Abstract
In this work, we resolve the cascaded channel estimation problem and the reflected channel estimation problem for the reconfigurable intelligent surface (RIS)-assisted millimeter-wave (mmWave) systems. The novel two-step method contains modified multiple population genetic algorithm (MMPGA), least squares (LS), residual network (ResNet), and multi-task regression model. In the first step, the proposed MMPGA-LS optimizes the crossover strategy and mutation strategy. Besides, the ResNet achieves cascaded channel estimation by learning the relationship between the cascaded channel obtained by the MMPGA-LS and the channel of the user (UE)-RIS-base station (BS). Then, the proposed multi-task-ResNet (MTRnet) is introduced for the reflected channel estimation. Relying on the output of ResNet, the MTRnet with multiple output layers estimates the coefficients of reflected channels and reconstructs the channel of UE-RIS and RIS-BS. Remarkably, the proposed MTRnet is capable of using a lower optimization model to estimate multiple reflected channels compared with the classical neural network with the single output layer. A series of experimental results validate the superiority of the proposed method in terms of a lower norm mean square error (NMSE). Besides, the proposed method also obtains a low NMSE in the RIS with the formulation of the uniform planar array.
1. Introduction
Intelligent reflecting surfaces (IRS), also denoted as reconfigurable intelligent surfaces (RISs), have the potential to improve the system performance of the 6G network [1]. Generally speaking, RIS was one kind of meta-surface composed of a vast number of passive reflecting elements, which could be controlled in real time to dynamically alter the amplitude and/or phase of the reflecting signal, thus collaboratively enabling smart reconfiguration of the radio propagation environment [2]. However, channel estimation in passive RIS-assisted millimeter-wave (mmWave) systems is challenging. It is because the passive RIS is unable to perform signal processing, and the large number of reflecting elements in the RIS leads to high complexity [3,4].
During the past decade, some methodologies have been used to address channel estimation. The authors of [5] proposed a tensor modeling approach aiming at reducing the channel estimation error. This channel estimation problem was translated into recovering multiple rand-1 matrix approximation sub-problems [5]. Authors of [6] investigated the direction-of-departure (DoD) and direction-of-arrival (DoA) estimation in a bistatic multiple input multiple output (MIMO) radar, in which a backward IRS was exploited to receive the echoes reflected by the targets from the NLOS viewpoint. Wei et al. [7] applied the least-squares (LS) channel estimation solution for the channel of the user (UE)-base station (BS). However, the channel estimation performance in [7] was sensitive to the additional Gaussian white noise. Compressed sensing methods in [8,9] transformed the channel estimation into a sparse signal recovery problem. The channel estimation method based on compressed sensing required traversing the dictionary matrix to attain the low norm mean square error (NMSE). In [10], authors developed an improved version of the differential evolution (DE) algorithm for cell-free MIMO systems assisted by RIS. By configuring phase shift vectors for the RIS-assisted reflected channel estimation, Byun et al. [11] improved the channel estimation accuracy. The evolution algorithm used in [11] paid attention to the improvement from the mutation operation and neglected the influence due to a random children selection in the crossover strategy. The convex optimization approach [12] and hybrid evolution method [13] reduced the error between the actual signal and the reconstructed signal via optimizing the corresponding channel matrix.
As a popular approach for improving communication systems performance, some researchers have introduced deep learning for the channel estimation problem [14,15,16]. In [14,15], the authors proposed a convolutional-neural-network (CNN)-based channel estimation method. The method in [14] required the RIS to process the transmitted signal. Therefore, this method could not be applied to the passive RIS system. A conditional generative adversarial network (cGAN) was designed to estimate the cascaded channel with the received signals as conditional information [16]. A deep-learning-based approach with the traditional orthogonal matching pursuit followed by the residual network was introduced for the cascaded uplink channel estimation problem [17]. However, the methods in [16,17] did not achieve the channel estimation of RIS-BS and UE-RIS. Without the information about the directive channel of UE-BS, a deep-learning-based channel estimation method in [18] did not estimate the reflected channels of RIS-BS and UE-RIS effectively.
To further reduce the channel estimation NMSE, some methods integrated deep learning and other methods [19,20,21]. In [19], Wang et al. proposed a channel estimation scheme based on an LS solution for estimating the cascaded channel. Differently, the authors of [20] modeled the channel estimation as a denoising problem and developed a versatile deep residual learning-based cascaded channel estimation framework. Besides, the channel estimation method adopted a CNN-based deep residual network to learn the mapping between the noisy channel matrix and the denoised channel matrix [21]. The optimized network architectures in [19,20,21] did not estimate the reflected channels of RIS-BS and UE-RIS simultaneously. Wang et al. proposed a machine learning-based CS channel estimation method for wireless communication [22]. In [23], authors propose a channel estimation method for the passive RIS-assisted systems. The authors of [24] performed two stages by following atomic norm minimization to recover the channel parameters. In [25], authors proposed a strategy for joint target and user assignment, power allocation, and subchannel allocation (JCAPASA) in the RIS-assisted systems. The framework used in [26] integrated the CNN and Lagrange optimization algorithms, which aimed at achieving cascaded channel estimation. The method in [26] required the additional optimization of Lagrange factors to obtain the low channel estimation NMSE.
Most of the above-mentioned methods mainly focused on cascaded channel estimation and did not simultaneously achieve the channel estimation of RIS-BS and UE-RIS without considering the UE-to-BS communication. To overcome this shortcoming, we propose a novel two-step channel estimation method for the RIS-assisted mmWave systems. The scope of this work is to fill in the gap in the literature on reflected channel estimation with the use of deep learning. The residual network (ResNet) with the cross-layers operation [27] further improves the non-linear processing ability relative to some common neural networks. Compared with the single regression model, the multi-task model [28] has stronger learning ability. With the multiple output layers, the multi-task solved many sub-problems simultaneously. Therefore, we introduce a neural network integrating the multi-task regression model and ResNet for the channel estimation problem. Remarkably, the two-step method integrates the proposed modified multiple population genetic algorithm (MMPGA), LS estimator, ResNet, and multi-task-ResNet (MTRnet). The main contributions of this paper are summarized as follows:
- In addition to the cascaded channel estimation, we further estimate the reflected channels of RIS-BS and UE-RIS. Remarkably, a novel two-step channel estimation method using MMPGA, LS estimator, ResNet, and MTRnet is introduced for the RIS-assisted mmWave systems.
- The MMPGA-LS-ResNet is proposed to estimate the cascaded channel of UE-RIS-BS. The MMPGA-LS optimizes the crossover strategy and mutation strategy compared with the common evolution algorithm. As a result, the proposed MMPGA-LS is capable of reducing the estimation error. Then, ResNet is applied to further reduce the cascaded channel error. Relying on the designed network architecture, including the multiple cross-layer operations and layers, the proposed ResNet learns the relationship between the output of MMPGA-LS and the channel of UE-RIS-BS effectively.
- Furthermore, the proposed MTRnet is introduced for estimating the reflected channels of RIS-UE and UE-RIS. Compared with the single regression model, the MTRnet integrates the multi-task learning model and ResNet. As a result, the proposed MTRnet with multiple output layers achieves the reflected channel estimation within fewer optimization models compared with that based on the single regression model.
- A series of experimental results have validated the superiority of the novel two-step channel estimation method. For the cascaded channel estimation performance, the MMPGA-LS achieves a lower NMSE compared with a genetic algorithm (GA) [29] and particle swarm algorithm (PSO) [30]. Besides, the proposed ResNet also obtains a lower NMSE compared with convolutional recurrent neural network (CRNN) [17] and CNN [15]. Additionally, the proposed MTRnet based on the multi-task learning ability still outperforms some single-learning models in terms of a lower NMSE. Besides, the proposed method also obtains a low NMSE in the RIS with the formulation of the uniform planar array.
The rest of this paper is organized into the following parts: In Section 2, the problem of channel estimation is introduced. In Section 3, the proposed MMPGA-ResNet-MTRnet-based method is described in detail. In Section 4, the proposed two-step method is utilized for the simulations of channel estimation. The numerical results compared with other algorithms are presented to validate the effectiveness of the proposed method. The conclusions are given in Section 5.
2. Channel Estimation System Model
In the uplink RIS-assisted mmWave communication systems, there is no point-to-point communication from UE to BS. Considering the N-elements BS with the formulation of a uniform linear array and M-elements RIS with the formulation of a uniform linear array [31], the received signal at the BS is given [32,33]
where denotes the channel of RIS-BS, represents the reflecting matrix, and is distributed in the interval . The channel of UE-RIS is denoted as , the transmitted pilot signal sequence with the length is [34], the Gaussian white noise with mean 0 and variance is .
In the RIS with the formulation of ULA, is expressed as
where the number of multipaths is P, is the complex gain, denotes the steering vector at the BS side, represents the steering vector from the departure direction at the RIS side, means the physical direction-of-arrival (DoA) at the BS side, is the direction-of-departure (DoD) at the RIS side, and expresses the conjugate transport operation, . The multipaths in the systems contain the single line-of-sight (LOS) path and non-line-of-sight (NLOS) paths.
where means the wavelength of the barrier frequency, is the spacing between adjacent elements, and presents the transport operation. The steering vector is expressed as
is given as
where is the complex gain; the steering vector at the arrival direction of RIS side is represented as ; is DoA at the RIS side;
In the RIS with the formulation of UPA, is expressed as
where . is given as
where stand for the elevation angle, mean the azimuth angle.
In the passive RIS system, we select the reflecting elements randomly, where . According to [16], the cascaded channel is given as follows:
According to Equations (1)–(15), there exists a relationship between , and , which is written as
The resolvable problem in this paper is expressed as
3. The Novel Two-Step Channel Estimation Method
The proposed channel estimation method contains the MMPGA-LS-ResNet-based cascaded channel estimation and the MTRnet-based reflected channel estimation. In the first step, the MMPGA-LS executes the population initialization, classification, crossover, adaptive mutation, and reservation strategies. Relying on the generation of MMPGA-LS, the proposed ResNet further improves cascaded channel estimation performance. Based on the predicted cascaded channel, MTRnet with multiple output layers simultaneously estimates the channel coefficients (DoAs, DoDs, and channel gains) in the second step. As a result, the proposed method reconstructs the reflected channels of RIS-BS and UE-RIS.
3.1. MMPGA-LS-ResNet-Based Cascaded Channel Estimation
In this subsection, the MMPGA-LS-ResNet-based cascaded channel estimation method is introduced for the RIS-assisted mmWave systems. The MMPGA-LS, with its improved crossover strategy and mutation strategy, initially estimates the cascaded channel. Then, the proposed ResNet learns the non-linear relationship between the cascaded channel obtained by the MMPGA-LS and the channel of the UE-RIS-BS. The ResNet aims at further reducing the channel estimation NMSE.
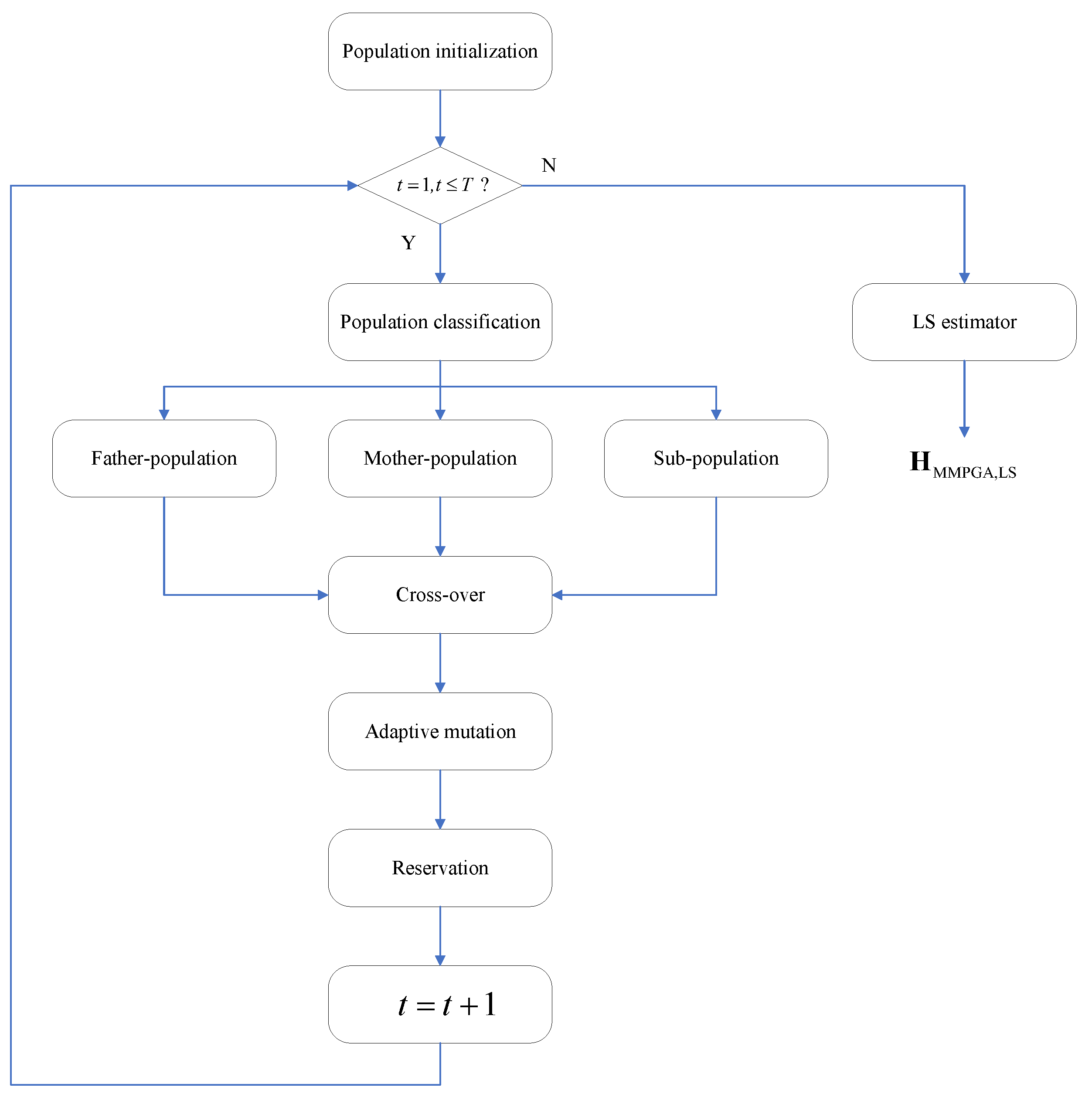
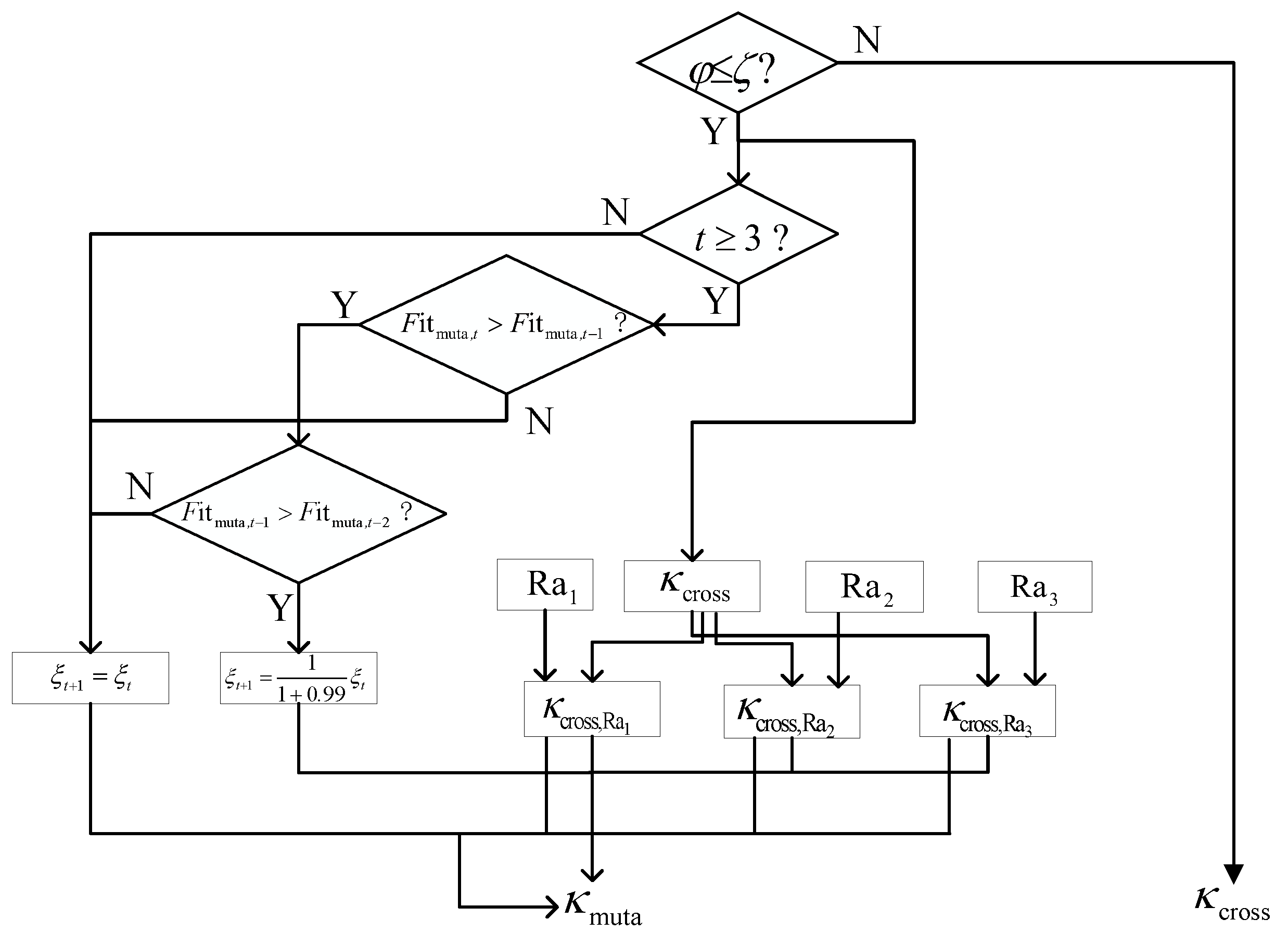
The proposed MMPGA-LS reduces the channel estimation error by optimizing the reflecting phases. Based on the population initialization, the MMPGA-LS classifies them via fitness ranking. The MMPGA-LS makes good use of the best one, corresponding to the highest fitness in the crossover strategy. Then, the adaptive mutation strategy flexibly adjusts the mutation factor according to fitness. Based on the generation of the mutation, the proposed method preserves the partial children with higher fitness. After using the LS estimator, the proposed method obtains . Figure 1 represents the flowcharts of the proposed MMPGA-LS.
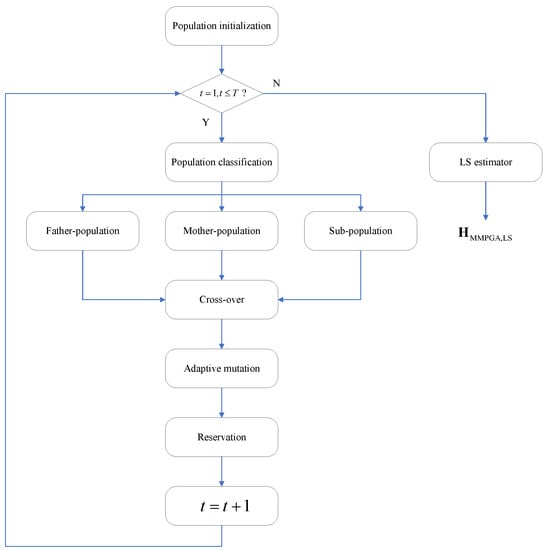
Figure 1.
The flowcharts of proposed MMPGA-LS.
3.1.1. Population Initialization
We assume that the initial population contains Q children, where denotes the number of active elements in the RIS. is given as below
where , , , , stands for the length of a binary-gene sequence, and means a decimal-transportation function.
where is the lower bound, means the upper bound, . The whole gene population is defined as . selects 0 or 1 randomly.
3.1.2. Population Classification
After using to obtain , the corresponding fitness is defined as
where expresses the expectation operation; means the square of the Frobenius norm.
According to the descending order criterion, the fitness set is divided into , , and , where . The father population corresponding to is defined as , and its gene population is given as . The mother-population corresponding to is defined as , and its gene population is given as . The sub-population corresponding to is defined as , and its gene population is given as .
3.1.3. Crossover
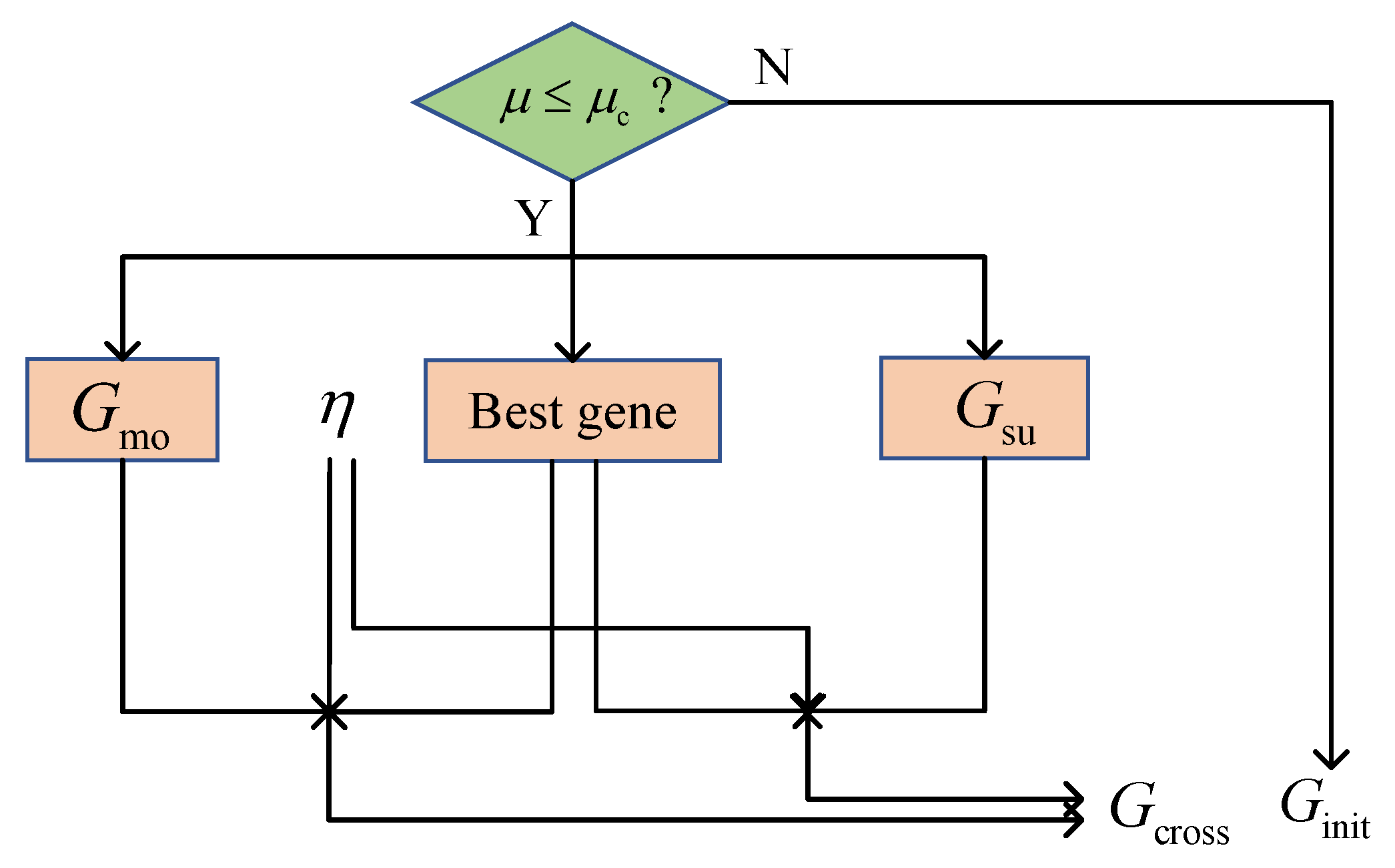
Figure 2 illustrates the proposed crossover strategy. The MMPGA-LS generates a crossover probability and compares it with . The execution of the crossover strategy satisfies a condition, where . Relying on , the best one is selected as
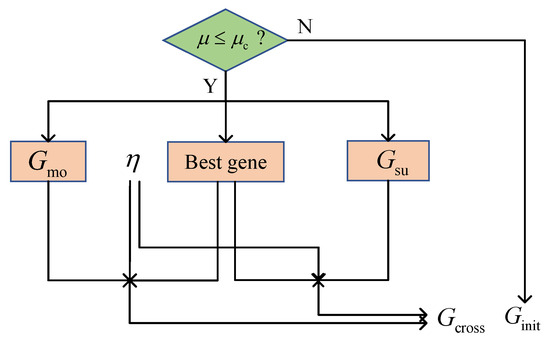
Figure 2.
The flowcharts of crossover strategy.
Then new gene populations are generated via , , , and an index of the crossover position
where ,
where . A new gene population is formulated according to Equations (24) and (25), where .
With the substitution of , the corresponding fitness is obtained. MMPGA-LS abandons the worst one corresponding to the lowest fitness in , reserves , and formulates .
3.1.4. Adaptive Mutation
Figure 3 represents the flowcharts of the adaptive mutation strategy. The proposed method randomly generates a mutation probability and compares it with . The condition of the adaptive mutation strategy satisfies . Based on the output of the crossover strategy, three random number sets and mutation scale factors , are given as
Sustain to construct the corresponding fitness . Compared with the fixed mutation factor, the proposed MMPGA-LS adjusts .
where t denotes the number of the current iteration.
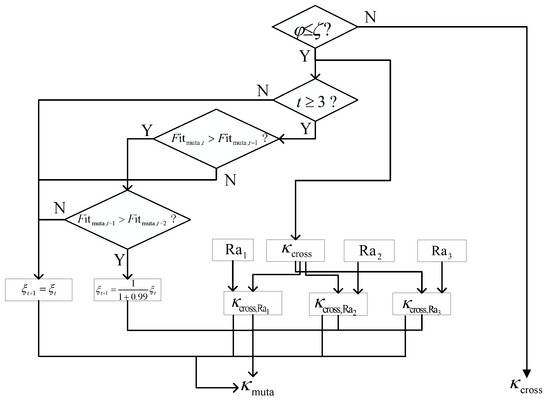
Figure 3.
The flowcharts of the adaptive mutation strategy.
3.1.5. Population Reservation
Relying on , the proposed method selects with higher fitness. is formulated via the binary transportation about . For an example of , the relationship between and is expressed as
where denotes the binary transportation function, and is an operation of the integral down. The proposed method replaces with .
The proposed MMPGA-LS stops the iteration until , where T is a number of the total iteration. Collecting the best one in each iteration, we get and its corresponding fitness set . Based on , is given as
After using , the cascaded channel is obtained via the LS algorithm [35]. To evaluate the performance obtained by the proposed MMPGA-LS, the error function is defined as
3.1.6. ResNet
Based on the output of the proposed MMPGA-LS, the proposed ResNet further reduces the cascaded channel estimation error. The dataset used in the network collects the real part and the imaginary part of to construct , where .
The corresponding operation between the input and the output is expressed as
where denotes the total layers of ResNet. Figure 4 represents some primary layers of the proposed ResNet. The flowcharts of the cascaded channel estimation based on MMPGA-ResNet are summarized below.
- Initialize ;
- Classify based on fitness ranking;
- Execute crossover operation shown in Figure 2;
- Execute adaption mutation operation shown in Figure 3;
- Reserve with the higher fitness;
- Select the best one with the highest fitness;
- Substitute into Equations (1)–(6) and LS algorithm;
- based on Equation (31);
- Substitute into the proposed ResNet shown in Figure 4;
- Train the network parameters in the ResNet;
- Attain the optimization model of ResNet;
- .
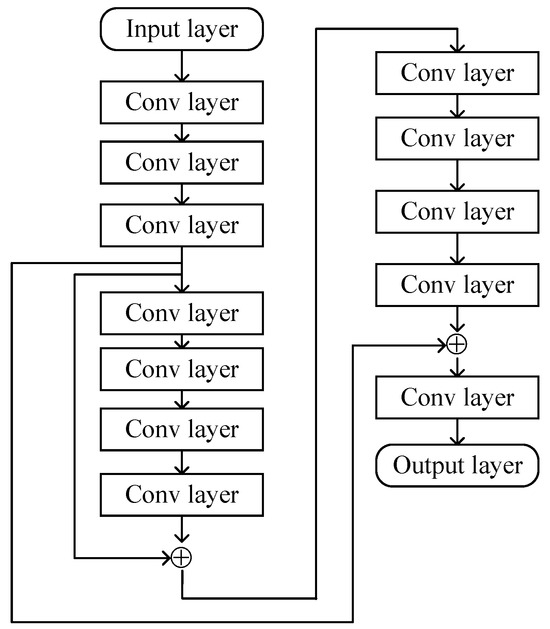
Figure 4.
The primary layers of the proposed ResNet.
Figure 4.
The primary layers of the proposed ResNet.
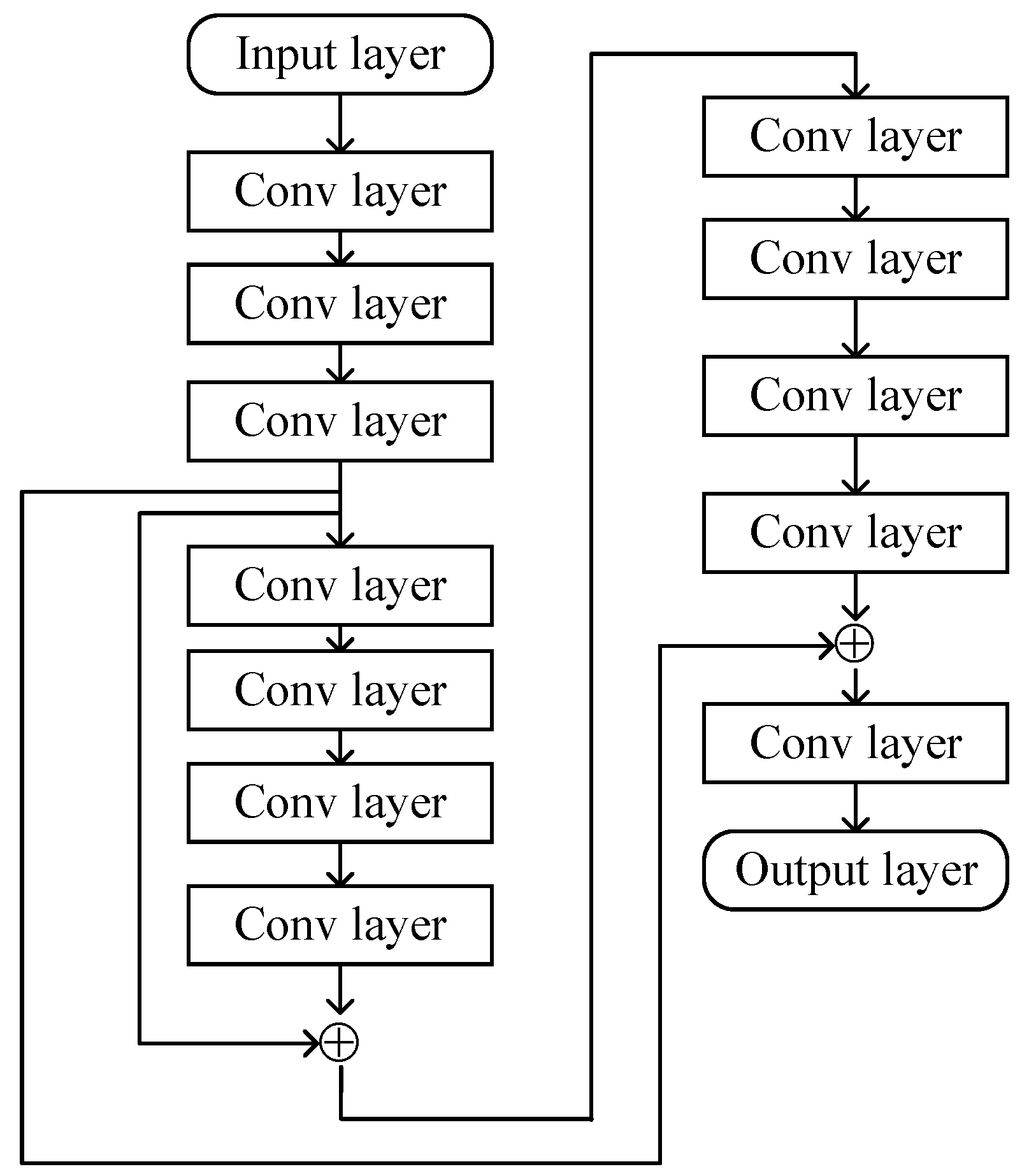
The first convolution layer extracts the information in . For each filter used in the convolution layer, the mathematical expression about the input and a 2D convolution kernel with the dimension of is expressed as
where means the weight of a kernel in the th layer. The corresponding bias b is added to , where b is an element of , and is the number of filters. The convolution layer selects the filter with a size of . Following each convolution layer, the activation function selects the LeakyReLU function, which is expressed as
Furthermore, the network utilizes the batch-normalization operation to avoid the over-fit [36]. In , we select 64 filters. The convolution layers in deploy 128 filters to further process the data from the current input. The operations in select 256 filters. The convolution layers in use 32 filters. Following , the ResNet processes the corresponding output in parallel. In , the proposed ResNet implements the cross-layers operation by adding the outputs of and . The cross-layers operation is also done in by adding the outputs of and . The classical InceptionNets [37] also uses the cross-layers operation to improve learning ability.
The flattening operation used in transforms the 2D matrix obtained by the last convolution layer into a column scalar. Finally, the hidden layer, with multiple neurons in the output layer, processes the column scalar. The corresponding mathematical operation between the current input and output is given as
In the output layer, the proposed ResNet predicts the real and imaginary parts of the cascaded channel. Subsequently, reformulates the predicted channel , which is expressed as .
To evaluate the estimation performance achieved by the ResNet, the NMSE function is used as the error function.
Based on the gradient descent algorithm, learning rate , , and momentum factors, the ResNet updates the prediction. Table 1 represents the configuration of some primary layers in the ResNet.

Table 1.
Configuration of some primary layers in the proposed ResNet.
3.2. MTRnet-Based Reflected Channel Estimation
Based on the output of the ResNet, the proposed MTRnet achieves the reflected channel estimation in the second step. The mapping between input and output is expressed as
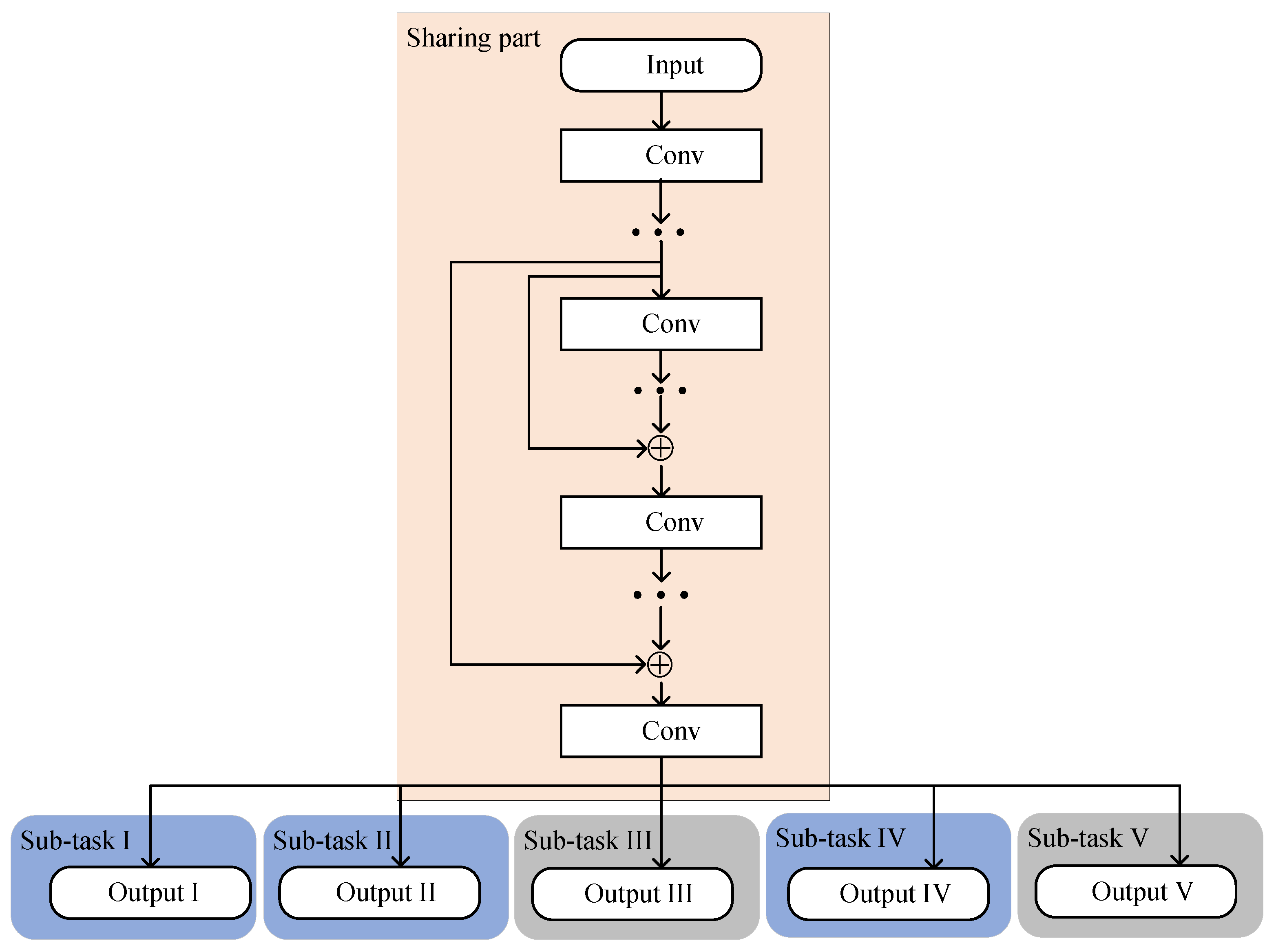
where means the total layers of the MTRnet. Based on Equations (2)–(6), there exists a relationship between and . Figure 5 represents the network structure of the proposed MTRnet.
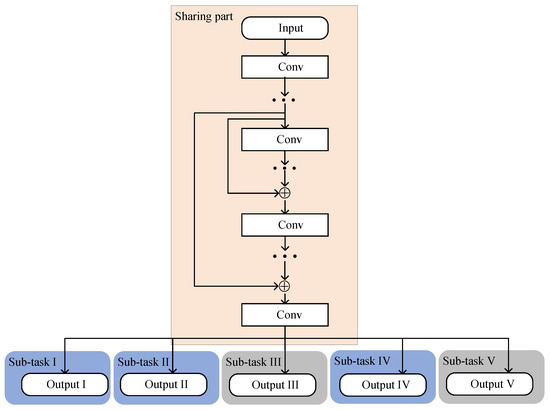
Figure 5.
Network structure of the proposed MTRnet.
The MTRnet mainly contains a sharing part and multiple sub-tasks. The sharing part implements some convolution layers. Except for the output layer, the convolution layers in the sharing part are the same as the ResNet. Considering the 2D convolution kernel, is firstly reshaped into .
The MTRnet selects the output of the sharing part as the input for all sub-tasks. Following the last convolution-activation-batch-normalization layers in the sharing part, five sub-tasks further process the current input simultaneously. Remarkably, each sub-task has its own exclusive training parameters. In sub-task I and sub-task II, the corresponding output layers both select P neurons to generate . Meanwhile, the third sub-task with neurons learns the mapping between the current input and . . The fourth sub-task with P neurons achieves the prediction of . The output layer in the fifth sub-task utilizes neurons to generate and formulate . The Tanh activation function is used as the activation function in the second network, which is expressed as . The proposed multi-task regression network selects the mean square error function and Adam optimizer to update the network parameters. Table 2 shows the configuration of network parameters in the five sub-tasks.
Table 2.
Configuration of network parameters in the five sub-tasks.
Finally, the proposed method achieves the reflected channel estimation through the mapping between outputs obtained by the multi-task regression network and . It is clear that and . To evaluate the estimation performance in the reflected channels, we also select the NMSE function.
3.3. Implementation of the Novel Two-Step Method
The proposed method is decomposed into two steps, including the MMPGA-LS-ResNet-based cascaded channel estimation and the MTRnet-based reflected channel estimation. In the cascaded channel estimation, the proposed MMPGA-LS first generates the population . Then, the proposed MMPGA attains via the population classification, crossover operation, adaptive mutation operation, and population reservation. Based on and the LS estimator, is formulated from . Furthermore, the proposed method achieves the cascaded channel estimation via learning the relationship between the cascaded channel obtained by MMPGA-LS and the channel of UE-RIS-BS. is used as the input of the proposed ResNet. The corresponding output in the ResNet is expressed as . As a strong de-noise ability, the ResNet is capable of further reducing the cascaded channel estimation error. The output of the ResNet is reshaped into and used as the input to the proposed MTRnet. The MTRnet using a multi-task regression model and ResNet estimates the channels of RIS-BS and UE-RIS simultaneously. As a result, the channel parameters are used as the output of the MTRnet. Finally, the proposed method reconstructs the reflected channels based on the output of MTRnet.
The flowcharts of the proposed two-step method are shown in Figure 6, which can be summarized as follows:
- Generate population ;
- Attain via the proposed MMPGA;
- Obtain by LS estimator;
- ;
- Substitute into the proposed ResNet;
- Generate via the optimization model of ResNet;
- ;
- Substitute into the proposed MTRnet;
- Achieve via the optimization model of MTRnet;
- , .
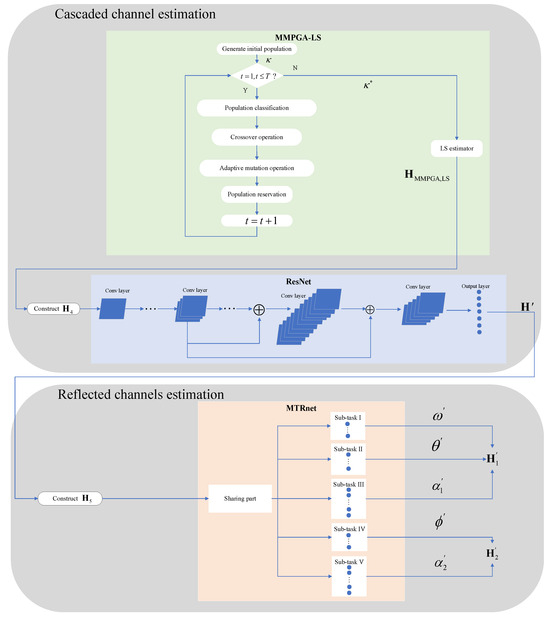
Figure 6.
The flowcharts of the novel two-step method.
Figure 6.
The flowcharts of the novel two-step method.
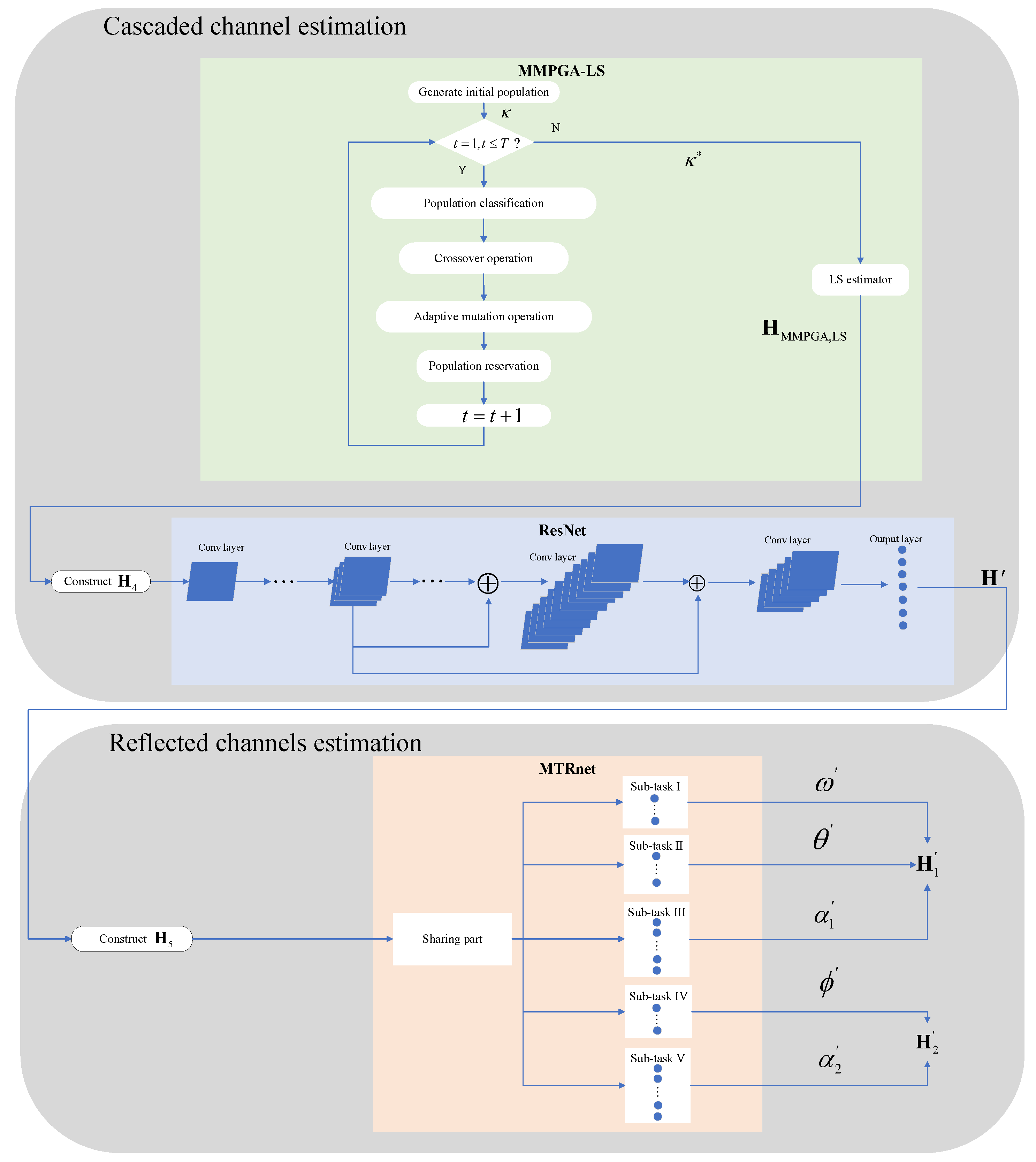
In Figure 6, the light green part represents the MMPGA-LS. The portion with light blue stand for the ResNet. The beige colored part of Figure 6 denotes the MTRnet.
With much discussion of the cascaded channel estimation, the proposed MMPGA-LS-ResNet can be summarized as follows:
- Initialize population;
- Classify via the descending order criterion of fitness;
- Execute the crossover operation based on Equations (24) and (25);
- Adopt the adaptive mutation strategy based on Equations (26) and (27);
- Select with higher fitness;
- Replace with ;
- Replace with ;
- Estimate ;
- Construct ;
- Predict via the optimization model of ResNet.
As a result, is exported and used as the input to the MTRnet. Then, after much discussion of reflected channel estimation, the MTRnet-based method can be summarized as follows:
- Construct ;
- Predict and by the optimization model of MTRnet;
- Evaluate the channel estimation performance based on Equations (39) and (40).
4. Simulation Results and Discussion
In this section, a series of results validate the superiority of the proposed method. The SNR regimes contain dB. In each SNR, the network uses a dataset with a length of 110,000. The length of the training dataset is 90000, and the validation dataset contains the dataset with a length of 10,000. The remaining data belong to the test dataset. Throughout the simulations, the RIS implements the formulation of the uniform linear array with elements and . The BS uses the uniform linear array with elements, , , and the half-wavelength spacing. Besides, we select . Keras 2.2 is used to implement the proposed neural networks. The networks are running on Python 3.5, cuda 10.0, cuDNN 7.6, and GPU 8G. MMPGA-LS is compared with GA [29] and PSO [30] in terms of cascaded channel estimation NMSE. For the reflected channel estimation performance, CNN [15] and CRNN [17] are compared with the proposed method in terms of the NMSE.
4.1. Comparisons with Reported Methods
Table 3 summarizes the computation complexity of different methods. The computation in the proposed MMPGA is mainly concentrated on initialization, crossover, and mutation operations. The computation complexity of the initialization is about the population and the complexity of the LS algorithm, which is expressed as . The computational complexity of the crossover operation is proportional to and the LS algorithm, which is shown as . The computational complexity of the mutation is proportional to and , and its computational complexity is denoted as . As a result, the complexity of the proposed MMPGA is written as . The computational complexity of PSO [30] is . The computational complexity of GA [29] stands for . The training parameters are widely used for evaluating the computational complexity of the neuron network. In the convolution layer, the training parameters are expressed as , where means the filter numbers in the current layer and are the filter numbers in the next layer [38]. The training parameters in the hidden layer are denoted as , where stands for the neurons number in the current layer and is denoted as the neurons number in the next layer [38]. According to Table 1 and Figure 5, the computational complexity of the proposed neuron networks is expressed as . The computational complexity of CRNN [17] stands for , where means the 2D dimension of filters, is the number of the convolution layers, and stands for the number of hidden layers. The computational complexity of CNN [15] is .
Table 3.
Computational complexity comparison of different methods.
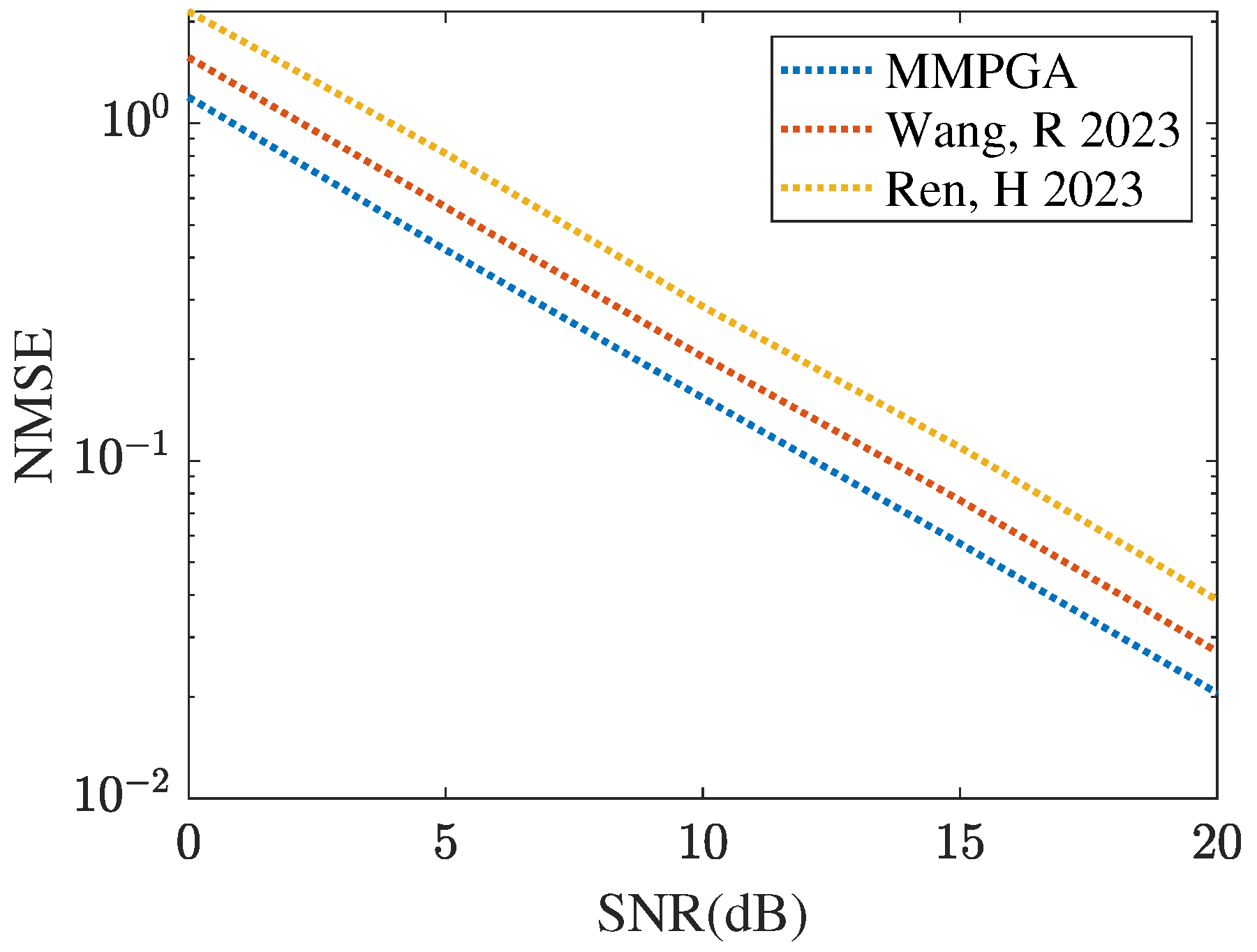
Figure 7 represents the cascaded channel estimation performance obtained by different heuristic algorithms, including GA [29], PSO [30], and the proposed MMPGA-LS. As shown in Figure 7, the proposed MMPGA-LS achieves a lower channel estimation compared with that achieved by GA [29] and PSO [30]. In SNR 20 dB, the MMPGA-LS obtains the NMSE of , which is lower than achieved by PSO [30] and achieved by GA [29]. Compared with GA [29], the proposed MMPGA-LS abandons the random operation in the crossover operation and adaptively changes the factors in the mutation operation. As a result, the proposed MMPGA-LS is capable of further reducing the channel estimation error. It is concluded from Figure 7 that the proposed MMPGA-LS outperforms GA [29] and PSO [30] in terms of a lower NMSE.
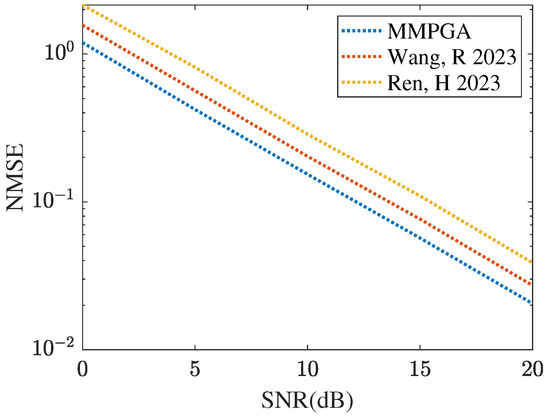
Figure 7.
Cascaded channel estimation performance obtained by different evolution algorithms.
In the next sub-simulation, we compare the cascaded channel estimation performance achieved by the traditional algorithm and some existing deep-learning-based methods. Figure 8a compares the channel estimation NMSE in the LS algorithm [35] and the proposed ResNet. The ResNet, with its strong de-noise ability, effectively suppresses the inference from the noise. Relying on the curves plotted in Figure 8a, the proposed ResNet obtains a lower NMSE across a range of SNR regimes. In Figure 8b, we compare the cascaded channel estimation NMSE obtained by CRNN [17], CNN [15], and the proposed ResNet. It is clear that the deep-learning-based methods significantly reduce the NMSE compared with the LS algorithm [35]. In SNR 20 dB, the ResNet achieves NMSE 0.0052, which is reduced by 32.47% relative to CRNN [17] and 36.25% relative to CNN [15]. The proposed ResNet with the cross-layers operation explores the relationship between different layers and has a stronger learning ability compared with CRNN [17] and CNN [15]. Therefore, the proposed ResNet can further reduce the cascaded channel estimation NMSE. It is concluded from Figure 8 that the proposed ResNet is superior to the LS algorithm [35], CRNN [17], and CNN [15].
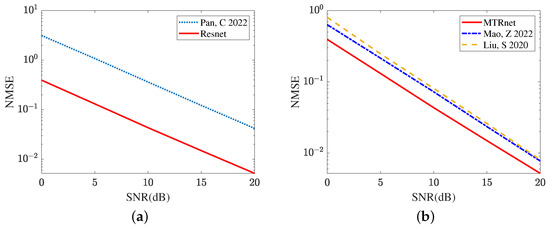
Figure 8.
Cascaded channel estimation performance comparison by different models. (a) Cascaded channel estimation performance comparison between the deep learning and model-driven. (b) Cascaded channel estimation performance comparison among different deep learning models.
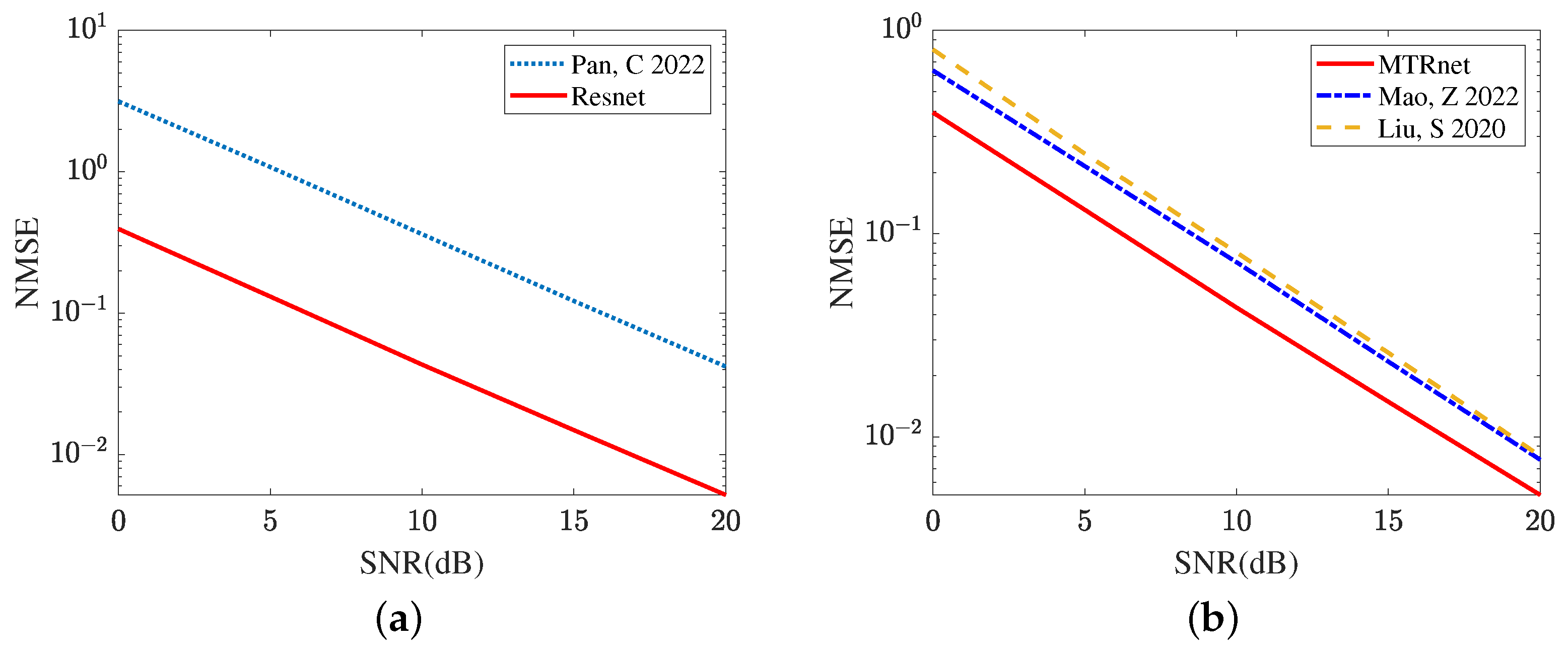
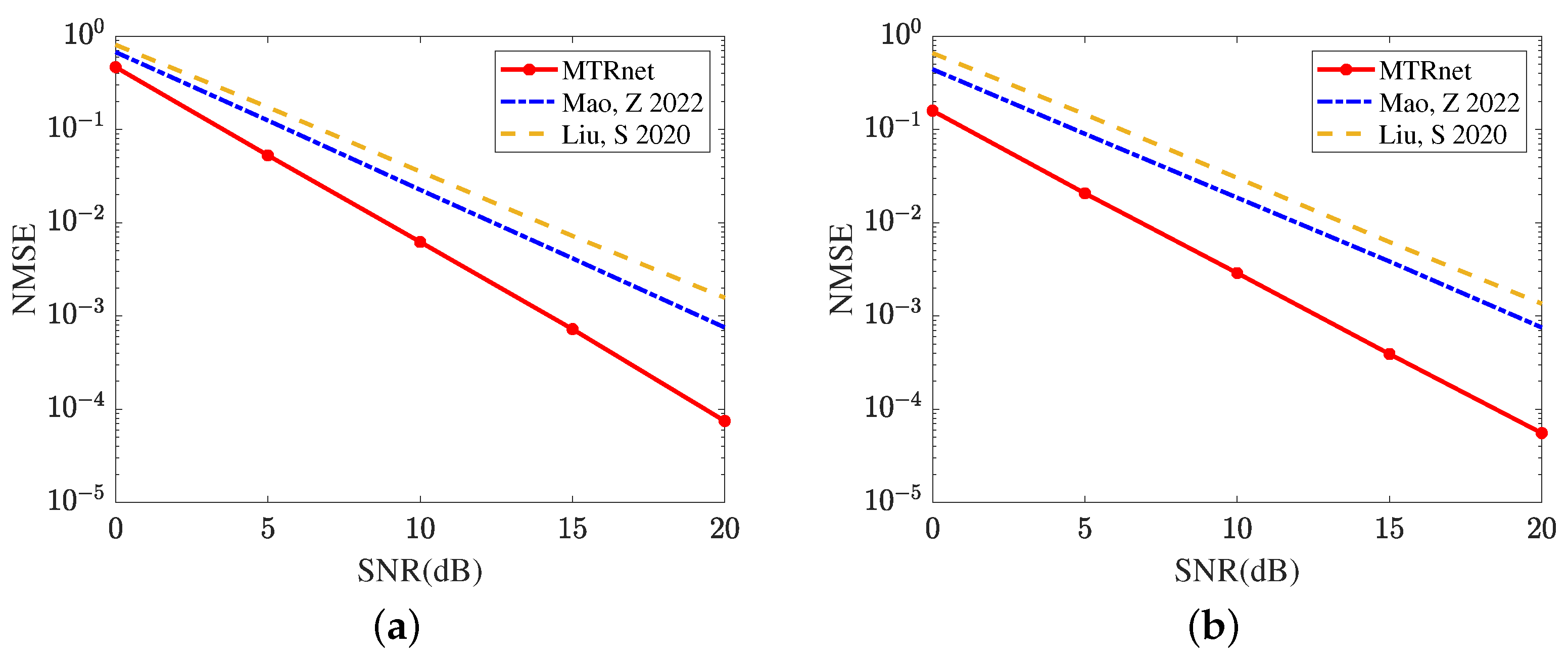
Figure 9 compares the reflected channel estimation performance obtained by different deep learning models, including CRNN [17], CNN [15], and the proposed MTRnet. Figure 9a evaluates the channel estimation NMSE of RIS-BS. As the single output layer, CRNN [17] and CNN [15] both use multiple optimization models to achieve this channel estimation. Remarkably, the proposed MTRnet with multiple output layers only requires one model. In SNR 20 dB, the proposed MTRnet obtains an NMSE of , which is lower than achieved by CRNN [17] and achieved by CNN [15]. Figure 9b exhibits the channel estimation NMSE of UE-RIS. The proposed MTRnet also obtains a lower NMSE compared with CRNN [17] and CNN [15]. In SNR 0 dB, the proposed MTRnet obtains an NMSE of , which is lower than achieved by CRNN [17] and achieved by CNN [15]. It is observed from Figure 9 that the proposed MTRnet can achieve the lower reflected channel estimation NMSE simultaneously.
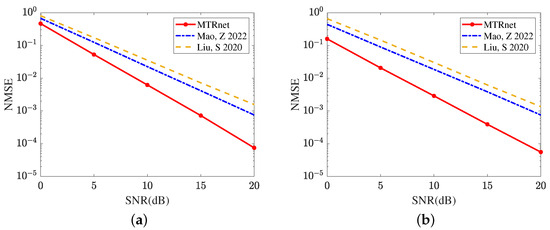
Figure 9.
Reflected channel estimation performance comparison in different deep learning models (a) Channel estimation NMSE of RIS-BS. (b) Channel estimation NMSE of UE-RIS.
4.2. Numerical Results of The Proposed Two-Step Mehod
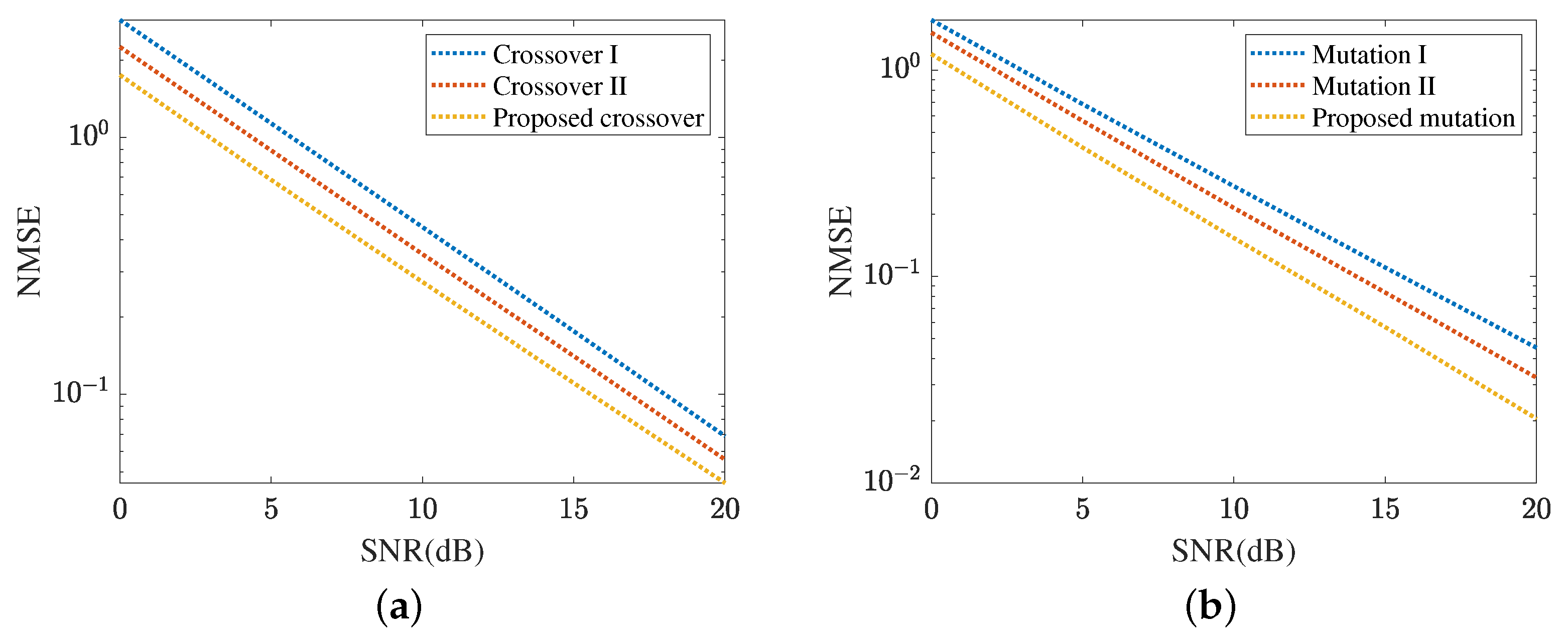
Figure 10 demonstrates the cascaded channel estimation NMSE obtained by the proposed MMPGA-LS. In Figure 10a, we investigate the performance comparison with three crossover strategies. In crossover I, one randomly selected child of the father population, mother population, and sub-population execute the crossover operation. Differently, children in the father population and mother population are paired in descending order of fitness and perform crossover operations in turn. Besides, one randomly selected child of the father population and sub-population execute the crossover operation in the crossover II. As shown in Figure 10a, the proposed crossover strategy achieves a lower NMSE compared with crossover I and crossover II. The NMSE obtained by the crossover II is minor. The crossover I achieves the highest NMSE. The proposed crossover strategy takes advantage of the best one with the highest fitness and is conducive to reducing the cascaded channel estimation error. In SNR 20 dB, the proposed crossover strategy obtains an NMSE of , which is lower than achieved by crossover II and achieved by crossover I. Figure 10b compares the cascaded channel estimation NMSE in different mutation strategies. In mutation I, this mutation is based on the binary children, and a random position corresponding to each gene is changed to 0/1. Mutation II uses the decimal children and a fixed scale factor. The cascaded channel estimation performance in mutation I is sensitive to the length and requires a sufficiently long sequence to achieve a low NMSE. The proposed mutation strategy can adjust the scale factor set according to different fitness levels. As a result, the proposed mutation strategy reduces cascaded channel estimation NMSE compared with mutation I and mutation II. In SNR 20 dB, the proposed mutation strategy obtains an NMSE of , which is lower than achieved by mutation II and achieved by mutation I.
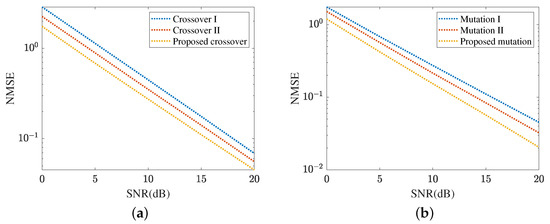
Figure 10.
Cascaded channel estimation performance of the proposed MMPGA-LS. (a) Performance comparison in different crossover strategies. (b) Performance comparison in different mutation strategies.
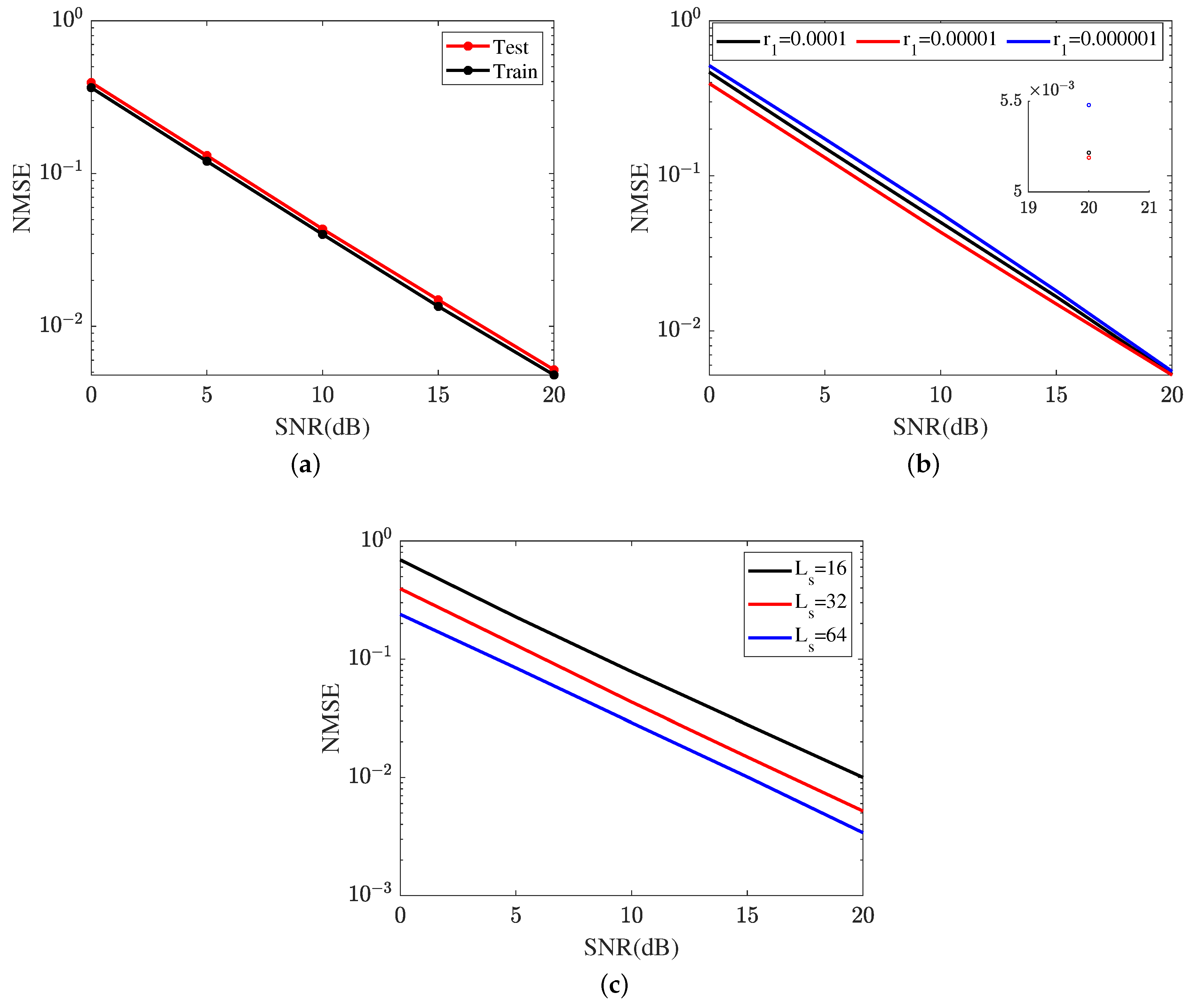
Figure 11 represents the cascaded channel estimation performance achieved by the proposed ResNet. In Figure 11a, we compare the cascaded channel estimation NMSE in the training dataset and test dataset. As shown in Figure 11a, the proposed ResNet achieves a lower NMSE in the training dataset compared with that in the test dataset. Figure 11b investigates the impact of different learning rates on the cascaded channel estimation performance, including . The learning rate is one of the key parameters in neural network optimization and has an important influence on the learning ability of the ResNet. The ResNet achieves the lowest NMSE in . The NMSE in is minor. Based on the curves plotted in Figure 11b, the proposed ResNet selects in terms of a lower cascaded channel estimation NMSE. In Figure 11c, we investigate the impact of different lengths of signal sequence on the cascaded channel estimation performance, including . In SNR 20 dB, the proposed ResNet obtains an NMSE of in , which is higher than in and lower than in . Relying on the result shown in Figure 11c, the cascaded channel estimation NMSE reduces as the length of the signal sequence increases.
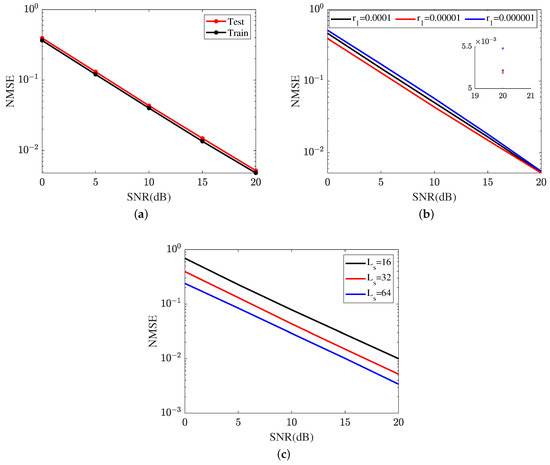
Figure 11.
Cascaded channel estimation performance of the proposed ResNet. (a) Cascaded channel estimation performance in different datasets. (b) Cascaded channel estimation performance at different learning rates. (c) Cascaded channel estimation performance in different lengths of signal sequence.
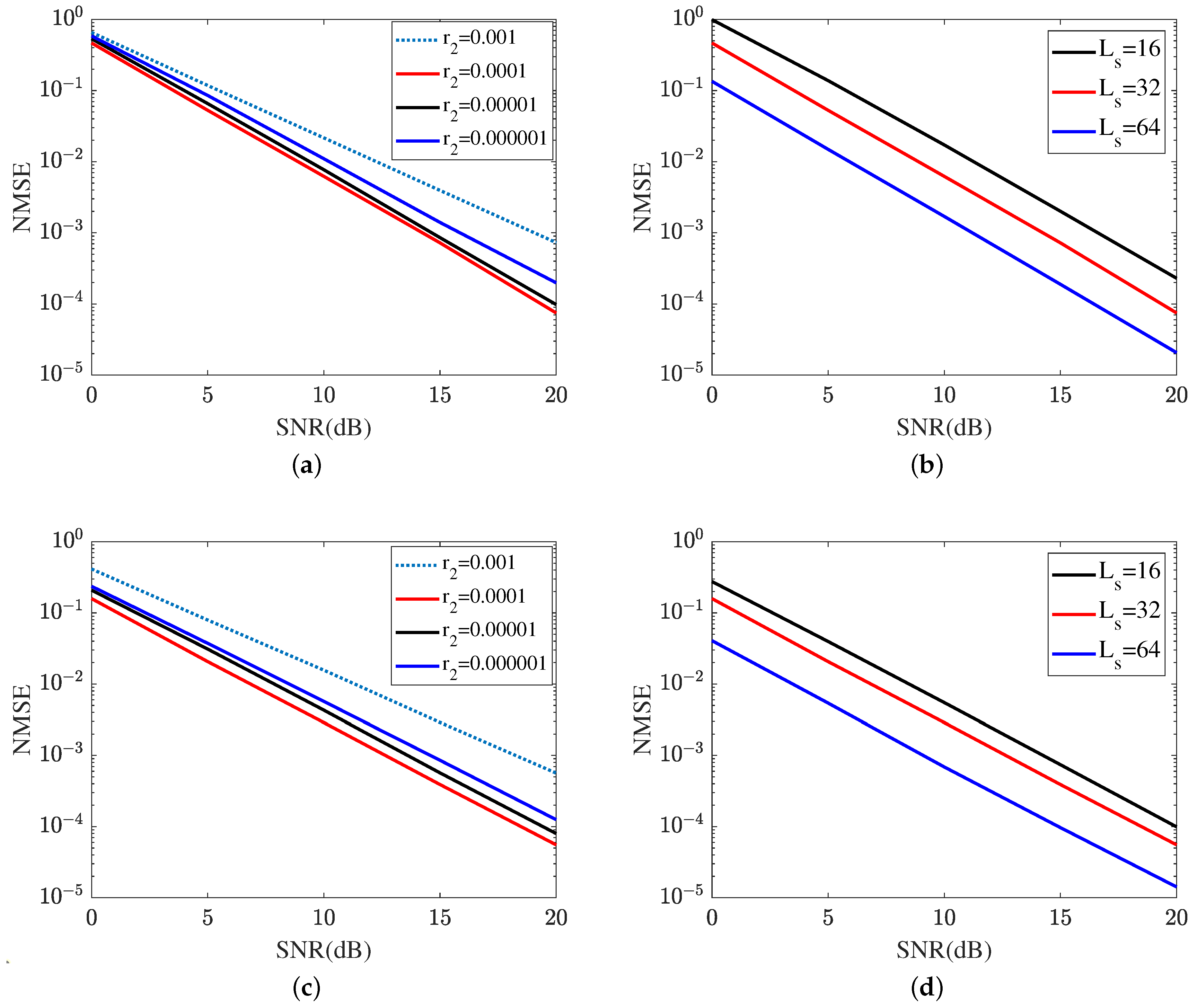
Figure 12 shows the reflected channel estimation performance achieved by the proposed MTRnet. Figure 12a,b represent the reflected channel estimation NMSE of RIS-BS. As shown in Figure 12a, the MTRnet with attains the lowest NSME within the same iteration. In SNR 20 dB, the proposed ResNet with obtains an NMSE of , which is lower than in and in , and in . Therefore, is applied for the next sub-simulations. In Figure 12b, we investigate the impact of different lengths of signal sequence on the cascaded channel estimation performance of RIS-BS. The reflected channel estimation NMSE versus the growth of signal sequence reduces. Figure 12c,d represent the reflected channel estimation NMSE of UE-RIS. Figure 12c represents the impact of different learning rates on the reflected channel estimation performance of UE-RIS, including . Based on the result plotted in Figure 12c, the proposed MRRnet with also attains the lowest NMSE in the reflected channel of UR-RIS. As a result, the proposed MTRnet selects the learning rate . Figure 12d illustrates the reflected channel estimation performance in . As shown in Figure 12d, the proposed MTRnet achieves the highest NMSE in . In SNR 20 dB, the proposed ResNet obtains an NMSE of in , which is lower than in and in . It is concluded from Figure 11c and Figure 12b,d that the channel estimation NMSE reduces as the length of the signal sequence grows.
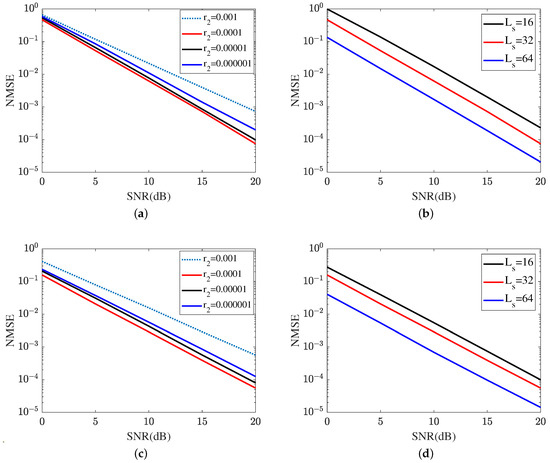
Figure 12.
Reflected channel estimation is achieved by the proposed MTRnet. (a) Reflected channel estimation of RIS-BS at different learning rates. (b) Reflected channel estimation of RIS-BS at different lengths of signal sequence. (c) Reflected channel estimation of UE-RIS at different learning rates. (d) Reflected channel estimation of UE-RIS at different lengths of signal sequence.
4.3. Discussion of the Proposed Method
In the cascaded channel estimation problem, the proposed MMPGA-LS is capable of generating more children compared to GA [29], which does contribute to reducing the cascaded channel estimation NMSE. Besides, MMPGA-LS does not select one randomly and makes good use of the best gene during the crossover operation. The corresponding result shown in Figure 10a has validated the effectiveness of the proposed crossover strategy. Furthermore, the MMPGA-LS refers to the fitness and adjusts the scale factor during the adaptive mutation operation compared with the fixed factor in common evolution algorithms. Therefore, the proposed MMPGA-LS is capable of achieving a lower NMSE. The proposed ResNet with the cross-layers operation and key parameter optimization has a stronger non-linear processing ability compared with CRNN [17] and CNN [15]. As a result, the proposed ResNet with the designed network architecture can attain a lower cascaded channel estimation NMSE compared with CRNN [17] and CNN [15].
For the reflected channels estimation, the proposed MTRnet, integrating the multi-task regression model and ResNet, is introduced. The MTRnet with multiple output layers has a smaller number of network trainings. This is because the MTRnet abandons repetitive network training compared with the single regression model. However, CRNN [17] and CNN [15] with the single output layer require multiple optimization models to estimate the reflected channels. Additionally, the proposed MTRnet obtains a lower reflected channel estimation NMSE compared with CRNN [17] and CNN [15].
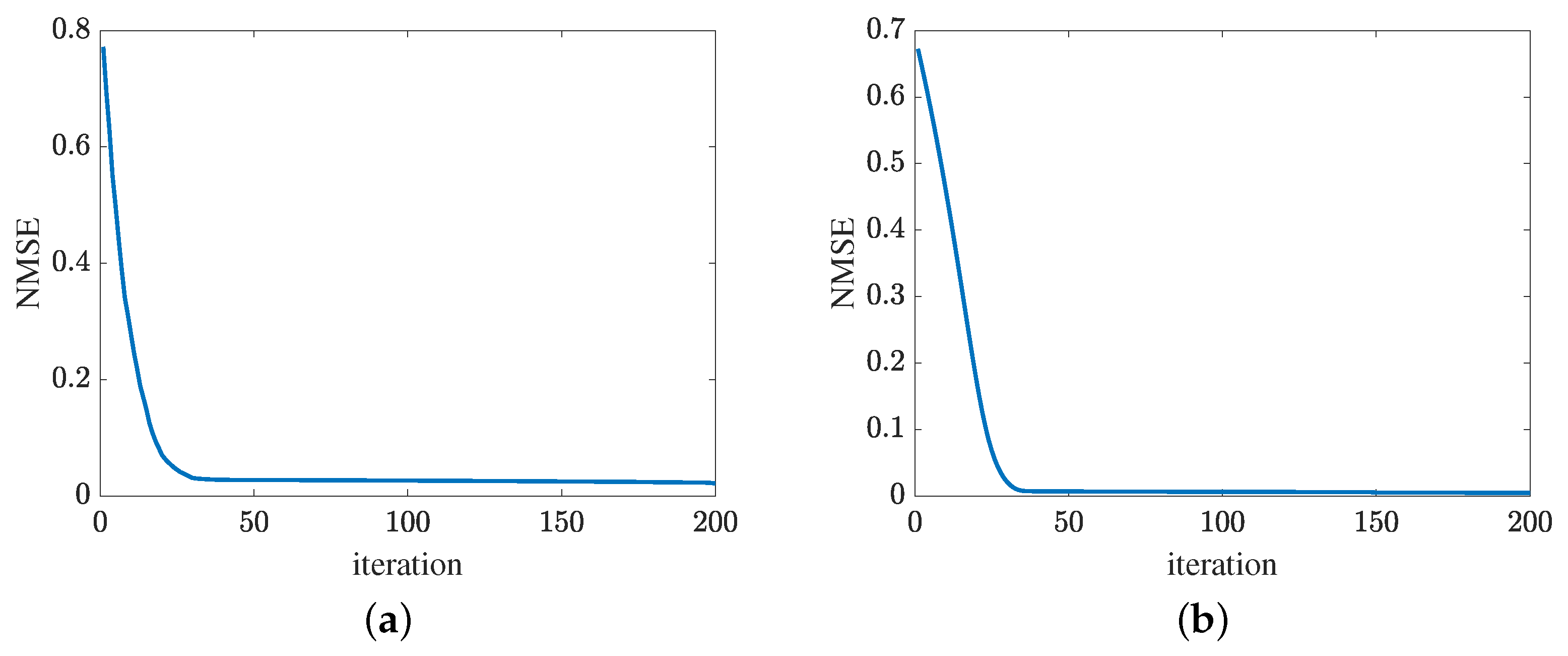
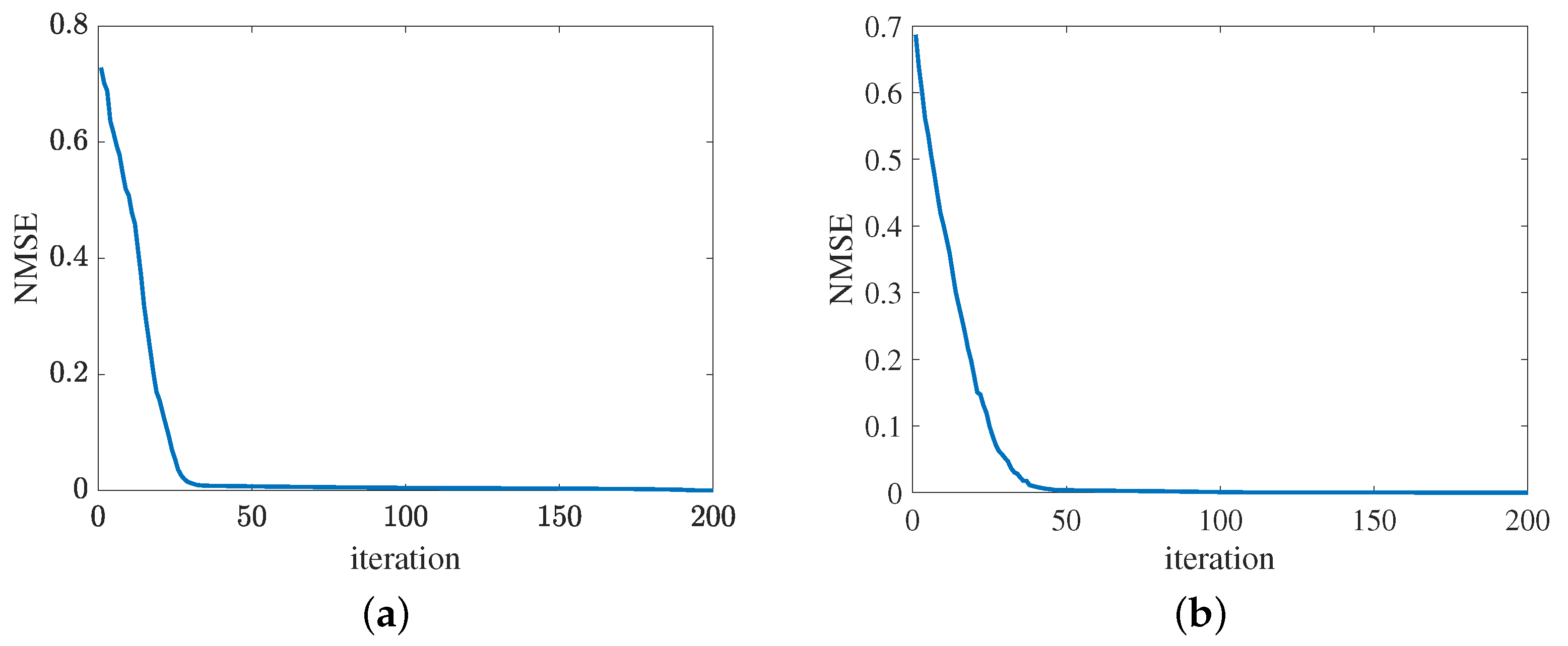
Figure 13 presents the convergence of the proposed method in terms of the cascaded channel estimation performance. As shown in Figure 13a, the NMSE versus the growth of iterations decreases. Besides, the error obtained by the proposed MMPGA slightly decreases in later iterations. In Figure 13b, the proposed ResNet also represents the same tendency as the MMPGA. It is concluded from Figure 13, the proposed method has good convergence on the cascaded channel estimation. The convergence of reflected channel estimation performance is shown in Figure 14. As observed from Figure 14a, the channel estimation error decreases as the neuron network with the gradient descent optimization trains. At NMSE , the channel estimation performance of RIS-BS obtained by the MTRnet decreases slowly. Figure 14b exhibits the convergence of UE-RIS channel estimation performance. The tendency of reflected channel estimation performance degradation can also be seen in Figure 14b. It is clear from Figure 14 that the proposed method has good convergence in terms of the reflected estimation NMSE.
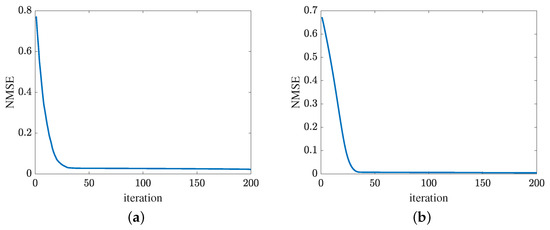
Figure 13.
Cascaded channel estimation performance. (a) Convergence of the proposed MMPGA. (b) Convergence of the proposed ResNet.
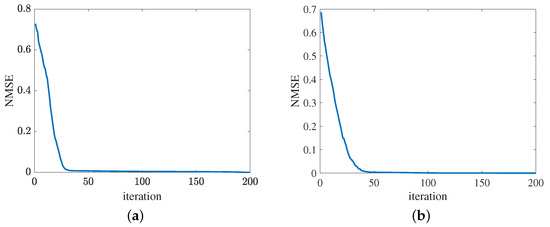
Figure 14.
Convergence of reflected channel estimation performance. (a) IRS-BS channel estimation. (b) UE-RIS channel estimation.
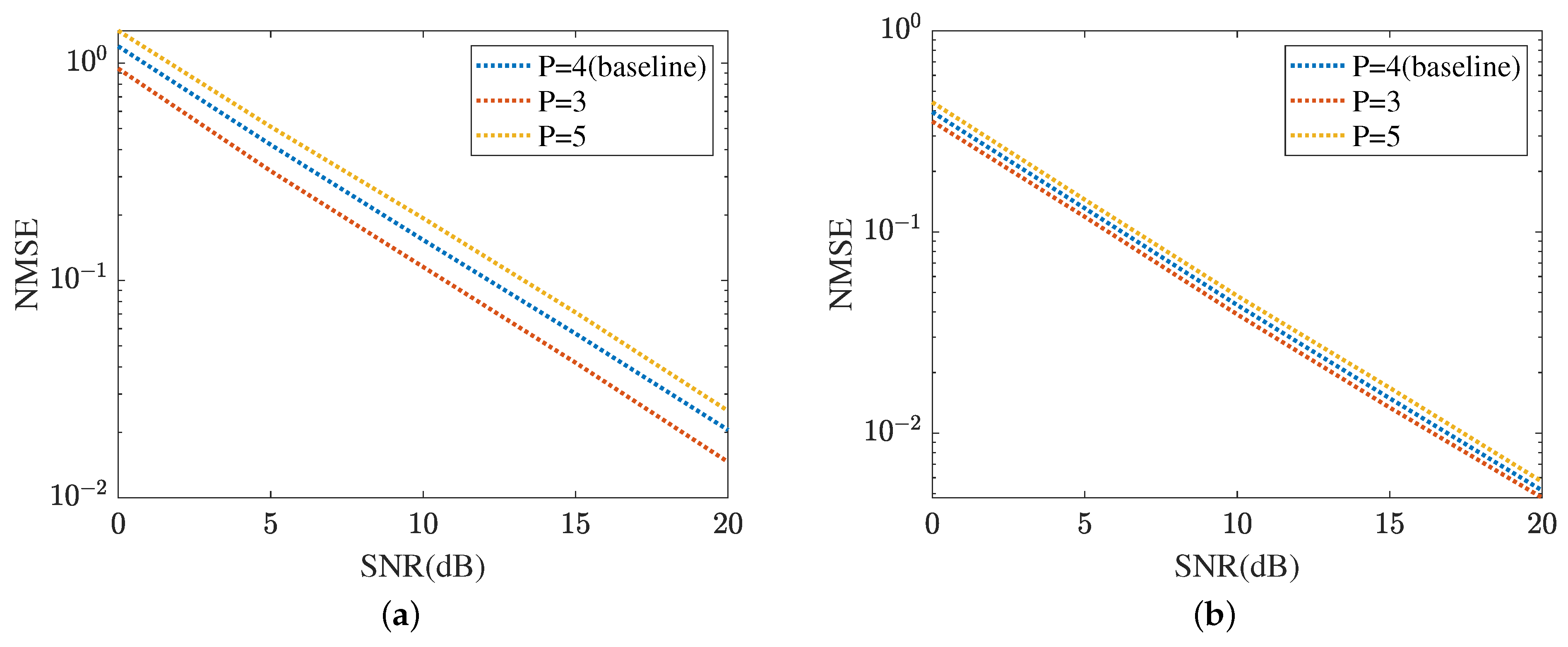
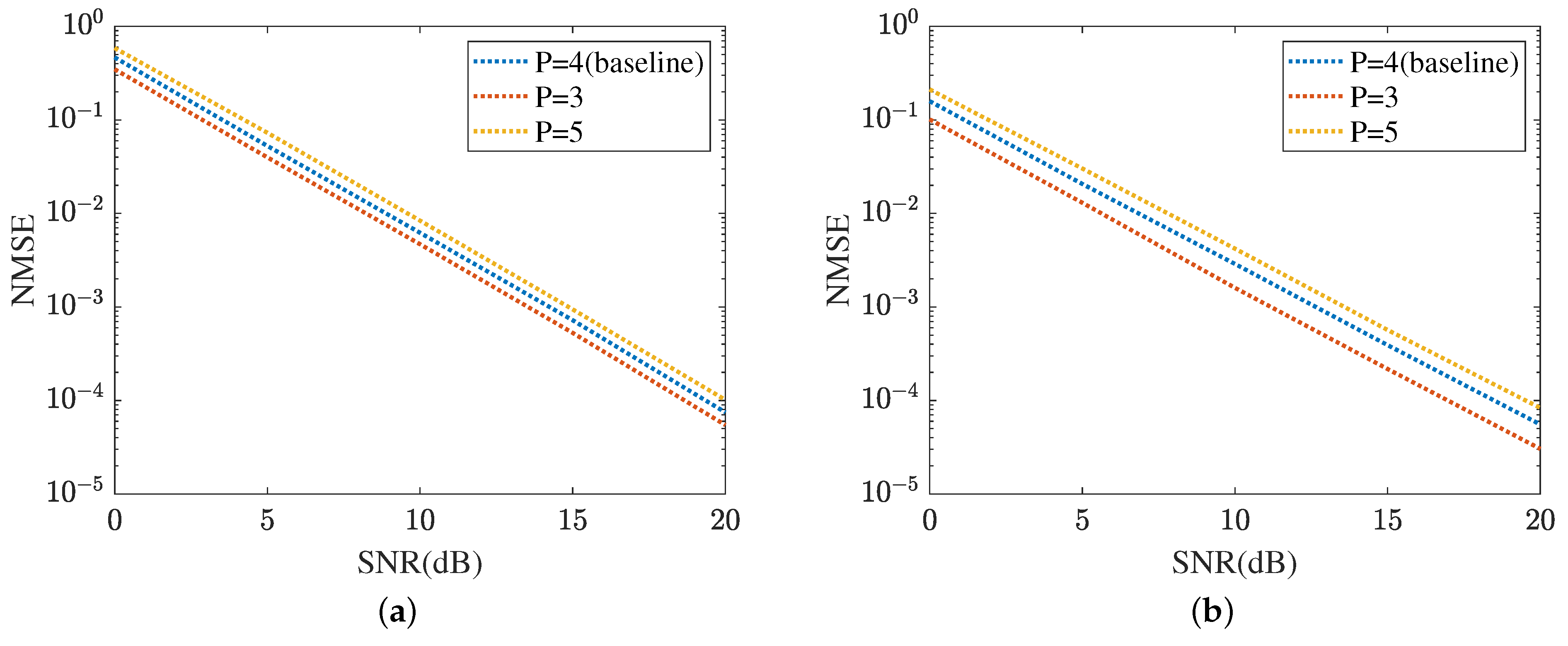
The robustness of the proposed method is shown in Figure 15 and Figure 16, respectively. Figure 15 displays the robustness of the MMPGA and ResNet, where . The proposed method selects as the baseline. As shown in Figure 15a, the NMSE in obtained by the MMPGA is lower than that in . This is because the cascaded channel in is associated with fewer channel parameters. Therefore, the channel parameters in can be simply seen as a subset of those in . As a result, the proposed method is capable of obtaining a lower NMSE in compared with that in . In dB, the MMPGA achieves an NMSE of 0.0146, which is lower than 0.0205 in . Figure 15b represents the robustness of the proposed ResNet in terms of the cascaded channel estimation performance. The model is trained in and tested in . The NMSE in is slightly higher than that in . The proposed ResNet has less robustness in . Due to the increased channel parameters, the ResNet can adjust the network architecture to obtain a lower NMSE. The robustness of the MTRnet is also shown in Figure 16. Figure 16a evaluates the robustness of the proposed MTRnet in terms of the RIS-BS channel. The proposed method has good robustness in . Besides, Figure 16b shows the robustness of the proposed MTRnet in terms of the UE-RIS channel. The proposed method has less robustness in .
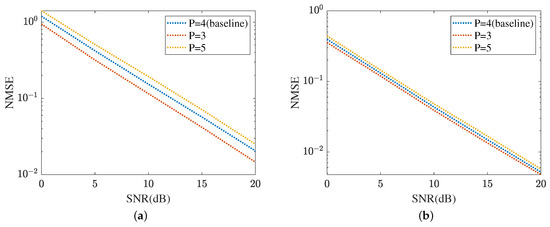
Figure 15.
Cascaded channel estimation performance. (a) Robustness of the proposed MMPGA. (b) Robustness of the proposed ResNet.
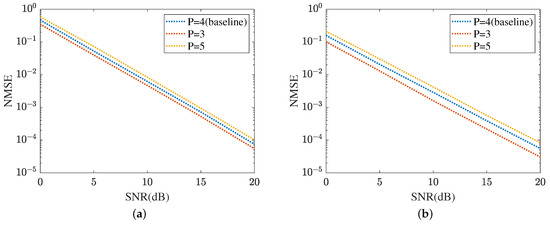
Figure 16.
Robustness of reflected channels estimation performance. (a) IRS-BS channel estimation. (b) UE-RIS channel estimation.
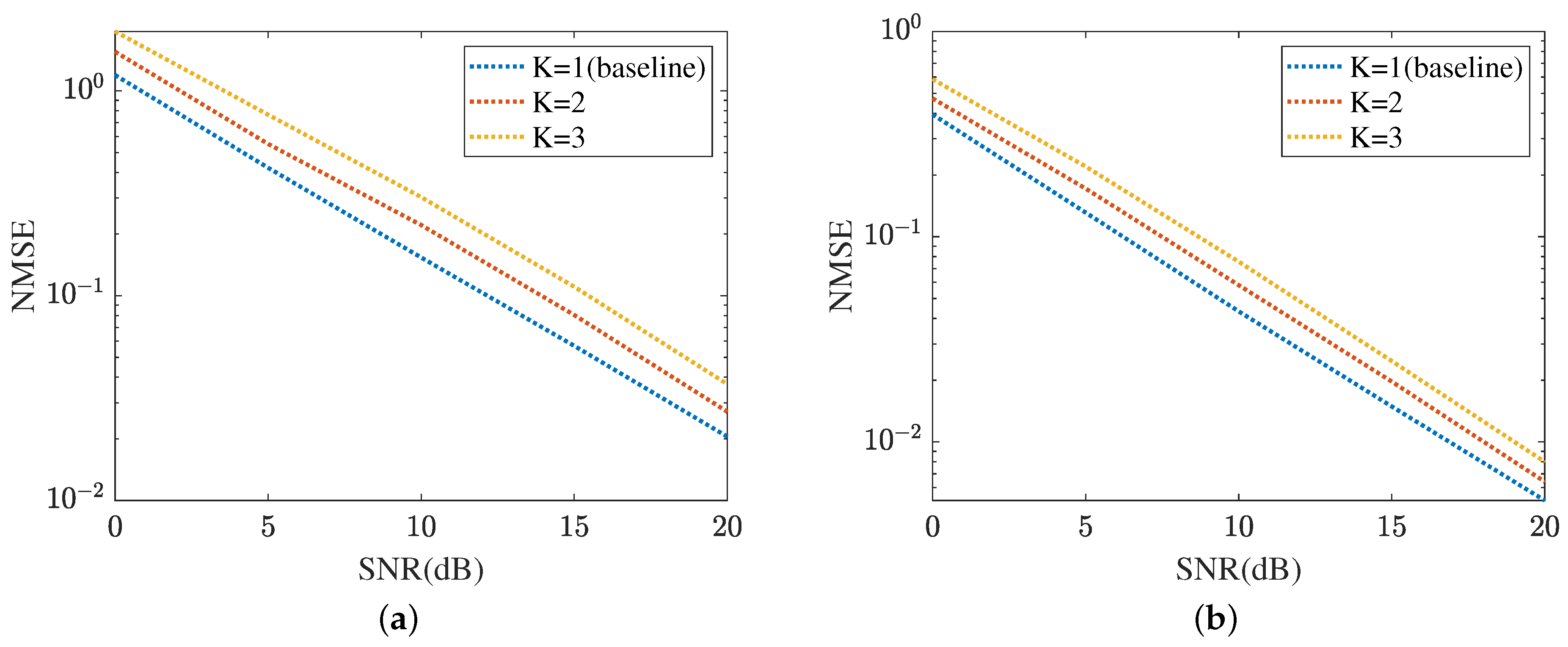
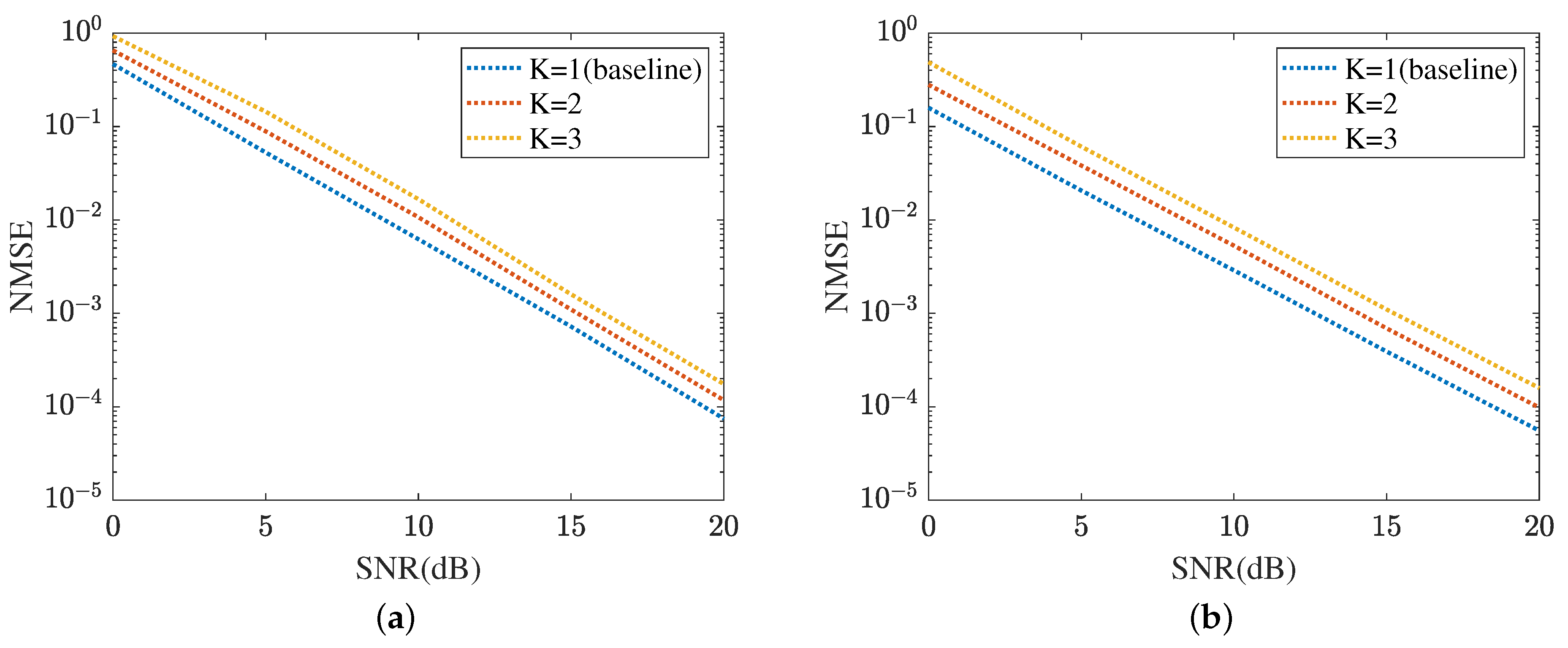
Figure 17 displays the cascaded channel estimation under varying levels of interference, where , K means the number of UEs. The proposed method selects as the baseline. Based on the curves plotted in Figure 17a, the cascaded channel estimation NMSE versus the growth of interference level decreased. This is because the cascaded channel performance deteriorates with the interference among the multipath signals, including multi-UEs. Figure 17b evaluates the robustness of the proposed ResNet in terms of varying levels of interference. In dB, the proposed ResNet obtains the lowest NMSE in and the highest NMSE in . The NMSE in is minor. Figure 18 summarizes the reflected channel estimation performance under varying levels of interference. The tendency shown in Figure 17 is also represented in Figure 18. Figure 18a focuses on the reflected channel of RIS-BS. Differently, Figure 18b represents the UE-RIS channel estimation performance in terms of varying levels of interference. The proposed MTRnet achieves an NMSE of in , which is slightly higher than in and lower than 0.00016 in . According to Figure 17 and Figure 18, the proposed method can achieve a low NMSE under varying levels of interference.
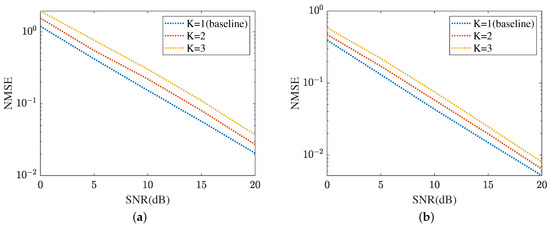
Figure 17.
Cascaded channel estimation performance under varying levels of interference. (a) MMPGA. (b) ResNet.
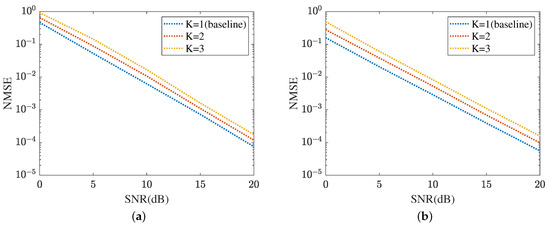
Figure 18.
Reflected channel estimation performance under varying levels of interference. (a) IRS-BS channel estimation. (b) UE-RIS channel estimation.
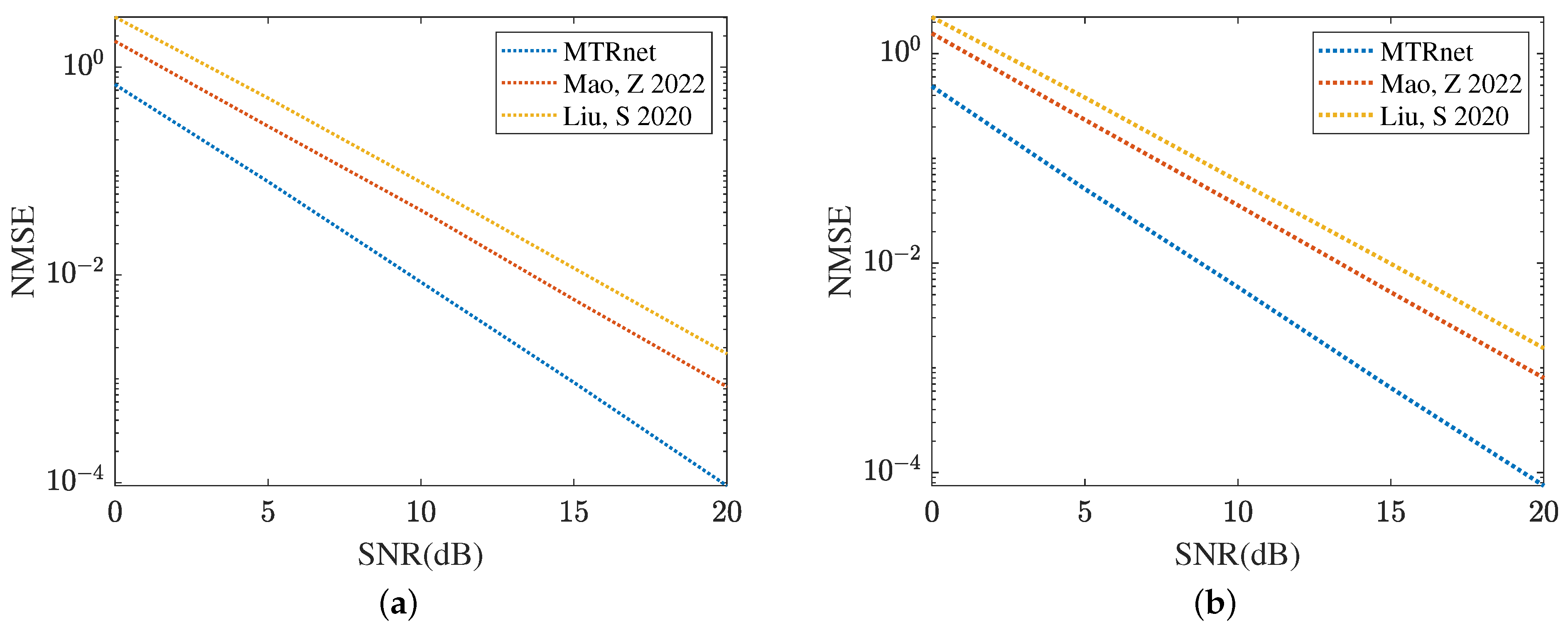
Figure 19 and Figure 20 compare the channel estimation performance based on different models in the RIS with the formulation of UPA, where . As shown in Figure 19a, the proposed MMPGA also outperforms PSO [30] and GA [29] in terms of a lower NMSE. Based on the results plotted in Figure 19b, the proposed ResNet obtains the lowest NMSE across a range of SNR regimes. The NMSE obtained by CRNN [17] is minor. Figure 20 displays the reflected channel estimation performance in UPA. Relying on the results shown in Figure 20a,b, the proposed MTRnet simultaneously obtains a lower NMSE compared with that achieved by CRNN [17] and CNN [15].
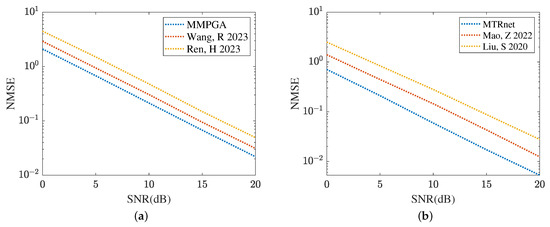
Figure 19.
Cascaded channel estimation performance in UPA. (a) Comparison of different heuristic algorithms. (b) Comparison of different learning models.
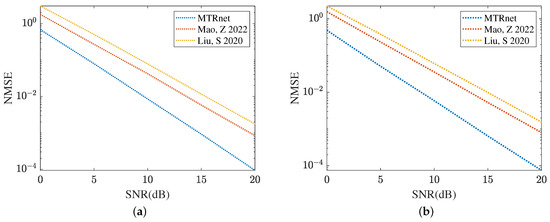
Figure 20.
Reflected channels estimation performance comparison in UPA. (a) IRS-BS channel estimation. (b) UE-RIS channel estimation.
5. Conclusions
In this paper, we proposed a novel two-step channel estimation method for RIS-assisted mmWave systems. In the first step, the proposed MMPGA-LS-ResNet is introduced for cascaded channel estimation. The MMPGA-LS is capable of reducing the NMSE compared with some existing methods. Furthermore, the proposed ResNet, with its strong non-linear processing ability, further reduces the cascaded channel estimation NMSE. Based on the output of ResNet, the proposed MTRnet, integrating multi-task regression model and ResNet, can estimate multiple reflected channels simultaneously. Remarkably, the MTRnet has a lower number of optimization models compared with CRNN [17] and CNN [15]. Besides, the proposed MTRnet outperforms CRNN [17] and CNN [15] in terms of lower NMSE. The future work will focus on the active RIS-mmWace systems and optimization of neural networks.
Funding
This work was funded by Beijing University of Posts and Telecommunications-China Mobile Research Institute Joint Innovation Center.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data are contained within the article.
Conflicts of Interest
The author declares no conflicts of interest.
References
- Ji, B.; Han, Y.; Liu, S.; Tao, F.; Zhang, G.; Fu, Z.; Li, C. Several key technologies for 6G: Challenges and opportunities. IEEE Commun. Stand. Mag. 2021, 5, 44–51. [Google Scholar] [CrossRef]
- Yuan, X.; Zhang, Y.-J.A.; Shi, Y.; Yan, W.; Liu, H. Reconfigurable-intelligent-surface empowered wireless communications: Challenges and opportunities. IEEE Wirel. Commun. 2021, 28, 136–143. [Google Scholar] [CrossRef]
- Guan, X.; Wu, Q.; Zhang, R. Anchor-assisted channel estimation for intelligent reflecting surface aided multiuser communication. IEEE Trans. Wirel. Commun. 2022, 21, 3764–3778. [Google Scholar] [CrossRef]
- Cui, M.; Wu, Z.; Lu, Y.; Wei, X.; Dai, L. Near-Field MIMO Communications for 6G: Fundamentals, Challenges, Potentials, and Future Directions. IEEE Commun. Mag. 2023, 61, 40–46. [Google Scholar] [CrossRef]
- Araújo, G.T.D.; Almeida, A.L.F.D.; Boyer, R. Channel estimation for intelligent reflecting surface assisted MIMO systems: A tensor modeling approach. IEEE J. Sel. Top. Signal Process. 2021, 15, 789–802. [Google Scholar] [CrossRef]
- Wen, F.; Shi, J.; Lin, Y.; Gui, G.; Yuen, C.; Sari, H. Joint DOD and DOA Estimation for NLOS Target using IRS-aided Bistatic MIMO Radar. IEEE Trans. Veh. Technol. 2021, 1–6. [Google Scholar] [CrossRef]
- Wei, Y.; Zhao, M.-M.; Zhao, M.-J.; Cai, Y. Channel estimation for IRS-aided multiuser communications with reduced error propagation. IEEE Trans. Wirel. Commun. 2022, 21, 2725–2741. [Google Scholar] [CrossRef]
- Zhou, G.; Pan, C.; Ren, H.; Popovski, P.; Swindlehurst, A.L. Channel estimation for RIS-aided multiuser millimeter-wave systems. IEEE Trans. Signal Process. 2022, 70, 1478–1492. [Google Scholar] [CrossRef]
- Wang, P.; Fang, J.; Duan, H.; Li, H. Compressed channel estimation for intelligent reflecting surface-assisted millimeter wave systems. IEEE Signal Process. Lett. 2020, 27, 905–909. [Google Scholar] [CrossRef]
- Chien, T.V.; Le, C.V.; Binh, H.T.T.; Ngo, H.Q.; Chatzinotas, S. Phase Shift Design for RIS-Aided Cell-Free Massive MIMO With Improved Differential Evolution. IEEE Trans. Veh. Technol. 2023, 12, 1499–1503. [Google Scholar] [CrossRef]
- Byun, Y.; Kim, H.; Kim, S.; Shim, B. Channel Estimation and Phase Shift Control for UAV-Carried RIS Communication Systems. IEEE Trans. Veh. Technol. 2023, 72, 13695–13700. [Google Scholar] [CrossRef]
- Lin, T.; Yu, X.; Zhu, Y.; Schober, R. Channel estimation for IRS-assisted millimeter-wave MIMO systems: Sparsity-inspired approaches. IEEE Trans. Commun. 2022, 70, 4078–4092. [Google Scholar] [CrossRef]
- Chen, Z.; Tang, J.; Zhang, X.Y.; So, D.K.C.; Jin, S.; Wong, K.-K. Hybrid evolutionary-based sparse channel estimation for IRS-assisted mmWave MIMO systems. IEEE Trans. Wirel. Commun. 2022, 21, 1586–1601. [Google Scholar] [CrossRef]
- Gao, T.; He, M. Two-Stage Channel Estimation Using Convolutional Neural Networks for IRS-Assisted mmWave Systems. IEEE Syst. J. 2023, 17, 3183–3191. [Google Scholar] [CrossRef]
- Liu, S.; Lei, M.; Zhao, M.-J. Deep learning based channel estimation for intelligent reflecting surface aided MISO-OFDM system. In Proceedings of the 2020 IEEE 92nd Vehicular Technology Conference (VTC2020-Fall), Victoria, BC, Canada, 18 November–16 December 2020; pp. 1–5. [Google Scholar]
- Ye, M.; Zhang, H.; Wang, J.-B. Channel Estimation for Intelligent Reflecting Surface Aided Wireless Communications Using Conditional GAN. IEEE Commun. Lett. 2022, 26, 2340–2344. [Google Scholar] [CrossRef]
- Mao, Z.; Liu, X.; Peng, M. Channel estimation for intelligent reflecting surface assisted massive MIMO systems—A deep learning approach. IEEE Commun. Lett. 2022, 26, 798–802. [Google Scholar] [CrossRef]
- Liu, Y.; Al-Nahhal, I.; Dobre, O.A.; Wang, F. Deep-Learning Channel Estimation for IRS-Assisted Integrated Sensing and Communication System. IEEE Trans. Veh. Technol. 2022, 72, 6181–6193. [Google Scholar] [CrossRef]
- Wang, Y.; Lu, H.; Sun, H. Channel estimation in IRS-enhanced mmWave system with super-resolution network. IEEE Commun. Lett. 2021, 25, 2599–2603. [Google Scholar] [CrossRef]
- Liu, C.; Liu, X.; Ng, D.W.K.; Yuan, J. Deep residual learning for channel estimation in intelligent reflecting surface-assisted multiuser communications. IEEE Trans. Wirel. Commun. 2021, 21, 898–912. [Google Scholar] [CrossRef]
- Liu, C.; Liu, X.; Ng, D.W.K.; Yuan, J. Deep residual network empowered channel estimation for IRS-assisted multi-user communication systems. In Proceedings of the ICC 2021-IEEE International Conference on Communications, Montreal, QC, Canada, 14–23 June 2021; pp. 1–7. [Google Scholar]
- Wang, H.; Memon, F.H.; Wang, X.P.; Li, X.; Zhao, N.; Dev, K. Machine learning-enabled MIMO-FBMC communication channel parameter estimation in IIoT: A distributed CS approach. Digit. Commun. Netw. 2023, 9, 306–312. [Google Scholar] [CrossRef]
- Choi, J.; Cho, H.J. A Joint Optimization of Pilot and Phase Shifts in Uplink Channel Estimation for Hybrid RIS-Aided Multi-User Communication Systems. IEEE Trans. Veh. Technol. 2024, 73, 5197–5212. [Google Scholar] [CrossRef]
- Schroeder, R.; He, J.; Brante, G.; Juntti, M. Two-Stage Channel Estimation for Hybrid RIS Assisted MIMO Systems. IEEE Trans. Veh. Technol. 2022, 70, 4793–4806. [Google Scholar] [CrossRef]
- Zhang, H.; Liu, W.; Zhang, Q.; Liu, B. Joint Customer Assignment, Power Allocation, and Subchannel Allocation in a UAV-Based Joint Radar and Communication Network. IEEE Internet Things J. 2024, 1. [Google Scholar] [CrossRef]
- Chen, Z.; Tang, J.; Zhang, X.Y.; Wu, Q.; Wang, Y.; So, D.K.; Jin, S.; Wong, K.K. Offset Learning Based Channel Estimation for Intelligent Reflecting Surface-Assisted Indoor Communication. IEEE J. Sel. Top. Signal Process. 2022, 16, 41–55. [Google Scholar] [CrossRef]
- Zhang, K.; Sun, M.; Han, T.X.; Yuan, X.; Guo, L.; Liu, T. Residual networks of residual networks: Multilevel residual networks. IEEE Trans. Circuits Syst. Video Technol. 2018, 28, 1303–1314. [Google Scholar] [CrossRef]
- Ranjan, R.; Patel, V.M.; Chellappa, R. HyperFace: A deep multi task learning framework for face detection, landmark localization, pose estimation, and gender recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 121–135. [Google Scholar] [CrossRef]
- Ren, H.; Liu, X.; Pan, C.; Peng, Z.; Wang, J. Performance analysis for RIS-aided secure massive MIMO systems with statistical CSI. IEEE Wirel. Commun. Lett. 2023, 12, 124–128. [Google Scholar] [CrossRef]
- Wang, R.; Wen, X.; Xu, F.; Ye, Z.; Cao, H.; Hu, Z.; Yuan, X. Joint particle swarm optimization of power and phase shift for IRS-aided D2D underlaying cellular systems. Sensors 2023, 23, 5266. [Google Scholar] [CrossRef] [PubMed]
- Noh, S.; Yu, H.; Sung, Y. Training signal design for sparse channel estimation in intelligent reflecting surface-assisted millimeter-wave communication. IEEE Trans. Wirel. Commun. 2021, 21, 2399–2413. [Google Scholar] [CrossRef]
- Rappaport, T.S.; Ben-Dor, E.; Murdock, J.N.; Qiao, Y. 38 GHz and 60 GHz angle-dependent propagation for cellular & peer-to-peer wireless communications. In Proceedings of the 2012 IEEE International Conference on Communications (ICC), Ottawa, ON, Canada, 10–15 June 2012; pp. 4568–4573. [Google Scholar]
- Amadori, P.V.; Masouros, C. Low RF-complexity millimeter-wave beamspace-MIMO systems by beam selection. IEEE Trans. Commun. 2015, 63, 2212–2223. [Google Scholar] [CrossRef]
- Guo, H.; Lau, V.K.N. Uplink Cascaded Channel Estimation for Intelligent Reflecting Surface Assisted Multiuser MISO Systems. IEEE Trans. Signal Process. 2022, 70, 3964–3977. [Google Scholar] [CrossRef]
- Pan, C.; Zhou, G.; Zhi, K.; Hong, S.; Wu, T.; Pan, Y.; Ren, H.; Di Renzo, M.; Swindlehurst, A.L.; Zhang, R.; et al. An overview of signal processing techniques for RIS/IRS-aided wireless systems. IEEE J. Sel. Topics Signal Process. 2022, 16, 883–917. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Zhong, J.-L.; Pun, C.-M. An end-to-end dense-InceptionNet for imagecopy-move forgery detection. IEEE Trans. Inf. Forensics Secur. 2020, 15, 2134–2146. [Google Scholar] [CrossRef]
- Miethig, B.; Huangfu, Y.; Dong, J.; Tjong, J.; Mohrenschildt, M.V.; Habibi, S. A Novel Method for Approximating Object Location Error in Bounding Box Detection Algorithms Using a Monocular Camera. IEEE Trans. Veh. Technol 2021, 70, 8682–8691. [Google Scholar] [CrossRef]
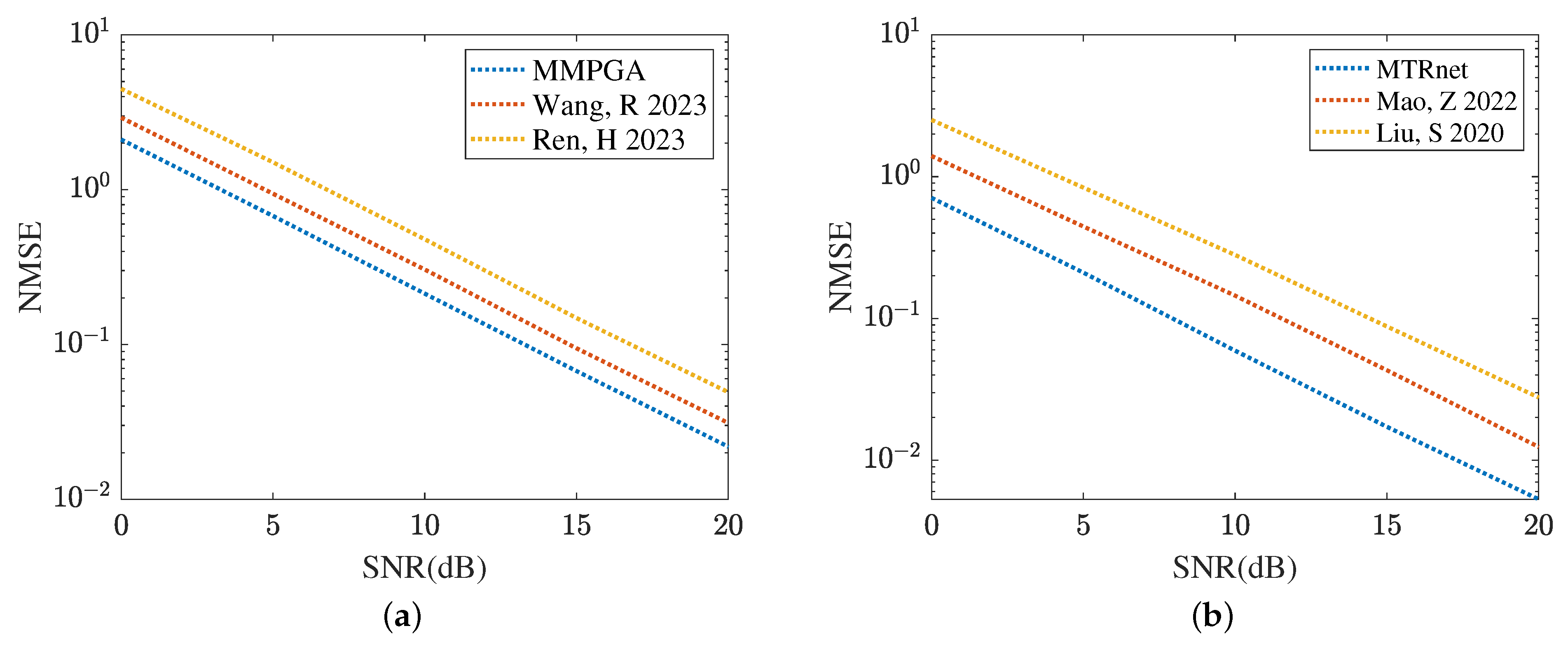
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).