
Classification of Adventitious Sounds Combining Cochleogram and Vision Transformers

 , , ,
, , ,  and
and
Abstract
:1. Introduction
2. Proposed Methodology
2.1. Feature Extraction
2.1.1. Short-Time Frequency Transform (STFT)
2.1.2. Mel-Frequency Cepstral Coefficients (MFCC)
2.1.3. Constant-Q Transform (CQT)
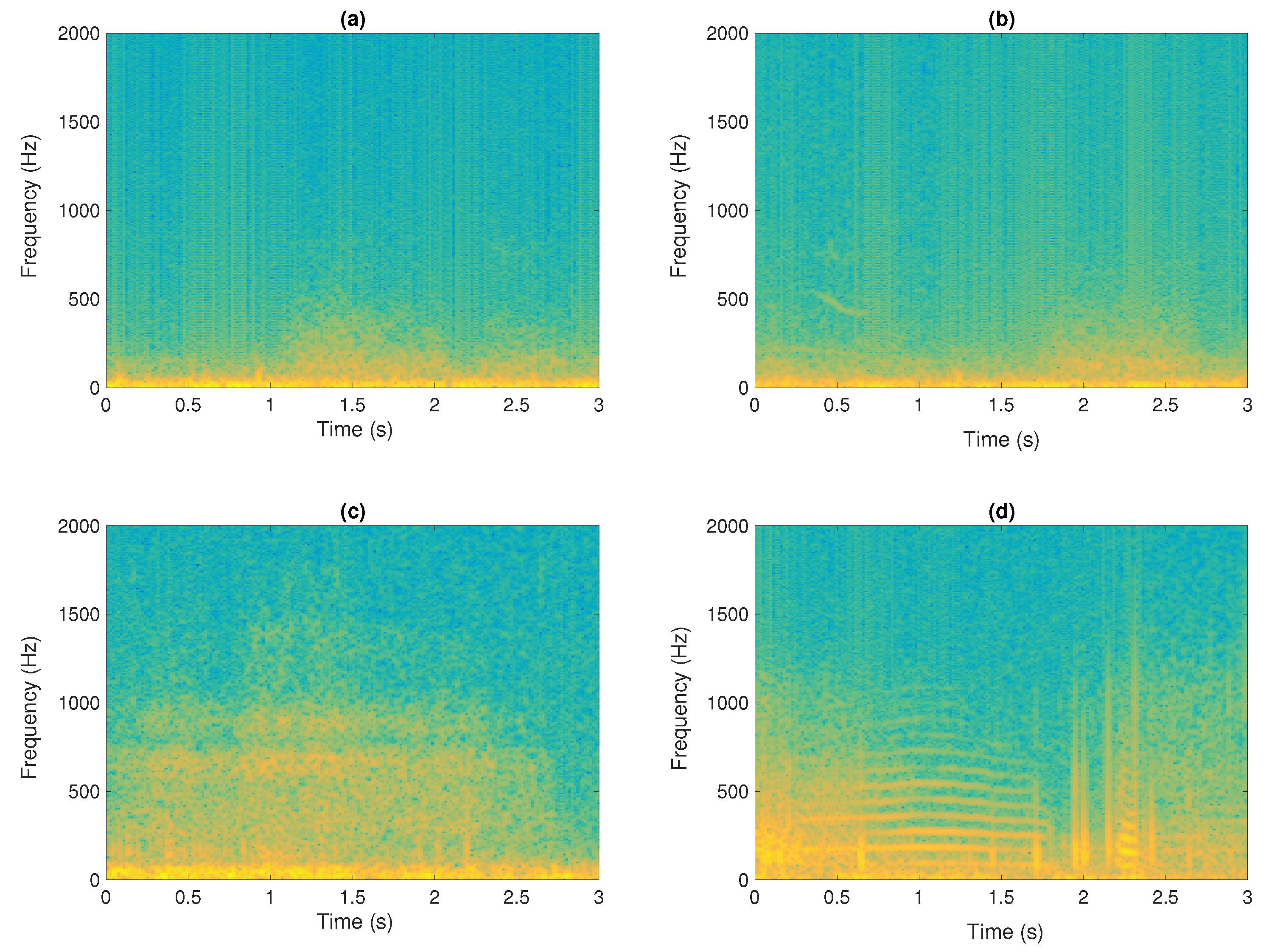
2.1.4. Cochleogram
3. Vision Transformer-Based Classifier
4. Materials and Methods
4.1. Dataset
4.2. Metrics
- Accuracy () measures the number of correctly classified adventitious sounds and normal respiratory sounds cycles from the total number of test samples.
- Sensitivity () is defined as the number of correctly detected adventitious sounds class from the total number of predicted adventitious sound events.
- Precision () is defined as the positive predictive value (PPV) where a true positive is considered as the target event, when the test makes a positive forecast, and the subject has a positive result.
- Specificity () represents the correctly labelled normal respiratory sound events (TN) from the total number of normal respiratory sound events (TN + FP).
- Score () represents a general measure of the quality of the classifier as an average of the sensitivity and specificity metrics.
4.3. Compared State-of-the-Art Architectures
4.4. Training Procedure
5. Evaluation
5.1. 2-Class (Binary) Classification Results
5.2. 4-Class Classification Results
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Respiratory Diseases in the World, Realities of Today—Opportunities for Tomorrow, Forum of International Respiratory Societies (FIRS). Available online: https://www.thoracic.org/about/global-public-health/firs/resources/firs-report-for-web.pdf (accessed on 26 November 2023).
- World Health Organization. Chronic Obstructive Pulmonary Disease (COPD). Available online: https://www.who.int/news-room/fact-sheets/detail/chronic-obstructive-pulmonary-disease-(copd) (accessed on 26 November 2023).
- World Health Organization. Asthma. Available online: https://www.who.int/news-room/fact-sheets/detail/asthma (accessed on 26 November 2023).
- World Health Organization. Pneumonia. Available online: https://www.who.int/health-topics/pneumonia#tab=tab_1 (accessed on 26 November 2023).
- World Health Organization. Tuberculosis. Available online: https://www.who.int/news-room/fact-sheets/detail/tuberculosis (accessed on 26 November 2023).
- World Health Organization. Cancer. Available online: https://www.who.int/news-room/fact-sheets/detail/cancer (accessed on 26 November 2023).
- Tanveer, M.; Rastogi, A.; Paliwal, V.; Ganaie, M.; Malik, A.; Del Ser, J.; Lin, C.T. Ensemble deep learning in speech signal tasks: A review. Neurocomputing 2023, 550, 126436. [Google Scholar] [CrossRef]
- Xiang, H.; Zou, Q.; Nawaz, M.A.; Huang, X.; Zhang, F.; Yu, H. Deep learning for image inpainting: A survey. Pattern Recognit. 2023, 134, 109046. [Google Scholar] [CrossRef]
- Tanveer, M.; Richhariya, B.; Khan, R.U.; Rashid, A.H.; Khanna, P.; Prasad, M.; Lin, C. Machine learning techniques for the diagnosis of Alzheimer’s disease: A review. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2020, 16, 1–35. [Google Scholar] [CrossRef]
- Sovijarvi, A.; Dalmasso, F.; Vanderschoot, J.; Malmberg, L.; Righini, G.; Stoneman, S. Definition of terms for applications of respiratory sounds. Eur. Respir. Rev. 2000, 10, 597–610. [Google Scholar]
- Gross, V.; Dittmar, A.; Penzel, T.; Schuttler, F.; Von Wichert, P. The relationship between normal lung sounds, age, and gender. Am. J. Respir. Crit. Care Med. 2000, 162, 905–909. [Google Scholar] [CrossRef] [PubMed]
- Pasterkamp, H.; Kraman, S.S.; Wodicka, G.R. Respiratory sounds: Advances beyond the stethoscope. Am. J. Respir. Crit. Care Med. 1997, 156, 974–987. [Google Scholar] [CrossRef] [PubMed]
- Ulukaya, S.; Sen, I.; Kahya, Y.P. Feature extraction using time-frequency analysis for monophonic-polyphonic wheeze discrimination. In Proceedings of the 2015 37th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Milan, Italy, 25–29 August 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 5412–5415. [Google Scholar]
- Pramono, R.X.A.; Bowyer, S.; Rodriguez-Villegas, E. Automatic adventitious respiratory sound analysis: A systematic review. PLoS ONE 2017, 12, e0177926. [Google Scholar] [CrossRef]
- Zhang, K.; Wang, X.; Han, F.; Zhao, H. The detection of crackles based on mathematical morphology in spectrogram analysis. Technol. Health Care 2015, 23, S489–S494. [Google Scholar] [CrossRef]
- Wisniewski, M.; Zielinski, T.P. Tonality detection methods for wheezes recognition system. In Proceedings of the 2012 19th International Conference on Systems, Signals and Image Processing (IWSSIP), Vienna, Austria, 11–13 April 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 472–475. [Google Scholar]
- Wiśniewski, M.; Zieliński, T.P. Joint application of audio spectral envelope and tonality index in an e-asthma monitoring system. IEEE J. Biomed. Health Inform. 2014, 19, 1009–1018. [Google Scholar] [CrossRef]
- Bahoura, M. Pattern recognition methods applied to respiratory sounds classification into normal and wheeze classes. Comput. Biol. Med. 2009, 39, 824–843. [Google Scholar] [CrossRef]
- Aras, S.; Gangal, A. Comparison of different features derived from mel frequency cepstrum coefficients for classification of single channel lung sounds. In Proceedings of the 2017 40th International Conference on Telecommunications and Signal Processing (TSP), Barcelona, Spain, 5–7 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 346–349. [Google Scholar]
- Okubo, T.; Nakamura, N.; Yamashita, M.; Matsunaga, S. Classification of healthy subjects and patients with pulmonary emphysema using continuous respiratory sounds. In Proceedings of the 2014 36th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Chicago, IL, USA, 26–30 August 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 70–73. [Google Scholar]
- Oletic, D.; Bilas, V. Asthmatic wheeze detection from compressively sensed respiratory sound spectra. IEEE J. Biomed. Health Inform. 2017, 22, 1406–1414. [Google Scholar] [CrossRef] [PubMed]
- Jakovljević, N.; Lončar-Turukalo, T. Hidden markov model based respiratory sound classification. In Proceedings of the Precision Medicine Powered by pHealth and Connected Health: ICBHI 2017, Thessaloniki, Greece, 18–21 November 2017; Springer: Singapore, 2018; pp. 39–43. [Google Scholar]
- Nabi, F.G.; Sundaraj, K.; Lam, C.K.; Palaniappan, R. Characterization and classification of asthmatic wheeze sounds according to severity level using spectral integrated features. Comput. Biol. Med. 2019, 104, 52–61. [Google Scholar] [CrossRef] [PubMed]
- Hadjileontiadis, L.J. Wavelet-based enhancement of lung and bowel sounds using fractal dimension thresholding-Part II: Application results. IEEE Trans. Biomed. Eng. 2005, 52, 1050–1064. [Google Scholar] [CrossRef] [PubMed]
- Pinho, C.; Oliveira, A.; Jácome, C.; Rodrigues, J.; Marques, A. Automatic crackle detection algorithm based on fractal dimension and box filtering. Procedia Comput. Sci. 2015, 64, 705–712. [Google Scholar] [CrossRef]
- Pal, R.; Barney, A. Iterative envelope mean fractal dimension filter for the separation of crackles from normal breath sounds. Biomed. Signal Process. Control 2021, 66, 102454. [Google Scholar] [CrossRef]
- Hadjileontiadis, L.J. Empirical mode decomposition and fractal dimension filter. IEEE Eng. Med. Biol. Mag. 2007, 26, 30. [Google Scholar]
- Rocha, B.M.; Pessoa, D.; Marques, A.; de Carvalho, P.; Paiva, R.P. Automatic wheeze segmentation using harmonic-percussive source separation and empirical mode decomposition. IEEE J. Biomed. Health Inform. 2023. [Google Scholar] [CrossRef]
- Bahoura, M.; Pelletier, C. Respiratory sounds classification using Gaussian mixture models. In Proceedings of the Canadian Conference on Electrical and Computer Engineering, Niagara Falls, ON, Canada, 2–5 May 2004; IEEE: Piscataway, NJ, USA, 2004; Volume 3, pp. 1309–1312. [Google Scholar]
- Mayorga, P.; Druzgalski, C.; Morelos, R.; Gonzalez, O.; Vidales, J. Acoustics based assessment of respiratory diseases using GMM classification. In Proceedings of the 2010 Annual International Conference of the IEEE Engineering in Medicine and Biology, Buenos Aires, Argentina, 31 August–4 September 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 6312–6316. [Google Scholar]
- Maruf, S.O.; Azhar, M.U.; Khawaja, S.G.; Akram, M.U. Crackle separation and classification from normal Respiratory sounds using Gaussian Mixture Model. In Proceedings of the 2015 IEEE 10th International Conference on Industrial and Information Systems (ICIIS), Peradeniya, Sri Lanka, 18–20 December 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 267–271. [Google Scholar]
- Kaisia, T.; Sovijärvi, A.; Piirilä, P.; Rajala, H.; Haltsonen, S.; Rosqvist, T. Validated method for automatic detection of lung sound crackles. Med. Biol. Eng. Comput. 1991, 29, 517–521. [Google Scholar] [CrossRef]
- Taplidou, S.A.; Hadjileontiadis, L.J. Wheeze detection based on time-frequency analysis of breath sounds. Comput. Biol. Med. 2007, 37, 1073–1083. [Google Scholar] [CrossRef]
- Jain, A.; Vepa, J. Lung sound analysis for wheeze episode detection. In Proceedings of the 2008 30th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Vancouver, BC, Canada, 20–25 August 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 2582–2585. [Google Scholar]
- Jin, F.; Krishnan, S.; Sattar, F. Adventitious sounds identification and extraction using temporal–spectral dominance-based features. IEEE Trans. Biomed. Eng. 2011, 58, 3078–3087. [Google Scholar]
- Mendes, L.; Vogiatzis, I.; Perantoni, E.; Kaimakamis, E.; Chouvarda, I.; Maglaveras, N.; Tsara, V.; Teixeira, C.; Carvalho, P.; Henriques, J.; et al. Detection of wheezes using their signature in the spectrogram space and musical features. In Proceedings of the 2015 37th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Milan, Italy, 25–29 August 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 5581–5584. [Google Scholar]
- Hadjileontiadis, L.; Panas, S. Nonlinear separation of crackles and squawks from vesicular sounds using third-order statistics. In Proceedings of the 18th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Amsterdam, The Netherlands, 31 October–3 November 1996; IEEE: Piscataway, NJ, USA, 1996; Volume 5, pp. 2217–2219. [Google Scholar]
- Cortes, S.; Jane, R.; Fiz, J.; Morera, J. Monitoring of wheeze duration during spontaneous respiration in asthmatic patients. In Proceedings of the 2005 IEEE Engineering in Medicine and Biology 27th Annual Conference, Shanghai, China, 17–18 January 2006; IEEE: Piscataway, NJ, USA, 2006; pp. 6141–6144. [Google Scholar]
- Charleston-Villalobos, S.; Martinez-Hernandez, G.; Gonzalez-Camarena, R.; Chi-Lem, G.; Carrillo, J.G.; Aljama-Corrales, T. Assessment of multichannel lung sounds parameterization for two-class classification in interstitial lung disease patients. Comput. Biol. Med. 2011, 41, 473–482. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Ser, W.; Yu, J.; Zhang, T. A novel wheeze detection method for wearable monitoring systems. In Proceedings of the 2009 International Symposium on Intelligent Ubiquitous Computing and Education, Chengdu, China, 15–16 May 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 331–334. [Google Scholar]
- Liu, X.; Ser, W.; Zhang, J.; Goh, D.Y.T. Detection of adventitious lung sounds using entropy features and a 2-D threshold setting. In Proceedings of the 2015 10th International Conference on Information, Communications and Signal Processing (ICICS), Singapore, 2–4 December 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 1–5. [Google Scholar]
- Rizal, A.; Hidayat, R.; Nugroho, H.A. Pulmonary crackle feature extraction using tsallis entropy for automatic lung sound classification. In Proceedings of the 2016 1st International Conference on Biomedical Engineering (IBIOMED), Yogyakarta, Indonesia, 5–6 October 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1–4. [Google Scholar]
- Hadjileontiadis, L.J.; Panas, S.M. Separation of discontinuous adventitious sounds from vesicular sounds using a wavelet-based filter. IEEE Trans. Biomed. Eng. 1997, 44, 1269–1281. [Google Scholar] [CrossRef] [PubMed]
- Lu, X.; Bahoura, M. An integrated automated system for crackles extraction and classification. Biomed. Signal Process. Control 2008, 3, 244–254. [Google Scholar] [CrossRef]
- Le Cam, S.; Belghith, A.; Collet, C.; Salzenstein, F. Wheezing sounds detection using multivariate generalized Gaussian distributions. In Proceedings of the 2009 IEEE International Conference on Acoustics, Speech and Signal Processing, Taipei, Taiwan, 19–24 April 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 541–544. [Google Scholar]
- Hashemi, A.; Arabalibiek, H.; Agin, K. Classification of wheeze sounds using wavelets and neural networks. In Proceedings of the International Conference on Biomedical Engineering and Technology, Shanghai China, 28–30 October 2011; IACSIT Press: Singapore, 2011; Volume 11, pp. 127–131. [Google Scholar]
- Serbes, G.; Sakar, C.O.; Kahya, Y.P.; Aydin, N. Pulmonary crackle detection using time–frequency and time–scale analysis. Digit. Signal Process. 2013, 23, 1012–1021. [Google Scholar] [CrossRef]
- Ulukaya, S.; Serbes, G.; Kahya, Y.P. Wheeze type classification using non-dyadic wavelet transform based optimal energy ratio technique. Comput. Biol. Med. 2019, 104, 175–182. [Google Scholar] [CrossRef] [PubMed]
- Stasiakiewicz, P.; Dobrowolski, A.P.; Targowski, T.; Gałązka-Świderek, N.; Sadura-Sieklucka, T.; Majka, K.; Skoczylas, A.; Lejkowski, W.; Olszewski, R. Automatic classification of normal and sick patients with crackles using wavelet packet decomposition and support vector machine. Biomed. Signal Process. Control 2021, 67, 102521. [Google Scholar] [CrossRef]
- Li, J.; Hong, Y. Crackles detection method based on time-frequency features analysis and SVM. In Proceedings of the 2016 IEEE 13th International Conference on Signal Processing (ICSP), Chengdu, China, 6–10 November 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1412–1416. [Google Scholar]
- Grønnesby, M.; Solis, J.C.A.; Holsbø, E.; Melbye, H.; Bongo, L.A. Feature extraction for machine learning based crackle detection in lung sounds from a health survey. arXiv 2017, arXiv:1706.00005. [Google Scholar]
- Pramudita, B.A.; Istiqomah, I.; Rizal, A. Crackle detection in lung sound using statistical feature of variogram. In AIP Conference Proceedings; AIP Publishing LLC: Melville, NY, USA, 2020; Volume 2296, p. 020014. [Google Scholar]
- Park, J.S.; Kim, K.; Kim, J.H.; Choi, Y.J.; Kim, K.; Suh, D.I. A machine learning approach to the development and prospective evaluation of a pediatric lung sound classification model. Sci. Rep. 2023, 13, 1289. [Google Scholar] [CrossRef]
- García, M.; Villalobos, S.; Villa, N.C.; González, A.J.; Camarena, R.G.; Corrales, T.A. Automated extraction of fine and coarse crackles by independent component analysis. Health Technol. 2020, 10, 459–463. [Google Scholar] [CrossRef]
- Hong, K.J.; Essid, S.; Ser, W.; Foo, D.G. A robust audio classification system for detecting pulmonary edema. Biomed. Signal Process. Control 2018, 46, 94–103. [Google Scholar] [CrossRef]
- Torre-Cruz, J.; Canadas-Quesada, F.; García-Galán, S.; Ruiz-Reyes, N.; Vera-Candeas, P.; Carabias-Orti, J. A constrained tonal semi-supervised non-negative matrix factorization to classify presence/absence of wheezing in respiratory sounds. Appl. Acoust. 2020, 161, 107188. [Google Scholar] [CrossRef]
- Cruz, J.D.L.T.; Quesada, F.J.C.; Orti, J.J.C.; Candeas, P.V.; Reyes, N.R. Combining a recursive approach via non-negative matrix factorization and Gini index sparsity to improve reliable detection of wheezing sounds. Expert Syst. Appl. 2020, 147, 113212. [Google Scholar] [CrossRef]
- Cruz, J.D.L.T.; Quesada, F.J.C.; Martínez-Muñoz, D.; Reyes, N.R.; Galán, S.G.; Orti, J.J.C. An incremental algorithm based on multichannel non-negative matrix partial co-factorization for ambient denoising in auscultation. Appl. Acoust. 2021, 182, 108229. [Google Scholar] [CrossRef]
- De La Torre Cruz, J.; Cañadas Quesada, F.J.; Ruiz Reyes, N.; García Galán, S.; Carabias Orti, J.J.; Peréz Chica, G. Monophonic and polyphonic wheezing classification based on constrained low-rank non-negative matrix factorization. Sensors 2021, 21, 1661. [Google Scholar] [CrossRef] [PubMed]
- Rocha, B.M.; Filos, D.; Mendes, L.; Serbes, G.; Ulukaya, S.; Kahya, Y.P.; Jakovljevic, N.; Turukalo, T.L.; Vogiatzis, I.M.; Perantoni, E.; et al. An open access database for the evaluation of respiratory sound classification algorithms. Physiol. Meas. 2019, 40, 035001. [Google Scholar] [CrossRef] [PubMed]
- ICBHI 2017 Challenge, Respiratory Sound Database. Available online: https://bhichallenge.med.auth.gr/ICBHI_2017_Challenge (accessed on 18 January 2024).
- Messner, E.; Fediuk, M.; Swatek, P.; Scheidl, S.; Smolle-Juttner, F.M.; Olschewski, H.; Pernkopf, F. Crackle and breathing phase detection in lung sounds with deep bidirectional gated recurrent neural networks. In Proceedings of the 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Honolulu, HI, USA, 18–21 July 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 356–359. [Google Scholar]
- Messner, E.; Fediuk, M.; Swatek, P.; Scheidl, S.; Smolle-Jüttner, F.M.; Olschewski, H.; Pernkopf, F. Multi-channel lung sound classification with convolutional recurrent neural networks. Comput. Biol. Med. 2020, 122, 103831. [Google Scholar] [CrossRef] [PubMed]
- Asatani, N.; Kamiya, T.; Mabu, S.; Kido, S. Classification of respiratory sounds using improved convolutional recurrent neural network. Comput. Electr. Eng. 2021, 94, 107367. [Google Scholar] [CrossRef]
- Petmezas, G.; Cheimariotis, G.A.; Stefanopoulos, L.; Rocha, B.; Paiva, R.P.; Katsaggelos, A.K.; Maglaveras, N. Automated Lung Sound Classification Using a Hybrid CNN-LSTM Network and Focal Loss Function. Sensors 2022, 22, 1232. [Google Scholar] [CrossRef]
- Wall, C.; Zhang, L.; Yu, Y.; Kumar, A.; Gao, R. A deep ensemble neural network with attention mechanisms for lung abnormality classification using audio inputs. Sensors 2022, 22, 5566. [Google Scholar] [CrossRef]
- Alqudah, A.M.; Qazan, S.; Obeidat, Y.M. Deep learning models for detecting respiratory pathologies from raw lung auscultation sounds. Soft Comput. 2022, 26, 13405–13429. [Google Scholar] [CrossRef]
- Aykanat, M.; Kılıç, Ö.; Kurt, B.; Saryal, S. Classification of lung sounds using convolutional neural networks. EURASIP J. Image Video Process. 2017, 2017, 65. [Google Scholar] [CrossRef]
- Kochetov, K.; Putin, E.; Balashov, M.; Filchenkov, A.; Shalyto, A. Noise masking recurrent neural network for respiratory sound classification. In Proceedings of the International Conference on Artificial Neural Networks, Rhodes, Greece, 4–7 October 2018; Springer: Cham, Switzerland, 2018; pp. 208–217. [Google Scholar]
- Bardou, D.; Zhang, K.; Ahmad, S.M. Lung sounds classification using convolutional neural networks. Artif. Intell. Med. 2018, 88, 58–69. [Google Scholar] [CrossRef] [PubMed]
- Liu, R.; Cai, S.; Zhang, K.; Hu, N. Detection of adventitious respiratory sounds based on convolutional neural network. In Proceedings of the 2019 International Conference on Intelligent Informatics and Biomedical Sciences (ICIIBMS), Shanghai, China, 21–24 November 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 298–303. [Google Scholar]
- Perna, D.; Tagarelli, A. Deep auscultation: Predicting respiratory anomalies and diseases via recurrent neural networks. In Proceedings of the 2019 IEEE 32nd International Symposium on Computer-Based Medical Systems (CBMS), Cordoba, Spain, 5–7 June 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 50–55. [Google Scholar]
- Minami, K.; Lu, H.; Kim, H.; Mabu, S.; Hirano, Y.; Kido, S. Automatic classification of large-scale respiratory sound dataset based on convolutional neural network. In Proceedings of the 2019 19th International Conference on Control, Automation and Systems (ICCAS), Jeju, Republic of Korea, 15–18 October 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 804–807. [Google Scholar]
- Ma, Y.; Xu, X.; Yu, Q.; Zhang, Y.; Li, Y.; Zhao, J.; Wang, G. LungBRN: A smart digital stethoscope for detecting respiratory disease using bi-resnet deep learning algorithm. In Proceedings of the 2019 IEEE Biomedical Circuits and Systems Conference (BioCAS), Nara, Japan, 17–19 October 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–4. [Google Scholar]
- Ngo, D.; Pham, L.; Nguyen, A.; Phan, B.; Tran, K.; Nguyen, T. Deep learning framework applied for predicting anomaly of respiratory sounds. In Proceedings of the 2021 International Symposium on Electrical and Electronics Engineering (ISEE), Ho Chi Minh, Vietnam, 15-16 April 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 42–47. [Google Scholar]
- Nguyen, T.; Pernkopf, F. Lung sound classification using snapshot ensemble of convolutional neural networks. In Proceedings of the 2020 42nd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Montreal, QC, Canada, 20–24 July 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 760–763. [Google Scholar]
- Acharya, J.; Basu, A. Deep neural network for respiratory sound classification in wearable devices enabled by patient specific model tuning. IEEE Trans. Biomed. Circuits Syst. 2020, 14, 535–544. [Google Scholar] [CrossRef] [PubMed]
- Demir, F.; Ismael, A.M.; Sengur, A. Classification of lung sounds with CNN model using parallel pooling structure. IEEE Access 2020, 8, 105376–105383. [Google Scholar] [CrossRef]
- Saraiva., A.; Santos., D.; Francisco., A.; Sousa., J.; Ferreira., N.; Soares., S.; Valente., A. Classification of Respiratory Sounds with Convolutional Neural Network. In Proceedings of the 13th International Joint Conference on Biomedical Engineering Systems and Technologies—BIOINFORMATICS, INSTICC, Valletta, Malta, 24–26 February 2020; SciTePress: Setúbal, Portugal, 2020; pp. 138–144. [Google Scholar] [CrossRef]
- Ma, Y.; Xu, X.; Li, Y. LungRN+ NL: An Improved Adventitious Lung Sound Classification Using Non-Local Block ResNet Neural Network with Mixup Data Augmentation. In Proceedings of the Interspeech, Shanghai, China, 25–29 October 2020; pp. 2902–2906. [Google Scholar]
- Yang, Z.; Liu, S.; Song, M.; Parada-Cabaleiro, E.; Schuller, B.W. Adventitious respiratory classification using attentive residual neural networks. In Proceedings of the Interspeech, Shanghai, China, 25–29 October 2020. [Google Scholar]
- Ntalampiras, S.; Potamitis, I. Automatic acoustic identification of respiratory diseases. Evol. Syst. 2021, 12, 69–77. [Google Scholar] [CrossRef]
- Chanane, H.; Bahoura, M. Convolutional neural network-based model for lung sounds classification. In Proceedings of the 2021 IEEE International Midwest Symposium on Circuits and Systems (MWSCAS), Lansing, MI, USA, 9–11 August 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 555–558. [Google Scholar]
- Zulfiqar, R.; Majeed, F.; Irfan, R.; Rauf, H.T.; Benkhelifa, E.; Belkacem, A.N. Abnormal respiratory sounds classification using deep CNN through artificial noise addition. Front. Med. 2021, 8, 714811. [Google Scholar] [CrossRef] [PubMed]
- Belkacem, A.N.; Ouhbi, S.; Lakas, A.; Benkhelifa, E.; Chen, C. End-to-end AI-based point-of-care diagnosis system for classifying respiratory illnesses and early detection of COVID-19: A theoretical framework. Front. Med. 2021, 8, 585578. [Google Scholar] [CrossRef]
- Kim, Y.; Hyon, Y.; Jung, S.S.; Lee, S.; Yoo, G.; Chung, C.; Ha, T. Respiratory sound classification for crackles, wheezes, and rhonchi in the clinical field using deep learning. Sci. Rep. 2021, 11, 17186. [Google Scholar] [CrossRef]
- Song, W.; Han, J.; Song, H. Contrastive embeddind learning method for respiratory sound classification. In Proceedings of the ICASSP 2021–2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1275–1279. [Google Scholar]
- Gairola, S.; Tom, F.; Kwatra, N.; Jain, M. Respirenet: A deep neural network for accurately detecting abnormal lung sounds in limited data setting. In Proceedings of the 2021 43rd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Guadalajara, Mexico, 1–5 November 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 527–530. [Google Scholar]
- Srivastava, A.; Jain, S.; Miranda, R.; Patil, S.; Pandya, S.; Kotecha, K. Deep learning based respiratory sound analysis for detection of chronic obstructive pulmonary disease. PeerJ Comput. Sci. 2021, 7, e369. [Google Scholar] [CrossRef]
- Tariq, Z.; Shah, S.K.; Lee, Y. Feature-based fusion using CNN for lung and heart sound classification. Sensors 2022, 22, 1521. [Google Scholar] [CrossRef]
- Choi, Y.; Choi, H.; Lee, H.; Lee, S.; Lee, H. Lightweight Skip Connections with Efficient Feature Stacking for Respiratory Sound Classification. IEEE Access 2022. [Google Scholar] [CrossRef]
- Nguyen, T.; Pernkopf, F. Lung Sound Classification Using Co-tuning and Stochastic Normalization. IEEE Trans. Biomed. Eng. 2022, 69, 2872–2882. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Z.; Gong, Z.; Niu, M.; Ma, J.; Wang, H.; Zhang, Z.; Li, Y. Automatic Respiratory Sound Classification Via Multi-Branch Temporal Convolutional Network. In Proceedings of the ICASSP 2022–2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 9102–9106. [Google Scholar]
- Saldanha, J.; Chakraborty, S.; Patil, S.; Kotecha, K.; Kumar, S.; Nayyar, A. Data augmentation using Variational Autoencoders for improvement of respiratory disease classification. PLoS ONE 2022, 17, e0266467. [Google Scholar] [CrossRef] [PubMed]
- Kim, H.S.; Park, H.S. Ensemble Learning Model for Classification of Respiratory Anomalies. J. Electr. Eng. Technol. 2023, 18, 3201–3208. [Google Scholar] [CrossRef]
- Alice, R.S.; Wendling, L.; Santosh, K. 2D Respiratory Sound Analysis to Detect Lung Abnormalities. In Proceedings of the Recent Trends in Image Processing and Pattern Recognition: 5th International Conference, RTIP2R 2022, Kingsville, TX, USA, 1–2 December 2022; Revised Selected Papers. Springer: Cham, Switzerland, 2023; pp. 46–58. [Google Scholar]
- Chudasama, V.; Bhikadiya, K.; Mankad, S.H.; Patel, A.; Mistry, M.P. Voice Based Pathology Detection from Respiratory Sounds using Optimized Classifiers. Int. J. Comput. Digit. Syst. 2023, 13, 327–339. [Google Scholar] [CrossRef] [PubMed]
- Cinyol, F.; Baysal, U.; Köksal, D.; Babaoğlu, E.; Ulaşlı, S.S. Incorporating support vector machine to the classification of respiratory sounds by Convolutional Neural Network. Biomed. Signal Process. Control 2023, 79, 104093. [Google Scholar] [CrossRef]
- Dianat, B.; La Torraca, P.; Manfredi, A.; Cassone, G.; Vacchi, C.; Sebastiani, M.; Pancaldi, F. Classification of pulmonary sounds through deep learning for the diagnosis of interstitial lung diseases secondary to connective tissue diseases. Comput. Biol. Med. 2023, 160, 106928. [Google Scholar] [CrossRef] [PubMed]
- Shuvo, S.B.; Ali, S.N.; Swapnil, S.I.; Hasan, T.; Bhuiyan, M.I.H. A lightweight cnn model for detecting respiratory diseases from lung auscultation sounds using emd-cwt-based hybrid scalogram. IEEE J. Biomed. Health Inform. 2020, 25, 2595–2603. [Google Scholar] [CrossRef]
- Zhang, Q.; Ma, P. Classification of pulmonary arterial pressure using photoplethysmography and bi-directional LSTM. Biomed. Signal Process. Control 2023, 86, 105071. [Google Scholar] [CrossRef]
- Rocha, B.M.; Pessoa, D.; Marques, A.; Carvalho, P.; Paiva, R.P. Automatic classification of adventitious respiratory sounds: A (un) solved problem? Sensors 2020, 21, 57. [Google Scholar] [CrossRef]
- Mang, L.; Canadas-Quesada, F.; Carabias-Orti, J.; Combarro, E.; Ranilla, J. Cochleogram-based adventitious sounds classification using convolutional neural networks. Biomed. Signal Process. Control 2023, 82, 104555. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Gemmeke, J.F.; Ellis, D.P.W.; Freedman, D.; Jansen, A.; Lawrence, W.; Moore, R.C.; Plakal, M.; Ritter, M. Audio Set: An ontology and human-labeled dataset for audio events. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 776–780. [Google Scholar] [CrossRef]
- Warden, P. Speech Commands: A Dataset for Limited-Vocabulary Speech Recognition. arXiv 2018, arXiv:1804.03209. [Google Scholar]
- Neto, J.; Arrais, N.; Vinuto, T.; Lucena, J. Convolution-Vision Transformer for Automatic Lung Sound Classification. In Proceedings of the 2022 35th SIBGRAPI Conference on Graphics, Patterns and Images (SIBGRAPI), Natal, Brazil, 24–27 October 2022; Volume 1, pp. 97–102. [Google Scholar] [CrossRef]
- Das, S.; Pal, S.; Mitra, M. Acoustic feature based unsupervised approach of heart sound event detection. Comput. Biol. Med. 2020, 126, 103990. [Google Scholar] [CrossRef] [PubMed]
- Gao, B.; Woo, W.L.; Khor, L. Cochleagram-based audio pattern separation using two-dimensional non-negative matrix factorization with automatic sparsity adaptation. J. Acoust. Soc. Am. 2014, 135, 1171–1185. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.; Wang, Y.; Wang, D. A feature study for classification-based speech separation at low signal-to-noise ratios. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 22, 1993–2002. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł; Polosukhin, I. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Torre-Cruz, J.; Canadas-Quesada, F.; Carabias-Orti, J.; Vera-Candeas, P.; Ruiz-Reyes, N. A novel wheezing detection approach based on constrained non-negative matrix factorization. Appl. Acoust. 2019, 148, 276–288. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Jayalakshmy, S.; Sudha, G.F. Scalogram based prediction model for respiratory disorders using optimized convolutional neural networks. Artif. Intell. Med. 2020, 103, 101809. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Zakaria, N.; Mohamed, F.; Abdelghani, R.; Sundaraj, K. VGG16, ResNet-50, and GoogLeNet Deep Learning Architecture for Breathing Sound Classification: A Comparative Study. In Proceedings of the 2021 International Conference on Artificial Intelligence for Cyber Security Systems and Privacy (AI-CSP), El Oued, Algeria, 20–21 November 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–6. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Wilcoxon, F. Individual comparisons by ranking methods. In Breakthroughs in Statistics; Springer: New York, NY, USA, 1992; pp. 196–202. [Google Scholar]
- Mann, H.B.; Whitney, D.R. On a test of whether one of two random variables is stochastically larger than the other. Ann. Math. Stat. 1947, 18, 50–60. [Google Scholar] [CrossRef]
- Chambres, G.; Hanna, P.; Desainte-Catherine, M. Automatic detection of patient with respiratory diseases using lung sound analysis. In Proceedings of the 2018 International Conference on Content-Based Multimedia Indexing (CBMI), La Rochelle, France, 4–6 September 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–6. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type of Respiratory Cycle | Number of Respiratory Cycles |
|---|---|
| Crackle | |
| Wheeze | 886 |
| Crackle + Wheeze | 506 |
| Normal | |
| Total |
| Architectures | (Conv. Layers) | (Pool Layers) | (Activation) | (Parameters) |
|---|---|---|---|---|
| BaselineCNN | ||||
| AlexNet | ||||
| VGG16 | ||||
| ResNet50 |
| Comparison | Time (min)/Epoc |
|---|---|
| AlexNet | |
| ResNet50 | |
| VGG16 | |
| BaselineCNN | |
| ViT |
| Comparison | Mann-Whitney U Test | Wilcoxon Signed-Rank Test | Significantly Better |
|---|---|---|---|
| Cochleogram | (p-Value) | (p-Value) | (Yes/No) |
| ViT vs. VGG16 | yes | ||
| ViT vs. BaselineCNN | yes | ||
| ViT vs. AlexNet | yes | ||
| ViT vs. ResNet50 | yes |
| Comparison | Mann-Whitney U Test | Wilcoxon Signed-Rank Test | Significantly Better |
|---|---|---|---|
| Cochleogram | (p-Value) | (p-Value) | (Yes/No) |
| ViT vs. VGG16 | yes | ||
| ViT vs. BaselineCNN | yes | ||
| ViT vs. AlexNet | yes | ||
| ViT vs. ResNet50 | yes |
| Sensibility () | Specificity () | Score () | Precision () | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Model | TF | Wheezes | Crackles | Wheezes | Crackles | Wheezes | Crackles | Wheezes | Crackles |
| AlexNet | STFT | ||||||||
| MFCC | |||||||||
| CQT | |||||||||
| Cochleogram | |||||||||
| ResNet50 | STFT | ||||||||
| MFCC | |||||||||
| CQT | |||||||||
| Cochleogram | |||||||||
| VGG16 | STFT | ||||||||
| MFCC | |||||||||
| CQT | |||||||||
| Cochleogram | |||||||||
| BaselineCNN | STFT | ||||||||
| MFCC | |||||||||
| CQT | |||||||||
| Cochleogram | |||||||||
| ViT | STFT | ||||||||
| MFCC | |||||||||
| CQT | |||||||||
| Cochleogram | |||||||||
| Comparison | Mann-Whitney U Test | Wilcoxon Signed-Rank Test | Significantly Better |
|---|---|---|---|
| Cochleogram | (p-Value) | (p-Value) | (Yes/No) |
| ViT vs. VGG16 | yes | ||
| ViT vs. BaselineCNN | yes | ||
| ViT vs. AlexNet | yes | ||
| ViT vs. ResNet50 | yes |
| Model | TF | Sensibility () | Specificity () | Score () | Precision () |
|---|---|---|---|---|---|
| AlexNet | STFT | ||||
| MFCC | |||||
| CQT | |||||
| Cochleogram | |||||
| ResNet | STFT | ||||
| MFCC | |||||
| CQT | |||||
| Cochleogram | |||||
| VGG16 | STFT | ||||
| MFCC | |||||
| CQT | |||||
| Cochleogram | |||||
| BaselineCNN | STFT | ||||
| MFCC | |||||
| CQT | |||||
| Cochleogram | |||||
| ViT | STFT | ||||
| MFCC | |||||
| CQT | |||||
| Cochleogram |
| Authors | Time-Frequency Representation | RC (s) | Technique | Train/Test | Results (%) | ||||
|---|---|---|---|---|---|---|---|---|---|
| Type | Parameters | ||||||||
| [22] | STFT | 30 ms | − | HMM | − | − | − | ||
| [69] | STFT | 500 ms | − | RNN | − (5-fold) | − | |||
| [121] | STFT | 512 ms | − | HMM SVM | |||||
| [72] | Mel | 250 ms | − | RNN | − | ||||
| [74] | STFT, Wavelet | 20 ms, | − | bi-ResNet | − (10-fold) | ||||
| [73] | STFT, Scalogram | 40 ms | − | CNN | − | ||||
| [78] | STFT | ms | − | CNN SVM | − (10-fold) | − | − | − | |
| [80] | STFT | 20 ms | − | ResNet NL | − | ||||
| [77] | Mel | 60 ms | − | CNN RNN | − | − | − | ||
| [81] | STFT | 100 ms | ResNet SE SA | − | |||||
| [79] | STFT | − | 5 | CNN | − | − | − | ||
| [83] | Mel | − | − | CNN | − | − | − | ||
| [64] | STFT | 40 ms | − | CNN bi-LSTM | − (5-fold) | − | |||
| [82] | Wavelet | 30 ms | − | DAG HMM | − | − | − | − | |
| [88] | Mel | − | 7 | CNN | − | ||||
| [102] * | STFT | 32 ms 64 filters | 6 | CNN | (10-fold) | ||||
| Mel | CNN | ||||||||
| STFT + Mel | CNN | ||||||||
| [92] | STFT, Log-mel | 32 ms, 50 bins | 8 | ResNet | − | ||||
| [107] | Mel-Spec, MFCC, CQT | 1024 ms | − | CNN + ViT | − | ||||
| This work | Cochleogram | 84 ms 64 filters | 6 | CNN (AlexNet) | (10-fold) | ||||
| CNN (ResNet50) | |||||||||
| CNN (VGG16) | |||||||||
| CNN (Baseline) | |||||||||
| ViT | |||||||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mang, L.D.; González Martínez, F.D.; Martinez Muñoz, D.; García Galán, S.; Cortina, R. Classification of Adventitious Sounds Combining Cochleogram and Vision Transformers. Sensors 2024, 24, 682. https://doi.org/10.3390/s24020682
Mang LD, González Martínez FD, Martinez Muñoz D, García Galán S, Cortina R. Classification of Adventitious Sounds Combining Cochleogram and Vision Transformers. Sensors. 2024; 24(2):682. https://doi.org/10.3390/s24020682
Chicago/Turabian StyleMang, Loredana Daria, Francisco David González Martínez, Damian Martinez Muñoz, Sebastián García Galán, and Raquel Cortina. 2024. "Classification of Adventitious Sounds Combining Cochleogram and Vision Transformers" Sensors 24, no. 2: 682. https://doi.org/10.3390/s24020682
APA StyleMang, L. D., González Martínez, F. D., Martinez Muñoz, D., García Galán, S., & Cortina, R. (2024). Classification of Adventitious Sounds Combining Cochleogram and Vision Transformers. Sensors, 24(2), 682. https://doi.org/10.3390/s24020682