
Multi-Task Environmental Perception Methods for Autonomous Driving
Abstract
:1. Introduction
2. Related Work
2.1. Detection of Traffic Scene Objects
2.2. Drivable Area Detection
2.3. Lane Line Detection
2.4. Multi-Task Network
3. Design of Multi-Task Perception Methods
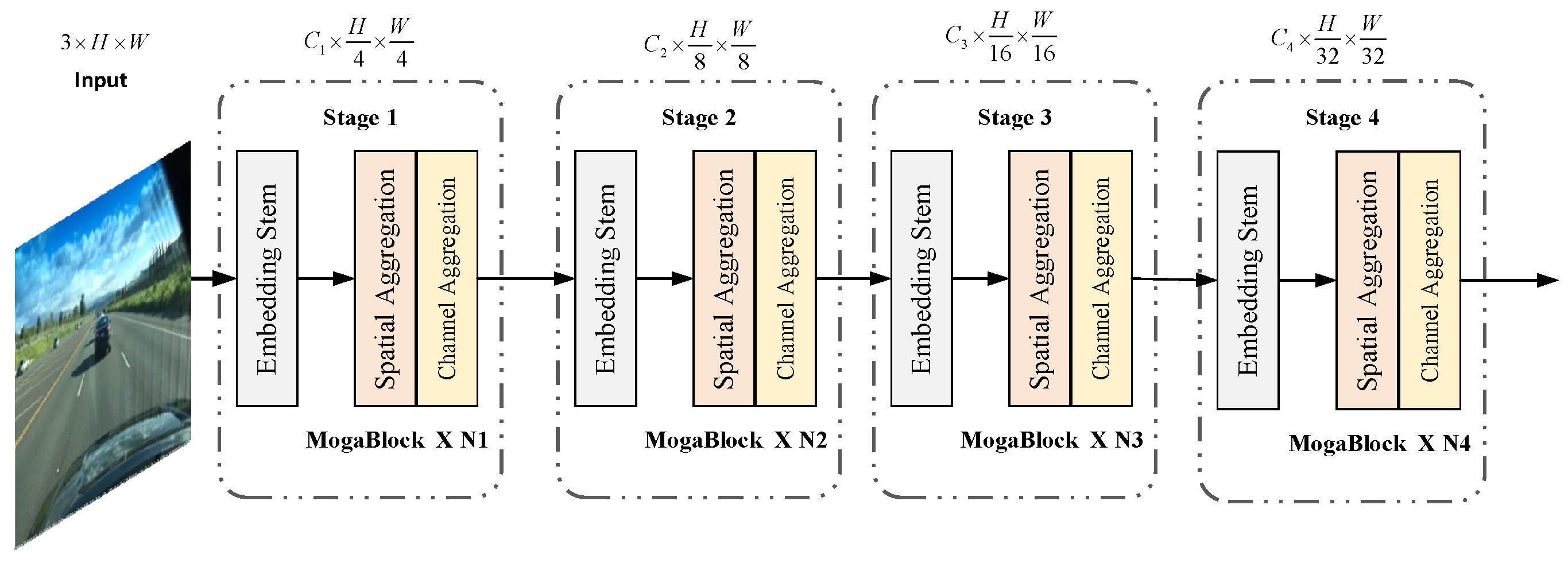
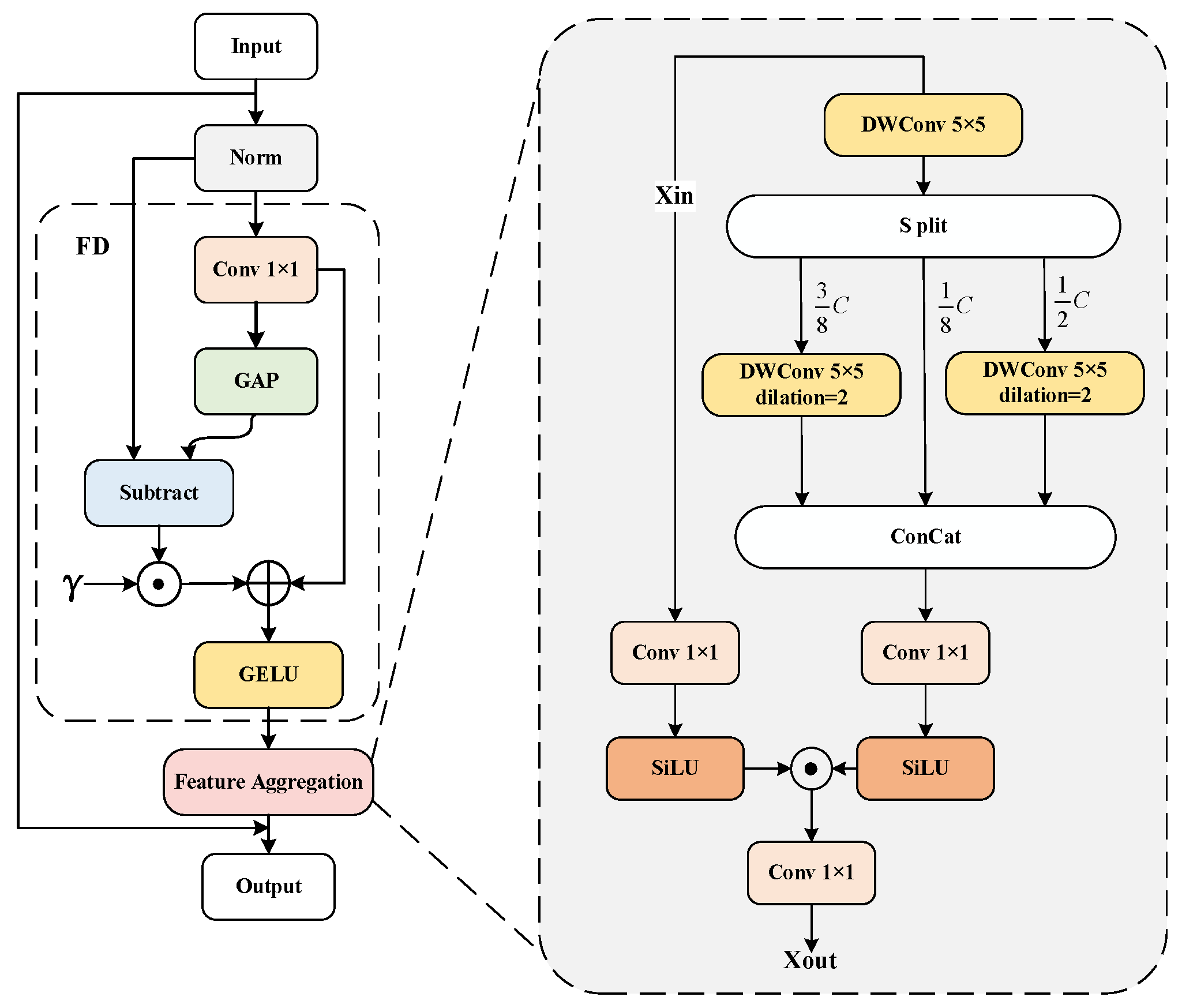
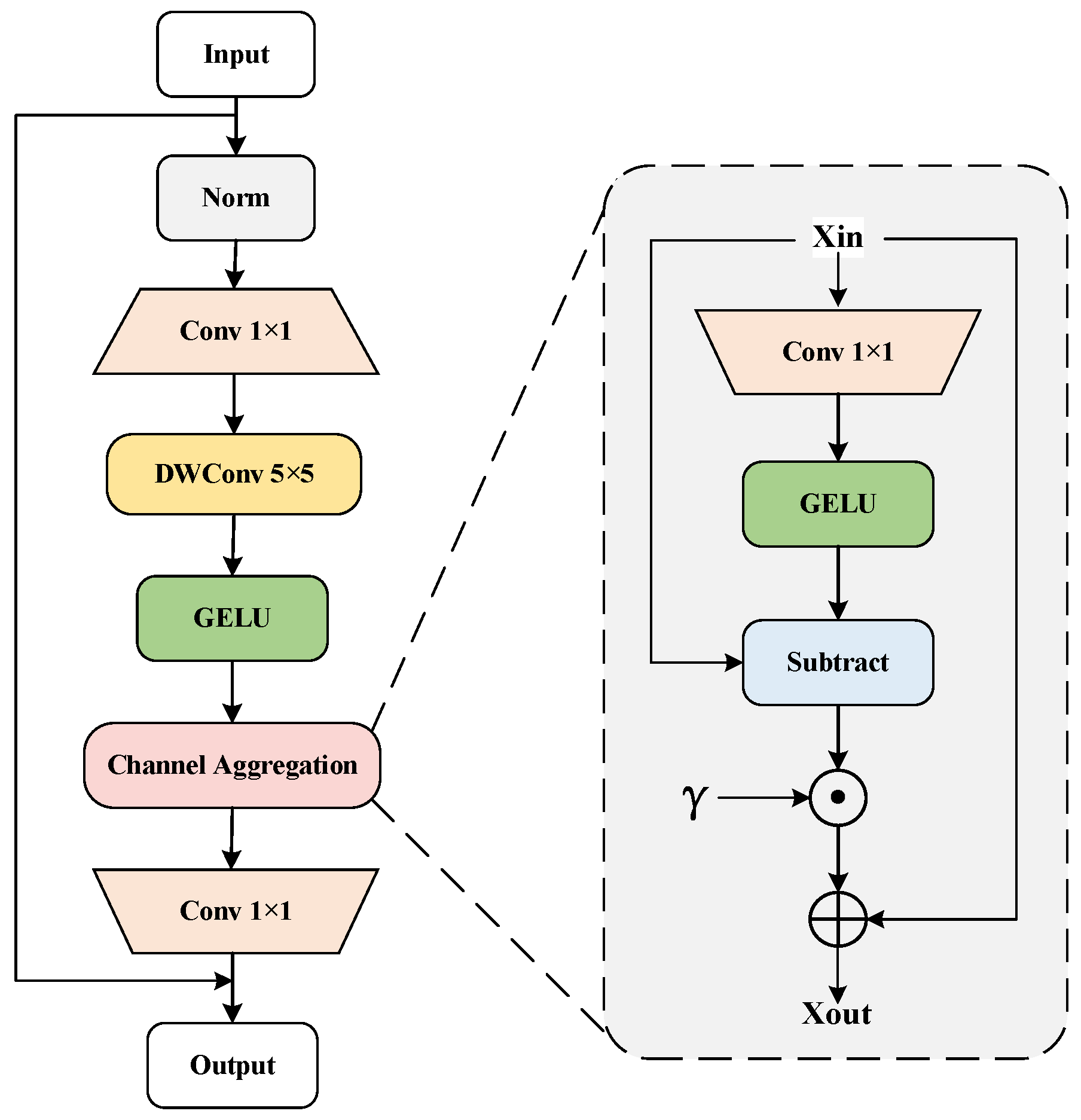
3.1. Backbone Network
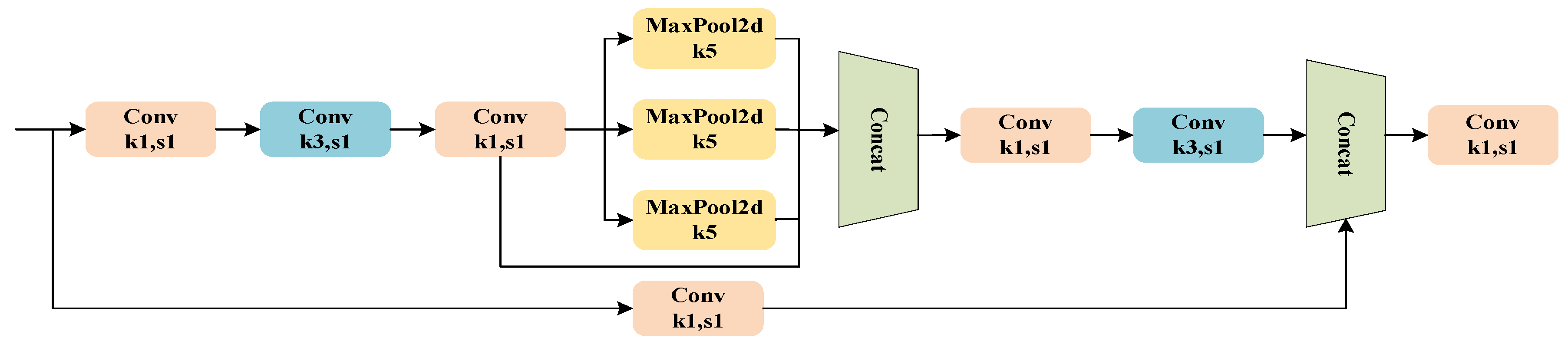
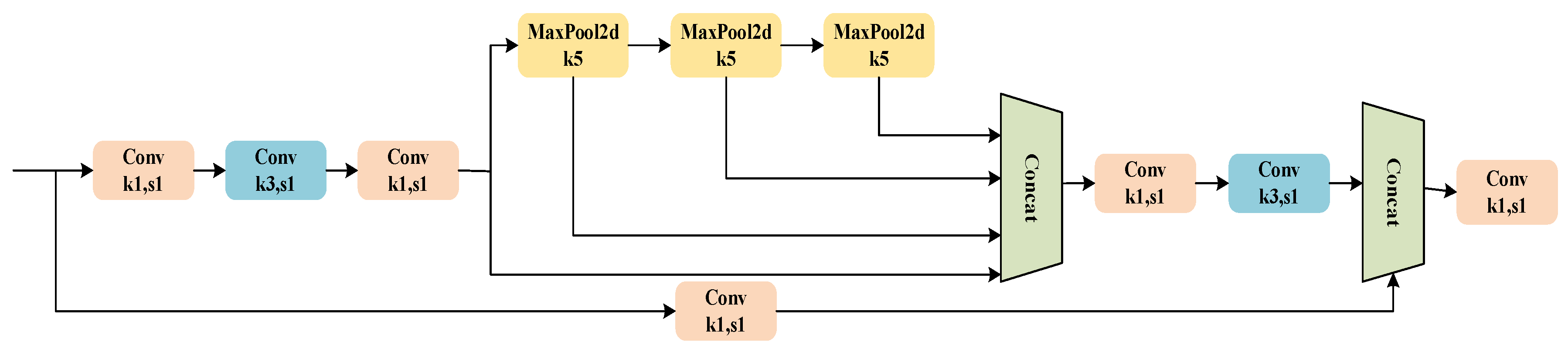
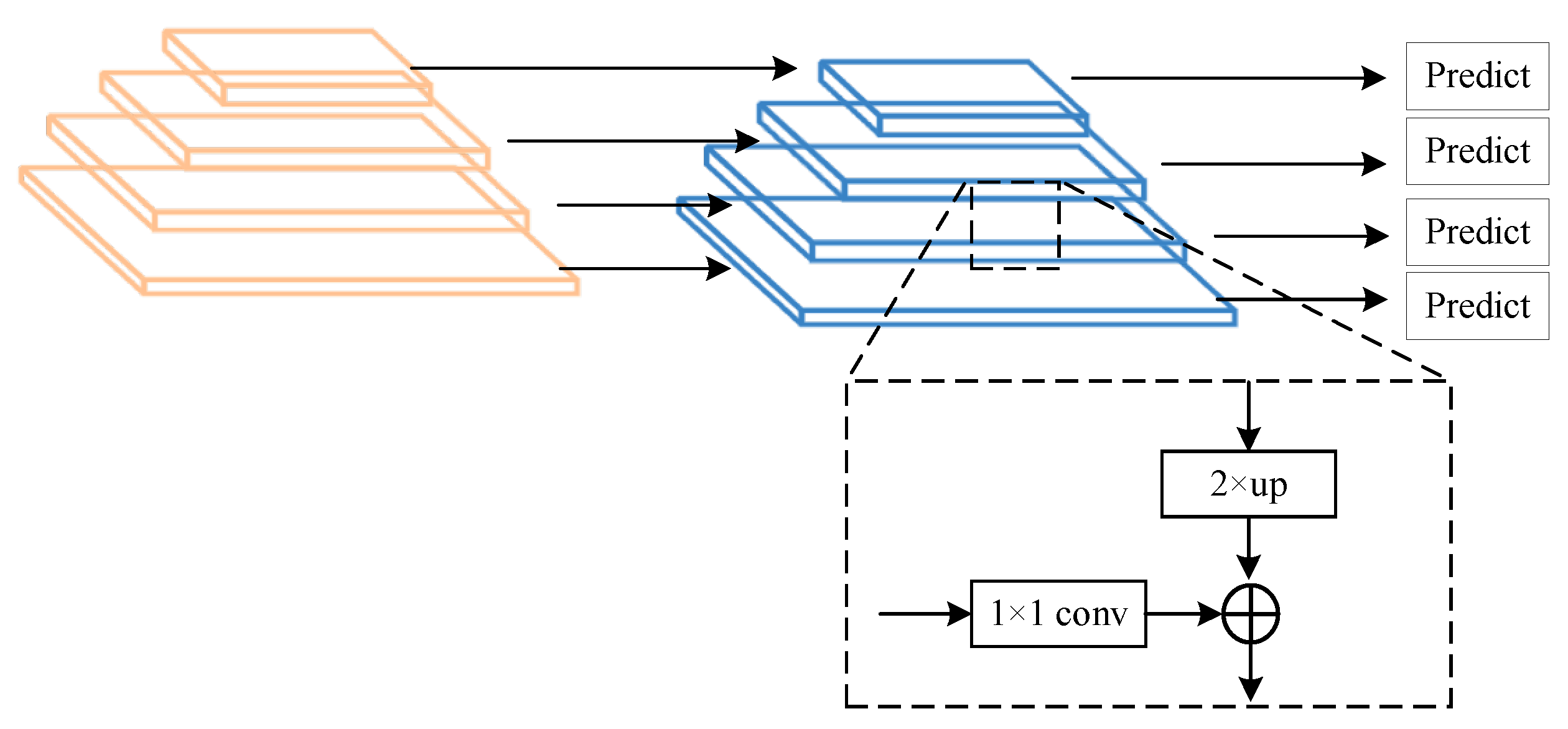
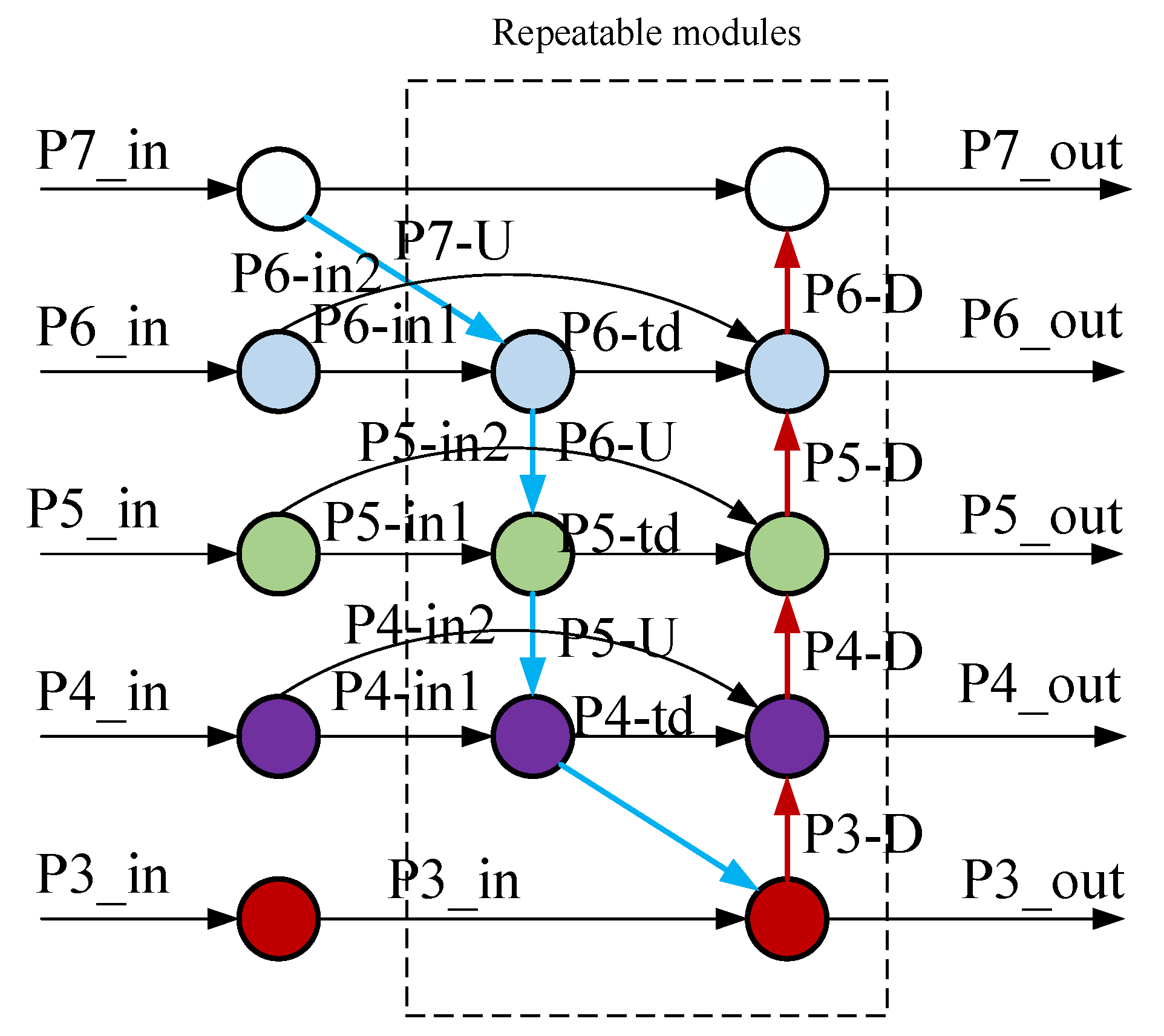
3.2. Feature Fusion Network
3.3. Detection Network
- During module initialization, the weight parameter W is set to 5.0, and then the weight is activated using the Sigmoid function. The activation function δ is defined as follows:
- Based on the activation result, the module path is selected as follows: if δ(w) > 0.5, a concatenation operation is performed; otherwise, the first input tensor is returned.
- The input tensor list is concatenated along the specified dimension dim if concatenation is performed. The formula is as follows:
- Subsequently, the concatenated tensor Xconcat undergoes a convolutional layer operation. The formula is as follows:The term ∑ch represents the sum of the input channels, ch[0] indicates the number of output channels, and 1 denotes the size and stride of the convolution kernel.
- Finally, the output is determined based on the result of the Sigmoid function, as expressed by the following formula:
3.4. Loss Function
4. Experimental Validation and Results Analysis
4.1. Experimental Setup
4.2. Experimental Results Analysis
4.2.1. Object Detection
4.2.2. Lane Line Segmentation
4.2.3. Drivable Area Segmentation
4.3. Visualization Results
4.4. Ablation Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Chen, Q.; Wang, Y.; Yang, T.; Zhang, X.; Cheng, J.; Sun, J. You only look one-level feature. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2021, Nashville, TN, USA, 20–25 June 2021; pp. 13039–13048. [Google Scholar]
- Zhang, S.; Wang, X.; Wang, J.; Pang, J.; Lyu, C.; Zhang, W.; Luo, P.; Chen, K. Dense distinct query for end-to-end object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2023, Vancouver, BC, Canada, 17–24 June 2023; pp. 7329–7338. [Google Scholar]
- Qin, Z.; Zhang, P.; Li, X. Ultra fast deep lane detection with hybrid anchor driven ordinal classification. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 46, 2555–2568. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Ma, Y.; Huang, S.; Hui, T.; Wang, F.; Qian, C.; Zhang, T. A keypoint-based global association network for lane detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2022, New Orleans, LA, USA, 18–24 June 2022; pp. 1392–1401. [Google Scholar]
- Wang, R.; Qin, J.; Li, K.; Li, Y.; Cao, D.; Xu, J. BEV-LaneDet: A simple and effective 3D lane detection baseline. arXiv 2022, arXiv:2210.06006. [Google Scholar]
- Tian, Y.; Liu, Y.; Pang, G.; Liu, F.; Chen, Y.; Carneiro, G. Pixel-wise energy-biased abstention learning for anomaly segmentation on complex urban driving scenes. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer Nature: Cham, Switzerland, 2022; pp. 246–263. [Google Scholar]
- Shen, F.; Gurram, A.; Liu, Z.; Wang, H.; Knoll, A. DiGA: Distil to generalize and then adapt for domain adaptive semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2023, Vancouver, BC, Canada, 17–24 June 2023; pp. 15866–15877. [Google Scholar]
- Wang, Z.; Zhao, Z.; Xing, X.; Xu, D.; Kong, X.; Zhou, L. Conflict-based cross-view consistency for semi-supervised semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2023, Vancouver, BC, Canada, 17–24 June 2023; pp. 19585–19595. [Google Scholar]
- Teichmann, M.; Weber, M.; Zoellner, M.; Cipolla, R.; Urtasun, R. Multinet: Real-time joint semantic reasoning for autonomous driving. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Suzhou, China, 26–30 June 2018; pp. 1013–1020. [Google Scholar]
- Wu, D.; Liao, M.-W.; Zhang, W.-T.; Wang, X.-G.; Bai, X.; Cheng, W.-Q.; Liu, W.-Y. Yolop: You only look once for panoptic driving perception. Mach. Intell. Res. 2022, 19, 550–562. [Google Scholar] [CrossRef]
- Vu, D.; Ngo, B.; Phan, H. Hybridnets: End-to-end perception network. arXiv 2022, arXiv:2203.09035. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Qiu, J. Ultralytics YOLO (Version 8.0.0). 2023. Available online: https://github.com/ultralytics/ultralytics (accessed on 13 July 2024).
- Deng, W.; Liu, B. Deep Learning-Based Pedestrian Detection Combined with Semantics. Comput. Syst. Appl. 2018, 27, 165–170. [Google Scholar]
- Xu, B.; Liu, X.; Feng, G.; Liu, C. A monocular-based framework for accurate identification of spatial-temporal distribution of vehicle wheel loads under occlusion scenarios. Eng. Appl. Artif. Intell. 2024, 133, 107972. [Google Scholar] [CrossRef]
- Wu, Y.; Wang, T.; Gu, R.; Liu, C.; Xu, B. Nighttime vehicle detection algorithm based on image translation technology. J. Intell. Fuzzy Syst. 2024, 46, 5377–5389. [Google Scholar] [CrossRef]
- Xu, B.; Liu, C. Keypoint detection-based and multi-deep learning model integrated method for indentifying vehicle axle load spatial-temporal distribution. Adv. Eng. Inform. 2024, 62, 102688. [Google Scholar] [CrossRef]
- Fan, R.; Wang, H.; Cai, P.; Liu, M. Sne-roadseg: Incorporating surface normal information into semantic segmentation for accurate freespace detection. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 340–356. [Google Scholar]
- Asgarian, H.; Amirkhani, A.; Shokouhi, S.B. Fast drivable area detection for autonomous driving with deep learning. In Proceedings of the 2021 5th International Conference on Pattern Recognition and Image Analysis (IPRIA), Kashan, Iran, 28–29 April 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–6. [Google Scholar]
- Liu, Z.; Yu, S.; Wang, X.; Zheng, N. Detecting drivable area for self-driving cars: An unsupervised approach. arXiv 2017, arXiv:1705.00451. [Google Scholar]
- Wang, Z.; Ren, W.; Qiu, Q. Lanenet: Real-time lane detection networks for autonomous driving. arXiv 2018, arXiv:1807.01726. [Google Scholar]
- Zheng, T.; Fang, H.; Zhang, Y.; Tang, W.; Yang, Z.; Liu, H.; Cai, D. Resa: Recurrent feature-shift aggregator for lane detection. In Proceedings of the AAAI Conference on Artificial Intelligence 2021, Vancouver, BC, Canada, 2–9 February 2021; Volume 35, pp. 3547–3554. [Google Scholar]
- Baxter, J. A model of inductive bias learning. J. Artif. Intell. Res. 2000, 12, 149–198. [Google Scholar] [CrossRef]
- Zhang, Y.; Yang, Q. A Survey on Multi-Task Learning. IEEE Trans. Knowl. Data Eng. 2022, 34, 5586–5609. [Google Scholar] [CrossRef]
- Qian, Y.; John, M.; Yang, M. DLT-Net: Joint Detection of Drivable Areas, Lane Lines, and Traffic Objects. IEEE Trans. Intell. Transp. Syst. 2020, 21, 4670–4679. [Google Scholar] [CrossRef]
- Wu, Q.; Wang, W.; Fan, P.; Fan, Q.; Wang, J.; Letaief, K.B. Urllc-awared resource allocation for heterogeneous vehicular edge computing. IEEE Trans. Veh. Technol. 2024, 73, 11789–11805. [Google Scholar] [CrossRef]
- Li, S.; Wang, Z.; Liu, Z.; Tan, C.; Lin, H.; Wu, D.; Chen, Z.; Zheng, J.; Li, S.Z. Moganet: Multi-order gated aggregation network. In Proceedings of the Twelfth International Conference on Learning Representations, Kigali, Rwanda, 1–5 May 2023. [Google Scholar]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Garcia-Rodriguez, J. A review on deep learning techniques applied to semantic segmentation. arXiv 2017, arXiv:1704.06857. Available online: https://arxiv.org/abs/1704.06857 (accessed on 1 June 2023).
- Hou, Y.; Ma, Z.; Liu, C.; Loy, C.C. Learning lightweight lane detection cnns by self attention distillation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1013–1021. [Google Scholar]
- Miraliev, S.; Abdigapporov, S.; Kakani, V.; Kim, H. Real-time memory efficient multi-task learning model for autonomous driving. IEEE Trans. Intell. Veh. 2023, 9, 247–258. [Google Scholar] [CrossRef]
- Guo, J.; Wang, J.; Wang, H.; Xiao, B.; He, Z.; Li, L. Research on road scene understanding of autonomous vehicles based on multi-task learning. Sensors 2023, 23, 6238. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | mAP50 | Recall | FPS |
|---|---|---|---|
| MultiNet | 60.2 | 81.3 | 25 |
| Faster R-CNN | 64.9 | 81.2 | 19 |
| YOLOV5s | 77.2 | 86.8 | 82 |
| YOLOP | 76.4 | 88.6 | 51 |
| HybridNet | 77.2 | 89.9 | 29 |
| RegNetY [30] | 77.5% | 86.1 | - |
| YOLO-ODL [31] | 79.7% | 94.2 | 94 |
| Ours | 81.4 | 87.3 | 61 |
| Model | Accuracy | IoU |
|---|---|---|
| SCNN | 35.78 | 15.48 |
| Enet-SAD | N/A | 16.02 |
| YOLOP | 76.4 | 25.6 |
| HybridNet | 77.2 | 27.9 |
| RegNetY | 76.9 | 33.8 |
| YOLO-ODL | 75.0 | 27.5 |
| Ours | 79.6 | 28.9 |
| Model | Drivable mIoU |
|---|---|
| MultiNet | 71.6 |
| DLT-Net | 72.3 |
| PSPNet | 89.6 |
| YOLOP | 91.1 |
| HybridNet | 90.5 |
| RegNetY | 91.9 |
| YOLO-ODL | 92.3 |
| Ours | 92.6 |
| Method | Model | FPS | mAP50 | Lane IoU | Drivable mIoU |
|---|---|---|---|---|---|
| A | V8 | 83.7 | 71.8 | 24.1 | 88 |
| B | V8 + Moganet | 56.4 | 76.9 | 25.4 | 89.2 |
| C | B + SPPCSPC | 67.8 | 77.1 | 25.3 | 89.5 |
| D | B + Improve SPPCSPC | 67.1 | 77.2 | 25.1 | 89.7 |
| E | D + BiFPN | 61.9 | 80.8 | 28.5 | 90.8 |
| F | D + Improve BiFPN | 61 | 81.4 | 28.9 | 92.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, R.; Yang, S.; Tang, W.; Yuan, J.; Chan, Q.; Yang, Y. Multi-Task Environmental Perception Methods for Autonomous Driving. Sensors 2024, 24, 5552. https://doi.org/10.3390/s24175552
Liu R, Yang S, Tang W, Yuan J, Chan Q, Yang Y. Multi-Task Environmental Perception Methods for Autonomous Driving. Sensors. 2024; 24(17):5552. https://doi.org/10.3390/s24175552
Chicago/Turabian StyleLiu, Ri, Shubin Yang, Wansha Tang, Jie Yuan, Qiqing Chan, and Yunchuan Yang. 2024. "Multi-Task Environmental Perception Methods for Autonomous Driving" Sensors 24, no. 17: 5552. https://doi.org/10.3390/s24175552