

Enhancing Radar Echo Extrapolation by ConvLSTM2D for Precipitation Nowcasting

Abstract
:1. Introduction
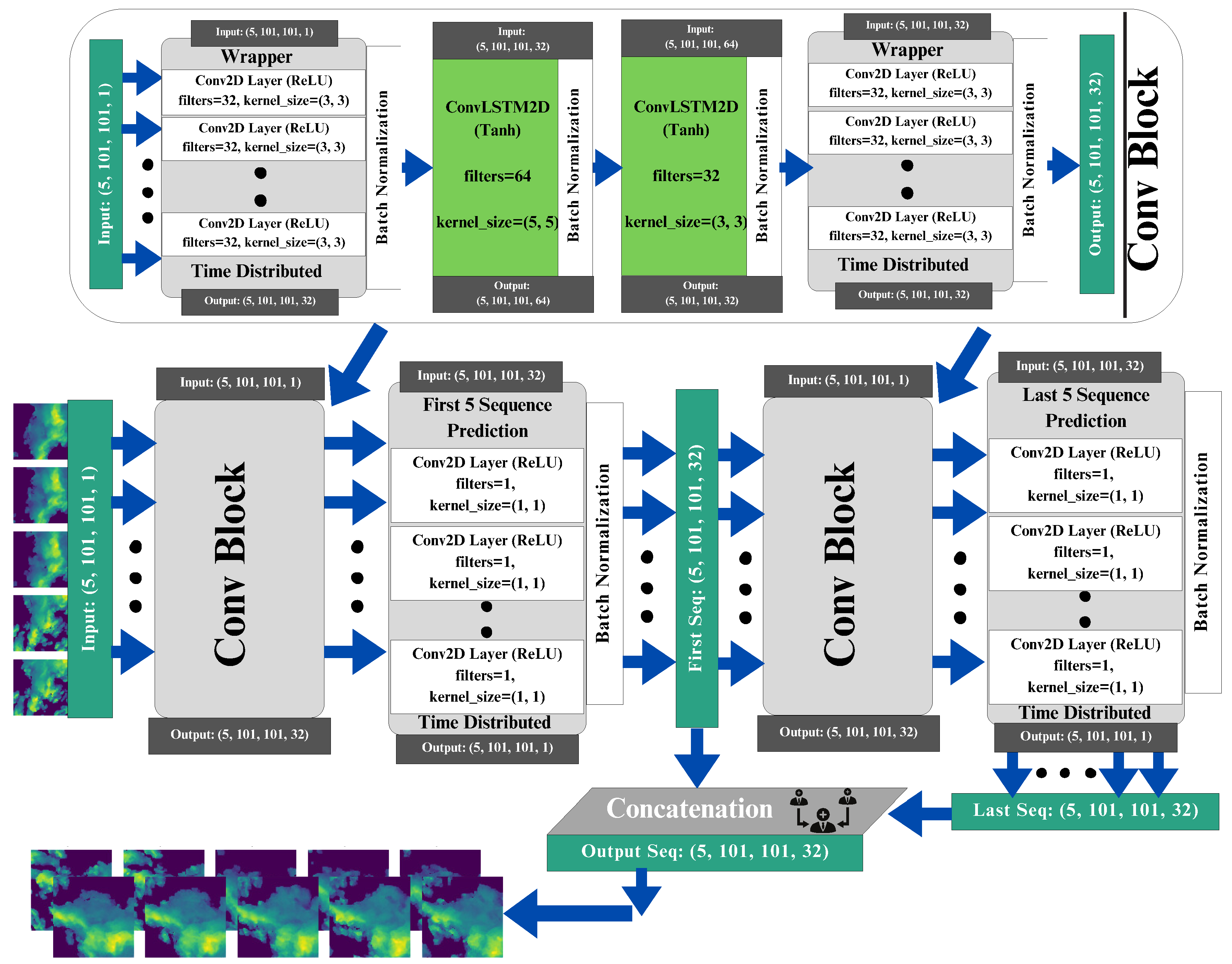
- We introduce ConvLSTM2D, a dual-component neural network architecture tailored for precipitation nowcasting. The proposed model incorporates ConvLayers, which are effective in extracting spatial and temporal features through the use of Conv2D and ConvLSTM2D operations.
- In previous studies, the limitation of fixed kernel sizes constrains models to local feature extraction. To address this, we explore multiple combinations of time-distributed Conv2D and ConvLSTM2D layers. The deliberate utilization of mixed kernel sizes enables the model to effectively capture both detailed information and broader spatial relationships.
- The performance of the ConvLSTM2D model is comprehensively assessed, demonstrating competitive outcomes through the use of metrics including CSI, HSS, SSIM, and MAE. The model’s predictability and accuracy in precipitation nowcasting is compared against the state-of-the-art models in the field.
2. Related Work
3. Preliminaries
3.1. Mathematical Problem Formulation of Precipitation Nowcasting
3.2. Long Short-Term Memory in Sequence Modeling
4. Methodology
| Algorithm 1 Pseudocode for the ConvLSTM2D model for sequence data processing. |
|
5. Experimental Setup
5.1. Evaluation Dataset
5.2. Data Preprocessing
5.3. Training Setting
5.4. Evaluation Criteria
6. Results and Discussions
6.1. Comparison Studies
6.2. Visualization of Prediction Results
6.3. Ablation Studies
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Inness, P.M.; Dorling, S. Operational Weather Forecasting; John Wiley & Sons: Hoboken, NJ, USA, 2013. [Google Scholar]
- Bakkay, M.C.; Serrurier, M.; Burda, V.K.; Dupuy, F.; Cabrera-Gutierrez, N.C.; Zamo, M.; Mader, M.; Mestre, O.; Oller, G.; Jouhaud, J.; et al. Precipitaion Nowcasting using Deep Neural Network. arXiv 2022, arXiv:2203.13263. [Google Scholar]
- Liu, J.; Xu, L.; Chen, N. A spatiotemporal deep learning model ST-LSTM-SA for hourly rainfall forecasting using radar echo images. J. Hydrol. 2022, 609, 127748. [Google Scholar] [CrossRef]
- Kin Wong, W.; Yeung, L.H.Y.; Chun Wang, Y.; Chen, M. Towards the Blending of NWP with Nowcast—Operation Experience in B08FDP. In Proceedings of the WMO Symposium on Nowcasting, Whistler, BC, Canada, 30 August–4 September 2009. [Google Scholar]
- Woo, W.-C.; Wong, W.-K. Operational Application of Optical Flow Techniques to Radar-Based Rainfall Nowcasting. Atmosphere 2017, 8, 48. [Google Scholar] [CrossRef]
- Tran, Q.-K.; Song, S.-K. Computer Vision in Precipitation Nowcasting: Applying Image Quality Assessment Metrics for Training Deep Neural Networks. Atmosphere 2019, 10, 244. [Google Scholar] [CrossRef]
- Marrocu, M.; Massidda, L. Performance Comparison between Deep Learning and Optical Flow-Based Techniques for Nowcast Precipitation from Radar Images. Forecasting 2020, 2, 194–210. [Google Scholar] [CrossRef]
- Park, S.J.; Lee, D.K. Prediction of coastal flooding risk under climate change impacts in South Korea using machine learning algorithms. Environ. Res. Lett. 2020, 15, 094052. [Google Scholar] [CrossRef]
- Bochenek, B.; Ustrnul, Z. Machine Learning in Weather Prediction and Climate Analyses—Applications and Perspectives. Atmosphere 2022, 13, 180. [Google Scholar] [CrossRef]
- Holmstrom, M.; Liu, D.; Vo, C. Machine Learning Applied to Weather Forecasting; Technical Report; Stanford University: Stanford, CA, USA, 2016. [Google Scholar]
- Sidder, A. The AI Forecaster: Machine Learning Takes on Weather Prediction. Eos 2022, 103. [Google Scholar] [CrossRef]
- Singh, N.; Chaturvedi, S.; Akhter, S. Weather Forecasting Using Machine Learning Algorithm. In Proceedings of the 2019 International Conference on Signal Processing and Communication (ICSC), Noida, India, 7–9 March 2019; pp. 171–174. [Google Scholar]
- Rasp, S.; Dueben, P.D.; Scher, S.; Weyn, J.A.; Mouatadid, S.; Thuerey, N. WeatherBench: A Benchmark Data Set for Data-Driven Weather Forecasting. J. Adv. Model. Earth Syst. 2020, 12, e2020MS002203. [Google Scholar] [CrossRef]
- Luo, C.; Li, X.; Wen, Y.; Ye, Y.; Zhang, X. A Novel LSTM Model with Interaction Dual Attention for Radar Echo Extrapolation. Remote Sens. 2021, 13, 164. [Google Scholar] [CrossRef]
- Wang, Y.; Jiang, L.; Yang, M.; Li, L.; Long, M.; Fei-Fei, L. Eidetic 3D LSTM: A Model for Video Prediction and Beyond. In Proceedings of the 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Wang, Y.; Long, M.; Wang, J.; Gao, Z.; Yu, P.S. PredRNN: Recurrent Neural Networks for Predictive Learning using Spatiotemporal LSTMs. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; pp. 879–888. [Google Scholar]
- Wang, Y.; Gao, Z.; Long, M.; Wang, J.; Yu, P.S. PredRNN++: Towards A Resolution of the Deep-in-Time Dilemma in Spatiotemporal Predictive Learning. In Proceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholm, Sweden, 10–15 July 2018; pp. 5110–5119. [Google Scholar]
- Trebing, K.; Stanczyk, T.; Mehrkanoon, S. SmaAt-UNet: Precipitation nowcasting using a small attention-UNet architecture. Pattern Recognit. Lett. 2021, 145, 178–186. [Google Scholar] [CrossRef]
- Li, D.; Liu, Y.; Chen, C. MSDM v1.0: A machine learning model for precipitation nowcasting over eastern China using multisource data. Geosci. Model Dev. 2021, 14, 4019–4034. [Google Scholar] [CrossRef]
- Chen, L.; Cao, Y.; Ma, L.; Zhang, J. A Deep Learning-Based Methodology for Precipitation Nowcasting with Radar. Earth Space Sci. 2020, 7, e2019EA000812. [Google Scholar] [CrossRef]
- Zhuang, Y.; Ding, W. Long-lead prediction of extreme precipitation cluster via a spatiotemporal convolutional neural network. In Proceedings of the 6th International Workshop on Climate Informatics, Boulder, CO, USA, 21–23 September 2016. [Google Scholar]
- Agrawal, S.; Barrington, L.; Bromberg, C.; Burge, J.; Gazen, C.; Hickey, J. Machine Learning for Precipitation Nowcasting from Radar Images. arXiv 2019, arXiv:1912.12132. [Google Scholar]
- Ayzel, G.; Scheffer, T.; Heistermann, M. RainNet v1.0: A convolutional neural network for radar-based precipitation nowcasting. Geosci. Model Dev. 2020, 13, 2631–2644. [Google Scholar] [CrossRef]
- Han, L.; Liang, H.; Chen, H.; Zhang, W.; Ge, Y. Convective Precipitation Nowcasting Using U-Net Model. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4103508. [Google Scholar] [CrossRef]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.; Wong, W.; Woo, W. Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting. In Proceedings of the Advances in Neural Information Processing Systems 28: Annual Conference on Neural Information Processing Systems 2015, Montreal, QC, Canada, 7–12 December 2015; pp. 802–810. [Google Scholar]
- Shi, X.; Gao, Z.; Lausen, L.; Wang, H.; Yeung, D.; Wong, W.; Woo, W. Deep Learning for Precipitation Nowcasting: A Benchmark and A New Model. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; pp. 5617–5627. [Google Scholar]
- Yang, Z.; Wu, H.; Liu, Q.; Liu, X.; Zhang, Y.; Cao, X. A self-attention integrated spatiotemporal LSTM approach to edge-radar echo extrapolation in the Internet of Radars. ISA Trans. 2023, 132, 155–166. [Google Scholar] [CrossRef]
- Fernández, J.G.; Mehrkanoon, S. Broad-UNet: Multi-scale feature learning for nowcasting tasks. Neural Netw. 2021, 144, 419–427. [Google Scholar] [CrossRef]
- Tang, R.; Zhang, P.; Wu, J.; Chen, Y.; Dong, L.; Tang, S.; Li, C. Pred-SF: A Precipitation Prediction Model Based on Deep Neural Networks. Sensors 2023, 23, 2609. [Google Scholar] [CrossRef]
- Ionescu, V.; Czibula, G.; Mihulet, E. DeePS at: A deep learning model for prediction of satellite images for nowcasting purposes. Procedia Comput. Sci. 2021, 192, 622–631. [Google Scholar] [CrossRef]
- Geng, H.; Ge, X.; Xie, B.; Min, J.; Zhuang, X. LSTMAtU-Net: A Precipitation Nowcasting Model Based on ECSA Module. Sensors 2023, 23, 5785. [Google Scholar] [CrossRef] [PubMed]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to Sequence Learning with Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems 27: Annual Conference on Neural Information Processing Systems 2014, Montreal, QC, Canada, 8–13 December 2014; pp. 3104–3112. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, Conference Track Proceedings, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Kernel Size | Padding | Filters | Activation | Output Size |
|---|---|---|---|---|---|
| Time Distributed (Conv2D) | 3 × 3 | 1 × 1 | 32 | ReLU | 5 × 101 × 101 × 32 |
| ConvLSTM2D | 5 × 5 | 1 × 1 | 64 | Tanh | 5 × 101 × 101 × 64 |
| ConvLSTM2D | 3 × 3 | 1 × 1 | 32 | Tanh | 5 × 101 × 101 × 64 |
| Time Distributed (Conv2D) | 3 × 3 | 1 × 1 | 32 | ReLU | 5 × 101 × 101 × 32 |
| dBZ Threshold | HSS ↑ | CSI ↑ | MAE ↓ | SSIM ↑ | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 5 | 20 | 40 | Avg | 5 | 20 | 40 | Avg | |||
| PredRNN [16] | 0.7080 | 0.4911 | 0.1558 | 0.4516 | 0.7691 | 0.4048 | 0.0839 | 0.4198 | 14.54 | 0.3341 |
| PredRNN++ [17] | 0.7075 | 0.4993 | 0.1574 | 0.4548 | 0.7670 | 0.4137 | 0.0862 | 0.4223 | 14.51 | 0.3357 |
| E3D-LSTM [15] | 0.7111 | 0.4810 | 0.1361 | 0.4427 | 0.7720 | 0.4060 | 0.0734 | 0.4171 | 14.78 | 0.3089 |
| DA-LSTM [14] | 0.7184 | 0.5251 | 0.2127 | 0.4854 | 0.7765 | 0.4376 | 0.1202 | 0.4448 | 14.10 | 0.3479 |
| IDA-LSTM [14] | 0.7179 | 0.5264 | 0.2262 | 0.4902 | 0.7752 | 0.4372 | 0.1287 | 0.4470 | 14.09 | 0.3506 |
| ConvLSTM2D | 0.8063 | 0.6867 | 0.1550 | 0.5493 | 0.8026 | 0.6005 | 0.1072 | 0.5035 | 11.16 | 0.3847 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Naz, F.; She, L.; Sinan, M.; Shao, J. Enhancing Radar Echo Extrapolation by ConvLSTM2D for Precipitation Nowcasting. Sensors 2024, 24, 459. https://doi.org/10.3390/s24020459
Naz F, She L, Sinan M, Shao J. Enhancing Radar Echo Extrapolation by ConvLSTM2D for Precipitation Nowcasting. Sensors. 2024; 24(2):459. https://doi.org/10.3390/s24020459
Chicago/Turabian StyleNaz, Farah, Lei She, Muhammad Sinan, and Jie Shao. 2024. "Enhancing Radar Echo Extrapolation by ConvLSTM2D for Precipitation Nowcasting" Sensors 24, no. 2: 459. https://doi.org/10.3390/s24020459