
A Real-Time License Plate Detection and Recognition Model in Unconstrained Scenarios

 ,
,
Abstract
1. Introduction
- We propose a new license plate detection and recognition model called YOLOv5-PDLPR, which employs the YOLOv5 target detection algorithm in the license plate detection part and the newly proposed license plate recognition algorithm PDLPR. PDLPR has three main newly designed components: a Multi-Head Attention mechanism for accurately recognizing individual characters, a feature extraction network for improving the integrity of the global feature extraction network, and a state-of-the-art parallel decoder architecture for improving inference efficiency.
- Experimental results on the CCPD dataset [25] show that the proposed method achieves an average accuracy of 99.4% and a recognition speed of 159.8 FPS, which are better than those of the comparison algorithms.
2. Related Work
2.1. License Plate Detection
2.2. License Plate Recognition
2.2.1. Traditional License Plate Character Recognition Method
2.2.2. Deep Learning-Based License Plate Character Recognition Method
- (1)
- Methods that require character segmentation
- (2)
- Methods without character segmentation
2.3. Transformer
3. Proposed Method
3.1. License Plate Detection
3.2. License Plate Recognition
3.2.1. Improved Global Feature Extractor
- (1)
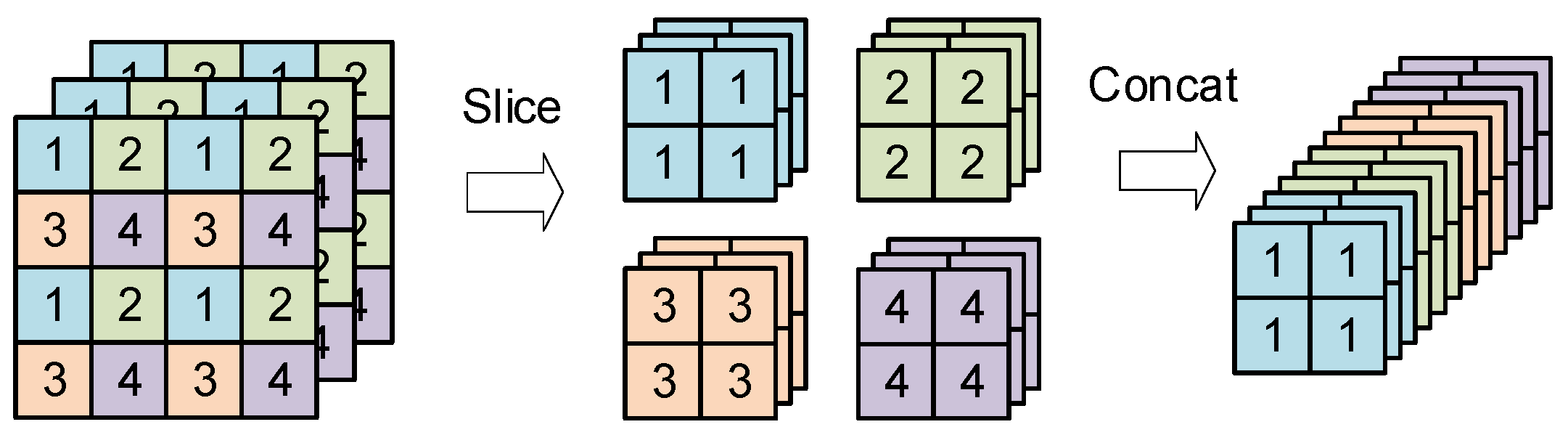
- Focus Structure Module
- (2)
- RESBLOCK module
- (3)
- ConvDownSampling module
3.2.2. Encoder
3.2.3. Parallel Decoder
4. Experimental Setup
4.1. Datasets
4.2. Implementation Details
4.3. Evaluation Indicator
5. Experiment Results
5.1. Experiments on the CCPD Dataset
5.2. Experiments on CLPD and PKUData Datasets
5.3. Experiments on the AOLP Dataset
6. Ablation Study
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Weihong, W.; Jiaoyang, T. Research on license plate recognition algorithms based on deep learning in complex environment. IEEE Access 2020, 8, 91661–91675. [Google Scholar] [CrossRef]
- Shashirangana, J.; Padmasiri, H.; Meedeniya, D.; Perera, C. Automated license plate recognition: A survey on methods and techniques. IEEE Access 2020, 9, 11203–11225. [Google Scholar] [CrossRef]
- Abolghasemi, V.; Ahmadyfard, A. An edge-based color-aided method for license plate detection. Image Vis. Comput. 2009, 27, 1134–1142. [Google Scholar] [CrossRef]
- Lalimi, M.A.; Ghofrani, S.; McLernon, D. A vehicle license plate detection method using region and edge based methods. Comput. Electr. Eng. 2013, 39, 834–845. [Google Scholar] [CrossRef]
- Wu, Y.; Liu, S.; Wang, X. License plate location method based on texture and color. In Proceedings of the 2013 IEEE 4th International Conference on Software Engineering and Service Science, Beijing, China, 23–25 May 2013. [Google Scholar]
- Gou, C.; Wang, K.; Yao, Y.; Li, Z. Vehicle license plate recognition based on extremal regions and restricted boltzmann machines. IEEE Trans. Intell. Transp. Syst. 2016, 17, 1097–1107. [Google Scholar] [CrossRef]
- Ashtari, A.H.; Nordin, M.J.; Fathy, M. An Iranian license plate recognition system based on color features. IEEE Trans. Intell. Transp. Syst. 2014, 15, 1690–1705. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Ammar, A.; Koubaa, A.; Boulila, W.; Benjdira, B.; Alhabashi, Y. A Multi-Stage Deep-Learning-Based Vehicle and License Plate Recognition System with Real-Time Edge Inference. Sensors 2023, 23, 2120. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Hendry; Chen, R.C. Automatic License Plate Recognition Via Sliding-Window Darknet-Yolo Deep Learning. Image Vis. Comput. 2019, 87, 47–56. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Zhuang, J.; Hou, S.; Wang, Z.; Zha, Z.J. Towards human-level license plate recognition. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Castro-Zunti, R.D.; Yépez, J.; Ko, S.B. License plate segmentation and recognition system using deep learning and OpenVINO. IET Intell. Transp. Syst. 2020, 14, 119–126. [Google Scholar] [CrossRef]
- Zherzdev, S.; Gruzdev, A. Lprnet: License plate recognition via deep neural networks. arXiv 2018, arXiv:1806.10447. [Google Scholar]
- Xiao, D.; Zhang, L.; Li, J.; Li, J. Robust license plate detection and recognition with automatic rectification. J. Electron. Imaging 2021, 30, 013002. [Google Scholar] [CrossRef]
- Yousaf, U.; Khan, A.; Ali, H.; Khan, F.G.; Rehman, Z.u.; Shah, S.; Ali, F.; Pack, S.; Ali, S. A deep learning based approach for localization and recognition of pakistani vehicle license plates. Sensors 2021, 21, 7696. [Google Scholar] [CrossRef]
- Gao, F.; Cai, Y.; Ge, Y.; Lu, S. EDF-LPR: A new encoder–decoder framework for license plate recognition. IET Intell. Transp. Syst. 2020, 14, 959–969. [Google Scholar] [CrossRef]
- Gong, Y.; Deng, L.; Tao, S.; Lu, X.; Wu, P.; Xie, Z.; Xie, M. Unified Chinese license plate detection and recognition with high efficiency. J. Vis. Commun. Image Represent. 2022, 86, 103541. [Google Scholar] [CrossRef]
- Xu, H.; Zhou, X.D.; Li, Z.; Liu, L.; Li, C.; Shi, Y. EILPR: Toward end-to-end irregular license plate recognition based on automatic perspective alignment. IEEE Trans. Intell. Transp. Syst. 2021, 23, 2586–2595. [Google Scholar] [CrossRef]
- Zou, Y.; Zhang, Y.; Yan, J.; Jiang, X.; Huang, T.; Fan, H.; Cui, Z. A robust license plate recognition model based on bi-lstm. IEEE Access 2020, 8, 211630–211641. [Google Scholar] [CrossRef]
- Zhang, L.; Wang, P.; Li, H.; Li, Z.; Shen, C.; Zhang, Y. A robust attentional framework for license plate recognition in the wild. IEEE Trans. Intell. Transp. Syst. 2020, 22, 6967–6976. [Google Scholar] [CrossRef]
- Xu, Z.; Yang, W.; Meng, A.; Lu, N.; Huang, H.; Ying, C.; Huang, L. Towards end-to-end license plate detection and recognition: A large dataset and baseline. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Qin, S.; Liu, S. Towards end-to-end car license plate location and recognition in unconstrained scenarios. Neural Comput. Appl. 2022, 34, 21551–21566. [Google Scholar] [CrossRef]
- Murugan, V.; Sowmyayani, S.; Kavitha, J.; Meenakshi, S. AI Driven Smart Number Plate Identification for Automatic Identification. In Proceedings of the 2024 IEEE International Conference on Computing, Power and Communication Technologies (IC2PCT), Greater Noida, India, 9–10 February 2024. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Polosukhin, I. Attention is all you need. Advances in neural information processing systems. arXiv 2017, arXiv:1706.0376230. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Jocher, G. Yolov5. Available online: https://github.com/ultralytics/yolov5 (accessed on 26 July 2022).
- Du, S.; Ibrahim, M.; Shehata, M.; Badawy, W. Automatic license plate recognition (ALPR): A state-of-the-art review. IEEE Trans. Circuits Syst. Video Technol. 2012, 23, 311–325. [Google Scholar] [CrossRef]
- Tian, J.; Wang, G.; Liu, J.; Xia, Y. License plate detection in an open environment by density-based boundary clustering. J. Electron. Imaging 2017, 26, 33017. [Google Scholar] [CrossRef]
- Yuan, Y.; Zou, W.; Zhao, Y.; Wang, X.; Hu, X.; Komodakis, N. A robust and efficient approach to license plate detection. IEEE Trans. Image Process. 2016, 26, 1102–1114. [Google Scholar] [CrossRef] [PubMed]
- Dun, J.; Zhang, S.; Ye, X.; Zhang, Y. Chinese license plate localization in multi-lane with complex background based on concomitant colors. IEEE Intell. Transp. Syst. Mag. 2015, 7, 51–61. [Google Scholar] [CrossRef]
- Kim, S.K.; Kim, D.W.; Kim, H.J. A recognition of vehicle license plate using a genetic algorithm based segmentation. In Proceedings of the 3rd IEEE International Conference on Image Processing, Lausanne, Switzerland, 19 September 1996. [Google Scholar]
- Zhang, H.; Jia, W.; He, X.; Wu, Q. Learning-based license plate detection using global and local features. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06), Hong Kong, China, 20–24 August 2006. [Google Scholar]
- Yu, S.; Li, B.; Zhang, Q.; Liu, C.; Meng, M.Q.H. A novel license plate location method based on wavelet transform and EMD analysis. Pattern Recognit. 2015, 48, 114–125. [Google Scholar] [CrossRef]
- Cho, B.K.; Ryu, S.H.; Shin, D.R.; Jung, J.I. License plate extraction method for identification of vehicle violations at a railway level crossing. Int. J. Automot. Technol. 2011, 12, 281–289. [Google Scholar] [CrossRef]
- Li, B.; Tian, B.; Li, Y.; Wen, D. Component-based license plate detection using conditional random field model. IEEE Trans. Intell. Transp. Syst. 2013, 14, 1690–1699. [Google Scholar] [CrossRef]
- Li, H.; Wang, P.; Shen, C. Toward end-to-end car license plate detection and recognition with deep neural networks. IEEE Trans. Intell. Transp. Syst. 2018, 20, 1126–1136. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Fan, X.; Zhao, W. Improving robustness of license plates automatic recognition in natural scenes. IEEE Trans. Intell. Transp. Syst. 2022, 23, 18845–18854. [Google Scholar] [CrossRef]
- Andriyanov, N.A.; Dementiev, V.E.; Tashlinskiy, A.G. Development of a Productive Transport Detection System Using Convolutional Neural Networks. Pattern Recognit. Image Anal. 2022, 32, 495–500. [Google Scholar] [CrossRef]
- Hui, T.W.; Tang, X.; Loy, C.C. A lightweight optical flow CNN—Revisiting data fidelity and regularizatio. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 2555–2569. [Google Scholar] [CrossRef] [PubMed]
- Maglad, K.W. A vehicle license plate detection and recognition system. J. Comput. Sci. 2012, 8, 310–315. [Google Scholar]
- Hsu, G.S.; Chen, J.C.; Chung, Y.Z. Application-oriented license plate recognition. IEEE Trans. Veh. Technol. 2012, 62, 552–561. [Google Scholar] [CrossRef]
- Rahman, C.A.; Badawy, W.; Radmanesh, A. A real time vehicle’s license plate recognition system. In Proceedings of the IEEE Conference on Advanced Video and Signal Based Surveillance, Miami, FL, USA, 22–22 July 2003. [Google Scholar]
- Björklund, T.; Fiandrotti, A.; Annarumma, M.; Francini, G.; Magli, E. Robust license plate recognition using neural networks trained on synthetic images. Pattern Recognit. 2019, 93, 134–146. [Google Scholar]
- Yao, D.; Zhu, W.; Chen, Y.; Zhang, L. Chinese license plate character recognition based on convolution neural network. In Proceedings of the 2017 Chinese Automation Congress (CAC), Jinan, China, 20–22 October 2017. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Zisserman, A. Spatial transformer networks. Advances in neural information processing systems. arXiv 2015, arXiv:1506.02025. [Google Scholar]
- Luo, C.; Jin, L.; Sun, Z. Moran: A multi-object rectified attention network for scene text recognition. Pattern Recognit. 2019, 90, 109–118. [Google Scholar] [CrossRef]
- Wang, T.; Zhu, Y.; Jin, L.; Luo, C.; Chen, X.; Wu, Y.; Cai, M. Decoupled attention network for text recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, New York Hilton Midtown, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Yang, L.; Wang, P.; Li, H.; Li, Z.; Zhang, Y. A holistic representation guided attention network for scene text recognition. Neurocomputing 2020, 414, 67–75. [Google Scholar] [CrossRef]
- Kang, L.; Riba, P.; Rusiñol, M.; Fornés, A.; Villegas, M. Pay attention to what you read: Non-recurrent handwritten text-line recognition. Pattern Recognit. 2022, 129, 108766. [Google Scholar] [CrossRef]
- Mahdavi, M.; Zanibbi, R.; Mouchere, H.; Viard-Gaudin, C.; Garain, U. ICDAR 2019 CROHME+ TFD: Competition on recognition of handwritten mathematical expressions and typeset formula detection. In Proceedings of the 2019 International Conference on Document Analysis and Recognition (ICDAR), Sydney, NSW, Australia, 20–25 September 2019. [Google Scholar]
- Ma, J.; Liang, Z.; Zhang, L. A text attention network for spatial deformation robust scene text image super-resolution. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
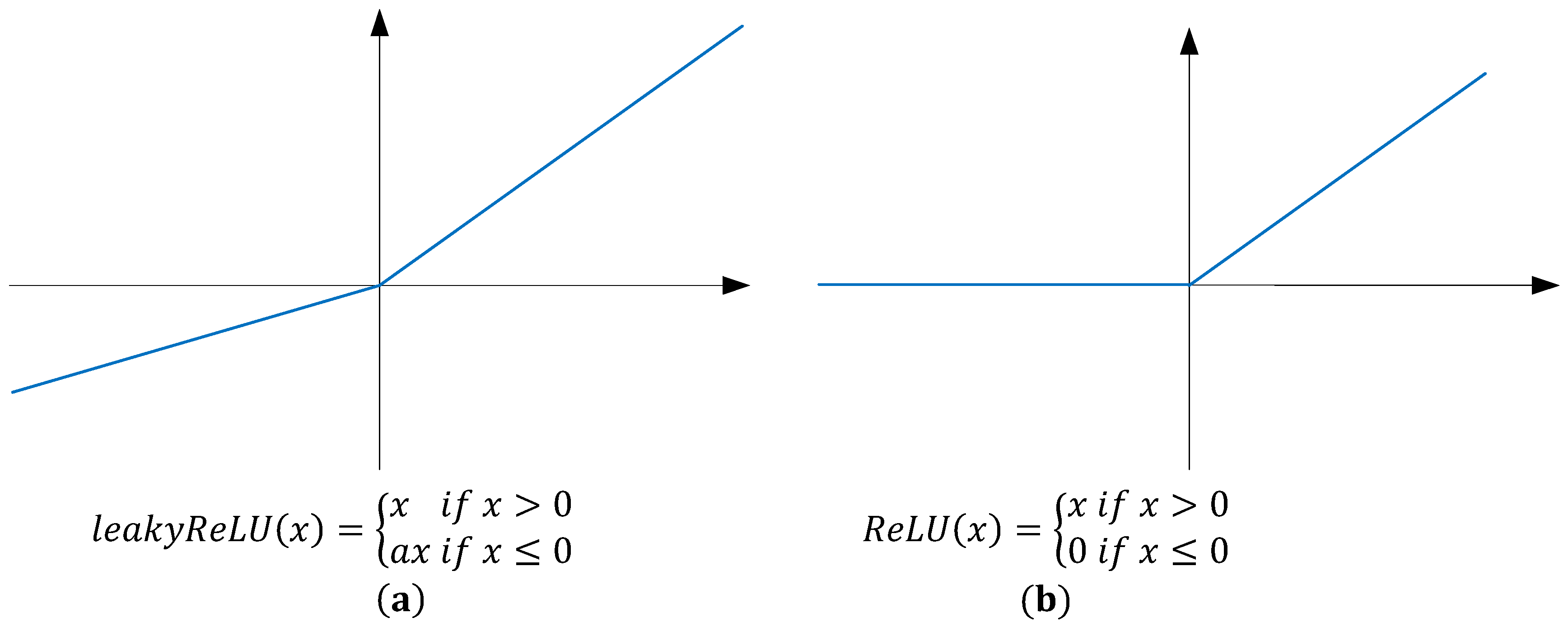
- Maas, A.L.; Hannun, A.Y.; Ng, A.Y. Rectifier nonlinearities improve neural network acoustic models. In Proceedings of the 30 th International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 11–13 April 2011. [Google Scholar]
- Zhang, K.; Zhang, Z.; Li, Z.; Qiao, Y. Joint face detection and alignment using multitask cascaded convolutional networks. IEEE Signal Process. Lett. 2016, 23, 1499–1503. [Google Scholar] [CrossRef]
- Zou, Y.; Zhang, Y.; Yan, J.; Jiang, X.; Huang, T.; Fan, H.; Cui, Z. License plate detection and recognition based on YOLOv3 and ILPRNET. Signal Image Video Process. 2022, 16, 473–480. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets Information | CCPD | PKUData | CLPD | AOLP |
|---|---|---|---|---|
| Year | 2018 | 2016 | 2019 | 2012 |
| Number of images | 283k | 2253 | 1200 | 2049 |
| Chinese province codes | 29 | 23 | 31 | 0 |
| Sequence length | 7 | 7 | 7~8 | 6 |
| Image size | 720 × 1160 | 1082 × 727 | 220 × 165~4596 × 2388 | 640 × 480 |
| LP colors | blue | blue + yellow | blue + yellow + green + white | white |
| Sub-Dataset | Description | Image Number |
|---|---|---|
| CCPD-Base | Ordinary license plate picture | 200 k |
| CCPD-FN | License plate is relatively close or far from the camera’s shooting position | 20 k |
| CCPD-DB | Brighter, darker or unevenly lit license plate areas | 20 k |
| CCPD-Rotate | License plate tilted 20 to 50 degrees horizontally, −10 to 10 degrees vertically | 10 k |
| CCPD-Tilt | License plate tilted 15 to 45 degrees horizontally and 15 to 45 degrees vertically | 10 k |
| CCPD-Weather | License plate photographed in rain, snow and fog | 10 k |
| CCPD-Challenge | The more challenging pictures in the plate detection recognition task | 10 k |
| CCPD-Blur | Blurred plate images due to camera lens shake | 5 k |
| CCPD-NP | Picture of a new car without plates fitted | 5 k |
| Method | Overall Accuracy | Base (100 k) | DB (20 k) | FN (20 k) | Rotate (10 k) | Tilt (10 k) | Weather (10 k) | Challenge (10 k) | Speed (FPS) |
|---|---|---|---|---|---|---|---|---|---|
| Faster RCNN [9] | 92.9 | 98.1 | 92.1 | 83.7 | 91.8 | 89.4 | 81.8 | 83.9 | 17.6 |
| YOL09000 [12] | 93.1 | 98.8 | 89.6 | 77.3 | 93.3 | 91.8 | 84.2 | 88.6 | 43.9 |
| SSD300 [42] | 94.4 | 99.1 | 89.2 | 84.7 | 95.6 | 94.9 | 83.4 | 93.1 | 40.7 |
| TE2E [41] | 94.2 | 98.5 | 91.7 | 83.8 | 95.1 | 94.5 | 83.6 | 93.1 | 3.2 |
| RPnet [25] | 94.5 | 99.3 | 89.5 | 85.3 | 94.7 | 93.2 | 84.1 | 92.8 | 85.5 |
| YOLOv5 | 96.7 | 97.2 | 97.7 | 92.9 | 98.9 | 98.9 | 99.0 | 90.6 | 218.3 |
| Method | Overall Accuracy | Base (100 k) | DB (20 k) | FN (20 k) | Rotate (10 k) | Tilt (10 k) | Weather (10 k) | Challenge (10 k) | Speed (FPS) |
|---|---|---|---|---|---|---|---|---|---|
| Ren et al., 2015 [9] | 92.8 | 97.2 | 94.4 | 90.9 | 82.9 | 87.3 | 85.5 | 76.3 | 17.4 |
| Liu et al., 2016 [42] | 95.2 | 98.3 | 96.6 | 95.9 | 88.4 | 91.5 | 87.3 | 83.8 | 39.1 |
| Joseph et al., 2016 [12] | 93.7 | 98.1 | 96.0 | 88.2 | 84.5 | 88.5 | 87.0 | 80.5 | 42.0 |
| Li et al., 2017 [41] | 94.4 | 97.8 | 94.8 | 94.5 | 87.9 | 92.1 | 86.8 | 81.2 | 3.2 |
| Zherzdev et al., 2018 [17] | 93.0 | 97.8 | 92.2 | 91.9 | 79.4 | 85.8 | 92.0 | 69.8 | 56.2 |
| Xu et al., 2018 [25] | 95.5 | 98.5 | 96.9 | 94.3 | 90.8 | 92.5 | 87.9 | 85.1 | 85.5 |
| Zhang et al., 2019 [17,61] | 93.0 | 99.1 | 96.3 | 97.3 | 95.1 | 96.4 | 97.1 | 83.2 | 6.5 |
| Luo et al., 2019 [52] | 98.3 | 99.5 | 98.1 | 98.6 | 98.1 | 98.6 | 97.6 | 86.5 | 54.9 |
| Wang et al., 2020 [53] | 96.6 | 98.9 | 96.1 | 96.4 | 91.9 | 93.7 | 95.4 | 83.1 | 51.8 |
| Zou et al., 2020 [23] | 97.8 | 99.3 | 98.5 | 98.6 | 92.5 | 96.4 | 99.3 | 86.6 | - |
| Zhang et al., 2020 [24] | 98.5 | 99.6 | 98.8 | 98.8 | 96.4 | 97.6 | 98.5 | 88.9 | 40.2 |
| Zhang et al., 2020 [24] | 98.9 | 99.8 | 99.2 | 99.1 | 98.1 | 98.8 | 98.6 | 89.7 | 40.2 |
| (SYNTHETIC DATA) | |||||||||
| Qin et al., 2021 [26] | 97.2 | 99.3 | 92.9 | 93.2 | 97.9 | 95.5 | 98.8 | 92.4 | 36.0 |
| (ResNet-18) | |||||||||
| Qin et al., 2021 [26] | 97.6 | 99.5 | 93.3 | 93.7 | 98.2 | 95.9 | 98.9 | 92.9 | 26.0 |
| (ResNet-50) | |||||||||
| Fan et al., 2022 [43] | 98.8 | 99.7 | 99.1 | 99.0 | 99.1 | 99.3 | 98.5 | 88.0 | 11.7 |
| Fan et al., 2022 [43] | 99.0 | 99.8 | 99.2 | 99.2 | 99.6 | 99.6 | 98.5 | 88.8 | 26.0 |
| (SYNTHETIC DATA) | |||||||||
| YOLOv5-PDLPR (Ours) | 99.4 | 99.9 | 99.5 | 99.5 | 99.5 | 99.3 | 99.4 | 94.1 | 159.8 |
| Method | CLPD | PKUData | ||
|---|---|---|---|---|
| ACC | ACC (Without Chinese Characters) | ACC | ACC (Without Chinese Characters) | |
| Xu et al., 2017 [25] | 66.5 | 78.9 | 77.6 | 78.4 |
| Zhang et al., 2020 [24] | 76.8 | 87.6 | 88.2 | 90.5 |
| Fan et al., 2022 [43] | 55.8 | 79.3 | 81.6 | 81.8 |
| Fan et al., 2022 [43] (SYNTHETIC DATA) | 82.4 | 88.5 | 92.4 | 92.5 |
| YOLOv5-PDLPR | 80.3 | 93.1 | 95.5 | 95.7 |
| Method | AOLP-AC | AOLP-LE | AOLP-RP |
|---|---|---|---|
| Li et al., 2017 [41] | 95.3 | 96.6 | 83.7 |
| Wu et al., 2018 [43] | 96.6 | 97.8 | 91.0 |
| Zhang et al., 2020 [24] | 97.3 | 98.3 | 91.9 |
| Zou et al., 2020 [23] | 97.1 | 96.6 | 93.4 |
| Zou et al., 2021 [62] (Box) | 96.3 | 97.9 | 95.0 |
| YOLOv5-PDLPR (Box) | 98.5 | 99.1 | 96.1 |
| Method | AOLP-AC | AOLP-LE | AOLP-RP |
|---|---|---|---|
| Zou et al., 2021 [62] (GT) | 99.3 | 98.7 | 95.1 |
| YOLOv5-PDLPR (GT) | 99.6 | 99.9 | 99.8 |
| Module Backbone | Focus Structure | ConvDownSampling | Accuracy | |||
|---|---|---|---|---|---|---|
| DB | Tilt | Challenge | Overall Accuracy | |||
| ResNet-18 | - | - | 99.0 | 99.3 | 93.3 | 97.7 |
| IGFE (our) | × | × | 98.8 | 98.3 | 90.3 | 96.6 |
| × | √ | 98.9 | 98.6 | 90.7 | 96.8 | |
| √ | × | 99.1 | 98.8 | 91.0 | 97.0 | |
| √ | √ | 99.5 | 99.7 | 94.4 | 98.3 | |
| Decoder | Accuracy | ||
|---|---|---|---|
| CCPD-DB | CCPD-Tilt | CCPD-Challenge | |
| LSTM | 97.9 | 97.7 | 87.8 |
| BiLSTM | 96.2 | 95.2 | 80.6 |
| Linear | 90.3 | 81.9 | 70.1 |
| Parallel Decoder | 99.5 | 99.7 | 94.4 |
| Head Number | Accuracy | ||
|---|---|---|---|
| CCPD-DB | CCPD-Tilt | CCPD-Challenge | |
| 1 | 99.2 | 99.4 | 93.4 |
| 4 | 99.4 | 99.5 | 93.4 |
| 8 | 99.5 | 99.7 | 94.4 |
| 16 | 98.7 | 98.6 | 90.6 |
| Decoder Unit Number | Accuracy | ||
|---|---|---|---|
| CCPD-DB | CCPD-Tilt | CCPD-Challenge | |
| 1 | 97.3 | 94.9 | 84.4 |
| 2 | 97.8 | 96.4 | 86.4 |
| 3 | 99.5 | 99.7 | 94.4 |
| 4 | 99.2 | 99.2 | 91.8 |
| 5 | 99.0 | 98.7 | 91.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tao, L.; Hong, S.; Lin, Y.; Chen, Y.; He, P.; Tie, Z. A Real-Time License Plate Detection and Recognition Model in Unconstrained Scenarios. Sensors 2024, 24, 2791. https://doi.org/10.3390/s24092791
Tao L, Hong S, Lin Y, Chen Y, He P, Tie Z. A Real-Time License Plate Detection and Recognition Model in Unconstrained Scenarios. Sensors. 2024; 24(9):2791. https://doi.org/10.3390/s24092791
Chicago/Turabian StyleTao, Lingbing, Shunhe Hong, Yongxing Lin, Yangbing Chen, Pingan He, and Zhixin Tie. 2024. "A Real-Time License Plate Detection and Recognition Model in Unconstrained Scenarios" Sensors 24, no. 9: 2791. https://doi.org/10.3390/s24092791
APA StyleTao, L., Hong, S., Lin, Y., Chen, Y., He, P., & Tie, Z. (2024). A Real-Time License Plate Detection and Recognition Model in Unconstrained Scenarios. Sensors, 24(9), 2791. https://doi.org/10.3390/s24092791