Abstract
In few-shot fault diagnosis tasks in which the effective label samples are scarce, the existing semi-supervised learning (SSL)-based methods have obtained impressive results. However, in industry, some low-quality label samples are hidden in the collected dataset, which can cause a serious shift in model training and lead to the performance of SSL-based method degradation. To address this issue, the latest prototypical network-based SSL techniques are studied. However, most prototypical network-based scenarios consider that each sample has the same contribution to the class prototype, which ignores the impact of individual differences. This article proposes a new SSL method based on pseudo-labeling multi-screening for few-shot bearing fault diagnosis. In the proposed work, a pseudo-labeling multi-screening strategy is explored to accurately screen the pseudo-labeling for improving the generalization ability of the prototypical network. In addition, the AdaBoost adaptation-based weighted technique is employed to obtain accurate class prototypes by clustering multiple samples, improving the performance that deteriorated by low-quality samples. Specifically, the squeeze and excitation block technique is used to enhance the useful feature information and suppress non-useful feature information for extracting accuracy features. Finally, three well-known bearing datasets are selected to verify the effectiveness of the proposed method. The experiments illustrated that our method can receive better performance than that of the state-of-the-art methods.
1. Introduction
As an indispensable component in industrial applications, mechanical equipment is an important force in promoting sustainable development and industrial upgrading [1,2]. However, any tiny failure may cause production downtime or even catastrophic consequences. Furthermore, it is prone to component failure when the mechanical equipment operates under high loads for a long time [3]. It is of great significance to carry out an equipment fault diagnosis study to improve equipment safety and reliability, which has attracted increasing attention in the industrial safety community [4,5].
In the last decade, there has been a rapid development of information technology, which brings new perspectives and challenges for the traditional fault diagnosis methods of rotating machinery and promotes the development of fault diagnosis from traditional shallow models to deep learning models. Zhang et al. [6] proposed an improved residual network (ResNet) based on hybrid attention for wind turbine gearbox fault diagnosis. Shao et al. [7] presented a novel deep belief network (DBN) based on convolutional for bearing fault diagnosis. He et al. [8] explored a transfer learning fault diagnosis method based on a convolutional neural network (CNN), Shao et al. [9] provided a modified stacked autoencoder (SAE) based on adaptive Morlet wavelet for rotating machinery fault diagnosis. Nie et al. [10] developed a fault diagnosis framework to relax the impact of noisy labels with recurrent neural networks (RNN). These existing deep learning models can achieve results and overcome the shortcomings of shallow models, which heavily rely on manual feature extraction. However, the number of samples selected to train the deep model will seriously affect the deep model training accuracy. Moreover, in real industrial applications, it is difficult or even impossible to collect a large amount of label data, which gives the deep learning-based methods poor generalization ability. To this end, it is essential to capture discriminative knowledge from limited training data to obtain a generalized deep model.
FSL (FSL) is an impressive scenario to utilize limited labeled samples to quickly learn and achieve stable classification results, which has received widespread attention and obtained encouraging progress [11,12]. Up to now, there several FLS methods have been reported, such as Prototypical Network (ProNet) [13,14], Match Network (MatNet) [15,16], Siamese Network (SiaNet) [17,18], etc. Among them, the ProNet transforms the classification problem into a distance measurement problem in the feature embedding space, which has lower time complexity and wildly applied in pattern recognition fields. Chowdhury et al. [19] used the maximum mean discrepancy (MMD) to evaluate the influence of distributions, including and excluding the sample and obtained the sample weights by subtracting from 1 only. Wang et al. [20] presented a weight prototypical network for bearing fault diagnosis, and the Kullback–Leibler (KL) divergence was adopted to estimate the influence of specific samples from a sample distribution. Gao et al. [21] designed a novel prototypical network for noisy few-shot problems based on instance-level and feature-level attention schemes to accentuate the significance of instances and features, respectively. Ye et al. [22] proposed a learning with a strong teacher framework for few-shot learning, in which a strong classifier was constructed to supervise the few-shot learner for image recognition. Zhao et al. [23] employed a dual adaptive representation alignment network for cross-domain few-shot learning, which can update the support instances as prototypes and renew the prototypes with the differentiable. To this end, the above-mentioned FSL-based methods provide a new idea and make certain progress in solving the problem of training scarce samples. However, they only focus on how to evaluate the weight of samples and do not overcome the limitation of small samples. To tackle the problem of FSL from the root, semi-supervised learning (SSL), utilizing a few labeled samples and massive unlabeled samples to improve learning performance, can be divided into three categories: adversarial generation, consistency regularization, and pseudo-labeling. Pseudo-labeling techniques—explored to label unlabeled samples, which are easier to obtain for expanding the training set—have been paid increasing attention recently. He et al. [24] proposed a semi-supervised prototypical network based on pseudo-labeling for bearing fault diagnosis. A fixed threshold was used to select pseudo-labeling and obtain the optimal threshold by a large number of experiments. Fan et al. [25] presented a semi-supervised fault diagnosis method, screened pseudo-labeling with thresholds, and adjusted the dependence of the model on pseudo-labeling through learning. Zhang et al. [26] explored a self-training semi-supervised method that selects unlabeled data with high predictive confidence on a trained model and extracts pseudo-labeling iteratively. Zhang et al. [27] adopted Monte Carlo uncertainty as the threshold to screen the pseudo-labeling and built a gearbox fault diagnosis scenario with small samples based on a momentum prototypical network. Zhou et al. [28] designed an adaptive prototypical network for few-shot learning with sample quality and pseudo-labeling screening to weaken the impact of unreliable pseudo-labeling.
Most of these existing SSL methods based on pseudo-labeling learning achieved impressive accuracy in few-shot learning tasks by increasing the number of training samples by labeling the unlabeled samples. However, there are still the following limitations: (1) A single threshold selected for pseudo-labeling screening cannot guarantee the accuracy of pseudo-labeling collections, which dramatically degrades the performance of SSL methods. (2) Insufficient consideration of iteration-stopping conditions can easily lead to the propagation and accumulation of incorrect information during the iteration process. To resolve the trouble of network degradation caused by the low accuracy of pseudo-labeling screening and insufficient selection samples, a semi-supervised learning method based on a pseudo-labeling multi-screening strategy for a few-shot bearing fault diagnosis is proposed. In this paper, a composite threshold for pseudo-labeling screening combined with Monte Carlo uncertainty and classification probability is explored to overcome the limitations of pseudo-labeling screening with a single threshold. Then, a multi-pseudo-labeling accumulation model based on network optimization is employed to solve the problem of network degradation caused by mislabeling. Finally, three well-known bearing datasets were used to verify the effectiveness of the proposed model. The main contributions are summarized as follows:
(1) A multi-screening strategy based on Monte Carlo uncertainty and classification was proposed for pseudo-labeling selection, which can assist in ensuring the accuracy of pseudo-labeling screening and improve generalization ability.
(2) A semi-supervised learning method based on AdaBoost adaptation was explored to integrate multiple samples into a class prototype to obtain a more accurate class prototype, which can overcome the drawbacks caused by low-quality label samples hidden in the dataset.
(3) An estimation strategy for individual sample contribution rate was presented to accurately obtain individual sample weights for improving the performance of AdaBoost adaptation, which can tackle the problem that ignored the impact from individual differences.
2. Theoretical Background
2.1. Few-Shot Learning
Learning classification information from limited labeled samples to new samples to improve generalization ability, FSL increases attention in pattern recognition and has achieved interesting progress [29,30].
For a typical FSL task T, the whole dataset was described as , where the and denoted the training set and testing set with , , respectively. The samples come from a particular domain , which consists of a data space and a marginal probability distribution In task T, the K samples were selected from N and randomly classed in , i.e., N-way, K-shot [31], aiming to generate an objective prediction function to predict the samples in It was an enormous challenge to achieve a high-accuracy model in the training process under the limited samples in Consequently, in the majority of instances, a supervised query dataset is employed: , which was selected to randomly assess task T.
2.2. Prototypical Network
As one of the most attention-attracting techniques of FSL, the prototypical network (PN) aims to generate a prototype for each class with labeled data being widely applied to image recognition and fault diagnosis [32,33].
Specifically, given a support set , the average of the feature vectors from the same class was used to define the prototype; thus, prototype of class l is expressed as:
where is the feature extractor, represents the n-th sample of class l, and N denotes the number of samples in class l.
For unlabeled samples, the Euclidean distance between the sample and the prototypes of each category is calculated, which is normalized by the Softmax function to obtain the probability that the sample belongs to each class. The metric-based meta-learning method of prototypical networks is an effective means of alleviating the overfitting problem that can arise when insufficient data are available.
2.3. AdaBoost
Ensemble learning is a type of method that combines multiple models through specific mechanisms to obtain a more robust model. As a classic ensemble algorithm, the main idea of AdaBoost is to construct a strong classifier by the linear combination of several weak classifiers [34]. The performance requirements for weak classifiers need not be too high, they just need to be better than random assumptions. Weak classifiers with high accuracy were given higher weights; conversely, their weights were reduced. Assuming the error rate of a weak classifier is , its weight is:
Thus, multiple base classifiers are weighted and combined to improve classification performance:
3. Semi-Supervised Learning Method of the Proposed
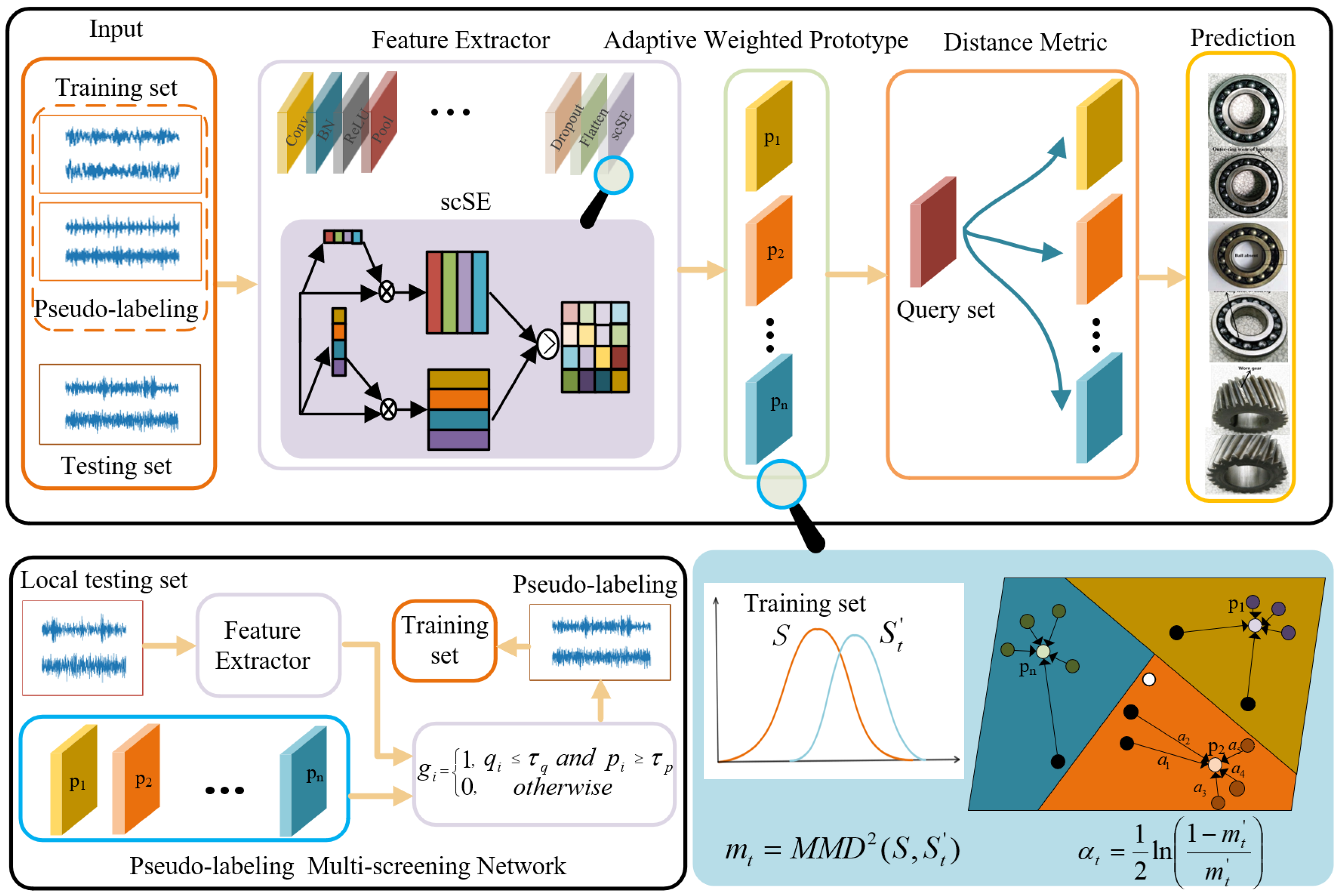
In this section, a pseudo-labeling multi-screening-based semi-supervised learning method for few-shot fault diagnosis is proposed. The overall structure is presented in Figure 1, which includes three main components: (1) AdaBoost-based adaptive weighted prototypical network (AWPN); (2) pseudo-labeling multi-screening strategy; and (3) semi-supervised learning-based fault diagnosis.
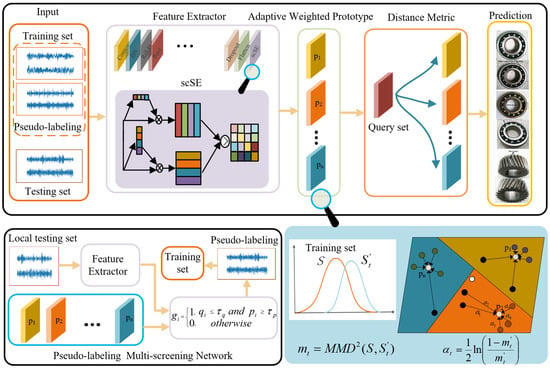
Figure 1.
The overall structure diagram of the proposed method.
3.1. Squeeze and Excitation-Based Feature Extractor
To make the model pay attention to the differences between different perspectives in the learning process and automatically learn the importance of features from different perspectives, Roy et al. [35] proposed spatial and channel squeeze and channel excitation (scSE) for achieving feature recalibration in both space and channel.
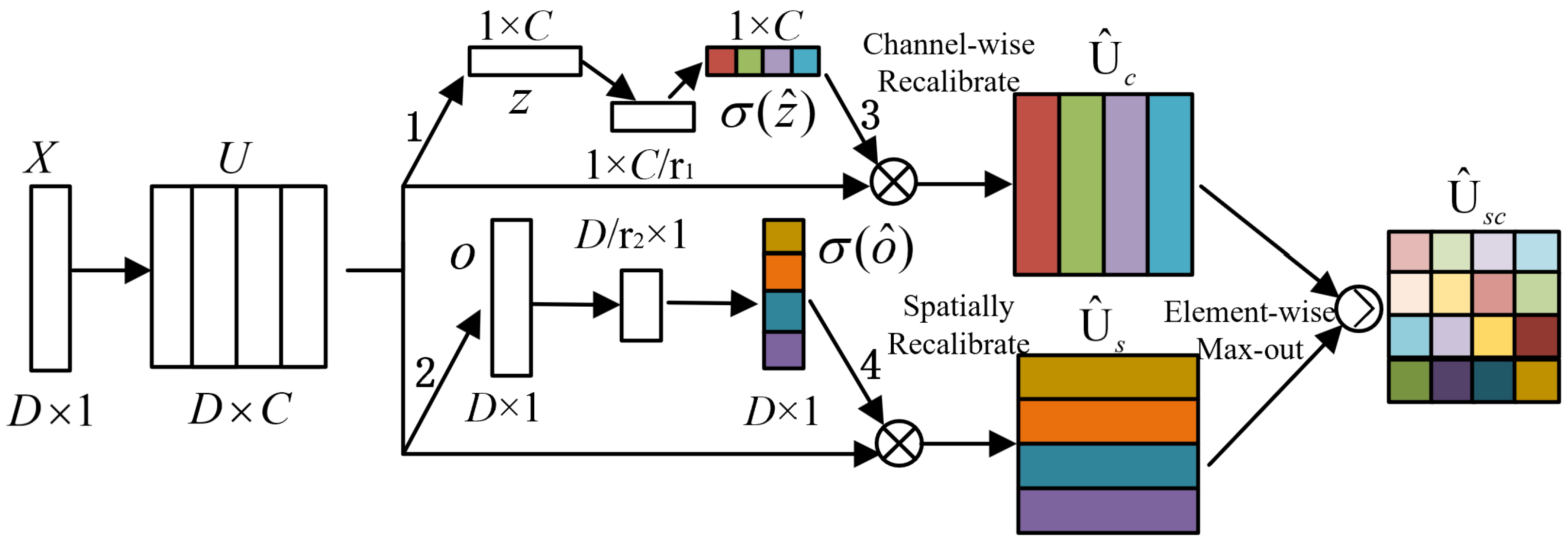
The application of scSE to one-dimensional data is given in Figure 2. Given that an input feature set is a combination of C channels , and can also be rewritten as a combination of D feature layer slices . Vector is generated by spatial squeeze, which is executed by the global average pooling layer, and vector is generated by channel squeeze, obtained by convolution , . It is actually a projection of multi-channel features at a feature level. The vector z is converted into vector through two fully connected layers , where represents the bottleneck in the channel excitation. To ensure that the excitation channel remains within an appropriate range, is mapped to [0, 1] through a sigmoid function It is worth noting that after channel squeeze, the obtained feature projection is still applicable to the encode–decode operation. Therefore, two fully connected layers are used to convert o to . represents the bottleneck in the spatial excitation, and the sigmoid function is also used to keep within an appropriate range. Finally, the calibrated features are used in a max-out manner.
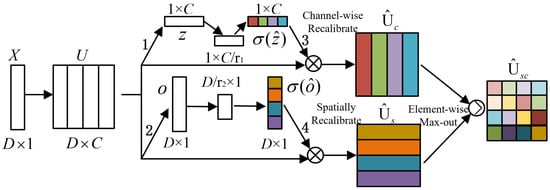
Figure 2.
Architectural configuration of scSE.
The calculation process of scSE is shown in Equations (4) to (10):
where and are the ReLU function and sigmoid function, respectively. * represents the convolution operation.
3.2. Adaptive Weighted Prototypical Network
Inspired by the AdaBoost theory that weak classifiers can be integrated into strong classifiers, a prototypical network is proposed that adaptively weights the features into strong feature representation. First, each sample is treated as a weak classifier, its weight is calculated by measuring the influence of missing specific samples against the whole sample distribution, which is weighted to build a strong feature representation, that is, class prototype.
As a commonly used criterion, maximum mean discrepancy is adopted to widely measure the distribution discrepancy between the two domains. For a given feature set is the feature extractor based on squeeze and excitation mechanism. represents the absence of feature in feature set U. Therefore, the influence of sample against the distribution of the sample set can be converted to calculate the maximum mean distribution discrepancy between U and , as shown below:
where represents the mapping function for any The smaller is, the closer the samples are, and vice versa; the sample deviates from the sample distribution. When and are the same distribution. AdaBoost does not have high performance requirements for weak classifiers and only needs to be better than the random hypothesis, so is projected to [0, 0.5) by (12).
Therefore, the weight of feature extractor is rewritten:
Noting that may be set to 0, a sufficiently small positive number should be added into the denominator term in (13).
Define the support set as the label for L-class samples. is the set of samples with the labeled class l, and the prototype of support class l can be calculated by
Assuming that sample x needs to be classified, the feature extractor is used to obtain the feature space, and then the Euclidean distance is adopted to compute the and L prototype vectors, respectively. The probability that sample x belongs to category l is:
Therefore, the loss function of the query set is:
3.3. Pseudo-Labeling Multi-Screening Strategy
For data-driven classification models, the number of trainable samples affects the accuracy of the model, especially in semi-supervised learning. In this paper, a pseudo-labeling multi-screening strategy based on uncertainty and classification probability is proposed, which can effectively expand the training set and improve the model training accuracy.
There is a positive correlation between network correction and model output uncertainty. The lower the uncertainty of the model, the smaller the network correction error, and the higher the accuracy of the model [36]. Therefore, the uncertainty of the model is used as one of the indicators of pseudo-label screening. The uncertainty of the output of each sample is calculated by using the Monte Carlo dropout model. In the forward propagation of dropout layers in the testing phase, the Monte Carlo dropout was employed to generate output distributions that emulate the variability observed across different network architectures. The predictive outcomes and the uncertainty of the model are calculated by averaging the outputs and the statistical variance.
Supposing is the output of PN after t iterations of random dropout, its uncertainty can be calculated as in Equation (17) [37].
where represents the predicted posterior mean. The model architectures do not need to be modified, which can reduce the overfitting of the network and improve the computation efficiency. It assesses the predictive mean and model uncertainty by collecting the results of stochastic forward passes.
A pseudo-labeling multi-screening strategy based on the dual threshold of Monte Carlo dropout uncertainty and softmax output probability is constructed as:
where is the estimated uncertainty of sample is the maximum value of the predicted probability. and represent the thresholds of uncertainty and prediction probability, respectively. When is l, it means that sample i is filtered as a pseudo-labeled sample.
In order to select as many trainable samples as possible on the premise of ensuring the accuracy of pseudo-labeling, a multi-accumulation strategy is proposed in this paper. The pseudo-label samples selected in the previous round were combined with the training samples to update the AWPN, and the updated AWPN was used for a new round of pseudo-label screening, which was accumulated layer-by-layer until the conditions for stopping were met. If incorrect pseudo-labeling is added to the shallow network, the error information will accumulate in the iteration up to the deep network layer, greatly reducing the accuracy of fault diagnosis. Therefore, a timely stop accumulation strategy is the key to ensure the accuracy of the model. The labeled training set is used to judge whether the network is degraded. If the addition of pseudo-labeling reduces the accuracy of the AWPN on the training set, it indicates that the false pseudo-labeling causes network degradation, and the accumulation strategy is stopped. The accumulation strategy stops in two cases: 1. the filtered pseudo-labeling sample is empty; 2. network degradation.
3.4. Overview of the Proposed Method
The semi-supervised few-shot learning based on an adaptive prototypical network and multiple accumulation of pseudo-labeling samples is proposed in this article, with the pseudo code shown in Algorithm 1.
| Algorithm 1: The proposed learning strategy |
 |
4. Results of Experiments
4.1. Dataset Description
Dataset A: The CWRU dataset is a classic dataset in bearing fault diagnosis and is widely used in the field of bearing fault diagnosis [38]. The fault types are divided into inner race fault (IF), outer race fault (OF), roller fault (RF), and normal state (N). Each type of fault is composed of vibration signals collected under different working conditions, with a sampling frequency of 12 kHz. In this experiment, a sliding window with a length of 2048 and a step size of 80 was used to obtain vibration data samples. The CWRU dataset experimental platform is shown in Figure 3, and the data introduction is shown in Table 1.

Figure 3.
CWRU bearing test bed.

Table 1.
Description of CWRU dataset.
Dataset B: The petrochemical dataset is collected in industrial environments. Under industrial operating conditions, the collected vibration signals usually contain more noise [39]. For example, environmental noise, temperature changes, equipment aging, and other factors may have an impact on vibration signals, making the data more in line with the actual conditions of industrial operation. The petrochemical experiment platform is shown in Figure 4. The dataset contains six different fault states, normal, defect (s) in gearwheels (F1), defect (s) in gearwheels along with the outer-ring wear of the left-hand side bearing (F2), defect (s) in gearwheels along with the inter-ring wear of the left-hand side bearing (F3), defect (s) in gearwheels along with the absence of balls on the left-hand side bearing (F4), defect (s) in pinions along with the defect (s) in gearwheels (F5). A vibration sensor mounted on the bearing seat is used to collect vibration acceleration signal data, and the data introduction is shown in Table 2.

Figure 4.
Petrochemical experiment platform.
Table 2.
Description of petrochemical dataset.
Dataset C: The IMS bearing dataset was constructed by the Intelligent Maintenance Systems Center at the University of Cincinnati in the United States [40]. The bearings are subjected to simulated degradation tests from a bearing test bench consisting of a 2000 RPM motor and four bearings mounted on the same shaft. During the experiment, the vibration signal generated by the bearing during the operation of the test bench is collected by installing an accelerometer on the bearing seat, with a sampling frequency of 20 kHz. This dataset is the full life cycle data of bearings. In multiple running fault tests, three bearings occurred: outer race failure (ORF), inner race failure (IRF), and ball failure (BF). The data introduction is shown in Table 3.
Table 3.
Description of IMS dataset.
4.2. Results and Analysis
In order to prove the effectiveness of the proposed, three methods are selected for comparative experiments:
The kernel principal analysis-based semi-supervised prototypical network (K-kernel PN) [24], in which the classical prototypical network is used to realize fault diagnosis with the principal component analysis of the Gaussian kernel function to process the original vibration signal.
The robust re-weighting prototypical networks (WProNet) [41], which incorporate a re-weighting mechanism to set a weight for each summation item.
(IPNet) [19], which adjusts the weights of prototypical networks based on the largest average differences between data.
In order to ensure the fairness of comparison, the parameters of the three data sets are the optimal parameters provided in the paper, and all the results are obtained by running 10 times. A time window of length 1024 and step length 128 is used to divide the original oscillation signal. Each type of fault randomly selects 500 samples as the training set, with 1400 samples as the test set. The unlabeled test set is also used for the pseudo-label screening. Table 4, Table 5 and Table 6 show the simulation results of the four methods in three data sets.
Table 4.
Average accuracies of the results for CWRU (%).
Table 5.
Average accuracies of the results for petrochemical (%).
Table 6.
Average accuracies of the results for IMS (%).
It can be seen from the results in Table 4, Table 5 and Table 6 that the proposed method is superior to other models in all tasks of small sample classification. WProNet and IPNet use weighted prototypical networks, but the weighting method is too simple and does not use pseudo-labeling technology to increase the number of available samples, resulting in poor performance in the petrochemical dataset. Although pseudo-labeling technology is used in PSSPN, a single criterion cannot guarantee the accuracy of screening, so the accuracy is lower than that of the proposed method, which proves the effectiveness of the AWPN and dual-threshold multi-accumulation pseudo-labeling screening strategy.
4.3. Ablation Experiment
To demonstrate the effectiveness of the adaptive weighting module and pseudo-labeling screen module, we conducted ablation experiments on three datasets, and the experimental results are shown in Table 7. The original prototypical network incorporates pseudo-labeling screening (PNIPS) to compare the effectiveness of the adaptive weighting module. The AWPN does not include a pseudo-labeling module to compare the effectiveness of the pseudo-labeling screen. The experimental results show that the addition of adaptive weights can generate a more representative class prototype. The screen of pseudo-labeling can increase the amount of valid data. Therefore, both can improve the classification accuracy of the mode.
Table 7.
Results of ablation experiment (%).
4.4. Visualization Analysis
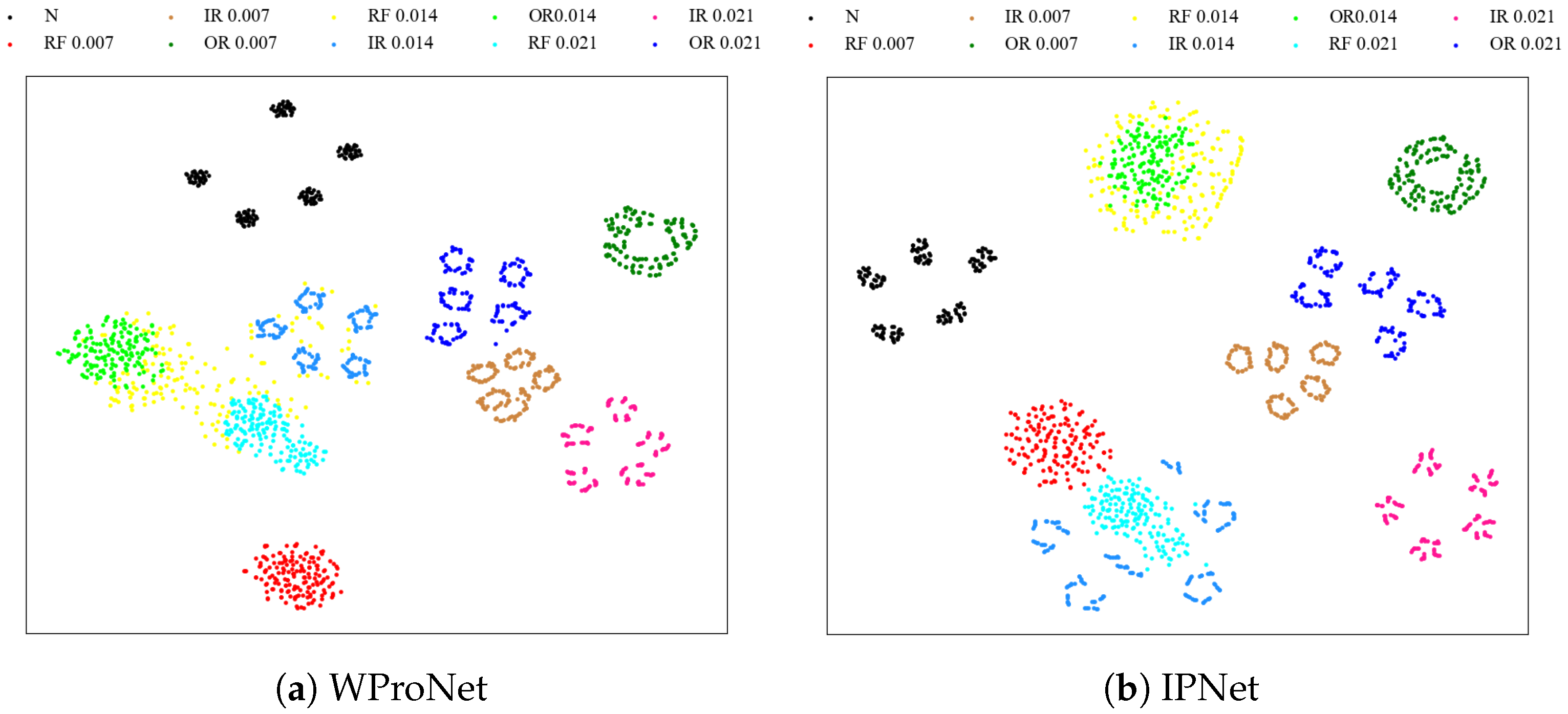
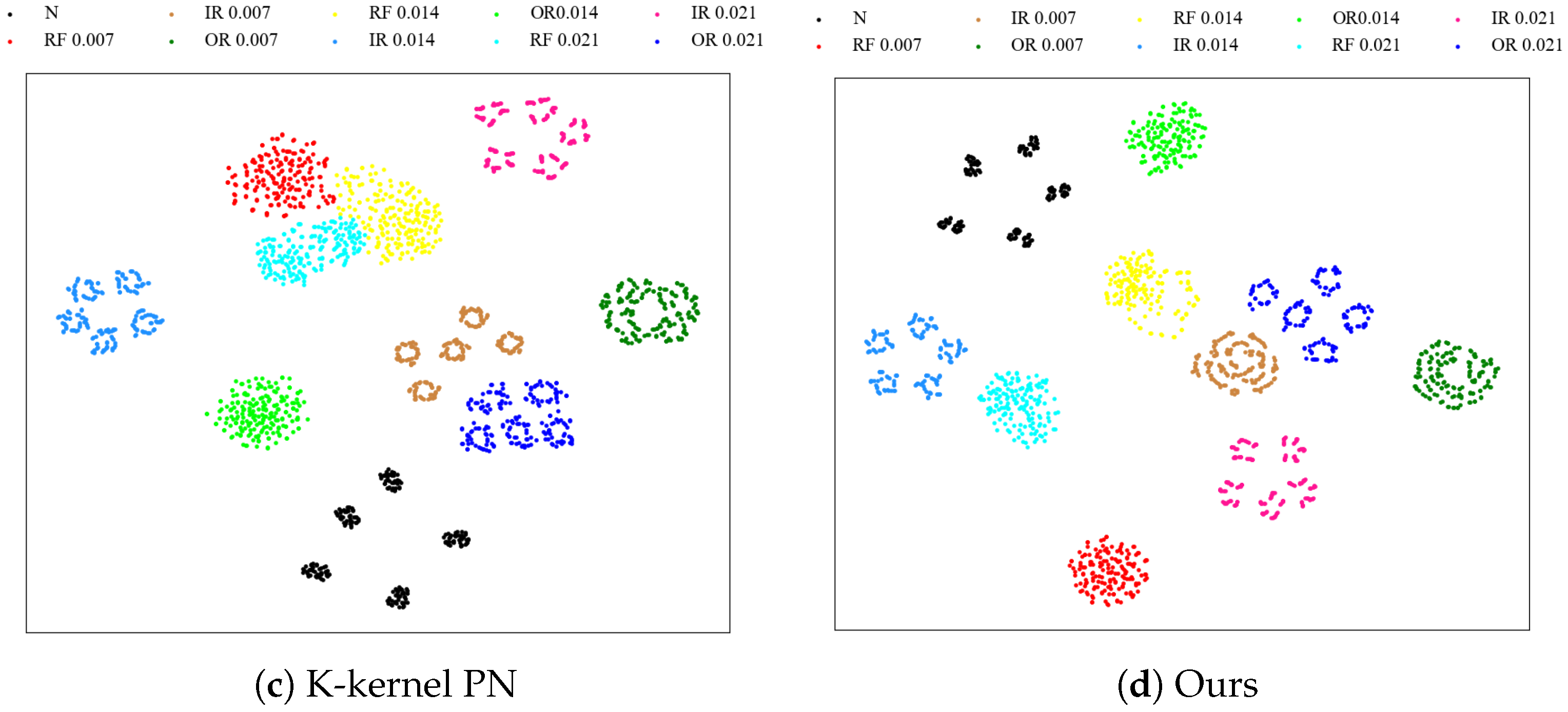
The t-distributed random domain embedding (t-SNE) is used to display the visualization images of the CWRU dataset in the 10-way 5-shot scenario under the four models mentioned in Section 4.2. The experimental results are shown in Figure 5; as can be seen from the figure, the same type of features in our model are close to each other, and the overall boundary is relatively obvious. Different class features are far from each other, resulting in the best classification performance. However, the classification performance of other models still needs to be improved, with a few features of different classes crossing each other and a few features overlapping together. Possible reasons may be the misclassification of the model, as well as the prototype generated from the extracted features not maximizing the distance between different classes as much as possible.


Figure 5.
Visualization of CWRU data set features under four models.
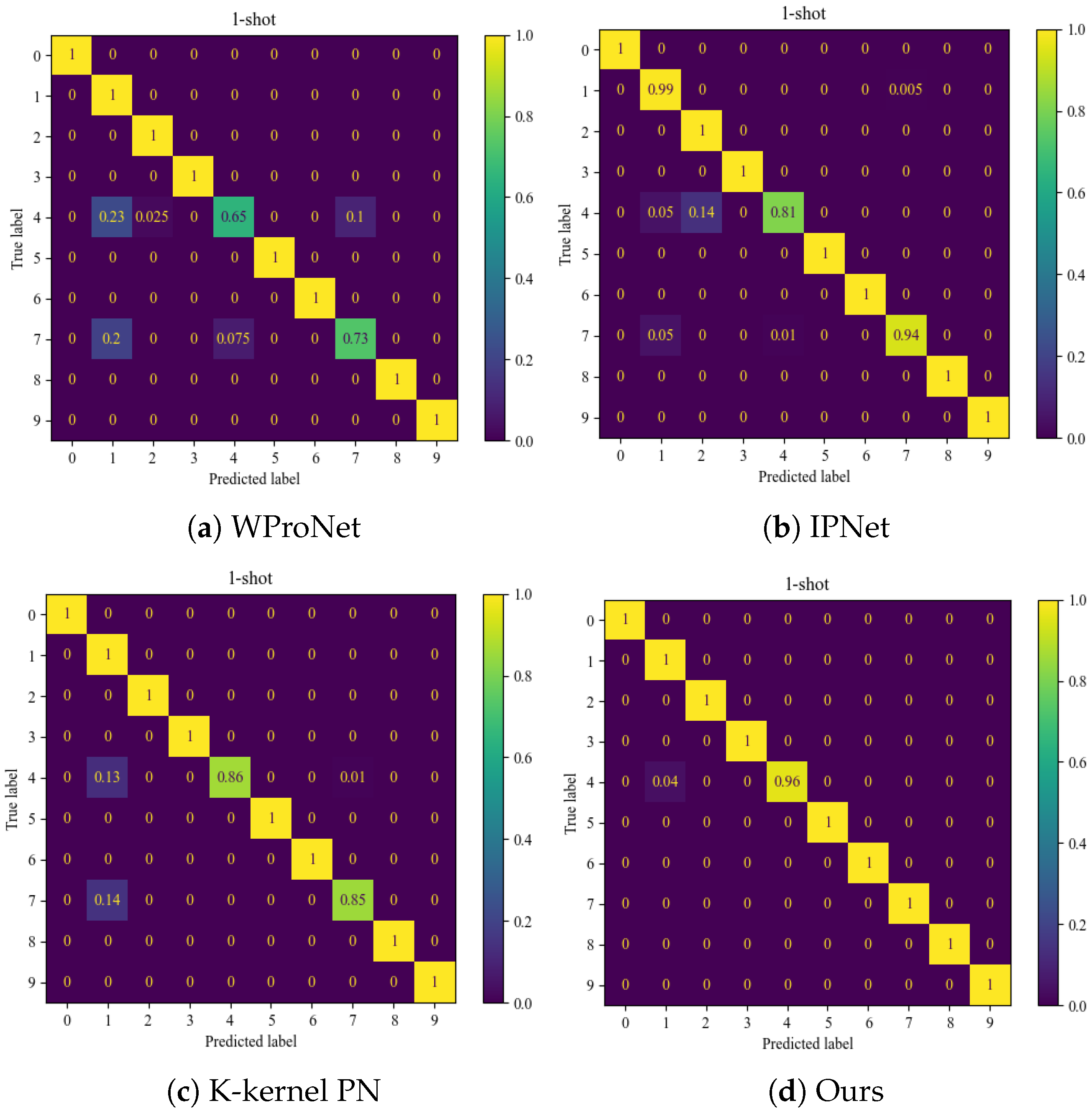
Figure 6 shows the confusion matrices obtained from the classification of the CWRU dataset in the case of 10-way 5-shot. According to the testing results, the WProNet and K-kernel PN models performed poorly in classifying label 4 (inner race fault with a fault diameter of 0.007) and label 7 (outer race faults with a fault diameter of 0.007), while performing well for other categories. The classification performance of IPNet is better than that of WProNet and K-kernel PN, but it still performs poorly in classifying label 4. WProNet and IPNet do not use pseudo-labeling techniques to increase the number of trainable samples, which can lead to overfitting in the training. K-kernel PN has conducted pseudo-label screening and uses the original prototype network, causing the network performance to degrade. Among these four methods, the proposed method had the best classification effect.

Figure 6.
Confusion matrix of CWRU data set under four models.
4.5. Related Parameters
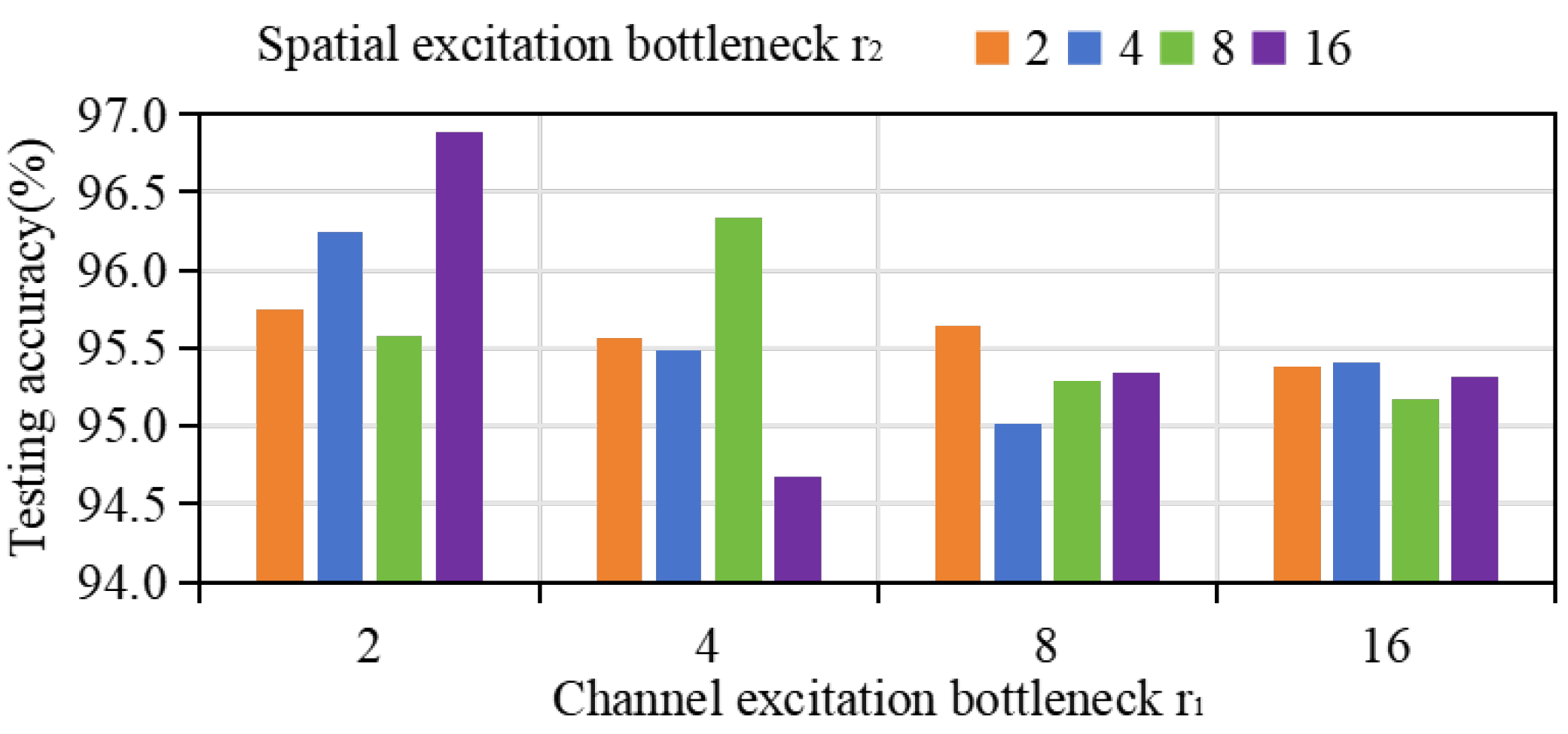
The hyperparameters involved here are mainly the bottlenecks and representing channel excitation and spatial excitation, and and represent uncertainty and category probability thresholds. Appropriate and can improve the efficiency of feature extraction, enabling the extracted features to accurately depict different types of fault expressions, and and determine the accuracy of pseudo-labeling screening. Therefore, the selection of parameters will greatly affect the performance of the model. For and , the values are usually In order to remove the influence of parameters in pseudo-labeling screening, the adaptive weighted prototypical network (without pseudo-labeling screening) and CWRU dataset were selected for parameter evaluation, and the results were obtained as shown in Figure 7; the optimal parameters are and . The detailed system parameter settings in this article are shown in Table 8 and Table 9.

Figure 7.
Accuracy of CWRU data set under different values of hyperparameters and .
Table 8.
The feature extractor parameters.
Table 9.
The scSE parameters.
4.6. Validity of Dual-Threshold Pseudo-Labeling Screen
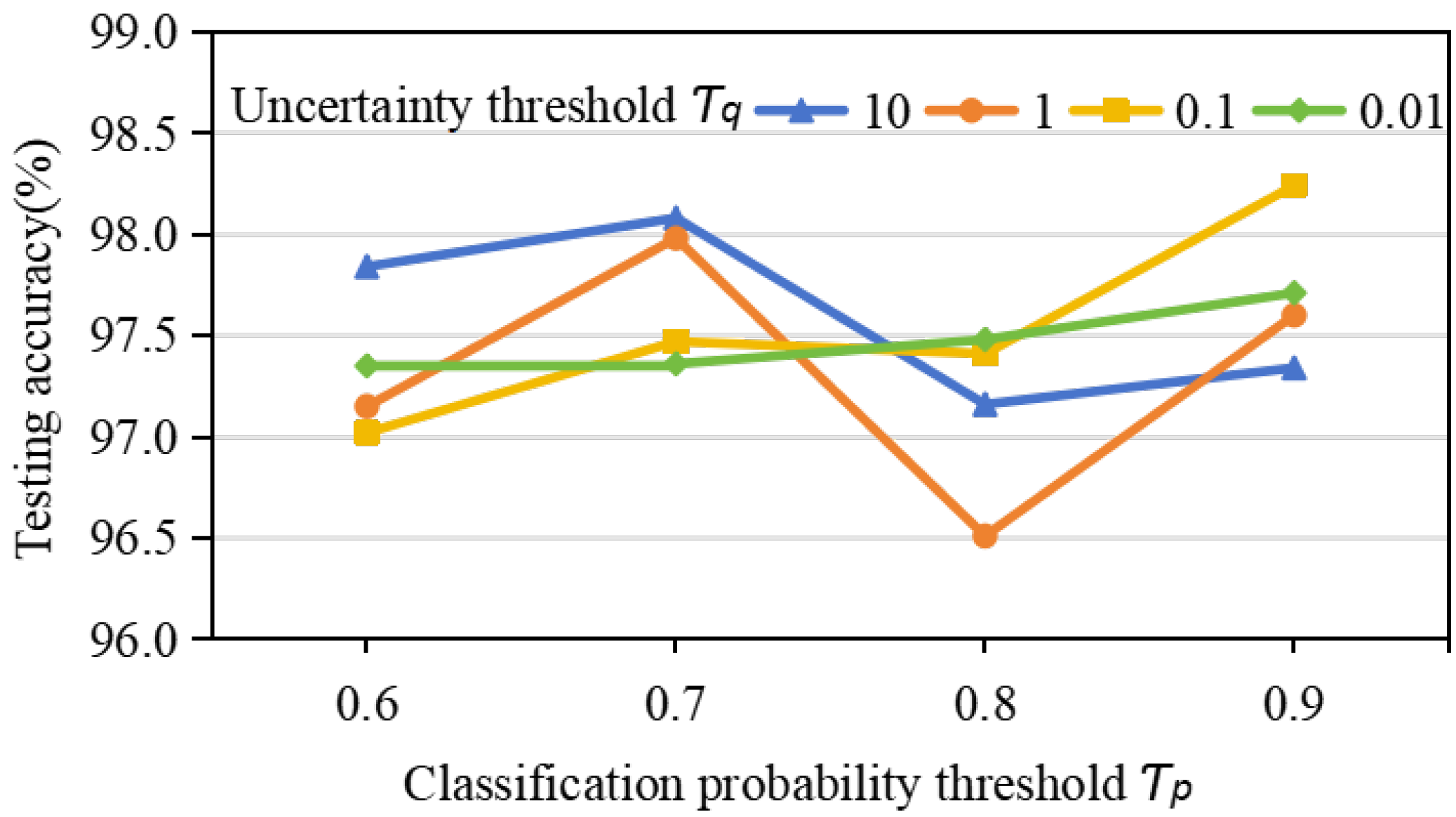
The range of uncertainty threshold is , and the range of output probability threshold is . The results obtained by adding a pseudo-labeling screen module to the AWPN with determined parameters are shown in Figure 8, and the optimal parameters are and
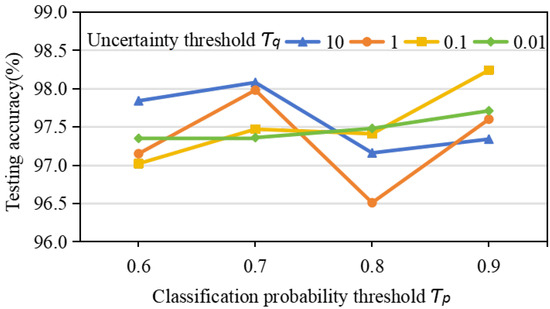
Figure 8.
Accuracy of CWRU data set under different values of hyperparameters and .
4.7. Effectiveness of Dual-Threshold Pseudo-Labeling Screen
The output probability is usually selected as the criterion for false label screening, and a single threshold is prone to producing false pseudo-labeling. In this paper, the dual-threshold of output probability and uncertainty are adopted, and multiple selection strategies are adopted to screen out more samples without reducing the accuracy of pseudo-labeling. To demonstrate the effectiveness of the dual threshold strategy, a single output probability threshold and a single uncertainty threshold were selected as the comparison terms for the dual threshold strategy. In the application of the CWRU dataset, the accuracy of the model is shown in Table 10.
Table 10.
Accuracy of the model under different hyperparameters (%).
5. Conclusions
The article proposed a pseudo-labeling multi-screening-based semi-supervised learning method for few-shot fault diagnosis to improve the generalization ability under limited label samples. The proposed method consists of a squeeze and excitation block-based feature extractor, an AdaBoost adaptation-based prototypical clustering, and a pseudo-labeling multi-screening strategy. The feature extractor of the proposed method achieves effective information by squeeze and excitation; high accuracy pseudo-labeling samples are generated with pseudo-labeling screening to expand the number of trainable data points to verify the effectiveness of the proposed method compared with the existing methods in two ways (5-way and 10-way) with three shots (1-shot, 5-shot, and 10-shot). A comparison result of feature visualization and confusion matrix with other related scenarios illustrated that the proposed method has significant performance in the different shots diagnosis tasks. However, our proposed method still has certain limitations, which reduced the time cost in the process of pseudo-labeling multi-screening. Therefore, in future research, it is necessary to study the method with simpler structure and lower complexity.
Author Contributions
Conceptualization, S.L. and Z.Z.; methodology, Z.C. (Zibin Chen) and J.H.; validation, X.C.; writing—original draft preparation, S.L.; writing—review and editing, J.H.; supervision, Z.C. (Zhiwen Chen). All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data are contained within the article.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Gawde, S.; Patil, S.; Kumar, S.; Kamat, P.; Kotecha, K.; Abraham, A. Multi-fault diagnosis of Industrial Rotating Machines using Data-driven approach: A review of two decades of research. Eng. Appl. Artif. Intell. 2023, 123, 106139. [Google Scholar] [CrossRef]
- Zhou, D.; Zhao, Y.; Wang, Z.; He, X.; Gao, M. Review on Diagnosis Techniques for Intermittent Faults in Dynamic Systems. IEEE Trans. Ind. Electron. 2020, 67, 2337–2347. [Google Scholar] [CrossRef]
- Liu, D.; Cui, L.; Cheng, W. A review on deep learning in planetary gearbox health state recognition: Methods, applications, and dataset publication. Meas. Sci. Technol. 2024, 35, 012002. [Google Scholar] [CrossRef]
- Brito, L.C.; Susto, G.A.; Brito, J.N.; Duarte, M.A.V. An explainable artificial intelligence approach for unsupervised fault detection and diagnosis in rotating machinery. Mech. Syst. Signal Process. 2022, 163, 108105. [Google Scholar] [CrossRef]
- Zhao, C.; Shen, W. Adversarial Mutual Information-Guided Single Domain Generalization Network for Intelligent Fault Diagnosis. IEEE Trans. Ind. Inform. 2023, 19, 2909–2918. [Google Scholar] [CrossRef]
- Zhang, K.; Tang, B.; Deng, L.; Liu, X. A hybrid attention improved ResNet based fault diagnosis method of wind turbines gearbox. Measurement 2021, 179, 109491. [Google Scholar] [CrossRef]
- Shao, H.; Jiang, H.; Zhang, H.; Liang, T. Electric Locomotive Bearing Fault Diagnosis Using a Novel Convolutional Deep Belief Network. IEEE Trans. Ind. Electron. 2018, 65, 2727–2736. [Google Scholar] [CrossRef]
- He, J.; Li, X.; Chen, Y.; Chen, D.; Guo, J.; Zhou, Y. Deep Transfer Learning Method Based on 1D-CNN for Bearing Fault Diagnosis. Shock Vib. 2021, 2021, 6687331. [Google Scholar] [CrossRef]
- Shao, H.; Xia, M.; Wan, J.; de Silva, C.W. Modified Stacked Autoencoder Using Adaptive Morlet Wavelet for Intelligent Fault Diagnosis of Rotating Machinery. IEEE-ASME Trans. Mechatron. 2022, 27, 24–33. [Google Scholar] [CrossRef]
- Nie, X.; Xie, G. A Fault Diagnosis Framework Insensitive to Noisy Labels Based on Recurrent Neural Network. IEEE Sens. J. 2021, 21, 2676–2686. [Google Scholar] [CrossRef]
- Wang, J.; Liu, K.; Zhang, Y.; Leng, B.; Lu, J. Recent advances of few-shot learning methods and applications. Sci. China Technol. Sci. 2023, 66, 920–944. [Google Scholar] [CrossRef]
- Liang, X.; Zhang, M.; Feng, G.; Wang, D.; Xu, Y.; Gu, F. Few-Shot Learning Approaches for Fault Diagnosis Using Vibration Data: A Comprehensive Review. Sustainability 2023, 15, 14975. [Google Scholar] [CrossRef]
- Zhan, Z.; Zhou, J.; Xu, B. Fabric defect classification using prototypical network of few-shot learning algorithm. Comput. Ind. 2022, 138, 103628. [Google Scholar] [CrossRef]
- Su, Z.; Zhang, X.; Wang, G.; Wang, S.; Luo, M.; Wang, X. The Semisupervised Weighted Centroid Prototype Network for Fault Diagnosis of Wind Turbine Gearbox. IEEE-ASME Trans. Mechatron. 2023, 29, 1567–1578. [Google Scholar] [CrossRef]
- Gou, Y.; Fu, X. Broadband Electrical Impedance Matching of Transmitter Transducer for Acoustic Logging While Drilling Tool. IEEE Sens. J. 2022, 22, 1382–1390. [Google Scholar] [CrossRef]
- Peng, Q.; Wang, W.; Liu, H.; Wang, Y.; Xu, H.; Shao, M. Towards comprehensive expert finding with a hierarchical matching network. Knowl.-Based Syst. 2022, 257, 109933. [Google Scholar] [CrossRef]
- Zhang, H.; Xing, W.; Yang, Y.; Li, Y.; Yuan, D. SiamST: Siamese network with spatio-temporal awareness for object tracking. Inf. Sci. 2023, 634, 122–139. [Google Scholar] [CrossRef]
- Chiplunkar, R.; Huang, B. Siamese Neural Network-Based Supervised Slow Feature Extraction for Soft Sensor Application. IEEE Trans. Ind. Electron. 2021, 68, 8953–8962. [Google Scholar] [CrossRef]
- Chowdhury, R.R.; Bathula, D.R. Influential Prototypical Networks for Few Shot Learning: A Dermatological Case Study. arXiv 2021, arXiv:2111.00698. [Google Scholar]
- Wang, Z.; Shen, H.; Xiong, W.; Zhang, X.; Hou, J. Method for Diagnosing Bearing Faults in Electromechanical Equipment Based on Improved Prototypical Networks. Sensors 2023, 23, 4485. [Google Scholar] [CrossRef]
- Gao, T.; Han, X.; Liu, Z.; Sun, M. Hybrid attention-based prototypical networks for noisy few-shot relation classification. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 6407–6414. [Google Scholar]
- Ye, H.J.; Ming, L.; Zhan, D.C.; Chao, W.L. Few-Shot Learning With a Strong Teacher. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 1425–1440. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Y.; Zhang, T.; Li, J.; Tian, Y. Dual Adaptive Representation Alignment for Cross-Domain Few-Shot Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 11720–11732. [Google Scholar] [CrossRef] [PubMed]
- He, J.; Zhu, Z.; Fan, X.; Chen, Y.; Liu, S.; Chen, D. Few-Shot Learning for Fault Diagnosis: Semi-Supervised Prototypical Network with Pseudo-Labels. Symmetry 2022, 14, 1489. [Google Scholar] [CrossRef]
- Fan, C.; Liu, X.; Xue, P.; Wang, J. Statistical characterization of semi-supervised neural networks for fault detection and diagnosis of air handling units. Energy Build. 2021, 234, 110733. [Google Scholar] [CrossRef]
- Zhang, L.; Yang, L.; Ma, T.; Shen, F.; Cai, Y.; Zhou, C. A self-training semi-supervised machine learning method for predictive mapping of soil classes with limited sample data. Geoderma 2021, 384, 114809. [Google Scholar] [CrossRef]
- Zhang, X.; Su, Z.; Hu, X.; Han, Y.; Wang, S. Semisupervised Momentum Prototype Network for Gearbox Fault Diagnosis Under Limited Labeled Samples. IEEE Trans. Ind. Inform. 2022, 18, 6203–6213. [Google Scholar] [CrossRef]
- Zhou, F.; Xu, W.; Wang, C.; Hu, X.; Wang, T. A Semi-Supervised Federated Learning Fault Diagnosis Method Based on Adaptive Class Prototype Points for Data Suffered by High Missing Rate. J. Intell. Robot. Syst. 2023, 109, 93. [Google Scholar] [CrossRef]
- Che, C.C.; Wang, H.W.; Xiong, M.L.; Ni, X.M. Few-shot fault diagnosis of rolling bearing under variable working conditions based on ensemble meta-learning. Digit. Signal Process. 2022, 131, 103777. [Google Scholar] [CrossRef]
- Kang, S.; Liang, X.; Wang, Y.; Wang, Q.; Qiao, C.; Mikulovich, V.I. Few-shot rolling bearing fault classification method based on improved relation network. Meas. Sci. Technol. 2022, 33, 125020. [Google Scholar] [CrossRef]
- Wang, S.; Wang, D.; Kong, D.; Wang, J.; Li, W.; Zhou, S. Few-Shot Rolling Bearing Fault Diagnosis with Metric-Based Meta Learning. Sensors 2020, 20, 6437. [Google Scholar] [CrossRef]
- Wang, X.; Liang, J.; Xiao, Y.; Wang, W. Prototypical Concept Representation. IEEE Trans. Knowl. Data Eng. 2023, 35, 7357–7370. [Google Scholar] [CrossRef]
- Tian, X.M.; Chen, L.; Zhang, X.L.; Chen, E.R. Improved Prototypical Network Model for Forest Species Classification in Complex Stand. Remote Sens. 2020, 12, 3839. [Google Scholar] [CrossRef]
- Wang, R. AdaBoost for Feature Selection, Classification and Its Relation with SVM, A Review. Phys. Procedia 2012, 25, 800–807. [Google Scholar] [CrossRef]
- Roy, A.G.; Navab, N.; Wachinger, C. Recalibrating Fully Convolutional Networks With Spatial and Channel Squeeze and Excitation Blocks. IEEE Trans. Med. Imaging 2019, 38, 540–549. [Google Scholar] [CrossRef]
- Rizve, M.N.; Duarte, K.; Rawat, Y.S.; Shah, M. In Defense of Pseudo-Labeling: An Uncertainty-Aware Pseudo-label Selection Framework for Semi-Supervised Learning. arXiv 2021, arXiv:2101.06329. [Google Scholar]
- Islam, M.F.; Zabeen, S.; Islam, M.A.; Rahman, F.B.; Ahmed, A.; Karim, D.Z.; Rasel, A.A.; Manab, M.A. How certain are tansformers in image classification: Uncertainty analysis with monte carlo dropout. In Proceedings of the Fifteenth International Conference on Machine Vision, Rome, Italy, 18–20 November 2022; Volume 12701. [Google Scholar]
- Smith, W.A.; Randall, R.B. Rolling element bearing diagnostics using the Case Western Reserve University data: A benchmark study. Mech. Syst. Signal Process. 2015, 64–65, 100–131. [Google Scholar] [CrossRef]
- Zhang, J.; Zhang, Q.; He, X.; Sun, G.; Zhou, D. Compound-Fault Diagnosis of Rotating Machinery: A Fused Imbalance Learning Method. IEEE Trans. Control. Syst. Technol. 2021, 29, 1462–1474. [Google Scholar] [CrossRef]
- Qiu, H.; Lee, J.; Lin, J.; Yu, G. Wavelet filter-based weak signature detection method and its application on rolling element bearing prognostics. J. Sound Vib. 2006, 289, 1066–1090. [Google Scholar] [CrossRef]
- Zhu, J.; Yi, X.; Guan, N.; Cheng, H. Robust Re-weighting Prototypical Networks for Few-Shot Classification. In Proceedings of the 2020 6th International Conference on Robotics and Artificial Intelligence, Singapore, 20–22 November 2020. [Google Scholar]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).