


Modeling Structured Dependency Tree with Graph Convolutional Networks for Aspect-Level Sentiment Classification



Abstract
1. Introduction
- We propose a structured dependency tree based on node weights, incorporating positional, sentiment commonsense, part-of-speech, and syntactic dependency distance information to enrich the generic dependency tree. This enables sufficient extraction of relationships between aspects and corresponding opinion words. We further aggregate node information using a weighted graph convolutional network.
- We utilize part-of-speech tags and dependency distances to discover connections between pivotal nodes without direct dependency edges in the trees, thereby analyzing sentiment orientations of specific aspects.
- Experimental results on five benchmark datasets demonstrate the effectiveness of our proposed method in aspect sentiment analysis, outperforming existing state-of-the-art approaches.
2. Related Work
2.1. Aspect-Level Sentiment Analysis
2.2. Graph Neural Networks
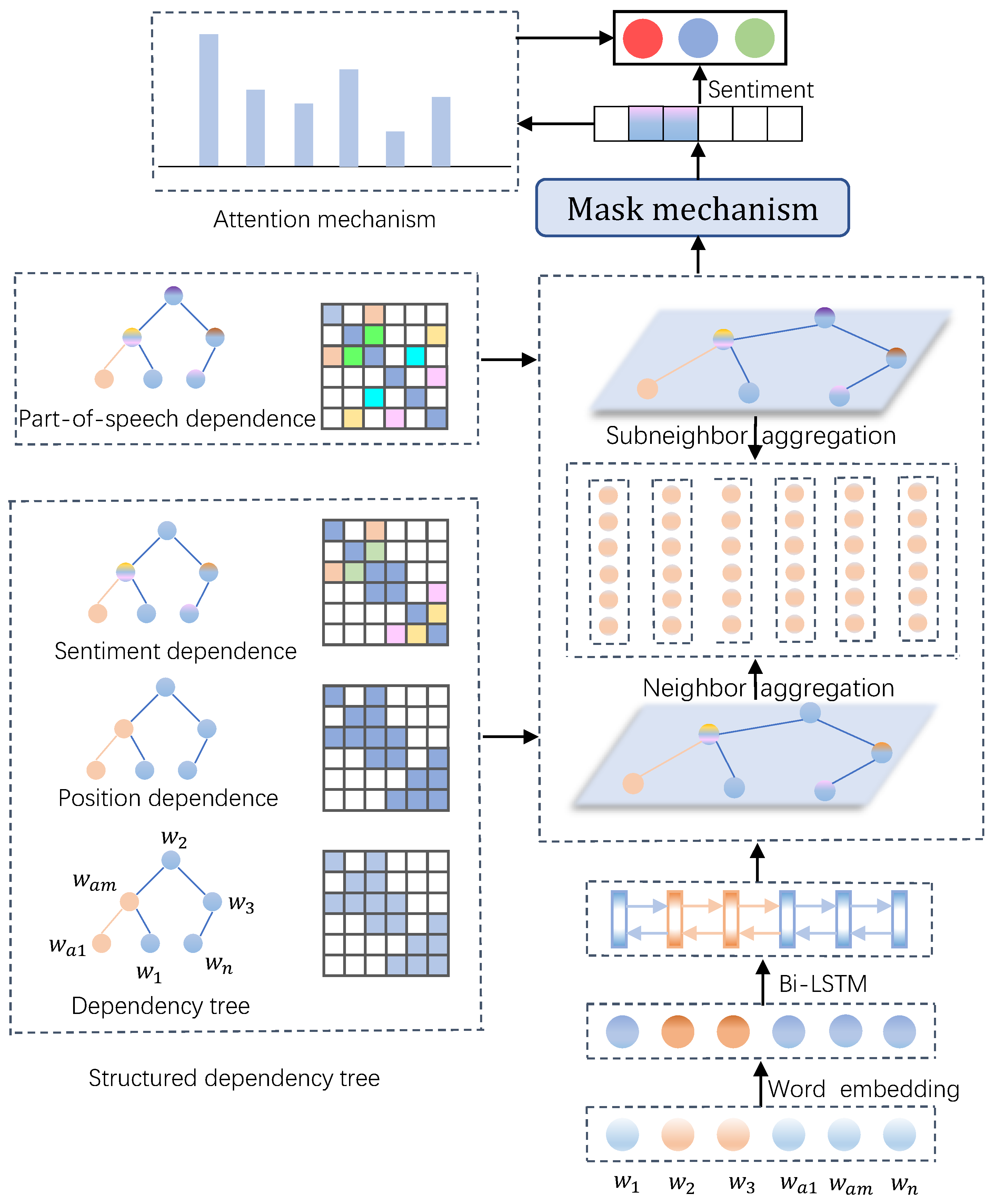
3. The Proposed Method
3.1. Definitions
3.2. Text Representation
3.2.1. Word Embedding
3.2.2. Bi-LSTM Embedding
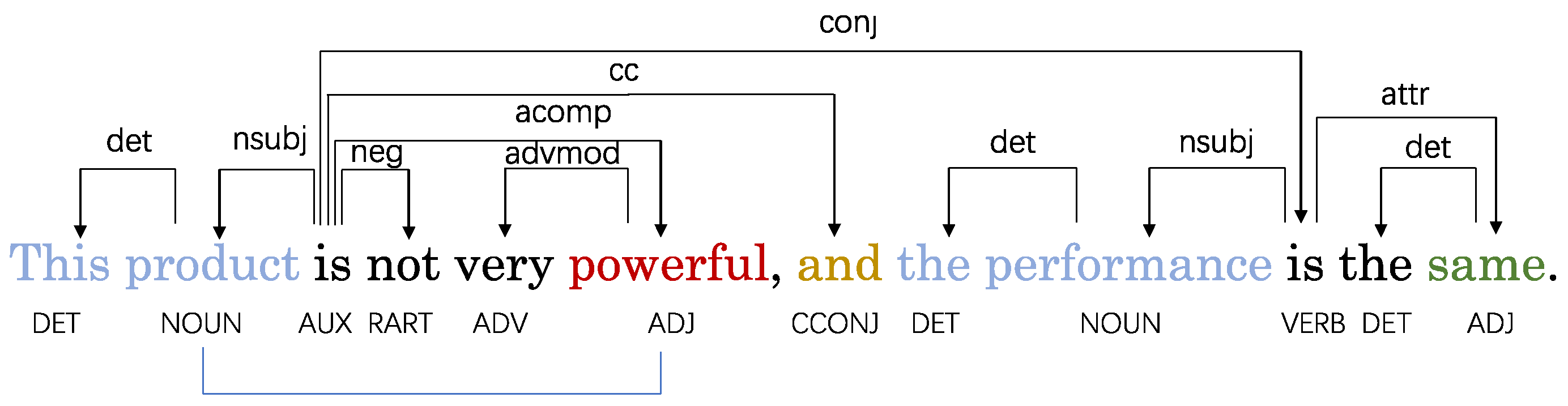
3.3. Structured Dependency Trees
3.3.1. Adjacency Enhanced Dependency Weight Matrix
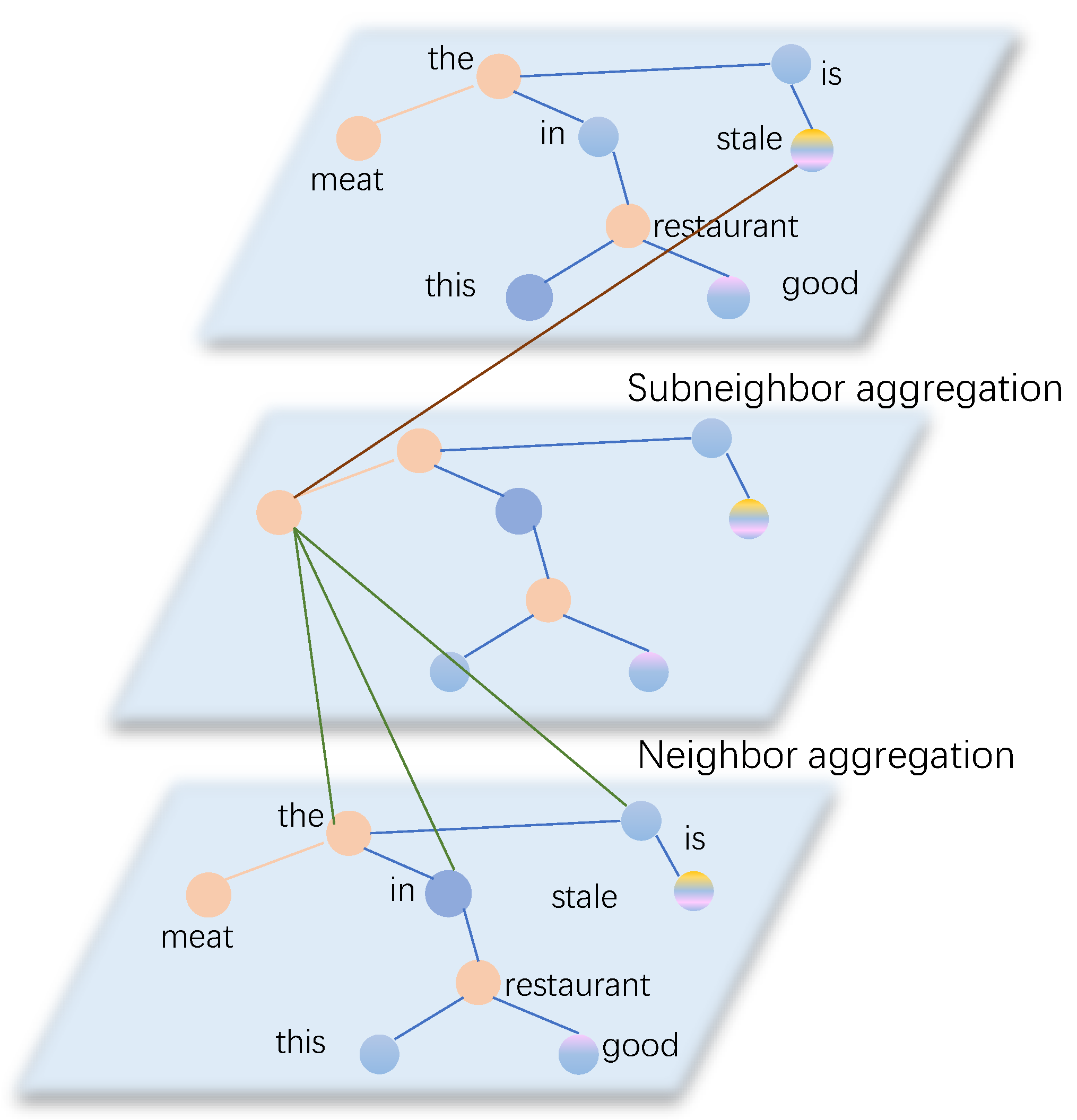
3.3.2. Subadjacent Dependency Weight Matrix
3.4. Weighted Aggregation Graph Convulutional Network
3.5. Atterntion Mechanism
3.6. Training
4. Expriments
4.1. Datasets and Setting
4.2. Baseline Models
- TD-LSTM [39]: The TD-LSTM model employs two target-dependent LSTM networks to capture dependencies between specific aspects and left and right contexts separately.
- ATAE-LSTM [5]: The ATAE-LSTM model utilizes an attention-based LSTM model to compute attention scores for specific aspects, thus enabling the model to focus on pivotal contextual information around different aspects in the sentence.
- IAN [14]: The IAN model uses two interactive attention networks to learn representations of contexts and targets, which allows for focusing on pertinent parts of contexts and targets by utilizing inter-attention. It generates aspect-specific representations for contexts and targets separately.
- MGAN [40]: The MGAN model proposes a fine-grained attention mechanism that can capture word-level interactions between aspects and contexts.
- MemNet [4]: This model develops a deep memory network to capture pertinent contextual information for aspect-level sentiment classification. Compared to RNN models like LSTM, this approach is simpler and faster.
- AOA [41]: This model captures interactions between context and aspects via an attention mechanism that focuses on salient parts of the sentence.
- TNet-LF [42]: This model utilizes CNN layers to extract pertinent features based on LSTM layers from transformed lexical representations.
- ASCNN [7]: This model simplifies ASGCN by substituting two CNN layers for the two GCN layers in ASGCN.
- R-GAT [9]: The R-GAT model defines an aspect-oriented dependency tree structure rooted at the target aspect by reshaping and pruning the original dependency tree. It then leverages graph attention networks to encode the new tree and analyze the sentiment orientation of specific aspects.
- SK-GCN [29]: This model employs a novel syntax and knowledge-based graph convolutional network for aspect-level sentiment classification, primarily by modeling syntactic dependency trees and common sense knowledge graphs to enhance sentence representations for given aspects.
- CDT [6]: The CDT model simply aggregates GCN and BiLSTM models, demonstrating convolutional operations of GCNs on dependency trees to distill BiLSTM embeddings, thereby effectively capturing both structural and contextual information of sentences.
- ASGCN [7]: The ASGCN model constructs a dependency graph for each sentence and extracts syntactic information and word dependencies via graph convolutional networks.
- BiGCN [43]: This model proposes a novel hierarchical architecture of lexical and syntactical graphs. It utilizes a global word-level graph to encode co-occurrence information of words, and separate hierarchical syntax to distinguish various types of dependency relationships or word pair relations.
- AGCN [11]: This model introduces two aggregating functions to iteratively update each node’s representation from its neighborhood and leverage sub-dependencies of nodes to incorporate more relevant node information.
- RMN [44]: The RMN model proposes an innovative relation-constructing multitask learning network that generates aspect representations via graph convolutional networks with semantic dependency graphs and acquires relationships between aspects for sentiment classification.
- InterGCN [45]: This work introduces a novel interactively graph-perceiving model based on graph convolutional networks for sentiment analysis by constructing a heterogeneous graph for each example using aspect-oriented and inter-aspect contextual dependencies.
- GL-GCN [46]: This model concurrently introduces global and local structural information in aspect-based tasks to sufficiently extract accurate representations of specific aspects and contexts.
- SenticGCN [17]: The SenticGCN model aggregates sentiment knowledge from SenticNet to construct graph neural networks, enhancing dependency graphs of sentences. The novel sentiment-enhanced graph model can accurately acquire distinct affective features of different aspects and fully capture relationships between specific aspects and contextual information.
4.3. Results and Analysis
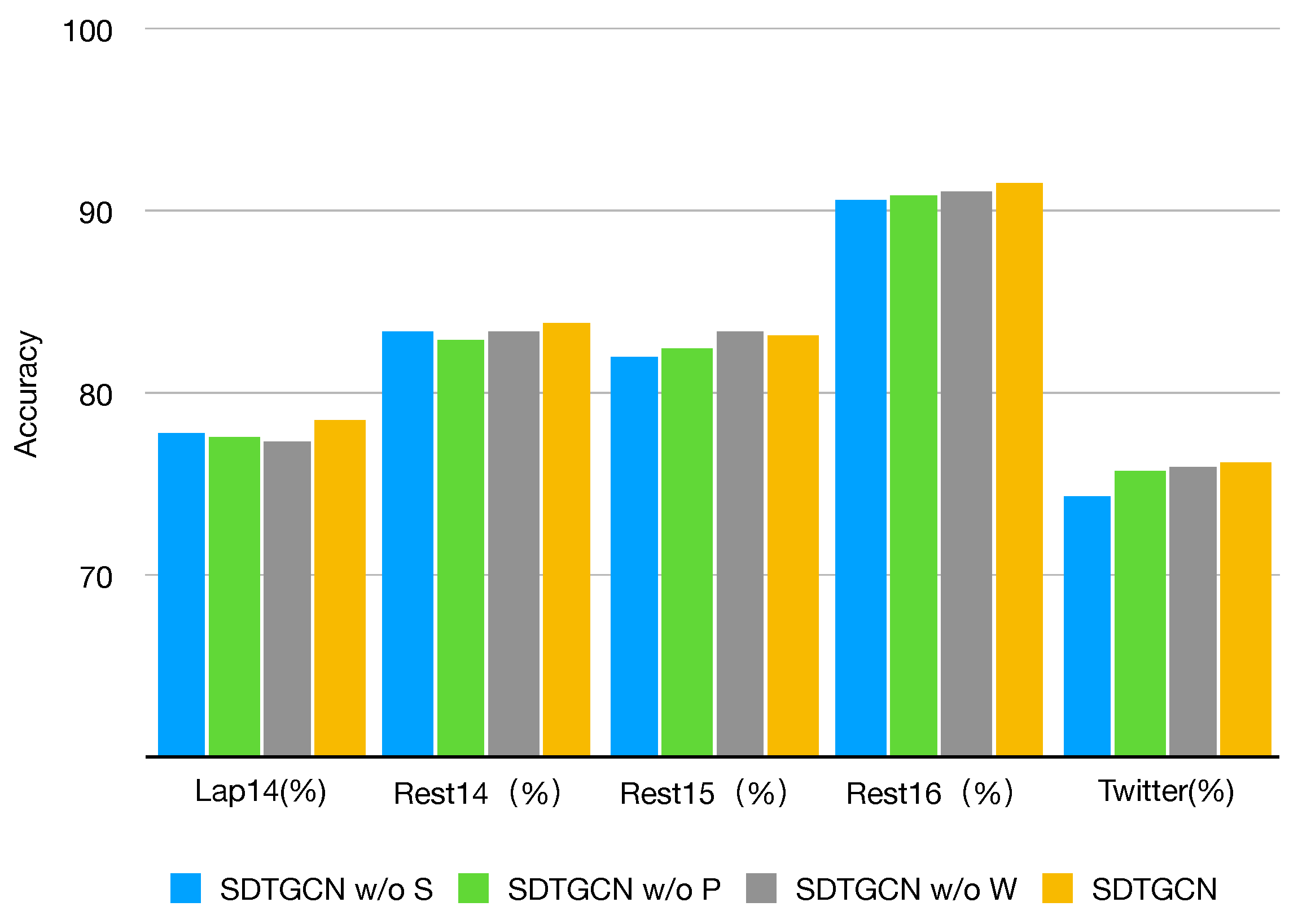
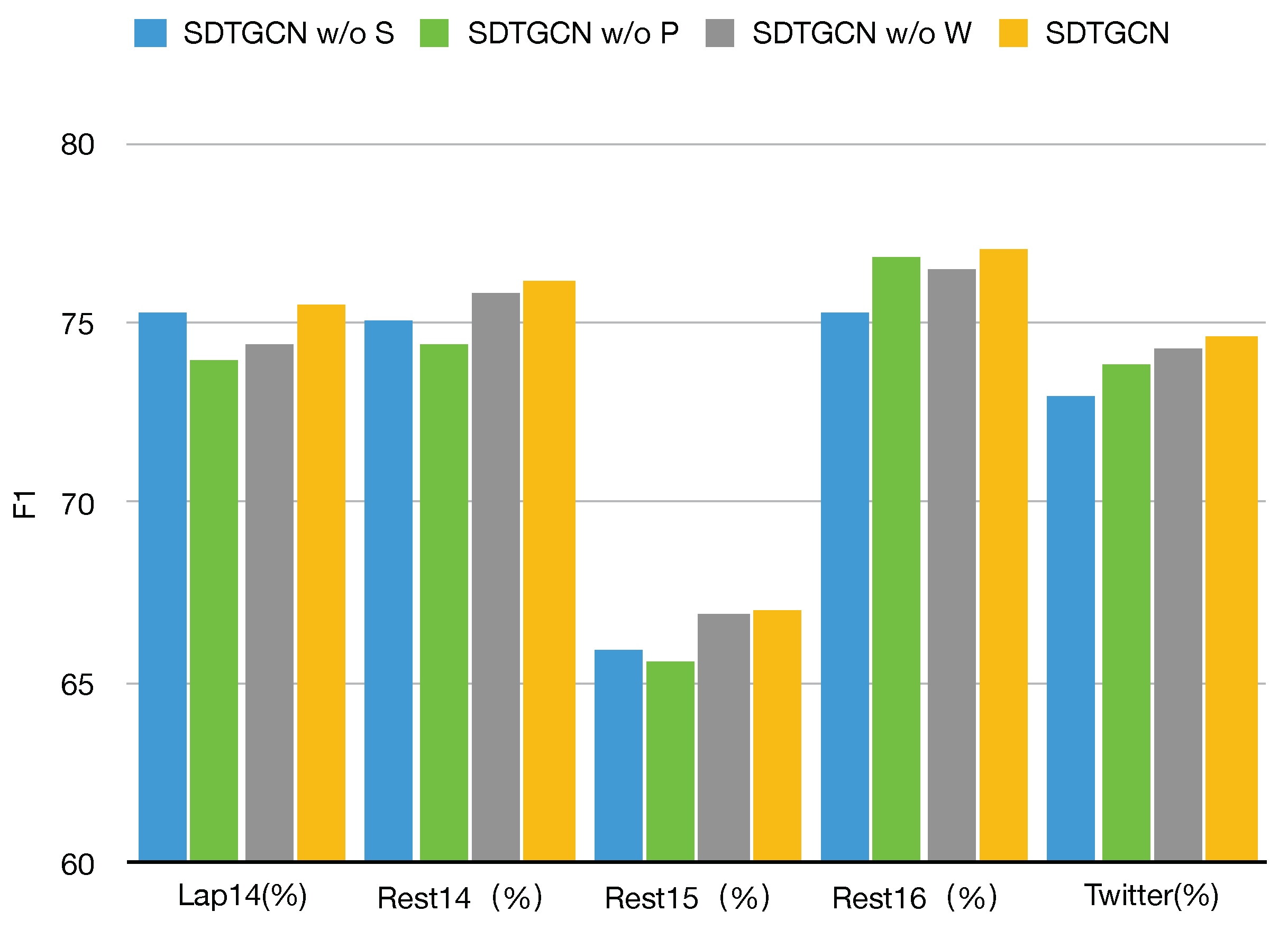
4.4. Ablation Study
- SDTGCN w/o S: This represents the model with the structured dependency tree module removed, making it unable to fully investigate the relationships between aspects and context in sentences. As shown, there is a significant decrease in performance across all datasets when the structured syntax dependency tree module is removed compared to the SDTGCN model. This indicates that the structured syntax dependency tree enriches the general dependency tree, strengthens the contextual information in sentences, and effectively extracts and identifies specific aspect information.
- SDTGCN w/o P: This indicates the model with the subadjacent module that considers part-of-speech and syntactic dependency distance removed. As observed, removing this subadjacent module results in a relatively minor decrease in performance compared to the SDTGCN model. This suggests that considering part-of-speech and syntactic distance can effectively explore relationships between important nodes that lack direct dependencies, leading to noticeable improvements in aspect-based sentiment analysis.
- SDTGCN w/o W: This represents the model with the weighted aggregation graph convolutional network removed, which means it does not effectively aggregate information from adjacency-enhanced matrices and subadjacent matrices. Instead, it uses a regular graph convolutional network to aggregate neighbor node information. It is evident that removing the weighted aggregation graph convolutional network results in a relatively modest decline in performance compared to the SDTGCN model. This indicates that the weighted aggregation graph convolutional network plays a certain role in the SDTGCN model by aggregating node information based on importance levels, thereby enhancing the accuracy of node representations.
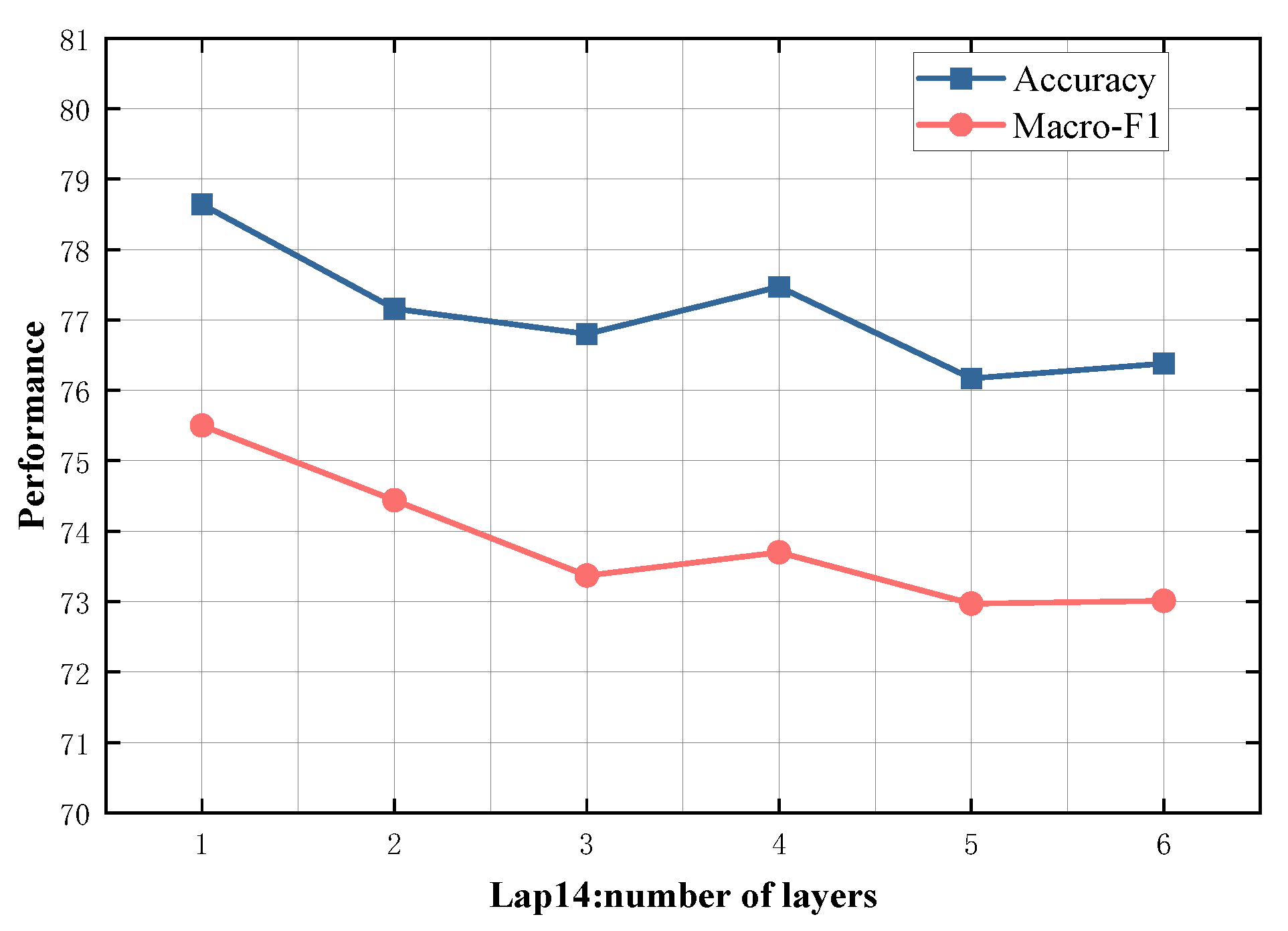
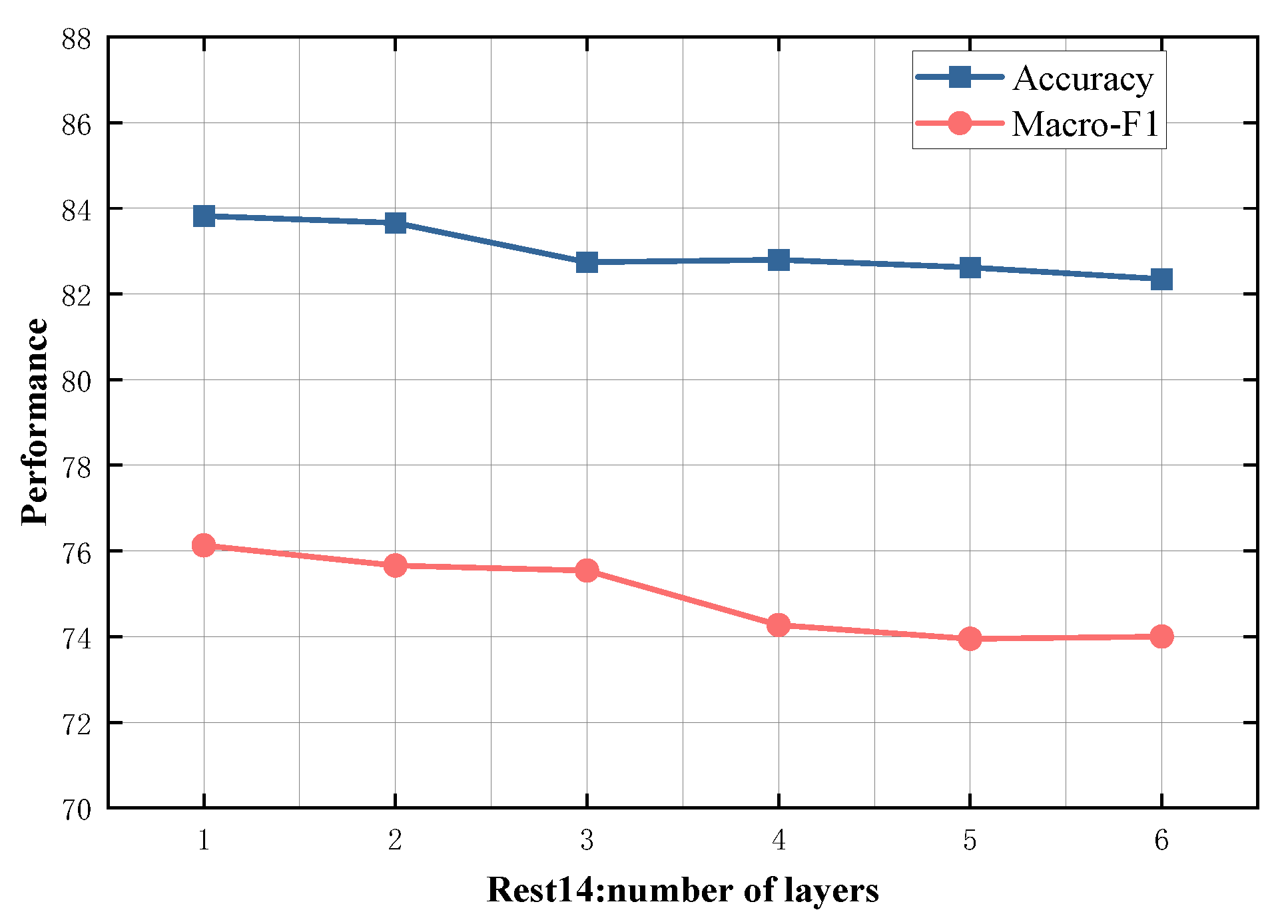
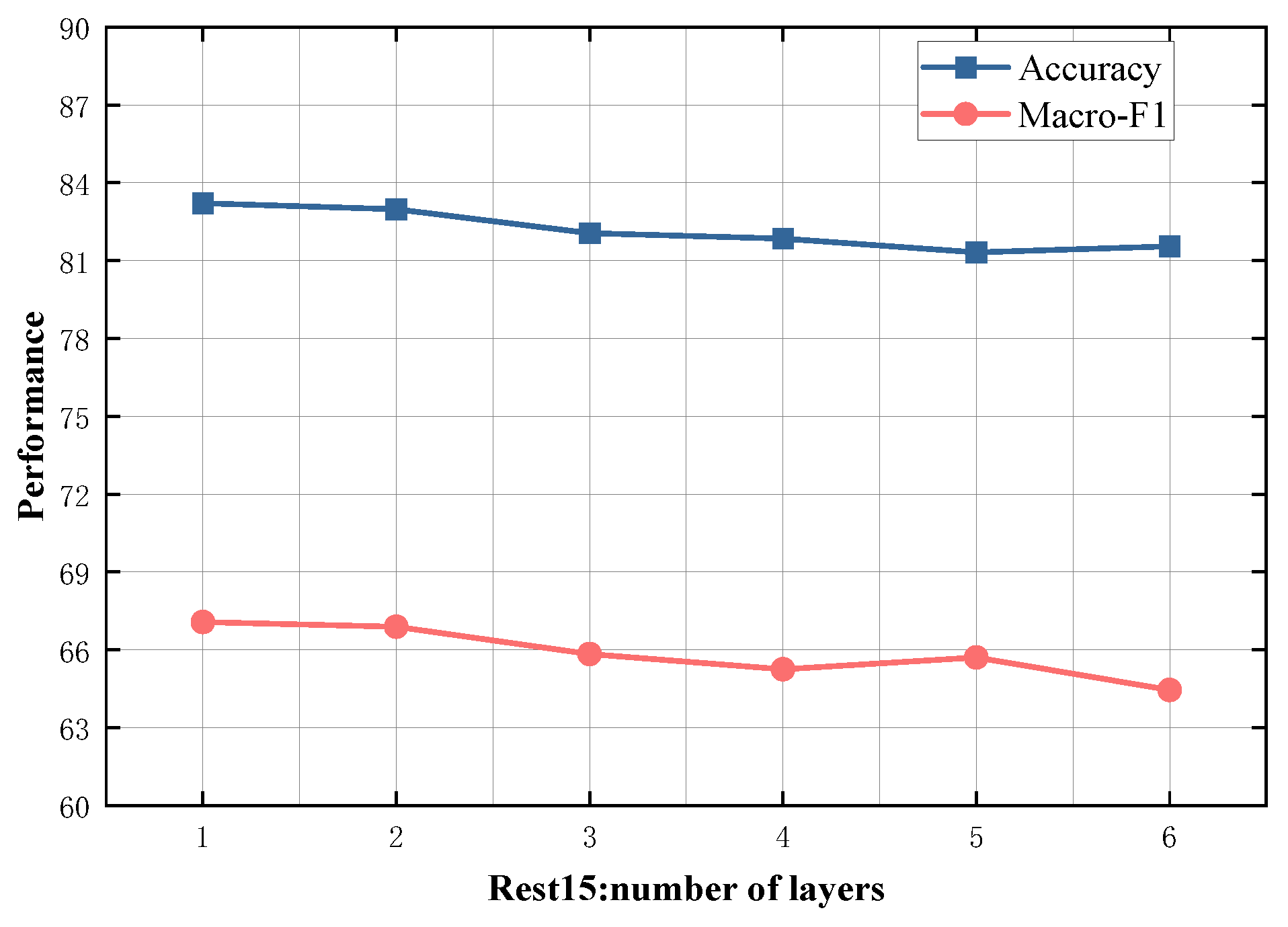
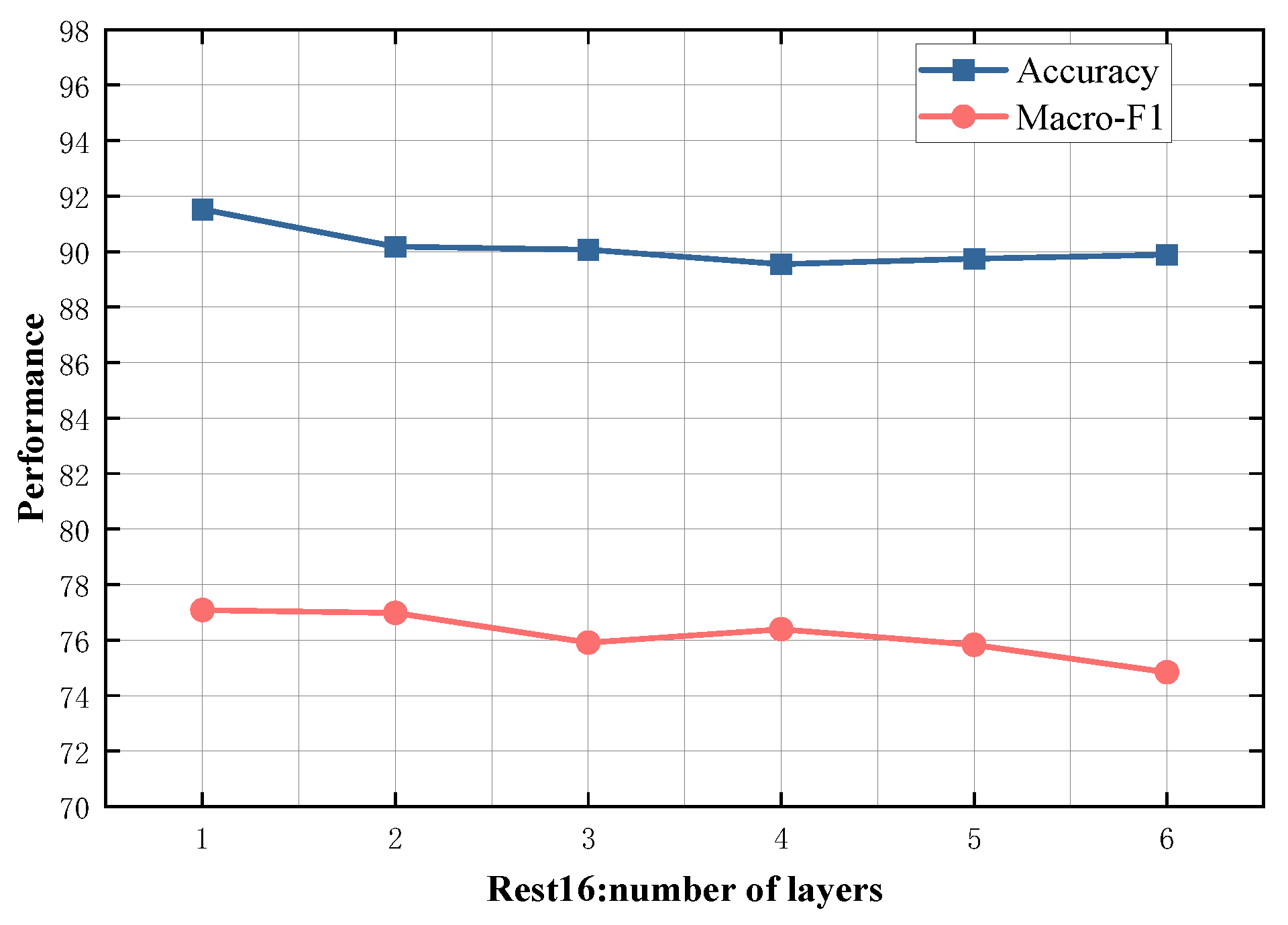
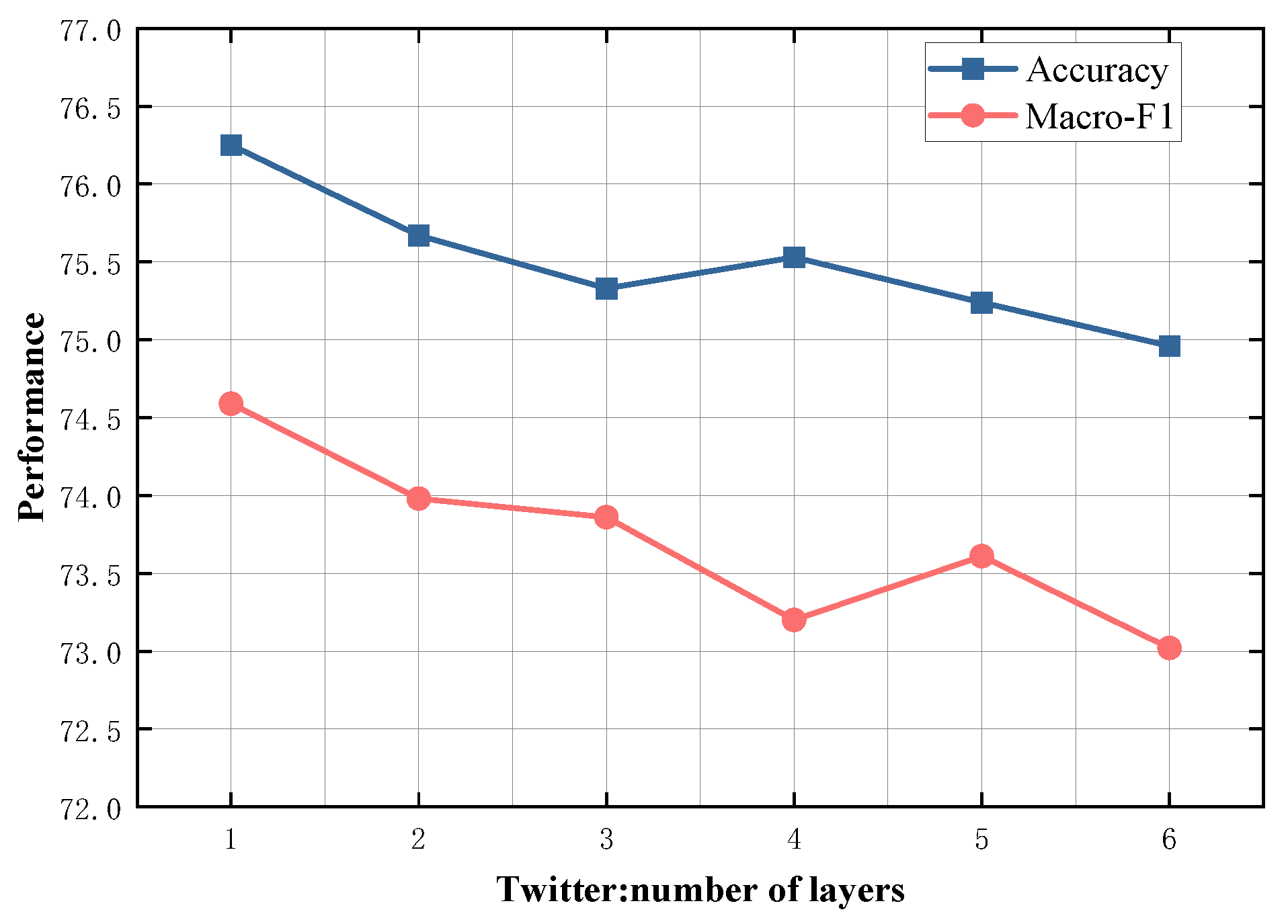
4.5. Study on Model Depth
4.6. Case Study
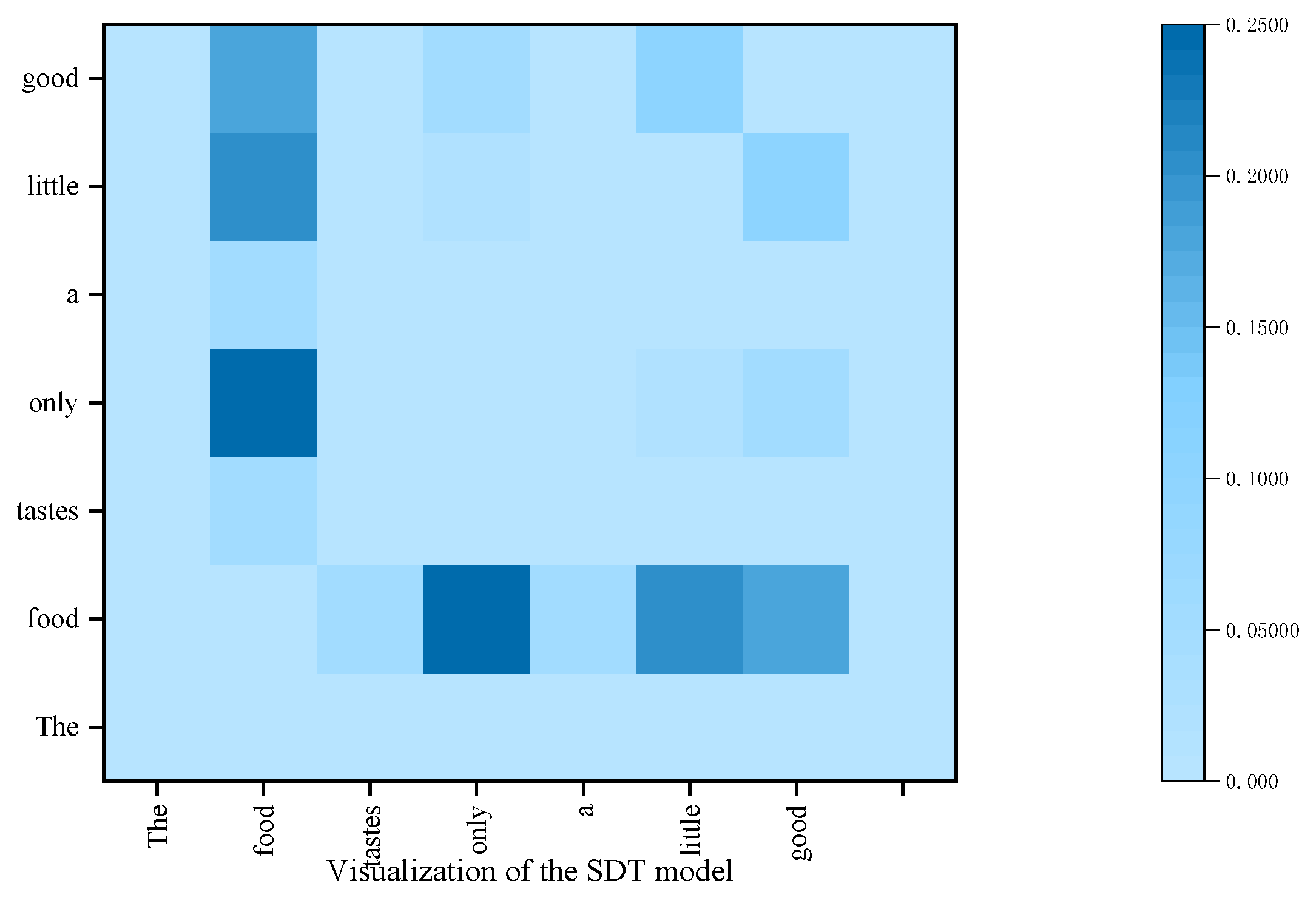
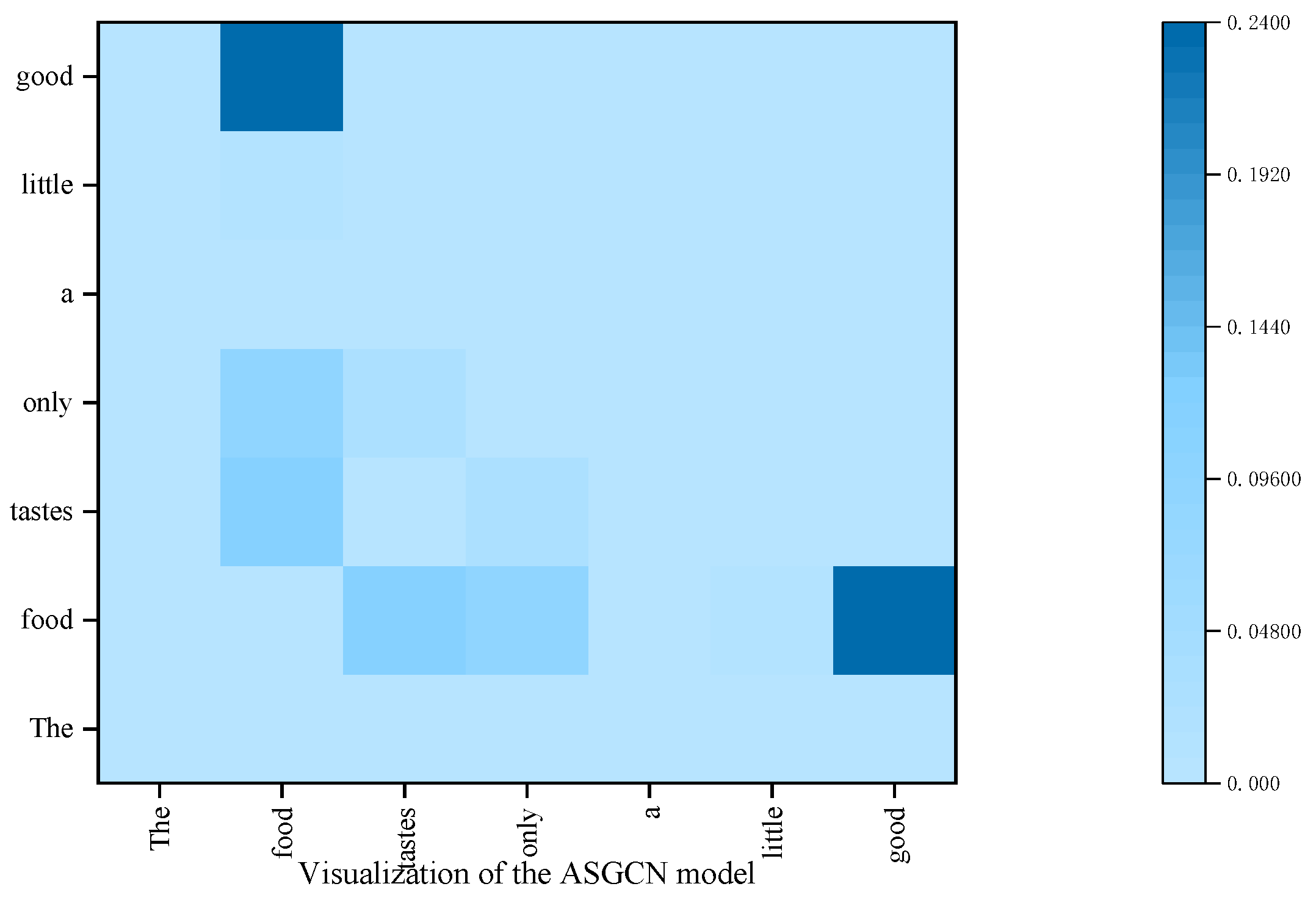
4.7. Visualization of the SDTGCN
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhang, S.; Wei, Z.; Wang, Y.; Liao, T. Sentiment analysis of Chinese micro-blog text based on extended sentiment dictionary. Future Gener. Comput. Syst. 2018, 81, 395–403. [Google Scholar] [CrossRef]
- Mubarok, M.S.; Adiwijaya, A.; Aldhi, M.D. Aspect-based sentiment analysis to review products using Naïve Bayes. In AIP Conference Proceedings; AIP Publishing: Long Island, NY, USA, 2017; Volume 1867. [Google Scholar]
- Dong, L.; Wei, F.; Tan, C.; Tang, D.; Zhou, M.; Xu, K. Adaptive recursive neural network for target-dependent twitter sentiment classification. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short papers), Baltimore, MD, USA, 23–24 June 2014; pp. 49–54. [Google Scholar]
- Tang, D.; Qin, B.; Liu, T. Aspect Level Sentiment Classification with Deep Memory Network. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016. [Google Scholar]
- Wang, Y.; Huang, M.; Zhu, X.; Zhao, L. Attention-based LSTM for aspect-level sentiment classification. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 606–615. [Google Scholar]
- Sun, K.; Zhang, R.; Mensah, S.; Mao, Y.; Liu, X. Aspect-level sentiment analysis via convolution over dependency tree. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 5679–5688. [Google Scholar]
- Zhang, C.; Li, Q.; Song, D. Aspect-based Sentiment Classification with Aspect-specific Graph Convolutional Networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019. [Google Scholar]
- Li, R.; Chen, H.; Feng, F.; Ma, Z.; Wang, X.; Hovy, E. Dual graph convolutional networks for aspect-based sentiment analysis. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Online, 1–6 August 2021; pp. 6319–6329. [Google Scholar]
- Wang, K.; Shen, W.; Yang, Y.; Quan, X.; Wang, R. Relational Graph Attention Network for Aspect-based Sentiment Analysis. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020. [Google Scholar]
- Li, W.; Yin, S.; Pu, T. Lexical attention and aspect-oriented graph convolutional networks for aspect-based sentiment analysis. J. Intell. Fuzzy Syst. 2022, 42, 1643–1654. [Google Scholar] [CrossRef]
- Zhao, M.; Yang, J.; Zhang, J.; Wang, S. Aggregated graph convolutional networks for aspect-based sentiment classification. Inf. Sci. 2022, 600, 73–93. [Google Scholar] [CrossRef]
- Majumder, N.; Bhardwaj, R.; Poria, S.; Gelbukh, A.; Hussain, A. Improving aspect-level sentiment analysis with aspect extraction. Neural Comput. Appl. 2022, 34, 8333–8343. [Google Scholar] [CrossRef]
- Chen, P.; Sun, Z.; Bing, L.; Yang, W. Recurrent attention network on memory for aspect sentiment analysis. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017; pp. 452–461. [Google Scholar]
- Ma, D.; Li, S.; Zhang, X.; Wang, H. Interactive Attention Networks for Aspect-Level Sentiment Classification. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, IJCAI-17, Melbourne, Australia, 19–25 August 2017; pp. 4068–4074. [Google Scholar]
- Gu, S.; Zhang, L.; Hou, Y.; Song, Y. A position-aware bidirectional attention network for aspect-level sentiment analysis. In Proceedings of the 27th International Conference on Computational Linguistics, Santa Fe, NM, USA, 20–26 August 2018; pp. 774–784. [Google Scholar]
- Song, Y.; Wang, J.; Jiang, T.; Liu, Z.; Rao, Y. Attentional Encoder Network for Targeted Sentiment Classification. arXiv 2019, arXiv:1902.09314. [Google Scholar]
- Liang, B.; Su, H.; Gui, L.; Cambria, E.; Xu, R. Aspect-based sentiment analysis via affective knowledge enhanced graph convolutional networks. Knowl.-Based Syst. 2022, 235, 107643. [Google Scholar] [CrossRef]
- Xue, W.; Li, T. Aspect Based Sentiment Analysis with Gated Convolutional Networks. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018. [Google Scholar]
- Ayetiran, E.F. Attention-based aspect sentiment classification using enhanced learning through CNN-BiLSTM networks. Knowl.-Based Syst. 2022, 252, 109409. [Google Scholar] [CrossRef]
- Phan, H.T.; Nguyen, N.T.; Hwang, D. Aspect-level sentiment analysis: A survey of graph convolutional network methods. Inf. Fusion 2023, 91, 149–172. [Google Scholar] [CrossRef]
- Truşcǎ, M.M.; Frasincar, F. Survey on aspect detection for aspect-based sentiment analysis. Artif. Intell. Rev. 2023, 56, 3797–3846. [Google Scholar] [CrossRef]
- Nazir, A.; Rao, Y.; Wu, L.; Sun, L. Issues and challenges of aspect-based sentiment analysis: A comprehensive survey. IEEE Trans. Affect. Comput. 2020, 13, 845–863. [Google Scholar] [CrossRef]
- Zhang, D.; Zhu, Z.; Kang, S.; Zhang, G.; Liu, P. Syntactic and semantic analysis network for aspect-level sentiment classification. Appl. Intell. 2021, 51, 6136–6147. [Google Scholar] [CrossRef]
- Phan, M.H.; Ogunbona, P.O. Modelling context and syntactical features for aspect-based sentiment analysis. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 3211–3220. [Google Scholar]
- Veyseh, A.P.B.; Nour, N.; Dernoncourt, F.; Tran, Q.H.; Dou, D.; Nguyen, T.H. Improving Aspect-based Sentiment Analysis with Gated Graph Convolutional Networks and Syntax-based Regulation. In Proceedings of the Findings of the Association for Computational Linguistics: Online, 5–10 July 2020; pp. 4543–4548. [Google Scholar]
- Zhao, P.; Hou, L.; Wu, O. Modeling sentiment dependencies with graph convolutional networks for aspect-level sentiment classification. Knowl.-Based Syst. 2020, 193, 105443. [Google Scholar] [CrossRef]
- Lu, Q.; Zhu, Z.; Zhang, G.; Kang, S.; Liu, P. Aspect-gated graph convolutional networks for aspect-based sentiment analysis. Appl. Intell. 2021, 51, 4408–4419. [Google Scholar] [CrossRef]
- Xu, K.; Zhao, H.; Liu, T. Aspect-specific heterogeneous graph convolutional network for aspect-based sentiment classification. IEEE Access 2020, 8, 139346–139355. [Google Scholar] [CrossRef]
- Zhou, J.; Huang, J.X.; Hu, Q.V.; He, L. Sk-gcn: Modeling syntax and knowledge via graph convolutional network for aspect-level sentiment classification. Knowl.-Based Syst. 2020, 205, 106292. [Google Scholar] [CrossRef]
- Ke, W.; Gao, J.; Shen, H.; Cheng, X. Incorporating explicit syntactic dependency for aspect level sentiment classification. Neurocomputing 2021, 456, 394–406. [Google Scholar] [CrossRef]
- Phan, H.T.; Nguyen, N.T.; Hwang, D. Convolutional attention neural network over graph structures for improving the performance of aspect-level sentiment analysis. Inf. Sci. 2022, 589, 416–439. [Google Scholar] [CrossRef]
- Lu, Q.; Sun, X.; Sutcliffe, R.; Xing, Y.; Zhang, H. Sentiment interaction and multi-graph perception with graph convolutional networks for aspect-based sentiment analysis. Knowl.-Based Syst. 2022, 256, 109840. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhou, Z.; Wang, Y. SSEGCN: Syntactic and semantic enhanced graph convolutional network for aspect-based sentiment analysis. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 10–15 July 2022; pp. 4916–4925. [Google Scholar]
- Liang, C.; Fu, Y.; Lv, C. Structurally Enhanced Interactive Attention Network for Aspect-Level Sentiment Classification. In Proceedings of the 2020 International Conference on Asian Language Processing (IALP), Kuala Lumpur, Malaysia, 4–6 December 2020; pp. 282–287. [Google Scholar]
- Ma, Y.; Peng, H.; Cambria, E. Targeted aspect-based sentiment analysis via embedding commonsense knowledge into an attentive LSTM. In Proceedings of the AAAI Conference on Artificial Intelligence, Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Kirange, D.; Deshmukh, R.R.; Kirange, M. Aspect based sentiment analysis semeval-2014 task 4. Asian J. Comput. Sci. Technol. (AJCST) 2014, 4, 72–75. [Google Scholar] [CrossRef]
- Pontiki, M.; Galanis, D.; Papageorgiou, H.; Manandhar, S.; Androutsopoulos, I. Semeval-2015 task 12: Aspect based sentiment analysis. In Proceedings of the 9th International Workshop on Semantic Evaluation (SemEval 2015), Denver, CO, USA, 4–5 June 2015; pp. 486–495. [Google Scholar]
- Brun, C.; Perez, J.; Roux, C. XRCE at SemEval-2016 task 5: Feedbacked ensemble modeling on syntactico-semantic knowledge for aspect based sentiment analysis. In Proceedings of the 10th International Workshop on Semantic Evaluation (SemEval-2016), San Diego, CA, USA, 16–17 June 2016; pp. 277–281. [Google Scholar]
- Tang, D.; Qin, B.; Feng, X.; Liu, T. Effective LSTMs for Target-Dependent Sentiment Classification. arXiv 2015, arXiv:1512.01100. [Google Scholar]
- Fan, F.; Feng, Y.; Zhao, D. Multi-grained attention network for aspect-level sentiment classification. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 3433–3442. [Google Scholar]
- Huang, B.; Ou, Y.; Carley, K.M. Aspect level sentiment classification with attention-over-attention neural networks. In Proceedings of the Social, Cultural, and Behavioral Modeling: 11th International Conference, SBP-BRiMS 2018, Washington, DC, USA, 10–13 July 2018; Proceedings 11. Springer: Berlin/Heidelberg, Germany, 2018; pp. 197–206. [Google Scholar]
- Li, X.; Bing, L.; Lam, W.; Shi, B. Transformation Networks for Target-Oriented Sentiment Classification. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018. [Google Scholar]
- Zhang, M.; Qian, T. Convolution over hierarchical syntactic and lexical graphs for aspect level sentiment analysis. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 3540–3549. [Google Scholar]
- Zeng, J.; Liu, T.; Jia, W.; Zhou, J. Relation construction for aspect-level sentiment classification. Inf. Sci. 2022, 586, 209–223. [Google Scholar] [CrossRef]
- Liang, B.; Yin, R.; Gui, L.; Du, J.; Xu, R. Jointly learning aspect-focused and inter-aspect relations with graph convolutional networks for aspect sentiment analysis. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain, 8–13 December 2020; pp. 150–161. [Google Scholar]
- Zhu, X.; Zhu, L.; Guo, J.; Liang, S.; Dietze, S. GL-GCN: Global and local dependency guided graph convolutional networks for aspect-based sentiment classification. Expert Syst. Appl. 2021, 186, 115712. [Google Scholar] [CrossRef]














{kind=link}
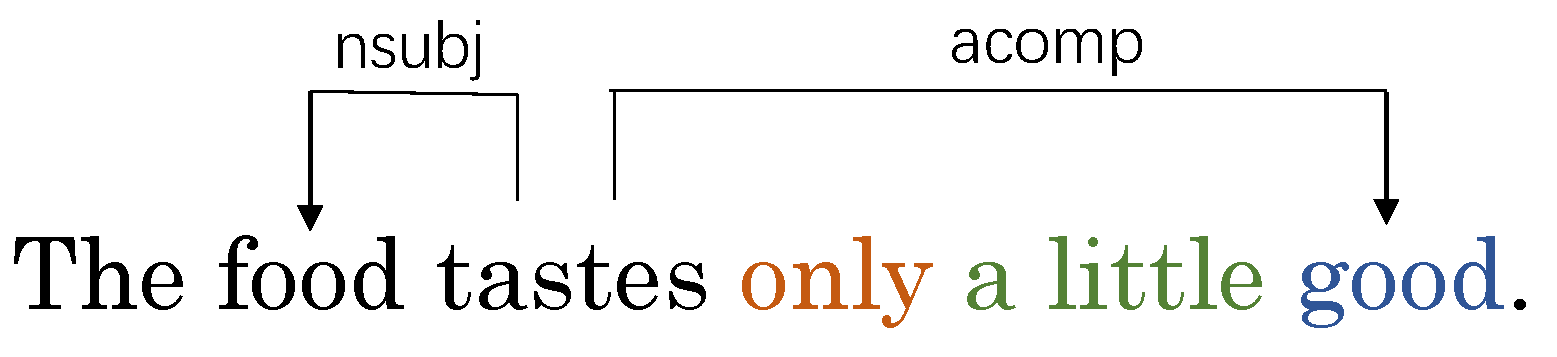{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | RNN | Attention | CNN | GCN | GAT | Syntactic | Knowledge |
|---|---|---|---|---|---|---|---|
| TD-LSTM | ✓ | ||||||
| ATAE-LSTM | ✓ | ✓ | |||||
| ASCNN | ✓ | ✓ | |||||
| R-GAT | ✓ | ✓ | ✓ | ✓ | |||
| SK-GCN | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| CDT | ✓ | ✓ | ✓ | ||||
| ASGCN | ✓ | ✓ | ✓ | ✓ | |||
| RMN | ✓ | ✓ | ✓ | ✓ | |||
| InterGCN | ✓ | ✓ | ✓ | ✓ | |||
| GL-GCN | ✓ | ✓ | ✓ | ✓ | |||
| SenticGCN | ✓ | ✓ | ✓ | ✓ |
| Notation | Type | Definition |
|---|---|---|
| s | Set | A sentence with n-words |
| One-hot vector | The i-th word in the sentence | |
| One-hot vector | The i-th word in the aspect terms | |
| n | Scalar | The length of the context word |
| m | Scalar | The length of the aspect word |
| Scalar | The dimension of word embedding | |
| Scalar | The dimension of hidden representation | |
| X | Matrix | The GloVe embedding matrix |
| D | Matrix | The adjacency matrix |
| P | Matrix | The position weight matrix |
| Set | The set of aspects in the sentence | |
| E | Matrix | The sentiment knowledge matrix |
| A | Matrix | The aspect matrix |
| Matrix | The adjacency enhanced dependency weight matrix | |
| Matrix | The subadjacency matrix | |
| Matrix | HcThe final representation of the sentence |
| Dataset | Positive | Neural | Negative | |||
|---|---|---|---|---|---|---|
| Train | Test | Train | Test | Train | Test | |
| Lap14 | 994 | 341 | 464 | 169 | 870 | 128 |
| Rest14 | 2164 | 728 | 637 | 196 | 807 | 193 |
| Rest15 | 978 | 326 | 36 | 34 | 307 | 182 |
| Rest16 | 1230 | 440 | 62 | 28 | 417 | 107 |
| 1561 | 173 | 3127 | 346 | 1560 | 1743 | |
| Models | Lap14 | Rest14 | Rest15 | Rest16 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Acc | F1 | Acc | F1 | Acc | F1 | Acc | F1 | Acc | F1 | |
| TD-LSTM | 71.83 | 68.43 | 78.00 | 66.73 | 76.39 | 58.70 | 82.16 | 54.21 | 70.80 | 69.00 |
| ATAE-LSTM | 68.70 | 63.93 | 77.20 | 67.02 | 78.48 | 60.53 | 83.77 | 61.71 | - | - |
| IAN | 72.05 | 67.38 | 79.26 | 71.94 | 78.54 | 57.26 | 84.74 | 62.29 | 72.50 | 70.81 |
| MemNet | 70.64 | 65.17 | 79.61 | 69.64 | 77.31 | 58.28 | 85.44 | 65.99 | 71.48 | 69.90 |
| AOA | 72.62 | 67.52 | 79.97 | 70.42 | 78.17 | 57.02 | 87.50 | 66.21 | 72.30 | 70.20 |
| TNet-LF | 74.61 | 70.14 | 80.42 | 71.03 | 78.47 | 59.47 | 89.07 | 70.43 | 72.98 | 71.43 |
| ASCNN | 72.62 | 66.72 | 81.73 | 73.10 | 78.47 | 58.90 | 87.39 | 64.56 | 71.05 | 69.45 |
| R-GAT | 77.42 | 73.76 | 83.30 | 76.08 | 80.83 | 64.17 | 88.92 | 70.89 | 75.57 | 73.82 |
| SK-GCN | 73.20 | 69.18 | 80.36 | 70.43 | 80.12 | 60.70 | 85.17 | 68.08 | 71.97 | 70.22 |
| CDT | 77.19 | 72.99 | 82.30 | 74.02 | - | - | 85.58 | 69.93 | 74.66 | 73.66 |
| ASGCN | 75.55 | 71.05 | 80.77 | 72.02 | 79.89 | 61.89 | 88.99 | 67.48 | 72.15 | 70.40 |
| BiGCN | 74.59 | 71.84 | 81.97 | 73.48 | 81.16 | 64.79 | 88.96 | 70.84 | 74.16 | 73.35 |
| AGCN | 75.07 | 70.96 | 80.02 | 71.02 | 80.07 | 62.70 | 87.98 | 65.78 | 73.98 | 72.48 |
| RMN | 74.50 | 69.79 | 81.16 | 73.17 | 80.69 | 64.41 | 88.75 | 71.54 | - | - |
| InterGCN | 77.86 | 74.32 | 82.23 | 74.01 | 81.76 | 65.67 | 89.77 | 73.05 | - | - |
| GL-GCN | 76.91 | 72.76 | 82.11 | 73.46 | 80.81 | 64.99 | 88.47 | 69.64 | 73.26 | 71.26 |
| SenticGCN | 77.90 | 74.71 | 84.03 | 75.38 | 82.84 | 67.32 | 90.88 | 75.91 | - | - |
| SDTGCN | 78.64 | 75.50 | 83.82 | 76.13 | 83.21 | 67.07 | 91.53 | 77.08 | 76.25 | 74.59 |
| Case | IAN | ASGCN | SDTGCN | Ground Truth |
|---|---|---|---|---|
| The screen on this phone is not very good. | P | N | N | N |
| The food tastes only a little good. | N | P | N | N |
| The meat in this good restaurant is stale. | N | N | P | P |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, Q.; Yang, F.; An, D.; Lian, J. Modeling Structured Dependency Tree with Graph Convolutional Networks for Aspect-Level Sentiment Classification. Sensors 2024, 24, 418. https://doi.org/10.3390/s24020418
Zhao Q, Yang F, An D, Lian J. Modeling Structured Dependency Tree with Graph Convolutional Networks for Aspect-Level Sentiment Classification. Sensors. 2024; 24(2):418. https://doi.org/10.3390/s24020418
Chicago/Turabian StyleZhao, Qin, Fuli Yang, Dongdong An, and Jie Lian. 2024. "Modeling Structured Dependency Tree with Graph Convolutional Networks for Aspect-Level Sentiment Classification" Sensors 24, no. 2: 418. https://doi.org/10.3390/s24020418
APA StyleZhao, Q., Yang, F., An, D., & Lian, J. (2024). Modeling Structured Dependency Tree with Graph Convolutional Networks for Aspect-Level Sentiment Classification. Sensors, 24(2), 418. https://doi.org/10.3390/s24020418