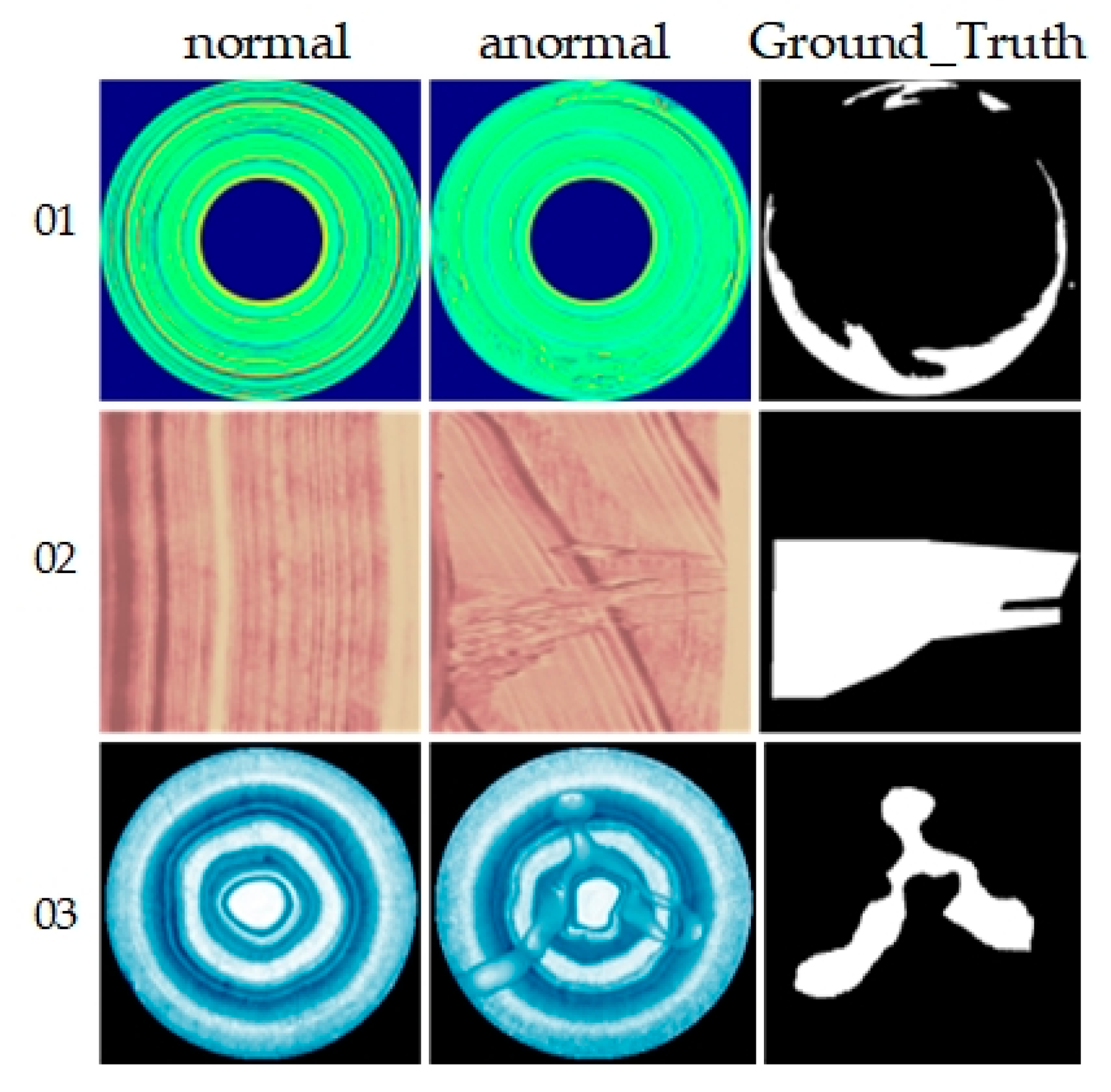
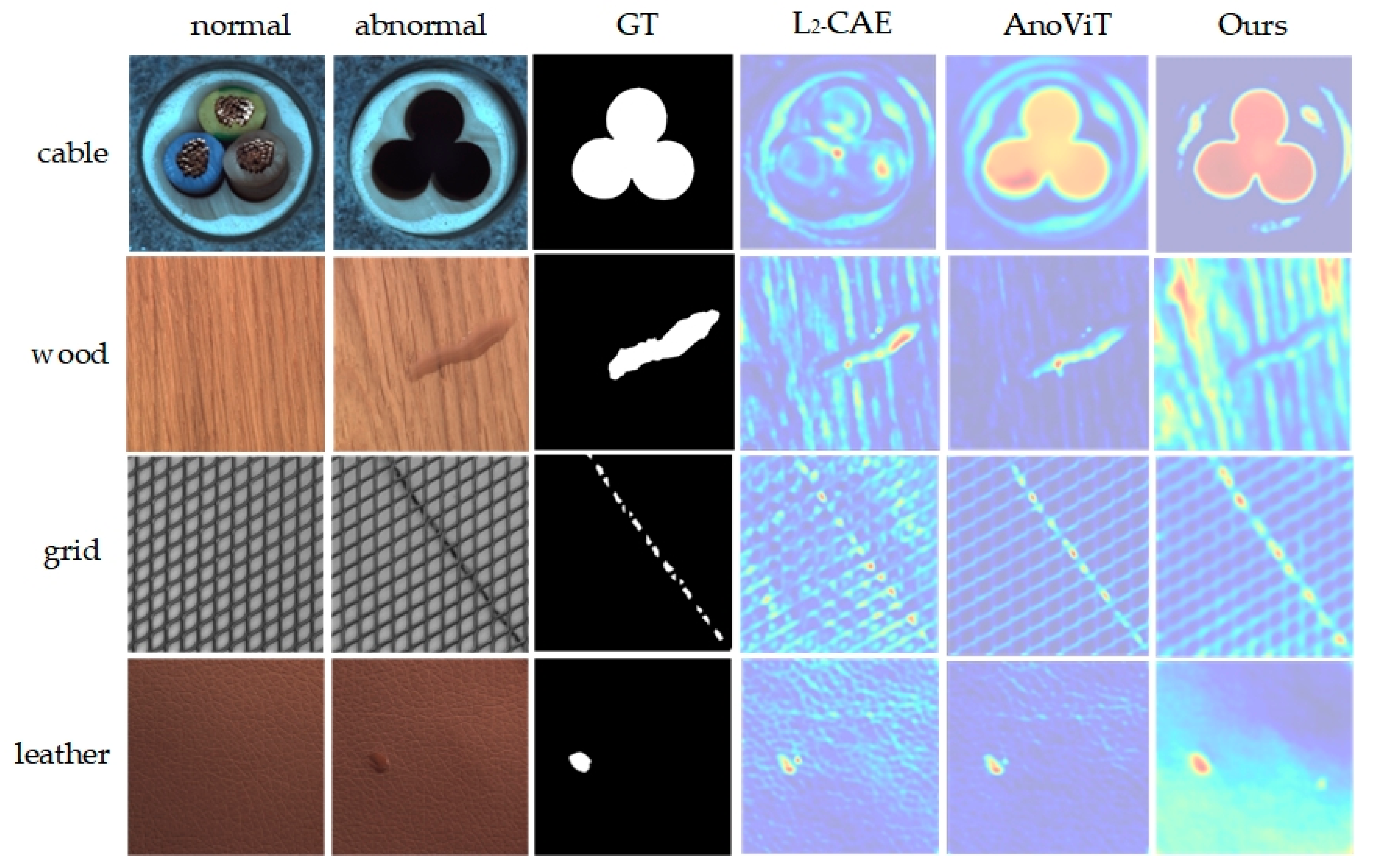
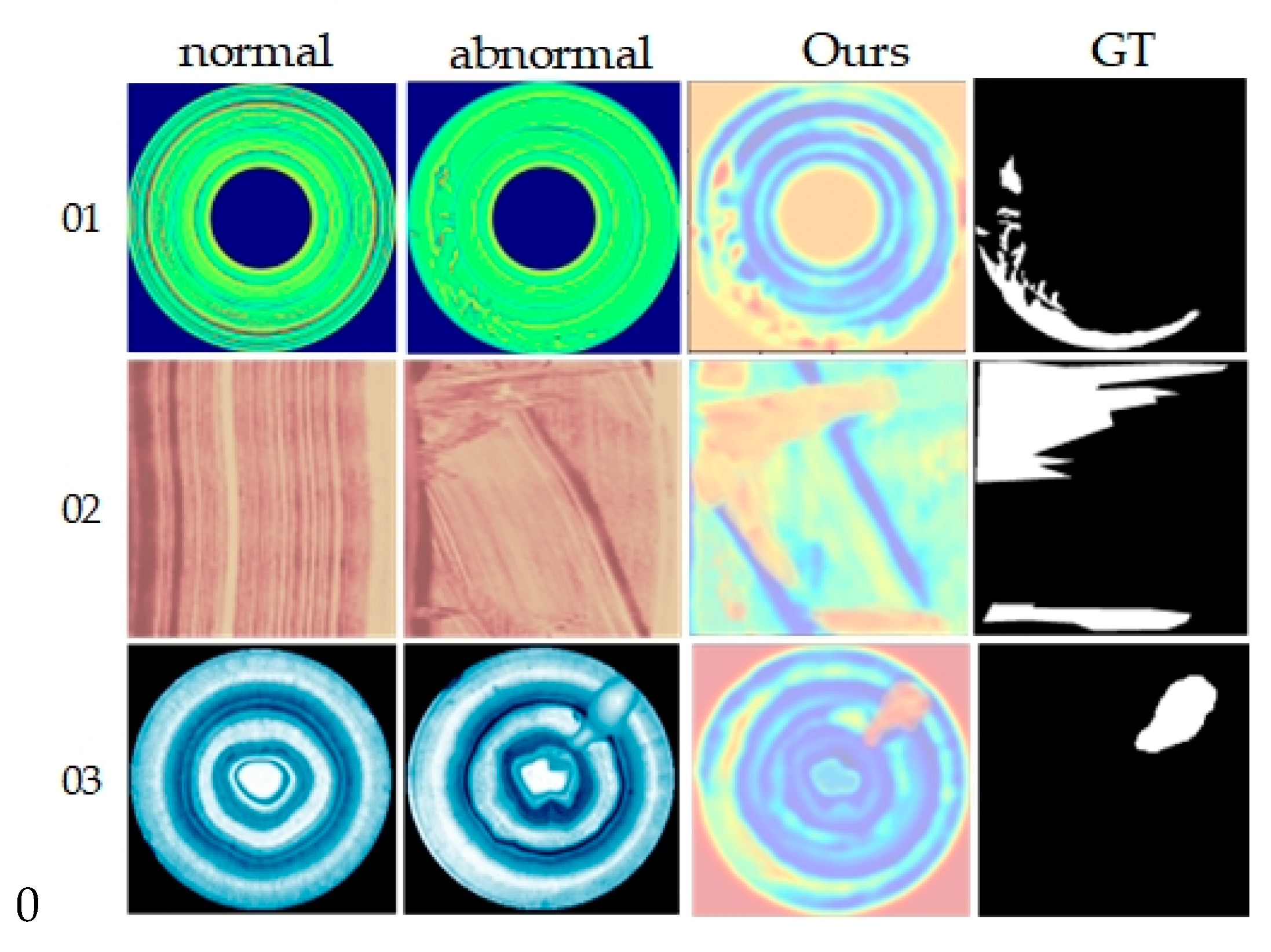
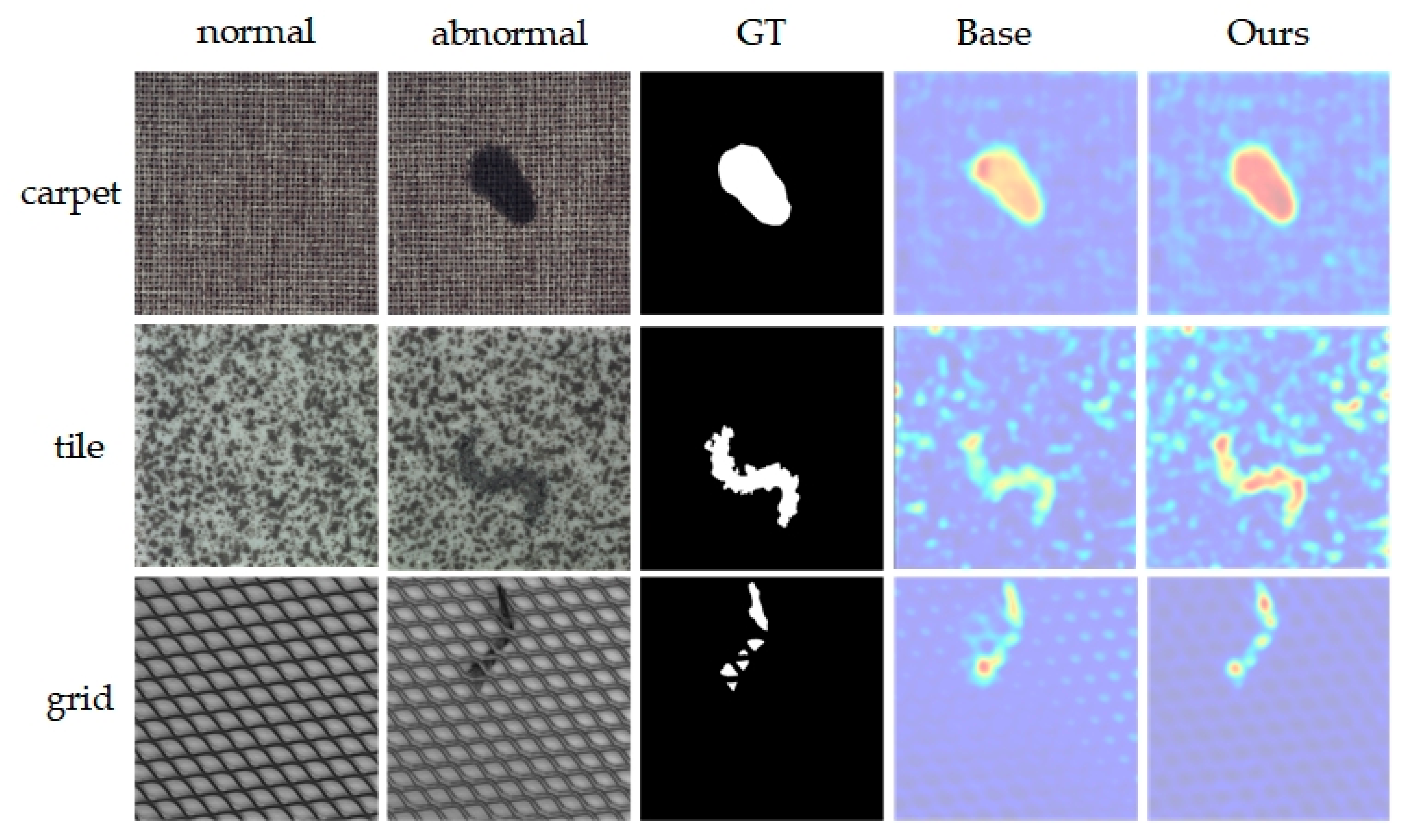
1. Introduction
With the improvement of national living standards and the rapid development of the domestic manufacturing industry, the variety and quantity of industrial products have increased dramatically. This has elevated consumer expectations regarding product quality, particularly in terms of appearance. Currently, appearance quality is at the forefront of market competitiveness, necessitating meticulous management of product appearance in industrial production. Manufacturing processes face challenges from various defects, including porosity, fractures, and wear, which impact not only appearance but also performance and market competitiveness. Hence, implementing effective anomaly detection in manufacturing processes is crucial to ensuring production safety, maintaining product quality, and enhancing competitiveness. In practice, industrial anomaly detection demonstrates significant application value [
1,
2]. The goal of industrial image anomaly detection is to identify nonconforming products from images, safeguarding quality and enhancing economic returns. This task is challenging because anomalies often occupy only a small portion of the image, and industrial images are characterized by high data dimensionality, making feature extraction and anomaly detection and localization difficult. Thus, exploring effective anomaly detection methods to enhance efficiency remains a significant challenge.
Traditional image anomaly detection [
3,
4] is predicated on the manual definition and extraction of features, a process that is both cumbersome and time-consuming, particularly with extensive industrial image data. The rapid advancements in deep learning within artificial intelligence, notably in natural language processing and computer vision, have expanded its application to industrial anomaly detection [
5]. Deep learning anomaly detection techniques are categorized based on the availability of data labels into fully supervised, unsupervised, and semi-supervised methods. Fully supervised learning methods [
6,
7], used in deep learning, depend on datasets meticulously labeled by experts for model training. Although effective, this approach poses a significant financial burden on many facilities due to the high labor costs involved. Confronted with the challenge of high data labeling costs, researchers have advocated for semi-supervised learning as a feasible solution. Semi-supervised learning employs a modest amount of labeled data to direct model training, enhancing the model’s generalization capability by incorporating substantial volumes of unlabeled data, making it particularly apt for scenarios with limited labeling resources or high labeling costs. For instance, Qiu et al. [
8] developed a framework featuring an image alignment module and a defect detection module for identifying defects on metal surfaces. Wan et al. [
9] introduced a Logit Inducing Loss (LIS) for training with imbalanced data distributions, alongside an Anomaly Capture Module to characterize anomalies, efficiently leveraging limited anomaly data. Despite their effectiveness in certain contexts, supervised learning models see limited use in industrial image anomaly detection. Collecting a substantial volume of anomaly samples for training supervised models is challenging in practice, with the labeling process being both time-consuming and expensive. While semi-supervised learning can mitigate labeling costs to some extent, it does not address the underlying issue. Conversely, unsupervised methods, which require only normal samples for training and eschew detailed labeling of abnormal samples, theoretically can identify all unknown defects, rendering them ideal for anomaly detection.
In unsupervised anomaly detection, deep codec structures based on convolutional neural networks (CNNs) are commonly employed, notably the Convolutional AutoEncoder (CAE) [
10], which compresses a normal image and reconstructs it to resemble the original. However, the limited sensory field of traditional CNNs constrains CAE to learning merely local information, hindering the capture of global contextual image information, resulting in inferior image reconstruction quality. Furthermore, while the CAE’s widespread use in image reconstruction and anomaly detection owes to CNNs’ robust generalization capabilities, this generalizability can prove to be a drawback. Specifically, CAE may inadvertently reconstruct anomalous regions during image reconstruction, thereby diminishing anomaly detection accuracy. Recently, the application of the Transformer architecture [
11] in computer vision [
12] has garnered increasing research interest. This architecture, an encoder-decoder structure, leverages a self-attention mechanism to capture long-range dependencies in the input sequence, extracting global feature information. Such capability enables the Transformer to enhance processing efficiency and accuracy, maintaining global feature representation without dependence on traditional convolutional or Recurrent Neural Network (RNN) architectures. Mishra et al. [
13] proposed a framework based on the Transformer for patch-level image reconstruction, utilizing Gaussian Mixture Density Networks to localize anomalous regions. Lee et al. [
14] introduced AnoViT, an encoder-decoder model based on the Vision Transformer, asserting its superiority over CNN-based L2-CAE in anomaly detection. HaloAE [
15] integrates the Transformer with HaloNet [
16], facilitating image reconstruction and achieving competitive results on the MVTec AD dataset. Despite the Transformer’s exemplary performance and versatility in computer vision, the nuances of industrial image anomaly detection—namely, sensitivity to anomaly details and the scarcity of samples—necessitate focused optimization and enhancement of the architecture.
Given the challenges in practical industrial inspection applications—namely, the scarcity of anomaly samples, high labeling costs, and limitations of traditional CAE in extracting global features and controlling anomaly generalization—this study proposes an unsupervised industrial image anomaly detection method leveraging the Vision Transformer (ViT). The primary contributions of this study are as follows:
Addressing the challenge of traditional CAE in learning global image features, the method incorporates a Transformer structure to understand the global context between image blocks, utilizing ViT’s encoder for high-level feature representation.
To mitigate the issue of anomaly generalization that reduces detection accuracy, a memory module is designed to record the normal image features extracted by the encoder, suppressing anomaly generalization.
A coordinate attention mechanism is introduced to concentrate on image features at both spatial and channel levels, enabling more precise anomaly localization and identification.
L2 loss, block-based SSIM loss, and entropy loss functions are employed to define the relationship between original and reconstructed images and calculate the anomaly score, thereby enhancing detection accuracy.
3. Proposed Method
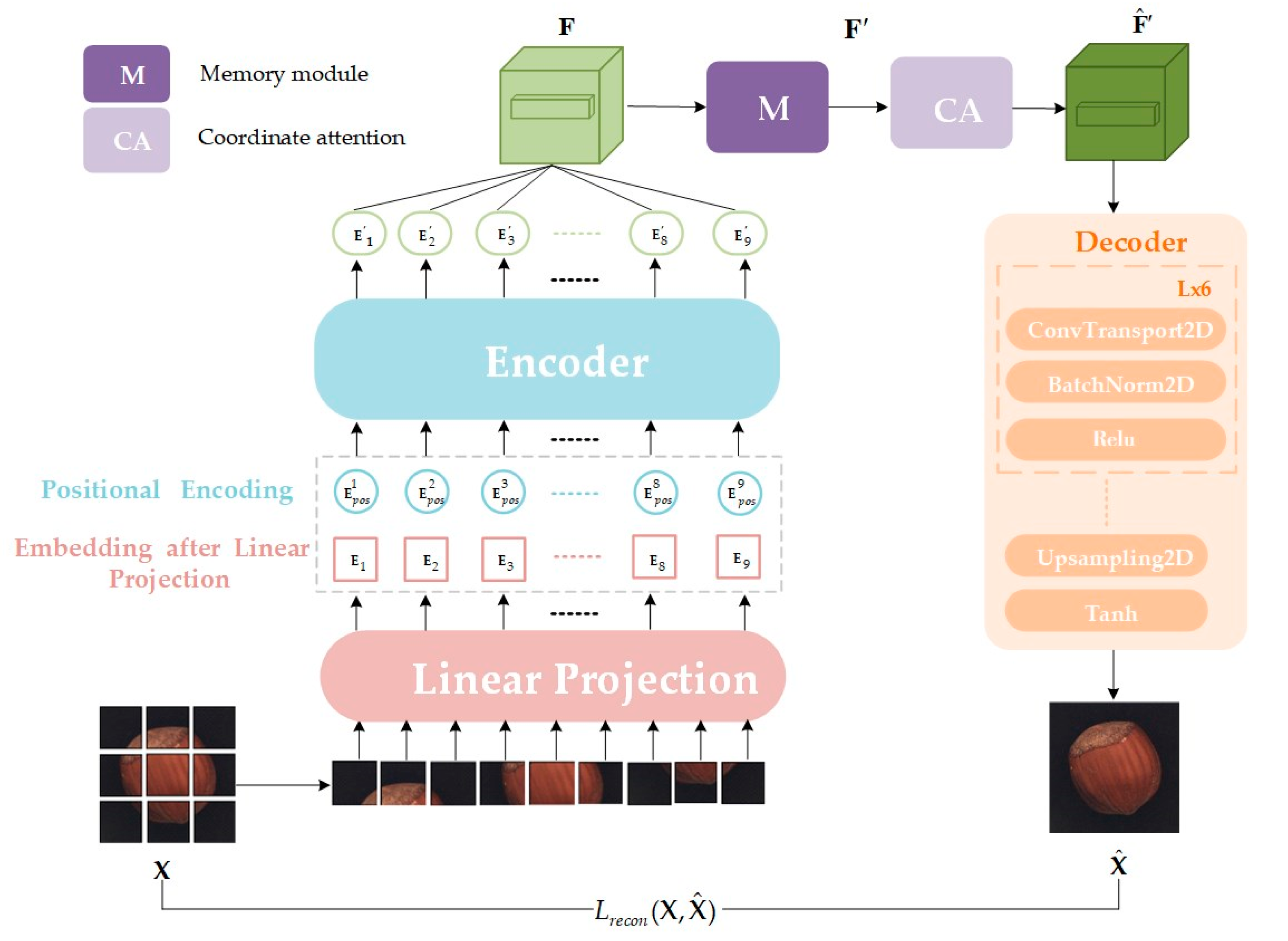
The method proposed in this study leverages the benefits of both reconstruction-based and patch-based approaches. The model comprises a ViT-based encoder, a memory module (M), a coordinate attention (CA) mechanism, and a decoder, as depicted in
Figure 2. The specific workflow is as follows:
Input image processing: Initially, the input image is decomposed into patches of size (P, P). These patches are then mapped into a D-dimensional space to form two-dimensional patch embeddings. Here, H, W, and C denote the height, width, and number of channels of the image, respectively, while N = HW/P2 represents the total number of patches.
Position embedding and sequence encoding: To preserve spatial location information among patches, position embedding is added to each patch embedding E, and a [cls] token is introduced for global image representation.
Encoder processing: The encoder processes the encoded sequence Z0 and outputs a series of block embeddings, each detailing information about the corresponding image block. These block embeddings are rearranged to form a feature mapping map F that approximates the structure of the original image.
Memory module: The feature mapping map F is input into the memory module, generating a feature representation of the normal data pattern through matching and weighted summation with stored normal pattern features. This step allows the model to “remember” the normal data patterns.
Coordinate Attention: The feature maps F’ computed by the memory network are conveyed to the CA module for further processing, yielding enhanced feature representations.
Decoding and image reconstruction: Finally, the decoder reverses the high-dimensional feature representation from the coordinate attention module, rendering it into a reconstructed image. Comparing differences between the input image X and the reconstructed image enables anomaly detection and localization.
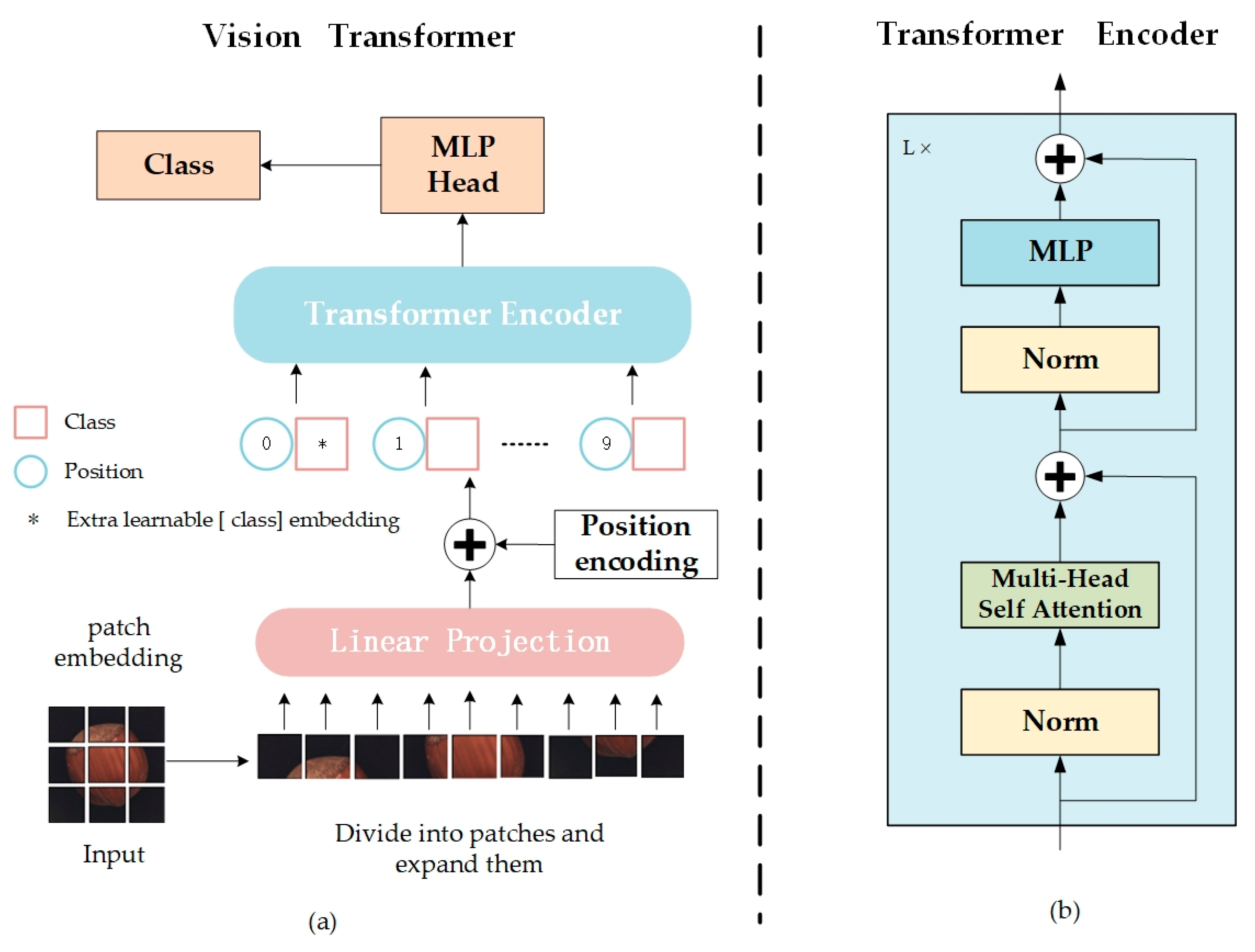
3.1. ViT-Based Encoder
In the model, the encoder employs a processing flow akin to the Vision Transformer (ViT), transforming the input image patches into a series of high-dimensional feature representations for subsequent processing and analysis.
The input image patches are initially mapped to the embedding space and augmented with positional information, as described in Equation (4):
Subsequently, the patch embedding sequences, augmented with location information, are fed into the Multihead Self-Attention (MSA) module (Equation (5)) and the Multilayer Perceptron (MLP) module (Equation (6)), where Layer Normalization (LN) is applied to the feature sequences before they are passed to the MSA and the MLP, a step that aids in stabilizing the training process, with
l (
l ∈ [1,
L]) denoting the number of layers:
Finally, residual connections are introduced to the outputs of the MSA and MLP modules, meaning the module inputs are directly added to their outputs. This approach mitigates the issue of vanishing gradients during deep network training and enhances the network’s training stability. Through these steps, the encoder efficiently extracts and processes the features of the input image patches, generating a rich feature representation. Additionally, this process ensures the model’s ability to fully leverage the spatial information and intrinsic features of the image, thereby enhancing overall performance.
3.2. Memory Network
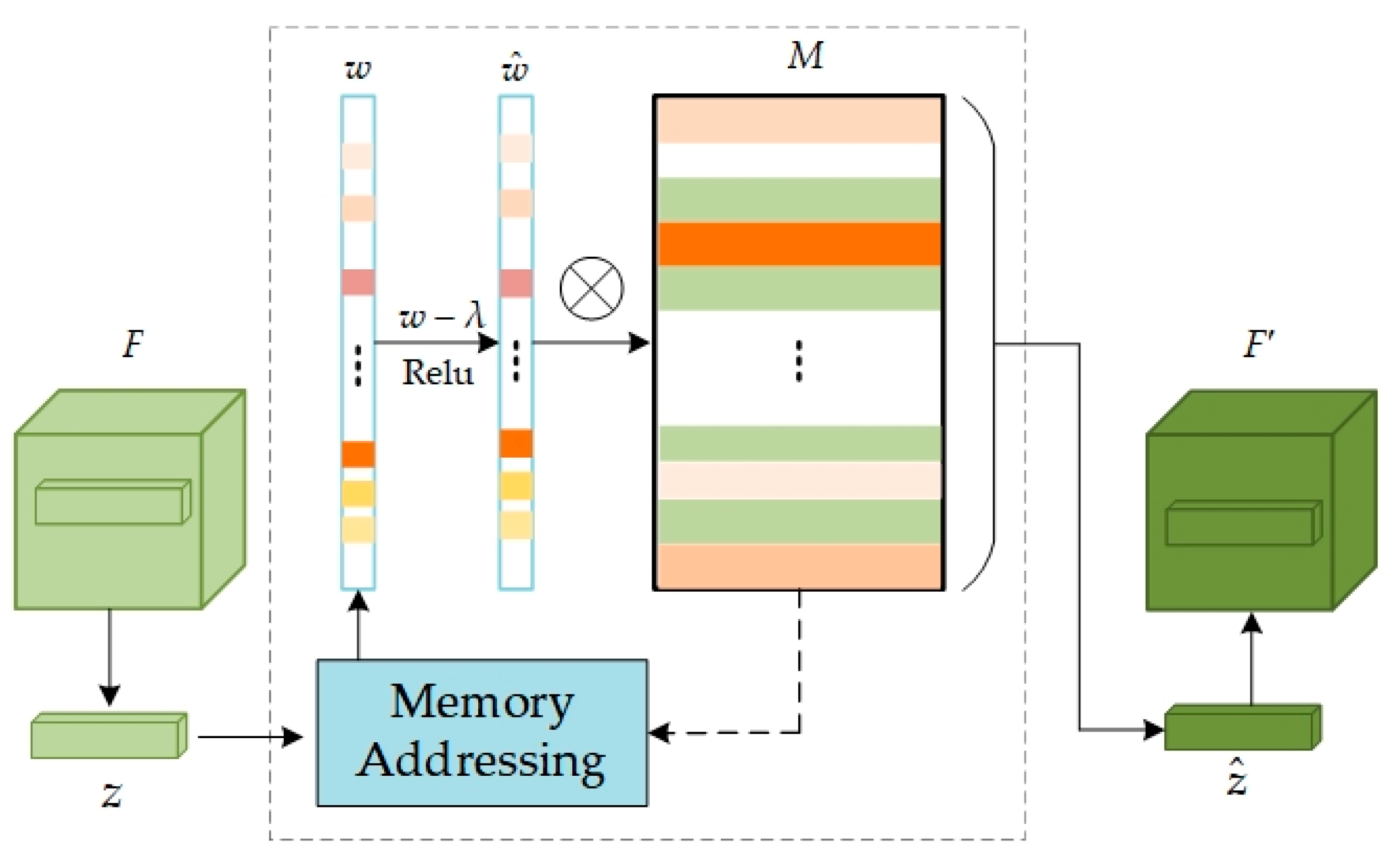
The memory module, a pivotal component, is designed to bolster the model’s capacity for memorizing normal data patterns, thereby aiding in more accurate recognition of deviations from these patterns. This functionality is realized by storing and processing the query mapping
z extracted from the feature map F, output by Encoder, with its network structure depicted in
Figure 3. In essence, the memory module is represented by a matrix
, where
M is an addressable memory matrix,
N denotes the number of feature information items in the memory, and
C represents the dimensionality of each feature vector. This matrix functions as a long-term memory bank, storing valid feature information acquired during the training on normal data. Each element
(where i = 1, 2, 3...N) in the memory
M represents the i-th memory item, with each item being a C-dimensional feature vector representing a specific normal data pattern learned during training.
To access the memory item, the similarity between the input feature
z and the memory item
in the
M is initially calculated:
In Equation (7), d(•,•) is defined as the cosine similarity [
32]. Subsequently, a softmax operation is applied to the similarity scores between
z and all memory items in
, yielding the weight coefficient
w (
w∈R
1×C) for the input feature
z with respect to the memory storage unit
M:
The weighting coefficients indicate the degree of match between the current feature and the memory items in
M. Memory items corresponding to the input feature
z are retrieved, weighted, and summed to acquire a new feature representation
:
To mitigate the issue of certain anomalies being reconstructible during the model’s reconstruction process and to minimize interference from excessive irrelevant memory terms, a sparsification operation can be applied to the weights
w:
where, the shrinkage threshold
λ is set to 1/N (N represents the number of memory items), and
ε is a very small positive number to prevent division by zero in subsequent calculations and ensure numerical stability. The weights
w are processed through a shrinkage function to diminish the values of less significant weights. The contraction function
here refers to the ReLU activation function. The processed weights then undergo a normalization operation
to ensure their sum equals 1. This step aims to maintain weight distribution consistency and ensure the model output’s stability. Finally, the sparsified and normalized weights are utilized to calculate the weighted sum of all memory terms, generating the final feature representation
This feature representation will thus be more focused on the most critical and useful information for the current input.
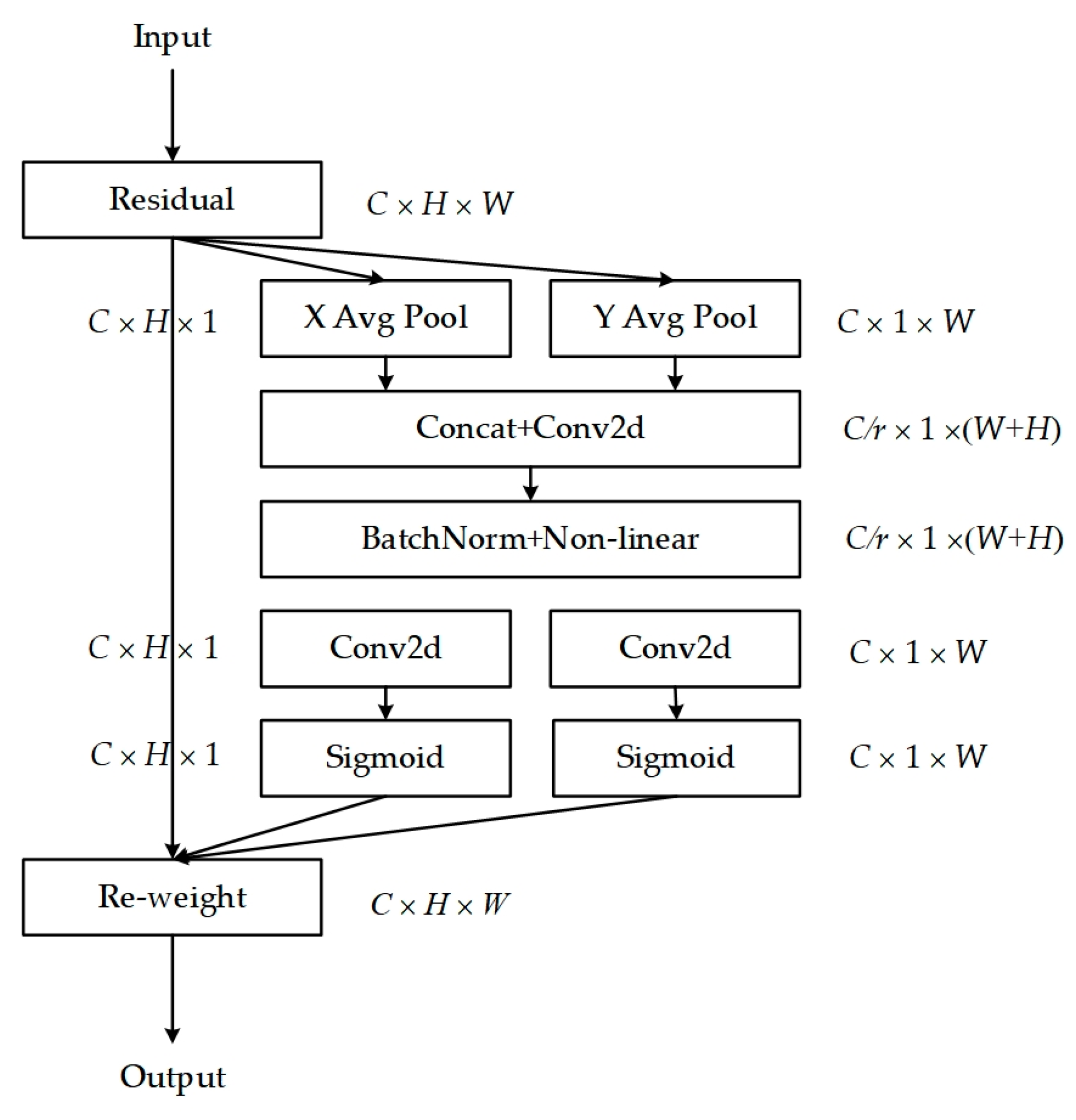
3.3. Coordinate Attention
Coordinate Attention (CA) [
33] is a lightweight attention mechanism designed to enhance feature representation. It can process any intermediate feature tensor
within the network, transforming it into a tensor
with identical size and dimensions, with its structure illustrated in
Figure 4.
Specifically, the input feature maps undergo a 1D global average pooling operation along the horizontal (H, 1) and vertical (1, W) directions, respectively, aggregating features in both spatial directions to form feature maps that capture the long-distance dependencies along each spatial direction. The resulting feature maps are then encoded to emphasize the weights of target regions within the original feature maps. This mechanism integrates coordinate information into channel attention, capturing long-range dependencies while preserving precise positional information, facilitating more accurate target location and recognition by the model. The Coordinate Attention (CA) module is positioned between the memory module and the encoder, with the feature map F′ processed by the memory module passed onto the CA module, enabling further feature enhancement. The enhanced feature representations are then directed to the decoder for image reconstruction, whereby the decoder, leveraging the rich and precise feature information from the CA module, reconstructs the image with greater accuracy, particularly in the presence of subtle abnormalities. Furthermore, the CA module is flexible, with a minimal parameter count, allowing for easy integration into network modules to achieve notable performance improvements without substantial computational resources.
3.4. Decoder
The decoder is tasked with inversely mapping the high-dimensional feature representations processed by the encoder or the memory module back into the image space, thereby generating the reconstructed image. As depicted in
Figure 2, the decoder incrementally increases the size of the feature map using six transposed convolutional layers, each consisting of two sublayers: a normalization layer and a ReLU layer. The normalization layer normalizes small batches of data, accelerating the training process and enhancing model stability, while the ReLU function introduces non-linear processing capabilities, enabling the model to capture complex input-output relationships. Applying ReLU after each normalization layer allows the decoder to more effectively learn and reconstruct image details. The final layer employs tanh as the last non-linear activation function. Through these operations, the decoder inversely maps the high-dimensional feature vectors back into the image space, generating a reconstructed image
akin to the original input image. Differences between the reconstructed and original input images are utilized to assess the model’s performance, with anomalous regions often efficiently identified through significant differences in the reconstructed image.
3.5. Loss Functions
In this study, normal images serve as training samples, with both normal and abnormal images being input into the model during the testing phase to attempt data reconstruction. Given the model’s learning and memorization of normal image patterns, the use of abnormal images as inputs results in poor reconstruction of abnormal regions, leading to significant reconstruction errors. To ensure the model’s predictions closely align with actual values, multiple loss functions are employed in training. The loss function utilized in this study comprises two components: image reconstruction loss and entropy loss associated with the query weights in the memory module.
- 1.
Reconstruction loss function
Reconstruction loss comprises two components: per-pixel mean squared error loss
(Equation (11)) and block-based Structural Similarity (SSIM) loss [
14] (Equation (12)). Per-pixel mean squared error loss quantifies pixel-level differences between the reconstructed and original images, while block-based SSIM loss evaluates similarity in structure and texture, ensuring visual consistency between the reconstructed and original images.
where
X and
denote the original and reconstructed images, respectively, with
H and
W representing their height and width, and
W ×
H indicating the total number of pixels, and
represents the SSIM value for two corresponding blocks in
X and
centered at coordinates (i, j). Finally, the reconstruction loss is defined as follows:
Here, λ is a hyperparameter utilized to balance the contributions of the two types of loss: mean squared error loss and SSIM loss.
- 2.
Entropy loss function
In the memory module, the entropy loss on the matching probability
wi of each memory item assists in evaluating the model’s utilization of various memory items, thus optimizing memory utilization efficiency and the model’s generalization ability, defined as follows:
where
represents the matching probability of the
i-th memory item in the memory module. Minimizing the entropy loss encourages the model to adjust the matching probability of certain memory items close to 1 and others near 0, indicating increased model “confidence” in selected memory items and reduced decision-making uncertainty.
To balance the reconstruction loss and entropy loss, a comprehensive loss function is constructed for model training:
where
Lrecon represents the reconstruction loss, assessing the similarity between the reconstructed and original images;
Lent represents the entropy loss, quantifying the model’s certainty regarding the probability of matching memory items; and
λrecon and
λent are the weight parameters regulating the impact of the respective losses on the total loss.
5. Conclusions
This study proposes an unsupervised industrial image anomaly detection method based on the Vision Transformer (ViT) to address the scarcity of anomalous image samples, high tagging costs in industry, limitations of traditional convolutional encoders in extracting global features, and anomalous generalization issues, utilizing a ViT-based encoder for feature extraction to effectively capture global contextual information, thereby enhancing detailed and holistic image understanding. The memory module stores feature information, enabling effective inference of abnormal regions and suppression of anomalous reconstruction. The introduced Coordinate Attention (CA) mechanism further enhances the model’s ability to capture image features, particularly at spatial and channel levels. By precisely focusing on important features and regions, the CA mechanism minimizes feature information loss and enhances anomaly recognition accuracy. The effectiveness of the proposed method has been fully validated through ablation studies on two public datasets and comparisons with contemporary mainstream models. Experimental results demonstrate the method’s strong detection performance and generalizability. However, the substantial content required for storage in the memory unit leads to increased computational demands. Future work will focus on reducing computational demands while further improving anomaly detection performance. Additionally, improving the clarity of stored potential features is essential, given the limitations of current memory module storage methods. Future efforts will aim to identify more efficient storage structures to enhance the memory module’s operational efficiency through improved query efficiency.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}