
Wearable Sensor-Based Assessments for Remotely Screening Early-Stage Parkinson’s Disease

 , ,
, ,
Abstract
1. Introduction
2. Materials and Methods
2.1. Study Design and Sample
2.2. Mobile Assessment Battery
- Visual Short-Term Memory (VSTM): Participants were instructed to remember four colored squares and to respond, after a brief blank display screen, as to whether a single probe color matched one of the previously remembered squares. Response accuracy was the primary outcome measure.
- Symbol Digit Modalities Test (SDMT): Participants completed a modified SDMT in which they were presented with a symbol, matched this symbol to an appropriate number within a symbol–number key, and then verbalized the appropriate number before proceeding to the next symbol. The total number of completed symbols was the primary outcome measure.
- Trails: Participants completed a digital version of the Trail-Making Test, in which they were instructed to draw lines between target objects in either numerical order (i.e., 1-2-3-4) or in alternating number-letter order (i.e., 1-A-2-B-3-C). The total time to completion was the primary outcome measure.
- Fine Motor: Participants were presented with a randomly positioned and oriented major circular sector and were instructed to drag and rotate the object to match the position and orientation of a target sector. The total number of completed objects was the primary outcome measure.
- Finger Tapping: Participants were presented with two circular target locations and instructed to rapidly tap the center of each location with their pointer and middle fingers in alternating order. The total number of taps was the primary outcome measure.
- Gait and Balance: During the Gait task, participants were instructed to walk as they normally would for 60 s. During the Balance task, participants were instructed to stand with their feet shoulder-width apart and remain motionless for 30 s. Motion data were then captured from smartphone and smartwatch sensors during the Gait and Balance tasks.
- Tremor: Tremor testing comprised Postural and Resting Tremor sub-tasks. During the Postural Tremor sub-task, the participants were seated and instructed to maintain their arms in a straight line at a 90-degree angle with respect to their body for 10 s. During the Resting Tremor sub-task, the participants were seated and instructed to maintain their arms at rest by their sides for 10 s. Motion data were captured from smartwatch sensors during the Tremor tasks.
- Phonation: Participants were instructed to speak and sustain the phoneme ‘ahh’ for as long as possible within a 15-s measurement window. Speech data were captured from the smartphone microphone and encoded in .wav format.
- Articulation: Participants were instructed to speak and repeat the phoneme sequence ‘pa-ta-ka’ as many times as possible within a 15-s measurement window. Speech data were captured from the smartphone microphone and encoded in .wav format.
- Reading: Participants were instructed to read three sentences sampled from the Harvard Sentences Bank at a rate reflecting their typical reading speed. Speech data were captured from the smartphone microphone and encoded in .wav format. In the present work, the Reading task data were excluded from the analysis.
2.3. Feature Engineering
2.4. Machine Learning Modeling
2.5. Reliability Analysis
2.6. Cross-Platform Validation
2.7. Feature Comparison
3. Results
3.1. Study Sample and Data
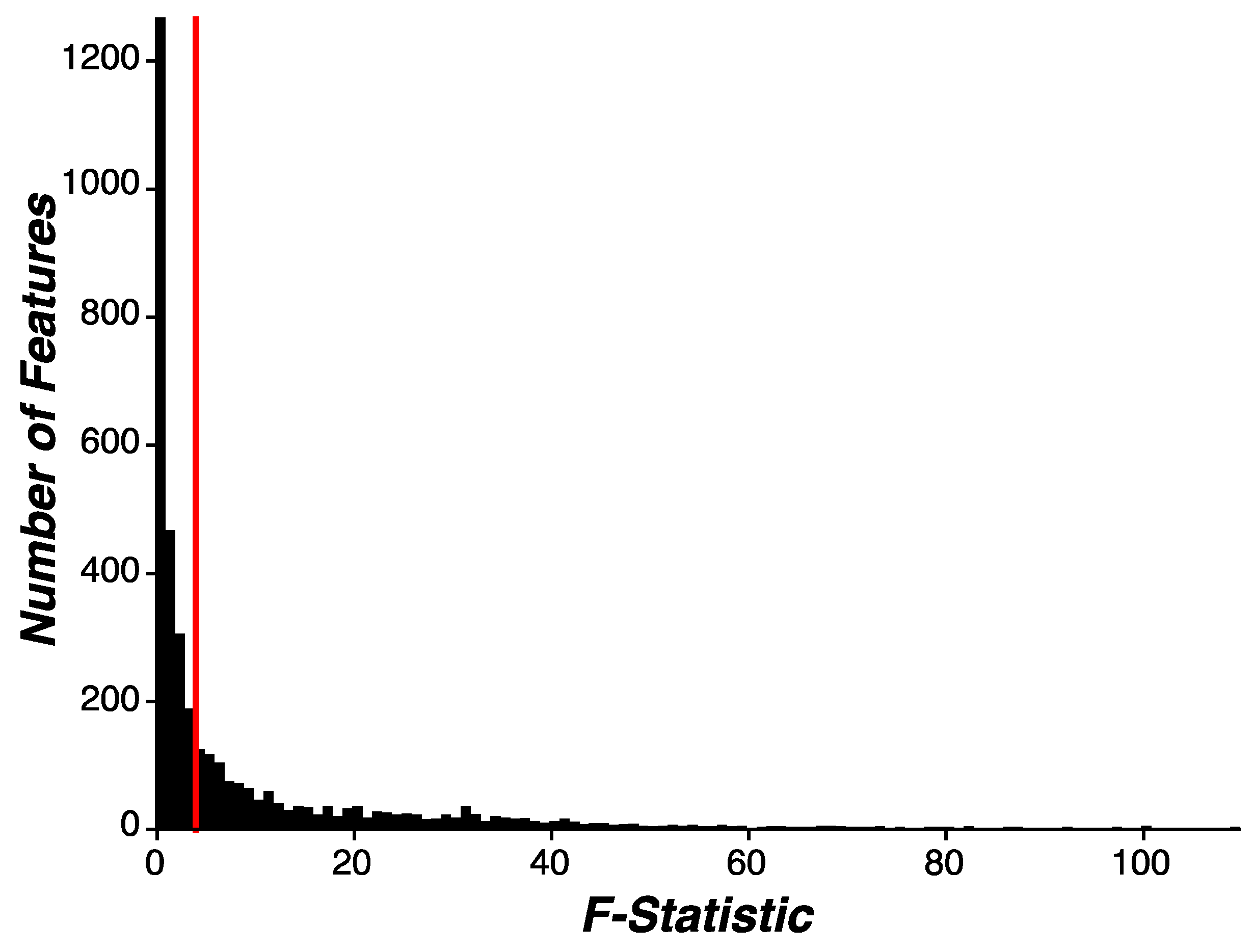
3.2. Feature Engineering
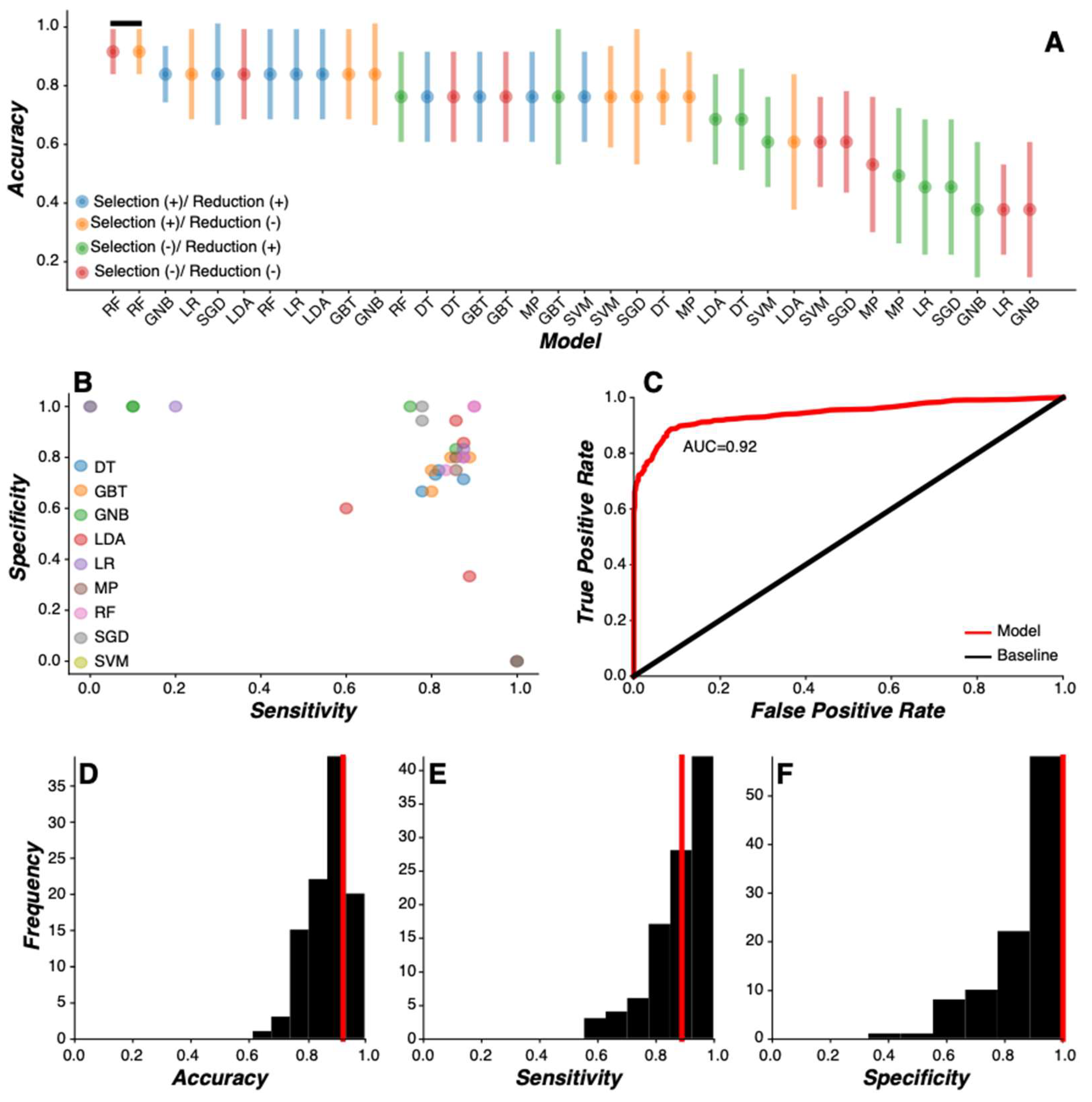
3.3. Machine Learning Model Comparison
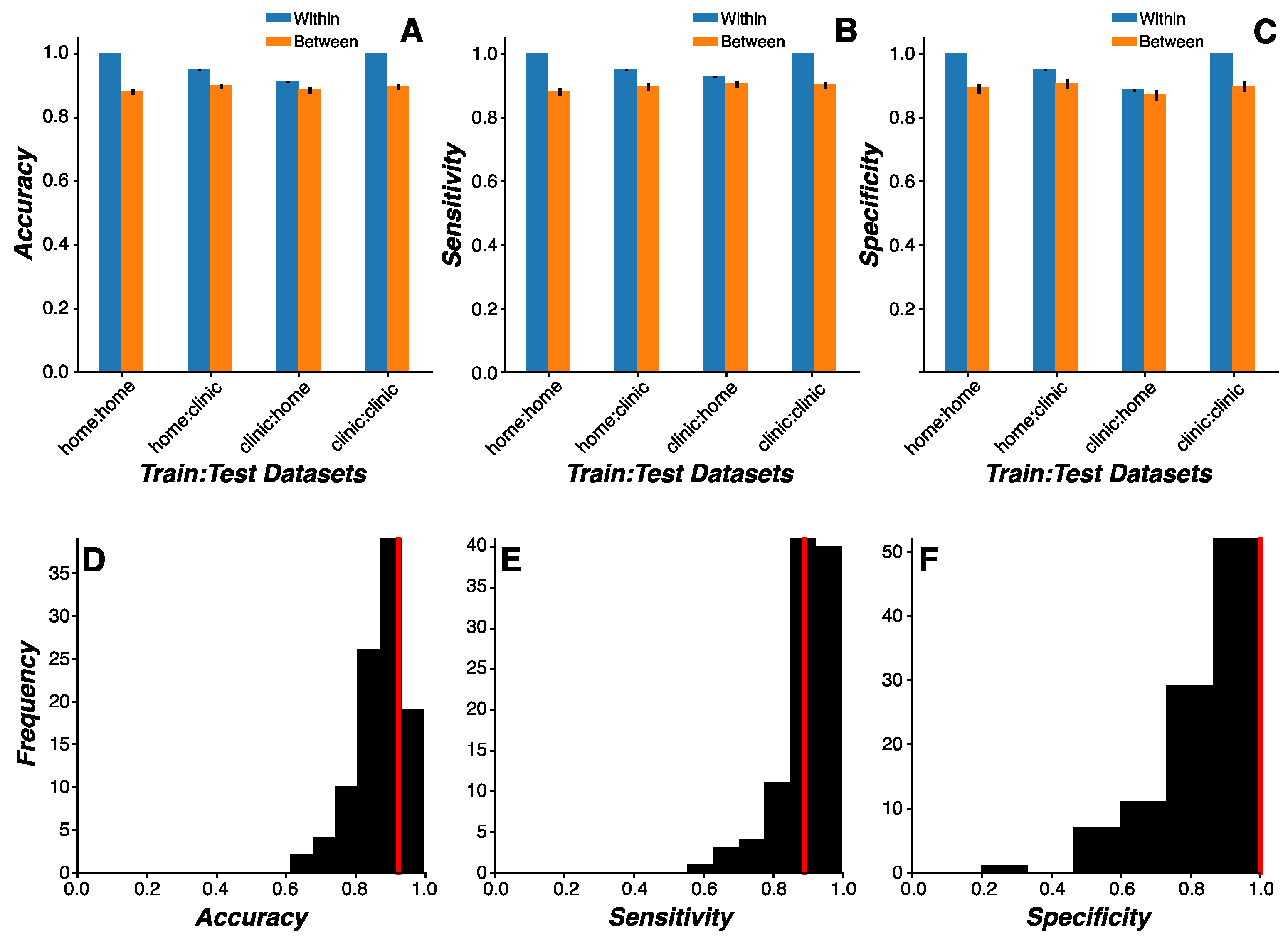
3.4. Cross-Environmental Predictions
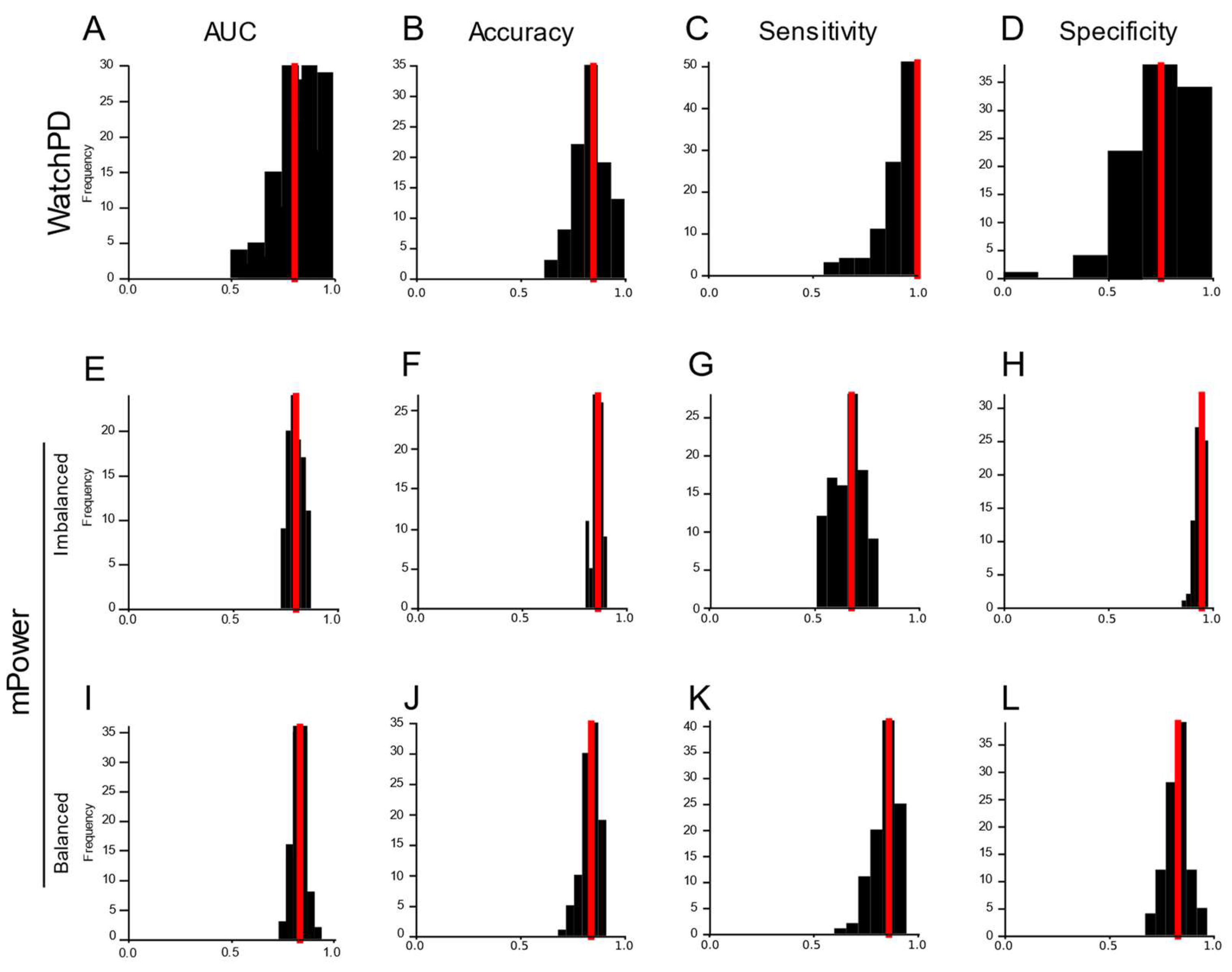
3.5. Cross-Platform Analysis
3.6. Feature Reliability
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Dorsey, E.R.; Bloem, B.R. The Parkinson Pandemic—A Call to Action. JAMA Neurol. 2018, 75, 9. [Google Scholar] [CrossRef]
- Marras, C.; Beck, J.C.; Bower, J.H.; Roberts, E.; Ritz, B.; Ross, G.W.; Abbott, R.D.; Savica, R.; Van Den Eeden, S.K.; Willis, A.W.; et al. Prevalence of Parkinson’s Disease across North America. NPJ Park. Dis. 2018, 4, 21. [Google Scholar] [CrossRef] [PubMed]
- Rossi, A.; Berger, K.; Chen, H.; Leslie, D.; Mailman, R.B.; Huang, X. Projection of the Prevalence of Parkinson’s Dis-ease in the Coming Decades: Revisited. Mov. Disord. 2018, 33, 156. [Google Scholar] [CrossRef] [PubMed]
- Achey, M.; Aldred, J.L.; Aljehani, N.; Bloem, B.R.; Biglan, K.M.; Chan, P.; Cubo, E.; Ray Dorsey, E.; Goetz, C.G.; Guttman, M.; et al. The Past, Present, and Future of Telemedicine for Parkinson’s Disease. Mov. Disord. 2014, 29, 871. [Google Scholar] [CrossRef] [PubMed]
- Postuma, R.B.; Berg, D.; Stern, M.; Poewe, W.; Olanow, C.W.; Oertel, W.; Obeso, J.; Marek, K.; Litvan, I.; Lang, A.E.; et al. MDS Clinical Diagnostic Criteria for Parkinson’s Disease. Mov. Disord. 2015, 30, 1591–1601. [Google Scholar] [CrossRef] [PubMed]
- Dorsey, E.R.; Venuto, C.; Venkataraman, V.; Harris, D.A.; Kieburtz, K. Novel Methods and Technologies for 21st-Century Clinical Trials: A Review. JAMA Neurol. 2015, 72, 582. [Google Scholar] [CrossRef] [PubMed]
- Goetz, C.G.; Tilley, B.C.; Shaftman, S.R.; Stebbins, G.T.; Fahn, S.; Martinez-Martin, P.; Poewe, W.; Sampaio, C.; Stern, M.B.; Dodel, R.; et al. Movement Disorder Society-Sponsored Revision of the Unified Parkinson’s Disease Rating Scale (MDS-UPDRS): Scale Presentation and Clinimetric Testing Results. Mov. Disord. 2008, 23, 2129–2170. [Google Scholar] [CrossRef]
- Adler, C.H.; Beach, T.G.; Hentz, J.G.; Shill, H.A.; Caviness, J.N.; Driver-Dunckley, E.; Sabbagh, M.N.; Sue, L.I.; Jacobson, S.A.; Belden, C.M.; et al. Low Clinical Diagnostic Accuracy of Early vs Advanced Parkinson Disease: Clinicopathologic Study. Neurology 2014, 83, 406. [Google Scholar] [CrossRef]
- Beach, T.G.; Adler, C.H. Importance of Low Diagnostic Accuracy for Early Parkinson’s Disease. Mov. Disord. 2018, 33, 1551–1554. [Google Scholar] [CrossRef]
- Dahodwala, N.; Siderowf, A.; Baumgarten, M.; Abrams, A.; Karlawish, J. Screening Questionnaires for Parkinson-ism: A Systematic Review. Park. Relat. Disord. 2012, 18, 216. [Google Scholar] [CrossRef]
- Berg, D.; Postuma, R.B. From Prodromal to Overt Parkinson’s Disease: Towards a New Definition in the Year 2040. J. Park. Dis. 2018, 8, S19. [Google Scholar] [CrossRef]
- Bellomo, G.; De Luca, C.M.G.; Paoletti, F.P.; Gaetani, L.; Moda, F.; Parnetti, L. α-Synuclein Seed Amplification Assays for Diagnosing Synucleinopathies: The Way Forward. Neurology 2022, 99, 195. [Google Scholar] [CrossRef] [PubMed]
- Izmailova, E.S.; Wagner, J.A.; Perakslis, E.D. Wearable Devices in Clinical Trials: Hype and Hypothesis. Clin. Pharmacol. Ther. 2018, 104, 42–52. [Google Scholar] [CrossRef] [PubMed]
- Coravos, A.; Khozin, S.; Mandl, K.D. Developing and Adopting Safe and Effective Digital Biomarkers to Improve Patient Outcomes. NPJ Digit. Med. 2019, 2, 14. [Google Scholar] [CrossRef] [PubMed]
- Dorsey, E.R.; Papapetropoulos, S.; Xiong, M.; Kieburtz, K. The First Frontier: Digital Biomarkers for Neurodegenerative Disorders. Digit. Biomark. 2017, 1, 6. [Google Scholar] [CrossRef]
- Landers, M.; Dorsey, R.; Saria, S. Digital Endpoints: Definition, Benefits, and Current Barriers in Accelerating Development and Adoption. Digit Biomark 2021, 5, 216. [Google Scholar] [CrossRef]
- Adams, J.L.; Dinesh, K.; Snyder, C.W.; Xiong, M.; Tarolli, C.G.; Sharma, S.; Dorsey, E.R.; Sharma, G. A Real-World Study of Wearable Sensors in Parkinson’s Disease. NPJ Park. Dis. 2021, 7, 1. [Google Scholar] [CrossRef]
- Arora, S.; Venkataraman, V.; Zhan, A.; Donohue, S.; Biglan, K.M.; Dorsey, E.R.; Little, M.A. Detecting and Monitoring the Symptoms of Parkinson’s Disease Using Smartphones: A Pilot Study. Park. Relat. Disord. 2015, 21, 650. [Google Scholar] [CrossRef]
- Burq, M.; Rainaldi, E.; Ho, K.C.; Chen, C.; Bloem, B.R.; Evers, L.J.W.; Helmich, R.C.; Myers, L.; Marks, W.J.; Kapur, R. Virtual Exam for Parkinson’s Disease Enables Frequent and Reliable Remote Measurements of Motor Function. NPJ Digit. Med. 2022, 5, 65. [Google Scholar] [CrossRef] [PubMed]
- Lipsmeier, F.; Taylor, K.I.; Kilchenmann, T.; Wolf, D.; Scotland, A.; Schjodt-Eriksen, J.; Cheng, W.Y.; Fernandez-Garcia, I.; Siebourg-Polster, J.; Jin, L.; et al. Evaluation of Smartphone-Based Testing to Generate Exploratory Outcome Measures in a Phase 1 Parkinson’s Disease Clinical Trial. Mov. Disord. 2018, 33, 1287. [Google Scholar] [CrossRef]
- Lipsmeier, F.; Taylor, K.I.; Postuma, R.B.; Volkova-Volkmar, E.; Kilchenmann, T.; Mollenhauer, B.; Bamdadian, A.; Popp, W.L.; Cheng, W.-Y.; Zhang, Y.-P.; et al. Reliability and Validity of the Roche PD Mobile Application for Remote Monitoring of Early Parkinson’s Disease. Sci. Rep. 2022, 12, 12081. [Google Scholar] [CrossRef]
- Lonini, L.; Dai, A.; Shawen, N.; Simuni, T.; Poon, C.; Shimanovich, L.; Daeschler, M.; Ghaffari, R.; Rogers, J.A.; Jayaraman, A. Wearable Sensors for Parkinson’s Disease: Which Data Are Worth Collecting for Training Symptom Detection Models. NPJ Digit. Med. 2018, 1, 64. [Google Scholar] [CrossRef] [PubMed]
- Omberg, L.; Neto, E.C.; Perumal, T.M.; Pratap, A.; Tediarjo, A.; Adams, J.; Bloem, B.R.; Bot, B.M.; Elson, M.; Goldman, S.M.; et al. Remote Smartphone Monitoring of Parkinson’s Disease and Individual Response to Therapy. Nat. Biotechnol. 2021, 40, 480–487. [Google Scholar] [CrossRef] [PubMed]
- Powers, R.; Etezadi-Amoli, M.; Arnold, E.M.; Kianian, S.; Mance, I.; Gibiansky, M.; Trietsch, D.; Alvarado, A.S.; Kretlow, J.D.; Herrington, T.M.; et al. Smartwatch Inertial Sensors Continuously Monitor Real-World Motor Fluctuations in Parkinson’s Disease. Sci. Transl. Med. 2021, 13, eabd7865. [Google Scholar] [CrossRef]
- Zhan, A.; Mohan, S.; Tarolli, C.; Schneider, R.B.; Adams, J.L.; Sharma, S.; Elson, M.J.; Spear, K.L.; Glidden, A.M.; Little, M.A.; et al. Using Smartphones and Machine Learning to Quantify Parkinson Disease Severity: The Mobile Parkinson Disease Score. JAMA Neurol. 2018, 75, 876. [Google Scholar] [CrossRef] [PubMed]
- Sieberts, S.K.; Schaff, J.; Duda, M.; Pataki, B.Á.; Sun, M.; Snyder, P.; Daneault, J.F.; Parisi, F.; Costante, G.; Rubin, U.; et al. Crowdsourcing Digital Health Measures to Predict Parkinson’s Disease Severity: The Parkinson’s Disease Digital Biomarker DREAM Challenge. Npj Digit. Med. 2021, 4, 53. [Google Scholar] [CrossRef] [PubMed]
- Kubota, K.J.; Chen, J.A.; Little, M.A. Machine Learning for Large-Scale Wearable Sensor Data in Parkinson’s Disease: Concepts, Promises, Pitfalls, and Futures. Mov. Disord. 2016, 31, 1314. [Google Scholar] [CrossRef]
- Adams, J.L.; Kangarloo, T.; Tracey, B.; O’donnell, P.; Volfson, D.; Latzman, R.D.; Zach, N.; Alexander, R.; Bergethon, P.; Cosman, J.; et al. Using a Smartwatch and Smartphone to Assess Early Parkinson’s Disease in the WATCH-PD Study. NPJ Park. Dis. 2023, 9, 64. [Google Scholar] [CrossRef]
- Prince, J.; De Vos, M. A Deep Learning Framework for the Remote Detection of Parkinson’s Disease Using Smart-Phone Sensor Data. In Proceedings of the Annual International Conference of the IEEE Engineering in Medicine and Biology Society, EMBS, Honolulu, HI, USA, 18–21 July 2018. [Google Scholar]
- Woods, D.L.; Wyma, J.M.; Herron, T.J.; Yund, E.W. The Effects of Aging, Malingering, and Traumatic Brain Injury on Computerized Trail-Making Test Performance. PLoS ONE 2015, 10, e0124345. [Google Scholar] [CrossRef]
- Tracy, J.M.; Özkanca, Y.; Atkins, D.C.; Ghomi, R.H. Investigating Voice as a Biomarker: Deep Phenotyping Methods for Early Detection of Parkinson’s Disease. J. Biomed. Inform. 2020, 104, 103362. [Google Scholar] [CrossRef]
- Valstar, M.; Schuller, B.; Smith, K.; Eyben, F.; Jiang, B.; Bilakhia, S.; Schnieder, S.; Cowie, R.; Pantic, M. AVEC 2013—The Continuous Audio/Visual Emotion and Depression Recognition Challenge. In Proceedings of the 3rd ACM International Workshop on Audio/Visual Emotion Challenge, Barcelona, Spain, 21 October 2013. [Google Scholar]
- San-Segundo, R.; Blunck, H.; Moreno-Pimentel, J.; Stisen, A.; Gil-Martín, M. Robust Human Activity Recognition Using Smartwatches and Smartphones. Eng. Appl. Artif. Intell. 2018, 72, 190–202. [Google Scholar] [CrossRef]
- Sigcha, L.; Pavón, I.; Costa, N.; Costa, S.; Gago, M.; Arezes, P.; López, J.M.; De Arcas, G. Automatic Resting Tremor Assessment in Parkinson’s Disease Using Smartwatches and Multitask Convolutional Neural Networks. Sensors 2021, 21, 291. [Google Scholar] [CrossRef] [PubMed]
- Zhang, A.; San-Segundo, R.; Panev, S.; Tabor, G.; Stebbins, K.; Whitford, A.; De La Torre, F.; Hodgins, J. Automated Tremor Detection in Parkinson’s Disease Using Accelerometer Signals. In Proceedings of the 2018 IEEE/ACM International Conference on Connected Health: Applications, Systems and Engineering Technologies, CHASE 2018, Washington, DC, USA, 26–28 September 2018. [Google Scholar]
- Taber, K.S. The Use of Cronbach’s Alpha When Developing and Reporting Research Instruments in Science Education. Res. Sci. Educ. 2018, 48, 1273–1296. [Google Scholar] [CrossRef]
- Bot, B.M.; Suver, C.; Neto, E.C.; Kellen, M.; Klein, A.; Bare, C.; Doerr, M.; Pratap, A.; Wilbanks, J.; Dorsey, E.R.; et al. The MPower Study, Parkinson Disease Mobile Data Collected Using ResearchKit. Sci. Data 2016, 3, 160011. [Google Scholar] [CrossRef]
- Adams, J.L.; Kangarloo, T.; Gong, Y.; Khachadourian, V.; Tracey, B.; Volfson, D.; Latzman, R.D.; Cosman, J.; Edgerton, J.; Anderson, D.; et al. Using a Smartwatch and Smartphone to Assess Early Parkinson’s Disease in the WATCH-PD Study over 12 Months. NPJ Park. Dis. 2024, 10, 112. [Google Scholar] [CrossRef]
- Tougui, I.; Jilbab, A.; El Mhamdi, J. Impact of the Choice of Cross-Validation Techniques on the Results of Machine Learning-Based Diagnostic Applications. Healthc. Inform. Res. 2021, 27, 189–199. [Google Scholar] [CrossRef]
- Anderson, D.; Keil, A.; Amato, D.; Merickel, M.; Kantartjis, M.; Jezewski, S.; Johnson, S.; Polyak, S.; Severson, B.; Severson, J. Predicting ALS Progression Using Remote Sensor-Based Assessments. Mov. Disord. 2023, 38, S1–S62. [Google Scholar] [CrossRef]
- Karas, M.; Olsen, J.; Straczkiewicz, M.; Johnson, S.A.; Burke, K.M.; Iwasaki, S.; Lahav, A.; Scheier, Z.A.; Clark, A.P.; Iyer, A.S.; et al. Tracking Amyotrophic Lateral Sclerosis Disease Progression Using Passively Collected Smartphone Sensor Data. Ann. Clin. Transl. Neurol. 2024, 11, 1380–1392. [Google Scholar] [CrossRef]
- Hill, D.L.; Stephenson, D.; Brayanov, J.; Claes, K.; Badawy, R.; Sardar, S.; Fisher, K.; Lee, S.J.; Bannon, A.; Roussos, G.; et al. Metadata Framework to Support Deployment of Digital Health Technologies in Clinical Trials in Parkinson’s Disease. Sensors 2022, 22, 2136. [Google Scholar] [CrossRef]
- Griffiths, R.I.; Kotschet, K.; Arfon, S.; Xu, Z.M.; Johnson, W.; Drago, J.; Evans, A.; Kempster, P.; Raghav, S.; Horne, M.K. Automated Assessment of Bradykinesia and Dyskinesia in Parkinson’s Disease. J. Park. Dis. 2012, 2, 47–55. [Google Scholar] [CrossRef]
- Mahadevan, N.; Demanuele, C.; Zhang, H.; Volfson, D.; Ho, B.; Erb, M.K.; Patel, S. Development of Digital Bi-omarkers for Resting Tremor and Bradykinesia Using a Wrist-Worn Wearable Device. NPJ Digit. Med. 2020, 3, 5. [Google Scholar] [CrossRef] [PubMed]
- Espay, A.J.; Hausdorff, J.M.; Sánchez-Ferro, Á.; Klucken, J.; Merola, A.; Bonato, P.; Paul, S.S.; Horak, F.B.; Vizcarra, J.A.; Mestre, T.A.; et al. A Roadmap for Implementation of Patient-Centered Digital Outcome Measures in Parkinson’s Disease Obtained Using Mobile Health Technologies. Mov. Disord. 2019, 34, 657–663. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Assessment | Functional Domain | Device(s) | Sensors | Data Elements | Sampling Interval |
|---|---|---|---|---|---|
| VSTM | Working memory | Smartphone | Phone screen | Trial type, response accuracy, and response time | Trial-by-trial |
| SDMT | Processing speed, working memory | Smartphone | Phone screen | Trial symbol, expected number, observed number, response accuracy, and trial duration | Trial-by-trial |
| Trails | Processing speed, executive function | Smartphone | Phone screen | Completion time, number of restarts, number of errors, sample time, detected screen position (x, y), nearest target, and target locations | Screen position change (23.9 ± 6.3 Hz; 8.1–54.2 Hz) |
| Finger Tapping | Psychomotor performance | Smartphone | Phone screen | Total taps, total alternating taps, tap time, tap location, tap duration, tap position (x, y), and tap-to-target distance | Each tap |
| Fine Motor | Psychomotor performance | Smartphone | Phone screen | Total completed, sample time, shape position (x, y), shape orientation, target position (x, y), and target orientation | Screen position change (10.5 ± 2.8 Hz; 1.9–23.4 Hz) |
| Phonation | Speech | Smartphone | Phone microphone | Speech duration, speech onset time, and raw signal (.wav) | 32 kHz |
| Articulation | Diadochokinetic speech | Smartphone | Phone microphone | Speech duration, speech onset time, and raw signal (.wav) | 32 kHz |
| Tremor | Postural stability and resting tremor | Smartwatch | Accelerometer, gyroscope, magnetometer, and compass | Acceleration (x, y, z), gravitational acceleration (x, y, z), orientation (roll, pitch, yaw), angular velocity (x, y, z), magnetic field (x, y, z), and heading | 99.99 ± 0.5 Hz [82.5–100.8 Hz] |
| Gait and Balance | Gait and postural sway | Smartphone, Smartwatch | Accelerometer, gyroscope, magnetometer, and compass | Acceleration (x, y, z), gravitational acceleration (x, y, z), orientation (roll, pitch, yaw), angular velocity (x, y, z), magnetic field (x, y, z), and heading | Watch: 99.99 ± 0.5 Hz [82.5–100.8 Hz] Phone: 99.99 ± 0.5 Hz [99.2–100.8 Hz] |
| Assessment | Total (n) | PD (n) | HC (n) | % PD * | Device(s) |
|---|---|---|---|---|---|
| Participants | 132 | 82 | 50 | 62.1 | |
| VSTM | 2820 | 1775 | 1045 | 62.9 | Smartphone |
| SDMT | 2817 | 1773 | 1044 | 62.9 | Smartphone |
| Trails | 2815 | 1772 | 1043 | 62.9 | Smartphone |
| Finger Tapping | 2814 | 1770 | 1044 | 62.9 | Smartphone |
| Fine Motor | 2812 | 1769 | 1043 | 62.9 | Smartphone |
| Verbal Phonation | 2820 | 1776 | 1044 | 63.0 | Smartphone |
| Verbal Articulation | 2813 | 1771 | 1042 | 63.0 | Smartphone |
| Tremor | 2605 | 1620 | 985 | 62.2 | Smartwatch |
| Gait and Balance | 2566 | 1597 | 969 | 62.2 | Smartphone, Smartwatch |
| Assessment | Features (n) | Percentage of All Features | Selectivity (%) * |
|---|---|---|---|
| VSTM | 2 | 0.05% | 0% |
| SDMT | 2 | 0.05% | 50% |
| Trails | 12 | 0.3% | 50% |
| Finger Tapping | 28 | 0.8% | 78.6% |
| Fine Motor | 19 | 0.5% | 73.7% |
| Verbal Phonation | 495 | 13.7% | 11.5% |
| Verbal Articulation | 495 | 13.7% | 14.5% |
| Tremor | 462 | 12.7% | 62.1% |
| Gait and Balance | 2106 | 58.2% | 44.1% |
| External Reliability | Test-Retest Reliability | |||
|---|---|---|---|---|
| Above Threshold (%) * | Above Threshold (p-Value) ** | Above Threshold (%) | Above Threshold (p-Value) | |
| VSTM | 100 | <0.00001 | 100 | 0 |
| SDMT | 100 | 0.073 | 100 | 0.13 |
| Trails | 50.0 | 0.73 | 33.3 | 0.35 |
| Finger Tapping | 92.9 | <0.00001 | 92.9 | <0.00001 |
| Fine Motor | 78.9 | 0.0017 | 84.2 | <0.001 |
| Verbal Phonation | 75.8 | <0.00001 | 78.2 | <0.00001 |
| Verbal Articulation | 74.7 | <0.00001 | 80.6 | <0.00001 |
| Tremor | 88.1 | <0.00001 | 79.2 | <0.00001 |
| Gait and Balance | 74.3 | <0.00001 | 76.3 | <0.00001 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Johnson, S.; Kantartjis, M.; Severson, J.; Dorsey, R.; Adams, J.L.; Kangarloo, T.; Kostrzebski, M.A.; Best, A.; Merickel, M.; Amato, D.; et al. Wearable Sensor-Based Assessments for Remotely Screening Early-Stage Parkinson’s Disease. Sensors 2024, 24, 5637. https://doi.org/10.3390/s24175637
Johnson S, Kantartjis M, Severson J, Dorsey R, Adams JL, Kangarloo T, Kostrzebski MA, Best A, Merickel M, Amato D, et al. Wearable Sensor-Based Assessments for Remotely Screening Early-Stage Parkinson’s Disease. Sensors. 2024; 24(17):5637. https://doi.org/10.3390/s24175637
Chicago/Turabian StyleJohnson, Shane, Michalis Kantartjis, Joan Severson, Ray Dorsey, Jamie L. Adams, Tairmae Kangarloo, Melissa A. Kostrzebski, Allen Best, Michael Merickel, Dan Amato, and et al. 2024. "Wearable Sensor-Based Assessments for Remotely Screening Early-Stage Parkinson’s Disease" Sensors 24, no. 17: 5637. https://doi.org/10.3390/s24175637
APA StyleJohnson, S., Kantartjis, M., Severson, J., Dorsey, R., Adams, J. L., Kangarloo, T., Kostrzebski, M. A., Best, A., Merickel, M., Amato, D., Severson, B., Jezewski, S., Polyak, S., Keil, A., Cosman, J., & Anderson, D. (2024). Wearable Sensor-Based Assessments for Remotely Screening Early-Stage Parkinson’s Disease. Sensors, 24(17), 5637. https://doi.org/10.3390/s24175637