Abstract
Occlusion presents a major obstacle in the development of pedestrian detection technologies utilizing computer vision. This challenge includes both inter-class occlusion caused by environmental objects obscuring pedestrians, and intra-class occlusion resulting from interactions between pedestrians. In complex and variable urban settings, these compounded occlusion patterns critically limit the efficacy of both one-stage and two-stage pedestrian detectors, leading to suboptimal detection performance. To address this, we introduce a novel architecture termed the Attention-Guided Feature Enhancement Network (AGFEN), designed within the deep convolutional neural network framework. AGFEN improves the semantic information of high-level features by mapping it onto low-level feature details through sampling, creating an effect comparable to mask modulation. This technique enhances both channel-level and spatial-level features concurrently without incurring additional annotation costs. Furthermore, we transition from a traditional one-to-one correspondence between proposals and predictions to a one-to-multiple paradigm, facilitating non-maximum suppression using the prediction set as the fundamental unit. Additionally, we integrate these methodologies by aggregating local features between regions of interest (RoI) through the reuse of classification weights, effectively mitigating false positives. Our experimental evaluations on three widely used datasets demonstrate that AGFEN achieves a 2.38% improvement over the baseline detector on the CrowdHuman dataset, underscoring its effectiveness and potential for advancing pedestrian detection technologies.
1. Introduction
Pedestrian detection [1,2,3] is a crucial technology in intelligent transportation systems [4,5,6], with numerous practical applications in advanced driver assistance systems, autonomous driving, area monitoring, human–computer interaction, and other fields [7]. In recent years, the development of deep convolutional neural networks (CNNs) has driven rapid advancements in computer vision, evolving from object recognition [8] to general object detection [9,10,11], and now making significant progress in occluded pedestrian detection [12,13,14,15,16,17,18,19,20,21]. While most pedestrian detection algorithms perform well in non-occluded and lightly occluded scenarios, state-of-the-art algorithms still struggle in heavily occluded scenes. Therefore, unlike general object detection techniques, pedestrian detection algorithms must focus on addressing the challenges posed by occluded pedestrians. To illustrate the impact of occlusion on detection, Figure 1 shows the performance of a pedestrian detector with a feature pyramid network (FPN) [22] based on the Faster R-CNN [9] architecture when applied to a heavily occluded scene. The higher missed detection rate is attributed to significant intra-class occlusion among pedestrians, resulting in some pedestrians only having small regions (such as heads or limbs) exposed in the camera’s field of view, which lowers the confidence for these targets. Consequently, improving the ability of CNNs to identify visible features has become a research hotspot in the field of pedestrian detection.

Figure 1.
Pedestrian detection results in a crowded scenario. The green boxes indicate correct predictions, and the red boxes indicate missed predictions. (a) Baseline results; (b) our results.
Holistic detection [12,13] is the current mainstream strategy for pedestrian detection, assuming that pedestrians are fully visible and training networks with full-body annotations. However, it is inevitable that pedestrians will be partially or heavily occluded, making the partial pedestrian features provided during network training with the holistic detection strategy incomplete. Such fragmentary features are likely to lead to inaccuracies in the final model. Additionally, the full-body detection window may be mostly filled with obstructions (background), further weakening the accuracy of the pedestrian detector.
Eager to further improve the performance of pedestrian detectors, some researchers combine multiple detectors that recognize specific parts of pedestrians to address occlusion [23,24,25,26]. This approach decomposes a pedestrian model into multiple sub-models (such as head, hands, feet, etc.) and then trains each sub-model separately to describe each part of the pedestrian. Ultimately, all sub-models are integrated to obtain a complete pedestrian detection framework. However, the improvement in the accuracy of such pedestrian detection algorithms comes at the cost of increased computational complexity. Additionally, these manually configured subcomponents may be suboptimal.
Unlike the strategy of combining multiple sub-models to solve the occlusion problem, other researchers have focused on the feedback effect of the visible parts of pedestrians on the full body. More specifically, these networks [15,27] integrate various attention modules within the standard pedestrian detection framework, aiming to make the computer focus on visible features or highlight visible regions while suppressing occluded parts, thereby achieving a higher detection rate. However, current attention-based pedestrian detection networks [14,16] often require an additional visible region training branch. This branch produces RoI features for the visible body under supervised conditions and then integrates them with RoI features generated by the full body branch. The essence of the fusion process is to re-modulate the RoI features of the full body branch using those of the visible body branch. Additionally, some methods, such as [14], enhance the representation of RoIs for the visible body by converting them into masks. Consequently, utilizing masks to emphasize pedestrian-visible region features constitutes an efficient and accurate solution. Finally, the confidence score for integrated RoIs is calculated by the classification network. However, this method has two shortcomings: First, obtaining annotations for visible regions, especially dense pixel segmentation annotations, is challenging. Secondly, the fusion method of the two RoI features needs to be finely designed, increasing the detector’s complexity.
Furthermore, when pedestrians are heavily occluded, the number of pixels belonging to them is minimal, posing a significant challenge for current CNN-based pedestrian detectors. Small-scale pedestrians have very little feature information, which becomes even more incomplete after multiple downsamplings. For the task of small-scale pedestrian detection, it is natural to consider improving the detector’s accuracy by fusing the position information of low-level feature maps with the semantic information of high-level feature maps. Liu [28] initially attempted to use multi-layer feature maps to detect objects of different scales. However, due to the small receptive field and insufficient semantic information, this method’s detection ability for small-scale objects is still not ideal. Fortunately, the Feature Pyramid Network (FPN) [22] adopts a top-down path and lateral connections to compensate for these shortcomings, truly realizing the coexistence of high-resolution and high-level semantic information. This network is easy to integrate into various object detection frameworks, significantly improving the detection rate of each network [29,30,31]. Therefore, this network is included in the deep architecture of this paper. Although FPN enriches pedestrian features to a certain extent, its top-down fusion method is somewhat simplistic, only transmitting high-layer semantic information to lower layers through element-wise addition without fully capturing the texture information of lower layers. Consequently, the performance of FPN in crowded scenarios is not optimal, leaving room for improvement. In this work, we constructed an FPN-like network based on the idea of FPN, operating from top to bottom, first extracting high-layer channel-level semantic information and then using this information to guide sampling layer by layer, thereby mapping channel-level semantic information onto low-layer spatial-level information to enhance pedestrian detail features.
Additionally, a two-stage pedestrian detector with FPN first generates a large number of target proposals with high repetition rates using the Region Proposal Network (RPN) and then removes duplicates using Non-Maximum Suppression (NMS) in the post-processing stage. The purpose of NMS is to ensure that one proposal corresponds to one prediction, which inevitably leads to the removal of certain true positives. As shown in Figure 1a, the head of the pedestrian on the right is likely recognized by the detector, but due to occlusion, the two pedestrians share most of the same features, resulting in significant overlap between the two predictions. However, the confidence score of the pedestrian behind is lower than that of the pedestrian in front, leading to the prediction for the pedestrian behind being mistakenly deleted by NMS. There are already several improvement strategies for this issue. Refs. [32,33] add a re-scoring step to traditional NMS, which reduces the scores of overlapping boxes instead of directly setting them to zero, to retain true positives. Ref. [34] builds a neural network that runs on scored detection to learn and adapt to data distribution, thereby overcoming the shortcomings of naive NMS. However, the above methods either perform poorly in heavily occluded scenarios or are difficult to implement and integrate into detectors. Therefore, ref. [35] re-examined the intrinsic relationship between proposals and predictions and designed a Set NMS method to remove duplicates while retaining true positives as much as possible. More specifically, Set NMS binds a proposal with multiple overlapping predictions to form a prediction set and then compares and removes duplicates between each prediction set. Due to the effectiveness and low cost of Set NMS in handling crowded scenarios, we will use it instead of naive NMS to further improve the detector’s performance.
To sum up, the main contributions of this paper are as follows:
- (1)
- We develop an FPN-like network called the AGFEN, which connects the feature maps of each layer through a top-down path. AGFEN extracts high-layer channel-level semantic features and leverages them to guide low-layer features for sampling, resulting in the simultaneous enhancement of pedestrian semantic information and detailed information. AGFEN achieves similar effects to mask-based feature re-modulation approaches without requiring an additional attention branch.
- (2)
- We combine the Set NMS method with the constructed pedestrian detection network in a reasonable manner, enabling the detector to exhibit stronger competitiveness in crowded scenarios.
- (3)
- To enhance collaboration with Set NMS and minimize false positives, we propose a RoI feature aggregate (RoI-A) approach that reuses the classifier’s weights to aggregate local features of each RoI, thereby mitigating object confusion. Experimental results validate the exceptional pedestrian detection capability achieved through this combination strategy.
- (4)
- We conduct extensive experiments on three commonly used datasets, confirming that the designed pedestrian detector can effectively handle detection tasks in crowded scenarios, achieving a gain of 2.38% relative to the baseline FPN.
The rest of this paper is arranged as follows: Section 2 describes the current state of the art in pedestrian detection and occlusion handling. In Section 3, the specific details of AGFEN, RoI-A, and Set NMS are presented. In Section 4, we experimentally verify the performance of the proposed network and conclude the paper in Section 5.
2. Related Work
Pedestrian detection research has made significant progress over the past decade, with implementation methods continually evolving and deep learning-based approaches now dominating the field. The main challenge in pedestrian detection is that occlusion significantly reduces the amount of information available to the detector, leading to missed detections. Therefore, this section will first briefly introduce deep learning-based pedestrian detection methods and then review current popular strategies for handling occlusion.
2.1. Pedestrian Detection
Currently, many effective pedestrian detection methods are built on convolutional neural network models. In generic object detection architectures, the process of generating object bounding boxes and refining them reflects whether the detection is two-stage or single-stage, and the same applies to pedestrian detection. Both single-stage and two-stage pedestrian detectors typically rely on anchor box-based methods, which are effective for identifying potential regions where pedestrians might be located. The method involves using anchor points as centers and defining multiple prior boxes with different aspect ratios to represent the initial states of candidate objects. These boxes are then classified and regressioned. This detection process can be repeated, with the result of anchor box regression being used as the new anchor box, followed by further classification and regression, thereby improving accuracy. Thus, whether or not this operation is repeated is a key distinction between single-stage and two-stage detectors. Since the introduction of the anchor box, it has become an indispensable part of high-precision object detection (e.g., Faster R-CNN [9], SSD [28], YOLO series [36,37,38], etc.). Theoretical analysis and experimental results have shown that two-stage pedestrian detectors [14,15,17,18] often achieve higher precision, whereas the real-time performance of single-stage strategies [12,13,39] is typically achieved at the expense of accuracy.
Single-stage detectors, such as SSD and the YOLO series, do not require generating region proposals but directly generate object class probabilities and position coordinates. Because single-stage detectors offer a one-step process, some researchers argue that they are more aligned with industry demands for real-time object detection algorithms and are easier to implement. Consequently, many single-stage pedestrian detection algorithms have been designed based on this concept. For instance, Ren [12] designed an end-to-end object detection network by introducing a recurrent rolling convolution architecture on multi-scale feature maps. Cong [13] addressed the problem of pedestrian occlusion in crowded scenes by using a repulsion loss function to optimize YOLOv3’s performance. Ref. [39] proposed an asymptotic localization fitting (ALF) module and a bottleneck block; the ALF gradually refines the default anchor boxes in SSD, while the bottleneck block optimizes the predictor by integrating residual learning and multi-scale context encoding. The integration of these modules in a single-stage detection architecture strikes a good balance between accuracy and real-time performance. In sparse scenes, some single-stage pedestrian detectors can even outperform two-stage networks in detecting large objects.
As for current research, Faster R-CNN [9] truly integrates feature extraction, candidate region generation, object classification, and bounding box regression into a deep structure, significantly enhancing its overall performance. In terms of detection speed, the RPN shares underlying convolutional features with Fast R-CNN and incorporates candidate sets into end-to-end learning, greatly improving the efficiency of candidate box generation. The exceptional performance of Faster R-CNN has made it a milestone algorithm in pedestrian detection and a typical two-stage pedestrian detector. As a result, Faster R-CNN is widely used as a benchmark network in pedestrian detection, and many pedestrian detectors based on Faster R-CNN have achieved excellent results. For example, Zou [17] added a multitask correction attention module to Faster R-CNN to generate masks for multiple visible parts of pedestrians and correct false regions, enhancing the correlation of pedestrian body features. Wang et al. [18] improved RPN by constructing a new pedestrian area generation network and using a soft cascaded decision tree to combine features of various resolutions and layers to handle classification problems. Given the excellent detection accuracy of the two-stage pipeline, this paper builds on this foundation.
2.2. Schemes for Handling Occlusion
Part-based models are currently a popular strategy [23,24,25,26,40] that divides and integrates various parts of pedestrians to handle occlusion. Noh et al. [23] proposed training local detectors individually, then comprehensively considering the scores of all local detectors to reduce the miss rate. Zhang [24] designed a novel aggregation loss function and an occlusion-aware RoI pooling operation to improve overall detection accuracy by predicting various parts of the human body. Ref. [25] proposed DeepParts, composed of multiple part detectors, which can be trained even with data lacking part annotations and can also calibrate positive proposals that differ significantly from the ground truth. Ref. [26] utilized a strategy of sharing a set of decision trees among multiple part detectors, improving the correlation between detectors and effectively reducing the computational complexity of the overall network. This multi-detector joint learning method outperforms approaches where each detector learns separately. Ref. [40] constructed a reciprocating feature adaptation and iterative pedestrian detection network called CircleNet, which uses multiple circle structures to learn different features of pedestrians.
Another approach to dealing with occlusion is to introduce an attention mechanism. These methods commonly exploit the visible regions of pedestrians to generate attention feature maps, which guide the detector to learn the visible features of pedestrians. Wang [41] focused on dense crowd scenes and proposed a repulsion loss between pedestrians, ensuring the current object’s prediction is as far from others as possible. Ref. [14] integrated a novel mask-guided module into a standard pedestrian detector and proposed an occlusion-sensitive hard example mining method, leading to significant improvements in detection performance. Similar to [14], Refs. [16,27] introduced additional visible region branches to enable the network to learn the visible features of pedestrians under the supervision of visible region annotations. However, some researchers argue that attention-based (or saliency-based) methods are unreliable because detection networks struggle to distinguish attention regions of positives from those of negatives. Consequently, Ref. [19] intensified multi-channel features by sharing classifier weights in convolutional layers to obtain higher-level semantic information. The enhanced multi-channel features are superimposed to form a pedestrian self-activation map, selectively highlighting the visible parts of pedestrians. Although the self-activation map undergoes pixel-level and region-level corrections, its performance in crowded scenes still lags behind that of attention mechanism-based methods. Therefore, we continue to focus on the application of attention mechanisms to enhance feature representation. Ref. [15] argued that different channels activate different body parts. Drawing inspiration from this study but differing from approaches that add an attention branch [14,15,16,27], we construct a top-down feature enhancement network that maps channel-level activations.
3. Improvement Proposal
In this work, we focus primarily on pedestrians who are either obscured or appear small in the camera’s field of view. It is evident that these pedestrians are challenging to identify, necessitating targeted solutions. Inspired by the FPN’s ability to extract multi-scale features, we designed an attention-guided deterministic sampling module with an FPN-like structure to capture detailed pedestrian features. We then developed a novel pedestrian detector based on the standard Faster R-CNN framework. Specifically, the semantic information from the high-level feature map guides the high-resolution feature map to sample specific local regions, thereby directing the computer’s attention to the visible parts of occluded pedestrians. Simultaneously, the second-stage classifier’s weights are employed to aggregate the local features of RoIs, enabling the network to distinguish easily confused samples and thereby improving detection performance.
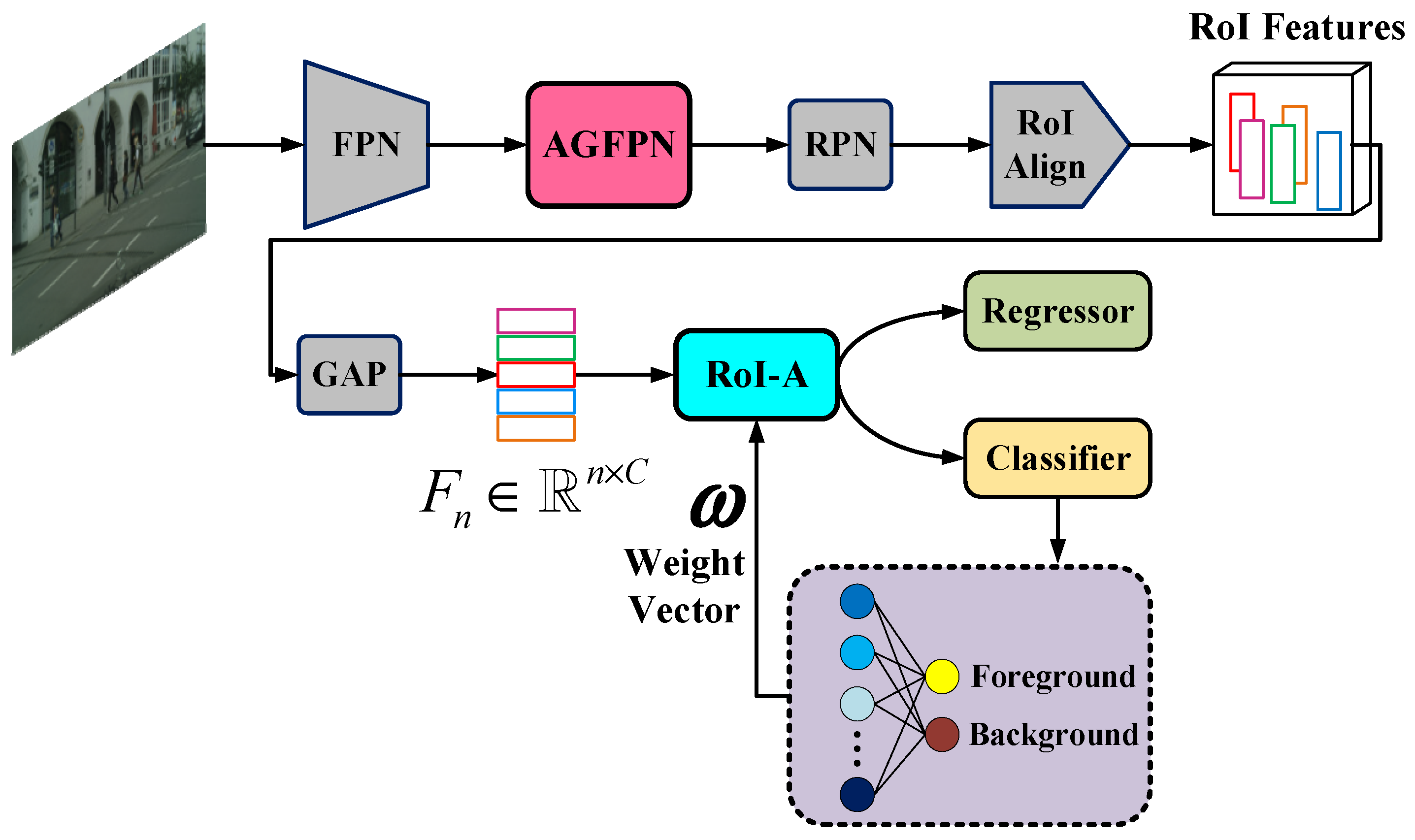
The overall architecture of the novel pedestrian detector is illustrated in Figure 2. Although ResNet has more layers than VGG-16 and VGG-19, we replace the fully connected layer with global average pooling (GAP), allowing the model to occupy relatively less memory while effectively preventing overfitting. Therefore, we adopt ResNet-50 with FPN as the backbone to extract pedestrian features and then feed the resulting feature map into the FPN-like multi-scale feature extraction network, aiming to emphasize partial features by capturing spatial details. Finally, after completing the RoI-A operation using shared classifier weights, the classification and regression tasks are performed based on the aggregated features.
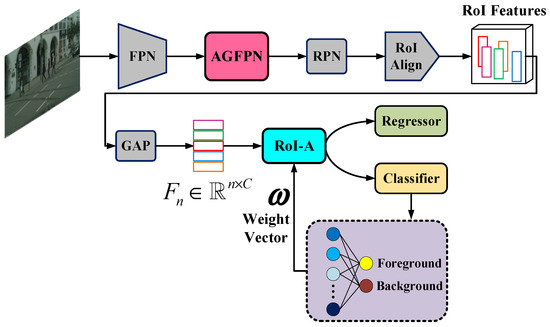
Figure 2.
An overall architecture of the attention-guided feature enhancement network (AGFEN). It is a faster R-CNN with a ResNet-50+FPN as its backbone, also with an additional attention-guided feature pyramid network (AGFPN) and a RoI features aggregation (RoI-A) operation. AGFEN uses high-level semantic features to enhance the texture of low-level features and strengthen the boundary information between pedestrians and background so as to achieve the purpose of highlighting pedestrians while suppressing background. In the meantime, the detection network also makes full use of the weight of the classifier to aggregate the features of each RoI, thereby improving the representation of RoIs.
3.1. Attention-Guided Feature Pyramid Network
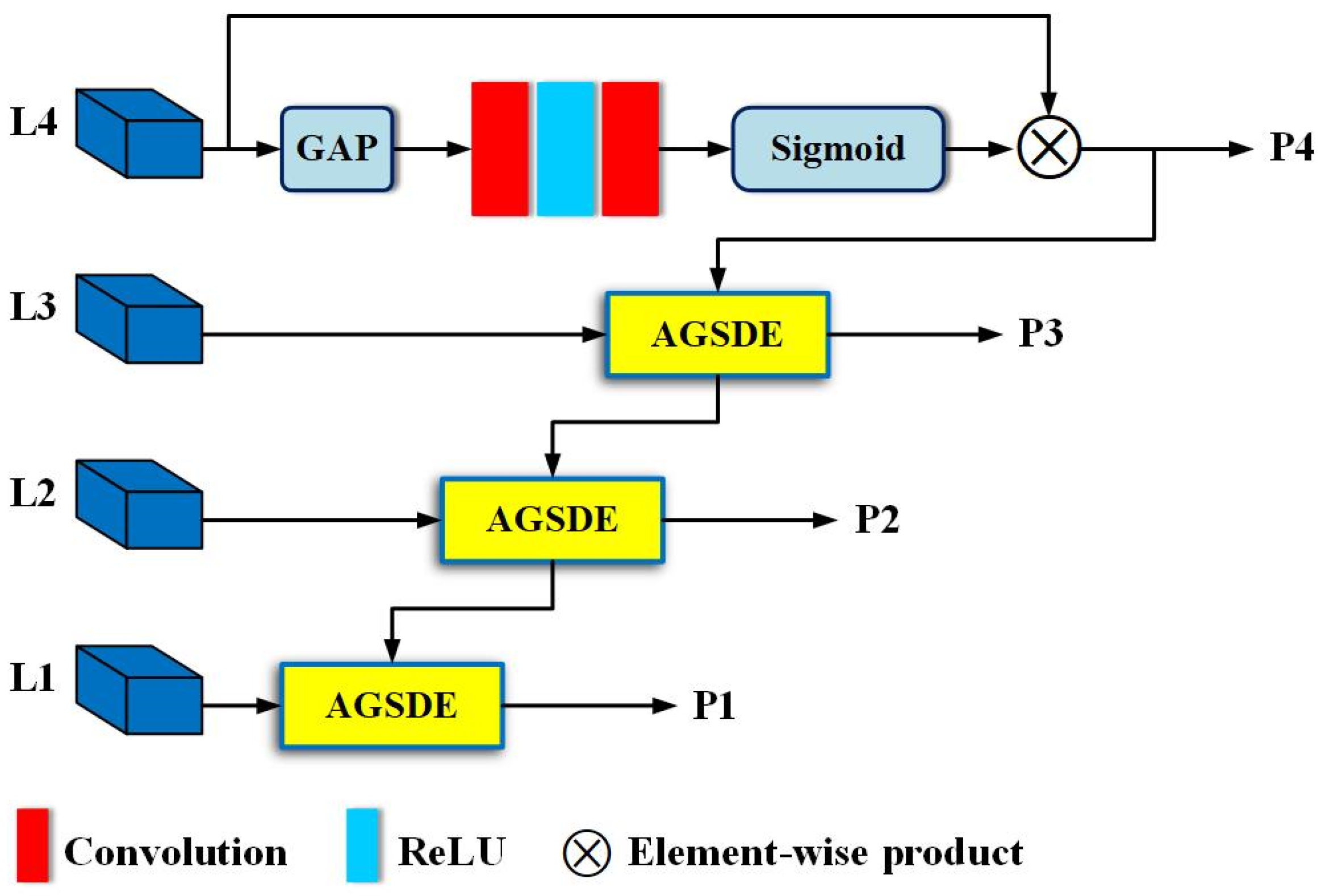
Figure 2 clearly illustrates the position of the Attention-Guided Feature Pyramid Network (AGFPN) within the overall pedestrian detection pipeline, with its structure and functions detailed below. As is well known, the backbone network uses max pooling layers to capture the feature textures of pedestrians while reducing interference from non-target objects such as vehicles, trees, and buildings. Although max pooling ensures insensitivity to feature changes caused by local pedestrian displacement, features of pedestrians that are distant from the camera or heavily occluded may vanish after downsampling and max pooling. This means that relying solely on the features extracted from the backbone cannot achieve satisfactory detection accuracy. While embedding an FPN can effectively enhance detection capability, the performance in crowded scenarios remains suboptimal. Therefore, we propose an AGFPN that not only preserves global contextual relationships but also highlights local features. Similar to the FPN, it operates through top-down and horizontal connections, aiming to fully integrate high-level semantic information and low-level visual information while compensating for some of the errors introduced by score-level fusion methods.
Specifically, as illustrated in Figure 3, we perform GAP on the output feature map of the fourth convolutional layer, trying to retain the background information that contributes to classification in the deep feature map, and obtain a channel-wise statistic descriptor . Given the output of the fourth convolutional layer is , then . Next, based on descriptor , we explore the interaction relationships between multiple channels that constitute the high-level semantic feature map. The output of GAP is followed by a convolution layer, an activation function ReLU, and another convolution layer, and then a Sigmoid function is used to obtain the correlation between channels. Thus, a new channel statistical descriptor, , is yielded from the above process. Finally, is fed back to L4, and both are conducted element-wise to generate a channel attention feature map P4.
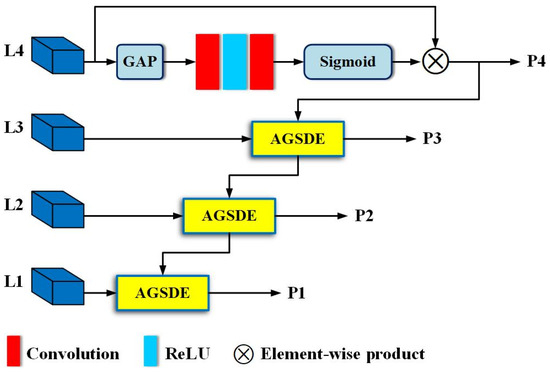
Figure 3.
The structure of AGFPN. This is the FPN-like network, which is used to add attention information to high-resolution visual information. This process is implemented under the guidance of high-level semantic information.
Researchers suggest that the activation of different body parts is influenced by various channel features, and the relationship between cross-channel feature mapping can improve the detector’s discrimination [15,42,43]. Specifically, P4 utilizes squeeze and excitation to establish intrinsic relationships within each channel and uses these relationships as weights to enhance high-layer features extracted by the backbone. As a result, a channel-wise enhanced version with high-level semantic information is generated. However, relying solely on the relationship between channels in high-layer features for detector optimization may yield limited or even negative results. This is because high-level semantic information has the potential to obscure target object details, leading to inaccurate regressions or missed detections in heavily occluded environments.
Inspired by FPN [29], we utilize the enhanced high-level semantic information as a guide for low-layer visual information, enhancing features at all levels except for L4 in a top-down manner to alleviate the problem of ambiguous detail information. Unlike FPN, AGFPN does not directly adopt the operation mode of upsampling and element-wise addition, which may avoid conflicts between high-level semantic features and low-level visual features at certain pixel points after upsampling, thus preventing feature degradation. Figure 3 illustrates, on the other hand, that P4 is not directly used to guide L1 and L2 to pay attention to the special details within them. This decision aligns with the original intention of developing AGFPN. We aim to preserve contextual information as much as possible and tolerate certain errors caused by layer-by-layer guidance. This approach is particularly applicable in heavily occluded scenes, where contextual relationships can enhance the detector’s understanding of complex scenes, such as pedestrians typically appearing on roads rather than in the sky or rivers. Therefore, sampling solely from the current layer to guide the previous layer in strengthening target object details is an intuitively effective scheme.
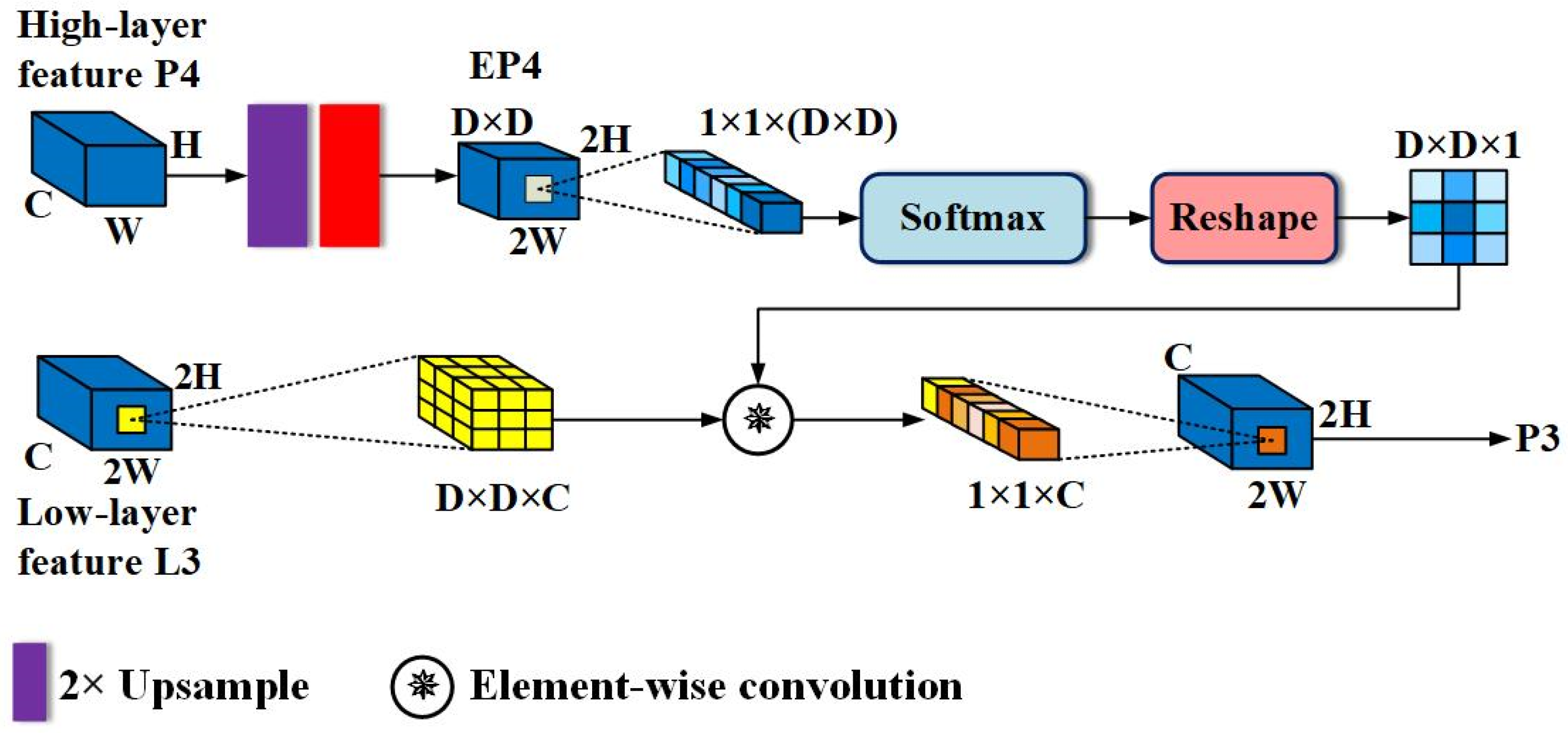
Attention-Guided Sampling-Based Detail Enhancement Module: as mentioned earlier, both semantic information and detailed information are indispensable for the accurate classification and regression of pedestrians. Semantic information ensures the correct classification of pixels, while detail information can determine which pixels belong to pedestrians, providing relatively accurate information for the detector to learn occlusion patterns. Thus, enhancing the detail features of pedestrians with semantic information can boost detector recognition of hard examples. This idea is similar to a pedestrian detector trained using external visible region annotations, which essentially focuses on learning the features of visible parts of the pedestrian and then uses the training results to enhance the full body features or implement score-level fusion of two branches. In contrast, we directly utilize the existing cross-channel attention feature P4 to produce similar effects without additional attention branches. To achieve this, a module called Attention-Guided Sampling-Based Details Enhancement (AGSDE) was constructed. Figure 4 shows AGSDE in detail.
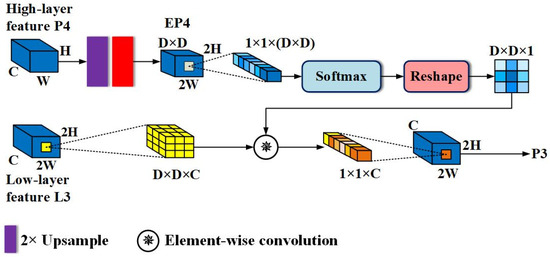
Figure 4.
The structure of the attention-guided sampling-based details enhancement module. Note that for simplicity, the diagram uses L3 link as an example to show AGSDE in detail. The AGSDE on the rest of the links follows exactly how this diagram operates.
For the sake of simplicity, only the AGSDE module on the L3 link will be explained. Firstly, perform a bilinear upsampling with a factor of 2 on the enhanced high-layer feature P4 to obtain a feature map that matches the scale of low-level feature L3. Next, pass it through a convolutional layer of size 3 × 3, with the aim of compressing the number of channels to (D × D), where (D × D) also represents a region in L3 that is about to be sampled. Now, P4 has transformed to EP4 with dimensions of (D × D) × 2H × 2W. Then, take any point (i, j) from EP4 and perform Softmax normalization on this point in channel dimension, and obtain a vector of the contribution degree of each channel at this point, whose size is (D × D) × 1 × 1. This vector is then reshaped to a two-dimensional plane with size D × D × 1, and the plane is treated as the convolution kernel. The kernel will convolve with the region centered on (i, j) in L3, and the convolution operation is as follows:
where , K represents the convolution kernel generated from any point in EP4. By executing Formula (1) for each point on L3, feature P3, guided and enhanced by a high-layer semantic feature, is obtained. Similarly, P3 can guide L2 to yield P2, and P2 can guide L1 to yield P1. As such, the structure of the entire AGFP is a standard pyramid shape.
After embedding the AGSDE module, the output will occur in the following three cases: (i) When sampling points inside a pedestrian (such as a pixel on the head), a certain channel will exhibit a higher value. As a result, the higher value will be reshaped into the center of a two-dimensional plane, and the further away from the center, the smaller the corresponding channel value. Thus, the pixel is significantly enhanced after convolution. (ii) When sampling the boundary between pedestrians and background, these points will be affected by nearby points, so the boundary may be slightly enhanced or suppressed. (iii) When sampling points outside of pedestrians, the channel reflecting the background will dominate. Meanwhile, the values of background and its surroundings are small, and the convolutional result is also small, thus the background is suppressed relative to pedestrians. After modulating the features of the backbone in this way, there is abundant contextual information to assist prediction. For boundary and small-scale pedestrians, it will also show relative stronger activation.
3.2. RoI Aggregation
After the aforementioned work is completed, generally, the enhanced features are used to generate a large number of proposals through RPN, and then R-CNN is used to achieve fine classification and regression for each proposal. However, intra-class occlusion results in a narrow gap between individuals; the detector is likely to regard multiple overlapping pedestrians as a single target. Meanwhile, AGFPN activates pedestrian features based on channel-level attention; certain background regions similar to pedestrian features will also exhibit high activation. In addition, we have adjusted the way instances are generated and removed (details will be shown in Section 3.3). There will be multiple prediction instances corresponding to one proposal, so that some false positives may be incorrectly retained, ultimately leading to an increase in detector false positives. As such, it is necessary to design solutions from the perspective of RoIs.
Considering that the inherent connections between various RoIs can reflect the local clues of each RoI, and aggregating the local information of each RoI can improve the internal features of the RoI, helping to prevent object confusion [44,45], and ultimately having the potential to further improve detection performance. More specifically, we first perform GAP on the RoI features and then use the weight vector of the R-CNN classifier to aggregate the local channel features of each RoI, where C represents the number of channels. As a result, a new feature to be classified is yielded, which is calculated as follows:
where represents a channel-level feature matrix composed of n RoI features arranged in rows, and represents the LeakyReLU activation function. Next, split into rows and feed these vectors to the classification and regression network. Note that is pre-trained and updated during training.
3.3. Loss Function
The loss function of the standard Faster R-CNN includes two sub-parts of RPN loss and R-CNN loss. The confidence of the RPN part adopts the binary cross-entropy loss, the confidence of the R-CNN part uses the multi-class cross-entropy loss, and their position offsets all use the Smooth-L1 loss. Therefore, the backbone can be trained end-to-end with the following loss functions:
Although this loss function achieves unexpected results in pedestrian detection, it still suffers from a high and unsatisfactory miss rate when faced with crowded scenes. For this reason, we enhance the ability of the original Faster R-CNN to acquire pedestrian features through a series of additional modules described above and expect the detector to eliminate the interference of occlusion as much as possible. However, in an overcrowded scenario, certain proposals have very similar features and will inevitably produce highly overlapping predictions. Unfortunately, partially overlapping predictions can be discarded by NMS operations, making it impossible for the detector to generate unique detection results for each proposal. In order to preserve these positives and evolve the network towards a better direction, we adopted the scheme proposed in [31], which uses each proposal box to predict a set of highly overlapping instances and makes simple modifications to the NMS so that proposals belonging to different pedestrians but overlapping will be retained. The following will introduce the details that need to be modified to implement this plan.
3.3.1. Instance Set Prediction
Instead of one proposal box corresponds to only one instance, we associate with a set of ground-truth instances based on the predefined intersection-over-union (IoU) threshold:
where is the set of all the ground-truth boxes. In this work, the number of elements in the set is set to 2.
At the same time, refer to [35], an additional prediction branch is introduced into the detection framework so that each proposal box can predict different instances and through two detection functions, where is the class confidence of the prediction object, and is the relative coordinate. Therefore, the prediction set of any can be expressed as follows:
3.3.2. Formulate a Loss Function
Once obtaining the prediction set and the ground-truth instance set , the Earth Mover’s Distance (EMD) can be used to convert the similarity measurement between the two sets into the calculation of relative distance [35,46], and then minimize the EMD function to narrow the gap between the prediction set and the ground-truth instance set. The loss function constructed based on EMD can be represented as:
where represents a certain permutation of (1, 2) whose k-th item is ; is the -th ground-truth box; the meanings of and are consistent with the previous content, representing the classification loss and regression loss of R-CNN network. Note that if the number of elements in the ground-truth set is less than 2, it is feasible to manually add ground-truth instances that are labeled as background but without regression loss to meet this condition. Finally, the loss function of the entire pedestrian detection network can be expressed as follows:
3.3.3. Set NMS
In addition to modifying the correspondence between proposal boxes and ground truth instances, as well as adjusting the loss function for training, a simple fine-tuning of the naive NMS operations is also required. When standard NMS is used, predictions that overlap but belong to different individuals are still removed. After the above two steps, each proposal will produce two predictions unique to itself, and by setting a trigger for the NMS, these two predictions will not suppress each other, even if their IoU is close to 1. At this stage, suppression occurs between different proposals, meaning it acts on different prediction sets. Only if two prediction boxes originate from different prediction sets can one prediction box suppress the other. In other words, the fine-tuned NMS operates on prediction sets as the minimum unit rather than on individual predictions. This fine-tuned NMS is also referred to as the Set NMS.
3.4. Complexity Analysis
The loss function of the standard Faster R-CNN includes two sub-parts of RPN loss and R-CNN loss. The confidence of the RPN part adopts the binary cross-entropy loss, the confidence of the R-CNN part uses the multi-class cross-entropy loss, and their position offsets all use the Smooth-L1 loss. Therefore, the backbone can be trained end-to-end with the following loss functions:
To analyze the complexity of the proposed network, we studied the model’s floating point operations (FLOPs) under different parameters. For consistency, we represent the scale of FLOPs as GFLOPs. From the perspective of the overall pipeline, AGFEN does not alter the structure of the baseline detector. Therefore, the total GFLOPs of the proposed model equals the sum of the GFLOPs of the baseline model and the GFLOPs of the embedded modules. In AGFEN, the modules that contribute significantly to the total GFLOPs are AGFPN and RoI-A. We first analyze AGFPN. Given the smallest feature map output by the FPN module, the complexity of AGFPN can be expressed as . Since the size of the feature map is fixed by FPN, the GFLOPs of AGFPN are mainly related to the size of the sampling region . It is evident that the larger the sampling region, the higher the computational complexity of the model, but the detection capability of the model also improves. For example, when selecting a 5 × 5 sampling region, the GFLOPs of the improved model increase by 22.486 compared with the baseline model.
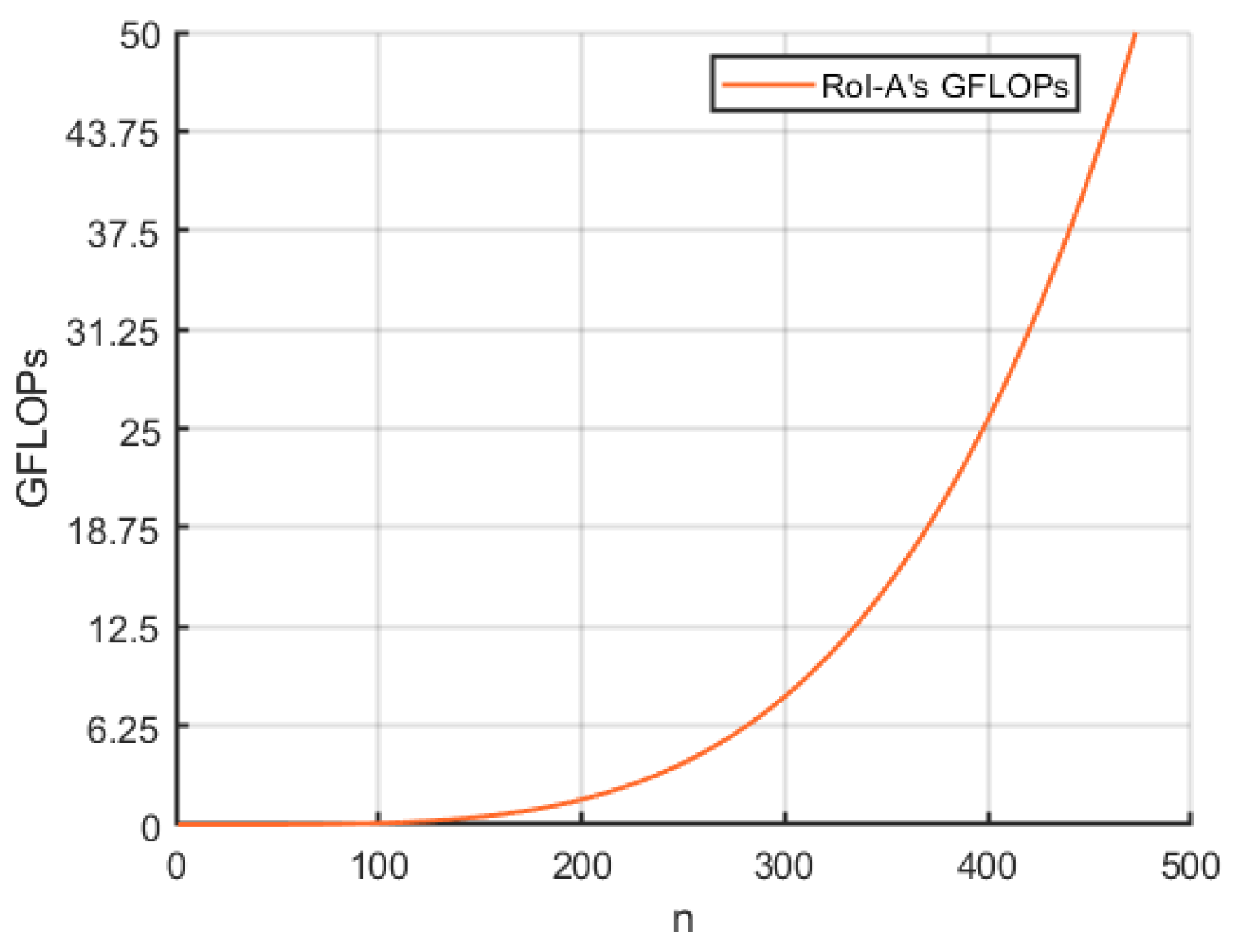
Next, we analyze the computational complexity of RoI-A. As discussed in Section 3.2, RoI-A primarily involves matrix operations, and thus, its computational complexity can be expressed as , where represents the number of RoI feature maps. Figure 5 illustrates the trend of GFLOPs in the RoI-A module as varies. Both Figure 5 and mathematical analysis indicate that has an exponential relationship with GFLOPs. In summary, when deploying AGFEN, the model’s performance and computational cost can be flexibly balanced according to practical requirements.
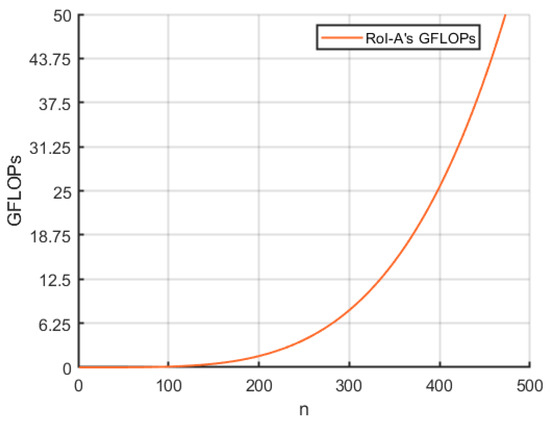
Figure 5.
The relationship between the number of RoI feature maps and GFLOPs of ROI-A module.
4. Results
In this section, we first describe the implementation details of the datasets, evaluation metrics, and experiments. We then evaluate the effectiveness of our modifications to the baseline network using three public and widely used pedestrian datasets. For simplicity in the subsequent discussion, AGFEN will be used to refer to the proposed pedestrian detector. Finally, we present and compare the performance of AGFEN with state-of-the-art pedestrian detectors.
4.1. Experimental Program
4.1.1. Datasets
In order to verify the effectiveness of the network proposed in this paper, three commonly used datasets, CrowdHuman [47], CityPersons [48], and Caltech [49], are used to evaluate AGFEN. The CrowdHuman is a relatively challenging pedestrian detection dataset, which contains a large amount of data, including 15,000 training images, 5000 test images, and 4370 validation images. In the CrowdHuman dataset, the average number of pedestrians per image is as high as 23, showing a very rich occlusion pattern, and the degree of occlusion of pedestrians is high. The CityPersons dataset is a subset of CityScapes that only contains pedestrian annotations. The images in CityPersons are all recorded based on on-board cameras. The recorded scenes are multiple cities in Germany, and the image size is 2048 × 1024. It has a total of 5000 images, of which 2975 images are used for training and 500 and 1575 for validation and testing. The average number of pedestrians in an image in this dataset is 7. The image size of the Caltech dataset is 640 × 480; its image acquisition method is similar to that of CityPersons, whereas the location is relatively single and the number of people is much smaller. This dataset divides all the images into two parts, in which the six sequences from S0 to S5 are used as the training set, and the five sequences from S6 to S10 are used as the test set. Table 1 lists the representative statistics for these three datasets.

Table 1.
Representative statistics of three commonly used datasets.
4.1.2. Evaluation Metric
In order to comprehensively evaluate the performance of the proposed detector, we mainly use the following three common metrics:
- Average precision (AP) is one of the evaluation metrics of the target detection model. It is the result of smoothing the precision-recall curve and then averaging the precision value. The larger the AP, the better the detection performance.
- Log-average Miss Rate (MR−2) is over false positive per image (FPPI) within [10−2, 100]. In this paper, the pedestrian detection performance of AGFEN is evaluated using the three most commonly used criteria: reasonable, heavy, and partial. Among them, the visibility ratio of reasonable sets exceeds 65%. The visibility ratio of heavy sets is ranging [0.2, 0.65]. Note that the heavy set range used by some detectors is [0, 0.65], and we will add * superscripts to the data to distinguish between the two differences. The visibility ratio of the partial set is ranging [0.65, 0.9]. The heavy set is mainly used to evaluate the performance of each pedestrian detection network under heavy occlusion conditions. For simplicity, write R for the reasonable subset and HO for the heavy subset. The lower the MR−2, the better the detection performance.
- Jaccard index (JI) is used to compare the similarity between the prediction set and the corresponding ground-truth set, where the prediction set is generated by a confidence threshold. The higher the JI score, the better the detection performance.
4.1.3. Implementation Details
We set the baseline pedestrian detector Faster R-CNN with FPN according to the guidance provided by [22]. Additionally, the related structures and parameter changes refer to open source projects [50]. On the CrowdHuman dataset, we set the initial learning rate at 10−5 and decayed by a factor of 10 at the 25th and 35th epochs, respectively. A total of 50 epochs are trained. On the CityPersons dataset, we set the basic learning rate to 10−4 and reduce the learning rate by a factor of 10 after performing 5k iterations. The implementation details of Caltech are basically the same as those of CityPersons. First, train with a learning rate of 0.0001 for the first three epochs. Then, change the learning rate to 0.00001.
4.2. Ablation Study
To verify the effectiveness of the proposed method, we performed ablation experiments on three datasets.
- (1)
- Baseline Comparison: We take the two-stage pedestrian detection network ResNet-50+FPN as the baseline and then add different modules in turn to observe the performance of the network containing different modules on the CrowdHuman dataset. Since we have modified the one-to-one correspondence between proposals and ground-truth instances in the baseline to One Proposal to Multiple Predictions (OPMP) and adjusted loss functions and a NMS operation, OPMP can be used to represent the entire modification operation. Note that in order to compare the performance of each module at one level, the network with each module added is trained using the same set of ground-truth pedestrian instances.
Table 2 reports the performance changes of pedestrian detectors after adding each module sequentially, and the best scores are shown in bold. As we changed the baseline, the new model obtained higher AP and JI scores on the CrowdHuman validation set and lower MR−2 scores, indicating that our changes effectively enhanced the performance of the baseline. The last row in Table 2 is the full version of the proposed network, which achieves optimal pedestrian detection performance. Compared with the baseline, the gains of the complete pedestrian detection model on AP, MR−2, and JI were 6.73%, 2.38%, and 3.61%, respectively. Rows 2 and 3 also clearly reflect the performance differences between FPN and AGFPN. The AGFPN replaces the score-level fusion scheme of element-wise addition by the way of guided sampling, which has great advantages in transferring high-level semantic information layer-by-layer and retaining contextual information. Especially in the AGSDE module, this sampling-based feature enhancement method can organically fuse the features of local regions, thereby enlarging the gap between the visible part of the pedestrian and the background. This is an application that maps spatial locations from channel features and is also an embodiment of the idea of semantic segmentation, which helps RPN to generate more accurate recommendations. Therefore, it is not surprising that AGFPN performs better when no other modules are introduced. It is also worth noting that RoI-A should be used with OPMP. When the model is AGFPN + RoI-A, the improvement relative to the detector without the RoI-A module is minimal; for example, the gain on the MR−2 metric is only 0.29%. However, when the model is AGFPN + OPMP, OPMP and AGFPN complement each other. AGFPN provides informative features for OPMP, and OPMP reduces the probability of true positives being suppressed by errors. As a result, AGFPN + OPMP can significantly improve AP, with a gain of up to 3.03%. However, because AGFPN causes multiple occlusion objects to share some RoI features in crowded scenarios, which is likely to generate false positives, the MR−2 score of AGFPN + OPMP is limited. Fortunately, by aggregating the local features of each RoI through the ROI-A module, this problem can be effectively improved, so that the performance of the complete detector can reach the optimal 92.52%, 40.54%, and 83.44%.
Table 2.
Ablation study on CrowdHuman validation set. The baseline is ResNet-50 with FPN, and then three modules, AGFP, RoI-A, and OPMP, are embedded in the baseline successively to obtain the scores of different models under the three evaluation metrics. The optimal scores are shown in bold. “✓” indicates that the module is embedded.
- (2)
- Comparison With Other FPN-Like Structres: We construct an FPN-like network to enhance pedestrian feature information and then use the enhanced features to boost the performance of RPN. Similar work appears in PANet [51] and CircleNet [40]. PANet adds a bottom-up information transfer path to FPN, while CircleNet uses multiple top-down and bottom-up paths to enhance pedestrian features and share information between the up and down paths, forming a circle-like network. Based on the number of circles, the model is simply named Circle-T. Structurally, our AGFPN and PANet can be seen as CircleNet-1/2. To make a fair comparison, the FPN is used as the baseline, then the network is set up according to [40], and the input image is scaled by a factor of 1.3.
Table 3 shows that all the improvements to FPN result in a positive gain in the detector’s performance. In particular, our FPN-like structure achieved the lowest MR−2 scores of 10.24% and 66.48%, respectively, on two subsets of the Caltech dataset. Due to the fact that the other two structures both use element-wise addition to transmit information between layers, there is a lack of exploration and leverage channel-level semantic information, resulting in limited gain to the baseline. Although CircleNet learns different occlusion patterns by constructing multiple circles, there are significant differences in the activated features between different circles, and the lack of a more efficient circle-level feature fusion method meant that increasing the number of circles cannot yield the desired benefits. For example, on the R set, the performance of CircleNet-2 was reduced by 0.88% relative to CircleNet-1, while the performance of CircleNet-3 was further reduced to 14.72%. By comparison, AGFPN is a more effective approach to enhance pedestrian features through attention-guided sampling.
Table 3.
Three FPN-like structures are compared on Caltech dataset. The evaluation metric is MR−2. The optimal scores are shown in bold.
- (3)
- Comparison With Other Visible-Box Attention Strategies: Our AGFPN maps channel features with high-level semantic information layer-by-layer onto features at all levels, enhancing the visible regions of pedestrians at all levels. From the final result, AGFPN is similar to methods that partially contain two training branches, such as Bi-box [27], OR-CNN [23], MGAN [14], and DMSFLM [16]. These methods were trained separately on the full body and visible regions of pedestrians, ultimately combining the results of the two parts to enhance detection performance. Therefore, AGFPN is embedded in a detector with VGG-16 as the backbone, and its results are compared with the above method.
Table 4 reports the scores of each attention strategy under the same backbone and the same scaling conditions. Note that both MGAN and DMSFLN only consider classified loss of visible body parts. All detectors with an extra visible body region branch achieved similar performance on the R set, but their performance on the HO set seriously varied due to the different design of loss functions and fusion methods. The best overall performance is MGAN, thanks to its specially designed occlusion-sensitive loss function and weak box-based segmentation annotation. Our AGFPN ranked in the middle, achieving MR−2 scores of 10.8% and 46.5% on the R and HO sets, respectively. Compared with the worst OR-CNN, our method achieved an improvement of 0.2% and 4.8%, respectively. However, it is worth noting that AGFPN enhances the pedestrian visible region through guided sampling, which saves the network overhead, because the cost of obtaining the visible region annotation or the more demanding dense pixel segmentation annotation is too high, and our method provides an approximate enhancement effect. Thus, AGFPN can be used as an alternative to the visible-box attention strategy when visible region annotations are missing. In addition, AGFPN can be easily embedded into other backbones.
Table 4.
A Comparison with other visible-box attention strategies on the CityPersons validation set with MR−2. All models use VGG-16 as the backbone. VBB indicates whether a visible region branch is used. The optimal scores are shown in bold.
- (4)
- Comparison With Other NMS Strategies: We use different NMS approaches to handle the excess boxes and show the corresponding scores in Table 5. Note that the detector is a ResNet-50+FPN with AGFPN, and the threshold of the IoU is fixed at 0.5 according to [31]. Unsurprisingly, the naive NMS method scored lowest, and it roughly removed all overlapping prediction boxes. For Soft-NMS, although it improved the AP score relative to NMS, the MR−2 benefit in crowded scenarios was small, only 0.05%. It is clear that OPMP exhibits high AP and lower MR−2 compared with Soft-NMS and naive NMS. Therefore, for cost reasons, OPMP is the best choice.
Table 5. Comparison of three NMS approaches and further evaluation of RoI-A on CrowdHuman dataset. The optimal scores are shown in bold.
- (5)
- Further Study on RoI-A: We also explored the universality of RoI-A. Table 5 indicates that RoI-A can effectively improve the recognition capability of the network, even when paired with the naive NMS. When paired with RoI-A, the gain of Soft-NMS over the naive NMS increased from 2.4%, 0.05%, and 0.02% to 2.8%, 0.41%, and 0.29%, respectively. Experiments show that RoI-A can be combined with different NMS methods and can improve recall precision and reduce miss rates in complex, crowded scenarios.
4.3. State-of-the-Art Comparison on CrowdHuman Dateset
Table 6 reports the scores of our AGFEN, including AGFPN, RoI-A, and OPMP, against other state-of-the-art detectors on the CrowdHuman validation set. It can be clearly observed that our detector has the optimal results on the three evaluation metrics, that is, the scores are shown in bold. It is worth noting that we used the Faster R-CNN with FPN as the baseline, and it performed unexpectedly, especially under the evaluation criteria of MR−2, where it achieved a good second place. Most detectors did not report scores on the JI metric, but the baseline was only 1.57% different from S-RCNN [52] and performs better on the MR−2, achieving a gain of 1.78%. FPN only superimposes upper-layer features after up-sampling to lower-layer features and unifies the feature dimensions to facilitate the fusion of deep semantic information and shallow texture information, so as to achieve the purpose of enhancing the feature maps of each layer. The remaining detectors either improve the loss function or introduce additional attention branches, which are relatively complex to implement. However, from the perspective of the relatively important MR−2 index, this means of blending semantic features and texture features is very effective in enhancing the performance of the detector. For this purpose, our AGFPN superimposes semantic features onto texture features in a softer way, which not only highlights the pedestrian regions but also reinforces the boundary between pedestrians and the background. As mentioned earlier, this is similar to an enhanced feature modulated by a mask of the visible part, but AGFPN does not require additional visible region annotation. Therefore, AGFPN further increases the baseline performance while supplementing RoI-A and OPMP to minimize false positive rates and improve detection rates, which is why AGFEN performs best. In addition to this, we also made a comparison with the latest one-stage detector, the YOLOv5s [38]. As expected, the one-stage method only has an advantage in speed and even lags behind the baseline in detection accuracy, with a gap of up to 7.02% and 8.61% compared with AGFEN in AP and MR−2, respectively. Figure 6 is a visual comparison of the two detectors on the CrowdHuman dataset.
Table 6.
Score comparison with state-of-the-art detectors on CrowdHuman dataset. The optimal scores are shown in bold.

Figure 6.
The two detectors were compared visually on CrowdHuman validation set. The solid red line boxes in these pictures represent ground truth, the solid green line boxes represent predictions of the detector, and the dotted red line boxes represent missed detections, respectively. (a) The recent DMSFLN; (b) Our AGFEN.
4.4. State-of-the-Art Comparison on CityPersons Dateset
To further validate the universality of the proposed detector, we also compared it with other representative and advanced detection approaches on the CityPersons dataset, namely Adaptive FasterRCNN [48], OR-CNN [24], Bi-box [27], Repulsion Loss [41], CircleNet [40], FRCN + A + DT [58], FC-Net [19], MGAN+ [14], DMSFLN [16], CSP + HRNet [59], DDAD [60], and ChainDetection + three Modules(CIoU) [61]. The performance of each detector at three commonly used occlusion levels is shown in Table 7. Obviously, DMSFLN and MGAN+ achieved the best scores on the R and HO sets, respectively. Notably both approaches introduce a visible region branch for learning visible part features and then organically combine the full body branch with the visible body branch. The detector ultimately evaluates the fusion results of the two branches. The difference is that DMSFLN uses cosine similarity to reduce the gap between the two branches, while MGAN+ directly modulates RoI features through spatial attention masks. Therefore, MGAN+ is more direct and effective in dealing with heavy occlusion. Despite the lack of a branch, our AGFEN enhances pedestrian features through two top-down paths and avoids the noise introduced during the fusion of the two branches, making its performance on the R set comparable to the first place, only 0.3% behind on the HO set, and optimal on the partial set.
Table 7.
Comparison with the state-of-the-art models on CityPersons validation set with MR−2. The optimal scores are shown in bold.
Moreover, due to the inclusion of FPN in the detection model, we also conducted a simple comparison and analysis with respect to the capability of small-scale pedestrian detection on the CityPersons dataset. The detectors participating in the comparison are ALFNet [62], CSP [63], and CSP + Offset [63], where +Offset indicates additional offset prediction. The scores in Table 8 demonstrate that our method also has excellent performance in detecting small objects, with improvements of 3.9%, 3.1%, and 1.1% compared with the other three methods.
Table 8.
Comparison of small-scale pedestrian detection performance on the CityPersons validation set. The evaluation metric is MR−2, and the best results are presented in bold.
4.5. Comparison with Other Pedestrian Detectors on the Caltech Dataset
Finally, we conducted experiments on Caltech datasets with different occlusion ranges. We have also selected a portion of representative detectors except the previously compared approaches, including DeepParts [25], F-DNN + SS [64], GDFL [65], SDS-RCNN [66], AR Ped [67], etc. From Table 9, it is clear that our AGFEN still exhibits strong competitiveness, achieving MR−2 of 6.5%, 36.5%, and 12.9% at three occlusion sets, respectively, without any additional design for occlusion, such as adding a visible region branch. Unconsciously, DMSFLN and MGAN+ once again topped the R and HO sets, respectively. From the results of the three datasets, it can be seen that an extra visible body branch can indeed improve the performance of detectors, but they must bear extra overhead and design a reasonable fusion scheme. Therefore, in the absence of visible part annotations, our method is a good choice.
Table 9.
Comparison with the state-of-the-art models on Caltech test set with MR−2. The optimal scores are shown in bold.
5. Conclusions
We propose an attention-guided feature enhancement network (AGFEN) for pedestrian detection, with a particular focus on detecting pedestrians in crowded scenes. To achieve this, we introduce an FPN-like structure following the FPN to address its limitations and enhance the texture features of pedestrians. Additionally, a classifier’s weight vector is utilized to aggregate various RoI features, thereby improving RoI feature representation and preventing object confusion. Furthermore, an improved NMS strategy is employed during post-processing to eliminate redundant predictions and reduce the likelihood of suppressing true positives. Finally, we validate the effectiveness of the proposed method on three commonly used datasets: CrowdHuman, CityPersons, and Caltech.
Author Contributions
Conceptualization, S.T. and Y.Z.; methodology, S.T. and Y.Z.; investigations, S.T.; writing—original draft preparation, S.T.; writing—review and editing, Y.Z. and C.L.; supervision, Y.Z. and J.L.; funding acquisition, Y.Z., J.L. and J.S. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Key Research and Development Plan, grant number 2022YFC3320801-2.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data are contained within the article.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Lin, C.; Lu, J.; Wang, G.; Zhou, J. Graininess-Aware Deep Feature Learning for Robust Pedestrian Detection. IEEE Trans. Image Process. 2020, 29, 3820–3834. [Google Scholar]
- Cao, J.; Song, C.; Peng, S.; Song, S.; Zhang, X.; Shao, Y.; Xiao, F. Pedestrian Detection Algorithm for Intelligent Vehicles in Complex Scenarios. Sensors 2020, 20, 3646. [Google Scholar] [CrossRef]
- Cao, J.; Pang, Y.; Han, J.; Gao, B.; Li, X. Taking a Look at Small-Scale Pedestrians and Occluded Pedestrians. IEEE Trans. Image Process. 2020, 29, 3143–3152. [Google Scholar] [CrossRef] [PubMed]
- Peng, Y.; Tang, X.G.; Zhou, Y.; Li, J.T.; Qi, Y.; Liu, L.; Lin, H. Computing and Communication Cost-Aware Service Migration Enabled by Transfer Reinforcement Learning for Dynamic Vehicular Edge Computing Networks. IEEE Trans. Mob. Comp. 2024, 23, 257–269. [Google Scholar] [CrossRef]
- Liu, J.H.; Zhou, Y.; Liu, L. Communication Delay-Aware Cooperative Adaptive Cruise Control with Dynamic Network Topologies-a Convergence of Communication and Control. Dig. Comm. Netw. 2023. [Google Scholar] [CrossRef]
- Qi, Y.; Zhou, Y.; Liu, Y.F.; Liu, L.; Pan, Z.G. Traffic-Aware Task Offloading Based on Convergence of Communication and Sensing in Vehicular Edge Computing. IEEE Internet Things J. 2021, 8, 17762–17777. [Google Scholar] [CrossRef]
- Chen, Y.X.; Liu, Z.Z.; Zhang, B.H.; Fok, W.; Qi, X.J.; Wu, Y.C. MGFN: Magnitude-Contrastive Glance-and-Focus Network for Weakly-Supervised Video Anomaly Detection. In Proceedings of the Thirty-Seventh AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef]
- Xu, H.; Jiang, C.H.; Liang, X.; Lin, L.; Li, Z. Reasoning-RCNN: Unifying Adaptive Global Reasoning in to Large-Scale Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 6419–6428. [Google Scholar]
- Nataprawira, J.; Gu, Y.; Goncharenko, I.; Kamijo, S. Pedestrian Detection Using Multispectral Images and a Deep Neural Network. Sensors 2021, 21, 2536. [Google Scholar] [CrossRef]
- Ren, J.; Chen, X.; Liu, J.; Sun, W.; Pang, J.; Yan, Q.; Tai, Y.-W.; Xu, L. Accurate Single Stage Detector Using Recurrent Rolling Convolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 June 2017; pp. 5420–5428. [Google Scholar]
- Cong, C.; Yang, Z.; Song, Y.; Pagnucco, M. Towards Enforcing Social Distancing Regulations with Occlusion-Aware Crowd Detection. In Proceedings of the 2020 16th International Conference on Control, Automation, Robotics and Vision (ICARCV), Shenzhen, China, 13–15 December 2020; pp. 297–302. [Google Scholar]
- Xie, J.; Pang, Y.; Khan, M.H.; Anwer, R.M.; Khan, F.S.; Shao, L. Mask-Guided Attention Network and Occlusion-Sensitive Hard Example Mining for Occluded Pedestrian Detection. IEEE Trans. Image Process. 2021, 30, 3872–3884. [Google Scholar] [CrossRef]
- Zhang, S.; Yang, J.; Schiele, B. Occluded Pedestrian Detection Through Guided Attention in CNNs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 6995–7003. [Google Scholar]
- He, Y.; Zhu, C.; Yin, X.C. Occluded Pedestrian Detection via Distribution-Based Mutual-Supervised Feature Learning. IEEE Trans. Intel. Transp. Syst. 2021, 23, 10514–10529. [Google Scholar] [CrossRef]
- Zou, F.; Li, X.; Xu, Q.; Sun, Z.; Zhu, J. Correlation-and-Correction Fusion Attention Network for Occluded Pedestrian Detection. IEEE Sen. J. 2023, 23, 6061–6073. [Google Scholar] [CrossRef]
- Wang, H.; Li, Y.; Wang, S. Fast Pedestrian Detection with Attention-Enhanced Multi-Scale RPN and Soft-Cascaded Decision Trees. IEEE Trans. Intel. Transp. Syst. 2020, 21, 5086–5093. [Google Scholar] [CrossRef]
- Zhang, T.; Ye, Q.; Zhang, B.; Liu, J.; Zhang, X.; Tian, Q. Feature Calibration Network for Occluded Pedestrian Detection. IEEE Trans. Intel. Transp. Syst. 2022, 23, 4151–4163. [Google Scholar] [CrossRef]
- Gonzalo, G.; Sergio, A.V.; Nicolas, L.; Ramirez, H.; Sebastian, S.; Gonzalo, F. Train Station Pedestrian Monitoring Pilot Study Using an Artificial Intelligence Approach. Sensors 2024, 24, 3377. [Google Scholar] [CrossRef]
- Wu, J.; Zhou, C.; Yang, M.; Zhang, Q.; Li, Y.; Yuan, J. Temporal-Context Enhanced Detection of Heavily Occluded Pedestrians. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 13430–13439. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Noh, J.; Lee, S.; Kim, B.; Kim, G. Improving Occlusion and Hard Negative Handling for Single-Stage Pedestrian Detectors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 966–974. [Google Scholar]
- Zhang, S.; Wen, L.; Bian, X.; Lei, Z.; Li, S.Z. Occlusion-aware R-CNN: Detecting Pedestrians in a Crowd. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 637–653. [Google Scholar]
- Tian, Y.; Luo, P.; Wang, X.; Tang, X. Deep Learning Strong Parts for Pedestrian Detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1904–1912. [Google Scholar]
- Zhou, C.; Yuan, J. Multi-Label Learning of Part Detectors for Heavily Occluded Pedestrian Detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 3486–3495. [Google Scholar]
- Zhou, C.; Yuan, J. Bi-box Regression for Pedestrian Detection and Occlusion Estimation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 135–151. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Ghiasi, G.; Lin, T.Y.; Le, Q.V. NAS-FPN: Learning Scalable Feature Pyramid Architecture for Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 7036–7045. [Google Scholar]
- Yang, G.; Wang, Z.; Zhuang, S. PFF-FPN: A Parallel Feature Fusion Module Based on FPN in Pedestrian Detection. In Proceedings of the IEEE International Conference on Computer Engineering and Artificial Intelligence (ICCEAI), Shanghai, China, 27–29 August 2021; pp. 377–381. [Google Scholar]
- Li, J.; Zhou, G.; Chen, A.; Lu, C.; Li, L. BCMNet: Cross-Layer Extraction Structure and Multiscale Down sampling Network with Bidirectional Transpose FPN for Fast Detection of Wildfire Smoke. IEEE Syst. J. 2022, 17, 1235–1246. [Google Scholar] [CrossRef]
- Bodla, N.; Singh, B.; Chellappa, R.; Davis, L.S. Soft-NMS-Improving Object Detection with One Line of Code. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 5561–5569. [Google Scholar]
- He, Y.; Zhu, C.; Wang, J.; Savvides, M.; Zhang, X. Bounding Box Regression with Uncertainty for Accurate Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 2883–2892. [Google Scholar]
- Hosang, J.; Benenson, R.; Schiele, B. Learning Non-Maximum Suppression. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 20–26 July 2017; pp. 6469–6477. [Google Scholar]
- Chu, X.; Zheng, A.; Zhang, X.; Sun, J. Detection in Crowded Scenes: One Proposal, Multiple Predictions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 12211–12220. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. Available online: https://arxiv.org/abs/1804.02767 (accessed on 26 August 2024).
- Jocher, G.; Chaurasia, A.; Stoken, A.; Borovec, J.; NanoCode012; Kwon, Y.; TaoXie; Fang, J.; Imyhxy; Michael, K.; et al. Ultralytics/YOLOv5: V6.1-TensorRT, TensorFlow edge TPU and OpenVINO Export and Inference. Zenodo 2022. Available online: https://zenodo.org/records/6222936 (accessed on 26 August 2024).
- Liu, W.; Liao, S.; Hu, W. Efficient Single-Stage Pedestrian Detector by Asymptotic Localization Fitting and Multi-Scale Context Encoding. IEEE Trans. Image Process. 2020, 29, 1413–1425. [Google Scholar] [CrossRef]
- Zhang, T.; Han, Z.; Xu, H.; Zhang, B.; Ye, Q. CircleNet: Reciprocating Feature Adaptation for Robust Pedestrian Detection. IEEE Trans. Intell. Transp. Syst. 2020, 21, 4593–4604. [Google Scholar] [CrossRef]
- Wang, X.; Xiao, T.; Jiang, Y.; Shao, S.; Sun, J.; Shen, C. Repulsion Loss: Detecting Pedestrians in a Crowd. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 7774–7783. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Bao, Q.; Gang, B.; Yang, W.; Zhou, J.; Liao, Q. Attention-Driven Graph Neural Network for Deep Face Super-Resolution. IEEE Trans. Image Process. 2022, 31, 6455–6470. [Google Scholar] [CrossRef]
- Chen, C.; Yang, X.; Zhang, J.; Dong, B.; Xu, C. Category Knowledge-Guided Parameter Calibration for Few-Shot Object Detection. IEEE Trans. Image Process. 2023, 32, 1092–1107. [Google Scholar]
- Yang, Z.; Wang, Y.; Chen, X.; Liu, J.; Qiao, J. Context-Transformer: Tackling Object Confusion for Few-Shot Detection. In Proceedings of the Thirty-Fourth AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 12653–12660. [Google Scholar]
- Russell, S.; Mykhaylo, A.; Ng, N.Y. End-to-End People Detection in Crowded Scenes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2325–2333. [Google Scholar]
- Shao, S.; Zhao, Z.; Li, B.; Xiao, T.; Yu, G.; Zhang, X.; Sun, J. CrowdHuman: A Benchmark for Detecting Human in a Crowd. arXiv 2018, arXiv:1805.00123. Available online: http://arxiv.org/abs/1805.00123 (accessed on 26 August 2024).
- Zhang, S.; Benenson, R.; Schiele, B. CityPersons: A Diverse Dataset for Pedestrian Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3213–3221. [Google Scholar]
- Dollar, P.; Wojek, C.; Schiele, B.; Perona, P. Pedestrian Detection: An Evaluation of the State of the Art. IEEE Trans. Patt. Anal. Mach. Intel. 2012, 34, 743–761. [Google Scholar] [CrossRef]
- Chen, K.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Xu, J.; et al. MMDetection: Open Mmlab Detection Toolbox and Benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar] [CrossRef]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Sun, P.; Zhang, R.; Jiang, Y.; Kong, T.; Xu, C.; Zhan, W.; Tomizuka, M.; Li, L.; Yuan, Z.; Wang, C.; et al. Sparse R-CNN: End-to-end Object Detection with Learnable Proposals. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 14454–14463. [Google Scholar]
- Liu, S.; Huang, D.; Wang, Y. Adaptive NMS: Refining Pedestrian Detection in a Crowd. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 6452–6461. [Google Scholar]
- Chi, C.; Zhang, S.; Xing, J.; Lei, Z.; Li, S.Z.; Zou, X. Relational Learning for Joint Head and Human Detection. In Proceedings of the Thirty-Fourth AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 10647–10654. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable DETR: Deformable Transformers for End-to-End Object Detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Lin, M.; Li, C.; Bu, X.; Sun, M.; Lin, C.; Yan, J.; Ouyang, W.; Deng, Z. DETR for Crowd Pedestrian Detection. arXiv 2020, arXiv:2012.06785. [Google Scholar]
- Huang, X.; Ge, Z.; Jie, Z.; Yoshie, O. NMS by Representative Region: Towards Crowded Pedestrian Detection by Proposal Pairing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 10750–10759. [Google Scholar]
- Zhou, C.; Yang, M.; Yuan, J. Discriminative Feature Transformation for Occluded Pedestrian Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9557–9566. [Google Scholar]
- Bevi, A.; Shaamili, R. A State-of-the-art High-Resolution Network based Dipolar Detector for Occluded Pedestrian Detection. In Proceedings of the International Conference on Advances in Electrical, Electronics and Computational Intelligence (ICAEECI), Tiruchengode, India, 19–20 October 2023; pp. 1–5. [Google Scholar]
- Tang, W.; Liu, K.; Shakeel, M.; Wang, H.; Kang, W. DDAD: Detachable Crowd Density Estimation Assisted Pedestrian Detection. IEEE Trans. Intell. Transp. Syst. 2023, 24, 1867–1878. [Google Scholar] [CrossRef]
- Yuan, Q.; Huang, G.; Zhong, G.; Yuan, X.; Tan, Z.; Lu, Z.; Pun, C.M. Triangular Chain Closed-Loop Detection Network for Dense Pedestrian Detection. IEEE Trans. Instrument. Meas. 2024, 24, 5003714. [Google Scholar] [CrossRef]
- Liu, W.; Liao, S.; Hu, W.; Liang, X.; Chen, X. Learning Efficient Single-Stage Pedestrian Detectors by Asymptotic Localization Fitting. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 618–634. [Google Scholar]
- Liu, W.; Liao, S.; Ren, W.; Hu, W.; Yu, Y. High-Level Semantic Feature Detection: A New Perspective for Pedestrian Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5182–5191. [Google Scholar]
- Du, X.; El-Khamy, M.; Lee, J.; Davis, L. Fused DNN: A Deep Neural Network Fusion Approach to Fast and Robust Pedestrian Detection. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 27–29 March 2017; pp. 953–961. [Google Scholar]
- Lin, C.; Lu, J.; Wang, G.; Zhou, J. Graininess-Aware Deep Feature Learning for Pedestrian Detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 732–747. [Google Scholar]
- Brazil, G.; Yin, X.; Liu, X. Illuminating Pedestrians via Simultaneous Detection & Segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 4950–4959. [Google Scholar]
- Brazil, G.; Liu, X. Pedestrian Detection with Autoregressive Network Phases. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2019; pp. 7231–7240. [Google Scholar]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).