1. Introduction
Continuous breakthroughs in key robotics technologies have made autonomous mobile robots a focal point in intelligent robotics research. Currently, autonomous mobile robots are widely used in transportation, industry, agriculture, the service sector, and aerospace, and are capable of performing tasks such as patrolling, rescue, logistics, transportation, and planetary exploration [
1,
2]. Thus, a robust autonomous navigation system is crucial for the deployment of intelligent robots, enabling them to avoid collisions with dynamic and static obstacles, safely reach the target point via an optimal or suboptimal route, and complete assigned subsystem tasks.
Navigation, which encompasses both global and local aspects [
3], is a critical task in autonomous mobile robot research. Since the 1980s, researchers have extensively explored and studied navigation planning for autonomous mobile robots, yielding numerous mature findings. In 1968, Hart et al. [
4] developed the A* algorithm, an enhancement of Dijkstra’s method [
5] for finding the shortest paths in graphs or networks. A* distinguishes itself by incorporating a heuristic function, a mechanism that intelligently guides the selection of the next node during the search process, unlike Dijkstra’s algorithm. In 1994, Kavraki et al. [
6] introduced the Probabilistic Roadmap Method (PRM), a sampling-based algorithm for robot motion planning aimed at efficiently identifying collision-free paths within complex, high-dimensional environments. Following this, researchers have proposed improvements to original methods, achieving more refined navigation planning techniques. Shentu et al. [
7] developed a hybrid navigation control system using a motion controller designed via the backpropagation method and incorporated Kalman filtering to minimize localization errors. The system adapts to various guidance sensors across different distances. Yufeng Li et al. [
8] enhanced navigation accuracy and stability by combining an improved A* algorithm with the Dynamic Window Approach (DWA) for global and local path planning, outperforming traditional fusion algorithms. Additionally, Chien-Yen Wang et al. [
9] introduced a partition-based map representation to augment the A* path planner (PBPP), effectively narrowing the search space and reducing time consumption, leading to more efficient path planning. The classical approach currently combines various algorithms, like SLAM (Simultaneous Localization and Mapping), to convert perceived environmental information into a global map for path-planning modules. Based on global and local path planning results, the control module dynamically adjusts speed, direction, and other parameters to guide the robot toward the target. In summary, traditional navigation frameworks depend on high-precision global maps, necessitating costly sensors and manual calibration to meet requirements. Additionally, the integrated computation in traditional navigation frameworks leads to cumulative errors, and the high sensitivity of the sensors to noise significantly reduces the effectiveness of these methods in complex, dynamic, or unknown environments [
10,
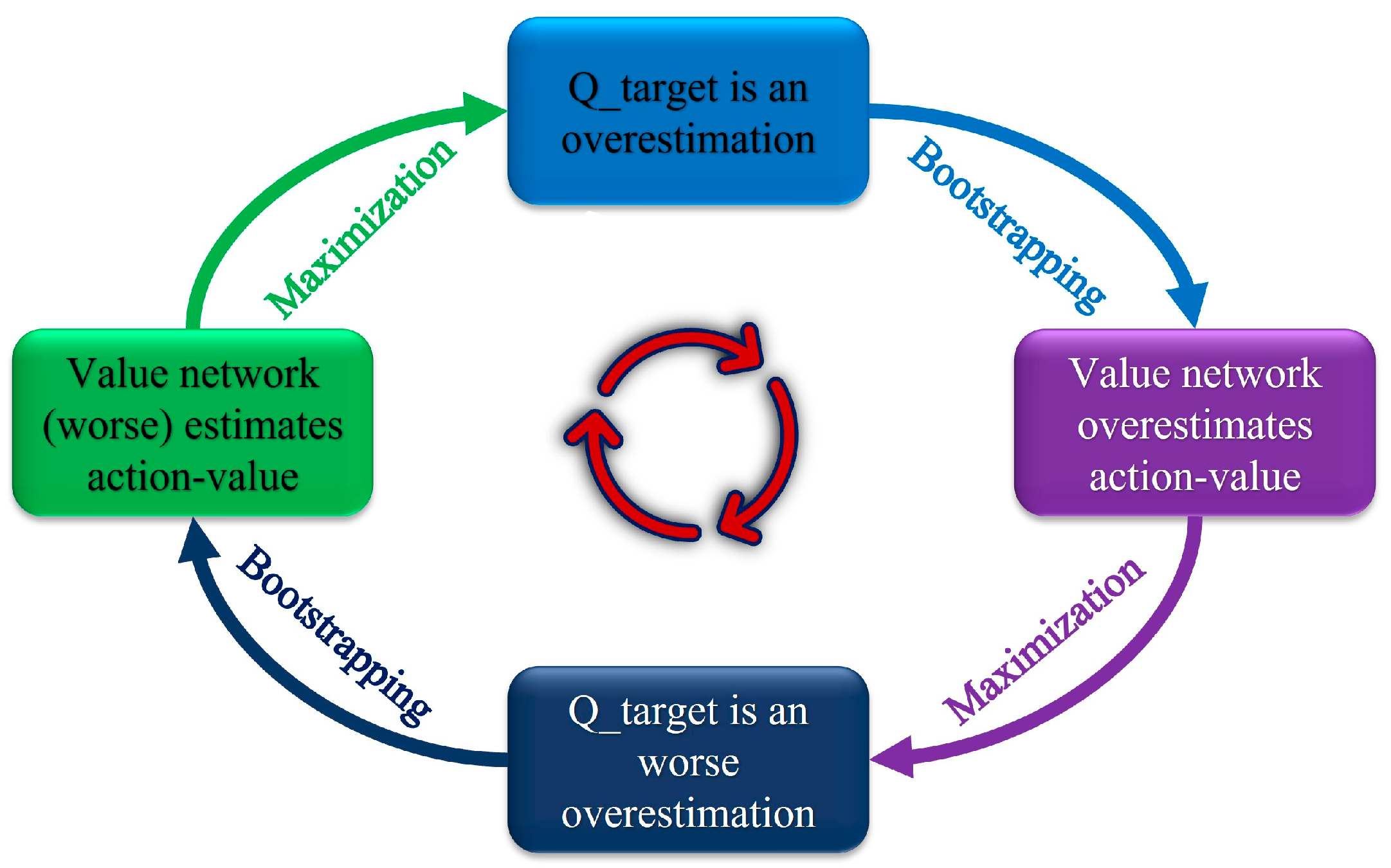
11].
The rapid advancement in deep reinforcement learning techniques and hardware has drawn increasing attention from researchers. Among these, learning-based methods have become a research focus, achieving significant success across diverse fields. In 2013, Mnih et al. [
12] introduced the first deep learning model capable of learning control strategies directly from high-dimensional perceptual input, achieving success in this endeavor. Applying this model to the Atari 2600 game, they found it outperformed human experts. In 2015, David Silver et al. [
13] developed the Double Deep Q-Network (DDQN) to address the issue of overestimation of DQN, with experimental results that indicate improved performance. In 2016, to address the limitations with continuous actions, Timothy P. Lillicrap et al. [
14] introduced the Model-free Deterministic Policy Gradient-Based Algorithm (DDPG), which showed promising results in various simulation control scenarios. Subsequent studies introduced algorithms like the Asynchronous Dominant Action Evaluation (A3C) [
15], Proximal Policy Optimization (PPO) [
16], Two-Delay Deep Deterministic Policy Gradient (TD3) [
17], and Deep Spiking Q-Network (DSQN) [
18]. These frameworks aim to solve issues such as slow convergence, low model robustness, and weak generalization during training.
Deep reinforcement learning-based schemes, with their powerful characterization capabilities and excellence in handling high-dimensional dynamic scenarios (e.g., LiDAR, images) have been introduced to intelligent robot navigation research. Deep reinforcement learning offers a flexible, adaptive, and efficient way to solve robot navigation problems by learning decision strategies or value functions directly from raw data, without the need for human intervention or feature engineering. The end-to-end model enables autonomous robot–environment interaction for learning navigation strategies without depending on predefined rules or map information. Through the trained model, the robot makes real-time decisions in a mapless environment, enabling it to navigate and perform inspection tasks in unknown environments effectively.
2. Related Work
SLAM technology, comprising laser SLAM and visual SLAM, utilizes laser and visual sensors, respectively, to achieve real-time localization and mapping in unknown environments, facilitating autonomous robot navigation. Visual SLAM depends on precise image features but is affected by lighting, sensor parameters, and environmental changes. Laser SLAM, requiring high-precision LiDAR, suffers from low computational efficiency and large cumulative errors in extensive environments, limiting its application. Wang, X et al. [
19] proposed a SLAM application system based on the fusion of multi-line LiDAR and visual perception, tailored to sensor characteristics and application scenarios, incorporating a hybrid path-planning algorithm that combines the A* and Time Elastic Band (TEB) algorithms. Experimental results indicate that the designed SLAM and path planning methods exhibit good reliability and stability.
In the realm of learning-based strategies, Piotr Mirowski et al. [
20] developed an agent capable of navigating complex 3D mazes by integrating goal-driven reinforcement learning with auxiliary depth prediction and loop-closure classification tasks, achieving human-level performance even with frequent changes in the target location. Lei Tai et al. [
21] developed a mapless motion planner using deep reinforcement learning, dubbed ADDPG. They separated the sample collection process into another thread, achieving parallel training through multiple threads. This planner accepts 10-dimensional sparse laser data and the target location in the robot’s relative coordinate system as inputs, requiring only minor adjustments for direct application in unknown real-world environments. Yuke Zhu et al. [
22] introduced a deep reinforcement learning framework tailored for goal-driven visual navigation. Uniquely, this framework treats task objectives as model inputs, avoiding the integration of goals directly into the model’s parameters. This methodology effectively tackles the problem of generalizing across varied scenes and objectives. Furthermore, they presented the AI2-THOR framework, which supports economical and efficient data collection. Linhai Xie et al. [
23] proposed the Dueling DQN approach (D3QN), inspired by the Fully Convolutional Residual Networks (FCRN) [
24] for predicting depth information from RGB images. The network, trained in a simulator using monocular RGB images as an input, successfully transfers the model from virtual to real-world settings, with D3QN outperforming traditional DQN methods.
The primary aim of this research is to equip robots with navigation skills through learning-based strategies, focusing on enhancing the learning efficiency and generalization of DRL models in subsequent studies. Junli Gao et al. [
25] merged the PRM algorithm with TD3, employing incremental training to fast-track learning and notably enhance the model’s generalization ability. Lu Chang et al. [
26] integrated local path planning with deep reinforcement learning to develop an enhanced DWA [
27] based on Q-learning. They refined the original evaluation function to increase the scores of better trajectories in each specific sub-function and introduced two additional sub-functions to accommodate more complex scenarios, thus improving global navigation performance. Hartmut Surmann et al. [
28] developed a fast parallel robot simulation environment, addressing the problem of slow neural network learning speeds in existing simulation frameworks. Meiqiang Zhu et al. [
29] proposed a universal reward function based on Matching Networks (MN) to address the issue of sparse rewards. This function facilitates reward shaping from similar navigation task trajectories without human supervision, thus accelerating the training speed of DRL for new tasks. Lastly, Reinis Cimurs et al. [
30] developed an autonomous navigation system based on the double-delayed deep deterministic policy gradient algorithm, utilizing perceptual data to identify points of interest and select optimal waypoints. This system, trained through deep reinforcement learning, facilitates autonomous navigation from waypoints to global objectives without any prior map information, achieving superior navigation performance in complex static and dynamic environments.
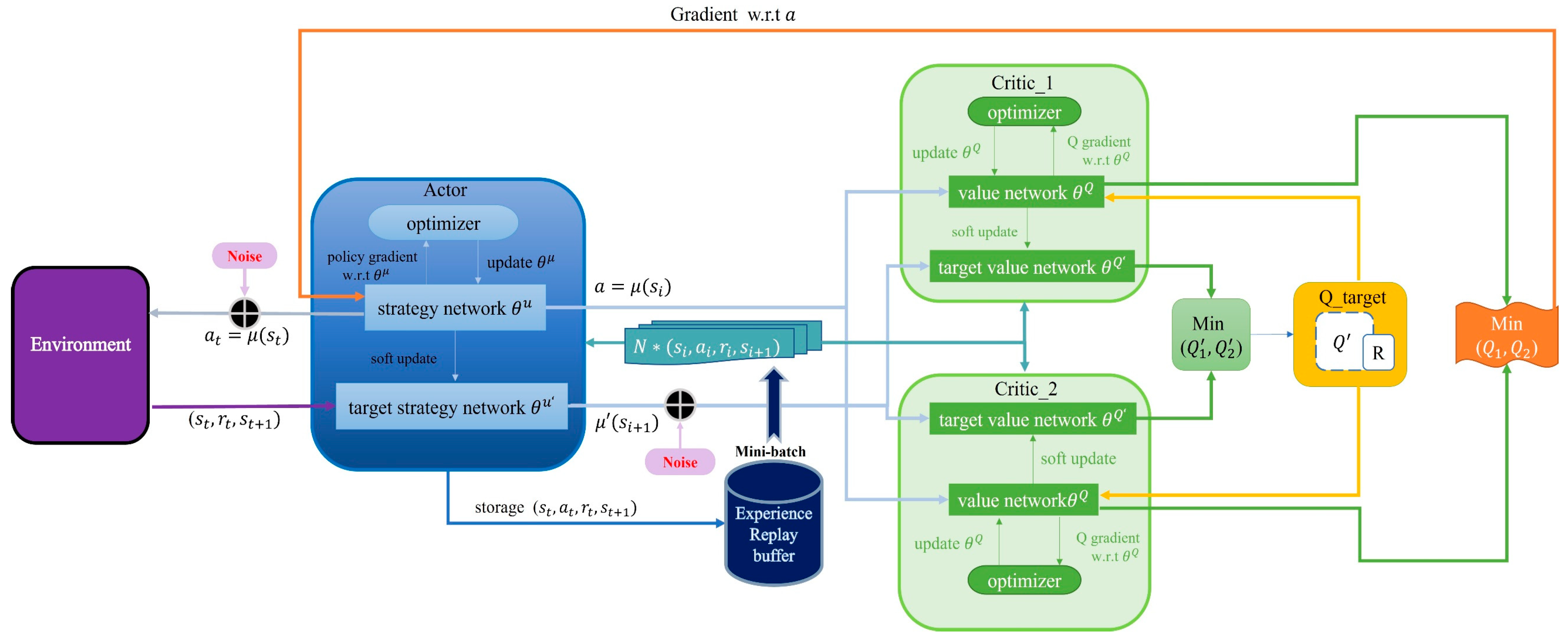
This study aims to improve dual-delay deep deterministic policy gradient algorithms for autonomous robot navigation by better utilizing empirical data, speeding up convergence, and addressing reward sparsity. LiDAR data was chosen for training due to their simplicity, reduced resource demands relative to camera data, and their advantages in real-time performance, stability, and deployment in diverse settings.
The main contributions of the research are summarized as follows:
- (1)
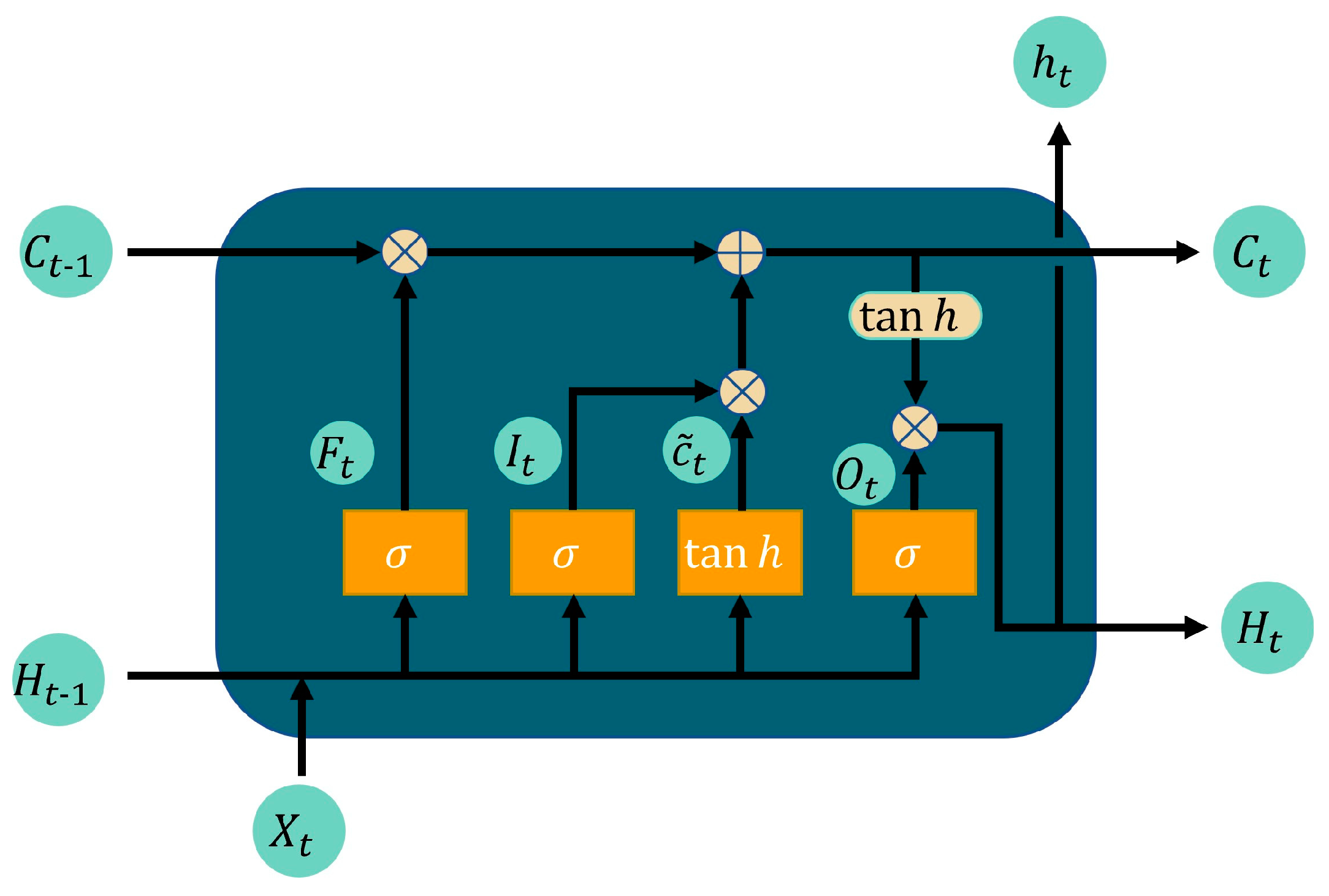
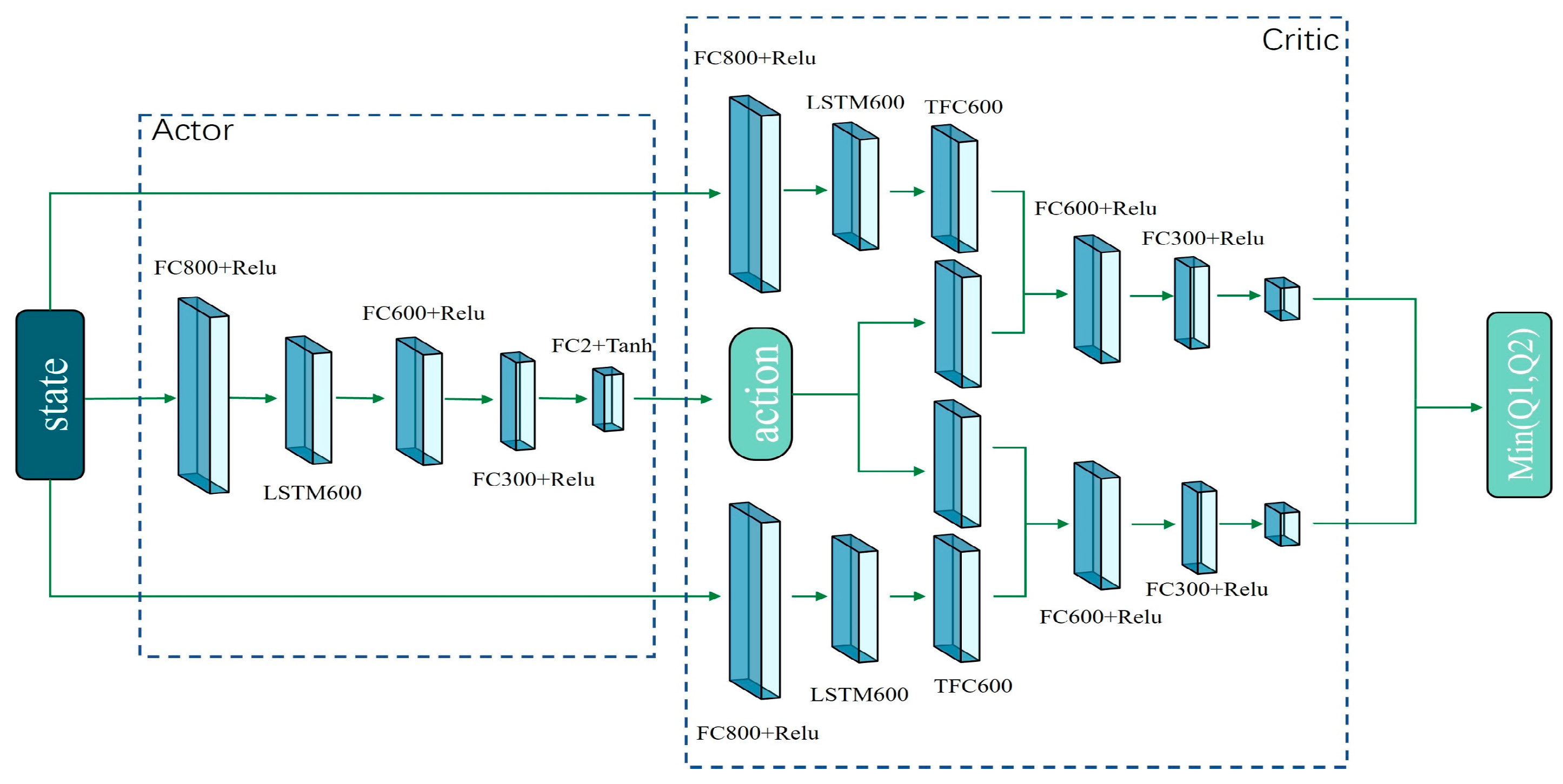
We propose a training framework that incorporates temporal navigation experience by integrating the long–short-term memory module (LSTM) with Prioritized Experience Replay (PER) into the TD3 network structure, enhancing sample data utilization, and speeding up the learning process.
- (2)
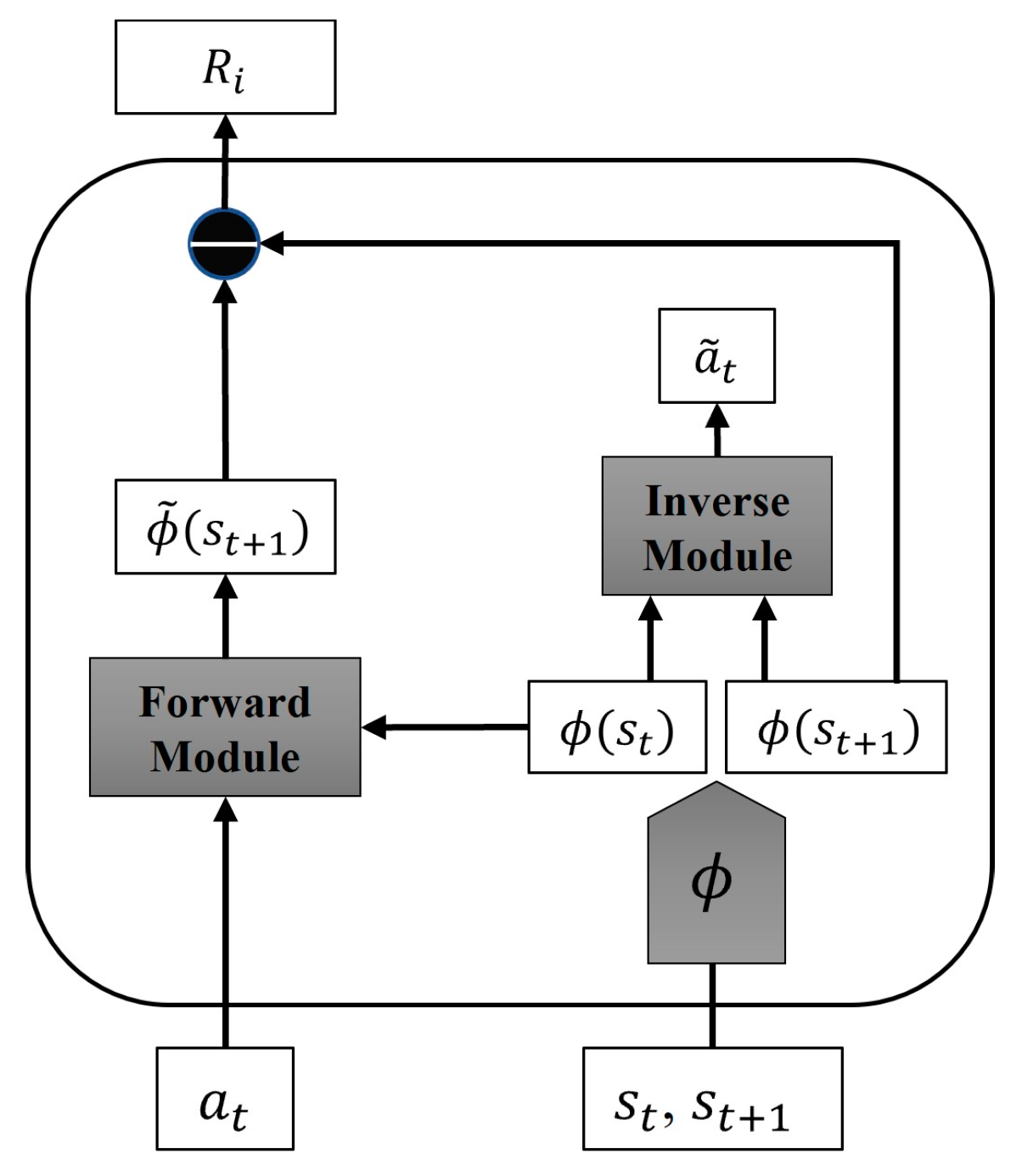
We introduce an Intrinsic Curiosity Module (ICM) to the dual-delay deep deterministic policy gradient algorithm’s reward system to address reward sparsity and boost exploration capabilities.
- (3)
We propose a new state representation that incorporates laser sensor data, the robot’s current state, and the distance to the target point as input during model training, thus enabling adaptation to various environments.
The remainder of this paper is organized as follows:
Section 3, Part 1 introduces the DDPG algorithm within deep reinforcement learning methods and the background of the TD3 algorithm.
Section 3, Part 2 details the mapless robot navigation approach utilizing the Long-Short-Term Memory Module and the Prioritized Experience Playback mechanism (LP-TD3).
Section 3, Part 3 explores the application of curiosity-driven exploration strategies in robot navigation.
Section 4 will present simulation experiment results and analysis. Finally,
Section 5 will conclude and outline future research directions.
4. Experiments
This section will validate the proposed LP-TD3 navigation method. This method necessitates extensive training data. Training in a real-world environment is time-consuming and poses a risk of damaging the equipment due to interactions between the agent and the environment. To rapidly assess the method’s effectiveness, training will be conducted in a simulation environment.
4.1. Experimental Parameters and Environment
The experiment will utilize two platforms, ROS and GAZEBO, with the open-source Turtlebot3 two-wheeled differential robot serving as the testbed. A computer equipped with an i7-11800H CPU, NVIDIA Geforce 3060 GPU, and 32 G RAM will serve as the training platform for this experiment. Hyperparameters were empirically set based on the performance capabilities of the training platform, as detailed in
Table 1.
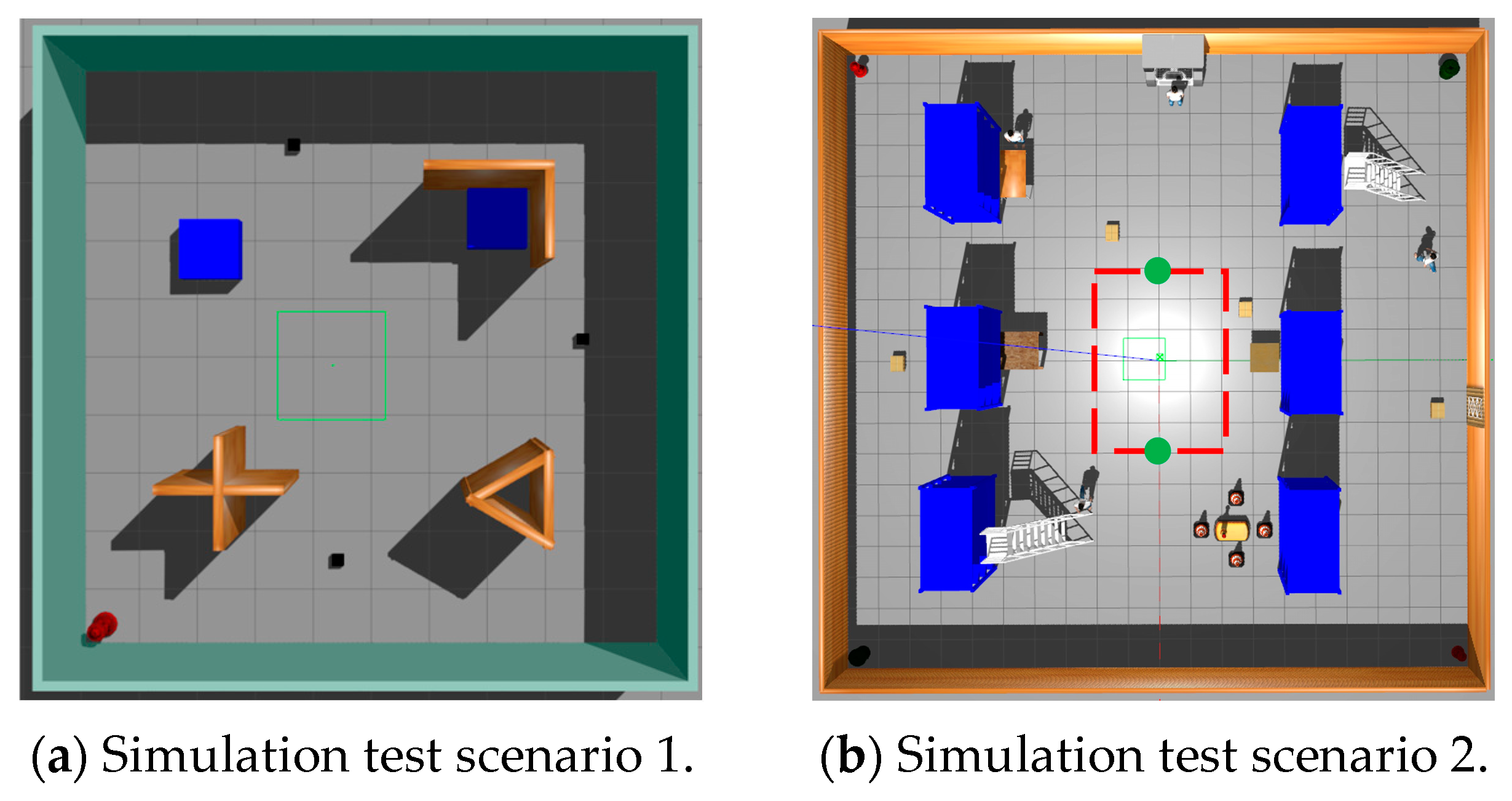
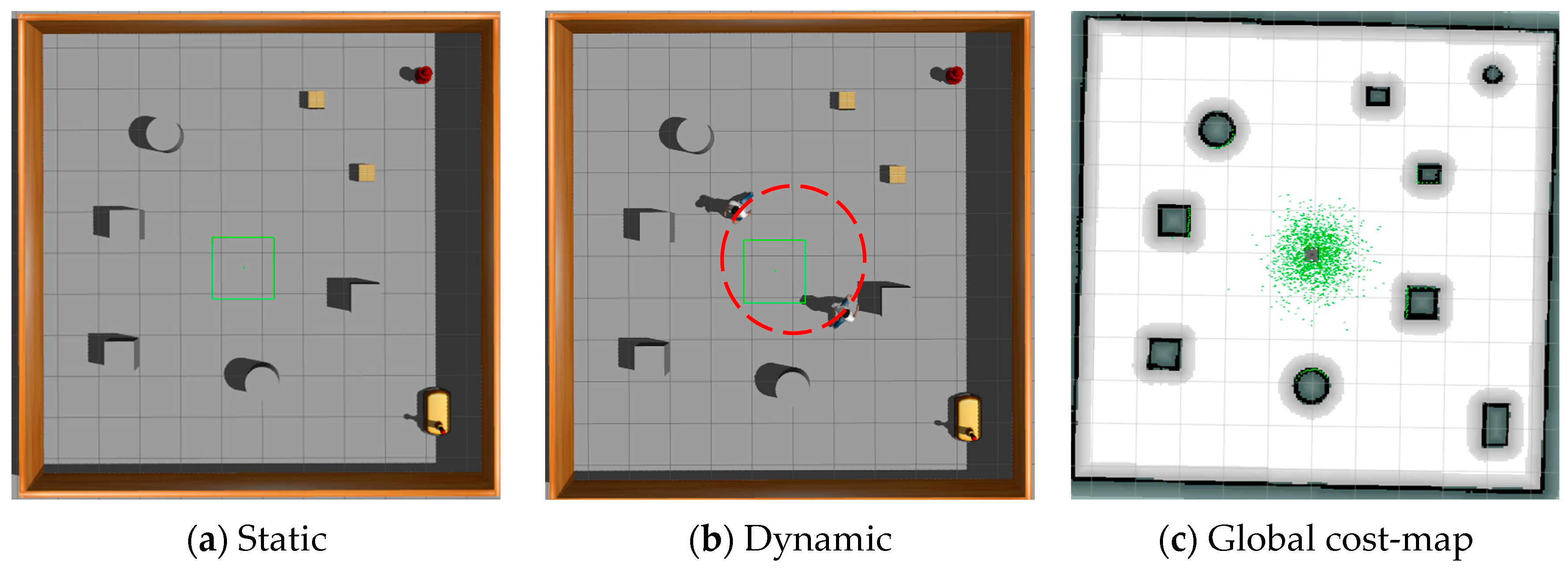
This study undertakes a comparative analysis of the LP-TD3 navigation strategy and the original TD3 method, utilizing two simulated scenarios within the Gazebo environment, as illustrated in
Figure 6. The first scenario assumes a static environment brimming with obstacles, such as fire hydrants, cardboard boxes, and cross-shaped walls. The second scenario, however, is more intricate and encompasses a larger map with the addition of dynamic pedestrian obstacles. Two such dynamic pedestrians are programmed to move in a clockwise direction along the trajectory delineated by the red dotted line in the figure, at a speed of 0.5 m/s. The green origin in the figure denotes the initial position of these two dynamic pedestrian obstacles in each episode. Moreover, four yellow cardboard boxes, each with dimensions of 0.5 m × 0.5 m × 0.5 m (as represented in the figure), are programmed to appear randomly at any location within this scene. This scene is designed to mimic a warehouse inspection environment, complete with warehouse shelves, randomly dispersed cardboard boxes, and designated maintenance areas. These scenarios partially replicate the real inspection environment and validate the comprehensiveness of the proposed navigation method.
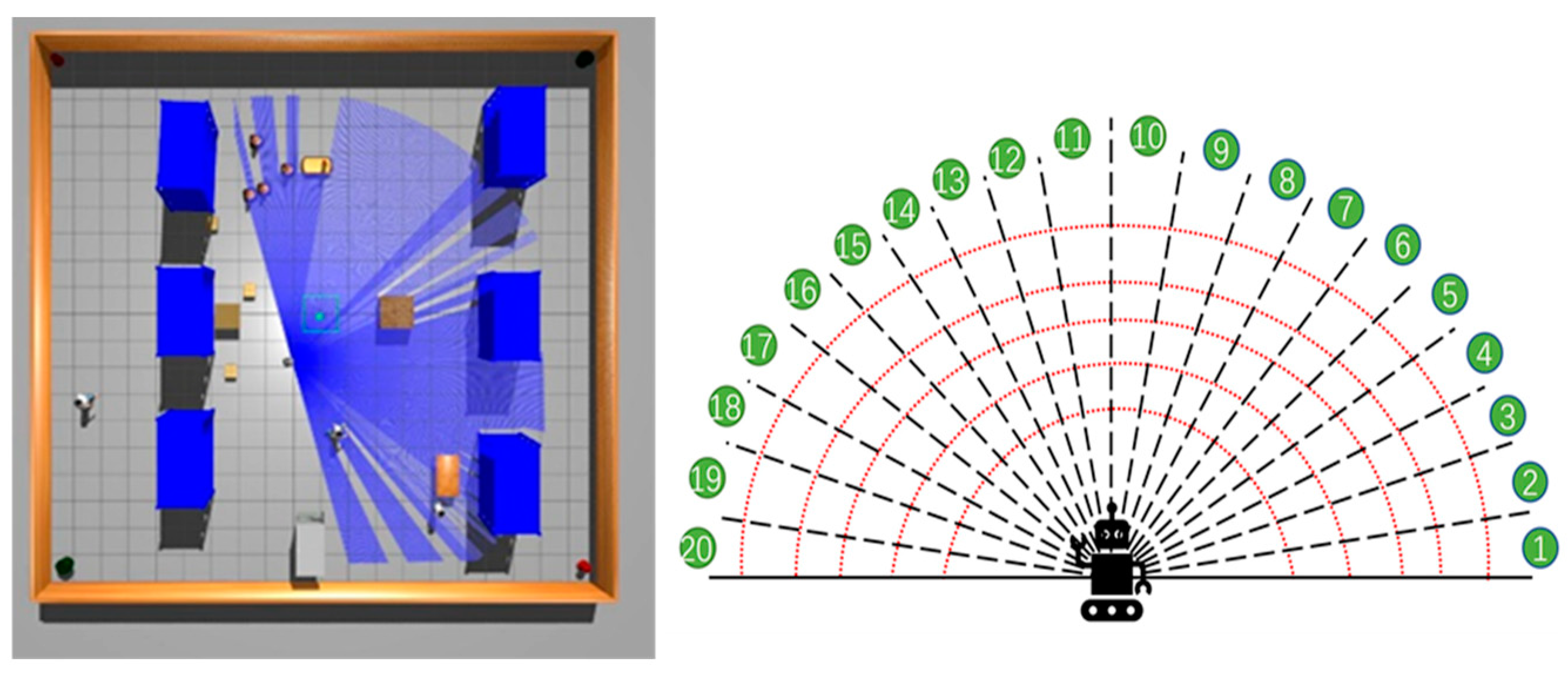
The robot’s workflow involves gathering environmental data via external sensors and executing actions through its decision-making model based on these data. In this experiment’s simulation, the Turtlebot3 robot features a 16-line LIDAR with a 180-degree scan and a camera for visual inspection, with the LIDAR’s scan segmented into 20 dimensions. The blue ray in
Figure 7 illustrates the visualization of the LIDAR scan. LIDAR scan data serve as state inputs to minimize discrepancies between the simulated and real environments. Navigation is achieved using 20-dimensional laser data, previous actions, and the target’s relative position. Each round randomly sets the robot’s initial position and the target point to avoid training overfitting. If the robot collides with an obstacle or misses the target within a round’s step limit, it ends the round to assess if it meets the decision-making model’s learning criteria before proceeding.
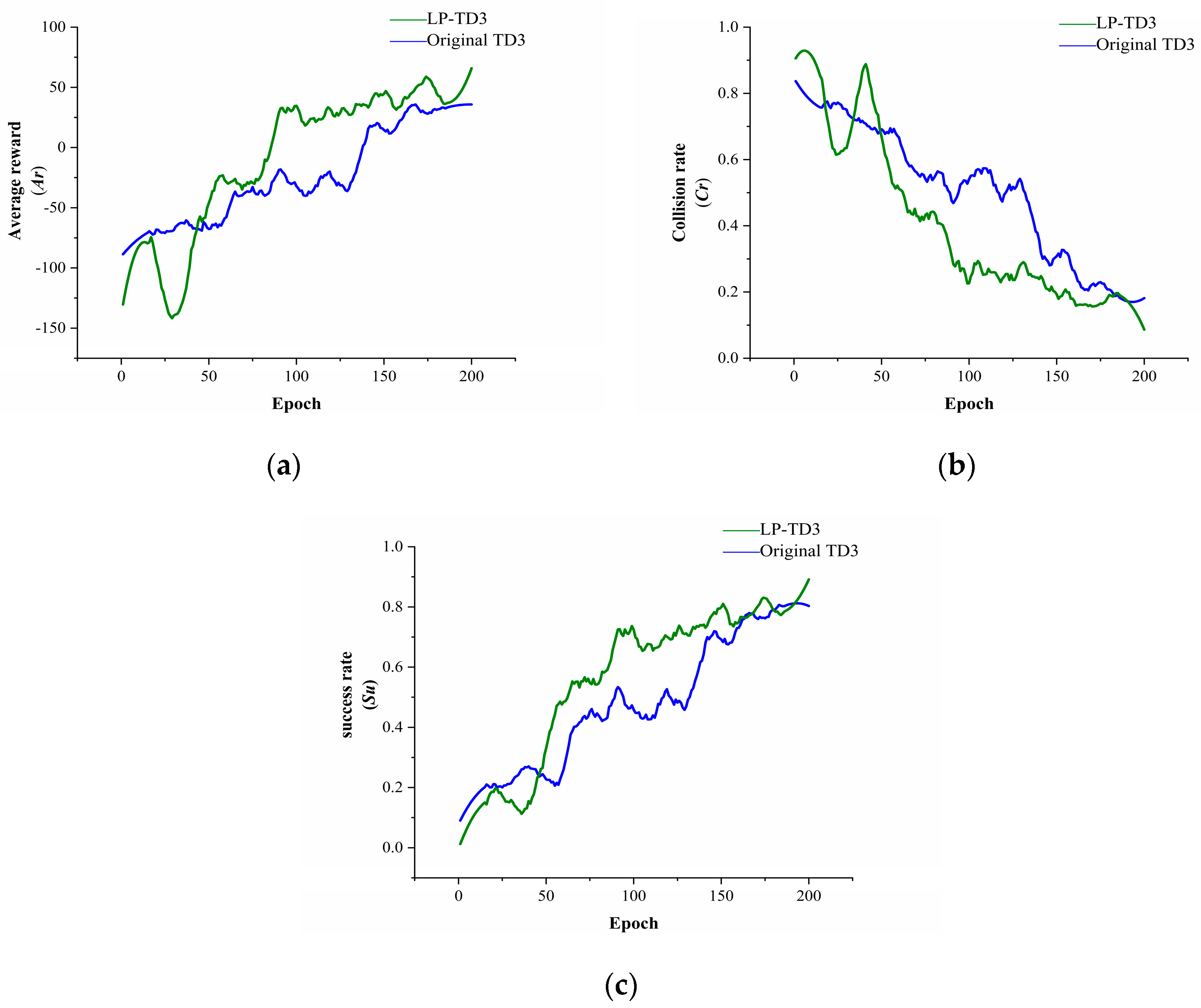
4.2. Analysis of Training Results
To compare the performance of the proposed method with the original method in different test environments, we define three performance metrics.
- (1)
Average reward : is the average of the sum of episodes rewards when the model is evaluated.
- (2)
Collision rate : is the ratio of total collisions to the number of episodes, assessing the model’s obstacle avoidance capability.
- (3)
Success rate : measures the ratio of episodes where the robot successfully reaches the goal to the total number of episodes, evaluating the navigation performance.
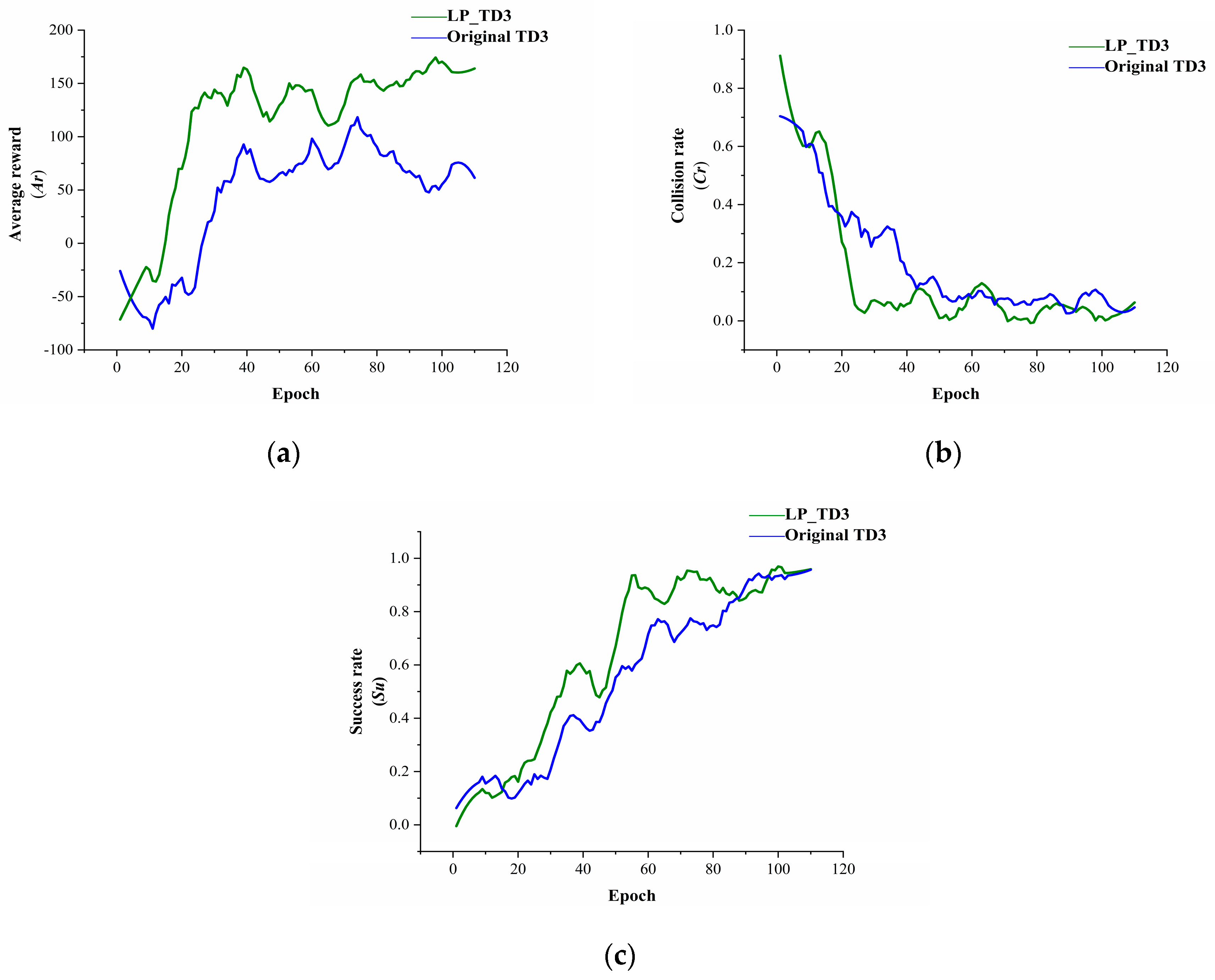
The results for scenario 1 are presented in
Figure 8. Identical hyperparameters were used to train both algorithms. Training initiates upon the robot reaching the target or encountering a collision, with evaluations conducted every 5000 steps, repeated 15 times, to accurately showcase the model’s current performance. The figure shows smoothed evaluation results; the green curve represents the LP-TD3 algorithm, and the blue curve, the original TD3 algorithm.
In scenario 1, LP-TD3 significantly outperforms the original TD3 in average reward, collision rate, and success rate. The average reward curve indicates LP-TD3’s superior sample utilization efficiency, converging around the 20th Epoch compared to the 40th for TD3, showcasing faster convergence. Scene 1, with its small area and static obstacles like cross-shaped and L-shaped walls, can lead to local optima challenges for the robot. However, the experimental results suggest that the proposed strategy explores the environment more effectively than the original, successfully navigating to challenging targets, like those near cross-shaped and L-shaped walls.
The training index curves for scenario 2, as illustrated in
Figure 9, employ the same experimental parameters and methods as for scenario 1. Compared to scenario 1, scenario 2 presents a greater challenge with its larger size and complexity, especially due to the presence of dynamic obstacles that significantly hinder the robot’s ability to reach its destination. In such environments, robots are required to learn more sophisticated navigation strategies to effectively deal with these ever-present obstacles. Experimental results for scenario 2 indicate that, although both the proposed and original strategies necessitate additional time for environmental exploration, the proposed method surpasses the original in terms of model convergence speed, success rate, and collision rate. Initially, the LP-TD3 strategy, which emphasizes comprehensive exploration and leverages intrinsic curiosity rewards, exhibits lower performance metrics compared to the original TD3, as it facilitates the exploration of new states and prevents the robot from simply rotating in place, a limitation that the original TD3 strategy could not overcome. However, by the 50th epoch, LP-TD3 begins to outperform the original strategy, and by the 100th epoch, it adeptly navigates around obstacles, successfully reaching the destination, and completing the navigation task.
4.3. Analysis of Evaluation Results
To assess the effectiveness of the local planning algorithm proposed in this study, we constructed a test environment in GAZEBO. As depicted in
Figure 10, the test environment comprises a 10 × 10 square meter area featuring multiple obstacles. The test environment is divided into two levels to evaluate the algorithm’s performance. The first level features a static environment, while the second introduces a dynamic setting with two pedestrians moving counterclockwise, as indicated by the red dotted line in the figure, at a speed of 0.6 m/s. For the test task, we designated 10 sequential points for the planner; the robot must navigate these sub-objectives in sequence while avoiding obstacles.
To demonstrate the distinctions between the proposed method and traditional approaches, we will compare it with the original TD3 algorithm and the move_base. The move_base is a fundamental navigation component offered within the Robot Operating System (ROS). This intricate component is responsible for executing paths that are generated collaboratively by both the global and local planners, thereby performing motion control. In addition to this, move_base also incorporates local position estimation coupled with dynamic map updates to enhance navigation capabilities. In the comparative experiment conducted, the default global planner of move_base, which is based on Dijkstra’s algorithm, is utilized alongside the local planner that employs the Dynamic Window Approach (DWA) algorithm. The specific parameter settings utilized for this experiment are detailed in
Appendix A.
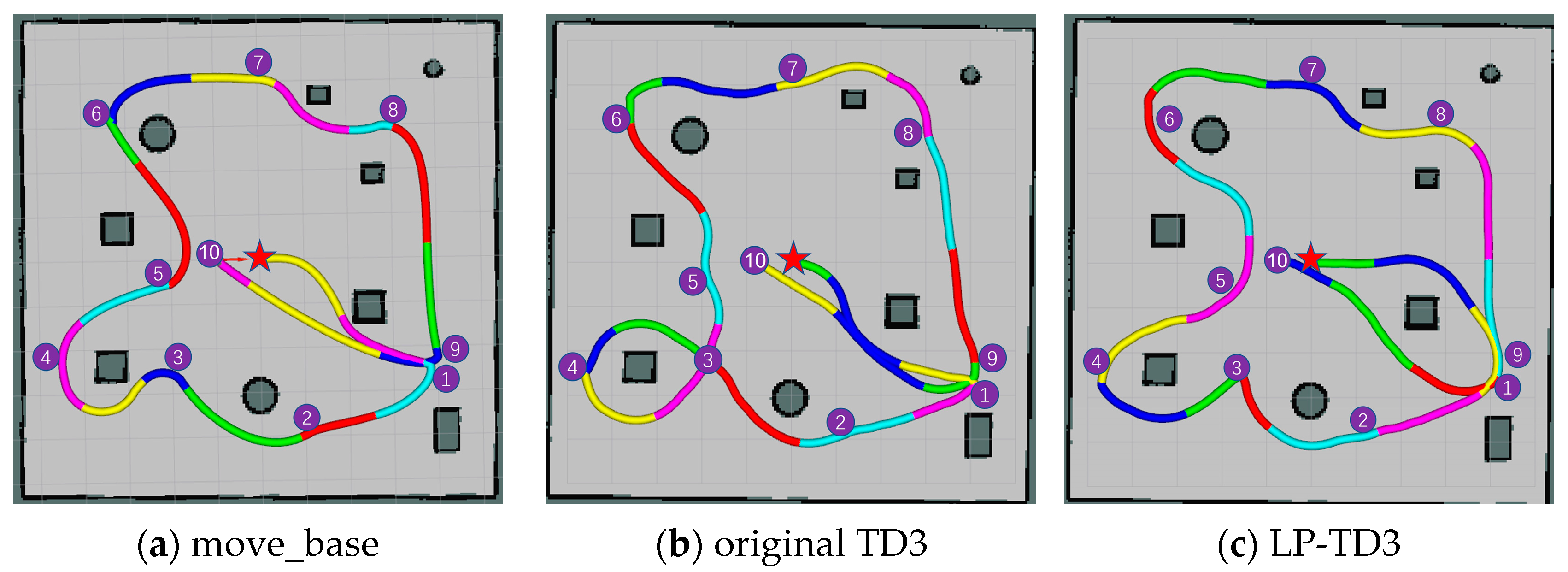
The move_base requires construction of a global map for path planning, whereas the proposed method uses this map solely for visual display. The navigation path results for the three methods in both static and dynamic environments are depicted in
Figure 11, marked by a red pentagram indicating the robot’s starting point. To effectively illustrate the impact of varying methods under identical experimental parameters, the robot’s position was recorded at 5 s intervals. As depicted in
Figure 11, line segments of diverse colors signify the paths traversed by the robot during these 5 s intervals. This color-coded representation facilitates a clear understanding of the robot’s movement under different methods.
We selected two metrics to evaluate the planners: the time taken by the robot to complete the navigation task and the total distance traveled. Within the testing environment, each method was executed 10 times.
Figure 11 demonstrates one of the generated paths for each method. The generated experimental data are presented in
Table 2, which details the test results for both static and dynamic environments.
In the static test environment,
Figure 11a–c displays the trajectory plots for the navigation tasks, showing that all methods can complete the tasks without collisions. According to
Table 2, the conventional navigation method, move_base, reduces the cumulative distance traveled by 15.13% and 9.57% compared to the original TD3 and LP-TD3 algorithms, respectively, suggesting that the paths generated using deep reinforcement learning-based methods are not optimal. In a static environment, while the method proposed in this paper does not surpass the performance of the classical algorithm, it indeed shows a marked improvement over the original TD3.
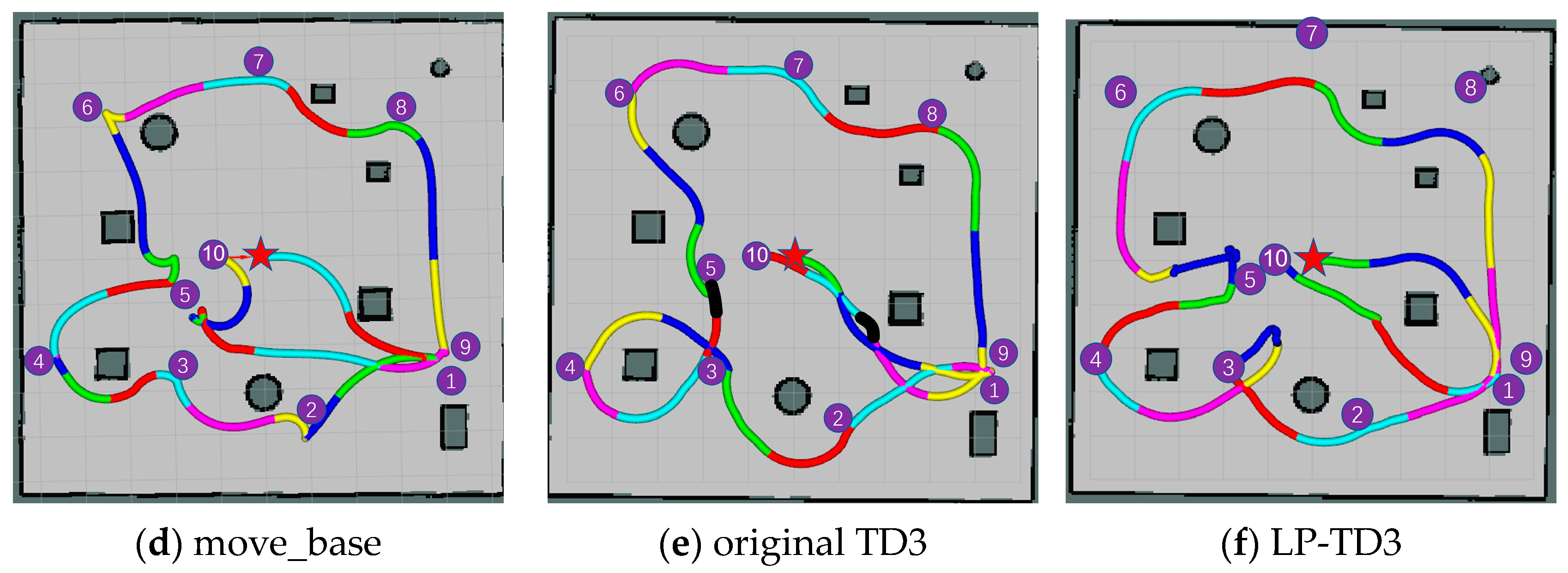
In a dynamic environment, the move_base successfully completes the navigation task most of the time. However, in certain instances, such as during the robot’s journey from navigation point 9 to navigation point 10 as illustrated in
Figure 11d, the robot encountered challenges when avoiding pedestrians. Specifically, while the robot managed to plan a route to circumvent the first pedestrian it encountered, it struggled to react in time to a second approaching pedestrian. This delay resulted in the robot remaining stationary until the pedestrian was very close, at which point the robot hastily reversed and altered its path. The original TD3 algorithm’s inability to effectively navigate around dynamic pedestrians is highlighted by the interruption indicated by a black line segment in
Figure 11e, requiring human intervention to resume the navigation task. In contrast, our proposed LP-TD3 method, presented in
Figure 11f, successfully completes the navigation task under similar circumstances. For instance, during the robot’s movement from navigation point 5 to navigation point 6, as pedestrians gradually approached, the robot swiftly opted to turn left to avoid them. The experimental results demonstrate that LP-TD3 is capable of successfully completing navigation tasks even in the absence of a map.
5. Conclusions
This study introduces a mapless navigation solution for indoor inspection scenarios, addressing the poor performance of current navigation methods via deep reinforcement learning. Building on the existing TD3 algorithm, we propose the LP-TD3 algorithm, which combines intrinsic curiosity rewards with extrinsic rewards to motivate the robot to explore its environment. LP-TD3 equips the robot with both long-term and short-term memory modules, enhancing learning from beneficial navigational experiences through a prioritized experience replay mechanism. The model inputs comprise the robot’s current actions, LiDAR scan data, and its relative position to the target, offering comprehensive learning data. In the training phase, the algorithm surpasses the original TD3 in average reward, collision rate, success rate, and achieves faster convergence. Simulation tests demonstrate that the LP-TD3 local planning algorithm enables efficient navigation amidst both static and dynamic obstacles. Therefore, the method proposed in this paper is applicable to inspection scenarios, such as in factories, to facilitate smarter and safer production activities. This paper focuses on enhancing learning efficiency and addressing the reward sparsity issue of the original method. Future research will aim at deploying these learning algorithms on actual detection robots, enabling ongoing post-deployment learning for optimal real-world performance and long-range navigation path optimization.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}











