

Physical Activity Detection for Diabetes Mellitus Patients Using Recurrent Neural Networks

 ,
,  , ,
, ,  , ,
, ,  and
and
Abstract
1. Introduction
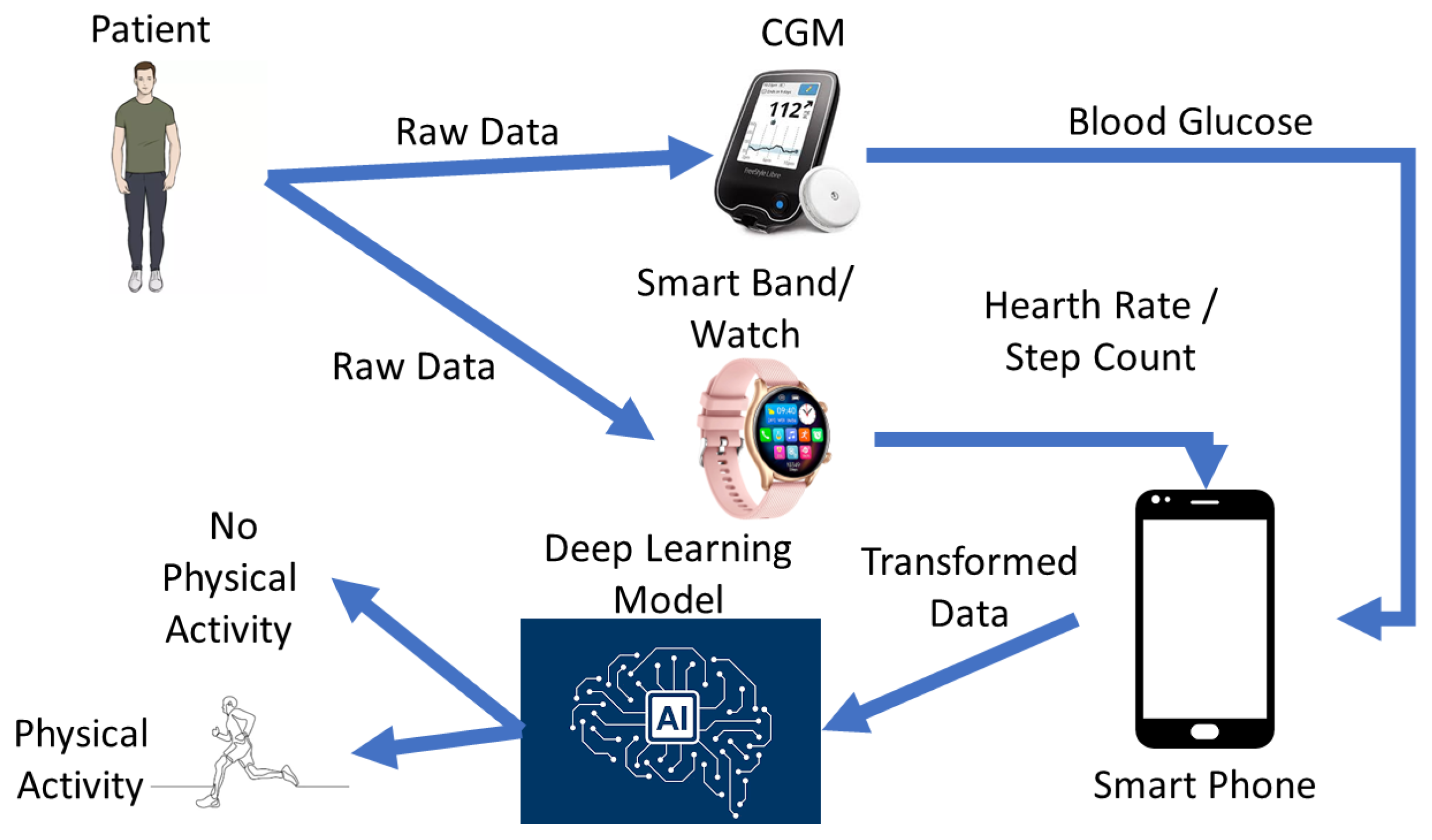
2. Materials and Methods
2.1. Preliminary Results
2.2. Development Environments
2.3. Datasets
OHIO T1DM Dataset
- glucose_level: The glucose data comprise continuous glucose monitoring (CGM) measurements in milligrams per deciliter (mg/dL), with corresponding timestamps recorded at five-minute intervals. The timestamp format follows the DD-MM-YYYY HH:MM:SS pattern.
- basis_heart_rate: Heart rate information is aggregated in five-minute increments and is exclusively accessible for individuals who utilized the Basis Peak sensor band. Heart rate recordings include timestamps, denoting the date and time (in DD-MM-YYYY HH:MM:SS format), along with corresponding heart rate data measured at five-minute intervals (in beats per minute).
- basis_steps: The dataset comprises step counts aggregated every 5 min in the DD-MM-YYYY HH:MM:SS format. These data are also exclusively accessible for individuals using the Basis Peak sensor band.
- (i)
- The first dataset structure exclusively comprised glucose data. This univariate configuration allowed for an in-depth analysis of glucose dynamics, unencumbered by the influence of additional physiological variables.In this case, the data record for each patient in this dataset had the following structure: [Date stamp (DD-MM-YYYY), Time stamp (HH:MM:SS), Blood glucose level from CGMS (concentration)].
- (ii)
- In the second dataset structure, our analytical scope expanded to encompass the dynamic interplay between glucose levels and heart rate. This bivariate approach facilitated a more nuanced examination by integrating heart rate data, also aggregated at five-minute intervals. Importantly, this dataset structure was specifically tailored for individuals who wore the Basis Peak sensor band, ensuring methodological consistency and uniformity in data acquisition practices.In this case, the data record for each patient in this dataset had the following structure: [Date stamp (DD-MM-YYYY), Time stamp (HH:MM:SS), Blood glucose level from CGMS (concentration), HR value (integer)].
- (iii)
- The third dataset structure extended the integrative paradigm by pairing glucose data with step information. Similar to the previous approach, the aggregation of data occurred at five-minute intervals, and exclusivity was maintained for individuals employing the Basis Peak sensor band.In this case, the data record for each patient in this dataset had the following structure: [Date stamp (DD-MM-YYYY), Time stamp (HH:MM:SS), Blood glucose level from CGMS (concentration), Step value (integer)].
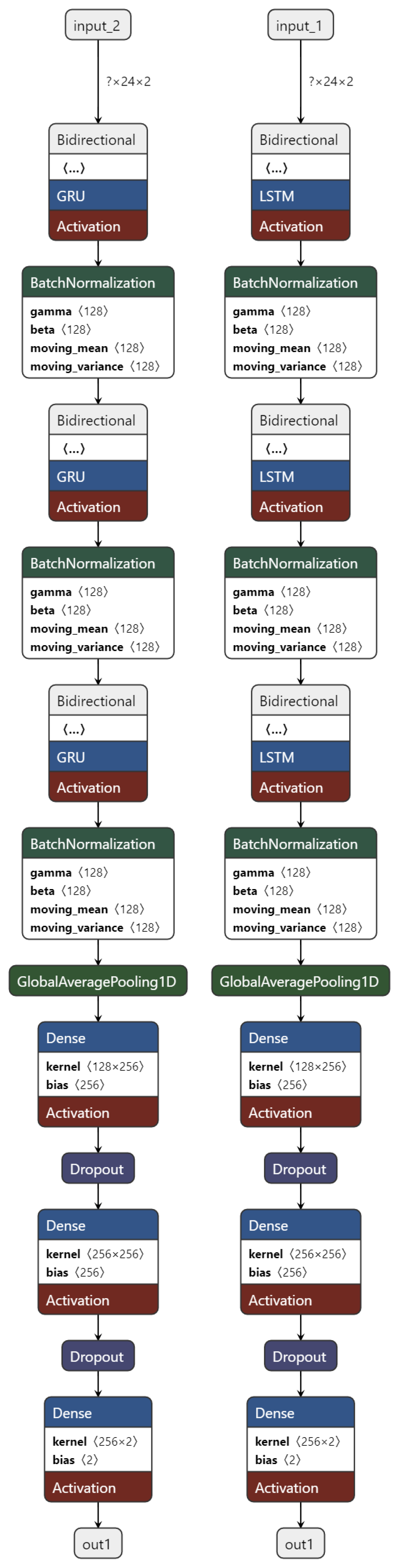
2.4. Investigated Machine Learning Methods
Our Network Proposal
2.5. Training and Testing
2.6. Performance Metrics
- Accuracy () represents the rate of correct decisions, defined as
- Recall, also known as sensitivity or the true positive rate (), is defined as
- Specificity, also known as the true negative rate (), is defined as
- Precision, also known as the positive prediction value (), is defined as
- The false positive rate, (), is defined as
- The -score (), also known as the Dice score, is defined as
3. Results
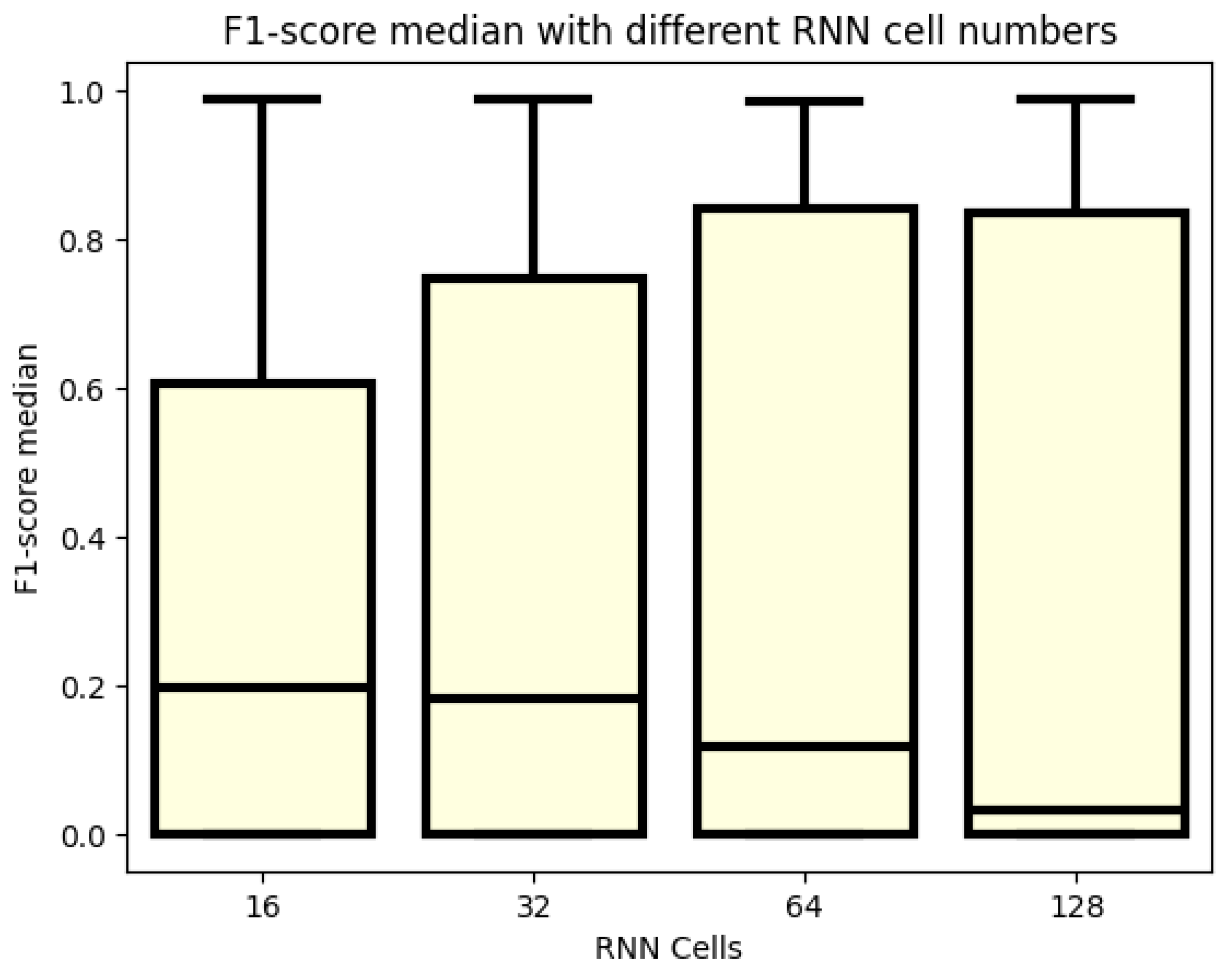
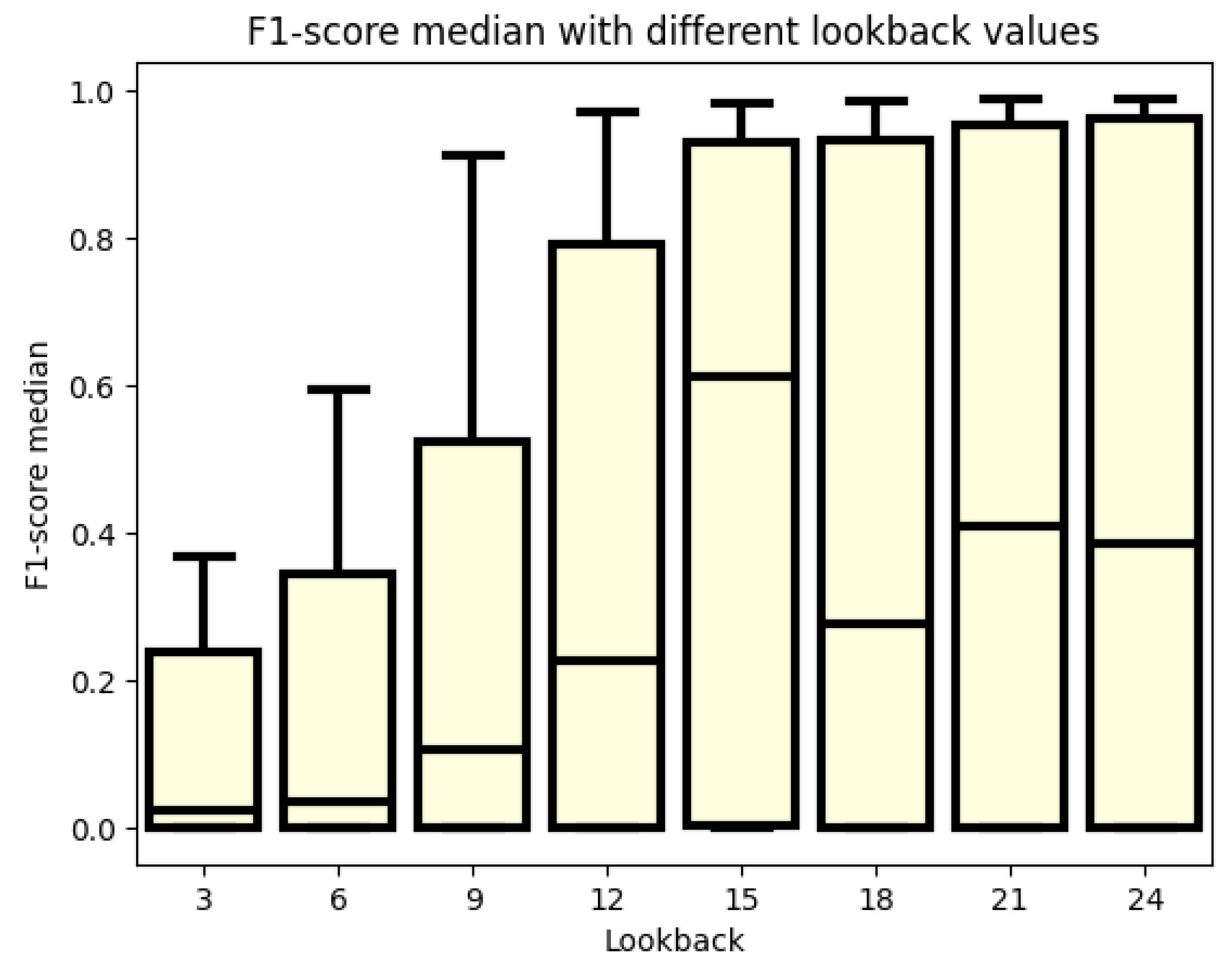
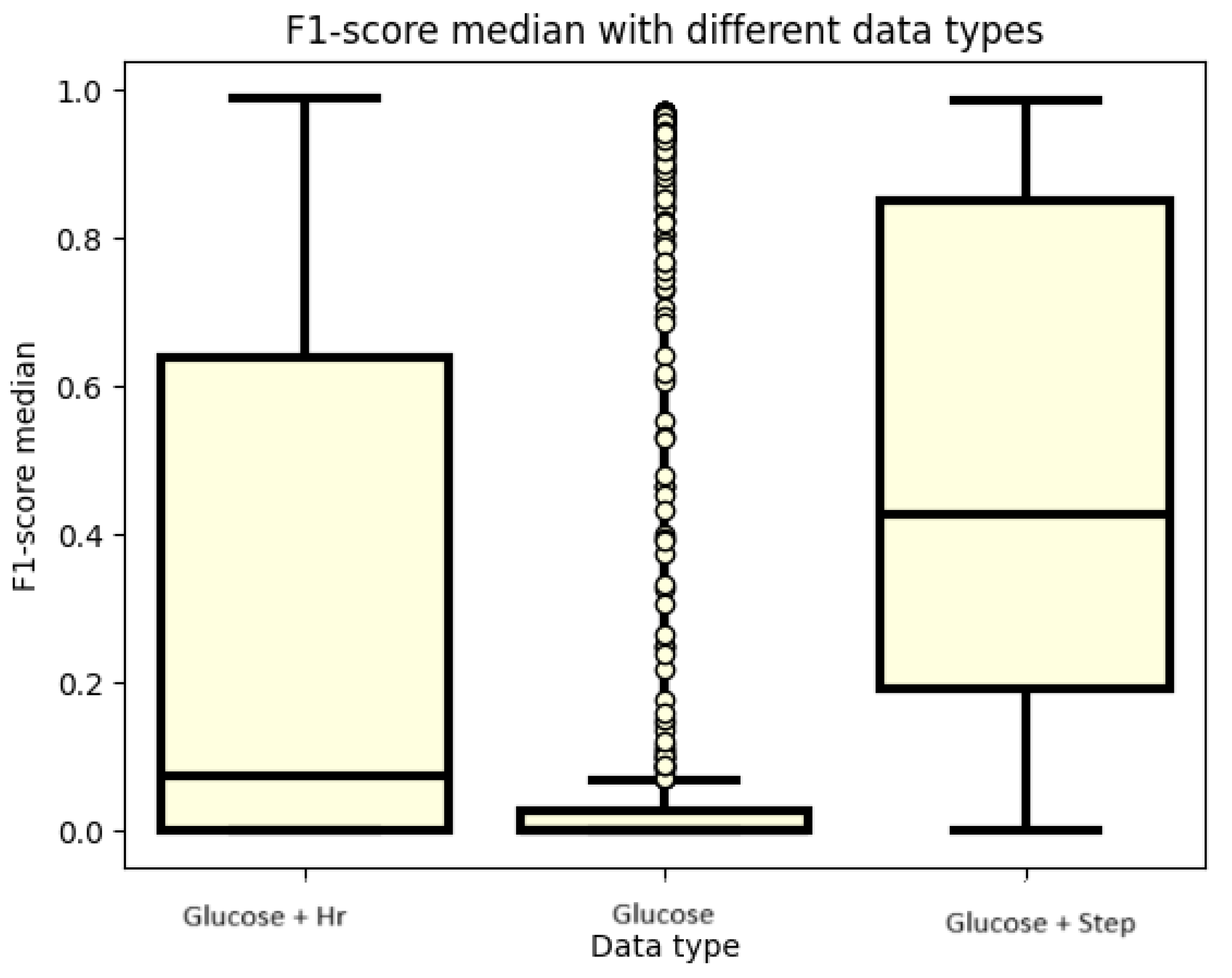
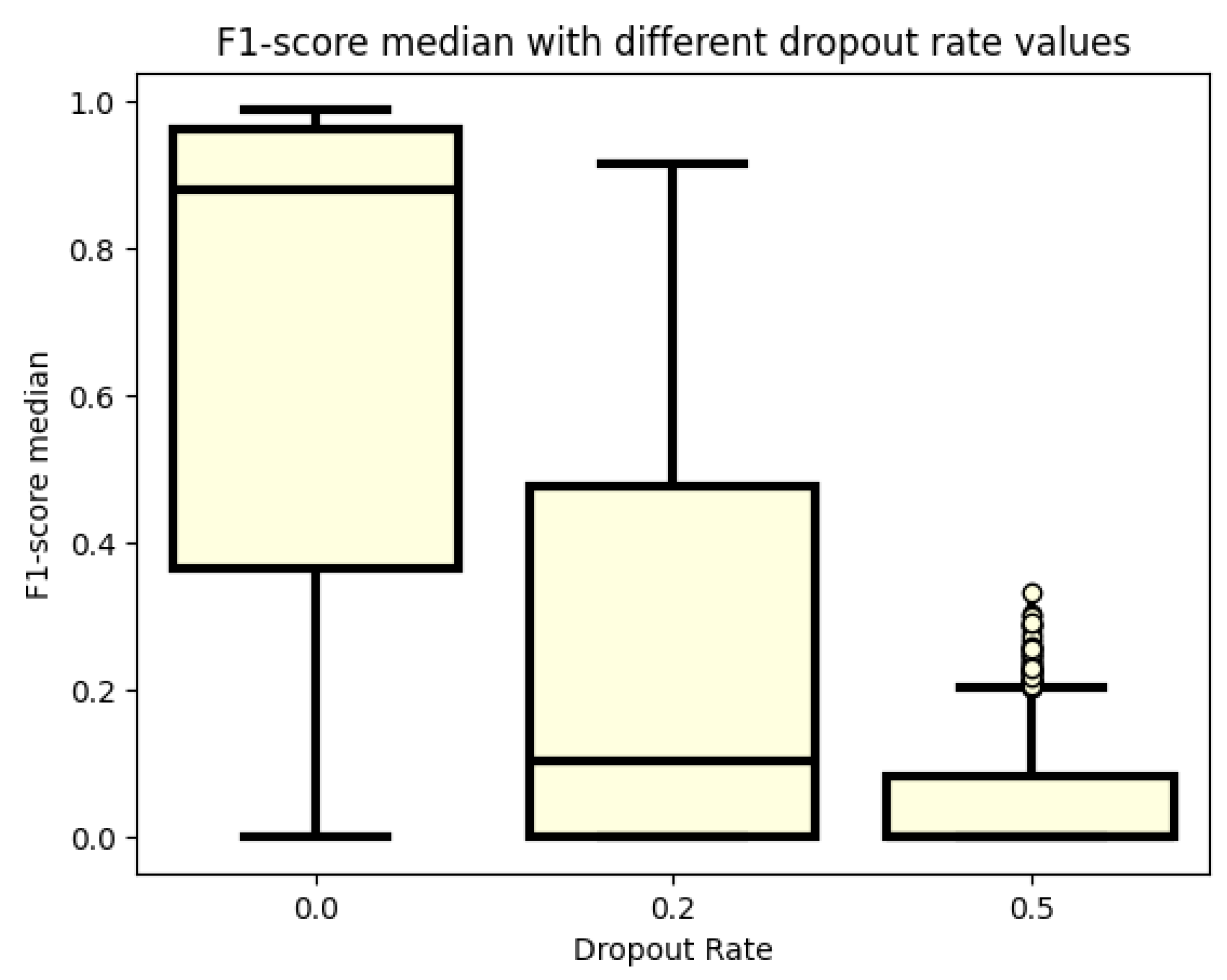
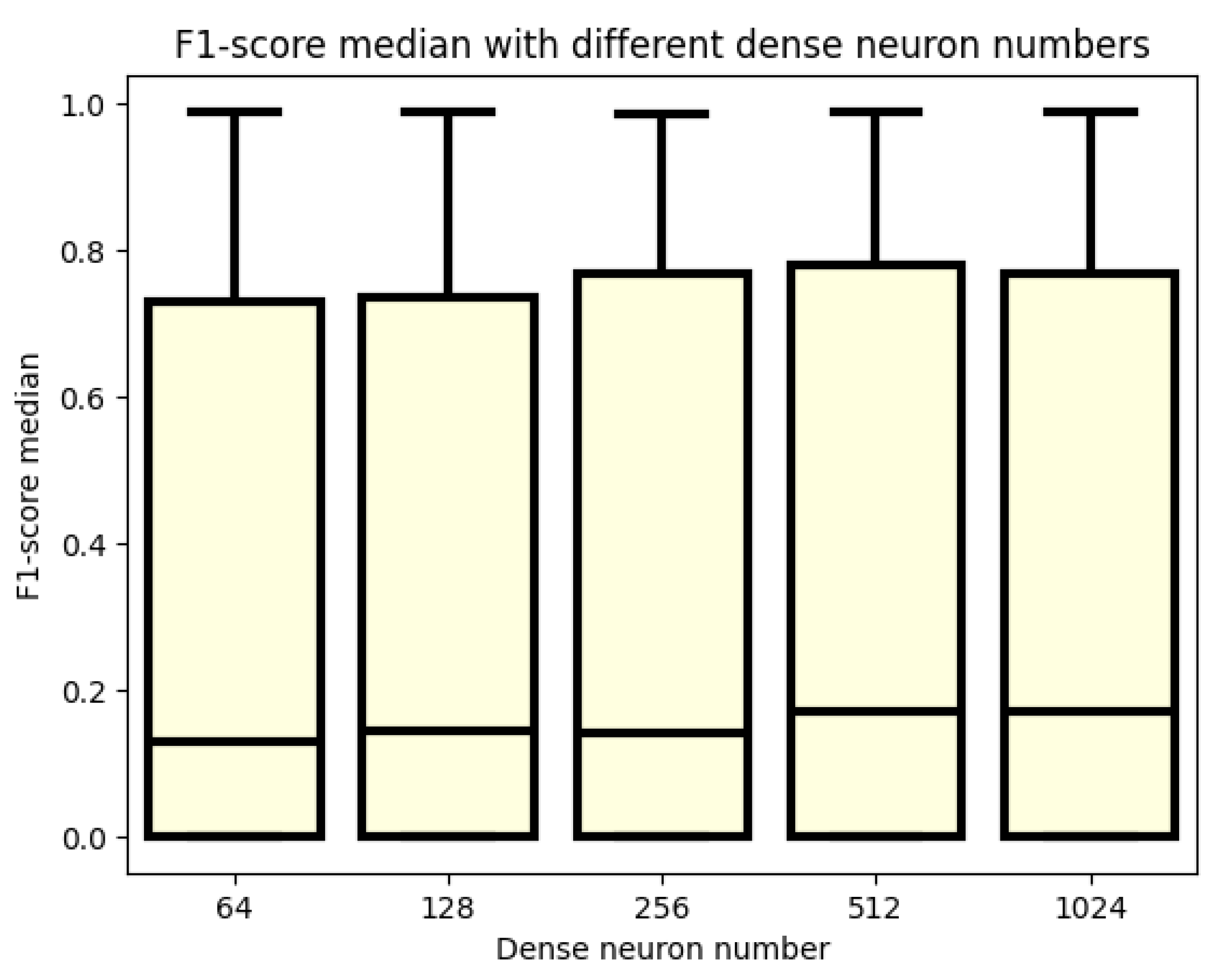
3.1. F1 Score
3.2. Analyzation of the Best 30 Models
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| KNN | K-Nearest Neighbors |
| CGMS | Continuous Glucose Monitoring System |
| HR | Hearth Rate |
| BiRNN | Bidirectional Recurrent Neural Network |
| GRU | Gated Recurrent Unit |
| AUC | Area Under the Curve |
| ROC | Receiver Operating Characteristic Curve |
| LSTM | Long Short-Term Memory |
| RNN | Recurrent Neural Network |
| ADAM | Adaptive Moment Estimation |
| AI | Artificial Intelligence |
| ReLU | Rectified Linear Unit |
| TP | True Positive |
| AUC | Area Under the ROC Curve |
| IMU | Inertial Measurement Unit |
References
- Holt, R.I.; Cockram, C.; Flyvbjerg, A.; Goldstein, B.J. Textbook of Diabetes; John Wiley & Sons: Chichester, UK, 2017. [Google Scholar]
- Bird, S.R.; Hawley, J.A. Update on the effects of physical activity on insulin sensitivity in humans. BMJ Open Sport Exerc. Med. 2017, 2, e000143. [Google Scholar] [CrossRef] [PubMed]
- Martyn-Nemeth, P.; Quinn, L.; Penckofer, S.; Park, C.; Hofer, V.; Burke, L. Fear of hypoglycemia: Influence on glycemic variability and self-management behavior in young adults with type 1 diabetes. J. Diabetes Its Complicat. 2017, 31, 735–741. [Google Scholar] [CrossRef] [PubMed]
- Jeandidier, N.; Riveline, J.P.; Tubiana-Rufi, N.; Vambergue, A.; Catargi, B.; Melki, V.; Charpentier, G.; Guerci, B. Treatment of diabetes mellitus using an external insulin pump in clinical practice. Diabetes Metab. 2008, 34, 425–438. [Google Scholar] [CrossRef] [PubMed]
- Adams, P.O. The impact of brief high-intensity exercise on blood glucose levels. Diabetes Metab. Syndr. Obes. 2013, 6, 113–122. [Google Scholar] [CrossRef] [PubMed]
- Sylow, L.; Kleinert, M.; Richter, E.A.; Jensen, T.E. Exercise-stimulated glucose uptake—Regulation and implications for glycaemic control. Nat. Rev. Endocrinol. 2017, 13, 133–148. [Google Scholar] [CrossRef] [PubMed]
- Stavdahl, Ø.; Fougner, A.L.; Kölle, K.; Christiansen, S.C.; Ellingsen, R.; Carlsen, S.M. The artificial pancreas: A dynamic challenge. IFAC-PapersOnLine 2016, 49, 765–772. [Google Scholar]
- Tagougui, S.; Taleb, N.; Molvau, J.; Nguyen, É.; Raffray, M.; Rabasa-Lhoret, R. Artificial pancreas systems and physical activity in patients with type 1 diabetes: Challenges, adopted approaches, and future perspectives. J. Diabetes Sci. Technol. 2019, 13, 1077–1090. [Google Scholar] [CrossRef] [PubMed]
- Ekelund, U.; Poortvliet, E.; Yngve, A.; Hurtig-Wennlöv, A.; Nilsson, A.; Sjöström, M. Heart rate as an indicator of the intensity of physical activity in human adolescents. Eur. J. Appl. Physiol. 2001, 85, 244–249. [Google Scholar] [CrossRef]
- Crema, C.; Depari, A.; Flammini, A.; Sisinni, E.; Haslwanter, T.; Salzmann, S. IMU-based solution for automatic detection and classification of exercises in the fitness scenario. In Proceedings of the 2017 IEEE Sensors Applications Symposium (SAS), Glassboro, NJ, USA, 13–15 March 2017; pp. 1–6. [Google Scholar]
- Allahbakhshi, H.; Hinrichs, T.; Huang, H.; Weibel, R. The key factors in physical activity type detection using real-life data: A systematic review. Front. Physiol. 2019, 10, 75. [Google Scholar] [CrossRef]
- Cescon, M.; Choudhary, D.; Pinsker, J.E.; Dadlani, V.; Church, M.M.; Kudva, Y.C.; Doyle, F.J., III; Dassau, E. Activity detection and classification from wristband accelerometer data collected on people with type 1 diabetes in free-living conditions. Comput. Biol. Med. 2021, 135, 104633. [Google Scholar] [CrossRef]
- Verrotti, A.; Prezioso, G.; Scattoni, R.; Chiarelli, F. Autonomic neuropathy in diabetes mellitus. Front. Endocrinol. 2014, 5, 205. [Google Scholar] [CrossRef] [PubMed]
- Agashe, S.; Petak, S. Cardiac autonomic neuropathy in diabetes mellitus. Methodist Debakey Cardiovasc. J. 2018, 14, 251. [Google Scholar] [CrossRef]
- Helleputte, S.; De Backer, T.; Lapauw, B.; Shadid, S.; Celie, B.; Van Eetvelde, B.; Vanden Wyngaert, K.; Calders, P. The relationship between glycaemic variability and cardiovascular autonomic dysfunction in patients with type 1 diabetes: A systematic review. Diabetes/Metab. Res. Rev. 2020, 36, e3301. [Google Scholar] [CrossRef] [PubMed]
- Vijayan, V.; Connolly, J.P.; Condell, J.; McKelvey, N.; Gardiner, P. Review of Wearable Devices and Data Collection Considerations for Connected Health. Sensors 2021, 21, 5589. [Google Scholar] [CrossRef] [PubMed]
- Liang, L.; Kong, F.W.; Martin, C.; Pham, T.; Wang, Q.; Duncan, J.; Sun, W. Machine learning–based 3-D geometry reconstruction and modeling of aortic valve deformation using 3-D computed tomography images. Int. J. Numer. Methods Biomed. Eng. 2017, 33, e2827. [Google Scholar] [CrossRef] [PubMed]
- Lundberg, S.M.; Nair, B.; Vavilala, M.S.; Horibe, M.; Eisses, M.J.; Adams, T.; Liston, D.E.; Low, D.K.W.; Newman, S.F.; Kim, J.; et al. Explainable machine-learning predictions for the prevention of hypoxaemia during surgery. Int. J. Numer. Methods Biomed. Eng. 2018, 2, 749–760. [Google Scholar] [CrossRef]
- Ostrogonac, S.; Pakoci, E.; Sečujski, M.; Mišković, D. Morphology-based vs unsupervised word clustering for training language models for Serbian. Acta Polytech. Hung. J. Appl. Sci. 2019, 16, 183–197. [Google Scholar]
- Machová, K.; Mach, M.; Hrešková, M. Classification of Special Web Reviewers Based on Various Regression Methods. Acta Polytech. Hung. 2020, 17, 229–248. [Google Scholar] [CrossRef]
- Bednár, P.; Ivančáková, J.; Sarnovskỳ, M. Semantic Composition of Data Analytical Processes. Acta Polytech. Hung. 2024, 21, 167–185. [Google Scholar] [CrossRef]
- Hayeri, A. Predicting Future Glucose Fluctuations Using Machine Learning and Wearable Sensor Data. Diabetes 2018, 67, A193. [Google Scholar] [CrossRef]
- Daskalaki, E.; Diem, P.; Mougiakakou, S.G. Model-free machine learning in biomedicine: Feasibility study in type 1 diabetes. PLoS ONE 2016, 11, e0158722. [Google Scholar] [CrossRef] [PubMed]
- Woldaregay, A.Z.; Årsand, E.; Botsis, T.; Albers, D.; Mamykina, L.; Hartvigsen, G. Data-Driven Blood Glucose Pattern Classification and Anomalies Detection: Machine-Learning Applications in Type 1 Diabetes. J. Med. Internet Res. 2019, 21, e11030. [Google Scholar] [CrossRef] [PubMed]
- Contreras, I.; Vehi, J. Artificial intelligence for diabetes management and decision support: Literature review. J. Med. Internet Res. 2018, 20, e10775. [Google Scholar] [CrossRef] [PubMed]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Cogn. Model. 1988, 5, 1. [Google Scholar]
- Askari, M.R.; Rashid, M.; Sun, X.; Sevil, M.; Shahidehpour, A.; Kawaji, K.; Cinar, A. Detection of Meals and Physical Activity Events From Free-Living Data of People with Diabetes. J. Diabetes Sci. Technol. 2022, 17, 1482–1492. [Google Scholar] [CrossRef] [PubMed]
- Zeng, Y.; Zhang, J.; Starly, B. Recurrent neural networks with long term temporal dependencies in machine tool wear diagnosis and prognosis. SN Appl. Sci. 2021, 3, 442. [Google Scholar] [CrossRef]
- Dénes-Fazakas, L.; Szilágyi, L.; Tasic, J.; Kovács, L.; Eigner, G. Detection of physical activity using machine learning methods. In Proceedings of the 2020 IEEE 20th International Symposium on Computational Intelligence and Informatics (CINTI), Budapest, Hungary, 5–7 November 2020; pp. 167–172. [Google Scholar]
- Dénes-Fazakas, L.; Siket, M.; Szilágyi, L.; Kovács, L.; Eigner, G. Detection of Physical Activity Using Machine Learning Methods Based on Continuous Blood Glucose Monitoring and Heart Rate Signals. Sensors 2022, 22, 8568. [Google Scholar] [CrossRef] [PubMed]
- TensorFlow Core v2.4.0. Available online: https://www.tensorflow.org/api_docs (accessed on 21 January 2020).
- Scikit-Learn User Guide. Available online: https://scikit-learn.org/0.18/_downloads/scikit-learn-docs.pdf (accessed on 21 January 2020).
- NumPy Documentation. Available online: https://numpy.org/doc/ (accessed on 21 January 2020).
- Pandas Documentation. Available online: https://pandas.pydata.org/docs/ (accessed on 21 January 2020).
- Razvan Bunescu, C.M.; Shubrook, J. Blood Glucose Prediction Using Physiological Models and Support Vector Regression. In Proceedings of the 2013 12th International Conference on Machine Learning and Applications, Miami, FL, USA, 4–7 December 2013. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Cho, K.; van Merrienboer, B.; Bahdanau, D.; Bengio, Y. Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1724–1734. [Google Scholar]
- Schuster, M.; Paliwal, K.K. Bidirectional recurrent neural networks. IEEE Trans. Signal Process. 1997, 45, 2673–2681. [Google Scholar] [CrossRef]
- Graves, A.; Schmidhuber, J. Framewise phoneme classification with bidirectional LSTM and other neural network architectures. Neural Netw. 2005, 18, 602–610. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Habib, G.; Qureshi, S. GAPCNN with HyPar: Global Average Pooling convolutional neural network with novel NNLU activation function and HYBRID parallelism. Front. Comput. Neurosci. 2022, 16, 1004988. [Google Scholar] [CrossRef] [PubMed]
- Agarap, A.F. Deep learning using rectified linear units (relu). arXiv 2018, arXiv:1803.08375. [Google Scholar]
- Kouretas, I.; Paliouras, V. Simplified Hardware Implementation of the Softmax Activation Function. In Proceedings of the 2019 8th International Conference on Modern Circuits and Systems Technologies (MOCAST), Thessaloniki, Greece, 13–15 May 2019; pp. 1–4. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar]
- Gordon-Rodriguez, E.; Loaiza-Ganem, G.; Pleiss, G.; Cunningham, J.P. Uses and Abuses of the Cross-Entropy Loss: Case Studies in Modern Deep Learning. arXiv 2020, arXiv:2011.05231. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Available online: http://www.deeplearningbook.org (accessed on 1 February 2022).
- Liu, Y.; Wang, Y.; Qi, H.; Ju, X. SuperPruner: Automatic Neural Network Pruning via Super Network. Sci. Program. 2021, 2021, 9971669. [Google Scholar] [CrossRef]
- Koctúrová, M.; Juhár, J. EEG-based Speech Activity Detection. Acta Polytech. Hung. 2021, 18, 65–77. [Google Scholar]
- Géron, A. Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems; O’Reilly Media: Sebastapol, CA, USA, 2019. [Google Scholar]
- Czmil, A.; Czmil, S.; Mazur, D. A Method to Detect Type 1 Diabetes Based on Physical Activity Measurements Using a Mobile Device. Appl. Sci. 2019, 9, 2555. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 540 | 544 | 552 | 559 | 563 | 567 | 570 | 575 | 584 | 588 | 591 | 596 |
| 1242 | 1115 | 960 | 1115 | 1228 | 1112 | 1148 | 1213 | 224 | 1290 | 1138 | 1140 |
| Modell | Data Type | Look Back | Dropout Rate | RNN Cells | Dense Neuron Number | F1 Score | ||
|---|---|---|---|---|---|---|---|---|
| Mean | Median | STD | ||||||
| LSTM | Glucose and HR | 24.0000 | 0.0000 | 32.0000 | 64.0000 | 0.9843 | 0.9884 | 0.0063 |
| LSTM | Glucose and HR | 21.0000 | 0.0000 | 128.0000 | 128.0000 | 0.9876 | 0.9875 | 0.0021 |
| LSTM | Glucose and HR | 24.0000 | 0.0000 | 16.0000 | 1024.0000 | 0.9839 | 0.9869 | 0.0068 |
| LSTM | Glucose and HR | 24.0000 | 0.0000 | 128.0000 | 512.0000 | 0.9847 | 0.9869 | 0.0052 |
| GRU | Glucose and HR | 24.0000 | 0.0000 | 128.0000 | 1024.0000 | 0.9873 | 0.9860 | 0.0054 |
| LSTM | Glucose and HR | 24.0000 | 0.0000 | 64.0000 | 64.0000 | 0.9835 | 0.9858 | 0.0040 |
| GRU | Glucose and HR | 24.0000 | 0.0000 | 128.0000 | 256.0000 | 0.9840 | 0.9852 | 0.0045 |
| LSTM | Glucose and HR | 21.0000 | 0.0000 | 128.0000 | 64.0000 | 0.9852 | 0.9849 | 0.0012 |
| LSTM | Glucose and HR | 24.0000 | 0.0000 | 128.0000 | 64.0000 | 0.9856 | 0.9848 | 0.0044 |
| GRU | Glucose and HR | 24.0000 | 0.0000 | 128.0000 | 64.0000 | 0.9854 | 0.9848 | 0.0033 |
| LSTM | Glucose and HR | 21.0000 | 0.0000 | 128.0000 | 1024.0000 | 0.9840 | 0.9848 | 0.0051 |
| LSTM | Glucose and HR | 24.0000 | 0.0000 | 64.0000 | 128.0000 | 0.9820 | 0.9845 | 0.0051 |
| LSTM | Glucose and Stpes | 24.0000 | 0.0000 | 128.0000 | 128.0000 | 0.9839 | 0.9844 | 0.0038 |
| LSTM | Glucose and HR | 24.0000 | 0.0000 | 16.0000 | 256.0000 | 0.9821 | 0.9843 | 0.0051 |
| LSTM | Glucose and HR | 18.0000 | 0.0000 | 128.0000 | 256.0000 | 0.9843 | 0.9842 | 0.0012 |
| LSTM | Glucose and HR | 24.0000 | 0.0000 | 128.0000 | 128.0000 | 0.9840 | 0.9841 | 0.0028 |
| LSTM | Glucose and Stpes | 24.0000 | 0.0000 | 128.0000 | 256.0000 | 0.9835 | 0.9841 | 0.0017 |
| GRU | Glucose and HR | 24.0000 | 0.0000 | 128.0000 | 128.0000 | 0.9838 | 0.9841 | 0.0031 |
| GRU | Glucose and Stpes | 24.0000 | 0.0000 | 128.0000 | 128.0000 | 0.9835 | 0.9840 | 0.0053 |
| LSTM | Glucose and HR | 24.0000 | 0.0000 | 64.0000 | 256.0000 | 0.9827 | 0.9837 | 0.0046 |
| LSTM | Glucose and HR | 24.0000 | 0.0000 | 128.0000 | 256.0000 | 0.9839 | 0.9836 | 0.0028 |
| LSTM | Glucose and HR | 24.0000 | 0.0000 | 32.0000 | 256.0000 | 0.9800 | 0.9835 | 0.0081 |
| LSTM | Glucose and HR | 24.0000 | 0.0000 | 32.0000 | 512.0000 | 0.9851 | 0.9834 | 0.0048 |
| LSTM | Glucose and Stpes | 24.0000 | 0.0000 | 128.0000 | 64.0000 | 0.9833 | 0.9833 | 0.0025 |
| GRU | Glucose and HR | 24.0000 | 0.0000 | 64.0000 | 256.0000 | 0.9824 | 0.9833 | 0.0024 |
| LSTM | Glucose and HR | 21.0000 | 0.0000 | 128.0000 | 512.0000 | 0.9786 | 0.9833 | 0.0101 |
| GRU | Glucose and Stpes | 24.0000 | 0.0000 | 128.0000 | 64.0000 | 0.9823 | 0.9832 | 0.0040 |
| GRU | Glucose and HR | 24.0000 | 0.0000 | 64.0000 | 512.0000 | 0.9815 | 0.9831 | 0.0040 |
| GRU | Glucose and HR | 21.0000 | 0.0000 | 64.0000 | 1024.0000 | 0.9788 | 0.9830 | 0.0097 |
| LSTM | Glucose and HR | 24.0000 | 0.0000 | 32.0000 | 128.0000 | 0.9826 | 0.9830 | 0.0038 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dénes-Fazakas, L.; Simon, B.; Hartvég, Á.; Kovács, L.; Dulf, É.-H.; Szilágyi, L.; Eigner, G. Physical Activity Detection for Diabetes Mellitus Patients Using Recurrent Neural Networks. Sensors 2024, 24, 2412. https://doi.org/10.3390/s24082412
Dénes-Fazakas L, Simon B, Hartvég Á, Kovács L, Dulf É-H, Szilágyi L, Eigner G. Physical Activity Detection for Diabetes Mellitus Patients Using Recurrent Neural Networks. Sensors. 2024; 24(8):2412. https://doi.org/10.3390/s24082412
Chicago/Turabian StyleDénes-Fazakas, Lehel, Barbara Simon, Ádám Hartvég, Levente Kovács, Éva-Henrietta Dulf, László Szilágyi, and György Eigner. 2024. "Physical Activity Detection for Diabetes Mellitus Patients Using Recurrent Neural Networks" Sensors 24, no. 8: 2412. https://doi.org/10.3390/s24082412
APA StyleDénes-Fazakas, L., Simon, B., Hartvég, Á., Kovács, L., Dulf, É.-H., Szilágyi, L., & Eigner, G. (2024). Physical Activity Detection for Diabetes Mellitus Patients Using Recurrent Neural Networks. Sensors, 24(8), 2412. https://doi.org/10.3390/s24082412