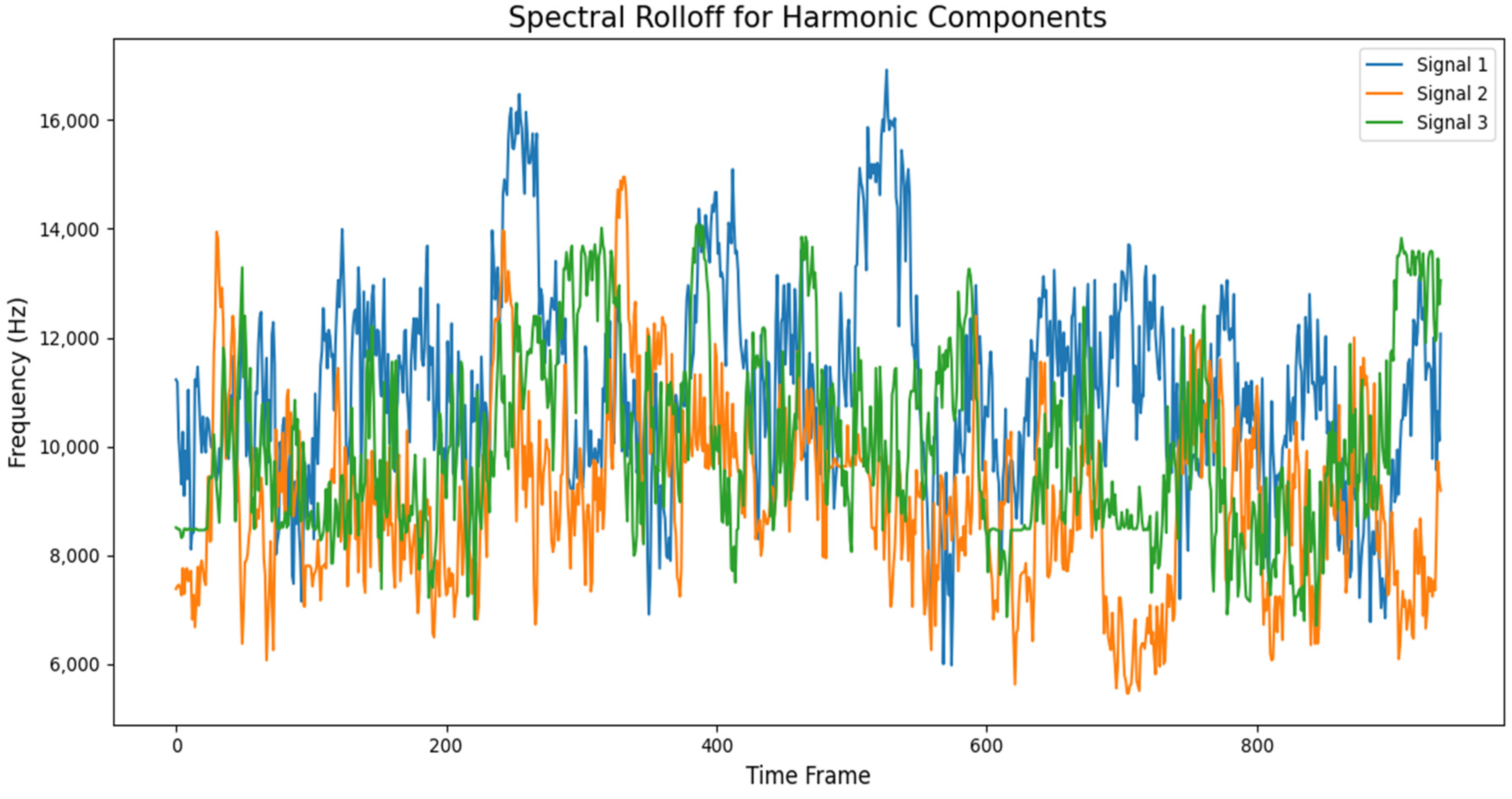
3.4. Spectral Feature Extraction
3.5. Machine Learning
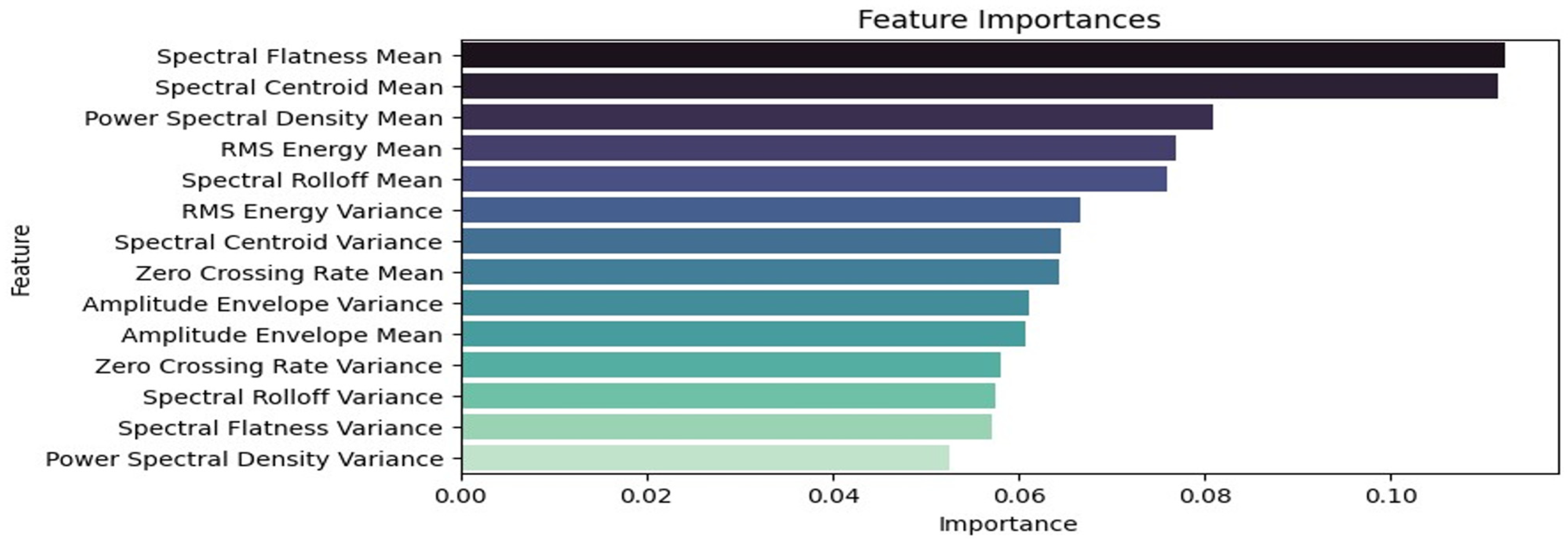
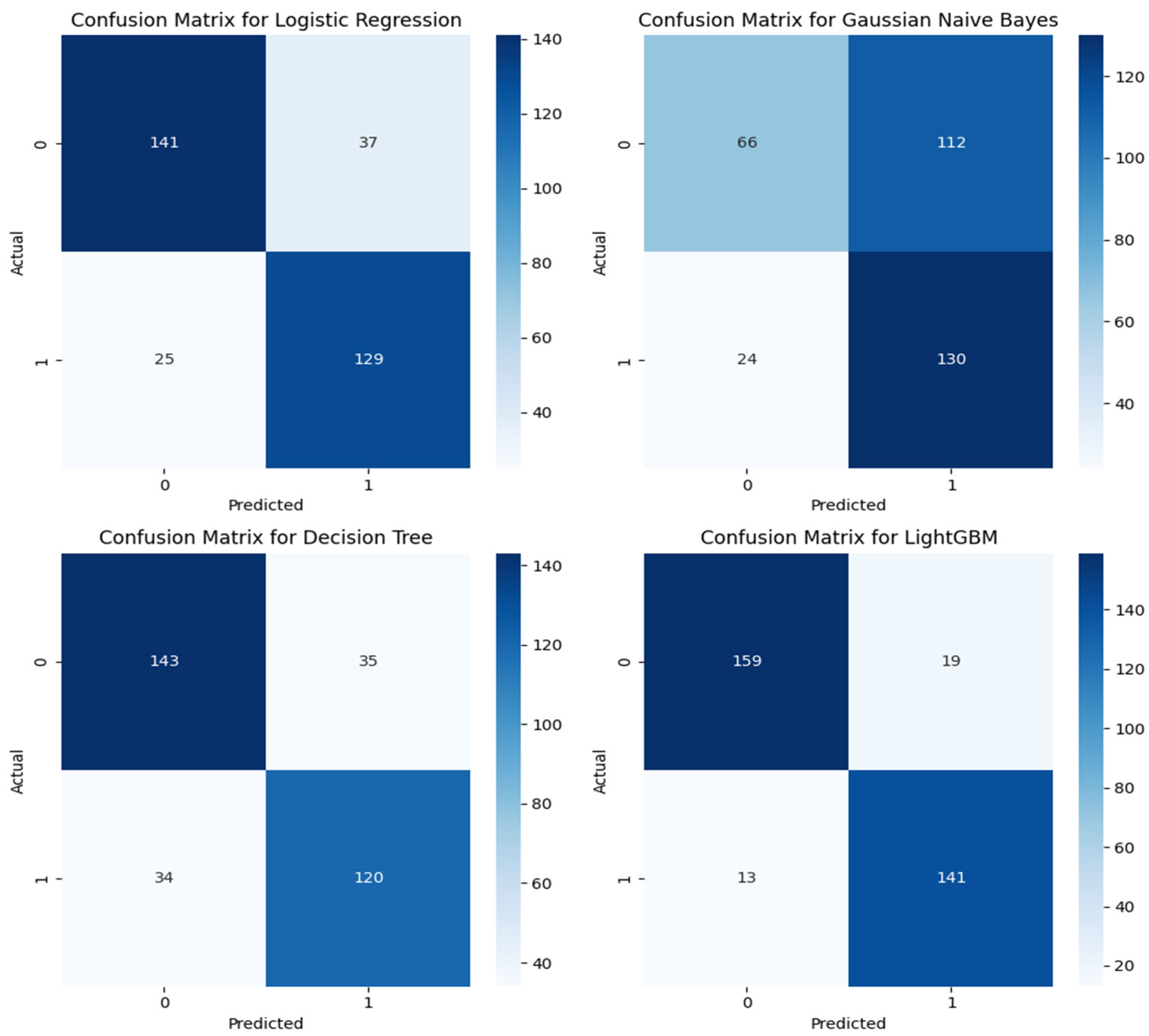
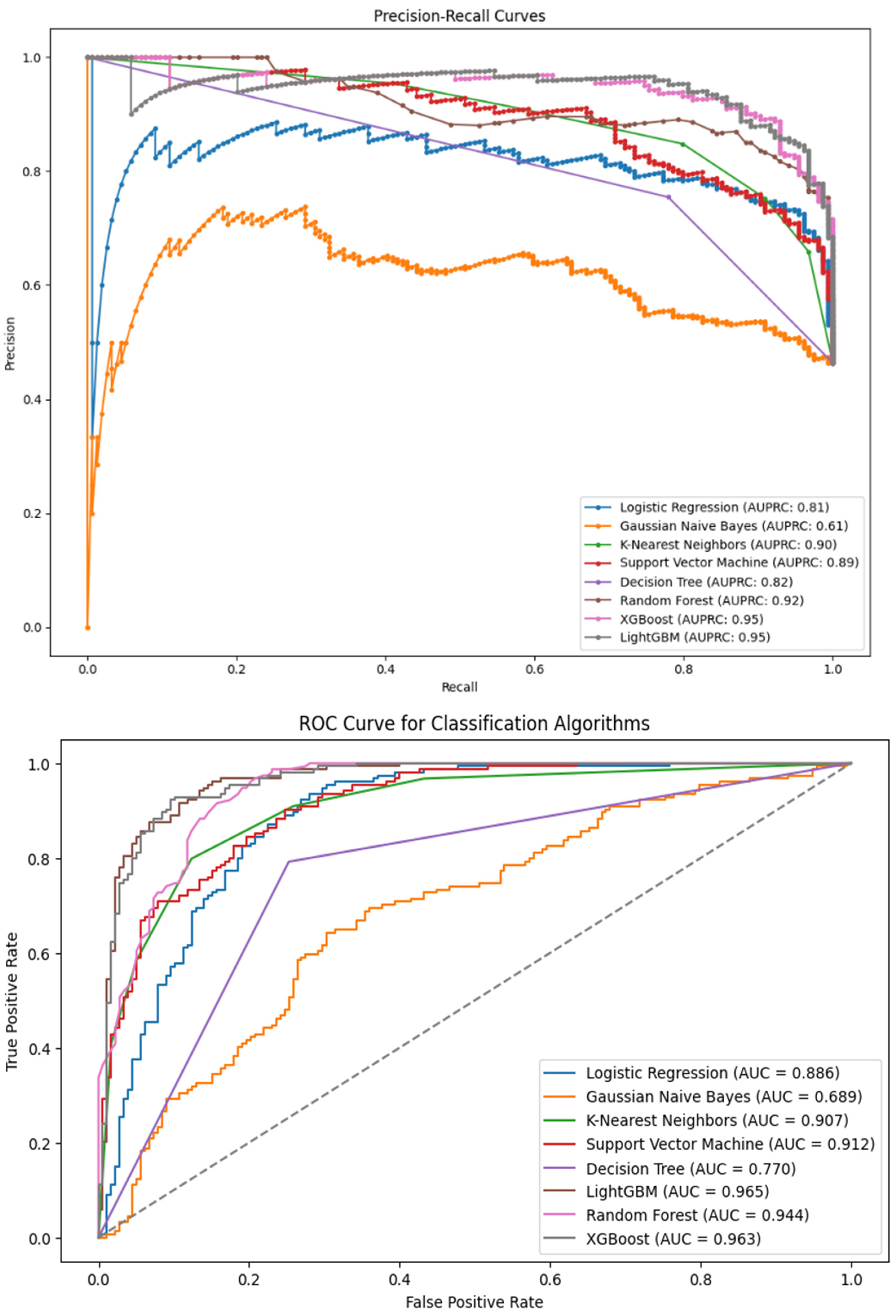
4. Results and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Jaisingh Sheoran, A.; Kumar, H. Fused Deposition Modeling Process Parameters Optimization and Effect on Mechanical Properties and Part Quality: Review and Reflection on Present Research. Mater. Today Proc. 2020, 21, 1659–1672. [Google Scholar] [CrossRef]
- Mohamed, O.A.; Masood, S.H.; Bhowmik, J.L. Optimization of Fused Deposition Modeling Process Parameters: A Review of Current Research and Future Prospects. Adv. Manuf. 2015, 3, 42–53. [Google Scholar] [CrossRef]
- Parupelli, S.K.; Desai, S. A Comprehensive Review of Additive Manufacturing (3D Printing): Processes, Applications and Future Potential. Am. J. Appl. Sci. 2019, 16, 244–272. [Google Scholar] [CrossRef]
- Charalampous, P.; Kostavelis, I.; Kopsacheilis, C.; Tzovaras, D. Vision-Based Real-Time Monitoring of Extrusion Additive Manufacturing Processes for Automatic Manufacturing Error Detection. Int. J. Adv. Manuf. Technol. 2021, 115, 3859–3872. [Google Scholar] [CrossRef]
- Cao, L.; Li, J.; Hu, J.; Liu, H.; Wu, Y.; Zhou, Q. Optimization of Surface Roughness and Dimensional Accuracy in LPBF Additive Manufacturing. Opt. Laser Technol. 2021, 142, 107246. [Google Scholar] [CrossRef]
- Du Plessis, A.; Sperling, P.; Beerlink, A.; Du Preez, W.B.; Le Roux, S.G. Standard Method for microCT-Based Additive Manufacturing Quality Control 4: Metal Powder Analysis. MethodsX 2018, 5, 1336–1345. [Google Scholar] [CrossRef] [PubMed]
- Korshunova, N.; Jomo, J.; Lékó, G.; Reznik, D.; Balázs, P.; Kollmannsberger, S. Image-Based Material Characterization of Complex Microarchitectured Additively Manufactured Structures. Comput. Math. Appl. 2020, 80, 2462–2480. [Google Scholar] [CrossRef]
- Cunha, F.G.; Santos, T.G.; Xavier, J. In Situ Monitoring of Additive Manufacturing Using Digital Image Correlation: A Review. Materials 2021, 14, 1511. [Google Scholar] [CrossRef]
- Almakayeel, N.; Desai, S.; Alghamdi, S.; Qureshi, M.R.N.M. Smart Agent System for Cyber Nano-Manufacturing in Industry 4.0. Appl. Sci. 2022, 12, 6143. [Google Scholar] [CrossRef]
- Ogunsanya, M.; Isichei, J.; Parupelli, S.K.; Desai, S.; Cai, Y. In-Situ Droplet Monitoring of Inkjet 3D Printing Process Using Image Analysis and Machine Learning Models. Procedia Manuf. 2021, 53, 427–434. [Google Scholar] [CrossRef]
- Elhoone, H.; Zhang, T.; Anwar, M.; Desai, S. Cyber-Based Design for Additive Manufacturing Using Artificial Neural Networks for Industry 4.0. Int. J. Prod. Res. 2020, 58, 2841–2861. [Google Scholar] [CrossRef]
- Akhavan, J.; Lyu, J.; Manoochehri, S. In-Situ Quality Assessment and Control in Additive Manufacturing Processes Using Laser Surface Profilometer and Deep Learning Techniques. 2022. Available online: https://www.researchgate.net/publication/364393729_In-Situ_Quality_Assessment_and_Control_in_Additive_Manufacturing_Processes_Using_Laser_Surface_Profilometer_and_Deep_Learning_Techniques (accessed on 22 July 2024).
- Wang, C.; Tan, X.P.; Tor, S.B.; Lim, C.S. Machine Learning in Additive Manufacturing: State-of-the-Art and Perspectives. Addit. Manuf. 2020, 36, 101538. [Google Scholar] [CrossRef]
- Qin, J.; Hu, F.; Liu, Y.; Witherell, P.; Wang, C.C.L.; Rosen, D.W.; Simpson, T.W.; Lu, Y.; Tang, Q. Research and Application of Machine Learning for Additive Manufacturing. Addit. Manuf. 2022, 52, 102691. [Google Scholar] [CrossRef]
- Chen, L.; Yao, X.; Tan, C.; He, W.; Su, J.; Weng, F.; Chew, Y.; Ng, N.P.H.; Moon, S.K. In-Situ Crack and Keyhole Pore Detection in Laser Directed Energy Deposition through Acoustic Signal and Deep Learning. Addit. Manuf. 2023, 69, 103547. [Google Scholar] [CrossRef]
- Shen, B.; Xie, W.; Kong, Z.J. Clustered Discriminant Regression for High-Dimensional Data Feature Extraction and Its Applications in Healthcare and Additive Manufacturing. IEEE Trans. Automat. Sci. Eng. 2021, 18, 1998–2010. [Google Scholar] [CrossRef]
- Chang, L.-K.; Chen, R.-S.; Tsai, M.-C.; Lee, R.-M.; Lin, C.-C.; Huang, J.-C.; Chang, T.-W.; Horng, M.-H. Machine Learning Applied to Property Prediction of Metal Additive Manufacturing Products with Textural Features Extraction. Int. J. Adv. Manuf. Technol. 2024, 132, 83–98. [Google Scholar] [CrossRef]
- Lin, X.; Shen, A.; Ni, D.; Fuh, J.Y.H.; Zhu, K. In Situ Defect Detection in Selective Laser Melting Using a Multi-Feature Fusion Method. IFAC-Pap. 2023, 56, 4725–4732. [Google Scholar] [CrossRef]
- Liu, C.; Kong, Z. (James); Babu, S.; Joslin, C.; Ferguson, J. An Integrated Manifold Learning Approach for High-Dimensional Data Feature Extractions and Its Applications to Online Process Monitoring of Additive Manufacturing. IISE Trans. 2021, 53, 1215–1230. [Google Scholar] [CrossRef]
- Shi, Z.; Mandal, S.; Harimkar, S.; Liu, C. Hybrid Data-Driven Feature Extraction-Enabled Surface Modeling for Metal Additive Manufacturing. Int. J. Adv. Manuf. Technol. 2022, 121, 4643–4662. [Google Scholar] [CrossRef]
- Herzog, T.; Brandt, M.; Trinchi, A.; Sola, A.; Hagenlocher, C.; Molotnikov, A. Defect Detection by Multi-Axis Infrared Process Monitoring of Laser Beam Directed Energy Deposition. Sci. Rep. 2024, 14, 3861. [Google Scholar] [CrossRef]
- Grasso, M.; Demir, A.G.; Previtali, B.; Colosimo, B.M. In Situ Monitoring of Selective Laser Melting of Zinc Powder via Infrared Imaging of the Process Plume. Robot. Comput.-Integr. Manuf. 2018, 49, 229–239. [Google Scholar] [CrossRef]
- Shevchik, S.A.; Kenel, C.; Leinenbach, C.; Wasmer, K. Acoustic Emission for in Situ Quality Monitoring in Additive Manufacturing Using Spectral Convolutional Neural Networks. Addit. Manuf. 2018, 21, 598–604. [Google Scholar] [CrossRef]
- Taheri, H.; Koester, L.W.; Bigelow, T.A.; Faierson, E.J.; Bond, L.J. In Situ Additive Manufacturing Process Monitoring with an Acoustic Technique: Clustering Performance Evaluation Using K-Means Algorithm. J. Manuf. Sci. Eng. 2019, 141, 041011. [Google Scholar] [CrossRef]
- Jierula, A.; Wang, S.; Oh, T.-M.; Wang, P. Study on Accuracy Metrics for Evaluating the Predictions of Damage Locations in Deep Piles Using Artificial Neural Networks with Acoustic Emission Data. Appl. Sci. 2021, 11, 2314. [Google Scholar] [CrossRef]
- Ogunsanya, M.; Isichei, J.; Desai, S. Grid Search Hyperparameter Tuning in Additive Manufacturing Processes. Manuf. Lett. 2023, 35, 1031–1042. [Google Scholar] [CrossRef]
- Ogunsanya, M.; Desai, S. Physics-Based and Data-Driven Modeling for Biomanufacturing 4.0. Manuf. Lett. 2023, 36, 91–95. [Google Scholar] [CrossRef]
- Ogunsanya, M.; Desai, S. Predictive Modeling of Additive Manufacturing Process Using Deep Learning Algorithm. In Proceedings of the IISE Annual Conference & Expo 2022, Seattle, WA, USA, 21–24 May 2022; IISE: Norcross, GA, USA, 2022; pp. 1–6. [Google Scholar]
- Saeedifar, M.; Najafabadi, M.A.; Zarouchas, D.; Toudeshky, H.H.; Jalalvand, M. Clustering of Interlaminar and Intralaminar Damages in Laminated Composites under Indentation Loading Using Acoustic Emission. Compos. Part B Eng. 2018, 144, 206–219. [Google Scholar] [CrossRef]
- Pichika, S.V.V.S.N.; Meganaa, G.; Geetha Rajasekharan, S.; Malapati, A. Multi-Component Fault Classification of a Wind Turbine Gearbox Using Integrated Condition Monitoring and Hybrid Ensemble Method Approach. Appl. Acoust. 2022, 195, 108814. [Google Scholar] [CrossRef]
- Wu, H.; Yu, Z.; Wang, Y. Experimental Study of the Process Failure Diagnosis in Additive Manufacturing Based on Acoustic Emission. Measurement 2019, 136, 445–453. [Google Scholar] [CrossRef]
- Yang, Z.; Yan, W.; Jin, L.; Li, F.; Hou, Z. A Novel Feature Representation Method Based on Original Waveforms for Acoustic Emission Signals. Mech. Syst. Signal Process. 2020, 135, 106365. [Google Scholar] [CrossRef]
- Liu, J.; Hu, Y.; Wu, B.; Wang, Y. An Improved Fault Diagnosis Approach for FDM Process with Acoustic Emission. J. Manuf. Process. 2018, 35, 570–579. [Google Scholar] [CrossRef]
- Prem, P.R.; Sanker, A.P.; Sebastian, S.; Kaliyavaradhan, S.K. A Review on Application of Acoustic Emission Testing during Additive Manufacturing. J. Nondestruct. Eval. 2023, 42, 96. [Google Scholar] [CrossRef]
- Manson, G.; Worden, K.; Holford, K.; Pullin, R. Visualisation and Dimension Reduction of Acoustic Emission Data for Damage Detection. J. Intell. Mater. Syst. Struct. 2001, 12, 529–536. [Google Scholar] [CrossRef]
- Pashmforoush, F.; Khamedi, R.; Fotouhi, M.; Hajikhani, M.; Ahmadi, M. Damage Classification of Sandwich Composites Using Acoustic Emission Technique and K-Means Genetic Algorithm. J. Nondestruct. Eval. 2014, 33, 481–492. [Google Scholar] [CrossRef]
- Adeniji, D.; Oligee, K.; Schoop, J. A Novel Approach for Real-Time Quality Monitoring in Machining of Aerospace Alloy through Acoustic Emission Signal Transformation for DNN. J. Manuf. Mater. Process. 2022, 6, 18. [Google Scholar] [CrossRef]
- Nguyen-Le, D.H.; Tao, Q.B.; Nguyen, V.-H.; Abdel-Wahab, M.; Nguyen-Xuan, H. A Data-Driven Approach Based on Long Short-Term Memory and Hidden Markov Model for Crack Propagation Prediction. Eng. Fract. Mech. 2020, 235, 107085. [Google Scholar] [CrossRef]
- Kraljevski, I.; Duckhorn, F.; Tschope, C.; Wolff, M. Machine Learning for Anomaly Assessment in Sensor Networks for NDT in Aerospace. IEEE Sens. J. 2021, 21, 11000–11008. [Google Scholar] [CrossRef]
- Por, E.; van Kooten, M.; Sarkovic, V. Nyquist–Shannon Sampling Theorem; Leiden University: Leiden, The Netherlands, 2019; Volume 1, pp. 1–2. [Google Scholar]
- Driedger, J.; Müller, M.; Disch, S. Extending Harmonic-Percussive Separation of Audio Signals. In Proceedings of the 15th Conference of the International Society for Music Information Retrieval (ISMIR 2014), Taipei, Taiwan, 27–31 October 2014; pp. 611–616. [Google Scholar]
- Lordelo, C.; Benetos, E.; Dixon, S.; Ahlback, S.; Ohlsson, P. Adversarial Unsupervised Domain Adaptation for Harmonic-Percussive Source Separation. IEEE Signal Process. Lett. 2021, 28, 81–85. [Google Scholar] [CrossRef]
- Joo, S.; Choi, J.; Kim, N.; Lee, M.C. Zero-Crossing Rate Method as an Efficient Tool for Combustion Instability Diagnosis. Exp. Therm. Fluid Sci. 2021, 123, 110340. [Google Scholar] [CrossRef]
- Yuan, Y.; Wayland, R.; Oh, Y. Visual Analog of the Acoustic Amplitude Envelope Benefits Speech Perception in Noise. J. Acoust. Soc. Am. 2020, 147, EL246–EL251. [Google Scholar] [CrossRef]
- Yildirim, S.; Bulut, M.; Lee, C.M.; Kazemzadeh, A.; Deng, Z.; Lee, S.; Narayanan, S.; Busso, C. An Acoustic Study of Emotions Expressed in Speech. In Proceedings of the Interspeech 2004, Jeju Island, Republic of Korea, 4–8 October 2004; ISCA: Singapore, 2004; pp. 2193–2196. [Google Scholar]
- Signal Processing Methods for Music Transcription; Klapuri, A., Davy, M., Eds.; Springer: Boston, MA, USA, 2006; ISBN 978-0-387-30667-4. [Google Scholar]
- Canadas-Quesada, F.J.; Vera-Candeas, P.; Ruiz-Reyes, N.; Munoz-Montoro, A.; Bris-Penalver, F.J. A Method to Separate Musical Percussive Sounds Using Chroma Spectral Flatness. In Proceedings of the SIGNAL 2016, The First International Conference on Advances in Signal, Image and Video Processing, Lisbon, Portugal, 26–30 June 2016; p. 54. [Google Scholar]
- Lech, M.; Stolar, M. Detection of Adolescent Depression from Speech Using Optimised Spectral Roll-Off Parameters. Biomed. J. Sci. Tech. Res. 2018, 5, 1–10. [Google Scholar] [CrossRef]
- Baby, D.; Devaraj, S.J.; Hemanth, J.; Anishin Raj, M.M. Leukocyte Classification Based on Feature Selection Using Extra Trees Classifier: Atransfer Learning Approach. Turk. J. Electr. Eng. Comput. Sci. 2021, 29, 2742–2757. [Google Scholar] [CrossRef]
- Kharwar, A.R.; Thakor, D.V. An Ensemble Approach for Feature Selection and Classification in Intrusion Detection Using Extra-Tree Algorithm. Int. J. Inf. Secur. Priv. 2021, 16, 1–21. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| S/N | Algorithm Name | Method | Acoustics Applications |
|---|---|---|---|
| 1 | Principal Component Analysis [35] | Preserves important information while reducing the dimensionality of the dataset | Creates clusters of AE events to identify similar patterns |
| 2 | K-means Clustering [36] | Partitions data points into groups with minimum variance within each group or cluster | For identifying different types of acoustic emissions |
| 3 | Convolutional/Deep Neural Networks [37] | Uses interconnected layers with different activation functions to extract complex features | Feature extraction, handles complex AE dataset |
| 4 | Recurrent Neural Network/Long Short-Term Memory [38] | Uses sequential and memory functions to process sequential tasks | For identifying abnormalities in temporal patterns |
| 5 | Isolation Forest/One-Class SVM [39] | Creates decision trees with much lower instances in isolated partitions | For defect detection in AM processes |
| 6 | Ensemble Methods /Random Forest [30] | Aggregates predictions from multiple classes of models | Better prediction accuracy, minimizes overfitting |
| Feature | Definition | Domain | Mathematical Representation |
|---|---|---|---|
| Zero Crossing Rate (ZCR) [43] | Number of times the waveform changes sign in a window. | Time | |
| - sgn: sign of function (+1, −1, or 0) | |||
| Amplitude Envelope(AE) [44] | AE indicates how the energy of the signal fluctuates over time and shows the magnitude of variations directly. | Time | |
| - frame t - : amplitude of sample - K: number of samples in a frame | |||
| Root Mean Squared Energy (RMSE) [45] | Root mean square of all samples in a frame. It is an indication of loudness. | Time | |
| Spectral Centroid (SC) [46] | It is the center of mass of the magnitude spectrum, which is determined by calculating the weighted mean of all frequencies. | Frequency | |
| Spectral Flatness (SF) [47] | The geometric mean divided by the arithmetic mean of the spectra: it determines how much of a sound is noise-like versus tone-like. | Frequency | |
| Spectral Roll-off (SR) [15] | Fraction of bins in the power spectrum at which 85% of the power is at lower frequencies. | Frequency | |
| Power Spectral Density (PSD) [48] | Estimates the distribution of a signal’s strength across a frequency spectrum. | Frequency |
| Classifier | Description |
|---|---|
| Decision Tree (DT) | Decision tree is a graph to represent choices and their results in the form of a tree. The nodes in the graph represent an event or choice and the edges of the graph represent the decision rules or conditions. Each tree consists of nodes and branches. Each node represents attributes in a group that is to be classified, and each branch represents a value that the node can take. |
| K-Nearest Neighbors (KNN) | KNN uses data and classifies new data points based on similarity measures (e.g., Euclidean distance function). Classification is computed from a simple majority vote of the K-Nearest Neighbors of each point. KNN can be used both for classification and regression. |
| Random Forest (RF) | It is well known as an ensemble classification technique that uses parallel ensembling to fit several decision tree classifiers on different dataset sub-samples and uses majority voting for the outcome. |
| Gaussian Naive Bayes (GNB) | The naive Bayes algorithm is based on Bayes’ theorem with the assumption of independence between each pair of features. It works well and can be used for both binary and multi-class categories in many real-world situations. |
| Extreme Gradient Boosting (XGB) | Gradient Boosting, like Random Forests above, is an ensemble learning algorithm that generates a final model based on a series of individual models, typically decision trees. The gradient is used to minimize the loss function, similar to how neural networks work. |
| Logistic Regression (LR) | Logistic regression typically uses a logistic function to estimate the probabilities, which is also referred to as the mathematically defined sigmoid function. |
| Support Vector Machine (SVM) | A support vector machine constructs a hyperplane or set of hyperplanes which has the greatest distance from the nearest training data points in any class. It is effective in high-dimensional spaces and can behave differently based on different mathematical functions (kernel). |
| Light Gradient Boosting Machine (LightGBM) | It is a variant of the gradient boosting algorithm, which uses multiple sets of decision trees to create a strong predictive model. The algorithm iteratively trains DTs to minimize the loss function by trying to improve on the mistakes made by the previous trees. |
| Accuracy | Precision | Recall | F1 Score | Best Algorithm | |
|---|---|---|---|---|---|
| All features | 91.2 | 88.8 | 92.9 | 90.8 | XGB |
| Top six features | 84.3 | 81.4 | 85.7 | 84.2 | LightGBM |
| Top eight features | 86.1 | 84.2 | 86.4 | 85.3 | LightGBM |
| Removing two highly correlated | 87 | 86.1 | 84.4 | 85.2 | Random Forest |
| Removing four highly correlated | 88.9 | 87.7 | 88.3 | 88 | LightGBM |
| PCA- 8 | 82.5 | 83.3 | 77.9 | 80.5 | KNN |
| Algorithm | Avg. Training Time (ms) |
|---|---|
| Logistic Regression | 25.7 |
| Gaussian Naïve Bayes | 2.2 |
| K-Nearest Neighbors | 3.7 |
| Support Vector Machines | 324.2 |
| Decision Tree | 17.1 |
| Random Forest | 448.5 |
| XGBoost | 194.4 |
| LightGBM | 167.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Olowe, M.; Ogunsanya, M.; Best, B.; Hanif, Y.; Bajaj, S.; Vakkalagadda, V.; Fatoki, O.; Desai, S. Spectral Features Analysis for Print Quality Prediction in Additive Manufacturing: An Acoustics-Based Approach. Sensors 2024, 24, 4864. https://doi.org/10.3390/s24154864
Olowe M, Ogunsanya M, Best B, Hanif Y, Bajaj S, Vakkalagadda V, Fatoki O, Desai S. Spectral Features Analysis for Print Quality Prediction in Additive Manufacturing: An Acoustics-Based Approach. Sensors. 2024; 24(15):4864. https://doi.org/10.3390/s24154864
Chicago/Turabian StyleOlowe, Michael, Michael Ogunsanya, Brian Best, Yousef Hanif, Saurabh Bajaj, Varalakshmi Vakkalagadda, Olukayode Fatoki, and Salil Desai. 2024. "Spectral Features Analysis for Print Quality Prediction in Additive Manufacturing: An Acoustics-Based Approach" Sensors 24, no. 15: 4864. https://doi.org/10.3390/s24154864
APA StyleOlowe, M., Ogunsanya, M., Best, B., Hanif, Y., Bajaj, S., Vakkalagadda, V., Fatoki, O., & Desai, S. (2024). Spectral Features Analysis for Print Quality Prediction in Additive Manufacturing: An Acoustics-Based Approach. Sensors, 24(15), 4864. https://doi.org/10.3390/s24154864