Abstract
Typical SLAM systems adhere to the assumption of environment rigidity, which limits their functionality when deployed in the dynamic indoor environments commonly encountered by household robots. Prevailing methods address this issue by employing semantic information for the identification and processing of dynamic objects in scenes. However, extracting reliable semantic information remains challenging due to the presence of motion blur. In this paper, a novel visual SLAM algorithm is proposed in which various approaches are integrated to obtain more reliable semantic information, consequently reducing the impact of motion blur on visual SLAM systems. Specifically, to accurately distinguish moving objects and static objects, we introduce a missed segmentation compensation mechanism into our SLAM system for predicting and restoring semantic information, and depth and semantic information is then leveraged to generate masks of dynamic objects. Additionally, to refine keypoint filtering, a probability-based algorithm for dynamic feature detection and elimination is incorporated into our SLAM system. Evaluation experiments using the TUM and Bonn RGB-D datasets demonstrated that our SLAM system achieves lower absolute trajectory error (ATE) than existing systems in different dynamic indoor environments, particularly those with large view angle variations. Our system can be applied to enhance the autonomous navigation and scene understanding capabilities of domestic robots.
1. Introduction
Numerous home-oriented and human-centered robotic applications have emerged during the past two decades [1,2]. The International Federation of Robotics estimates that sales of household robots reached 40 million units in 2023, corresponding to an annual increase of 25%. For household robots, simultaneous localization and mapping (SLAM) is an essential technology for achieving intelligence and automation [3,4,5]. Visual SLAM, which employs cameras to estimate the robot’s pose and map its surroundings, has been widely studied and received considerable attention in recent years [5].
Nevertheless, operating mobile robots in indoor environments characterized by dynamic human activities remains technically challenging, especially for service applications such as household robotics. This challenge is particularly significant for the advancement of household robotics in real-world applications. A critical limitation arises from the environment rigidity assumption of typical visual SLAM systems, which is invalid in dynamic scenarios [3]. Following this assumption leads to incorrect data associations and thus poor performance of these visual SLAM systems. Therefore, there is an urgent need to resolve the limitations of traditional visual SLAM in dynamic indoor environments, which arises from this assumption [6].
Considering the various proposed methods, the predominant research strategy used in developing solutions involves the combination of semantic information and multi-view geometric information [7,8,9]. Within their frameworks, semantic information plays a crucial role in detecting dynamic objects in scenes, with specialized algorithms subsequently implemented to suppress the negative impact of these dynamic objects on state estimation in SLAM systems. However, the problem of motion blur, caused by dynamic objects within the scene as well as the large view angle variation of the robot, makes it severely challenging for segmentation networks to acquire reliable semantic information from complex dynamic indoor environments. As demonstrated in Figure 1, these challenges manifest in three fundamental forms across both theoretical and experimental aspects [10,11,12]: (1) failure of object identification by the segmentation network; (2) incomplete segmentation results despite correct object identification; and (3) degradation of segmentation mask accuracy in boundary regions.

Figure 1.
Examples of motion blur impacting semantic information extraction: (a) failure of object identification by the segmentation network; (b) incomplete segmentation results despite correct object identification; (c) degradation of segmentation mask accuracy in boundary regions.
Unsuccessful object recognition and inadequate segmentation can cause feature points from dynamic objects to be erroneously incorporated into pose estimation, while blurred boundaries create uncertainty in the classification of feature points. The aforementioned problems impose considerable limitations on the practical performance of visual SLAM systems within complex dynamic indoor environments.
For such complex environments, it is essential to fully exploit the characteristics of the environment and apply more robust methods for SLAM system processing to address the discussed challenges [13]. Based on the assumption that dynamic object motion maintains continuity within brief time intervals, we employ temporal information to predict the potential locations where semantic information is missing and recover the missing semantic information. Under the assumption that dynamic objects maintain spatial continuity in space, we explore the integration of two methodologies that reflect this fundamental property to enhance our method. Depth information reflects the distance between the camera and the detected objects, and this property is exploited to restore segmentation results in cases of incomplete segmentation. The identification of dynamic objects in dynamic SLAM resembles a classification problem, and probabilistic approaches have demonstrated excellent performance when controversies arise in classification tasks [14,15,16,17]. Thus, a probability-based approach is introduced into our SLAM system as a reliable basis for feature point classification, compensating for the inadequate precision of mask boundaries. Therefore, the aforementioned benefits motivated us to leverage temporal information, depth information, and a probability-based mechanism in our dynamic visual SLAM system, particularly to address the challenges that motion blur poses for semantic information utilization in dynamic SLAM systems. In summary, our contributions are as follows:
- We present a semantic information compensation mechanism that predicts and recovers missing semantic information based on temporal analysis. This mechanism empowers our method to cope with failure of object identification.
- We propose a fusion method to generate segmented depth masks that incorporate reliable depth information. In contrast to semantic masks susceptible to incomplete segmentation, our proposed masks augment the integrity of RGB-derived semantic information, thus allowing superior discrimination between dynamic objects and background.
- We introduce a probability-based detection and elimination algorithm combined with segmented depth masks, which effectively eliminates the impacts of dynamic feature points and overcomes the unreliability of mask boundaries in the presence of motion blur.
2. Related Works
2.1. Dynamic SLAM by Fusing Semantic and Geometric Constraints
For SLAM systems operating in indoor dynamic environments, eliminating the effects of moving objects is crucial [7,18]. Methods for recognizing moving objects have long been studied [7,8,9,18,19,20,21], and various types of semantic and geometric information are used to aid SLAM systems in distinguishing dynamic objects. For instance, in DynaSLAM [7] and DynaSLAM2 [7], Mask R-CNN [22] is used to segment each frame and obtain semantic masks of moving objects. Multi-view geometry is then used with the semantic masks to identify and remove moving features. Ji et al. [23] adopted SegNet [24] as their semantic module and proposed a geometry clustering method as their geometry module. To achieve the geometry clustering method, they computed an average reprojection error for all features points against their corresponding points in 3D space. Detect-SLAM [25] utilizes Single Shot Multibox Object Detector (SSD) [26] as its detector module. Detect-SLAM exclusively detects moving objects in keyframes and updates the probability of points being in motion. In DS-SLAM [20], SegNet [24] is combined with a moving consistency check to reduce the impact of moving objects, and an optional flow pyramid is then calculated to obtain matched feature points. CFP-SLAM [8] is a dynamic scene-oriented visual SLAM system based on the object detection network YOLOv5 and a coarse-to-fine probability. Furthermore, it employs projection constraints and epipolar constraints as its multi-view geometric constraints. Blitz-SLAM [12] utilizes BlitzNet [27] to obtain semantic information and generate a global point cloud map. GGC-SLAM [28] calculates epipolar distance and uses object detection results to eliminate dynamic feature points.
In the aforementioned approaches, semantic information plays an essential role, whereas multi-view geometric information serves as a complementary cue for detecting dynamic objects. Semantic information facilitates high-level understanding of scene contents, enabling efficient object categorization and behavior prediction. Therefore, addressing the unreliability of semantic information caused by motion blur becomes particularly crucial in visual SLAM systems, as it directly impacts the system’s ability to maintain consistent object tracking.
2.2. Dynamic SLAM Using Depth Images
Since visual SLAM can employ RGB images and depth images for localization and mapping, the use of various types of information from depth images to identify dynamic objects and dynamic feature points has been explored for some dynamic SLAM methods.
CFP-SLAM [8] uses depth images for DBSCAN clustering. Refusion [29] registers the current RGB-D frame with respect to the pose model. After registration, Refusion computes the residual of each pixel, together with depth images, to identify dynamic parts of the scene. YOLO-SLAM [19] uses depth images and Darknet19-YOLOv3 to perform Geometric Depth RANSAC clustering. Jing et al. [30] utilized depth image sequences and semantic labels to generate a clean point cloud map with semantic information. In [23], Ji et al. segmented each depth image into N clusters using the K-means algorithm for dynamic object detection and removal. In Virgolino et al. [31], depth images are processed using a 3D Kalman filter and short-term data association mechanism to achieve dynamic object classification. Vincent et al. [32] developed an approach called DOTMask to improve both localization and mapping in visual SLAM. For DAM-SLAM [33], a depth attention module and adaptive impact factor were proposed to achieve dynamic point removal. OVD-SLAM [16] employs a chi-square test with YOLOv5 and depth images to perform foreground and background segmentation. The chi-square test is then implemented once more to identify the bounding box of dynamic objects. In YPR-SLAM [34], the Geometric Depth-PROSAC algorithm was introduced to effectively utilize depth images. Li et al. [35] developed a novel method that uses depth values to segregate non-static points. This method included an SDF-based feature point filtering algorithm.
The aforementioned methods have demonstrated promising results, yet opportunities for improvement remain. In our approach, we attempt to address the uncertain boundaries caused by motion blur by incorporating depth information.
3. Method
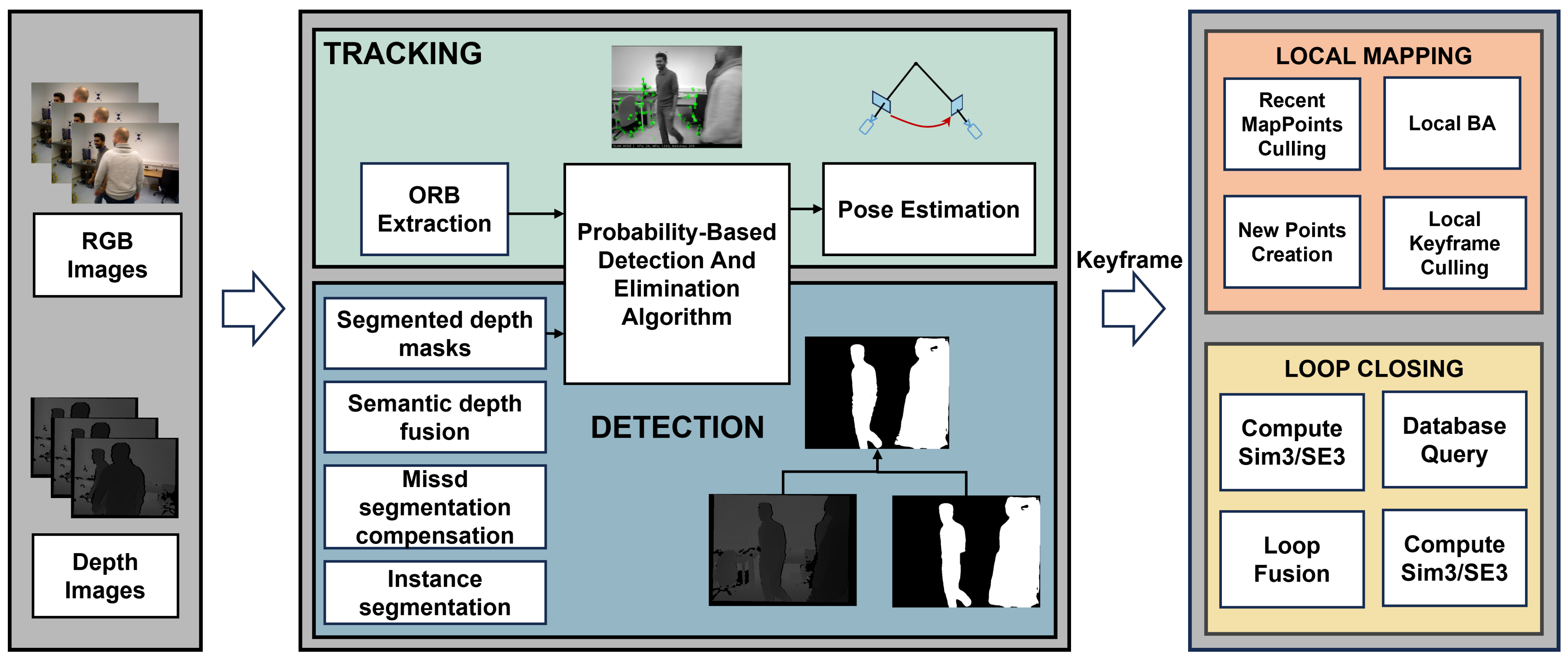
The overview of our SLAM system is shown in Figure 2.
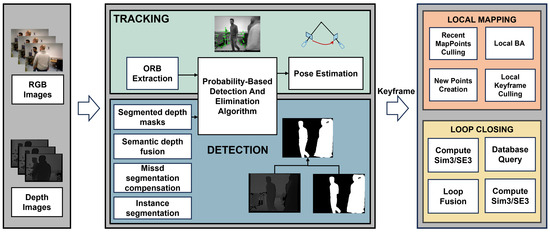
Figure 2.
The framework of our method. A new detection thread has been added to the ORB-SLAM2 framework. In this detection thread, the RGB images are fed into a segmentation network to obtain segmented masks. Following the missed segmentation compensation process, these masks are combined with their corresponding depth images to generate segmented depth masks. The feature points and segmented depth masks are input into a probability-based detection and elimination algorithm, which decides whether to retain or discard feature points.
Within our SLAM system architecture, a detection thread is established and coupled with the tracking thread through a probability-based detection and elimination algorithm to complete our overall framework. We present the details of our system architecture in this section. The ORB feature is employed for the overall system. Our loop closing module follows the same approach as ORB-SLAM2, while in the mapping stage, our system constructs a global dense 3D point cloud map. Initially, the missed segmentation compensation mechanism is employed to address the segmentation deficiencies in our methodology. Subsequently, a fusion method combining depth information with semantic information extracted from RGB images is utilized. Finally, the details of the probability-based detection and elimination algorithm are demonstrated.
3.1. Missed Segmentation Compensation
Semantic information was primarily obtained from the instance segmentation network SparseInst [36]. Within the segmentation output, humans were classified as dynamic objects, where the bounding box information for each dynamic object was extracted and stored, denoted as . represents an individual bounding box, where o represents the total number of bounding boxes. Subsequently, the segmentation results were converted into masks through binarization processing, in which dynamic object regions are represented in white, while the remaining areas are displayed in black. However, the missed segmentation problem arises due to the blurred boundaries of moving objects in images. This renders our method incapable of handling dynamic objects. Furthermore, the unexpected introduction of dynamic objects leads to the acquisition of extensive erroneous keypoints within our SLAM system, with subsequent induction of inter-frame correspondence anomalies, thus compromising overall system performance. Therefore, recovering the semantic information in frames with missed segmentation is crucial. When the missed segmentation problem occurs, the mask obtained from the current frame shows significant differences compared to the masks from previous frames. Specifically, we choose to represent this difference using a ratio r:
where denotes the area of the white region in the mask corresponding to the current frame and denotes the area of the white region in the mask corresponding to the last frame. Through empirical evaluations, we establish the criterion that a missed segmentation problem arises when . Local template matching was then utilized to locate objects with missed segmentation, after which the prediction process was initiated. In our prediction process, the coordinates of the upper left corner of the boundary box are saved. These coordinates are integrated with the timestamp corresponding to the frame in which they are located. This combination is treated as a point , denoted as
where is the horizontal coordinate, is the vertical coordinate, and is the timestamp. Using the abovementioned combination, the prediction problem is transformed into a line fitting task for a series of points in the space. We employ the least squares technique to fit these points. Specifically, the equation of a three-dimensional line can be expressed as follows:
where represents a point on this line and are constant values. This line can also be expressed as
Using the L2 norm of the residuals, the parameters , , and can be estimated as follows:
Utilizing the aforementioned formula, the values for the parameters , , and are estimated as follows:
where n denotes the number of points involved in the estimation process. In the proposed method, points from the three preceding frames of the current frame are selected for estimation, hence . For the current frame where missed segmentation occurs, the timestamp of this frame is already known. Consequently, the predicted points for the current frame are as follows:
where , are the predicted horizontal coordinate and the predicted vertical coordinate, and is the timestamp of current frame. After predicting the potential location for the bounding box of the missing mask within the current frame, we copy the mask from the previous frame to this location, thereby achieving the recovery of missing semantic information.
3.2. Fusion of Depth Information with RGB-Derived Semantics
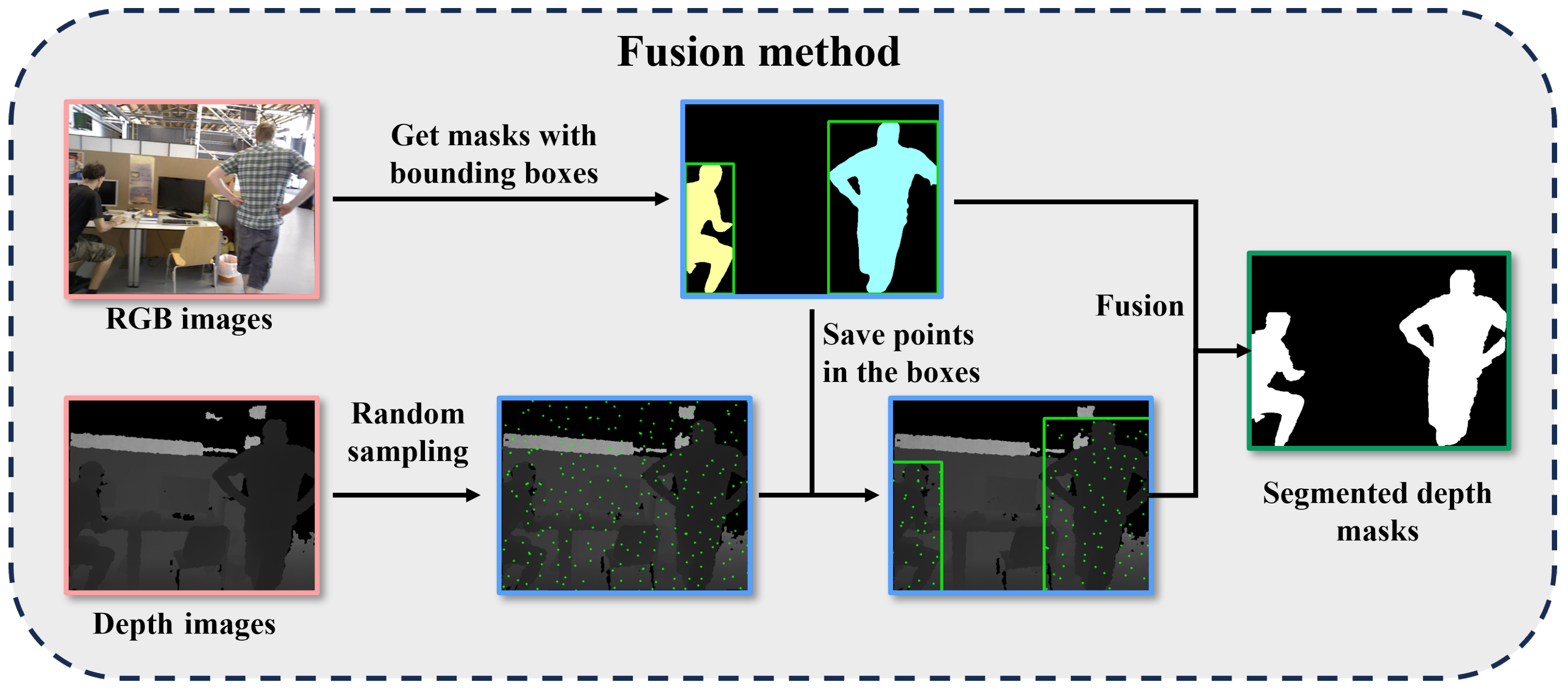
The fusion method process is presented in Figure 3. As previously described, semantic information was recovered through implementation of the missed segmentation compensation mechanism.
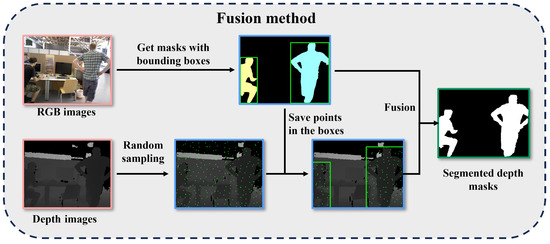
Figure 3.
The fusion method process. The images in orange boxes are the inputs, the images in blue boxes are the visualization of intermediate steps, and the image in the green box is the output.
The first step involves sampling from depth images. We perform stratified, rather than random, sampling directly on the depth images. Stratified sampling can reduce sampling error and bias, thereby accurately reflecting the characteristics of the population. We divide depth image into n regions, denoted as . Each region has uniform length and width.
We define a vector to represent the characteristics of a sampling point. This vector can be expressed as
where is the grayscale value of and is the coordinates of . Given each , can be expressed as
where is uniform sampling function. The probability density function of uniform sampling function can be written as follows:
where G is the area of . Let be the set of . can be expressed using the following equation:
We apply a filtering process to refine , which is based on the bounding boxes . For each bounding box , the filtering process can be formulated as follows:
where is the outcome of filtering process applied to . Therefore, has the same representation as and can be expressed as
where is the grayscale value of , and represents the coordinates of . Let be the set of , and can be denoted as
To speed up our fusion method, we do not perform random sampling in the bounding boxes. We use the bounding boxes and the sampled points to extract human regions within the depth images. Our approach is based on the property that grayscale values of a continuous object maintain spatial continuity within depth images. Therefore, for every bounding box in depth images, the average grayscale values can be computed as follows:
where n is the total number of . This computed value , denoted as “human average value”, is regard as the average grayscale value of the human region corresponding to the bounding box . Given “human average value” , a range called “human value range” can be written as
where is the threshold used to determine the upper and lower limits of this range. We analyzed the distribution of grayscale values within the bounding box and retained those within three standard deviations. If a grayscale value is excluded from the random sampling process but within the range , we add this value into and subsequently update . Grayscale values within are regarded as part of the overall grayscale value of this human region. In this way, we can effectively avoid the problem of missed samples that may occur in the sampling process. For each grayscale value belonging to “human value range” , we extract the regions corresponding to this grayscale value in the bounding box and then copy this region to the semantic masks . The corresponding regions are set as white in the masks. Using these approaches, we create segmented depth masks containing both depth and semantic information.
We apply a dilation function to the segmented depth masks. In the dilation function, the kernel size is a critical parameter that affects the performance of the algorithm, and kernel selection will be discussed in the experimental section.
Finally, segmented depth masks are fed into a probability-based detection and elimination algorithm, which will be detailed in the subsequent section.
3.3. The Probability-Based Detection and Elimination Algorithm
A probability-based detection and elimination algorithm is developed to identify and eliminate dynamic feature points, in which “probability” refers to the likelihood that a feature point belongs to a dynamic object.
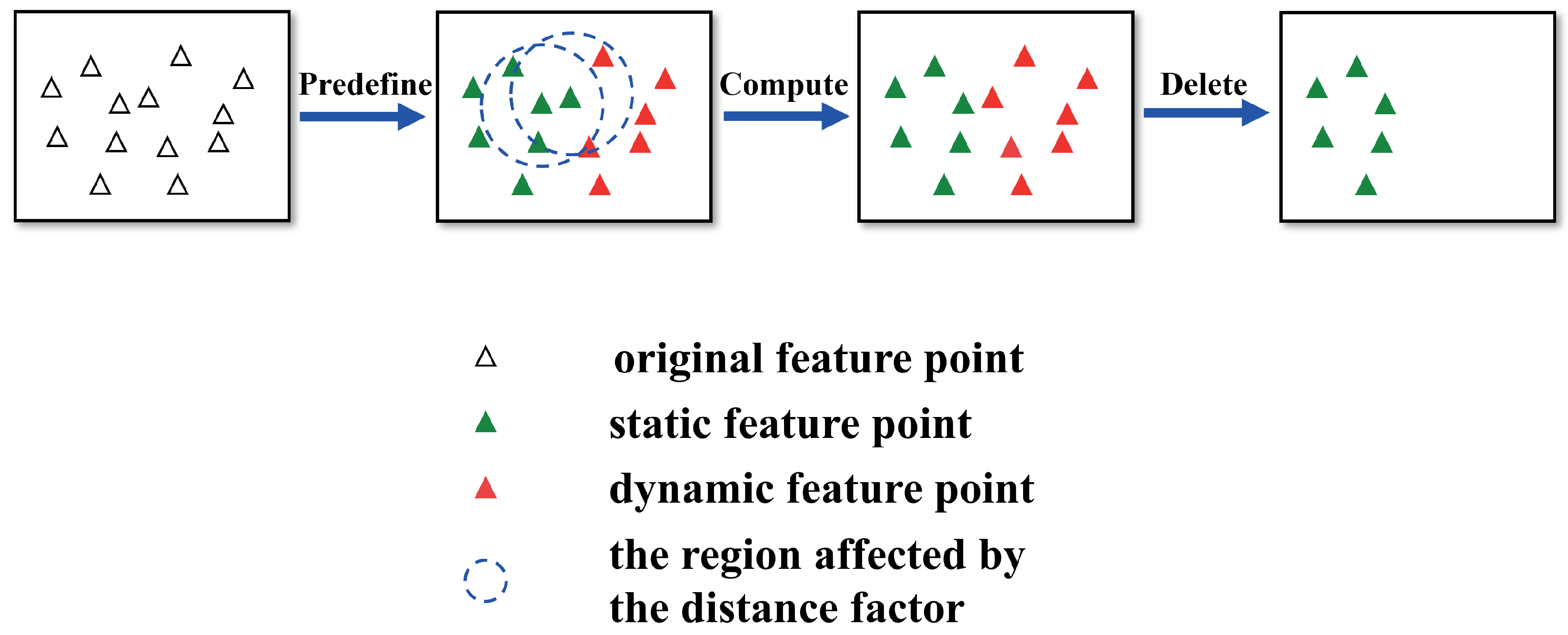
For the ORB feature points extracted in each frame, the entire approach of this algorithm is illustrated in Figure 4.
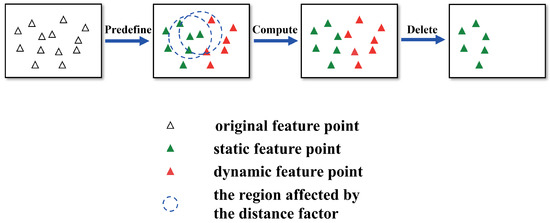
Figure 4.
The process of probability-based detection and elimination algorithm.
The first step is to “Pre-define”, which means to coarsely assign a probability of being a dynamic point to all ORB feature points. Relying on segmented depth masks , if a feature point with falls within the white region of segmented depth masks, we consider this point a dynamic feature point with probability set to 100%; otherwise, it is a static point with probability set to 0%, as defined in Equation (20).
The second step is to “Compute”, which is to refine the probability of the detected points.
For each static feature point , all neighbor feature points with a Euclidean distance of less than D to are searched using KD tree and recorded into a set , with . The refined probability is computed as follows:
where is a distance decay factor. is the Euclidean distance between and . The distance decay factor is defined as follows:
Here, , are the scaling and exponential parameters of the distance decay factor. The natural exponential function is used to reflect the effect of Euclidean distance. If , this indicates that there are no neighbor feature points around that can be utilized to refine , then is set to 0%. By using the aforementioned method, we obtain the fine probability of these original static points.
Therefore, dynamic feature points do not only exist within mask boundaries and sometimes also appear outside the mask boundaries. The “Compute” step effectively extends the possible locations of dynamic feature points.
The last step is to “Delete”. The “Delete” step is designed to mitigate the adverse effects of dynamic feature points. In the “Delete” step, a filtering mechanism is employed to eliminate all the dynamic feature points that we have identified. We set a threshold for the classification of dynamic feature points. Through this process, we separate all feature points into two categories, and . means feature point with its probability and means a feature point of probability . If the fine probability of some original static points exceeds , they will be classified as dynamic feature points. This demonstrates that despite being located outside mask boundaries, these feature points are computationally identified as being unreliable due to the influence of motion blur. Using the filtering mechanism, all dynamic points are located and the eliminated during subsequent processing stages. This mechanism prevents incorrect data associations caused by dynamic feature points. Finally, static feature points, which are inherently more reliable, are utilized for the pose estimation task within the SLAM system. The other modules of the SLAM system also use static feature points instead of the original extracted feature points.
4. Experimental Results and Discussion
In this study, five “fr3” sequences from the TUM RGB-D dataset and five sequences from the Bonn dataset were selected for the evaluation of our proposed method [29,37]. The five “fr3” sequences from the TUM RGB-D dataset contain both high- and low-dynamic environment sequences, in which the high-dynamic environment sequences, named “fr3/walking” (fr3/w for short), contain four kinds of camera motion: xyz, halfsphere, static, rpy. The low-dynamic environment sequences are called “fr3/sitting/static” (fr3/s/static for short). From the Bonn dataset, we selected sequences of “crowd”, with multiple people present, as well as “person_tracking” (person for short), which are sequences focused on person tracking. Absolute trajectory error (ATE) was employed to evaluate the differences between the estimated trajectories and the ground truth trajectories. Root mean square error (RMSE) and standard deviation (S.D.) were employed for the statistical analysis of ATE, as the evaluation metrics of different SLAM methods. With the transformation matrix corresponding to the estimated camera pose and ground truth at frame t using the least squares method, and the corresponding and can be computed as
where n was the number of frames in a sequence.
Initially, we showed the effectiveness of our missed segmentation compensation and fusion method. Subsequently, we compared our method with different baseline methods. We then performed ablation experiments to verify the effect of each module in our method. After that, we presented the dense mapping results and then analyzed and visualized the influence of mask size on performance. Lastly, we illustrated the runtime efficiency of our method. The hyperparameters utilized in our methodology were configured according to the default settings prescribed by ORB-SLAM2, except that the number of ORB features to be extracted from each image had been increased to 3000 from the default 1000. We ran each sequence five times to minimize systematic errors. All experiments were conducted on a computer with Intel i5-13400F CPU, 16 GB memory, and NVIDIA GeForce GTX 1660 SUPER GPU.
4.1. Evaluation of the Missed Segmentation Compensation and Fusion Method
In dynamic visual SLAM scenarios, the motion of objects and the camera poses significant challenges to segmentation networks, resulting in problems of missed and incomplete segmentation. Semantic masks that suddenly disappear or are partially missing compromise the effectiveness of our method. Consequently, we predict the position and supplement the semantic masks for frames that have experienced missed segmentation, utilizing depth information to complement the partially segmented masks. Figure 5 illustrates cases of missed segmentation problems found in two different sequences along with the results when using our method for compensation. Due to the non-negligible motion of dynamic objects between consecutive frames, we refrained from simply copying the correct semantic masks to the frames where segmentation failure was detected. Instead, our missed segmentation compensation mechanism effectively forecasted the potential locations of the missing semantic masks based on the results of line fitting and successfully compensated for the missing semantic masks. Figure 6 demonstrates the effectiveness of our fusion method. For the RGB images shown in the figure, although the segmentation network produced incomplete masks due to motion blur, our fusion method successfully completed these masks by leveraging depth information. The experimental results substantiate that our missed segmentation compensation mechanism and fusion method effectively recover the missing parts of human segmentation, leading to more complete and accurate dynamic object detection while maintaining robust performance.

Figure 5.
Illustration of the effect of our proposed missed segmentation compensation mechanism: (a) the original RGB images; (b) semantic masks before missed segmentation compensation; (c) our missed segmentation compensation results.

Figure 6.
Illustration of the effect of our proposed depth fusion method in completing the semantic masks in segmentation: (a) the original RGB images; (b) semantic masks without fusing depth information; (c) our segmented depth masks.
4.2. Comparison with Baseline Methods
Our method was compared with five baseline methods, ORBSLAM2 [38] and four advanced dynamic SLAM methods, Dyna-SLAM [7], Crowd-SLAM [39], YOLO-SLAM [19], and SG-SLAM [40]. The baseline data are from the source literature, and “/” means that the corresponding data were not provided in their source literature.
TUM RGB-D dataset. Our quantitative results are displayed in Table 1. The keypoint filtering results compared with ORB-SLAM2 and SG-SLAM are shown in Figure 7.

Table 1.
Results of metrics for absolute trajectory error (ATE) [m] using the TUM RGB-D dataset. The best results are in bold.

Figure 7.
Keypoint filtering results compared with ORB-SLAM2 and SG-SLAM.
The experimental results demonstrate that our method outperforms the baseline methods in terms of ATE in both high- and low-dynamic environments. In high-dynamic sequences, our method achieved an average reduction of 96.5% in RMSE and 96.6% in S.D. compared to ORBSLAM2. Moreover, in the “fr3/w/half” sequence characterized by severe motion blur, our method demonstrated optimal performance, with RMSE reduced by 94.5% and S.D. reduced by 95.5% compared to ORBSLAM2, and improvements of 14.8% in RMSE and 15.4% in S.D. over SG-SLAM. For the “fr3/w/rpy” sequence, both SG-SLAM and our method exhibited superior performance, whereas YOLO-SLAM did not yield comparable results. Experimental results from the “fr3/w/rpy” sequence demonstrate that degradation in the performance of YOLO-SLAM is primarily attributed to its substantial dependence on object detection outputs, wherein the detection network exhibits significant accuracy deterioration during the 45-degree camera rotation, thereby adversely affecting the system’s overall functionality. In low-dynamic environments, all baseline methods showed minimal improvements over ORBSLAM2, whose performance is already promising due to the limited motion of both camera and objects in these sequences. The visualization results showed that compared to ORB-SLAM2, both our method and SG-SLAM effectively filtered out dynamic feature points associated with moving humans, leading to more accurate localization of the SLAM system. Furthermore, while SG-SLAM retained feature points at human boundaries, our method demonstrated enhanced robustness in scenarios with frequent human movement by more precisely identifying and filtering these boundary features, effectively reducing localization drift.
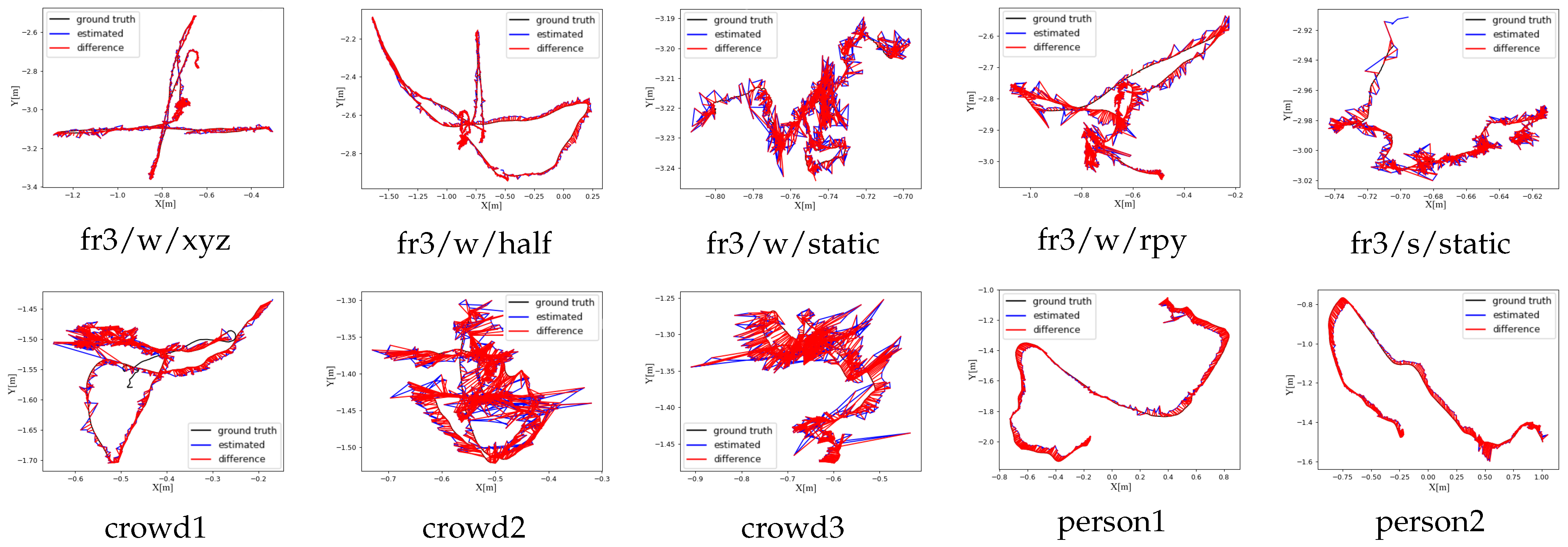
We draw our trajectory as plots using the evaluation tool provided with the TUM dataset. These ATE plots are shown in the first row of Figure 8.
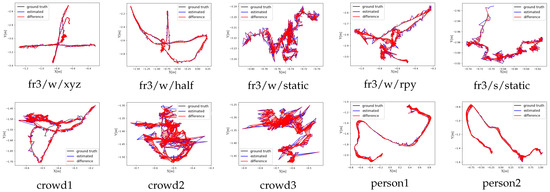
Figure 8.
The ATE [m] results of our method on the TUM RGB-D and Bonn datasets. The results on the TUM dataset are presented in the first row. The results on the Bonn dataset are presented in the second row.
Bonn dataset. The tracking results are exhibited in Table 2.
Table 2.
Results of metrics for absolute trajectory error (ATE) [m] using the Bonn dataset.The best results are in bold.
Compared with the TUM RGB-D dataset, which serves as a standard benchmark for SLAM evaluation, the Bonn dataset exhibits more complex dynamic scenarios, involving the motion of multiple objects, and includes more frequent occlusions and complex object interactions, which must be accurately handled by the SLAM system. Our method demonstrated a significant improvement over ORB-SLAM2, with superior robustness in handling dynamic objects and maintaining accurate camera pose estimation. Specifically, when evaluated on Bonn dataset sequences, our approach achieved average reductions of 96.6% in RMSE and 96.7% in S.D. compared to ORBSLAM2. Furthermore, when compared with the state-of-the-art SG-SLAM system, our method performed competitively, achieving comparable or better results using these sequences. Quantitative analysis revealed that our approach achieved a 24.8% reduction in RMSE compared to SG-SLAM, while demonstrating an even more significant improvement of 35.8% in S.D. The experimental results validate the effectiveness of our proposed method and its ability to handle complex dynamic environments. The ATE plots are shown in the second row of Figure 8.
4.3. Ablation Experiments
Ablation experiments were performed to evaluate the influence of each module in our method. “Ours” refers to our method. “w/o compensation” denotes that the missed segmentation compensation mechanism has not been applied. “w/o depth” indicates results without fusing depth information and masks provided by the segmentation network. “w/o probability” means the probability algorithm is not applied. The experimental results are shown in Table 3.
Table 3.
Results of metrics for absolute trajectory error (ATE) [m] with different modules.The best results are in bold.
Our experimental results on the “fr3/s/static” sequence demonstrate that optimal performance is achieved when operating without the fusion of depth information and masks. This phenomenon occurs because our approach is based on an implicit assumption: in high-dynamic scenes, segmentation networks are more susceptible to motion blur than depth information, making the application of depth information more robust compared to segmentation masks. Based on this assumption, the method of using robust depth information to complete segmentation masks proved effective in sequences with dramatic camera or human motion. However, in low-dynamic scenes, this assumption became invalid: the segmentation networks were capable of producing high-quality masks, whereas the inherent inaccuracy of depth information near object boundaries introduced undesired noise into our fusion approach.
We visualized our probability-based detection and elimination algorithm in different sequences, as illustrated in Figure 9. In Figure 9, three sequences are presented, where feature points are colored based on their refined classification: green for static feature points and red for dynamic feature points. These dynamic feature points are mainly situated near dynamic objects. The green feature points represent stable environmental features that are crucial for accurate pose estimation, while the red feature points effectively identify regions of dynamic activity that require special handling in the SLAM pipeline. Utilizing our probability algorithm, we implemented adaptive propagation of dynamic points around object boundaries, successfully addressing the precision limitations of binary classification methods that rely exclusively on mask boundaries. We judged these dynamic feature points to be unreliable, and they were disqualified from participation in the subsequent threads of the SLAM process. Ablation experiments show that the probability-based detection and elimination algorithm enhances the performance of our method, particularly in sequences like “fr3/w/rpy” and “fr3/w/half”, which exhibit significant motion blur caused by object and camera motions. In summary, our method achieved superior performance, highlighting that the three modules were successfully integrated.

Figure 9.
Visualization of results for our probability-based detection and elimination algorithm. The results from three different sequences are each presented in (a–c). In the visualization results, feature points that are ultimately determined to be static are represented in green, while those classified as dynamic are depicted in red.
4.4. Dense 3D Mapping
In this section, we evaluated our dense 3D mapping results using the TUM RGB-D dataset. The comparison of mapping results between our method and ORB-SLAM2 is presented in Figure 10. The dense map generated by ORB-SLAM2 exhibited severe ghost effects in the presence of dynamic human motion. In contrast, our approach demonstrated superior robustness against dynamic objects, exhibiting significantly reduced ghosting effects in the dense mapping process even in scenarios where motion blur was introduced by human movement. Overall, our method consistently produced clean and coherent dense 3D maps of the environment.

Figure 10.
Dense 3D maps for the TUM RGB-D dataset. The sequence of the top line is “fr3/s/static”, and the sequence of the bottom line is “fr3/w/static”.
4.5. Impact of Dilation Kernel Size on Performance
The masks were processed using the dilation function. The parameter “” was set when constructing the kernel that is used in the dilation function. Visualizations are depicted in Figure 11.

Figure 11.
Visualization of the number of feature points under different kernel sizes: ORBSLAM2 (left), our method without using dilation function (middle), and using dilation function with dilation_size = 30 (right).
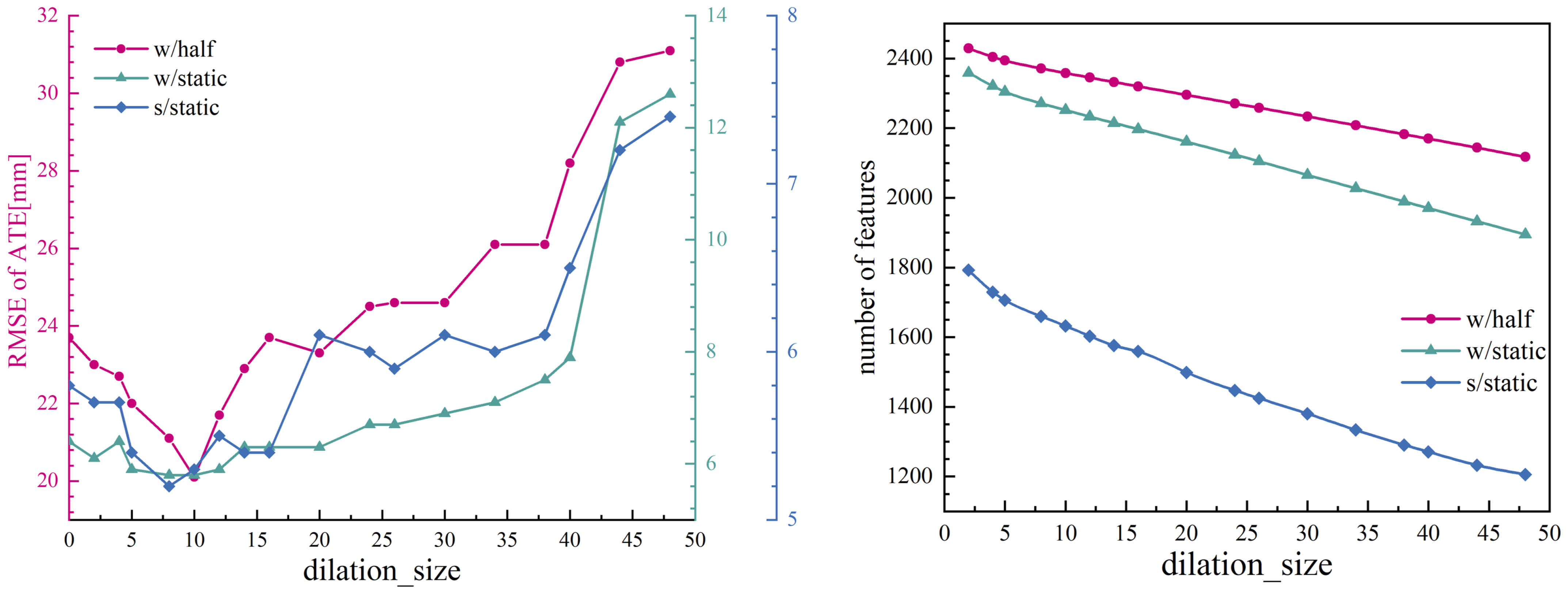
The experimental results and the average number of feature points used per image under different kernel sizes are presented in Figure 12.
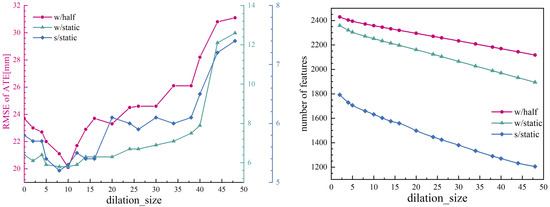
Figure 12.
Impacts of different dilation_size for our proposed SLAM system. Plots of SLAM performance under different dilation_size (left), and the average number of feature points used by the SLAM system under different dilation_size (right).
The empirical findings indicate that different kernel sizes do not cause a sudden changes in the average number of feature points utilized. However, it is observed that the performance of the SLAM system achieves a local optimal outcome when a certain kernel size is applied. The use of oversized masks decreases the quantity of static points incorporated into the SLAM system, consequently leading to a discernible decrease in system performance. Conversely, the utilization of undersized masks introduces dynamic points into the SLAM system, similarly leading to a degradation in overall performance. These findings suggest that kernel size plays a critical role in balancing the inclusion of static and dynamic feature points, thereby influencing the efficacy of the SLAM system. In practice, we found “” was the optimal choice.
4.6. Runtime Analysis
To complete the evaluation of our method, we considered the average computation time, as illustrated in Table 4. During empirical operation, we discovered that we could not run our system using the original parameters set by ORBSLAM2, so we adjusted “nFeature” to 3000. “Others” denotes the remaining system modules, which include loop closing and local mapping. The sequence “fr3/w/half” is more intricate compared to other sequences, requiring extensive computational resources for the SLAM system to utilize loop closing and local mapping in order to achieve accurate trajectory estimation, consequently entailing a longer runtime. In the “fr3/w/static” sequence, the human bodies are always present in the frame, leading to a larger computational requirement for Fusion method. SparseInst achieved an average segmentation speed of 17.1 ms per image. According to the runtime analysis, our method is capable of fulfilling real-time demands.
Table 4.
Average computation time [ms].
5. Conclusions
In this paper, we present our work in addressing the challenges of acquiring reliable semantic information in dynamic SLAM applications when there is motion blur present. We developed multiple strategies to minimize the influence of motion blur on visual SLAM system performance, as follows: first, a missed segmentation compensation mechanism using temporal information was developed to address the missed detection of dynamic objects; second, a fusion method that combines depth information with the semantic information extracted from RGB images was proposed to improve the accuracy in distinguishing between dynamic objects and the background; third, a probability-based detection and elimination algorithm was introduced to improve the results for the detection of dynamic feature points located at the boundaries of dynamic objects. Based on the experimental results, we can conclude the following: first, using temporal information to predict the motion and fusing depth information, it is possible to improve the robustness of segmentation to address motion blur problems in dynamic scenes; second, probability-based mechanisms can be used to effectively remove unreliable points for localization. In summary, our proposed multi-strategy visual SLAM system is effective in dealing with localization issues in dynamic indoor environments.
Although good results can be achieved using our method, our study only considered the impact of humans in the environment. Further research is required to expand the adaptability of our method. Moreover, the experimental results indicate that the trajectories estimated using our method and other similar approaches still exhibit certain deviations from the ground truth. This problem may arise from the insufficient robustness of the ORB feature points against rotational motion. In addition, research efforts on the substitution of ORB features with deep learning networks are actively being pursued [41]. This represents a possible avenue for achieving more accurate localization using dynamic SLAM systems. Therefore, in our future work, we plan to broaden the detection range of moving objects, particularly those affected by human intervention, and investigate the feasibility of using other feature points to enhance the robustness of our system.
Author Contributions
Conceptualization, S.H.; methodology, S.H.; software, S.H. and L.C.; validation, S.H. and L.C.; formal analysis, S.H. and L.C.; data curation, L.C.; writing—original draft preparation, S.H. and Y.Z.; writing—review and editing, Y.Z., Z.G. and J.G.; supervision, J.G.; project administration, J.G.; funding acquisition, J.G. All authors have read and agreed to the published version of the manuscript.
Funding
This project was funded by National Natural Science Foundation of China (Award No. U23A20330) and Specific Research Project of Guangxi for Research Bases and Talents (Award No. AD22035919).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The dataset used in this paper is the public TUM dataset and Bonn dataset. The download addresses are as follows: TUM dataset at https://vision.in.tum.de/data/datasets/rgbd-dataset (accessed on 7 January 2025), Bonn dataset at https://www.ipb.uni-bonn.de/data/rgbd-dynamic-dataset/index.html (accessed on 7 January 2025).
Conflicts of Interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
References
- Zachiotis, G.A.; Andrikopoulos, G.; Gornez, R.; Nakamura, K.; Nikolakopoulos, G. A survey on the application trends of home service robotics. In Proceedings of the 2018 IEEE International Conference on Robotics and Biomimetics (ROBIO), Kuala Lumpur, Malaysia, 12–15 December 2018; pp. 1999–2006. [Google Scholar]
- Doelling, K.; Shin, J.; Popa, D.O. Service robotics for the home: A state of the art review. In Proceedings of the 7th International Conference on PErvasive Technologies Related to Assistive Environments, Island of Rhodes, Greece, 27–30 May 2014; pp. 1–8. [Google Scholar]
- Cadena, C.; Carlone, L.; Carrillo, H.; Latif, Y.; Scaramuzza, D.; Neira, J.; Reid, I.; Leonard, J.J. Past, present, and future of simultaneous localization and mapping: Toward the robust-perception age. IEEE Trans. Robot. 2016, 32, 1309–1332. [Google Scholar] [CrossRef]
- Taketomi, T.; Uchiyama, H.; Ikeda, S. Visual SLAM algorithms: A survey from 2010 to 2016. IPSJ Trans. Comput. Vis. Appl. 2017, 9, 16. [Google Scholar] [CrossRef]
- Kazerouni, I.A.; Fitzgerald, L.; Dooly, G.; Toal, D. A survey of state-of-the-art on visual SLAM. Expert Syst. Appl. 2022, 205, 117734. [Google Scholar] [CrossRef]
- Beghdadi, A.; Mallem, M. A comprehensive overview of dynamic visual SLAM and deep learning: Concepts, methods and challenges. Mach. Vis. Appl. 2022, 33, 54. [Google Scholar] [CrossRef]
- Bescos, B.; Fácil, J.M.; Civera, J.; Neira, J. DynaSLAM: Tracking, mapping, and inpainting in dynamic scenes. IEEE Robot. Autom. Lett. 2018, 3, 4076–4083. [Google Scholar] [CrossRef]
- Hu, X.; Zhang, Y.; Cao, Z.; Ma, R.; Wu, Y.; Deng, Z.; Sun, W. CFP-SLAM: A real-time visual SLAM based on coarse-to-fine probability in dynamic environments. In Proceedings of the 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Kyoto, Japan, 23–27 October 2022; pp. 4399–4406. [Google Scholar]
- Xu, G.; Yu, Z.; Xing, G.; Zhang, X.; Pan, F. Visual odometry algorithm based on geometric prior for dynamic environments. Int. J. Adv. Manuf. Technol. 2022, 122, 235–242. [Google Scholar] [CrossRef]
- Xiang, Y.; Zhou, H.; Li, C.; Sun, F.; Li, Z.; Xie, Y. Deep learning in motion deblurring: Current status, benchmarks and future prospects. Vis. Comput. 2024, 1–27. [Google Scholar] [CrossRef]
- Xu, C.; Li, C.T.; Hu, Y.; Lim, C.P.; Creighton, D. Deep Learning Techniques for Video Instance Segmentation: A Survey. arXiv 2023, arXiv:2310.12393. [Google Scholar]
- Fan, Y.; Zhang, Q.; Tang, Y.; Liu, S.; Han, H. Blitz-SLAM: A semantic SLAM in dynamic environments. Pattern Recognit. 2022, 121, 108225. [Google Scholar] [CrossRef]
- Qin, Y.; Yu, H. A review of visual SLAM with dynamic objects. Ind. Robot. Int. J. Robot. Res. Appl. 2023, 50, 1000–1010. [Google Scholar] [CrossRef]
- Kruger, J.; Ehrhardt, J.; Handels, H. Probabilistic appearance models for segmentation and classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1698–1706. [Google Scholar]
- Ahmed, H.; Nandi, A.K. Probabilistic Classification Methods. In Condition Monitoring with Vibration Signals: Compressive Sampling and Learning Algorithms for Rotating Machines; Wiley Press: New York, NY, USA, 2019; pp. 225–237. [Google Scholar] [CrossRef]
- He, J.; Li, M.; Wang, Y.; Wang, H. OVD-SLAM: An online visual SLAM for dynamic environments. IEEE Sens. J. 2023, 23, 13210–13219. [Google Scholar] [CrossRef]
- Li, M.; He, J.; Jiang, G.; Wang, H. Ddn-slam: Real-time dense dynamic neural implicit slam with joint semantic encoding. arXiv 2024, arXiv:2401.01545. [Google Scholar]
- Bescos, B.; Campos, C.; Tardós, J.D.; Neira, J. DynaSLAM II: Tightly-coupled multi-object tracking and SLAM. IEEE Robot. Autom. Lett. 2021, 6, 5191–5198. [Google Scholar] [CrossRef]
- Wu, W.; Guo, L.; Gao, H.; You, Z.; Liu, Y.; Chen, Z. YOLO-SLAM: A semantic SLAM system towards dynamic environment with geometric constraint. Neural Comput. Appl. 2022, 34, 6011–6026. [Google Scholar] [CrossRef]
- Yu, C.; Liu, Z.; Liu, X.J.; Xie, F.; Yang, Y.; Wei, Q.; Fei, Q. DS-SLAM: A semantic visual SLAM towards dynamic environments. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1168–1174. [Google Scholar]
- Li, S.; Lee, D. RGB-D SLAM in dynamic environments using static point weighting. IEEE Robot. Autom. Lett. 2017, 2, 2263–2270. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Ji, T.; Wang, C.; Xie, L. Towards real-time semantic rgb-d slam in dynamic environments. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 11175–11181. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Zhong, F.; Wang, S.; Zhang, Z.; Wang, Y. Detect-SLAM: Making object detection and SLAM mutually beneficial. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1001–1010. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Dvornik, N.; Shmelkov, K.; Mairal, J.; Schmid, C. Blitznet: A real-time deep network for scene understanding. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4154–4162. [Google Scholar]
- Sun, Q.; Liu, W.; Zou, J.; Xu, Z.; Li, Y. GGC-SLAM: A VSLAM system based on predicted static probability of feature points in dynamic environments. Signal Image Video Process. 2024, 18, 7053–7064. [Google Scholar] [CrossRef]
- Palazzolo, E.; Behley, J.; Lottes, P.; Giguere, P.; Stachniss, C. ReFusion: 3D reconstruction in dynamic environments for RGB-D cameras exploiting residuals. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 7855–7862. [Google Scholar]
- Jin, J.; Jiang, X.; Yu, C.; Zhao, L.; Tang, Z. Dynamic visual simultaneous localization and mapping based on semantic segmentation module. Appl. Intell. 2023, 53, 19418–19432. [Google Scholar] [CrossRef]
- Virgolino Soares, J.C.; Medeiros, V.S.; Abati, G.F.; Becker, M.; Caurin, G.; Gattass, M.; Meggiolaro, M.A. Visual localization and mapping in dynamic and changing environments. J. Intell. Robot. Syst. 2023, 109, 95. [Google Scholar] [CrossRef]
- Vincent, J.; Labbé, M.; Lauzon, J.S.; Grondin, F.; Comtois-Rivet, P.M.; Michaud, F. Dynamic object tracking and masking for visual SLAM. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020; pp. 4974–4979. [Google Scholar]
- Ayman, B.; Malik, M.; Lotfi, B. DAM-SLAM: Depth attention module in a semantic visual SLAM based on objects interaction for dynamic environments. Appl. Intell. 2023, 53, 25802–25815. [Google Scholar] [CrossRef]
- Kan, X.; Shi, G.; Yang, X.; Hu, X. YPR-SLAM: A SLAM System Combining Object Detection and Geometric Constraints for Dynamic Scenes. Sensors 2024, 24, 6576. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Dai, J.; Su, Z.; Zhu, C. RGB-D Based Visual SLAM Algorithm for Indoor Crowd Environment. J. Intell. Robot. Syst. 2024, 110, 27. [Google Scholar] [CrossRef]
- Cheng, T.; Wang, X.; Chen, S.; Zhang, W.; Zhang, Q.; Huang, C.; Zhang, Z.; Liu, W. Sparse instance activation for real-time instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 4433–4442. [Google Scholar]
- Sturm, J.; Engelhard, N.; Endres, F.; Burgard, W.; Cremers, D. A benchmark for the evaluation of RGB-D SLAM systems. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura-Algarve, Portugal, 7–12 October 2012; pp. 573–580. [Google Scholar]
- Mur-Artal, R.; Tardós, J.D. Orb-slam2: An open-source slam system for monocular, stereo, and rgb-d cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef]
- Soares, J.C.V.; Gattass, M.; Meggiolaro, M.A. Crowd-SLAM: Visual SLAM towards crowded environments using object detection. J. Intell. Robot. Syst. 2021, 102, 50. [Google Scholar] [CrossRef]
- Cheng, S.; Sun, C.; Zhang, S.; Zhang, D. SG-SLAM: A real-time RGB-D visual SLAM toward dynamic scenes with semantic and geometric information. IEEE Trans. Instrum. Meas. 2022, 72, 7501012. [Google Scholar] [CrossRef]
- Fu, F.; Yang, J.; Ma, J.; Zhang, J. Dynamic visual SLAM based on probability screening and weighting for deep features. Measurement 2024, 236, 115127. [Google Scholar] [CrossRef]







Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).