Abstract
Object detection is applied extensively in various domains, including industrial manufacturing, road traffic management, warehousing and logistics, and healthcare. In ship object detection tasks, detection networks are frequently deployed on devices with limited computational resources, e.g., unmanned surface vessels. This creates a need to balance accuracy with a low parameter count and low computational load. This paper proposes an improved object detection network based on YOLOv5. To reduce the model parameter count and computational load, we utilize an enhanced ShuffleNetV2 network as the backbone. In addition, a split-DLKA module is devised and implemented in the small object detection layer to improve detection accuracy. Finally, we introduce the WIOUv3 loss function to minimize the impact of low-quality samples on the model. Experiments conducted on the SeaShips dataset demonstrate that the proposed method reduces parameters by 71% and computational load by 58% compared to YOLOv5s. In addition, the proposed method increases the mAP@0.5 and mAP@0.5:0.95 values by 3.9% and 3.3%, respectively. Thus, the proposed method exhibits excellent performance in both real-time processing and accuracy.
1. Introduction
Advances in 5G communication and artificial intelligence have advanced the development of unmanned surface vessels considerably. Such vessels play a crucial role in various fields, e.g., hydrological monitoring and maritime search and rescue, due to their low cost, low power consumption, and intelligent features. Key technologies for unmanned surface vessels include perception, control, and communication [1]. During mission execution, perception technology provides unmanned surface vessels with essential environmental information. For example, ship object detection technology enables unmanned surface vessels to identify surrounding ships, thereby offering vital positional and ship type information for effective collision avoidance and route planning. Thus, ship object detection is a fundamental component of unmanned vessel technology.
In ship target detection tasks, commonly used sensors include LiDAR and cameras. Note that the mainstream detection range of LiDAR is 150 m, however, in a maritime environment, ships are typically dispersed widely to ensure safe navigation, thereby resulting in sparse point clouds at greater distances. This sparsity causes LiDAR to provide insufficient information for target recognition, and processing LiDAR point clouds requires powerful hardware. In contrast, cameras have a larger detectable distance and produce visible light images with higher pixel density and rich texture information. Thus, cameras offer more data for target detection on unmanned ships. Studying target detection algorithms for visible ship images is crucial to ensure the safe navigation of unmanned vessels [2].
Object detection algorithms can be categorized into traditional methods and deep learning-based methods. Traditional methods primarily rely on handcrafted feature construction. In 2005, Dalal and Triggs proposed the histogram of oriented gradients (HOGs) feature descriptor [3]. To detect objects of various sizes, the HOG detector maintains a constant detection window size while performing multiple scales on the input image. In addition, DPM [4], which is an extension of HOG features, views training as a method for learning to decompose an object, with inference seen as a collection of detections of different object parts. Due to the limitations of handcrafted features, traditional methods often suffer from poor robustness against environmental changes, which leads to false positives and missed detections.
Deep learning-based object detection algorithms have advanced due to the strong feature learning capabilities of convolutional neural networks (CNNs). These algorithms are primarily divided into single-stage and two-stage object detection algorithms. Two-stage detection involves two steps. First, candidate regions are generated, and then algorithms, e.g., R-CNN [5], Fast R-CNN [6], and Faster R-CNN [7], are employed to classify and regress the candidate regions. In contrast, single-stage object detection networks, e.g., YOLO [8,9,10] and SSD [11], employ CNNs to extract the feature information of the targets and then sample and classify/regress the corresponding feature maps using anchor boxes of different aspect ratios. Note that two-stage methods offer higher accuracy, however, they struggle to satisfy real-time requirements. In contrast, single-stage object detection networks have an advantage in terms of real-time performance due to their fast inference speed, thereby making them suitable for rapid detection in maritime environments for unmanned surface vessels. In addition, single-stage object detection networks are being improved continually to balance accuracy and real-time performance, including advancements like YOLOv7 [12] and YOLOv10 [13].
Given that unmanned surface vessels typically have limited computational power, lightweight models are essential. Thus, this paper investigates the lightweight model of single-stage networks using YOLOv5s from the YOLO series as a baseline to design an efficient object detection network. The reasoning is that after extensive practice and optimization, YOLOv5 has proven its reliability across a wide range of scenarios. Thanks to its prolonged development period, the YOLOv5 model is relatively stable, with fewer potential issues. As the smaller variant in the YOLOv5 series, the YOLOv5s strikes an excellent balance between performance and efficiency. It performs well in resource-constrained environments, maintaining high detection accuracy while ensuring faster inference speeds. The primary contributions of this study are summarized as follows:
- To address the high number of parameters in the backbone of the YOLOv5s network, we introduce an improved ShuffleNetV2 network as the backbone. This modification attempts to maintain the model’s feature extraction capability while reducing the parameter count.
- We designed a split-DLKA attention module that leverages the ability of large kernels to expand the receptive field and the capacity of deformable convolutions to adjust to the convolution kernel shape adaptively. This enhances the network’s adaptability to samples of different shapes, thereby making it suitable for detecting vessels of varying sizes in maritime scenarios.
- By incorporating the WIOUv3 loss function into the network, the impact of low-quality samples on the model is reduced, which results in improved detection accuracy.
2. Related Work
Ship detection is a specialized area within object detection that requires balancing two key objectives: accuracy and real-time performance. Given the significant variation in ship sizes, the network must also have strong multi-scale detection capabilities. One of the most effective ways to enhance a neural network’s object detection accuracy is by improving its feature extraction capabilities, often achieved by increasing the network’s depth. However, this approach also increases computational complexity and the number of parameters, which can negatively impact the network’s real-time performance. Consequently, numerous scholars have conducted extensive research on improving accuracy, real-time efficiency, and the multi-scale detection capabilities of networks.
2.1. Attention Mechanism in Ship Detection
The attention mechanism plays a crucial role in enhancing feature extraction and multi-scale detection capabilities. For instance, Shen et al. [14] introduced a multiple information perception-based attention module (MIPAM). Their approach incorporates channel-level information collection through global covariance pooling and channel-wise global average pooling, while spatial-level information is collected in a similar way. This method enriches feature representation, leading to improved detection accuracy when integrated into the YOLO detector. Due to the diverse shapes of ships and the complexities of environmental interference, multi-scale detection has become an essential capability for ship detection networks. Many experts utilize attention mechanisms to dynamically adjust the weights within a network, designing and implementing them to enhance the network’s ability to capture important information across different scales. In [15], the author proposed an attention feature filter module (AFFM), which uses attention supervision generated from high-level semantic features in the feature pyramid to highlight information-rich targets, forming a spatial attention mechanism. Unlike traditional attention mechanisms such as CBAM, the attention signals in the AFFM are derived from higher-level feature maps, which better represent the distinctive characteristics of nearshore ships. Guo et al. [16] utilized sub-pixel convolution, sparse self-attention mechanisms, channel attention, and spatial attention mechanisms to enhance semantic features layer-by-layer, which ensures that the feature map contains richer high-level and low-level semantic information, effectively improving the detection performance of small ships. Yao et al. [17] designed a feature enhancement module based on channel attention, increasing the emphasis on ship features and expanding the receptive field through an adaptive fusion strategy. This enhances spatial perception for ships of varying sizes. Li et al. [18] developed an adaptive spatial channel attention module, effectively reducing the interference of dynamic background noise on large ships. Additionally, they designed a boundary box regression module with gradient thinning, improving gradient sensitivity and multi-scale detection accuracy. Li et al. [19] took a more intuitive approach by incorporating a transformer into the YOLOv5 backbone to enhance feature extraction. Zheng et al. [20] integrated a local attention module into a SSD to improve the detection accuracy of smaller models. Li et al. [21] enhanced YOLOv3 by adding the CBAM attention mechanism to the backbone, enabling the model to focus more on the target and thereby improving detection accuracy.
2.2. Attention Mechanism Combined with Other Improvements
Some authors combine attention mechanisms with other techniques, such as improved loss functions and enhanced convolution methods, to not only boost feature extraction capabilities but also reduce network parameters and improve real-time performance. For example, Zhao et al. [22] introduced the SA attention mechanism into YOLOv5n to enhance feature extraction and replaced standard convolution in the neck with Ghost Conv, reducing both network complexity and computational load. In [23], the author proposed a lightweight LWBackbone to decrease the number of model parameters and introduced a hybrid domain attention mechanism, which effectively suppressed complex land background interference and highlighted target areas, achieving a balance between precision and speed. Ye et al. [24] incorporated the CBAM attention module into the backbone of YOLOv4, replaced CIOU with EIOU, and substituted non-maximum suppression (NMS) with soft-NMS to reduce missed detections of overlapping ships. Bowen Xing et al. [25] added the CBAM attention mechanism to FasterNet, replaced the YOLOv8 backbone, and introduced lightweight GSConv convolution in the neck to enhance feature extraction and fusion. Additionally, they improved the loss function based on ship characteristics and integrated MPDIoU into the network, making it more suitable for ship detection.
2.3. Data Enhancement Prevent Overfitting
Some experts and scholars focus on the ship data themselves, utilizing data enhancement and preprocessing as primary methods to improve network detection performance, along with other enhancements. For instance, Zhang et al. [26] developed a new data enhancement algorithm called Sparse Target Mosaic, which improves training samples. By incorporating a feature fusion module based on attention mechanisms and refining the loss function, they were able to enhance detection accuracy. Gao et al. [27] applied gamma transform to preprocess infrared images, increasing the gray contrast between the target and background. They also replaced the YOLOv5 backbone with MobileNetV3, reducing parameters by 83% without significantly compromising detection performance. Chen et al. [28] designed pixel-space data enhancement in a two-stage target detection network, using set transformation and pixel transformation to enhance data diversity and reduce model overfitting. This approach improved network focus and accuracy, achieving a remarkable mAP of 99.63%. Qiu et al. [29] addressed the singleness of the dataset’s image style in ship detection datasets by proposing an anti-attention module. They inputted the original feature layer into a trained convolutional neural network, filtered the output weights, and removed feature layers that negatively impacted detection. This led to improvements in both the mAP and F1-score.
2.4. Improvement in Lightweight
Some scholars focused on improving convolutional methods, backbone, and loss functions to enhance ship detection performance. For example, Li et al. [30] integrated OD-Conv into the YOLOv7 backbone, effectively addressing the issue of complex background interference in ship images, thereby improving the model’s feature extraction capabilities. Additionally, they introduced the space-to-depth structure in the head network to tackle the challenge of detecting small- and medium-sized ship targets. These improvements led to a 2.3% increase in mAP compared to the baseline. Zheng et al. [31] proposed a differential-evolution-based K-means clustering method to generate anchors tailored to ship sizes. They also enhanced the loss function by incorporating focal loss and EIOU, resulting in a 7.1% improvement in average precision compared to YOLOv5s. Shi et al. [32] introduced the theta-EIOU loss function, which enhances the network’s learning and representation capabilities by reconstructing the bounding box regression loss function, improving background partitioning, and refining sample partitioning. The improved method outperformed the original YOLOX network. Zhang et al. [33] incorporated a multi-scale residual module into YOLOv7-Tiny and designed a lightweight feature extraction module. This reduced the number of parameters and computational load of the backbone while improving feature extraction accuracy. They used Mish and SiLU activation functions in the feature extraction module to enhance network performance and introduced CoordConv in the neck network to reduce feature loss and more accurately capture spatial information. Zheng et al. [34] replaced YOLOv5s’ original feature extraction backbone with the lightweight MobileNetV3-Small network and reduced the depth-separable convolutional channels in the C3 module to create a more efficient feature fusion module. As a result, the final network had 6.98MB fewer parameters and an improved mAP compared to YOLOv5s.
Due to the significant variations in the appearance and morphology of ships, scale distortion can affect detection accuracy. In addition, buildings along inland waterways can impact ship detection. Thus, enhancing the model’s robustness to size variations is essential. For deployment on unmanned surface vessels, reducing both the number of model parameters and the computational load while maintaining sufficient detection accuracy is crucial. The goal of this study is to strike a balance between these goals and improve the detection and differentiation of various ship types.
3. Introduction to YOLOv5s Algorithm
The structure of the YOLOv5 model is shown in Figure 1. YOLOv5 is widely used in engineering practices and comes in four versions: YOLOv5s, YOLOv5m, YOLOv5l, and YOLOv5x. These versions have progressively increased model width, depth, and parameter count, which results in improved detection accuracy. YOLOv5s is the smallest and fastest version, making it suitable for deployment on devices with low computing power. The model comprises four main components: input, backbone, neck, and prediction layers (head). The characteristics of each part are summarized as follows:
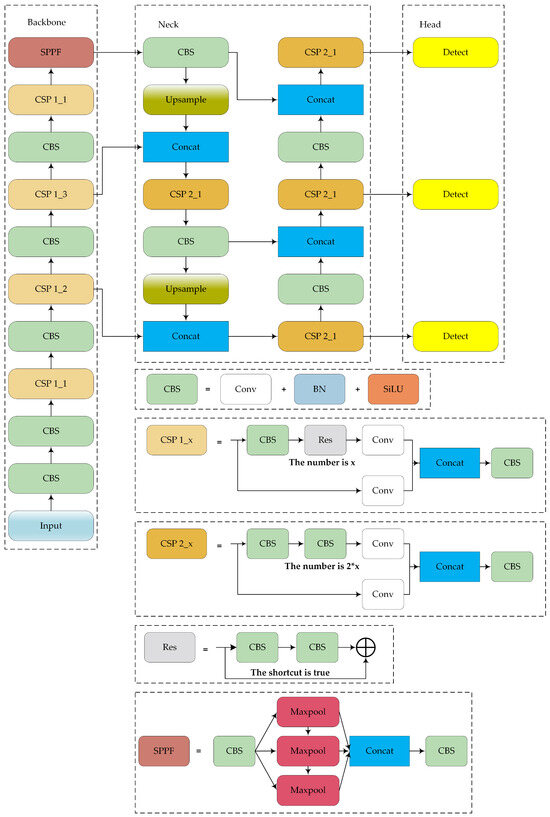
Figure 1.
Structure of YOLOv5s.
- -
- Input: The input layer processes raw images, resizing them to a standard dimension and normalizing the pixel values. This process prepares the data for further processing by the model.
- -
- Backbone: YOLOv5′s backbone is based on the cross-stage partial network (CSPNet) architecture. The main purpose of the backbone in YOLOv5 is to extract features from the input image through a series of convolutional layers. CSPNet helps enhance the model’s learning capability and reduces computational complexity by partitioning the feature map of the base layer into two parts and then merging them through a cross-stage hierarchy.
- -
- Neck: The neck network of YOLOv5 employs the path aggregation network (PANet) as its feature fusion module. PANet enhances feature fusion through both top–down and bottom–up pathways, which enables the network to fully leverage feature information from different levels. This design ensures effective utilization of multi-scale features, which improves the detection of objects of various sizes and shapes.
- -
- Head: The head of YOLOv5 contains three detection heads, which can predict objects at multiple scales simultaneously, thereby improving both accuracy and efficiency. Note that YOLOv5 uses CIOU loss as the bounding box loss function and weighted non-maximum suppression (NMS). CIOU loss improves bounding box regression by considering the overlap area, center point distance, and aspect ratio, and the weighted NMS increases the suppression weight of high-confidence bounding boxes, thereby helping to obtain more reliable results.
4. Proposed Method
Considering the power consumption issues under a limited power supply, the hardware of unmanned surface vessels typically has low power consumption, which in turn results in highly limited computational power. In addition, the memory of unmanned surface vessels is often limited. Thus, it is crucial to reduce the computational load and memory usage of the object detection network. In YOLOv5s, the backbone accounts for 66% of the total FLOPs (floating-point operations). To achieve a lightweight network, the computational load of the backbone must be reduced. Further, the role of the attention mechanism in terms of enhancing the local features and integrating global information can mitigate the feature extraction deficiencies caused by a lightweight backbone network.
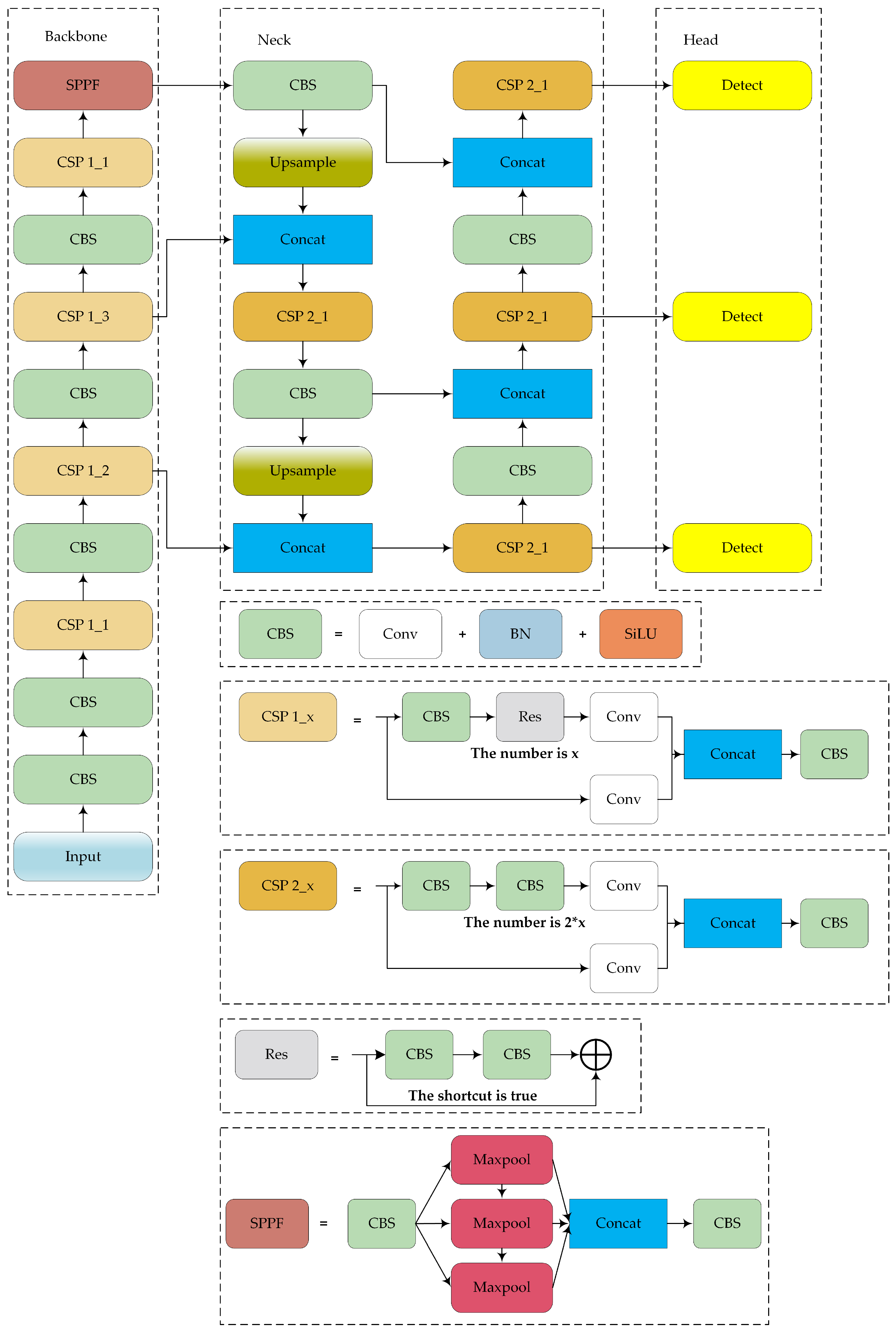
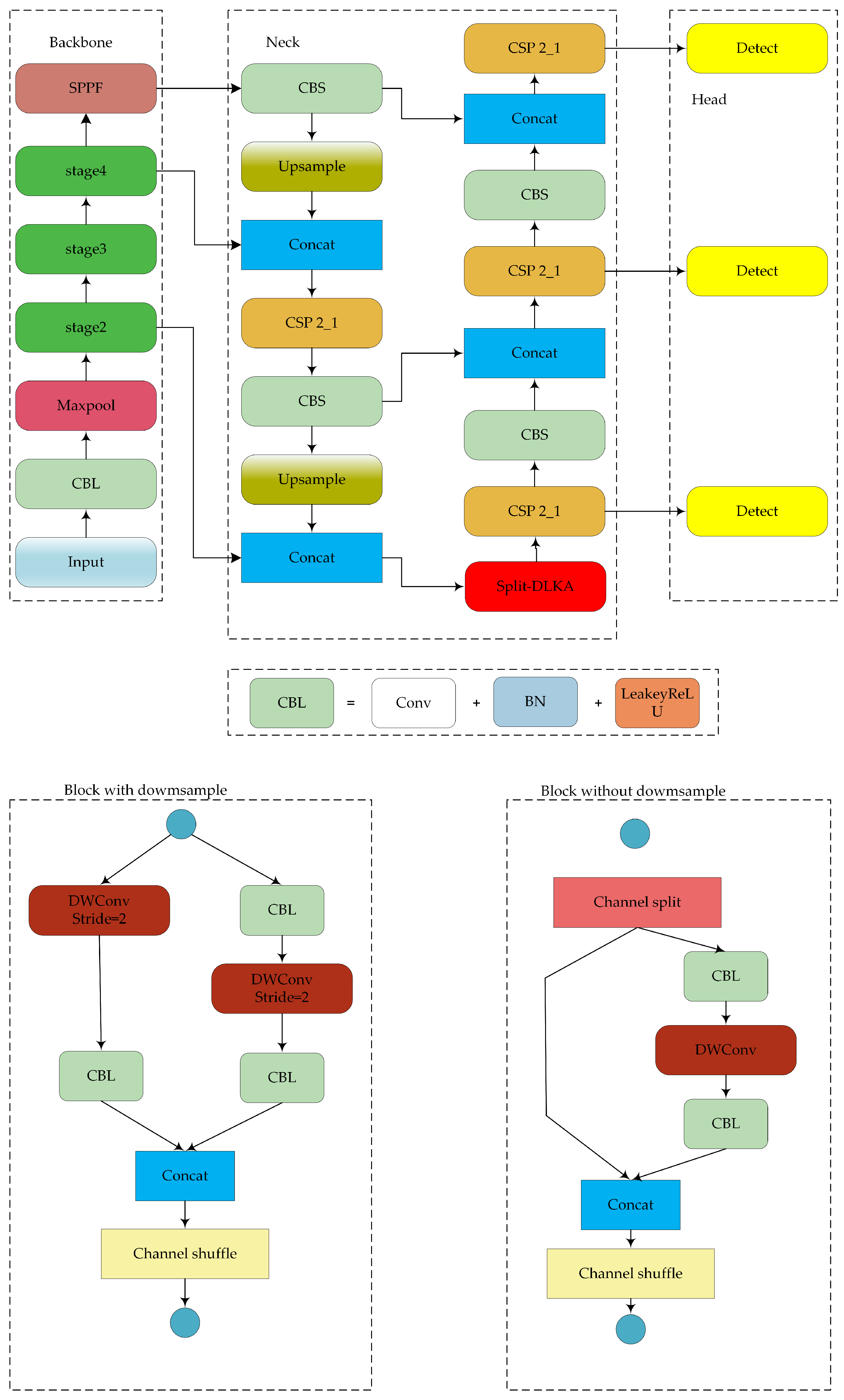
The structure of the proposed lightweight object detection network is shown in Figure 2. The model improvements focus on the backbone, neck, and loss function.
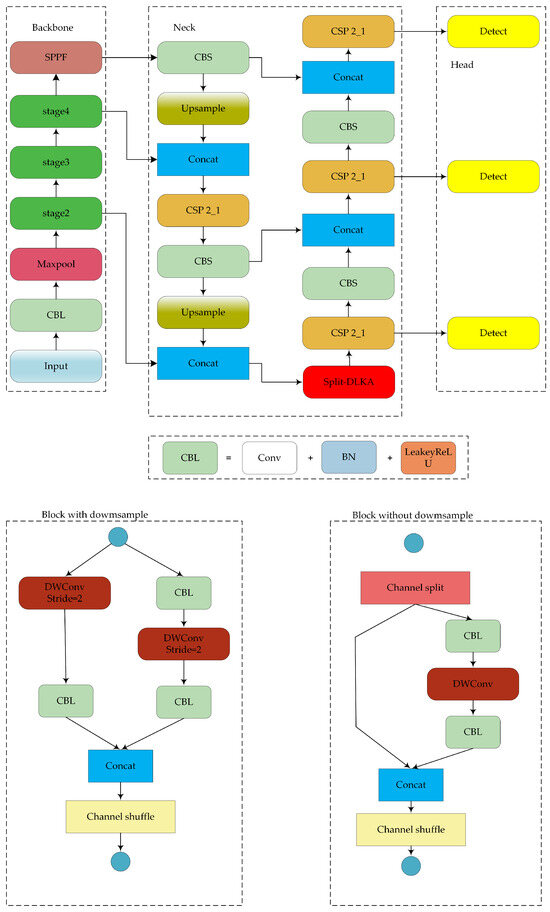
Figure 2.
Structure of the proposed model.
4.1. Backbone
4.1.1. ShufflenetV2 Backbone
Each stage of the ShuffleNetV2 [35] backbone comprises multiple blocks. The structural parameters of ShuffleNetV2 are detailed in Table 1.

Table 1.
ShuffleNetV2 structure parameters.
In each stage, the first block is a down sampling module, and the remaining three blocks are non-down sampling modules.
4.1.2. Activation Function
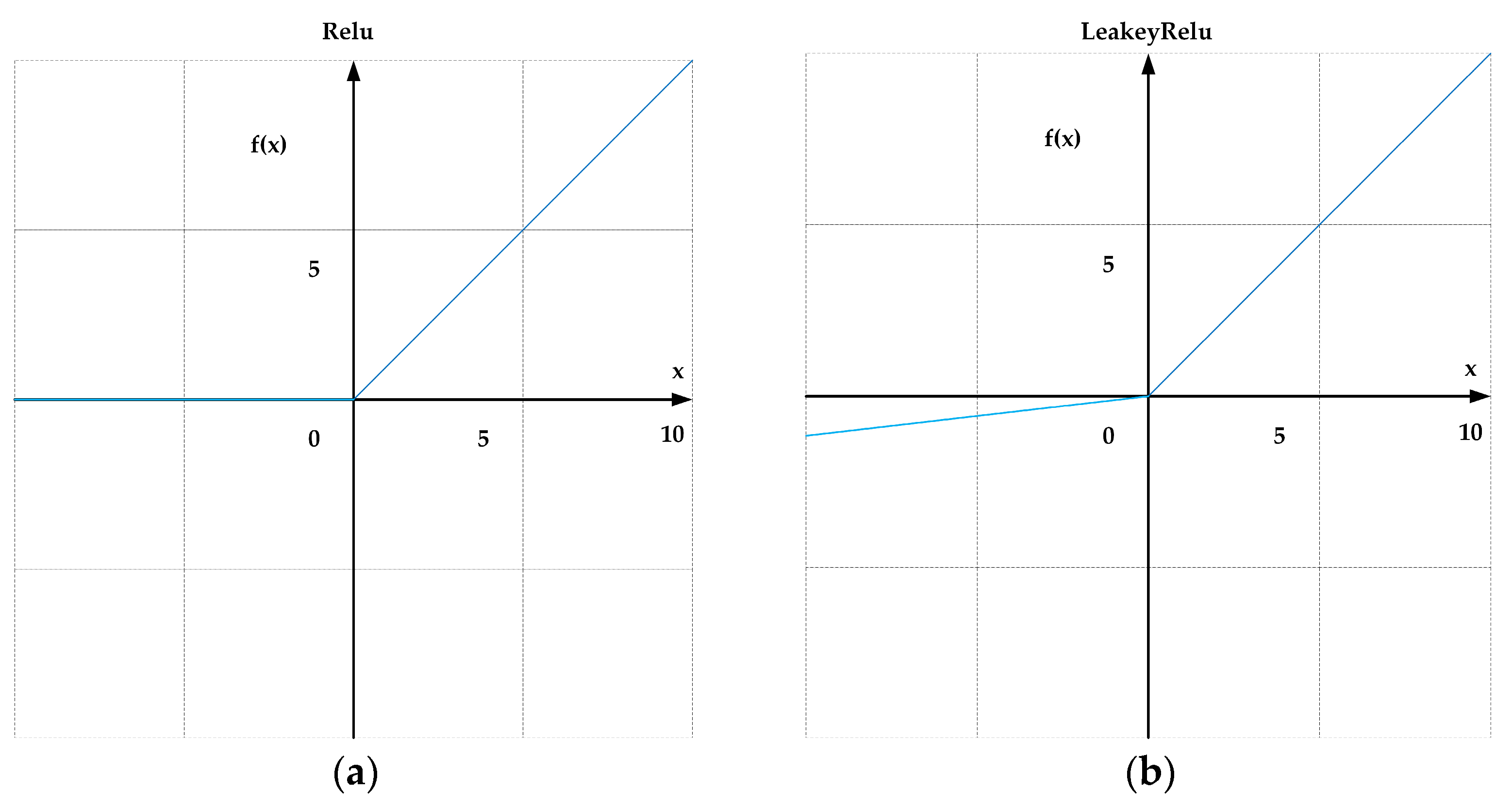
In ShuffleNetV2, the activation function is ReLU, which is defined as follows:
ReLU is a single-sided saturation function with robustness against noise interference. ReLU truncates negative values to zero, thereby introducing sparsity and improving computational efficiency (Figure 3a). However, the ReLU activation function outputs zero for negative input values, which can lead to neurons becoming “dead” or inactive during training, meaning their gradients are consistently zero and they cannot contribute to learning. The Leaky ReLU function addresses this issue by allowing a small, non-zero slope in the negative region, ensuring that all neurons remain partially active and continue to update during training. By preserving a small gradient for negative inputs, Leaky ReLU helps maintain gradient flow throughout the network, which enhances both the stability and convergence speed of the training process. This enhancement is particularly crucial for our object detection tasks, as these models often require deep network architectures to effectively capture complex features. The formula for LeakyReLU is given as follows:
where the parameter is generally set to 0.01. In the part where the input is less than zero, the function value is a negative value with a small gradient (rather than zero), as shown in Figure 3b.
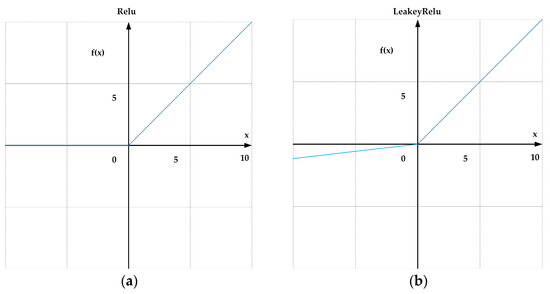
Figure 3.
(a) ReLU activation function plot. (b) LeakyReLU activation function plot.
When the input to the activation function is less than zero, the gradient can still be calculated. In our experiments, we observed that Leaky ReLU outperforms ReLU in terms of performance. Specifically, the use of Leaky ReLU resulted in the improved detection accuracy of the model. Experimental results show that in the ship object detection task, replacing the activation function of ShuffleNetV2 with LeakyReLU and using it as the backbone of YOLOv5s can yield a 0.3% increase in mAP@0.5 and a 7.7% increase in precision.
4.2. Attention Split-DLKA Module
In the task of ship target detection, the size and shape of different ship types can vary significantly, encompassing a wide range of morphologies and structures. This diversity necessitates that the detector be capable of adapting to multiple forms, which increases model complexity and makes it challenging to generalize across different ship types. Additionally, the maritime environment, including oceans, harbors, and other water contexts, is often complex and dynamic, with potential disturbances such as waves, other vessels, and infrastructure. Moreover, the diversity in ship sizes and shapes can lead to sample imbalance in the training data, resulting in sub-optimal model performance for certain ship categories.
An effective strategy to address these challenges is to expand the network’s receptive field, which defines the input region size on which the features at a particular network position depend. The receptive field is calculated as follows:
where represents the receptive field size corresponding to layer , denotes the kernel size or pooling size of layer , and represents the pixel distance between adjacent elements on the feature map. From Equation (3), it is evident that increasing the kernel size can result in a larger receptive field, ultimately producing many equivalent feature scales; a larger receptive field allows the model to capture a broader range of contextual information, which is crucial for detecting objects of different scales and shapes.
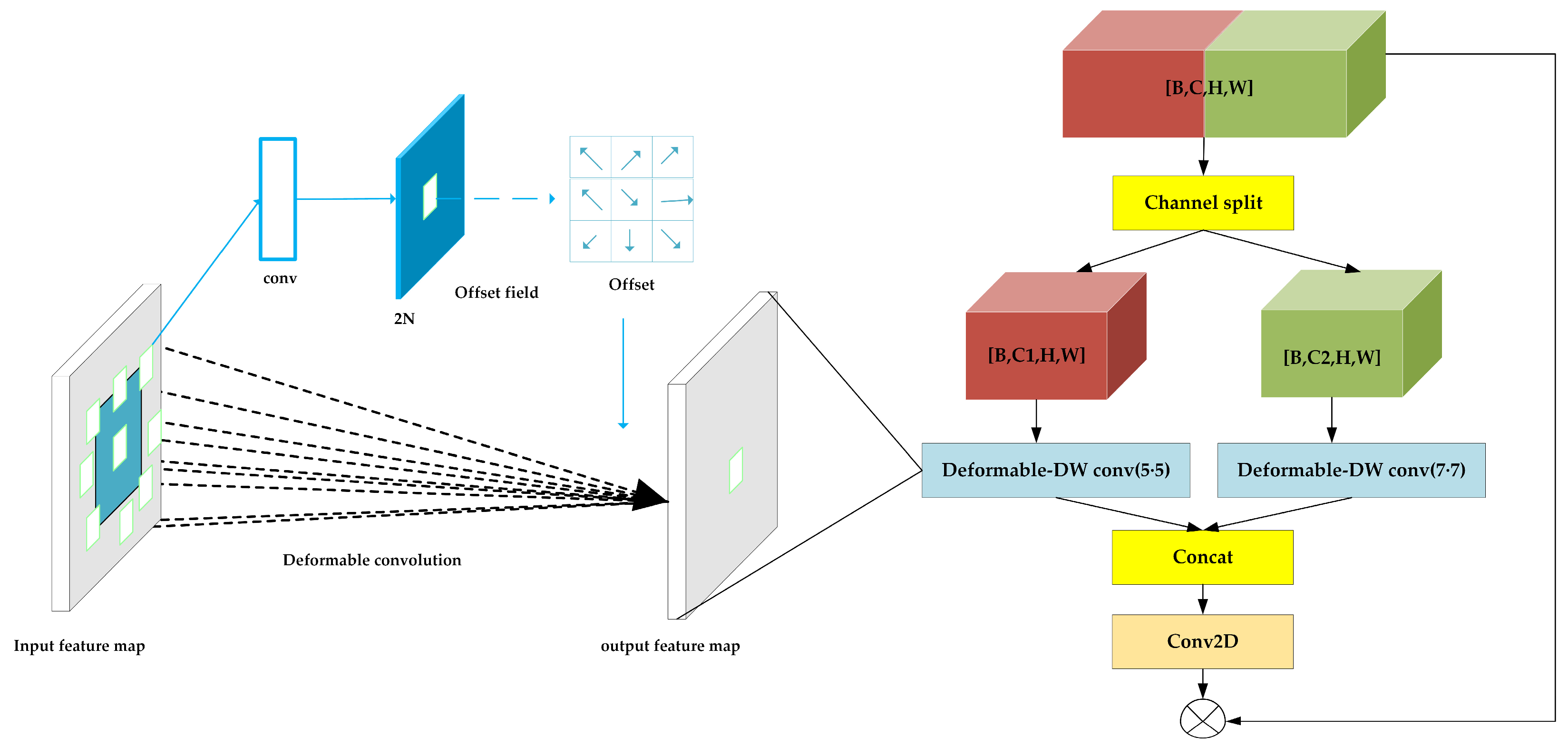
The structure of split-DLKA is illustrated in Figure 4. A tensor of size is divided into subsets along the channel dimension, denoted as , where . Here, each subset has input channels, which are passed separately to the deformable DW module.
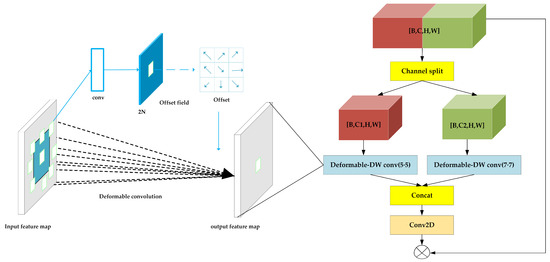
Figure 4.
Structure of split-DLKA.
To expand the receptive field of the neural network, large convolutional kernels of size 5 × 5 and 7 × 7 are applied to the deformable DW module, which can adaptively adjust its sampling positions to better align with the local features of the input data, thereby enhancing feature extraction capability. This improvement allows the model to adapt more effectively to geometric transformations, enabling the network to better handle irregularly shaped objects or features.
In the deformable DW module, 2D convolution can be described as using a grid to sample the feature map and the sampled values are assigned weights and summed; an offset is generated by convolving the input feature map. This offset (which is typically a non-integer offset) is added to the original sampling positions to obtain the new sampling positions. This process is expressed as follows:
where is feature map, is output feature map, is the offset of each point in the convolution kernel relative to the center point and, is the weight of each deviation.
Bilinear interpolation is employed to obtain the pixel values at the offset positions, and the expression is as follows:
where is in Equation (4), is the coordinate of an integer point, and is the bilinear interpolation kernel function.
here, . This restricts the interpolation point and its neighboring points to be within a distance of no greater than one pixel.
The parameter calculation for the split-DLKA module is described as follows:
The convolution generates an offset with an output channel number of . The parameter count for this process is .
Then, a deformable convolution is performed using the convolution and previously generated offset with the groups set to . The parameter count for this process is .
The parameter count of the split-DLKA is as follows:
4.3. Loss Function
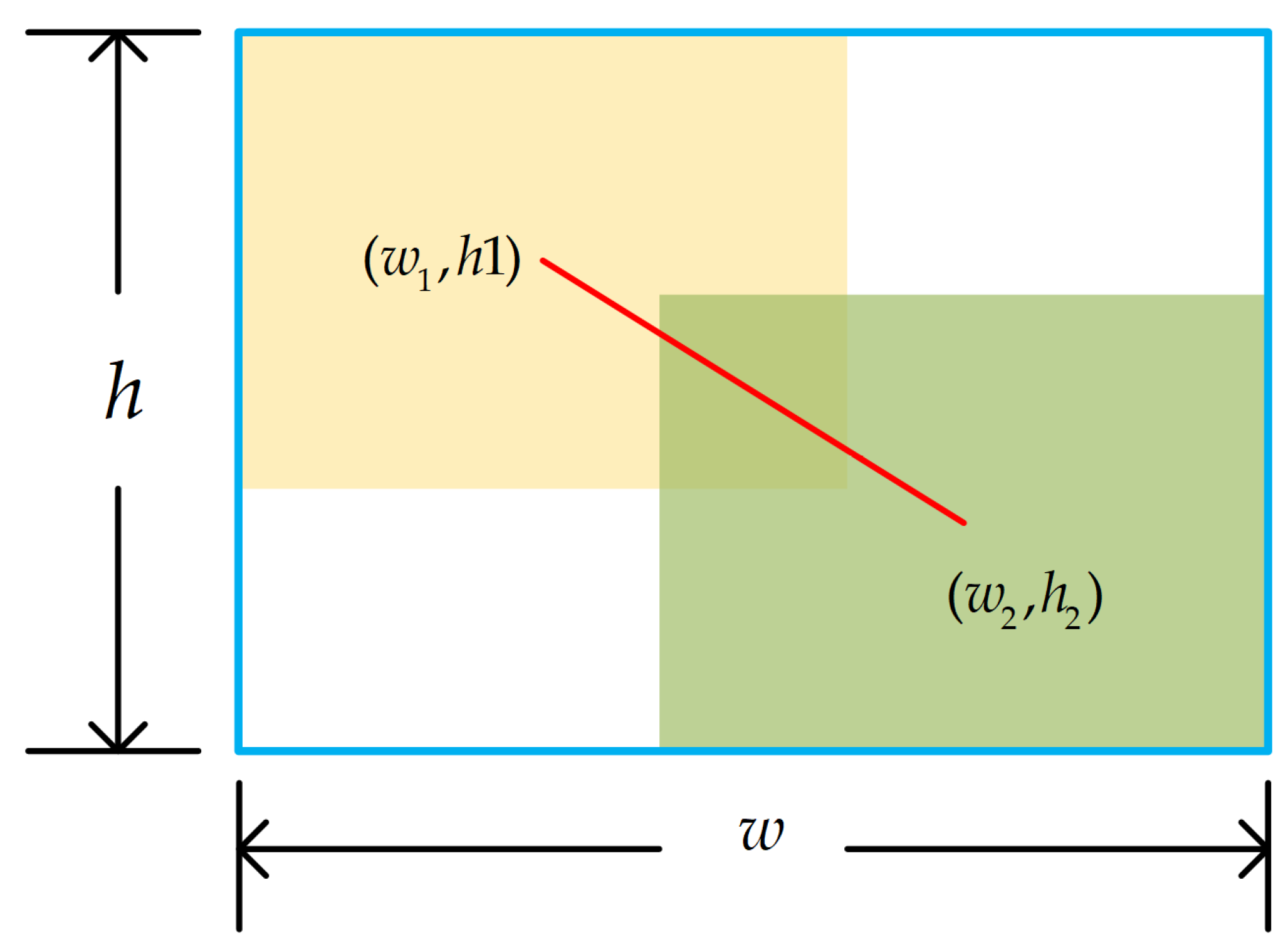
In YOLOv5, the complete intersection over union (CIOU) is used for bounding box regression. The CIOU considers the distance between the center points of the ground truth and the predicted box, as well as the aspect ratio consistency, as shown in Equation (8):
where is the ratio of the area of overlap between the predicted bounding box and the ground truth bounding box to the area of their combined region, is the distance between the center point of the predicted box and the real box, is the diagonal distance of the smallest external rectangle, measures the aspect ratio between the predicted box and the ground truth, and is the balance parameter, which increases when the predicted and target boxes increase in size.
When the training data contain low-quality examples, the geometric factors (distance and aspect ratio) increase the penalty, thereby reducing the model’s generalizability. To address this issue, WIOUv1 [36] introduces a distance attention mechanism that can amplify the of the ordinary-quality anchor box considerably.
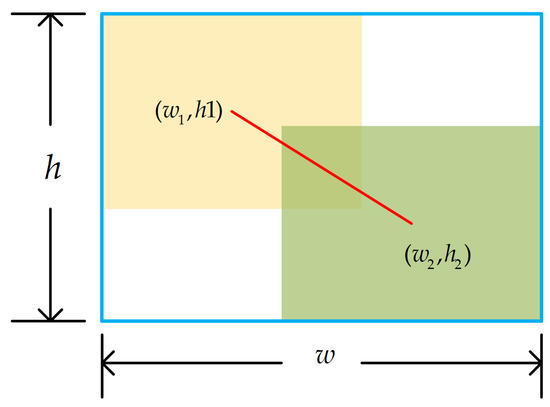
Figure 5.
Ground truth, predicted box, and their minimum enclosing rectangle.
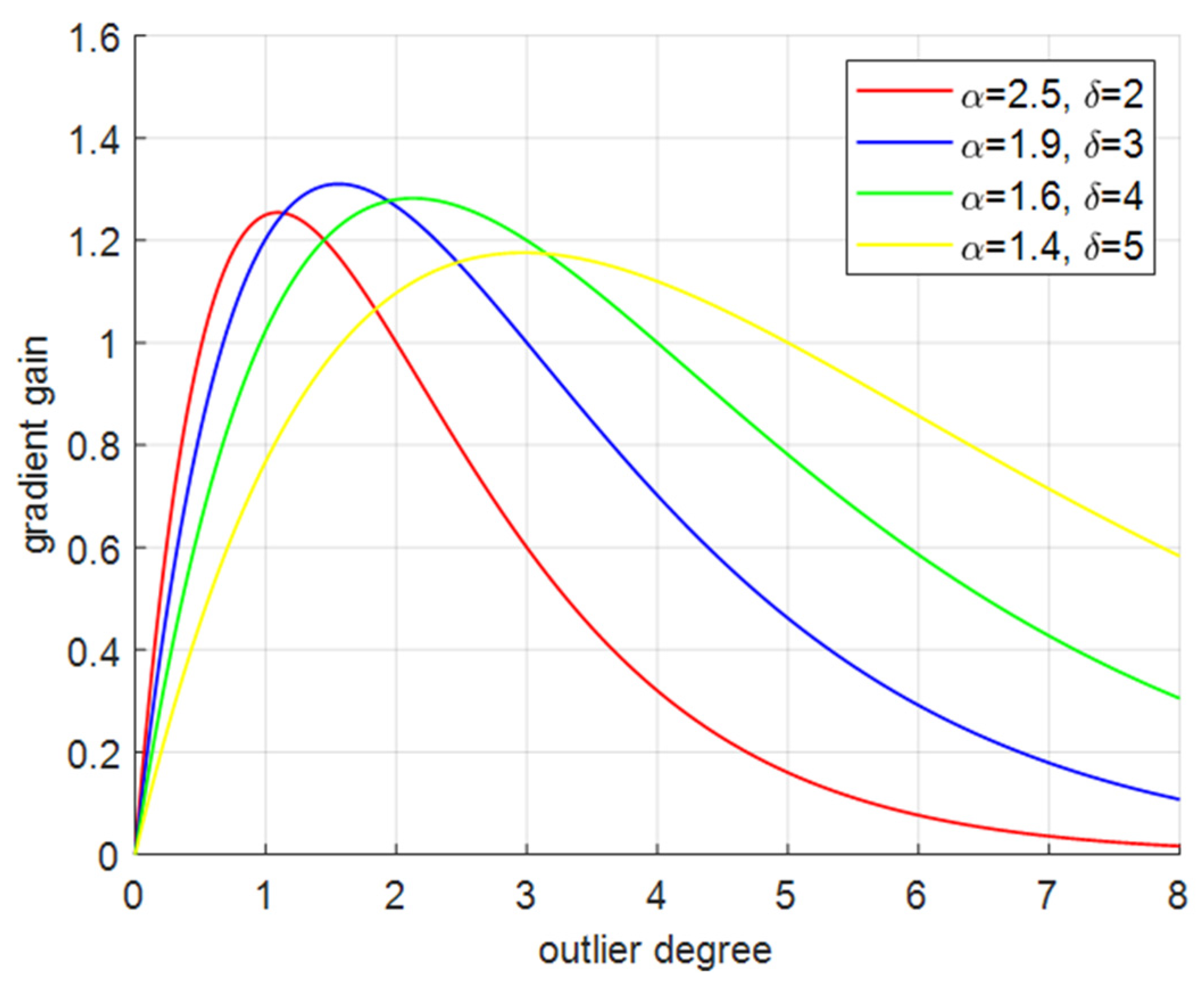
To prevent large harmful gradients from low-quality examples, a non-monotonic focusing coefficient, which is also the gradient gain , is constructed, where is the outlier degree of the anchor box, and , are dynamic parameters.
The WIOUv3 loss function replaces the original loss function, thereby reducing the model’s overfitting and enhancing its detection performance. Additionally, assigning a small gradient gain to the anchor box with a large outlier degree will effectively prevent large harmful gradients from low-quality examples. It can be seen from Figure 6 that when , we can obtain the biggest gradient and the smallest outlier degree.
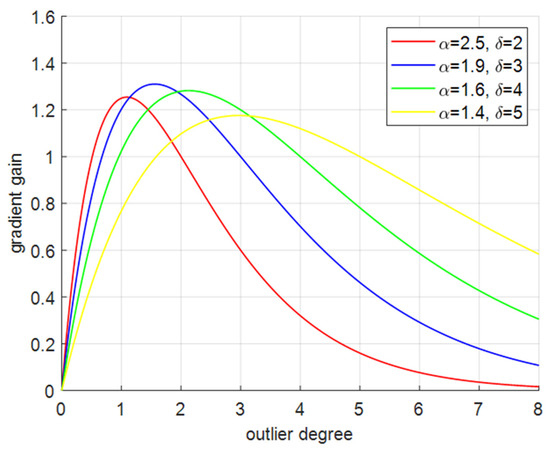
Figure 6.
Curves of outlier degree and gradient gain under different hyperparameters.
5. Experiment
Multiple experiments were conducted to demonstrate the effectiveness of the proposed method. First, a comparative experiment was performed with existing single-stage object detection networks to validate the advantages of the proposed method in terms of its real-time performance and accuracy. Then, ablation experiments were conducted to verify the effectiveness of the proposed split-DLKA module and the other improvements implemented in the proposed method. Finally, comparative experiments were conducted with other attention mechanisms to validate the effectiveness of split-DLKA in terms of improving mAP.
5.1. Experimental Dataset
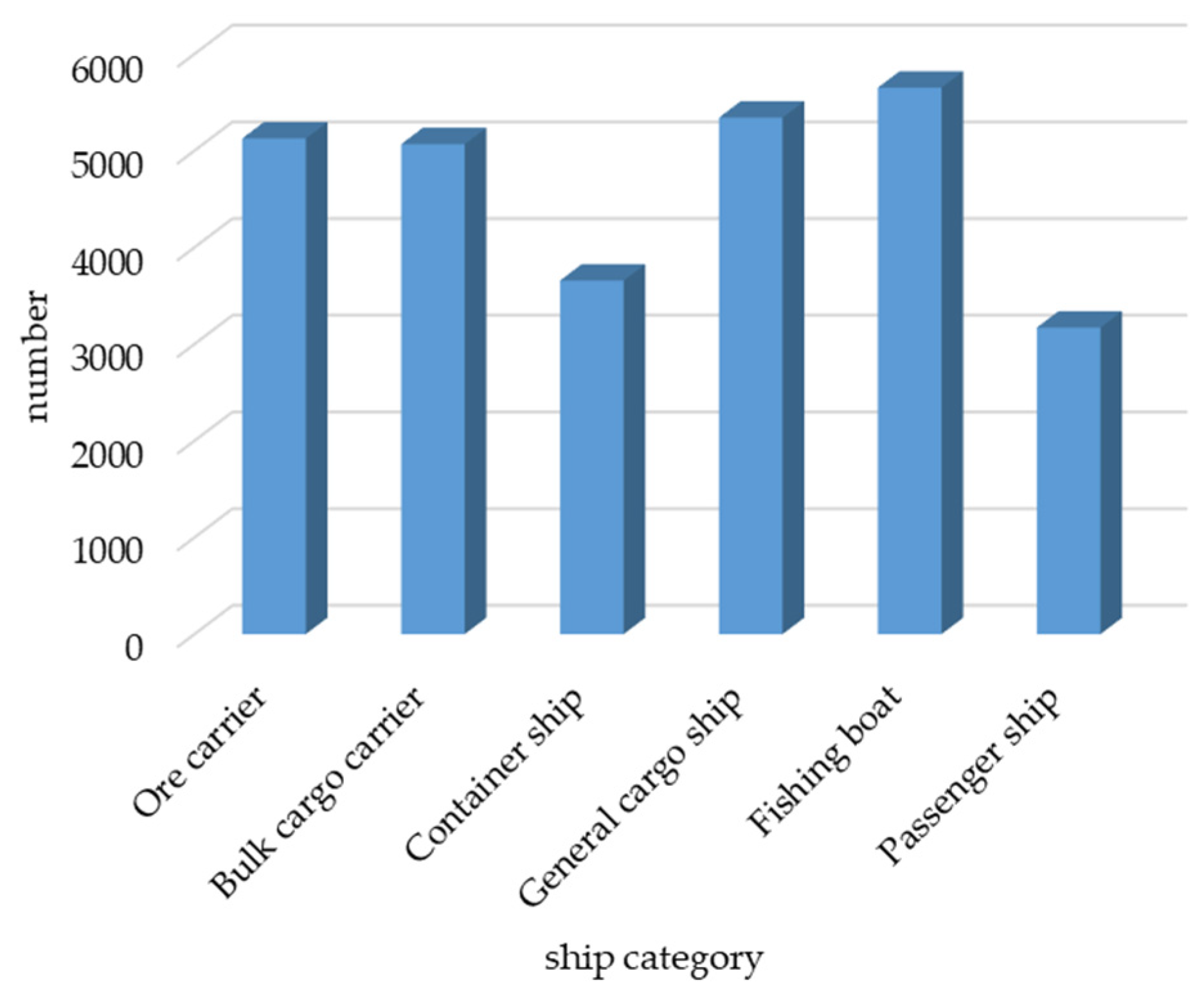
The dataset used in this study was the SeaShips dataset [38], which contains 7000 images (resolution: 1920 × 1080). This dataset includes six common types of ships, i.e., ore carriers, container ships, bulk carriers, general cargo ships, fishing boats, and passenger ships. The distribution of the number of each type of ship is shown in Figure 7, examples of various ship data are shown in the Figure 8.
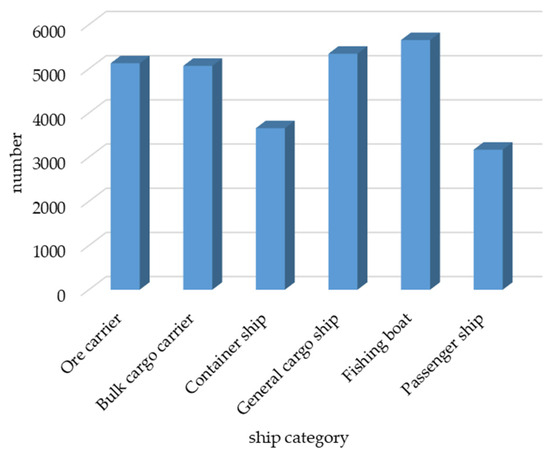
Figure 7.
Types of ships and their quantities.

Figure 8.
(a) Ore carrier; (b) general cargo ship; (c) bulk cargo carrier; (d) container ship; (e) fishing boat; and (f) passenger ship.
The dataset was divided into training, validation, and test sets at a ratio of 6:2:2. In addition, data augmentation techniques, e.g., cropping and stitching, were applied to enhance the dataset. The augmented data are illustrated in Figure 9.

Figure 9.
Augmented images.
5.2. Experimental Platform and Parameter Settings
The experiments conducted in this study were conducted with Ubuntu 20.04 system with a 12th Gen Intel(R) Core (TM) i7-12700F CPU (sourced from Intel, Santa Clara, CA, USA) with 16 GB of RAM and an NVIDIA GeForce RTX 3060 GPU (CUDA version: 12.1). The specific details are shown in Table 2.
Table 2.
Experimental platform and environment configuration.
In this experiment, training was performed over 100 epochs with a learning rate of 0.01, momentum of 0.937, and decay of 0.0005. Given the memory of the graphics card we use, we set the batch_size to 16. Here, a stochastic gradient descent (SGD) was used as the optimizer with a cosine learning rate decay strategy. All other parameters were set to the YOLOv5s’ default values.
5.3. Evaluation Metrics
We evaluated different models in terms of precision, recall, F1-score, and mean average precision (mAP). Precision (P) is defined as the ratio of true positive detections to the total number of positive detections made by the model. A higher precision indicates a lower likelihood of false positive detections; thus, it is also referred to as accuracy. In contrast, recall (R) is the ratio of true positive detections to the total number of actual positive samples. Precision and recall are calculated as follows:
here, (true positive) represents the samples that are positive and predicted correctly as positive by the model, (true negative) represents the samples that are negative and predicted correctly as negative by the model, and (false positive) represents the samples that are negative but predicted incorrectly as positive by the model. Finally, (false negative) represents the samples that are positive but predicted incorrectly as negative by the model.
Equations (13) and (14) can be used to calculate the precision and recall values at various thresholds, which are then used to plot the P-R curve. The area under the P-R curve and the coordinate axes represents the average precision (AP), which is calculated as follows:
The area under the P-R curve represents the AP for each class, and the mAP is the average of the AP values across all classes. The mAP is calculated as follows:
The F1-score is the harmonic mean of the precision and recall, where an equal weight is given to both metrics. The F1-score is calculated as follows:
To assess the extent to which the model is lightweight, the experiments also considered the network model’s parameter count, the size of the model’s weight, and the number of floating-point operations (FLOPs). Note that these metrics are inversely related to the model’s lightweight nature, and FPS (frames per second) describes the algorithm’s inference speed.
5.4. Experimental Results
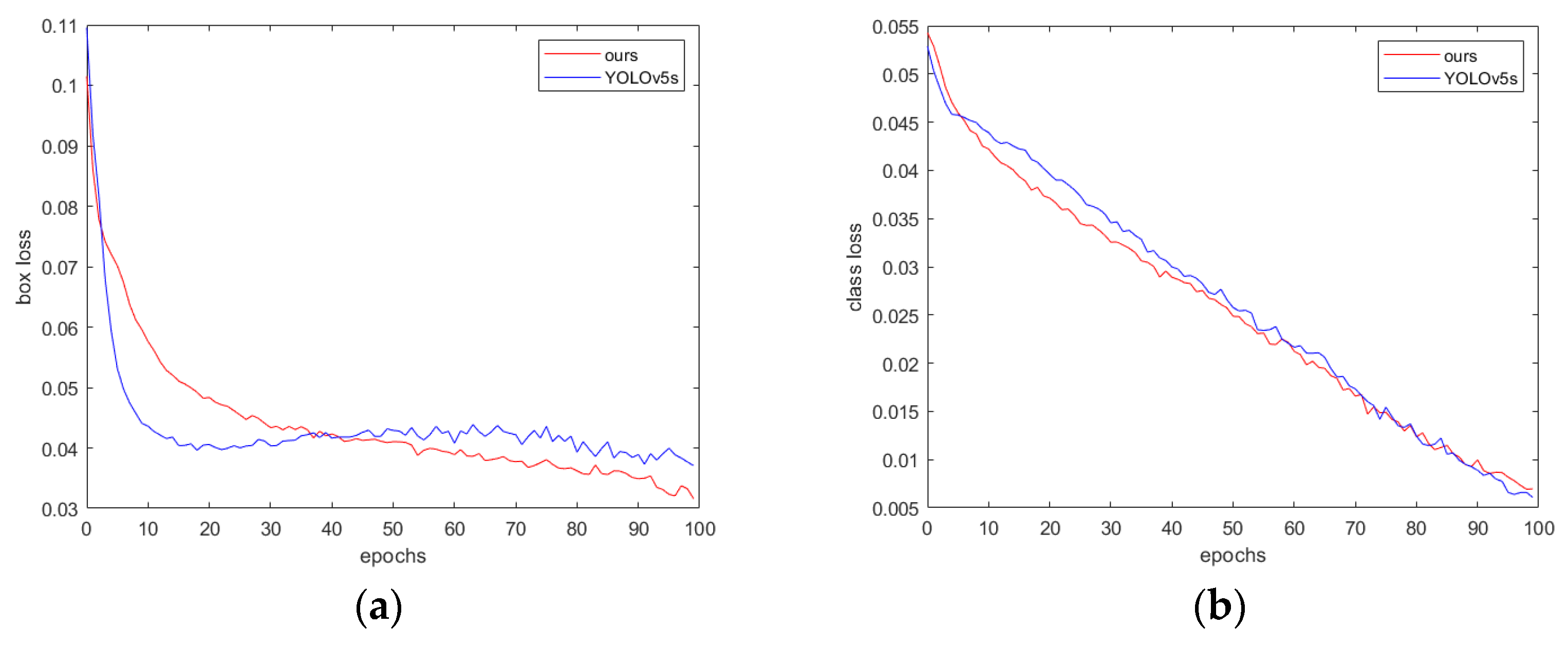
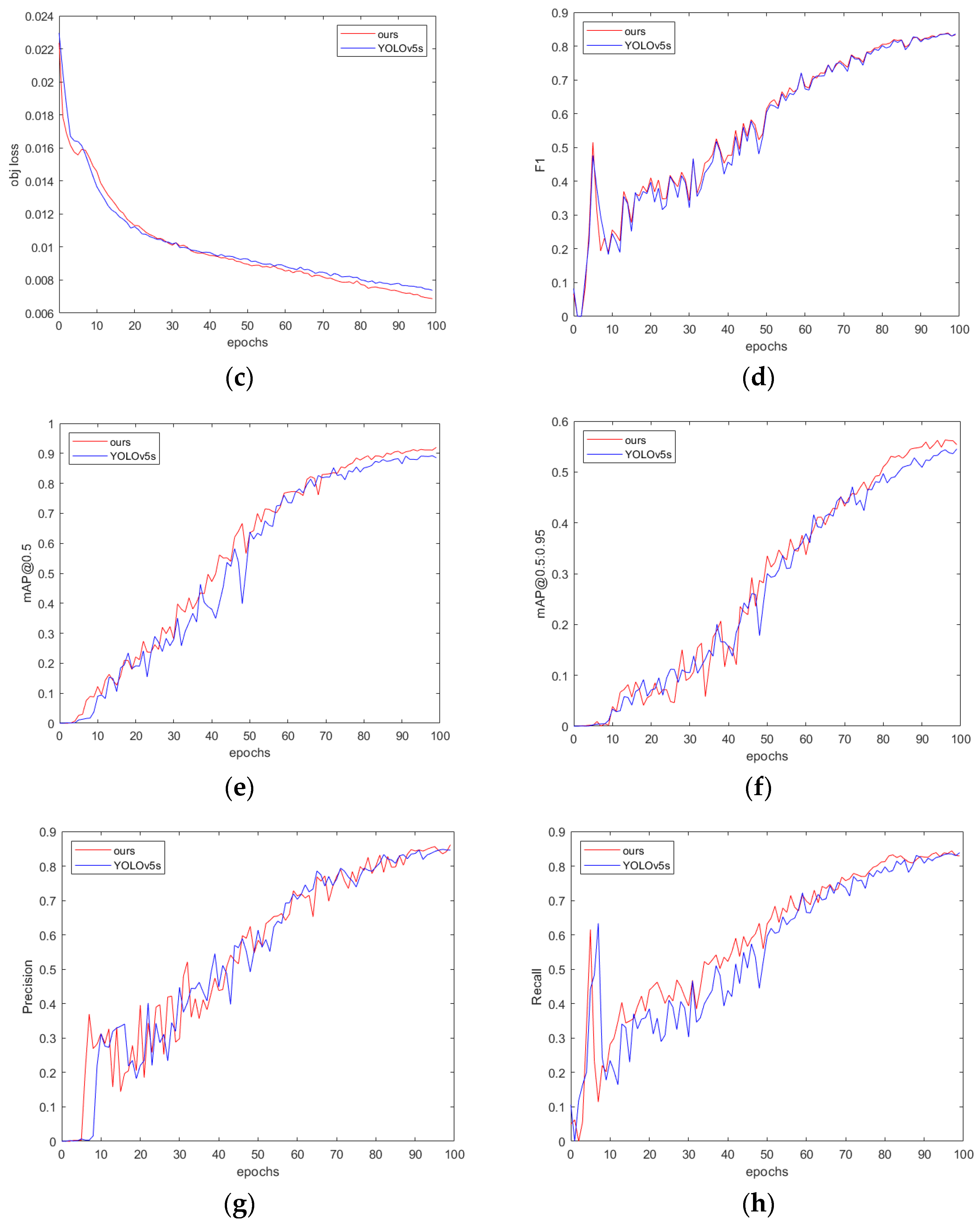
The training process of the proposed method is shown in Figure 10. As can be seen, over the same 100 training epochs, the loss of the proposed method decreases more quickly.
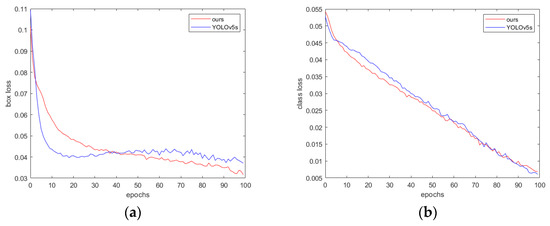
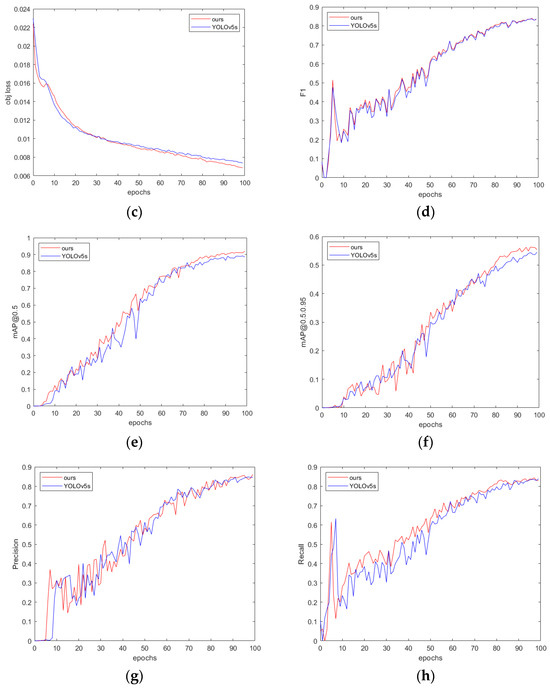
Figure 10.
(a) Box loss: measuring the difference between the predicted box position and the true label position; (b) class loss: measuring the accuracy of classifying different object categories; (c) object loss: measuring the accuracy of determining the presence of an object in the image; (d) F1 score; (e) mAP@0.5; (f) mAP@0.5:0.95; (g) precision; and (h) recall.
Table 3 compares the performance of the proposed method and the YOLOv5s model. As shown, the proposed method improves mAP@0.5 by 3.9% and mAP@0.5:0.95 by 3.3%. In addition, the proposed method reduces the number of parameters by 71%, and it reduces FLOPs by 58% compared to YOLOv5s.
Table 3.
Comparison of performance between YOLOv5 and the proposed method.
The FPS of our method is 20 lower than that of YOLOv5s. As shown in Table 4, the main increase in time occurs during the prediction frame generation stage due to the use of large convolution kernels (5 × 5 and 7 × 7) in the split-DLKA module, which lead to longer inference times. We traded off some inference speed to achieve higher detection accuracy.
Table 4.
Analysis of inference time between YOLOv5s and our method.
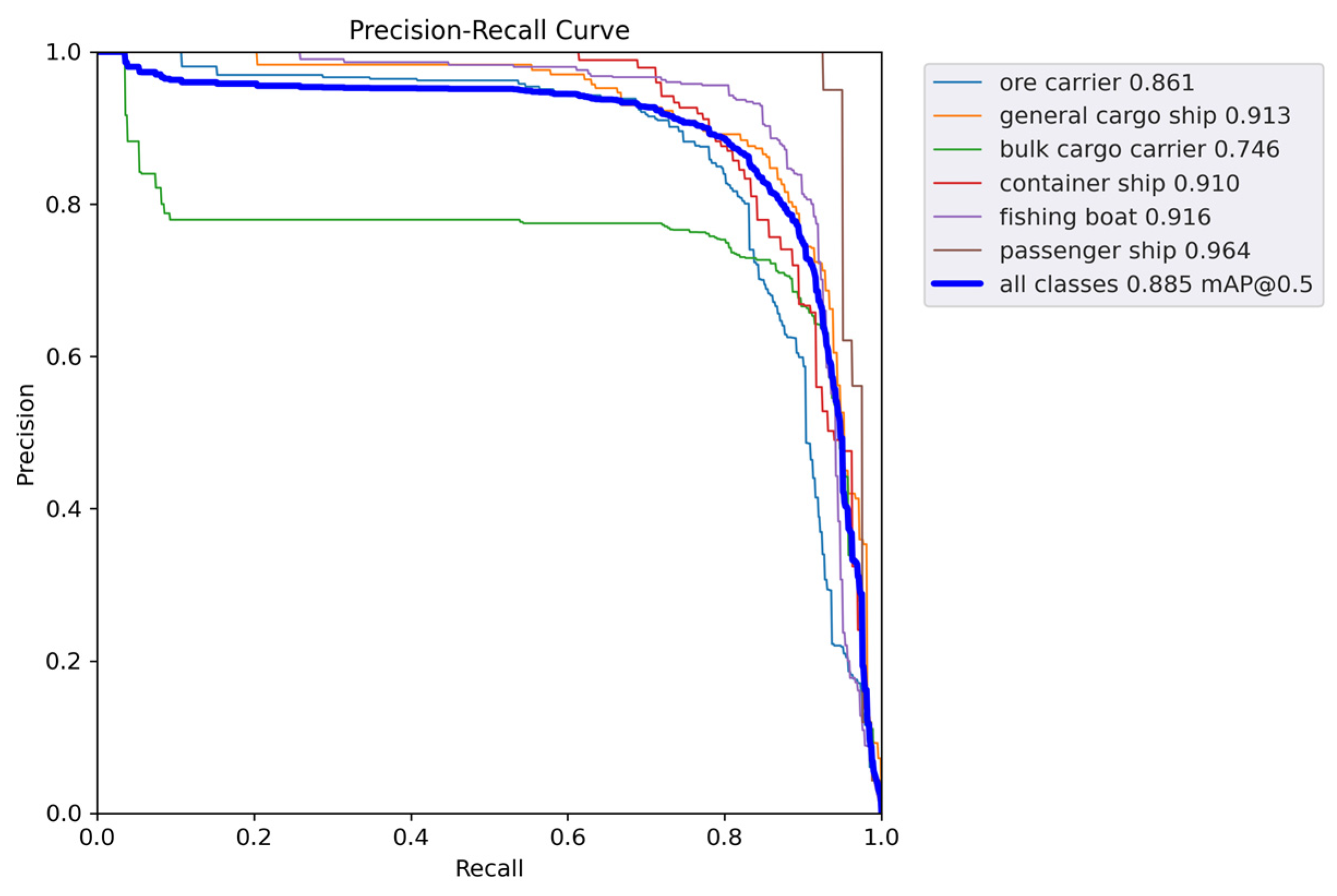
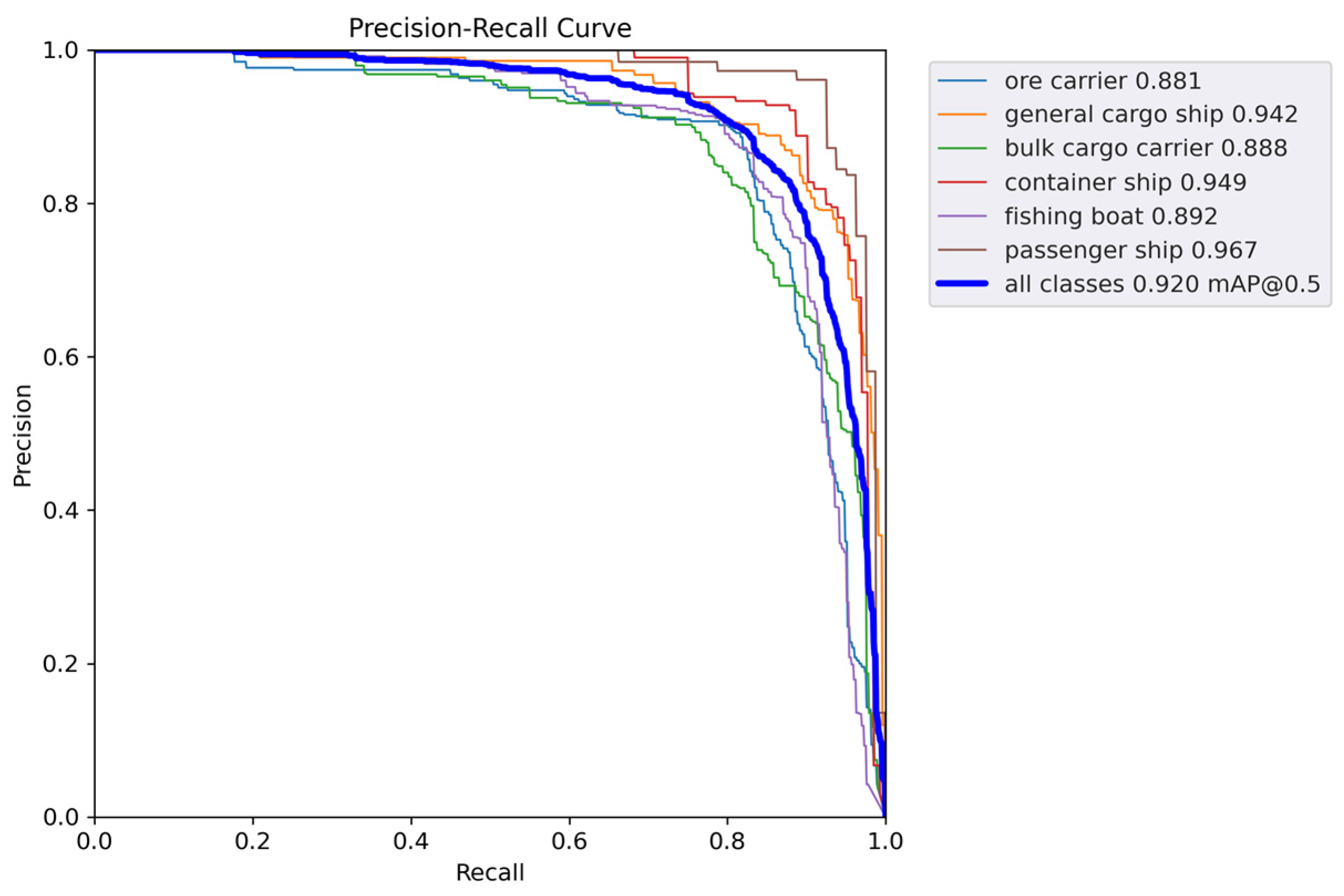
Figure 11 and Figure 12 show the P-R curves of the two models. As can be seen, the proposed method achieves a better balance between precision and recall, as well as a higher mAP value.
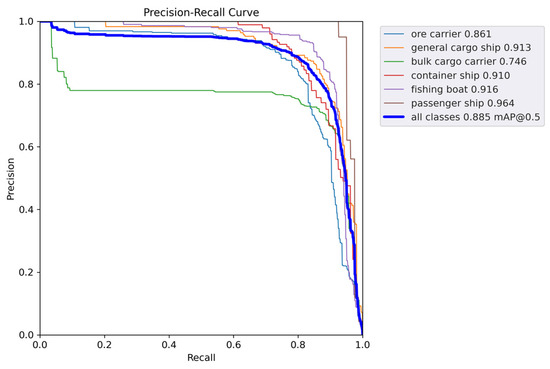
Figure 11.
mAP@0.5 curve of YOLOv5s.
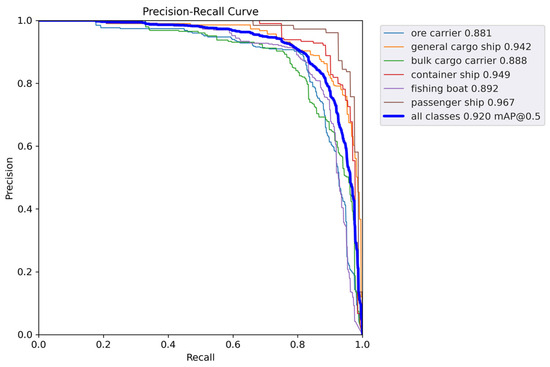
Figure 12.
mAP@0.5 curve of the proposed method.
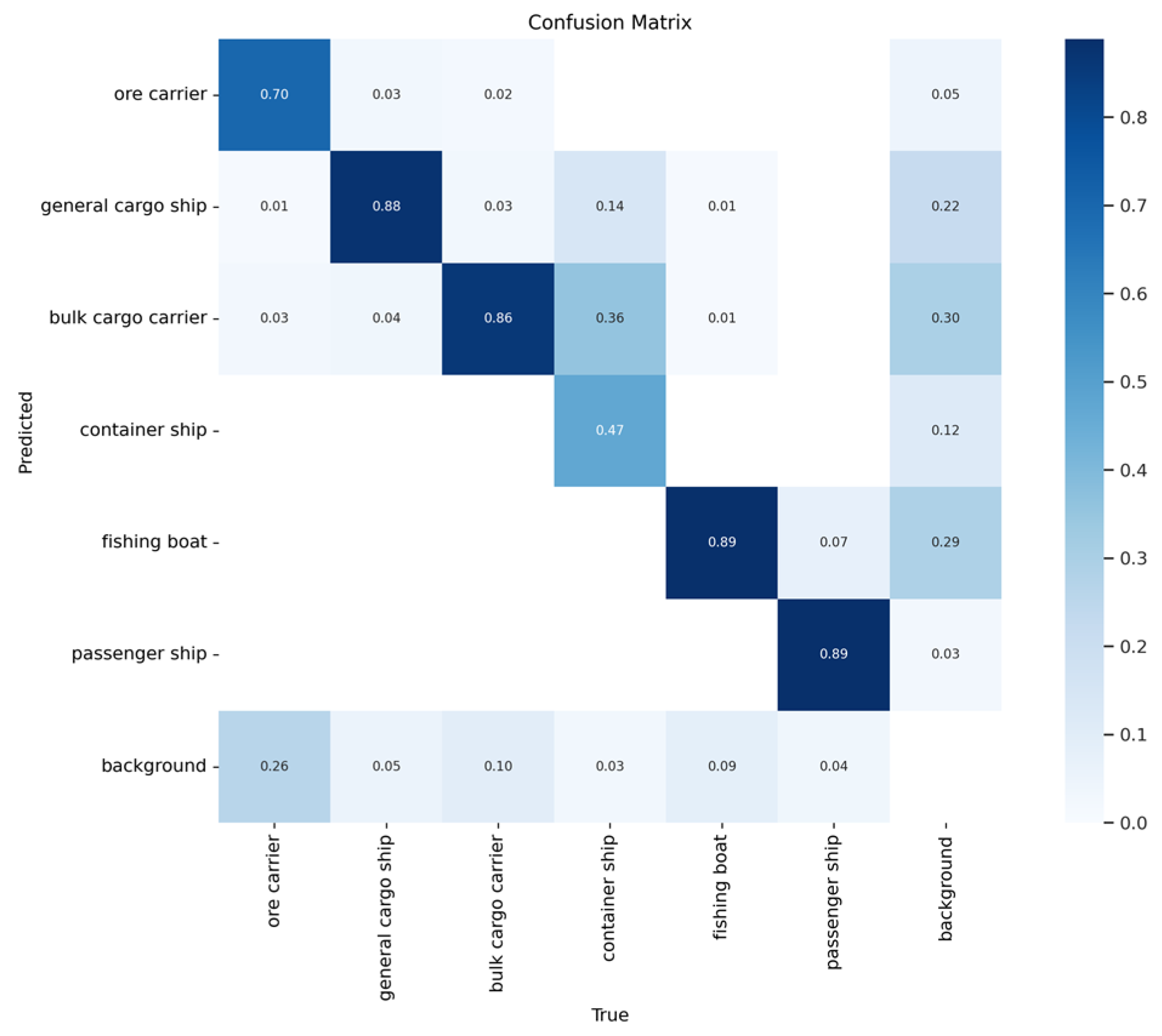
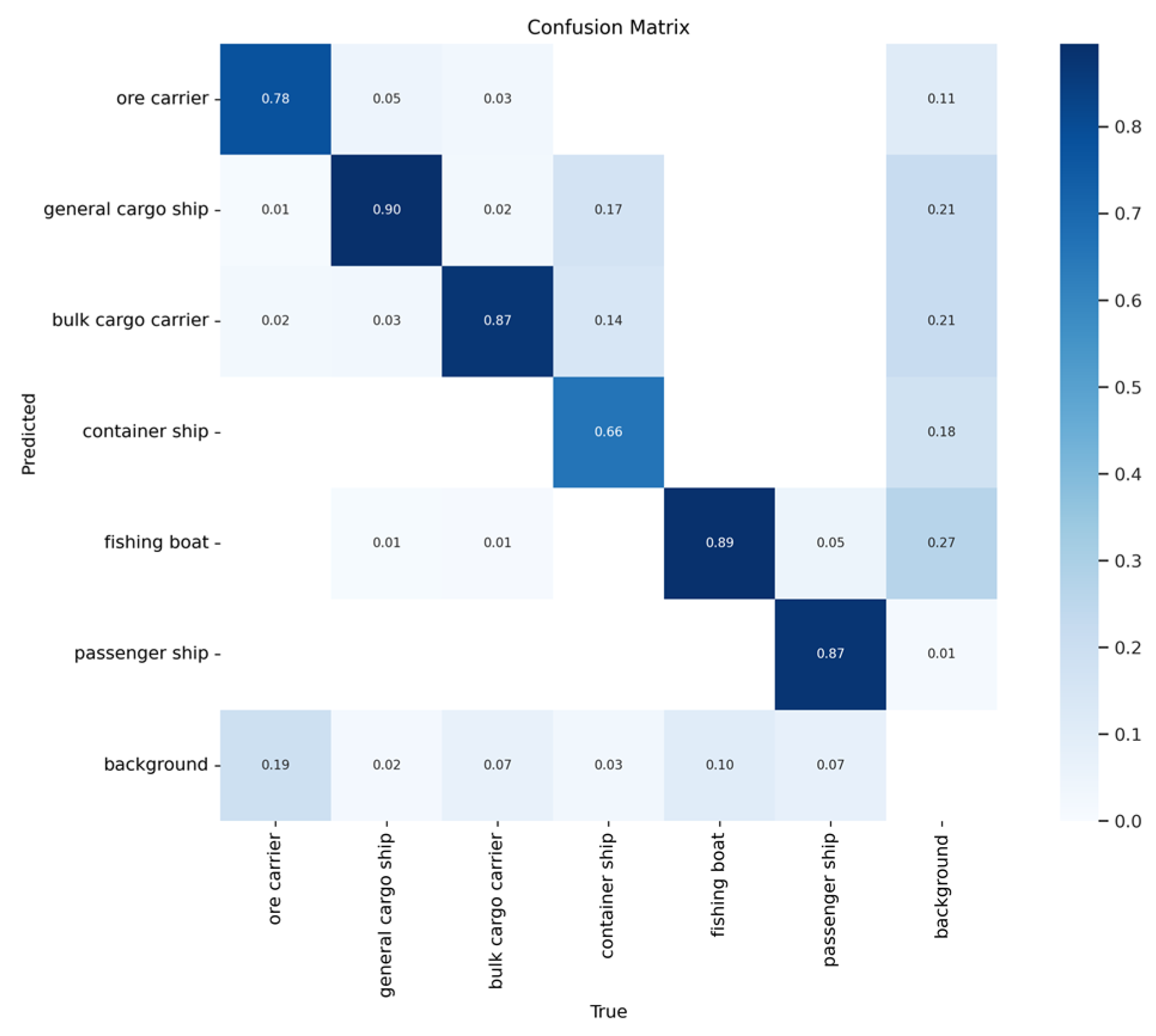
Figure 13 and Figure 14 show the confusion matrices of the two models. Here, it is evident that the proposed method achieves higher accuracy than YOLOv5s when detecting ore carriers, general cargo ships, bulk cargo carriers, and container ships.
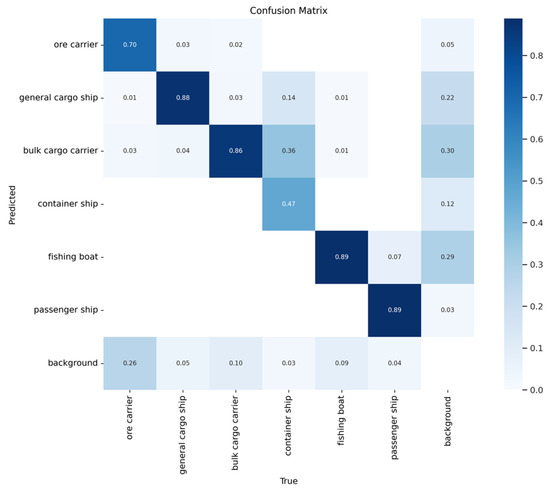
Figure 13.
Confusion matrix of YOLOv5s.
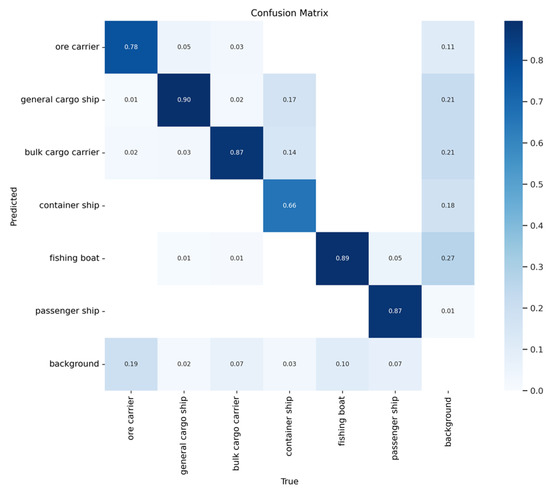
Figure 14.
Confusion matrix of the proposed method.
The results obtained on the test set, as shown in Figure 15, highlight the proposed model’s superior detection capabilities for various ship types. For example, in the fourth row of images, YOLOv5s exhibits false positives for the same ship and misses the detection of a small boat. In contrast, the proposed method demonstrates no false positives and performs well when detecting small vessels.

Figure 15.
(a) YOLOv5s detection results; (b) the proposed method’s detection results.
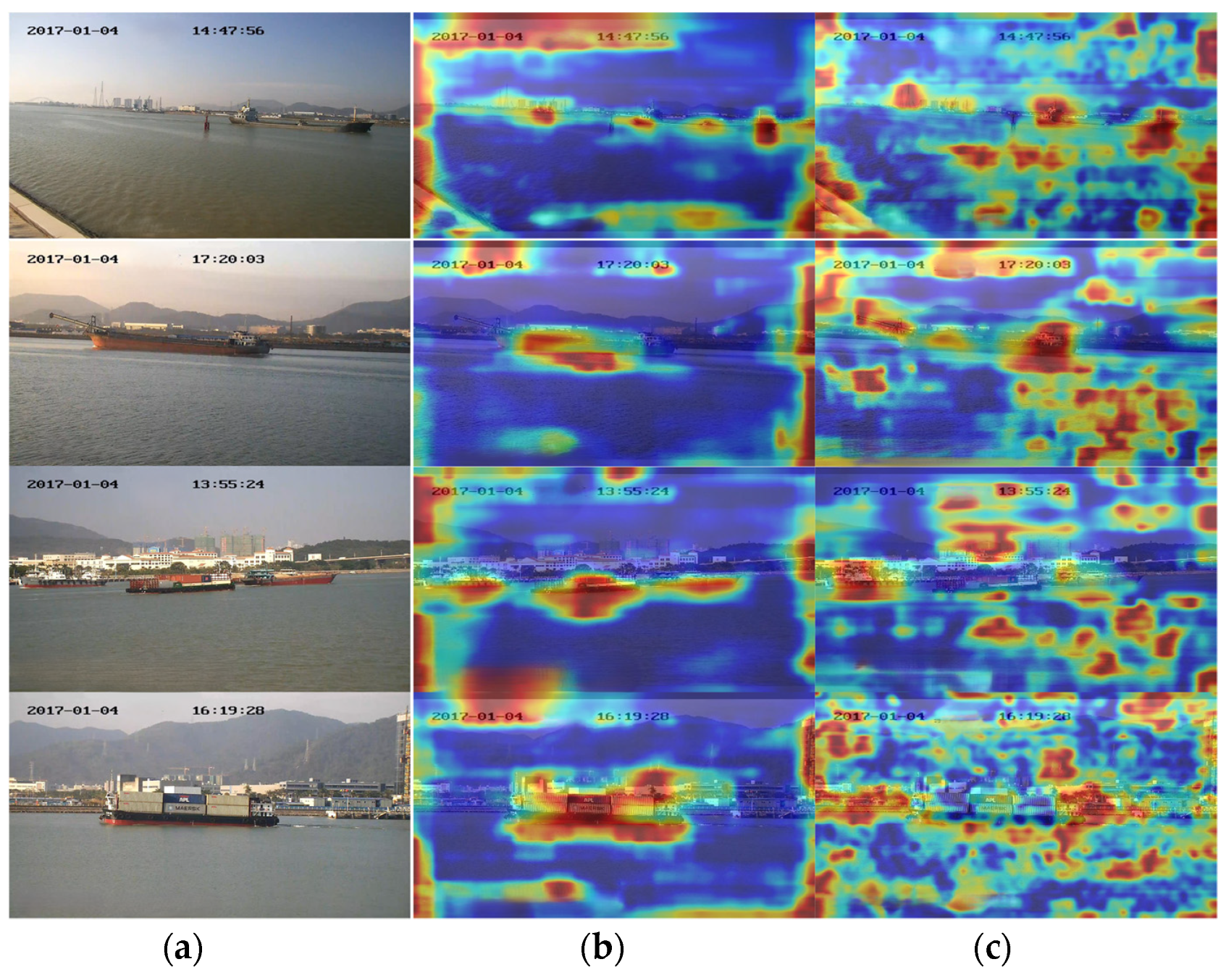
In the Grad-CAM++ heat map (Figure 16), darker colors represent areas that contribute more significantly to ship detection. In the heat map generated by YOLOv5s, the color distribution is relatively dispersed, with many high-intensity regions appearing in the background. This suggests that, in addition to focusing on the target object, YOLOv5s also allocates unnecessary attention to the background during detection. In contrast, our approach demonstrates clearer target edges (such as the ship’s outline) in the heat maps, with colors more concentrated around the target’s shape, indicating higher confidence in the detection of the target object.
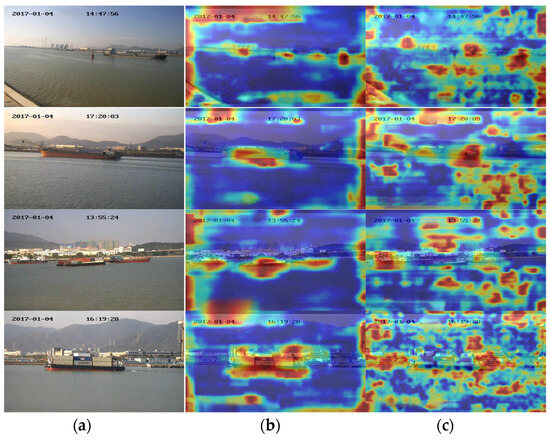
Figure 16.
(a) Original image; (b) heatmap of the proposed method; and (c) heatmap of YOLOv5s.
5.5. Comparison with Other Algorithms
We also selected several single-stage object detection networks for comparison, and the corresponding results are shown in Table 5.
Table 5.
Contrast experiments.
Table 5 compares several popular single-stage object detection algorithms based on their performance metrics. As can be seen, for ship detection tasks, the YOLOv9c, YOLOv5m, and YOLOv5l models exhibit superior performance. However, these networks exceed the parameters and computational costs of the proposed method considerably. For example, YOLOv9c has 12 times more parameters, 15.9 times more FLOPs, and 11.7 times more weight size to the proposed method. Despite these differences, the proposed method achieves competitive performance, trailing YOLOv9c by 7% in terms of mAP@0.5. Generally, a larger weight size implies that more memory and computational power are required to run the network, which is a significant drawback for unmanned surface vessels. Among the single-stage object detection networks of similar parameter levels, the proposed method has fewer parameters and FLOPs than YOLOv4-tiny while achieving the highest mAP. Compared with YOLOv9c, the proposed method strikes an effective balance between detection accuracy and model size, with a 7% decrease in mAP@0.5, a 91% reduction in the number of parameters, a 93% reduction in FLOPs, and a 12 ms faster inference time.
5.6. Ablation Experiment
First, we validated the improvement in the network realized by changing the activation function in ShuffleNetV2 from ReLU to LeakyReLU.
Table 6 shows that replacing the original backbone network with ShuffleNetV2 results in a 74% reduction in the number of parameters and a 75% reduction in FLOPs. However, this change leads to a slight decline in the precision, recall, and mAP values. To enhance detection performance, the activation function of the backbone network was switched to LeakyReLU, which resulted in a 1.2% increase in mAP@0.5 compared to ReLU.
Table 6.
Contrast experiment between ReLU and LeakyReLU activation functions.
An ablation study was conducted using YOLOv5s as the baseline model to validate the effectiveness of the proposed method. Here, the models were compared in terms of parameters, FLOPs, and mAP. For convenience, the version of ShuffleNetV2 with LeakyReLU replacing ReLU is referred to as LeakyShuffle. The corresponding experimental results are shown in Table 7.
Table 7.
Ablation experiment.
The following conclusions can be drawn from the results in Table 7:
The proposed method achieves the best performance in terms of mAP. Compared to the baseline YOLOv5s model, the proposed method increases mAP@0.5 by 3.9% and mAP@0.5:0.95 by 3.3%. Each of the three proposed improvements contribute to the increase in the mAP value. Replacing the backbone with ShuffleNetV2 primarily reduces the model’s parameter count and computational load by 74% and 75%, respectively; meanwhile, it also results in a slight mAP increase. The results of the third ablation experiment demonstrate the effectiveness of the proposed split-DLKA attention module. Ultimately, the final method also achieves the highest F1-score.
To further demonstrate the effectiveness of the split-DLKA in terms of parameter count reduction and detection accuracy improvement, we conducted comparative experiments with other attention mechanisms using YOLOv5s as the baseline. The results are shown in Table 8.
Table 8.
Comparison of different attention mechanisms.
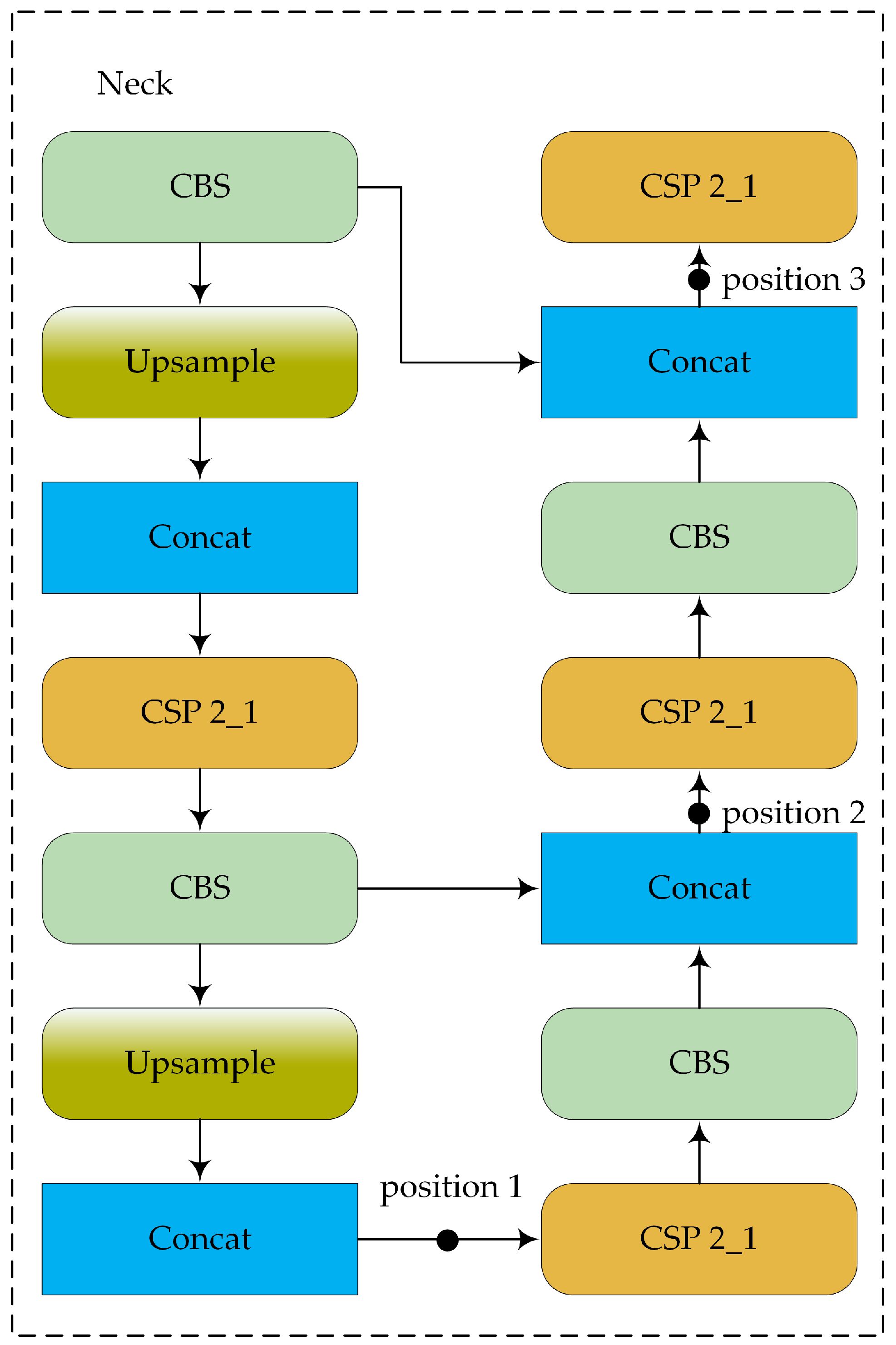
As can be seen, among the various attention mechanisms, split-DLKA shows the greatest improvement in terms of both mAP@0.5 and mAP@0.5:0.95. The increased computational effort of split-DLKA leads to a reduction in FPS; however, it achieves higher detection accuracy. Some of the FPS loss can be mitigated by optimizing the backbone network. In essence, split-DLKA offers a better trade-off between detection accuracy and speed. To determine the most suitable position for adding the attention layer, we conducted three comparative experiments using YOLOv5s with the replaced backbone network as the baseline (Figure 17). The results demonstrate that adding the split-DLKA at position 1 performs best in terms of detection performance, as shown in Table 9.
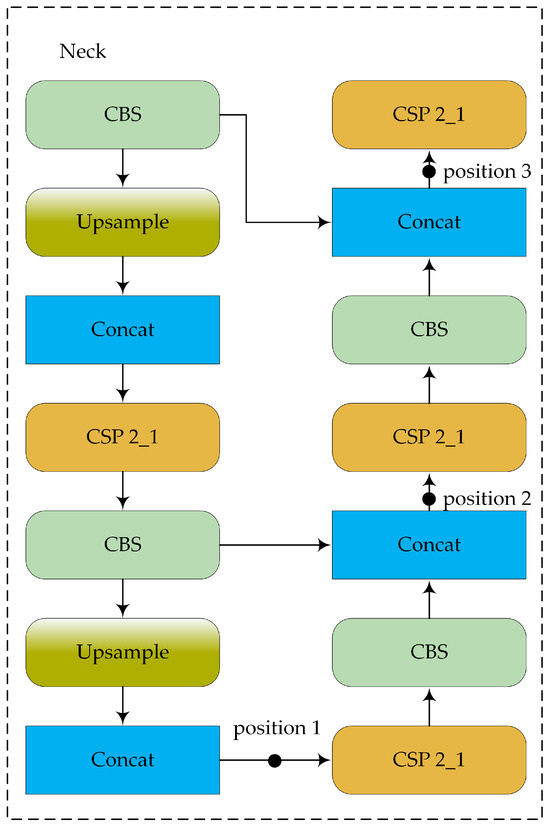
Figure 17.
Illustration of different insertion positions.
Table 9.
Experiments with split-DLKA at different insertion positions.
The impact of hyperparameters on experimental results is shown in Table 10. As can be seen from the table, when , the model has the highest detection accuracy.
Table 10.
Effects of different hyperparameters on model performance.
Adding the split-DLKA at position 1 yields the best results because the layers following position 1 are utilized by the detection head to detect small objects. In this case, split-DLKA processes a feature map with fewer channels compared to the other two positions, resulting in a higher FPS. Typically, small objects are the most challenging to detect in object detection tasks. This indicates that the proposed split-DLKA can improve the accuracy of small object detection significantly.
6. Conclusions
Ship object detection requires a detection network with a low parameter count and computational load to meet hardware requirements. To reduce the computational costs of the object detection network while improving detection accuracy, this paper proposed an improved lightweight single-stage object detection network. By replacing the original backbone network with ShuffleNetV2, the network parameter count and computational load of the proposed method are reduced considerably. In addition, various enhancements, e.g., improvements to the activation and loss functions, are implemented in the proposed method to improve detection accuracy.
This paper also designed a new large-kernel deformable convolution attention mechanism. The network’s performance is enhanced by leveraging the adaptability of deformable convolution to samples of different shapes and the larger receptive field of the large-kernel convolution. Experimental results demonstrate that compared to the baseline model, the proposed method achieves improvements in mAP@0.5, mAP@0.5:0.95, precision, and recall by 3.9%, 3.3%, 5.9%, and 1.2%, respectively. In addition, the proposed method demonstrates superior performance in terms of both detection accuracy and model size compared to other single-stage object detection algorithms.
However, our proposed method has a slower inference time compared to YOLOv5s and has not been tested under complex meteorological conditions. Future work should include real ship validation experiments and evaluate the detection model’s performance in challenging weather scenarios. With advancements in unmanned surface vessel hardware technology, multiple cameras will be installed on ships, generating large-scale multi-view data. In such scenarios, it is crucial to significantly reduce data size [39] and extract features from multi-view data [40]. This is also a key direction for future research.
Author Contributions
Conceptualization, H.S. and W.Z.; methodology, H.S.; software, W.Z.; validation, H.S., H.W. and S.Y.; formal analysis, H.S.; investigation, S.Y. and H.W.; resources, H.W.; data curation, H.S.; writing—original draft preparation, H.S.; writing—review and editing, W.Z. and H.W.; visualization, H.S.; supervision, H.W.; project administration, H.S.; funding acquisition, H.W. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported in part by the Innovation Fund of the Maritime Defense Technology Innovation Center under Grant JJ-2022-702-01. The authors acknowledge the anonymous reviewers for their helpful comments on the manuscript.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data presented in this study are available in SeaShips at https://github.com/jiaming-wang/SeaShips.git (accessed on 24 March 2024).
Acknowledgments
The authors would like to thank the provider of the dataset and all the members of our team for their contribution to the marine ship detection experiments.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Yuan, J.; Cai, Z.; Wang, S.; Kong, X. A Multitype Feature Perception and Refined Network for Spaceborne Infrared Ship Detection. IEEE Trans. Geosci. Remote Sens. 2024, 62, 4100311. [Google Scholar] [CrossRef]
- Iwin Thanakumar Joseph, S.; Sasikala, J.; Sujitha Juliet, D. Ship detection and recognition for offshore and inshore applications: A survey. Int. J. Intell. Unmanned Syst. 2019, 7, 177–188. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; pp. 886–893. [Google Scholar]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object Detection with Discriminatively Trained Part-Based Models. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1627–1645. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, IEEE Computer Society, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.E.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the European Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. YOLOv10: Real-Time End-to-End Object Detection. arXiv 2024, arXiv:2405.14458. [Google Scholar]
- Shen, X.; Wang, H.; Cui, T.; Guo, Z.; Fu, X. Multiple information perception-based attention in YOLO for underwater object detection. Vis. Comput. 2024, 40, 1415–1438. [Google Scholar] [CrossRef]
- Liu, D.; Zhang, Y.; Zhao, Y.; Shi, Z.; Zhang, J.; Zhang, Y.; Ling, F.; Zhang, Y. AARN: Anchor-guided attention refinement network for inshore ship detection. IET Image Process. 2023, 17, 2225–2237. [Google Scholar] [CrossRef]
- Guo, Y.; Yu, H.; Ma, L.; Zeng, L.; Luo, X. THFE: A Triple-hierarchy Feature Enhancement method for tiny boat detection. Eng. App.l. Artif. Intell. 2023, 123, 106271. [Google Scholar] [CrossRef]
- Yao, T.; Zhang, B.; Gao, Y.; Ren, Y.; Wang, Z. A Feature Enhanced Scale-adaptive Convolutional Network for Ship Detection in Maritime Surveillance*. In Proceedings of the 2023 International Conference on Digital Image Computing: Techniques and Applications (DICTA), Port Macquarie, Australia, 28 November–1 December 2023; pp. 97–104. [Google Scholar]
- Li, J.; Li, G.; Jiang, H.; Guo, W.; Gong, C. An Efficient Enhanced-YOLOv5 Algorithm for Multi-scale Ship Detection. In Proceedings of the Neural Information Processing: 30th International Conference, ICONIP 2023, Changsha, China, 20–23 November 2023; Proceedings, Part VI. Springer: Changsha, China, 2023; pp. 252–263. [Google Scholar]
- Li, Y.; Yuan, H.; Wang, Y.; Xiao, C. GGT-YOLO: A Novel Object Detection Algorithm for Drone-Based Maritime Cruising. Drones 2022, 6, 335. [Google Scholar] [CrossRef]
- Zheng, J.; Liu, Y. A Study on Small-Scale Ship Detection Based on Attention Mechanism. IEEE Access 2022, 10, 77940–77949. [Google Scholar] [CrossRef]
- Li, H.; Deng, L.; Yang, C.; Liu, J.; Gu, Z. Enhanced YOLO v3 Tiny Network for Real-Time Ship Detection from Visual Image. IEEE Access 2021, 9, 16692–16706. [Google Scholar] [CrossRef]
- Zhao, X.; Song, Y.; Shi, S.; Li, S. Improving YOLOv5n for lightweight ship target detection. In Proceedings of the 2023 IEEE 3rd International Conference on Computer Systems (ICCS), Qingdao, China, 22–24 September 2023; pp. 110–115. [Google Scholar]
- Lv, J.; Chen, J.; Huang, Z.; Wan, H.; Zhou, C.; Wang, D.; Wu, B.; Sun, L. An Anchor-Free Detection Algorithm for SAR Ship Targets with Deep Saliency Representation. Remote Sens. 2022, 15, 103. [Google Scholar] [CrossRef]
- Ye, Y.; Zhen, R.; Shao, Z.; Pan, J.; Lin, Y. A Novel Intelligent Ship Detection Method Based on Attention Mechanism Feature Enhancement. J. Mar. Sci. Eng. 2023, 11, 625. [Google Scholar] [CrossRef]
- Xing, B.; Wang, W.; Qian, J.; Pan, C.; Le, Q. A Lightweight Model for Real-Time Monitoring of Ships. Electronics 2023, 12, 3804. [Google Scholar] [CrossRef]
- Zhang, Q.; Huang, Y.; Song, R. A Ship Detection Model Based on YOLOX with Lightweight Adaptive Channel Feature Fusion and Sparse Data Augmentation. In Proceedings of the 2022 18th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Madrid, Spain, 29 November–2 December 2022; pp. 1–8. [Google Scholar]
- Gao, Z.; Zhang, Y.; Wang, S. Lightweight Small Ship Detection Algorithm Combined with Infrared Characteristic Analysis for Autonomous Navigation. J. Mar. Sci. Eng. 2023, 11, 1114. [Google Scholar] [CrossRef]
- Chen, H.; Xue, J.; Wen, H.; Hu, Y.; Zhang, Y. EfficientShip: A Hybrid Deep Learning Framework for Ship Detection in the River. CMES-Comput. Model. Eng. Sci. 2024, 138, 301. [Google Scholar] [CrossRef]
- Qiu, X.; Han, F.; Zhao, W. Anti-Attention Mechanism: A Module for Channel Correction in Ship Detection. In Proceedings of the 2023 IEEE International Conference on Electrical, Automation and Computer Engineering (ICEACE), Changchun, China, 29–31 December 2023; pp. 498–504. [Google Scholar]
- Li, Z.; Deng, Z.; Hao, K.; Zhao, X.; Jin, Z. A Ship Detection Model Based on Dynamic Convolution and an Adaptive Fusion Network for Complex Maritime Conditions. Sensors 2024, 24, 859. [Google Scholar] [CrossRef]
- Zheng, J.; Zhao, S.; Xu, Z.; Zhang, L.; Liu, J. Anchor boxes adaptive optimization algorithm for maritime object detection in video surveillance. Front. Mar. Sci 2023, 10, 1290931. [Google Scholar] [CrossRef]
- Shi, H.; Hu, Y.; Zhang, H. An Improved YOLOX Loss Function Applied to Maritime Video Surveillance. In Proceedings of the 2023 8th International Conference on Image, Vision and Computing (ICIVC), Dalian, China, 27–29 July 2023; pp. 633–638. [Google Scholar]
- Zhang, L.; Du, X.; Zhang, R.; Zhang, J. A Lightweight Detection Algorithm for Unmanned Surface Vehicles Based on Multi-Scale Feature Fusion. J. Mar. Sci. Eng. 2023, 11, 1392. [Google Scholar] [CrossRef]
- Zheng, Y.; Zhang, Y.; Qian, L.; Zhang, X.; Diao, S.; Liu, X.; Cao, J.; Huang, H. A lightweight ship target detection model based on improved YOLOv5s algorithm. PLoS ONE 2023, 18, e0283932. [Google Scholar] [CrossRef] [PubMed]
- Ma, N.; Zhang, X.; Zheng, H.-T.; Sun, J. ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design. In Proceedings of the Computer Vision—ECCV 2018, Cham, Switzerland, 8–14 September 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 122–138. [Google Scholar]
- Tong, Z.; Chen, Y.; Xu, Z.; Yu, R. Wise-IoU: Bounding Box Regression Loss with Dynamic Focusing Mechanism. arXiv 2023, arXiv:2301.10051. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar]
- Shao, Z.; Wu, W.; Wang, Z.; Du, W.; Li, C. SeaShips: A Large-Scale Precisely Annotated Dataset for Ship Detection. IEEE Trans. Multimed. 2018, 20, 2593–2604. [Google Scholar] [CrossRef]
- Wang, H.; Yao, M.; Jiang, G.; Mi, Z.; Fu, X. Graph-Collaborated Auto-Encoder Hashing for Multiview Binary Clustering. IEEE Trans. Neural Netw. Learn. Syst. 2024, 35, 10121–10133. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.; Yao, M.; Chen, Y.; Xu, Y.; Liu, H.; Jia, W.; Fu, X.; Wang, Y. Manifold-based Incomplete Multi-view Clustering via Bi-Consistency Guidance. IEEE Trans. Multimed. 2024, 3405650. [Google Scholar] [CrossRef]



Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).