Abstract
Developments in drones and imaging hardware technology have opened up countless possibilities for enhancing structural condition assessments and visual inspections. However, processing the inspection images requires considerable work hours, leading to delays in the assessment process. This study presents a semantic segmentation architecture that integrates vision transformers with Laplacian pyramid scaling networks, enabling rapid and accurate pixel-level damage detection. Unlike conventional methods that often lose critical details through resampling or cropping high-resolution images, our approach preserves essential inspection-related information such as microcracks and edges using non-uniform image rescaling networks. This innovation allows for detailed damage identification of high-resolution images while significantly reducing the computational demands. Our main contributions in this study are: (1) proposing two rescaling networks that together allow for processing high-resolution images while significantly reducing the computational demands; and (2) proposing Dmg2Former, a low-resolution segmentation network with a Swin Transformer backbone that leverages the saved computational resources to produce detailed visual inspection masks. We validate our method through a series of experiments on publicly available visual inspection datasets, addressing various tasks such as crack detection and material identification. Finally, we examine the computational efficiency of the adaptive rescalers in terms of multiply–accumulate operations and GPU-memory requirements.
1. Introduction
The aging United States infrastructure requires substantial financial investments for repairs or replacement. With 42% of all bridges being at least 50 years old [], an investment backlog of $132 billion is estimated for the rehabilitation of existing bridges []. A similar trend is observed for U.S. dams and waterway structures, with the cost of rehabilitation of the non-federally owned dams rising to $157.5 billion in 2023 []. It is evident that the choice of structural condition assessment strategies can influence the safety and economic growth of communities, as they directly impact the functionality of the constantly deteriorating infrastructure as well as the recovery process of urban areas following a natural hazard.
Traditionally, condition assessments are performed through field inspections with a preliminary visual evaluation and further non-destructive evaluation tests. Significant work hours and logistics are often utilized during this process, making it expensive, time-consuming, and unsafe for inspectors in many situations. In an effort to improve the efficiency and reliability of structural inspections, a noteworthy amount of research has been conducted to streamline the visual inspection process.
Vision-based structural health monitoring (SHM) and automated visual inspections rely on visual footage of the structure to identify structural materials and components or detect surface damage (e.g., cracks, spalling, and rust). By benefiting from extensive research in computer vision technology, vision-based systems can process massive amounts of inspection images, such as those collected from a large urban area hit by a catastrophic event. Therefore, vision-based SHM can significantly cut down the time needed for condition assessments. Traditional crack and spalling detection methods employ morphological operations, edge detection algorithms, binarization, and other image processing techniques [,]. More recently, machine-learning algorithms have been the preferred option for analyzing inspection images [].
Recent advancements in deep learning, coupled with improvements in computing and sensing technologies, have noticeably accelerated SHM research []. Wireless accelerometers have seen improvements in accuracy, efficiency, and cost, allowing the deployment of advanced SHM systems leveraging large sensor arrays [,]. In turn, numerous methodologies were proposed in recent years that leverage machine-learning methods to identify structural damage based on vibration measurements [,,]. Advances in strain sensing, especially radio frequency identification (RFID)-based wireless sensors, also allow for remote monitoring of structural components’ deformation as part of condition assessment frameworks []. RFID sensors have been used for crack width measurements [], concrete moisture monitoring [], and long-distance structural health monitoring [].
Sensing technology breakthroughs are also notable in vision-based SHM. Pipeline closed circuit television video (CCTV) inspections are increasingly being used to remotely identify pipe degradation and distress [,,]. The cost and efficiency of camera-equipped unmanned aerial vehicles (UAVs) have led to the wide adoption of their use in structural visual inspections [,]. Underwater robots [], infrared cameras [], LiDAR [], and depth sensors [] have also been adopted for performing visual inspections. The variety of visual-sensing technologies allows the fast collection of vast amounts of high-fidelity visual data with minimal risk to the safety of inspection personnel. However, manually inspecting thousands of collected images for structural defects is a time-consuming process. Therefore, developing machine-learning frameworks to precisely and efficiently parse inspection images is of paramount importance.
Multiple studies have focused on detecting building components and materials that can be used to facilitate the inspection process or for UAV motion planning. Examples of methods proposed include object detection [,] and semantic segmentation [,]. The bulk of automated visual inspection research focused on detecting various types of structural damage. For concrete cracks, some methods predicted crack regions using multi-stage or single-stage object detection networks, such as YOLOv2 [] or YOLOv8 []. Other methods relied on deep-learning semantic segmentation models to create crack maps including U-Net [], DenseNet [], stacked convolutional autoencoders [], and deep CNNs [,,]. Xu et al. [] proposed a lightweight crack segmentation model using DeepLabV3+ with a MobileNetV2 backbone. Choi et al. [] combined a CNN-based image classifier and clustering to identify the percentage of crack areas in thermal images. Sohaib et al. [] used an ensemble of YOLOv8 networks with various sizes to detect and segment concrete cracks. Yang et al. [] used K-Net to detect structural surface defects from UAV-acquired images and a texture-mapping method to map the defects to a BIM model. The attention mechanism has also been widely used in recent years in crack segmentation models. Hang et al. [] relied on feature compression and channel attention modules to improve crack segmentation performance. Yu et al. [] proposed a U-Net-like architecture with attention-based skip connections for the crack segmentation of a nuclear containment structure. Other examples of damage identification include rail surface defects [], building façades [], fatigue cracks, spalling, and corrosion [,,].
Super-resolution architectures have also been used in crack detection. Bae et al. proposed SrcNet for crack detection based on UAV images, which initially generates a super-resolution version of the image before processing it through a segmentation model []. Similarly, Xiang et al. used a super-resolution reconstruction network to refine fuzzy UAV images before performing crack segmentation []. Kim et al. proposed using SRGAN for enhancing input images to predict refined concrete crack masks [].
As is evident from the recent literature, using off-the-shelf deep-learning algorithms for developing vision-based SHM is a common approach. However, given their critical nature, structural inspections demand high precision and accuracy. Even though many visual data acquisition devices can capture high-resolution images, limited resources often dictate significant downsizing of images to allow the use of state-of-the-art deep-learning models. This is especially necessary for vision transformers (ViT), which are becoming increasingly expensive in terms of computational demands. Additionally, many visual inspection tasks, such as UAV motion planning, require efficient models capable of real-time inference. Recently, two models were proposed to analyze high-resolution inspection images based on two strategies, each suited to different visual inspection tasks []. Despite these efforts, no single model fully met the diverse requirements of various visual inspection tasks, and there were limited attempts to address these challenges.
In this study, we develop a unified framework for high-resolution visual inspection that can strike a balance between prediction quality and computational efficiency. Uniform downsizing of images, commonly performed when resources are limited, can distort the original image and cause a loss of fine details. We propose Dmg2Former with adaptive rescaling (Dmg2Former-AR), a transformer-based segmentation model paired with cascaded sub-pixel convolution rescaling networks for analyzing visual inspection images. Dmg2Former-AR brings the ViT technology into the field of vision-based SHM with minimal increase in computational costs. Our main contributions in this study are (1) proposing two rescaling networks that together allow for processing high-resolution images while significantly reducing the computational demands; and (2) proposing Dmg2Former, a low-resolution segmentation network with a Swin Transformer backbone that leverages saved computational resources to produce detailed visual inspection masks. We evaluate our proposed model for two tasks: materials segmentation and crack damage segmentation.
The remainder of this paper is organized as follows. The following section describes the Dmg2Former and the adaptive downscaler and upscaler architectures. Following this discussion, we dedicate a section to describing the two case studies and detailing the implementation of our models. Then, we present the results of the evaluation metrics used in testing. Finally, we provide a summary, conclusions, and future research directions for this study.
2. Architecture Design
Using off-the-shelf deep-learning models for the segmentation of high-resolution images can be significantly inefficient and is often constrained by GPU-memory limitations. There are two common strategies to deal with high-resolution images for semantic segmentation. The first is downscaling the input image using interpolation-based resampling techniques to reduce the computational overhead during inference and training (Figure 1a). If needed, a high-resolution mask can also be obtained via nearest-neighbor or interpolation-based resampling. This method, however, suffers from loss or distortion in fine details, which may be acceptable in some computer vision applications, but it can drastically jeopardize the visual inspection process as details such as thin cracks and edges can hold valuable information.
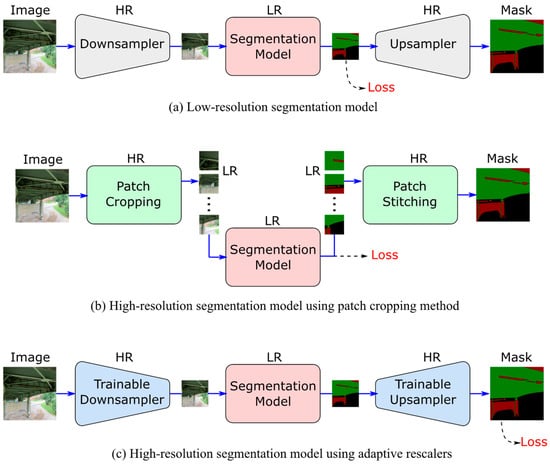
Figure 1.
High-resolution segmentation approaches (HR: high resolution; LR: low resolution).
The second method, which is more common for vision-based civil engineering applications, is cropping the image into smaller-sized patches to be fed to the deep-learning model (Figure 1b). The predicted mask patches are used to stitch the full-resolution image back together. While the local details remain primarily intact during cropping, the global contextual information of the image can be lost in the process. It is also worth mentioning that while this procedure makes the computational burden significantly smaller than if we used the full-resolution image as-is, it remains more computationally expensive than resampling the image because the model must make multiple forward passes to fully construct the mask.
We strive to deliver high-resolution segmentation of visual inspection images while upholding the efficiency of low-resolution segmentation models and adhering to the GPU memory constraints. To this end, we propose two neural networks that can adaptively and efficiently downscale the images and upscale the masks while preserving the fine details necessary for the visual inspection procedure (Figure 1c).
The overall framework of Dmg2Former-AR is shown in Figure 2. The architecture consists of three main modules: a downsampling encoder, an inner segmentation model, and an upsampling decoder. When fed with an HR image, the downsampling decoder adaptively produces an LR version of the image, which preserves the essential information in the limited number of pixels of the LR image at the expense of less-valued details. Then, the transformer-based segmentation model efficiently predicts an LR mask given the LR image input at significantly lower computational costs. Finally, the upsampling decoder upscales the LR mask and brings it as close as possible to the true HR mask.
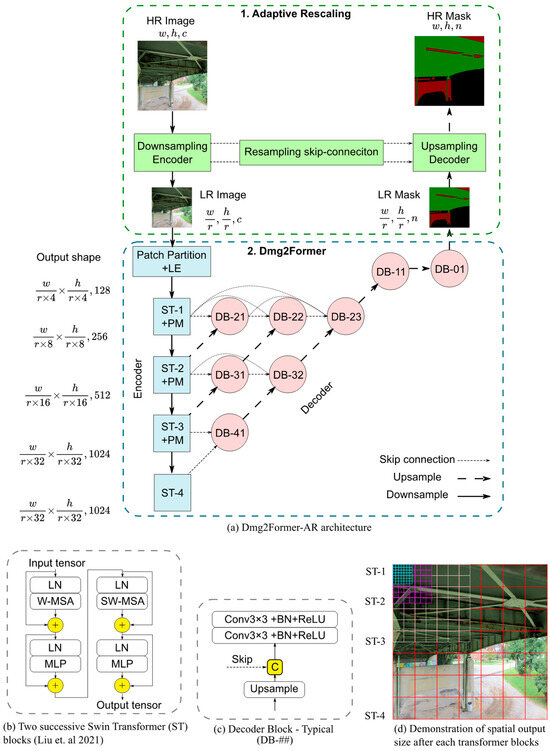
Figure 2.
Dmg2Former-AR architecture. (c: channels, n: classes, ST-i: Swin Transformer block, D-ij: decoder block, Conv: 2D convolution, BN: batch normalization, ReLU: rectified linear unit, LN: layer normalization, MLP: multi-layer perceptron, SW/W-MSA: regular and shifted windowed multi-head self-attention, LE: linear embedding, PM: patch merging []).
2.1. Adaptive Rescaling
When compressing visual inspection images, it is understood that certain pixels hold more significance than others. Consequently, adaptive resamplers are designed to learn how to sample valuable pixels more frequently during the sampling process, addressing the limitations of uniform sampling. They are adaptive in that, unlike uniform resamplers, they adjust the downsampling or upsampling grids according to the contents of the input image or mask. With this in mind, the downsampling encoder and upsampling decoder take inspiration from advances made in real-time image super-resolution models, including the efficient sub-pixel convolution network [], residual super-resolution networks [,,], and deep Laplacian pyramid networks [,].
The downsampling encoder and upsampling decoder are called Laplacian Subpixel Convolutional Network (LapSCN) and Laplacian Desubpixel Convolutional Network (LapDCN), respectively (Figure 3). These networks can progressively rescale images or masks based on a cascade of subpixel convolutional modules. LapSCN has a mask reconstruction stream comprising a set of feature extraction modules with residual learning, while LapDCN has an image deconstruction stream accompanied by its own feature extraction modules. At each stage, the feature extraction modules process the input data to predict lower- or upper-scale residuals. These residuals are then added to the resized data in the deconstruction or reconstruction stream, refining the output. The output of these streams can be used as the final resized output or can undergo further scaling by re-entering the feature extraction modules.
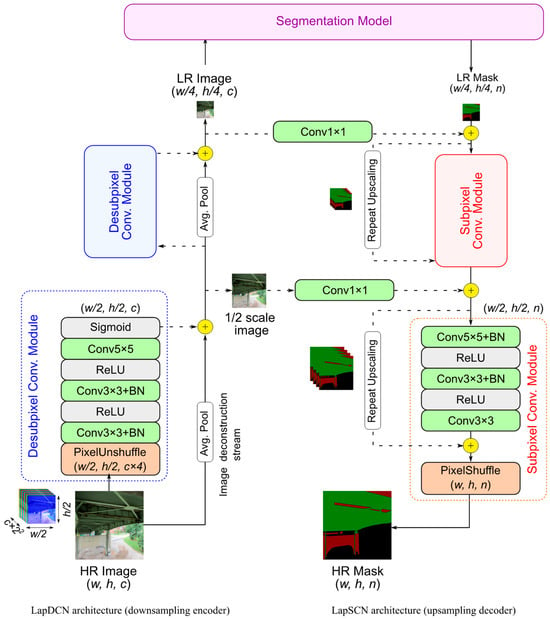
Figure 3.
Downsampling and upsampling network architectures. (c: channels, n: classes, Conv: 2D convolution, BN: batch normalization, ReLU: rectified linear unit).
Each feature extraction module in LapSCN is a subpixel convolutional module that predicts residuals for masks upscaled by a factor of two (right side of Figure 3). The module consists of three convolutional blocks, which include a convolutional layer (CN), batch normalization (BN) [], and rectified linear unit activation (ReLU), followed by a pixel shuffler operation. The pixel shuffle layer [] aggregates the low-resolution (w/2, h/2, n × 4) feature maps to form twice-upscaled masks (w, h, n), where n represents the number of classes (Figure 4). Pixel shuffle was shown to improve the performance of super-resolution networks compared to other upsampling convolution layers. It is highly efficient, reduces checkerboard artifacts, and allows the network to directly predict the high-resolution pixels without intermediate upsampling steps [].
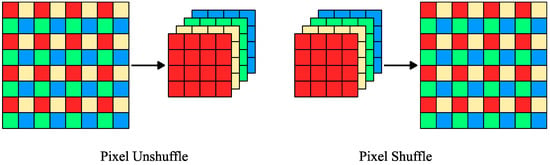
Figure 4.
Pixel Shuffle and Pixel Unshuffle operations.
The reconstruction stream is a global skip connection that helps stabilize the network training and facilitates convergence. In the deep Laplacian pyramid super-resolution network [], the bicubic interpolation was used to upscale the images to the target resolution in the reconstruction branch before adding the residuals. Instead, we use repeat upscaling, which is found to be significantly faster than interpolation upsampling methods [,]. Repeat upscaling is a special case of nearest neighbor interpolation. It repeats the low-resolution feature map along the channel dimension and is added to the residuals before the pixel shuffle operation. While conceptually, pixel shuffle of mask repeats should produce the same result as a nearest neighbor upscaling operation, experiments have shown that it is computationally cheaper to perform [,].
On the other side, LapDCN has desubpixel convolutional modules that start with downscaling the input image using a pixel unshuffle operation, a reverse of the pixel shuffle operation, followed by three convolutional blocks, that ends with a sigmoid activation (left side of Figure 3). By rearranging the pixels along the channels’ axis, the pixel unshuffle layer significantly reduces the computational cost without loss of information (Figure 4). Pixel unshuffle transforms a high-resolution image (w, h, c) to a twice-downscaled version (w/2, h/2, c × 4) with four times more channels. At the first convolutional layer, the computational savings obtained from downscaling the image are offset by the expenses due to the expansion of channels. However, substantial net computational savings are achieved in the subsequent convolutional operations as a result of the downscaling operation. Finally, the input image is downsized in the image deconstruction stream using adaptive average pooling before adding the residuals from the feature extraction module. Details regarding the filters of the convolutional layers of the feature extraction modules of both LapDCN and LapSCN are presented in Table 1.

Table 1.
DCN and UCN specification.
2.2. Dmg2Former
The internal segmentation model, Dmg2Former, uses a Swin Transformer backbone []. Originally used in natural language processing [], transformers have seen success in several computer vision tasks and have since achieved state-of-the-art results on well-known benchmarks, including ImageNet and ADE20k [,,]. The Swin Transformer introduced a multi-stage approach for vision transformers. It relies on patch merging operations to provide hierarchical feature maps, offering the possibility of using it as a backbone for well-established segmentation decoders. With a few adjustments, we used a Swin Transformer Base (Swin-B) model. Our decoder is inspired by U-Net++ [], a U-Net variant explicitly developed for medical imaging segmentation. Compared to U-Net, U-Net++ adds complex, dense convolutional blocks to the skip connections to bridge the semantic gap between the encoder and decoder. We modified the U-Net++ architecture implemented by Iakubovskii, P. [] to be compatible with the Swin Transformer encoder, making it four stages in depth instead of the original five. In summary, Dmg2Former is an encoder–decoder segmentation model with a base Swin Transformer backbone adapted with a custom-built decoder with inspirations from U-Net++. The architecture of Dmg2Former is shown in Figure 2.
3. Case Studies
3.1. Datasets Description
We used two visual inspection datasets for validation purposes. The first is the material segmentation dataset, a publicly available dataset containing 3817 images created from bridge inspection reports of the Virginia Department of Transportation [] with pixel-level annotation of three structural inspection materials: concrete, steel, and metal decking. The image resolution varies significantly with resolutions ranging from 258 × 37 to 5184 × 3456. With a sizable pool of high-resolution images, the dataset is a good candidate for testing our framework. The dataset is split by the original authors into 3436 samples for training and 381 samples for testing. We further set aside 352 samples from the training dataset for validation during network training (approximately 10% of the training set).
The other dataset is the Concrete Crack Conglomerate dataset, a publicly available dataset containing 10,995 images of cracks with pixel-level annotation obtained from multiple other datasets, shown in Table 2 [,]. As with the majority of the crack segmentation datasets, this dataset suffers from high class imbalance due to crack pixels occupying 2.8% of all pixels. All images in the dataset are 448 × 448 in size. Therefore, we train the resizers to upsize the segmentation model input and output resolution up to that resolution (factors of either two or four). Nevertheless, the model can be used to infer images that are larger in size due to the scaling capabilities of its Laplacian pyramids. Regarding the training/testing data split, the dataset was already split into a 90/10 ratio for training and testing by the original authors. We also reserve 10% from the training set for validation purposes.
Table 2.
Composition of the Concrete Crack Conglomerate dataset [].
3.2. Implementation
One of the main challenges in training the model to provide pixel-wise labeling of cracks is that the size of the cracks is insignificant compared to the background. Without taking measures, the model may classify all pixels as background and would still achieve sufficiently high accuracy. We use various training techniques to handle this class imbalance, including focal loss, regularization, and data augmentation.
The models were built and trained using the PyTorch library (v2.0.1) [] and a workstation equipped with Intel® Core i9-13900k CPU (Intel, Santa Clara, CA, USA) and an Nvidia RTX 4090 GPU (Nvidia, Santa Clara, CA, USA). We used the focal loss [] as our loss function. Focal loss can help reduce the effects of class imbalance by applying a modulating term to the cross-entropy loss to focus learning on hard, misclassified examples. The focal loss is defined as:
where is the balancing parameter and is the modulating parameter. Based on our experiments, the focal loss seems to improve the prediction accuracy compared to the cross-entropy loss. In this study, we use α = 0.6 for the crack segmentation tasks, α = 0.25 for other tasks, and γ = 2.0 for all visual inspection tasks.
For the optimizer, we use Adam with decoupled weight decay (AdamW) [] with an initial learning rate of 1 × 10−4 and a weight decay of 1 × 10−6. We also use cosine annealing with a warm restarts learning rate scheduler and a specified minimum learning rate of 1 × 10−7. All models were trained for 255 epochs, and the selected checkpoint corresponds to weights producing the maximum intersection-over-union (IoU) of the validation set. Furthermore, we initialized the parameters of the Swin Transformer backbone using the ImageNet [] training parameters made available by the original authors whenever possible, mainly when we use an input/output resolution of 224 × 224.
In addition, we used data augmentation techniques during training, adopted from the Albumentations library [], comprising multiple image transforms such as random horizontal flip, zoom, and perspective. It also included random color manipulations such as brightness, gamma, and saturation. Data augmentation proved to boost the model’s robustness to unseen data despite slowing the training process. Additionally, and to facilitate training, each channel of the input images was standardized based on the channel mean and standard deviation of the training images set. This means that the training images dataset would have a zero mean and a unit variance.
4. Results
4.1. Material Segmentation
We investigated three Dmg2Former architectures built for three input sizes: 112 × 112, 224 × 224, and 448 × 448, having all parameters randomly initialized. Additionally, we trained another set of Dmg2Former models with an input size of 224 × 224 and had the Swin encoder pre-trained with the ImageNet dataset. We paired the Dmg2Former versions with 112 and 224 input sizes with interpolation-type resizers (nearest-neighbor; Dmg2Former-NN) and our proposed adaptive resizers (Dmg2Former-AR), with factors of upscaling starting from a factor of two (2×) and up to a factor of eight (8×). Dmg2Former, Dmg2Former-NN, and Dmg2Former-AR, built using the exact internal resolution, share the same internal segmentation model. However, Dmg2Former-AR models get further fine-tuned to optimize the adaptive resizers.
It is worth noting that to implement Dmg2Former for an input size of 112, the Swin encoder had to be slightly adjusted. As 112 is not divisible by 32, we patch-partitioned using a patch size of 2 × 2, making the number of tokens at the final Swin encoder stage the multiplication of the input width and depth, each divided by 16.
Table 3 shows the average F1-score, IoU, recall, and precision of the examined models on the material segmentation dataset with randomly initialized parameters. The models are sorted in an ascending order based on the image/mask size they can process. The first observation when comparing Dmg2Former at two different input sizes (112 and 224) without any form of resizing is that the model trained on higher resolution images can better predict the segmentation masks, as seen by the improved performance across all metrics. This implies that the higher-resolution images contain additional non-redundant information that is valuable for parsing the visual inspection data.
Table 3.
Materials segmentation testing performance metrics (average) grouped by output image size—randomly initialized parameters. The best-obtained metrics in a group are shown in bold font.
Another finding is that when using an interpolation-based resampler, such as nearest neighbor, the model performance deteriorated compared to its low-resolution counterpart. For example, at size 112, Dmg2Former produced higher IoU (0.768) compared to Dmg2Former-NN 2× (0.739) and Dmg2Former-NN 4× (0.737). We also observed that the evaluation metrics stagnated or slightly deteriorated as we increased the upscale factor of the model using the nearest-neighbor algorithm. On the other hand, pairing Dmg2Former with adaptive rescalers (Dmg2Former-AR) allowed the model to improve its prediction capabilities and provide a higher-resolution mask. Moreover, as more adaptive down- and up-scalers were added to the same Dmg2Former model, we noticed improvements, though subtle, in the evaluation metrics results (e.g., based on 112-sized Dmg2Former: IoU of Dmg2Former-AR 2× (0.79) vs. Dmg2Former-AR 8× (0.802)). This resulted in the Dmg2Former-AR 4× relying on a 112-sized Dmg2Former outperforming a vanilla 224-sized Dmg2Former model. Additionally, Dmg2Former-AR 8× evaluation metrics showed the capabilities of the adaptive rescales in enabling a model to predict masks that have 64 times the pixels of the original segmentation model’s predictions.
Table 4 shows the class-average evaluation metrics of the 224-sized Dmg2Former with the Swin encoder initialized using ImageNet weights provided by the original authors of Swin Transformers. The ImageNet initialization of the Swin encoder resulted in noticeable improvements across all metrics for all 224-sized models. Overall, using adaptive rescalers has allowed for a slight increase in the evaluation metrics, with Dmg2Former-AR 2× achieving the best results. However, non-trainable rescalers (Dmg2Former-NN 2× and Dmg2Former-NN 4×) slightly deteriorated the model performance compared to the low-resolution segmentation model (Dmg2Former). It is worth noting that the differences in performance are subtle, and for this dataset, the use of interpolation-based resizers should not drastically impact the prediction results. Additionally, class-wise IoU results presented in Table 5 show a balanced class-wise prediction. Figure 5 visualizes example predictions of Dmg2Former-AR 4× and Dmg2Former-NN 4× side-by-side with the ground truth masks.
Table 4.
Materials segmentation testing performance metrics (average). Encoders were initialized with ImageNet-pre-trained weights. The best-obtained metrics are shown in bold font.
Table 5.
Materials segmentation class-wise IoU results. Encoders were initialized with ImageNet-pre-trained weights. The best-obtained metrics are shown in bold font.

Figure 5.
Material segmentation sample test images and their Dmg2Former-AR 4× and Dmg2Former-NN 4× predictions. Encoders were initialized with ImageNet-pre-trained weights.
4.2. Crack Segmentation
For crack segmentation, three different sizes of Dmg2Former were trained, two of which were paired with both adaptive and uniform resizers. As seen in Table 6, the improvements of the adaptive rescaling variants compared to the uniform rescaling ones are more pronounced for the crack segmentation task. This is mainly due to the highly unbalanced crack masks, as fine cracks can be significantly distorted if the image is uniformly resized, making it challenging to predict the masks. Figure 6 shows the output of the LapDCN and segmentation module for Dmg2Former-AR 4× at a 112 × 112 resolution along with their Dmg2Former-NN counterparts. As seen in the figure, when applying a uniform resampling algorithm, fine cracks are heavily distorted and may even vanish, especially when the image is radically downscaled. On the other hand, our adaptive downsampler, LapDCN, preserves the information necessary to predict the mask while discarding unnecessary pixels. In order to achieve this, the downsampler oversamples the cracks and other valuable pixels, as observed in Figure 6. In addition to that, our adaptive upsampler refines the predicted masks, such as resolving crack discontinuities, and upscales them to the desired higher resolution.
Table 6.
Crack segmentation testing performance metrics (average) grouped by output image size—randomly initialized parameters. The best-obtained metrics in a group are shown in bold font.

Figure 6.
Insights into the Dmg2Former-AR inference process. From the left, the ground-truth images and masks containing cracks at 448 × 448, the output of nearest-neighbor and LapDCN downsampling images by a factor of four (top) and the corresponding masks of Dmg2Former at 112 × 112 (bottom), and the LapSCN-upscaled mask at 448 × 448.
We also used the ImageNet pre-trained weights for the Swin encoder to improve the evaluation metrics. Three models sharing the same architecture of the internal segmentation model were trained and compared based on the evaluation metrics (Table 7). Using the same notation, the Dmg2Former model is the low-resolution segmentation model (224 × 224), while Dmg2Former-NN 2× and Dmg2Former-AR 2× are the upscaled variants when using interpolation-based resizers and adaptive resizers, respectively (448 × 448). Similar observations to the results of the materials segmentation can be made in Table 7.
Table 7.
Crack segmentation testing performance metrics. Encoders were initiated with ImageNet-pre-trained weights. The best-obtained metrics are shown in bold font.
Looking at the visualization of the models’ predictions for sample test images in Figure 7, we observe the following. First, Dmg2Former-AR can provide pixel-level crack predictions with a reasonable degree of accuracy for different conditions and crack characteristics. Second, the models provide “blank” predictions for non-crack images, indicating that the model does not operate as an edge detector. Finally, and unlike Dmg2Former-AR, the models equipped with interpolation-based resizers (Dmg2Former-NN) suffer significantly for images with fine cracks due to the distortion problem in the resizing operations.

Figure 7.
Crack segmentation sample test images and their Dmg2Former-AR 2× and Dmg2Former-NN 2× predictions. Encoders were initialized with ImageNet-pre-trained weights.
4.3. Computational Costs
Table 8 presents the number of parameters, multiple-accumulate (MAC) operations, the size of forward and backward passes, and the inference speed of a single image/mask of various Dmg2Former variants, offering insights into the computational demands and efficiency of each model. These statistics are obtained through the Python package Torchinfo (v1.8.0) [] for four-class output masks. A MAC operation consists of a multiplication followed by an addition (e.g., ) and therefore correlates with the model’s complexity and inference time. The forward pass size indicates the amount of memory (GPU memory if GPUs are utilized) needed to store a single image in a forward pass. When training, a similar amount of memory is needed to make a backward pass in addition to the amount needed for a forward pass. Training cannot be performed if there is simply not enough memory for a single image to make forward and backward passes, in addition to the size of the parameters themselves. Because batch-training is often used, both with MACs and the memory requirement scale with the batch size, it makes it extremely difficult to train models at higher resolutions.
Table 8.
Dmg2Former model statistics grouped by output image size—four classes output.
As seen in Table 8, Dmg2Former-AR offers higher resolution segmentation at 448 and 896 sizes with a slight increase in MACs and memory requirements. The requirements for running Dmg2Former natively at 896 can be prohibitive, as it needs approximately 5 GB in GPU memory for passing single images. Alternatively, using a lower resolution Dmg2Former with adaptive rescalers only needs more than four times less computational demands. The inference speed, presented in frames-per-second (FPS), is estimated on a single machine with an Nvidia 3060 Ti GPU with 8 GB of dedicated memory. By looking at the inference speed, we observed improvements in efficiency and real-time performance using adaptive rescaling as the resolution requirement increases, especially for models with an input size of 896 (10 FPS using Dmg2Former compared to 46 FPS Dmg2Former-AR 4×). At low resolutions (224 × 224), on the other hand, utilizing adaptive rescalers does not introduce efficiency improvements and may even slightly impact Dmg2Former speed, as seen in Table 8. Therefore, it is recommended to deploy adaptive rescaling when processing medium-to-higher resolution images.
5. Conclusions
As more progress is made in hardware and sensing technology, engineering inspectors gain access to an increasing amount of high-resolution data that would benefit from the advances in artificial intelligence. Fast and efficient visual inspection is preferred for real-time applications, but the resource demands of state-of-the-art vision transformer models are exponentially increasing. We proposed Dmg2Former-AR, a high-resolution visual inspection framework that encompasses a low-resolution transformer segmentation network, Dmg2Former, and two trainable resizers inspired by efficient subpixel convolution and Laplacian pyramid networks.
By testing our framework on the Material Segmentation dataset, we found an increase in IoU values and other evaluation metrics with progressive scaling using the proposed adaptive rescalers with factors of two, four, and eight. On the other hand, using interpolation-based resizers resulted in a deterioration of the model performance compared to the low-resolution segmentation model results. The differences in performance between the adaptive rescaling-based and interpolation-based models are more pronounced in the crack segmentation task. When inspecting the low-resolution output of the adaptive downsampler, uniform downsampler, and the segmentation model for both, we found that the use of adaptive rescalers in Dmg2Former-AR significantly helped in preserving the fine crack features, producing more accurate crack maps compared to the interpolation-based resizers. Furthermore, we inspected the computational demands for different configurations of Dmg2Former and found that upscaling Dmg2Former using adaptive rescalers offers a significantly efficient alternative to high-resolution segmentation.
Currently, this method only detects and maps cracks. However, there is a need to identify crack measurements, such as length and width, for some condition assessment tasks, such as alkali-silica reaction crack growth monitoring. Additionally, this is a supervised learning method which cannot generalize to other visual inspection tasks without being trained on such tasks. We anticipate that our approach can potentially predict masks for different damage types, such as spalling, rebar exposure, and steel rust, as long as they are trained on sufficient annotated data that include these classes. Finally, machine-learning models make mistakes, especially when attempting to extrapolate beyond their knowledge. Providing a measure of uncertainty as part of the given output can allow inspectors to take appropriate action when confidence drops. Uncertainty quantification is often implemented by formulating a posterior probability distribution (or an approximate) over the model parameters using Bayes’ theorem [,,]. Implementing an uncertainty quantification strategy for damage segmentation in Dmg2Former-AR is recommended for future studies.
Author Contributions
Conceptualization, K.E. and S.S.; methodology, K.E.; software, K.E. and S.S.; validation, K.E.; formal analysis, K.E.; investigation, K.E. and S.S.; resources, X.L.; data curation, K.E.; writing—original draft preparation, K.E.; writing—review and editing, X.L.; visualization, K.E. and S.S.; supervision, X.L.; project administration, X.L.; funding acquisition, X.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data are contained within the article.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- ASCE. The Report Card for America’s Infrastructure; ASCE: Reston, VI, USA, 2021. [Google Scholar]
- U.S. Department of Transportation; Federal Highway Adminstration; Federal Transit Administration. Chapter 7: Capital Investment Scenarios. In Status of the Nation’s Highways, Bridges, and Transit: Conditions & Performance Report to Congress, 24th ed.; US Department of Transportation: Washington, DC, USA, 2021; pp. 7–12. [Google Scholar]
- ASDSO. The Cost of Rehabilitating Dams in the U.S.: A Methodology and Estimate; ASDSO: Lexington, KY, USA, 2023. [Google Scholar]
- Abdel-Qader, I.; Abudayyeh, O.; Kelly, M.E. Analysis of edge-detection techniques for crack identification in bridges. J. Comput. Civ. Eng. 2003, 17, 255–263. [Google Scholar]
- Jahanshahi, M.R.; Masri, S.F. Adaptive vision-based crack detection using 3D scene reconstruction for condition assessment of structures. Autom. Constr. 2012, 22, 567–576. [Google Scholar]
- Munawar, H.S.; Hammad, A.W.; Haddad, A.; Soares, C.A.P.; Waller, S.T. Image-based crack detection methods: A review. Infrastructures 2021, 6, 115. [Google Scholar] [CrossRef]
- Eltouny, K.; Gomaa, M.; Liang, X. Unsupervised Learning Methods for Data-Driven Vibration-Based Structural Health Monitoring: A Review. Sensors 2023, 23, 3290. [Google Scholar] [CrossRef]
- Lynch, J.P.; Loh, K.J. A summary review of wireless sensors and sensor networks for structural health monitoring. Shock. Vib. Dig. 2006, 38, 91–130. [Google Scholar]
- Abdulkarem, M.; Samsudin, K.; Rokhani, F.Z.; Rasid, M.F.A. Wireless sensor network for structural health monitoring: A contemporary review of technologies, challenges, and future direction. Struct. Health Monit. 2020, 19, 693–735. [Google Scholar]
- Soleimani-Babakamali, M.H.; Sepasdar, R.; Nasrollahzadeh, K.; Lourentzou, I.; Sarlo, R. Toward a general unsupervised novelty detection framework in structural health monitoring. Comput. Aided Civ. Infrastruct. Eng. 2022, 37, 1128–1145. [Google Scholar]
- Eltouny, K.; Liang, X. Uncertainty-aware structural damage warning system using deep variational composite neural networks. Earthq. Eng. Struct. Dyn. 2023, 52, 3345–3368. [Google Scholar] [CrossRef]
- Wang, Z.; Cha, Y.-J. Unsupervised deep learning approach using a deep auto-encoder with a one-class support vector machine to detect damage. Struct. Health Monit. 2021, 20, 406–425. [Google Scholar]
- Liu, G.; Wang, Q.-A.; Jiao, G.; Dang, P.; Nie, G.; Liu, Z.; Sun, J. Review of wireless RFID strain sensing technology in structural health monitoring. Sensors 2023, 23, 6925. [Google Scholar] [CrossRef]
- Caizzone, S.; DiGiampaolo, E. Wireless passive RFID crack width sensor for structural health monitoring. IEEE Sens. J. 2015, 15, 6767–6774. [Google Scholar]
- Strangfeld, C.; Johann, S.; Bartholmai, M. Smart RFID sensors embedded in building structures for early damage detection and long-term monitoring. Sensors 2019, 19, 5514. [Google Scholar] [CrossRef] [PubMed]
- Wang, Q.A.; Zhang, C.; Ma, Z.G.; Jiao, G.Y.; Jiang, X.W.; Ni, Y.Q.; Wang, Y.C.; Du, Y.T.; Qu, G.B.; Huang, J. Towards long-transmission-distance and semi-active wireless strain sensing enabled by dual-interrogation-mode RFID technology. Struct. Control. Health Monit. 2022, 29, e3069. [Google Scholar]
- Kumar, S.S.; Wang, M.; Abraham, D.M.; Jahanshahi, M.R.; Iseley, T.; Cheng, J.C. Deep learning–based automated detection of sewer defects in CCTV videos. J. Comput. Civ. Eng. 2020, 34, 04019047. [Google Scholar]
- Wang, M.; Kumar, S.S.; Cheng, J.C. Automated sewer pipe defect tracking in CCTV videos based on defect detection and metric learning. Autom. Constr. 2021, 121, 103438. [Google Scholar]
- Chikamoto, Y.; Tsutsumi, Y.; Sawano, H.; Ishihara, S. Design and implementation of a video-frame localization system for a drifting camera-based sewer inspection system. Sensors 2023, 23, 793. [Google Scholar] [CrossRef]
- Dorafshan, S.; Thomas, R.J.; Maguire, M. Fatigue crack detection using unmanned aerial systems in fracture critical inspection of steel bridges. J. Bridge Eng. 2018, 23, 04018078. [Google Scholar]
- Liu, Y.F.; Nie, X.; Fan, J.S.; Liu, X.G. Image-based crack assessment of bridge piers using unmanned aerial vehicles and three-dimensional scene reconstruction. Comput. Aided Civ. Infrastruct. Eng. 2020, 35, 511–529. [Google Scholar]
- Chen, D.; Huang, B.; Kang, F. A review of detection technologies for underwater cracks on concrete dam surfaces. Appl. Sci. 2023, 13, 3564. [Google Scholar] [CrossRef]
- Xing, J.; Liu, Y.; Zhang, G. Concrete highway crack detection based on visible light and infrared silicate spectrum image fusion. Sensors 2024, 24, 2759. [Google Scholar] [CrossRef]
- Lou, Y.; Meng, S.; Zhou, Y. Deep learning-based three-dimensional crack damage detection method using point clouds without color information. Struct. Health Monit. 2024, 14759217241236929. [Google Scholar] [CrossRef]
- Huang, Y.-T.; Jahanshahi, M.R.; Shen, F.; Mondal, T.G. Deep learning–based autonomous road condition assessment leveraging inexpensive rgb and depth sensors and heterogeneous data fusion: Pothole detection and quantification. J. Transp. Eng. Part B Pavements 2023, 149, 04023010. [Google Scholar]
- Agyemang, I.O.; Zhang, X.; Mensah, I.A.; Mawuli, B.C.; Agbley, B.L.Y.; Arhin, J.R. Enhanced Deep Convolutional Neural Network for Building Component Detection Towards Structural Health Monitoring. In Proceedings of the 2021 4th International Conference on Pattern Recognition and Artificial Intelligence (PRAI), Yibin, China, 20–22 August 2021; pp. 202–206. [Google Scholar]
- Liang, X. Image-based post-disaster inspection of reinforced concrete bridge systems using deep learning with Bayesian optimization. Comput. Aided Civ. Infrastruct. Eng. 2019, 34, 415–430. [Google Scholar]
- Narazaki, Y.; Hoskere, V.; Hoang, T.A.; Fujino, Y.; Sakurai, A.; Spencer, B.F., Jr. Vision-based automated bridge component recognition with high-level scene consistency. Comput. Aided Civ. Infrastruct. Eng. 2020, 35, 465–482. [Google Scholar]
- Sajedi, S.O.; Liang, X. Uncertainty-assisted deep vision structural health monitoring. Comput. Aided Civ. Infrastruct. Eng. 2021, 36, 126–142. [Google Scholar]
- Teng, S.; Liu, Z.; Chen, G.; Cheng, L. Concrete crack detection based on well-known feature extractor model and the YOLO_v2 network. Appl. Sci. 2021, 11, 813. [Google Scholar] [CrossRef]
- Dong, X.; Liu, Y.; Dai, J. Concrete Surface Crack Detection Algorithm Based on Improved YOLOv8. Sensors 2024, 24, 5252. [Google Scholar] [CrossRef]
- Liu, Z.; Cao, Y.; Wang, Y.; Wang, W. Computer vision-based concrete crack detection using U-net fully convolutional networks. Autom. Constr. 2019, 104, 129–139. [Google Scholar]
- Zheng, Y.; Gao, Y.; Lu, S.; Mosalam, K.M. Multistage semisupervised active learning framework for crack identification, segmentation, and measurement of bridges. Comput. Aided Civ. Infrastruct. Eng. 2022, 37, 1089–1108. [Google Scholar]
- Tang, W.; Wu, R.-T.; Jahanshahi, M.R. Crack segmentation in high-resolution images using cascaded deep convolutional neural networks and Bayesian data fusion. Smart Struct. Syst. 2022, 29, 221–235. [Google Scholar]
- Zhang, K.; Cheng, H.; Zhang, B. Unified approach to pavement crack and sealed crack detection using preclassification based on transfer learning. J. Comput. Civ. Eng. 2018, 32, 04018001. [Google Scholar]
- Zhang, A.; Wang, K.C.; Li, B.; Yang, E.; Dai, X.; Peng, Y.; Fei, Y.; Liu, Y.; Li, J.Q.; Chen, C. Automated pixel-level pavement crack detection on 3D asphalt surfaces using a deep-learning network. Comput. Aided Civ. Infrastruct. Eng. 2017, 32, 805–819. [Google Scholar]
- Xu, Y.; Fan, Y.; Li, H. Lightweight semantic segmentation of complex structural damage recognition for actual bridges. Struct. Health Monit. 2023, 22, 3250–3269. [Google Scholar]
- Choi, Y.; Park, H.W.; Mi, Y.; Song, S. Crack detection and analysis of concrete structures based on neural network and clustering. Sensors 2024, 24, 1725. [Google Scholar] [CrossRef]
- Sohaib, M.; Jamil, S.; Kim, J.-M. An ensemble approach for robust automated crack detection and segmentation in concrete structures. Sensors 2024, 24, 257. [Google Scholar] [CrossRef]
- Yang, L.; Liu, K.; Ou, R.; Qian, P.; Wu, Y.; Tian, Z.; Zhu, C.; Feng, S.; Yang, F. Surface Defect-Extended BIM Generation Leveraging UAV Images and Deep Learning. Sensors 2024, 24, 4151. [Google Scholar] [CrossRef] [PubMed]
- Hang, J.; Wu, Y.; Li, Y.; Lai, T.; Zhang, J.; Li, Y. A deep learning semantic segmentation network with attention mechanism for concrete crack detection. Struct. Health Monit. 2023, 22, 3006–3026. [Google Scholar]
- Yu, J.; Xu, Y.; Xing, C.; Zhou, J.; Pan, P. Pixel-Level Crack Detection and Quantification of Nuclear Containment with Deep Learning. Struct. Control Health Monit. 2023, 2023, 9982080. [Google Scholar]
- Wu, Y.; Qin, Y.; Qian, Y.; Guo, F.; Wang, Z.; Jia, L. Hybrid deep learning architecture for rail surface segmentation and surface defect detection. Comput. Aided Civ. Infrastruct. Eng. 2022, 37, 227–244. [Google Scholar]
- Guo, J.; Wang, Q.; Li, Y. Semi-supervised learning based on convolutional neural network and uncertainty filter for façade defects classification. Comput. Aided Civ. Infrastruct. Eng. 2021, 36, 302–317. [Google Scholar]
- Hoskere, V.; Narazaki, Y.; Hoang, T.; Spencer, B., Jr. Vision-based structural inspection using multiscale deep convolutional neural networks. In Proceedings of the 3rd Huixian International Forum on Earthquake Engineering for Young Researchers, Urbana-Champaign, IL, USA, 10–11 August 2017. [Google Scholar]
- Hoskere, V.; Narazaki, Y.; Hoang, T.A.; Spencer, B., Jr. MaDnet: Multi-task semantic segmentation of multiple types of structural materials and damage in images of civil infrastructure. J. Civ. Struct. Health Monit. 2020, 10, 757–773. [Google Scholar]
- Zhou, Z.; Zhang, J.; Gong, C. Automatic detection method of tunnel lining multi-defects via an enhanced You Only Look Once network. Comput. Aided Civ. Infrastruct. Eng. 2022, 37, 762–780. [Google Scholar] [CrossRef]
- Bae, H.; Jang, K.; An, Y.-K. Deep super resolution crack network (SrcNet) for improving computer vision–based automated crack detectability in in situ bridges. Struct. Health Monit. 2021, 20, 1428–1442. [Google Scholar]
- Xiang, C.; Wang, W.; Deng, L.; Shi, P.; Kong, X. Crack detection algorithm for concrete structures based on super-resolution reconstruction and segmentation network. Autom. Constr. 2022, 140, 104346. [Google Scholar]
- Kim, J.; Shim, S.; Kang, S.-J.; Cho, G.-C. Learning Structure for Concrete Crack Detection Using Robust Super-Resolution with Generative Adversarial Network. Struct. Control Health Monit. 2023, 2023, 8850290. [Google Scholar]
- Sajedi, S.; Eltouny, K.; Liang, X. Twin models for high-resolution visual inspections. Smart Struct. Syst. 2023, 31, 351–363. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. arXiv 2021, arXiv:2103.14030. [Google Scholar]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1874–1883. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Mu Lee, K. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 136–144. [Google Scholar]
- Du, Z.; Liu, J.; Tang, J.; Wu, G. Anchor-based plain net for mobile image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2494–2502. [Google Scholar]
- Lai, W.-S.; Huang, J.-B.; Ahuja, N.; Yang, M.-H. Deep laplacian pyramid networks for fast and accurate super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 624–632. [Google Scholar]
- Denton, E.L.; Chintala, S.; Fergus, R. Deep generative image models using a laplacian pyramid of adversarial networks. Adv. Neural Inf. Process. Syst. 2015, 28, 1486–1494. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Guo, J.; Zou, X.; Chen, Y.; Liu, Y.; Hao, J.; Liu, J.; Yan, Y. Asconvsr: Fast and lightweight super-resolution network with assembled convolutions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, USA, 17–24 June 2023; pp. 1582–1592. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In Proceedings of the ICLR 2021, Vienna, Austria, 3–7 May 2021. [Google Scholar]
- Liu, Z.; Mao, H.; Wu, C.-Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A ConvNet for the 2020s. arXiv 2022, arXiv:2201.03545. [Google Scholar]
- PapersWithCode. Semantic Segmentation. Available online: https://paperswithcode.com/task/semantic-segmentation (accessed on 30 April 2022).
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. Unet++: A nested u-net architecture for medical image segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Berlin/Heidelberg, Germany, 2018; pp. 3–11. [Google Scholar]
- Iakubovskii, P. Segmentation Models Pytorch. Available online: https://github.com/qubvel/segmentation_models.pytorch (accessed on 29 July 2024).
- Bianchi, E.; Hebdon, M. Development of Extendable Open-Source Structural Inspection Datasets. J. Comput. Civ. Eng. 2022, 36, 04022039. [Google Scholar]
- Bianchi, E.; Hebdon, M. Concrete Crack Conglomerate Dataset; University Libraries Virginia Tech: Blacksburg, VA, USA, 2021. [Google Scholar] [CrossRef]
- Prasanna, P.; Dana, K.J.; Gucunski, N.; Basily, B.B.; La, H.M.; Lim, R.S.; Parvardeh, H. Automated Crack Detection on Concrete Bridges. IEEE Trans. Autom. Sci. Eng. 2016, 13, 591–599. [Google Scholar] [CrossRef]
- Yang, F.; Zhang, L.; Yu, S.; Prokhorov, D.; Mei, X.; Ling, H. Feature Pyramid and Hierarchical Boosting Network for Pavement Crack Detection. IEEE Trans. Intell. Transp. Syst. 2020, 21, 1525–1535. [Google Scholar] [CrossRef]
- Zou, Q.; Cao, Y.; Li, Q.; Mao, Q.; Wang, S. CrackTree: Automatic crack detection from pavement images. Pattern Recognit. Lett. 2012, 33, 227–238. [Google Scholar] [CrossRef]
- Liu, Y.; Yao, J.; Lu, X.; Xie, R.; Li, L. DeepCrack: A deep hierarchical feature learning architecture for crack segmentation. Neurocomputing 2019, 338, 139–153. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32, 8026–8037. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–27 October 2017; pp. 2980–2988. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Buslaev, A.; Iglovikov, V.I.; Khvedchenya, E.; Parinov, A.; Druzhinin, M.; Kalinin, A.A. Albumentations: Fast and flexible image augmentations. Information 2020, 11, 125. [Google Scholar] [CrossRef]
- Yep, T. Torchinfo. Available online: https://github.com/TylerYep/torchinfo (accessed on 28 July 2024).
- Zhang, Y.; d’Avigneau, A.M.; Hadjidemetriou, G.M.; de Silva, L.; Girolami, M.; Brilakis, I. Bayesian dynamic modelling for probabilistic prediction of pavement condition. Eng. Appl. Artif. Intell. 2024, 133, 108637. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).