An Approach of Query Audience’s Attention in Virtual Speech


Abstract
:1. Introduction
2. Related Work
2.1. Research on the Role of Eye Contact in Speech
2.2. Selection of Eye Feature Acquisition Method
3. System Structure
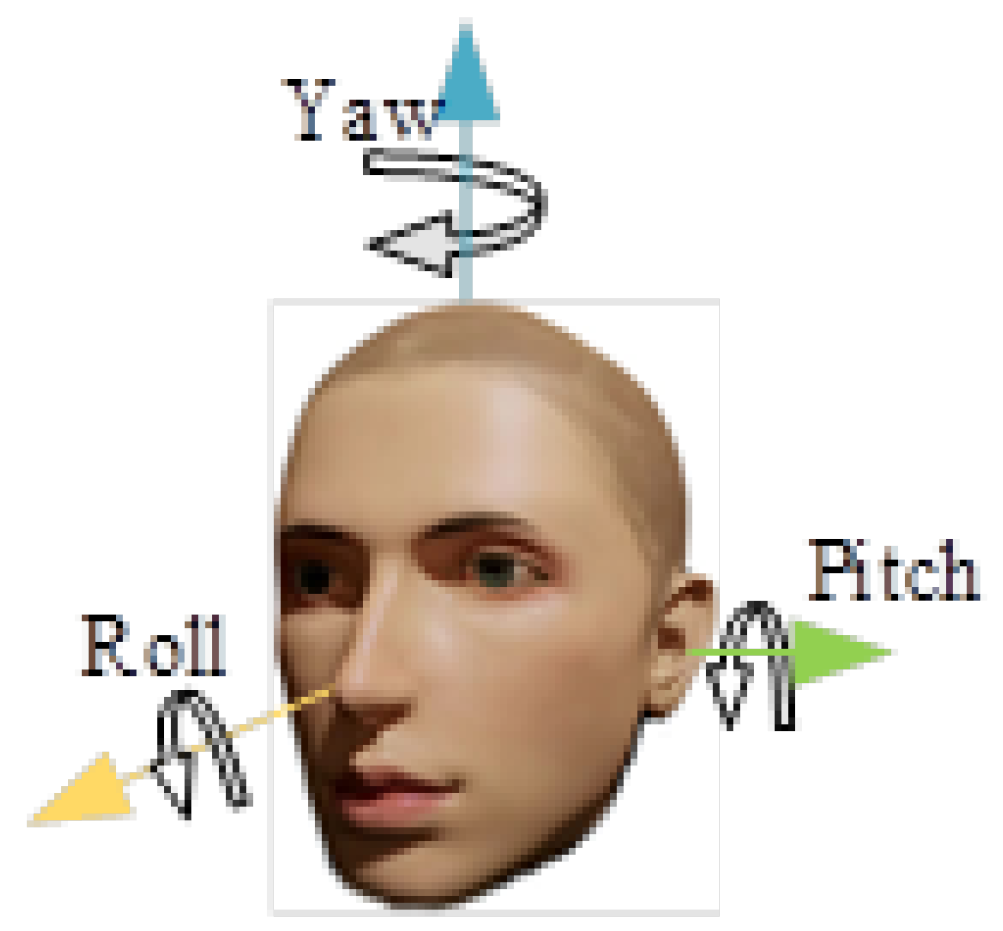
3.1. Acquisition of Facial Features and Eye Features
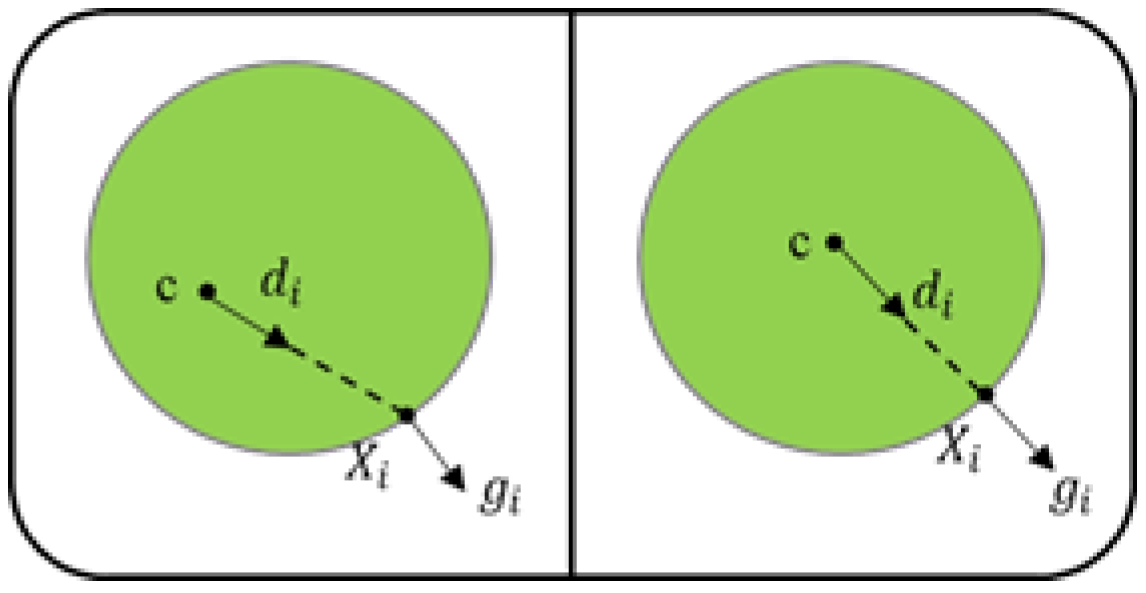
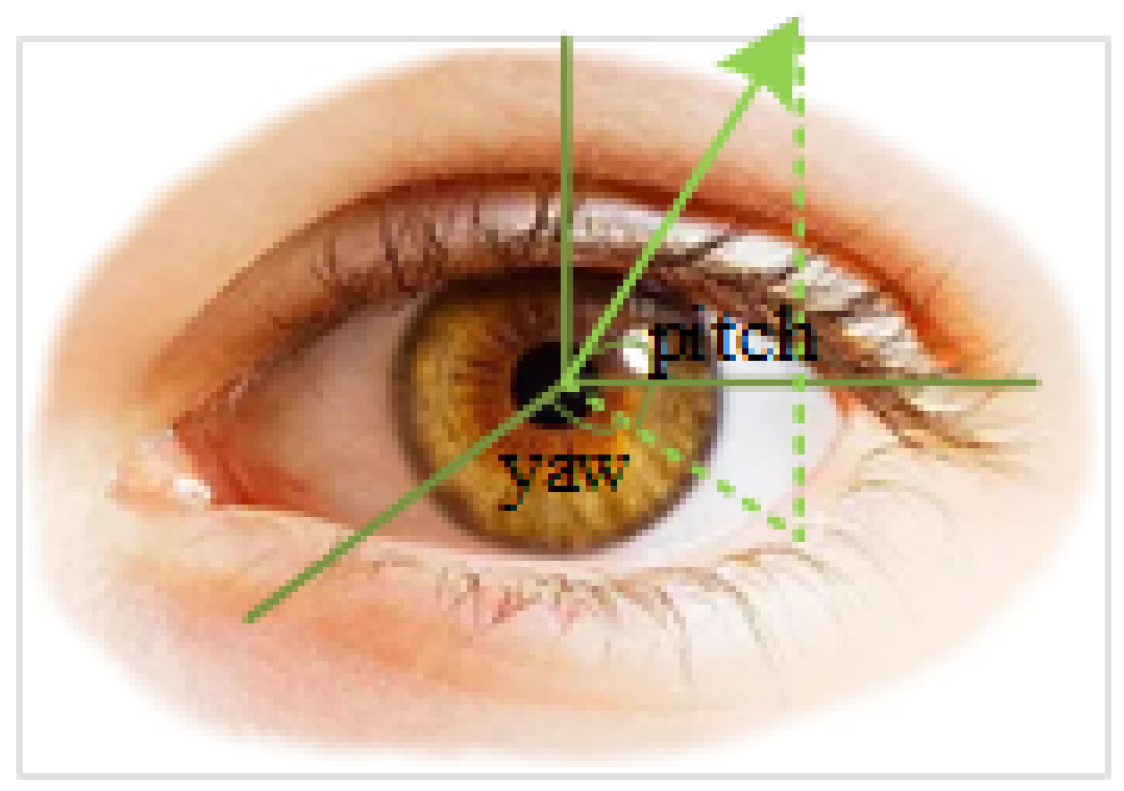
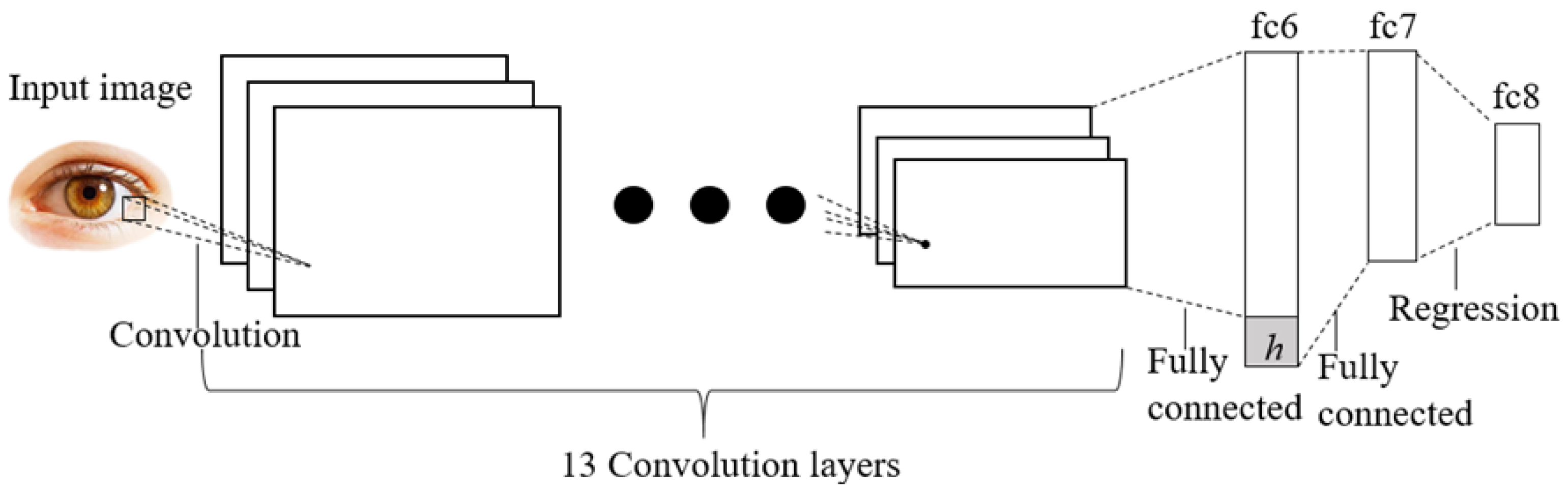
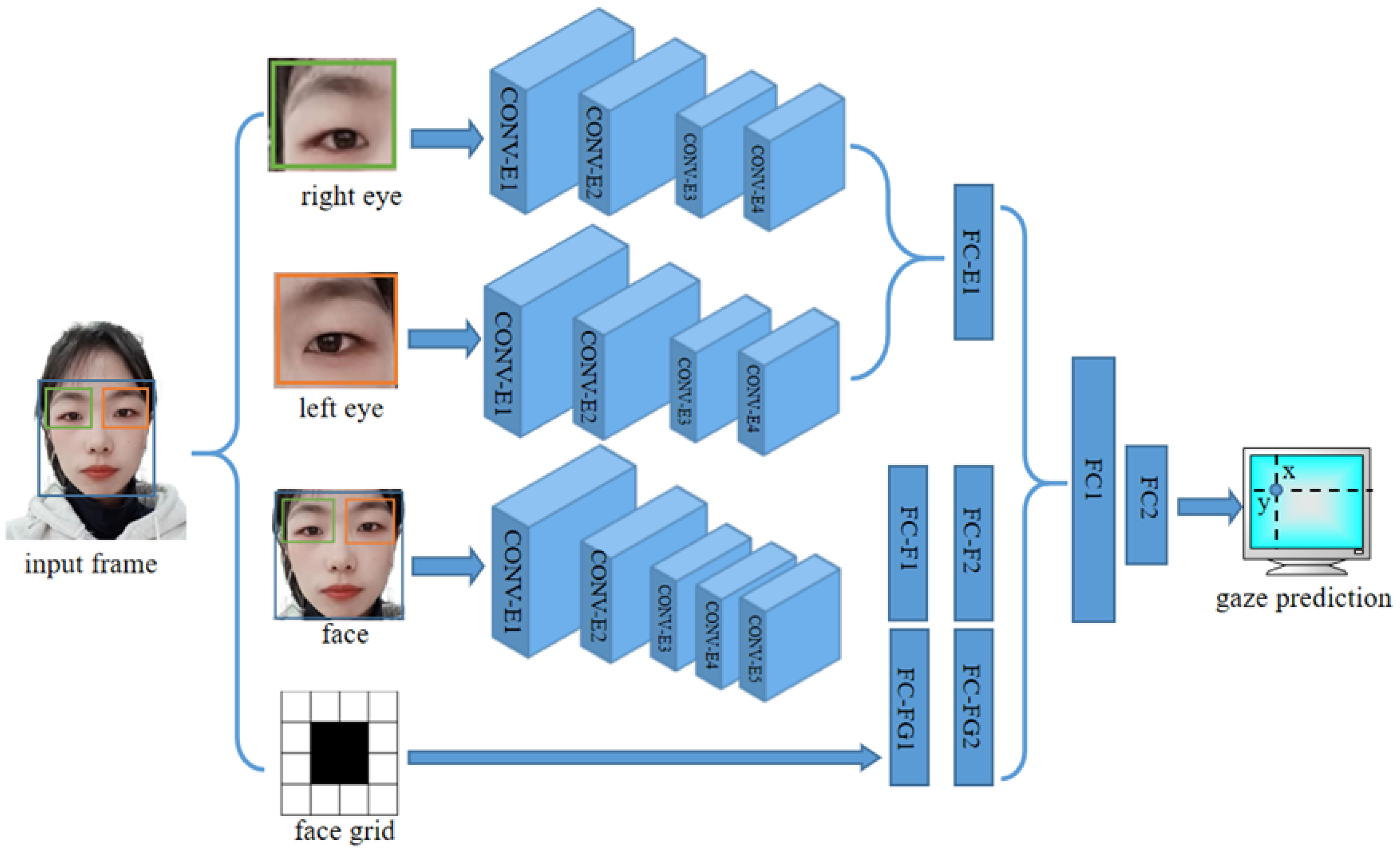
3.2. Gaze Tracking
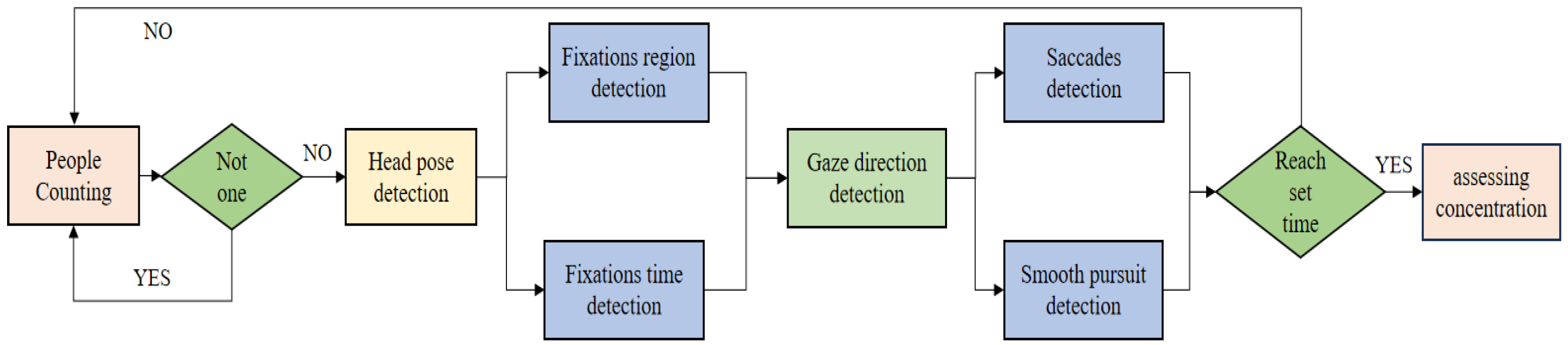
4. Evaluating Concentration
4.1. Index System
- The proportion of video frames with one face (POOF) is more than 95%.
- The proportion of video frames with a high concentration head pose (POHCHP) is more than 50%.
- The proportion of video frames with a medium concentration head pose (POMCHP) is more than 90%.
- The proportion of the effective fixation time to the total fixation time (POEFT) is more than 90%.
- The proportion of serious and effective fixation time to total fixation time (POSEFT) is more than 50%.
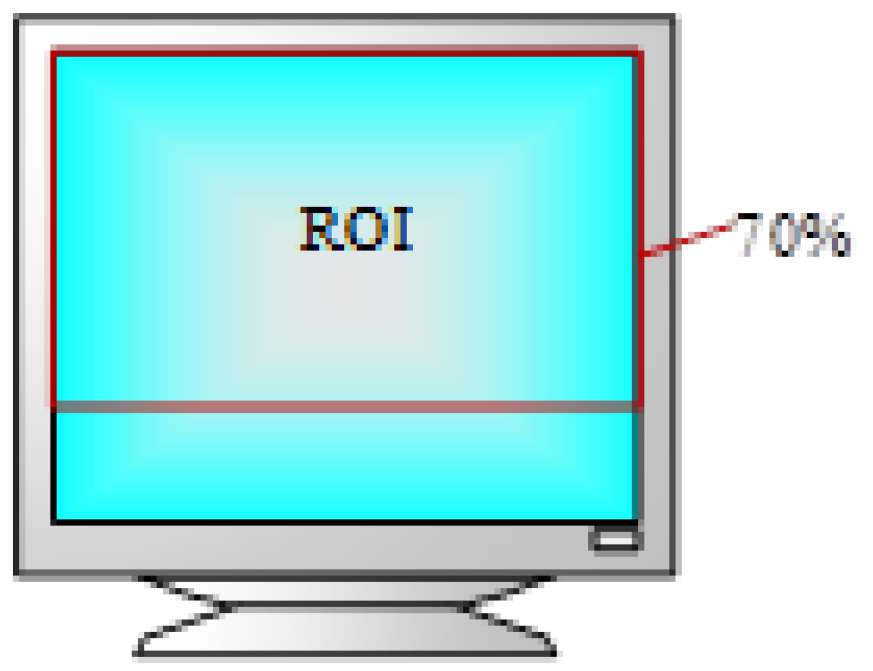
- Gazing at pictures and charts (GPC) accounts for more than 30% of the total gazing time.
- Gazing at teachers’ facial images (GTFI) accounts for more than 20% of the total gazing time.
- The variance in the number of saccades (NOS) per 100 frames is less than 10.
- There are more than five instances of reading smooth pursuit (NORSPs) every ten minutes.
4.2. Process of Evaluation
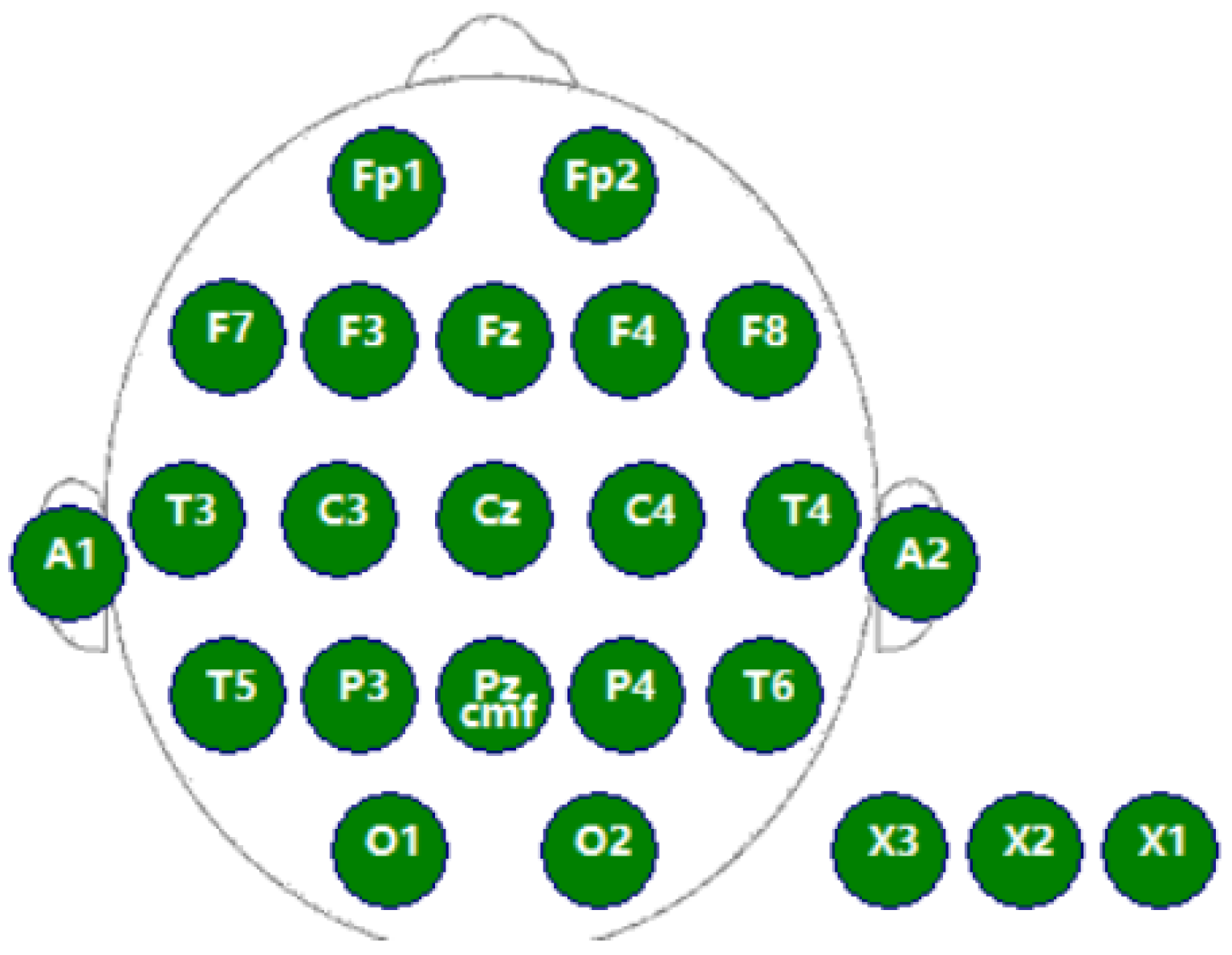
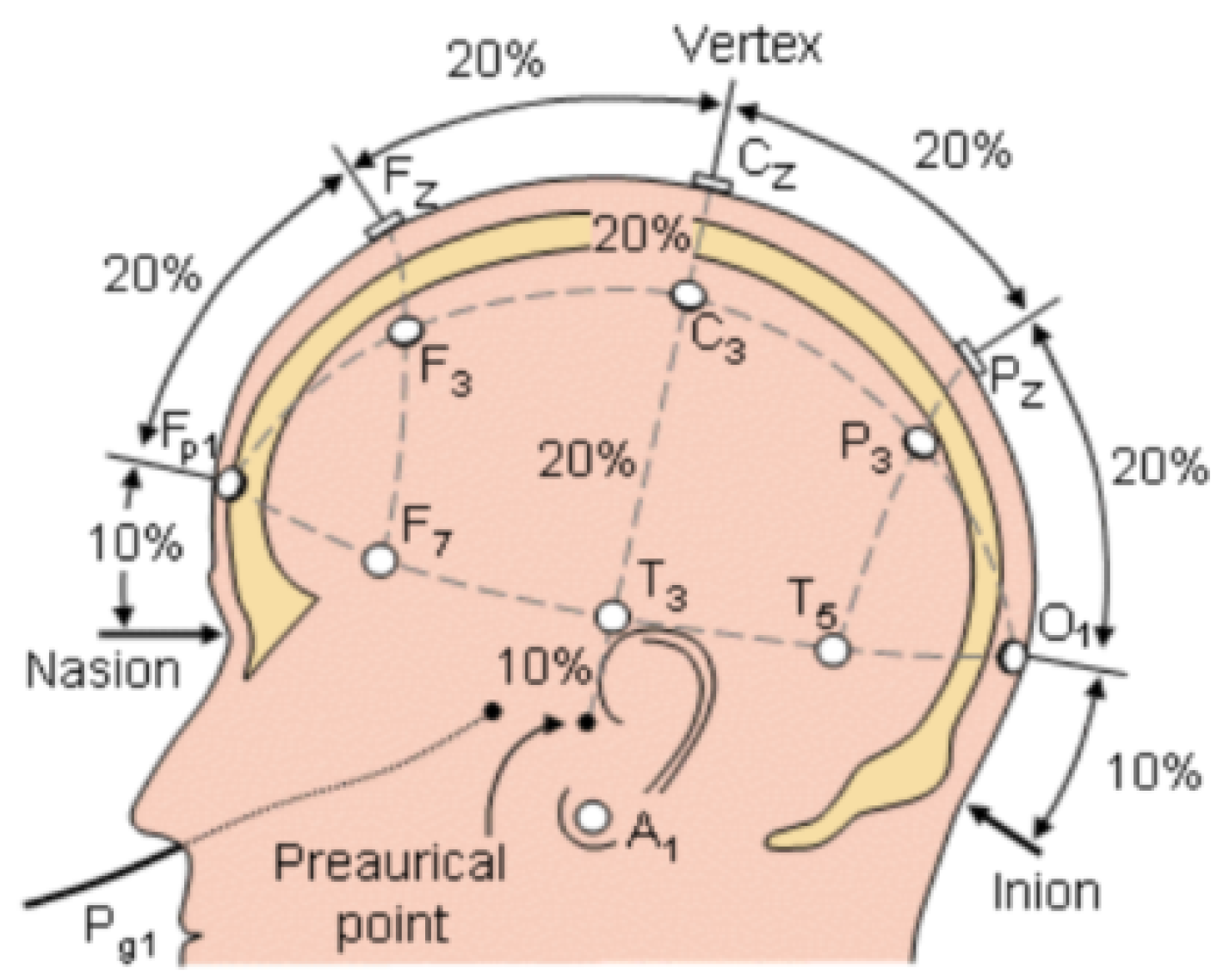
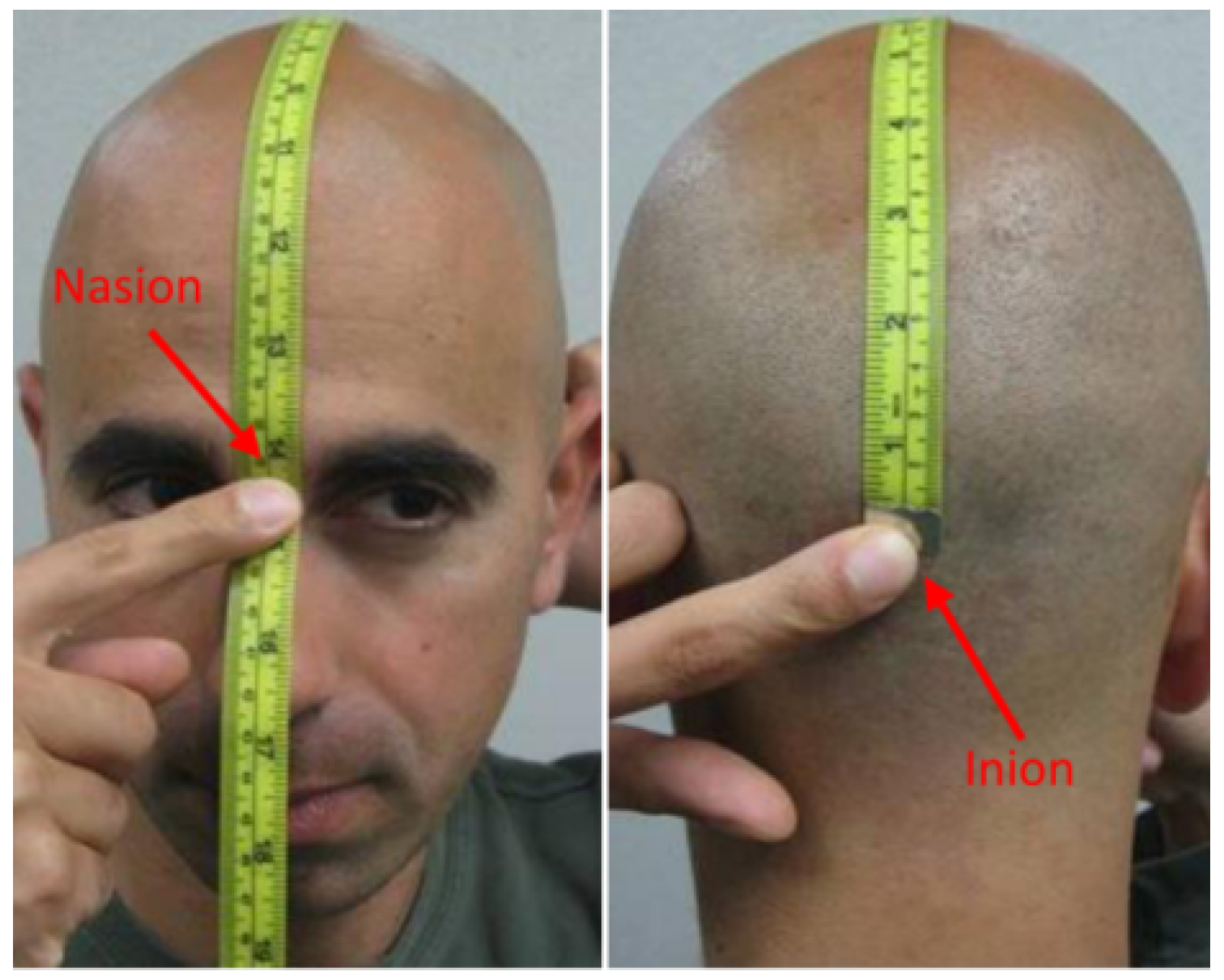
4.3. EEG Processing
- (1)
- Divide the M samples of the signal into L data segments (overlapping), where each data segment contains N samples; then, M = LN, and D sampling points overlap between two adjacent data segments;
- (2)
- Windows are added to the data segment, and the power spectral density of the data after Windows is calculated as by the period-graph method. The formula for calculating the power spectral density of section k is as follows:In the above formula, is the normalization factor and is the timing signal; is the window function; and N is the signal number.
- (3)
- After obtaining the power spectral density of each data segment, the period graph of all windowed data segments is averaged, and the average value is used as the final power spectral density estimateTo visualize the variation of power over frequency, we logarithmically process the calculated power.At this point, we sum over a specific frequency range, and then take the average as the basis for our evaluation. All the above operations can be realized in Matlab.
5. Tests
5.1. Test Content
5.2. Ethics Statement
5.3. System Accuracy Test
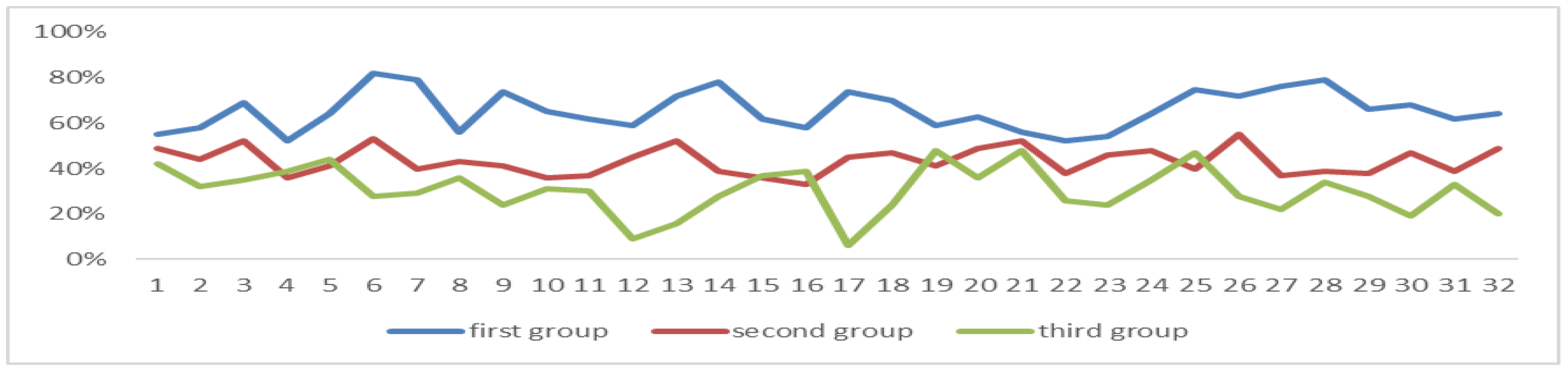
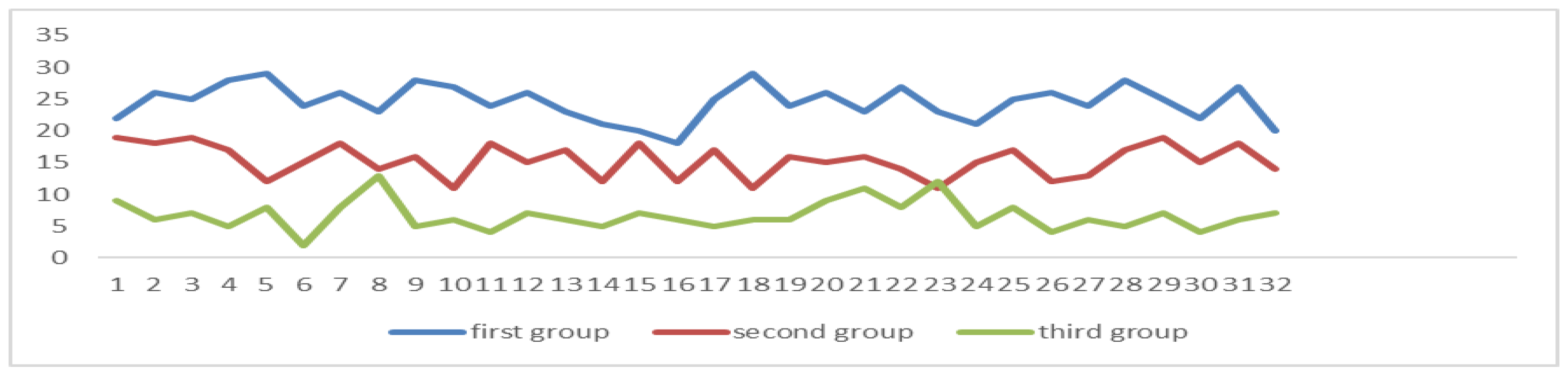
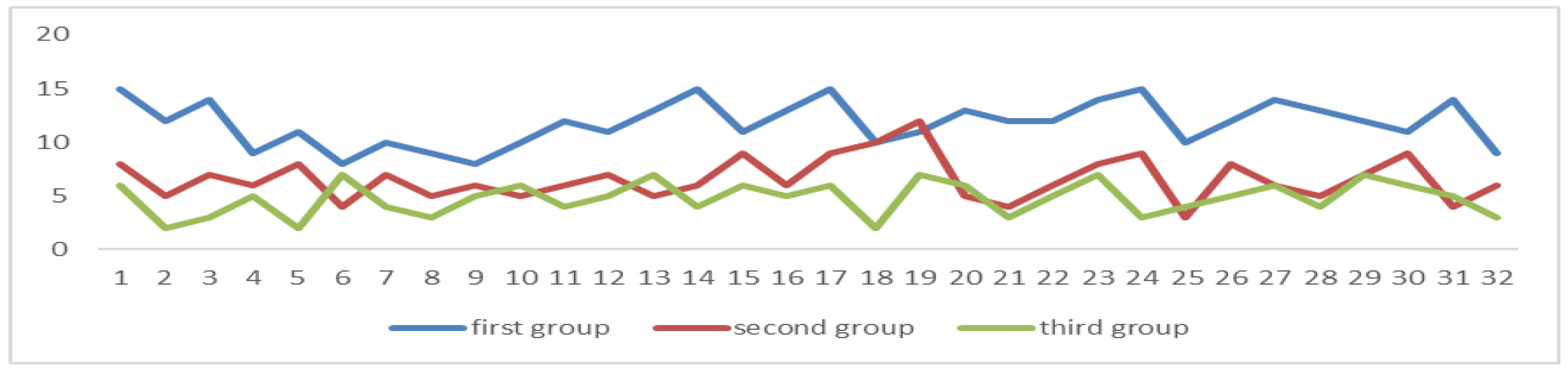
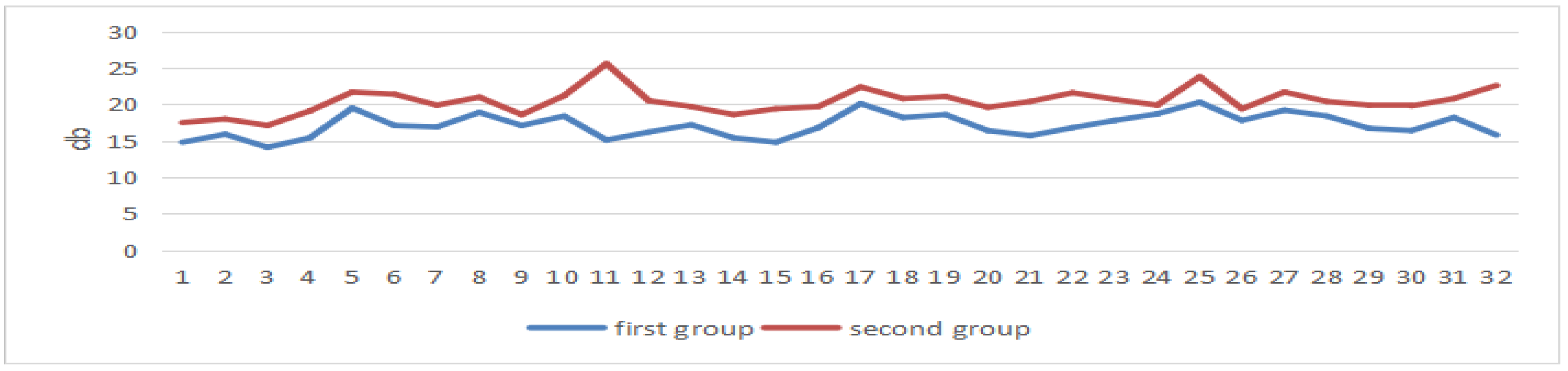
5.4. Classroom Simulation
5.5. Conclusions
6. Summary
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wu, L.F. On Paralinguistic Communication Strategies in Speeches. Home Drama 2017, 19, 225–226. [Google Scholar]
- LaCrosse, M.B. Nonverbal behavior and perceived counselor attractiveness and persuasiveness. J. Couns. Psychol. 1975, 22, 563. [Google Scholar] [CrossRef]
- Harper, R.G.; Wiens, A.N.; Matarazzo, J.D. Nonverbal Communication: The State of the Art; John Wiley & Sons: Hoboken, NJ, USA, 1978. [Google Scholar]
- Hains-Wesson, R. The impact of performance skills on students’ attitudes towards the learning experience in higher education. Home Drama 2011, 21, 22–41. [Google Scholar]
- Ni, D.; Wang, S.; Liu, G. The EEG-based attention analysis in multimedia m-learning. Comput. Math. Methods Med. 2020, 2020, 4837291. [Google Scholar] [CrossRef] [PubMed]
- Alirezaei, M.; Sardouie, S.H. Detection of human attention using EEG signals. In Proceedings of the 2017 24th National and 2nd International Iranian Conference on biomedical engineering (ICBME), Tehran, Iran, 30 November–1 December 2017; pp. 1–5. [Google Scholar]
- Janelle, C.M.; Hatfield, B.D. Visual attention and brain processes that underlie expert performance: Implications for sport and military psychology. Mil. Psychol. 2008, 20, S39–S69. [Google Scholar] [CrossRef]
- Toa, C.K.; Sim, K.S.; Tan, S.C. Electroencephalogram-based attention level classification using convolution attention memory neural network. IEEE Access 2021, 9, 58870–58881. [Google Scholar] [CrossRef]
- Wang, Y.; Shi, Y.; Du, J.; Lin, Y.; Wang, Q. A CNN-based personalized system for attention detection in wayfinding tasks. Adv. Eng. Inform. 2020, 46, 101180. [Google Scholar] [CrossRef]
- Al-Nafjan, A.; Aldayel, M. Predict students’ attention in online learning using eeg data. Sustainability 2022, 14, 6553. [Google Scholar] [CrossRef]
- Atilla, F.; Alimardani, M. EEG-based classification of drivers attention using convolutional neural network. In Proceedings of the 2021 IEEE 2nd International Conference on Human–Machine Systems (ICHMS), Magdeburg, Germany, 8–10 September 2021; pp. 1–4. [Google Scholar]
- Molina, A.I.; Navarro, Ó.; Ortega, M.; Lacruz, M. Evaluating multimedia learning materials in primary education using eye tracking. Comput. Stand. Interfaces 2018, 59, 45–60. [Google Scholar] [CrossRef]
- Krstić, K.; Šoškić, A.; Ković, V.; Holmqvist, K. All good readers are the same, but every low-skilled reader is different: An eye-tracking study using PISA data. Eur. J. Psychol. Educ. 2018, 33, 521–541. [Google Scholar] [CrossRef]
- Van Wermeskerken, M.; Van Gog, T. Seeing the instructor’s face and gaze in demonstration video examples affects attention allocation but not learning. Comput. Educ. 2017, 113, 98–107. [Google Scholar] [CrossRef]
- Zhou, M.; Ren, J. Use of Cognitive and Metacognitive Strategies in Online Search: An Eye-Tracking Study; International Association for Development of the Information Society: Lisbon, Portugal, 2016; Available online: http://www.iadisportal.org (accessed on 4 May 2023).
- Jian, Y.C. Eye-movement patterns and reader characteristics of students with good and poor performance when reading scientific text with diagrams. Read. Writ. 2017, 30, 1447–1472. [Google Scholar] [CrossRef]
- Karch, J.M.; Garcia Valles, J.C.; Sevian, H. Looking into the black box: Using gaze and pupillometric data to probe how cognitive load changes with mental tasks. J. Chem. Educ. 2019, 96, 830–840. [Google Scholar] [CrossRef]
- Fichtel, E.; Lau, N.; Park, J.; Henrickson Parker, S.; Ponnala, S.; Fitzgibbons, S.; Safford, S.D. Eye tracking in surgical education: Gaze-based dynamic area of interest can discriminate adverse events and expertise. Surg. Endosc. 2019, 33, 2249–2256. [Google Scholar] [CrossRef] [PubMed]
- Cibuļska, E.; Boločko, K. Virtual reality in education: Structural design of an adaptable virtual reality system. In Proceedings of the 2022 6th International Conference on Computer, Software and Modeling (ICCSM), Rome, Italy, 21–23 July 2022; pp. 76–79. [Google Scholar]
- Chen, G.; Xie, X.; Yang, Z.; Deng, R.; Huang, K.; Wang, C. Development of a Virtual Reality Game for Cultural Heritage Education: The Voyage of “Gotheborg”. In Proceedings of the 2023 9th International Conference on Virtual Reality (ICVR), Xianyang, China, 12–14 May 2023; pp. 531–535. [Google Scholar]
- Misbhauddin, M. VREdu: A framework for interactive immersive lectures using virtual reality. In Proceedings of the 2018 21st Saudi Computer Society National Computer Conference (NCC), Riyadh, Saudi Arabia, 25–26 April 2018; pp. 1–6. [Google Scholar]
- Modi, N.; Singh, J. Understanding online consumer behavior at e-commerce portals using eye-gaze tracking. Int. J. Hum.- Interact. 2023, 39, 721–742. [Google Scholar] [CrossRef]
- Ashby, N.J.; Walasek, L.; Glöckner, A. The effect of consumer ratings and attentional allocation on product valuations. Judgm. Decis. Mak. 2015, 10, 172–184. [Google Scholar] [CrossRef]
- Conley, Q.; Earnshaw, Y.; McWatters, G. Examining course layouts in blackboard: Using eye-tracking to evaluate usability in a learning management system. Int. J. Hum.- Interact. 2020, 36, 373–385. [Google Scholar] [CrossRef]
- Treur, J.; Van Wissen, A. Computational Analysis of the Impacts of Emotion on Learning in a Social Context. In Proceedings of the 2012 IEEE/WIC/ACM International Conferences on Web Intelligence and Intelligent Agent Technology, Macau, China, 4–7 December 2012; Volume 2, pp. 417–424. [Google Scholar]
- Li, X. How much do you know about “eye contact”? Encycl. Knowl. 2016, 8, 21–22. [Google Scholar] [CrossRef]
- Yatagai, M.; Sakai, S. Analysis of the Educational Effect of Eye-Contact and Former-Type Systems of Distance Learning through Video Conferencing Systems and Face-to-Face Learning. Educ. Technol. Res. 2008, 31, 49–60. [Google Scholar]
- Lin, C.A.; Creswell, K.W. Effects of televised lecture presentation styles on student learning. J. Educ. Telev. 1989, 15, 37–52. [Google Scholar] [CrossRef]
- Fiorella, L.; Stull, A.T.; Kuhlmann, S.; Mayer, R.E. Instructor presence in video lectures: The role of dynamic drawings, eye contact, and instructor visibility. J. Educ. Psychol. 2019, 111, 1162. [Google Scholar] [CrossRef]
- Beege, M.; Schneider, S.; Nebel, S.; Rey, G.D. Look into my eyes! Exploring the effect of addressing in educational videos. Learn. Instr. 2017, 49, 113–120. [Google Scholar] [CrossRef]
- Ouwehand, K.; van Gog, T.; Paas, F. Designing effective video-based modeling examples using gaze and gesture cues. Educ. Technol. Soc. 2015, 18, 78–88. Available online: https://www.jstor.org/stable/jeductechsoci.18.4.78 (accessed on 5 May 2023).
- Gower, R.; Walters, S.; Phillips, D. Teaching Practice Handbook; Heinemann: Oxford, UK, 1995; Volume 171. [Google Scholar]
- Snyder, D.W. Classroom Management for Student Teachers. Music Educ. J. 1998, 84, 37–40. [Google Scholar] [CrossRef]
- Zeki, C.P. The importance of non-verbal communication in classroom management. Procedia-Soc. Behav. Sci. 2009, 1, 1443–1449. [Google Scholar] [CrossRef]
- Wagner, T.; Hirzle, T.; Huckauf, A.; Rukzio, E. Exploring Gesture and Gaze Proxies to Communicate Instructor’s Nonverbal Cues in Lecture Videos. In Proceedings of the Extended Abstracts of the 2023 CHI Conference on Human Factors in Computing Systems, Hamburg, Germany, 23–28 April 2023; pp. 1–7. [Google Scholar] [CrossRef]
- Ding, J.; Zhao, B.; Huang, Y.; Wang, Y.; Shi, Y. GazeReader: Detecting Unknown Word Using Webcam for English as a Second Language (ESL) Learners. In Proceedings of the Extended Abstracts of the 2023 CHI Conference on Human Factors in Computing Systems, Hamburg, Germany, 23–28 April 2023; pp. 1–7. [Google Scholar] [CrossRef]
- Zhang, X.; Sugano, Y.; Fritz, M.; Bulling, A. Appearance-based gaze estimation in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 4511–4520. [Google Scholar] [CrossRef]
- Krafka, K.; Khosla, A.; Kellnhofer, P.; Kannan, H.; Bhandarkar, S.; Matusik, W.; Torralba, A. Eye tracking for everyone. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2176–2184. [Google Scholar]
- Liu, Y.; Zhu, Y.; Sun, J.; Wang, Y. Improved Adaboost face detection algorithm based on Haar-like feature statistics. J. Image Graph. 2020, 25, 1618–1626. [Google Scholar]
- Kazemi, V.; Sullivan, J. One millisecond face alignment with an ensemble of regression trees. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1867–1874. [Google Scholar] [CrossRef]
- Valenti, R.; Gevers, T. Accurate eye center location and tracking using isophote curvature. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar] [CrossRef]
- Meyer, A.; Böhme, M.; Martinetz, T.; Barth, E. A single-camera remote eye tracker. In Proceedings of the Perception and Interactive Technologies: International Tutorial and Research Workshop, PIT 2006, Kloster Irsee, Germany, 19–21 June 2006; Proceedings. Springer: Berlin/Heidelberg, Germany, 2006; pp. 208–211. [Google Scholar] [CrossRef]
- Sugano, Y.; Matsushita, Y.; Sato, Y. Learning-by-synthesis for appearance-based 3d gaze estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1821–1828. [Google Scholar] [CrossRef]
- Lai, H.; Tang, Z.; Zhang, X. RepEPnP: Weakly Supervised 3D Human Pose Estimation with EPnP Algorithm. In Proceedings of the 2023 International Joint Conference on Neural Networks (IJCNN), Gold Coast, Australia, 18–23 June 2023; pp. 1–8. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar] [CrossRef]
- Zhang, J.H.; Peng, C.Y.; Zhang, J.P. Eye-Tracking Technology and Its Application in e-Learning System. J. Distance Educ. 2009, 17, 74–78. [Google Scholar] [CrossRef]
- Klein, P.; Viiri, J.; Mozaffari, S.; Dengel, A.; Kuhn, J. Instruction-based clinical eye-tracking study on the visual interpretation of divergence: How do students look at vector field plots? Phys. Rev. Phys. Educ. Res. 2018, 14, 010116. [Google Scholar] [CrossRef]
- Singh, T.; Mohadikar, M.; Gite, S.; Patil, S.; Pradhan, B.; Alamri, A. Attention span prediction using head-pose estimation with deep neural networks. IEEE Access 2021, 9, 142632–142643. [Google Scholar] [CrossRef]
- Owens, J.W.; Shrestha, S. How do users browse a portal website? An examination of user eye movements. Usability News 2008, 10, 1–6. [Google Scholar]
- Nielsen, J. How Many Test Users in a Usability Study. Nielsen Norman Group 2012, 4. Available online: https://www.nngroup.com/articles/how-many-test-users/ (accessed on 25 April 2023).
- Yaffe, P. Why visual aids need to be less visual. Ubiquity 2008, 2008, 1–4. [Google Scholar] [CrossRef]
- Wechsler, T.F.; Pfaller, M.; Eickels, R.E.v.; Schulz, L.H.; Mühlberger, A. Look at the audience? a randomized controlled study of shifting attention from self-focus to nonsocial vs. social external stimuli during virtual reality exposure to public speaking in social anxiety. Front. Psychiatry 2021, 12, 751272. [Google Scholar] [CrossRef] [PubMed]
- van Son, D.; De Blasio, F.M.; Fogarty, J.S.; Angelidis, A.; Barry, R.J.; Putman, P. Frontal EEG theta/beta ratio during mind wandering episodes. Biol. Psychol. 2019, 140, 19–27. [Google Scholar] [CrossRef] [PubMed]
- Clarke, A.R.; Barry, R.J.; Johnstone, S. Resting state EEG power research in Attention-Deficit/Hyperactivity Disorder: A review update. Clin. Neurophysiol. 2020, 131, 1463–1479. [Google Scholar] [CrossRef] [PubMed]
- Smallwood, J.; Schooler, J.W. The restless mind. Psychol. Bull. 2013, 1, 130–149. [Google Scholar] [CrossRef]
- Stawarczyk, D.; Majerus, S.; Catale, C.; D’Argembeau, A. Relationships between mind-wandering and attentional control abilities in young adults and adolescents. Acta Psychol. 2014, 148, 25–36. [Google Scholar] [CrossRef] [PubMed]
- Smallwood, J.; Nind, L.; O’Connor, R.C. When is your head at? An exploration of the factors associated with the temporal focus of the wandering mind. Conscious. Cogn. 2009, 18, 118–125. [Google Scholar] [CrossRef] [PubMed]
- Unsworth, N.; McMillan, B.D. Similarities and differences between mind-wandering and external distraction: A latent variable analysis of lapses of attention and their relation to cognitive abilities. Acta Psychol. 2014, 150, 14–25. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Advantage | Disadvantage |
|---|---|---|
| Gaze tracking based on geometry | The system structure is simple and does not require complicated calibration | The head needs to maintain a fixed posture and cannot move widely |
| Gaze tracking based on 3D eye model | Allowing head movement | Calibration work is required |
| Gaze tracking based on eye appearance features | The accuracy requirements for equipment are low | Difficult to overcome the influence of light |
| Predicted Value | |||
|---|---|---|---|
| 1 | 0 | ||
| True value | 1 | 10,218 | 1237 |
| 0 | 1947 | 7598 |
| Predicted Value | |||
|---|---|---|---|
| 1 | 0 | ||
| True value | 1 | 8129 | 1213 |
| 0 | 1887 | 8794 |
| POOF | POHCHP | POMCHP | POEFT | POSEFT | NOS | NORSP | |
|---|---|---|---|---|---|---|---|
| Low light | 100% | 100% | 100% | 90% | 87% | 92% | 72% |
| Natural light | 100% | 100% | 100% | 95% | 93% | 98% | 87% |
| Strong light | 100% | 100% | 100% | 96% | 92% | 98% | 86% |
| POOF | POHCHP | POMCHP | POEFT | POSEFT | NOS | NORSP | |
|---|---|---|---|---|---|---|---|
| 30 cm | 100% | 100% | 100% | 99% | 95% | 98% | 85% |
| 50 cm | 100% | 100% | 100% | 100% | 95% | 97% | 87% |
| 70 cm | 100% | 100% | 100% | 97% | 96% | 89% | 86% |
| 90 cm | 100% | 100% | 100% | 89% | 84% | 51% | 42% |
| 110 cm | 100% | 100% | 100% | 75% | 69% | 14% | 10% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kang, H.; Yang, R.; Song, R.; Yang, C.; Wang, W. An Approach of Query Audience’s Attention in Virtual Speech. Sensors 2024, 24, 5363. https://doi.org/10.3390/s24165363
Kang H, Yang R, Song R, Yang C, Wang W. An Approach of Query Audience’s Attention in Virtual Speech. Sensors. 2024; 24(16):5363. https://doi.org/10.3390/s24165363
Chicago/Turabian StyleKang, Hongbo, Rui Yang, Ruoyang Song, Chunjie Yang, and Wenqing Wang. 2024. "An Approach of Query Audience’s Attention in Virtual Speech" Sensors 24, no. 16: 5363. https://doi.org/10.3390/s24165363