
An Artificial Intelligence Model for Sensing Affective Valence and Arousal from Facial Images



Abstract
:1. Introduction
2. Model Development
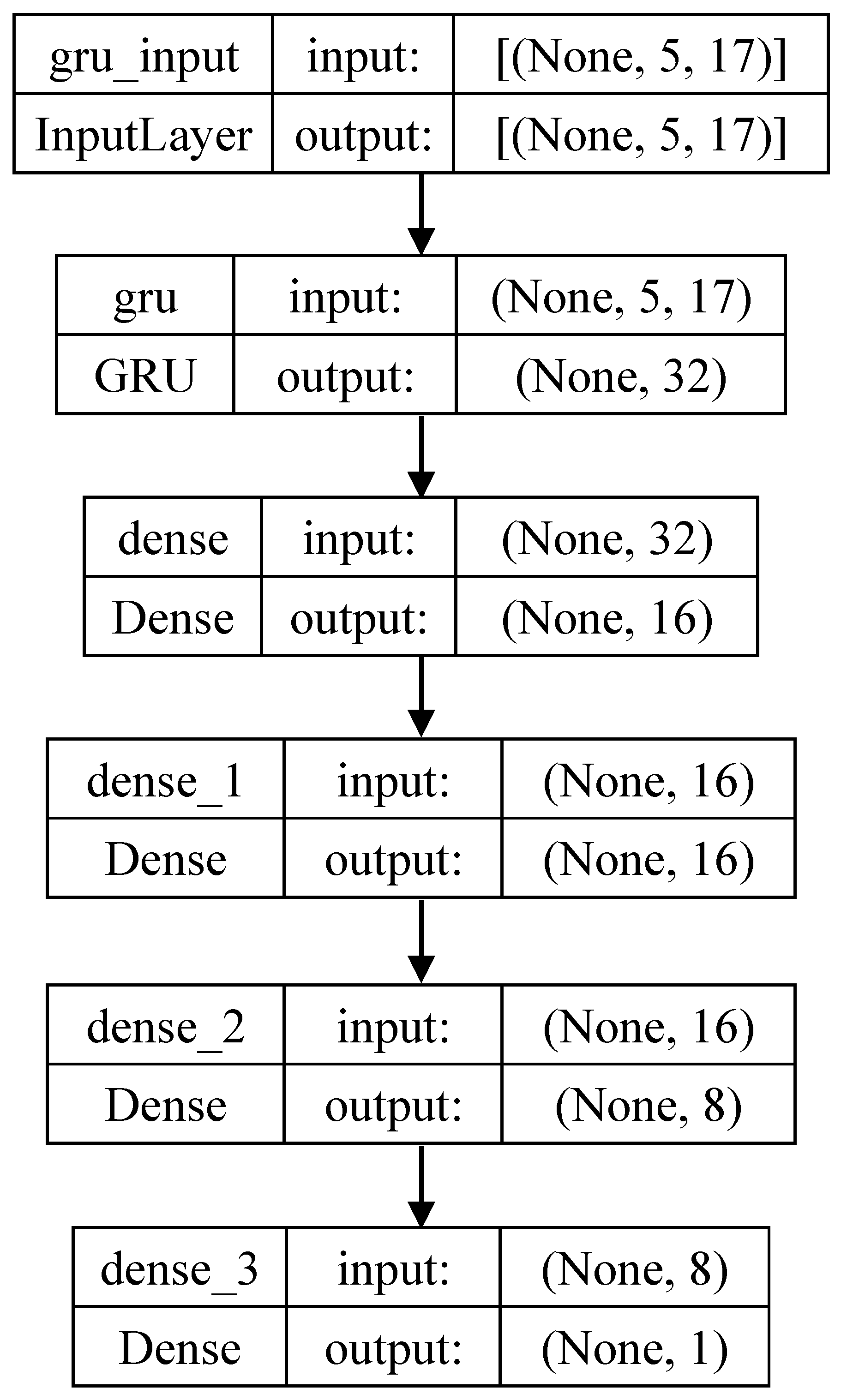
2.1. Model
2.2. Dataset
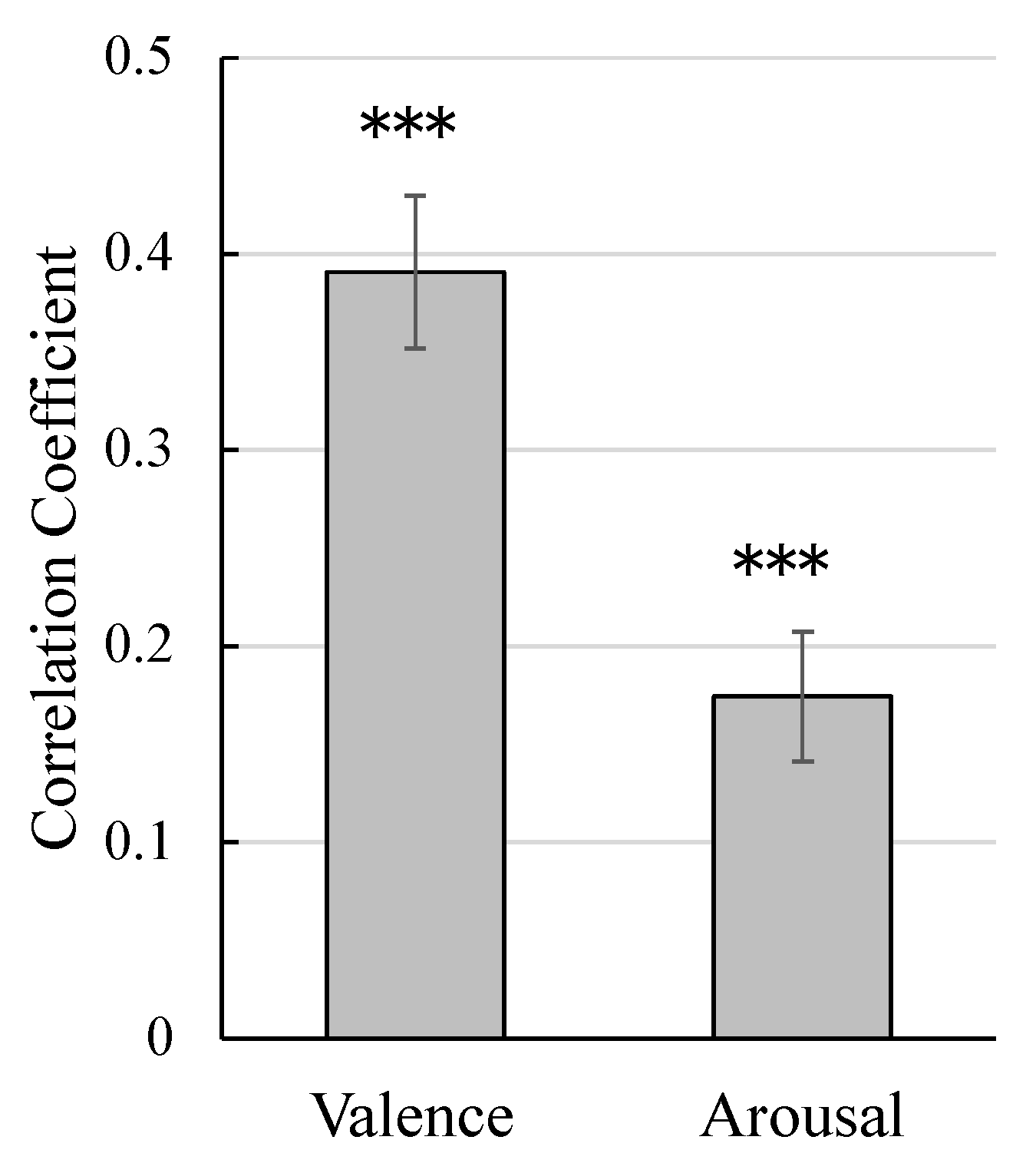
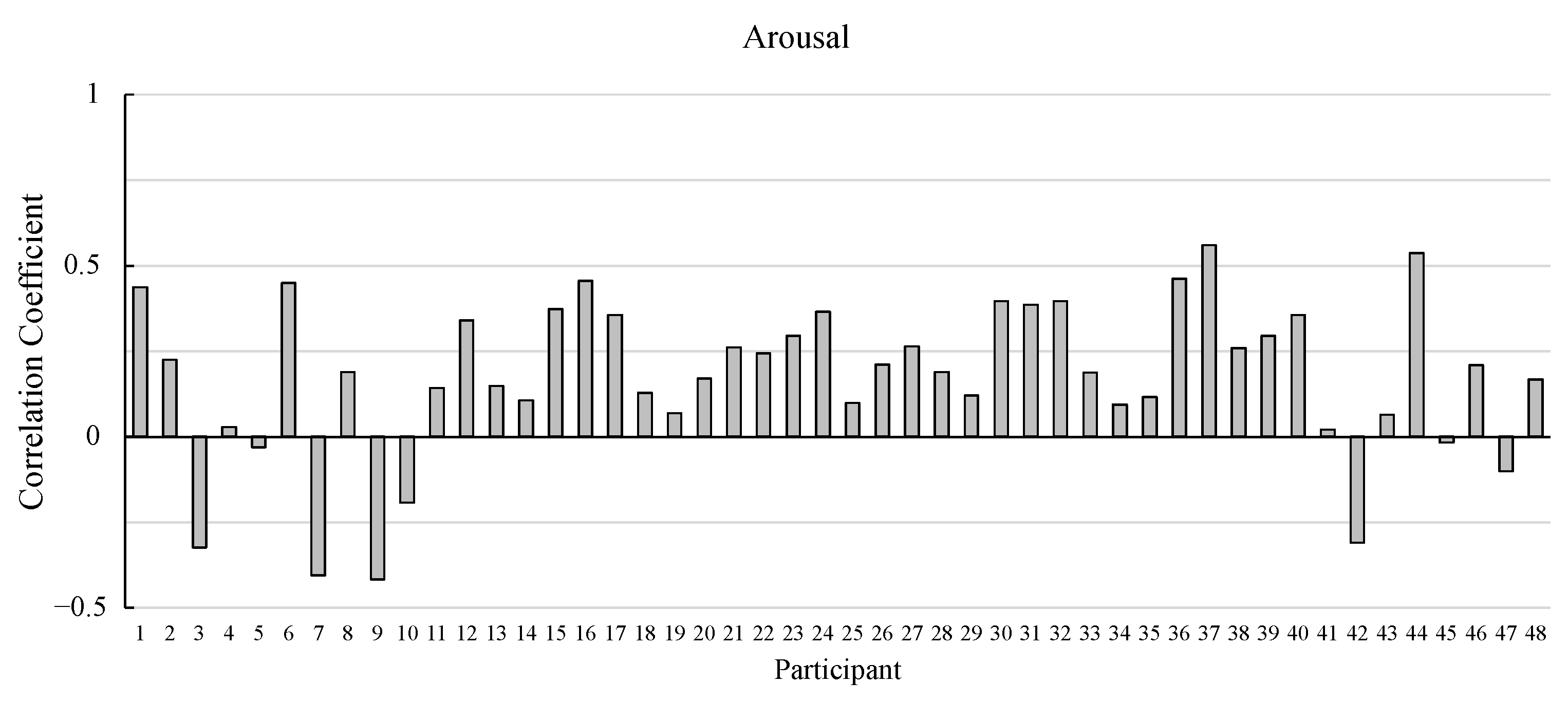
2.3. Cross-Validation Performance
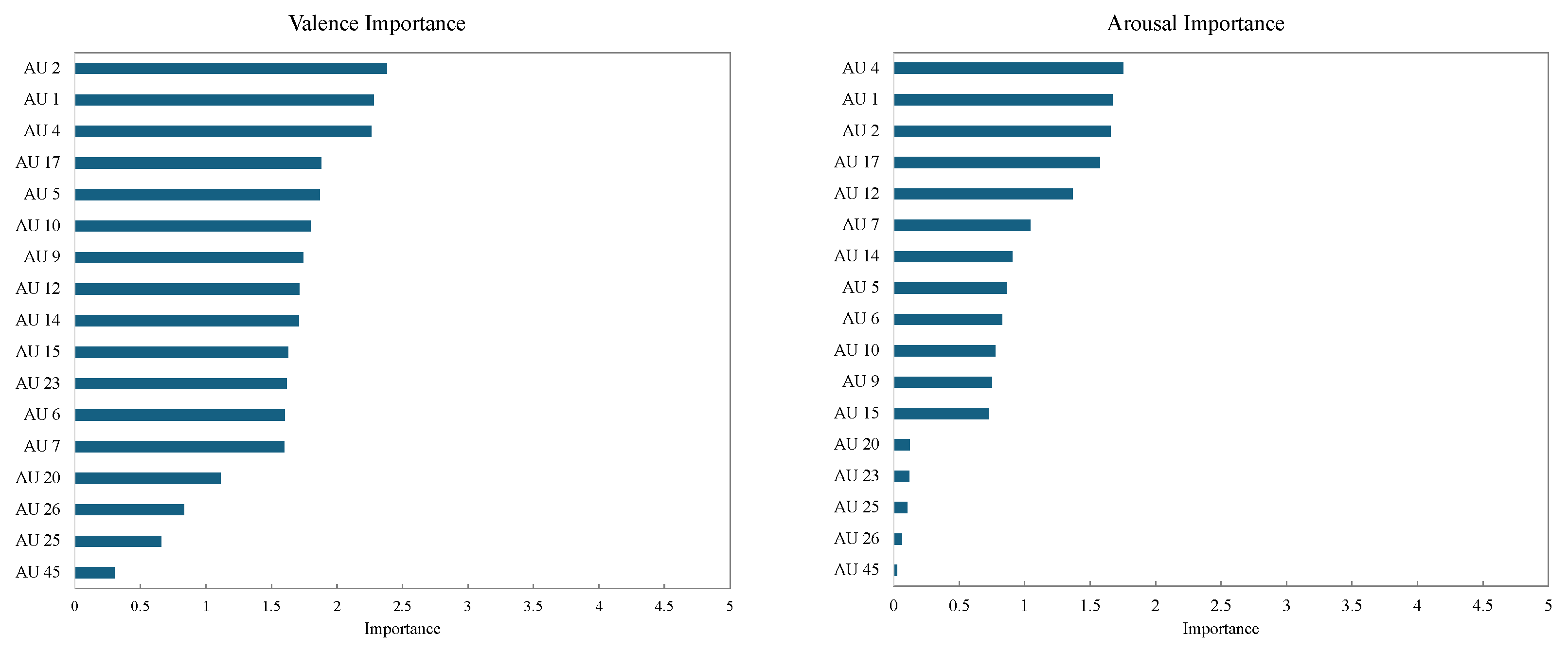
2.4. Feature Importance Analysis for Valence and Arousal Estimation
3. Experiment
3.1. Dataset
3.2. Experimental Settings
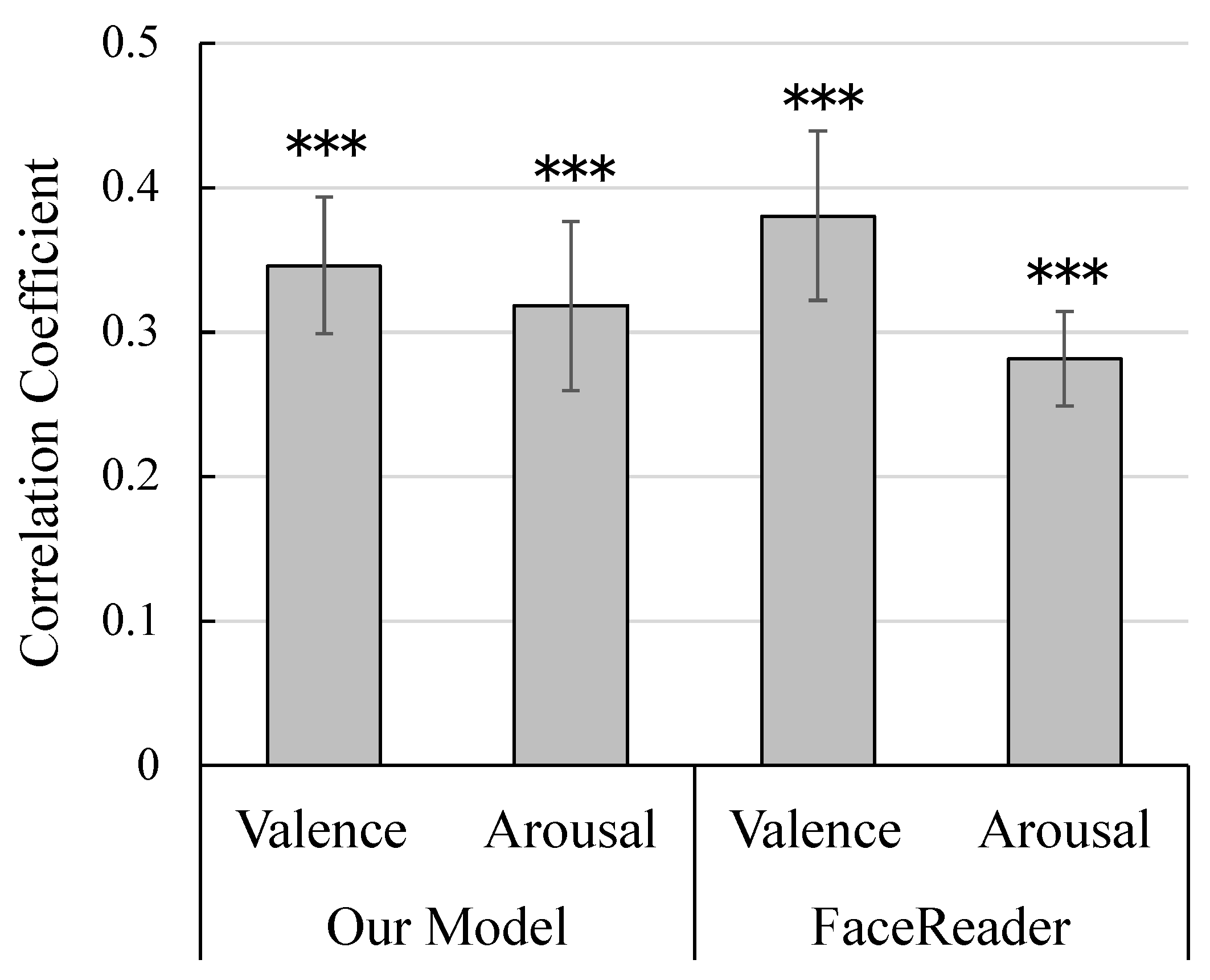
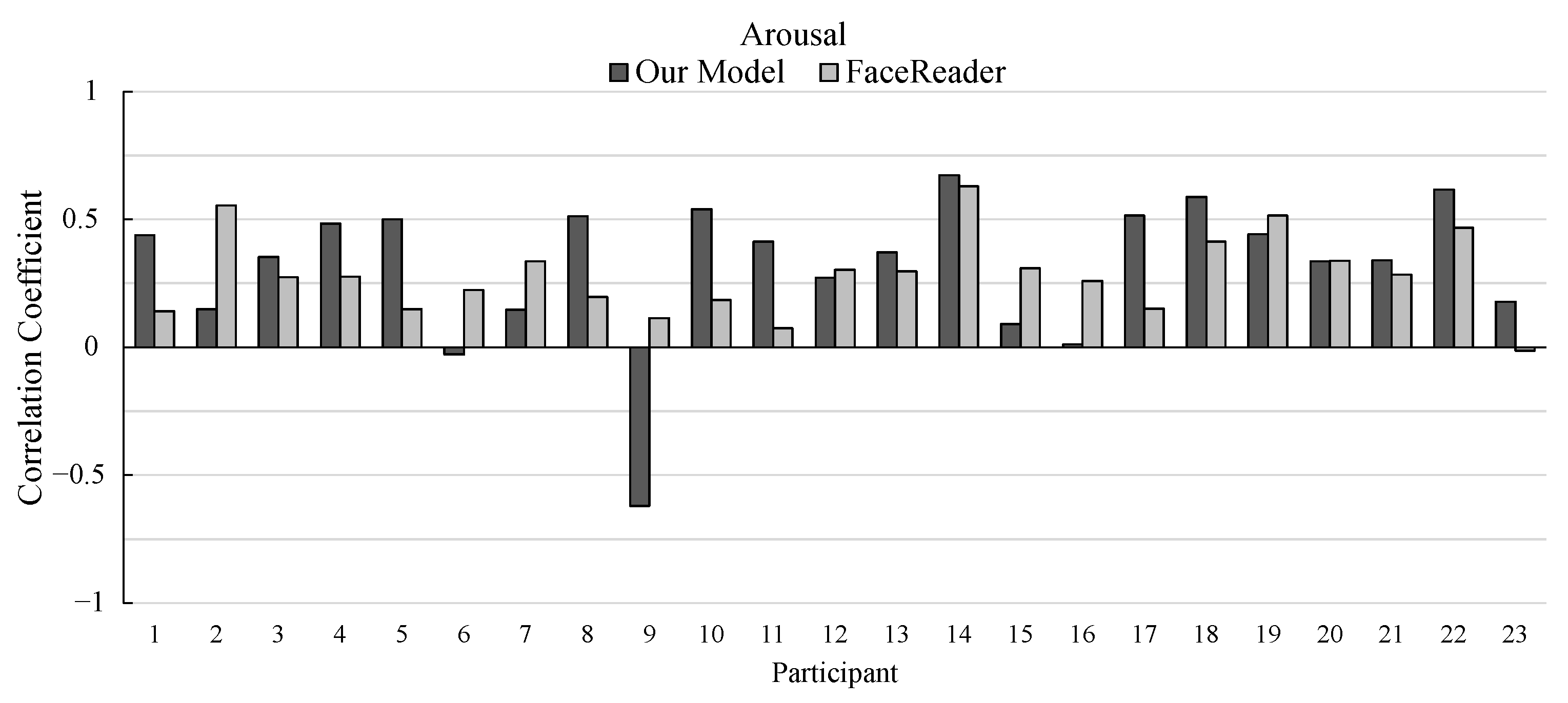
3.3. Results
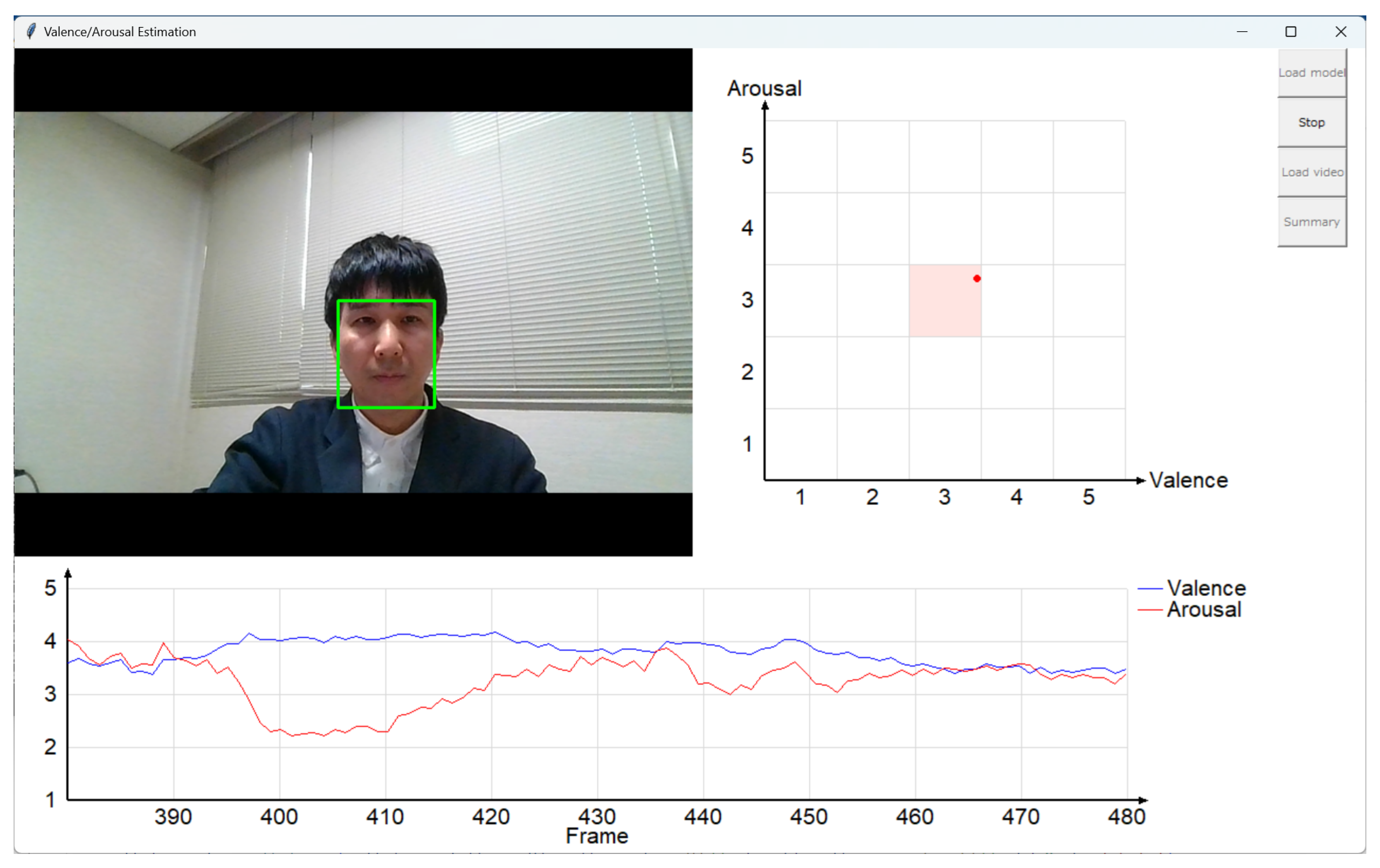
4. Application
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lyubomirsky, S. Why are some people happier than others? The role of cognitive and motivational processes in well-being. Am. Psychol. 2001, 56, 239–249. [Google Scholar] [CrossRef] [PubMed]
- Meiselman, H.L. A review of the current state of emotion research in product development. Food Res. Int. 2015, 76, 192–199. [Google Scholar] [CrossRef]
- Sato, W. Advancements in sensors and analyses for emotion sensing. Sensors 2024, 24, 4166. [Google Scholar] [CrossRef]
- Namba, S.; Sato, W.; Namba, S.; Nomiya, H.; Shimokawa, K.; Osumi, M. Development of the RIKEN database for dynamic facial expressions with multiple angles. Sci. Rep. 2023, 13, 21785. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Sato, W.; Kawamura, N.; Shimokawa, K.; Tang, B.; Nakamura, Y. Sensing emotional valence and arousal dynamics through automated facial action unit analysis. Sci. Rep. 2024, 14, 19563. [Google Scholar] [CrossRef] [PubMed]
- Ekman, P.; Friesen, W.V.; Hager, J.C. Facial Action Coding System, 2nd ed.; Research Nexus: Charleston, SC, USA, 2002. [Google Scholar]
- Ekman, P. Universals and cultural differences in facial expressions of emotion. In Nebraska Symposium on Motivation 1971; Cole, J.K., Ed.; University of Nebraska Press: Lincoln, NE, USA, 1971; pp. 207–283. [Google Scholar]
- Durán, J.I.; Reisenzein, R.; Fernández-Dols, J.-M. Coherence between emotions and facial expressions: A research synthesis. In The Science of Facial Expression; Fernández-Dols, J.-M., Russell, J.A., Eds.; Oxford University Press: New York, NY, USA, 2017; pp. 107–129. [Google Scholar]
- Fernández-Dols, J.-M.; Crivelli, C. Emotion and expression: Naturalistic studies. Emot. Rev. 2013, 5, 24–29. [Google Scholar] [CrossRef]
- Reisenzein, R.; Studtmann, M.; Horstmann, G. Coherence between emotion and facial expression: Evidence from laboratory experiments. Emot. Rev. 2013, 5, 16–23. [Google Scholar] [CrossRef]
- Barrett, L.F.; Adolphs, R.; Marsella, S.; Martinez, A.M.; Pollak, S.D. Emotional expressions reconsidered: Challenges to infer-ring emotion from human facial movements. Perspect. Psychol. Sci. 2019, 20, 1–68. [Google Scholar] [CrossRef] [PubMed]
- Dupré, D.; Krumhuber, E.G.; Küster, D.; McKeown, G.J. A performance comparison of eight commercially available auto-matic classifiers for facial affect recognition. PLoS ONE 2020, 15, e0231968. [Google Scholar] [CrossRef] [PubMed]
- Loijens, L.; Krips, O. FaceReader Methodology Note; Noldus Information Technology: Wageningen, The Netherlands, 2019. [Google Scholar]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Kauai, HI, USA, 8–14 December 2001; pp. 183–195. [Google Scholar]
- Cootes, T.; Taylor, C. Statistical Models of Appearance for Computer Vision; University of Manchester: Manchester, UK, 2000. [Google Scholar]
- Gudi, A. Recognizing semantic features in faces using deep learning. arXiv 2015, arXiv:1512.00743. [Google Scholar]
- van Kuilenburg, H.; Wiering, M.; den Uyl, M. A model-based method for facial expression recognition. In Machine Learning: ECML 2005, Proceedings of the 16th European Conference on Machine Learning, Porto, Portugal, 3–7 October 2005; Gama, J., Camacho, R., Brazdil, P., Jorge, A., Torgo, L., Eds.; Lectures Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2005; Volume 3720, pp. 194–205. [Google Scholar]
- Lewinski, P.; den Uyl, T.M.; Butler, C. Automated facial coding: Validation of basic emotions and FACS AUs in FaceReader. J. Neurosci. Psychol. Econ. 2014, 7, 227–236. [Google Scholar] [CrossRef]
- Kahneman, D. Thinking, Fast and Slow; Farrar Straus & Giroux: New York, NY, USA, 2011. [Google Scholar]
- Kumfor, F.; Hazelton, J.L.; Rushby, J.A.; Hodges, J.R.; Piguet, O. Facial expressiveness and physiological arousal in fronto-temporal dementia: Phenotypic clinical profiles and neural correlates. Cogn. Affect. Behav. Neurosci. 2019, 19, 197–210. [Google Scholar] [CrossRef] [PubMed]
- Li, S.; Scott, N.; Walters, G. Current and potential methods for measuring emotion in tourism experiences: A review. Curr. Issues Tour. 2015, 18, 805–827. [Google Scholar] [CrossRef]
- Hyniewska, S.; Sato, W.; Kaiser, S.; Pelachaud, S. Naturalistic emotion decoding from facial action sets. Front. Psychol. 2019, 9, 2678. [Google Scholar] [CrossRef] [PubMed]



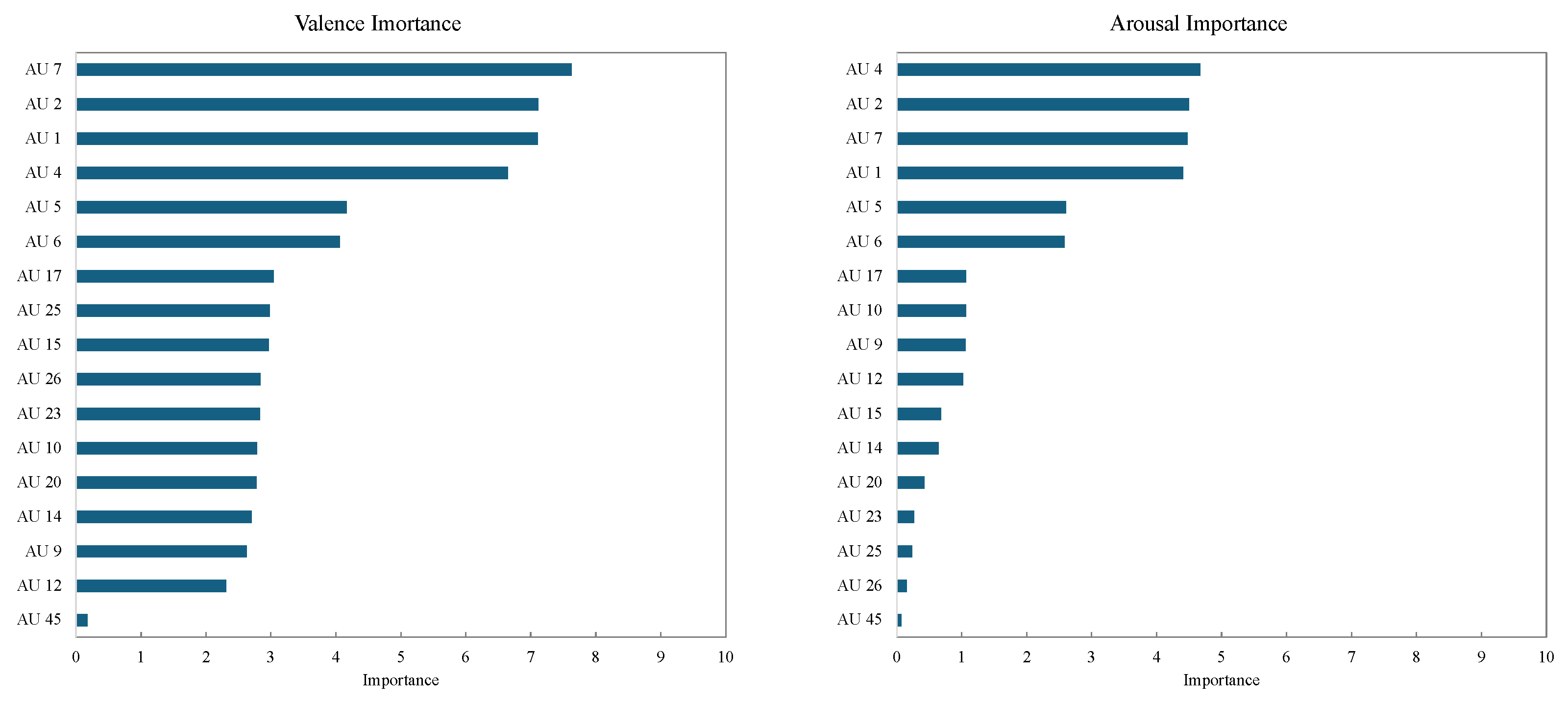


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| AU Number | Description | Image |
|---|---|---|
| 1 | Inner Brow Raiser |  |
| 2 | Outer Brow Raiser |  |
| 4 | Brow Lowerer |  |
| 5 | Upper Lid Raiser |  |
| 6 | Cheek Raiser |  |
| 7 | Lid Tightener |  |
| 9 | Nose Wrinkler |  |
| 10 | Upper Lip Raiser |  |
| 12 | Lip Corner Puller |  |
| 14 | Dimpler |  |
| 15 | Lip Corner Depressor |  |
| 17 | Chin Raiser |  |
| 20 | Lip Stretcher |  |
| 23 | Lip Tightener |  |
| 25 | Lips Part |  |
| 26 | Jaw Drop |  |
| 45 | Blink |  |
| Hyperparameter | Valence Model | Arousal Model |
|---|---|---|
| activation | ReLU | None |
| dropout | 0.530 | 0.680 |
| recurrent_dropout | 0.266 | 0.301 |
| learning_rate | ||
| batch_size | 48 | 32 |
| epochs | 100 | 100 |
| loss | Mean absolute error | Mean absolute error |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nomiya, H.; Shimokawa, K.; Namba, S.; Osumi, M.; Sato, W. An Artificial Intelligence Model for Sensing Affective Valence and Arousal from Facial Images. Sensors 2025, 25, 1188. https://doi.org/10.3390/s25041188
Nomiya H, Shimokawa K, Namba S, Osumi M, Sato W. An Artificial Intelligence Model for Sensing Affective Valence and Arousal from Facial Images. Sensors. 2025; 25(4):1188. https://doi.org/10.3390/s25041188
Chicago/Turabian StyleNomiya, Hiroki, Koh Shimokawa, Shushi Namba, Masaki Osumi, and Wataru Sato. 2025. "An Artificial Intelligence Model for Sensing Affective Valence and Arousal from Facial Images" Sensors 25, no. 4: 1188. https://doi.org/10.3390/s25041188
APA StyleNomiya, H., Shimokawa, K., Namba, S., Osumi, M., & Sato, W. (2025). An Artificial Intelligence Model for Sensing Affective Valence and Arousal from Facial Images. Sensors, 25(4), 1188. https://doi.org/10.3390/s25041188