
RCEAU-Net: Cascade Multi-Scale Convolution and Attention-Mechanism-Based Network for Laser Beam Target Image Segmentation with Complex Background in Coal Mine


 ,
,
Abstract
1. Introduction
- Aiming at the problem of multi-laser-beam segmentation and extraction faced by the remote distance vision positioning system in underground application, an RCEAU-Net model suitable for the laser beam image segmentation in the underground working face is proposed. The reliable segmentation and accurate extraction of laser beam features are realized under the condition of complex background interference, distance change, and constant change in dust concentration in the coal mine.
- The proposed RCEAU-Net model effectively fuses the underlying feature information by introducing residual connections in the convolution of the encoder and decoder structures of U-Net. Meanwhile, the problem of missing contextual semantic information in U-Net is compensated by introducing cascade multi-scale convolution in the skipping connection part. In addition, the introduction of an efficient multi-scale attention module with cross-spatial learning in the encoder enhances the feature extraction ability of the network for laser beams, which improves the segmentation effect of the network model on tiny laser beams at long distance.
- The LBTD was constructed with images collected from multiple scenarios of different distances, dust concentrations, low illumination, and overexposure in coal mines. Based on LBTD datasets, the experiment was carried out for the validation of the image segmentation performance of the constructed RCEAU-Net. The results demonstrated that the proposed RCEAU-Net realizes the accurate and reliable segmentation of the boundary features and tiny features of laser beam images in the complex background, and it can meet the demand for laser beam segmentation for long-distance visual localization in coal mines.
2. Related Work
3. Methods
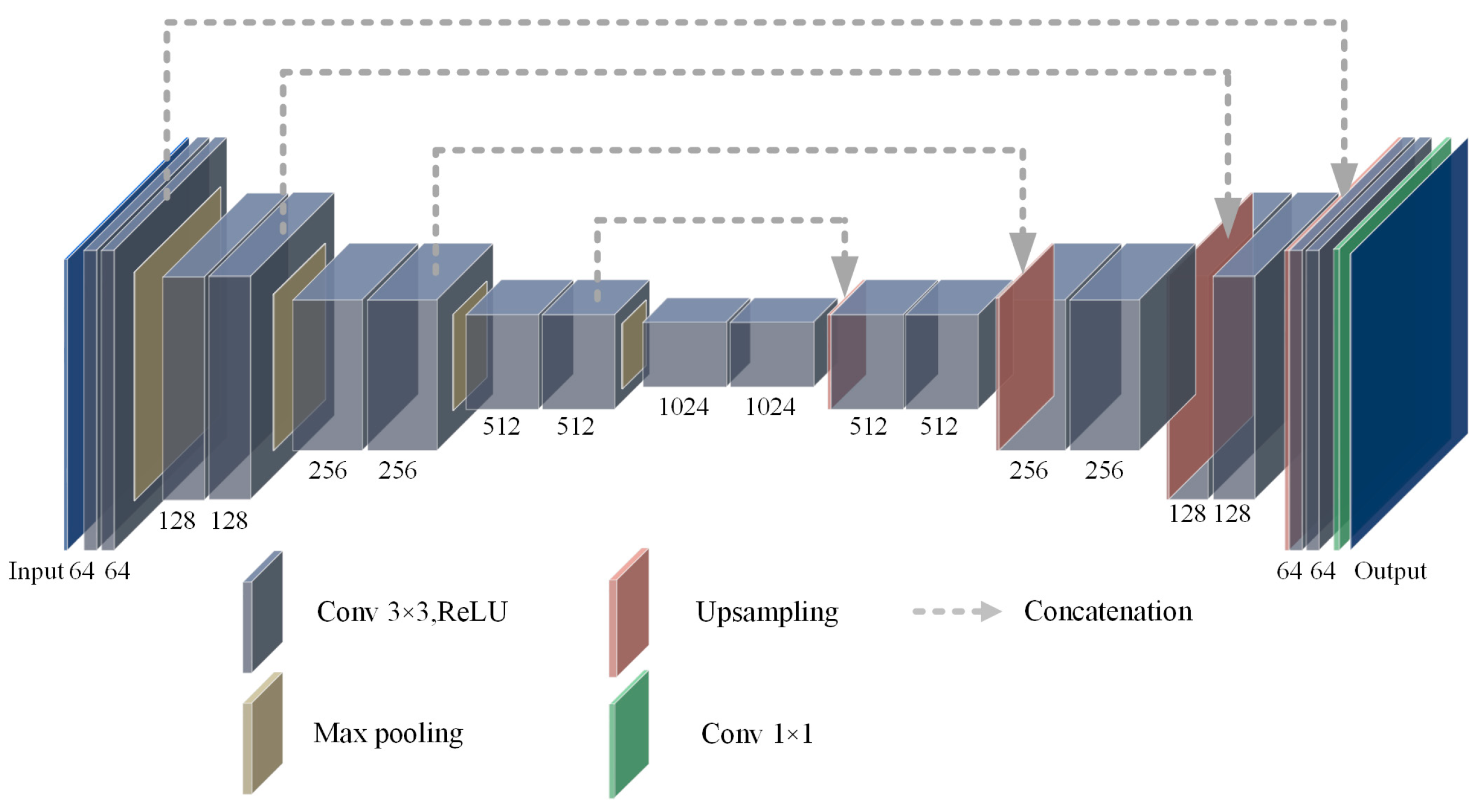
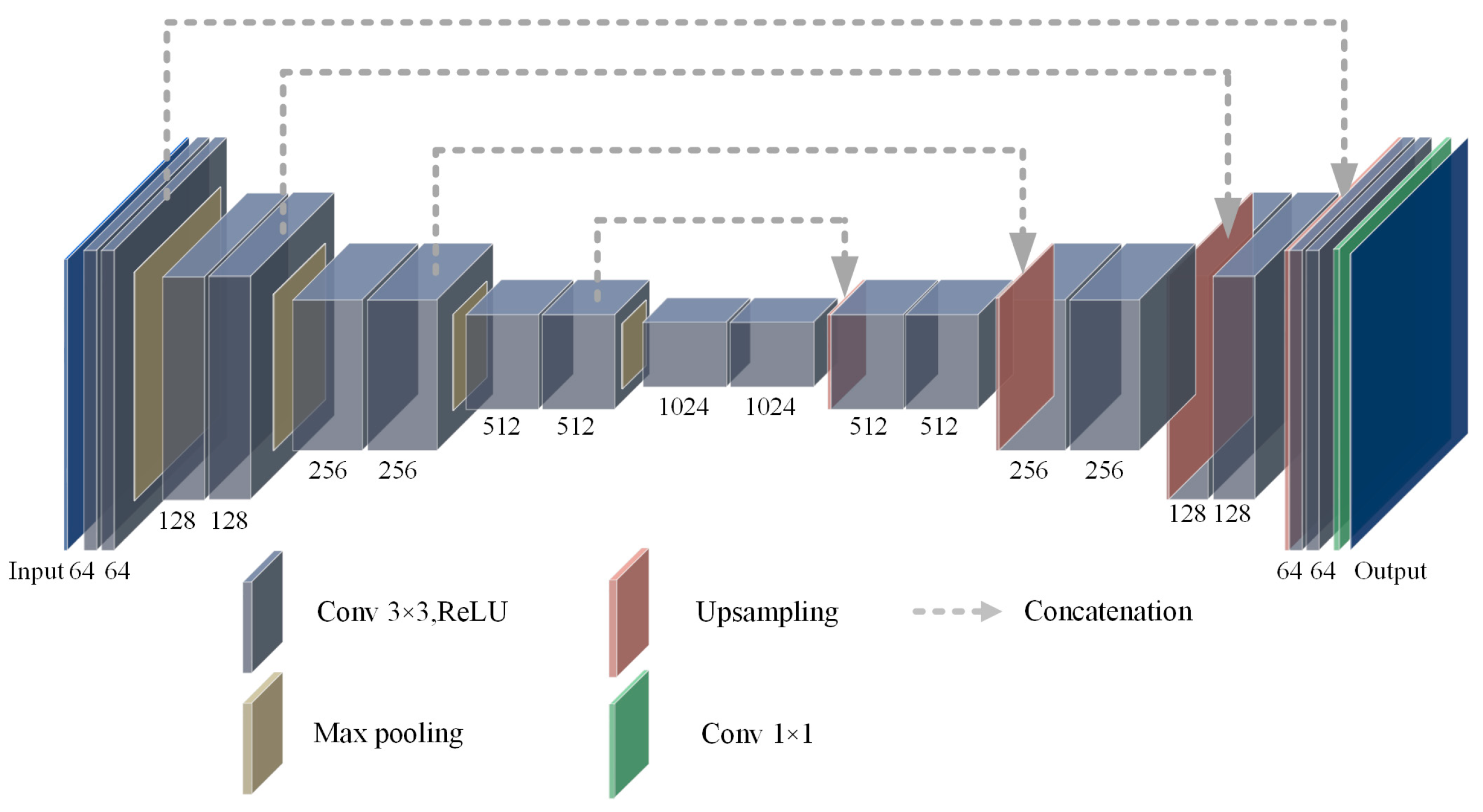
3.1. The U-Net Network Overview
3.2. RCEAU-Net
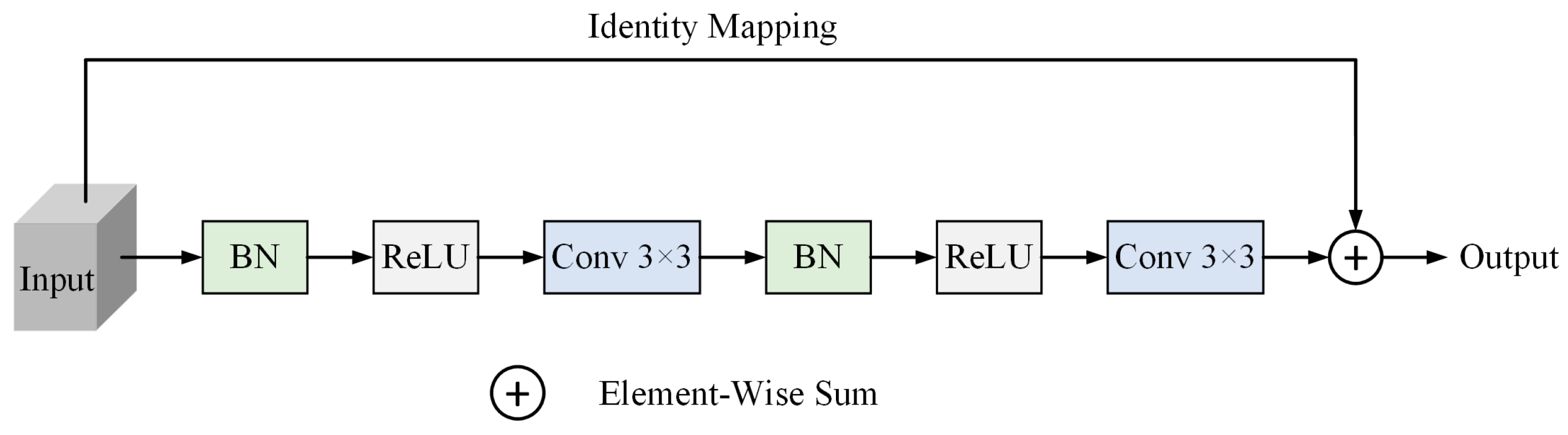
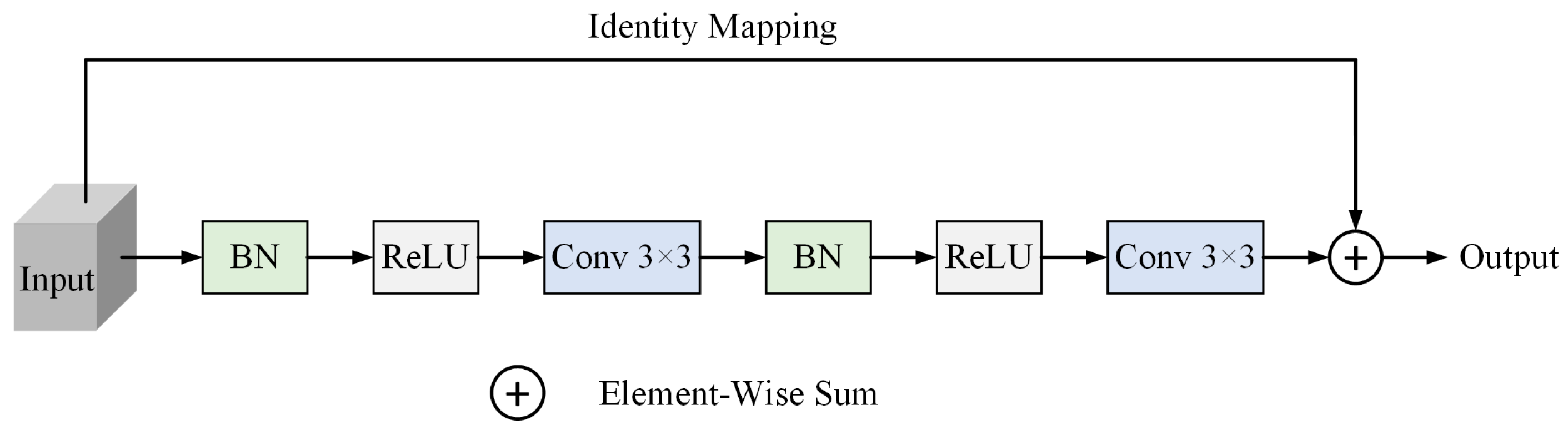
3.2.1. Residual Structure
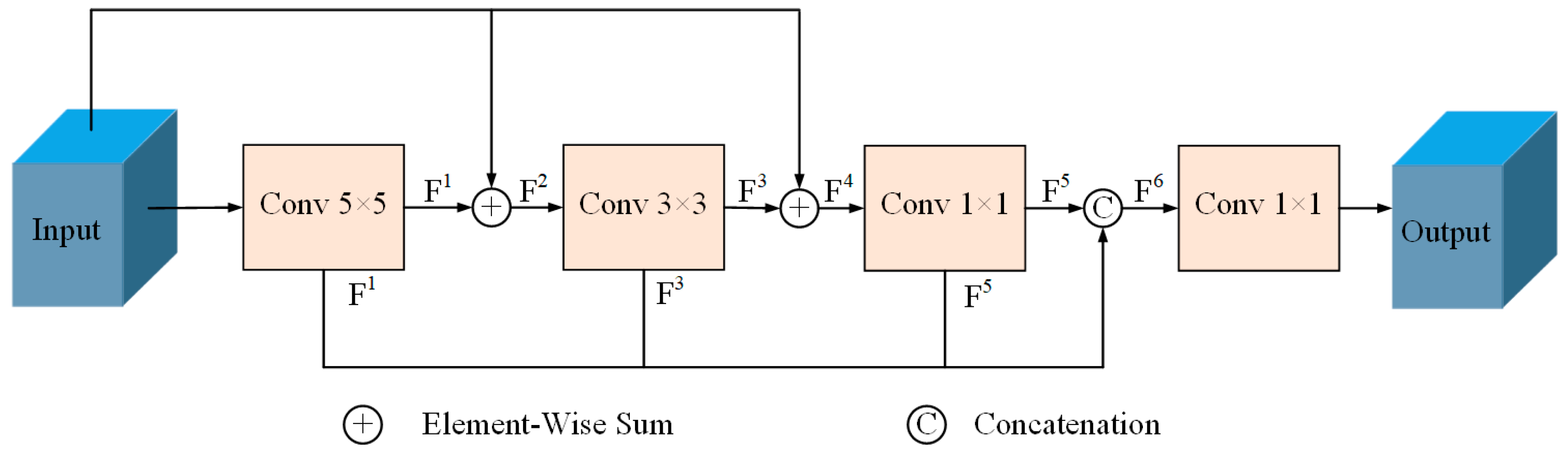
3.2.2. Cascade Multi-Scale Convolution Module
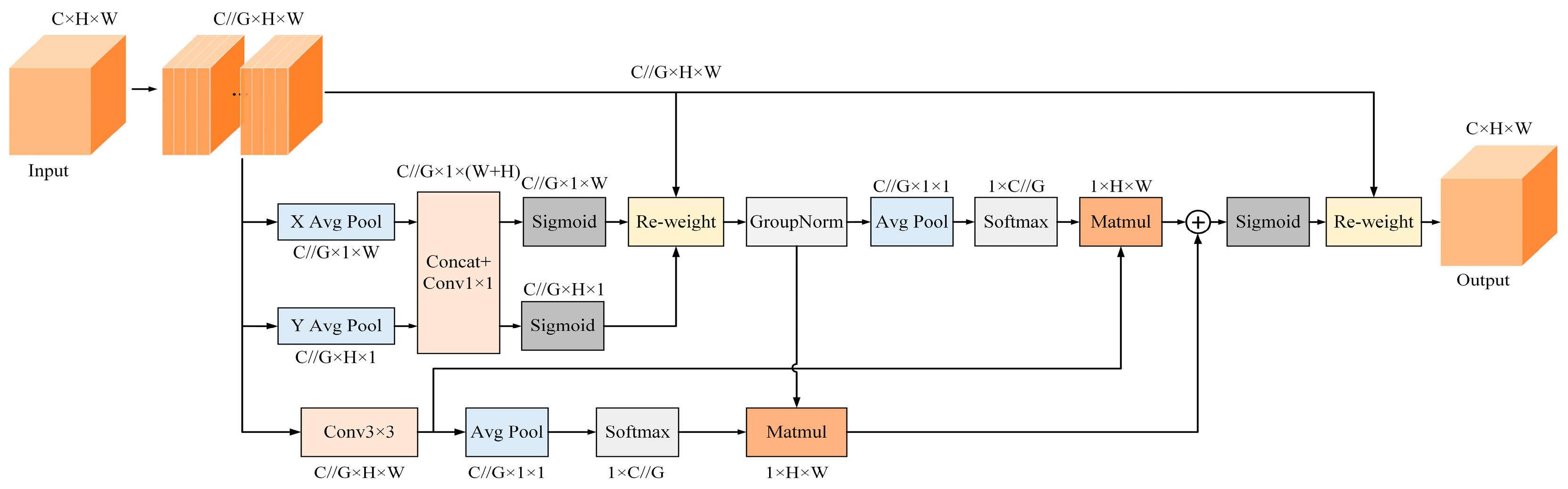
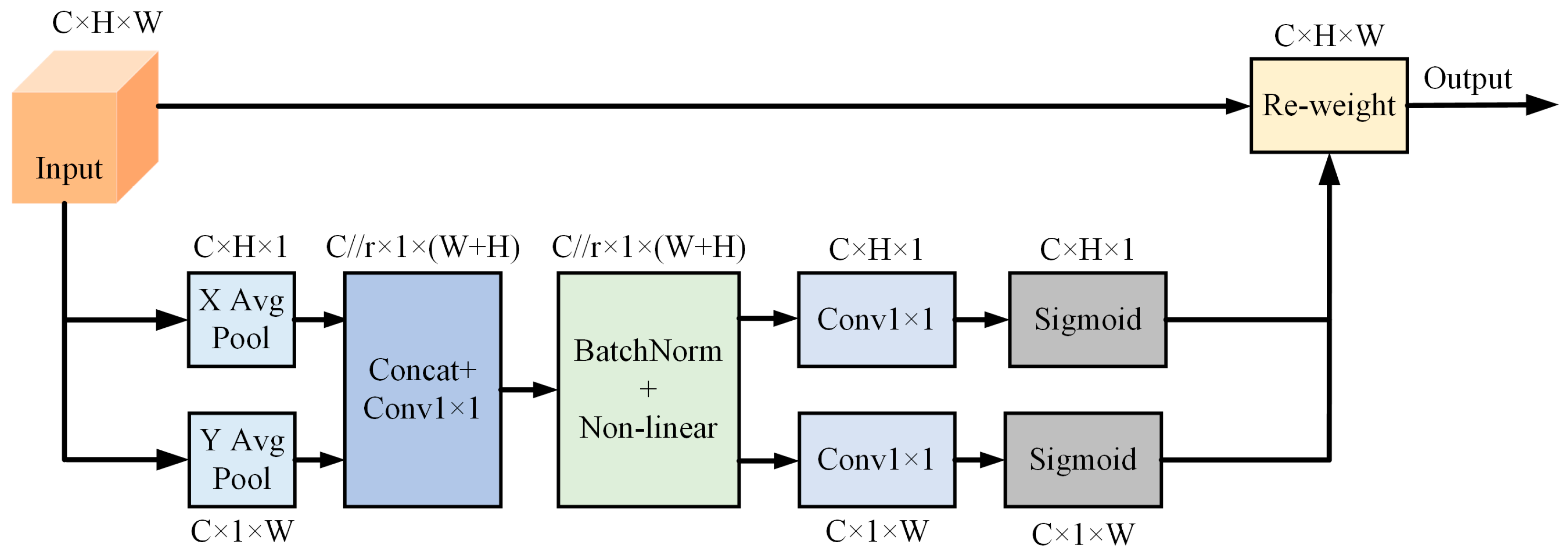
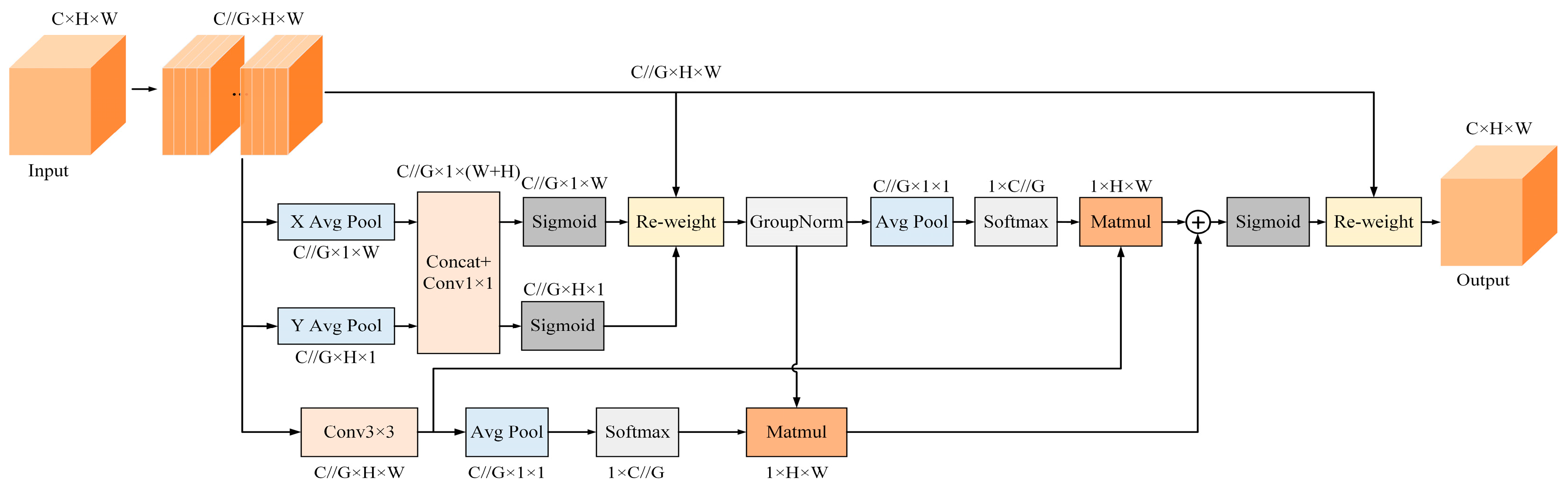
3.2.3. Efficient Multi-Scale Attention Module with Cross-Spatial Learning
3.2.4. Loss Function
3.3. Underground Coal Mine Laser Beam Target Dataset
4. Experiments and Performance
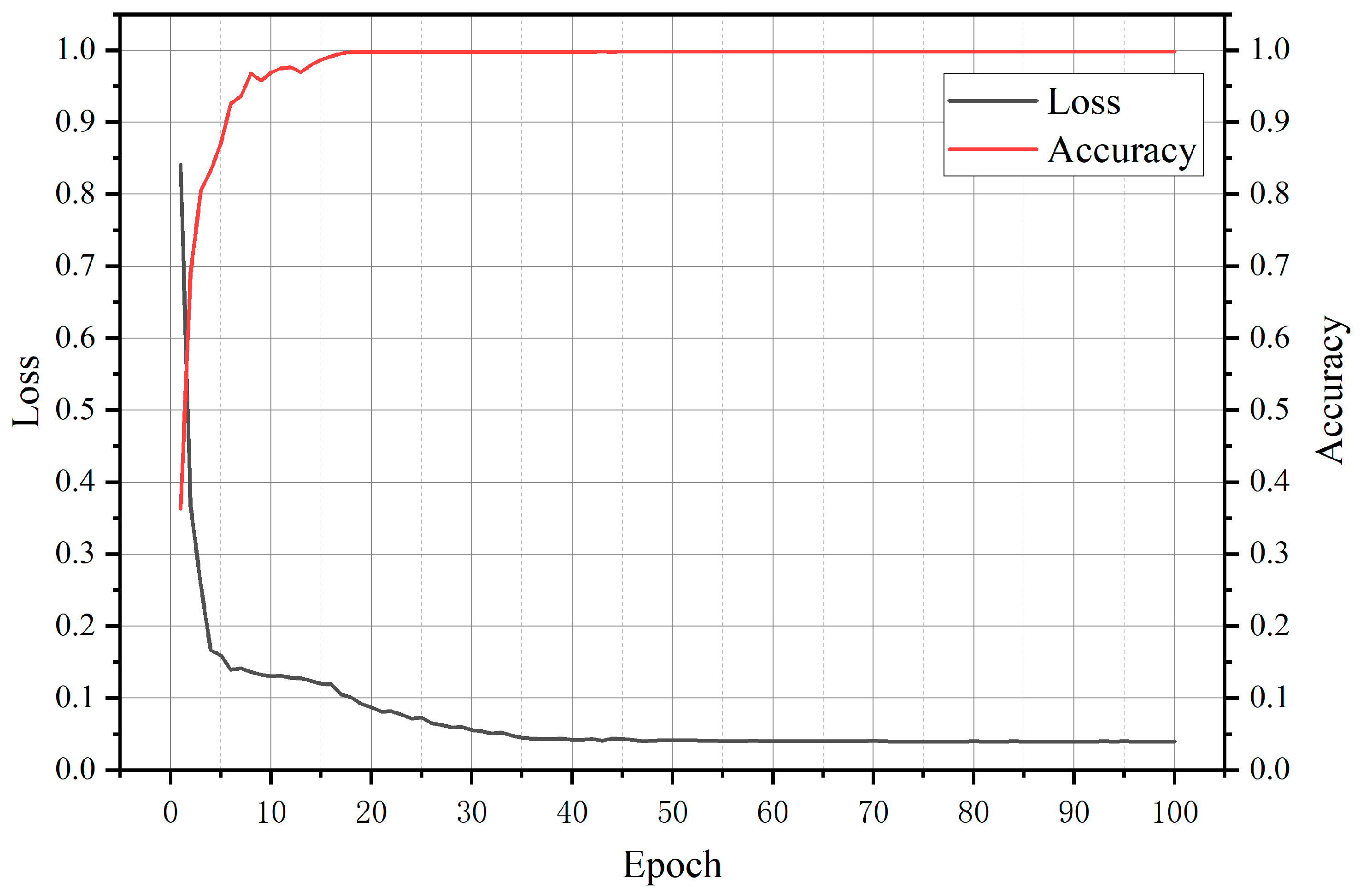
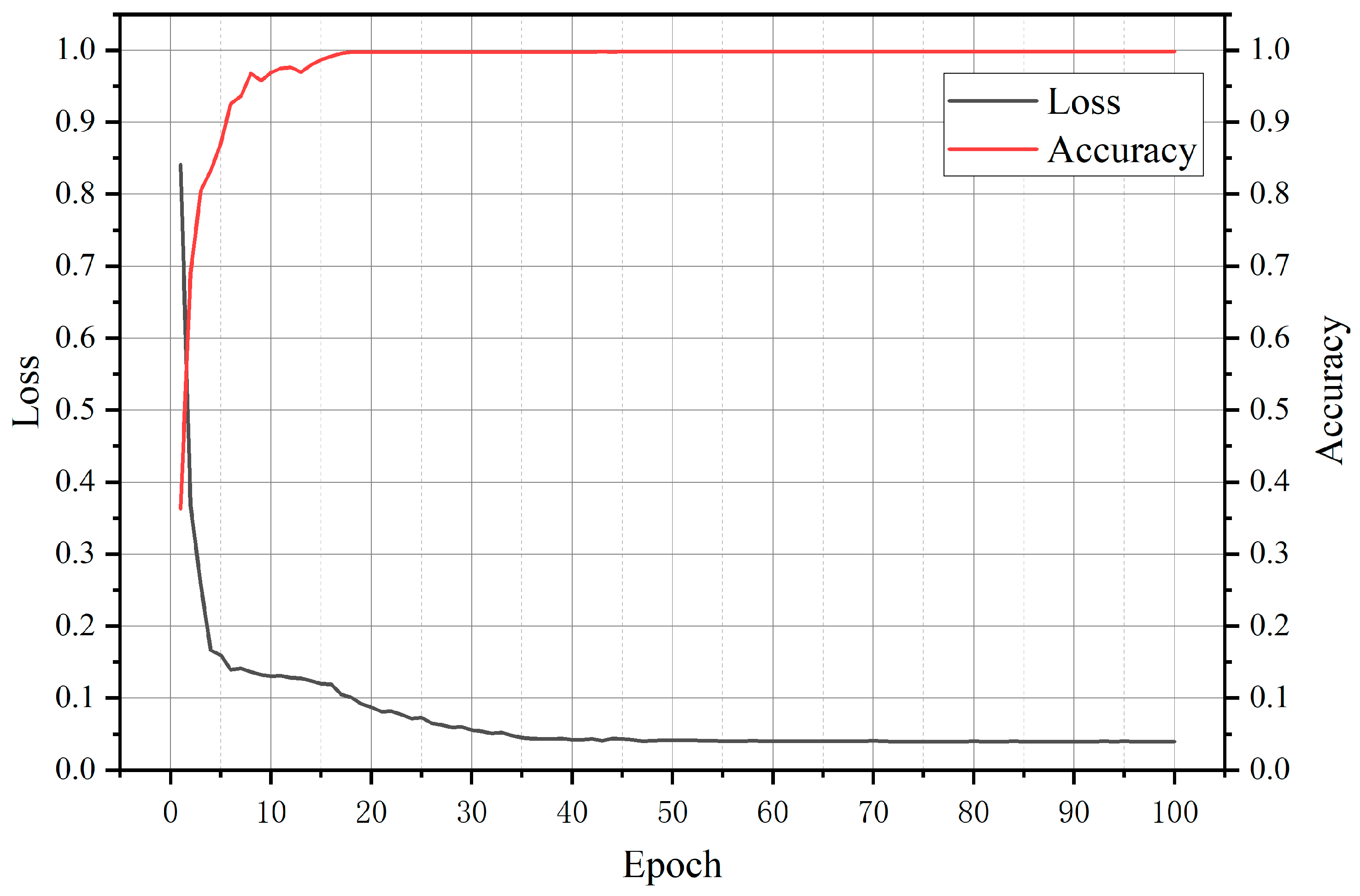
4.1. Training Environment and Parameter Settings
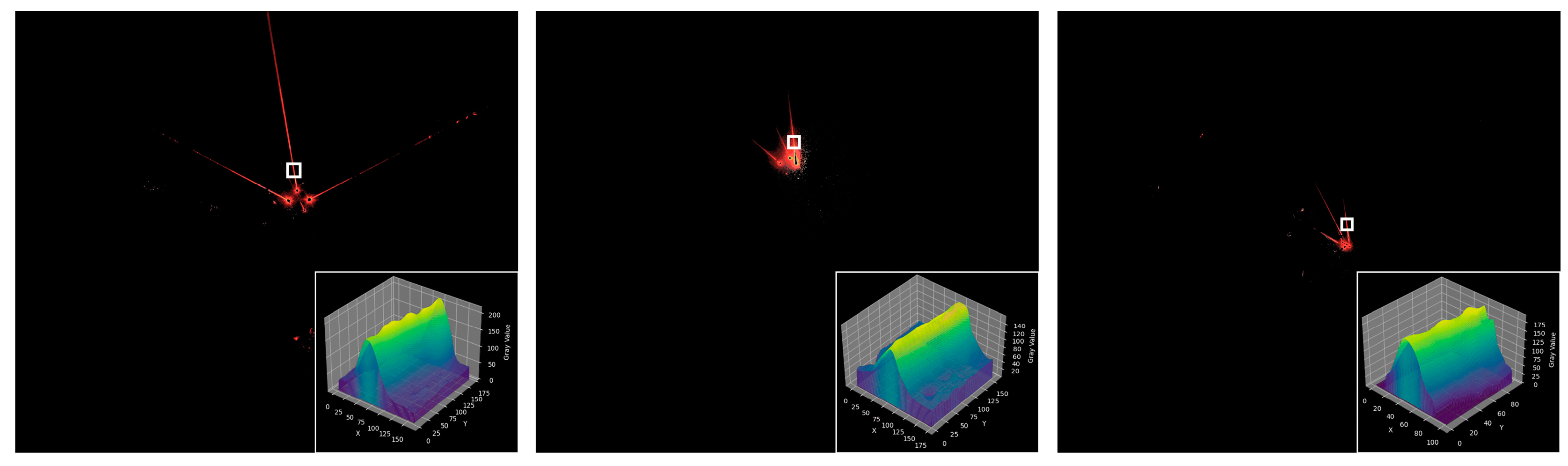
4.2. Experimental Results and Analysis
5. Discussion and Conclusions
- An RCEAU-Net model suitable for laser beam image segmentation in the working face is proposed for long-distance vision localization in an under-ground application. An LBTD was constructed with images collected from several different scenarios of a coal mine working face, which contains 3406 images and the laser beam target area that were manually labeled. The performance of the proposed RCEAU-Net model was significantly improved, and it can reliably segment and accurately extract laser beam features under the conditions of complex background interference, distance change, and coal dust concentration change.
- Considering that it is difficult for traditional segmentation networks to obtain stable and accurate characteristics of multi-laser-beam targets, a new RCEAU-Net network is proposed in this work, which can effectively solve the problem of segmentation errors or omissions of laser beam target images due to weak laser beam features, discontinuity, and easy confusion with background. Moreover, although its inference speed is slightly slower than that of the U-Net network, the reasoning speed of the RCEAU-Net model can meet the requirement of real-time segmentation and extraction of downhole laser beam images.
- The proposed underground laser beam segmentation network RCEAU-Net is verified on the established LBTD datasets. Compared with traditional U-Net, the accuracy is improved by 0.19%, precision is improved by 2.53%, recall is improved by 22.01%, and IoU is improved by 8.48%. The fitting accuracy of the laser beam center line is also verified and analyzed. The experimental results show that the maximum slope deviation between the fitted laser beam center line and the real center line is 0.0085, and the maximum intercept deviation is 0.4306 pixels, which can meet the accuracy requirements of laser beam feature extraction for long-distance visual localization in a coal mine.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, X.; Cao, Z.; Xu, Y. Characteristics and trends of coal mine safety development. Energy Sources Part A Recovery Util. Environ. Eff. 2020, 1–19. [Google Scholar] [CrossRef]
- Yang, W.; Zhang, X.; Ma, H.; Zhang, G. Laser Beams-Based Localization Methods for Boom-Type Roadheader Using Underground Camera Non-Uniform Blur Model. IEEE Access 2020, 8, 190327–190341. [Google Scholar] [CrossRef]
- Yang, W.; Zhang, X.; Zhang, C. Long distance vision localization method based on triple laser beams target in coal mine. J. China Coal Soc. 2022, 47, 986–1001. [Google Scholar]
- Zhang, X.; Wang, J.; Wang, Y.; Feng, Y.; Tang, S. Image Segmentation of Fiducial Marks with Complex Backgrounds Based on the mARU-Net. Sensors 2023, 23, 9347. [Google Scholar] [CrossRef]
- Liu, X.; Deng, Z.; Yang, Y. Recent progress in semantic image segmentation. Artif. Intell. Rev. 2019, 52, 1089–1106. [Google Scholar] [CrossRef]
- Li, H.; Sun, F.; Liu, L.; Wang, L. A novel traffic sign detection method via color segmentation and robust shape matching. Neurocomputing 2015, 169, 77–88. [Google Scholar] [CrossRef]
- Kaur, T.; Saini, B.S.; Gupta, S. Optimized Multi Threshold Brain Tumor Image Segmentation Using Two Dimensional Minimum Cross Entropy Based on Co-occurrence Matrix. Med. Imaging Clin. Appl. 2016, 651, 461–486. [Google Scholar]
- Singh, V.B.; Misra, A.K. Detection of plant leaf diseases using image segmentation and soft computing techniques. Inf. Process. Agric. 2017, 4, 41–49. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention MICCAI 2015, Munich, Germany, 5–9 October 2015. [Google Scholar]
- AL Qurri, A.; Almekkawy, M. Improved UNet with Attention for Medical Image Segmentation. Sensors 2023, 23, 8589. [Google Scholar] [CrossRef]
- Shojaiee, F.; Baleghi, Y. EFASPP U-Net for semantic segmentation of night traffic scenes using fusion of visible and thermal images. Eng. Appl. Artif. Intell. 2023, 117, 105627. [Google Scholar] [CrossRef]
- Luo, Z.; Yang, W.; Yuan, Y.; Gou, R.; Li, X. Semantic segmentation of agricultural images: A survey. Inf. Process. Agric. 2023, in press. [CrossRef]
- Elamin, A.; El-Rabbany, A. UAV-Based Image and LiDAR Fusion for Pavement Crack Segmentation. Sensors 2023, 23, 9315. [Google Scholar] [CrossRef]
- Xue, H.; Liu, K.; Wang, Y.; Chen, Y.; Huang, C.; Wang, P.; Li, L. MAD-UNet: A Multi-Region UAV Remote Sensing Network for Rural Building Extraction. Sensors 2024, 24, 2393. [Google Scholar] [CrossRef]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.J.; Heinrich, M.P.; Misawa, K.; Mori, K.; McDonagh, S.G.; Hammerla, N.Y.; Kainz, B.; et al. Attention U-Net: Learning Where to Look for the Pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. UNet++: A nested UNet architecture for medical image segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Berlin/Heidelberg, Germany, 2018; pp. 3–11. [Google Scholar]
- Diakogiannis, F.I.; Waldner, F.; Caccetta, P.; Wu, C. ResUNet-a: A deep learning framework for semantic segmentation of remotely sensed data. ISPRS J. Photogramm. Remote Sens. 2020, 162, 94–114. [Google Scholar] [CrossRef]
- Huang, H.; Lin, L.; Tong, R.; Hu, H.; Zhang, Q.; Iwamoto, Y.; Han, X.; Chen, Y.W.; Wu, J. Unet 3+: A full-scale connected UNet for medical image segmentation. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 1055–1059. [Google Scholar]
- Cao, H.; Wang, Y.; Chen, J.; Jiang, D.; Zhang, X.; Tian, Q.; Wang, M. Swin-UNet: UNet-like pure Transformer for medical image segmentation. arXiv 2021, arXiv:2105.05537. [Google Scholar]
- Li, C.; Tan, Y.; Chen, W.; Luo, X.; Gao, Y.; Jia, X.; Wang, Z. Attention Unet++: A Nested Attention-Aware U-Net for Liver CT Image Segmentation. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 25–28 October 2020; pp. 345–349. [Google Scholar]
- Li, Z.; Zhang, H.; Li, Z.; Ren, Z. Residual-Attention UNet++: A Nested Residual-Attention U-Net for Medical Image Segmentation. Appl. Sci. 2022, 12, 7149. [Google Scholar] [CrossRef]
- Gao, Y.; Cao, H.; Cai, W.; Zhou, G. Pixel-level road crack detection in UAV remote sensing images based on ARD-Unet. Measurement 2023, 219, 113252. [Google Scholar] [CrossRef]
- Nan, G.; Li, H.; Du, H.; Liu, Z.; Wang, M.; Xu, S. A Semantic Segmentation Method Based on AS-Unet++ for Power Remote Sensing of Images. Sensors 2024, 24, 269. [Google Scholar] [CrossRef]
- Li, Y.; Liu, W.; Ge, Y.; Yuan, S.; Zhang, T.; Liu, X. Extracting Citrus-Growing Regions by Multiscale UNet Using Sentinel-2 Satellite Imagery. Remote Sens. 2024, 16, 36. [Google Scholar] [CrossRef]
- Khan, M.A.-M.; Kee, S.-H.; Nahid, A.-A. Vision-Based Concrete-Crack Detection on Railway Sleepers Using Dense U-Net Model. Algorithms 2023, 16, 568. [Google Scholar] [CrossRef]
- Jin, H.; Cao, L.; Kan, X.; Sun, W.; Yao, W.; Wang, X. Coal petrography extraction approach based on multiscale mixed-attention-based residual U-net. Meas. Sci. Technol. 2022, 33, 075402. [Google Scholar] [CrossRef]
- Fan, J.; Du, M.; Liu, L.; Li, G.; Wang, D.; Liu, S. Macerals particle characteristics analysis of tar-rich coal in northern Shaanxi based on image segmentation models via the U-Net variants and image feature extraction. Fuel 2023, 341, 127757. [Google Scholar] [CrossRef]
- Lu, F.; Fu, C.; Shi, J.; Zhang, G. Attention based deep neural network for micro-fracture extraction of sequential coal rock CT images. Multimed. Tools Appl. 2022, 81, 26463–26482. [Google Scholar] [CrossRef]
- Fu, Y.; Aldrich, C. Online particle size analysis on conveyor belts with dense convolutional neural networks. Miner. Eng. 2023, 193, 108019. [Google Scholar] [CrossRef]
- Siddique, N.; Paheding, S.; Elkin, C.P.; Devabhaktuni, V. U-Net and Its Variants for Medical Image Segmentation: A Review of Theory and Applications. IEEE Access 2021, 9, 82031–82057. [Google Scholar] [CrossRef]
- Ouyang, D.; He, S.; Zhang, G.; Luo, M.; Guo, H.; Zhan, J.; Huang, Z. Efficient Multi-Scale Attention Module with Cross-Spatial Learning. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Liu, Y.; Shao, Z.; Teng, Y.; Hoffmann, N. NAM: Normalization-based Attention Module. arXiv 2021, arXiv:2111.12419. [Google Scholar]
- Zhang, Q.L.; Yang, Y.B. SA-Net: Shuffle Attention for Deep Convolutional Neural Networks. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate Attention for Efficient Mobile Network Design. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Fan, D.P.; Zhou, T.; Chen, G.; Fu, H.; Shen, J.; Shao, L. PraNet: Parallel Reverse Attention Network for Polyp Segmentation. In Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Yang, W.; Zhang, X.; Ma, B.; Wang, Y.; Wu, Y.; Yan, J.; Zhang, C.; Wan, J.; Wang, Y.; Huang, M.; et al. An open dataset for intelligent recognition and classification of abnormal condition in longwall mining. Sci. Data 2023, 10, 416. [Google Scholar] [CrossRef]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Ren, L.; Wang, X.; Wang, N.; Zhang, G.; Li, Y.; Yang, Z. An edge thinning algorithm based on newly defined single-pixel edge patterns. IET Image Process. 2023, 17, 1161–1169. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Network Model | mAcc | mPre | mRec | mIoU | Inference Time (per/ms) | Training Time per Epoch(s) |
|---|---|---|---|---|---|---|---|
| 1 | U-Net | 0.9962 | 0.7091 | 0.6236 | 0.6014 | 5.6132 | 351 |
| 2 | U-Net + StructLoss | 0.9972 | 0.7115 | 0.8056 | 0.6707 | 5.5005 | 354 |
| 3 | RU-Net + StructLoss | 0.9974 | 0.7151 | 0.8196 | 0. 6724 | 5.9147 | 243 |
| 4 | RU-Net + StructLoss + EMA | 0.9979 | 0.7251 | 0.8360 | 0.6746 | 6.9504 | 334 |
| 5 | RU-Net + StructLoss + CMSC | 0.9978 | 0.7191 | 0.8383 | 0.6768 | 7.1446 | 363 |
| 6 | RCEAU-Net | 0.9981 | 0.7344 | 0.8437 | 0.6862 | 8.1003 | 430 |
| No. | Network Model | Category | Acc | Pre | Rec | IoU |
|---|---|---|---|---|---|---|
| 1 | U-Net | Laser beam target | 0.9945 | 0.5073 | 0.3459 | 0.2817 |
| Background | 0.9979 | 0.9109 | 0.9013 | 0.9211 | ||
| 2 | Attention U-Net | Laser beam target | 0.9977 | 0.5247 | 0.7301 | 0.4236 |
| Background | 0.9981 | 0.9121 | 0.9033 | 0.9238 | ||
| 3 | Swin-Unet | Laser beam target | 0.9950 | 0.4969 | 0.3239 | 0.2758 |
| Background | 0.9982 | 0.9095 | 0.9089 | 0.9244 | ||
| 4 | U-Net3+ | Laser beam target | 0.9970 | 0.5300 | 0.7665 | 0.4445 |
| Background | 0.9986 | 0.9088 | 0.9101 | 0.9091 | ||
| 5 | DeepLabv3+ | Laser beam target | 0.9972 | 0.5281 | 0.7458 | 0.4337 |
| Background | 0.9980 | 0.9101 | 0.9132 | 0.9163 | ||
| 6 | RCEAU-Net | Laser beam target | 0.9979 | 0.5595 | 0.7767 | 0.4525 |
| Background | 0.9983 | 0.9093 | 0.9107 | 0.9199 |
| No. | Network Model | mAcc | mPre | mRec | mIoU |
|---|---|---|---|---|---|
| 1 | U-Net | 0.9962 | 0.7091 | 0.6236 | 0.6014 |
| 2 | Attention U-Net | 0.9979 | 0.7184 | 0.8167 | 0.6737 |
| 3 | Swin-Unet | 0.9966 | 0.7032 | 0.6164 | 0.6001 |
| 4 | U-Net3+ | 0.9978 | 0.7194 | 0.8383 | 0.6768 |
| 5 | DeepLabv3+ | 0.9976 | 0.7191 | 0.8295 | 0.6750 |
| 6 | RCEAU-Net | 0.9981 | 0.7344 | 0.8437 | 0.6862 |
| No. | Slope | Intercept (Pixels) | ||||
|---|---|---|---|---|---|---|
| GT | Fitting | Deviation | GT | Fitting | Deviation | |
| 1 | 0.5074 | 0.5075 | −0.0001 | 210.5813 | 210.5532 | 0.0281 |
| 2 | 5.7172 | 5.7087 | 0.0085 | −7036.5186 | −7036.7213 | 0.2027 |
| 3 | −0.4989 | −0.5005 | 0.0016 | 1600.8748 | 1601.2083 | −0.3335 |
| 4 | 0.5716 | 0.5743 | −0.0027 | 312.6917 | 312.5921 | 0.0996 |
| 5 | 1.8137 | 1.8145 | −0.0008 | −1454.4894 | −1454.1673 | −0.3221 |
| 6 | 6.5202 | 6.5191 | 0.0011 | −8169.6474 | −8170.0015 | 0.3541 |
| 7 | 0.3314 | 0.3289 | 0.0025 | 674.7073 | 674.2767 | 0.4306 |
| 8 | 1.0353 | 1.0294 | 0.0059 | −336.2056 | −335.799 | −0.4066 |
| 9 | 2.2483 | 2.2425 | 0.0058 | −2075.6864 | −2076.0135 | 0.3271 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, W.; Wang, Y.; Zhang, X.; Zhu, L.; Ren, Z.; Ji, Y.; Li, L.; Xie, Y. RCEAU-Net: Cascade Multi-Scale Convolution and Attention-Mechanism-Based Network for Laser Beam Target Image Segmentation with Complex Background in Coal Mine. Sensors 2024, 24, 2552. https://doi.org/10.3390/s24082552
Yang W, Wang Y, Zhang X, Zhu L, Ren Z, Ji Y, Li L, Xie Y. RCEAU-Net: Cascade Multi-Scale Convolution and Attention-Mechanism-Based Network for Laser Beam Target Image Segmentation with Complex Background in Coal Mine. Sensors. 2024; 24(8):2552. https://doi.org/10.3390/s24082552
Chicago/Turabian StyleYang, Wenjuan, Yanqun Wang, Xuhui Zhang, Le Zhu, Zhiteng Ren, Yang Ji, Long Li, and Yanbin Xie. 2024. "RCEAU-Net: Cascade Multi-Scale Convolution and Attention-Mechanism-Based Network for Laser Beam Target Image Segmentation with Complex Background in Coal Mine" Sensors 24, no. 8: 2552. https://doi.org/10.3390/s24082552
APA StyleYang, W., Wang, Y., Zhang, X., Zhu, L., Ren, Z., Ji, Y., Li, L., & Xie, Y. (2024). RCEAU-Net: Cascade Multi-Scale Convolution and Attention-Mechanism-Based Network for Laser Beam Target Image Segmentation with Complex Background in Coal Mine. Sensors, 24(8), 2552. https://doi.org/10.3390/s24082552