1. Introduction
Modern vehicles are equipped with a variety of Advanced Driver Assistance Systems (ADAS) functions, such as advanced emergency braking assistance, blind spot information system, and adaptive cruise control. These functions actively support the driver and require a reliable environment perception, typically on the object track level. Current-generation vehicles with Level 2 systems fuse and track object detections from multiple sensors with different sensing domains and mounting positions to increase the overall system’s Field of View (FoV), performance, and robustness.
This multi-sensor multi-object tracking problem can be solved by a variety of approaches. Approaches that estimate full trajectories by taking all measurements into account at once, such as shadowing filters [
1], are able to achieve good tracking results; however, these are typically not capable of processing the data sequentially, which is required by most online applications, where at each time only the measurements of the current time-step are known. Particle filters are one type of online-capable approach that processes measurements recursively. They have particular strengths in representing the uncertainties of nonlinear systems and non-Gaussian noise, but require a large number of particles to do this accurately, especially for high-dimensional systems. Although real-time-capable implementations are possible, as shown by [
2] using Rao–Blackwellization, the authors still estimated the computational speed to be slower compared to a Kalman filter by a factor of 100 with
particles and a state vector of dimension
. Because this paper is interested in solutions with computational requirements in the range of the Kalman filter and is less focused on highly nonlinear and non-Gaussian applications, the particle filter is not considered a viable choice.
A popular and computationally efficient solution to the multi-sensor multi-object tracking problem is the use of a Kalman Filter (KF), such as the examples in [
3,
4,
5,
6,
7,
8]. The states of each object are estimated by a separate KF [
9], which essentially makes it an extension of a single target filtering approach. Therefore, such approaches require a data association scheme that matches new measurements to the already tracked objects and a track management scheme to handle the appearance and disappearance of tracks. Errors such as incorrect assignment during data association can occur during these two supporting steps. Such a situation can then lead to incorrect estimation of the number of objects and their states.
In contrast, the family of Random Finite Set (RFS) filters estimates both the cardinality (the number of objects) and their states. Therefore, they offer true multi-target filtering without data association along with complex track management. The Probability Hypothesis Density (PHD) filter [
10] estimates the probability hypothesis density (or intensity function) of a random set variable. The Gaussian Mixture Probability Hypothesis Density (GM-PHD) filter [
11] is an efficient Gaussian implementation of the PHD filter. This paper shows an approach that makes this filter an alternative to KF with a performance advantage that is computationally lightweight and suitable for real-time applications. A key aspect of the presented approach is that it is designed in such a way that a Kalman filter-based approach can be replaced without much effort. Therefore, it is applicable to systems with partially overlapping or non-overlapping sensor FoVs and asynchronous sensor updates, which are common in real-world setups currently covered by KF approaches.
The standard GM-PHD filter assumes the use of a single sensor. Next to the single sensor PHD filter, Mahler introduced the inter-corrector PHD [
10] as a multi-sensor solution. This was achieved using multiple single-sensor Bayesian filters [
12]. Improvements for multi-sensor applications of the PHD filter followed in [
13] along with Gaussian mixture implementations and developments in [
14,
15]. However, these approaches assume sensor systems with completely overlapping FoVs and synchronous measurements, which is not the case in current-generation Level 2+ systems. In general, many GM-PHD-based fusion approaches use multiple single sensor filters together with a combination rule such as the Generalized Covariance Intersection (GCI) for fusion. These approaches are usually not suitable for partial/non-overlapping sensor FoVs. To overcome this shortage, ref. [
16] presented a collaborative GM-PHD filter that fuses the intensity functions of multiple filter sources using Covariance Intersection on nearby Gaussian components only.
In [
17], a comparison of two approaches to asynchronous radar sensor fusion with the PHD filter was presented. Sequence process PHD (SP-PHD) fusion fuses measurements of multiple sensors sequentially using a global filter, while fixed nodes PHD fusion uses separate sensor PHD filters that are fused using the GCI. This was followed by [
18], where distributed PHD fusion approaches were shown next to the SP-PHD fusion for asynchronous sensor setups. However, these approaches have not been described for partially overlapping FoVs. Overall, there are only a very few publications focusing on real-world automotive applications, where asynchronous sensor setups and partially/non-overlapping sensor FoVs are common.
Most publications have assumed constant values for sensor-specific parameters such as clutter density and detection probability. However, this is not the case for real-world sensors, and can lead to tracking errors in the case of partial/non-overlapping sensor FoVs. This paper shows that the application of sensor-specific models for these parameters can solve multiple problems of GM-PHD filters in real-world applications. In [
19], this was addressed by differentiating the detection probability between inside and outside the FoV [
16]. In addition [
20], introduced occlusion models for those areas where tracks are not detectable. Ref. [
21] proposed a detection probability model for sonar applications, taking the object distance into account. This paper proposes a more versatile model for the detection probability with distance dependency that fits the capabilities of automotive sensors. Compared to previous publications, the clutter density is modeled in a similar way.
Because many systems fuse additional track attributes such as the classification in addition to the track states, this paper presents a new approach to handle the propagation of additional attributes with the GM-PHD filter. In addition, an adaptive birth model and a gating process are proposed to increase computational efficiency.
The presented approach uses an SP-PHD scheme for asynchronous sensor measurements in a way that can replace typical KF implementations. This enables a direct performance comparison of the proposed GM-PHD approach to a KF approach on both the KITTI dataset [
22] and a custom dataset with multiple radars and a camera. In the evaluation, the proposed GM-PHD approach substitutes for the KF approach, with as many parameters as possible remaining the same in order to ensure robust comparability. By testing on two real-world datasets and considering multiple sensor combinations, a statement can be made about its suitability for real systems, which has not been possible to date.
2. The GM-PHD Filter
RFS filters estimate a set of multiple-target states; as such, they cover both the state estimation and the estimation of the number of states with their birth and death. Therefore, no explicit data association between individual measurements and tracks is required, as the state set is estimated as a whole.
The PHD filter [
10] approximates the exact multi-target filter by only propagating the first-order statistical moment (PHD) of an RFS. The PHD is also called the intensity function. Under the assumption of a Poisson RFS, there is a closed-form analytic solution for the prediction and update step, as both the cardinality distribution and the spatial distribution are defined by the PHD.
The GM-PHD filter uses a Gaussian mixture to represent the PHD
of an object state
at time step
, which has the advantage of fast computation. Because the first-order statistical moment of an RFS is estimated, the PHD
can be interpreted as the density of the expected number of targets at
. The PHD is always represented as a sum of
weighted Gaussians with weight
, mean
, and covariance
[
11]:
2.1. GM-PHD Prediction
Similar to the Kalman filter, the GM-PHD filter is divided into prediction and update. However, in practical implementations the additional computation steps prune and merge are used to keep the number of Gaussian components at a low number, as shown by [
23,
24]. The GM-PHD predicted intensity
is calculated by combining the prediction
with the spawn intensity
and birth intensity
[
11]:
The spawn intensity models the spawning of new targets from existing ones, while the birth intensity models the birth of new targets; both are represented as a Gaussian mixture. The developed model for the birth intensity is shown in
Section 3.4.2, while the spawn intensity is not used here. The prediction
is calculated by
using the survival probability
[
11]. The means and covariances are predicted using the state transition matrix
and process noise covariance matrix
. Similar to the extended Kalman filter, an extended Kalman PHD filter equation set is described in [
11], which allows nonlinear process models.
2.2. GM-PHD Update
After the prediction step, the predicted intensity
for time
k is represented by the Gaussian mixture
The GM-PHD update step then calculates the corrected intensity
at time
k using the detection probability
and the clutter density
. The update is calculated by iterating over all measurements
of the measurement set
[
11]:
with
Here, is the detection probability and is the clutter density, while updating of the Gaussian components is performed using the observation matrix and the observation noise covariance matrix .
The equations presented here are the basis of the proposed tracking approach. However, various optimizations and adaptations are proposed around them in order to create an implementation that allows a fast and reliable application in real-world scenarios. These can be found in the following sections.
3. Proposed Multi-Sensor Multi-Object Tracking Approach
Multi-sensor multi-object tracking is considered here as estimating the number of all surrounding objects as well as their states over time while assigning track attributes, a confidence rating, and unique IDs to form trajectories. Therefore, the i-th tracked object of time step k is represented by a tuple including the track’s unique ID , state , classification , and probability of existence . The classification is represented as a probability distribution or pseudo-probability distribution over all possible classes, which is necessary for fusion and estimation over time. The set of all n tracked objects is .
Multiple independent sensors that may have different FoVs update the tracks with measurements and classification measurements . The goal is to estimate the states and attributes of all existing tracks using the independent measurements provided by different sensors. Smart sensors with integrated object tracking capabilities might be used in real-world applications by treating the tracks of each time step as individual measurements.
3.1. Kalman Filter Approach
A Kalman filter-based approach is implemented here for comparison, as many current systems use this approach. In Kalman filter pipelines such as [
3,
4,
5,
6,
8], a separate filter estimates the states of each tracked object. This is supported by a gating and data association approach that maps the incoming measurements of a sensor to the existing tracks. In this implementation, the chi-square test following ([
25], p. 112) for gating and a global nearest neighbor data association scheme [
26] based on the Mahalanobis distance is used. The distances between detections and tracks are calculated using the Mahalanobis distance
with the predicted measurement
and the innovation covariance matrix
,
and the association is then solved using the Hungarian algorithm [
27]. A track management scheme is responsible for adding new appearing tracks and removing disappearing tracks accordingly. In this work, the Bayesian formulation for existence probability estimation from [
28] is used as a basis for the track management. Non-updated tracks are removed if the existence probability is below a certain threshold, while tracks are forwarded if the existence probability is above a minimum threshold.
The state vector of each track contains the two-dimensional position
and
, speed
and
, and acceleration
and
, as well as the Oriented Bounding Box (OBB) orientation
and OBB dimensions, consisting of length
l, width
w, and height
h. The state
vector is described as follows:
Similarly, the measurement vector
consists of the position
and
as well as the dimensions
l,
w, and
h and orientation
, resulting in
. The system dynamics are described by a constant acceleration model with transition function
f and time difference
, as the last time step
is defined by
with the control vector
including the ego velocity
and the ego yaw rate
, which results in
The extended Kalman filter equations are used for the prediction.
3.2. Substituting the KF with the GM-PHD Filter
In order to replace a KF-based Multi-Object Tracking (MOT) framework with a GM-PHD-based one, the interfaces must be similar. The input of a KF framework is a list of detections, each containing a measurement vector
and attributes, such as the classification
.
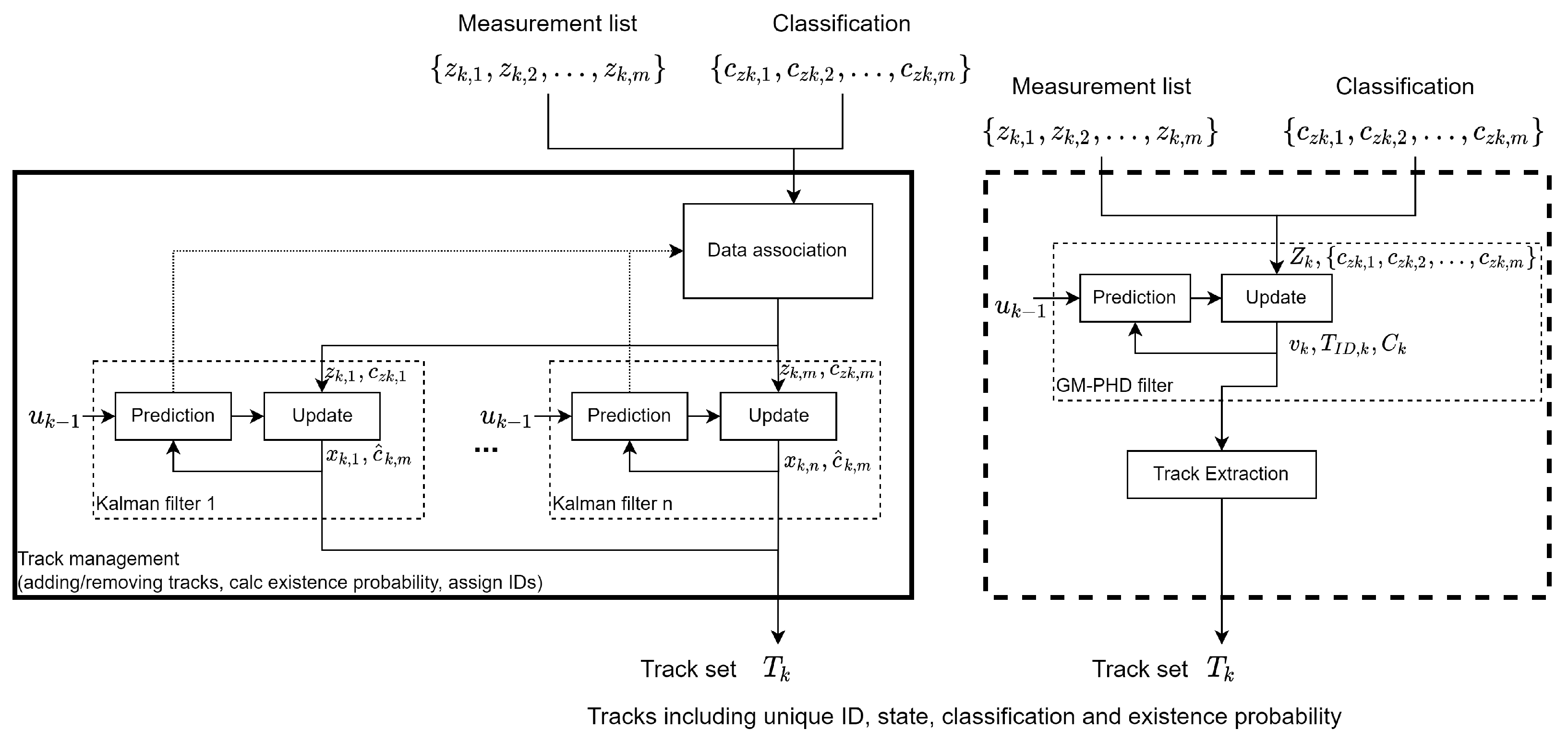
Figure 1 shows an overview of the Kalman filter framework on the left-hand side and substitution by a GM-PHD framework on the right-hand side. With the KF, the states are estimated separately for each track. This means that the additional attributes, such as the classification, can also be calculated separately for each track. In contrast, the GM-PHD filter estimates the global PHD. The tracks are then extracted from the PHD in a separate step.
Section 3.4 shows an approach to propagating additional attributes such as the classification alongside the PHD to provide this additional information for the extracted tracks.
3.3. Sensor-Based Parameter Models
3.3.1. Detection Probability
The original implementation of the GM-PHD filter [
11] assumes a constant detection probability over the entire state space. However, this assumption is not the case with real sensor systems. For example, if a track with state
is located outside the FoV of the sensor
, as shown in
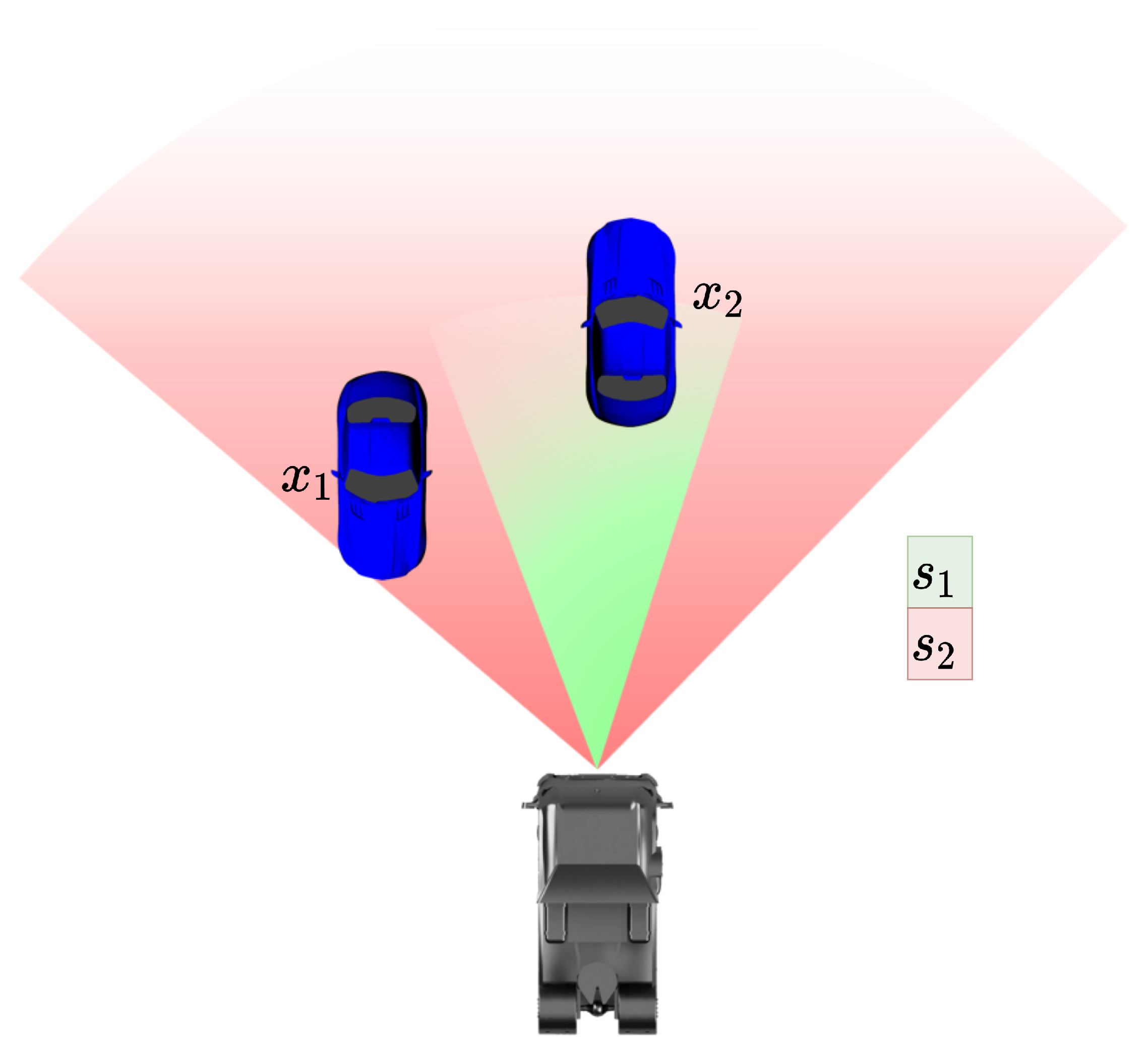
Figure 2, then the detection probability is 0; depending on the sensor technology, the detection probability will also change with environmental influences such as the weather or illumination conditions. For almost all sensors, there is a decrease in capability with increasing distance, which can be modeled mathematically.
The detection probability model is an important part of proper sensor fusion in the proposed framework; it strongly influences the appearance and disappearance, as it highly affects the weight calculation of the GM-PHD. In this framework, if a Gaussian component has a high detection probability and no corresponding measurement exists, then the weight will decrease; in turn, if a component has a very low detection probability and no corresponding measurement exists, then the weight is barely effected. Note that the detection probability model can also be applied to the existence probability estimation used for the KF framework.
We propose a detection probability model based on the FoV and the track’s distance. Therefore, a mathematical model for the detection probability of track is defined based on experimental measurements for each sensor . Next to the FoV, which obviously sets limits to the detection probability, the distance is a key parameter. Due to the decreasing resolution at higher distances, the detection probability will decrease with the distance for all types of perception sensors. In addition, certain sensors, such as automotive radars, can have direction-dependent sensitivities and maximum detection ranges, which can result in more complex detection probability models. To ensure general applicability to different types of sensors, the proposed model is based only on the distance and a radial FoV.
Overall, the formula for the detection probability model
is as follows:
In this description, is the second-order polynomial describing the distance dependency, with being the distance of the track’s OBB center.
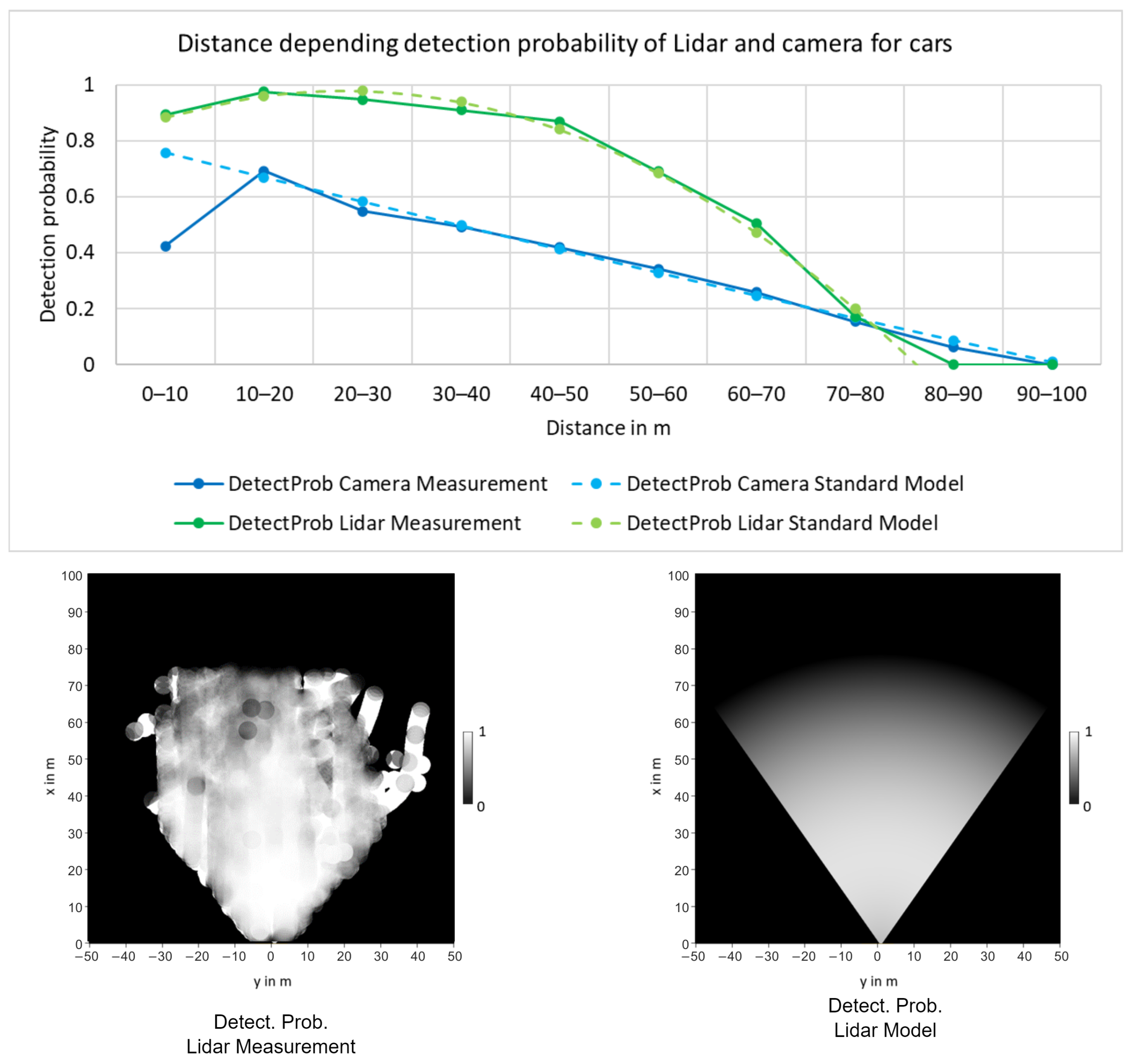
To verify this model and calculate the parameter values, the detection probabilities were experimentally determined for the “Car” class. Using the Point-RCNN [
29] detector for Lidar and Yolo-Mono-3D [
30] for monocular camera, the detection probability was calculated using the training data from the KITTI tracking dataset. For each time step, each of the ground truth tracks was compared with the respective measurements. If a measurement with an overlapping OBB was found for a ground truth track, it was counted as a true detection. Next, the percentage of detected tracks within the sensor FoV was calculated depending on the distance in order to obtain the detection probabilities.
As shown on the top of
Figure 3, the second-order polynomial used by the model can accurately represent the distance dependent detection probability for both the camera and the Lidar detector. The Bird’s Eye View (BEV) result of this polynomial model in combination with the sensor’s FoV is shown at the bottom of
Figure 3 and compared to the measured result.
The GM-PHD implementation from [
11] assumes the detection probability to be constant, but shows a closed-form update for a state-dependent detection probability provided as a mixture. However, this form results in numerous Gaussian components, which greatly increases the computational effort, as shown in
Section 4.4. To reduce this, the constant assumption is violated and
is used instead. The experiments in
Section 4.3 show that the proposed solution still works for real-world data. In [
16], state-dependent detection probability was similarly used without a mixture model. However, their emphasis was on FoV and occlusion rather than on presenting a comprehensive model that encompasses distance dependency. Likewise, ref. [
19] differentiated the detection probability depending on the object being inside or outside the FoV, and did not consider the distance dependency.
3.3.2. Clutter Density
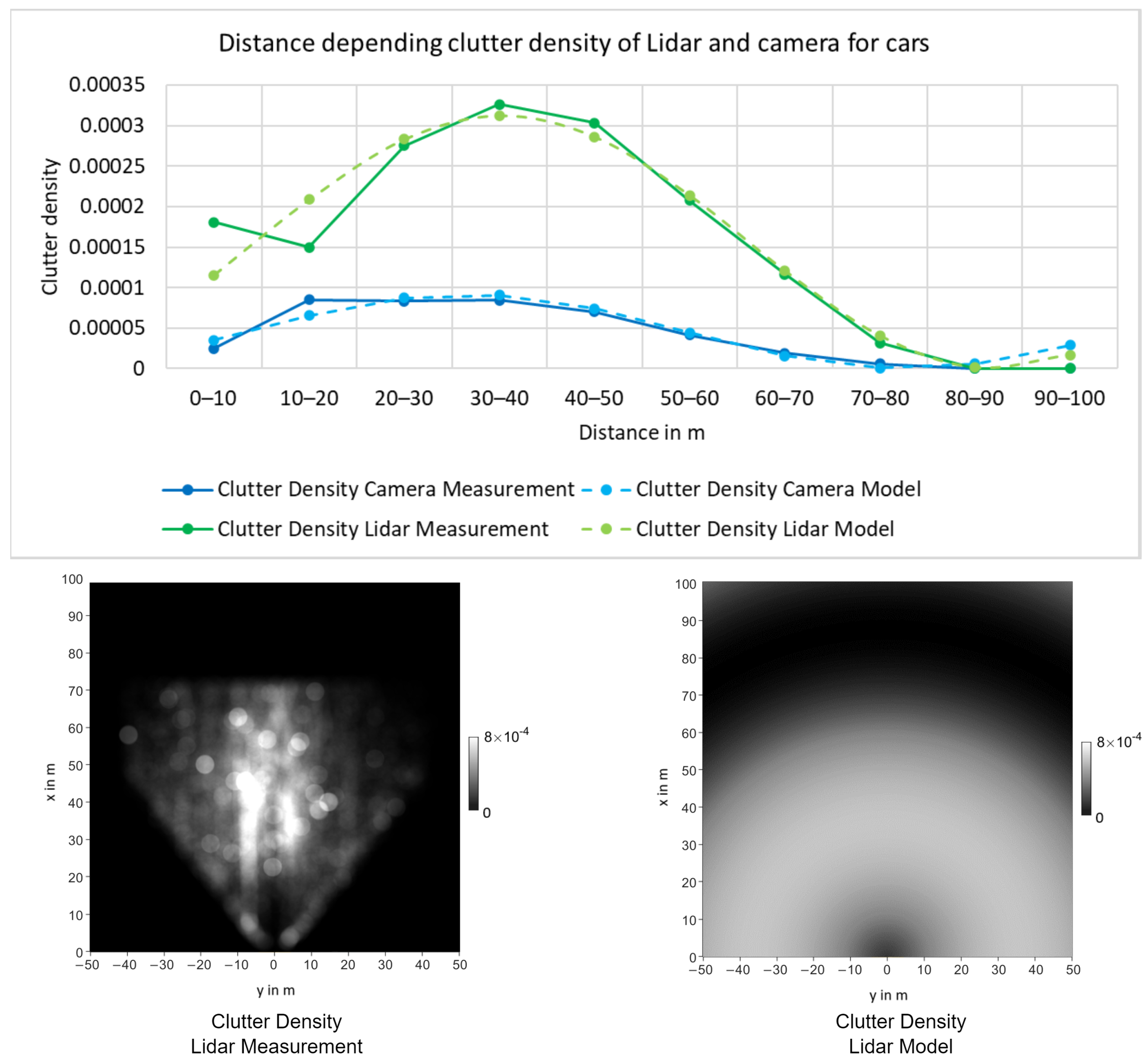
Similar to the detection probability, the clutter density is described as a mathematical model. In contrast to the detection probability, the GM-PHD standard filter equations do not include the assumption of a static value. Therefore, a mathematical model for the clutter density can be used directly.
The clutter density can be modeled similar to the detection probability. Therefore, the mathematical model for of sensor is experimentally defined based on the distance.
The distance dependency was experimentally determined using the Point-RCNN [
29] detector for Lidar and Yolo-Mono-3D [
30] for monocular camera on the training data of the KITTI tracking dataset.
Figure 4 shows the measured clutter density of the “Car” class for both the Lidar and the camera. As shown, the clutter density has a peak value for medium distances and appears to be lower for both near and far distances. This behavior can be modeled using a sinusoidal function, which leads to the approximations shown in
Figure 4.
The overall mathematical description for the clutter density
of measurement
is described by
3.4. Computational Steps for the GM-PHD Approach
This section describes the processing steps of the approach using the GM-PHD filter. These steps use the GM-PHD filter equations, and additionally propagate the tags for the unique ID and the classification over time. As described by [
23], a unique identifier, or tag,
, is assigned to each Gaussian component at time step
k, which together form a set
where
is the number of Gaussian components at time step
k and
is the currently highest unique ID. To additionally track the classification of each Gaussian component, the respective classification set
with
is introduced.
3.4.1. Step 0: Initialization
For initialization, the number of Gaussian components is set to and the tags and classification sets are empty, with and . After the one-time initialization, steps 1–5 are repeated.
3.4.2. Step 1: Prediction
The prediction step predicts the PHD at the current time step using the constant acceleration model from
Section 3.1 and the extended Kalman PHD equations from [
11]. In addition, the survival probability
is calculated for each time step using a base survival probability
and the time difference from the last time step
, as follows:
The proposed implementation does not model the spawning process of Equation (
2), which ignores crtain scenarios for simplicity and sets
. New objects can appear anywhere in the monitored space; however, as the computational effort should be kept low, we want to avoid creating a high number of random Gaussian component. Thus, adaptive birth models depending on the measurements are considered here, and a new adaptive approach is presented. In [
31,
32], the authors proposed adaptive birth processes which create new Gaussian components based on all measurements. However, this inevitably creates an overlap between birth components and already-tracked components in many areas. These overlaps do not truly represent the birth of new targets. Instead, Gaussian components should only be added in areas where no components are currently present. In this way, the influence of the newly added components on the update of the existing components is reduced, and both the total number of Gaussian components and the computational effort can be reduced while ensuring that the birth of new targets remains well-modeled.
In the presented approach, a birth measurement set
is generated in the previous update step
that includes all measurements with a sum of generated weights
below a threshold
:
The threshold was found experimentally and set to
. For the sum of weights, the measurement weights
from Equation (
10) are used combined with the predicted weights
from the previous time step:
The sum of weights indicates the influence of the j-th measurement on the PHD update. If the influence is very low, it is assumed that no Gaussian component of the intensity function is in close range to the measurement. Therefore, is a subset of the measurement set that only contains measurements in areas where no Gaussian components are present in the intensity function. Next, a Gaussian mixture is generated based on these measurements with , with initial covariance and and with initial weight . Then, is predicted to time step k using the GM-PHD prediction to form .
For each of the birth Gaussian components, a new birth tag is added along with the set of birth tags at the current time step, as proposed by [
23]. Each tag is initialized with a new unique ID based on
, which is increased by
afterwards:
Similarly, a classification probability vector is added for each Gaussian component. The initial classification is calculated by updating a uniform classification distribution
with the measurement classification probability vector
. In principle, this can be done with any classification update function
capable of updating the classification in a meaningful way; however, this is not further described here. The classification set is accordingly extended with
3.4.3. Step 2: Update
The update step follows the overall procedure from [
23], with adaptations for improved tracking results and computation speed in ADAS applications.
A gating step is introduced to improve the computation speed. The GM-PHD update step adds many Gaussian components due to the update of each prior Gaussian component with each measurement component. Many of these components have very low weights and would be pruned in the next step anyway. To reduce this number of low-weight components in advance, a gating process is introduced. Because gating in ADAS applications can be interpreted spatially, the gating is based solely on the position in terms of the X and Y coordinates. The minimum of the squared Mahalanobis distance
and the Euclidean distance
defining the gate are calculated using the position difference
and the position covariance
, which only include the elements related to the X–Y position:
The distances are then calculated with
Applying the gating based on these distances, Equation (
8) changes to
where only components of the gating indices
are taken into account. For these gating indices, either the squared Mahalanobis distance or the Euclidean distance is below the gating threshold
:
The update step uses the sensor-based parameter models proposed in
Section 3.3 for the detection probability and clutter density. Therefore, the following applies and is used in the update equations:
Because new Gaussian components are generated during the update step, new tags and classifications are added to the tag set and classification set with
m measurements, as follows:
For each Gaussian component created by a measurement, a tag is added that has the same value as the tag of the updated component. Similarly, for each Gaussian component created by a measurement, the classification probability vector is updated by the measurements’ classification probability vector using the function .
3.4.4. Step 3: Pruning
The pruning step from [
23] is implemented without adaptations, which means that all components with low weights below a truncation threshold
are eliminated. The classification set
is pruned in a similar way to the tag set.
3.4.5. Step 4: Merging
The merging procedure in general follows the one proposed in [
23], and has the goal of merging Gaussian components that have a low distance based on a distance criterion. In contrast to [
11,
23], and similar to [
33], this approach uses the Kullback-Leiber Divergence (KLD)
as the distance criterion, which is defined as follows:
Here, k is the dimension of the covariance matrices and . This distance is well-suited to being used as a criterion for whether two Gaussian components should be merged, as it provides an indication of the possible information loss.
When merging multiple components, the tag
of the component with the highest weight
is kept for the merged component. If components with the same tag still exist after the merging procedure, the component with the highest weight keeps the tag and all others are assigned a new one, similar to the proposal from [
23].
The classification is merged similarly to the mean. Therefore, the merged classification distribution vector
is calculated using the weighted average of all merged components
L:
3.4.6. Step 5: Track Extraction
In the last step, the tracks are extracted from the PHD estimation. To be interpreted as a track, the weight of a Gaussian component has to exceed a weight threshold
creating the track set
:
To provide an existence probability for further processing steps, the weight of the Gaussian component is interpreted as a pseudo-existence probability with .
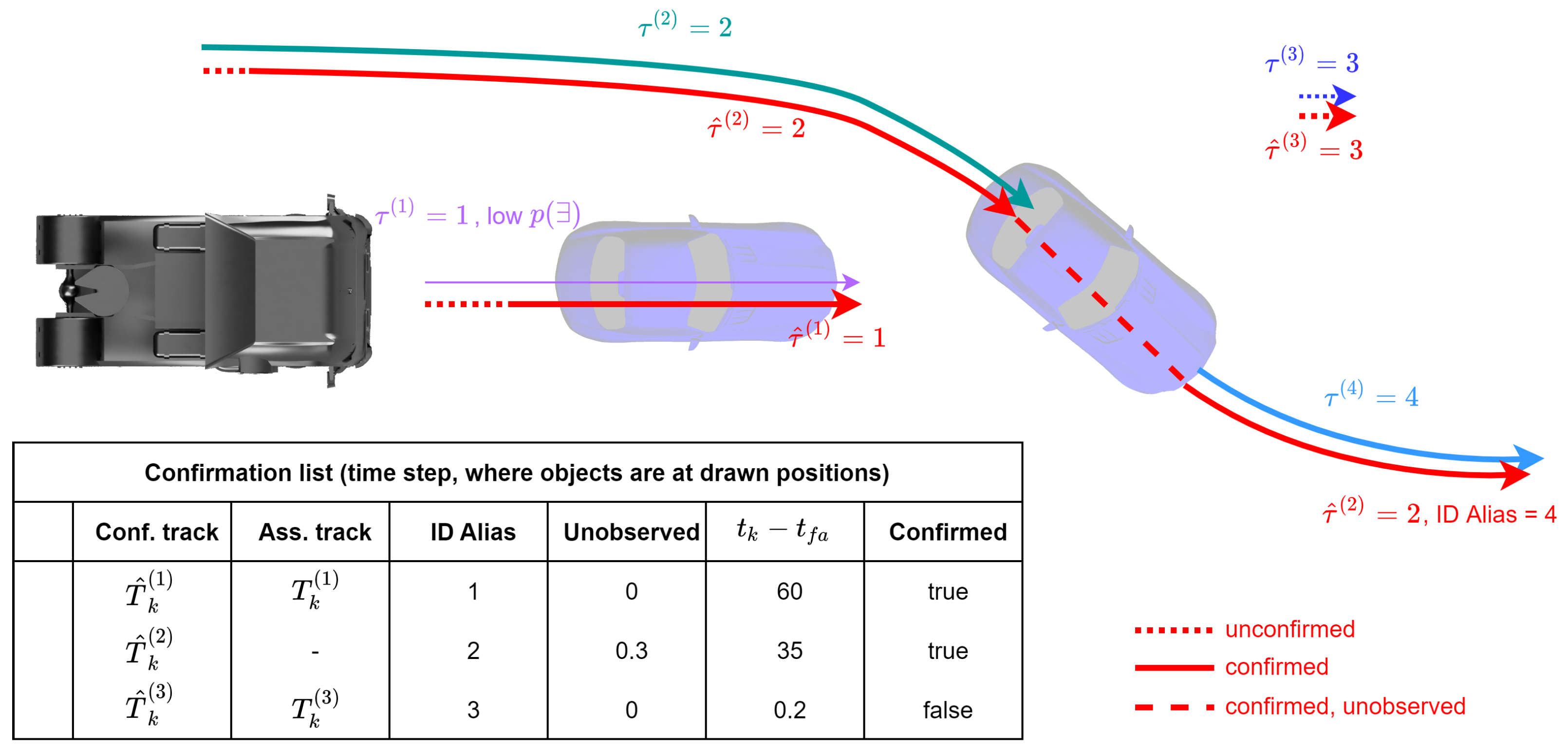
3.5. Track Confirmation Strategy
After the track extractions, the relevant information for ADAS functions, such as the unique IDs, states, classifications, and pseudo-existence probabilities, are available; however, the tracks may still be unstable. The existence and stability of the tracks is determined by the calculated weights of the Gaussian components and the propagated ID tags in the GM-PHD filter. However, there are situations in which these methods reach their limits:
Short-term occlusion of objects, where the track may disappear and a new one with a new ID is subsequently created.
Clutter tracks created due to random false detections.
If one of several sensors systematically fails to detect a target, the weight of the track may be low even though the object is tracked over a long period.
A track confirmation strategy is applied to overcome these limitations and pass only those tracks confirmed based on several criteria to the ADAS function. This consists of a confirmation list that is updated after each update cycle based on the track set
. Each element in the confirmation list consists of a confirmation track
, an ID alias, the unobserved time, the time of first appearance
, and a confirmation flag, as shown in the example in
Figure 5. The unobserved time is the time since the ID of the track was last updated.
Figure 5 shows an example scenario with two cars around the ego vehicle. The arrows show the trajectories of the tracks provided by MOT. One car is directly in front of the ego vehicle, but the provided existence probability is low. The other car is overtaking and occluded for a short duration, during which the tracks are lost. In addition, there is a false positive track in the right top corner. This scenario represents several different errors that can possibly occur for a MOT system.
In each update cycle of the confirmation strategy, the tracks in the confirmation list should be updated. Here, the ID alias of the stored confirmation track is compared with the ID of the tracks in the track set. If no match is found, then the unobserved time is increased and the state is predicted using the motion model. In
Figure 5, this is the case during occlusion of the overtaking car with
. Otherwise, the unobserved time is set to 0.
Next, ID switches are searched for all tracks in the confirmation list that have not yet received an assignment from the update track set. If a track is found in the update track set for a non-updated track in the confirmation list for which the Euclidean distance of the location is below the threshold, then an ID change is assumed and the ID alias is set to the new ID, which is indicated in
Figure 5 when the occluded car is tracked again. In this way, objects that have been lost for a short time, e.g., due to occlusion, can be found again while preserving their original unique ID. For all tracks in the update track set that have not yet been assigned to a track in the confirmation list, a new element is created in the confirmation list.
For all elements in the list, the next step checks whether they can be marked as confirmed. To be confirmed, one of the following criteria must be met:
In order to be confirmed, a track must either have an existence probability
greater than a threshold
and at the same time be tracked for a minimum duration
, or be tracked for a duration greater than
regardless of the existence probability. In
Figure 5, the car with low existence probability is confirmed, as it has been tracked for a long duration, while the false positive track is not confirmed, and consequently is not forwarded to the ADAS functions. All tracks in the confirmation list are then checked for deletion using the unobserved time. If the unobserved time is above the threshold, they are removed from the list. The threshold for already-confirmed tracks is higher than the threshold for unconfirmed tracks.
This confirmation strategy can filter out some of the errors shown in
Figure 5. In particular, situations where ID changes occur or tracks are lost for a short period of time can be resolved. In addition, it can reduce the amount of false positive tracks provided to the ADAS application. Therefore, the confirmation strategy can help to improve overall system performance. In our experiments, the confirmation strategy was applied to both the GM-PHD approach and the Kalman approach.
4. Results
The proposed approach was evaluated on both the KITTI dataset [
22] and a custom dataset recorded using a truck with multiple sensors that had partially overlapping sensor FoVs. The experiments show a comparison between the proposed approach and the KF reference approach on both datasets. In addition, the influence of the parameter models is shown and the runtimes are analyzed.
4.1. Datasets
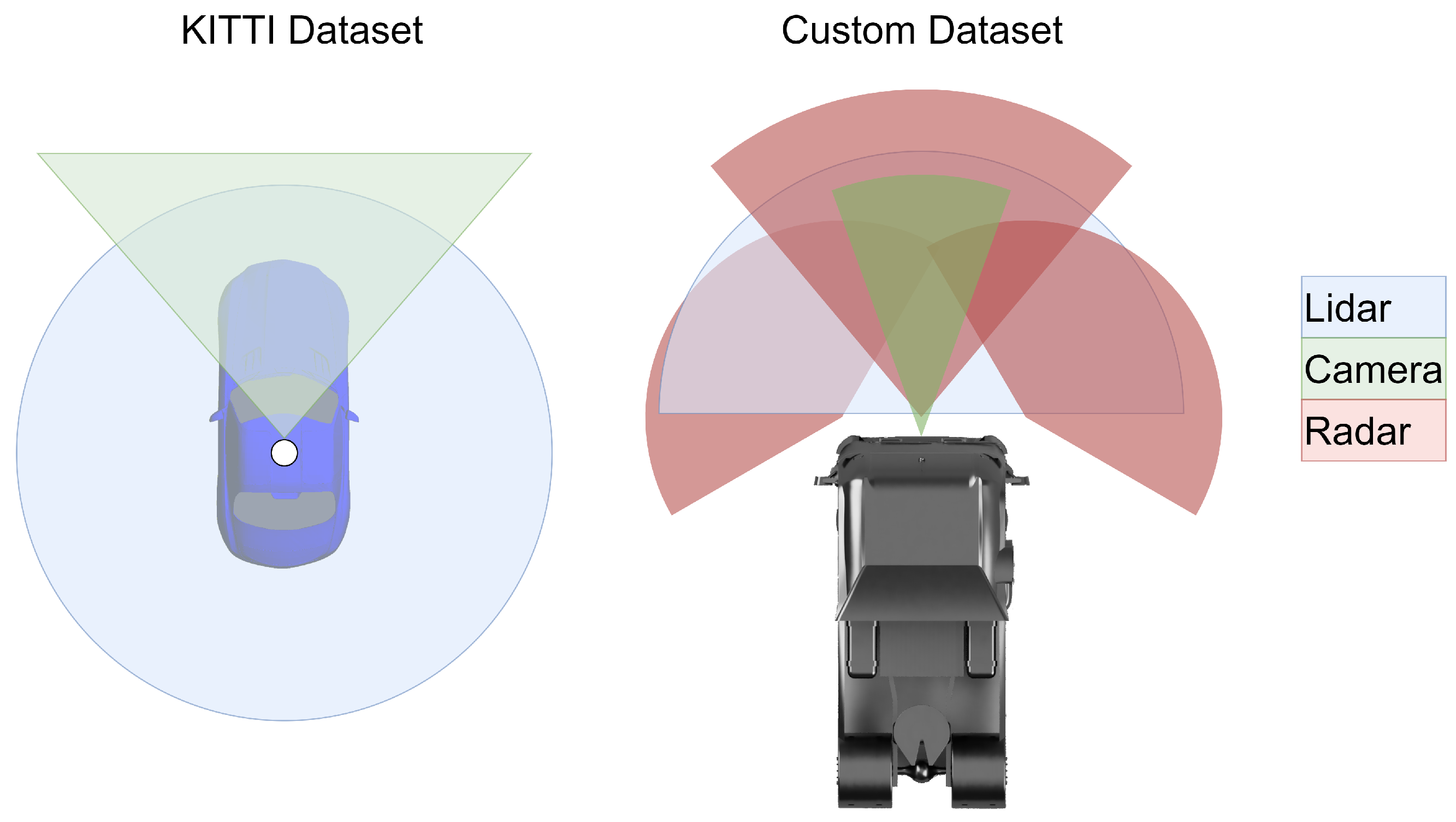
The sensor setup and sensor FoVs of both datasets are visualized in
Figure 6. As shown in the figure, both datasets have a forward-facing camera, while the KITTI dataset uses a larger FoV. The custom setup relies more on radars, with two corner Short Range Radar (SRR) and a central Long Range Radar (LRR). The KITTI dataset is well suited for the comparisons in this paper, as it is well studied, widely used, and contains ground truth data. For the experiments, only objects of the “Car” type were examined, as they occur most frequently in the dataset and as such are the most meaningful.
A new custom dataset was created to evaluate the tracking and fusion algorithms on the basis of current generation sensors and validate the results from the KITTI dataset. This dataset included sensors comparable to truck series equipment with integrated object detection in order to prove the validity and performance of the presented approaches for use in current-generation vehicles. The Lidar sensor was only used to generate ground truth OBB data in these experiments, with the other sensors used for tracking. The objects provided by the camera and radar sensors are geometrically represented either as a point, as a point with estimated width, or as an L-shape, depending on the situation and distance. In order to create a common representation, the detections of all sensors were converted to point objects without spatial expansion; thus, the length, width, height, and orientation are ignored for the custom dataset.
The custom dataset is small compared to KITTI, and contains three scenes from different operational design domains (highway, rural, and urban). Due to its smaller size, the custom dataset is less meaningful; however, it can still serve for confirmation or questioning of the results on the KITTI dataset, and provides the opportunity to study the fusion of more than two sensors with different and partially non-overlapping FoVs.
4.2. Comparison of Kalman and GM-PHD Filters on Real-World Data
First, a comparison of the GM-PHD approach and the Kalman approach is carried out to show the general potential of the presented approach. Only the FoV-dependency of the detection probability is used, with the parameters otherwise modeled as constant, as the Kalman approach does not take such dependencies into account either. The parameters are optimized for the fused setup for both datasets, and are kept the same for single-sensor tracking. Manual optimization of the parameters was carried out with the goal of achieving optimal results for both GM-PHD and KF. In order to provide a direct comparison of the filter outputs and prevent the comparison from being primarily dependent on the final optimization, the parameters were kept the same for both. Slight improvements were still possible by fine-tuning the parameters depending on the filter; thus, the results for separately tuned parameters are provided for the custom dataset.
The comparison was first conducted using the KITTI dataset. The training dataset of the MOT benchmark was used to show multiple comparisons. The Higher Order Tracking Accuracy (HOTA) metric [
34] was used as a performance measure. As the KITTI dataset only contains raw data, the Point-RCNN [
29] detection approach was used to provide detections based on Lidar and Yolo-Mono-3D [
30] was used to provide camera-based detections. Therefore, detections in the form of oriented bounding boxes suitable for processing are available. First, the performance of the Kalman and the GM-PHD approach is compared directly.
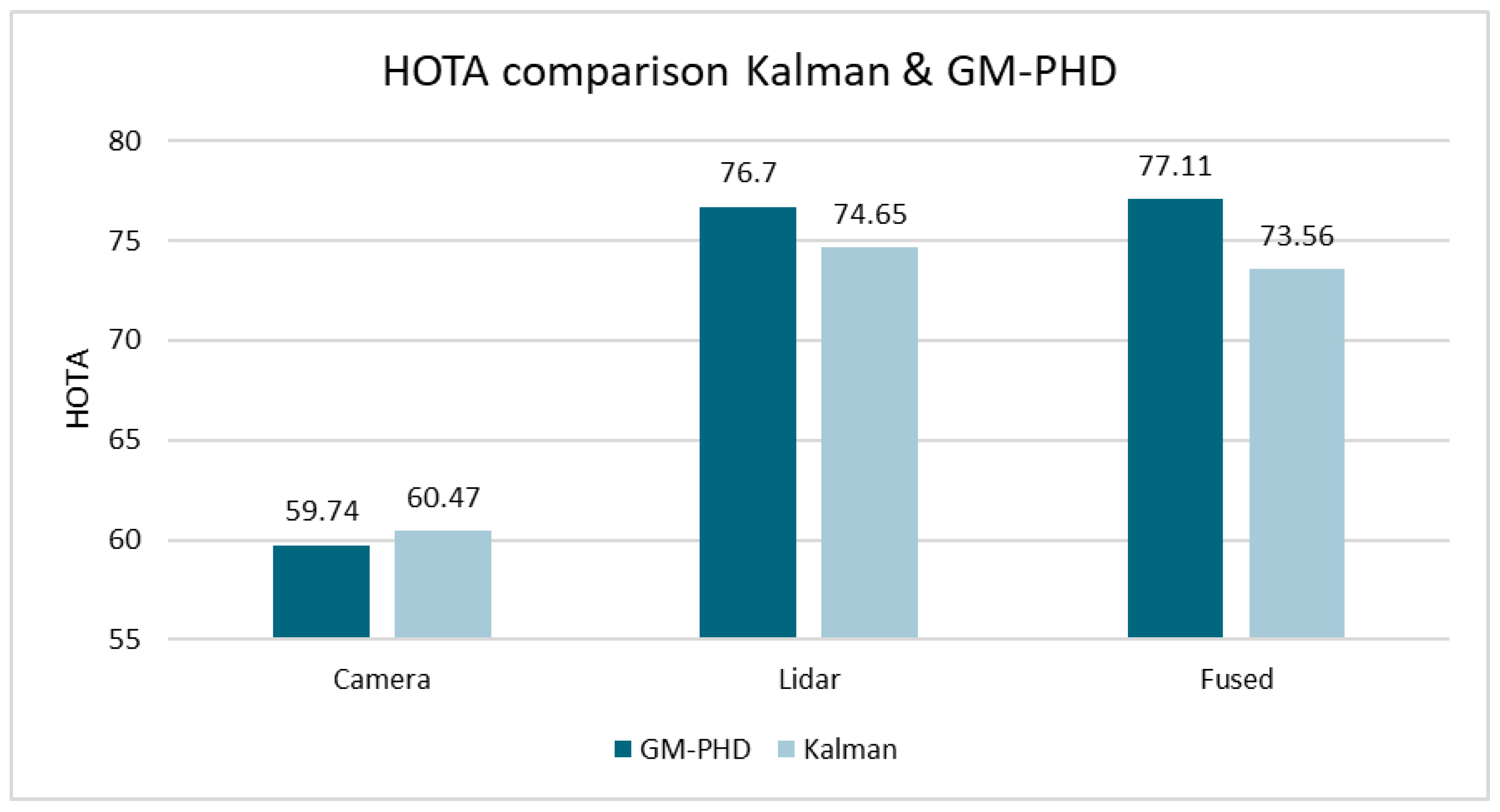
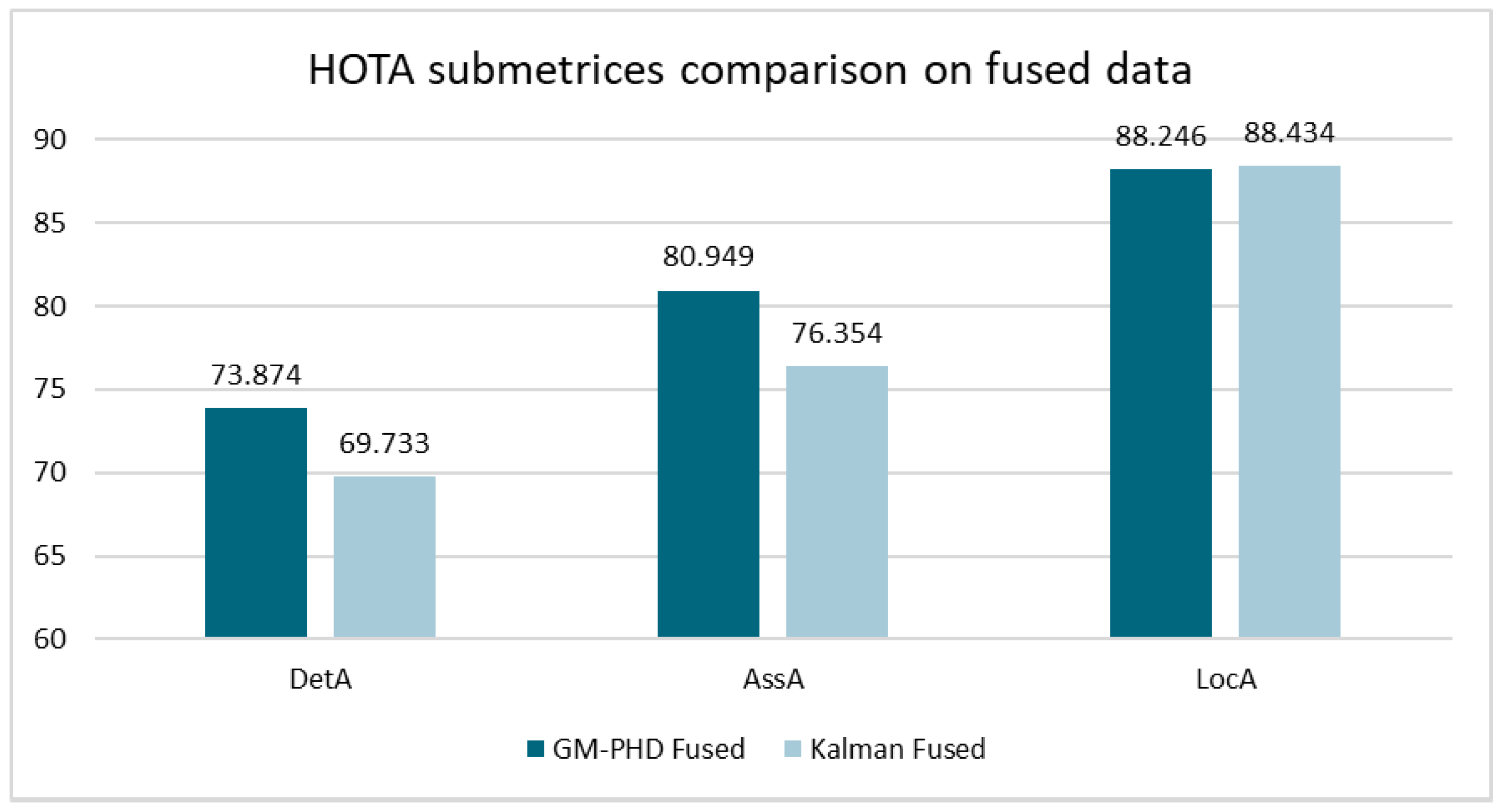
Figure 7 shows the HOTA results of both approaches on the KITTI dataset. The comparison is shown when using only Lidar, only camera, and fused data. The GM-PHD approach clearly outperforms the Kalman approach for Lidar only, and even more so for fused data. When comparing the sub-metrics on the fused data in
Figure 8, the differences are particularly evident for “DetA” and “AssA” [
34], which are measures of detection accuracy and association accuracy. This indicates that the GM-PHD approach has a particular advantage when creating/deleting tracks and ensuring correct ID assignment.
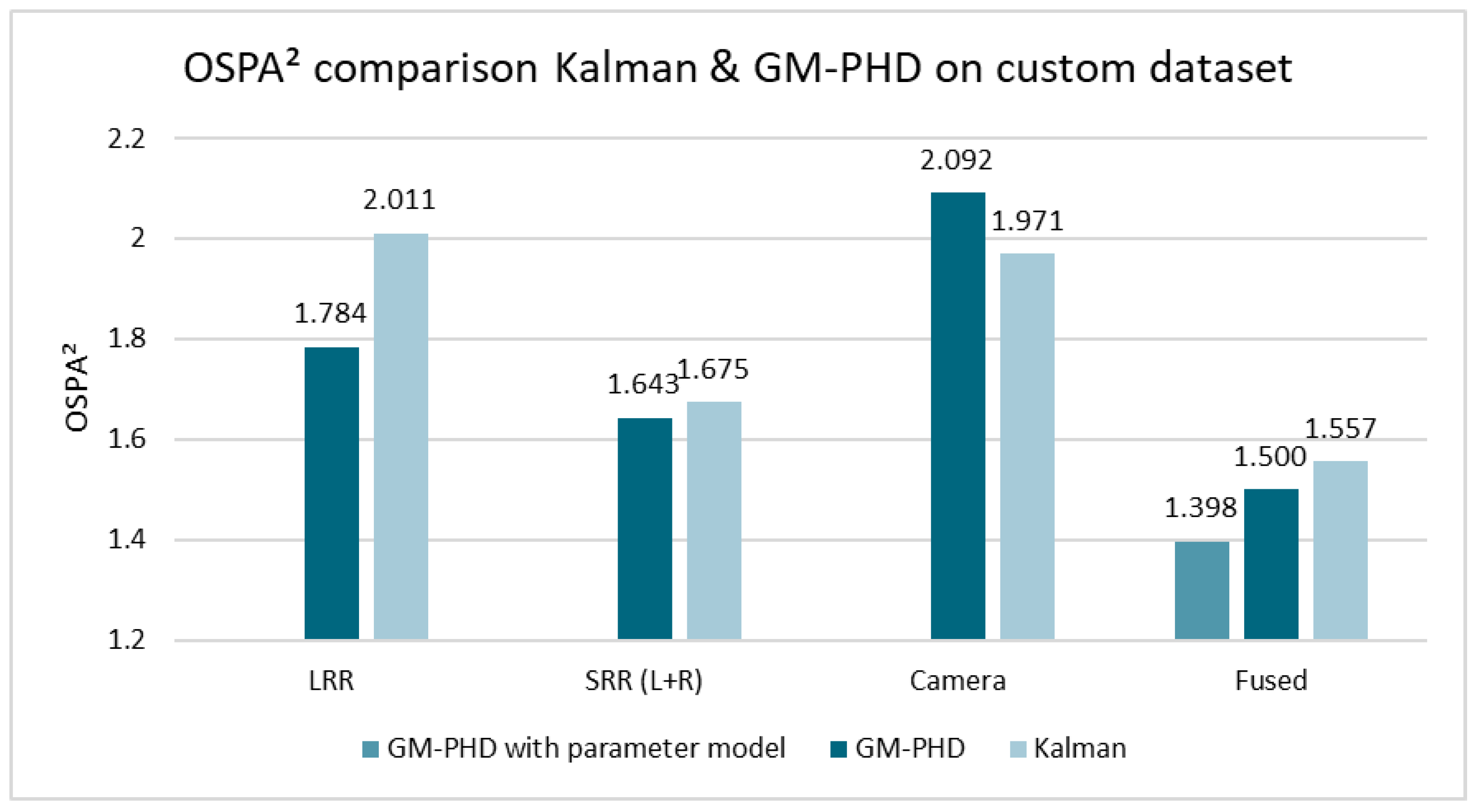
Both filters were then compared using the custom dataset. Here, the Second Order Optimal Sub-Pattern Assignment (OSPA
(2)) metric [
35] with cut-off
and order
was used, while the Euclidean distance was used as the base distance. Note that lower values of this metric represent a lower error. For a simplified comparison, the mean OSPA
(2) distance over all time steps of all three scenes was used.
Figure 9 shows the results for the single-sensor tracking and fused setups. As shown, the GM-PHD filter achieves lower mean distances for all tracking setups except camera-only. In addition to the results from
Figure 9, where the parameters were the same for the GM-PHD filter and the KF, the results for separately fine-tuned covariances are presented: the GM-PHD filter achieves an OSPA
(2) distance of 1.478, while the KF achieves 1.522 for the fused setup. While this performance difference is slightly decreased compared to the shared parameters, the GM-PHD approach still clearly outperforms the KF approach in this comparison.
Overall, the performance of the GM-PHD approach outperforms the Kalman approach in most tracking setups, and in particular for the fused data. The main advantages lie in its stable handling of appearing/disappearing tracks. For both datasets, the tracking performance in the camera-only setup is worse with the GM-PHD approach compared to the Kalman approach. This is probably due to the fact that the camera detections produce few clutter objects, but the position of the existing detections has a higher variance, which has a negative effect on the calculation of weights by the GM-PHD filter. In addition, the parameters are optimized for the fused setup and not fine-tuned for the single sensor tracking, which might have led to suboptimal results.
As shown by
Figure 9, sensor-based parameter models can further reduce the OSPA
(2) distance, which is shown in detail in the following section.
4.3. Influence of Sensor-Based Parameter Models
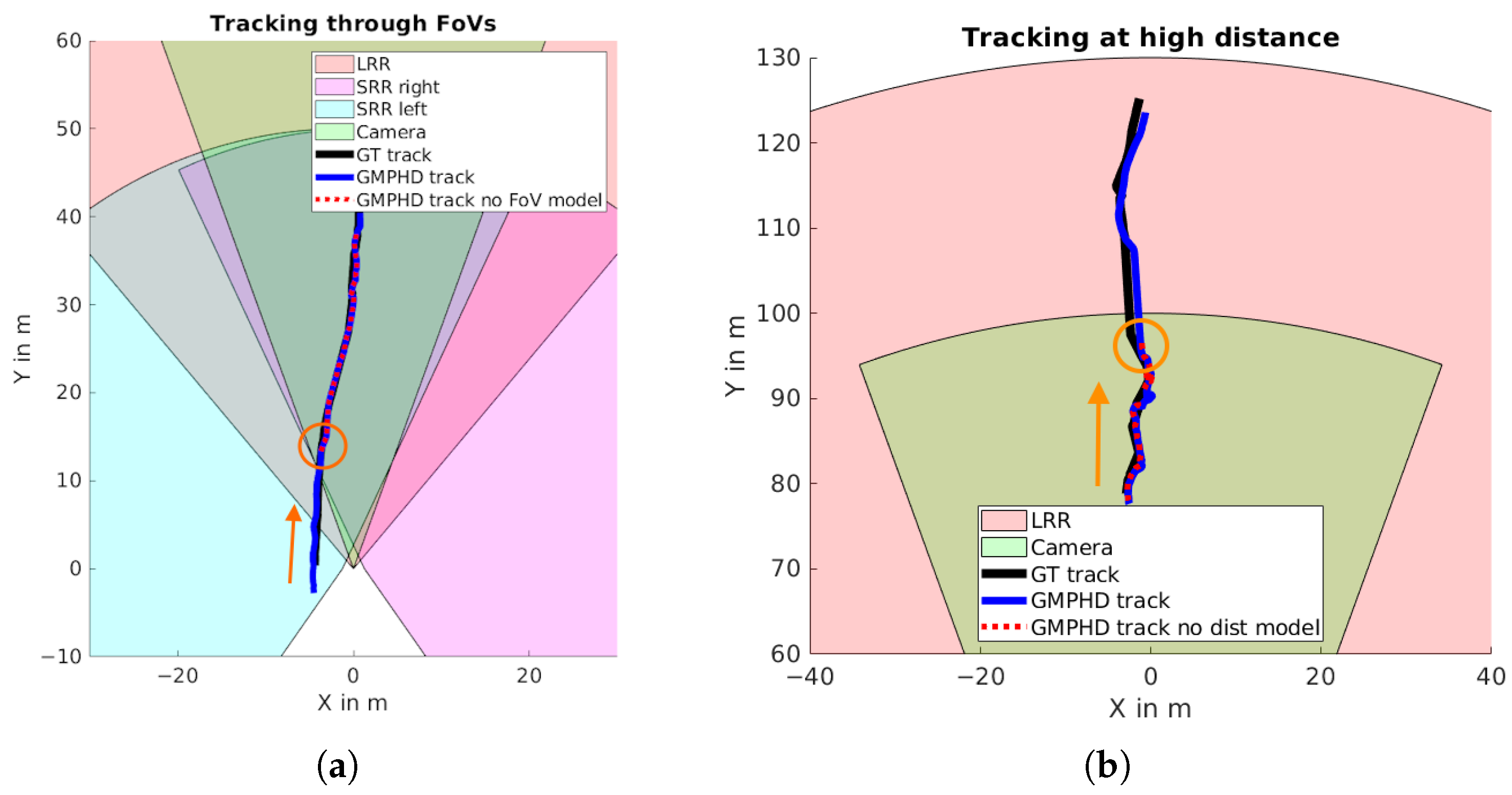
The sensor-based parameter models for detection probability and clutter density were evaluated with the GM-PHD approach. By applying the FoV to the detection probability, objects can be tracked through the FoVs of several sensors without applying additional rules.
Figure 10a shows this on the custom dataset with an overtaking vehicle that is initially only in the FoV of the left SRR, then moves into the FoVs of all combined sensors. Without FoV modeling, stable tracking only occurs in the area of the combined view of all sensors (marked with an orange circle).
Because the detection capabilities of all sensors are quite different with respect to the distance, a similar effect occurs at higher distances, where some sensors are no longer capable of detecting an object while others remain able to detect it.
Figure 10b shows a track from the custom dataset with a trajectory that is moving away from the ego vehicle. At a certain point, it is outside the capabilities of all sensors except the LRR; thanks to the distance-dependent model proposed here, it can still be tracked, while the track is lost when applying constant parameters (marked with an orange circle).
In addition to these detailed examples, a comparison of the performance with and without the sensor-based models was carried out for the tracking setups with sensor fusion. Because a comparison is not possible without modeling the FoV for the detection probability, this was applied to all scenarios, while the distance dependency was activated/deactivated depending on the test.
Table 1 shows the results on the KITTI dataset and on the custom dataset. For both datasets, improvements can be achieved using the detection probability and the clutter density parameter model. However, the improvements on the KITTI dataset are rather small, while the improvements on the custom dataset show more potential. Here, the differences in the detection capabilities between the sensors is high in certain areas of the observed space and therefore needs to be modeled accordingly, which explains the higher improvements. In addition, the clutter density model shows less improvement for both datasets compared to the detection probability model. However, this is no limitation in the usage of the models, since improvements can be achieved in all situations, although they are small for some scenarios.
4.4. Runtime Evaluation
The runtime of the presented GM-PHD approach was compared with the Kalman approach on the KITTI dataset and on the custom dataset with the Lidar-only setup. In addition, a variant without the gating in the update step was compared, as well as a variant where the detection probability was calculated using a mixture with seven components, as described in [
11].
Table 2 shows the HOTA results and the average runtime for one cycle. All approaches were implemented in C++ and tested on an Intel Core I7-9700K CPU.
The runtime can be greatly reduced without significantly affecting the HOTA results by the introduction of gating. The original variant with mixture implementation for the detection probability is considerably slower. Thanks to the presented optimizations, the runtime is only 2.5 times that of the Kalman filter, which is not possible with other GM-PHD approaches. This means that the approach presented here is expected to work in embedded devices.
In general, fast reactions are as important as accuracy for ADAS functions. If an emergency function needs to pursue the absolute minimum reaction times, KF might be the preferable choice. In real systems, it is necessary to calculate the updates for all sensors with cycle times of 10–20 Hz. If only limited computing power is available and these cycles cannot be achieved with the GM-PHD filter, then KF needs to be used. However, as KF has been used in sensor fusion systems for years and the available computing power continues to increase, experiments have shown that an update cycle of the GM-PHD filter can be calculated within the range of a millisecond; it can be assumed that this constraint can also be met by the GM-PHD filter in most systems nowadays. In these cases, the improved accuracy of the GM-PHD will benefit the system.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}