
An Autonomous Vehicle Behavior Decision Method Based on Deep Reinforcement Learning with Hybrid State Space and Driving Risk



Abstract
1. Introduction
2. Risk Analysis of Autonomous Vehicle Behavior
2.1. Behavior Model Construction of Autonomous Vehicle
2.2. Classification Discussion and Risk Analysis of Driving Behavior
3. Design of Deep Reinforcement Model
3.1. Problem Description of Autonomous Vehicle Behavior Decision by DRL
3.2. Deep Reinforcement Learning Method
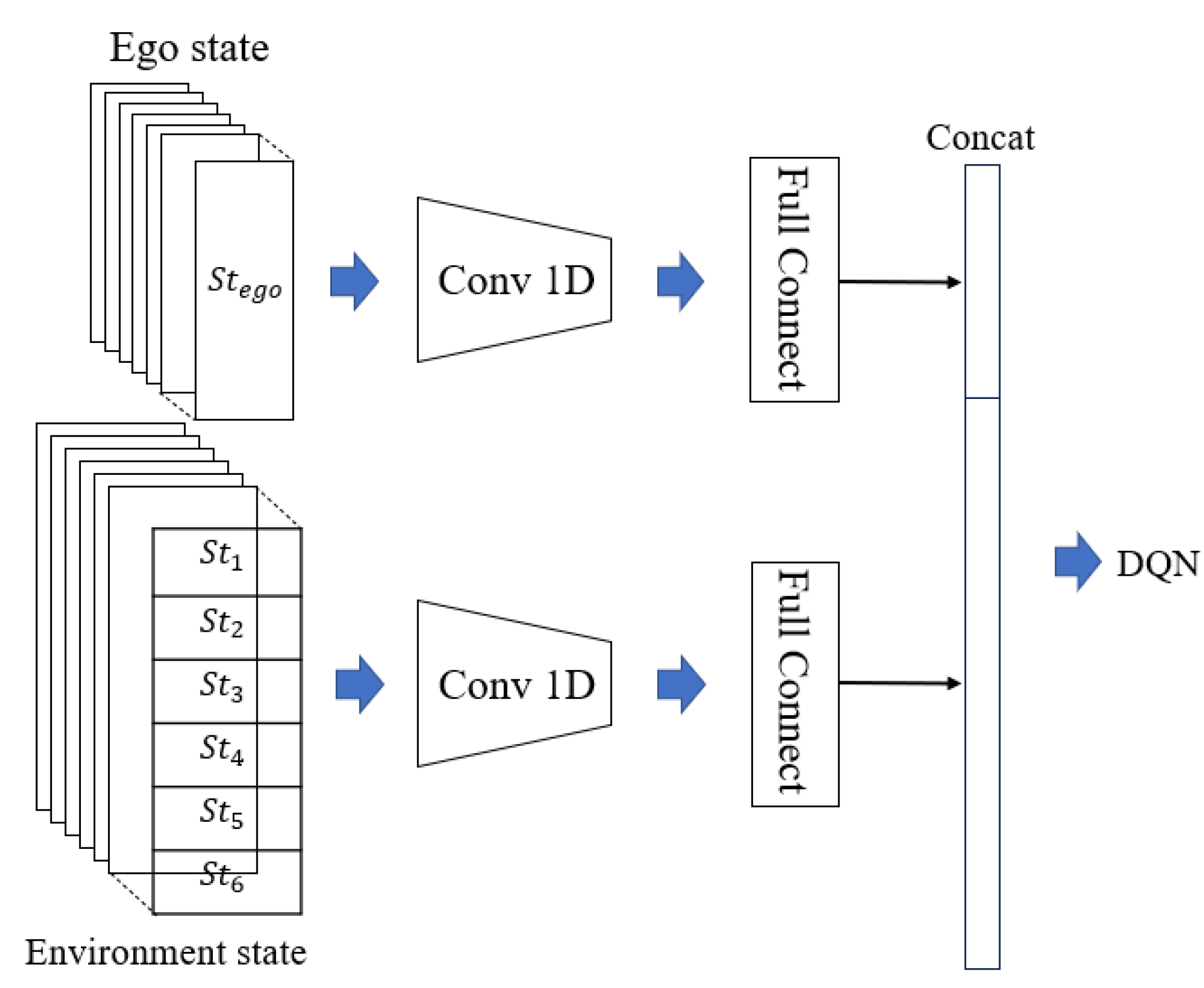
3.2.1. Hybrid State Space
3.2.2. Action Space
3.2.3. Reward Function Design
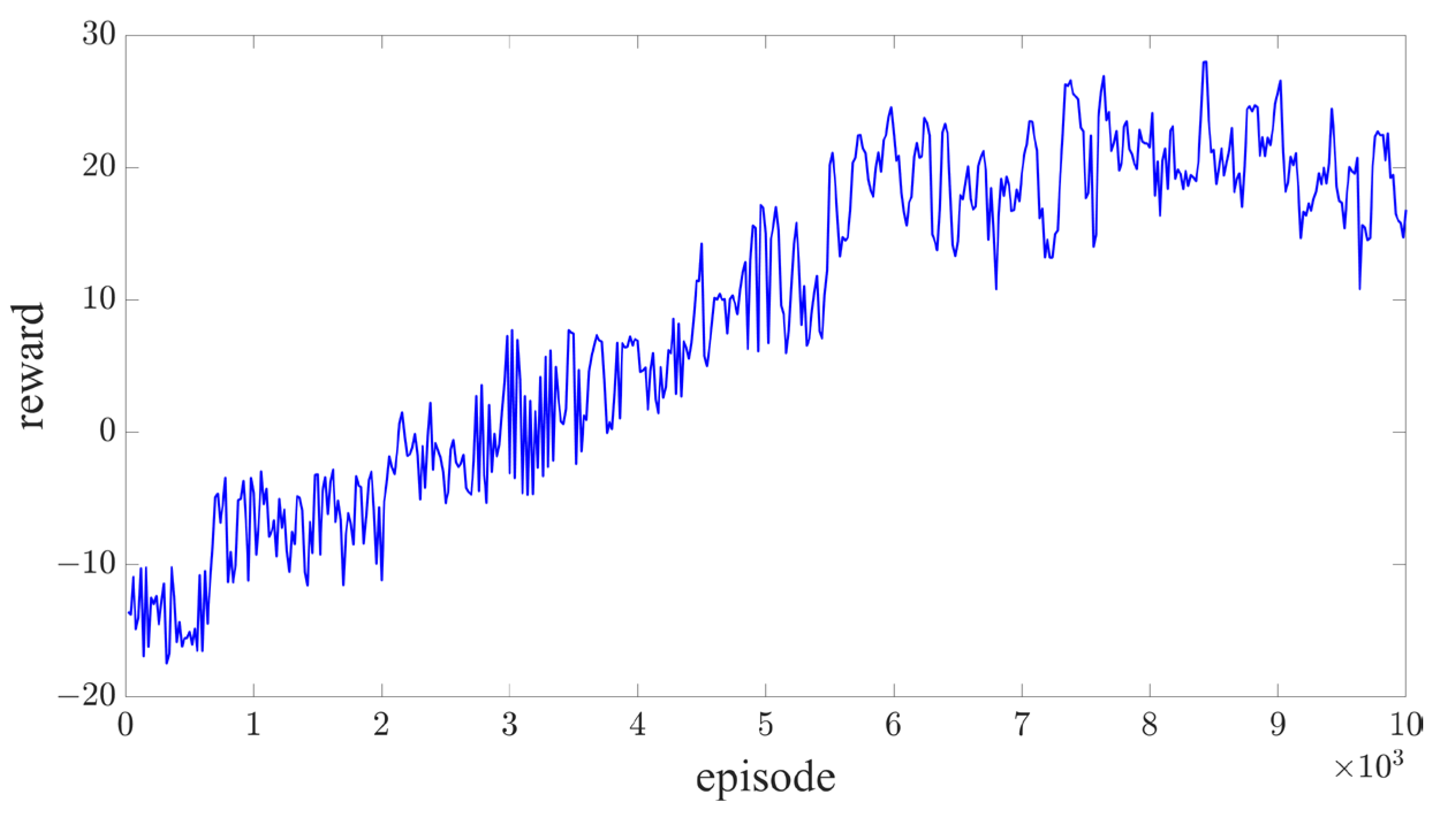
3.2.4. Implement Step and Training Parameter
| Algorithm 1. DQN implementation process |
| Input: Replay buffer size D, network update interval N, discount factor , learning rate , reward function, state space, action space. Output: Parameters of training network and target network.
|
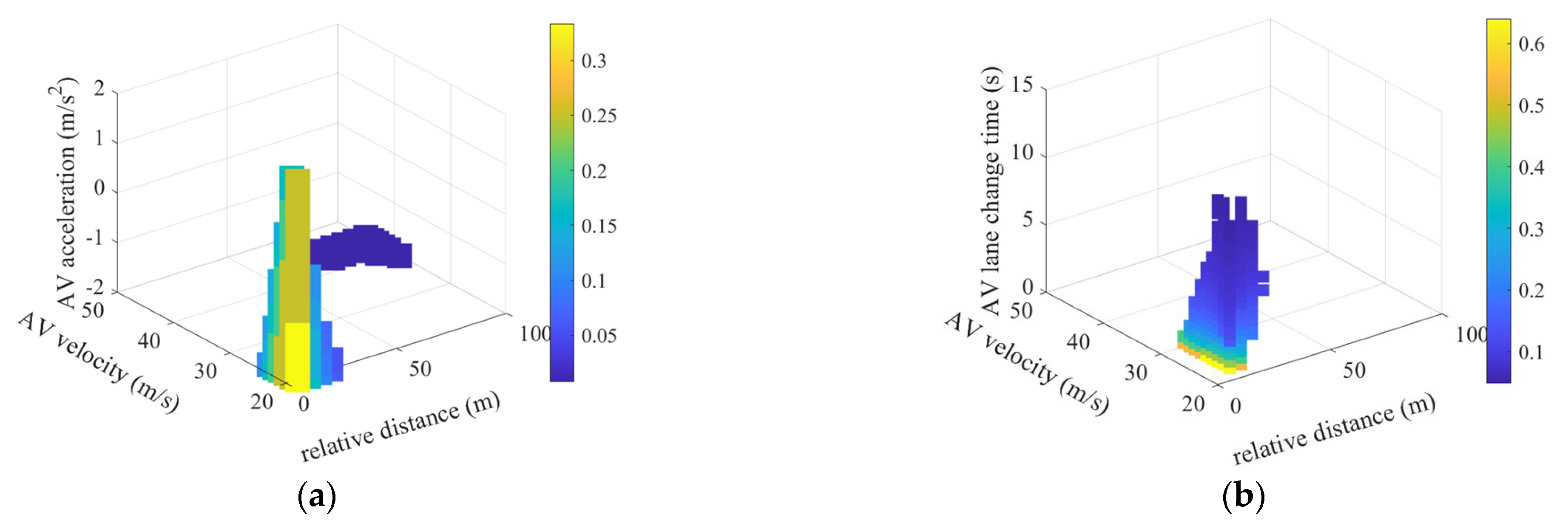
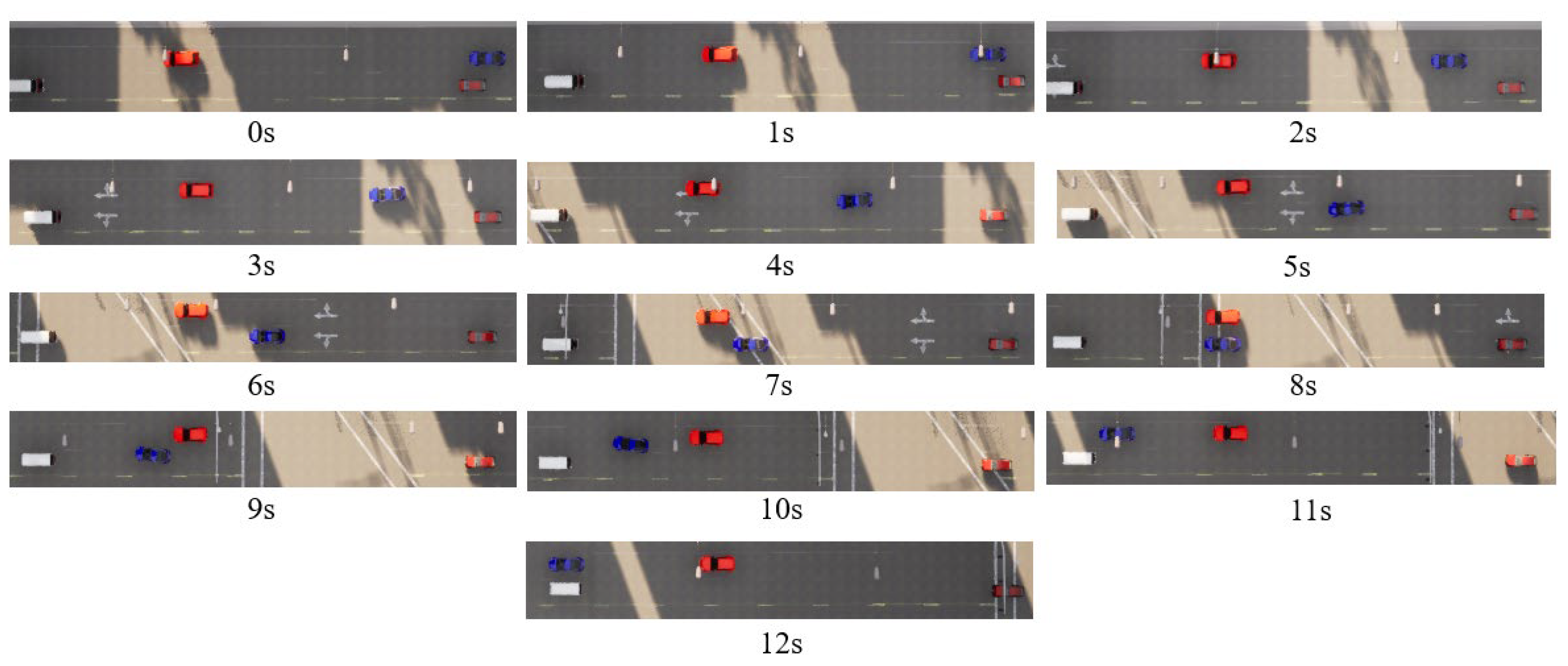
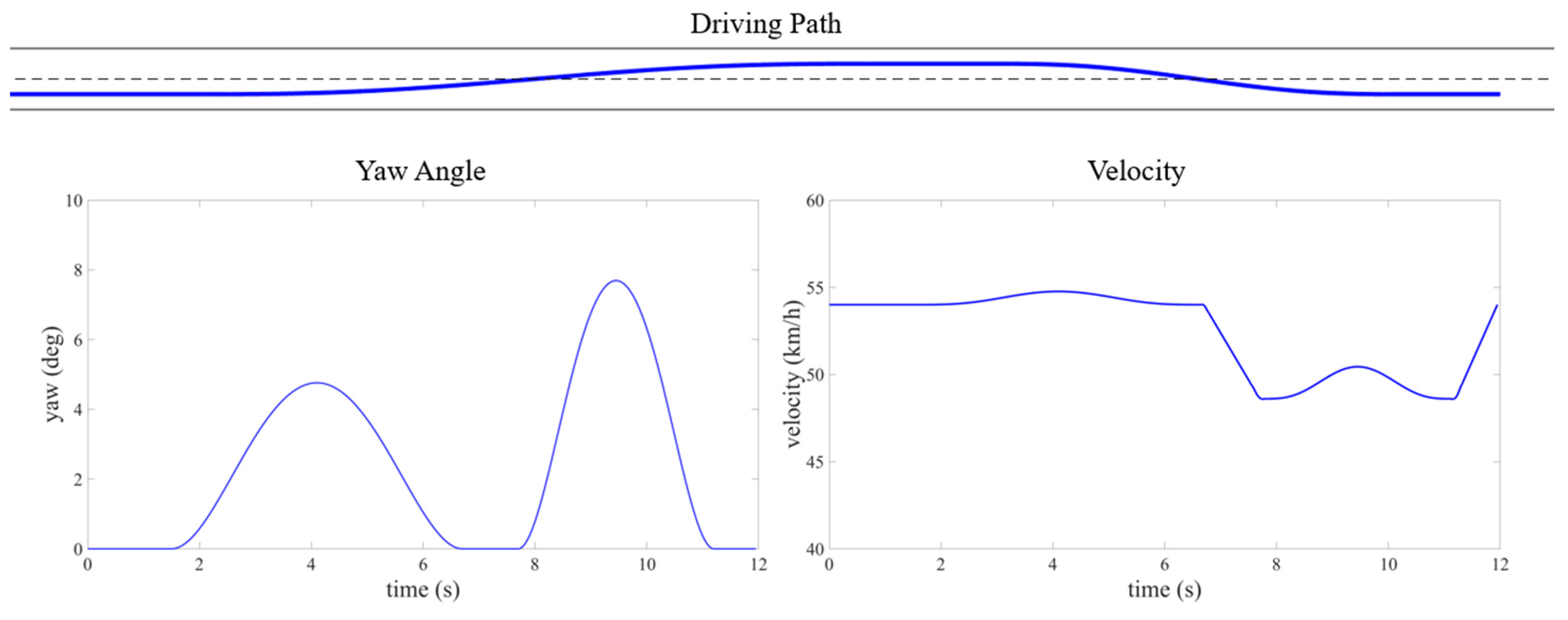
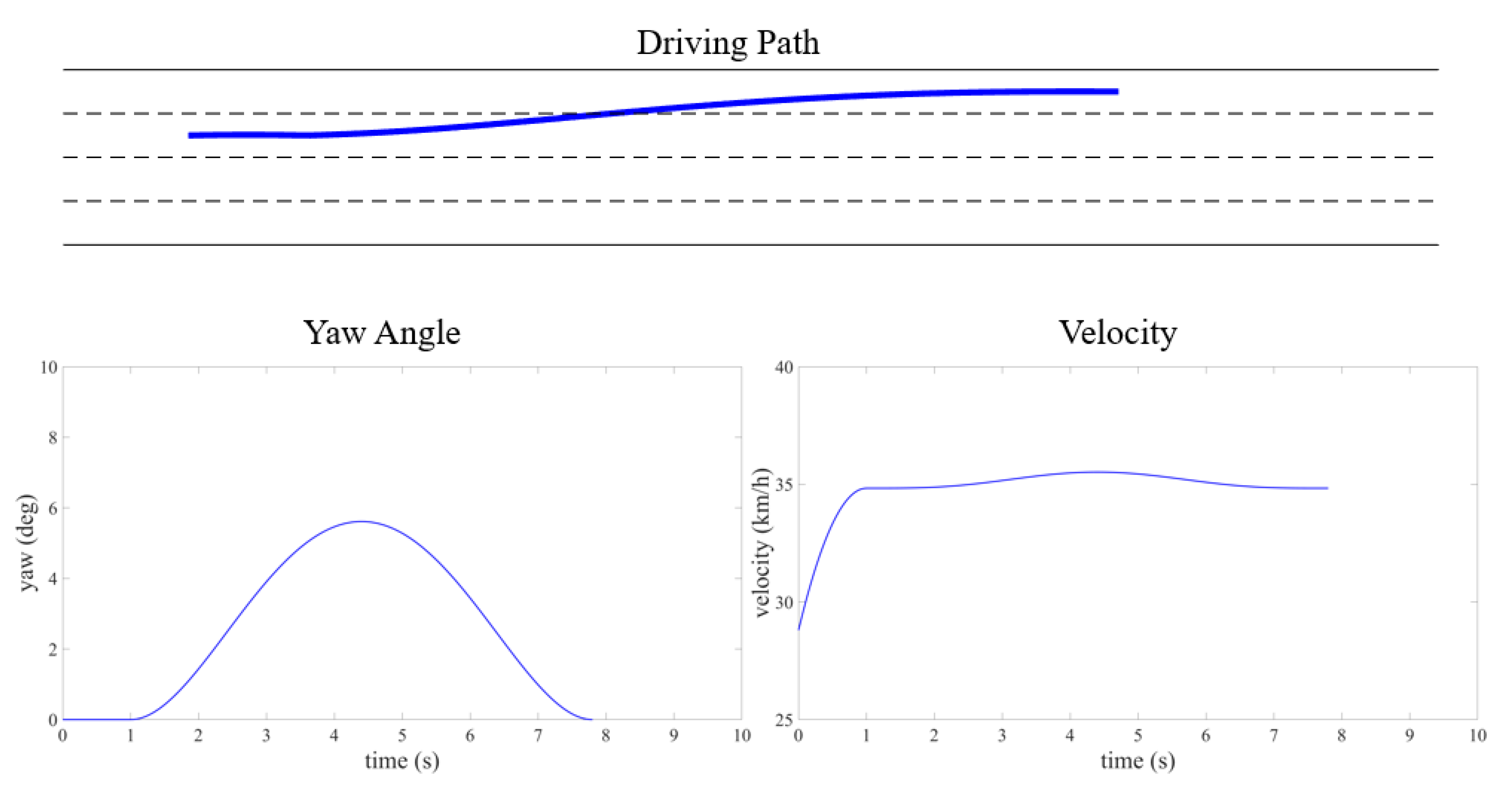
4. Experiment and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Xu, J.W.; Zhang, X.Q.; Park, S.H.; Guo, K. The Alleviation of Perceptual Blindness During Driving in Urban Areas Guided by Saccades Recommendation. IEEE Trans. Intell. Transp. Syst. 2022, 23, 16386–16396. [Google Scholar] [CrossRef]
- Bathla, G.; Bhadane, K.; Singh, R.K.; Kumar, R.; Aluvalu, R.; Krishnamurthi, R.; Kumar, A.; Thakur, R.N.; Basheer, S. Autonomous Vehicles and Intelligent Automation: Applications, Challenges, and Opportunities. Mob. Inf. Syst. 2022, 2022, 7632892. [Google Scholar] [CrossRef]
- Chan, T.K.; Chin, C.S. Review of Autonomous Intelligent Vehicles for Urban Driving and Parking. Electronics 2021, 10, 1021. [Google Scholar] [CrossRef]
- Negash, N.M.; Yang, J.M. Driver Behavior Modeling Toward Autonomous Vehicles: Comprehensive Review. IEEE Access 2023, 11, 22788–22821. [Google Scholar] [CrossRef]
- Rong, S.S.; Meng, R.F.; Guo, J.H.; Cui, P.F.; Qiao, Z. Multi-Vehicle Collaborative Planning Technology under Automatic Driving. Sustainability 2024, 16, 4578. [Google Scholar] [CrossRef]
- Ignatious, H.A.; El-Sayed, H.; Khan, M.A.; Mokhtar, B.M. Analyzing Factors Influencing Situation Awareness in Autonomous Vehicles-A Survey. Sensors 2023, 23, 4075. [Google Scholar] [CrossRef]
- Bagdatli, M.E.C.; Dokuz, A.S. Modeling discretionary lane-changing decisions using an improved fuzzy cognitive map with association rule mining. Transp. Lett. 2021, 13, 623–633. [Google Scholar] [CrossRef]
- Karle, P.; Geisslinger, M.; Betz, J.; Lienkamp, M. Scenario Understanding and Motion Prediction for Autonomous Vehicles-Review and Comparison. IEEE Trans. Intell. Transp. Syst. 2022, 23, 16962–16982. [Google Scholar] [CrossRef]
- Abdallaoui, S.; Ikaouassen, H.; Kribèche, A.; Chaibet, A.; Aglzim, E. Advancing autonomous vehicle control systems: An in-depth overview of decision-making and manoeuvre execution state of the art. J. Eng.-JOE 2023, 2023, e12333. [Google Scholar] [CrossRef]
- Khelfa, B.; Ba, I.; Tordeux, A. Predicting highway lane-changing maneuvers: A benchmark analysis of machine and ensemble learning algorithms. Phys. A 2023, 612, 16. [Google Scholar] [CrossRef]
- Yu, Y.W.; Luo, X.; Su, Q.M.; Peng, W.K. A dynamic lane-changing decision and trajectory planning model of autonomous vehicles under mixed autonomous vehicle and human-driven vehicle environment. Phys. A 2023, 609, 22. [Google Scholar] [CrossRef]
- Long, X.Q.; Zhang, L.C.; Liu, S.S.; Wang, J.J. Research on Decision-Making Behavior of Discretionary Lane-Changing Based on Cumulative Prospect Theory. J. Adv. Transp. 2020, 2020, 1291342. [Google Scholar] [CrossRef]
- Wang, C.; Sun, Q.Y.; Li, Z.; Zhang, H.J. Human-Like Lane Change Decision Model for Autonomous Vehicles that Considers the Risk Perception of Drivers in Mixed Traffic. Sensors 2020, 20, 2259. [Google Scholar] [CrossRef] [PubMed]
- Jain, G.; Kumar, A.; Bhat, S.A. Recent Developments of Game Theory and Reinforcement Learning Approaches: A Systematic Review. IEEE Access 2024, 12, 9999–10011. [Google Scholar] [CrossRef]
- Wang, J.W.; Chu, L.; Zhang, Y.; Mao, Y.B.; Guo, C. Intelligent Vehicle Decision-Making and Trajectory Planning Method Based on Deep Reinforcement Learning in the Frenet Space. Sensors 2023, 23, 9819. [Google Scholar] [CrossRef] [PubMed]
- Ahmad, F.; Shah, Z.; Al-Fagih, L. Applications of evolutionary game theory in urban road transport network: A state of the art review. Sustain. Cities Soc. 2023, 98, 104791. [Google Scholar] [CrossRef]
- Chen, C.Y.; Seff, A.; Kornhauser, A.; Xiao, J.X. DeepDriving: Learning Affordance for Direct Perception in Autonomous Driving. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 2722–2730. [Google Scholar]
- Xu, H.Z.; Gao, Y.; Yu, F.; Darrell, T. End-to-end Learning of Driving Models from Large-scale Video Datasets. In Proceedings of the 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3530–3538. [Google Scholar]
- Müller, M.; Dosovitskiy, A.; Ghanem, B.; Koltun, V. Driving policy transfer via modularity and abstraction. arXiv 2018, arXiv:1804.09364. [Google Scholar]
- Kendall, A.; Hawke, J.; Janz, D.; Mazur, P.; Reda, D.; Allen, J.M.; Shah, A. Learning to drive in a day. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 8248–8254. [Google Scholar]
- Hu, H.Y.; Lu, Z.Y.; Wang, Q.; Zheng, C.Y. End-to-End Automated Lane-Change Maneuvering Considering Driving Style Using a Deep Deterministic Policy Gradient Algorithm. Sensors 2020, 20, 443. [Google Scholar] [CrossRef]
- Gao, Z.H.; Yan, X.T.; Gao, F.; He, L. Driver-like decision-making method for vehicle longitudinal autonomous driving based on deep reinforcement learning. Proc. Inst. Mech. Eng. Part D-J. Automob. Eng. 2022, 236, 3060–3070. [Google Scholar] [CrossRef]
- Cao, J.Q.; Wang, X.L.; Wang, Y.S.; Tian, Y.X. An improved Dueling Deep Q-network with optimizing reward functions for driving decision method. Proc. Inst. Mech. Eng. Part D-J. Automob. Eng. 2023, 237, 2295–2309. [Google Scholar] [CrossRef]
- Liao, J.D.; Liu, T.; Tang, X.L.; Mu, X.Y.; Huang, B.; Cao, D.P. Decision-Making Strategy on Highway for Autonomous Vehicles Using Deep Reinforcement Learning. IEEE Access 2020, 8, 177804–177814. [Google Scholar] [CrossRef]
- Deng, H.F.; Zhao, Y.Q.; Wang, Q.W.; Nguyen, A.T. Deep Reinforcement Learning Based Decision-Making Strategy of Autonomous Vehicle in Highway Uncertain Driving Environments. Automot. Innov. 2023, 6, 438–452. [Google Scholar] [CrossRef]
- Tampuu, A.; Matiisen, T.; Semikin, M.; Fishman, D.; Muhammad, N. A Survey of End-to-End Driving: Architectures and Training Methods. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 1364–1384. [Google Scholar] [CrossRef] [PubMed]
- Liang, X.D.; Wang, T.R.; Yang, L.N.; Xing, E.R. CIRL: Controllable Imitative Reinforcement Learning for Vision-Based Self-driving. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 604–620. [Google Scholar]
- Liu, Q.; Li, X.Y.; Yuan, S.H.; Li, Z.R. Decision-Making Technology for Autonomous Vehicles: Learning-Based Methods, Applications and Future Outlook. In Proceedings of the IEEE Intelligent Transportation Systems Conference (ITSC), Indianapolis, IN, USA, Sep 19–22 September 2021; pp. 30–37. [Google Scholar]
- Liu, X.C.; Hong, L.; Lin, Y.R. Vehicle Lane Change Models-A Historical Review. Appl. Sci. 2023, 13, 12366. [Google Scholar] [CrossRef]
- Teng, S.; Hu, X.; Deng, P.; Li, B.; Li, Y.; Ai, Y.; Yang, D.; Li, L.; Xuanyuan, Z.; Zhu, F.; et al. Motion Planning for Autonomous Driving: The State of the Art and Future Perspectives. IEEE Trans. Intell. Veh. 2023, 8, 3692–3711. [Google Scholar] [CrossRef]
- Wang, X.; Li, B.; Su, X.; Peng, H.; Wang, L.; Lu, C. Autonomous dispatch trajectory planning on flight deck: A search-resampling-optimization framework. Eng. Appl. Artif. Intell. 2023, 119, 105792. [Google Scholar] [CrossRef]
- Zhang, D.X.; Jiao, X.H.; Zhang, T. Lane-changing and overtaking trajectory planning for autonomous vehicles with multi-performance optimization considering static and dynamic obstacles. Robot. Auton. Syst. 2024, 182, 104797. [Google Scholar] [CrossRef]
- Mu, Z.Y.; Jahedinia, F.; Park, B.B. Does the Intelligent Driver Model Adequately Represent Human Drivers? In Proceedings of the 9th International Conference on Vehicle Technology and Intelligent Transport Systems (VEHITS), Prague, Czech Republic, 26–28 April 2023; pp. 113–121. [Google Scholar]
- Zhang, Y.; Sun, H.; Zhou, J.; Pan, J.; Hu, J.; Miao, J. Optimal Vehicle Path Planning Using Quadratic Optimization for Baidu Apollo Open Platform. In Proceedings of the 2020 IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 19 October–13 November 2020; pp. 978–984. [Google Scholar]
- Chu, L.; Wang, J.; Cao, Z.; Zhang, Y.; Guo, C. A Human-Like Free-Lane-Change Trajectory Planning and Control Method With Data-Based Behavior Decision. IEEE Access 2023, 11, 121052–121063. [Google Scholar] [CrossRef]
- Liu, W.; Xiang, Z.; Fang, H.; Huo, K.; Wang, Z. A Multi-Task Fusion Strategy-Based Decision-Making and Planning Method for Autonomous Driving Vehicles. Sensors 2023, 23, 7021. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | Symbol | Value |
|---|---|---|
| discount factor | 0.99 | |
| learning rate | 0.001 | |
| replay buffer size | D | 5000 |
| network update interval | N | 5 |
| batch size | 128 | |
| weighting coefficients of risk | 0.5 | |
| weighting coefficients of efficiency | 1 | |
| weighting coefficients of comfort | 0.1 |
| Indicator | Scenario 1—Two Lanes | Scenario 2—Four Lanes | ||||||
|---|---|---|---|---|---|---|---|---|
| (m) | (m) | NoC | ACT (ms) | (m) | (m) | NoC | ACT (ms) | |
| Baseline | 15.3 | 8.2 | 100 | - | 19.5 | 9.2 | 100 | - |
| EM-Planner [34] | 170.7 | 4.2 | 5 | 109.3 | 206.9 | 8.5 | 7 | 124.7 |
| LSTM [35] | 142.8 | 11.2 | 18 | 52.9 | 168.4 | 11.4 | 16 | 53.5 |
| DQN-no risk | 62.5 | 14.7 | 57 | 2.84 | 73.2 | 11.8 | 44 | 2.88 |
| DDPG [36] | 174.8 | 3.9 | 4 | 4.96 | 210.5 | 8.1 | 5 | 5.13 |
| DQN (this paper) | 179.5 | 3.3 | 2 | 2.85 | 218.7 | 7.8 | 3 | 2.93 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, X.; Qian, B.; Zhuo, J.; Liu, W. An Autonomous Vehicle Behavior Decision Method Based on Deep Reinforcement Learning with Hybrid State Space and Driving Risk. Sensors 2025, 25, 774. https://doi.org/10.3390/s25030774
Wang X, Qian B, Zhuo J, Liu W. An Autonomous Vehicle Behavior Decision Method Based on Deep Reinforcement Learning with Hybrid State Space and Driving Risk. Sensors. 2025; 25(3):774. https://doi.org/10.3390/s25030774
Chicago/Turabian StyleWang, Xu, Bo Qian, Junchao Zhuo, and Weiqun Liu. 2025. "An Autonomous Vehicle Behavior Decision Method Based on Deep Reinforcement Learning with Hybrid State Space and Driving Risk" Sensors 25, no. 3: 774. https://doi.org/10.3390/s25030774
APA StyleWang, X., Qian, B., Zhuo, J., & Liu, W. (2025). An Autonomous Vehicle Behavior Decision Method Based on Deep Reinforcement Learning with Hybrid State Space and Driving Risk. Sensors, 25(3), 774. https://doi.org/10.3390/s25030774