



Defect Detection for Enhanced Traceability in Naval Construction

 , , ,
, , ,  ,
,  and
and 
Abstract
1. Introduction
2. Case of Study
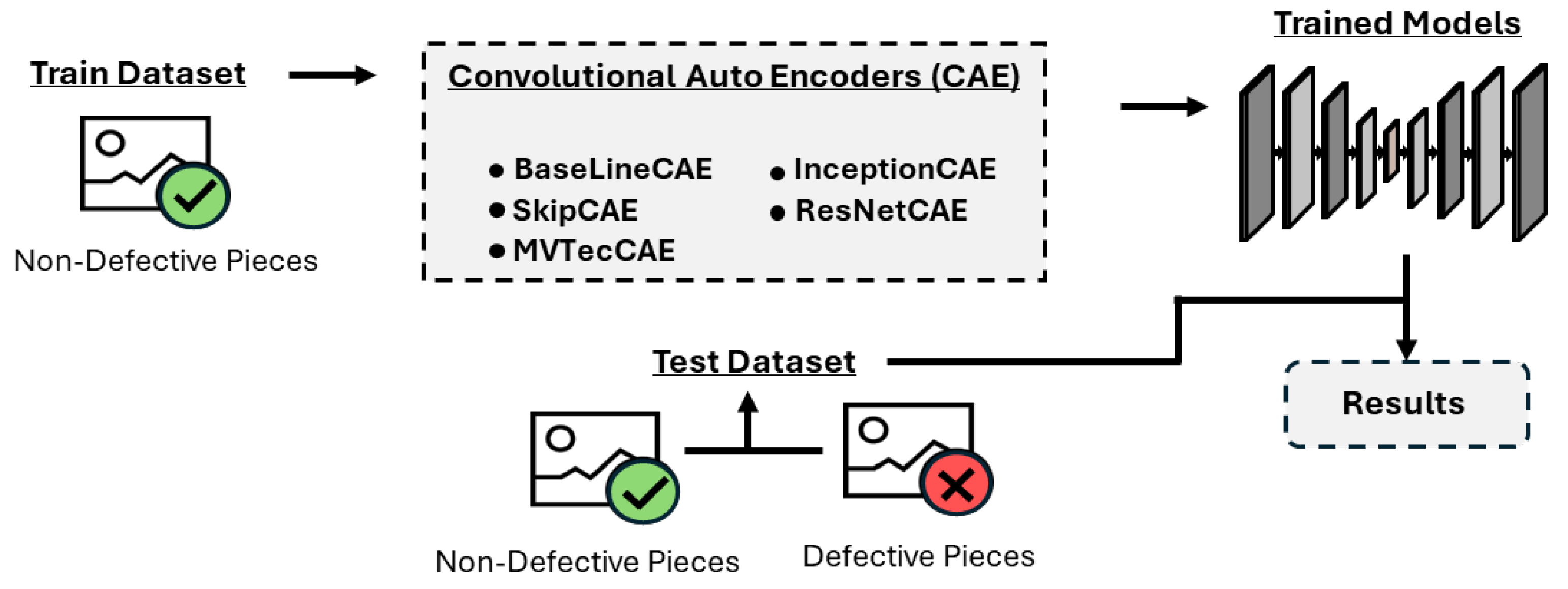
3. Approach
4. Methods and Materials
4.1. Physical Device
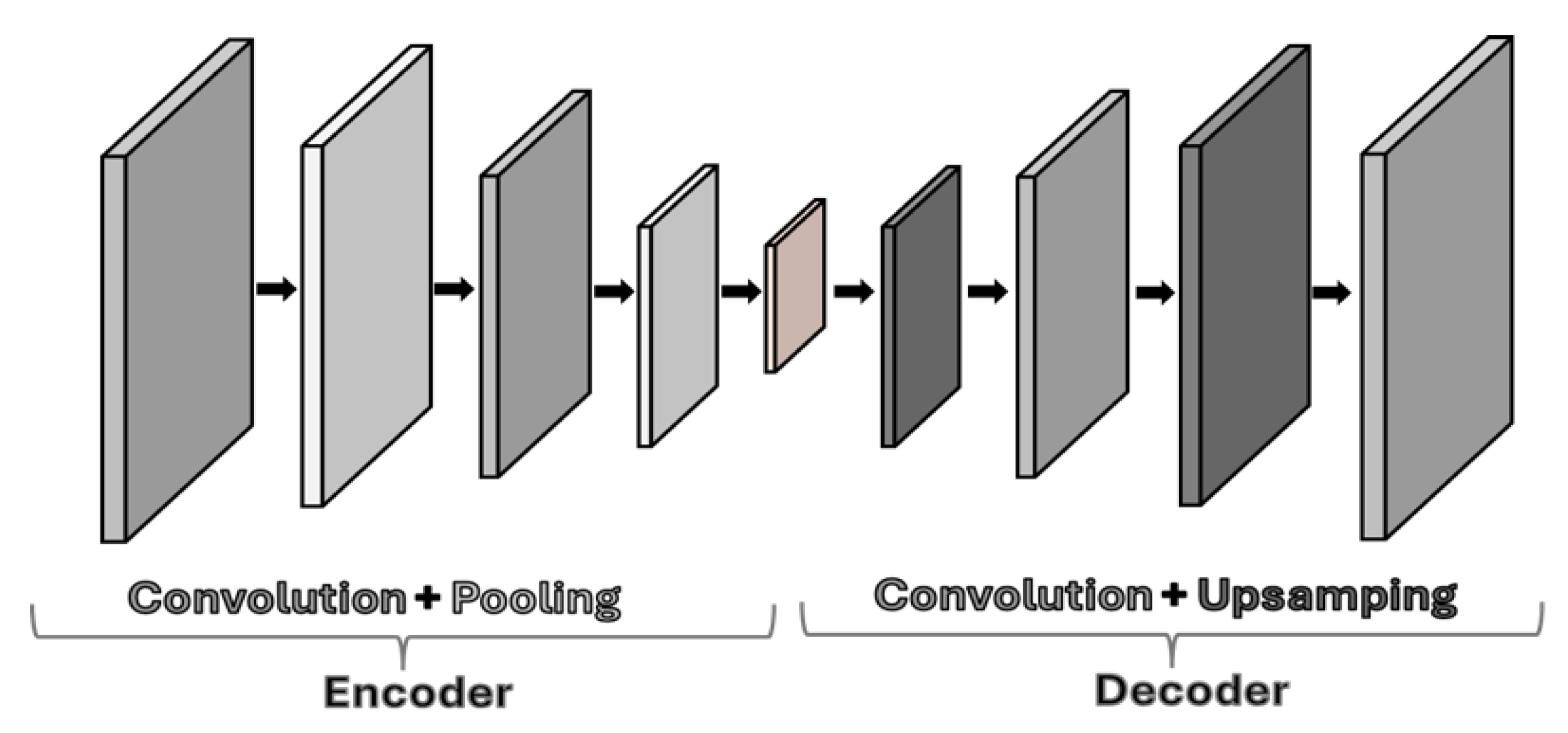
4.2. Convolutional Autoencoders
- x is the input image.
- and are the weights and biases of the encoder.
- ∗ denotes the convolution operation.
- h is the encoded representation.
- is the activation function (e.g., ReLU).
- is the reconstructed output.
- and are the weights and biases of the decoder.
- is the activation function.
- x is the input image.
- are the weights of the filters with kernel sizes 1 × 1, 3 × 3, and 5 × 5, respectively.
- are the biases corresponding to each filter.
- ∗ represents the convolution operation.
- is the activation function (ReLU or LeakyReLU).
- are the feature maps resulting from each filter.
- concat is the concatenation operation that merges the outputs from the multiple convolutional layers with different kernel sizes .
- x is the input image.
- is the activation function (e.g., ReLU or LeakyReLU).
- represent the convolution filters for each kernel size.
- are the bias terms.
- is the reconstructed output image,
- and are the weights and biases of the decoder convolutional layers,
- is the encoded feature map,
- is the activation function.
- x is the input image.
- are the weights of the filters for each layer.
- are the biases corresponding to each filter.
- ∗ represents the convolution operation.
- is the activation function (e.g., ReLU or LeakyReLU).
- represent intermediate feature maps at different stages of the encoder.
- is the reconstructed output image.
- and are the weights and biases of the decoder convolutional layers.
- is the encoded feature map from the encoder.
- denotes the feature map being added to the decoder at the corresponding layer to preserve finer details from the original image.
- is the activation function (e.g., ReLU or LeakyReLU).
- x is the input image.
- and are the weights and biases of the encoder convolutional layers.
- ∗ represents the convolution operation.
- is the activation function (e.g., ReLU).
- h is the feature map produced by the encoder.
- The addition of x represents the residual connection that helps the network learn the identity function, making the training process easier.
- is the reconstructed output image.
- and are the weights and biases of the decoder convolutional layers.
- h is the encoded feature map from the encoder.
- is the activation function (e.g., ReLU).
- x is the input image,
- are the weights of the convolutional layers,
- are the biases corresponding to each convolutional layer,
- ∗ represents the convolution operation,
- is the activation function (e.g., ReLU),
- are the feature maps produced at each layer.
- represents the compact representation of the input image,
- and are the weights and biases of the bottleneck layer,
- ∗ represents the convolution operation.
- is the reconstructed output image,
- and are the weights and biases of the decoder convolutional layers,
- is the compressed feature map,
- is the activation function (e.g., ReLU).
5. Experiments and Results
5.1. Experiments Setup
5.1.1. Models Setup
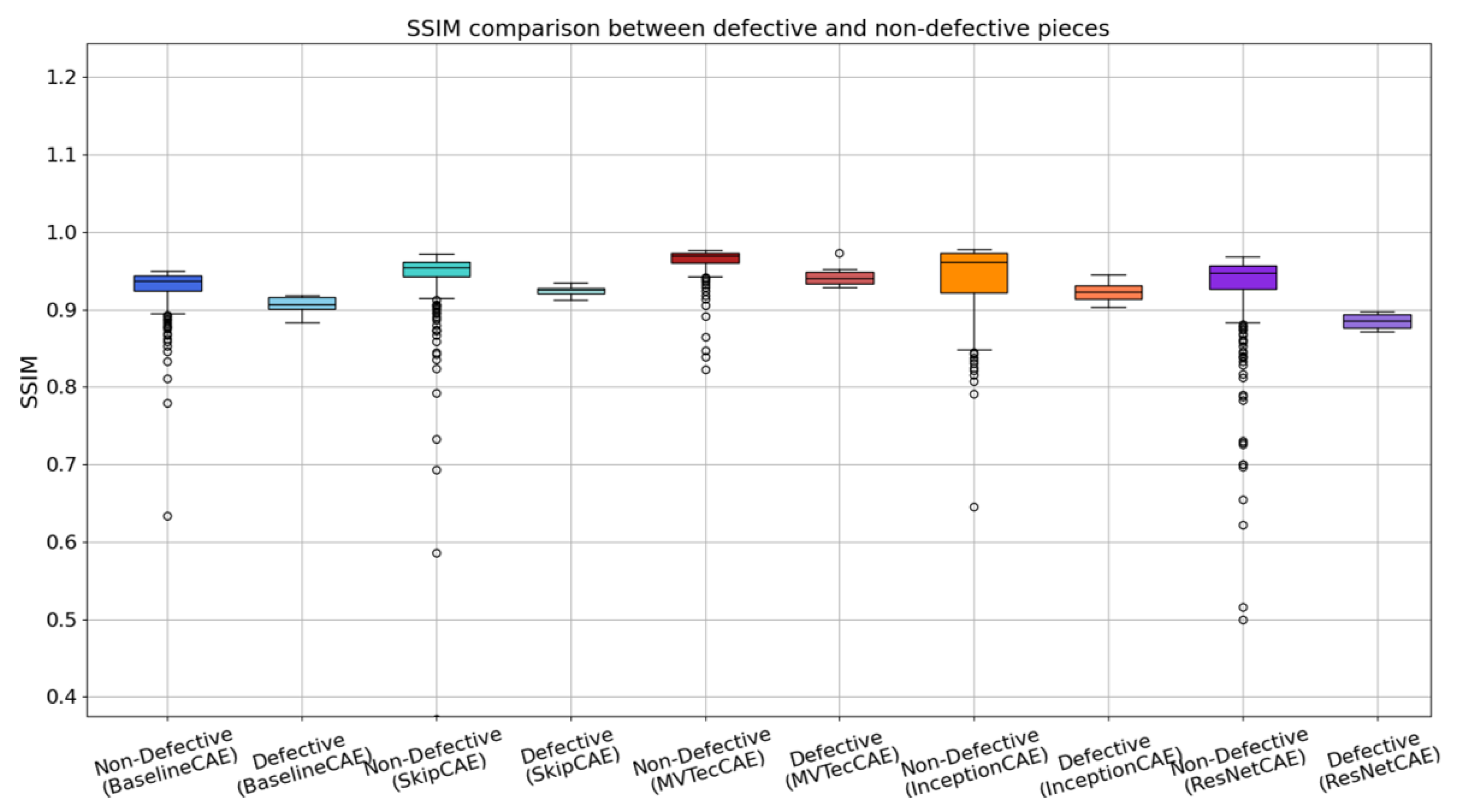
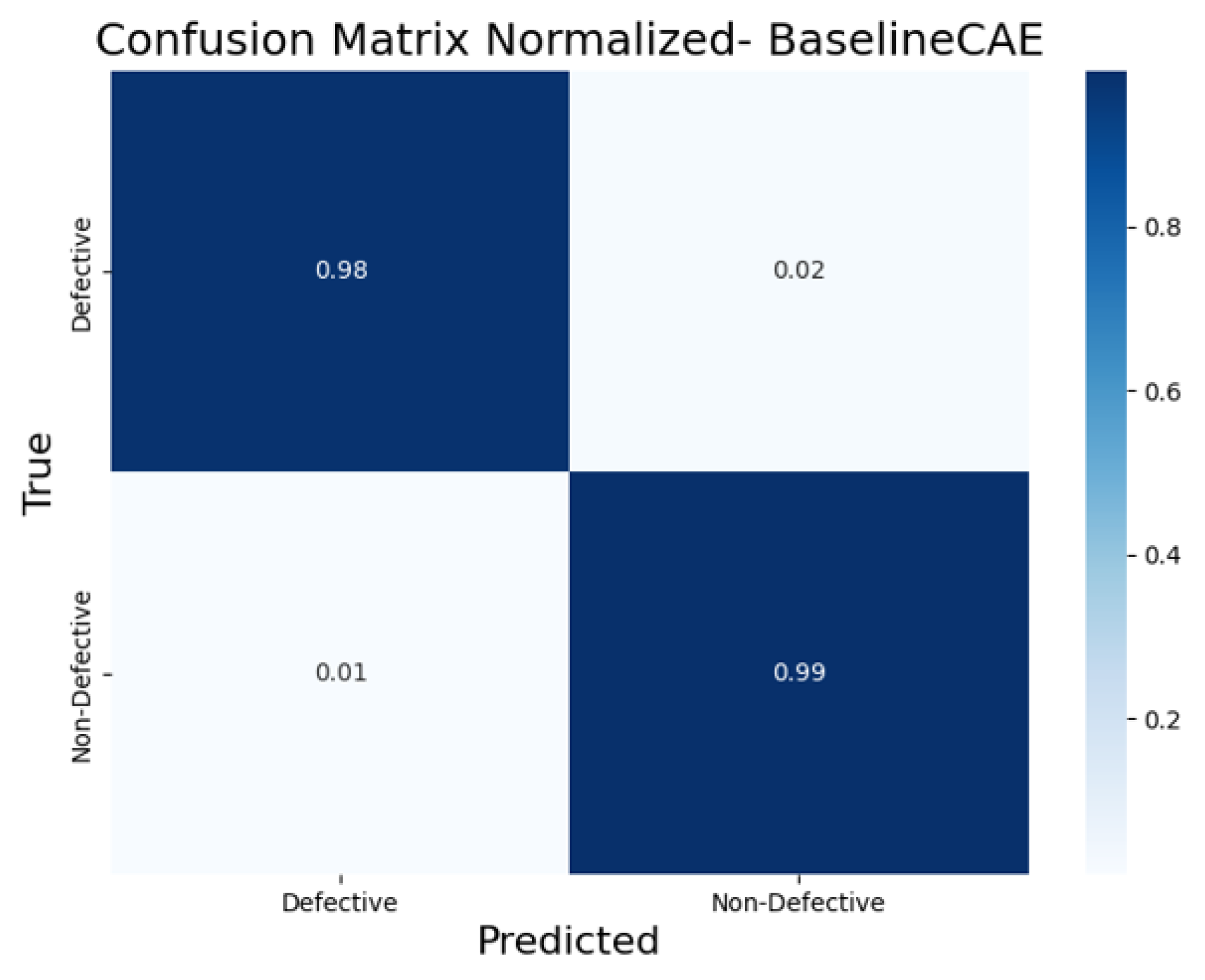
5.1.2. Evaluation Metrics
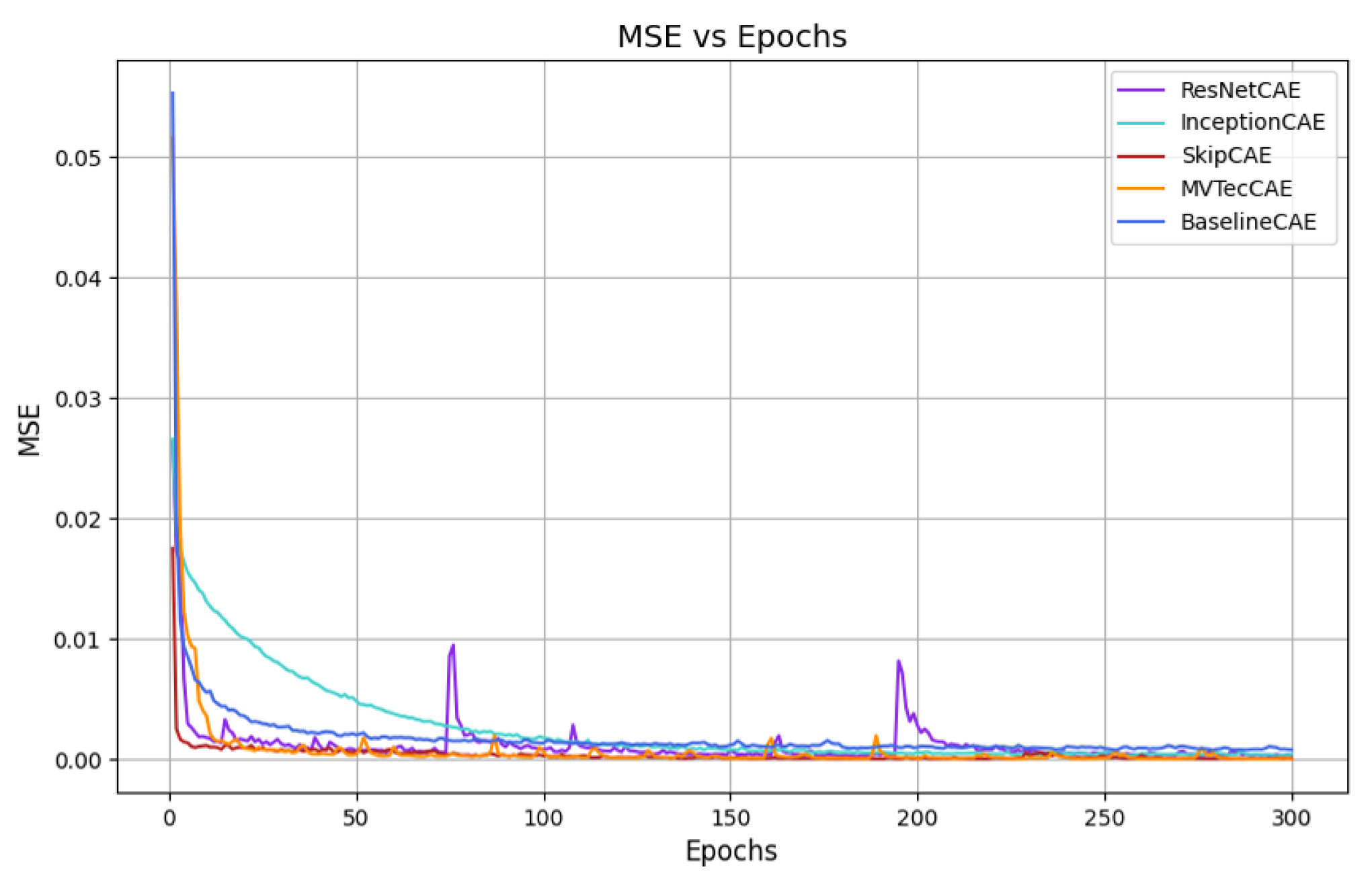
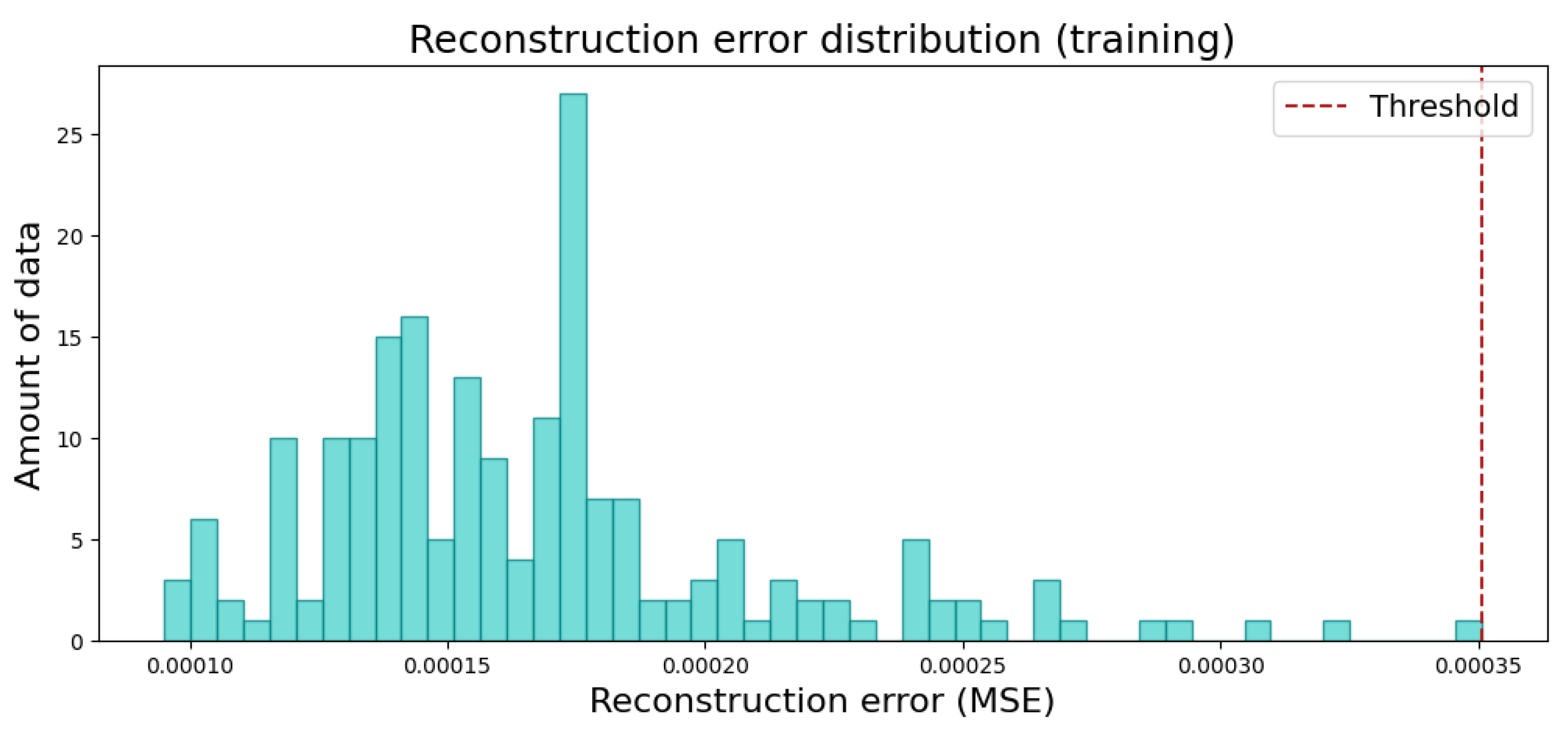
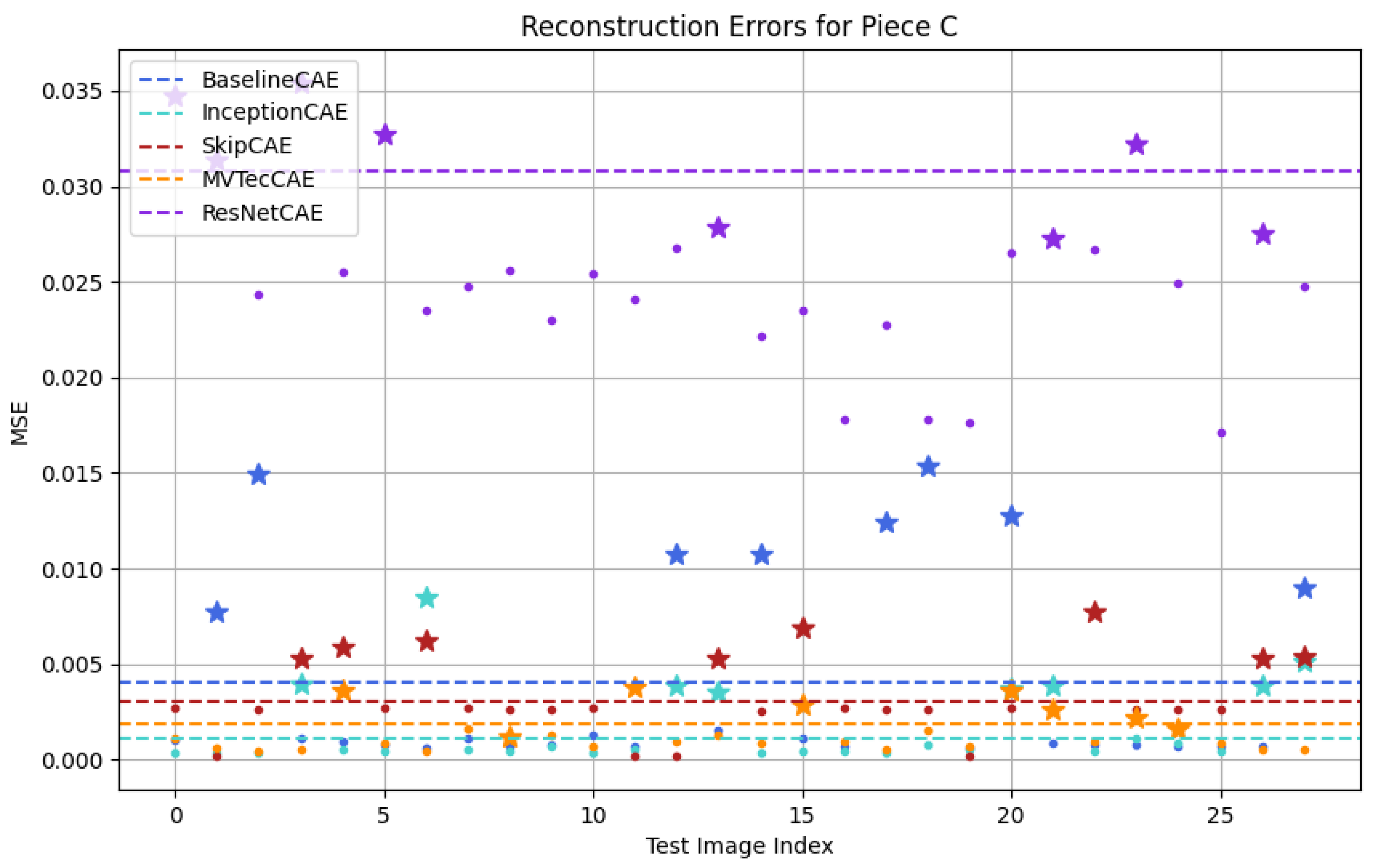
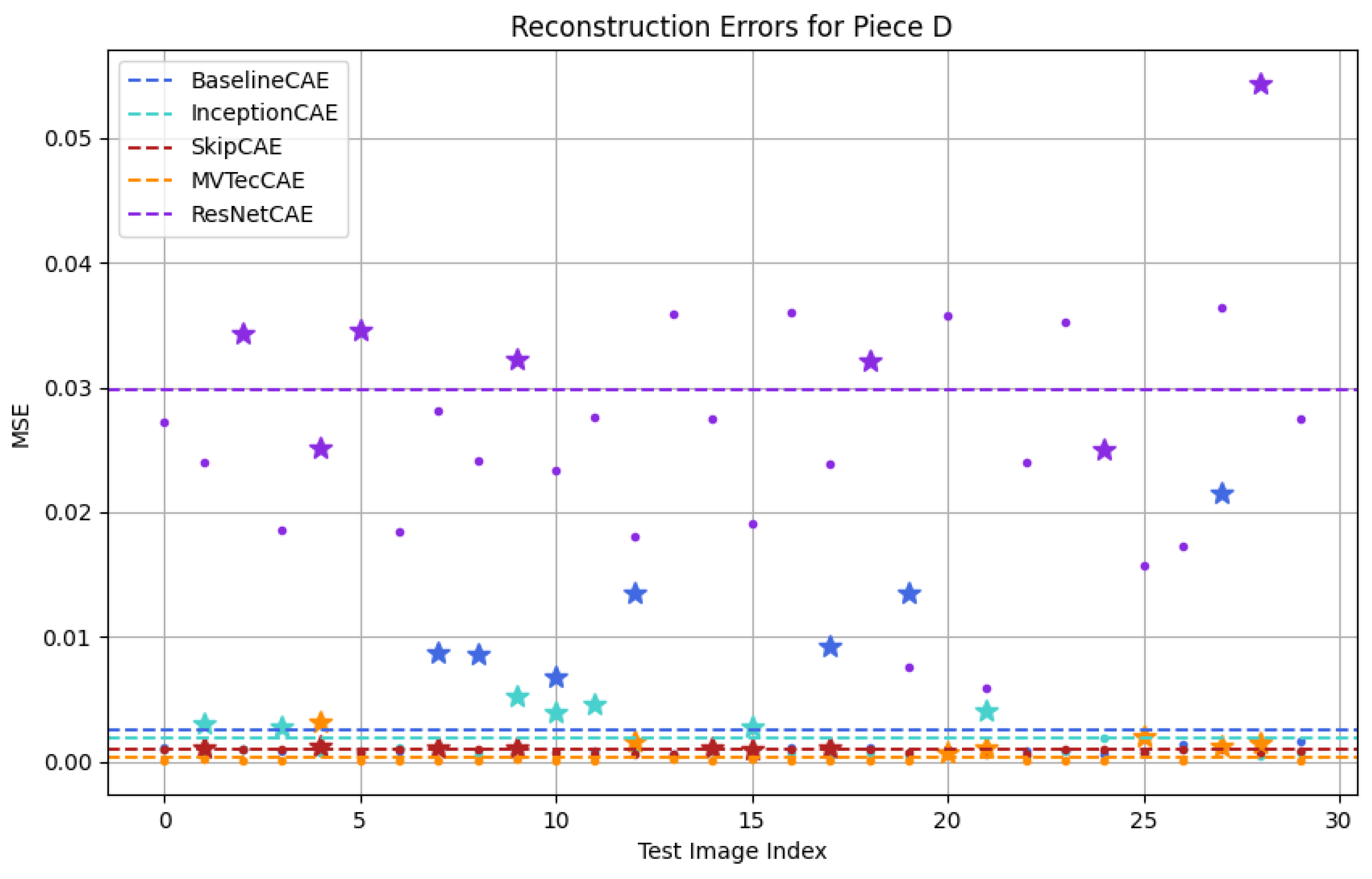
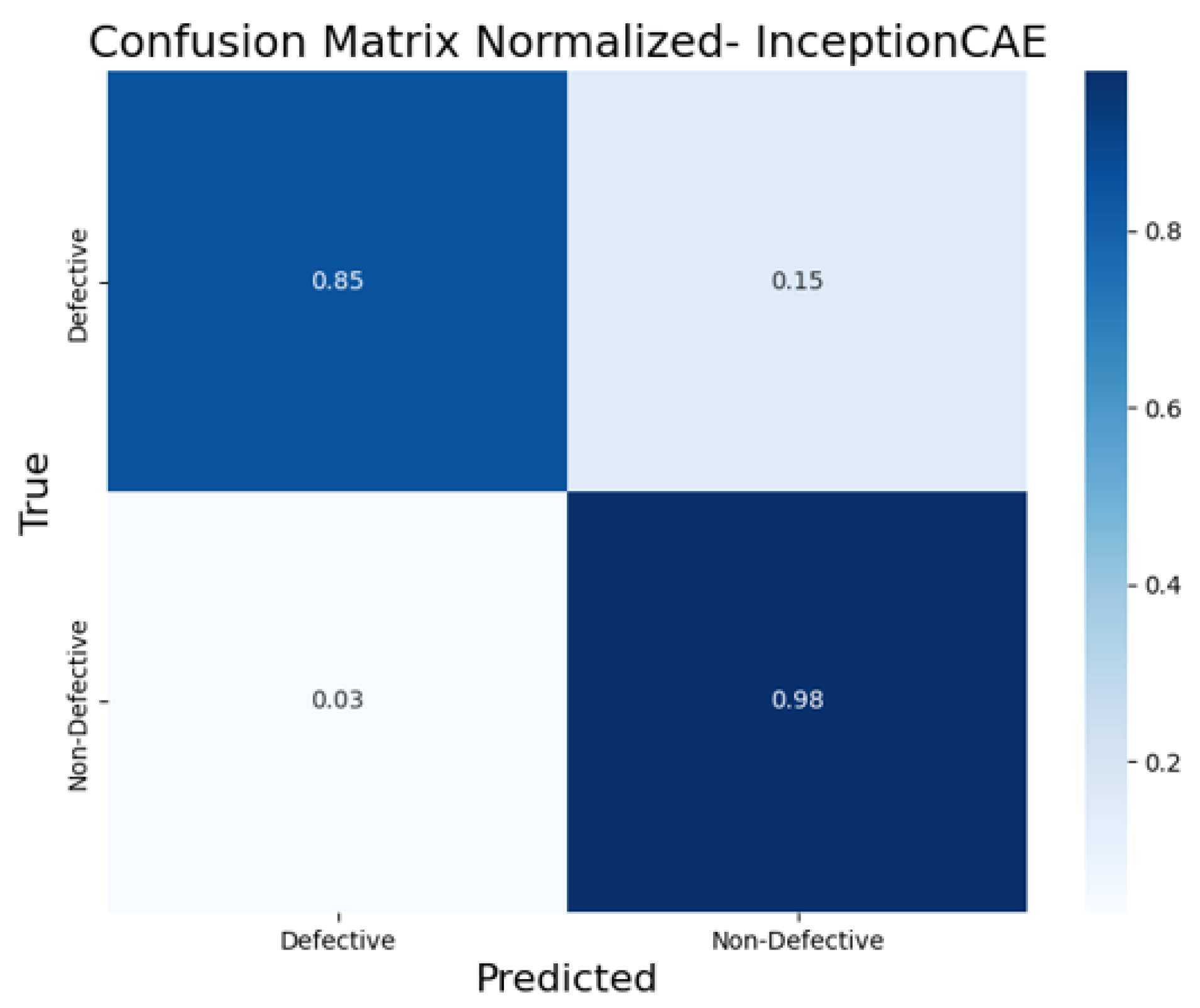
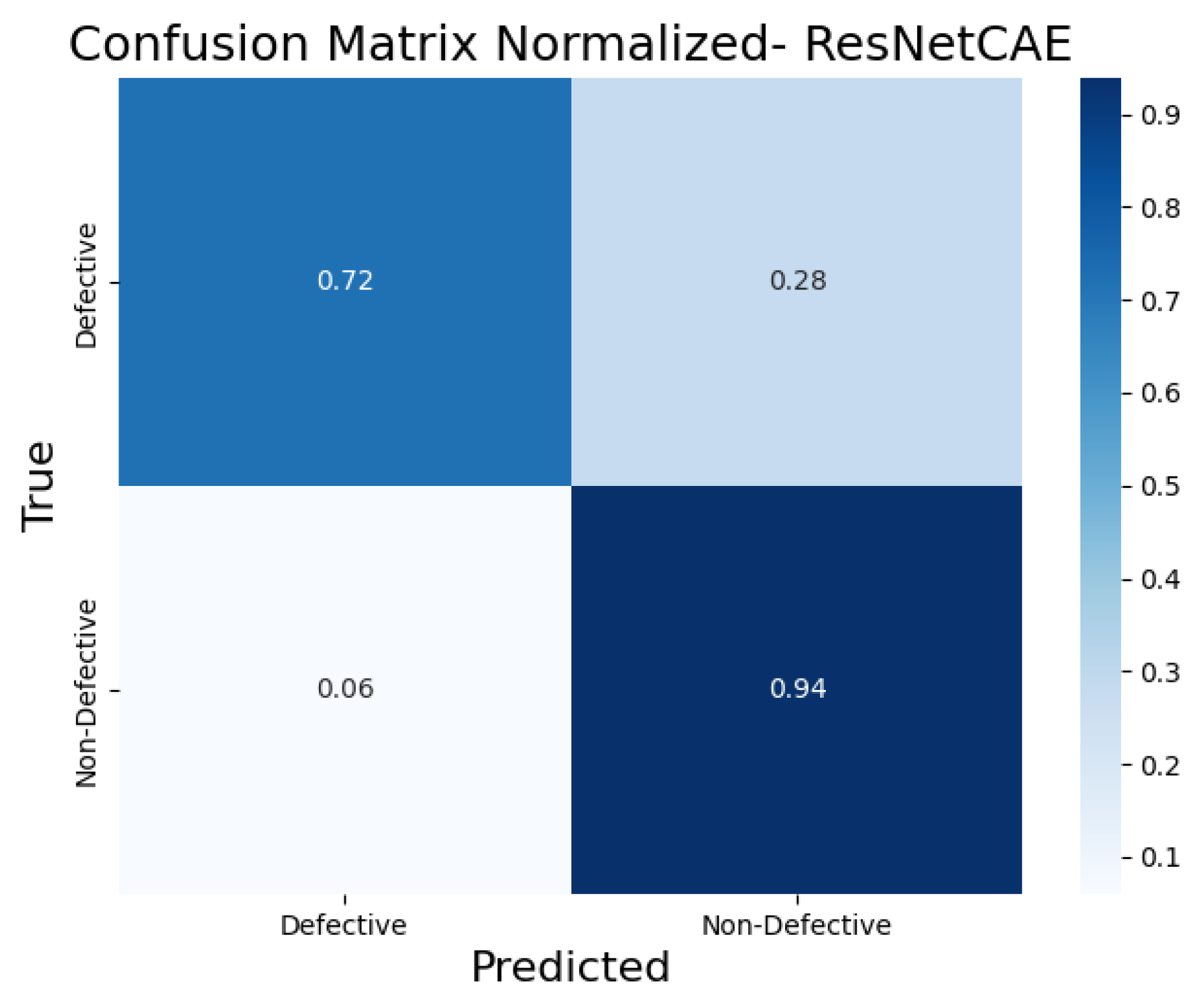
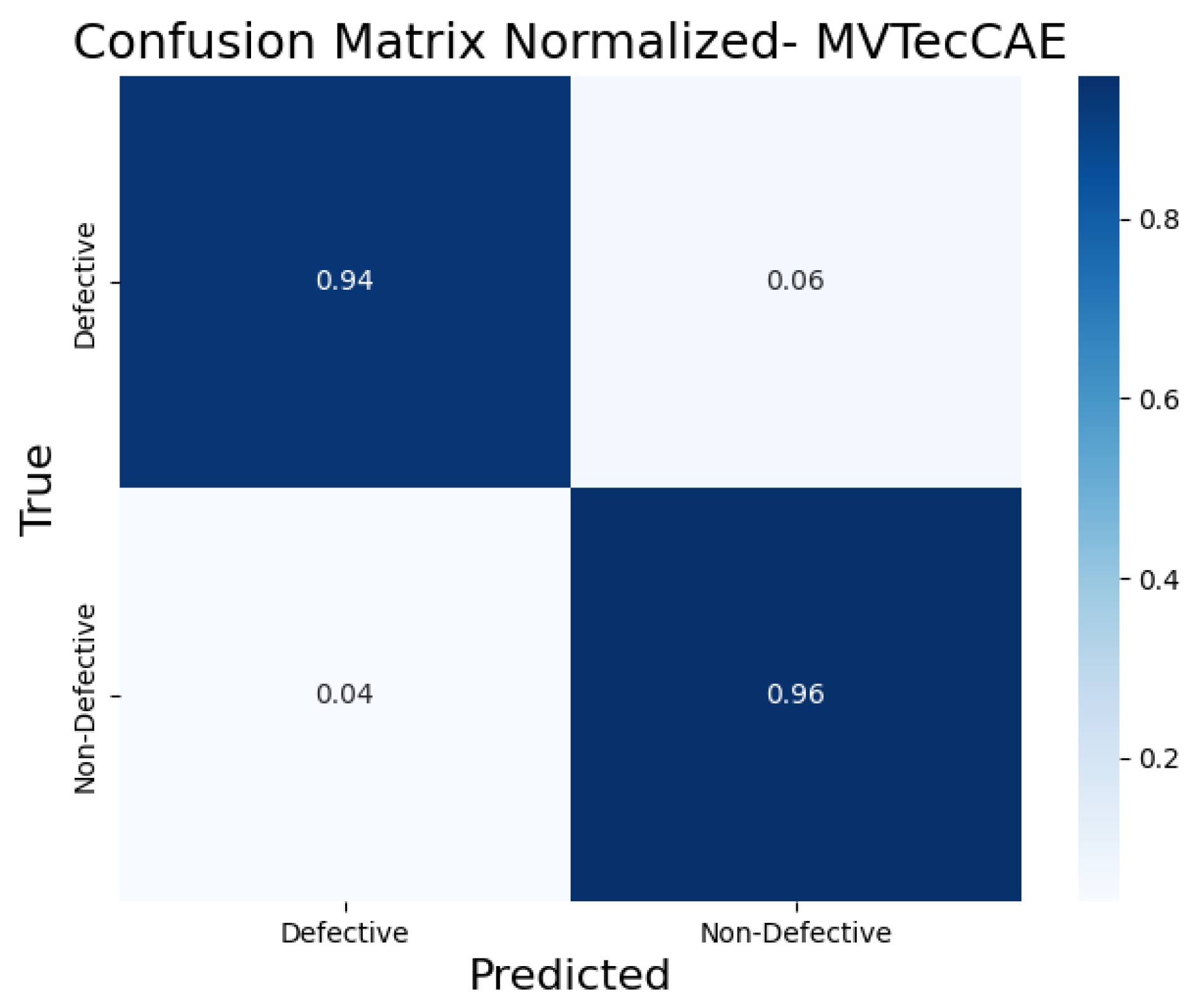
5.2. Results and Analysis
6. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhao, S.; Zhang, X. Did digitalization of manufacturing industry improved the carbon emission efficiency of exports: Evidence from China. Energy Strategy Rev. 2025, 57, 101614. [Google Scholar] [CrossRef]
- Lu, D.; Hui, E.C.M.; Shen, J.; Shi, J. Digital industry agglomeration and urban innovation: Evidence from China. Econ. Anal. Policy 2024, 84, 1998–2025. [Google Scholar] [CrossRef]
- Marti, L.; Puertas, R. Analysis of European competitiveness based on its innovative capacity and digitalization level. Technol. Soc. 2023, 72, 102206. [Google Scholar] [CrossRef]
- Bertagna, S.; Braidotti, L.; Bucci, V.; Marinò, A. Laser Scanning Application for the Enhancement of Quality Assessment in Shipbuilding Industry. Procedia Comput. Sci. 2024, 232, 1289–1298. [Google Scholar] [CrossRef]
- Wang, H.; Guo, Y.; Liang, X.; Yi, H. A function-oriented quality control method for shipbuilding. Ships Offshore Struct. 2019, 14, 220–228. [Google Scholar] [CrossRef]
- Yi, Z.; Mi, S.; Tong, T.; Li, H.; Lin, Y.; Wang, W.; Li, J. Intelligent initial model and case design analysis of smart factory for shipyard in China. Eng. Appl. Artif. Intell. 2023, 123, 106426. [Google Scholar] [CrossRef]
- Salonen, A.; Gabrielsson, M.; Al-Obaidi, Z. Systems sales as a competitive response to the Asian challenge: Case of a global ship power supplier. Ind. Mark. Manag. 2006, 35, 740–750. [Google Scholar] [CrossRef]
- Mickeviciene, R. Global competition in shipbuilding: Trends and challenges for Europe. In The Economic Geography of Globalization; IntechOpen: London, UK, 2011; pp. 201–222. [Google Scholar]
- Valero, E.; Forster, A.; Bosché, F.; Hyslop, E.; Wilson, L.; Turmel, A. Automated defect detection and classification in ashlar masonry walls using machine learning. Autom. Constr. 2019, 106, 102846. [Google Scholar] [CrossRef]
- Muzakir, M.; Ayob, A.; Irawan, H.; Pamungkas, I.; Pandria, T.; Fitriadi, F.; Hadi, K.; Amri, A.; Syarifuddin, S. Defect analysis to improve quality of traditional shipbuilding processes in West Aceh District, Indonesia. AIP Conf. Proc. 2023, 2484, 020004. [Google Scholar]
- Ma, H.; Lee, S. Smart system to detect painting defects in shipyards: Vision AI and a deep-learning approach. Appl. Sci. 2022, 12, 2412. [Google Scholar] [CrossRef]
- Hwang, H.G.; Kim, B.S.; Woo, Y.T.; Yoon, Y.W.; Shin, S.c.; Oh, S.j. A Development of Welding Information Management and Defect Inspection Platform based on Artificial Intelligent for Shipbuilding and Maritime Industry. J. Korea Inst. Inf. Commun. Eng. 2021, 25, 193–201. [Google Scholar]
- Liu, K.; Zheng, M.; Liu, Y.; Yang, J.; Yao, Y. Deep autoencoder thermography for defect detection of carbon fiber composites. IEEE Trans. Ind. Inform. 2022, 19, 6429–6438. [Google Scholar] [CrossRef]
- Liu, K.; Yu, Q.; Liu, Y.; Yang, J.; Yao, Y. Convolutional graph thermography for subsurface defect detection in polymer composites. IEEE Trans. Instrum. Meas. 2022, 71, 4506411. [Google Scholar] [CrossRef]
- Lu, F.; Tong, Q.; Jiang, X.; Du, X.; Xu, J.; Huo, J. Prior knowledge embedding convolutional autoencoder: A single-source domain generalized fault diagnosis framework under small samples. Comput. Ind. 2025, 164, 104169. [Google Scholar] [CrossRef]
- John, L.S.; Yoon, S.; Li, J.; Wang, P. Anomaly Detection Using Convolutional Autoencoder with Residual Gated Recurrent Unit and Weak Supervision for Photovoltaic Thermal Heat Pump System. J. Build. Eng. 2025, 100, 111694. [Google Scholar] [CrossRef]
- Almotiri, J.; Elleithy, K.; Elleithy, A. Comparison of autoencoder and principal component analysis followed by neural network for e-learning using handwritten recognition. In Proceedings of the 2017 IEEE Long Island Systems, Applications and Technology Conference (LISAT), Farmingdale, NY, USA, 5 May 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–5. [Google Scholar]
- Maggipinto, M.; Masiero, C.; Beghi, A.; Susto, G.A. A Convolutional Autoencoder Approach for Feature Extraction in Virtual Metrology. Procedia Manuf. 2018, 17, 126–133. [Google Scholar] [CrossRef]
- Cheng, Z.; Sun, H.; Takeuchi, M.; Katto, J. Deep Convolutional AutoEncoder-based Lossy Image Compression. In Proceedings of the 2018 Picture Coding Symposium (PCS), San Francisco, CA, USA, 24–27 June 2018; pp. 253–257. [Google Scholar] [CrossRef]
- Zhang, Y. A better autoencoder for image: Convolutional autoencoder. In Proceedings of the ICONIP17-DCEC, Guangzhou, China, 14–18 October 2017; Available online: https://users.cecs.anu.edu.au/~Tom.Gedeon/conf/ABCs2018/paper/ABCs2018_paper_58.pdf (accessed on 23 March 2017).
- Davila Delgado, J.M.; Oyedele, L. Deep learning with small datasets: Using autoencoders to address limited datasets in construction management. Appl. Soft Comput. 2021, 112, 107836. [Google Scholar] [CrossRef]
- Xu, Q.; Rong, J.; Zeng, Q.; Yuan, X.; Huang, L.; Yang, H. From data to dynamics: Reconstructing soliton collision phenomena in optical fibers using a convolutional autoencoder. Results Phys. 2024, 67, 108027. [Google Scholar] [CrossRef]
- Li, P.; Pei, Y.; Li, J. A comprehensive survey on design and application of autoencoder in deep learning. Appl. Soft Comput. 2023, 138, 110176. [Google Scholar] [CrossRef]
- Azarang, A.; Manoochehri, H.E.; Kehtarnavaz, N. Convolutional Autoencoder-Based Multispectral Image Fusion. IEEE Access 2019, 7, 35673–35683. [Google Scholar] [CrossRef]
- Zhang, Y.; Xu, C.; Liu, P.; Xie, J.; Han, Y.; Liu, R.; Chen, L. One-dimensional deep convolutional autoencoder active infrared thermography: Enhanced visualization of internal defects in FRP composites. Compos. Part B Eng. 2024, 272, 111216. [Google Scholar] [CrossRef]
- Ruff, L.; Vandermeulen, R.; Goernitz, N.; Deecke, L.; Siddiqui, S.A.; Binder, A.; Müller, E.; Kloft, M. Deep one-class classification. In Proceedings of the International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 4393–4402. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Mao, X.J. Image restoration using convolutional auto-encoders with symmetric skip connections. arXiv 2016, arXiv:1606.08921. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Bergmann, P.; Fauser, M.; Sattlegger, D.; Steger, C. MVTec AD—A comprehensive real-world dataset for unsupervised anomaly detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9592–9600. [Google Scholar]
- Sarafijanovic-Djukic, N.; Davis, J. Fast Distance-based Anomaly Detection in Images Using an Inception-like Autoencoder. arXiv 2020, arXiv:2003.08731. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| BaselineCAE | InceptionCAE | SkipCAE | ResNetCAE | MVTecCAE | |
|---|---|---|---|---|---|
| Piece A | 0.0027 | 0.0031 | 0.0004 | 0.0183 | 0.0002 |
| Piece B | 0.0032 | 0.0021 | 0.0061 | 0.0067 | 0.0008 |
| Piece C | 0.0041 | 0.0011 | 0.0031 | 0.0308 | 0.0019 |
| Piece D | 0.0026 | 0.0018 | 0.0011 | 0.0298 | 0.0004 |
| Average Training Time | Trainable Parameters | Non-Trainable Parameters | Computational Load (GPU VRAM) | |
|---|---|---|---|---|
| BaselineCAE | 922.45 s | 2,496,931 | 800 | 5.3 GB |
| InceptionCAE | 1684.09 s | 11,519,241 | 7174 | 6.2 GB |
| SkipCAE | 893.79 | 3,057,635 | 384 | 5.1 GB |
| ResNetCAE | 8529.74 | 34,935,427 | 56,960 | 7.9 GB |
| MVTecCAE | 3616.23 s | 751,332 | 0 | 5.4 GB |
| Aspect | Specification | Limitation |
|---|---|---|
| Dataset | Dataset consists of 4 piece types: 2 simple sub-assemblies and 2 minor sub-assemblies. | Dataset limited to these 4 types |
| Computational Resources | Training conducted on Nvidia RTX 4070 Ti | Training with other GPUs with less powerful hardware could affect training time |
| Generalizability | Results validated on the selected dataset. | Different dataset were not tested |
| Industrial Context | Data augmentation techniques were used to simulate a range of scenarios. | Industrial environments are complex and dynamic, there could be unforeseen scenarios. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Arcano-Bea, P.; Rubiños, M.; García-Fischer, A.; Zayas-Gato, F.; Calvo-Rolle, J.L.; Jove, E. Defect Detection for Enhanced Traceability in Naval Construction. Sensors 2025, 25, 1077. https://doi.org/10.3390/s25041077
Arcano-Bea P, Rubiños M, García-Fischer A, Zayas-Gato F, Calvo-Rolle JL, Jove E. Defect Detection for Enhanced Traceability in Naval Construction. Sensors. 2025; 25(4):1077. https://doi.org/10.3390/s25041077
Chicago/Turabian StyleArcano-Bea, Paula, Manuel Rubiños, Agustín García-Fischer, Francisco Zayas-Gato, José Luis Calvo-Rolle, and Esteban Jove. 2025. "Defect Detection for Enhanced Traceability in Naval Construction" Sensors 25, no. 4: 1077. https://doi.org/10.3390/s25041077
APA StyleArcano-Bea, P., Rubiños, M., García-Fischer, A., Zayas-Gato, F., Calvo-Rolle, J. L., & Jove, E. (2025). Defect Detection for Enhanced Traceability in Naval Construction. Sensors, 25(4), 1077. https://doi.org/10.3390/s25041077