



An Improved YOLOv8 OBB Model for Ship Detection through Stable Diffusion Data Augmentation


Abstract
1. Introduction
- (1)
- Multi-viewpoint of aerial images. As UAVs take images in the air, ships may appear from different viewpoints, such as front, side, rear, etc. [20].
- (2)
- Multiple scales of ship instances. The different distances between UAVs and ship instances lead to ship instances having numerous scales, and various types of ships also have multiple scales.
- (3)
- Environment variability. Natural illumination may change with the weather. Due to some interference factors, the background of aerial images is often cluttered. For instance, white caps caused by waves may change the background [21].
- (4)
- Dataset scarcity. Due to different hydrological conditions, the features of ships vary from one water area to another. In order to ensure the effectiveness of this work in the Pearl River Waterway, it is necessary to collect the images of ships in the Pearl River Waterway and then make a dataset of them.
- (1)
- We use camera-equipped UAVs to capture multi-viewpoint images of ships in the Pearl River waterway and apply our proposed data augmentation method for data augment.
- (2)
- Based on the BiFPN structure and EMA module, we integrate the P2 feature layer to improve the neck structure of YOLOv8 and propose the YOLOv8n-BiFPN-EMA OBB model.
- (3)
- Through multiple comparative experiments, we validate the effectiveness of our proposed data augmentation method and the efficiency of the YOLOv8n-BiFPN-EMA OBB model, leading to significant conclusions.
2. Materials and Methods
2.1. Data Capture
2.2. Data Augmentation
2.3. Model Framework
2.3.1. Improved BiFPN
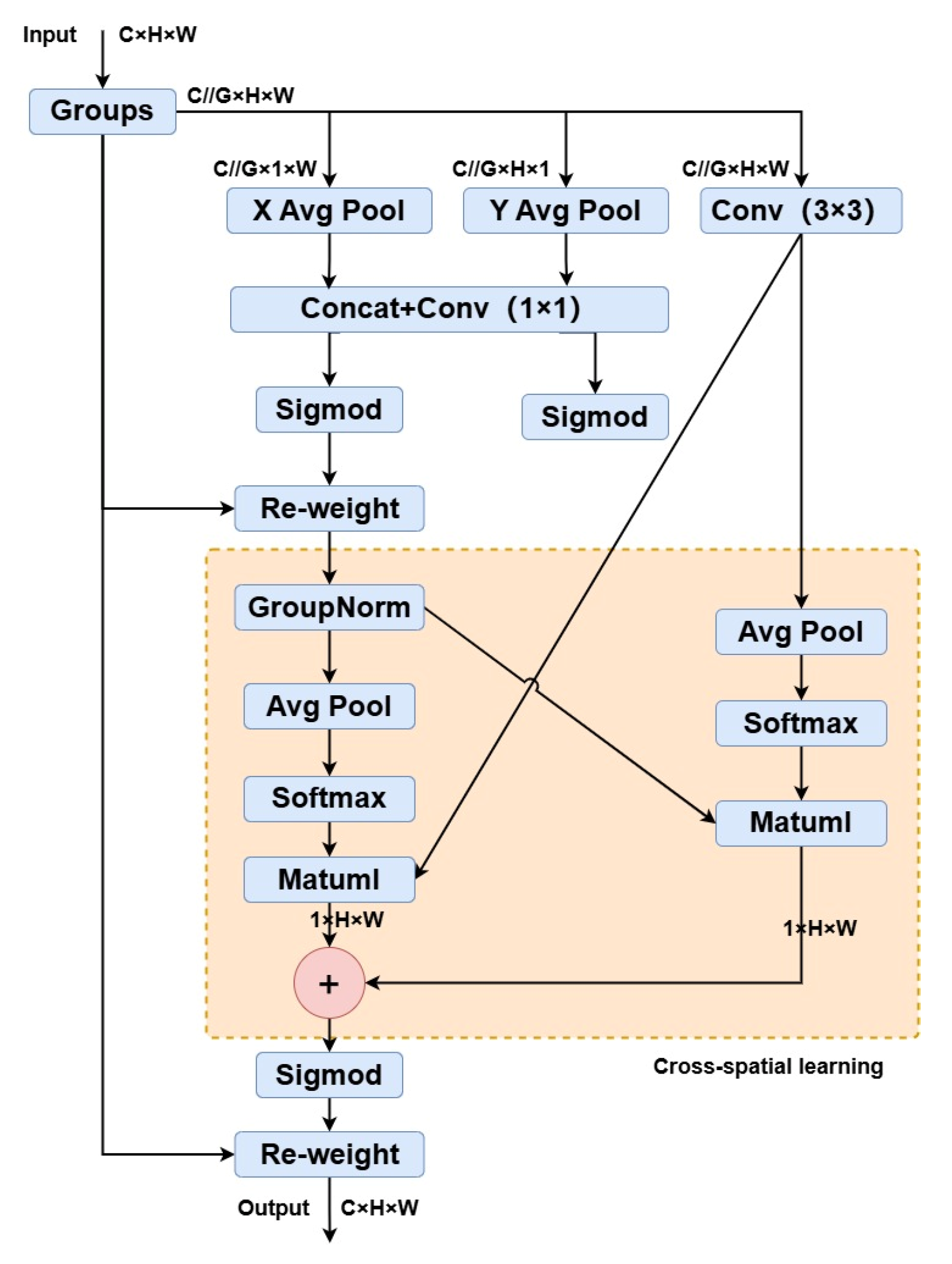
2.3.2. EMA Module
3. Experiments and Discussion
3.1. Environment and Configuration
3.2. Performance Evaluation of the Model
3.3. Data Augmentation Method Performance
3.4. Performance of Neck Structures
3.5. Performance of Attention Modules
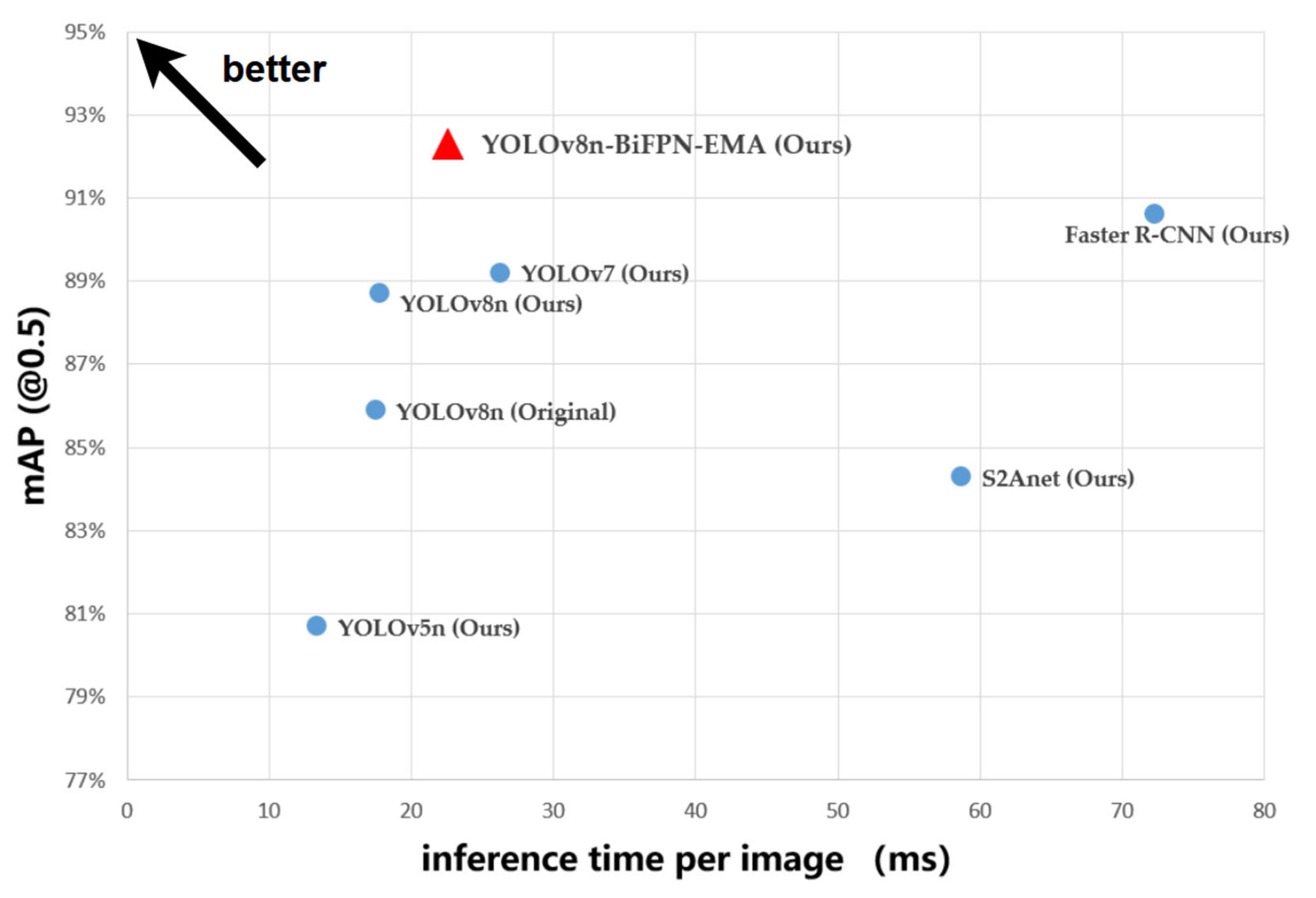
3.6. Overall Performance Evaluation
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lun, Y.H.V.; Lai, K.; Cheng, T.C.E. An Evaluation of Green Shipping Networks to Minimize External Cost in the Pearl River Delta Region. Technol. Forecast. Soc. Chang. 2013, 80, 320–328. [Google Scholar] [CrossRef]
- Li, S.; Haralambides, H.; Zeng, Q. Economic Forces Shaping the Evolution of Integrated Port Systems—The Case of the Container Port System of China’s Pearl River Delta. Res. Transp. Econ. 2022, 94, 101183. [Google Scholar] [CrossRef]
- Qu, J.; Liu, R.W.; Guo, Y.; Lu, Y.; Su, J.; Li, P. Improving Maritime Traffic Surveillance in Inland Waterways Using the Robust Fusion of AIS and Visual Data. Ocean Eng. 2023, 275, 114198. [Google Scholar] [CrossRef]
- Helgesen, H.H.; Leira, F.S.; Bryne, T.H.; Albrektsen, S.M.; Johansen, T.A. Real-Time Georeferencing of Thermal Images Using Small Fixed-Wing UAVs in Maritime Environments. ISPRS J. Photogramm. Remote Sens. 2019, 154, 84–97. [Google Scholar] [CrossRef]
- Liu, Y.; Yan, J.; Zhao, X. Deep Reinforcement Learning Based Latency Minimization for Mobile Edge Computing With Virtualization in Maritime UAV Communication Network. IEEE Trans. Veh. Technol. 2022, 71, 4225–4236. [Google Scholar] [CrossRef]
- Xiu, S.; Wen, Y.; Yuan, H.; Xiao, C.; Zhan, W.; Zou, X.; Zhou, C.; Shah, S.C. A Multi-Feature and Multi-Level Matching Algorithm Using Aerial Image and AIS for Vessel Identification. Sensors 2019, 19, 1317. [Google Scholar] [CrossRef] [PubMed]
- Gonçalves, L.; Damas, B. Automatic Detection of Rescue Targets in Maritime Search and Rescue Missions Using UAVs. In Proceedings of the 2022 International Conference on Unmanned Aircraft Systems (ICUAS), Dubrovnik, Croatia, 21–24 June 2022; pp. 1638–1643. [Google Scholar]
- Ojala, T.; Pietikainen, M.; Maenpaa, T. Multiresolution Gray-Scale and Rotation Invariant Texture Classification with Local Binary Patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Papageorgiou, C.P.; Oren, M.; Poggio, T. A General Framework for Object Detection. In Proceedings of the Sixth International Conference on Computer Vision (IEEE Cat. No.98CH36271), Bombay, India, 4–7 January 1998; pp. 555–562. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–26 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Shao, Y.; Yin, Y.; Du, S.; Xi, L. A Surface Connectivity Based Approach for Leakage Channel Prediction in Static Sealing Interface. J. Tribol. 2019, 141, 062201. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Wang, N.; Wang, Y.; Wei, Y.; Han, B.; Feng, Y. Marine Vessel Detection Dataset and Benchmark for Unmanned Surface Vehicles. Appl. Ocean Res. 2024, 142, 103835. [Google Scholar] [CrossRef]
- Jiang, Q.; Li, H. Silicon Energy Bulk Material Cargo Ship Detection and Tracking Method Combining YOLOv5 and DeepSort. Energy Rep. 2023, 9, 151–158. [Google Scholar] [CrossRef]
- Wang, Q.; Wang, J.; Wang, X.; Wu, L.; Feng, K.; Wang, G. A YOLOv7-Based Method for Ship Detection in Videos of Drones. J. Mar. Sci. Eng. 2024, 12, 1180. [Google Scholar] [CrossRef]
- Cheng, S. Deep Learning Based Efficient Ship Detection from Drone-Captured Images for Maritime Surveillance. Ocean Eng. 2023, 285, 115440. [Google Scholar] [CrossRef]
- Li, Y.; Yuan, H.; Wang, Y.; Zhang, B. Maritime Vessel Detection and Tracking under UAV Vision. In Proceedings of the 2022 International Conference on Artificial Intelligence and Computer Information Technology (AICIT), Yichang, China, 16–18 September 2022. [Google Scholar] [CrossRef]
- Cheng, J.; Wang, R.; Lin, A.; Jiang, D.; Wang, Y. A Feature Enhanced RetinaNet-Based for Instance-Level Ship Recognition. Eng. Appl. Artif. Intell. 2023, 126, 107133. [Google Scholar] [CrossRef]
- Zhao, C.; Liu, R.W.; Qu, J.; Gao, R. Deep Learning-Based Object Detection in Maritime Unmanned Aerial Vehicle Imagery: Review and Experimental Comparisons. Eng. Appl. Artif. Intell. 2024, 128, 107513. [Google Scholar] [CrossRef]
- Jiang, Y.; Zhu, X.; Wang, X.; Yang, S.; Li, W.; Wang, H.; Fu, P.; Luo, Z. R2CNN: Rotational Region CNN for Orientation Robust Scene Text Detection. arXiv 2017. [Google Scholar] [CrossRef]
- Xie, X.; Cheng, G.; Wang, J.; Yao, X.; Han, J. Oriented R-CNN for Object Detection. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 3500–3509. [Google Scholar]
- Yang, S.; Pei, Z.; Zhou, F.; Wang, G. Rotated Faster R-CNN for Oriented Object Detection in Aerial Images. In Proceedings of the 2020 3rd International Conference on Robot Systems and Applications, Chengdu, China, 14–16 June 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 35–39. [Google Scholar]
- Zhang, S.; Wang, X.; Li, P.; Wang, L.; Zhu, M.; Zhang, H.; Zeng, Z. An Improved YOLO Algorithm for Rotated Object Detection in Remote Sensing Images. In Proceedings of the 2021 IEEE 4th Advanced Information Management, Communicates, Electronic and Automation Control Conference (IMCEC), Chongqing, China, 18–20 June 2021; Volume 4, pp. 840–845. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. arXiv 2018. [Google Scholar] [CrossRef]
- Li, J.; Zhang, J.; Shao, Y.; Liu, F. SRE-YOLOv8: An Improved UAV Object Detection Model Utilizing Swin Transformer and RE-FPN. Sensors 2024, 24, 3918. [Google Scholar] [CrossRef] [PubMed]
- Elhamied, E.M.A.; Youssef, S.M.; Shenawy, M.E. Improved Model Integrating FPN with Refined IoU for Efficient Object Detection Algorithm in Remote Sensing Satellite Images. In Proceedings of the 2024 International Conference on Machine Intelligence and Smart Innovation (ICMISI), Alexandria, Egypt, 12–14 May 2024; pp. 244–250. [Google Scholar]
- Kaur, P.; Khehra, B.S.; Mavi, E.B.S. Data Augmentation for Object Detection: A Review. In Proceedings of the 2021 IEEE International Midwest Symposium on Circuits and Systems (MWSCAS), Lansing, MI, USA, 9–11 August 2021; pp. 537–543. [Google Scholar]
- Creswell, A.; White, T.; Dumoulin, V.; Arulkumaran, K.; Sengupta, B.; Bharath, A.A. Generative Adversarial Networks: An Overview. IEEE Signal Process. Mag. 2018, 35, 53–65. [Google Scholar] [CrossRef]
- Liu, R.; Liu, W.; Zheng, Z.; Wang, L.; Mao, L.; Qiu, Q.; Ling, G. Anomaly-GAN: A Data Augmentation Method for Train Surface Anomaly Detection. Expert Syst. Appl. 2023, 228, 120284. [Google Scholar] [CrossRef]
- Bird, J.J.; Barnes, C.M.; Manso, L.J.; Ekárt, A.; Faria, D.R. Fruit Quality and Defect Image Classification with Conditional GAN Data Augmentation. Sci. Hortic. 2022, 293, 110684. [Google Scholar] [CrossRef]
- Waheed, A.; Goyal, M.; Gupta, D.; Khanna, A.; Al-Turjman, F.; Pinheiro, P.R. CovidGAN: Data Augmentation Using Auxiliary Classifier GAN for Improved Covid-19 Detection. IEEE Access 2020, 8, 91916–91923. [Google Scholar] [CrossRef] [PubMed]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-Resolution Image Synthesis with Latent Diffusion Models. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 10674–10685. [Google Scholar]
- Ma, H.; Zheng, H. Text Semantics to Image Generation: A Method of Building Facades Design Base on Stable Diffusion Model. In The International Conference on Computational Design and Robotic Fabrication; Yan, C., Chai, H., Sun, T., Yuan, P.F., Eds.; Springer Nature: Singapore, 2024; pp. 24–34. [Google Scholar]
- Jeong, Y.; Ryoo, W.; Lee, S.; Seo, D.; Byeon, W.; Kim, S.; Kim, J. The Power of Sound (TPoS): Audio Reactive Video Generation with Stable Diffusion. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2–3 October 2023; pp. 7788–7798. [Google Scholar]
- Nguyen, L.X.; Sone Aung, P.; Le, H.Q.; Park, S.-B.; Hong, C.S. A New Chapter for Medical Image Generation: The Stable Diffusion Method. In Proceedings of the 2023 International Conference on Information Networking (ICOIN), Bangkok, Thailand, 11–14 January 2023; pp. 483–486. [Google Scholar]
- Liang, Y.; Feng, S.; Zhang, Y.; Xue, F.; Shen, F.; Guo, J. A Stable Diffusion Enhanced YOLOV5 Model for Metal Stamped Part Defect Detection Based on Improved Network Structure. J. Manuf. Process. 2024, 111, 21–31. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Munich, Germany, 5–9 October 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Yadav, G.; Maheshwari, S.; Agarwal, A. Contrast Limited Adaptive Histogram Equalization Based Enhancement for Real Time Video System. In Proceedings of the 2014 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Delhi, India, 24–27 September 2014; pp. 2392–2397. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 10778–10787. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate Attention for Efficient Mobile Network Design. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13708–13717. [Google Scholar]
- Ouyang, D.; He, S.; Zhang, G.; Luo, M.; Guo, H.; Zhan, J.; Huang, Z. Efficient Multi-Scale Attention Module with Cross-Spatial Learning. In Proceedings of the ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameters | Value |
|---|---|
| Learning Rate | 0.01 |
| Image Size | 640 × 640 |
| Epochs | 100 |
| Optimizer | SGD |
| Weight Decay | 0.0005 |
| Momentum | 0.937 |
| Method | Images | Bulk Carrier | Container Ship | Oil Tanker | Passenger Ship | Others |
|---|---|---|---|---|---|---|
| Original | 441 | 410 | 214 | 85 | 19 | 57 |
| Traditional | 4396 | 4077 | 2123 | 849 | 303 | 456 |
| Stable diffusion | 4649 | 3896 | 2448 | 1113 | 399 | 969 |
| Ours | 4649 | 3869 | 2448 | 1113 | 399 | 969 |
| Method | AP(@0.5) | mAP (@0.5) | mAP (@0.5:0.95) | ||||
|---|---|---|---|---|---|---|---|
| Bulk Carrier | Container Ship | Oil Tanker | Passenger Ship | Others | |||
| Original | 84.8% | 83.2% | 90.2% | 96.5% | 75.1% | 85.9% | 71.8% |
| Traditional | 85.3% | 86.2% | 94.7% | 94.4% | 78.2% | 87.8% | 74.3% |
| Stable diffusion | 81.1% | 84.6% | 98.8% | 93.8% | 78.4% | 87.3% | 73.6% |
| Ours | 84.4% | 83.7% | 99.5% | 94.7% | 81.1% | 88.7% | 75.0% |
| Model | mAP (@0.5) | mAP (@0.5:0.95) | Parameters (M) | FLOPs (B) | ms/img |
|---|---|---|---|---|---|
| YOLOv8n (Ours) | 88.7% | 75.0% | 3.1 | 8.4 | 17.8 |
| YOLOv8n- BiFPN (Ours) | 89.2% | 75.4% | 2.3 | 17.9 | 19.5 |
| Model | mAP (@0.5) | mAP (@0.5:0.95) | Parameters (M) | FLOPs (B) | ms/img |
|---|---|---|---|---|---|
| YOLOv8n- BiFPN (Ours) | 89.2% | 75.4% | 2.3 | 17.9 | 19.5 |
| +CA | 88.6% | 73.6% | 2.3 | 18.2 | 21.8 |
| +CBAM | 90.4% | 74.9% | 2.3 | 18.2 | 22.1 |
| +EMA | 92.3% | 77.5% | 2.3 | 18.3 | 22.6 |
| Model | mAP (@0.5) | mAP (@0.5:0.95) | Parameters (M) | FLOPs (B) | ms/img |
|---|---|---|---|---|---|
| YOLOv8n (Original) | 85.9% | 71.8% | 3.1 | 8.4 | 17.5 |
| YOLOv8n | 88.7% | 75.0% | 3.1 | 8.4 | 17.8 |
| (Ours) | |||||
| YOLOv8n-BiFPN | 92.3% | 77.5% | 2.3 | 18.3 | 22.6 |
| -EMA (Ours) | |||||
| Faster R-CNN | 90.6% | 74.3% | 41.8 | 207.8 | 72.3 |
| (Ours) | |||||
| S2ANet (Ours) | 84.3% | 69.2% | 34.2 | 160.1 | 58.7 |
| YOLOv5n (Ours) | 80.7% | 63.8% | 2.1 | 7.3 | 13.4 |
| YOLOv7 (Ours) | 89.2% | 74.6% | 37.4 | 105.4 | 26.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Feng, S.; Huang, Y.; Zhang, N. An Improved YOLOv8 OBB Model for Ship Detection through Stable Diffusion Data Augmentation. Sensors 2024, 24, 5850. https://doi.org/10.3390/s24175850
Feng S, Huang Y, Zhang N. An Improved YOLOv8 OBB Model for Ship Detection through Stable Diffusion Data Augmentation. Sensors. 2024; 24(17):5850. https://doi.org/10.3390/s24175850
Chicago/Turabian StyleFeng, Sang, Yi Huang, and Ning Zhang. 2024. "An Improved YOLOv8 OBB Model for Ship Detection through Stable Diffusion Data Augmentation" Sensors 24, no. 17: 5850. https://doi.org/10.3390/s24175850
APA StyleFeng, S., Huang, Y., & Zhang, N. (2024). An Improved YOLOv8 OBB Model for Ship Detection through Stable Diffusion Data Augmentation. Sensors, 24(17), 5850. https://doi.org/10.3390/s24175850