Abstract
The motion control system of a lower-limb exoskeleton rehabilitation robot (LLERR) is designed to assist patients in lower-limb rehabilitation exercises. This research designed a motion controller for an LLERR-based on the Twin Delayed Deep Deterministic policy gradient (TD3) algorithm to control the lower-limb exoskeleton for gait training in a staircase environment. Commencing with the establishment of a mathematical model of the LLERR, the dynamics during its movement are systematically described. The TD3 algorithm is employed to plan the motion trajectory of the LLERR’s right-foot sole, and the target motion curve of the hip (knee) joint is deduced inversely to ensure adherence to human physiological principles during motion execution. The control strategy of the TD3 algorithm ensures that the movement of each joint of the LLERR is consistent with the target motion trajectory. The experimental results indicate that the trajectory tracking errors of the hip (knee) joints are all within 5°, confirming that the LLERR successfully assists patient in completing lower-limb rehabilitation training in a staircase environment. The primary contribution of this study is to propose a non-linear control strategy tailored for the staircase environment, enabling the planning and control of the lower-limb joint motions facilitated by the LLERR.
1. Introduction
By the end of 2019, the global population of individuals aged 60 or above had reached 1 billion, with an estimated projection of 1.4 billion by 2030 [1]. The aging demographic has notably contributed to a rise in the number of stroke cases [2], with lower-limb motor dysfunction being a prevalent symptom among this group [3]. Additionally, lower-limb motor dysfunction ranks as the second most prevalent cause of mortality on a global scale [4], significantly affecting individual health [5]. Many stroke survivors need rehabilitation interventions to regain their mobility [6]. Nevertheless, the existing medical resources are insufficient [7]. The research and promotion of lower-limb exoskeleton rehabilitation robots (LLERRs) offer solutions to the disparity between supply and demand in rehabilitation medical resources, enhancing the quality of life for the elderly, and carrying substantial societal significance [8].
Lower-limb exoskeleton rehabilitation robotics is an interdisciplinary technology that integrates rehabilitation medicine, bionics, e-informatics, robotics, and mechanics to assist stroke patients in recovering their walking ability [9]. It aids in the restoration of lower-limb function and muscle strength, enhances balance and gait stability through tailored rehabilitation exercises [10,11]. Equipped with various sensors, the robot can continuously monitor the patient’s movement parameters in real time. This capability enables the evaluation of the patient’s progress and the delivery of individualized rehabilitation programs and guidance [12], thereby expediting the recovery process and enhancing its effectiveness [13].
Efforts have been undertaken by governmental bodies, businesses, scholars, and other stakeholders to work towards the objective of aiding a greater number of patients with lower-limb impairments in regaining motor functionality and advancing the utilization of lower-limb rehabilitation robotics.
Governments have been actively involved in promoting the research and development of rehabilitation robots since 2016. The Chinese government has implemented policies to encourage the advancement and utilization of rehabilitation robots [14]. Similarly, the Japanese government supports the development of assistive robots to enhance longevity and health by endorsing rehabilitation centers and fostering partnerships with medical research and development organizations [15]. The National Rehabilitation Center of Korea initiated the Translational Research Program for Rehabilitation Robotics. This program is designed to boost the growth of rehabilitation robotics and related industries by integrating technology-driven research and development with clinical applications [16].
Enterprises: Hocoma has introduced Andago, a mobile robot designed for lower-limb rehabilitation. This innovative device offers dynamic weight-bearing upright walking exercises along with features for fall prevention and real-time tracking [17]. Dai Ai Robotics has created AiWalker, a robot-assisted system for gait training that enhances the balance and walking capabilities of individuals recovering from strokes [18]. Shenzhen Maibu has developed BEAR-H1, a robotic system for lower-limb rehabilitation. Utilizing AI algorithms, it can anticipate the user’s movements and accommodate both active and passive training approaches. The robot assists patients in exercising their hip, knee, and ankle joints, facilitating comprehensive walking training [19].
Researchers: Glowinski, Sebastian et al. [20], in the field of inverse kinematics, proposed a redundant chain algorithm based on analytic equations. Chen Zhenlei et al. [21] introduced a control method for a lower-limb exoskeleton rehabilitation robot system that incorporated uncertain models. The approach utilized a deep Gaussian process for predicting motion intention and integrated a parameter for self-tuning the variable-conductance controller to enhance the system’s control strategy. Zhou Jie et al. [22] developed a trajectory deformation algorithm as a high-level trajectory planner to improve suppleness and motion smoothness in human–robot collaborative control. This algorithm planned the desired trajectory of a patient based on the interaction forces observed during physical human–robot interactions. Furthermore, Xu Jiajun et al. [23] presented a mirror therapy lower-limb rehabilitation robot designed for patients with a bias. They devised a motion generation scheme for the affected limb based on learning principles. The robot facilitated the active engagement of affected muscles by transferring movements from the healthy limb to the affected limb, encouraging imitation of the healthy limb’s movements.
According to the majority of scholarly investigations, advancements have been made in lower-limb rehabilitation robots; however, there are still deficiencies in specific areas. Current studies on environmental adaptability predominantly concentrate on level-ground terrains, whereas practical scenarios involve more intricate settings like stairs and inclines. Furthermore, although existing research considers the mechanical framework concerning patient dimensions, customized therapy requires further enhancement. In recent years, artificial intelligence technology has progressively been incorporated into the realm of robotics [24], equipping robots with enhanced cognitive, decision-making, and operational capabilities. This progression also presents greater potential for rehabilitation robots, which are expected to tackle current challenges and provide more accurate and individualized solutions for rehabilitation therapy.
Current scholarly investigations in the domain of artificial intelligence applied to lower-limb rehabilitation robots predominantly focus on two key areas: the utilization of machine learning technology for gait recognition and prediction in lower-limb movements, and the integration of reinforcement learning techniques to improve control strategies for lower-limb exoskeletons. Various innovative methodologies have been introduced by researchers for gait recognition and prediction. For instance, Li, Guoxin et al. [25] proposed a technique that employed Long Short-Term Memory networks to forecast the movement intentions of individuals by analyzing Surface Electromyography (sEMG) signals. This method enabled the activation of assistive devices to support rehabilitation patients during their training sessions. Furthermore, Lu, Yanzheng et al. [26] utilized stacked convolutional and Long Short-Term Memory networks to estimate joint angles (e.g., hip, knee, ankle) during activities such as walking, running, and stair climbing based on sEMG signals. Additionally, Zhang, Zaifang et al. [27] developed an integrated network model that combined a Sparse Autoencoder, a Bidirectional Long Short-Term Memory, and a Deep Neural Network to accurately identify different gait phases. Conversely, existing research also explores the integration of reinforcement learning into exoskeleton control to enhance the performance and adaptability of rehabilitation robots. For instance, Zhang, Qiang et al. [28] utilized a model-free reinforcement learning control framework to precisely adjust the standardized range of motion and gait patterns at the hip joint during walking, addressing the adaptability limitations associated with conventional methods. Additionally, Rose, Lowell et al. [29] proposed a new model free deep reinforcement learning method for learning gait patterns required for ground gait rehabilitation through exoskeletons. Furthermore, Li, Jingang et al. [30] addressed energy consumption challenges in lower-limb exoskeletons by implementing an energy management control strategy based on time-difference reinforcement learning. This strategy added a state-of-charge prediction model to effectively manage the energy consumption of the robots, thereby increasing their operational efficiency and sustainability in practical applications.
While AI algorithms have made significant progress in intent recognition and optimizing control algorithm parameters, there is a lack of research on the adaptability of rehabilitation robots in complex environments. This paper presents a motion controller for an LLERR using the TD3 algorithm to tackle motion control challenges in stair environments. The controller is designed to provide personalized rehabilitation treatment plans, improve the efficiency and safety of rehabilitation robots in real-world scenarios, and meet the diverse rehabilitation requirements of patients in different environments.
The main findings of this study include:
- (1)
- The development of a trajectory planning controller for the LLERR, using the TD3 algorithm. This controller is responsible for generating the desired motion trajectory for the hip and knee joints of the LLERR.
- (2)
- The development of a tracking controller for the LLERR using the TD3 algorithm. This controller aims to regulate the movement of the hip (knee) joint of the LLERR to follow a specified motion trajectory accurately, facilitating the execution of up-stairs movements.
- (3)
- The study involves performing motion planning and tracking experiments using the LLERR to showcase the efficacy of the TD3 algorithm and the dependability of the LLERR control system, as supported by the experimental findings.
The subsequent sections of this paper are organized as follows: Section 2 elaborates on the mathematical model of LLERR. Section 3 outlines the controller’s design process and showcases its viability. Section 4 delineates the experimental procedures and outcomes, along with an extensive analysis of the results. Lastly, Section 5 presents the conclusion.
2. Mathematical Model
To investigate the motion control system of the LLERR, a lumped parameter mathematical model was developed in this study to characterize its dynamics. Before modeling, three assumptions were made to streamline the system description:
- (1)
- The LLERR s’ exoskeleton was assumed to only move in the sagittal plane.
- (2)
- The thigh (calf) was assumed to be concentrated at its center of point.
- (3)
- We simplified the foot sole to a mass point, disregarding its specific shape.
2.1. Environmental Model
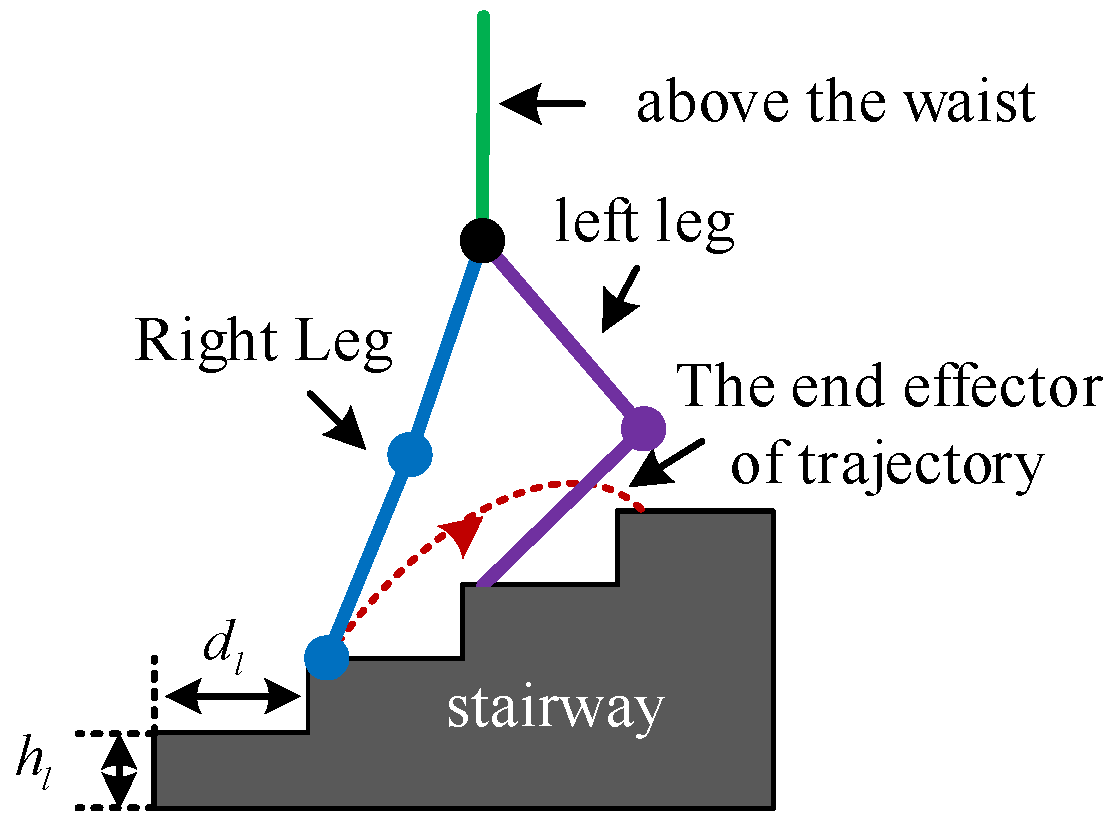
Structured terrain is the most common type of terrain encountered in human daily life, comprising flat ground, stairs, and ramps. To ensure safe and smooth movement of an LLERR in these environments, it is crucial to plan a reasonable gait. This paper aimed to adapt the LLERR to the staircase environment by designing and planning the LLERR’s joint motion trajectories. Figure 1 shows the LLERR’s terrain environment, with a step height of and a depth of .
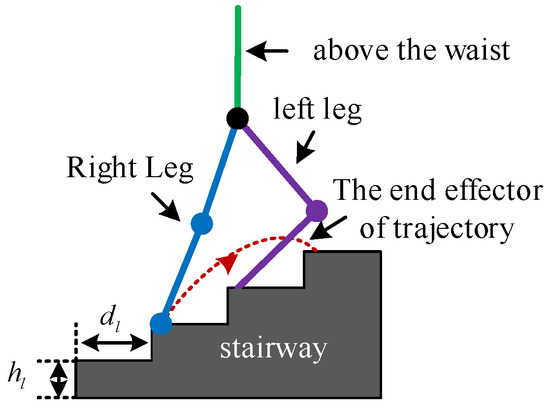
Figure 1.
Operating environment of lower-limb exoskeleton rehabilitation robot.
2.2. Lower-Limb Exoskeleton Rehabilitation Robot Model
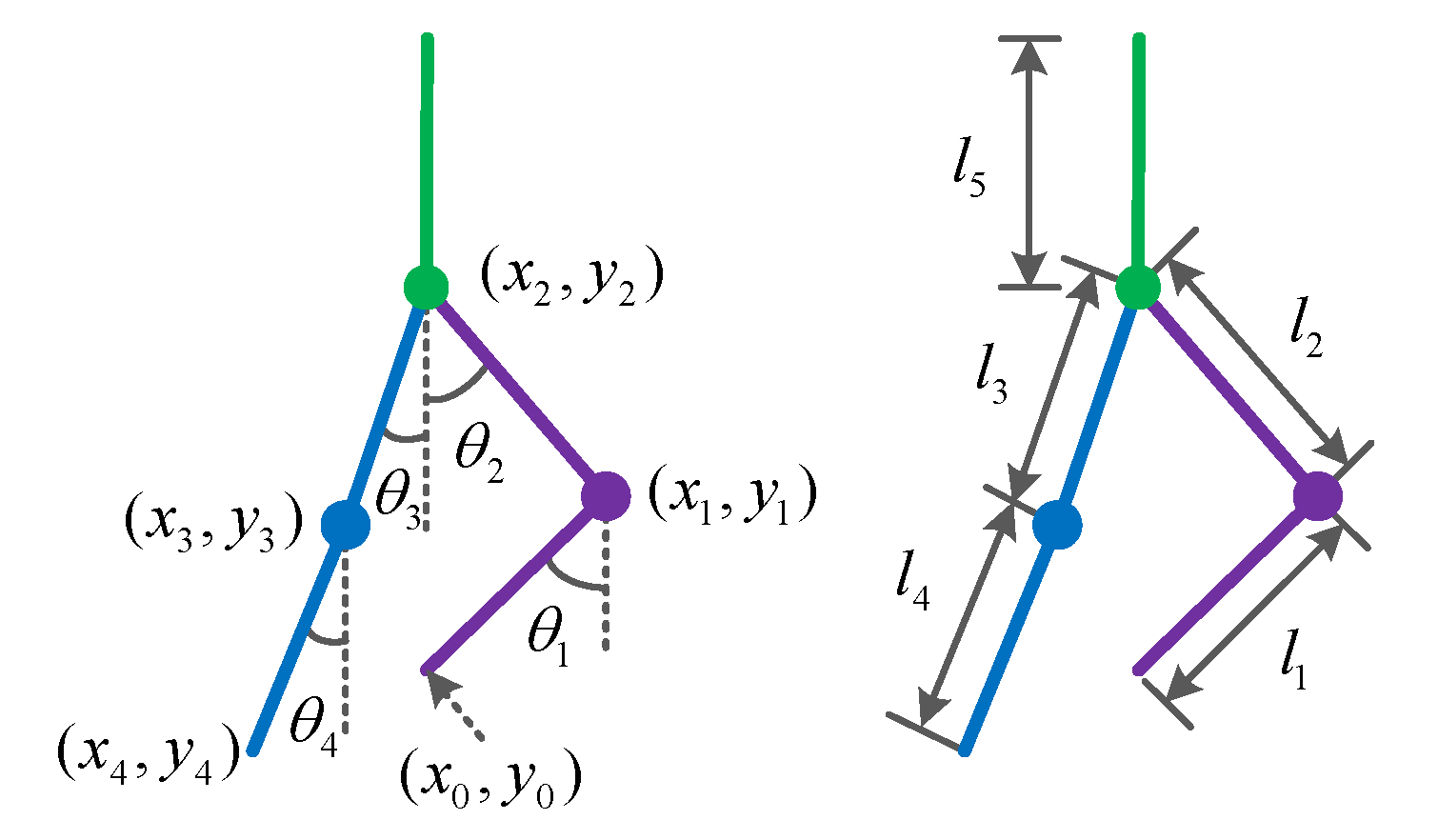
Figure 2 shows the LLERR on a staircase, with the left leg on a higher step and the right leg on a lower step. In order to describe the robot posture, a five connecting rod model is used, and the angles and parameters are defined. The angle between the left shank and the vertical is , the angle between the left thigh and the vertical is , the angle between the right thigh and the vertical is , and the angle between the right shank and the vertical is . The angle is defined as 0 degrees when the thigh (shank) overlaps with the vertical. Clockwise rotation is considered positive, while counterclockwise rotation is considered negative. The left shank has a length of and a mass point of . The left thigh has a length of and a mass point of . The right thigh has a length of and a mass point of . The right shank has a length of and a mass point of . The upper torso has a length of and a mass point of .
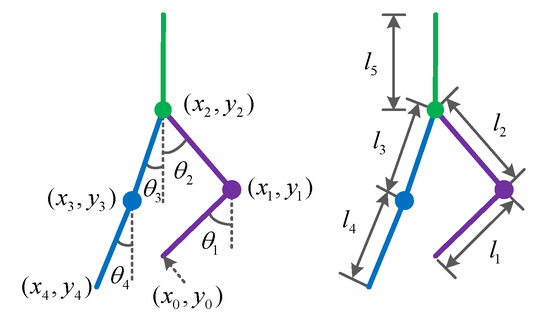
Figure 2.
Lower-limb exoskeleton rehabilitation robot model.
The dynamics equation of the LLERR is obtained from the Lagrange equation [31] as:
where is the hip (knee) joint driving force; is the hip (knee) joint angle. is the hip (knee) joint angular velocity; and is the Lagrange function with the expression:
where is the sum of the kinetic energy and is the sum of the potential energy of LLERR.
where is the velocity in the horizontal direction, is the velocity in the vertical direction, is the rotational inertia, and is the vertical coordinate.
The coordinates of the left sole are , and the coordinates of the hip (knee) joint as well as the right sole are:
Then, the Lagrange dynamical equation for LLERR is:
where is the hip (knee) joint angular acceleration; is the inertia matrix; is the centrifugal and kyphotic force matrix; is the gravity matrix; and its expression is:
The LLERR system equation is:
3. Motion Trajectory Planning and Control for a Lower-Limb Exoskeleton Rehabilitation Robot
The LLERR for lower-limb exoskeleton exhibits alternating cyclic reciprocal movements of the left and right legs while climbing stairs. This paper focused on studying and analyzing a complete motion cycle. In a current cycle, the left sole remained stationary while the left leg moved from flexion to extension, and the right leg moved from a lower step to a higher step. Figure 1 above shows a schematic diagram of this process.
3.1. Motion Path Planning for the Right-Foot Sole
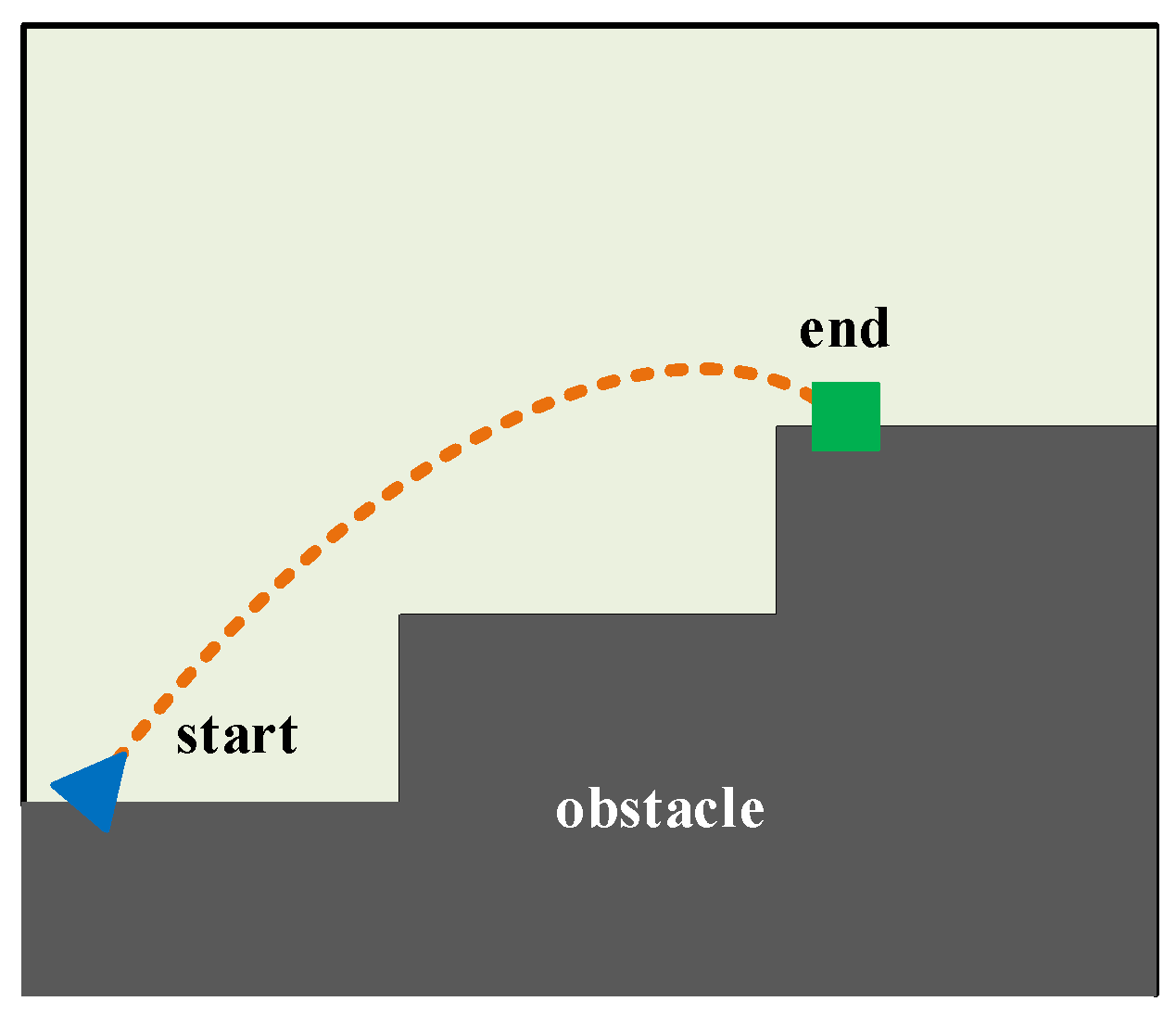
The aim of this subsection was to plan a reasonable motion path for the mass point U located at the right-foot sole. Therefore, we focused solely on the right-foot sole of the LLERR and disregarded the other parts. To better analyze the motion path of the mass point U, we established a grid map, as shown in Figure 3. The map illustrates the path that the mass point U takes, departing from the start, avoiding obstacles, and reaching the end along a shorter and smoother path. To achieve this goal, we used the TD3 algorithm in this subsection.
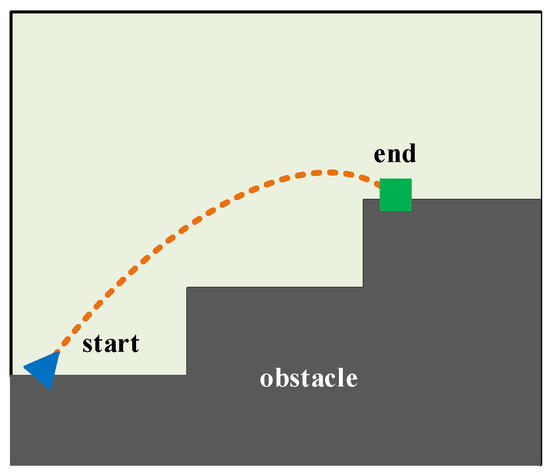
Figure 3.
Gridding of the motion space of the mass point U.
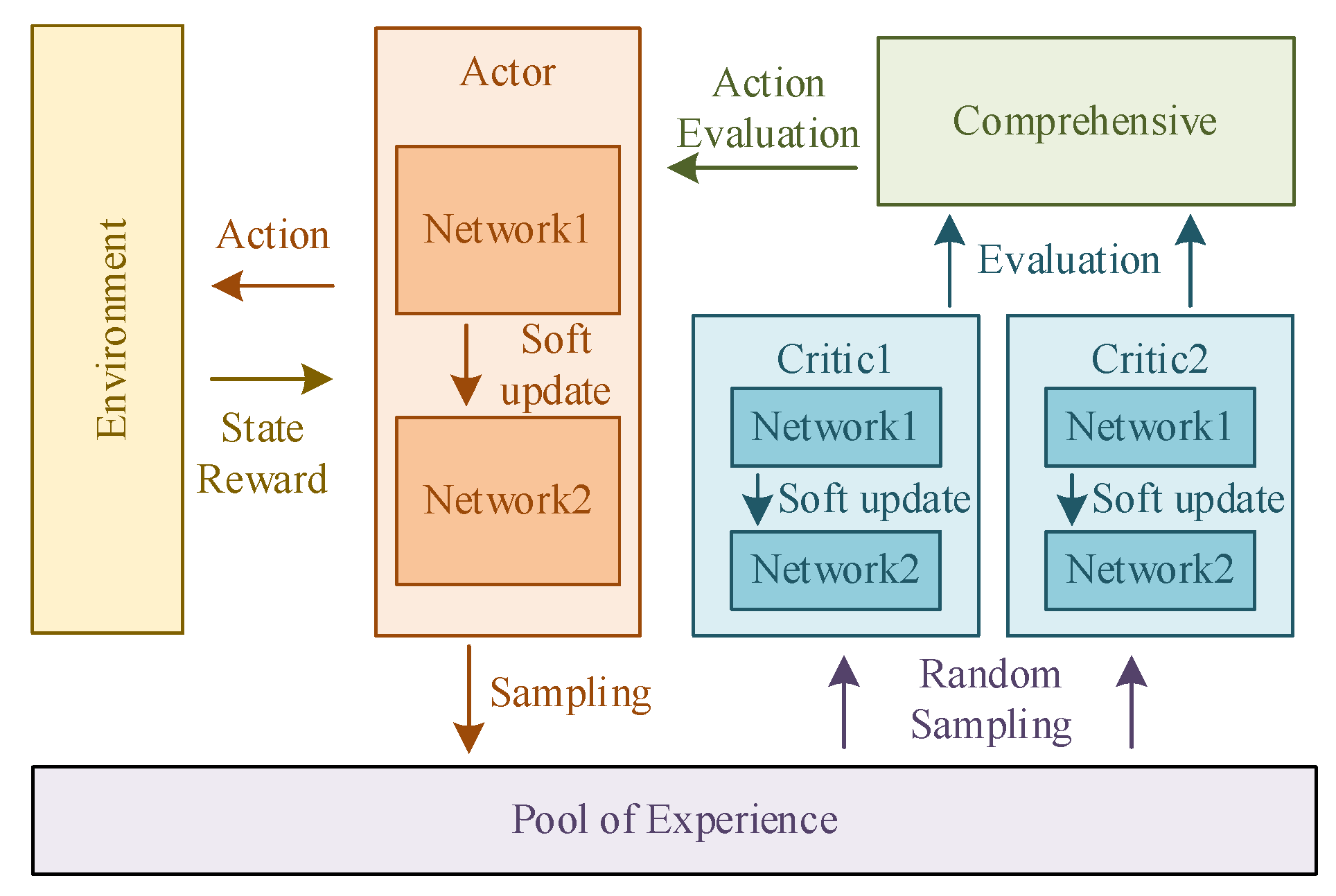
Figure 4 shows the framework of the TD3 algorithm. Critic networks evaluate the state of the mass point U in the environment and determine the next action to be performed. Critic networks learn to improve the accuracy of their evaluations. Actor networks make decisions on the movement of the mass point and execute the strategy in the environment to generate data into the data pool. Actor networks also learn based on the evaluations of Critic networks.
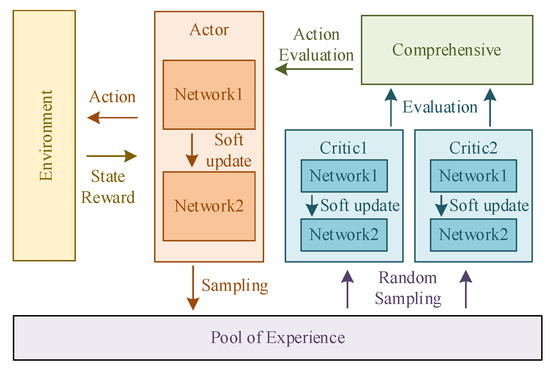
Figure 4.
The motion path planning framework of mass point U.
Define the state of the mass point U at the moment t to be , and are the coordinates of the mass point U at the moment t, and its spatial set is:
The action spatial set is:
where is the direction chosen by the mass point U at moment t. The single-step reward represents the reward obtained by the mass point U for performing the action in the current state :
where denotes the reward value for the next step to reach the end; is the reward value when the next step is a boundary or an obstacle; and is the reward value when the next step is not the end, an obstacle or a boundary.
The accumulated reward Rn represents the sum of the rewards earned by the mass point U for all the steps from start to end.
where is the discount factor used to constrain the mass point U to take the long route.
To find a path that maximizes the accumulated reward over multiple learning sessions, the TD3 algorithm is used.
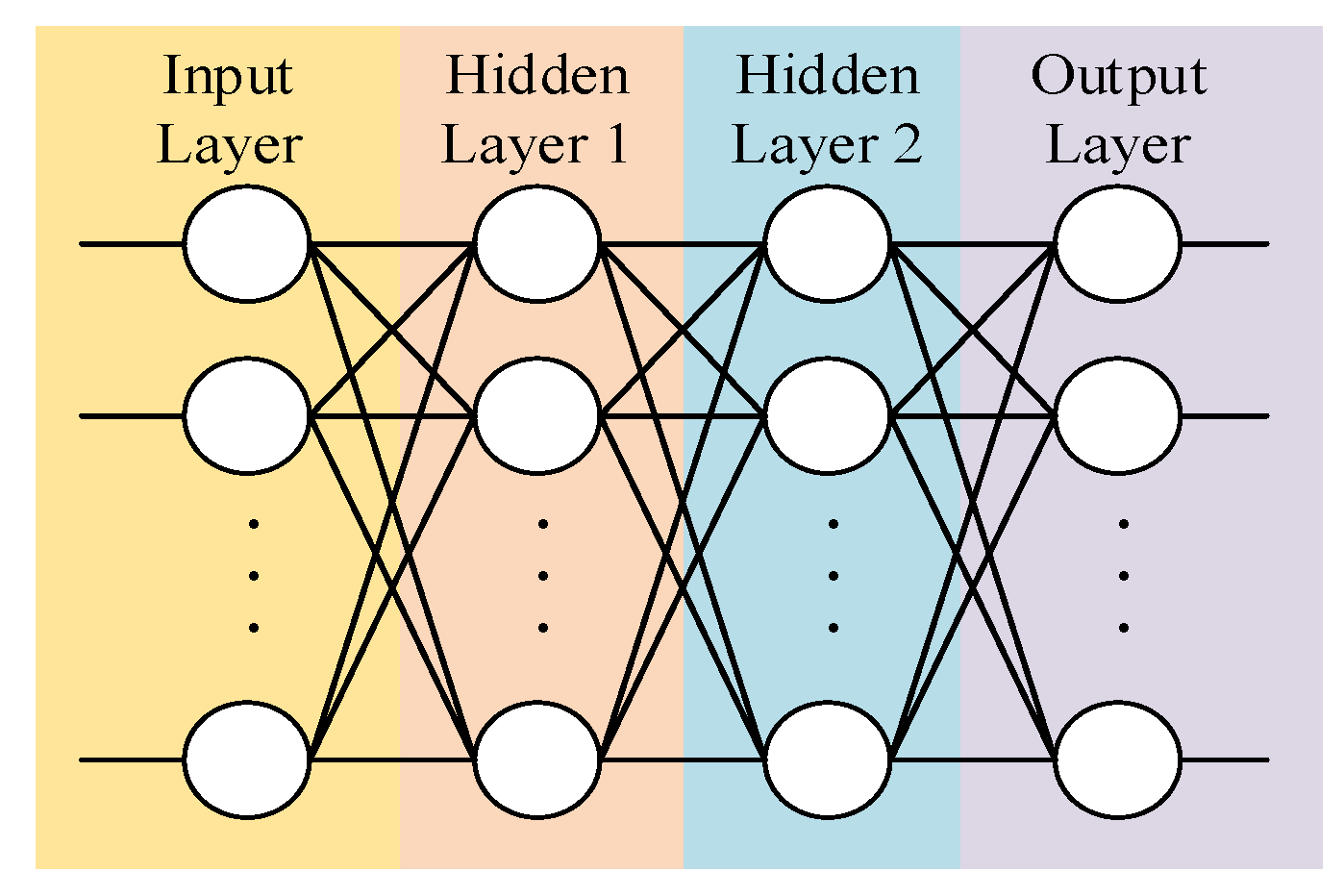
Defining a Critic network whose network topology is shown in Figure 5, the input is the state and action of the mass point U. The hidden layers 1 and 2 take 128 neurons, respectively, and the activation function adopts the Relu function. The output is the value evaluated on the input data.
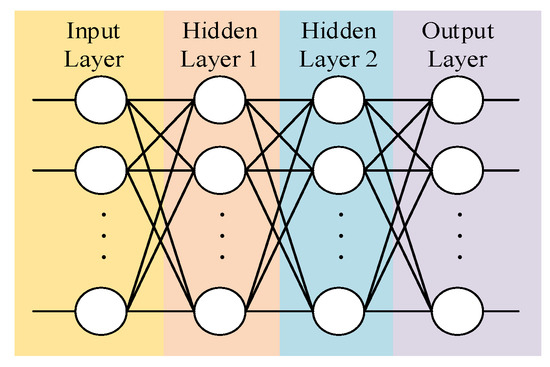
Figure 5.
Critic (Actor) neural network topology.
Defining an Actor network whose network topology is shown in Figure 5, the input is the state of the mass point U. The hidden layers 1 and 2 take 128 neurons, respectively, and the activation function adopts the Relu function. The output is the next actor.
Define the data pool for storing the planning trajectories of the mass point U. Define the synthesis module for synthesizing the Critic1 and Critic2 ratings to obtain the final action rating.
Critic network learning process: first, sample , , and calculate the TD target:
where is the Critic network’s evaluation value for state , and is the Critic network parameter.
Then, the TD error is calculated as:
Finally, the Critic network is trained using a gradient descent method:
where α is the learning rate.
The Actor network is trained using a gradient ascent method:
where λ is the Actor network parameters, is the decision made by the Actor network, and β is the learning rate.
To improve the astringency of Critic and Actor networks, during the network learning process, the dual network delay soft update is used.
The pseudocode for planning the path of the mass point U is as follows Algorithm 1:
| Algorithm 1 Planning the path of the point U | |
| 1 | |
| 2 | |
| 3 | |
| 4 | |
| 5 | for k = 1 to K do |
| 6 | |
| 7 | |
| 8 | by Equations (18) and (19) |
| 9 | are learned through Equation (20) |
| 10 | is learned through Equation (21) |
| 11 | if k mod d, then |
| 12 | |
| 13 | |
| 14 | |
| 15 | |
| 16 | end if |
| 17 | end for |
| 18 | |
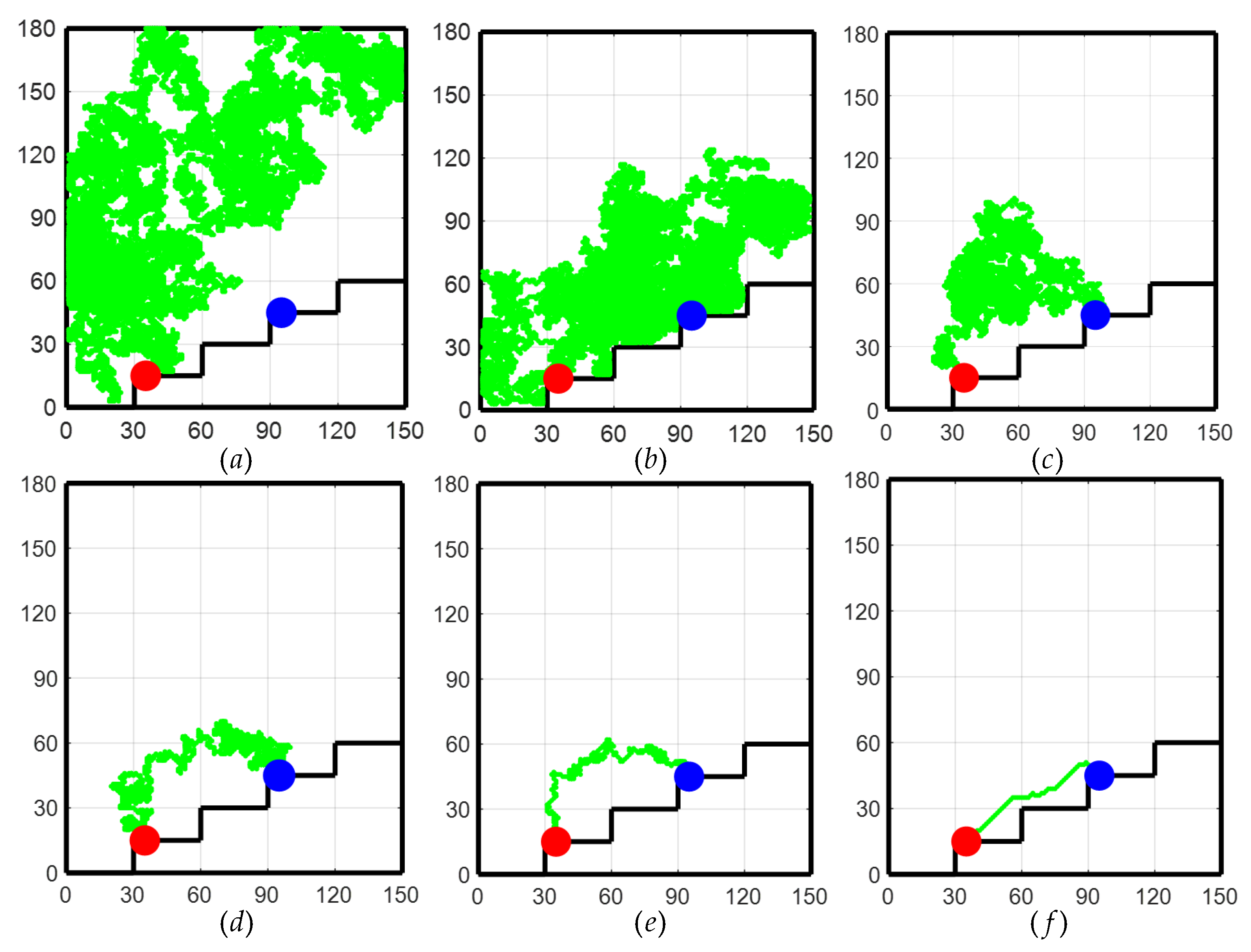
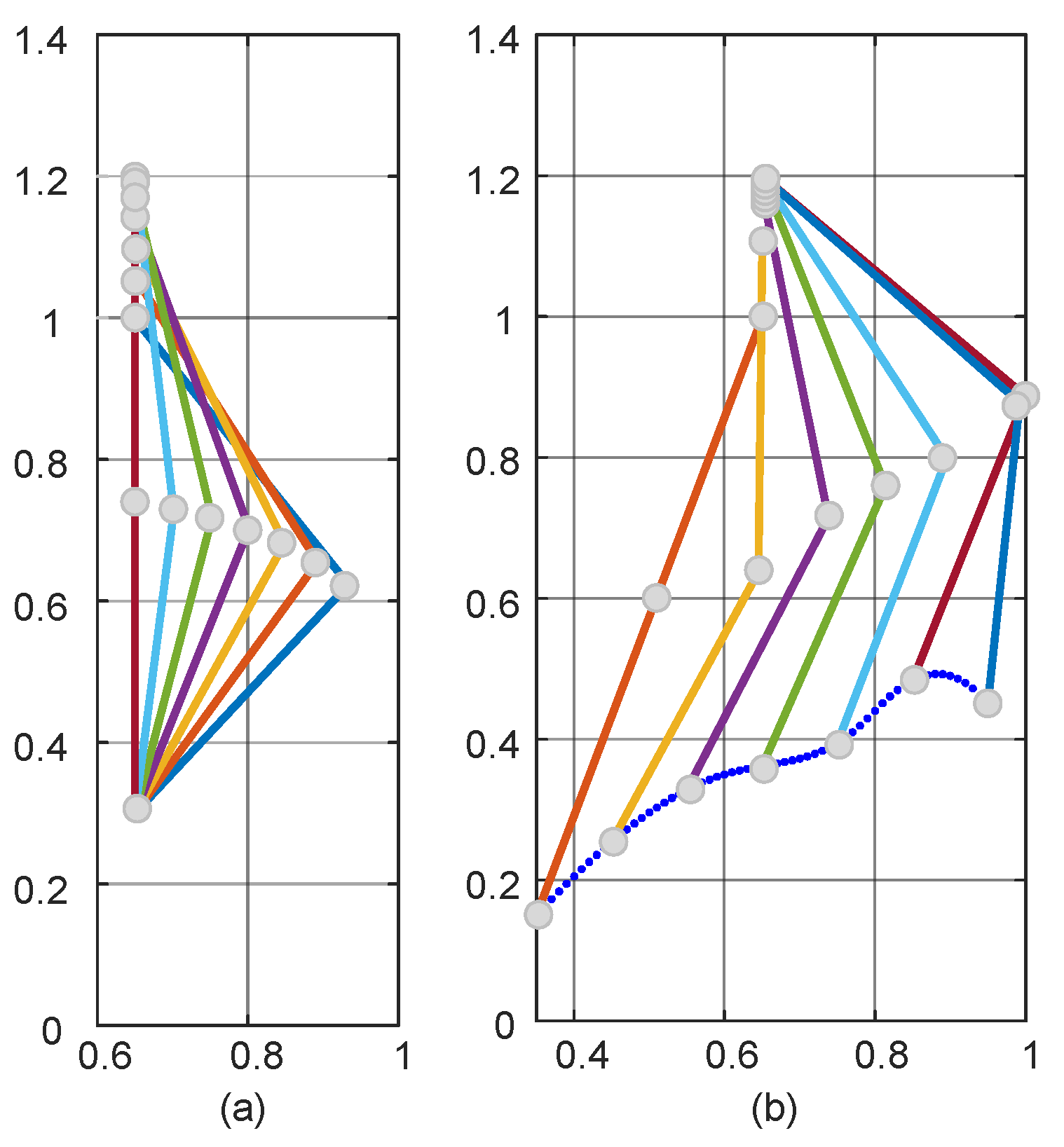
As shown in Figure 6 for the path planning process of the TD3 algorithm, initially, due to the lack of a priori knowledge, only the global exploration strategy could be used. This resulted in the LLERR struggling to find the end point, as shown in Figure 6a. However, with the passage of time and the accumulation of experience from a series of failures, the system gradually learned an effective path planning method and eventually succeeded in finding the end point, as shown in Figure 6b. After accumulating successful experiences, the system gradually optimized the planning of the movement path, resulting in shorter and more reasonable paths as shown in Figure 6c–e. After 2000 iterations of learning, the algorithm successfully planned a shorter, smoother, and more reasonable motion path. This path could initially be considered a target curve for subsequent LLERR control. It provided feasibility and guidance for the system to exhibit superior motion planning in applications. The result is shown in Figure 6f.
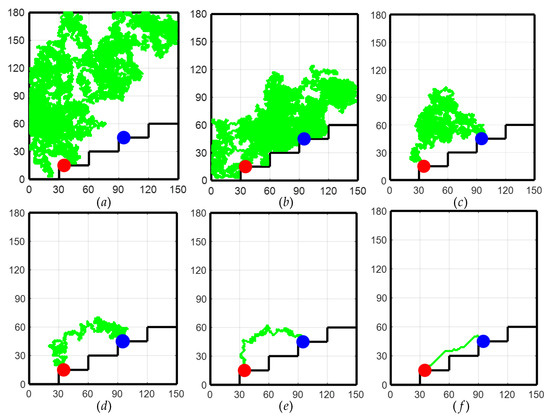
Figure 6.
Path planning process for the TD3 algorithm.
Remark 1.
In Figure 6, the red dots represent the starting point, the blue dots represent the target point, and the green dots represent the trajectory planned by the algorithm.
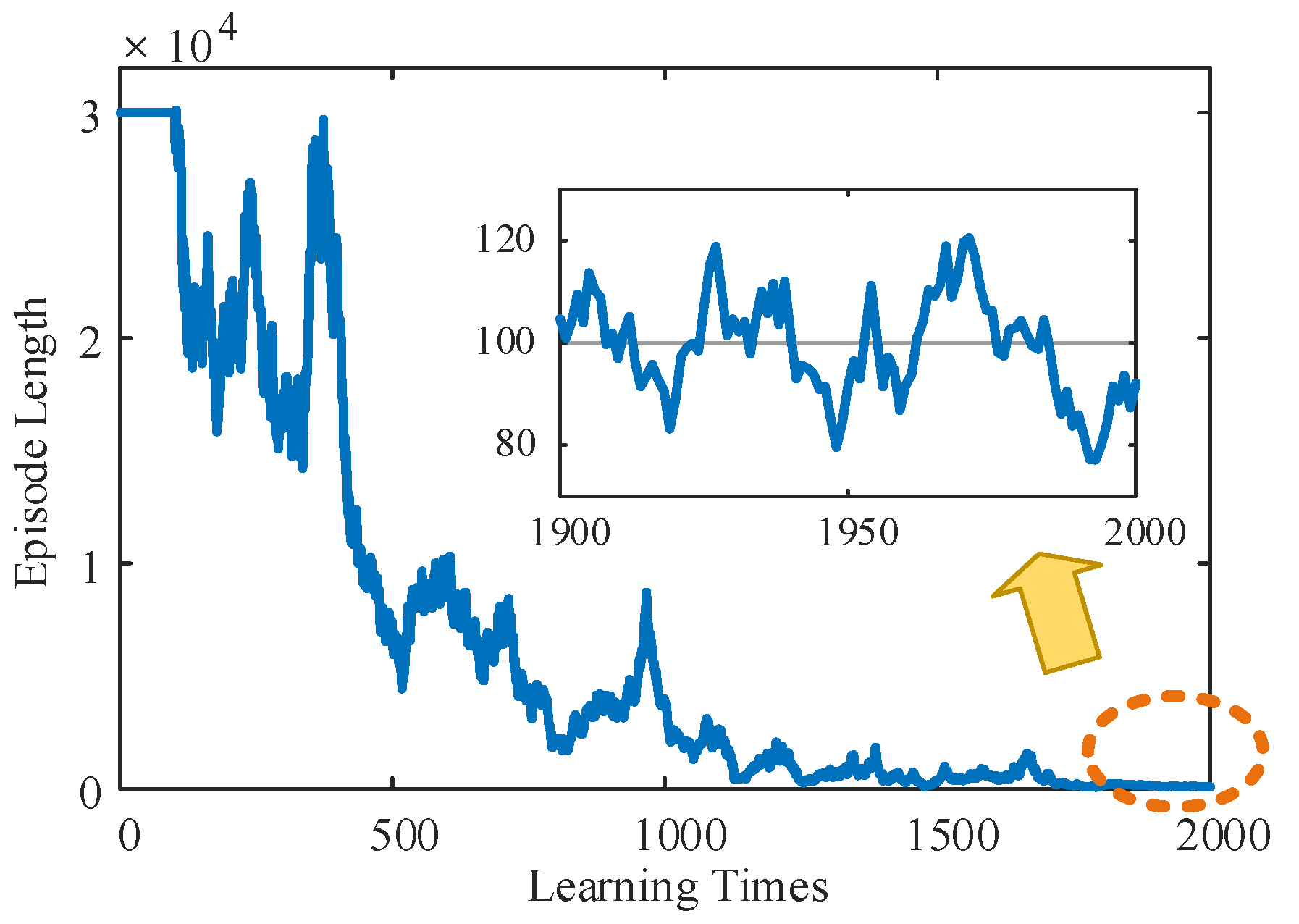
According to the learning stage of the TD3 algorithm shown in Figure 7, the relationship between the planning path length and learning times of mass point U, in the initial stage, due to the lack of experience, was not able to find the end point in 30,000 runs, which meant that the system was in the blind exploration stage and needed to carry out a wide exploration of the whole map. However, once the end point was successfully located, the LLERR began to accumulate experience in reaching it and entered the stage of searching for the optimal path. As successes accumulated, the length of planned paths tended to decrease. After approximately 2000 learnings, the length of the planned path stabilized at around 100 processes. This shows that the accumulation of experience and the optimization of the system make the search for the optimal path more efficient and stable.
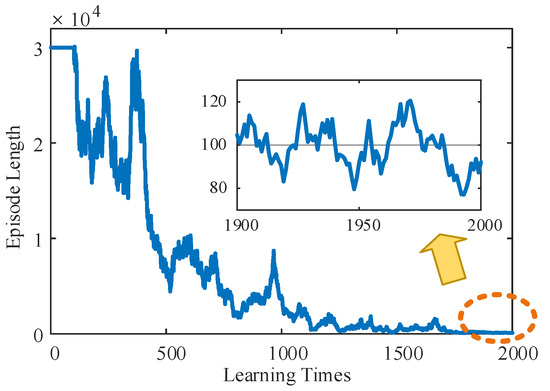
Figure 7.
The relationship between the planning path length and learning times of mass point U.
Remark 2.
In the previous paragraph, the TD3 algorithm reached a steady state after the 100th iteration and successfully planned the target trajectory of the right foot. Subsequently, the LLERR system followed this target trajectory and moved from the start point to the end point, thus assisting the patient to complete a full stride.
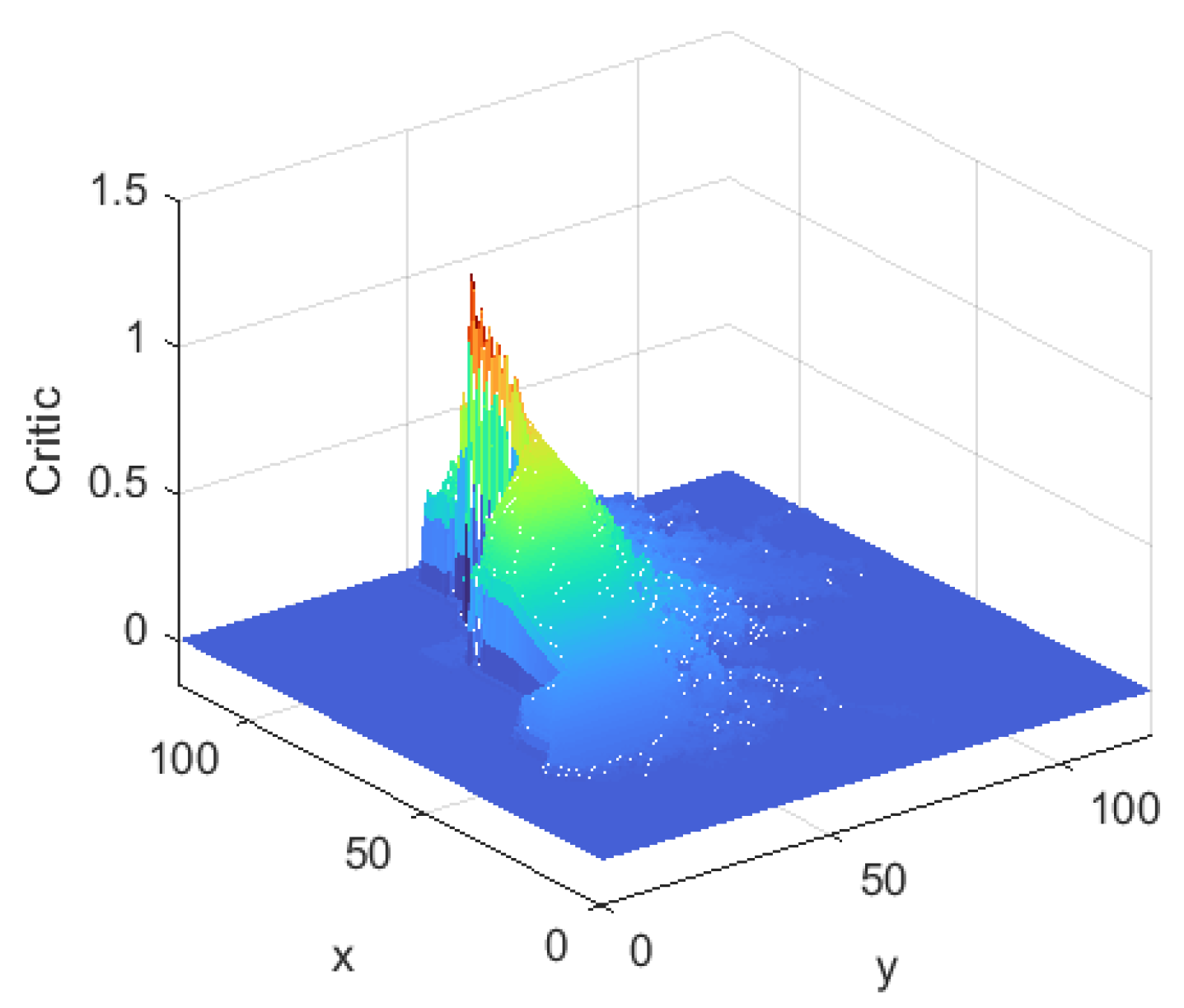
Figure 8 shows the evaluation system of the Critic after learning. It is red near the end point, with an evaluation value close to 1. In the color order of red, orange, yellow, green, green and blue, the evaluation value gradually decreases and eventually approaches 0. The rule that the farther away from the end point, the lower the evaluation value, clearly reflects the design principle of the evaluation system. The left side of the end point represents the inside of the staircase and therefore has a lower evaluated value in this area. Overall, the color distribution of the evaluation system was consistent with the characteristics of the environment and accurately reflected the evaluation values of different locations.
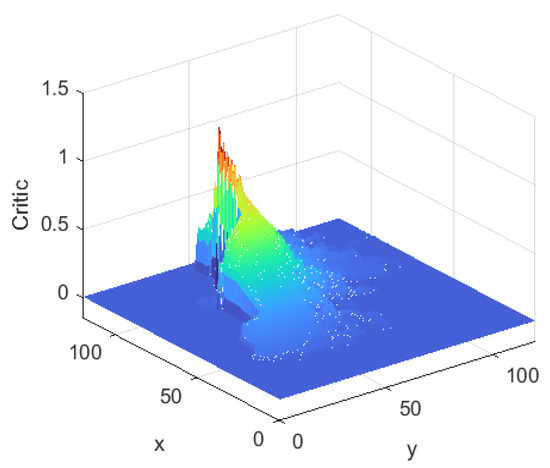
Figure 8.
Critic of TD3 algorithm.
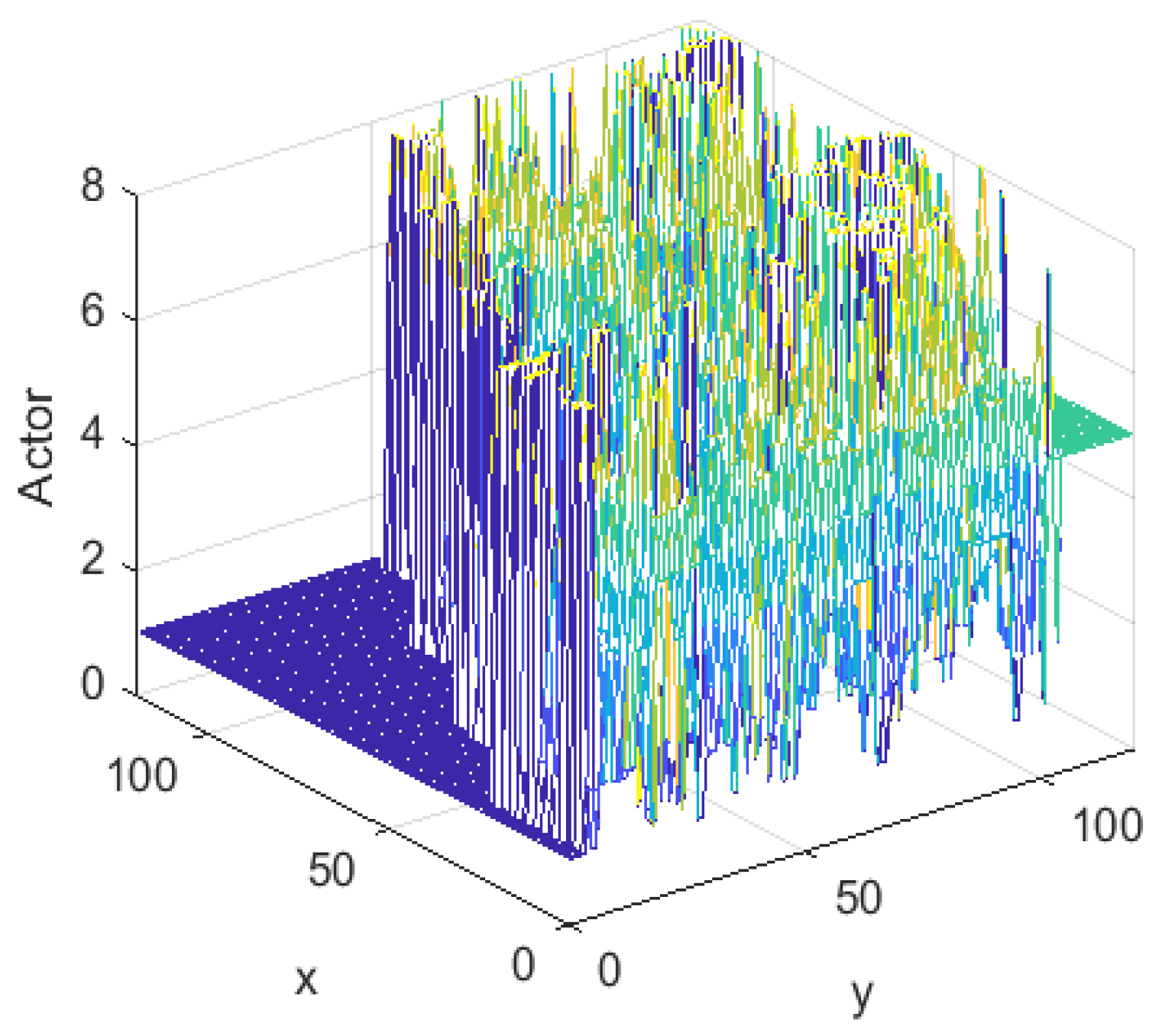
Figure 9 illustrates the Actor decision system that was learned. The left side of the figure represents the staircase region, which has a decision value of 90°. The colors, in order of purple, blue, cyan, green, yellow and orange correspond to different degrees of decision values between 90° and −270°, respectively. This decision system presented a reasonable distribution that matched the characteristics of the environment.
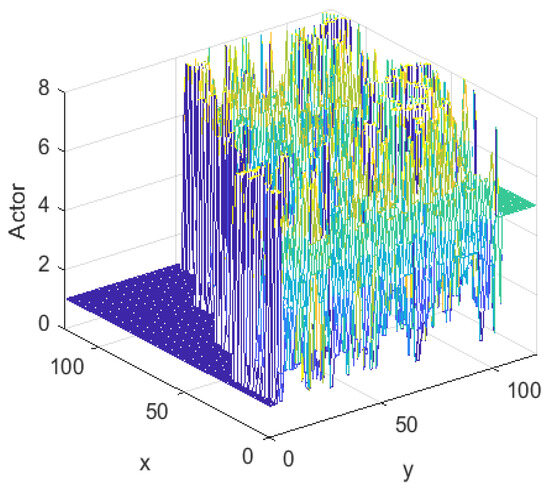
Figure 9.
Actor of TD3 algorithm.
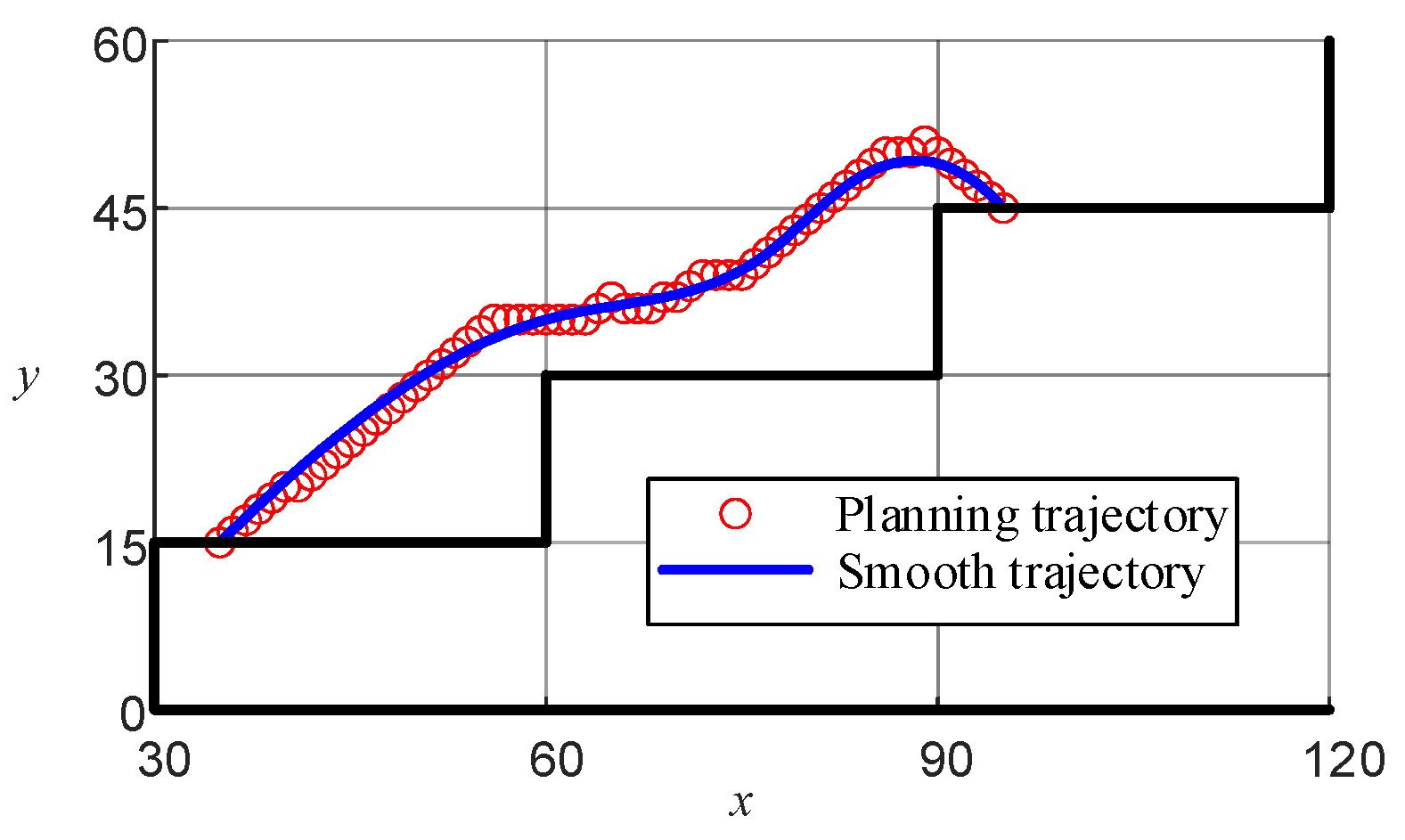
Figure 6f demonstrates that while the planning path could successfully navigate from the start to the end points, it lacked smoothness, which may negatively affect the motion control of the LLERR. To improve this, the cubic spline interpolation method was used to achieve a smoother planning path. The functional expression is shown in Equation (22), and the function plot is shown in Figure 10.
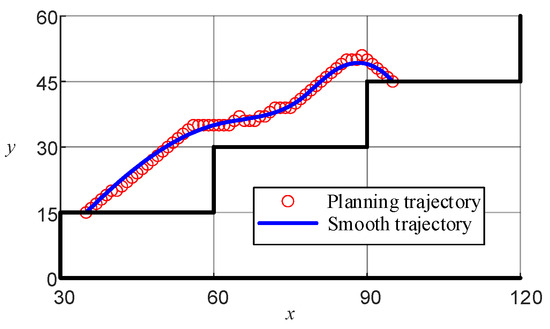
Figure 10.
Lower-limb exoskeleton right-sole target path.
3.2. Calculation of Angular Curves of Lower-Limb Motion Joints
The trajectories of the four joints of the left hip, left knee, right hip, and right knee can be deduced from the path of the right sole and the inverse kinematic equations of the LLERR. The expression is:
Figure 11 shows the schematic diagram of LLERR completing a stride. One cycle was 2 s. Figure 11a shows the movement process of the left leg, where the left sole’s position remains constant, and the knee contracts backward while the hip extends upward. Figure 11b shows the movement process of the right leg, where the sole is on the ground, and the leg is straight. Then, the sole gradually leaves the ground, and the knee starts to bend forward while the hip extends upward. The right and left legs move together to complete a single stride cycle.
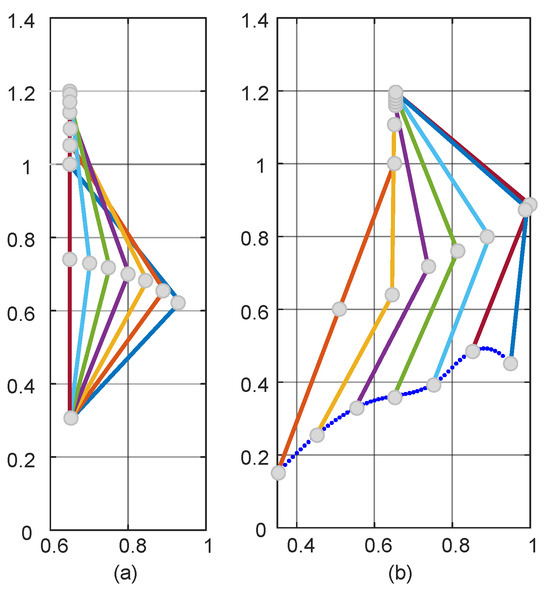
Figure 11.
Schematic diagram of lower-limb exoskeleton’s single-leg movement.
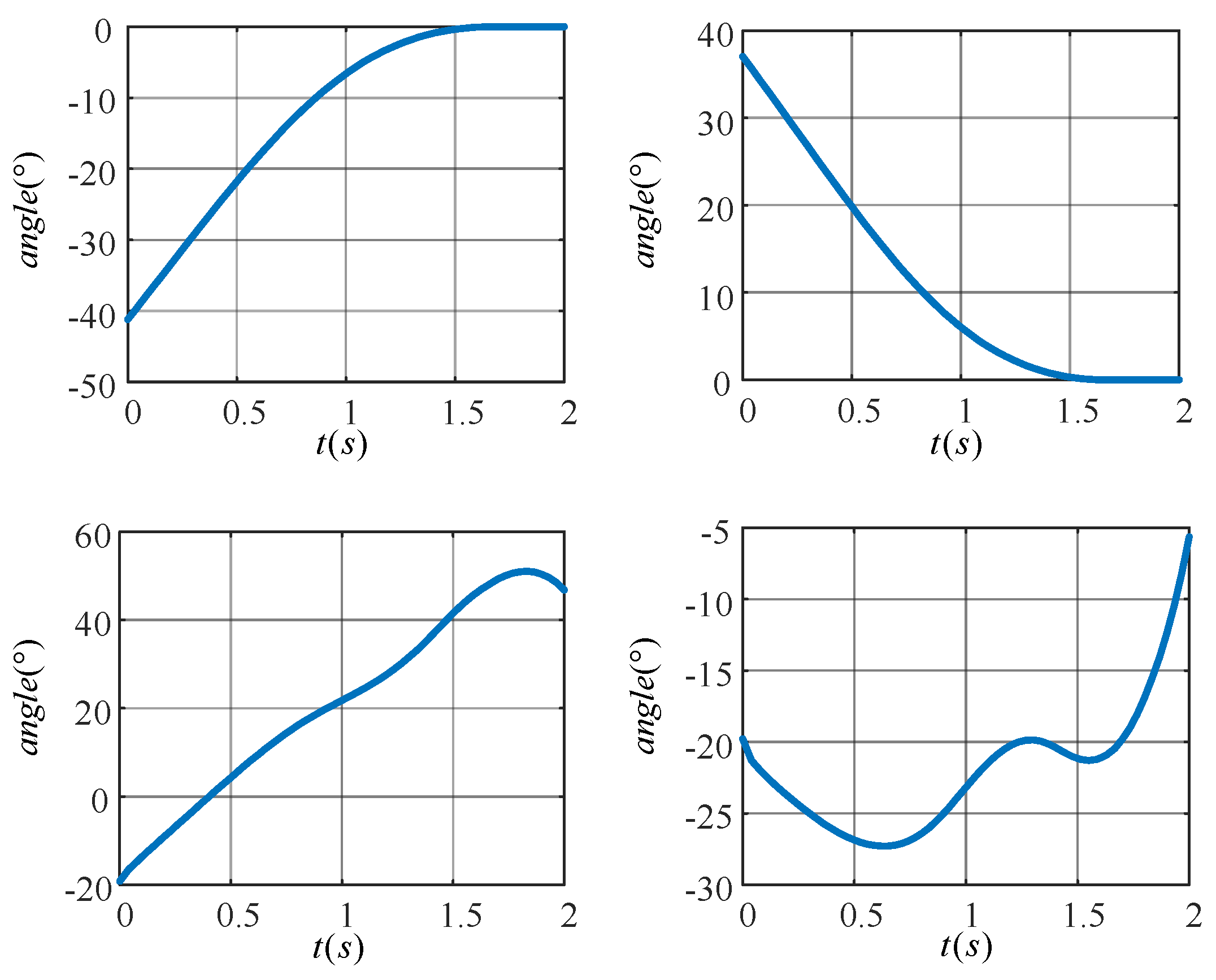
In Figure 12a,b, the target motion trajectories of the knee (hip) joint of the left leg are shown. The angle of the knee joint gradually increases to zero degrees while the angle of the hip joint gradually decreases to zero degrees as the left leg is shifted from a flexed state to an upright state. Figure 12c,d show the target motion trajectories of the knee (hip) joint of the right leg, which completes the movement up the stairs. The angle of the hip joint tends to increase, while the angle of the knee joint increases in a spiral fashion.
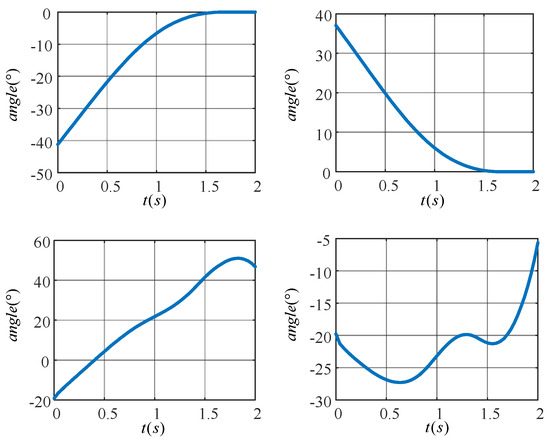
Figure 12.
Target motion trajectories of the joints of a lower extremity exoskeleton rehabilitation robot.
Compared with Habib Mohamad et al.’s paper [32], the lower-limb target motion trajectory planned by the method in this paper is smoother. This has a positive impact on the subsequent joint motor control process. At the same time, the smoother motion trajectory design is more in line with the law of natural human movement, which effectively reduces the patient’s discomfort and potential risk of injury during the rehabilitation training process.
3.3. Motion Trajectory Tracking Control of a Lower-Limb Exoskeleton Rehabilitation Robot
Motion control of the LLERR is a continuous output problem, so in this subsection, we adopted the use of the continuous output TD3 algorithm. The algorithm’s framework aligns with the depiction in Figure 4 as previously discussed.
Define the hip (knee) joint angle of the LLERR to be at moment t. The state space is continuous, and the space set is:
Define the hip (knee) joint drive of the LLERR as action with a continuous action space, and space set is:
Define the single-step reward function as:
Define the accumulated reward, the sum of all rewards earned by the LLERR after performing action as
The goal of using the TD3 algorithm for LLERR motion control is to find the appropriate over multiple learning sessions that allows the LLERR to track the planned trajectory, thus obtaining the maximum accumulated reward
Define a Critic network; its network topology is shown in Figure 5. The input is the joints’ angle and joints’ drive of the LLERR. The hidden layers 1 and 2 take 128 neurons, respectively, and the activation function adopts the Relu function. The output is the value of evaluating the input data.
Define an Actor network, whose network topology is shown in Figure 5 above; the input is the joints’ angle of the LLERR. The hidden layers 1 and 2 take 128 neurons, respectively, and the activation function adopts the Relu function. The output is the joints drive .
Define the data pool for storing the joints’ angle motion trajectory of the LLERR. Define the synthesis module for synthesizing the Critic1 and Critic2 ratings to obtain the final action rating.
The pseudocode for the TD3 algorithm to control the motion of the LLERR is as follows Algorithm 2:
| Algorithm 2 Motion control of a lower-limb exoskeleton rehabilitation robot | |
| 1 | initial and target angles. |
| 2 | |
| 3 | |
| 4 | |
| 5 | for k = 1 to K do |
| 6 | |
| 7 | and obtain 0 |
| 8 | by Equations (18) and (19) |
| 9 | are learned through Equation (20) |
| 10 | is learned through Equation (21) |
| 11 | if k mod d, then |
| 12 | |
| 13 | |
| 14 | |
| 15 | |
| 16 | end if |
| 17 | end for |
| 18 | were inputted into the lower-limb exoskeleton rehabilitation robot to enable it to accurately track the target motion trajectory shown in Figure 12. The patient’s lower limb was successfully trained to climb the stairs in a single cycle. |
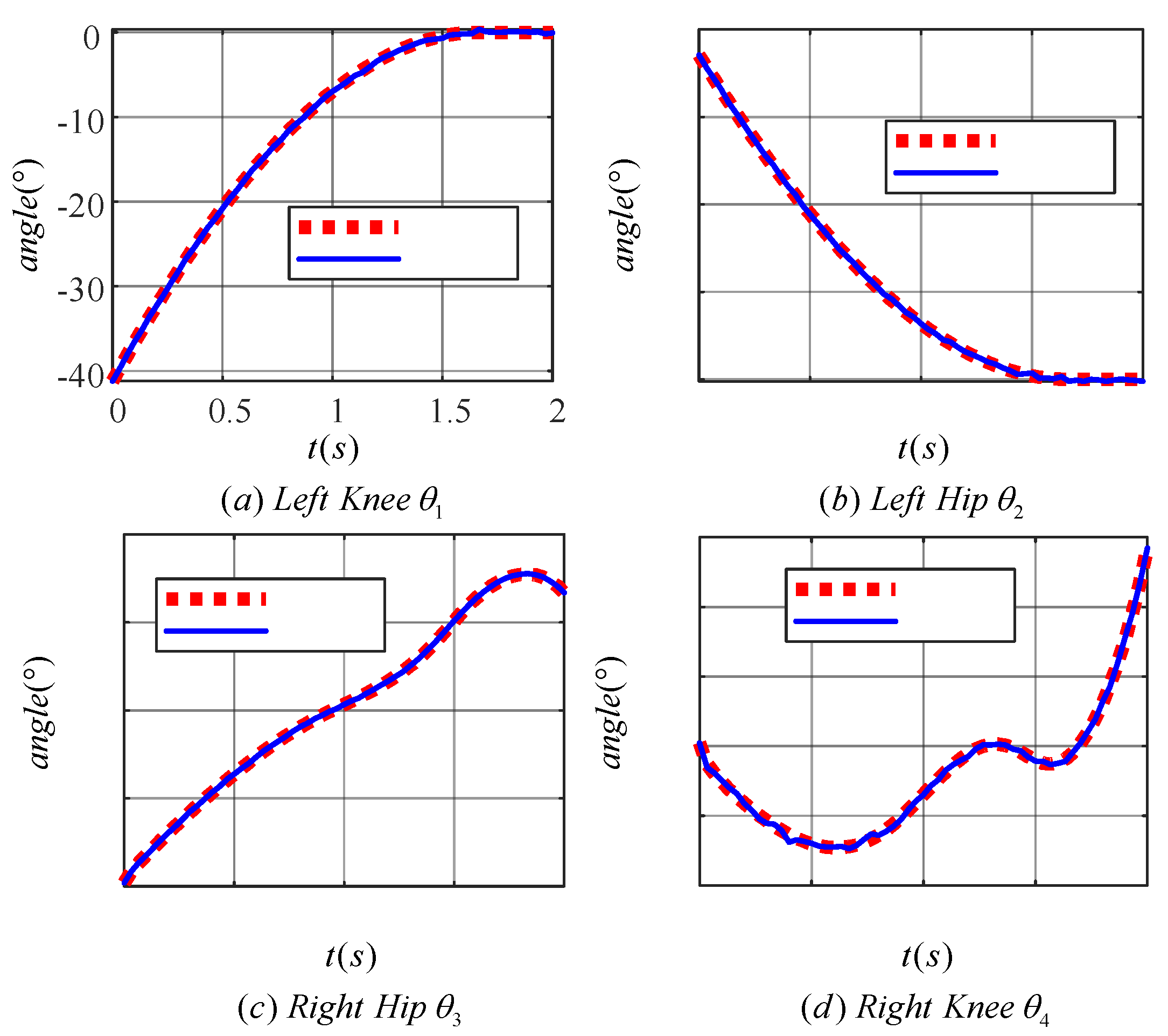
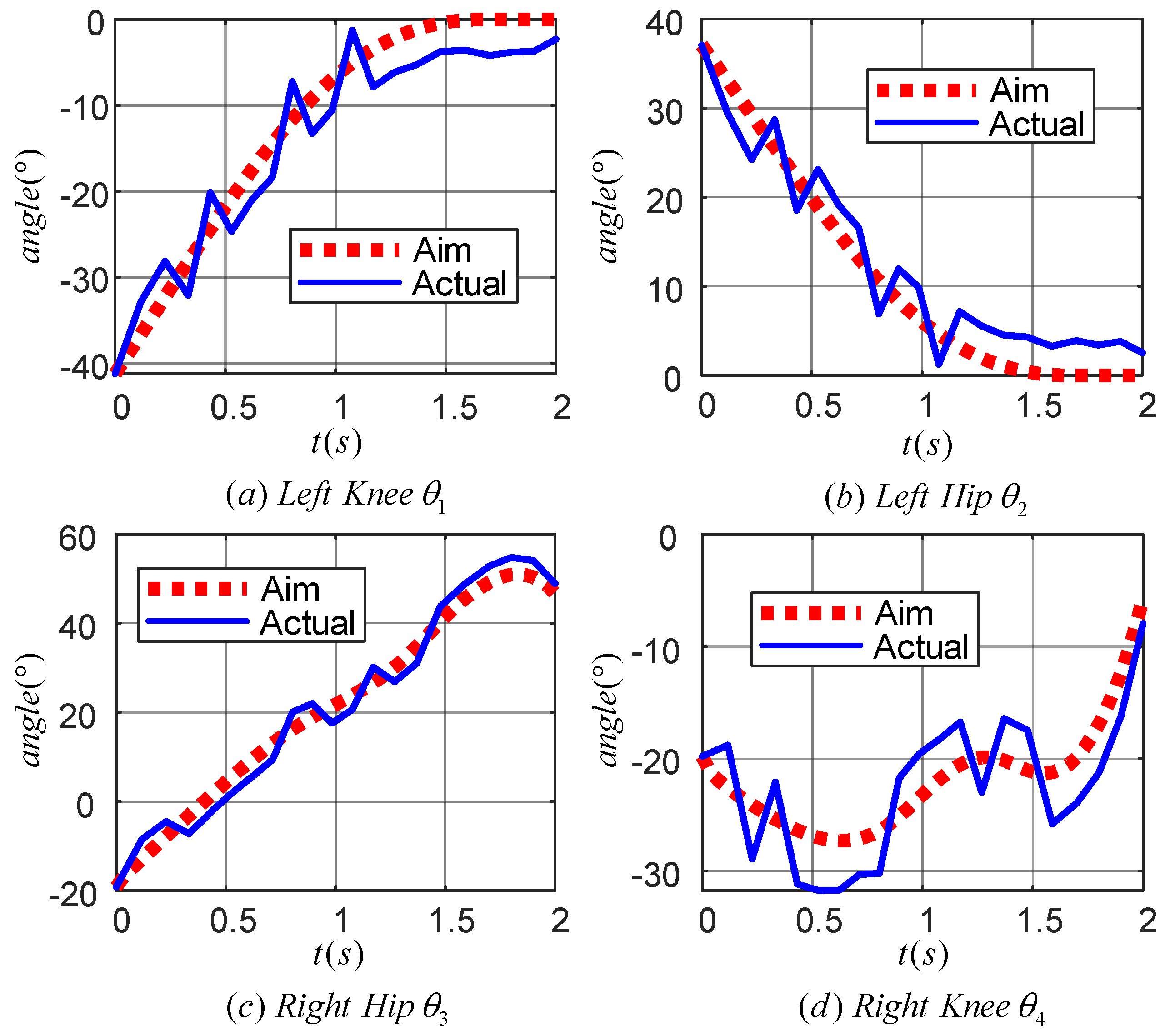
Figure 13 demonstrates the effect of the learned TD3 algorithm on the control of LLERR. Subplots (a) and (b) present the angle tracking curves of the left leg hip and knee joints, while (c) and (d) show the angle tracking curves of the right leg’s hip and knee joints. In these curves, the red dotted line indicates the target joint angle, while the blue solid line indicates the output curve of the actual joint angle of the LLERR under the action of the TD3 algorithm. By observing these plots, it was found that the red dotted line and the blue solid line trended in basically the same way. This indicated that the actual output angle of the LLERR under the action of the TD3 algorithm could effectively track the target trajectory, which made the LLERR meet the needs of patients’ lower-limb rehabilitation in the staircase environment.
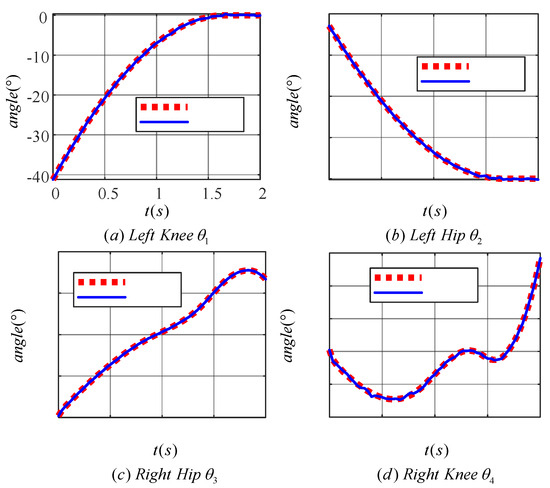
Figure 13.
Joint angle tracking curves of a lower-limb exoskeleton rehabilitation robot.
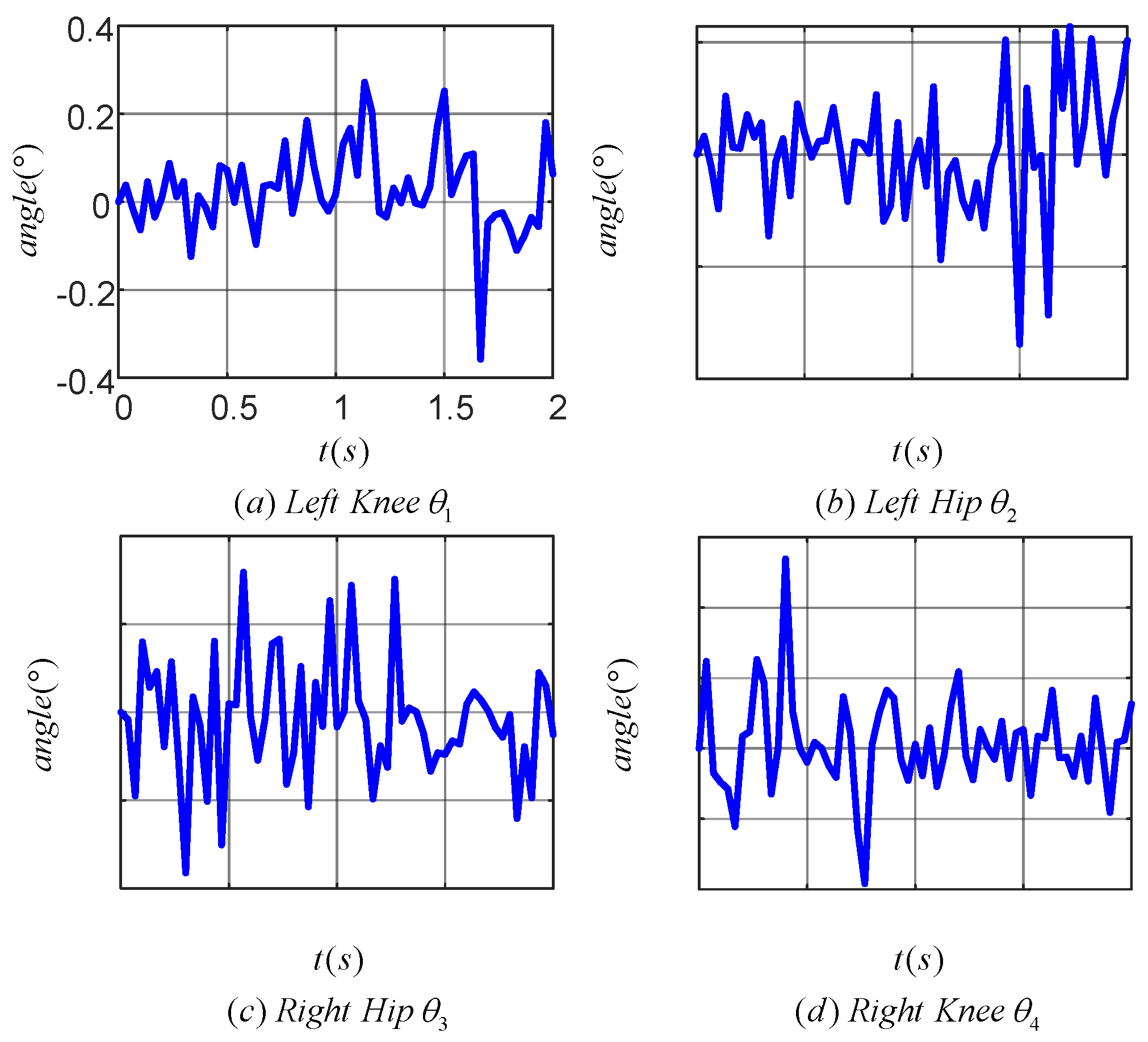
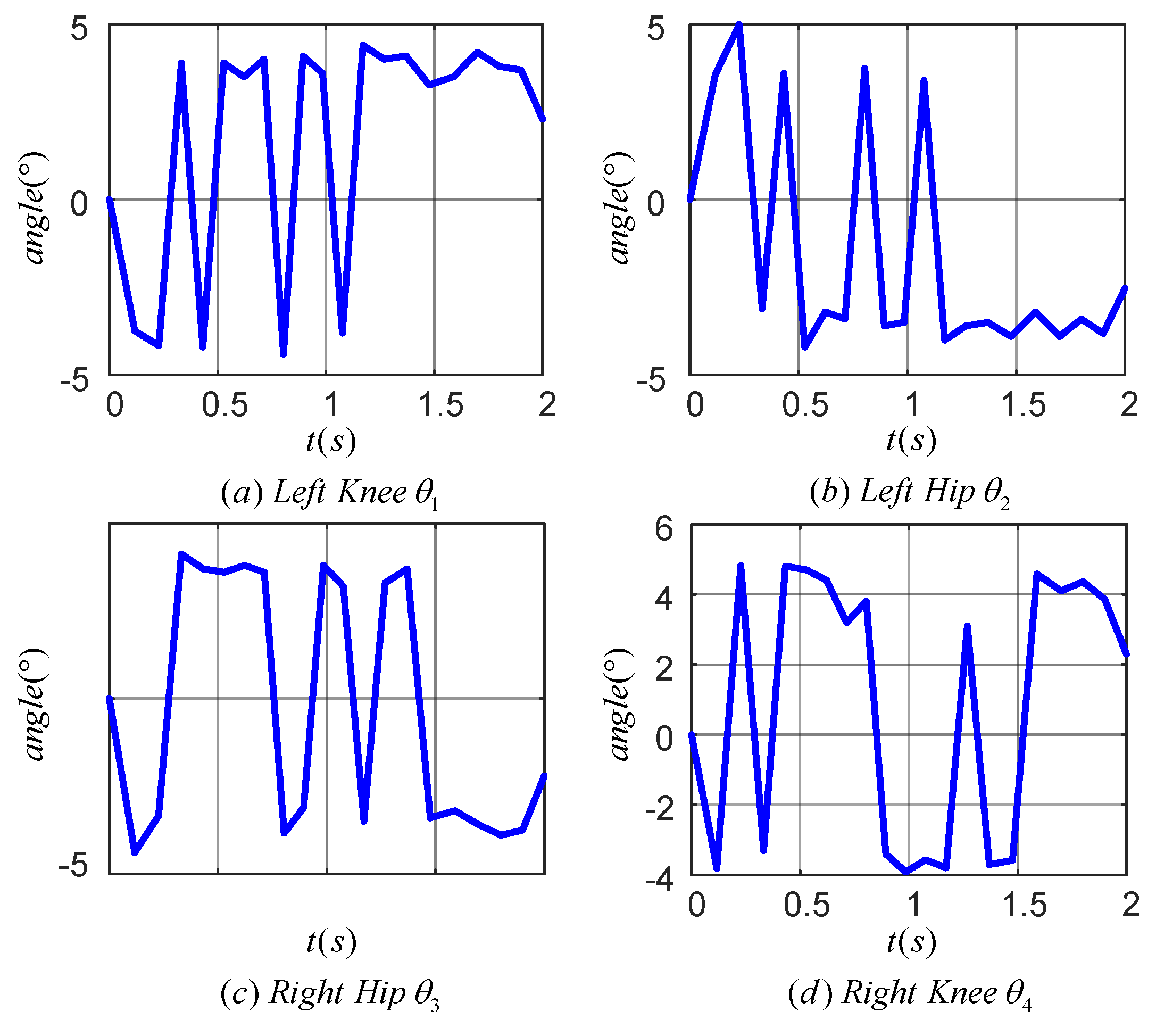
Figure 14 illustrates the tracking error of the TD3 algorithm for controlling the angle of the lower limb joints. Plots (a), (b), (c), and (d) correspond to the tracking errors of the left knee, left hip, right hip and right knee joints, respectively. The maximum tracking error was within 0.4° for the left knee, 0.4° for the left hip, 0.2° for the right hip, and 0.6° for the right knee. The results indicated that the TD3 algorithm was effective in reducing the angular tracking error of each joint of the LLERR. This demonstrated the TD3 algorithm’s efficacy from an error analysis perspective.
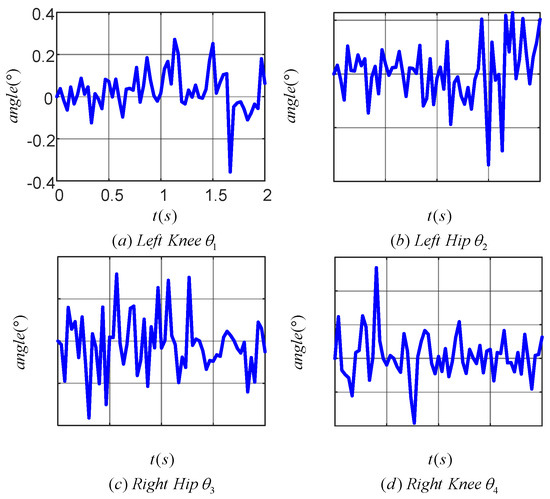
Figure 14.
Joint angle tracking error curves of a lower-limb exoskeleton rehabilitation robot.
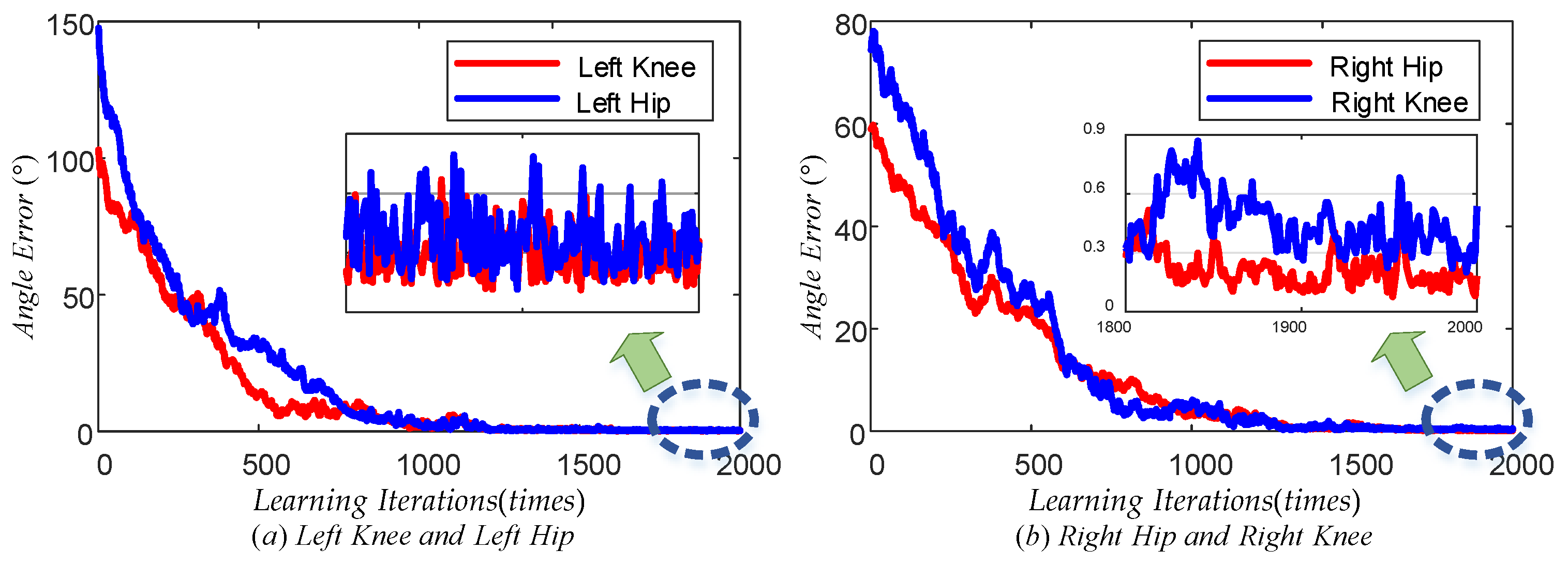
Figure 15 illustrates the maximum tracking error trend of the TD3 algorithm for the left knee, left hip, right hip, and right knee during the learning phase. The red line represents the maximum tracking error of the left knee, while the blue line represents the maximum tracking error of the left hip in plot (a). Similarly, the red line represents the maximum tracking error of the right hip, while the blue line represents the maximum tracking error of the right knee in plot (b). Observing these plots, it can be concluded that all four curves exhibited a decreasing trend from a global perspective. This indicated that the maximum tracking error of each joint angle gradually decreased as the number of learning times increased. From a local perspective, the trend of decreasing the maximum tracking error for each joint became slow once the number of learning times reached a specific threshold. Specifically, following 1800 learning sessions, the maximum error was stabilized at approximately 0.4° for the left knee, 0.5° for the left hip, 0.2° for the right hip, and 0.6° for the right knee. When the number of learning iterations was less, the blue line in both (a) and (b) plots showed an increasing trend, which indicated that the learning direction of the left hip joint and the right knee joint was not accurate enough at the beginning of learning due to the lack of experience, but with the accumulation of experience, the learning direction was gradually adjusted to the correct direction. The above results demonstrated that the TD3 algorithm could effectively reduce the error of the LLERR after multiple learning iterations. This proved the effectiveness of the TD3 algorithm from the learning process.
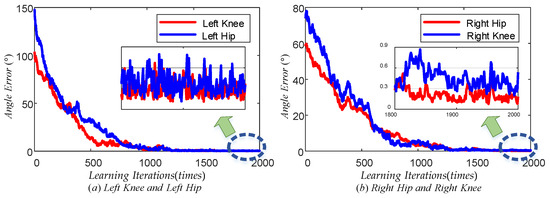
Figure 15.
Maximum joint angle error vs. learning iterations.
4. Prototype Experiment of Lower-Limb Exoskeleton Rehabilitation Robot
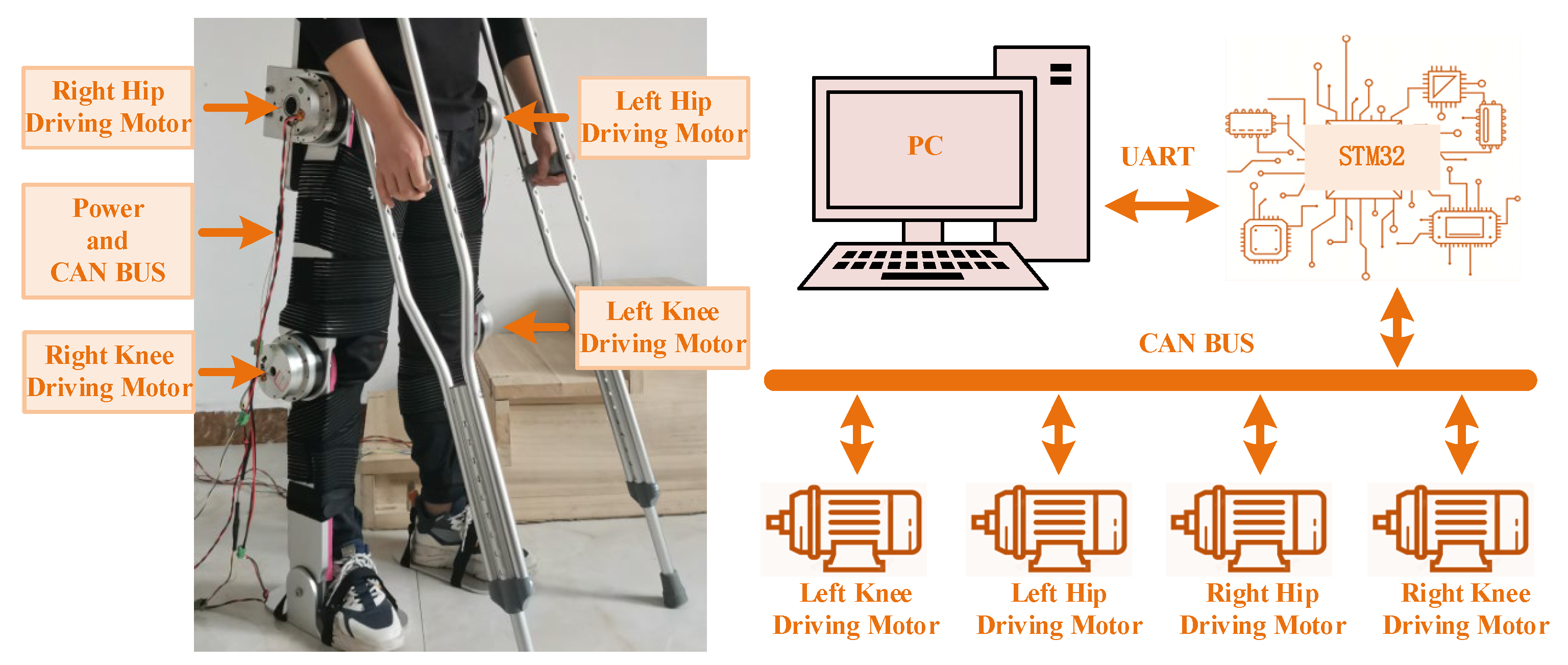
Figure 16 shows the experimental prototype test platform of the LLERR. We invited a volunteer with a height of 165 cm, weight of 65 kg, shank length of 43 cm, and thigh length of 47 cm to climb a staircase with a height of 15 cm per step in the experimental environment. The parameters of each drive motor of the LLERR were as follows: the hip joint drive motor had a rated speed of 27 PRM, a rated torque of 133 N∙M, and a peak torque of 194 N∙M; the knee joint drive motor had a rated speed of 35 PRM, a rated torque of 107 N∙M, and a peak torque of 169 N∙M. The encoder resolution was 17 bits. The entire prototype platform was powered by a 48 V supply voltage, and the CAN bus was used for communication. The bottom motor drive control core was an STM32F407, and the upper TD3 algorithm running platform was a PC (Intel i7).
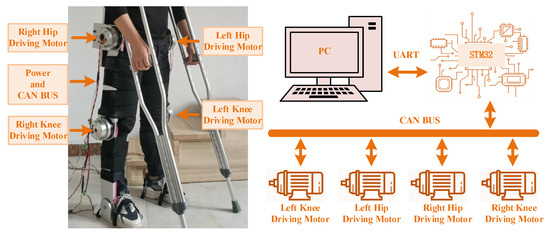
Figure 16.
Experimental prototype testing platform for lower-limb exoskeleton rehabilitation robot.
The trained model from the previous section was applied to the LLERR prototype testbed. It was used to plan the trajectory of the right sole and determine the motion curve of the target hip (knee) joint angle through backpropagation. Subsequently, the TD3 algorithm was used to control the joints of the LLERR to track the target curve. Finally, we observed the exercise effect of the LLERR and evaluated its performance and effectiveness in rehabilitation tasks.
Figure 17 shows the testing process of the LLERR prototype. Plot (a) shows the volunteer wearing the LLERR lower limb exoskeleton with upright legs and holding double crutches as the initial state. Plot (b) shows the volunteer adjusting the position of the crutches, then the LLERR starting to plan the motion trajectory of the left-foot sole and backpropagating the target angle profile of the left (right) hip (knee) joint. Plot (c) shows the LLERR running the TD3 algorithm to control the left leg to complete the movement of the previous step, then planning the movement trajectory of the right-foot sole and backpropagating the target angle curve of the left (right) hip (knee) joint. Plot (d) shows the LLERR running the TD3 algorithm to control the right leg to complete the movement of the previous step. Plot (e) shows the crutches moving one step and next, the LLERR planning the trajectory of the left-foot sole and inversely extrapolating the target angle profile of the left (right) hip (knee) joint. Plot (f) shows the LLERR running the TD3 algorithm to control the left leg to complete the movement of the previous step. Plot (g) shows the crutch moving one step and the test completing.

Figure 17.
Prototype control system testing process of lower-limb rehabilitation robot.
The test results showed that the LLERR successfully completed the following tasks: planning the movement path of the sole, inferring the target angle curve of the hip (knee) joint, and controlling the hip (knee) joint motor to track the target angle curve. These operations enabled the LLERR to guide the volunteer through the process of walking up the stairs. Therefore, the LLERR can effectively assist patients with lower-limb motor rehabilitation in a staircase.
Figure 18 displays the motion curves of the hip (knee) joint angle of the LLERR prototype in the staircase environment running one cycle. The red dotted line represents the target joint angle curve, while the blue solid line represents the actual output curve of the LLERR joint angle. Overall, the trend of the LLERR joint angles was consistent with the target curve, indicating that the TD3 algorithm could control the joints of the LLERR to move according to the target trajectory. However, based on local observations, the actual motion trajectories of each joint of the LLERR deviated from the target motion trajectories and differed from the simulation effect graph shown in Figure 13. Possible causes of the issue included the following: during the modelling process, only the motion of the lower limbs in the sagittal plane was considered. However, the actual LLERR moved in three-dimensional space, which introduced some errors into the modelling. Additionally, the application of the TD3 algorithm was carried out based on the model established in the mathematical model section, and it is difficult to achieve accurate control when the actual model of the LLERR does not exactly match the training model, resulting in a certain gap between the actual motion trajectory and the expected trajectory. Despite these deviations, from the perspective of the prototype’s operation, the LLERR could effectively assist volunteers in climbing the stairs, indicating the effectiveness of the TD3 algorithm.
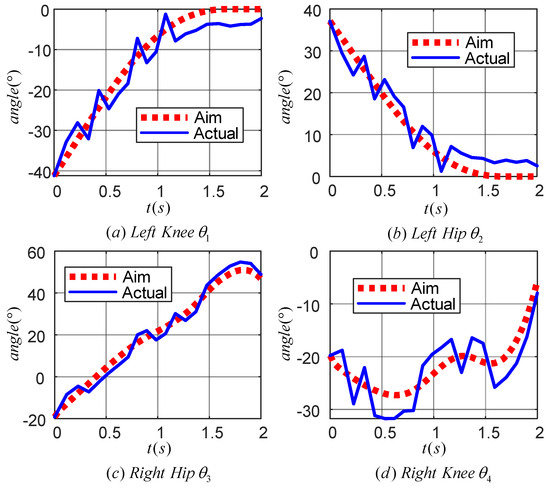
Figure 18.
Joint angle tracking curve of the prototype lower-limb exoskeleton rehabilitation robot.
Figure 19 displays the tracking error for each joint during one cycle of the LLERR. The angular tracking errors for the hip and knee joints were all within 5°, but there was an increase in error compared to the 0.6° error in Figure 14. Looking at the error curves for each joint, the errors were all above 2°. This could be attributed to the motor’s response delay and imprecise control of the current in the motor torque mode. However, overall, these tracking errors were not significant and did not hinder the LLERR’s success in climbing the stairs. This demonstrated the TD3 algorithm’s efficacy from an error analysis perspective.
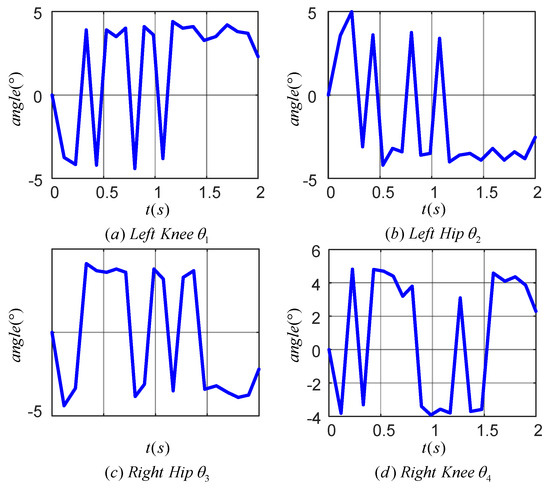
Figure 19.
Joint tracking error of lower limb exoskeleton rehabilitation robot prototype.
5. Conclusions
The aim of this study was to investigate the control of lower-limb joint movement of an LLERR in a staircase setting. Initially, a mathematical model was developed. The planning of motion for the right-foot sole was executed using the TD3 algorithm. The target motion curve of the hip (knee) joint was derived through the kinematic law, leading to successful control of the joint motion of the LLERR. Theoretical simulation experiments and prototype experiments illustrated that the motion trajectory of the LLERR corresponded with the target trajectory. Despite some errors, they did not impede the LLERR’s objective of assisting the patient in climbing the staircase.
The results presented in this paper have significant theoretical and practical implications for the design and application of LLERRs, providing valuable insights and references for future research. However, there are some limitations in this study. For example, the error in the experiment still needs to be further reduced. The robot only moved in the sagittal plane. Moreover, the applicability of the algorithm in complex environments needs to be further verified. Future research can further improve the algorithm and construct more accurate 3D dynamic models to enhance its stability and accuracy in practical applications. In addition, the motion control strategy of the LLERR in unpredictable environments will be explored to adapt to a wider range of rehabilitation application scenarios.
Author Contributions
Conceptualization, Y.G. and M.H.; methodology, Y.G.; software, M.H.; validation, M.H., X.T. and M.Z.; formal analysis, Y.G., X.T. and M.Z.; investigation, L.H.; resources, Y.G.; data curation, M.Z.; writing—original draft preparation, M.H., X.T. and M.Z.; writing—review and editing, Y.G., M.H. and L.H.; visualization, M.H.; supervision, Y.G. and L.H.; project administration, M.H. and M.Z.; funding acquisition, L.H. and M.H. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Sichuan Provincial Regional Innovation Cooperation Project, grant number 2023YFQ0092; the Sichuan Provincial Regional Innovation Cooperation Project, grant number 2024YFHZ0209; Project for Enhancing Young and Middle aged Teacher’s Research Basis Ability in Colleges of Guangxi, grant number 2024KY0723; the Sichuan Natural Science Foundation, grant number 2023NSFSC0368.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study.
Data Availability Statement
The data presented in this study are available on request from the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Stewart, C.E.; Sharples, A.P. Aging, Skeletal Muscle, and Epigenetics. Plast. Reconstr. Surg. 2022, 150, 27S–33S. [Google Scholar] [CrossRef] [PubMed]
- Béjot, Y.; Duloquin, G.; Graber, M.; Garnier, L.; Mohr, S.; Giroud, M. Current characteristics and early functional outcome of older stroke patients: A population-based study (Dijon Stroke Registry). Age Ageing 2021, 50, 898–905. [Google Scholar] [CrossRef] [PubMed]
- Zhang, M.K.; Wei, J.N.; Wu, X.P. Effects of whole-body vibration training on lower limb motor function and neural plasticity in patients with stroke: Protocol for a randomised controlled clinical trial. BMJ Open 2022, 12, 9. [Google Scholar] [CrossRef] [PubMed]
- Matuja, S.S.; Ngimbwa, J.; Andrew, L.; Shindika, J.; Nchasi, G.; Kasala, A.; Paul, I.K.; Ndalahwa, M.; Mawazo, A.; Kalokola, F.; et al. Stroke characteristics and outcomes in urban Tanzania: Data from the Prospective Lake Zone Stroke Registry. Int. J. Stroke 2024, 19, 536–546. [Google Scholar] [CrossRef]
- Xu, Q.; Lei, L.; Lin, Z.G.; Zhong, W.M.; Wu, X.H.; Zheng, D.Z.; Li, T.B.; Huang, J.Y.; Yan, T.B. An machine learning model to predict quality of life subtypes of disabled stroke survivors. Ann. Clin. Transl. Neurol. 2024, 11, 404–413. [Google Scholar] [CrossRef]
- Liu, B.L.; Gao, D.M.; An, W.H.; Zeng, F.S.; Cui, B.J.; Huang, L.G. Safety and effectiveness of rehabilitation training for stroke complicated with muscular call vein thrombosis: An observational study. Medicine 2023, 102, 5. [Google Scholar] [CrossRef]
- Wang, J.; Ma, R.; Qu, Y. Progress of Telerehabilitation Techniques in Stroke Patients with Lower Extremity Dysfunction. Chin. J. Med. Instrum. 2019, 43, 188–191. [Google Scholar]
- Shi, D.; Wang, L.D.; Zhang, Y.Q.; Zhang, W.X.; Xiao, H.; Ding, X.L. Review of human-robot coordination control for rehabilitation based on motor function evaluation. Front. Mech. Eng. 2022, 17, 14. [Google Scholar] [CrossRef]
- Xue, X.L.; Yang, X.W.; Tu, H.; Liu, W.N.; Kong, D.Z.; Fan, Z.H.; Deng, Z.Y.; Li, N. The improvement of the lower limb exoskeletons on the gait of patients with spinal cord injury A protocol for systematic review and meta-analysis. Medicine 2022, 101, 6. [Google Scholar] [CrossRef]
- Guo, Z.; Ye, J.; Zhang, S.S.; Xu, L.S.; Chen, G.; Guan, X.; Li, Y.Q.; Zhang, Z.M. Effects of Individualized Gait Rehabilitation Robotics for Gait Training on Hemiplegic Patients: Before-After Study in the Same Person. Front. Neurorobot. 2022, 15, 10. [Google Scholar] [CrossRef]
- Portaro, S.; Ciatto, L.; Raciti, L.; Aliberti, E.; Aliberti, R.; Naro, A.; Calabro, R.S. A Case Report on Robot-Aided Gait Training in Primary Lateral Sclerosis Rehabilitation: Rationale, Feasibility and Potential Effectiveness of a Novel Rehabilitation Approach. Innov. Clin. Neurosci. 2021, 18, 15–19. [Google Scholar] [PubMed]
- Lu, Y.; Cao, Y.D.; Chen, Y.; Li, H.; Li, W.H.; Du, H.P.; Zhang, S.W.; Sun, S.S. Investigation of a wearable piezoelectric-IMU multi-modal sensing system for real-time muscle force estimation. Smart Mater. Struct. 2023, 32, 11. [Google Scholar] [CrossRef]
- Hampshire, L.; Dehghani-Sanij, A.; O’Connor, R.J. Restorative rehabilitation robotics to promote function, independence and dignity: Users’ perspectives on clinical applications. J. Med. Eng. Technol. 2022, 46, 527–535. [Google Scholar] [CrossRef]
- Tao, J.; Yu, S.R. Developing Conceptual PSS Models of Upper Limb Exoskeleton based Post-stroke Rehabilitation in China. Procedia CIRP 2019, 80, 750–755. [Google Scholar] [CrossRef]
- Tsuji, Y. A Safety Review of Medical Device Robots in JAPAN. Asia Pac. J. Health Law Ethics 2018, 12, 1–27. [Google Scholar]
- Song, W.K. Trends in Rehabilitation Robots and Their Translational Research in National Rehabilitation Center, Korea. Biomed. Eng. Lett. (BMEL) 2016, 6, 1–9. [Google Scholar] [CrossRef]
- Van Hedel, H.J.A.; Rosselli, I.; Baumgartner-Ricklin, S. Clinical utility of the over-ground bodyweight-supporting walking system Andago in children and youths with gait impairments. J. Neuroeng. Rehabil. 2021, 18, 20. [Google Scholar] [CrossRef]
- Zhang, F.; Li, K.; Wu, D.L.; Chen, P.R.; Dou, Z.L. Therapeutic effect of AiWalker on balance and walking ability in patients with stroke: A pilot study. Top. Stroke Rehabil. 2021, 28, 236–240. [Google Scholar] [CrossRef]
- Li, D.X.; Zha, F.B.; Long, J.J.; Liu, F.; Cao, J.; Wang, Y.L. Effect of Robot Assisted Gait Training on Motor and Walking Function in Patients with Subacute Stroke: A Random Controlled Study. J. Stroke Cerebrovasc. Dis. 2021, 30, 6. [Google Scholar] [CrossRef]
- Glowinski, S.; Krzyzynski, T. An inverse kinematic algorithm for the human leg. J. Theor. Appl. Mech. 2016, 54, 53–61. [Google Scholar] [CrossRef]
- Chen, Z.L.; Guo, Q.; Li, T.S.; Yan, Y.; Jiang, D. Gait Prediction and Variable Admittance Control for Lower Limb Exoskeleton With Measurement Delay and Extended-State-Observer. IEEE Trans. Neural Netw. Learn. Syst. 2023, 34, 8693–8706. [Google Scholar] [CrossRef]
- Zhou, J.; Li, Z.J.; Li, X.M.; Wang, X.Y.; Song, R. Human-Robot Cooperation Control Based on Trajectory Deformation Algorithm for a Lower Limb Rehabilitation Robot. IEEE-ASME Trans. Mechatron. 2021, 26, 3128–3138. [Google Scholar] [CrossRef]
- Xu, J.J.; Xu, L.S.; Ji, A.H.; Cao, K. Learning robotic motion with mirror therapy framework for hemiparesis rehabilitation. Inf. Process. Manag. 2023, 60, 16. [Google Scholar] [CrossRef]
- Ko, S. A Study of Artificial Intelligence Robots as Legal Subjects. J. Prop. Law 2020, 37, 1–23. [Google Scholar]
- Li, G.X.; Li, Z.J.; Su, C.Y.; Xu, T. Active Human-Following Control of an Exoskeleton Robot With Body Weight Support. IEEE Trans. Cybern. 2023, 53, 7367–7379. [Google Scholar] [CrossRef] [PubMed]
- Lu, Y.Z.; Wang, H.; Zhou, B.; Wei, C.F.; Xu, S.Q. Continuous and simultaneous estimation of lower limb multi-joint angles from sEMG signals based on stacked convolutional and LSTM models. Expert. Syst. Appl. 2022, 203, 20. [Google Scholar] [CrossRef]
- Zhang, Z.F.; Wang, Z.Y.; Lei, H.; Gu, W.Q. Gait phase recognition of lower limb exoskeleton system based on the integrated network model. Biomed. Signal Process. Control 2022, 76, 13. [Google Scholar] [CrossRef]
- Zhang, Q.; Nalam, V.; Tu, X.K.; Li, M.H.; Si, J.N.; Lewek, M.D.; Huang, H. Imposing Healthy Hip Motion Pattern and Range by Exoskeleton Control for Individualized Assistance. IEEE Robot. Autom. Lett. 2022, 7, 11126–11133. [Google Scholar] [CrossRef]
- Rose, L.; Bazzocchi, M.C.F.; Nejat, G. A model-free deep reinforcement learning approach for control of exoskeleton gait patterns. Robotica 2022, 40, 2189–2214. [Google Scholar] [CrossRef]
- Li, J.G.; Chen, C. Machine learning-based energy harvesting for wearable exoskeleton robots. Sustain. Energy Technol. Assess. 2023, 57, 7. [Google Scholar] [CrossRef]
- Bergmann, L.; Lück, O.; Voss, D.; Buschermöhle, P.; Liu, L.; Leonhardt, S.; Ngo, C. Lower Limb Exoskeleton With Compliant Actuators: Design, Modeling, and Human Torque Estimation. IEEE-ASME Trans. Mechatron. 2023, 28, 758–769. [Google Scholar] [CrossRef]
- Habib, M.; Sadjaad, O. Online gait generator for lower limb exoskeleton robots: Suitable for level ground, slopes, stairs, and obstacle avoidance. Robot. Auton. Syst. 2023, 160, 104319. [Google Scholar]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).