
AnyFace++: Deep Multi-Task, Multi-Domain Learning for Efficient Face AI


Abstract
1. Introduction
2. Related Works
3. Methodology
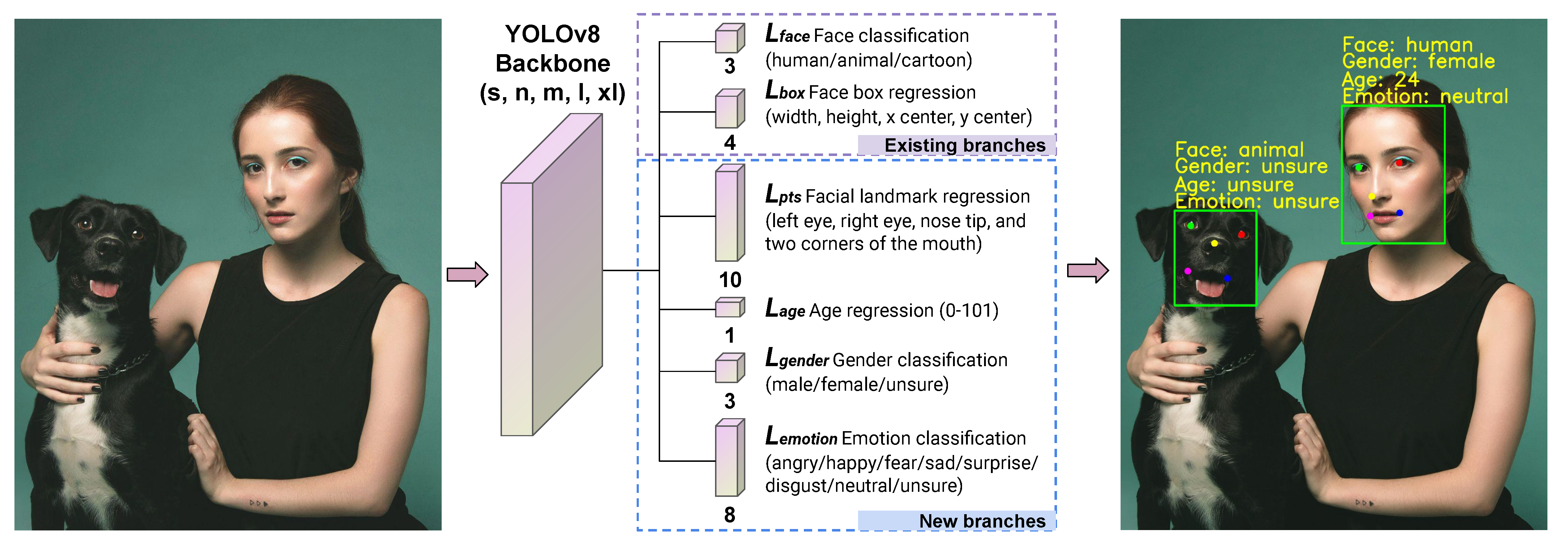
3.1. AnyFace++
3.2. Heterogeneous Loss Function
4. Experiments
4.1. Datasets
4.2. Training Details
5. Results and Discussion
5.1. Face Detection
5.2. Facial Landmark Detection
5.3. Emotion Classification
5.4. Gender Classification
5.5. Age Estimation
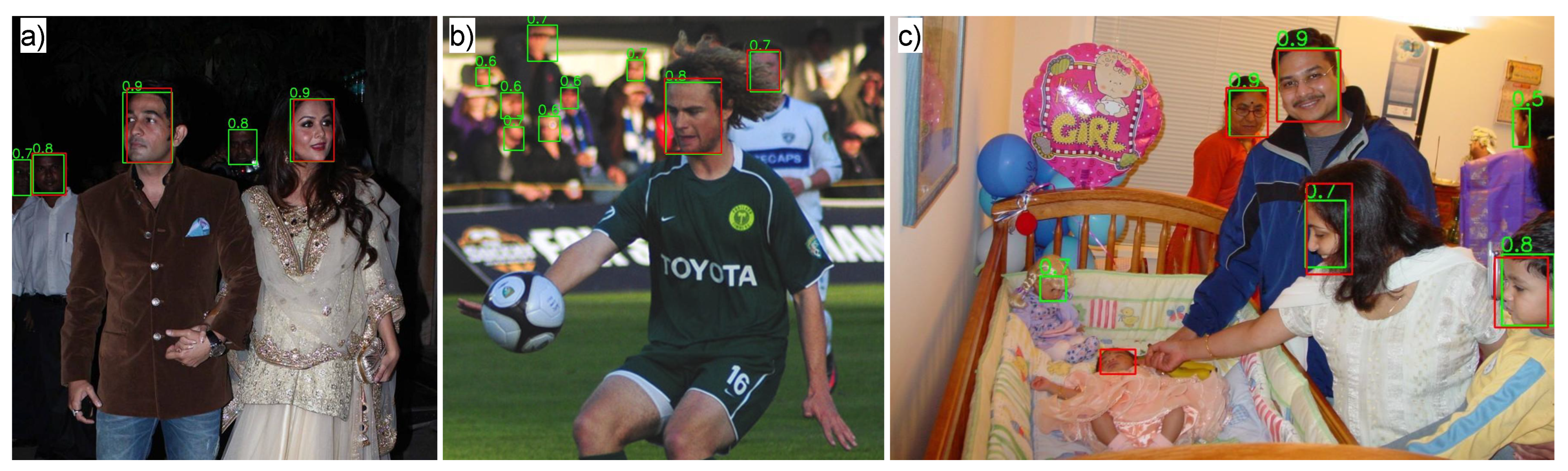
5.6. Qualitative Results
5.7. Environmental Impact
5.8. Limitations
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| GPUs | Graphics Processing Units |
| DL | Deep learning |
| SOTA | State-of-the-art |
| CNN | Convolutional neural network |
| DMTL | Deep multi-task learning |
| MTL | Multi-task learning |
| DFL | Distribution Focal Loss |
| CIoU | Complete Intersection over Union |
| MSE | Mean squared error |
| NME | Normalized Mean Error |
| MAE | Mean Absolute Error |
References
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaría, J.I.; Fadhel, M.A.; Al-Amidie, M.; Farhan, L. Review of deep learning: Concepts, CNN architectures, challenges, applications, future directions. J. Big Data 2021, 8, 1–74. [Google Scholar]
- Mehrish, A.; Majumder, N.; Bharadwaj, R.; Mihalcea, R.; Poria, S. A review of deep learning techniques for speech processing. Inf. Fusion 2023, 99, 101869. [Google Scholar] [CrossRef]
- Khurana, D.; Koli, A.; Khatter, K.; Singh, S. Natural language processing: State of the art, current trends and challenges. Multimed. Tools Appl. 2023, 82, 3713–3744. [Google Scholar] [CrossRef] [PubMed]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; van den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484–503. [Google Scholar] [CrossRef]
- Chen, L.; Li, S.; Bai, Q.; Yang, J.; Jiang, S.; Miao, Y. Review of Image Classification Algorithms Based on Convolutional Neural Networks. Remote Sens. 2021, 13, 4712. [Google Scholar] [CrossRef]
- Schwartz, R.; Dodge, J.; Smith, N.A.; Etzioni, O. Green AI. Commun. ACM 2020, 63, 54–63. [Google Scholar] [CrossRef]
- Sevilla, J.; Heim, L.; Ho, A.; Besiroglu, T.; Hobbhahn, M.; Villalobos, P. Compute Trends Across Three Eras of Machine Learning. In Proceedings of the International Joint Conference on Neural Networks (IJCNN), Padua, Italy, 18–23 July 2022; pp. 1–8. [Google Scholar] [CrossRef]
- Strubell, E.; Ganesh, A.; McCallum, A. Energy and Policy Considerations for Modern Deep Learning Research. In Proceedings of the Thirty-Fourth AAAI Conference on Artificial Intelligence (AAAI-20), New York, NY, USA, 7–12 February 2020; Volume 34, pp. 13693–13696. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.u.; Polosukhin, I. Attention is All you Need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates, Inc.: Red Hook, NY, USA, 2017; pp. 6000–6010. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. In Proceedings of the International Conference on Learning Representations, Vienna, Austria, 3–7 May 2021. [Google Scholar]
- Radford, A.; Kim, J.W.; Xu, T.; Brockman, G.; Mcleavey, C.; Sutskever, I. Robust Speech Recognition via Large-Scale Weak Supervision. In Proceedings of the International Conference on Machine Learning, San Diego, CA, USA, 23–29 July 2023; Krause, A., Brunskill, E., Cho, K., Engelhardt, B., Sabato, S., Scarlett, J., Eds.; Volume 202, pp. 28492–28518. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 6–12 December 2020; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2020; Volume 33, pp. 1877–1901. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Burstein, J., Doran, C., Solorio, T., Eds.; ACL: London, ON, USA, 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Faiz, A.; Kaneda, S.; Wang, R.; Osi, R.C.; Sharma, P.; Chen, F.; Jiang, L. LLMCarbon: Modeling the End-to-End Carbon Footprint of Large Language Models. In Proceedings of the International Conference on Learning Representations, Vienna, Austria, 22–26 April 2024. [Google Scholar]
- Strubell, E.; Ganesh, A.; McCallum, A. Energy and Policy Considerations for Deep Learning in NLP. In Proceedings of the Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28–30 July 2019; Korhonen, A., Traum, D., Màrquez, L., Eds.; ACL: London, ON, USA, 2019; pp. 3645–3650. [Google Scholar] [CrossRef]
- Han, H.; Siebert, J. TinyML: A Systematic Review and Synthesis of Existing Research. In Proceedings of the International Conference on Artificial Intelligence in Information and Communication (ICAIIC), Tokyo, Japan, 21–23 February 2022; pp. 269–274. [Google Scholar] [CrossRef]
- Banbury, C.R.; Reddi, V.J.; Lam, M.; Fu, W.; Fazel, A.; Holleman, J.; Huang, X.; Hurtado, R.; Kanter, D.; Lokhmotov, A.; et al. Benchmarking TinyML Systems: Challenges and Direction. arXiv 2021, arXiv:2003.04821. [Google Scholar]
- Li, Z.; Li, H.; Meng, L. Model Compression for Deep Neural Networks: A Survey. Computers 2023, 12, 60. [Google Scholar] [CrossRef]
- Caruana, R. Multitask Learning. Mach. Learn. 1997, 28, 41–75. [Google Scholar] [CrossRef]
- Dredze, M.; Kulesza, A.; Crammer, K. Multi-domain learning by confidence-weighted parameter combination. Mach. Learn. 2010, 79, 123–149. [Google Scholar] [CrossRef]
- Royer, A.; Blankevoort, T.; Bejnordi, B.E. Scalarization for Multi-Task and Multi-Domain Learning at Scale. In Proceedings of the Conference on Neural Information Processing Systems, New Orleans, LA, USA, 10–16 December 2023. [Google Scholar]
- He, R.; He, S.; Tang, K. Multi-Domain Active Learning: A Comparative Study. arXiv 2021, arXiv:2106.13516. [Google Scholar]
- Siddiqi, M.H.; Khan, K.; Khan, R.U.; Alsirhani, A. Face Image Analysis Using Machine Learning: A Survey on Recent Trends and Applications. Electronics 2022, 11, 1210. [Google Scholar] [CrossRef]
- Kumar, S.; Tiwari, S.; Singh, S.K. Face Recognition of Cattle: Can it be Done? Proc. Natl. Acad. Sci. India Sect. A Phys. Sci. 2016, 86, 137–148. [Google Scholar] [CrossRef]
- Nguyen, N.V.; Rigaud, C.; Burie, J.C. Comic Characters Detection Using Deep Learning. In Proceedings of the IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; pp. 41–46. [Google Scholar] [CrossRef]
- Qi, D.; Tan, W.; Yao, Q.; Liu, J. YOLO5Face: Why Reinventing a Face Detector. In Proceedings of the European Conference on Computer Vision (ECCV), Tel Aviv, Israel, 23–27 October 2022; Karlinsky, L., Michaeli, T., Nishino, K., Eds.; Springer: Cham, Switzerland, 2023; pp. 228–244. [Google Scholar]
- Zhang, K.; Zhang, Z.; Li, Z.; Qiao, Y. Joint Face Detection and Alignment Using Multitask Cascaded Convolutional Networks. IEEE Signal Process. Lett. 2016, 23, 1499–1503. [Google Scholar] [CrossRef]
- Deng, J.; Guo, J.; Ververas, E.; Kotsia, I.; Zafeiriou, S. RetinaFace: Single-Shot Multi-Level Face Localisation in the Wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 5202–5211. [Google Scholar] [CrossRef]
- Kuzdeuov, A.; Aubakirova, D.; Koishigarina, D.; Varol, H.A. TFW: Annotated Thermal Faces in the Wild Dataset. IEEE Trans. Inf. Forensics Secur. 2022, 17, 2084–2094. [Google Scholar] [CrossRef]
- Zhang, C.; Zhang, Z. Improving multiview face detection with multi-task deep convolutional neural networks. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Steamboat Springs, CO, USA, 24–26 March 2014; pp. 1036–1041. [Google Scholar] [CrossRef]
- Zhang, Z.; Luo, P.; Loy, C.C.; Tang, X. Facial Landmark Detection by Deep Multi-task Learning. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer: Cham, Switzerland, 2014; pp. 94–108. [Google Scholar]
- Xiang, J.; Zhu, G. Joint Face Detection and Facial Expression Recognition with MTCNN. In Proceedings of the International Conference on Information Science and Control Engineering (ICISCE), Beijing, China, 14–16 July 2017; pp. 424–427. [Google Scholar] [CrossRef]
- Xu, L.; Fan, H.; Xiang, J. Hierarchical Multi-Task Network For Race, Gender and Facial Attractiveness Recognition. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 3861–3865. [Google Scholar] [CrossRef]
- Liao, H.; Yuan, L.; Wu, M.; Zhong, L.; Jin, G.; Xiong, N. Face Gender and Age Classification Based on Multi-Task, Multi-Instance and Multi-Scale Learning. Appl. Sci. 2022, 12, 12432. [Google Scholar] [CrossRef]
- Sang, D.V.; Cuong, L.T.B. Effective Deep Multi-source Multi-task Learning Frameworks for Smile Detection, Emotion Recognition and Gender Classification. Informatica 2018, 42. [Google Scholar] [CrossRef]
- Savchenko, A.V. Facial expression and attributes recognition based on multi-task learning of lightweight neural networks. In Proceedings of the IEEE International Symposium on Intelligent Systems and Informatics (SISY), Novi Sad, Serbia, 9–10 September 2021; pp. 119–124. [Google Scholar] [CrossRef]
- Foggia, P.; Greco, A.; Saggese, A.; Vento, M. Multi-task learning on the edge for effective gender, age, ethnicity and emotion recognition. Eng. Appl. Artif. Intell. 2023, 118, 105651. [Google Scholar] [CrossRef]
- Lee, J.H.; Chan, Y.M.; Chen, T.Y.; Chen, C.S. Joint Estimation of Age and Gender from Unconstrained Face Images Using Lightweight Multi-Task CNN for Mobile Applications. In Proceedings of the IEEE Conference on Multimedia Information Processing and Retrieval (MIPR), Miami, FL, USA, 11–13 April 2018; pp. 162–165. [Google Scholar] [CrossRef]
- Xu, B.; Wang, W.; Guo, L.; Chen, G.; Wang, Y.; Zhang, W.; Li, Y. Evaluation of Deep Learning for Automatic Multi-View Face Detection in Cattle. Agriculture 2021, 11, 1062. [Google Scholar] [CrossRef]
- Song, S.; Liu, T.; Wang, H.; Hasi, B.; Yuan, C.; Gao, F.; Shi, H. Using Pruning-Based YOLOv3 Deep Learning Algorithm for Accurate Detection of Sheep Face. Animals 2022, 12, 1465. [Google Scholar] [CrossRef] [PubMed]
- Vidal, A.; Jha, S.; Hassler, S.; Price, T.; Busso, C. Face detection and grimace scale prediction of white furred mice. Mach. Learn. Appl. 2022, 8, 100312. [Google Scholar] [CrossRef]
- Mao, Y.; Liu, Y. Pet dog facial expression recognition based on convolutional neural network and improved whale optimization algorithm. Sci. Rep. 2023, 13, 3314. [Google Scholar] [CrossRef]
- Bremhorst, A.; Sutter, N.A.; Wurbel, H.; Mills, D.S.; Riemer, S. Differences in facial expressions during positive anticipation and frustration in dogs awaiting a reward. Sci. Rep. 2019, 9, 19312. [Google Scholar] [CrossRef]
- Feighelstein, M.; Shimshoni, I.; Finka, L.R.; Luna, S.P.L.; Mills, D.S.; Zamansky, A. Automated recognition of pain in cats. Sci. Rep. 2022, 12, 9575. [Google Scholar] [CrossRef] [PubMed]
- Khan, M.H.; McDonagh, J.; Khan, S.; Shahabuddin, M.; Arora, A.; Khan, F.S.; Shao, L.; Tzimiropoulos, G. AnimalWeb: A large-scale hierarchical dataset of annotated Animal Faces. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020. [Google Scholar] [CrossRef]
- Chu, W.T.; Li, W.W. Manga face detection based on deep neural networks fusing global and local information. Pattern Recognit. 2019, 86, 62–72. [Google Scholar] [CrossRef]
- Jha, S.; Agarwal, N.; Agarwal, S. Bringing Cartoons to Life: Towards Improved Cartoon Face Detection and Recognition Systems. arXiv 2018, arXiv:1804.01753. [Google Scholar]
- Qin, X.; Zhou, Y.; He, Z.; Wang, Y.; Tang, Z. A Faster R-CNN Based Method for Comic Characters Face Detection. In Proceedings of the IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; Volume 1, pp. 1074–1080. [Google Scholar] [CrossRef]
- Takayama, K.; Johan, H.; Nishita, T. Face Detection and Face Recognition of Cartoon Characters Using Feature Extraction. In Proceedings of the Image, Electronics and Visual Computing Workshop, Osaka, Japan, 28–30 November 2012; p. 5. [Google Scholar]
- Li, Y.; Lao, L.; Cui, Z.; Shan, S.; Yang, J. Graph Jigsaw Learning for Cartoon Face Recognition. IEEE Trans. Image Process. 2022, 31, 3961–3972. [Google Scholar] [CrossRef]
- Jain, N.; Gupta, V.; Shubham, S.; Madan, A.; Chaudhary, A.; Santosh, K.C. Understanding cartoon emotion using integrated deep neural network on large dataset. Neural Comput. Appl. 2021, 34, 21481–21501. [Google Scholar] [CrossRef]
- Cao, Q.; Zhang, W.; Zhu, Y. Deep learning-based classification of the polar emotions of “moe”-style cartoon pictures. Tsinghua Sci. Technol. 2021, 26, 275–286. [Google Scholar] [CrossRef]
- Kuzdeuov, A.; Koishigarina, D.; Varol, H.A. AnyFace: A Data-Centric Approach For Input-Agnostic Face Detection. In Proceedings of the IEEE International Conference on Big Data and Smart Computing (BigComp), Jeju, Republic of Korea, 13–16 February 2023; pp. 211–218. [Google Scholar] [CrossRef]
- Ultralytics. Available online: https://github.com/ultralytics/ultralytics (accessed on 10 September 2023).
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019. [Google Scholar]
- Li, X.; Wang, W.; Wu, L.; Chen, S.; Hu, X.; Li, J.; Tang, J.; Yang, J. Generalized Focal Loss: Learning Qualified and Distributed Bounding Boxes for Dense Object Detection. In Proceedings of the Advances in Neural Information Processing Systems, Virtual Event, 6–12 December 2020; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2020; Volume 33, pp. 21002–21012. [Google Scholar]
- Feng, Z.H.; Kittler, J.; Awais, M.; Huber, P.; Wu, X.J. Wing Loss for Robust Facial Landmark Localisation with Convolutional Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2235–2245. [Google Scholar] [CrossRef]
- Kuzdeuov, A.; Koishigarina, D.; Aubakirova, D.; Abushakimova, S.; Varol, H.A. SF-TL54: A Thermal Facial Landmark Dataset with Visual Pairs. In Proceedings of the IEEE/SICE International Symposium on System Integration (SII), Narvik, Norway, 9–12 January 2022; pp. 748–753. [Google Scholar] [CrossRef]
- Challenges in Representation Learning: Facial Expression Recognition Challenge. Available online: https://www.kaggle.com/c/challenges-in-representation-learning-facial-expression-recognition-challenge (accessed on 28 February 2023).
- Mollahosseini, A.; Hasani, B.; Mahoor, M.H. AffectNet: A database for facial expression, Valence, and arousal computing in the wild. IEEE Trans. Affect. Comput. 2019, 10, 18–31. [Google Scholar] [CrossRef]
- Rothe, R.; Timofte, R.; Gool, L.V. Deep expectation of real and apparent age from a single image without facial landmarks. Int. J. Comput. Vis. 2018, 126, 144–157. [Google Scholar] [CrossRef]
- Zhang, Z.; Song, Y.; Qi, H. Age Progression/Regression by Conditional Adversarial Autoencoder. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Eidinger, E.; Enbar, R.; Hassner, T. Age and gender estimation of unfiltered faces. IEEE Trans. Inf. Forensics Secur. 2014, 9, 2170–2179. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, L.; Li, C.; Loy, C.C. Quantifying facial age by posterior of age comparisons. In Proceedings of the British Machine Vision Conference, London, UK, 4–7 September 2017. [Google Scholar] [CrossRef]
- Niu, Z.; Zhou, M.; Wang, L.; Gao, X.; Hua, G. Ordinal regression with multiple output CNN FOR AGE estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar] [CrossRef]
- Moschoglou, S.; Papaioannou, A.; Sagonas, C.; Deng, J.; Kotsia, I.; Zafeiriou, S. AgeDB: The first manually collected, in-the-Wild Age Database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef]
- Karkkainen, K.; Joo, J. Fairface: Face attribute dataset for balanced race, gender, and age for bias measurement and mitigation. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), Virtual Conference, 5–9 January 2021. [Google Scholar] [CrossRef]
- Kong, C.; Luo, Q.; Chen, G. A Comparison Study: The Impact of Age and Gender Distribution on Age Estimation. In Proceedings of the ACM Multimedia Asia, MMAsia ’21, New York, NY, USA, 1–3 December 2021. [Google Scholar] [CrossRef]
- Lanitis, A.; Taylor, C.; Cootes, T. Toward automatic simulation of aging effects on face images. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 442–455. [Google Scholar] [CrossRef]
- Li, S.; Deng, W.; Du, J. Reliable Crowdsourcing and Deep Locality-Preserving Learning for Expression Recognition in the Wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2584–2593. [Google Scholar]
- Yang, S.; Luo, P.; Loy, C.C.; Tang, X. Wider face: A face detection benchmark. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar] [CrossRef]
- Zheng, Y.; Zhao, Y.; Ren, M.; Yan, H.; Lu, X.; Liu, J.; Li, J. Cartoon Face Recognition: A Benchmark Dataset. In Proceedings of the ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 2264–2272. [Google Scholar]
- Zheng, C.; Mendieta, M.; Chen, C. Poster: A Pyramid Cross-Fusion Transformer Network for facial expression recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Paris, France, 1–6 October 2023. [Google Scholar] [CrossRef]
- Rothe, R.; Timofte, R.; Gool, L.V. DEX: Deep EXpectation of apparent age from a single image. In Proceedings of the IEEE International Conference on Computer Vision Workshops (ICCVW), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Lin, Y.; Shen, J.; Wang, Y.; Pantic, M. FP-Age: Leveraging Face Parsing Attention for Facial Age Estimation in the Wild. arXiv 2021, arXiv:2106.11145. [Google Scholar] [CrossRef]
- Kuprashevich, M.; Tolstykh, I. MiVOLO: Multi-input Transformer for Age and Gender Estimation. arXiv 2023, arXiv:2307.04616. [Google Scholar]
- Zhang, B.; Li, J.; Wang, Y.; Cui, Z.; Xia, Y.; Wang, C.; Li, J.; Huang, F. ACFD: Asymmetric Cartoon Face Detector. arXiv 2020, arXiv:2007.00899. [Google Scholar]
- Ju Mao, J.; Xu, R.; Yin, X.; Chang, Y.; Nie, B.; Huang, A. POSTER V2: A simpler and stronger facial expression recognition network. arXiv 2023, arXiv:2301.12149. [Google Scholar]
- Fan, Y.; Lam, J.C.; Li, V.O. Multi-region ensemble Convolutional Neural Network for facial expression recognition. In Proceedings of the Artificial Neural Networks and Machine Learning—ICANN 2018: 27th International Conference on Artificial Neural Networks, Rhodes, Greece, 4–7 October 2018; pp. 84–94. [Google Scholar] [CrossRef]
- Ramachandran, S.; Rattani, A. Deep generative views to mitigate gender classification bias across gender-race groups. In Proceedings of the International Conference on Pattern Recognition (ICPR), Montreal, QC, Canada, 21–25 August 2022; pp. 551–569. [Google Scholar] [CrossRef]
- Levi, G.; Hassncer, T. Age and gender classification using Convolutional Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Boston, MA, USA, 7–12 June 2015. [Google Scholar] [CrossRef]
- Hung, S.C.; Lee, J.H.; Wan, T.S.; Chen, C.H.; Chan, Y.M.; Chen, C.S. Increasingly Packing Multiple Facial-Informatics Modules in A Unified Deep-Learning Model via Lifelong Learning. In Proceedings of the International Conference on Multimedia Retrieval, Ottawa, ON, Canada, 10–13 June 2019; pp. 339–343. [Google Scholar]
- Hung, C.Y.; Tu, C.H.; Wu, C.E.; Chen, C.H.; Chan, Y.M.; Chen, C.S. Compacting, Picking and Growing for Unforgetting Continual Learning. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 13647–13657. [Google Scholar]
- Cao, W.; Mirjalili, V.; Raschka, S. Rank consistent ordinal regression for neural networks with application to age estimation. Pattern Recognit. Lett. 2020, 140, 325–331. [Google Scholar] [CrossRef]
- Berg, A.; Oskarsson, M.; O’Connor, M. Deep ordinal regression with label diversity. In Proceedings of the International Conference on Pattern Recognition (ICPR), Virtual Conference, 10–15 January 2021; pp. 2740–2747. [Google Scholar]
- Shin, N.H.; Lee, S.H.; Kim, C.S. Moving Window Regression: A Novel Approach to Ordinal Regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–24 June 2022; pp. 18760–18769. [Google Scholar]
- Lacoste, A.; Luccioni, A.; Schmidt, V.; Dandres, T. Quantifying the Carbon Emissions of Machine Learning. arXiv 2019, arXiv:1910.09700. [Google Scholar]
- Sea Turtle Face Detection. Available online: https://www.kaggle.com/datasets/smaranjitghose/sea-turtle-face-detection (accessed on 9 September 2024).
- Wardle, S.G.; Taubert, J.; Teichmann, L.; Baker, C.I. Rapid and dynamic processing of face pareidolia in the human brain. Nat. Commun. 2020, 11, 4518. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Domain | Images | Labels | Modality | Resolution | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| FER [63] | Human | 35,887 | 35,887 | Grayscale | 48 × 48 | − | + | − | − | |
| AffectNet [64] | Human | 287,401 | 287,401 | RGB | 224 × 224 | + | + | − | − | |
| IMDB [65] | Human | 285,949 | 285,949 | RGB | various | + | − | − | + | + |
| UTKFace [66] | Human | 23,708 | 23,708 | RGB | 200 × 200 | + | − | + | + | |
| Adience [67] | Human | 13,023 | 13,023 | RGB | various | + | − | − | + | + |
| MegaAge [68] | Human | 41,941 | 41,941 | RGB | 178 × 218 | − | − | − | + | |
| MegaAge-Asian [68] | Human | 43,945 | 43,945 | RGB | 178 × 219 | − | − | − | + | |
| AFAD [69] | Human | 59,344 | 59,344 | RGB | various | − | − | + | + | |
| AgeDB [70] | Human | 16,488 | 16,488 | RGB | various | − | − | + | + | |
| FairFace [71] | Human | 108,501 | 108,501 | RGB | 224 × 224 | − | − | + | + | |
| UAGD [72] | Human | 11,852 | 11,852 | RGB | various | + | − | − | + | + |
| FG-NET [73] | Human | 1002 | 1002 | RGB | various | + | + | − | − | + |
| RAF-DB [74] | Human | 15,339 | 15,339 | RGB | various | + | + | + | + | + |
| Wider Face [75] | Human | 32,203 | 393,703 | RGB | various | + | + | − | − | − |
| TFW [31] | Human | 9982 | 16,509 | Thermal | 464 × 348 | + | + | − | + | + |
| iCartoonFace [76] | Cartoon | 60,000 | 109,810 | RGB | various | + | − | − | − | − |
| AnimalWeb [47] | Animal | 19,078 | 22,451 | RGB | various | + | + | − | − | − |
| Method | Validation Set | Test Set | Domain | Params (M) | GFLOPs | ||||
|---|---|---|---|---|---|---|---|---|---|
| Easy | Medium | Hard | Easy | Medium | Hard | ||||
| RetinaFace [30] | 96.9 | 96.1 | 91.8 | 96.3 | 95.6 | 91.4 | H | 29.5 | 37.6 |
| YOLO5Face [28] | 96.9 | 96.0 | 91.6 | 94.9 | 94.3 | 90.1 | H | 141.1 | 88.6 |
| AnyFace [55] | 96.7 | 95.9 | 91.8 | 95.2 | 94.7 | 90.5 | H-A-C | 76.7 | 45.3 |
| AnyFace++ (This Work) | 92.9 | 91.2 | 83.8 | 91.6 | 90.1 | 82.9 | H-A-C | 26.6 | 163.9 |
| Method | Dataset | AP50 | Domain |
|---|---|---|---|
| AnyFace [55] | AnimalWeb | 93.6 | H-A-C |
| AnyFace++ (This Work) | AnimalWeb | 93.9 | H-A-C |
| ACFD [81] | iCartoonFace | 90.9 | C |
| RetinaFace [76] | iCartoonFace | 91.0 | C |
| AnyFace [55] | iCartoonFace | 91.7 | H-A-C |
| AnyFace++ (This Work) | iCartoonFace | 90.8 | H-A-C |
| TFW [31] | TFW (outdoor) | 97.3 | H |
| AnyFace [55] | TFW (outdoor) | 99.5 | H-A-C |
| AnyFace++ (This Work) | TFW (outdoor) | 99.3 | H-A-C |
| TFW [31] | TFW (indoor) | 100.0 | H |
| AnyFace [55] | TFW (indoor) | 100.0 | H-A-C |
| AnyFace++ (This Work) | TFW (indoor) | 100.0 | H-A-C |
| Method | Dataset | Neutral | Happy | Sad | Surprise | Fear | Disgust | Anger | Overall |
|---|---|---|---|---|---|---|---|---|---|
| AlexNet + Weighted-Loss [64] | AffectNet | 53.3 | 72.8 | 61.7 | 69.9 | 70.4 | 68.6 | 65.8 | 66.0 |
| POSTER [77] | AffectNet | 67.2 | 89.0 | 67.0 | 64.0 | 64.8 | 56.0 | 62.6 | 67.2 |
| POSTER++ [82] | AffectNet | 65.4 | 89.4 | 68.0 | 66.0 | 64.2 | 54.4 | 65.0 | 67.5 |
| AnyFace++ (This Work) | AffectNet | 81.0 | 92.0 | 61.6 | 52.5 | 43.0 | 32.9 | 65.4 | 61.0 |
| MRE-CNN (VGG-16) [83] | RAF-DB | 80.2 | 88.8 | 79.9 | 86.0 | 60.8 | 57.5 | 83.9 | 76.7 |
| POSTER [77] | RAF-DB | 92.4 | 96.9 | 91.2 | 90.3 | 67.6 | 75.0 | 88.9 | 86.0 |
| POSTER++ [82] | RAF-DB | 92.1 | 97.2 | 92.9 | 90.6 | 68.9 | 71.9 | 88.3 | 86.0 |
| AnyFace++ (This Work) | RAF-DB | 92.0 | 94.0 | 83.2 | 83.0 | 45.9 | 42.0 | 71.8 | 85.0 |
| Method | Dataset | Acc (%) |
|---|---|---|
| CLIP + LP [84] | UTKFace | 96.6 |
| AnyFace++ (This Work) | UTKFace | 95.4 |
| Hassner et al. [85] | Adience | 86.8 |
| PAENet [86] | Adience | 89.1 |
| CPG [87] | Adience | 89.7 |
| AnyFace++ (This Work) | Adience | 94.5 |
| ResNet-34 [71] | FairFace | 94.4 |
| AnyFace++ (This Work) | FairFace | 93.0 |
| Method | Dataset | MAE (Age) |
|---|---|---|
| DEX [70] | AgeDB | 13.10 |
| MiVOLO-D1 [80] | AgeDB | 5.55 |
| AnyFace++ (This Work) | AgeDB | 5.85 |
| CORAL-CNN [88] | AFAD | 3.48 |
| AnyFace++ (This Work) | AFAD | 3.10 |
| CORAL-CNN [88] | UTKFace | 5.39 |
| Randomized Bins [89] | UTKFace | 4.55 |
| MWR [90] | UTKFace | 4.37 |
| AnyFace++ (This Work) | UTKFace | 5.17 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rakhimzhanova, T.; Kuzdeuov, A.; Varol, H.A. AnyFace++: Deep Multi-Task, Multi-Domain Learning for Efficient Face AI. Sensors 2024, 24, 5993. https://doi.org/10.3390/s24185993
Rakhimzhanova T, Kuzdeuov A, Varol HA. AnyFace++: Deep Multi-Task, Multi-Domain Learning for Efficient Face AI. Sensors. 2024; 24(18):5993. https://doi.org/10.3390/s24185993
Chicago/Turabian StyleRakhimzhanova, Tomiris, Askat Kuzdeuov, and Huseyin Atakan Varol. 2024. "AnyFace++: Deep Multi-Task, Multi-Domain Learning for Efficient Face AI" Sensors 24, no. 18: 5993. https://doi.org/10.3390/s24185993
APA StyleRakhimzhanova, T., Kuzdeuov, A., & Varol, H. A. (2024). AnyFace++: Deep Multi-Task, Multi-Domain Learning for Efficient Face AI. Sensors, 24(18), 5993. https://doi.org/10.3390/s24185993