


Utility-Driven End-to-End Network Slicing for Diverse IoT Users in MEC: A Multi-Agent Deep Reinforcement Learning Approach


Abstract
1. Introduction
- How to prevent assigning all common and urgent requests to the home cloudlet to avoid overloading a single cloudlet location;
- How to decide which request to assign to the adjacent cloudlet;
- When it is necessary to activate a VNF instance and when to deactivate it;
- How to ensure that common requests are assigned within their deadlines, even when urgent requests are also arriving;
- How to manage available resources in the cloudlet if a user’s demand changes in real time.
- We design a network slicing-based MEC system using multi-agent soft actor–critic (MAgSAC), where cloudlets are placed at various locations near IoT users to provide end-to-end resource allocation services. These cloudlets have computing capabilities in the form of VNF instances, which can be activated or deactivated as needed. This setup accommodates both common and urgent IoT user requests while balancing resource allocation across cloudlets, ultimately ensuring QoS.
- We propose an extensive optimization problem model that aims to optimize the overall utility of the MEC network. This is achieved through intelligent network slice utilization, which involves a trade-off between revenue, energy consumption cost, and overall execution time. By transforming this complex optimization problem into a DRL problem, we describe it as a Markov Decision Process (MDP) and approach it as a multi-agent DRL problem.
- We devise a multi-agent DRL-based MAgSAC algorithm, which intelligently provides resources for both common and urgent requests through prediction by activating and deactivating VNF instances in home cloudlets, as well as adjacent cloudlets. It minimizes energy consumption costs by reconsidering idle or remaining capacity before deactivating VNF instances, thereby maximizing overall utility and minimizing latency. This scheme efficiently facilitates user needs and prevents cloudlets from creating imbalanced network slicing during resource allocation. Our approach aims to intelligently handle the optimization challenges mentioned earlier.
- We conduct extensive simulations to compare our MAgSAC approach with benchmark methods, including MAA3C, SACT, DDPG, S2Vec, Random, and Greedy. The results indicate that our MAgSAC scheme achieves the highest utility with the lowest execution time, as well as minimum delay and energy consumption cost compared to the other approaches.
2. Related Work
3. Motivation
4. System Model
4.1. IoT Users Requests
4.2. Common and Urgent Requests
4.2.1. Common Requests
4.2.2. Urgent Requests
4.3. End-to-End Delay
4.4. Energy Consumption Cost and Profit
5. Optimization Problem for End-to-End Network Slicing
5.1. MAMDP-Based Problem Formulation
- Requests being processed in cloudlet at the time slot: , ;
- Available computing capacity of cloudlet at the time slot: , ;
- Idle VNF instances in cloudlet at the time slot: , ;
- Active VNF instances in cloudlet at the time slot: , ;
- Deactivated VNF instances in cloudlet at the time slot: , ;
- Available bandwidth resources at each edge at the time slot: , .
- Amount of computing resources in cloudlet that can be assigned to a VNF instance at the time slot: , ;
- Activation of a VNF instance in cloudlet to fulfill user requirements at the time slot: , ;
- Amount of remaining computing resources in cloudlet that can still be assigned at the time slot: , ;
- Deactivation of a VNF instance in cloudlet at the time slot: , ;
- Transfer of the request to the adjacent cloudlet () at the time slot: , ;
- One VNF instance must be activated in the cloudlet to assign the user request;
- If an idle instance is available, it must meet the needs of the user request to promote reuse;
- The remaining capacity in the cloudlet for the instance should be greater than the incoming request;
- To transfer the request to an adjacent cloudlet, the bandwidth available between the two cloudlet edges () should be sufficient for this transfer.
5.2. Multi-Agent Soft Actor–Critic-Based Learning
- Actor–Critic Structure: SAC operates according to the actor–critic structure, which includes an actor part and a critic part. The actor contributes to determination of the optimal strategy that maximizes expected utility, whereas the critic provides an estimation of the state and state–action value over that period. By leveraging the actor–critic structure, SAC effectively combines policy-based and value-based RL, which is a positive aspect of this approach.
- Entropy Maximization: By incorporating entropy assessments of policies into the utility function, the stochasticity of SAC’s policy substantially improves, thereby enabling the exploration of a wider range of potentially optimal decisions. Compared to previous policy-based DRL methods, the SAC approach demonstrates greater adaptability and scalability, allowing it to adapt effectively in stochastic environments. In short, maximizing entropy in the SAC algorithm promotes exploration and enhances the ability of the policy to adapt to complex and extremely large environments.
- Off-Policy Learning: To train network parameters based on the experience replay strategy, SAC utilizes an off-policy formulation. This approach enables the efficient utilization of sampled experiences to achieve smooth convergence. SAC leverages the following three key features: off-policy learning, the actor–critic framework, and entropy maximization. These features collectively contribute to SAC’s effectiveness in continuous control actions.
5.2.1. Soft Value Function
5.2.2. Policy Evaluation
5.2.3. Policy Improvement
5.3. Detailed Examination of Algorithms
| Algorithm 1 Request Assignment |
|
| Algorithm 2 Online Soft Actor–Critic-based Process to Assign Resources |
|
| Algorithm 3 Online Soft Actor–Critic-Based Algorithm to Assign Requests and Resource Allocation |
|
| Algorithm 4 Training of MAgSAC |
|
6. Complexity Analysis
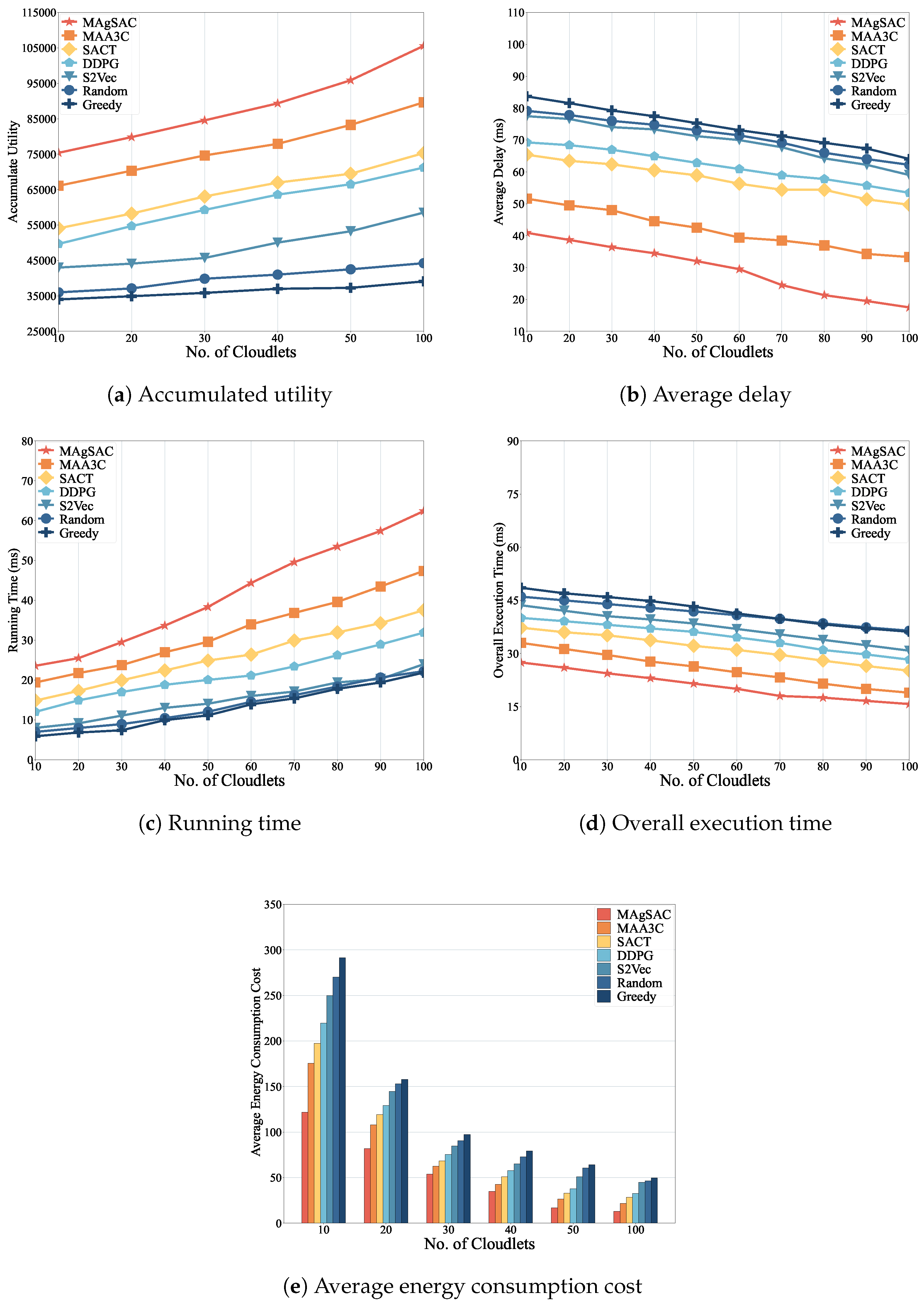
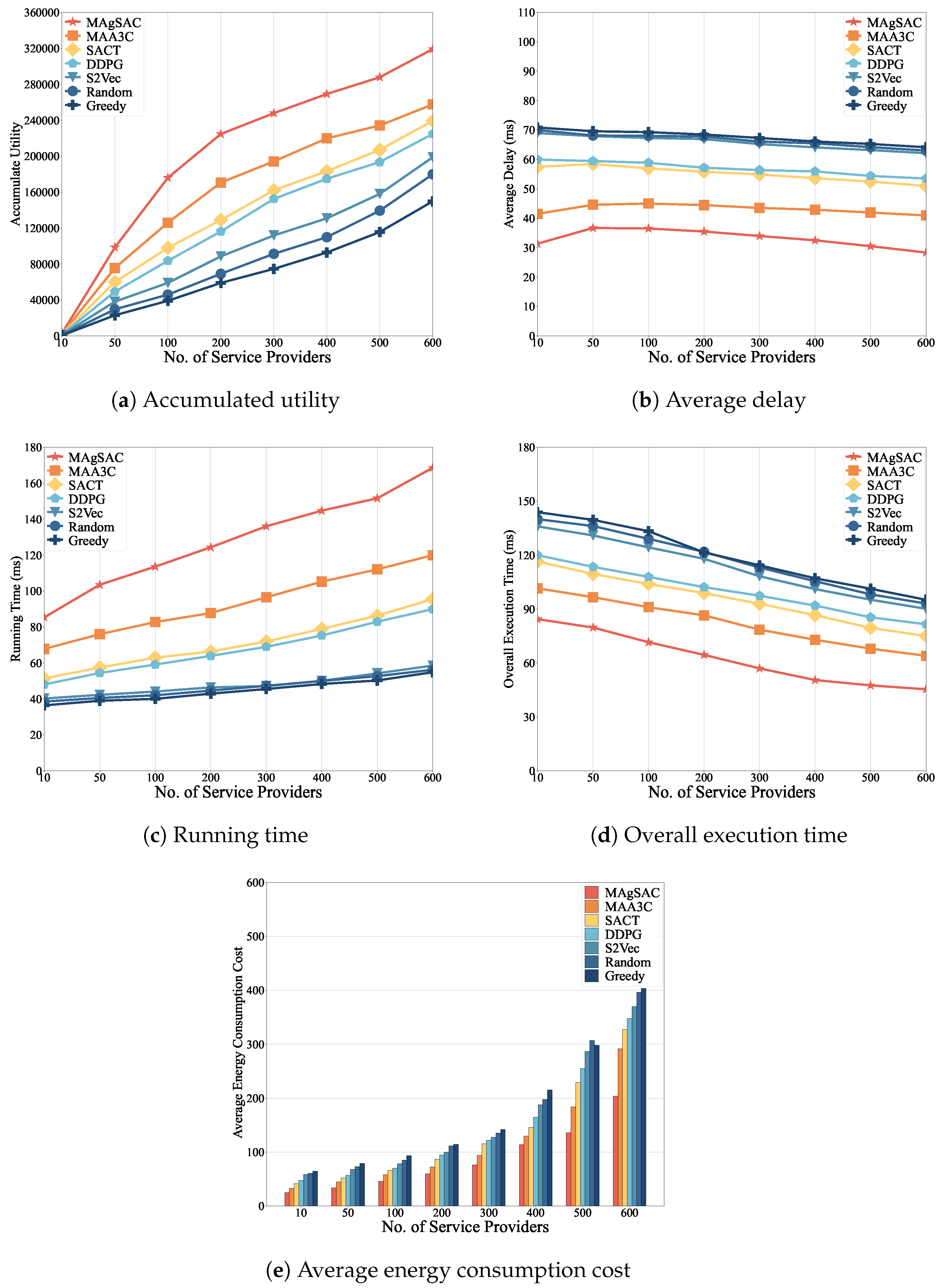
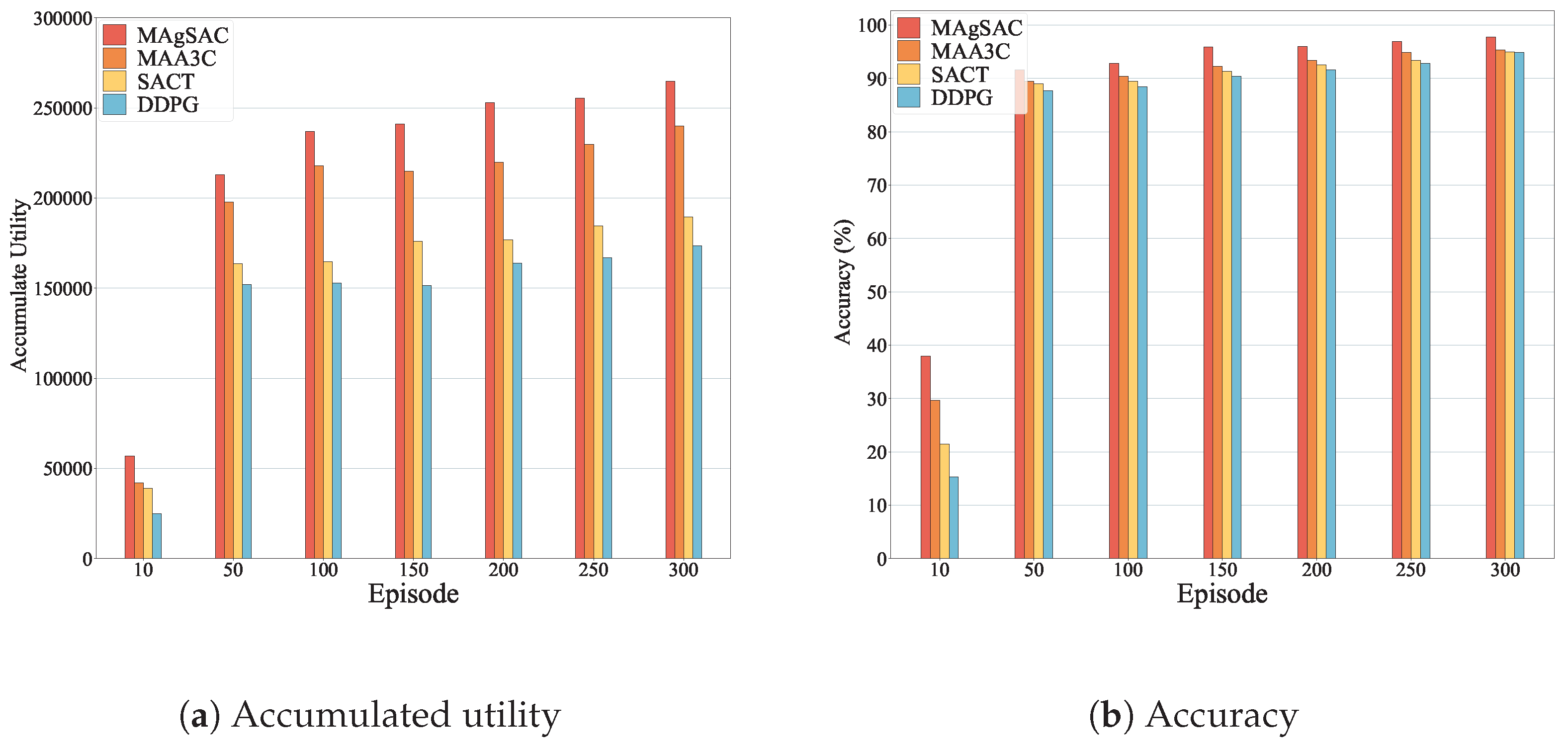
7. Results and Discussion
7.1. Parameter Setup
- MAA3C-based approach: The first benchmark [69] jointly considers the selection of edge nodes and resource allocation to optimize energy consumption, delay, and computing capabilities. We employ this approach with the same parameter settings for fair comparison.
- SAC-based approach: The second benchmark is a traditional approach referred to as SACT, which sets resource allocation to cloudlets based on available computing capacity.
- DDPG-based approach: The third benchmark, DDPG, makes resource allocation decisions based on environmental feedback.
- Structure2Vec approach: The forth benchmark is Structure2Vec (referred to as S2Vec), which facilitates learning through feature-embedding strategies.
- Random approach: The fifth benchmark randomly chooses cloudlets for resource allocation.
- Greedy approach: The sixth benchmark selects cloudlets greedily based on resource availability, considering the available bandwidth in links by assessing the closest paths.
7.2. Performance Analysis
8. Research Findings
9. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Pioli, L.; de Macedo, D.D.; Costa, D.G.; Dantas, M.A. Intelligent Edge-powered Data Reduction: A Systematic Literature Review. ACM Comput. Surv. 2024, 56, 1–39. [Google Scholar] [CrossRef]
- Liu, J.; Guo, S.; Wang, Q.; Pan, C.; Yang, L. Optimal multi-user offloading with resources allocation in mobile edge cloud computing. Comput. Netw. 2023, 221, 109522. [Google Scholar] [CrossRef]
- Chang, Z.; Liu, S.; Xiong, X.; Cai, Z.; Tu, G. A survey of recent advances in edge-computing-powered artificial intelligence of things. IEEE Internet Things J. 2021, 8, 13849–13875. [Google Scholar] [CrossRef]
- Hua, H.; Li, Y.; Wang, T.; Dong, N.; Li, W.; Cao, J. Edge computing with artificial intelligence: A machine learning perspective. ACM Comput. Surv. 2023, 55, 1–35. [Google Scholar] [CrossRef]
- Duan, S.; Wang, D.; Ren, J.; Lyu, F.; Zhang, Y.; Wu, H.; Shen, X. Distributed artificial intelligence empowered by end-edge-cloud computing: A survey. IEEE Commun. Surv. Tutor. 2022, 25, 591–624. [Google Scholar] [CrossRef]
- Maleki, E.F.; Mashayekhy, L.; Nabavinejad, S.M. Mobility-aware computation offloading in edge computing using machine learning. IEEE Trans. Mob. Comput. 2021, 22, 328–340. [Google Scholar] [CrossRef]
- Hao, T.; Hwang, K.; Zhan, J.; Li, Y.; Cao, Y. Scenario-based AI benchmark evaluation of distributed cloud/edge computing systems. IEEE Trans. Comput. 2022, 72, 719–731. [Google Scholar] [CrossRef]
- Al-Doghman, F.; Moustafa, N.; Khalil, I.; Sohrabi, N.; Tari, Z.; Zomaya, A.Y. AI-enabled secure microservices in edge computing: Opportunities and challenges. IEEE Trans. Serv. Comput. 2022, 16, 1485–1504. [Google Scholar] [CrossRef]
- Yao, Z.; Xia, S.; Li, Y.; Wu, G. Cooperative task offloading and service caching for digital twin edge networks: A graph attention multi-agent reinforcement learning approach. IEEE J. Sel. Areas Commun. 2023, 41, 3401–3413. [Google Scholar] [CrossRef]
- Xu, Z.; Ren, H.; Liang, W.; Xia, Q.; Zhou, W.; Zhou, P.; Xu, W.; Wu, G.; Li, M. Near optimal learning-driven mechanisms for stable nfv markets in multitier cloud networks. IEEE/ACM Trans. Netw. 2022, 30, 2601–2615. [Google Scholar] [CrossRef]
- Xu, Z.; Xia, Q.; Wang, L.; Zhou, P.; Lui, J.C.; Liang, W.; Xu, W.; Wu, G. Stable service caching in mecs of hierarchical service markets with uncertain request rates. IEEE Trans. Mob. Comput. 2022, 22, 4279–4296. [Google Scholar] [CrossRef]
- Zhang, Q.; Liu, F.; Zeng, C. Online adaptive interference-aware VNF deployment and migration for 5G network slice. IEEE/ACM Trans. Netw. 2021, 29, 2115–2128. [Google Scholar] [CrossRef]
- Pons, M.; Valenzuela, E.; Rodríguez, B.; Nolazco-Flores, J.A.; Del-Valle-Soto, C. Utilization of 5G technologies in IoT applications: Current limitations by interference and network optimization difficulties—A review. Sensors 2023, 23, 3876. [Google Scholar] [CrossRef]
- Cruz, P.; Achir, N.; Viana, A.C. On the edge of the deployment: A survey on multi-access edge computing. ACM Comput. Surv. 2022, 55, 1–34. [Google Scholar] [CrossRef]
- Li, R.; Zhou, Z.; Zhang, X.; Chen, X. Joint application placement and request routing optimization for dynamic edge computing service management. IEEE Trans. Parallel Distrib. Syst. 2022, 33, 4581–4596. [Google Scholar] [CrossRef]
- Vieira, J.L.; Macedo, E.L.; Battisti, A.L.; Noce, J.; Pires, P.F.; Muchaluat-Saade, D.C.; Oliveira, A.C.; Delicato, F.C. Mobility-aware SFC migration in dynamic 5G-Edge networks. Comput. Netw. 2024, 250, 110571. [Google Scholar] [CrossRef]
- Camargo, J.S.; Coronado, E.; Ramirez, W.; Camps, D.; Deutsch, S.S.; Pérez-Romero, J.; Antonopoulos, A.; Trullols-Cruces, O.; Gonzalez-Diaz, S.; Otura, B.; et al. Dynamic slicing reconfiguration for virtualized 5G networks using ML forecasting of computing capacity. Comput. Netw. 2023, 236, 110001. [Google Scholar] [CrossRef]
- Caballero, P.; Banchs, A.; De Veciana, G.; Costa-Pérez, X. Network slicing games: Enabling customization in multi-tenant mobile networks. IEEE/ACM Trans. Netw. 2019, 27, 662–675. [Google Scholar] [CrossRef]
- Promponas, P.; Tassiulas, L. Network slicing: Market mechanism and competitive equilibria. In Proceedings of the IEEE INFOCOM 2023-IEEE Conference on Computer Communications, New York, NY, USA, 17–20 May 2023; pp. 1–10. [Google Scholar]
- Liu, Y.; Lee, M.J.; Zheng, Y. Adaptive multi-resource allocation for cloudlet-based mobile cloud computing system. IEEE Trans. Mob. Comput. 2015, 15, 2398–2410. [Google Scholar] [CrossRef]
- Fang, C.; Hu, Z.; Meng, X.; Tu, S.; Wang, Z.; Zeng, D.; Ni, W.; Guo, S.; Han, Z. Drl-driven joint task offloading and resource allocation for energy-efficient content delivery in cloud-edge cooperation networks. IEEE Trans. Veh. Technol. 2023, 12, 16195–16207. [Google Scholar] [CrossRef]
- Wu, G.; Xu, Z.; Zhang, H.; Shen, S.; Yu, S. Multi-agent DRL for joint completion delay and energy consumption with queuing theory in MEC-based IIoT. J. Parallel Distrib. Comput. 2023, 176, 80–94. [Google Scholar] [CrossRef]
- Feriani, A.; Hossain, E. Single and multi-agent deep reinforcement learning for AI-enabled wireless networks: A tutorial. IEEE Commun. Surv. Tutor. 2021, 23, 1226–1252. [Google Scholar] [CrossRef]
- Mason, F.; Nencioni, G.; Zanella, A. Using distributed reinforcement learning for resource orchestration in a network slicing scenario. IEEE/ACM Trans. Netw. 2022, 31, 88–102. [Google Scholar] [CrossRef]
- Alharbi, A.; Aljebreen, M.; Tolba, A.; Lizos, K.A.; El-Atty, S.A.; Shawki, F. A normalized slicing-assigned virtualization method for 6g-based wireless communication systems. ACM Trans. Multimed. Comput. Commun. Appl. 2022, 18, 1–18. [Google Scholar] [CrossRef]
- Tsourdinis, T.; Chatzistefanidis, I.; Makris, N.; Korakis, T.; Nikaein, N.; Fdida, S. Service-aware real-time slicing for virtualized beyond 5G networks. Comput. Netw. 2024, 247, 110445. [Google Scholar] [CrossRef]
- Lodhi, M.A.; Obaidat, M.S.; Wang, L.; Mahmood, K.; Qureshi, K.I.; Chen, J.; Hsiao, K.F. Tiny Machine Learning (TinyML) for Efficient Channel Selection in LoRaWAN. IEEE Internet Things J. 2024, 1. [Google Scholar] [CrossRef]
- Garrido, L.A.; Dalgkitsis, A.; Ramantas, K.; Ksentini, A.; Verikoukis, C. Resource Demand Prediction for Network Slices in 5G using ML Enhanced with Network Models. IEEE Trans. Veh. Technol. 2024, 1–13. [Google Scholar] [CrossRef]
- Zheng, C.; Huang, Y.; Zhang, C.; Quek, T.Q. Learning for Intelligent Hybrid Resource Allocation in MEC-Assisted RAN Slicing Network. IEEE Trans. Veh. Technol. 2024, 1–15. [Google Scholar] [CrossRef]
- Liu, Z.; Wu, Y.; Su, J.; Wu, Z.; Chan, K.Y. Resource management for computational offload in MEC networks with energy harvesting and relay assistance. Comput. Commun. 2024, 222, 230–240. [Google Scholar] [CrossRef]
- Han, R.; Wang, J.; Qi, Q.; Chen, D.; Zhuang, Z.; Sun, H.; Fu, X.; Liao, J.; Guo, S. Dynamic Network Slice for Bursty Edge Traffic. IEEE/ACM Trans. Netw. 2024, 1–16. [Google Scholar] [CrossRef]
- Li, H.; Liu, Y.; Zhou, X.; Vasilakos, X.; Nejabati, R.; Yan, S.; Simenidou, D. Adaptive Resource Management for Edge Network Slicing using Incremental Multi-Agent Deep Reinforcement Learning. arXiv 2023, arXiv:2310.17523. [Google Scholar]
- Suzuki, A.; Kobayashi, M.; Oki, E. Multi-agent deep reinforcement learning for cooperative computing offloading and route optimization in multi cloud-edge networks. IEEE Trans. Netw. Serv. Manag. 2023, 20, 4416–4434. [Google Scholar] [CrossRef]
- Boni, A.K.C.S.; Hassan, H.; Drira, K. Oneshot Deep Reinforcement Learning Approach to Network Slicing for Autonomous IoT Systems. IEEE Internet Things J. 2024, 11, 17034–17049. [Google Scholar] [CrossRef]
- Liu, F.; Yu, H.; Huang, J.; Taleb, T. Joint service migration and resource allocation in edge IoT system based on deep reinforcement learning. IEEE Internet Things J. 2023, 11, 11341–11352. [Google Scholar] [CrossRef]
- Ale, L.; Zhang, N.; Fang, X.; Chen, X.; Wu, S.; Li, L. Delay-aware and energy-efficient computation offloading in mobile-edge computing using deep reinforcement learning. IEEE Trans. Cogn. Commun. Netw. 2021, 7, 881–892. [Google Scholar] [CrossRef]
- Chidume, C.S.; Nnamani, C.O. Intelligent user-collaborative edge device APC-based MEC 5G IoT for computational offloading and resource allocation. J. Parallel Distrib. Comput. 2022, 169, 286–300. [Google Scholar] [CrossRef]
- Xie, Y.; Kong, Y.; Huang, L.; Wang, S.; Xu, S.; Wang, X.; Ren, J. Resource allocation for network slicing in dynamic multi-tenant networks: A deep reinforcement learning approach. Comput. Commun. 2022, 195, 476–487. [Google Scholar] [CrossRef]
- Jiang, H.; Dai, X.; Xiao, Z.; Iyengar, A. Joint task offloading and resource allocation for energy-constrained mobile edge computing. IEEE Trans. Mob. Comput. 2022, 22, 4000–4015. [Google Scholar] [CrossRef]
- Zheng, K.; Luo, R.; Liu, X.; Qiu, J.; Liu, J. Distributed DDPG-Based Resource Allocation for Age of Information Minimization in Mobile Wireless-Powered Internet of Things. IEEE Internet Things J. 2024, 1. [Google Scholar] [CrossRef]
- Chen, Y.; Sun, Y.; Yu, H.; Taleb, T. Joint Task and Computing Resource Allocation in Distributed Edge Computing Systems via Multi-Agent Deep Reinforcement Learning. IEEE Trans. Netw. Sci. Eng. 2024, 11, 3479–3494. [Google Scholar] [CrossRef]
- Wang, Z.; Wei, Y.; Yu, F.R.; Han, Z. Utility optimization for resource allocation in multi-access edge network slicing: A twin-actor deep deterministic policy gradient approach. IEEE Trans. Wirel. Commun. 2022, 21, 5842–5856. [Google Scholar] [CrossRef]
- Reyhanian, N.; Luo, Z.Q. Data-driven adaptive network slicing for multi-tenant networks. IEEE J. Sel. Top. Signal Process. 2021, 16, 113–128. [Google Scholar] [CrossRef]
- Zharabad, A.J.; Yousefi, S.; Kunz, T. Network slicing in virtualized 5G Core with VNF sharing. J. Netw. Comput. Appl. 2023, 215, 103631. [Google Scholar]
- Li, Q.; Wang, Y.; Sun, G.; Luo, L.; Yu, H. Joint Demand Forecasting and Network Slice Pricing for Profit Maximization in Network Slicing. IEEE Trans. Netw. Sci. Eng. 2023, 11, 1496–1509. [Google Scholar] [CrossRef]
- Gohar, A.; Nencioni, G. An online cost minimization of the slice broker based on deep reinforcement learning. Comput. Netw. 2024, 241, 110198. [Google Scholar] [CrossRef]
- Ming, Z.; Yu, H.; Taleb, T. Federated Deep Reinforcement Learning for Prediction-Based Network Slice Mobility in 6 G Mobile Networks. IEEE Trans. Mob. Comput. 2024, 1–17. [Google Scholar] [CrossRef]
- Jiang, W.; Zhan, Y.; Zeng, G.; Lu, J. Probabilistic-forecasting-based admission control for network slicing in software-defined networks. IEEE Internet Things J. 2022, 9, 14030–14047. [Google Scholar] [CrossRef]
- Cai, Y.; Cheng, P.; Chen, Z.; Ding, M.; Vucetic, B.; Li, Y. Deep Reinforcement Learning for Online Resource Allocation in Network Slicing. IEEE Trans. Mob. Comput. 2023, 23, 7099–7116. [Google Scholar] [CrossRef]
- Sharif, Z.; Jung, L.T.; Ayaz, M.; Yahya, M.; Pitafi, S. Priority-based task scheduling and resource allocation in edge computing for health monitoring system. J. King Saud Univ.-Comput. Inf. Sci. 2023, 35, 544–559. [Google Scholar] [CrossRef]
- Wang, X.; Liu, W.; Lin, H.; Hu, J.; Kaur, K.; Hossain, M.S. AI-empowered trajectory anomaly detection for intelligent transportation systems: A hierarchical federated learning approach. IEEE Trans. Intell. Transp. Syst. 2022, 24, 4631–4640. [Google Scholar] [CrossRef]
- Ardagna, D.; Panicucci, B.; Passacantando, M. Generalized nash equilibria for the service provisioning problem in cloud systems. IEEE Trans. Serv. Comput. 2012, 6, 429–442. [Google Scholar] [CrossRef]
- Zhang, X.; Zhang, A.; Sun, J.; Zhu, X.; Guo, Y.E.; Qian, F.; Mao, Z.M. Emp: Edge-assisted multi-vehicle perception. In Proceedings of the 27th Annual International Conference on Mobile Computing and Networking, New Orleans, LA, USA, 25–29 October 2021; pp. 545–558. [Google Scholar]
- Liu, H.; Long, X.; Li, Z.; Long, S.; Ran, R.; Wang, H.M. Joint optimization of request assignment and computing resource allocation in multi-access edge computing. IEEE Trans. Serv. Comput. 2022, 16, 1254–1267. [Google Scholar] [CrossRef]
- Han, R.; Chen, D.; Guo, S.; Wang, J.; Qi, Q.; Lu, L.; Liao, J. Multi-SP Network Slicing Parallel Relieving Edge Network Conflict. IEEE Trans. Parallel Distrib. Syst. 2023, 34, 2860–2875. [Google Scholar] [CrossRef]
- Kallus, N.; Uehara, M. Double reinforcement learning for efficient off-policy evaluation in markov decision processes. J. Mach. Learn. Res. 2020, 21, 1–63. [Google Scholar]
- Wei, Z.; Li, B.; Zhang, R.; Cheng, X.; Yang, L. Many-to-many task offloading in vehicular fog computing: A multi-agent deep reinforcement learning approach. IEEE Trans. Mob. Comput. 2023, 23, 2107–2122. [Google Scholar] [CrossRef]
- Haarnoja, T.; Zhou, A.; Abbeel, P.; Levine, S. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In Proceedings of the International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 1861–1870. [Google Scholar]
- Wu, G.; Zhou, F.; Qu, Y.; Luo, P.; Li, X.Y. QoS-Ensured Model Optimization for AIoT: A Multi-Scale Reinforcement Learning Approach. IEEE Trans. Mob. Comput. 2023, 23, 4583–4600. [Google Scholar] [CrossRef]
- Ren, H.; Xu, Z.; Liang, W.; Xia, Q.; Zhou, P.; Rana, O.F.; Galis, A.; Wu, G. Efficient algorithms for delay-aware NFV-enabled multicasting in mobile edge clouds with resource sharing. IEEE Trans. Parallel Distrib. Syst. 2020, 31, 2050–2066. [Google Scholar] [CrossRef]
- Xia, Q.; Ren, W.; Xu, Z.; Zhou, P.; Xu, W.; Wu, G. Learn to optimize: Adaptive VNF provisioning in mobile edge clouds. In Proceedings of the 2020 17th Annual IEEE International Conference on Sensing, Communication, and Networking (SECON), Como, Italy, 22–25 June 2020; pp. 1–9. [Google Scholar]
- Ren, W.; Xu, Z.; Liang, W.; Dai, H.; Rana, O.F.; Zhou, P.; Xia, Q.; Ren, H.; Li, M.; Wu, G. Learning-driven service caching in MEC networks with bursty data traffic and uncertain delays. Comput. Netw. 2024, 250, 110575. [Google Scholar] [CrossRef]
- Calvert, K.L.; Doar, M.B.; Zegura, E.W. Modeling internet topology. IEEE Commun. Mag. 1997, 35, 160–163. [Google Scholar] [CrossRef]
- Hewlett-Packard Development Company. L.P. Servers for Enterprise BladeSystem, Rack & Tower and Hyperscale. 2019. Available online: https://www.tecnovasoluciones.com/wp-content/uploads/2016/10/4AA3-0132ENW.pdf (accessed on 7 July 2024).
- Knight, S.; Nguyen, H.X.; Falkner, N.; Bowden, R.; Roughan, M. The internet topology zoo. IEEE J. Sel. Areas Commun. 2011, 29, 1765–1775. [Google Scholar] [CrossRef]
- Gushchin, A.; Walid, A.; Tang, A. Scalable routing in SDN-enabled networks with consolidated middleboxes. In Proceedings of the 2015 ACM SIGCOMM Workshop on Hot Topics in Middleboxes and Network Function Virtualization, London, UK, 22–26 August 2015; pp. 55–60. [Google Scholar]
- Martins, J.; Ahmed, M.; Raiciu, C.; Olteanu, V.; Honda, M.; Bifulco, R.; Huici, F. {ClickOS} and the Art of Network Function Virtualization. In Proceedings of the 11th USENIX Symposium on Networked Systems Design and Implementation (NSDI 14), Seattle, WA, USA, 2–4 April 2014; pp. 459–473. [Google Scholar]
- Wang, S.; Guo, Y.; Zhang, N.; Yang, P.; Zhou, A.; Shen, X. Delay-aware microservice coordination in mobile edge computing: A reinforcement learning approach. IEEE Trans. Mob. Comput. 2019, 20, 939–951. [Google Scholar] [CrossRef]
- Zhang, W.; Yang, D.; Wu, W.; Peng, H.; Zhang, N.; Zhang, H.; Shen, X. Optimizing federated learning in distributed industrial IoT: A multi-agent approach. IEEE J. Sel. Areas Commun. 2021, 39, 3688–3703. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]




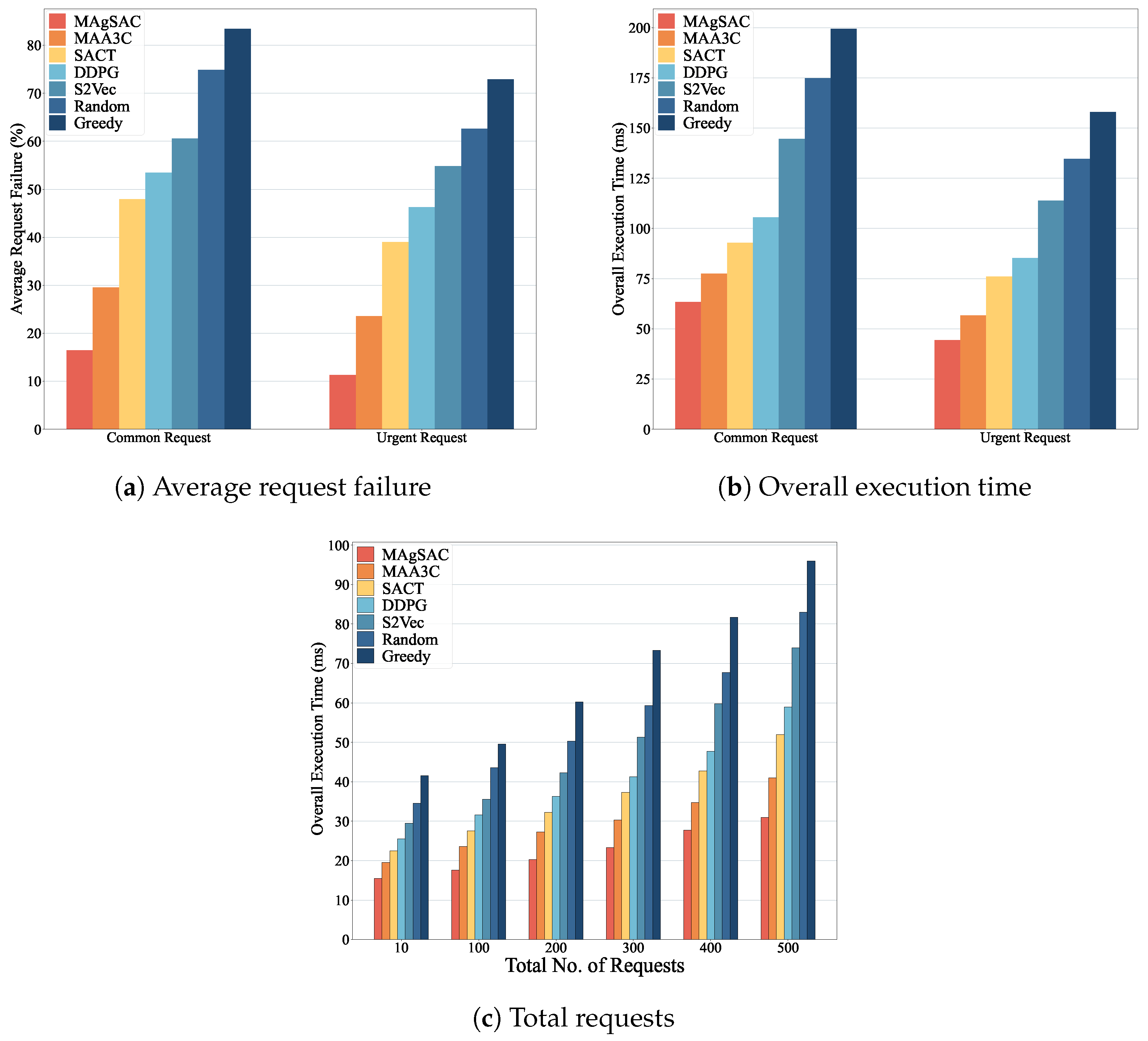

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Term | Definition |
|---|---|
| MEC network, where is a set of cloudlets, is a set of APs, and is a set of edge links | |
| A set of VNF instances | |
| Capacity of a cloudlet | |
| An activated VNF instance | |
| A deactivated VNF instance | |
| Computing resource requirement of VNF instance | |
| t | Time-slot index |
| Bandwidth at the edge (e) | |
| Delay at the edge (e) | |
| A set of links | |
| Network slice requests | |
| Arrival rate of requests | |
| Total number of unfinished requests | |
| Request currently being processed | |
| Common requests | |
| Urgent request | |
| T distribution | |
| Standard deviation | |
| Upper bound | |
| Lower bound | |
| Average T distribution | |
| Overall computational delay in the home cloudlet for urgent requests | |
| Additional queue delay in adjacent cloudlet | |
| Queue waiting delay | |
| Overall computational delay ub adjacent cloudlet for urgent requests | |
| A binary decision variable | |
| Overall computational delay in home cloudlet for common requests | |
| Overall computational in adjacent cloudlet for common requests | |
| Required bandwidth to transfer a request via the link | |
| Overall delay faced by common and urgent requests in the home and adjacent cloudlet | |
| Computing cost of accommodating one unit of traffic | |
| Overall energy consumption cost for urgent requests in the home cloudlet | |
| Overall energy consumption cost for urgent requests in the adjacent cloudlet | |
| Overall energy consumption cost for common requests in the home cloudlet | |
| Overall energy consumption cost for common requests in the adjacent cloudlet | |
| Overall energy consumption cost for common and urgent requests in the home and adjacent cloudlet | |
| Total profit earned by the cloudlet | |
| An idle VNF instance | |
| Remaining computing capacity of a cloudlet | |
| The decision on the assignment of resources for action | |
| Critic network with parameters | |
| Target network | |
| Temperature parameter | |
| Experience reply buffer | |
| Mini-batch | |
| £ | Loss function |
| Policy parameter | |
| Action space | |
| State space |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ejaz, M.A.; Wu, G.; Ahmed, A.; Iftikhar, S.; Bawazeer, S. Utility-Driven End-to-End Network Slicing for Diverse IoT Users in MEC: A Multi-Agent Deep Reinforcement Learning Approach. Sensors 2024, 24, 5558. https://doi.org/10.3390/s24175558
Ejaz MA, Wu G, Ahmed A, Iftikhar S, Bawazeer S. Utility-Driven End-to-End Network Slicing for Diverse IoT Users in MEC: A Multi-Agent Deep Reinforcement Learning Approach. Sensors. 2024; 24(17):5558. https://doi.org/10.3390/s24175558
Chicago/Turabian StyleEjaz, Muhammad Asim, Guowei Wu, Adeel Ahmed, Saman Iftikhar, and Shaikhan Bawazeer. 2024. "Utility-Driven End-to-End Network Slicing for Diverse IoT Users in MEC: A Multi-Agent Deep Reinforcement Learning Approach" Sensors 24, no. 17: 5558. https://doi.org/10.3390/s24175558
APA StyleEjaz, M. A., Wu, G., Ahmed, A., Iftikhar, S., & Bawazeer, S. (2024). Utility-Driven End-to-End Network Slicing for Diverse IoT Users in MEC: A Multi-Agent Deep Reinforcement Learning Approach. Sensors, 24(17), 5558. https://doi.org/10.3390/s24175558