



FusionVision: A Comprehensive Approach of 3D Object Reconstruction and Segmentation from RGB-D Cameras Using YOLO and Fast Segment Anything

 ,
,  and
and
Abstract
1. Introduction
- Improved object detection and tracking [36]: The depth information provided by RGB-D cameras allows for more accurate object detection and tracking, even in complex environments with occlusions and varying lighting conditions.
2. Related Work
- The system starts by obtaining 3D point-clouds from a single RGB-D camera along with the RGB stream.
- The 2D object detection algorithm is used to detect and localize objects in the RGB images. This provides useful prior information about the objects, including their position, width, and height.
- The information from the 2D object detection is then used to generate 3D frustums. A frustum is a pyramid-shaped volume that represents the possible location of an object in 3D space based on its 2D bounding box.
- The generated frustums are fed into the PointNets algorithm, which performs instance segmentation and predicts the 3D bounding box of each object within the frustum.
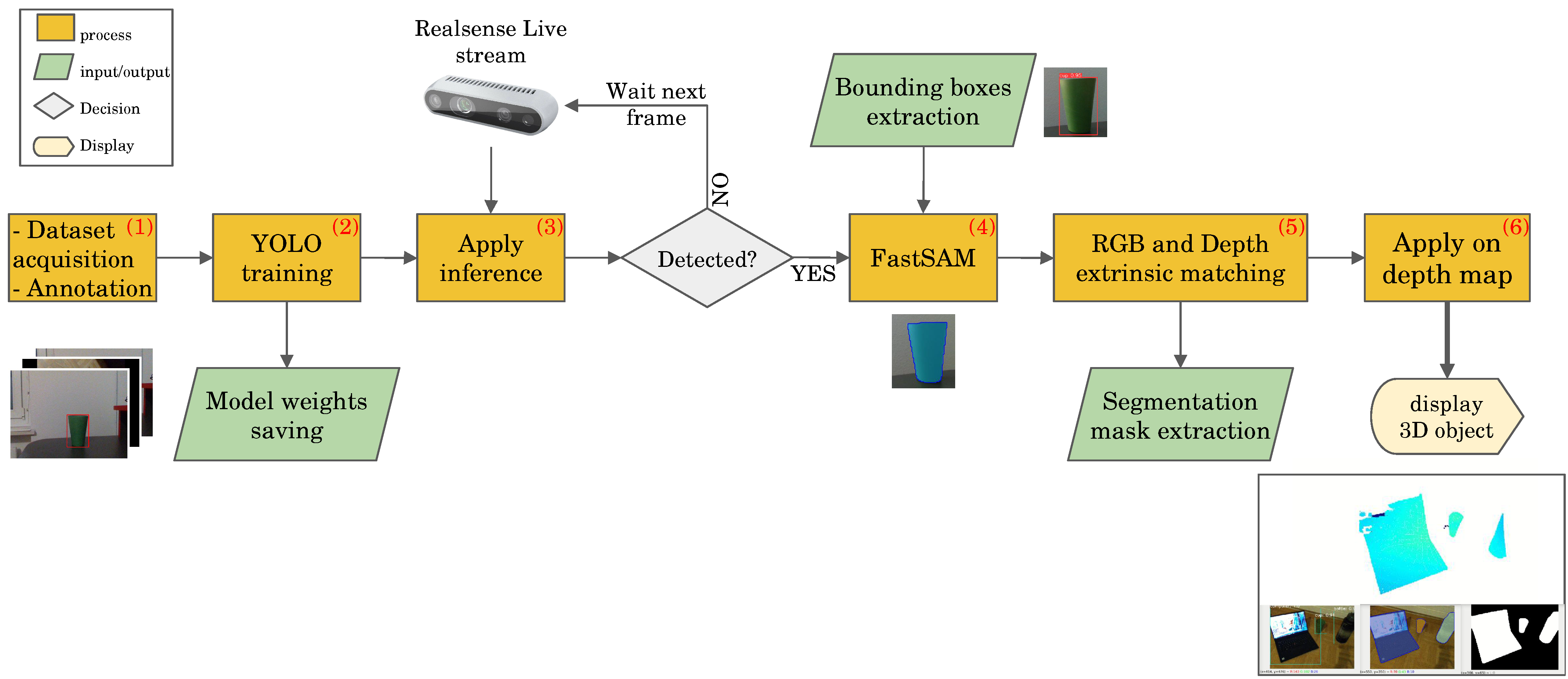
3. FusionVision Pipeline
- Data acquisition and Annotation: This initial phase involves obtaining images suitable for training the object detection model. This image collection can include single- or multi-class scenarios. As part of preparing the acquired data, splitting into separate subsets designated for training and testing purposes is required. If the object of interest is within the 80 classes of Microsoft COCO (Common Objects in Context) dataset [50], this step may be optional, allowing the utilization of existing pre-trained models. Otherwise, if the special object is to be detected, or object shape is uncommon or different from the ones in the datasets, this step is required.
- YOLO model training: Following data acquisition, the YOLO model undergoes training to enhance its ability to detect specific objects. This process involves optimizing the model’s parameters based on the acquired dataset.
- Apply model inference: Upon successful training, the YOLO model is deployed on the live stream of the RGB sensor from the RGB-D camera to detect objects in real-time. This step involves applying the trained model to identify objects within the camera’s field of view.
- FastSAM application: If any object is detected in the RGB stream, the estimated bounding boxes serve as input for the FastSAM algorithm, facilitating the extraction of object masks. This step refines the object segmentation process by leveraging FastSAM’s capabilities.
- RGB and Depth matching: The estimated mask generated from the RGB sensor is aligned with the depth map of the RGB-D camera. This alignment is achieved through the utilization of known intrinsic and extrinsic matrices, enhancing the accuracy of subsequent 3D object localization.
- Application of 3D reconstruction from depth map: Leveraging the aligned mask and depth information, a 3D point-cloud is generated to facilitate the real-time localization and reconstruction of the detected object in three dimensions. This final step results in an isolated representation of the object in the 3D space.
3.1. Data Acquisition
3.2. YOLO Training
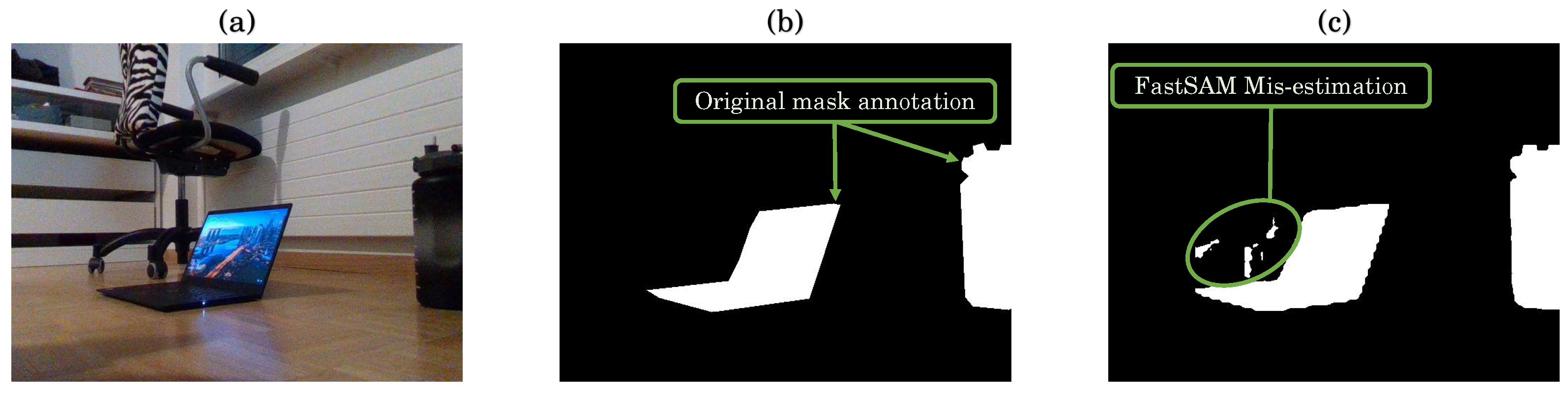
3.3. FastSAM Deployment
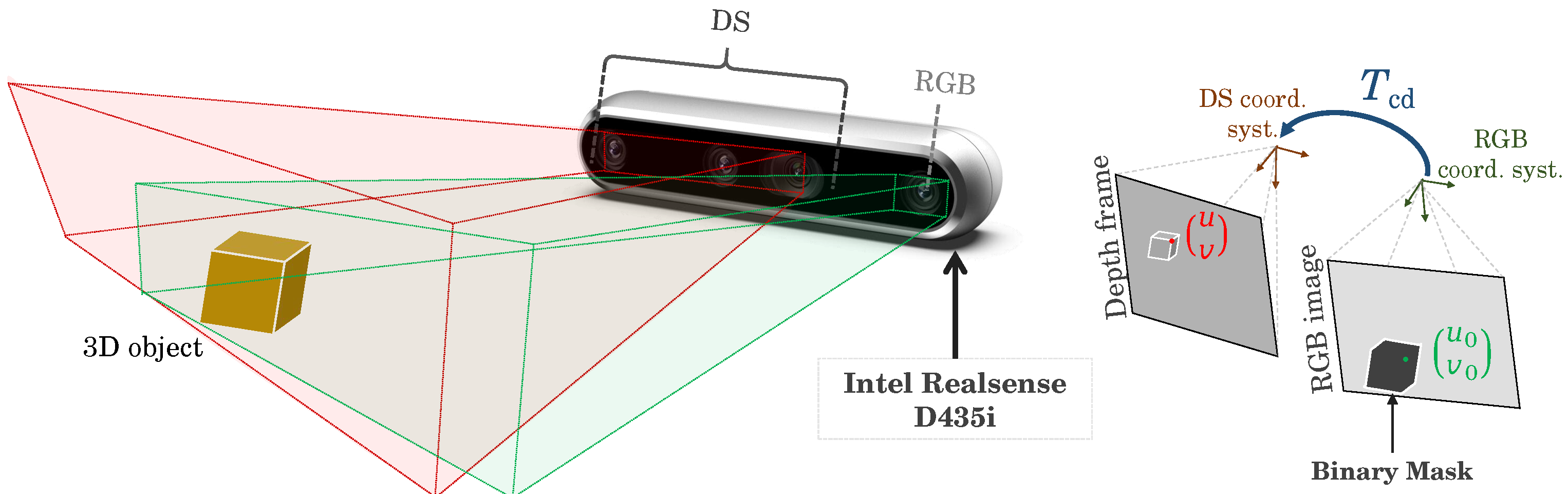
3.4. RGB and Depth Matching
- represent the depth value and pixel coordinates in the aligned depth image;
- is the depth value and pixel coordinates in the original depth image;
- is the RGB camera intrinsic matrices;
- is the DS intrinsic matrices;
- represents the rigid transformation between RGB and DS.
3.5. 3D Reconstruction of the Physical Object
4. Results and Discussion
4.1. Setup Configuration
4.2. Data Acquisition and Annotation
4.3. YOLO Training and FastSAM Deployment
4.3.1. Model Training and Deployment
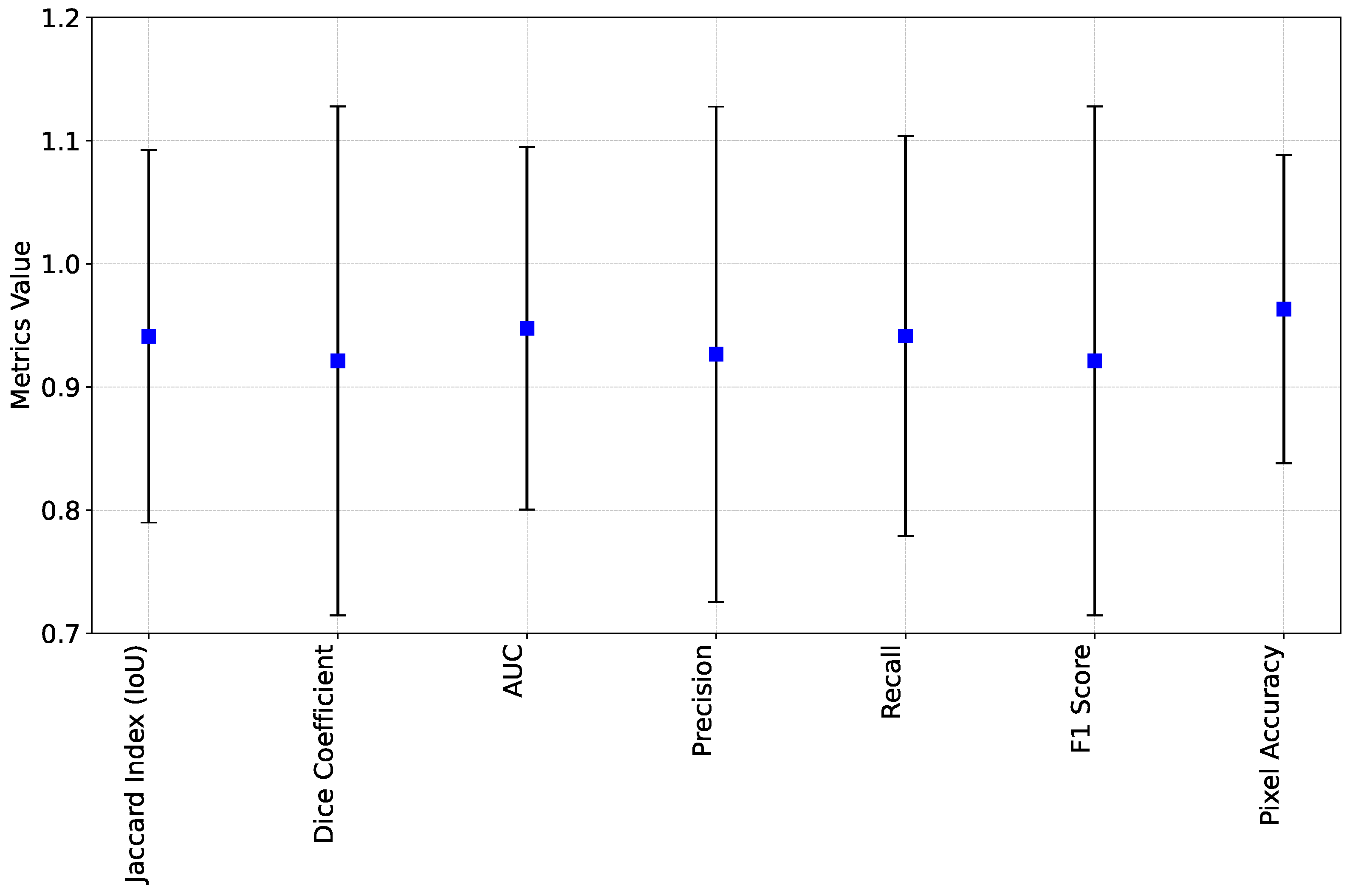
4.3.2. Quantitative Analysis
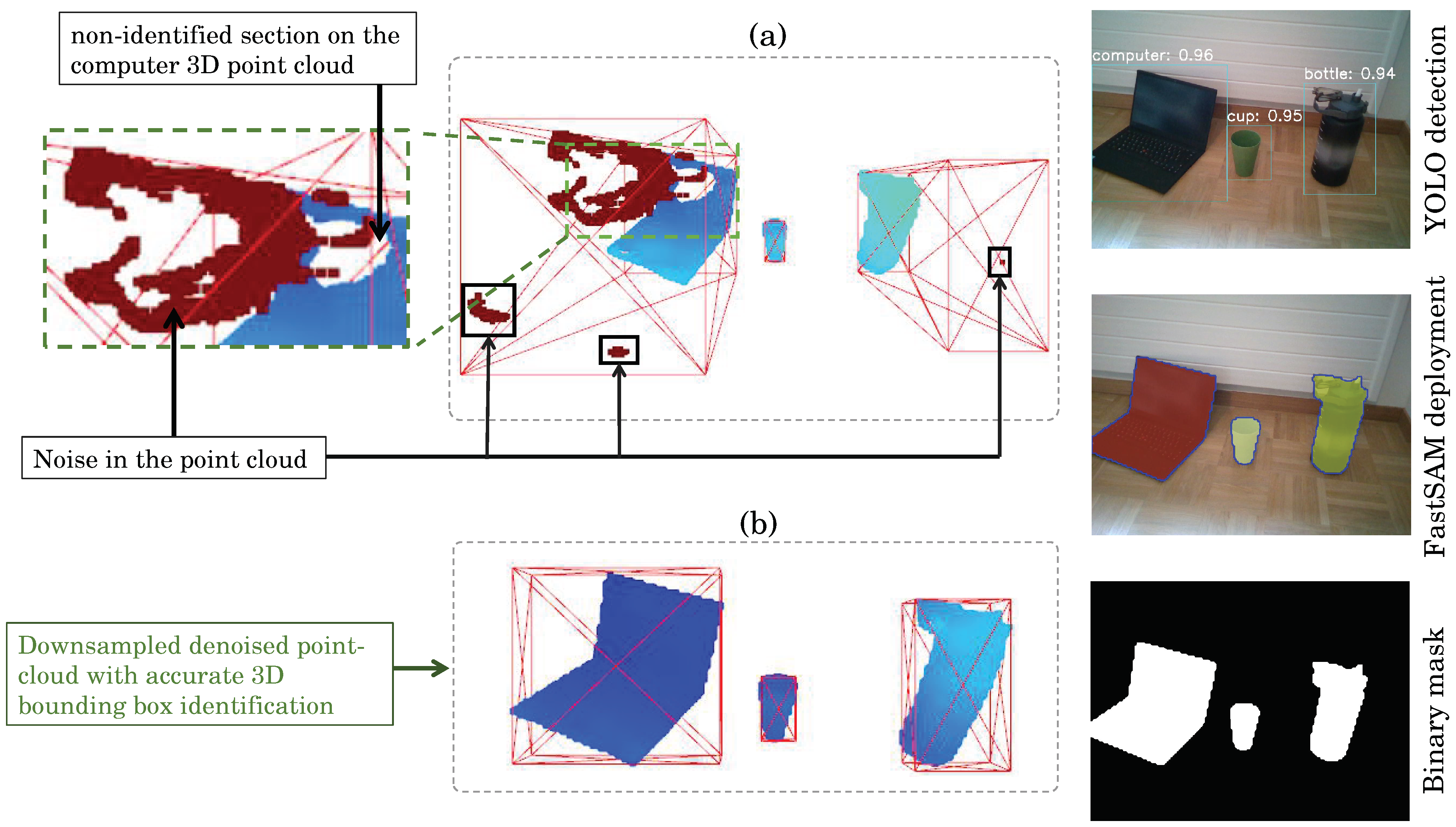
4.4. 3D Object Reconstruction and Discussion
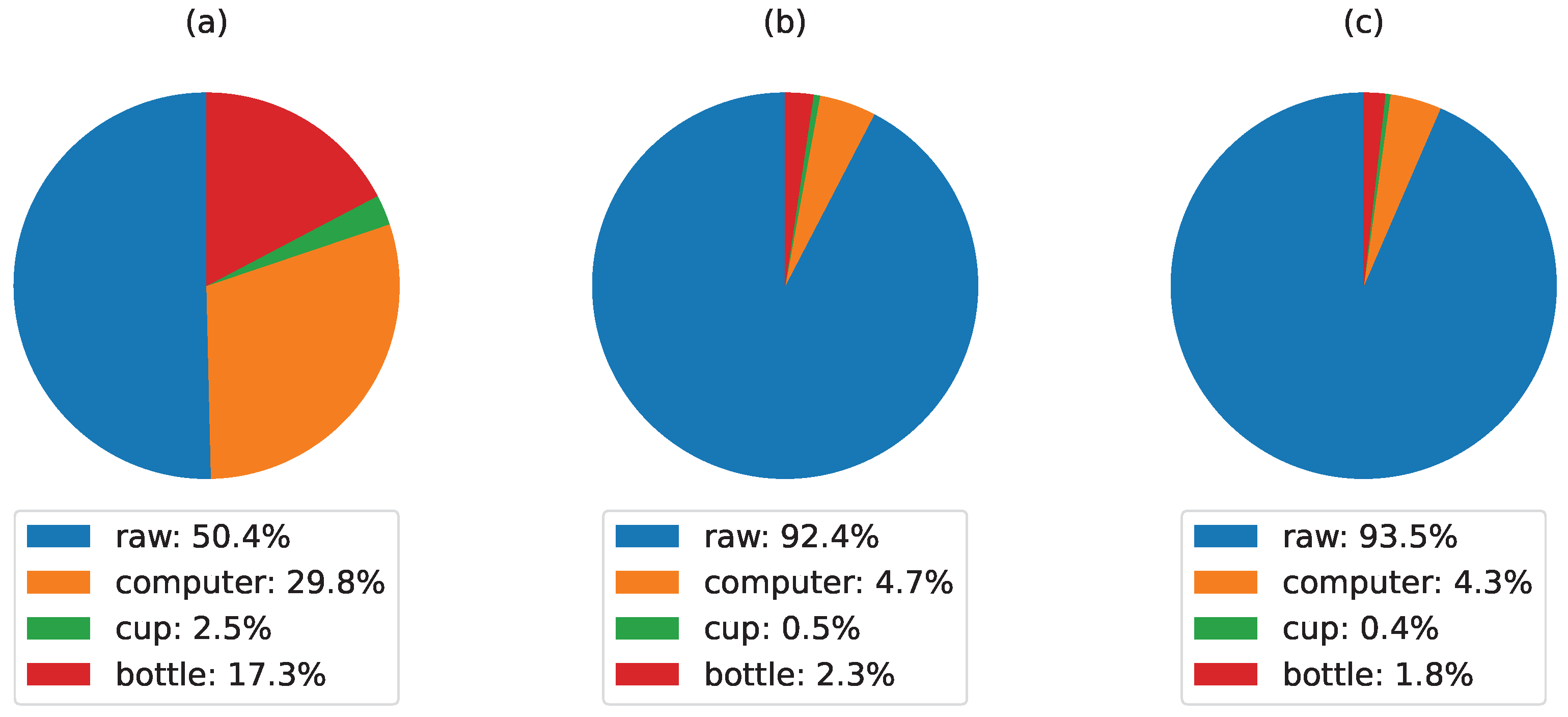
- In Figure 11a, the raw point-cloud displays a relatively balanced distribution among different object categories. Notably, the computer and bottle categories contribute significantly, comprising 29.8% and 17.3% of the points, respectively. Meanwhile, the cup and other objects make up smaller proportions. This point-cloud presented several noise and inaccurate 3D estimation.
- In Figure 11b, where the raw point-cloud undergoes downsampling with without denoising, a substantial reduction in points assigned to the computer and bottle categories (4.7% and 2.3%, respectively) is observed, which improves the real-time performance while maintaining a good estimation of the object 3D structure.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| RGB-D | Red, Green, Blue Depth |
| DS | Depth Sensor |
| YOLO | You Only Look Once |
| Bbox | Bounding Box |
| CLS | Classification Loss |
| SAM | Segment Anything |
| mAP | Mean Average Precision |
References
- Liu, M. Robotic Online Path Planning on Point Cloud. IEEE Trans. Cybern. 2016, 46, 1217–1228. [Google Scholar] [CrossRef]
- Ding, Z.; Sun, Y.; Xu, S.; Pan, Y.; Peng, Y.; Mao, Z. Recent Advances and Perspectives in Deep Learning Techniques for 3D Point Cloud Data Processing. Robotics 2023, 12, 100. [Google Scholar] [CrossRef]
- Krawczyk, D.; Sitnik, R. Segmentation of 3D Point Cloud Data Representing Full Human Body Geometry: A Review. Pattern Recognit. 2023, 139, 109444. [Google Scholar] [CrossRef]
- Wu, F.; Qian, Y.; Zheng, H.; Zhang, Y.; Zheng, X. A Novel Neighbor Aggregation Function for Medical Point Cloud Analysis. In Proceedings of the Computer Graphics International Conference, Shanghai, China, 28 August–1 September 2023; Springer: Berlin/Heidelberg, Germany, 2023; pp. 301–312. [Google Scholar]
- Xie, X.; Wei, H.; Yang, Y. Real-Time LiDAR Point-Cloud Moving Object Segmentation for Autonomous Driving. Sensors 2023, 23, 547. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, K.; Bao, H.; Zheng, Y.; Yang, Y. PMPF: Point-Cloud Multiple-Pixel Fusion-Based 3D Object Detection for Autonomous Driving. Remote Sens. 2023, 15, 1580. [Google Scholar] [CrossRef]
- D’Emilia, G.; Chiominto, L.; Gaspari, A.; Marsella, S.; Marzoli, M.; Natale, E. Extraction of a floor plan from a points cloud: Some metrological considerations. Acta IMEKO 2023, 12, 1–9. [Google Scholar] [CrossRef]
- Zhang, Z.M.; Catalucci, S.; Thompson, A.; Leach, R.; Piano, S. Applications of data fusion in optical coordinate metrology: A review. Int. J. Adv. Manuf. Technol. 2023, 124, 1341–1356. [Google Scholar] [CrossRef]
- Altuntas, C. Review of Scanning and Pixel Array-Based LiDAR Point-Cloud Measurement Techniques to Capture 3D Shape or Motion. Appl. Sci. 2023, 13, 6488. [Google Scholar] [CrossRef]
- Kurtser, P.; Lowry, S. RGB-D datasets for robotic perception in site-specific agricultural operations—A survey. Comput. Electron. Agric. 2023, 212, 108035. [Google Scholar] [CrossRef]
- Zhao, X.; Li, Q.; Wang, C.; Dou, H.; Liu, B. Robust Depth-Aided RGBD-Inertial Odometry for Indoor Localization. Measurement 2023, 209, 112487. [Google Scholar] [CrossRef]
- Gao, M.; Zheng, F.; Yu, J.J.; Shan, C.; Ding, G.; Han, J. Deep learning for video object segmentation: A review. Artif. Intell. Rev. 2023, 56, 457–531. [Google Scholar] [CrossRef]
- Hou, B.; Liu, Y.; Ling, N.; Ren, Y.; Liu, L. A Survey of Efficient Deep Learning Models for Moving Object Segmentation. APSIPA Trans. Signal Inf. Process. 2023, 12, e2. [Google Scholar] [CrossRef]
- Arkin, E.; Yadikar, N.; Xu, X.; Aysa, A.; Ubul, K. A survey: Object detection methods from CNN to transformer. Multimed. Tools Appl. 2023, 82, 21353–21383. [Google Scholar] [CrossRef]
- Kaur, R.; Singh, S. A comprehensive review of object detection with deep learning. Digit. Signal Process. 2023, 132, 103812. [Google Scholar] [CrossRef]
- Reshma Prakash, S.; Nath Singh, P. Object detection through region proposal based techniques. Mater. Today Proc. 2021, 46, 3997–4002. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.E.; Fu, C.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.K.; Girshick, R.B.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar] [CrossRef]
- Wang, Y.; Ahsan, U.; Li, H.; Hagen, M. A Comprehensive Review of Modern Object Segmentation Approaches. Found. Trends® Comput. Graph. Vis. 2022, 13, 111–283. [Google Scholar] [CrossRef]
- Liu, X.; Deng, Z.; Yang, Y. Recent progress in semantic image segmentation. Artif. Intell. Rev. 2018, 52, 1089–1106. [Google Scholar] [CrossRef]
- Hafiz, A.M.; Bhat, G.M. A survey on instance segmentation: State of the art. Int. J. Multimed. Inf. Retr. 2020, 9, 171–189. [Google Scholar] [CrossRef]
- Jocher, G.; Chaurasia, A.; Qiu, J. Ultralytics YOLOv8. 2023. Available online: https://github.com/ultralytics/ultralytics (accessed on 15 January 2024).
- Cong, S.; Zhou, Y. A review of convolutional neural network architectures and their optimizations. Artif. Intell. Rev. 2023, 56, 1905–1969. [Google Scholar] [CrossRef]
- Luo, Z.; Fang, Z.; Zheng, S.; Wang, Y.; Fu, Y. NMS-Loss: Learning with Non-Maximum Suppression for Crowded Pedestrian Detection. In Proceedings of the 2021 International Conference on Multimedia Retrieval, Taipei, Taiwan, 21–24 August 2021. [Google Scholar] [CrossRef]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.Y.; et al. Segment Anything. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023. [Google Scholar] [CrossRef]
- Shao, J.; Chen, S.; Zhou, J.; Zhu, H.; Wang, Z.; Brown, M. Application of U-Net and Optimized Clustering in Medical Image Segmentation: A Review. CMES-Comput. Model. Eng. Sci. 2023, 136, 2173–2219. [Google Scholar] [CrossRef]
- Zhang, S.; Zhang, C. Modified U-Net for plant diseased leaf image segmentation. Comput. Electron. Agric. 2023, 204, 107511. [Google Scholar] [CrossRef]
- Aghdam, E.K.; Azad, R.; Zarvani, M.; Merhof, D. Attention swin u-net: Cross-contextual attention mechanism for skin lesion segmentation. In Proceedings of the 2023 IEEE 20th International Symposium on Biomedical Imaging (ISBI), Cartagena, Colombia, 17–21 April 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1–5. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015. [Google Scholar] [CrossRef]
- He, S.; Bao, R.; Li, J.; Stout, J.; Bjornerud, A.; Grant, P.E.; Ou, Y. Computer-Vision Benchmark Segment-Anything Model (SAM) in Medical Images: Accuracy in 12 Datasets. arXiv 2023, arXiv:2304.09324. [Google Scholar] [CrossRef]
- Jiang, P.T.; Yang, Y. Segment Anything is A Good Pseudo-label Generator for Weakly Supervised Semantic Segmentation. arXiv 2023, arXiv:2305.01275. [Google Scholar] [CrossRef]
- Osco, L.P.; Wu, Q.; de Lemos, E.L.; Gonçalves, W.N.; Ramos, A.P.M.; Li, J.; Junior, J.M. The segment anything model (sam) for remote sensing applications: From zero to one shot. Int. J. Appl. Earth Obs. Geoinf. 2023, 124, 103540. [Google Scholar] [CrossRef]
- Xu, L.; Yan, W.; Ji, J. The research of a novel WOG-YOLO algorithm for autonomous driving object detection. Sci. Rep. 2023, 13, 3699. [Google Scholar] [CrossRef]
- Qureshi, R.; Ragab, M.G.; Abdulkader, S.J.; Alqushaib, A.; Sumiea, E.H.; Alhussian, H. A Comprehensive Systematic Review of YOLO for Medical Object Detection (2018 to 2023). 2023; Authorea Preprints. [Google Scholar] [CrossRef]
- Pan, F.; Liu, J.; Cen, Y.; Chen, Y.; Cai, R.; Zhao, Z.; Liao, W.; Wang, J. Accuracy of RGB-D camera-based and stereophotogrammetric facial scanners: A comparative study. J. Dent. 2022, 127, 104302. [Google Scholar] [CrossRef]
- Yan, S.; Yang, J.; Käpylä, J.; Zheng, F.; Leonardis, A.; Kämäräinen, J. DepthTrack: Unveiling the Power of RGBD Tracking. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021. [Google Scholar] [CrossRef]
- Tychola, K.A.; Tsimperidis, I.; Papakostas, G.A. On 3D Reconstruction Using RGB-D Cameras. Digital 2022, 2, 401–421. [Google Scholar] [CrossRef]
- Li, J.; Gao, W.; Wu, Y.; Liu, Y.; Shen, Y. High-quality indoor scene 3D reconstruction with RGB-D cameras: A brief review. Comput. Vis. Media 2022, 8, 369–393. [Google Scholar] [CrossRef]
- Linqin, C.; Shuangjie, C.; Min, X.; Jimin, Y.; Jianrong, Z. Dynamic hand gesture recognition using RGB-D data for natural human-computer interaction. J. Intell. Fuzzy Syst. 2017, 32, 3495–3507. [Google Scholar] [CrossRef]
- Gao, W.; Miao, P. RGB-D Camera Assists Virtual Studio through Human Computer Interaction. In Proceedings of the 2018 3rd International Conference on Materials Science, Machinery and Energy Engineering (MSMEE 2018), Chennai, India, 16–17 September 2018; Institute of Management Science and Industrial Engineering: Shanghai, China, 2018; Volume 6. [Google Scholar]
- Schwarz, M.; Milan, A.; Periyasamy, A.S.; Behnke, S. RGB-D object detection and semantic segmentation for autonomous manipulation in clutter. Int. J. Robot. Res. 2018, 37, 437–451. [Google Scholar] [CrossRef]
- Lee, Y.H.; Medioni, G. RGB-D camera based wearable navigation system for the visually impaired. Comput. Vis. Image Underst. 2016, 149, 3–20. [Google Scholar] [CrossRef]
- Endres, F.; Hess, J.; Sturm, J.; Cremers, D.; Burgard, W. 3-D mapping with an RGB-D camera. IEEE Trans. Robot. 2013, 30, 177–187. [Google Scholar] [CrossRef]
- Lai, K.; Bo, L.; Ren, X.; Fox, D. RGB-D object recognition: Features, algorithms, and a large scale benchmark. In Consumer Depth Cameras for Computer Vision: Research Topics and Applications; Springer: Berlin/Heidelberg, Germany, 2013; pp. 167–192. [Google Scholar]
- Prankl, J.; Aldoma, A.; Svejda, A.; Vincze, M. RGB-D object modelling for object recognition and tracking. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent robots And Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 96–103. [Google Scholar]
- Gené-Mola, J.; Llorens, J.; Rosell-Polo, J.R.; Gregorio, E.; Arnó, J.; Solanelles, F.; Martínez-Casasnovas, J.A.; Escolà, A. Assessing the Performance of RGB-D Sensors for 3D Fruit Crop Canopy Characterization under Different Operating and Lighting Conditions. Sensors 2020, 20, 7072. [Google Scholar] [CrossRef]
- Wang, Y.; Xu, S.; Zell, A. Real-time 3D Object Detection from Point Clouds using an RGB-D Camera. In Proceedings of the 9th International Conference on Pattern Recognition Applications and Methods—Volume 1: ICPRAM, INSTICC, Valletta, Malta, 22–24 February 2020; SciTePress: Setúbal, Portugal, 2020; pp. 407–414. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar] [CrossRef]
- Qi, C.R.; Liu, W.; Wu, C.; Su, H.; Guibas, L.J. Frustum PointNets for 3D Object Detection from RGB-D Data. arXiv 2017, arXiv:1711.08488. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Bourdev, L.; Girshick, R.; Hays, J.; Perona, P.; Ramanan, D.; Zitnick, C.L.; Dollár, P. Microsoft COCO: Common Objects in Context. arXiv 2015, arXiv:1405.0312. [Google Scholar] [CrossRef]
- Dwyer, B.; Nelson, J.; Solawetz, J. Roboflow (Version 1.0). [Software]. 2022. Available online: https://roboflow.com (accessed on 5 February 2024).
- Tzutalin. LabelImg. Free Software: MIT License. 2015. Available online: https://github.com/HumanSignal/labelImg (accessed on 1 February 2024).
- Dutta, A.; Gupta, A.; Zissermann, A. VGG Image Annotator (VIA). Version: 2.0.1. 2016. Available online: http://www.robots.ox.ac.uk/~vgg/software/via/ (accessed on 1 February 2024).
- Maharana, K.; Mondal, S.; Nemade, B. A review: Data pre-processing and data augmentation techniques. Glob. Transit. Proc. 2022, 3, 91–99. [Google Scholar] [CrossRef]
- El Ghazouali, S.; Vissiere, A.; Lafon, L.F.; Bouazizi, M.L.; Nouira, H. Optimised calibration of machine vision system for close range photogrammetry based on machine learning. J. King Saud Univ.-Comput. Inf. Sci. 2022, 34, 7406–7418. [Google Scholar] [CrossRef]
- Paradiso, V.; Crivellaro, A.; Amgarou, K.; de Lanaute, N.B.; Fua, P.; Liénard, E. A versatile calibration procedure for portable coded aperture gamma cameras and RGB-D sensors. Nucl. Instrum. Methods Phys. Res. Sect. A Accel. Spectrometer Detect. Assoc. Equip. 2018, 886, 125–133. [Google Scholar] [CrossRef]
- Moreno, C. A Comparative Study of Filtering Methods for Point Clouds in Real-Time Video Streaming. In Proceedings of the World Congress on Engineering and Computer Science, San Francisco, CA, USA, 19–21 October 2016. [Google Scholar]
- Balta, H.; Velagic, J.; Bosschaerts, W.; De Cubber, G.; Siciliano, B. Fast Statistical Outlier Removal Based Method for Large 3D Point Clouds of Outdoor Environments. IFAC-PapersOnLine 2018, 51, 348–353. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar] [CrossRef]
- Bertels, J.; Eelbode, T.; Berman, M.; Vandermeulen, D.; Maes, F.; Bisschops, R.; Blaschko, M.B. Optimizing the Dice Score and Jaccard Index for Medical Image Segmentation: Theory and Practice. In Medical Image Computing and Computer Assisted Intervention—MICCAI 2019; Springer International Publishing: Berlin/Heidelberg, Germany, 2019; pp. 92–100. [Google Scholar] [CrossRef]
- Jena, R.; Zhornyak, L.; Doiphode, N.; Chaudhari, P.; Buch, V.; Gee, J.; Shi, J. Beyond mAP: Towards better evaluation of instance segmentation. arXiv 2023, arXiv:2207.01614. [Google Scholar] [CrossRef]
- Gimeno, P.; Mingote, V.; Ortega, A.; Miguel, A.; Lleida, E. Generalizing AUC Optimization to Multiclass Classification for Audio Segmentation With Limited Training Data. IEEE Signal Process. Lett. 2021, 28, 1135–1139. [Google Scholar] [CrossRef]
- Hurtado, J.V.; Valada, A. Semantic Scene Segmentation for Robotics. arXiv 2024, arXiv:2401.07589. [Google Scholar] [CrossRef]
- Intel Corporation. Intel RealSense SDK 2.0–Python Documentation. Developer Documentation. 2022. Available online: https://dev.intelrealsense.com/docs/python2 (accessed on 15 January 2024).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Version | Description |
|---|---|---|
| Linux | 22.04 LTS | Operating system |
| Python | 3.10 | Baseline programming language |
| Camera | D435i | Intel RealSense RGB-D camera |
| GPU | RTX 2080 TI | GPU for data parallelization |
| OpenCV | 3.10 | Open source Framework for computer vision operations |
| CUDA | 11.2 | Platform for GPU based processing |
| Metrics | Test Sets | Cup | Bottle | Computer | Overall |
|---|---|---|---|---|---|
| IoU | 1 | 0.96 | 0.96 | 0.95 | 0.95 |
| 2 | 0.93 | 0.90 | 0.91 | 0.92 | |
| 3 | 0.83 | 0.52 | 0.72 | 0.70 | |
| Precision | 1 | 0.99 | 0.96 | 0.98 | 0.98 |
| 2 | 0.91 | 0.77 | 0.85 | 0.87 | |
| 3 | 0.6 | 0.31 | 0.54 | 0.49 |
| Process | Processing Time (ms) | Frame Rate (fps) | Point-Cloud Density |
|---|---|---|---|
| Raw point-cloud visualization | ∼16 | up to 60 | ∼302.8 k |
| RGB + Depth map (Without point-cloud visualization) | ∼11 | up to 90 | - |
| + YOLO | ∼31.7 | ∼34 | - |
| + FastSAM | ∼29.7 | ∼33.7 | - |
| + Raw 3D Object visualization | ∼189 | ∼5 | ∼158.4 k |
| complete FusionVision Pipeline | ∼30.6 | ∼27.3 | ∼20.8 k |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
El Ghazouali, S.; Mhirit, Y.; Oukhrid, A.; Michelucci, U.; Nouira, H. FusionVision: A Comprehensive Approach of 3D Object Reconstruction and Segmentation from RGB-D Cameras Using YOLO and Fast Segment Anything. Sensors 2024, 24, 2889. https://doi.org/10.3390/s24092889
El Ghazouali S, Mhirit Y, Oukhrid A, Michelucci U, Nouira H. FusionVision: A Comprehensive Approach of 3D Object Reconstruction and Segmentation from RGB-D Cameras Using YOLO and Fast Segment Anything. Sensors. 2024; 24(9):2889. https://doi.org/10.3390/s24092889
Chicago/Turabian StyleEl Ghazouali, Safouane, Youssef Mhirit, Ali Oukhrid, Umberto Michelucci, and Hichem Nouira. 2024. "FusionVision: A Comprehensive Approach of 3D Object Reconstruction and Segmentation from RGB-D Cameras Using YOLO and Fast Segment Anything" Sensors 24, no. 9: 2889. https://doi.org/10.3390/s24092889
APA StyleEl Ghazouali, S., Mhirit, Y., Oukhrid, A., Michelucci, U., & Nouira, H. (2024). FusionVision: A Comprehensive Approach of 3D Object Reconstruction and Segmentation from RGB-D Cameras Using YOLO and Fast Segment Anything. Sensors, 24(9), 2889. https://doi.org/10.3390/s24092889