
GMS-YOLO: An Algorithm for Multi-Scale Object Detection in Complex Environments in Confined Compartments

 ,
,
Abstract
:1. Introduction
2. Method
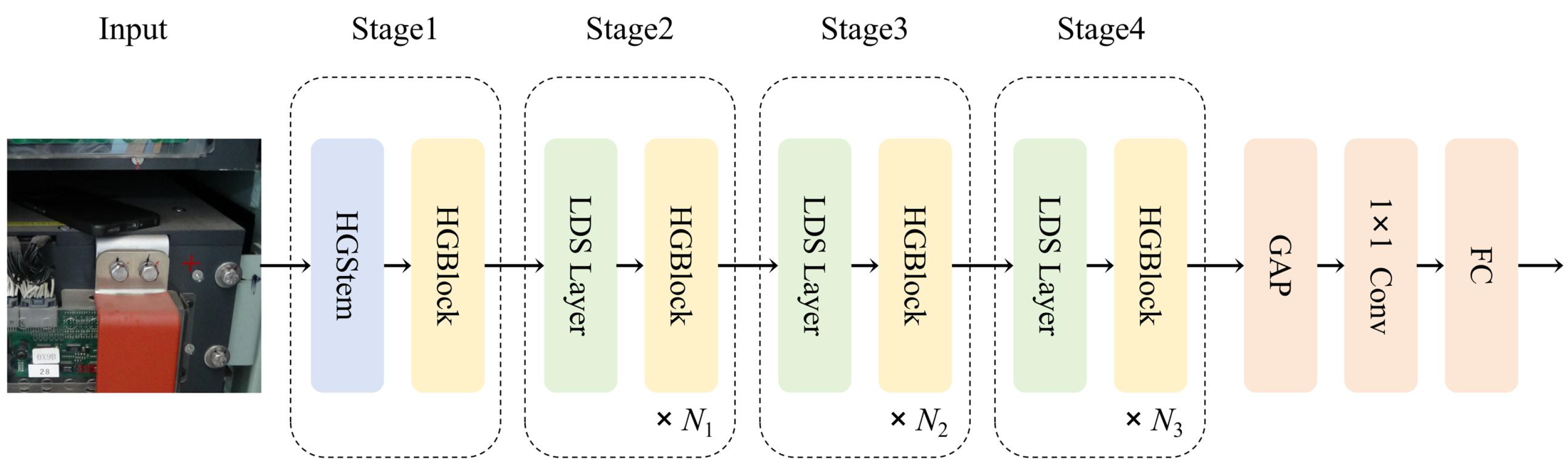
2.1. Overview of the Network Framework
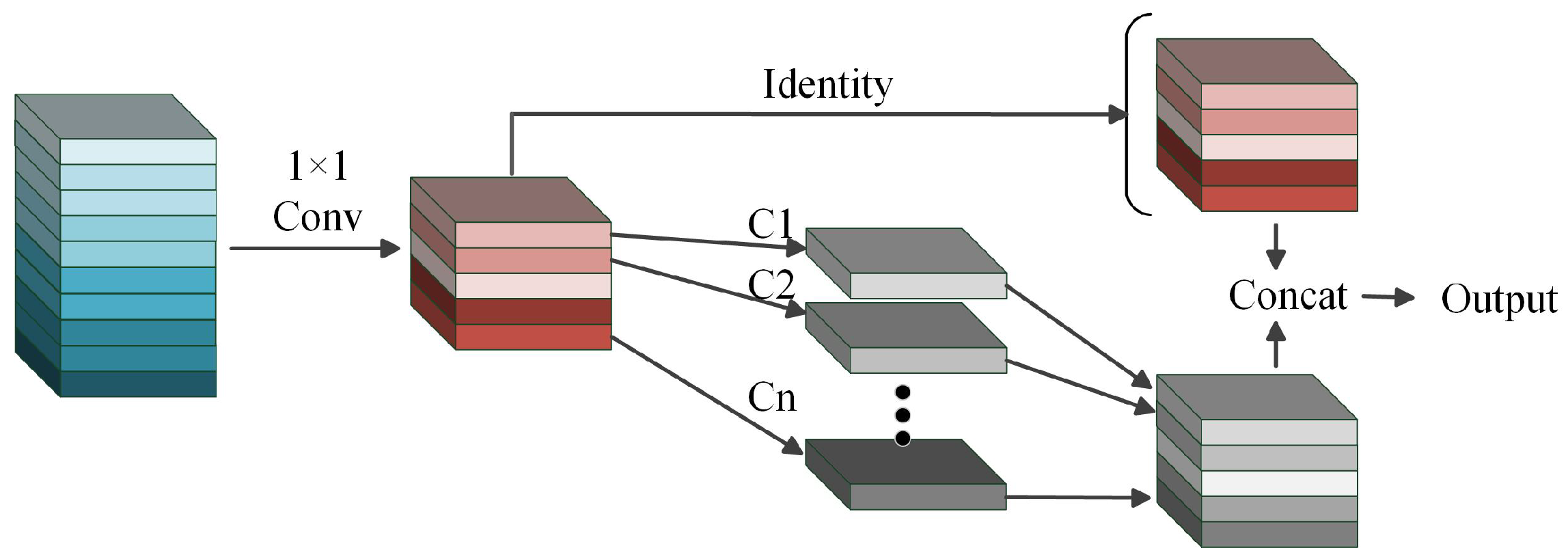
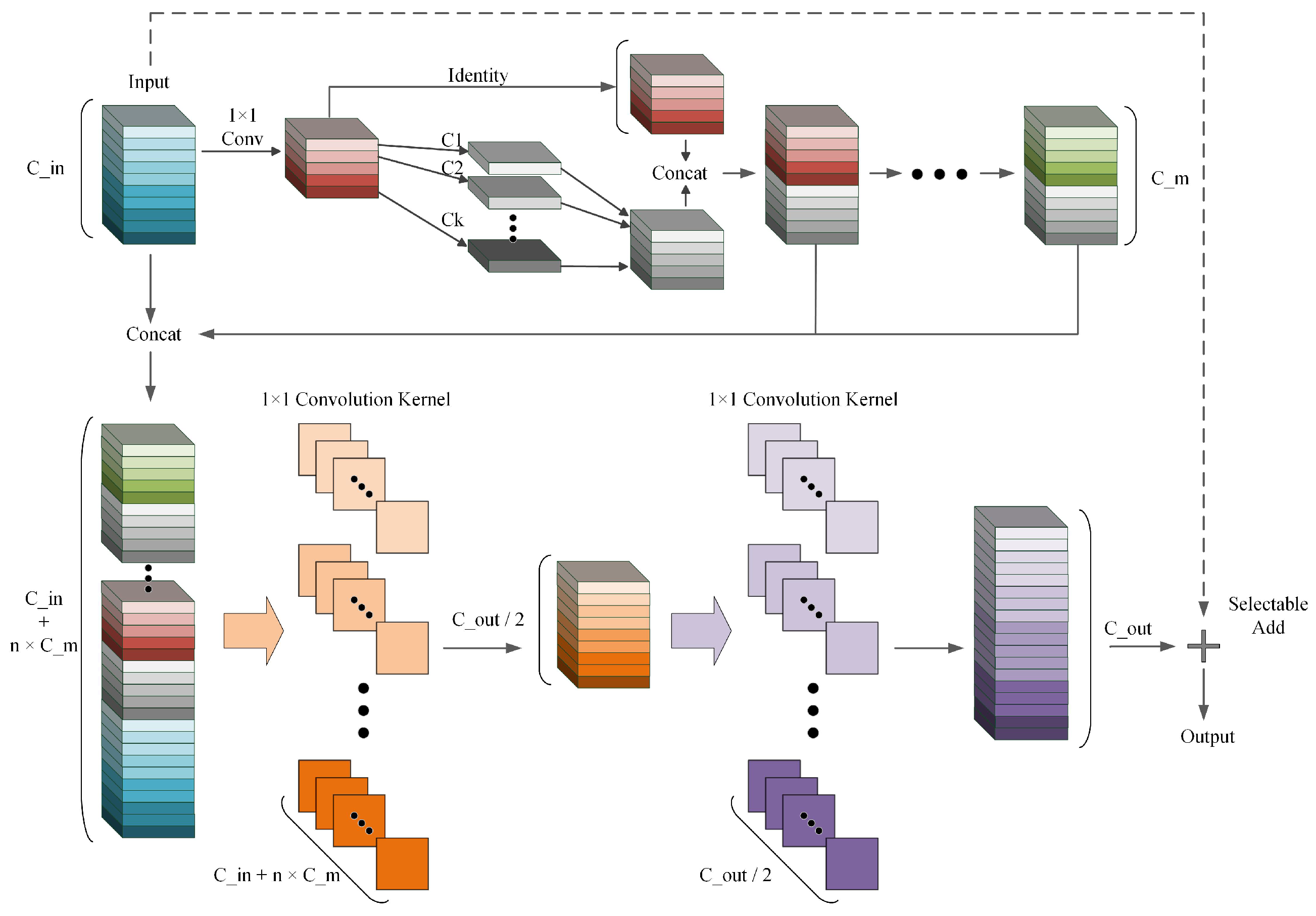
2.2. Feature Extraction Network Based on an Enhanced HGNetv2
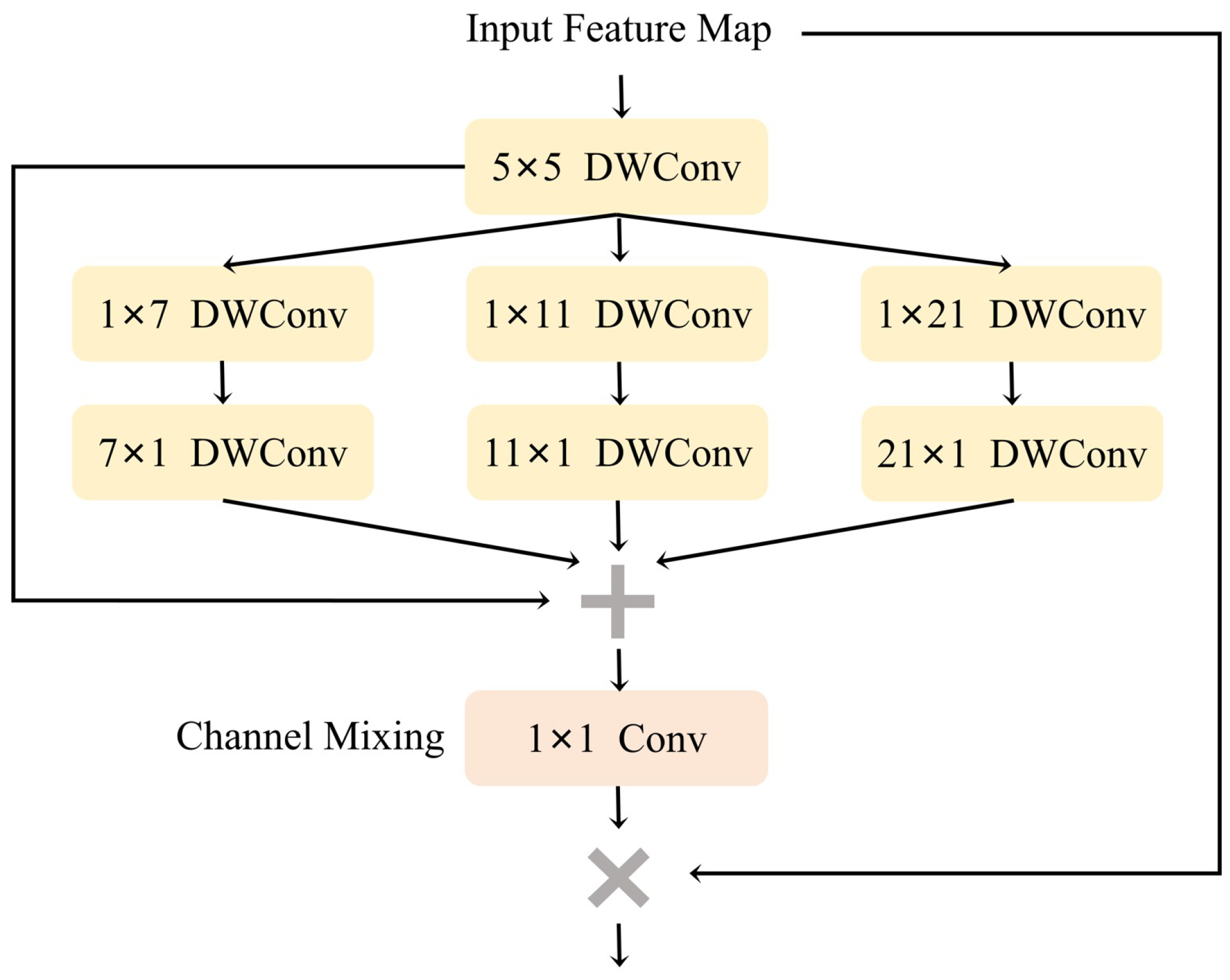
2.3. Multi-Scale Convolutional Attention
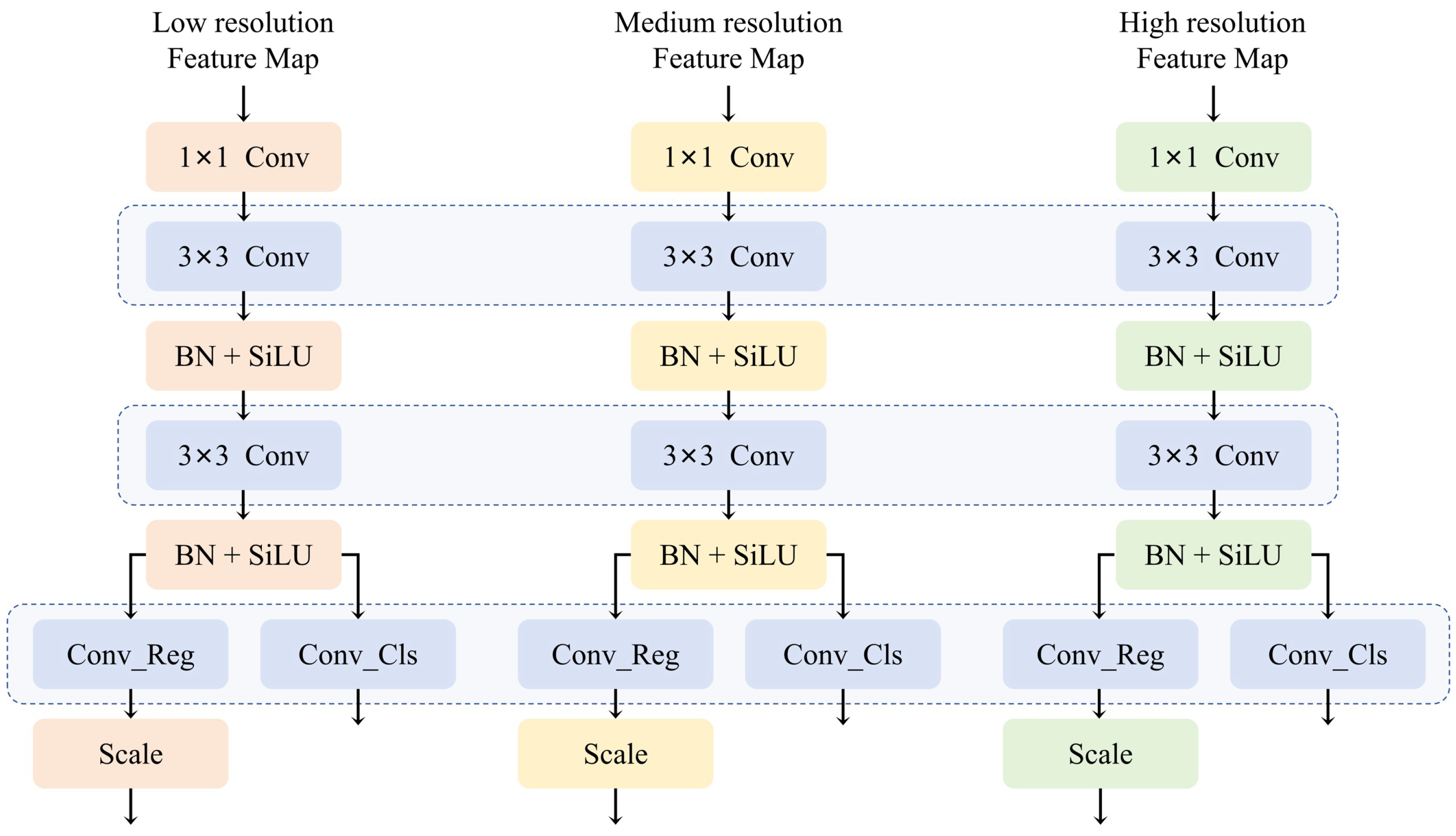
2.4. Shared Convolutional Detection Head
3. Experiment
3.1. Dataset Construction and Experimental Environment
3.2. Evaluation Indicators
3.3. Experimental Analysis
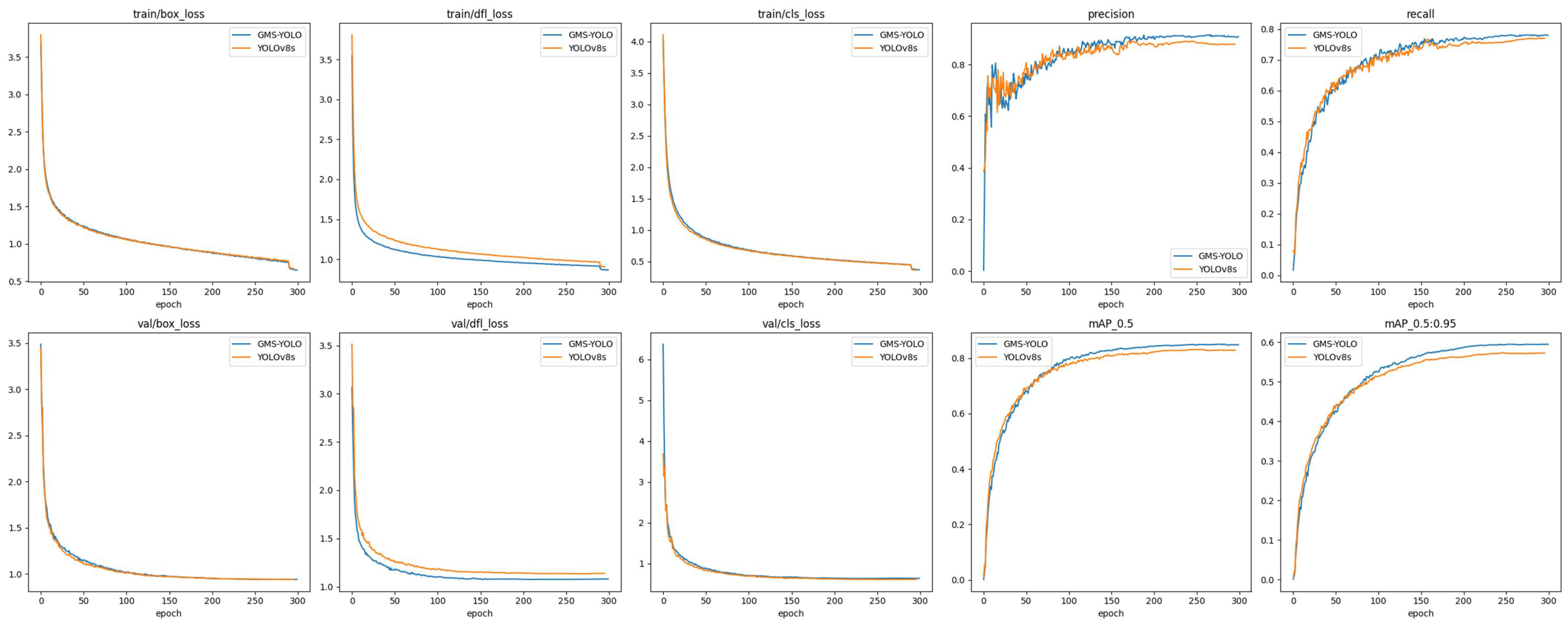
3.3.1. Contrast Experiment
3.3.2. Ablation Experiment
3.3.3. Visualized Analysis
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zou, Z.; Chen, K.; Shi, Z.; Guo, Y.; Ye, J. Object Detection in 20 Years: A Survey. Proc. IEEE 2023, 111, 257–276. [Google Scholar] [CrossRef]
- Ramezani, F.; Parvez, S.; Fix, J.P.; Battaglin, A.; Whyte, S.; Borys, N.J.; Whitaker, B.M. Automatic detection of multilayer hexagonal boron nitride in optical images using deep learning-based computer vision. Sci. Rep. 2023, 13, 1595. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar] [CrossRef]
- Zaidi, S.S.A.; Ansari, M.S.; Aslam, A.; Kanwal, N.; Asghar, M.; Lee, B. A survey of modern deep learning based object detection models. Digit. Signal Process. 2022, 126, 103514. [Google Scholar] [CrossRef]
- Bello, R.W.; Oladipo, M. Mask YOLOv7-Based Drone Vision System for Automated Cattle Detection and Counting. Artif. Intell. Appl. 2024, 2, 1–5. [Google Scholar] [CrossRef]
- Li, H.; Gu, Z.; He, D.; Wang, X.; Huang, J.; Mo, Y.; Li, P.; Huang, Z.; Wu, F. A lightweight improved YOLOv5s model and its deployment for detecting pitaya fruits in daytime and nighttime light-supplement environments. Comput. Electron. Agric. 2024, 220, 108914. [Google Scholar] [CrossRef]
- Mokayed, H.; Quan, T.; Alkhaled, L.; Sivakumar, V. Real-Time Human Detection and Counting System Using Deep Learning Computer Vision Techniques. Artif. Intell. Appl. 2023, 1, 221–229. [Google Scholar] [CrossRef]
- Yi, W.; Ma, S.; Li, R. Insulator and Defect Detection Model Based on Improved YOLO-S. IEEE Access 2023, 11, 93215–93226. [Google Scholar] [CrossRef]
- Zhou, M.; Li, B.; Wang, J.; He, S. Fault Detection Method of Glass Insulator Aerial Image Based on the Improved YOLOv5. IEEE Trans. Instrum. Meas. 2023, 72, 1–10. [Google Scholar] [CrossRef]
- Gao, Z.; Yang, G.; Li, E.; Liang, Z. Novel Feature Fusion Module-Based Detector for Small Insulator Defect Detection. IEEE Sens. J. 2021, 21, 16807–16814. [Google Scholar] [CrossRef]
- Hao, K.; Chen, G.; Zhao, L.; Li, Z.; Liu, Y.; Wang, C. An Insulator Defect Detection Model in Aerial Images Based on Multiscale Feature Pyramid Network. IEEE Trans. Instrum. Meas. 2022, 71, 1–12. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar] [CrossRef]
- Ghiasi, G.; Lin, T.Y.; Le, Q.V. NAS-FPN: Learning Scalable Feature Pyramid Architecture for Object Detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar] [CrossRef]
- Liu, S.; Huang, D.; Wang, Y. Learning Spatial Fusion for Single-Shot Object Detection. arXiv 2019, arXiv:1911.09516. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar] [CrossRef]
- Cheng, G.; Lang, C.; Wu, M.; Xie, X.; Yao, X.; Han, J. Feature Enhancement Network for Object Detection in Optical Remote Sensing Images. J. Remote Sens. 2021, 2021. [Google Scholar] [CrossRef]
- Zhang, K.; Shen, H. Multi-Stage Feature Enhancement Pyramid Network for Detecting Objects in Optical Remote Sensing Images. Remote Sens. 2022, 14, 579. [Google Scholar] [CrossRef]
- Chang, J.; Lu, Y.; Xue, P.; Xu, Y.; Wei, Z. ACP: Automatic Channel Pruning via Clustering and Swarm Intelligence Optimization for CNN. arXiv 2021, arXiv:2101.06407. [Google Scholar]
- Guo, S.; Wang, Y.; Li, Q.; Yan, J. DMCP: Differentiable Markov Channel Pruning for Neural Networks. arXiv 2020, arXiv:2005.03354. [Google Scholar]
- He, Y.; Zhang, X.; Sun, J. Channel Pruning for Accelerating Very Deep Neural Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar] [CrossRef]
- Liu, Z.; Li, J.; Shen, Z.; Huang, G.; Yan, S.; Zhang, C. Learning Efficient Convolutional Networks through Network Slimming. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar] [CrossRef]
- Howard, A.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. GhostNet: More Features from Cheap Operations. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar] [CrossRef]
- Ren, F.; Yao, M.; Doma, B.; Zhang, T.; Wang, J.; Liu, S. Research on Algorithm for License Plate Detection in Complex Scenarios Based on Artificial Intelligence. In Proceedings of the 2023 3rd International Conference on Communication Technology and Information Technology (ICCTIT), Xi’an, China, 24–26 November 2023. [Google Scholar]
- Kwon, Y.M.; Bae, S.; Chung, D.K.; Lim, M.J. Semantic Segmentation by Using Down-Sampling and Subpixel Convolution: DSSC-UNet. Comput. Mater. Contin. 2023, 75, 683–696. [Google Scholar] [CrossRef]
- Yang, X.; Zhang, Y.; Li, T.; Guo, Y.; Zhou, D. Image Super-Resolution Based on the Down-Sampling Iterative Module and Deep CNN. Circuits Syst. Signal Process. 2021, 40, 3437–3455. [Google Scholar] [CrossRef]
- Guo, M.H.; Lu, C.Z.; Hou, Q.; Liu, Z.N.; Cheng, M.M.; Hu, S.M. SegNeXt: Rethinking Convolutional Attention Design for Semantic Segmentation. Adv. Neural Inf. Process. Syst. 2022, 35, 1140–1156. [Google Scholar]
- Guo, M.H.; Xu, T.X.; Liu, J.J.; Liu, Z.N.; Jiang, P.T.; Mu, T.J.; Zhang, S.H.; Martin, R.R.; Cheng, M.M.; Hu, S.M. Attention Mechanisms in Computer Vision: A Survey. Comput. Vis. Media 2022, 8, 331–368. [Google Scholar] [CrossRef]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable Convolutional Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Guo, M.H.; Cai, J.X.; Liu, Z.N.; Mu, T.J.; Martin, R.R.; Hu, S.M. PCT: Point cloud transformer. Comput. Vis. Media 2021, 7, 187–199. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021. [Google Scholar] [CrossRef]
- Chen, L.; Zhang, H.; Xiao, J.; Nie, L.; Shao, J.; Liu, W.; Chua, T.S. SCA-CNN: Spatial and Channel-wise Attention in Convolutional Networks for Image Captioning. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar] [CrossRef]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar] [CrossRef]
- Peng, C.; Zhang, X.; Yu, G.; Luo, G.; Sun, J. Large Kernel Matters—Improve Semantic Segmentation by Global Convolutional Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef]
- Hou, Q.; Zhang, L.; Cheng, M.M.; Feng, J. Strip Pooling: Rethinking Spatial Pooling for Scene Parsing. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar] [CrossRef]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar] [CrossRef]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: A simple and strong anchor-free object detector. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 1922–1933. [Google Scholar] [CrossRef] [PubMed]
- Lyu, C.; Zhang, W.; Huang, H.; Zhou, Y.; Wang, Y.; Liu, Y.; Zhang, S.; Chen, K.; Conv, C.; Concat, R. RTMDet: An Empirical Study of Designing Real-Time Object Detectors. arXiv 2022, arXiv:2212.07784. [Google Scholar]
- He, M.; Qin, L.; Deng, X.; Liu, K. MFI-YOLO: Multi-fault insulator detection based on an improved YOLOv8. IEEE Trans. Power Deliv. 2023, 39, 168–179. [Google Scholar] [CrossRef]
- Wang, X.; Gao, H.; Jia, Z.; Li, Z. BL-YOLOv8: An Improved Road Defect Detection Model Based on YOLOv8. Sensors 2023, 10, 8361. [Google Scholar] [CrossRef]
- Chen, Y.; Liu, H.; Chen, J.; Hu, J.; Zheng, E. Insu-YOLO: An Insulator Defect Detection Algorithm Based on Multiscale Feature Fusion. Electronics 2023, 12, 3210. [Google Scholar] [CrossRef]
- Lou, H.; Guo, J.; Chen, H.; Liu, H.; Gu, J.; Bi, L.; Duan, X. CS-YOLO: A new detection algorithm for alien intrusion on highway. Sci. Rep. 2023, 13, 10667. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Target | Training Set | Validation Set | Total |
|---|---|---|---|
| bolt | 14,283 | 3662 | 17,945 |
| a-bind | 328 | 84 | 412 |
| n-bind | 8242 | 2018 | 10,260 |
| a-plug | 352 | 108 | 460 |
| e-plug | 1296 | 330 | 1626 |
| water | 1217 | 302 | 1519 |
| fod | 12,637 | 2984 | 15,621 |
| flaw | 1191 | 338 | 1529 |
| Image Number | 4492 | 1124 | 5616 |
| Laboratory Setting | Configuration Information |
|---|---|
| CPU | Intel Xeon Gold 6248 R Processor, 24 Core, 48 Thread |
| GPU | Nvidia GeForce RTX 3090 GPU 24 G |
| Running System | Windows 10 Professional |
| Random Access Memory | 128 GB (4 × 32 GB) |
| Read-Only Memory | 4.5 TB (512 GB + 4 TB) |
| Programming Language | Python 3.10 |
| Deep Learning Framework | PyTorch 1.11.0 + CUDA 11.5 |
| Model | Parameters (M) | Precision (%) | Recall (%) | F1-Score | mAP50 (%) | mAP50:95 (%) | GFLOPs (G) |
|---|---|---|---|---|---|---|---|
| YOLOv3-Tiny | 12.1 | 84.7 | 64.6 | 0.733 | 72.5 | 44.7 | 19.0 |
| YOLOv5s | 9.1 | 87.5 | 75.3 | 0.809 | 82.1 | 56.4 | 24.0 |
| YOLOv6s | 16.3 | 86.3 | 72.9 | 0.790 | 79.5 | 54.9 | 44.1 |
| YOLOv7-Tiny | 6.0 | 82.4 | 73.1 | 0.775 | 78.5 | 47.2 | 13.2 |
| YOLOv8s | 11.1 | 87.8 | 77.0 | 0.820 | 82.7 | 57.2 | 28.5 |
| RT-DETR-l | 28.5 | 79.8 | 72.4 | 0.759 | 77.6 | 50.3 | 100.7 |
| RT-DETR-Resnet50 | 42.0 | 82.9 | 73.6 | 0.780 | 79.1 | 52.2 | 125.8 |
| Model | Parameters (M) | Precision (%) | Recall (%) | F1-Score | mAP (%) | GFLOPs (G) |
|---|---|---|---|---|---|---|
| MFI-YOLO | 9.2 | 87.6 | 74.8 | 0.807 | 81.6 | 22.4 |
| CS-YOLO | 21.8 | 92.0 | 77.0 | 0.838 | 84.2 | 48.4 |
| BL-YOLOv8 | 7.8 | 90.4 | 74.9 | 0.819 | 82.5 | 25.4 |
| Insu-YOLO | 4.2 | 86.9 | 72.6 | 0.791 | 80.6 | 13.8 |
| GMS-YOLOv5s | 5.8 | 88.6 | 75.4 | 0.815 | 83.3 | 18.1 |
| GMS-YOLO(ours) | 6.9 | 91.1 | 78.0 | 0.840 | 85.0 | 20.6 |
| Module | AP (%) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| GhostHG Netv2 | MSCA | SCDH | Bolt | a-Bind | n-Bind | a-Plug | e-Plug | Water | Fod | Flaw |
| ✕ | ✕ | ✕ | 77.8 | 86.7 | 94.1 | 72.9 | 91.4 | 89.0 | 90.8 | 61.8 |
| ✔ | ✕ | ✕ | 78.2 | 88.9 | 93.7 | 76.4 | 90.7 | 88.7 | 90.5 | 62.7 |
| ✕ | ✔ | ✕ | 78.0 | 87.2 | 94.0 | 73.6 | 92.0 | 89.8 | 90.8 | 60.6 |
| ✕ | ✕ | ✔ | 78.5 | 89.0 | 93.9 | 75.9 | 91.6 | 90.7 | 91.5 | 60.8 |
| ✔ | ✔ | ✕ | 78.8 | 88.8 | 93.8 | 76.1 | 92.0 | 90.4 | 91.4 | 61.2 |
| ✔ | ✕ | ✔ | 78.4 | 88.8 | 93.6 | 75.7 | 90.5 | 89.5 | 91.1 | 63.2 |
| ✕ | ✔ | ✔ | 78.9 | 89.1 | 94.0 | 75.3 | 92.8 | 91.3 | 91.6 | 61.9 |
| ✔ | ✔ | ✔ | 78.8 | 91.2 | 94.0 | 75.6 | 92.0 | 90.9 | 90.8 | 66.0 |
| Module | Parameters (M) | Precision (%) | Recall (%) | F1-Score | mAP50 (%) | mAP50:95 (%) | GFLOPs (G) | ||
|---|---|---|---|---|---|---|---|---|---|
| GhostHGNetv2 | MSCA | SCDH | |||||||
| ✕ | ✕ | ✕ | 11.1 | 87.8 | 77.0 | 0.820 | 82.7 | 57.2 | 28.5 |
| ✔ | ✕ | ✕ | 8.3 | 90.1 | 76.8 | 0.829 | 83.8 | 58.0 | 23.0 |
| ✕ | ✔ | ✕ | 11.4 | 88.6 | 78.7 | 0.834 | 83.3 | 58.2 | 28.8 |
| ✕ | ✕ | ✔ | 9.4 | 90.9 | 76.4 | 0.830 | 84.0 | 58.7 | 25.9 |
| ✔ | ✔ | ✕ | 8.6 | 90.0 | 78.0 | 0.836 | 84.2 | 58.7 | 23.3 |
| ✔ | ✕ | ✔ | 6.6 | 88.8 | 76.4 | 0.821 | 83.9 | 58.4 | 20.4 |
| ✕ | ✔ | ✔ | 9.8 | 89.3 | 77.4 | 0.829 | 84.4 | 59.0 | 26.1 |
| ✔ | ✔ | ✔ | 6.9 | 91.1 | 78.0 | 0.840 | 85.0 | 59.5 | 20.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ding, Q.; Li, W.; Xu, C.; Zhang, M.; Sheng, C.; He, M.; Shan, N. GMS-YOLO: An Algorithm for Multi-Scale Object Detection in Complex Environments in Confined Compartments. Sensors 2024, 24, 5789. https://doi.org/10.3390/s24175789
Ding Q, Li W, Xu C, Zhang M, Sheng C, He M, Shan N. GMS-YOLO: An Algorithm for Multi-Scale Object Detection in Complex Environments in Confined Compartments. Sensors. 2024; 24(17):5789. https://doi.org/10.3390/s24175789
Chicago/Turabian StyleDing, Qixiang, Weichao Li, Chengcheng Xu, Mingyuan Zhang, Changchong Sheng, Min He, and Nanliang Shan. 2024. "GMS-YOLO: An Algorithm for Multi-Scale Object Detection in Complex Environments in Confined Compartments" Sensors 24, no. 17: 5789. https://doi.org/10.3390/s24175789
APA StyleDing, Q., Li, W., Xu, C., Zhang, M., Sheng, C., He, M., & Shan, N. (2024). GMS-YOLO: An Algorithm for Multi-Scale Object Detection in Complex Environments in Confined Compartments. Sensors, 24(17), 5789. https://doi.org/10.3390/s24175789