
Mood Disorder Severity and Subtype Classification Using Multimodal Deep Neural Network Models

Abstract
1. Introduction
- Improve mood disorder diagnostic performance with a multimodal analysis algorithm.
- Classify the difference of severity and subtype within the same mood disorder by deep learning technique.
- Reduce healthcare costs and improve efficiency by proving the possibility of primary screening tools even within limited biomarker data.
2. Related Works
2.1. Mood Disorder Analysis
2.2. Multimodal Analysis on Medical Dataset
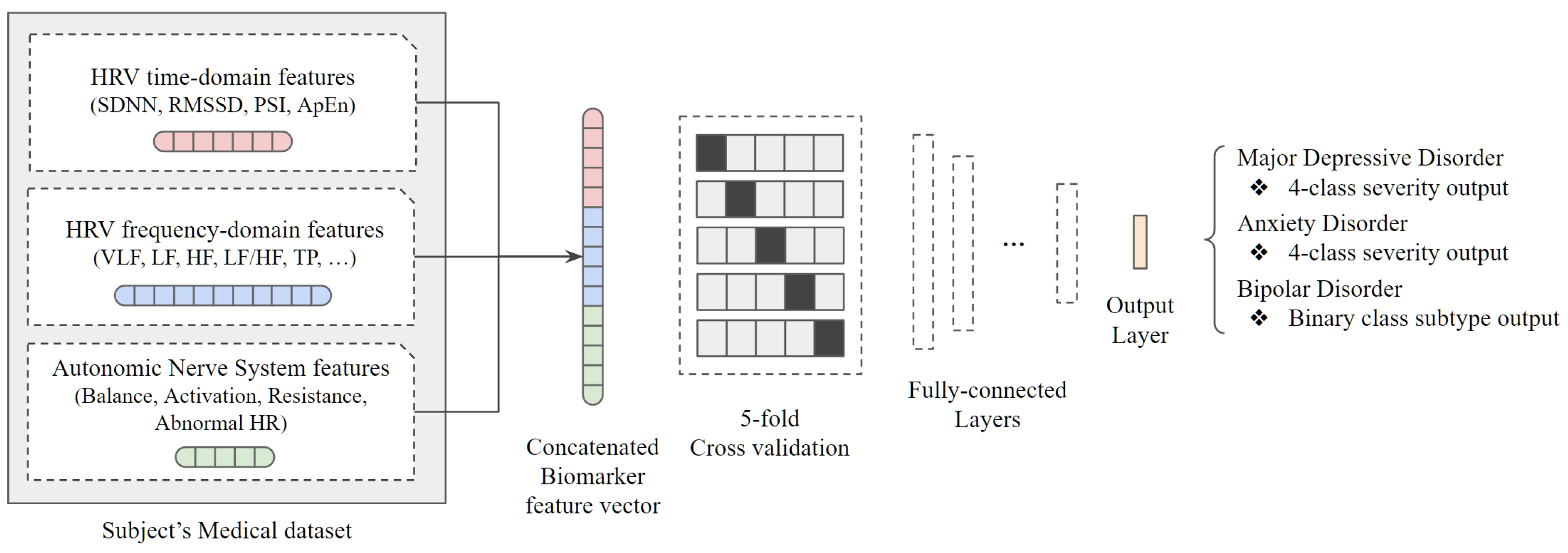
3. Mood Disorder Classification
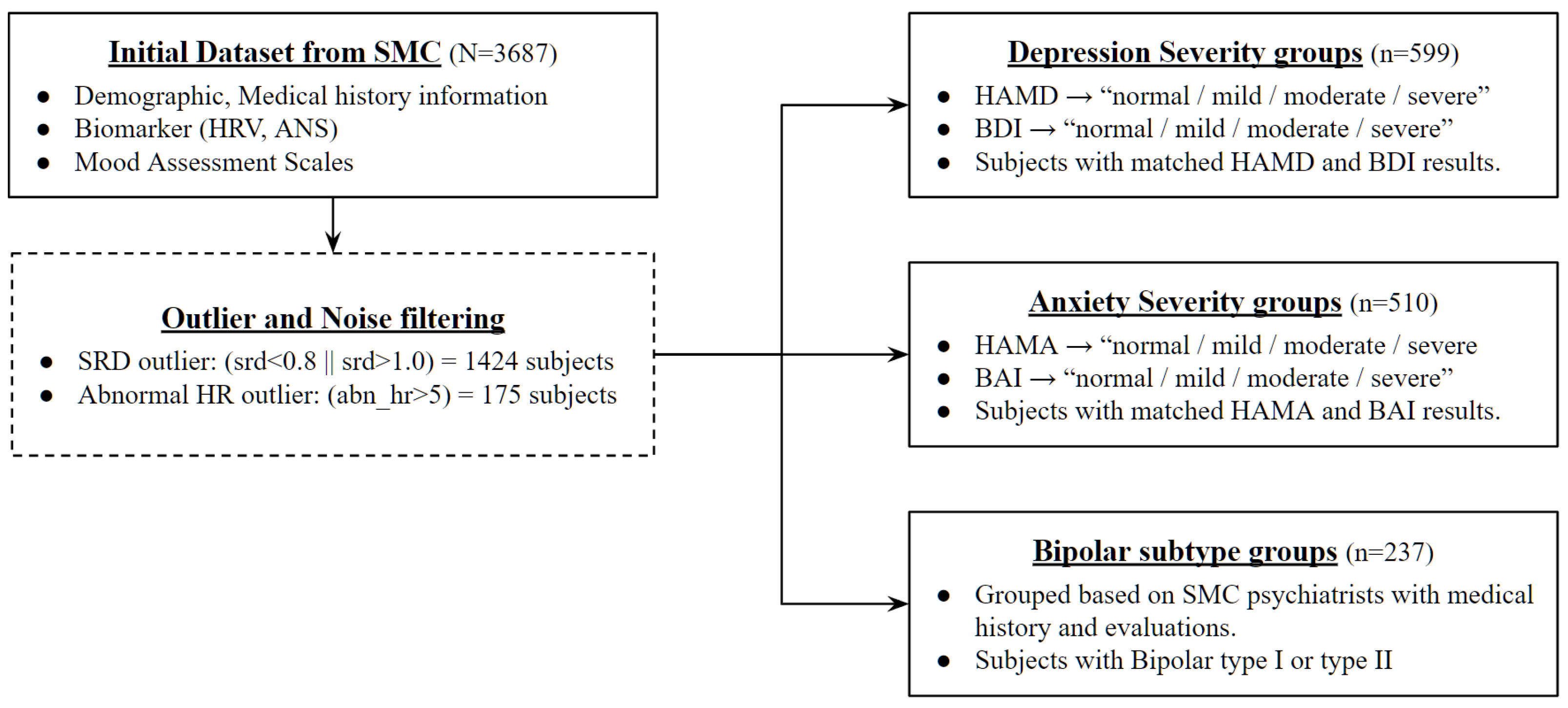
3.1. Dataset
3.2. Data Preprocessing
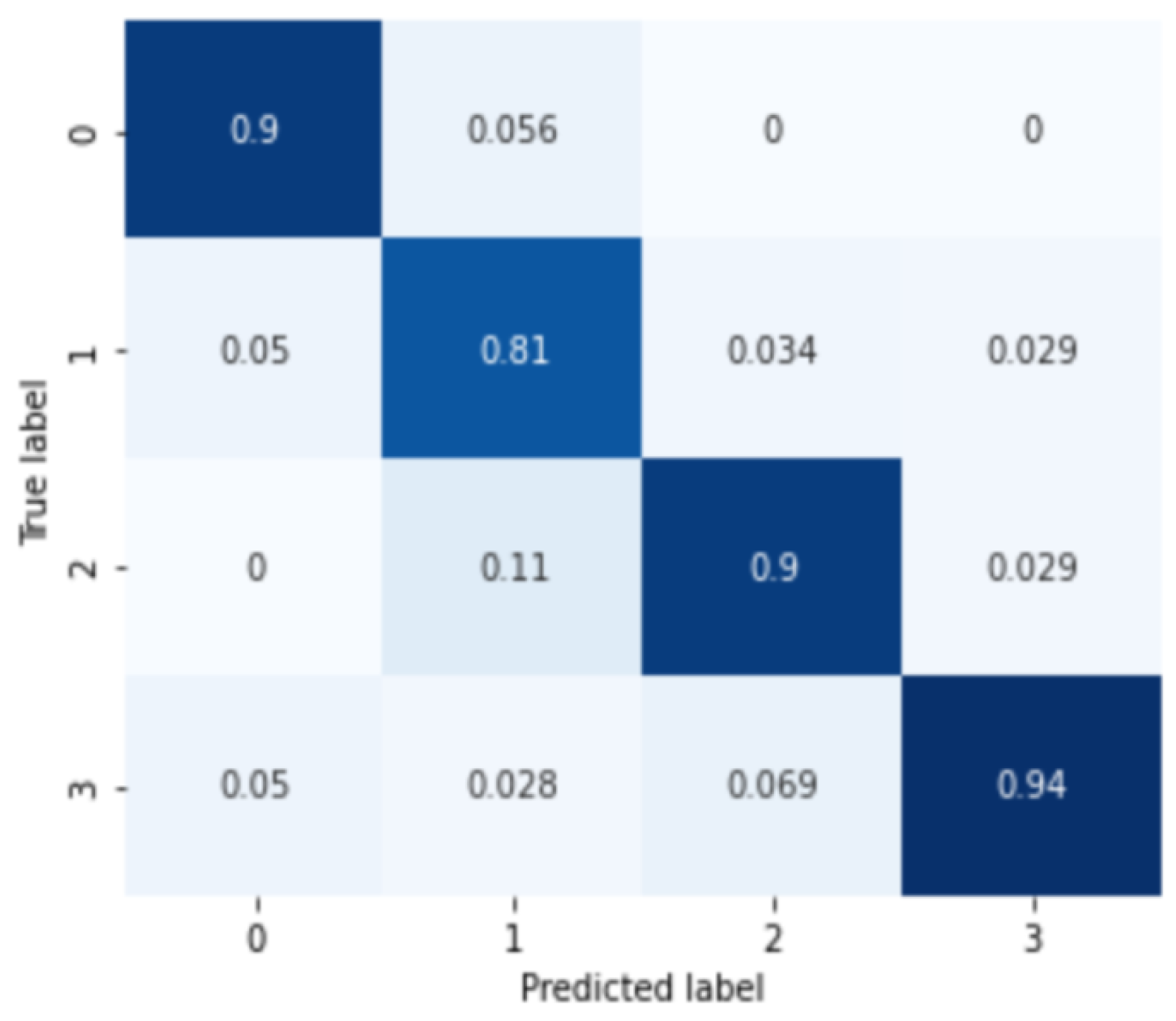
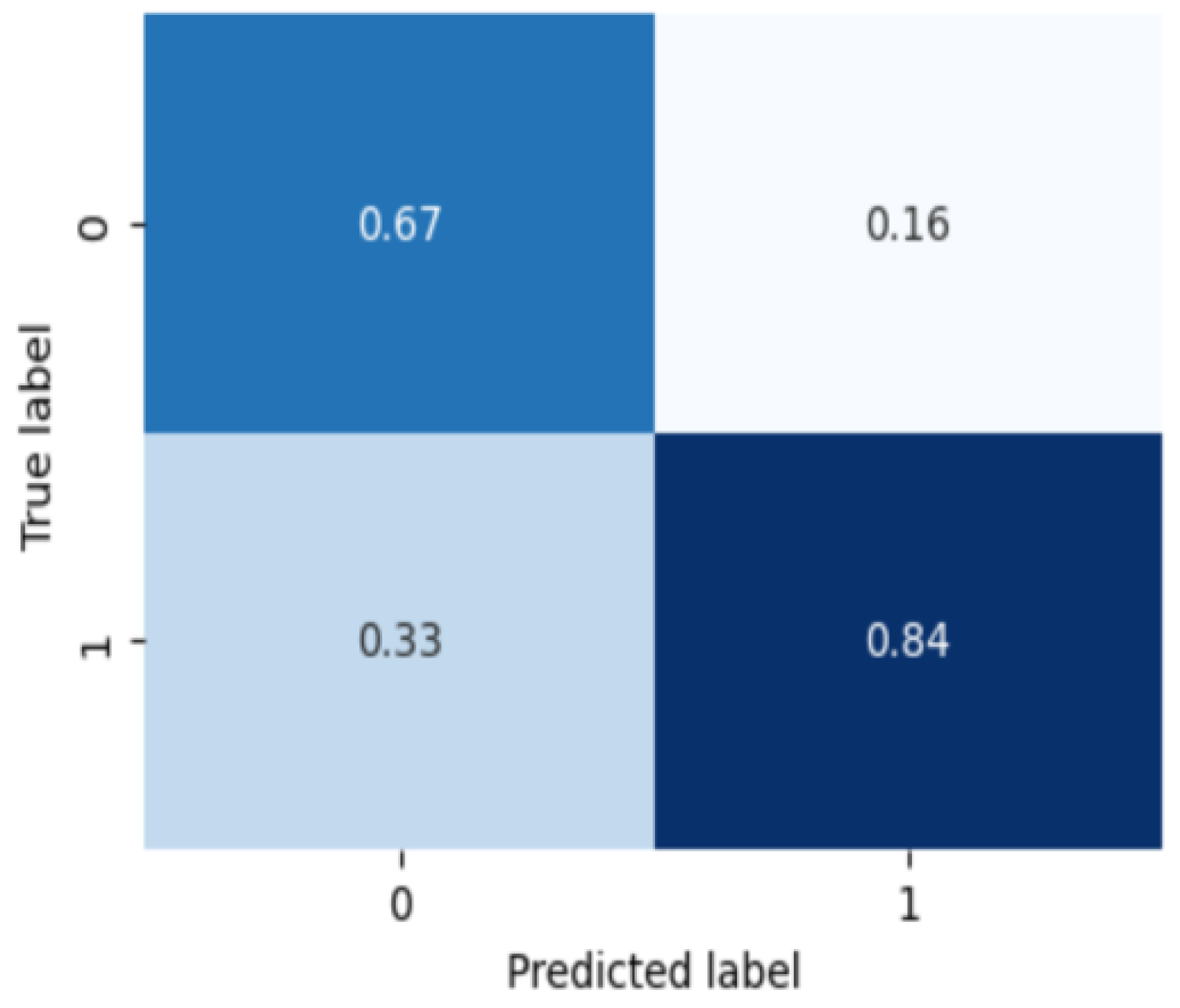
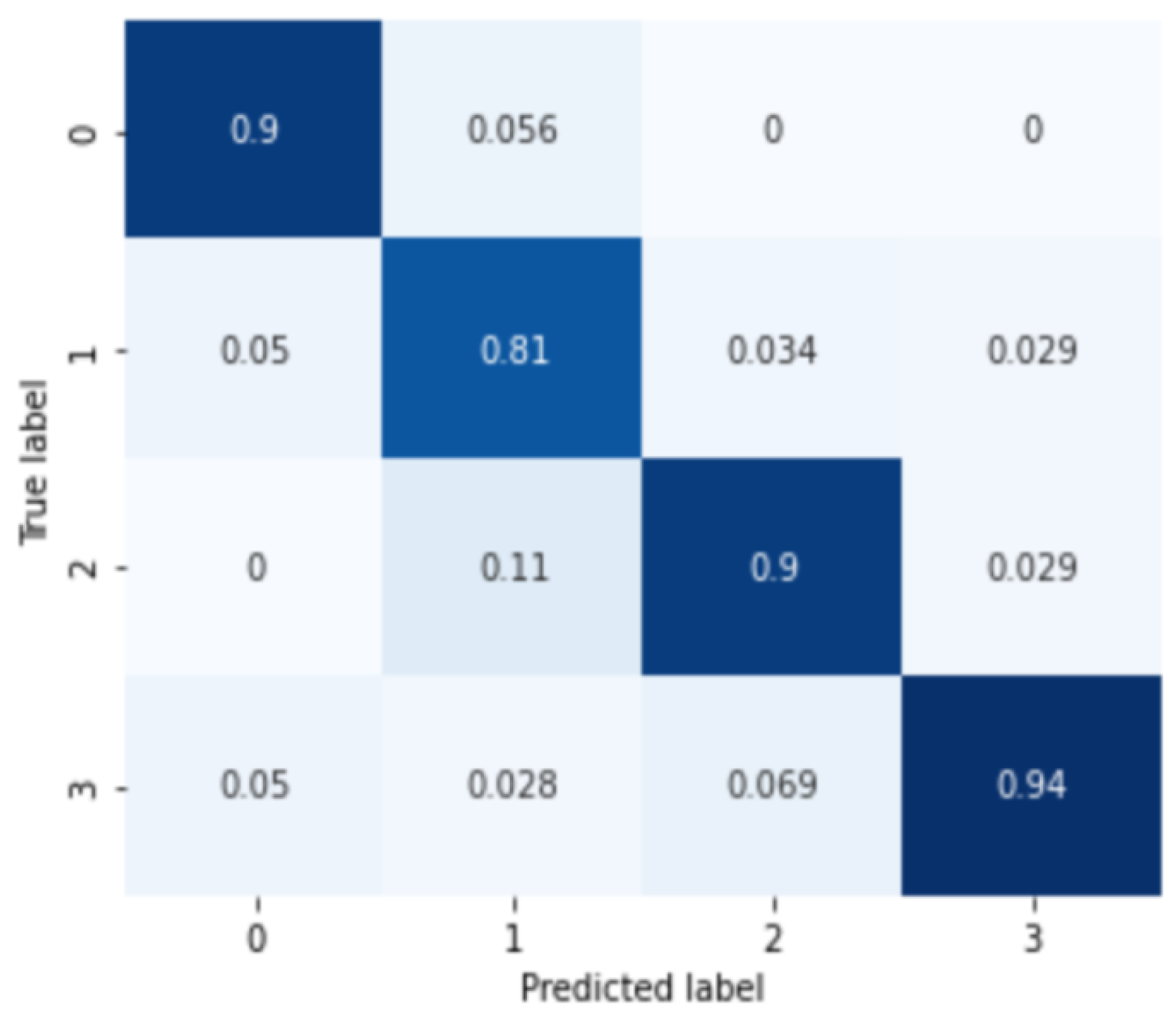
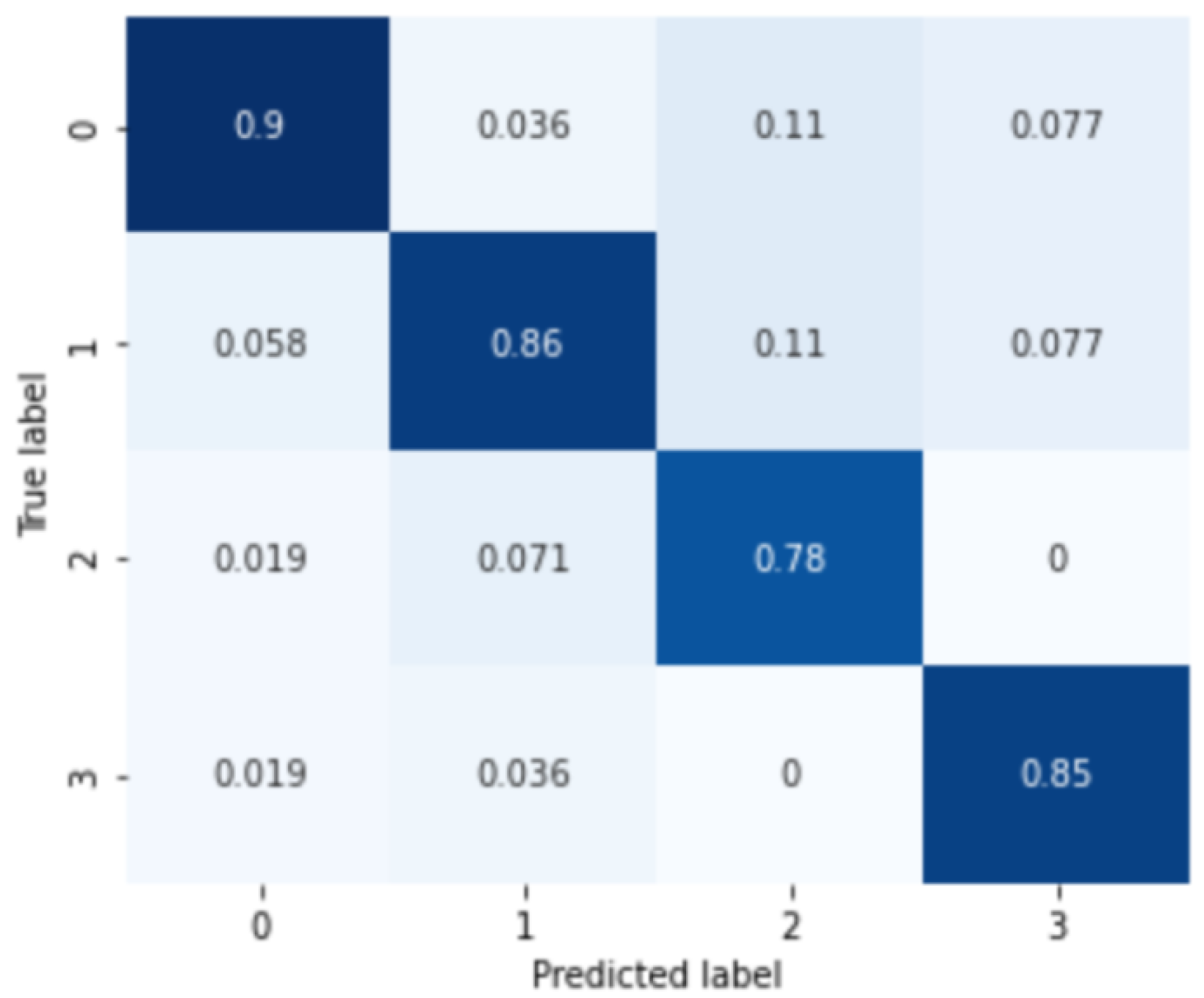
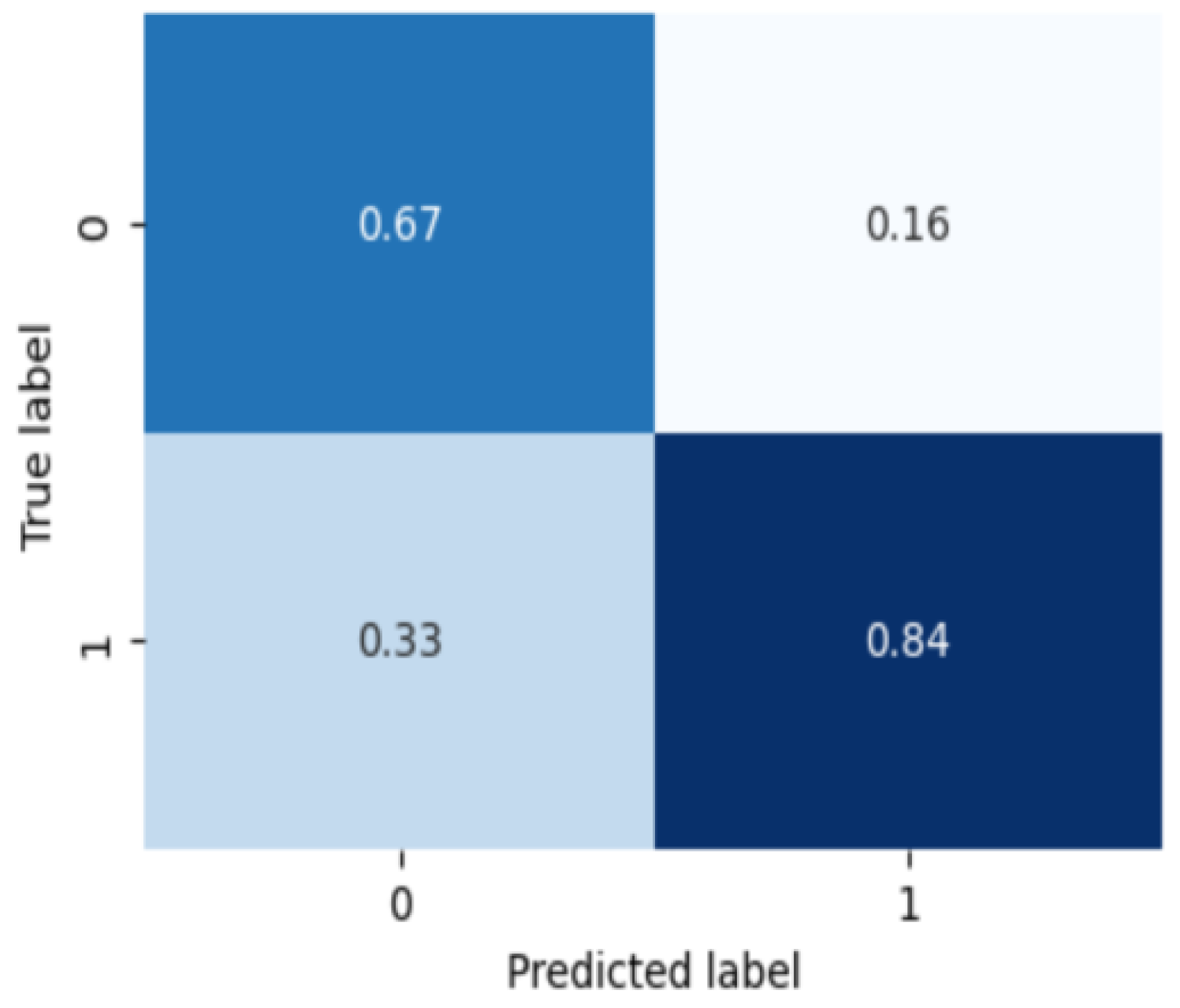
3.3. Severity and Subtype Diagnosis Model
4. Discussion
Limitations
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| MDD | Major Depressive Disorder |
| AD | Anxiety Disorder |
| BD | Bipolar Disorder |
| ANS | Autonomic Nerve System |
| CDSS | Clinical Decision Support System |
| HRV | Heart Rate Variability |
| DNN | Deep Neural Network |
References
- Cai, H.; Xie, X.M.; Zhang, Q.; Cui, X.; Lin, J.X.; Sim, K.; Ungvari, G.S.; Zhang, L.; Xiang, Y.T. Prevalence of suicidality in major depressive disorder: A systematic review and meta-analysis of comparative studies. Front. Psychiatry 2021, 12, 690130. [Google Scholar] [CrossRef]
- Yonkers, K.A.; Samson, J.A. Mood Disorders Measures. In Handbook of Psychiatric Measures; American Psychiatric Publishing, Inc.: Arlington, VA, USA, 2008. [Google Scholar]
- Hashimoto, K. Brain-derived neurotrophic factor as a biomarker for mood disorders: An historical overview and future directions. Psychiatry Clin. Neurosci. 2010, 64, 341–357. [Google Scholar] [CrossRef] [PubMed]
- Savitz, J.; Rauch, S.L.; Drevets, W. Clinical application of brain imaging for the diagnosis of mood disorders: The current state of play. Mol. Psychiatry 2013, 18, 528–539. [Google Scholar] [CrossRef] [PubMed]
- Zhou, X.H.; McClish, D.K.; Obuchowski, N.A. Statistical Methods in Diagnostic Medicine; John Wiley & Sons: Hoboken, NJ, USA, 2009. [Google Scholar]
- Pepe, M.S. The Statistical Evaluation of Medical Tests for Classification and Prediction; Oxford University Press: Oxford, UK, 2003. [Google Scholar]
- Kim, Y.K.; Na, K.S. Application of machine learning classification for structural brain MRI in mood disorders: Critical review from a clinical perspective. Prog.-Neuro-Psychopharmacol. Biol. Psychiatry 2018, 80, 71–80. [Google Scholar] [CrossRef] [PubMed]
- Cohen, S.E.; Zantvoord, J.B.; Wezenberg, B.N.; Bockting, C.L.; van Wingen, G.A. Magnetic resonance imaging for individual prediction of treatment response in major depressive disorder: A systematic review and meta-analysis. Transl. Psychiatry 2021, 11, 168. [Google Scholar] [CrossRef] [PubMed]
- Califf, R.M. Biomarker definitions and their applications. Exp. Biol. Med. 2018, 243, 213–221. [Google Scholar] [CrossRef] [PubMed]
- Rajendra Acharya, U.; Paul Joseph, K.; Kannathal, N.; Lim, C.M.; Suri, J.S. Heart rate variability: A review. Med. Biol. Eng. Comput. 2006, 44, 1031–1051. [Google Scholar] [CrossRef]
- Chattipakorn, N.; Incharoen, T.; Kanlop, N.; Chattipakorn, S. Heart rate variability in myocardial infarction and heart failure. Int. J. Cardiol. 2007, 120, 289–296. [Google Scholar] [CrossRef]
- Evrengul, H.; Tanriverdi, H.; Kose, S.; Amasyali, B.; Kilic, A.; Celik, T.; Turhan, H. The relationship between heart rate recovery and heart rate variability in coronary artery disease. Ann. Noninvasive Electrocardiol. 2006, 11, 154–162. [Google Scholar] [CrossRef]
- Thayer, J.F.; Yamamoto, S.S.; Brosschot, J.F. The relationship of autonomic imbalance, heart rate variability and cardiovascular disease risk factors. Int. J. Cardiol. 2010, 141, 122–131. [Google Scholar] [CrossRef]
- Pham, T.; Lau, Z.J.; Chen, S.A.; Makowski, D. Heart rate variability in psychology: A review of HRV indices and an analysis tutorial. Sensors 2021, 21, 3998. [Google Scholar] [CrossRef] [PubMed]
- Gorman, J.M.; Sloan, R.P. Heart rate variability in depressive and anxiety disorders. Am. Heart J. 2000, 140, S77–S83. [Google Scholar] [CrossRef] [PubMed]
- Zhuo, C.; Li, G.; Lin, X.; Jiang, D.; Xu, Y.; Tian, H.; Wang, W.; Song, X. The rise and fall of MRI studies in major depressive disorder. Transl. Psychiatry 2019, 9, 335. [Google Scholar] [CrossRef] [PubMed]
- Mousavian, M.; Chen, J.; Traylor, Z.; Greening, S. Depression detection from sMRI and rs-fMRI images using machine learning. J. Intell. Inf. Syst. 2021, 57, 395–418. [Google Scholar] [CrossRef]
- Chao, J.; Zheng, S.; Wu, H.; Wang, D.; Zhang, X.; Peng, H.; Hu, B. fNIRS evidence for distinguishing patients with major depression and healthy controls. IEEE Trans. Neural Syst. Rehabil. Eng. 2021, 29, 2211–2221. [Google Scholar] [CrossRef]
- Hartmann, R.; Schmidt, F.M.; Sander, C.; Hegerl, U. Heart rate variability as indicator of clinical state in depression. Front. Psychiatry 2019, 9, 735. [Google Scholar] [CrossRef] [PubMed]
- Yoo, J.H.; Son, H.M.; Jeong, H.; Jang, E.H.; Kim, A.Y.; Yu, H.Y.; Jeon, H.J.; Chung, T.M. Personalized federated learning with clustering: Non-IID heart rate variability data application. In Proceedings of the 2021 International Conference on Information and Communication Technology Convergence (ICTC), Jeju Island, Republic of Korea, 20–22 October 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1046–1051. [Google Scholar]
- Hilbert, K.; Lueken, U.; Muehlhan, M.; Beesdo-Baum, K. Separating generalized anxiety disorder from major depression using clinical, hormonal, and structural MRI data: A multimodal machine learning study. Brain Behav. 2017, 7, e00633. [Google Scholar] [CrossRef] [PubMed]
- Shen, Z.; Li, G.; Fang, J.; Zhong, H.; Wang, J.; Sun, Y.; Shen, X. Aberrated multidimensional EEG characteristics in patients with generalized anxiety disorder: A machine-learning based analysis framework. Sensors 2022, 22, 5420. [Google Scholar] [CrossRef]
- Ma, T.; Lyu, H.; Liu, J.; Xia, Y.; Qian, C.; Evans, J.; Xu, W.; Hu, J.; Hu, S.; He, S. Distinguishing bipolar depression from major depressive disorder using fnirs and deep neural network. Prog. Electromagn. Res. 2020, 169, 73–86. [Google Scholar] [CrossRef]
- Teixeira, A.L.; Colpo, G.D.; Fries, G.R.; Bauer, I.E.; Selvaraj, S. Biomarkers for bipolar disorder: Current status and challenges ahead. Expert Rev. Neurother. 2019, 19, 67–81. [Google Scholar] [CrossRef]
- AbaeiKoupaei, N.; Al Osman, H. A multi-modal stacked ensemble model for bipolar disorder classification. IEEE Trans. Affect. Comput. 2020, 14, 236–244. [Google Scholar] [CrossRef]
- Abaei, N.; Al Osman, H. A Hybrid Model for Bipolar Disorder Classification from Visual Information. In Proceedings of the ICASSP, Barcelona, Spain, 4–8 May 2020; Volume 2020, pp. 4107–4111. [Google Scholar]
- Behrad, F.; Abadeh, M.S. An overview of deep learning methods for multimodal medical data mining. Expert Syst. Appl. 2022, 200, 117006. [Google Scholar] [CrossRef]
- Sleeman, W.C., IV; Kapoor, R.; Ghosh, P. Multimodal classification: Current landscape, taxonomy and future directions. ACM Comput. Surv. 2022, 55, 1–31. [Google Scholar] [CrossRef]
- Huang, B.; Yang, F.; Yin, M.; Mo, X.; Zhong, C. A review of multimodal medical image fusion techniques. Comput. Math. Methods Med. 2020, 2020, 8279342. [Google Scholar] [CrossRef] [PubMed]
- Taleb, A.; Lippert, C.; Klein, T.; Nabi, M. Multimodal self-supervised learning for medical image analysis. In Proceedings of the International Conference on Information Processing in Medical Imaging, Virtual, 28–30 June 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 661–673. [Google Scholar]
- Guo, Z.; Li, X.; Huang, H.; Guo, N.; Li, Q. Deep learning-based image segmentation on multimodal medical imaging. IEEE Trans. Radiat. Plasma Med. Sci. 2019, 3, 162–169. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MDD Subjects (n = 599) | AD Subjects (n = 510) | BD Subjects (n = 237) | |
|---|---|---|---|
| Age | 41.81 ± 13.95 | 40.99 ± 14.11 | 30.80 ± 10.55 |
| Gender | F (368), M (231) | F (291), M (219) | F (160), M (77) |
| HAMD | 16.13 ± 8.57 | 14.71 ± 7.44 | 16.79 ± 6.96 |
| HAMA | 17.51 ± 8.29 | 17.24 ± 12.67 | 17.22 ± 7.76 |
| BDI | 22.29 ± 13.80 | 20.37 ± 14.24 | 32.91 ± 13.65 |
| BAI | 19.65 ± 14.30 | 12.44 ± 13.43 | 23.94 ± 14.13 |
| Major Depressive Disorder (MDD) | Anxiety Disorder (AD) | Bipolar Disorder (BD) | ||||
|---|---|---|---|---|---|---|
| HRV Features | F-Value | p-Value | F-Value | p-Value | F-Value | p-Value |
| SDNN | 1.83785 | 0.13907 | 0.26939 | 0.84747 | 7.35061 | 0.00719 |
| RMSSD | 0.69511 | 0.55526 | 0.36338 | 0.77947 | 2.79095 | 0.09612 |
| ApEN | 2.83537 | 0.03661 | 0.96904 | 0.40703 | 0.34025 | 0.56024 |
| TP | 1.91545 | 0.12586 | 0.81340 | 0.48683 | 3.29967 | 0.07056 |
| VLF | 1.61488 | 0.18474 | 0.12525 | 0.94515 | 4.77567 | 0.02985 |
| LF | 2.12205 | 0.09629 | 1.00413 | 0.39063 | 0.71508 | 0.39862 |
| HF | 0.41216 | 0.74432 | 1.19709 | 0.31026 | 1.26335 | 0.26216 |
| LF/HF | 0.79464 | 0.49717 | 1.60874 | 0.18640 | 2.40641 | 0.12218 |
| LF norm | 1.66954 | 0.17239 | 1.53822 | 0.20368 | 0.03966 | 0.84231 |
| HF norm | 1.66955 | 0.17239 | 1.53822 | 0.20368 | 0.03966 | 0.84231 |
| SRD | 0.70152 | 0.55138 | 0.73285 | 0.53274 | 0.02533 | 0.87366 |
| TSRD | 0.58352 | 0.62599 | 0.37995 | 0.76749 | 3.09363 | 0.07990 |
| ln(TP) | 2.13602 | 0.09455 | 0.31154 | 0.81704 | 11.09756 | 0.00101 |
| ln(VLF) | 2.01519 | 0.11063 | 0.17302 | 0.91462 | 16.83902 | 0.00005 |
| ln(LF) | 2.86199 | 0.03621 | 0.47418 | 0.70039 | 5.30771 | 0.02211 |
| ln(HF) | 0.45809 | 0.71167 | 0.56139 | 0.64071 | 5.90915 | 0.01581 |
| Layer (Type) | Output Shape | Param Count |
|---|---|---|
| dense_1 (Dense) | (None, 64) | 1152 |
| dense_2 (Dense) | (None, 256) | 16,640 |
| batch_normalization_1 (BatchNormalization) | (None, 256) | 1024 |
| activation_1 (Activation) | (None, 256) | 0 |
| dense_3 (Dense) | (None, 256) | 65,792 |
| batch_normalization_2 (BatchNormalization) | (None, 256) | 1024 |
| activation_2 (Activation) | (None, 256) | 0 |
| dense_4 (Dense) | (None, 256) | 65,792 |
| dense_5 (Dense) | (None, 64) | 16,448 |
| dense_6 (Dense) | (None, class number) | 260 |
| SVM | SVM-RFE | DNN | Diff | |
|---|---|---|---|---|
| Major Depressive Disorder | 0.752 | 0.765 | 0.883 | +0.118 |
| Anxiety Disorder | 0.625 | 0.642 | 0.873 | +0.231 |
| Bipolar Disorder | 0.708 | 0.708 | 0.833 | +0.125 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yoo, J.H.; Jeong, H.; An, J.H.; Chung, T.-M. Mood Disorder Severity and Subtype Classification Using Multimodal Deep Neural Network Models. Sensors 2024, 24, 715. https://doi.org/10.3390/s24020715
Yoo JH, Jeong H, An JH, Chung T-M. Mood Disorder Severity and Subtype Classification Using Multimodal Deep Neural Network Models. Sensors. 2024; 24(2):715. https://doi.org/10.3390/s24020715
Chicago/Turabian StyleYoo, Joo Hun, Harim Jeong, Ji Hyun An, and Tai-Myoung Chung. 2024. "Mood Disorder Severity and Subtype Classification Using Multimodal Deep Neural Network Models" Sensors 24, no. 2: 715. https://doi.org/10.3390/s24020715
APA StyleYoo, J. H., Jeong, H., An, J. H., & Chung, T.-M. (2024). Mood Disorder Severity and Subtype Classification Using Multimodal Deep Neural Network Models. Sensors, 24(2), 715. https://doi.org/10.3390/s24020715