




LNMVSNet: A Low-Noise Multi-View Stereo Depth Inference Method for 3D Reconstruction


Abstract
:1. Introduction
- We propose LNMVSNet, a network with low sensitivity to noise, through the introduction of a multi-level depth feature fusion mechanism and a novel attention filtering mechanism. These innovations effectively utilize the varying sensitivities of multi-level features to noise and pixel weight scoring, resulting in noise being less sensitive in the preliminary step of depth estimation in MVS reconstruction.
- Our LNMVSNet achieved exceptional results on multiple benchmark datasets, yielding smooth and low-noise depth estimates as well as reconstructed point clouds. Additionally, we analyzed the impact of noise on reconstruction evaluation metrics through qualitative experimental results.
2. Literature Review
2.1. Traditional Multi-View Stereo Methods
2.2. Learning-Based Multi-View Stereo Method
3. Motivation and Contribution
- We incorporated a mechanism for the fusion of depth map features at different scales, effectively diminishing the influence of noise on the final reconstruction results. Features at varying scales have their respective advantages in handling noise; by integrating these features, we achieve complementarity and reduce error propagation, making the overall reconstruction process more robust.
- During the cost volume regularization process, we utilized an attention-based filter with a noise-aware mechanism for selecting and emphasizing important features while suppressing irrelevant or noisy components. Through this weighted allocation, the network can focus more on significant signals, thereby reducing the impact of noise.
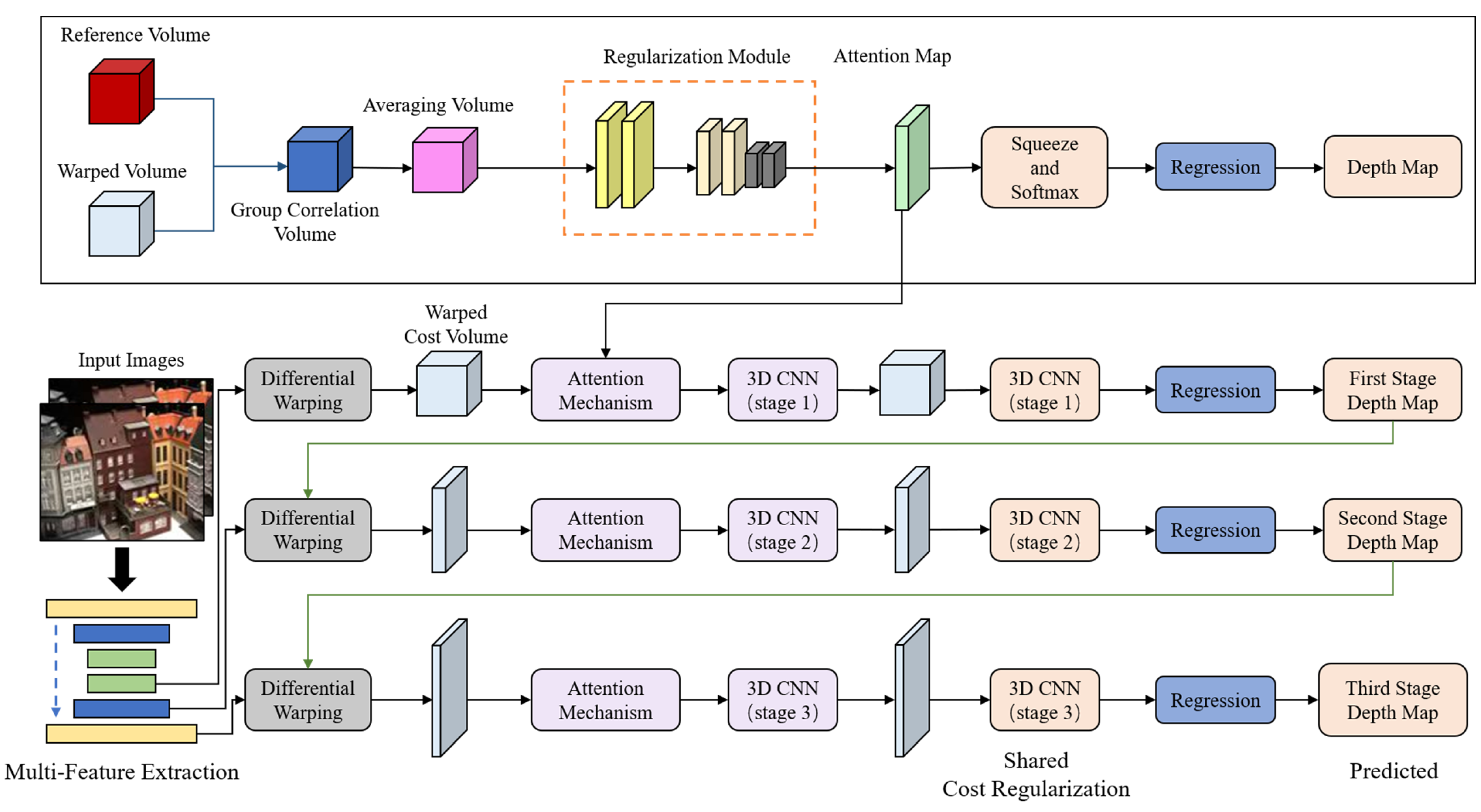
4. Method
4.1. Cascaded Structure
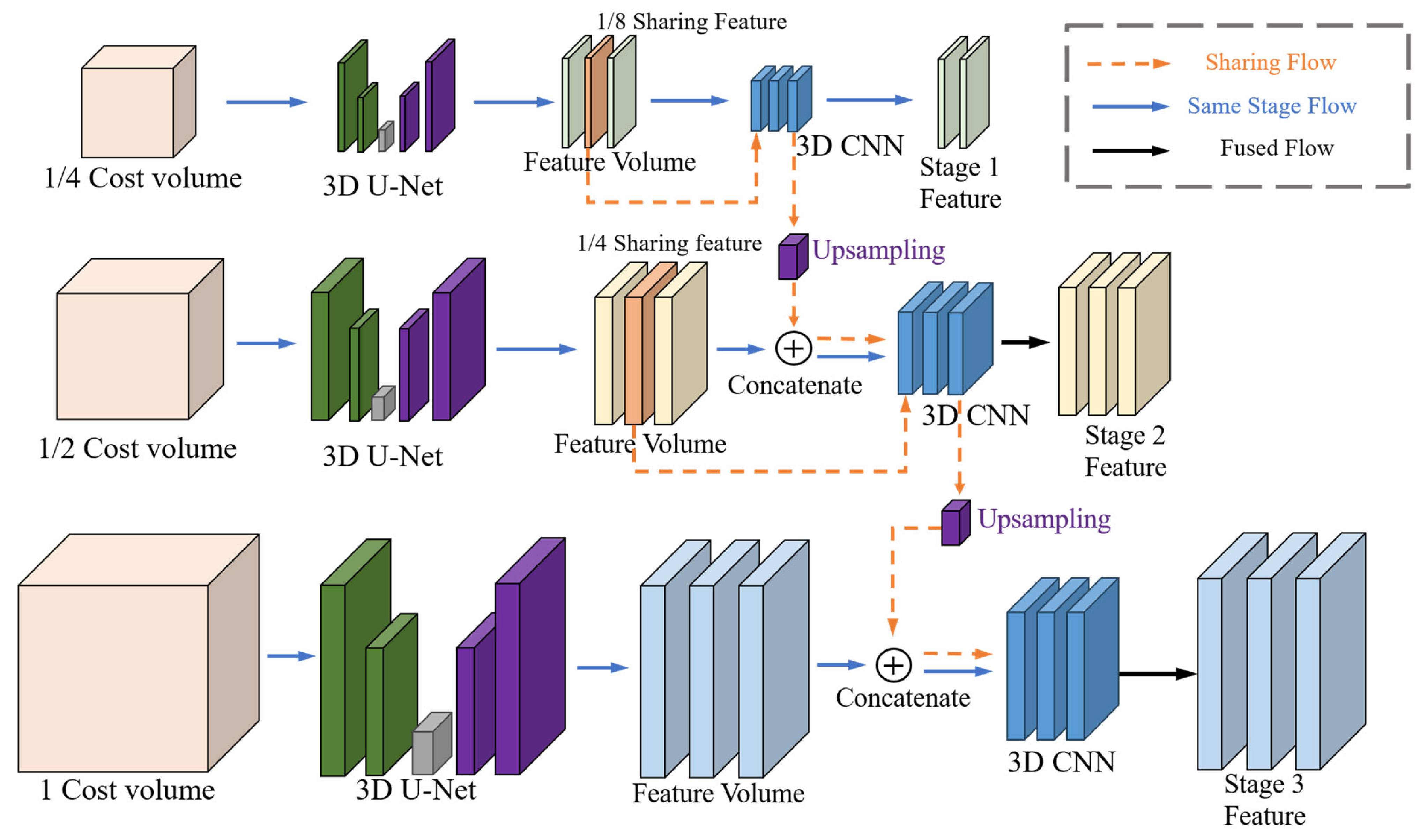
4.2. Depth Feature Sharing
4.3. Cost Attention Mechanism
4.4. Depth Map Filtering and Fusion
5. Experiment
5.1. Dataset Description
5.2. Quantitative DTU Results
5.3. Tank and Temple Quantitative Results
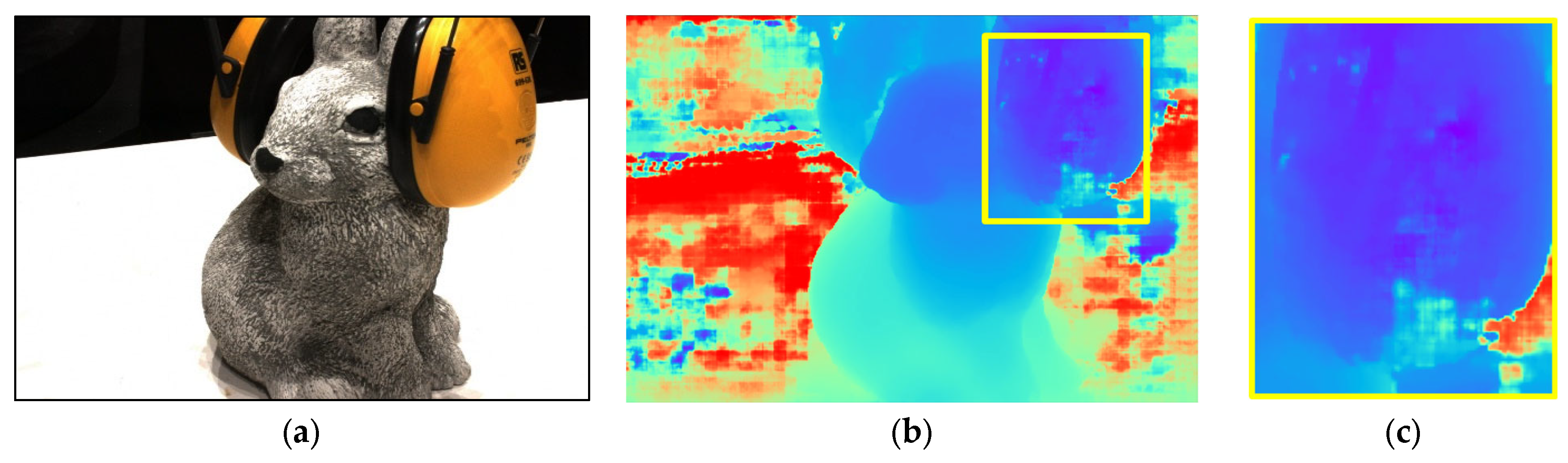
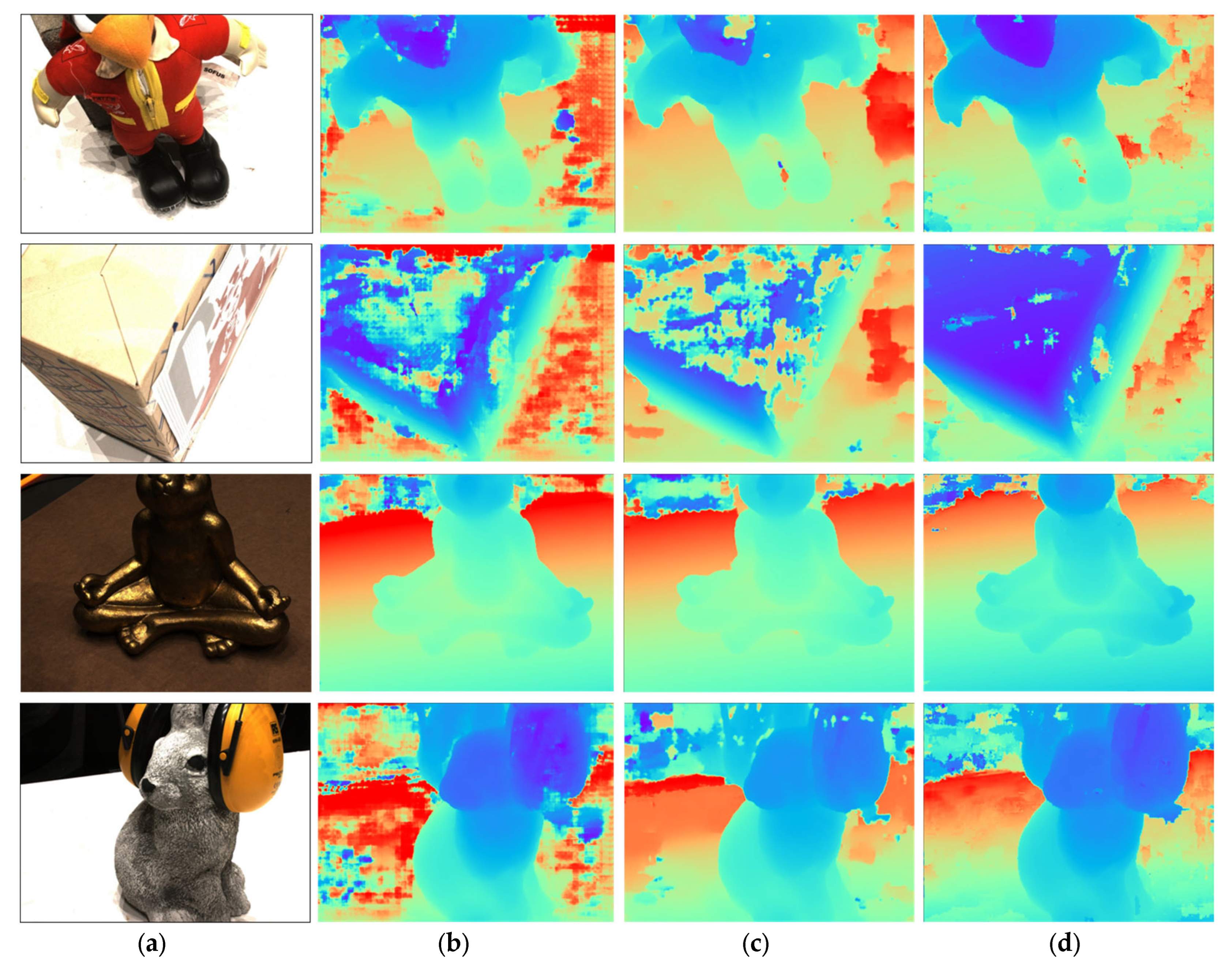
6. Qualitative Analysis
7. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chen, X.; Ma, H.; Wan, J.; Li, B.; Xia, T. Multi-view 3D object detection network for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6526–6534. [Google Scholar] [CrossRef]
- Schmid, K.; Hirschmüller, H.; Dömel, A.; Grixa, I.; Suppa, M.; Hirzinger, G. View planning for multi-view stereo 3D reconstruction using an autonomous multicopter. J. Intell. Robot. Syst. 2012, 65, 309–323. [Google Scholar] [CrossRef]
- Bae, G.; Budvytis, I.; Yeung, C.K.; Cipolla, R. Deep multi-view stereo for dense 3D reconstruction from monocular endoscopic video. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Lima, Peru, 4–8 October 2020; Springer International Publishing: Cham, Switzerland, 2020; pp. 774–783. [Google Scholar] [CrossRef]
- He, P.; Hu, D.; Hu, Y. Deployment of a deep-learning based multi-view stereo approach for measurement of ship shell plates. Ocean Eng. 2022, 260, 111968. [Google Scholar] [CrossRef]
- Muzzupappa, M.; Gallo, A.; Spadafora, F.; Manfredi, F.; Bruno, F.; Lamarca, A. 3D reconstruction of an outdoor archaeological site through a multi-view stereo technique. In Proceedings of the Digital Heritage International Congress (DigitalHeritage), Marseille, France, 28 October–1 November 2013; Volume 1, pp. 169–176. [Google Scholar] [CrossRef]
- Prokopetc, K.; Dupont, R. Towards dense 3d reconstruction for mixed reality in healthcare: Classical multi-view stereo vs. deep learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27–28 October 2019. [Google Scholar] [CrossRef]
- Jang, M.; Lee, S.; Kang, J.; Lee, S. Technical consideration towards robust 3D reconstruction with multi-view active stereo sensors. Sensors 2022, 22, 4142. [Google Scholar] [CrossRef] [PubMed]
- Campbell, N.D.; Vogiatzis, G.; Hernández, C.; Cipolla, R. Using multiple hypotheses to improve depth-maps for multi-view stereo. In Computer Vision–ECCV 2008, Proceedings of the 10th European Conference on Computer Vision, Marseille, France, 12–18 October 2008, Part I 10; Springer: Berlin/Heidelberg, Germany, 2008; pp. 766–779. [Google Scholar] [CrossRef]
- Xu, Q.; Tao, W. Multi-scale geometric consistency guided multi-view stereo. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020. [Google Scholar] [CrossRef]
- Aanæs, H.; Jensen, R.R.; Vogiatzis, G.; Tola, E.; Dahl, A.B. Large-scale data for multiple-view stereopsis. Int. J. Comput. Vis. 2016, 120, 153–168. [Google Scholar] [CrossRef]
- Knapitsch, A.; Park, J.; Zhou, Q.-Y.; Koltun, V. Tanks and temples: Benchmarking large-scale scene reconstruction. ACM Trans. Graph. 2017, 36, 78. [Google Scholar] [CrossRef]
- Kutulakos, K.N.; Seitz, S.M. A theory of shape by space carving. Int. J. Comput. Vis. 2000, 38, 199–218. [Google Scholar] [CrossRef]
- Seitz, S.M.; Dyer, C.R. Photorealistic scene reconstruction by voxel coloring. Int. J. Comput. Vis. 1999, 35, 151–173. [Google Scholar] [CrossRef]
- Lhuillier, M.; Quan, L. A quasi-dense approach to surface reconstruction from uncalibrated images. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 418–433. [Google Scholar] [CrossRef] [PubMed]
- Furukawa, Y.; Ponce, J. Accurate, dense, and robust multi-view stereopsis. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 1362–1376. [Google Scholar] [CrossRef] [PubMed]
- Hiep, V.H.; Keriven, R.; Labatut, P.; Pons, J.-P. Towards high-resolution large-scale multi-view stereo. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009; pp. 1430–1437. [Google Scholar] [CrossRef]
- Lafarge, F.; Keriven, R.; Brédif, M. Insertion of 3D-primitives in mesh-based representations: Towards compact models preserving the details. IEEE Trans. Image Process. 2010, 19, 1683–1694. [Google Scholar] [CrossRef] [PubMed]
- Li, Z.; Wang, K.; Zuo, W.; Meng, D.; Zhang, L. Detail-preserving and content-aware variational multi-view stereo reconstruction. IEEE Trans. Image Process. 2015, 25, 864–877. [Google Scholar] [CrossRef] [PubMed]
- Galliani, S.; Lasinger, K.; Schindler, K. Massively parallel multiview stereopsis by surface normal diffusion. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 873–881. [Google Scholar] [CrossRef]
- Ji, M.; Gall, J.; Zheng, H.; Liu, Y.; Fang, L. Surfacenet: An end-to-end 3D neural network for multiview stereopsis. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2307–2315. [Google Scholar]
- Kar, A.; Häne, C.; Malik, J. Learning a multi-view stereo machine. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar] [CrossRef]
- Yao, Y.; Luo, Z.; Li, S.; Fang, T.; Quan, L. MVSNet: Depth inference for unstructured multi-view stereo. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 767–783. [Google Scholar] [CrossRef]
- Gu, X.; Fan, Z.; Zhu, S.; Dai, Z.; Tan, F.; Tan, P. Cascade cost volume for high-resolution multi-view stereo and stereo matching. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 2495–2504. [Google Scholar] [CrossRef]
- Yang, J.; Mao, W.; Alvarez, J.M.; Liu, M. Cost volume pyramid-based depth inference for multi-view stereo. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 4877–4886. [Google Scholar] [CrossRef]
- Ma, X.; Gong, Y.; Wang, Q.; Huang, J.; Chen, L.; Yu, F. EPP-MVSNet: Epipolar-assembling based depth prediction for multi-view stereo. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual Event, 11–17 October 2021; pp. 5732–5740. [Google Scholar] [CrossRef]
- Wang, F.; Galliani, S.; Vogel, C.; Speciale, P.; Pollefeys, M. Patchmatchnet: Learned multi-view patchmatch stereo. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 14194–14203. [Google Scholar] [CrossRef]
- Yao, Y.; Luo, Z.; Li, S.; Shen, T.; Fang, T.; Quan, L. Recurrent MVSNet for high-resolution multi-view stereo depth inference. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5525–5534. [Google Scholar] [CrossRef]
- Yan, J.; Wei, Z.; Yi, H.; Ding, M.; Zhang, R.; Chen, Y.; Wang, G.; Tai, Y.-W. Dense hybrid recurrent multi-view stereo net with dynamic consistency checking. In Proceedings of the 16th European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 674–689. [Google Scholar]
- Su, W.; Tao, W. Efficient Edge-Preserving Multi-View Stereo Network for Depth Estimation. AAAI Conf. Artif. Intell. 2023, 37, 2348–2356. [Google Scholar] [CrossRef]
- Liu, F.; Shen, C.; Lin, G. Deep convolutional neural fields for depth estimation from a single image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5162–5170. [Google Scholar] [CrossRef]
- Walz, S.; Gruber, T.; Ritter, W.; Dietmayer, K. Uncertainty depth estimation with gated images for 3D reconstruction. In Proceedings of the 2020 IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC), Rhodes, Greece, 20–23 September 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Masoumian, A.; Rashwan, H.A.; Cristiano, J.; Asif, M.S.; Puig, D. Monocular depth estimation using deep learning: A review. Sensors 2022, 22, 5353. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, N.A.D.; Huynh, H.N.; Tran, T.N. Improvement of the Performance of Scattering Suppression and Absorbing Structure Depth Estimation on Transillumination Image by Deep Learning. Appl. Sci. 2023, 13, 10047. [Google Scholar] [CrossRef]
- Zhao, Q.; Deng, Y.; Yang, Y.; Li, Y.; Yuan, D. NTPP-MVSNet: Multi-View Stereo Network Based on Neighboring Tangent Plane Propagation. Appl. Sci. 2023, 13, 8388. [Google Scholar] [CrossRef]
- Çiçek, Ö.; Abdulkadir, A.; Lienkamp, S.S.; Brox, T.; Ronneberger, O. 3D U-Net: Learning dense volumetric segmentation from sparse annotation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2016; Springer International Publishing: Berlin/Heidelberg, Germany, 2016; Volume 19, pp. 424–432. [Google Scholar] [CrossRef]
- Guo, X.; Yang, K.; Yang, W.; Wang, X.; Li, H. Group-wise correlation stereo network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3273–3282. [Google Scholar] [CrossRef]
- Le, A.V.; Jung, S.W.; Won, C.S. Directional joint bilateral filter for depth images. Sensors 2014, 14, 11362–11378. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Han, D.; Wang, X.; Yi, P.; Yan, L.; Li, X. Multi-sensor medical-image fusion technique based on embedding bilateral filter in least squares and salient detection. Sensors 2023, 23, 3490. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Li, S.; Luo, Z.; Fang, T.; Yao, Y. Vis-MVSNet: Visibility-aware multi-view stereo network. Int. J. Comput. Vis. 2023, 131, 199–214. [Google Scholar] [CrossRef]
- Xue, Y.; Chen, J.; Wan, W.; Huang, Y.; Yu, C.; Li, T.; Bao, J. MVSCRF: Learning multi-view stereo with conditional random fields. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 4312–4321. [Google Scholar] [CrossRef]
- Liu, H.; Heynderickx, I. A perceptually relevant no-reference blockiness metric based on local image characteristics. EURASIP J. Adv. Signal Process. 2009, 2009, 263540. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Acc. (mm) | Comp. (mm) | Overall 1 |
|---|---|---|---|
| Colmap [8] | 0.400 | 0.664 | 0.532 |
| Tola [10] | 0.342 | 1.190 | 0.766 |
| Furu [15] | 0.612 | 0.939 | 0.775 |
| Gipuma [19] | 0.283 | 0.873 | 0.578 |
| Colmap | 0.400 | 0.644 | 0.532 |
| MVSNet [22] | 0.456 | 0.646 | 0.551 |
| CasMVSNet [23] | 0.325 | 0.385 | 0.355 |
| EPPNet [24,25] | 0.413 | 0.296 | 0.355 |
| CVP-Net [25] | 0.296 | 0.406 | 0.351 |
| PatchNet [26] | 0.427 | 0.277 | 0.352 |
| R-MVSNet [27] | 0.383 | 0.452 | 0.417 |
| EP-Net [29] | 0.299 | 0.323 | 0.311 |
| LNMVSNet | 0.305 | 0.311 | 0.308 |
| Method | Family | Francis | Horse | Lighthouse | M60 | Panther | Playground | Train | Mean 1 |
|---|---|---|---|---|---|---|---|---|---|
| COLMAP [8] | 50.41 | 22.25 | 26.63 | 56.43 | 44.83 | 46.97 | 48.53 | 42.04 | 42.14 |
| ACMM [9] | 69.24 | 51.45 | 46.97 | 63.20 | 55.07 | 57.64 | 60.08 | 54.48 | 57.27 |
| PatchNet [26] | 66.99 | 52.64 | 43.24 | 54.87 | 52.87 | 49.54 | 54.21 | 50.81 | 53.15 |
| R-MVSNet [27] | 73.01 | 54.46 | 43.42 | 43.88 | 46.80 | 46.69 | 50.87 | 54.25 | 50.55 |
| CasMVSNet [23] | 76.37 | 58.45 | 46.26 | 55.81 | 56.11 | 54.06 | 58.18 | 49.51 | 56.84 |
| Vis-MVSNet [39] | 77.40 | 60.23 | 47.07 | 63.44 | 62.21 | 57.28 | 60.54 | 52.07 | 60.03 |
| MVSCRF [40] | 59.83 | 30.60 | 29.93 | 51.15 | 50.61 | 51.45 | 52.60 | 39.68 | 45.73 |
| LNMVSNet | 76.77 | 59.95 | 47.92 | 64.17 | 58.39 | 58.06 | 60.27 | 57.96 | 60.44 |
| Method | Resolution | Mean Error 1 | <2 mm 2 | <4 mm | <8 mm |
|---|---|---|---|---|---|
| MVSNet | 1/4 | 11.63 | 63.1% | 79.95% | 87.86% |
| CasMVSNet | 1 | 8.30 | 82.6% | 86.70% | 90.10% |
| LNMVSNet | 1 | 6.82 | 77.67% | 85.65% | 91.8% |
| Methods | Blockiness Factor 1 |
|---|---|
| MVSNet | 0.76 |
| CasMVSNet | 0.61 |
| LNMVSNetap | 0.34 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luo, W.; Lu, Z.; Liao, Q. LNMVSNet: A Low-Noise Multi-View Stereo Depth Inference Method for 3D Reconstruction. Sensors 2024, 24, 2400. https://doi.org/10.3390/s24082400
Luo W, Lu Z, Liao Q. LNMVSNet: A Low-Noise Multi-View Stereo Depth Inference Method for 3D Reconstruction. Sensors. 2024; 24(8):2400. https://doi.org/10.3390/s24082400
Chicago/Turabian StyleLuo, Weiming, Zongqing Lu, and Qingmin Liao. 2024. "LNMVSNet: A Low-Noise Multi-View Stereo Depth Inference Method for 3D Reconstruction" Sensors 24, no. 8: 2400. https://doi.org/10.3390/s24082400