Abstract
Focusing on the problem that it is difficult to maintain a high diagnostic accuracy rate, short running time, and robust generalization capability in the face of a strong-noise environment in rolling bearing fault diagnosis, a bearing fault diagnosis model (GMNR-CABA-MAGRU) founded upon a new attention-mechanism-improved residual network (ResNet-CABA) and a Gram denoising module (GMNR) is proposed, and the CWRU bearing dataset is used for verification. Under the 0-load condition in a noise-free environment, the diagnostic accuracy of this model reached 99.66%, and the running time was only 52.74 s. Then, a bearing dataset with added Gaussian noise from −4 db to 4 db was verified, and this model was still able to maintain a diagnostic accuracy of 90.32% under the strong-noise environment of −4 db SNR. And migration experiments were carried out under different load conditions, and this model was also able to maintain a very high accuracy rate. Moreover, in all the above experiments, this model performed better than various comparative models. The developed framework demonstrated superior diagnostic precision, enhanced robustness, and improved generalization capability.
1. Introduction
In the field of modern mechanical equipment, the key role of rotating machinery cannot be ignored. However, bearing faults often occur in rotating machinery. Faults inside rotating machinery may destroy the accuracy of the equipment, and in extreme cases, due to the domino effect, catastrophic system-wide failures will be triggered. When a failure occurs, it can directly impact industrial processes, sometimes resulting in substantial financial losses or even harm to personnel. This highlights the importance of creating a dependable and rapid bearing fault diagnosis system to safeguard industrial machinery’s performance and operational safety.
The method of bearing fault diagnosis mainly includes two parts: extracting fault features and identifying and classifying fault states. In traditional bearing fault diagnosis methods, the extraction of bearing faults is mainly composed of signal processing methods and feature values. Signal processing methods include wavelet transform [1], empirical mode decomposition (EMD) [2], and variational mode decomposition (VMD) [3]. Feature values mainly include sample entropy, permutation entropy, energy entropy, and fractal dimension. Traditional methods for identifying and classifying fault states are mainly machine learning algorithms such as the K-nearest neighbor algorithm, support vector machine (SVM), and random forest [4]. However, these traditional fault diagnosis methods are greatly affected by noise and vibration in complex environments, and they overly rely on the work experience and professional knowledge of experts as well as knowledge of prior conditions. It is difficult to ensure efficiency and accuracy for large amounts of fault signal data, making it difficult to meet the requirements of complex modern industrial environments.
In recent years, CNNs, represented by deep learning technology, have made long-term progress and have made important contributions to the development of modern industry. Deep learning technology can automatically extract fault features from bearing signal data and automatically classify and identify fault features, removing the influence of human factors on the fault diagnosis process, liberating productivity, and reducing the professionalism of fault diagnosis, which allows non-experts to become proficient after certain training and to use trained deep learning models to complete bearing trouble diagnosis tasks. For example, Xu et al. developed a hybrid deep learning model based on a CNN and gcForest, and experimental analysis showed that the proposed hybrid deep learning model could achieve higher detection accuracy than the CNN and gcForest separately [5]. Wu et al. proposed a new multi-scale feature fusion deep residual network for rolling bearing fault diagnosis, and experimental verification showed that the diagnostic performance of the model was superior to that of several popular models [6]. Wu et al. developed a deep reinforcement transfer convolutional neural network (DRTCNN) to solve the urgent problem of completing fault diagnosis tasks using limited labeled samples [7]. Jin et al. proposed a bearing fault diagnosis method based on a synthetic minority over-sampling technique, nominal and continuous (SMOTENC), and deep transfer learning, providing an effective solution for research in the field of bearing fault diagnosis [8]. Niu et al. proposed a rolling bearing fault diagnosis method based on principal component analysis and an adaptive deep belief network with a parameter correction linear unit activation layer, and they proved the effectiveness and accuracy of the proposed method [9]. Li proposed a multi-scale attention-based transfer model (MSATM), providing a promising tool for cross-bearing fault diagnosis [10]. Tang et al. proposed a bearing fault diagnosis method based on a hybrid pooling deep belief network (MP-DBN). The results showed that the MP-DBN is a powerful rolling bearing composite fault diagnosis technology with excellent feature extraction ability and diagnostic efficiency [11]. Wen et al. proposed a new motor bearing fault diagnosis method under small samples, and the results showed the effectiveness and feasibility of the introduced method for motor bearing fault diagnosis under small samples [12].
In bearing fault diagnosis, the removal of noise interference has always been a very important issue. Noise signals are often contained in bearing signal data, seriously affecting the extraction and identification of fault signal features, greatly reducing the accuracy of fault diagnosis. For this reason, many people have made many attempts to mitigate noise interference. For example, Lei Chunli et al. proposed a rolling bearing fault diagnosis method based on a depthwise separable residual network (DS-ResNet). Experimental verification proved that the proposed method has better anti-noise performance, generalization performance, and higher diagnostic efficiency than existing methods [13]. Matania et al. proposed a novel hybrid algorithm that enables the classification of the spall type based on zero-fault-shot learning. The novel algorithm combines physics-based algorithms with machine learning to overcome the lack of faulty data [14]. Berredjem et al. proposed an Improved Range Overlaps method (IRO) to select input feature vectors by giving them validity degrees. The Similarity method partition was found to be confused by features presenting range overlap. Consequently, they proposed a new Improved Range Overlaps method, which was found quite suitable for improving the classifier accuracy [15]. Chen et al. designed a neural network model named multi-scale CNN-LSTM (convolutional neural network–long short-term memory) and a deep residual learning model. Experimental results showed that this model has better anti-noise performance and better rolling bearing fault diagnosis generalization ability [16]. Tang et al. proposed a credible multi-scale quadratic attention embedded CNN (TMQACNN) for bearing fault diagnosis. Experimental results showed that under the interference of noise superimposed on small samples or load changes, the proposed network is superior to six state-of-the-art networks [17]. Shan et al. proposed a bearing fault diagnosis method based on acoustic fingerprint features and deep learning and proposed the Mel-CNN model for application to motor noise data for bearing faults [18]. Wang et al. proposed a deep feature enhancement reinforcement learning method for rolling bearing fault diagnosis, establishing a deep Q network. Experimental results showed that the proposed method is superior to other intelligent diagnosis methods [19]. Xu et al. proposed a new model called Deep Spiking Residual Contraction Network (DSRSN) based on spiking neural networks (SNNs) for bearing fault diagnosis. Tested on fault signal datasets with different noise intensities, the proposed model achieved higher recognition accuracy [20]. Zhai et al. proposed an Adaptive Depthwise Separable Dilated Convolution and multi-grained cascade forest ADSD-gcForest fault diagnosis model, comparing the effects of three bearing fault diagnoses under various noise and load conditions. Experimental results demonstrated the effectiveness and practicality of the proposed method [21]. Zhang et al. proposed an improved noise environment bearing fault diagnosis method based on a dilated convolutional neural network, called MAB-DrNet. Experimental verification showed that it can maintain high diagnostic accuracy even in high-noise environments [22]. However, the various models detailed above can maintain accuracy at a high level in low-noise environments, but when facing strong-noise environments, such as −6 db or even −8 db, their diagnostic accuracy will significantly decrease. Also, some models overly emphasize the structure of the feature representation component to achieve the denoising task, neglecting the design of the feature extraction module, for example, resulting in deficiencies in aspects such as the required running time, diagnostic accuracy, and generalization ability.
To address these shortcomings, this research presents a new attention mechanism, CABA, combines it with ResNet to construct the ResNet-CABA network, combines this network with the attention gate recurrent unit (MAGRU) in a dual-channel manner, integrates the Gram denoising module (GMNR) into the bearing trouble diagnosis model, and fuses the information from the two channels through feature fusion to obtain data after dual-channel fusion. At the same time, the fully connected layer in the classification recognition module is replaced by a global average pooling layer to avoid overfitting. The experimental validation utilized the Case Western Reserve University (CWRU) bearing vibration dataset as the benchmark to rigorously evaluate the model’s diagnostic reliability across heterogeneous noise conditions. Through comparative analyses with state-of-the-art bearing fault detection frameworks, the proposed methodology demonstrated superior performance metrics.
2. Basic Theory
2.1. Gram Denoising Module
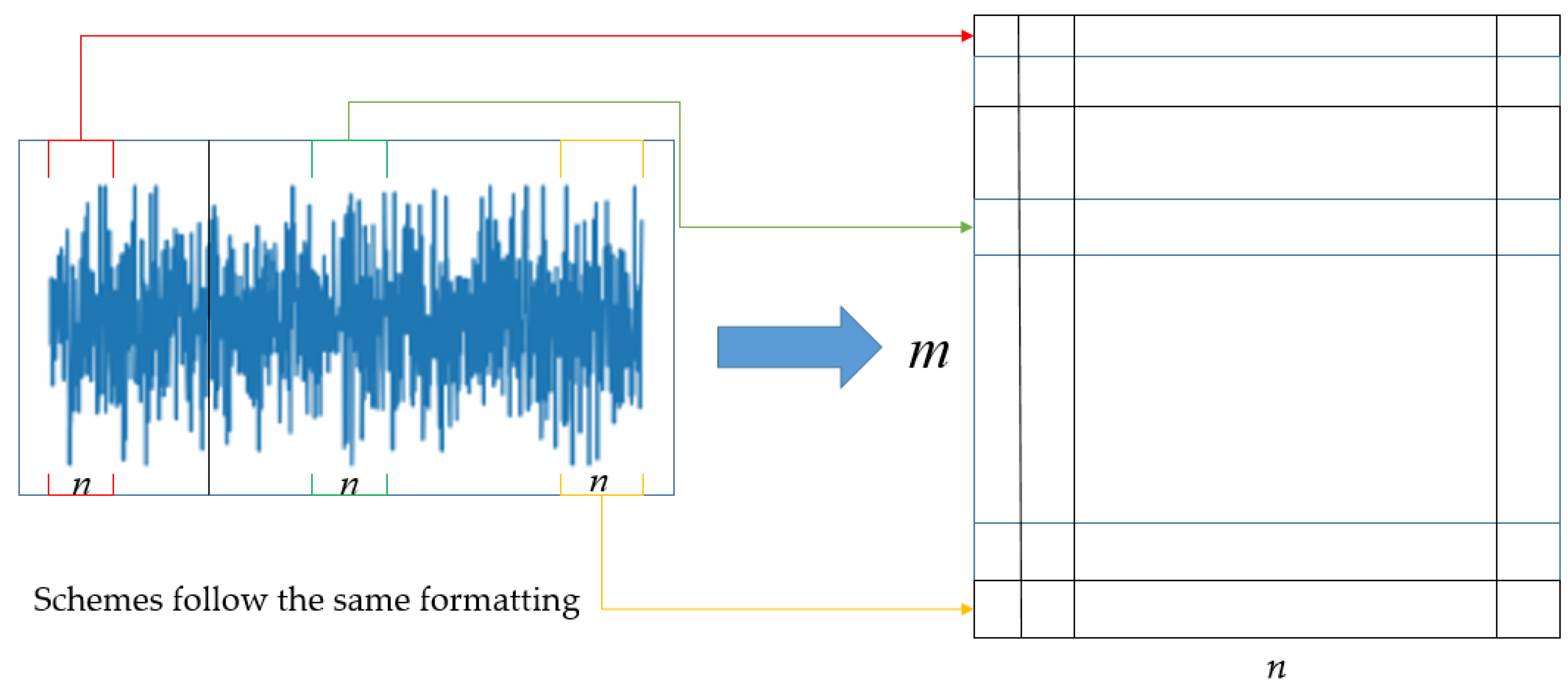
Gram denoising theory achieves denoising by adopting matrix transformation methods. The first step is to segment the 1D vibration signal of the rolling bearing according to rules and then arrange the segments according to their respective orders. This can result in the following matrix. As shown in Figure 1:
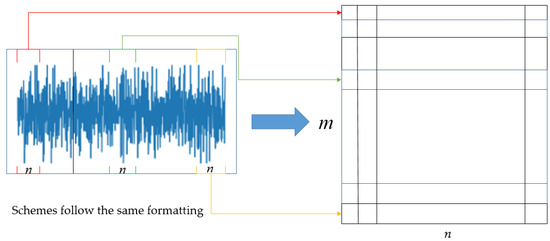
Figure 1.
Gram matrix.
Here, .
By enhancing the signal using the Gram matrix, the signal enhancement matrix of the input signal can be obtained as follows:
When a rolling bearing fails, a broadband pulse force will occur, causing the equipment to resonate at high frequencies. When the bearing rotates, different fault types result in different frequencies of the collected periodic pulse signals. However, the vibration signal of the bearing has periodic self-similarity. Therefore, each row of the matrix X obtained from the periodic signal is approximately the same. According to matrix theory, similar rows or columns of the matrix make the rank of matrix X relatively small, and most of the energy is concentrated on a small number of large singular values of the matrix. However, after the vibration signal is polluted by noise, the rank of the signal matrix is mostly distributed among the small singular values. Therefore, as long as the proportion of larger singular values is increased and the proportion of smaller singular values is decreased, noise filtering goals are realizable. This is the principle of the Gram noise reduction theory.
For the -th singular value of X, the definition of the ordinary nuclear norm is
If the nuclear norm is small, then the rank of matrix X will be low. Therefore, the nuclear norm can be used to solve the low-rank problem of the matrix, thus solving the noise reduction problem in the trouble diagnosis of rolling bearings [23].
2.2. ResNet-CABA Network
2.2.1. Residual Neural Network
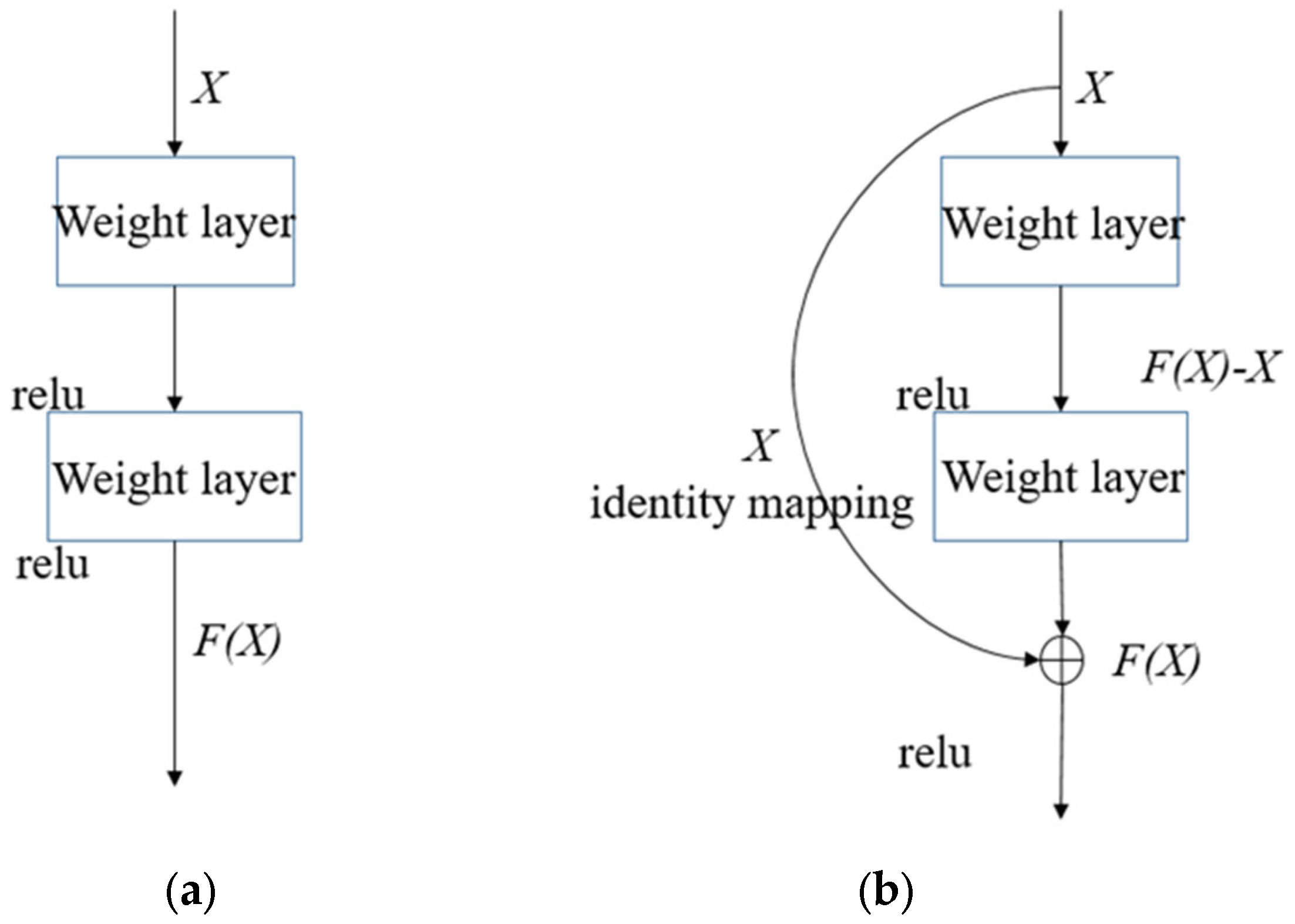
Increasing the depth of the neural network architecture complicates the training process, leading to accuracy saturation and potential model degradation. The residual network, which is composed of several residual modules of network layer identity mapping, solves this problem by fast connection.
The residual module does not choose to fit the direct mapping of hierarchical layer architecture, but rather fits the residual mapping. As shown in Figure 2, given an initial input X, the target function F(X) denotes the theoretically perfect output mapping. In the left-hand component of the diagram, a conventional neural module directly parameterizes the target transformation F(X). Conversely, the right-hand architecture is designed to learn the residual function through differential optimization. In reality, the residual mapping has a greater possibility of being optimized. The input in the residual block can be propagated forward at a faster speed along the cross-layer data path. This effectively reduces the difficulty of learning the mapping and speeds up the convergence of the model.
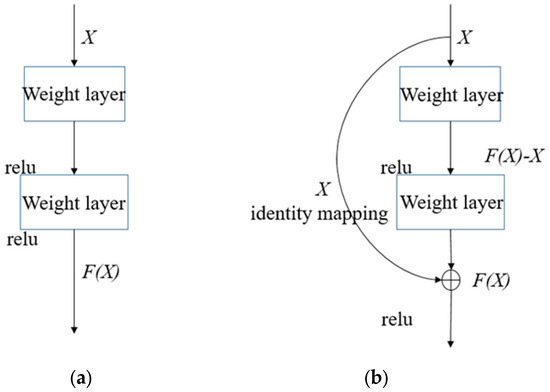
Figure 2.
Normal block and residual block. (a) Normal block. (b) Residual block.
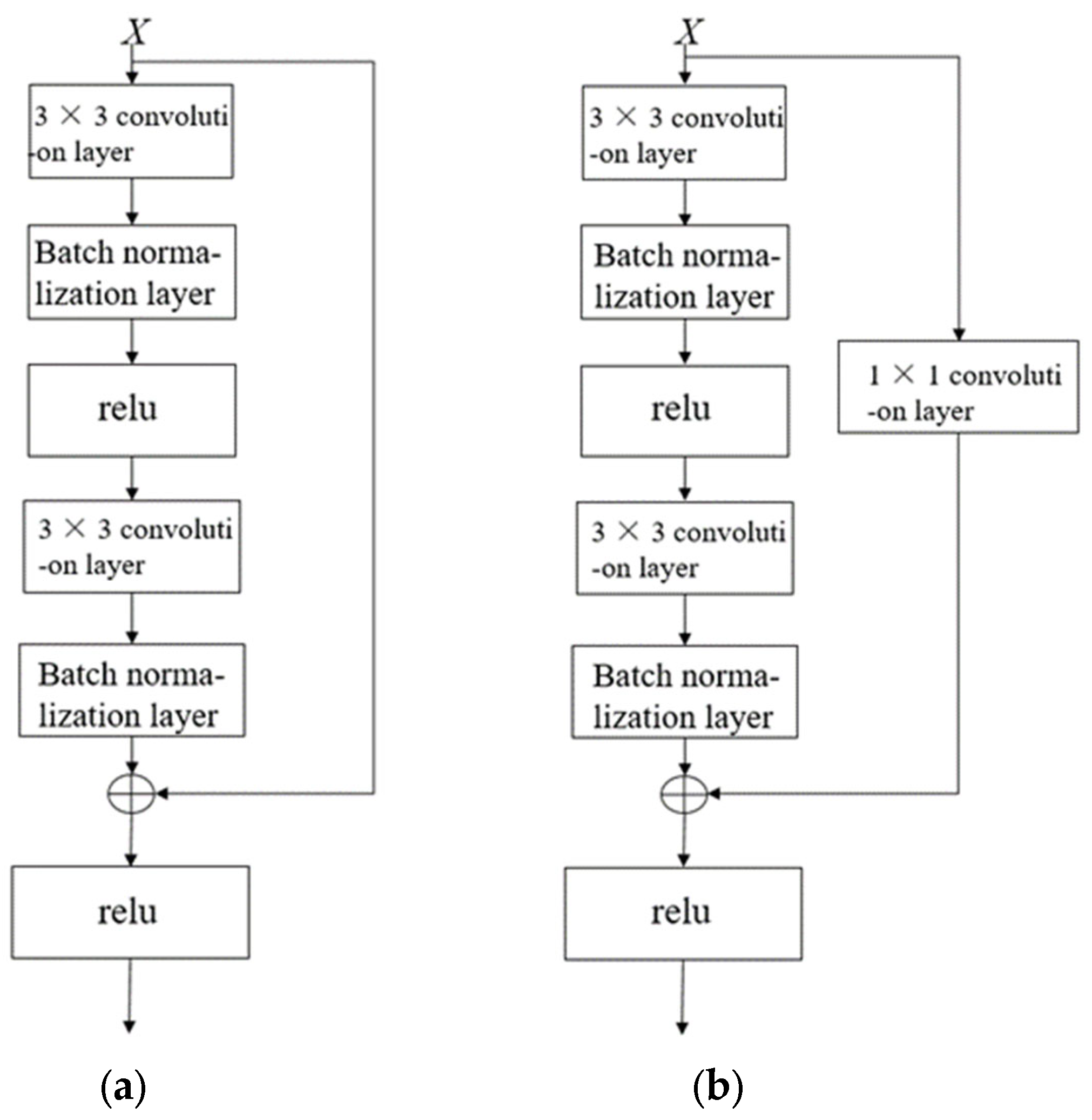
As depicted in the network topology visualization in Figure 3, the subsampling operator within residual blocks performs feature map alignment via two mechanisms: spatial resolution preservation through stride manipulation and channel matching via learnable linear transformations.
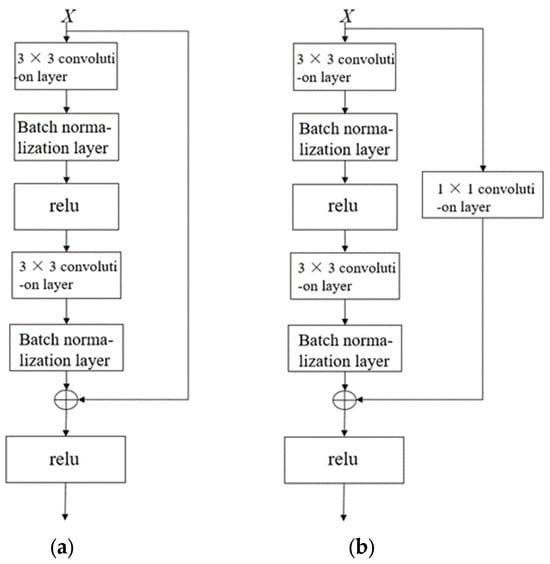
Figure 3.
Standard residual block and residual block with downsampling layer. (a) Standard residual block. (b) Residual block with downsampling layer.
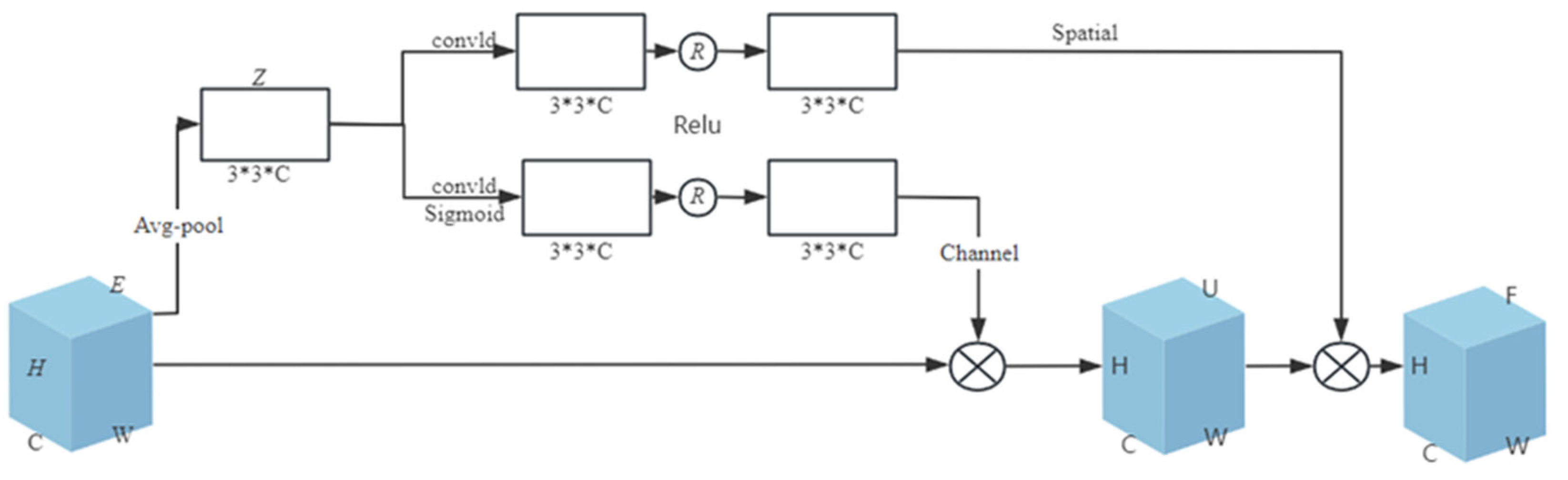
2.2.2. CABA (Convolutional Avgpool Block Attention)
The attention mechanism is summarized according to the customary law of human observation of the environment. The core mechanism involves strategically amplifying the weighting of critical components to optimize the extraction of actionable insights. From a mathematical point of view, the attention mechanism operates through context-aware weighting and dynamic aggregation of input features. The main function of the attention mechanism fundamentally operates through differentiated weighting of input elements to modulate their contextual influence on different local learning of the input sequence, and then the distinct positional segments within the source sequence are multiplied by their corresponding weight values to obtain the corresponding local feature vectors, thereby amplifying and reducing the distinct positional segments within the source sequence.
Traditional attention mechanisms (such as SE attention, channel attention, etc.) have problems such as high computational complexity, dependence on local information, and poor adaptability. These problems will increase the computational cost when the model deals with the larger features of the input, and the performance is different on different datasets, which makes the model pay too much attention to some features and neglect the other important information, affecting the computational performance and stability of the model. Accordingly, this study introduces a new attention mechanism, CABA, whose principle is shown in Figure 4. Through adaptively weighting feature channels based on their contextual relevance and adaptively assigning the corresponding weight value to the feature channel, the feature channel with a larger weight value is focused on by the network; that is, task-relevant feature channels are prioritized, while irrelevant ones are suppressed. Moreover, this attention module combines channel and spatial features simultaneously, which further improves the feature representational capacity and generalization performance of the model.
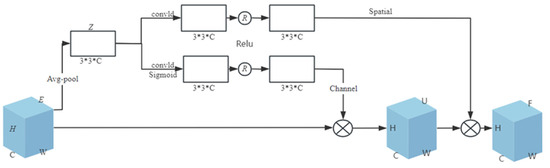
Figure 4.
CABA schematic diagram.
An input feature E, which has a height of H, a width of W, and a number of feature channels of C, is given in the figure. The first step is to use global average pooling to compress the two-dimensional feature of each channel of feature E and reduce the feature of the channel to a scalar . The mathematical expression is as follows:
In the preceding equation, subscript i denotes the positional identifier of channels; is the global statistical information of the ith channel. This is a kind of spatial dimension feature compression. Since all the values of the two-dimensional feature are calculated based on the scalar , it has a global receptive field to some extent. Then, the global average pooling operation is completed for feature E to obtain the global information Z of feature E; , and is a vector space composed of C real numbers.
Then the channel-gated linear transformation and spatial linear transformation are performed on the global information Z. Usually, the linear transformation is performed through the fully connected layer, but there are problems such as high computational complexity, a lack of position information between features, and easy overfitting. To address these limitations, our methodology employs 1D convolutional layers as substitutes for fully connected layers, coupled with expanded 3 × 3 kernels. This architectural modification achieves dual objectives, namely significant parameter reduction (O(n2)→O(n)) and enhanced computational throughput and generalization ability of the model, and enhances the local perception ability of the model for input data.
The channel-gated linear transformation uses one-dimensional convolution to linearly transform the global information Z and then uses the Sigmoid activation function to nonlinearly map the export. Finally, the Relu function is employed to turn the mapping result into a likelihood value in the range of (0, 1), which is used to characterize the emphasis of every pathway, so as to obtain the weight of channel attention. This is multiplied by the entry signature E to generate the signature U containing the channel information. The formula of channel-gated linear transformation is as follows:
In the above formula, and refer to the weight and bias of the convolution kernel respectively.
The spatial linear transformation, similar to the above, also uses one-dimensional convolution to perform linear transformation on the global information Z and then uses the Relu function to transform the transformation result into the weight of the spatial attention, which is multiplied by the signature U to generate the signature F. The signature F has both channel information and spatial information. The algebraic formulation governing linear spatial transformations is expressed by
In the above formula, and refer to the weight and bias of the convolution kernel respectively.
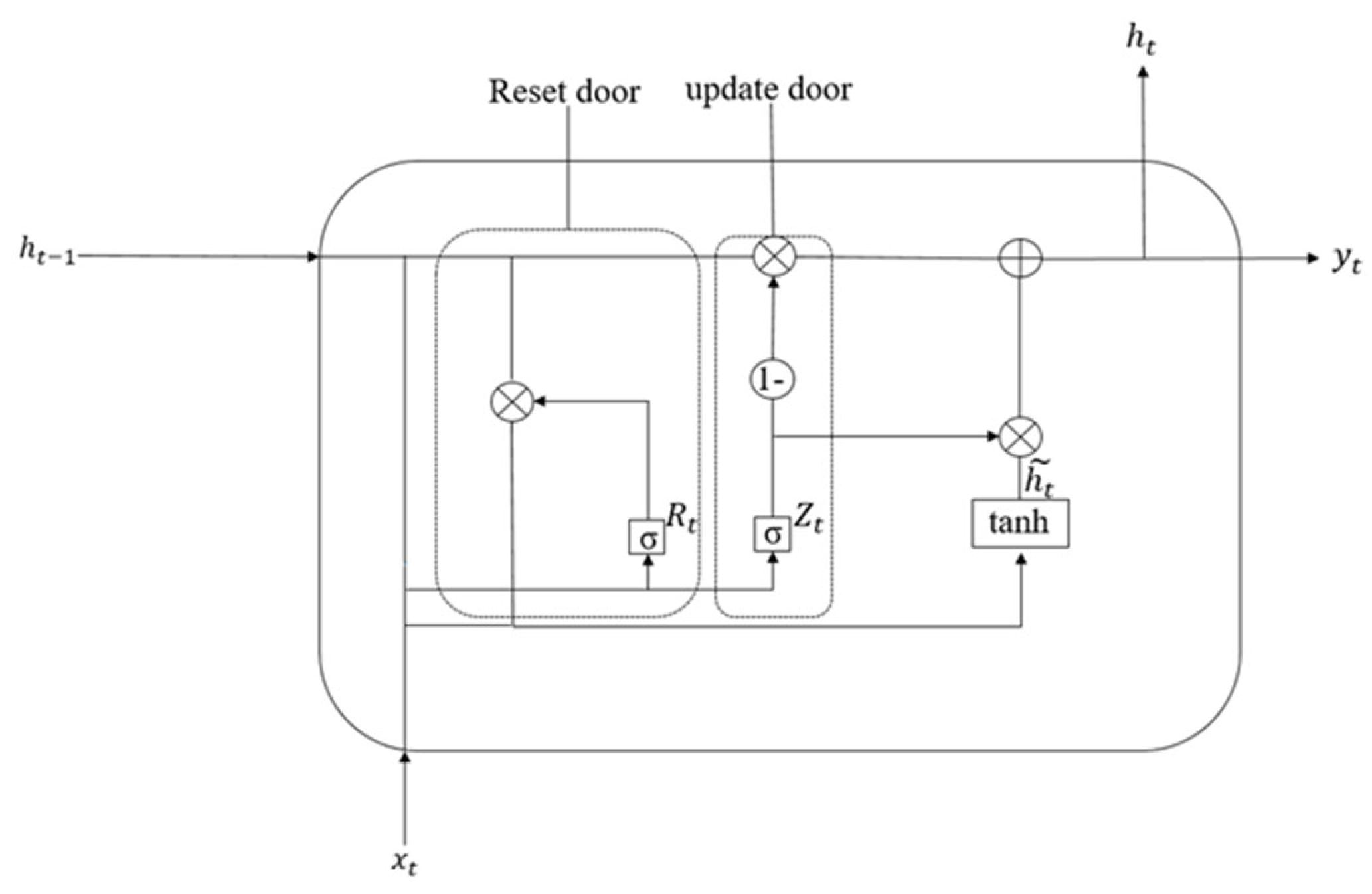
2.3. Attention Gated Loop Unit
The gated recurrent unit (GRU) represents a streamlined adaptation of long short-term memory (LSTM) architectures, maintaining temporal dependency modeling capabilities while eliminating redundant gating mechanisms. However, unlike the latter, the GRU merges the forgetting gate and the output gate into an update gate, integrates the unit state and output into a hidden state, and realizes the function of transmitting information by hiding information. The system of the GRU is shown in Figure 5.
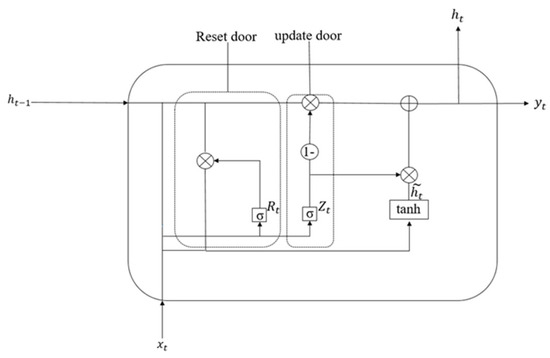
Figure 5.
GRU schematic diagram.
The principle formula of the GRU is shown as follows:
Update the gate formula:
Reset door formula:
Candidate hidden state formula:
Hidden state formula:
Here, W, and refer to the learnable proportion, and σ refers to the Sigmoid activation function.
Compared with LSTM, the GRU has obvious advantages: the possibility of overfitting is reduced due to the reduction of parameters; in the face of many training data, it can significantly improve the training speed and reduce the time required for the operation; and the GRU itself is scalable, making it possible to build a larger model.
Because the characteristics of different moments can make different contributions to the next trouble diagnosis in the research of bearing trouble diagnosis, by adding an attention mechanism layer in the GRU module, the contribution of the main time characteristics to the fault diagnosis can be improved, so the attention mechanism can be used for self-regulation to obtain the best diagnostic results. The mechanism of attention-weighted summation is as follows:
In the above formula, is the attention weight distribution; is the hidden layer output [24].
2.4. Global Average Pooling
The traditional convolutional neural network model usually uses several fully connected layers to perform feature dimension reduction. However, the full connection layer uses the full connection method to work, resulting in the phenomenon of too many parameters being generated in the trial period, which makes the calculation process of the model too complex and prone to overfitting.
The global average pooling layer (GAP) matches the categories to the attribute chart one by one and gives the actual category meaning to each channel so that each feature map can be regarded as a category confidence map relative to the category and so that the internal parameters of each feature map do not need to be optimized. The dimensionality reduction work is well completed, while the arguments of the network model can be greatly lowered, and the global feature information can be integrated, which greatly reduces the probability of overfitting. Therefore, we choose to use the global average pooling layer instead of the fully connected layer.
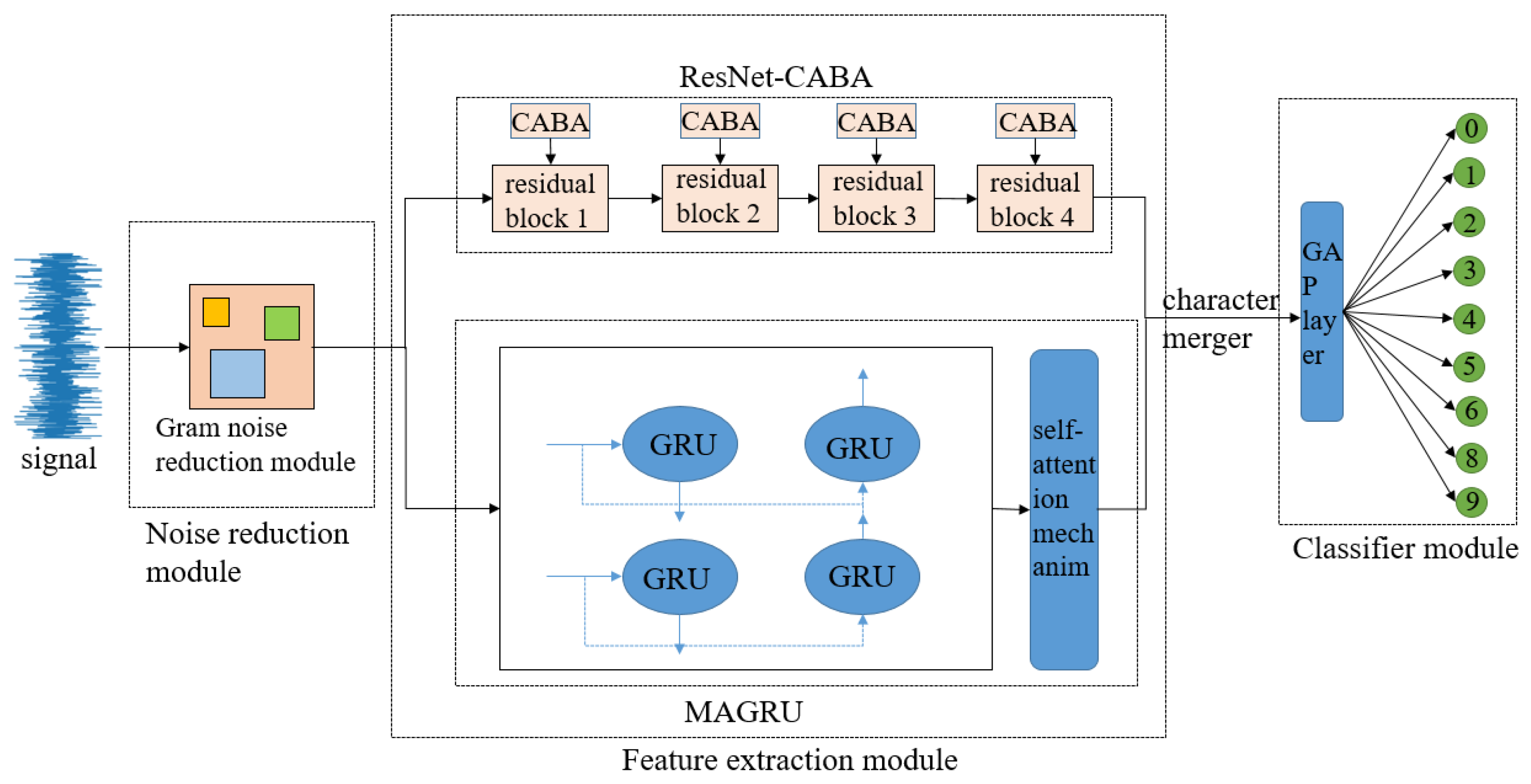
3. Fault Diagnosis Method Based on CABA-GMNR-MAGRU
The CABA-GMNR-MAGRU model designed in this text is mainly composed of a denoise module, a feature extraction module, and a classifier module. The noise reduction module is composed of a Gram denoise module, and the feature extraction module is composed of a ResNet-CABA module and a MAGRU module. The classifier module is composed of a global average pooling layer and a Softmax function layer, and the precise architectural configuration is graphically delineated in Figure 6.
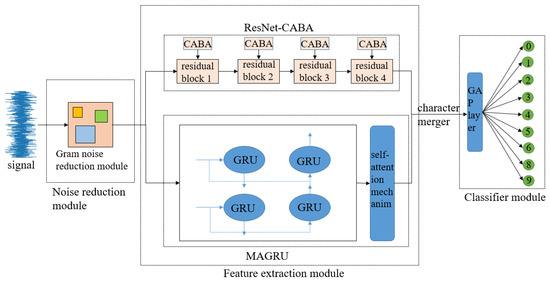
Figure 6.
CABA-GMNR-MAGRU model structure diagram.
The vibration signature characterizing bearing degradation is ingested into the computational framework for subsequent analysis; the original signal is first denoised by the Gram noise reduction module to lower the interference of the noise signal and simultaneously optimize computational latency and predictive fidelity through architectural refinements.
The attribute abstraction module of the model is set as a dual path. One part is composed of four ResNet-CABA networks composed of four residual blocks added with the CABA module, which efficiently settles the question of network degradation, increases the computational effectiveness and generalization ability of the model, and enhances the local perception capacity of the model for incoming data. The other part is generated by two strata of gated recurrent units and a stratum of an attention mechanism layer. The gated recurrent unit has a powerful capacity to adaptively abstract temporal attributes in the data, but it has difficulty abstracting spatial attributes, and when the length of the sequential sign is greater than 200 data lengths, ‘forgetting’ may occur. Adding an attention mechanism layer can effectively settle this question and ensure the accuracy of the model’s recognition of signal data. Then the data obtained by the two pathways are fused, and the data are dimensionally spliced to obtain the fused data.
The classifier module of the model consists of two parts: the global average pooling layer and the Softmax function layer. The model inputs the data after feature fusion into the global average pooling layer for classification and then inputs it into the Softmax function layer for output using the Softmax function. Here, the global average pooling layer is selected to replace the commonly used fully connected layer. The method effectively mitigates overfitting risks and boosts diagnostic accuracy simultaneously.
Table 1 presents the detailed information of each layer of this model.

Table 1.
The detailed information of each layer of this model.
4. Experiment Research and Analysis
4.1. Experimental Environment
The environment required for the test is as follows: the programming language used is Python3.8, the deep learning framework is Tensorflow 2.10.1, the operating system is 64-bit Microsoft Windows 10, the CPU is an i5-7300H, the graphics card is a GeForce GTX1050ti graphics card, CUDA11.1 is installed on the host, and Cudnn8.2 accelerates the graphics card operation.
4.2. Dataset Introduction
For this text, the rolling bearing dataset of Case Western Reserve University (CWRU) was used for experiments. The experimental platform of CWRU is shown in Figure 7. The test bench consisted of a 1.5 KW motor, torque sensor, dynamometer, and electrical control device. The bearing vibration signals of the drive end were collected by the acceleration sensor installed on the base shell, including normal, inner ring fault, outer ring fault, and rolling element fault signals. The bearing model used was SKF6205. The single-point faults of the inner ring, outer ring, and rolling body were formed by the electric spark method. The fault diameters were 0.1778 mm, 0.3556 mm, and 0.5334 mm, respectively. The sampling frequency was 12 kHz, and the load was 0 hp~3 hp. The vibration signal was collected, and each size had three faults of the inner ring, outer ring, and rolling body, for a total of nine kinds. The addition of a normal state resulted in a total of 10 sample types, as shown in Table 2.

Figure 7.
Bearing data acquisition test bench of Case Western Reserve University [25].
Table 2.
Experimental dataset situation.
The dataset was constructed, and the length of each type of sample was 1024, with a total of 1410 data samples. Among them, 80% of the samples were randomly selected as the training set to train the model, and 20% of the samples were used as the test set to test the model.
4.3. Results and Analysis of Different Models
This study conducted comparative benchmarking of the proposed deep learning architecture against established models using identical fault diagnosis datasets. This paper selected four classical deep learning models (WDCNN [26], Resnet [27], CNN-LSTM [28], BP [29]) as comparative experiments.
Firstly, under the load of 0 hp, the bearing vibration dataset under specified operational conditions underwent stratified 8:2 partitioning (training/test). And the test set was used as the training set. Comparative evaluations were conducted between our proposed DL architecture and four canonical models using identical preprocessing protocols. According to the training environment proposed above, 50 iterations were carried out, and each model was repeated for 5 experiments. The diagnosis precision and running time of every model were recorded, and data were averaged across five runs under identical test conditions. The results are shown in Table 3.
Table 3.
Diagnostic accuracy and running time of the five models.
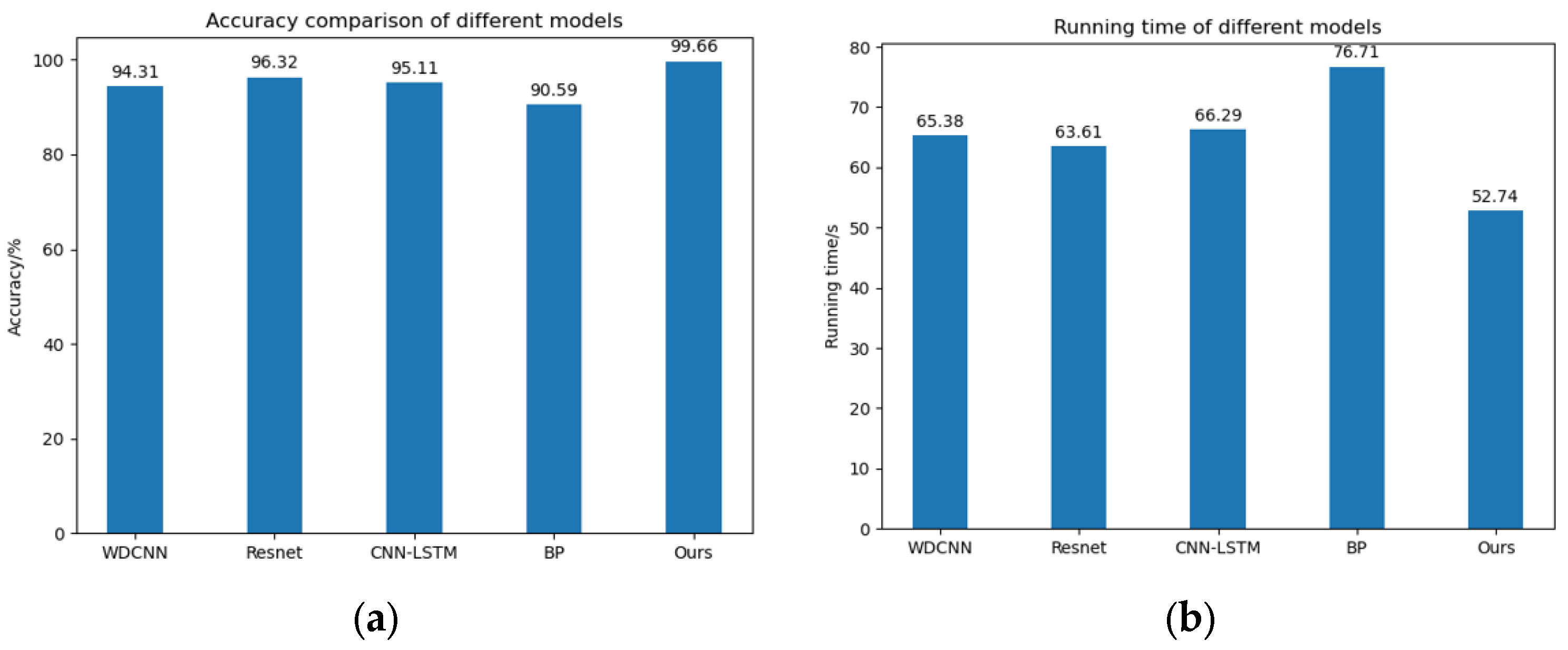
The histograms of the diagnosis precision and running time of each model are shown in Figure 8.
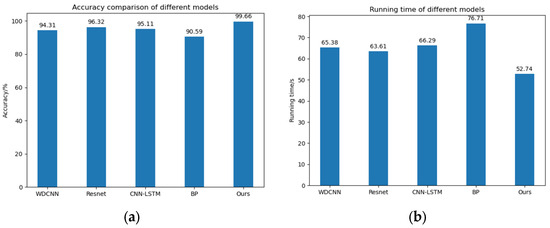
Figure 8.
Diagnostic accuracy and running time of the five models. (a) Diagnostic accuracy of the five models. (b) Running time of five models.
The experimental results validate the superiority of the proposed framework; compared with the other four conventional deep learning models, it can reach an accuracy of 99.66%, while the other four models reach only 96.32%, so the proposed model has a 3% accuracy advantage. In terms of running time, this paper proposes that the CABA-GMNR-MAGRU model needs only 52.74 s to iterate 50 times, while the other four models need at least 63.61 s. The CABA-GMNR-MAGRU model has a time advantage of 10 s. It follows that the CABA-GMNR-MAGRU model proposed in this text has obvious merits over the traditional deep learning models in both diagnostic accuracy and running time. Therefore, the CABA-GMNR-MAGRU model proposed in this paper is feasible.
4.4. The Operation Results and Analysis of This Model Under Different Working Conditions
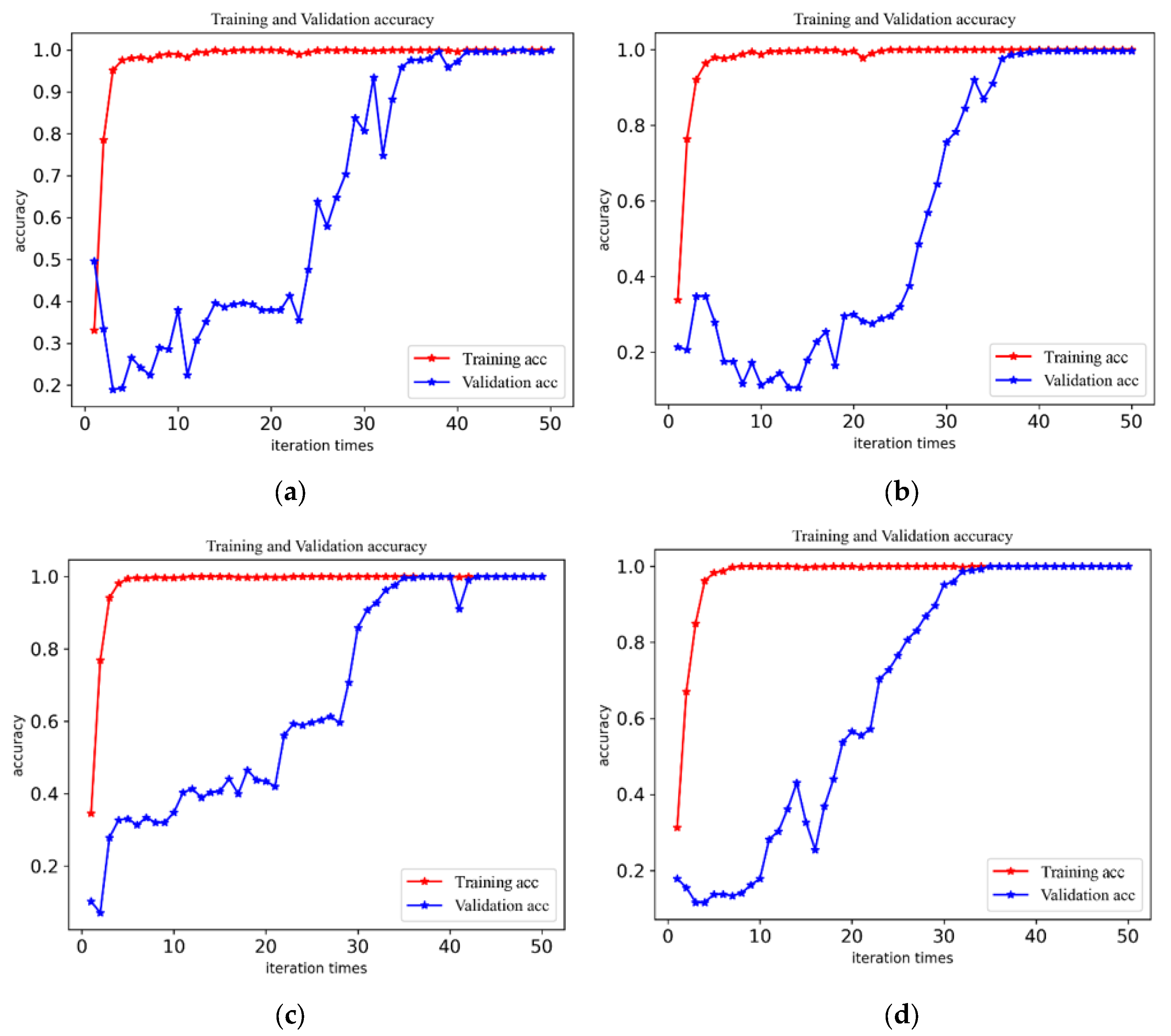
To check the accuracy and stability of the fault diagnosis of the CABA-GMNR-MAGRU model proposed in the paper in the various working environments, vibration signal datasets with a load of 0 hp–3 hp were used to verify the model. The training environment and other configurations were the same as above. Under each load, the model proposed in this paper was used for 50 iterations, and the precision lines of the model in the four load environments were obtained, as shown in Figure 9.
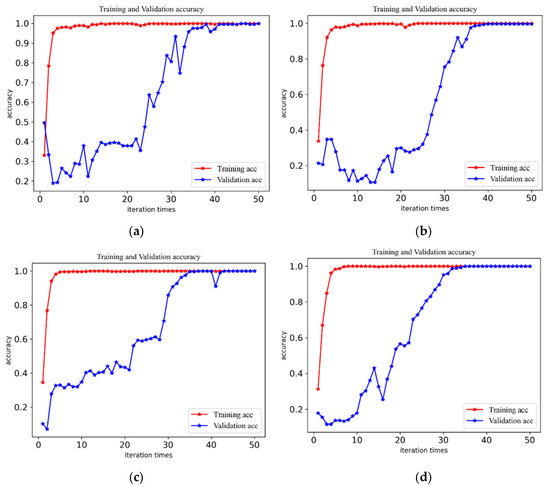
Figure 9.
The diagnostic precision of the model under four loads. (a) The diagnostic precision curves of the model when the load is 0 hp. (b) The diagnostic precision curves of the model when the load is 1 hp. (c) The diagnostic precision curves of the model when the load is 2 hp. (d) The diagnostic precision curves of the model when the load is 3 hp.
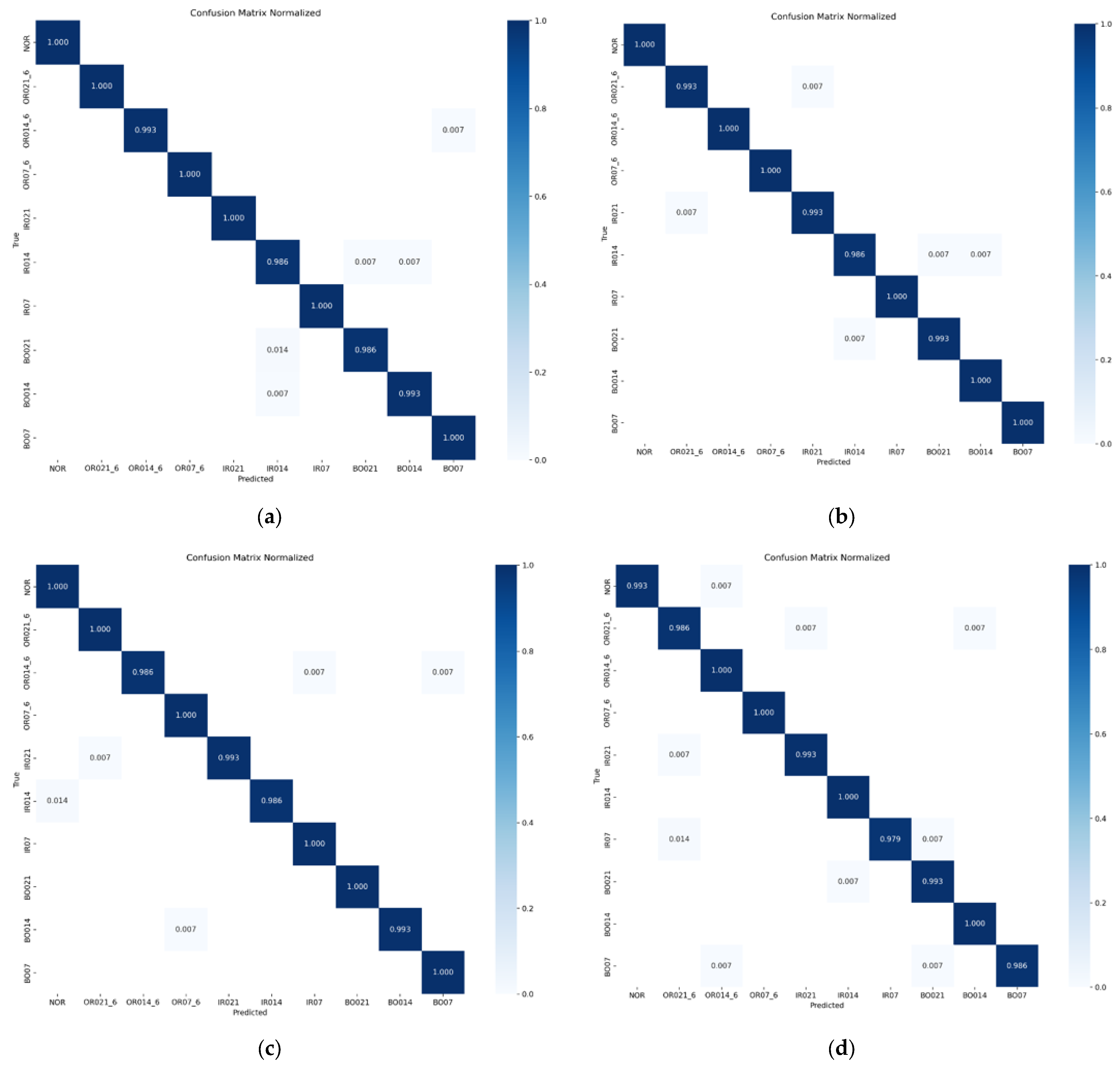
The figure demonstrates that stability is achieved beyond around 35 iterations, and the accuracy rates are 99.66%, 99.66%, 99.57%, and 99.31%, respectively, all of which maintain a very high accuracy. With the increase in speed, although the diagnostic accuracy rate has a certain decline, it can still maintain a very high level. Furthermore, to show the model’s identification of bearing faults more clearly and accurately, the confusion matrix of model diagnosis under four loads is presented in Figure 10.
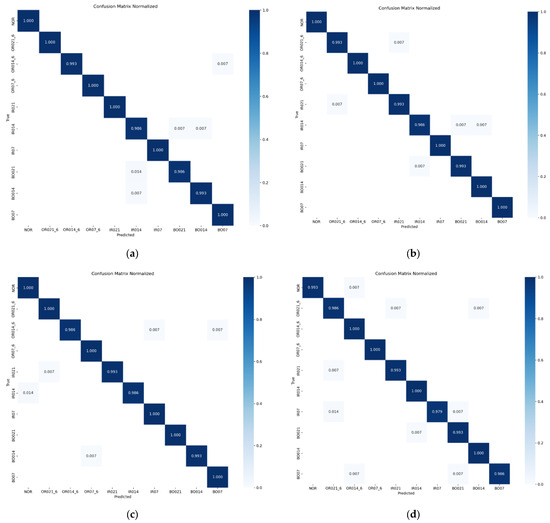
Figure 10.
Model diagnosis confusion matrix under four loads. (a) The diagnostic confusion matrix of the model when the load is 0 hp. (b) The diagnostic confusion matrix of the model when the load is 1 hp. (c) The diagnostic confusion matrix of the model when the load is 2 hp. (d) The diagnostic confusion matrix of the model when the load is 3 hp.
It can be seen from the diagram that under the four loads, the number of label recognition errors in the CABA-GMNR-MAGRU model proposed in this paper is very low. The proportion of single label recognition errors is only 2.1% of the samples under the label. On the whole, under the four loads, the proportion of model recognition errors is only 0.69% of the total samples.
Therefore, in summary, the CABA-GMNR-MAGRU model proposed in this paper can maintain a very high trouble diagnosis precision under different speed environments, and the diagnostic accuracy fluctuates little with the change of speed, which demonstrates the model’s robustness and reliability across varying operational scenarios. Hereby, the CABA-GMNR-MAGRU model proposed in this paper is feasible.
4.5. The Operation Results and Analysis of This Model in Noise Environment
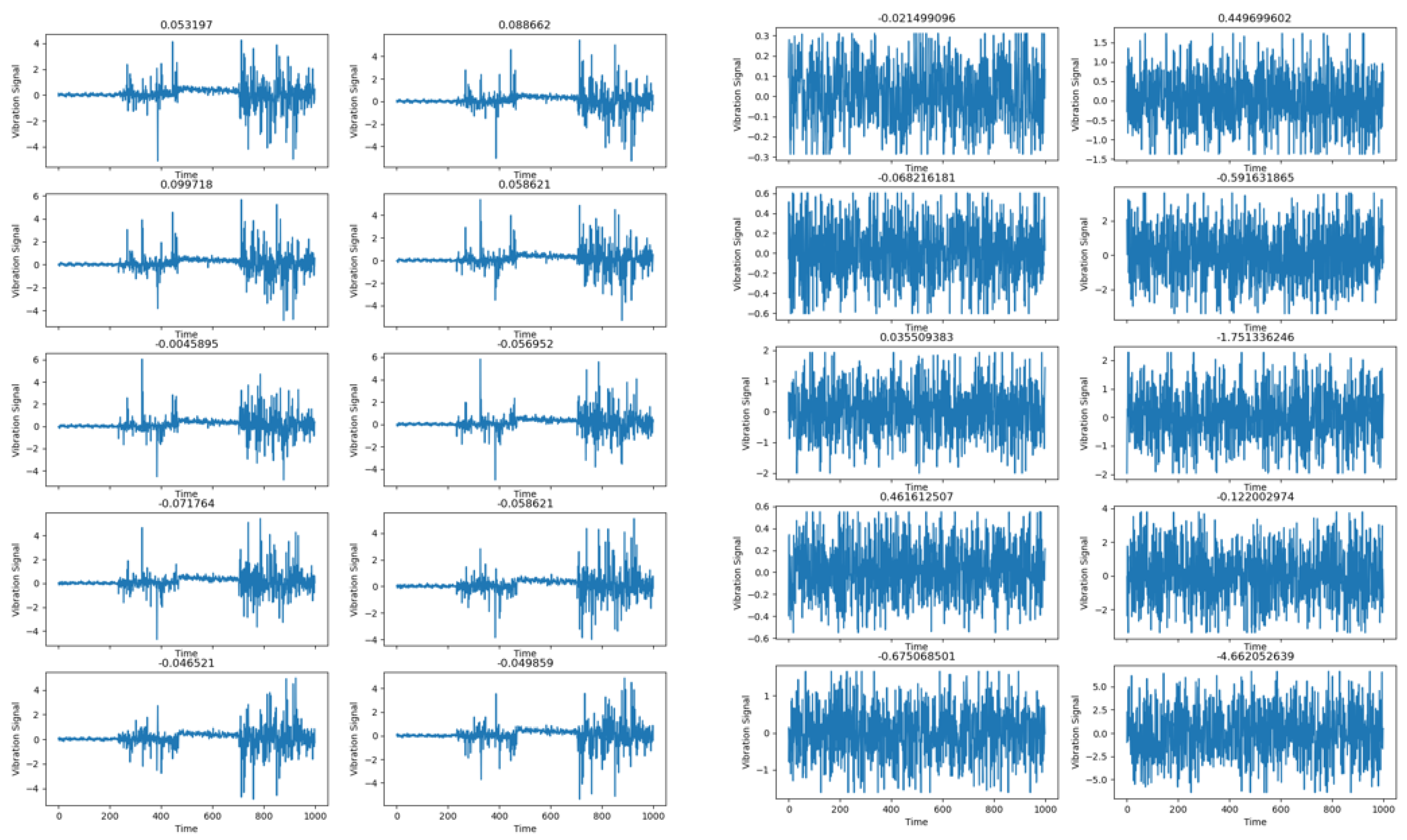
Maintaining the precision of bearing trouble diagnosis in various-intensity noise environments is an important topic of fault diagnosis. The CABA-GMNR-MAGRU model proposed in this paper uses the Gram denoise module (GMNR) for noise reduction. In order to verify the noise reduction ability of the model, Gaussian noise and impulse noise with different SNRs were added to the bearing dataset used above to simulate the influence of noise on fault diagnosis under actual working conditions. The data timing diagram of the dataset before and after adding Gaussian noise is shown in Figure 11.
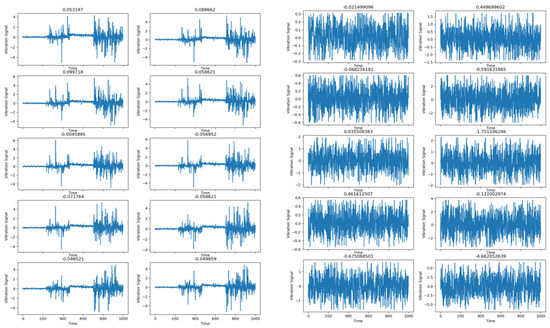
Figure 11.
Data timing diagram of dataset before and after adding Gaussian noise.
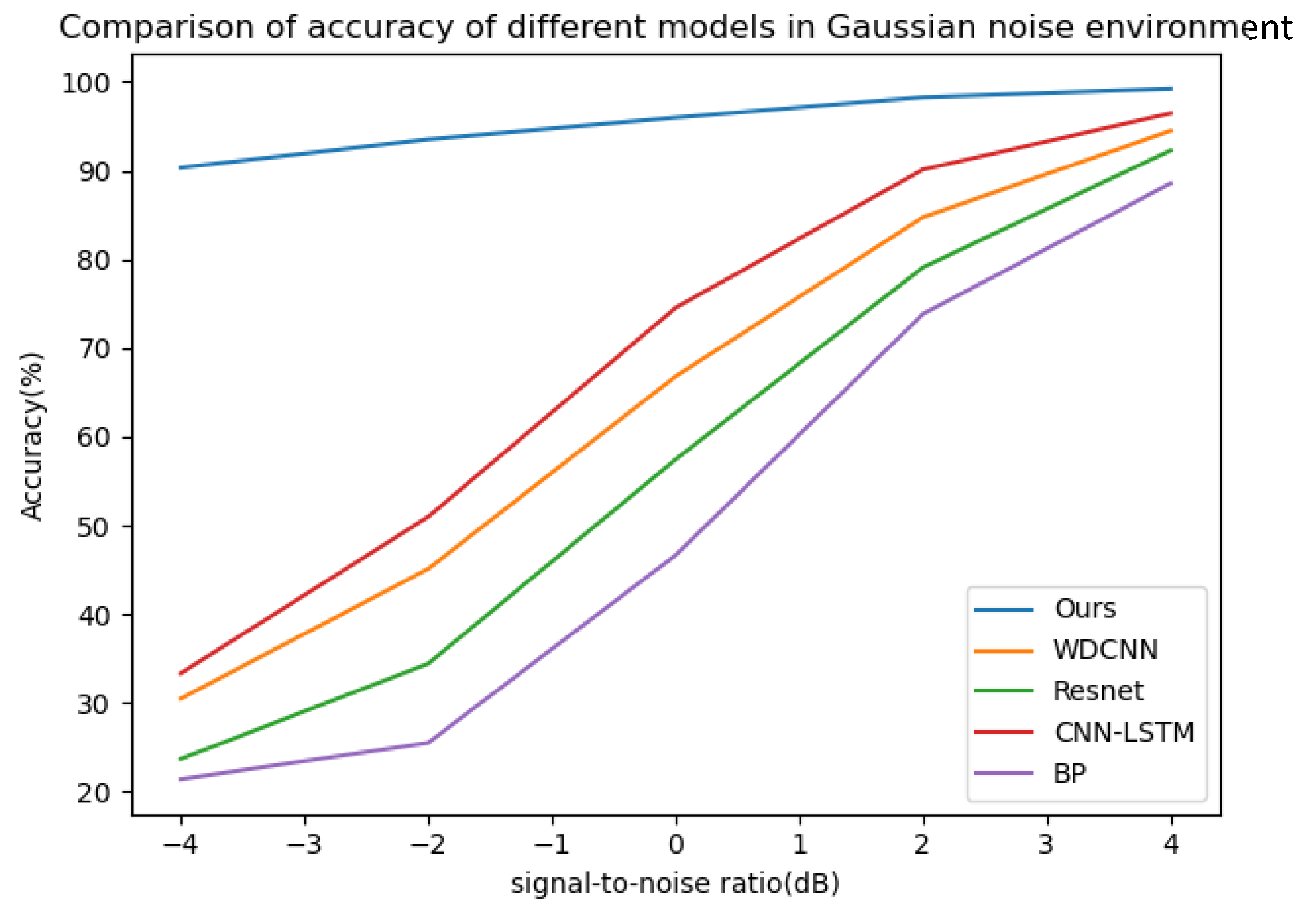
Gaussian noise with SNRs of −4 db to 4 db and impulse noise with a probability of occurrence (p) and intensity amplitude (k) of 5% and 10, 2% and 8, 1% and 5, 0.5% and 3, 0.1% and 3, respectively, were added to the bearing dataset with a load of 0 hp. The probability of occurrence here refers to the probability of contamination of each data point, and the intensity amplitude refers to the multiple of the noise amplitude relative to the standard deviation of the signal. Fourteen datasets were used to verify the model, and the training environment and other configurations were the same as above. The model proposed in this paper was used for 50 iterations in each SNR and combined noise environment, and then the four classical deep learning models (WDCNN, Resnet, CNN-LSTM, BP) mentioned above were used for 50 iterations in the noise environment of the same SNR and combined as a comparative experiment; five experiments were carried out, and the average value of the experimental results was taken. The curves of diagnostic accuracy of the five models in different Gaussian noise intensity and pulse environments are shown in Figure 12 and Figure 13.
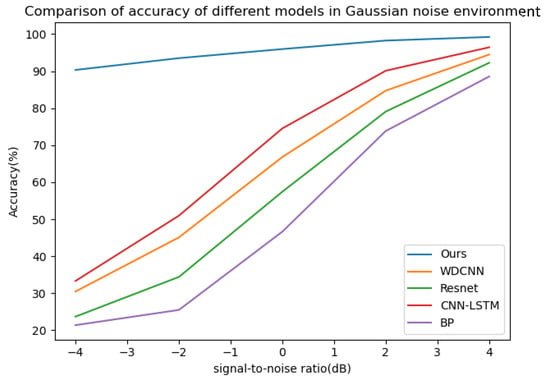
Figure 12.
The diagnostic accuracy of the five models in different signal–noise ratios in a Gaussian noise environment.
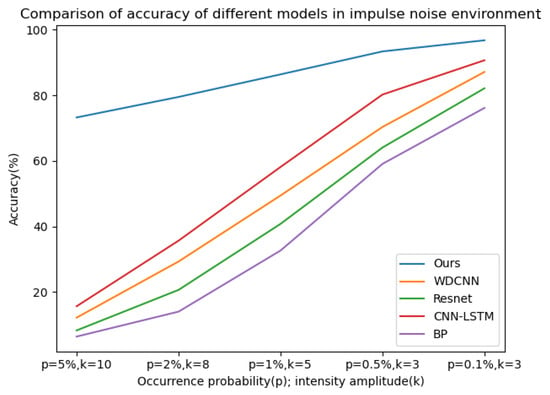
Figure 13.
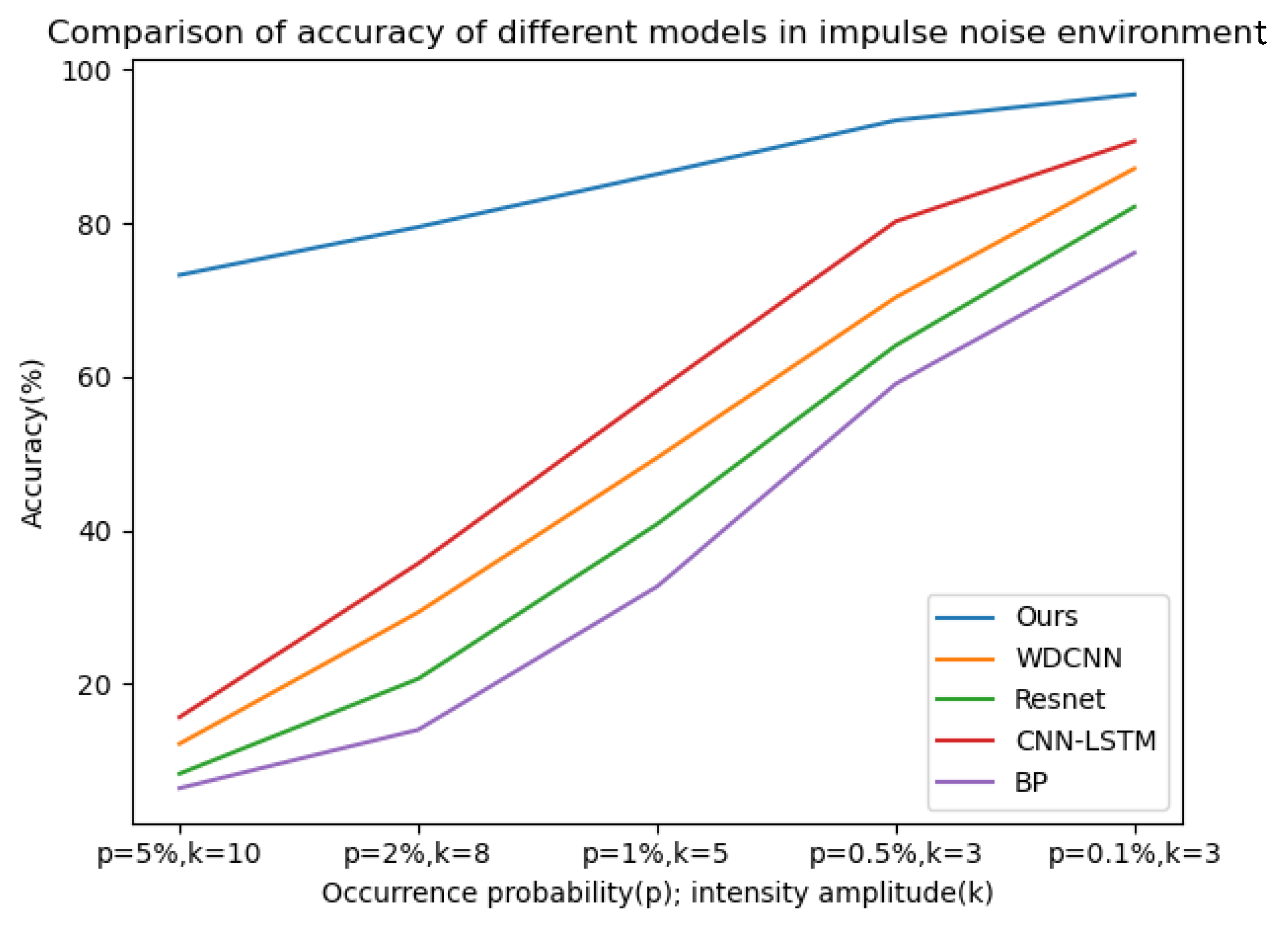
The diagnostic accuracy of the five models in different signal–noise ratios in an impluse noise environment.
It can be seen from the above line charts that the CABA-GMNR-MAGRU model proposed in this paper can maintain a high diagnostic accuracy of about 90% under an extremely high Gaussian noise environment (−4 db), while for the other four models, the highest accuracy is only about 30%, and the lowest is even only about 21%. With the gradual weakening of noise, the diagnostic accuracy of the five models increases. The diagnostic accuracy of the CABA-GMNR-MAGRU model proposed in this paper is able to reach about 97% in a 4 db noise environment, and compared with the diagnostic accuracy in a noise-free environment, the gap is small. The remaining four models have been greatly improved compared with the diagnostic accuracy under −4 db, but there is still a big gap in their diagnostic accuracy in a noise-free environment. In the impulse noise environment with greater interference in fault diagnosis, the diagnostic accuracy of the other four models is as low as 6%, and the highest is only 15% in the extremely high impulse noise environment with p = 5% and k = 10, indicating that these models are completely unable to work normally. Even with the weakening of noise, the diagnostic accuracy of most models cannot reach more than 90%. The CABA-GMNR-MAGRU model proposed in this paper has a diagnostic accuracy of 73% even in the extremely high impulse noise environment with p = 5% and k = 10. With the decrease in noise, in the slight impulse noise environment with p = 0.1% and k = 3, its accuracy, about 96%, is also much higher than the accuracy of the other four models. Therefore, compared with other fault diagnosis models, the CABA-GMNR-MAGRU model proposed in this paper can maintain higher diagnostic accuracy in the face of a noise environment, especially in a strong-noise environment, so it has better anti-noise ability and robustness.
4.6. Results and Analysis of Different Model Migration Tests Under Different Working Conditions
Using the bearing datasets of four different loads used above, the model was trained under the condition of 0 hp load and then directly migrated to the conditions of 1 hp (735 W), 2 hp (1470 W), and 3 hp (2205 W) load. All the data were the data of the validation set, and the training environment was the same as above. At the same time, three classical attention mechanism modules, CBAM [30], SE [31], and ECA [32], were selected to replace the CABA module in the CABA-GMNR-MAGRU model proposed in this paper as a comparative experiment. For the convenience of observation, the model replaced by the CBAM module is named Model B, the model replaced by the SE module is named Model C, the model replaced by the ECA module is named Model D, and the CABA-GMNR-MAGRU model proposed in this paper is named Model A. The specific results are shown in Table 4 and Figure 14.
Table 4.
Migration test results of different models under different working conditions.
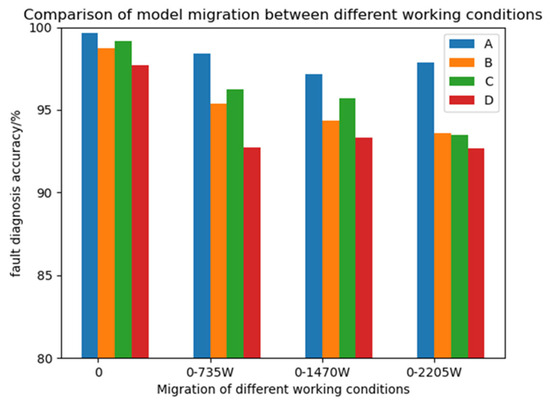
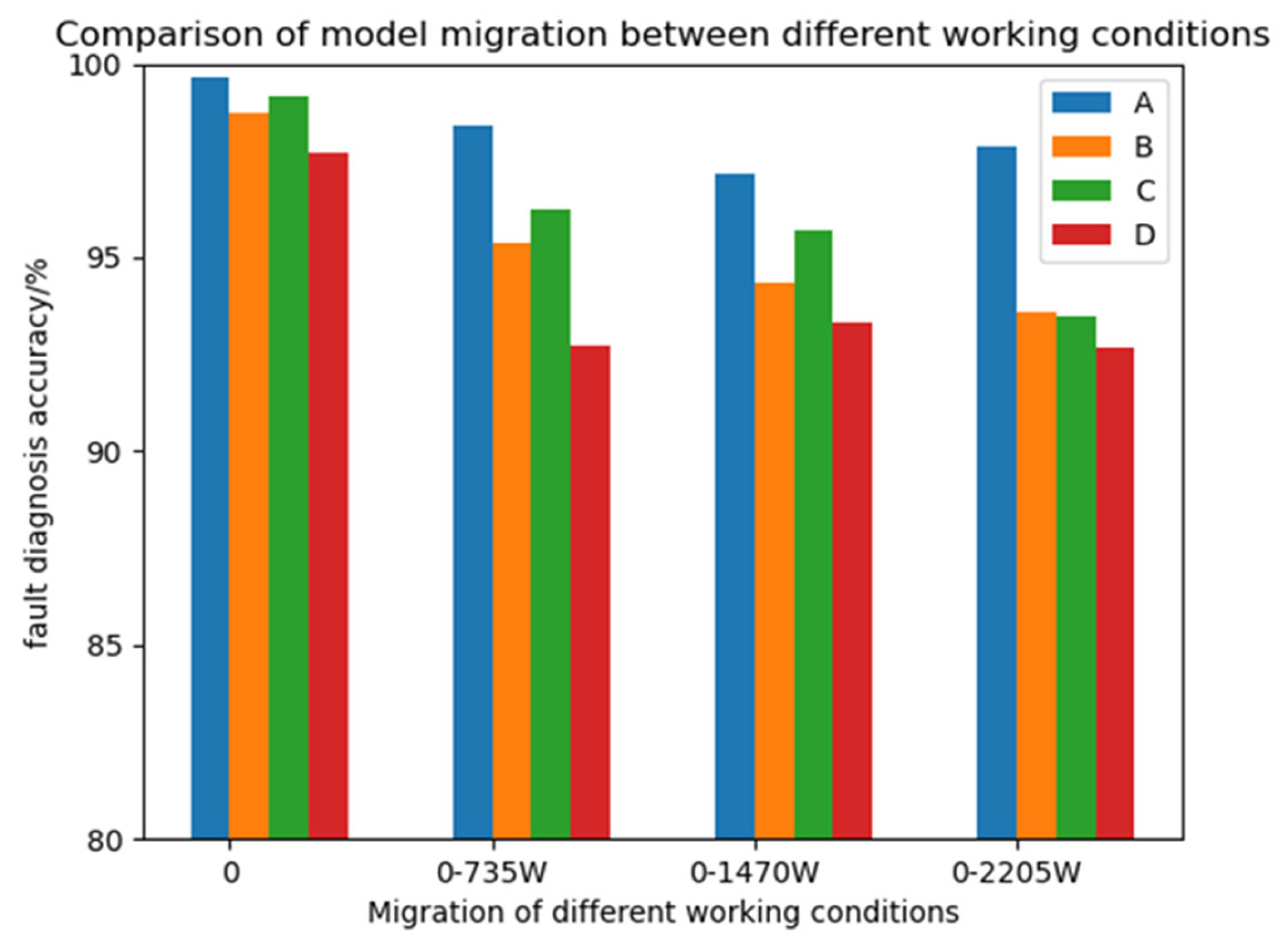
Figure 14.
Different model migration tests in the various working environments.
From the diagram above, it can be observed that the diagnostic precision of the CABA-GMNR-MAGRU model proposed in this paper is directly migrated to the other three load conditions when there is no training set. Compared with the diagnostic precision in the environment of 0 load, although the diagnostic accuracy is also decreased, the decrease is not large, and the accuracy is decreased by no more than 2%. The diagnosis precision of the three models that replace the other three attention mechanism modules directly migrating to the other three load conditions when there is no training set is more than 6% less than the diagnostic precision of the 0-load condition. The diagnostic precision of the CABA-GMNR-MAGRU model in the condition of 0 load demonstrates a clear advantage over its three counterparts that replace the other three attention mechanism modules. The proposed CABA-GMNR-MAGRU framework demonstrates superior diagnostic precision coupled with enhanced generalization capabilities.
4.7. Ablation Experiment
For testing the influence of the removal of every part of the CABA-GMNR-MAGRU model proposed in this paper on the capacity of the model, the original model is named Model A, the model of removing the Gram noise reduction module (GMNR) in the model is named Model B, the model of removing the CABA module in the model is named Model C, the model of removing the residual network (ResNet-CABA) with the CABA module in the model is named Model D, and the model of removing the attention gated recurrent unit (MAGRU) in the model is named Model E. The above five models were trained and tested using the noise-free bearing dataset used above and the Gaussian noise bearing dataset with an SNR of −2 db. The training environment and other configurations were the same as above, and the number of iterations was 50. The experimental outcomes are shown in Table 5.
Table 5.
Ablation experiment results.
As shown in the table, the diagnostic precision of Model B in the noise-free environment is similar to that of Model A, but the diagnostic accuracy in the noise condition with an SNR of −2 db is only 65.94%, which is reduced by more than 30%. This shows that the Gram denoise module can efficiently decrease the influence of noise on diagnostic accuracy. In comparison to the primitive Model A, the diagnostic precision of Models C, D, and E decreased to a certain extent in both noise-free and noisy environments, which fully proves the role of each part of the model in fault diagnosis.
5. Conclusions
The concomitant pursuit of diagnostic precision, real-time responsiveness, and cross-domain robustness poses significant challenges for rolling element bearing fault detection under high-noise industrial conditions. A bearing fault diagnostic model based on a novel deep residual learning framework enhanced an attention-based module and Gram noise reduction module is proposed. The key takeaways can be summarized as follows:
(1) The CABA-GMNR-MAGRU model proposed in this paper has high diagnostic precision, low diagnostic time, favorable anti-noise ability, and robustness. The test precision of this model is better than that of four other classical deep learning models (WDCNN, Resnet, CNN-LSTM, BP) in both a noise-free environment and −4 db to −4 db noise environments, and the running time of the proposed model in the noise-free environment is less than that of the other deep learning models. Under varying SNR conditions, this model can sustain diagnostic precision, that is, it has good robustness, while the diagnostic accuracy of other models will fluctuate greatly.
(2) The CABA-GMNR-MAGRU model proposed in this paper has good generalization performance. For the models that replace the CABA module proposed in this paper with the three classic attention mechanism modules CBAM, SE, and ECA, the accuracy of migration in a single load environment and different load conditions is lower than that of the model proposed in this paper. This shows that the new attention mechanism, CABA, proposed in this paper can efficiently improve the diagnostic precision and generalization capacity of the model.
In spite of this, the method presented in this paper still has some shortcomings. For example, this model was only checked using the bearing dataset of Case Western Reserve University. It is not known whether the model can maintain approximate diagnostic accuracy when other bearing datasets and bearing datasets collected under actual working conditions are used. These problems need to be further discussed and studied in the future.
Author Contributions
Conceptualization, N.M. and L.C.; methodology, L.C.; data curation, N.M.; writing—original draft preparation, L.C. and S.Y.; writing—review and editing, W.S. and S.T.; visualization, L.C. and Y.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data presented in this study are available on request from the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| DL | Deep learning |
| SNR | Signal-to-noise ratio |
| CABA | Convolutional Avgpool Block Attention |
| GMNR | Gram denoising module |
| MAGRU | Attention gated loop unit |
| CWRU | Case Western Reserve University |
References
- Yan, R.; Shang, Z.; Xu, H.; Wen, J.; Zhao, Z.; Chen, X.; Gao, R. Wavelet transform for rotary machine fault diagnosis:10 years revisited. Mech. Syst. Signal Process. 2023, 200, 110545. [Google Scholar] [CrossRef]
- Han, D.; Liang, K.; Shi, P. Intelligent fault diagnosis of rotating machinery based on deep learning with feature selection. J. Low Freq. Noise Vib. Act. Control 2021, 39, 939–953. [Google Scholar] [CrossRef]
- Liu, H.; Xu, Q.; Han, X.; Wang, B.; Yi, X. Attention on the key modes: Machinery fault diagnosis transformers through variational mode decomposition. Knowl.-Based Syst. 2024, 289, 111479. [Google Scholar] [CrossRef]
- Wang, Q.; Huang, R.; Xiong, J.; Yang, J.; Dong, X.; Wu, Y.; Wu, Y.; Lu, T. A survey on fault diagnosis of rotating machinery based on machine learning. Meas. Sci. Technol. 2024, 35, 102001. [Google Scholar] [CrossRef]
- Xu, Y.; Li, Z.; Wang, S.; Li, W.; Sarkodie-Gyan, T.; Feng, S. A hybrid deep-learning model for fault diagnosis of rolling bearings. Measurement 2021, 169, 108502. [Google Scholar] [CrossRef]
- Wu, X.; Shi, H.; Zhu, H. Fault Diagnosis for Rolling Bearings Based on Multiscale Feature Fusion Deep Residual Networks. Electronics 2023, 12, 768. [Google Scholar] [CrossRef]
- Wu, Z.; Jiang, H.; Liu, S.; Wang, R. A deep reinforcement transfer convolutional neural network for rolling bearing fault diagnosis. Isa Trans. 2022, 129, 505–524. [Google Scholar] [CrossRef]
- Jin, Y.; Yang, J.; Yang, X.; Liu, Z. Cross-domain bearing fault diagnosis method based on SMOTENC and deep transfer learning under imbalanced data. Meas. Sci. Technol. 2023, 35, 015121. [Google Scholar] [CrossRef]
- Niu, G.; Wang, X.; Golda, M.; Mastro, S.; Zhang, B. An optimized adaptive PReLU-DBN for rolling element bearing fault diagnosis. Neurocomputing 2021, 445, 26–34. [Google Scholar] [CrossRef]
- Li, P. A Multi-scale Attention-Based Transfer Model for Cross-bearing Fault Diagnosis. Int. J. Comput. Intell. Syst. 2024, 17, 42. [Google Scholar] [CrossRef]
- Tang, J.; Wu, J.; Qing, J. A feature learning method for rotating machinery fault diagnosis via mixed pooling deep belief network and wavelet transform. Results Phys. 2022, 39, 105781. [Google Scholar] [CrossRef]
- Wen, C.; Xue, Y.; Liu, W.; Chen, G.; Liu, X. Bearing fault diagnosis via fusing small samples and training multi-state Siamese neural networks. Neurocomputing 2024, 576, 127355. [Google Scholar] [CrossRef]
- Lei, C.; Shi, J.; Ma, S.; Miao, C.; Wan, H.; Li, J. Fault diagnosis method of rolling bearing based on MSDCNN in strong noise environment. J. Beijing Univ. Aeronaut. Astronaut. 2023, 1–13. [Google Scholar] [CrossRef]
- Matania, O.; Cohen, R.; Bechhoefer, E.; Bortman, J. Zero-fault-shot learning for bearing spall type classification by hybrid approach. Mech. Syst. Signal Process. 2024, 224, 112117. [Google Scholar] [CrossRef]
- Berredjem, T.; Benidir, M. Bearing faults diagnosis using fuzzy expert system relying on an Improved Range Overlaps and Similarity method. Expert Syst. Appl. 2018, 108, 134–142. [Google Scholar] [CrossRef]
- Chen, H.; Meng, W.; Li, Y.; Xiong, Q. An anti-noise fault diagnosis approach for rolling bearings based on multiscale CNN-LSTM and a deep residual learning model. Meas. Sci. Technol. 2023, 34, 045013. [Google Scholar] [CrossRef]
- Tang, Y.; Zhang, C.; Wu, J.; Xie, Y.; Shen, W.; Wu, J. Deep Learning-Based Bearing Fault Diagnosis Using a Trusted Multiscale Quadratic Attention-Embedded Convolutional Neural Network. IEEE Trans. Instrum. Meas. 2024, 73, 3513215. [Google Scholar] [CrossRef]
- Shan, S.; Liu, J.; Wu, S.; Shao, Y.; Li, H. A motor bearing fault voiceprint recognition method based on Mel-CNN model. Measurement 2022, 207, 112408. [Google Scholar] [CrossRef]
- Wang, R.; Jiang, H.; Zhu, K. A deep feature enhanced reinforcement learning method for rolling bearing fault diagnosis. Adv. Eng. Inform. 2022, 54, 112408. [Google Scholar] [CrossRef]
- Xu, Z.; Ma, Y.; Pan, Z.; Zheng, X. Deep Spiking Residual Shrinkage Network for Bearing Fault Diagnosis. IEEE Trans. Cybern. 2024, 54, 1608–1613. [Google Scholar] [CrossRef]
- Zhai, S.; Wang, Z.; Gao, D. Bearing Fault Diagnosis Based on a Novel Adaptive ADSD-gcForest Model. Processes 2022, 10, 209. [Google Scholar] [CrossRef]
- Zhang, F.Q.; Yin, Z.Y.; Xu, F.L.; Li, Y.; Xu, G. MAB-DrNet: Bearing Fault Diagnosis Method Based on an Improved Dilated Convolutional Neural Network. Sensors 2023, 23, 5532. [Google Scholar] [CrossRef]
- Zhu, X.; Ren, Y.; Wei, W. Research on bearing fault diagnosis of wind turbine based on MSACNN-GMNR. Control Eng. 2023, 1–7. [Google Scholar] [CrossRef]
- Ge, C.; Yang, Q.; Liu, J.; Zang, L.; Chen, L.; Sun, R. Rolling bearing fault diagnosis based on dilated convolutional neural network and attention mechanism GRU. China Metall. 2022, 32, 99–105+131. [Google Scholar]
- Smith, W.; Randall, R. Rolling element bearing diagnostics using the Case Western Reserve University data: A benchmark study. Mech. Syst. Signal Process. 2015, 64–65, 100–131. [Google Scholar] [CrossRef]
- Zhang, W.; Peng, G.; Li, C.; Chen, Y.; Zhang, Z. A new deep learning model for fault diagnosis with good anti-noise and domain adaptation ability on raw vibration signals. Sensors 2017, 17, 425. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2016, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.; Wong, W.; Woo, W. Convolutional LSTM network: A machine learning approach for precipitation nowcasting. Adv. Neural Inf. Process. Syst. 2015, 28, 802–810. [Google Scholar]
- Rumelhart, D.; Hinton, G.; Williams, R. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.; Kweon, I. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision (ECCV), PT VII, 2018, Munich, Germany, 8–14 September 2018; Volume 11211, pp. 3–19. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.H.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference On Computer Vision And Pattern Recognition (CVPR 2020), Seattle, WA, USA, 13–19 June 2020; pp. 11531–11539. [Google Scholar]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).