Abstract
SLAM is regarded as a fundamental task in mobile robots and AR, implementing localization and mapping in certain circumstances. However, with only RGB images as input, monocular SLAM systems suffer problems of scale ambiguity and tracking difficulty in dynamic scenes. Moreover, high-level semantic information can always contribute to the SLAM process due to its similarity to human vision. Addressing these problems, we propose a monocular object-level SLAM system enhanced by real-time joint depth estimation and semantic segmentation. The multi-task network, called JSDNet, is designed to predict depth and semantic segmentation simultaneously, with four contributions that include depth discretization, feature fusion, a weight-learned loss function, and semantic consistency optimization. Specifically, feature fusion facilitates the sharing of features between the two tasks, while semantic consistency aims to guarantee the semantic segmentation and depth consistency among various views. Based on the results of JSDNet, we design an object-level system that combines both pixel-level and object-level semantics with traditional tracking, mapping, and optimization processes. In addition, a scale recovery process is also integrated into the system to evaluate the truth scale. Experimental results on NYU depth v2 demonstrate state-of-the-art depth estimation and considerable segmentation precision under real-time performance, while the trajectory accuracy on TUM RGB-D shows less errors compared with other SLAM systems.
1. Introduction
Simultaneous localization and mapping (SLAM) determines the 6-DoF pose of a moving camera and establishes a map of the unknown scene, which enables a variety of applications in augmented reality (AR)/virtual reality (VR)/ mixed reality (MR), robotics, and autonomous driving [1,2,3,4,5,6,7,8]. Compared with stereo- or RGB-D-based techniques, monocular SLAM algorithms are attractive to many mobile applications in indoor scenarios because of cheap hardware, a simple calibration process, and no limitations in the depth range.
However, with only monocular RGB input, two kinds of constraints appear. Firstly, the compound of scale drift and accumulative error may incapacitate data collection entirely. Secondly, the hand-crafted point features are always sensitive to environmental changes such as light or dynamic factors. By contrast, for humans scale drift does not occur routinely even if acting as cyclopean observers. Moreover, human vision systems can fuse various kinds of prior information. For example, from a single image, people can basically detect objects, perceive spatial layout, and estimate approximate depth.
To avoid the above limitations, semantic information from deep networks is exploited by different strategies, covering object detection, semantic segmentation, and saliency detection [9,10,11,12,13]. On the one side, with prior semantic inputs, both localization accuracy and robustness are enhanced due to the higher stability of high-level semantic information, which is also more similar to human vision. On the other side, through the typical size of objects, semantic information is always helpful to recover the truth scale in monocular SLAM [14]. However, the intrinsic error in object size leads to less accuracy than in RGB-D SLAM systems. The estimated depth result of the deep network also contributes to the scale recovery, but the long tail may reduce the accuracy of depth prediction. Meanwhile, with the development of multi-task deep networks, research on joint learning between depth prediction and semantic segmentation indicates that the two tasks can improve each other [15,16].
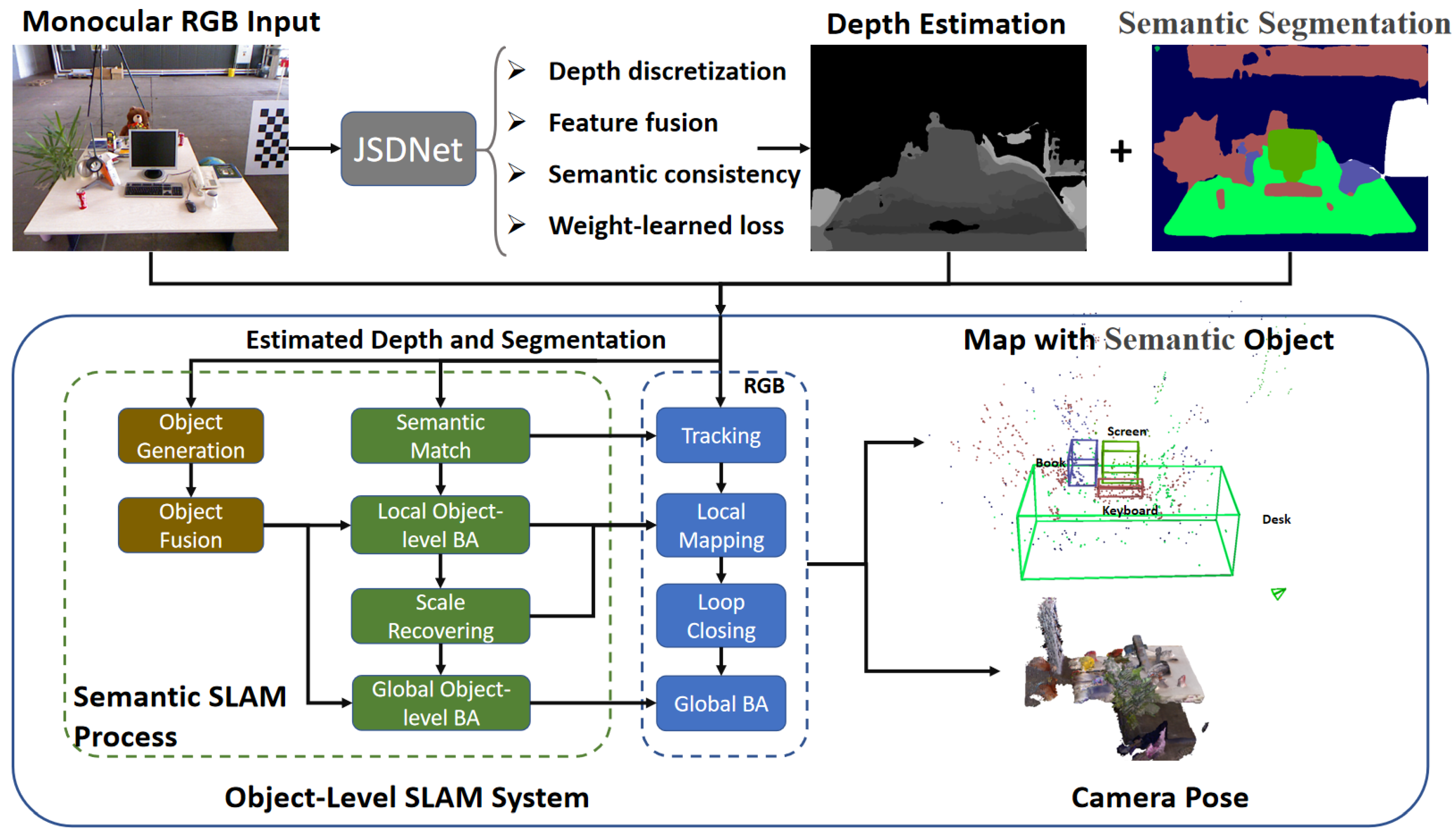
Inspired by the above, we enhance the monocular SLAM system with real-time joint depth estimation and semantic segmentation, aiming to solve the scale drift and improve the localization performance, as shown in Figure 1. Firstly, a real-time joint network called JSDNet is proposed to achieve simultaneous depth prediction and semantic segmentation. Secondly, with the evaluated results, we design an object-level semantic SLAM system based on ORB-SLAM2 [17]. The proposed system enhances the common SLAM process covering feature matching, local mapping, and global bundle adjustment (BA), implementing object-level SLAM. Furthermore, scale optimization is added to recover the scale with depth prediction. In summary, our work makes the following contributions.
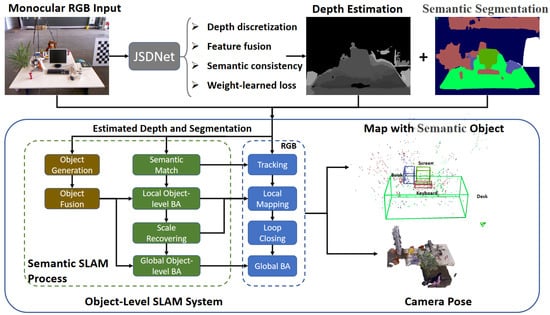
Figure 1.
Outline of whole SLAM system. With estimated depth and segmentation results from JSDNet, the object-level SLAM system is implemented with enhancement of tracking, local mapping, and global BA processes.
- 1.
- We propose JSDNet for joint learning of depth estimation and semantic segmentation, focusing on fixed depth estimation and a feature fusion block.
- 2.
- We suggest a semantic consistency process to keep the spatial consistency of semantic segmentation and depth estimation, with the aim of not only contributing to the two tasks, but also improving localization robustness.
- 3.
- We design an object-level SLAM system based on JSDNet with the utilization of pixel-level and object-level semantic information. In detail, the system optimizes the process covering feature matching, and local and global BA to improve accuracy and robustness. In addition to this, we add a scale uniformization procedure to recover a stable scale.
To validate the performance of the above contributions, experiments on both depth and segmentation datasets demonstrate the considerable results. Moreover, results on TUM RGB-D show accurate localization performance.
2. Related Work
2.1. Monocular Visual SLAM
In recent years, keyframe-based SLAM systems have come to predominate, such as DTAM [18], and ORB-SLAM [19] and its extended systems [17,20]. Monocular SLAM methods have been developed for accurate, robust, and efficient tracking and mapping. With the development of SLAM, keyframe-based and direct methods are two main kinds of techniques. Keyframe-based SLAM approaches represent the map by a few selected frames and enhance the localization performance through BA optimization. Among these methods, the representative system PTAM [21] processes tracking and mapping tasks in parallel threads to estimate motion and builds the map of the unknown scene. DTAM [18] minimizes a global energy function to produce a surface patchwork with millions of vertices, with hundreds of images as inputs instead of a simple photometric data term. ORB-SLAM2 [17] utilizes fast ORB features and bags of words for tracking, relocalization, loop closure, and mapping, achieving state-of-the-art pose estimation accuracy. ORB-SLAM3 [20] exploits maximum a posteriori estimation during the IMU initialization phase to improve localization robustness. DM-VIO [22] uses delayed marginalization and pose graph bundle adjustment into visual–inertial odometry. DynaVINS [23] uses a robust bundle adjustment that can reject the features from dynamic objects by leveraging pose priors estimated by IMU preintegration.
2.2. Semantic SLAM
Semantic SLAM combines semantic information with the traditional pipeline to obtain more accurate and robust performance [24,25,26,27]. DynaSLAM [24] adds dynamic object detection and background inpainting by multi-view geometry, deep learning, or both. Moreover, DynaSLAM II [26] optimizes jointly static and dynamic parts with the trajectories of both the camera and the moving agents using a novel bundle adjustment proposal. DS-SLAM [25] combines a deep network with a moving consistency check method to improve robustness in dynamic environments. Frost et al. [14] adopted semantic information to recover the ground truth scale by adding scale evaluation into the BA process. CubeSLAM [12] proposes both single-image detection and multi-view object SLAM, and demonstrates that the two parts can improve each other. RigidFusion [28] presents a novel RGB-D SLAM approach to simultaneously segment, track, and reconstruct the static background and large dynamic rigid objects. YOLO-SLAM [29] proposes a dynamic-environment-robust visual SLAM system with a lightweight object detection network and a new geometric constraint method. Qiu et al. [30] proposed a novel method to resolve the object-scale ambiguity with a generic image-based two-dimensional tracker, which enables accurate metric three-dimensional tracking of arbitrary objects. Dynam-SLAM [31] loosely couples the visual scene stream with an IMU for dynamic feature detection and then optimizes the data measured using tight coupling. DGM-VINS [32] exploits a joint geometric dynamic feature extraction module and a temporal instance segmentation module to enhance system stability and localization accuracy. RLD-SLAM [33] combines object detection and Bayesian filtering to maintain high accuracy while quickly acquiring static feature points.
Different from these ideas, we enhance the performance of monocular SLAM with joint segmentation and depth estimation, exploiting pixel-level and object-level semantic information.
2.3. Joint Semantic Segmentation and Depth Estimation
As the depth and semantic labels share context information, many researchers focus on joint depth estimation and semantic segmentation [16,34,35,36]. Silberman et al. [37] proposed an RGB-D dataset with color, depth, and semantic information called NYU. Then, an extended dataset called SUN RGB-D with about ten thousand training and testing images was proposed [38]. Based on this dataset, Eigen et al. [39] addressed depth prediction, surface normal estimation, and semantic labeling with a multi-scale convolutional network. Furthermore, more CNN models [40,41] were proposed to improve segmentation performance through leveraging depth information. On the contrary, prior semantic labels can also improve depth prediction. Jiao et al. [15] designed a synergy network with an attention-driven loss to adopt semantic information to improve depth estimation. Focusing on time consumption, Nekrasov et al. [16] proposed a real-time network with asymmetric annotations for these two tasks. CI-Net [36] presented a network injected with contextual information to improve the accuracy of the two tasks.
The network presented in [16] satisfies the real-time requirements for SLAM systems. However, the accuracy of both branches still needs to be improved, especially for the depth estimation. To solve these limitations, we transform the depth to segmentation labels, focusing on the fixed range instead of the full depth. Moreover, we propose a fusion block, semantic consistency, and corresponding loss function to make the two branches improve each other.
3. JSDNet
3.1. Architecture
Improvements of JSDNet. Compared with previous works, four improvements are made to improve depth and segmentation precision in JSDNet. Firstly, we convert the depth regression to segmentation by a discretization strategy, addressing a fixed range instead of the full range. Secondly, to make the two branches improve each other, we define a feature fusion block in the decoder part. Thirdly, the learning-weighted loss function is designed to balance the two branches. Finally, we use the semantic consistency strategy to further improve depth and segmentation accuracy.
Depth discretization. In terms of depth prediction, JSDNet outputs depth information with a fixed depth range to achieve more accurate results. The method for this goal is to transform the depth regression task to a classification task with a spacing-increasing discretization strategy. The detailed formula is as follows:
where and denote the minimum and maximum values of the depth range, K represents the truncated number, and is the original depth value.
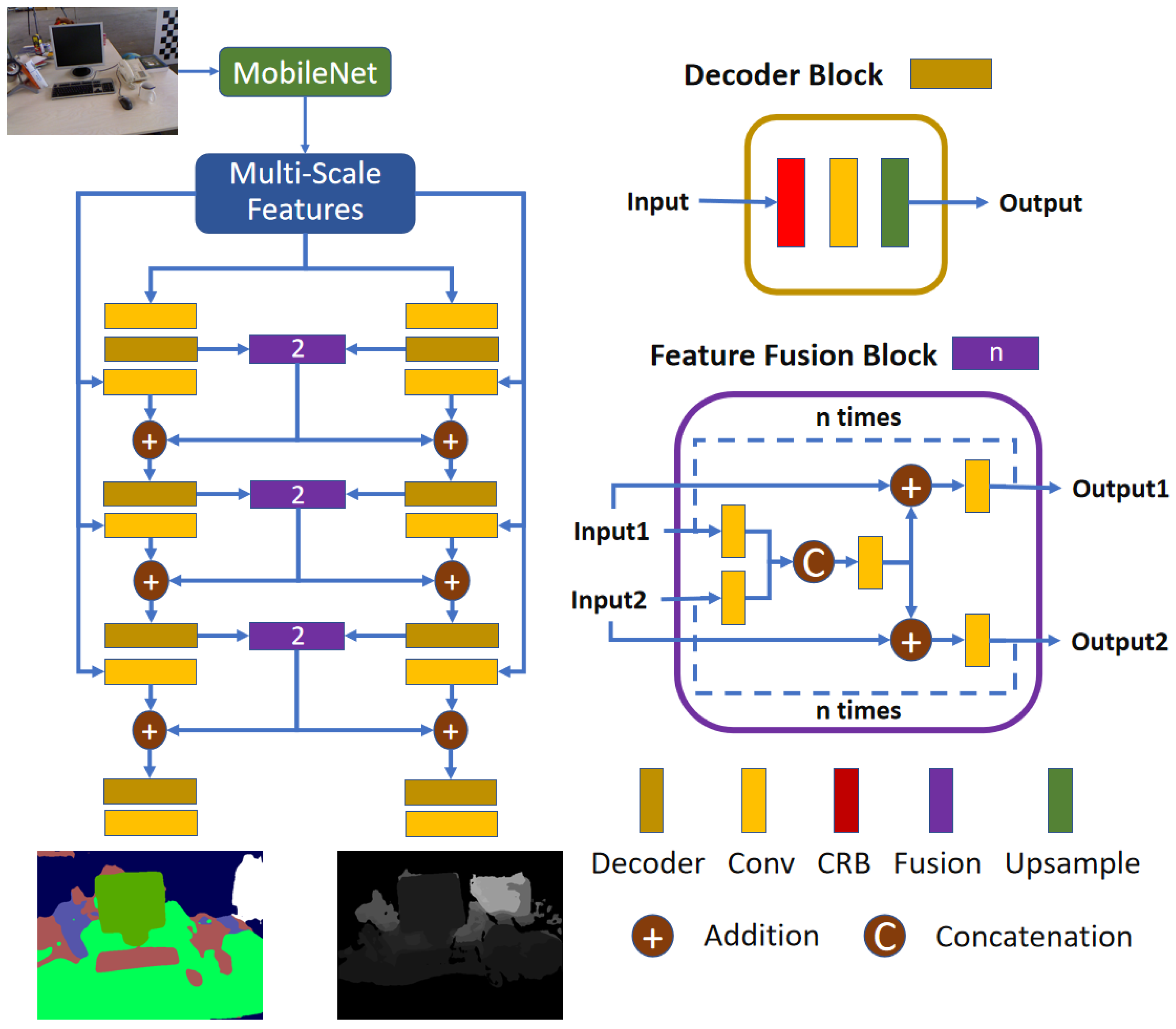
Feature fusion. We propose a feature fusion block in JSDNet to make the two branches improve each other. As demonstrated in Figure 2, JSDNet is composed of three branches covering feature extraction, depth estimation, and segmentation. Taking real-time property as the main consideration, JSDNet selects MobileNet_v3 [42] as the backbone. In the decoder part, both depth prediction and segmentation adopt a mirror-network structure using multi-scale features. The two branches keep the same architecture, composed of four blocks with each block containing two convolution layers: one CRB layer [16] and one upsample layer.
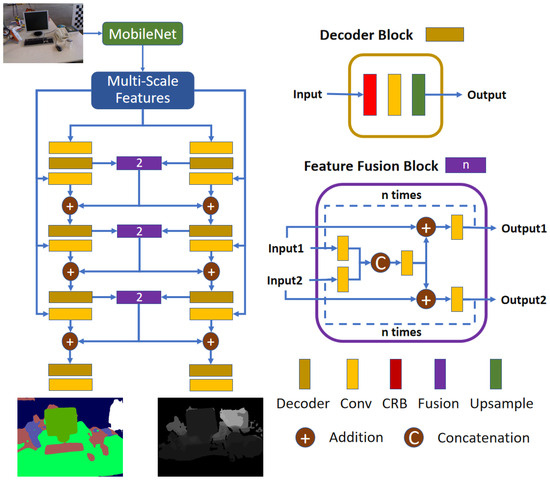
Figure 2.
Architecture of JSDNet. JSDNet regresses depth and segmentation with a monocular RGB image as input.
In particular, before the last three CRB layers, JSDNet sums the original outputs and fused features to implement parameter sharing between the two decoders. The architecture of the feature fusion block is shown in the purple box of Figure 2. Firstly, the depth and semantic features are applied with a convolution layer, and then concatenated. Secondly, the fused features are added to the original features, and a convolution layer is subsequently employed. Thirdly, the above two steps are performed n times to obtain the final outputs. In the actual implementation, we set . Obviously, the fusion block and the depth and semantic branches can affect each other, which the aim of improving the accuracy of both tasks, as shown in later experiments.
3.2. Loss Function
Corresponding to the outputs, the loss function also includes the segmentation and depth estimation terms. Since JSDNet converts depth regression to segmentation, both semantic and depth branches use the cross-entropy loss. The purpose of the depth estimation branch is to recover the ground truth scale value using Formula (10). As a consequence, the depth loss multiplies an inversion of the depth value by the cross-entropy loss. To balance these two losses, JSDNet uses homoscedastic uncertainty [43] with the following formula:
where W and H denote the image’s width and height, and represent the prediction and ground truth of the semantic labels, and express the prediction and ground truth of the depth labels, and D and S are parameters learned by the network.
3.3. Semantic Consistency
Semantic consistency process. To keep the consistency of depth estimation and segmentation, we design a consistency optimization process as follows. Firstly, we select any two frames (denoted as ) of images in the same scene, and obtain the depth and segmentation from JSDNet. Secondly, based on the camera pose of , we transform the depth and semantic labels of into the camera space of . Then, the loss (2) is employed to train JSDNet. Thirdly, similar to the second step, we also calculate the loss by transforming the camera space of to .
Semantic consistency dataset. With the above step, JSDNet can be trained with spatial consistency. Moreover, it is noticeable that the dataset for training semantic consistency does not need to contain semantic and depth labels. Instead, the dataset only includes RGB and its corresponding camera pose, which is easy to obtain.
Semantic consistency training. In particular, in each round of training, JSDNet is firstly trained by the ground truth depth and semantics, and then trained by consistency optimization.
4. Semantic SLAM
4.1. Visual Odometry
Traditional point features are always sensitive to environmental changes such as lighting or dynamics. We leverage semantic and depth information to enhance feature matching in visual odometry in terms of three aspects. Firstly, we add semantic label matching to the original ORB feature matching process. Secondly, the pixel matching in textureless areas and dynamic areas such as ground, wall, window, and person is removed. Thirdly, we discard the matching that goes out of the depth scope.
4.2. Three-Dimensional Object Representation and Generation
Compared with point feature-based maps, object-level representations are always more stable. In our SLAM system, we adopt both the 3D rectangular bounding box and hand-crafted feature points to represent the 3D object. For convenience, the bounding box of the 3D object is parameterized as 6 degrees covering the position and object size. The orientation is set the same as the three coordinate axes.
The construction process of semantic objects is the following. Through the combination of semantic segmentation and depth estimation, the 3D bounding box under the camera coordinate system is generated. Then, by means of the obtained camera pose with feature matching, the 3D object is mapped into the world space. Furthermore, 3D objects in the world space from different frames are judged in terms of uniqueness according to the union of objects and point feature matching.
By the above process, we establish the map with semantic objects, combining low-level point features with high-level semantic features. The built map is later exploited in the optimization process to achieve more accurate camera poses.
4.3. Object-Level Bundle Adjustment
By means of the traditional BA process, multiple components such as map points and camera poses are jointly optimized. In our implementations, the object constraint is also added to the optimization procedure, taking advantage of high-level semantic information to enhance accuracy and robustness. Camera poses, points, and objects are denoted as , , , respectively, for convenience, then BA can be expressed as the following nonlinear optimization problem:
where represent the camera-point, object-point and camera-object errors.
In the aspect of the camera-point error, we adopt the standard 3D point reprojection error from ORB-SLAM [17,19], with the following form:
where denotes the pixel coordinates of the 3D point, and represent the transformation matrices from world to camera and from camera to pixel. The object-point error measures the spatial relations between feature points and 3D objects. If a pixel point is identified as belonging to an object, then the corresponding 3D point in world coordinates should be located exactly on the object’s surface. This property can be utilized to design the object-point error by comparing the distance between the feature point and the center of the 3D object in pixel coordinates, which can be computed in two ways, either through a series of projections or measured directly in the pixel space:
where and denote the center and size of the object, respectively, and represents the center of the object in pixel coordinates.
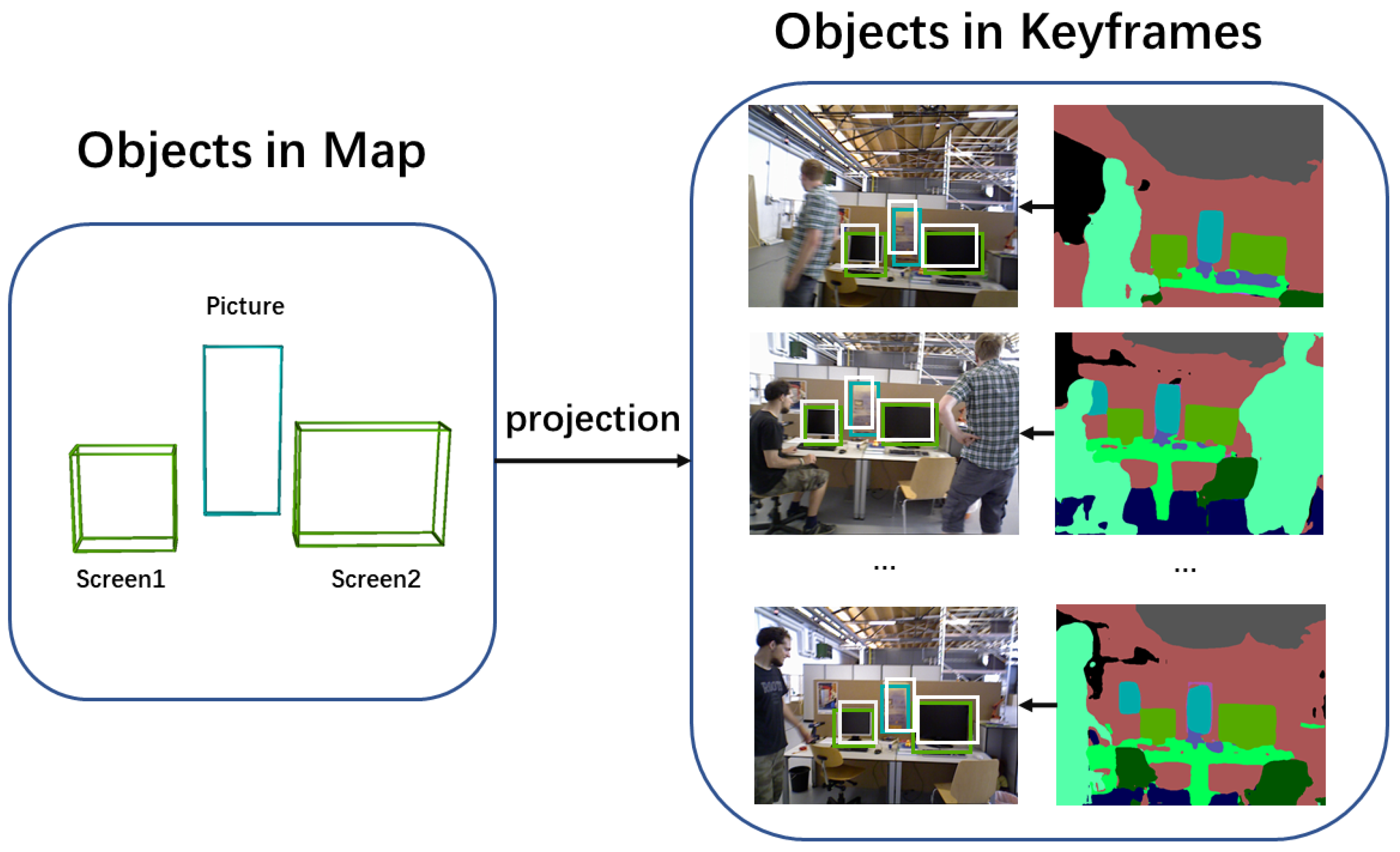
As Figure 3 demonstrates, each object in the world space is reprojected onto the image plane. Then, the object-camera error is calculated by comparing the reprojected 2D bounding box with the detected 2D bounding box from JSDNet.
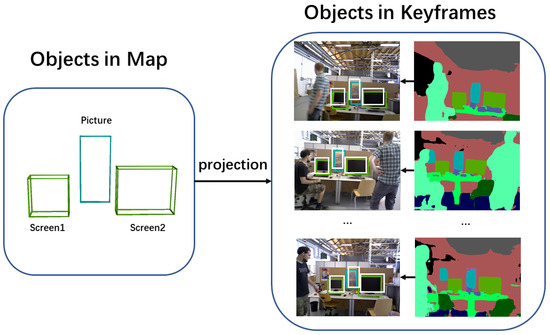
Figure 3.
Reprojection of semantic objects in map onto the keyframe plane. White boxes state the reprojection of objects in map, while green and blue boxes denote results detected by semantic segmentation.
4.4. Scale Restoring
After visual odometry and back-end optimization with additional semantic and depth information, the camera pose is refined and the semantic map is established. However, the scale drift and ambiguity problems still exist. In this subsection, we design a scale recovery process that outputs a scale-unified map with estimated depth information.
As Figure 1 shows, the scale recovery process is added to the system after local mapping. The problem is defined as follows:
where represents the set of map points, () denotes the observation keyframes of point , and is the estimated depth value. For convenience, is marked as . Then, the solution to (9) is obtained as follows:
Through the above formula, the scale value is estimated.
5. Experiments
5.1. Datasets and Implementation Details
Datasets. To verify the performance of our framework, we conduct experiments on NYU depth v2 [37] with depth estimation and segmentation, and on TUM RGB-D [44] with camera localization.
NYU depth v2 [37] is an indoor dataset with 795 training images and 654 testing images. The dataset is comprised of video sequences from a variety of indoor scenes as recorded by both the RGB and depth cameras from the Microsoft Kinect, which can support joint depth estimation and semantic segmentation.
TUM RGB-D [44] comprises a large number of color and depth images captured using a Kinect sensor. The ground truth camera pose of each image is estimated through a high-accuracy motion capture system. We select eight sequences from the dynamic object category to verify the dynamic localization performance.
Implementation details. In JSDNet, the RGB image is unified to pixels and enhanced with scale, flip, and padding. The depth information is truncated into 120 labels from m to 3 m. In addition, two extra labels are added to denote depths of less than m and more than 3 m. The feature extraction of JSDNet adopts the MobileNet_v2 architecture pretrained on the ImageNet dataset. To balance the depth and segmentation loss, learned coefficients of camera pose S and D are both initialized as . Moreover, the training strategy in the work [16] is also adopted. In addition to the above, JSDNet leverages the ADAM optimizer with an initial learning rate of for MobileNet_v3 and for the decoder. The implementation of our SLAM system is based on ORB-SLAM2. In the match process, the feature pixels with depths of more than 3.0 m or less than 1.0 m are discarded. Meanwhile, the textureless and dynamic semantic labels like wall, ceiling, window, and person are also removed from the match.
In the object generation process, objects identified with fewer than 10 feature points are also discarded. Moreover, objects generated from different frames are considered identical if the IoU is larger than 0.6 and the feature points match. In the BA process, the objects observed by more than of keyframes are added to the optimization.
5.2. Depth and Segmentation Results
Depth estimation results. In terms of depth prediction, we exploit the root mean square error (RMSE), average relative error (Rel), root mean square error in log space (RMSE-Log), and accuracy with threshold () as metrics, which is the same as previous works [16,34,35,36]. In detail, the metric is expressed by , where and denote the depth ground truth and prediction, respectively.
Table 1 lists the depth estimation results on NYU depth v2 compared with multi-task methods, including those of Eigen et al. [39], Mousavian et al. [34], Nekrasov et al. [16], SOSD-Net [35], CINet [36] Hoyer et al. [45], and Lopes et al. [46]. All methods focus on joint depth estimation and semantic segmentation.

Table 1.
Depth estimation results compared with other methods on NYU depth v2.
For the absolute metrics (RMSE and RMSE-Log), it is obvious that our result with depths of 0.5 m–3 m obtains the least error. Moreover, with full depth estimation, we also obtain a lower error compared with other methods. In the aspect of the relative metrics (Rel, , , and ), we also achieve the most accurate results. In short, both the above results demonstrate the state-of-the-art performance of our method.
Semantic segmentation results. The semantic segmentation results are illustrated in Table 2 on NYU depth v2 with pixel accuracy (Pixel-acc), mean accuracy (Mean-acc), and mean intersection over union (IoU) as metrics. The contrasted approaches are the same as for depth prediction in Table 1. It is obvious that our results are more accurate on Pixel-acc and IoU, but less accurate than SOSD-Net [35] on Mean-acc.
Table 2.
Semantic segmentation results compared with other methods on NYU depth v2.
Running time. In terms of inference speed, JSDNet achieves milliseconds for one image with a size on an Nvidia 3090 GPU, satisfying the real-time need of SLAM systems. Compared with the real-time approach [16], we obtain a improvement in the IoU metric.
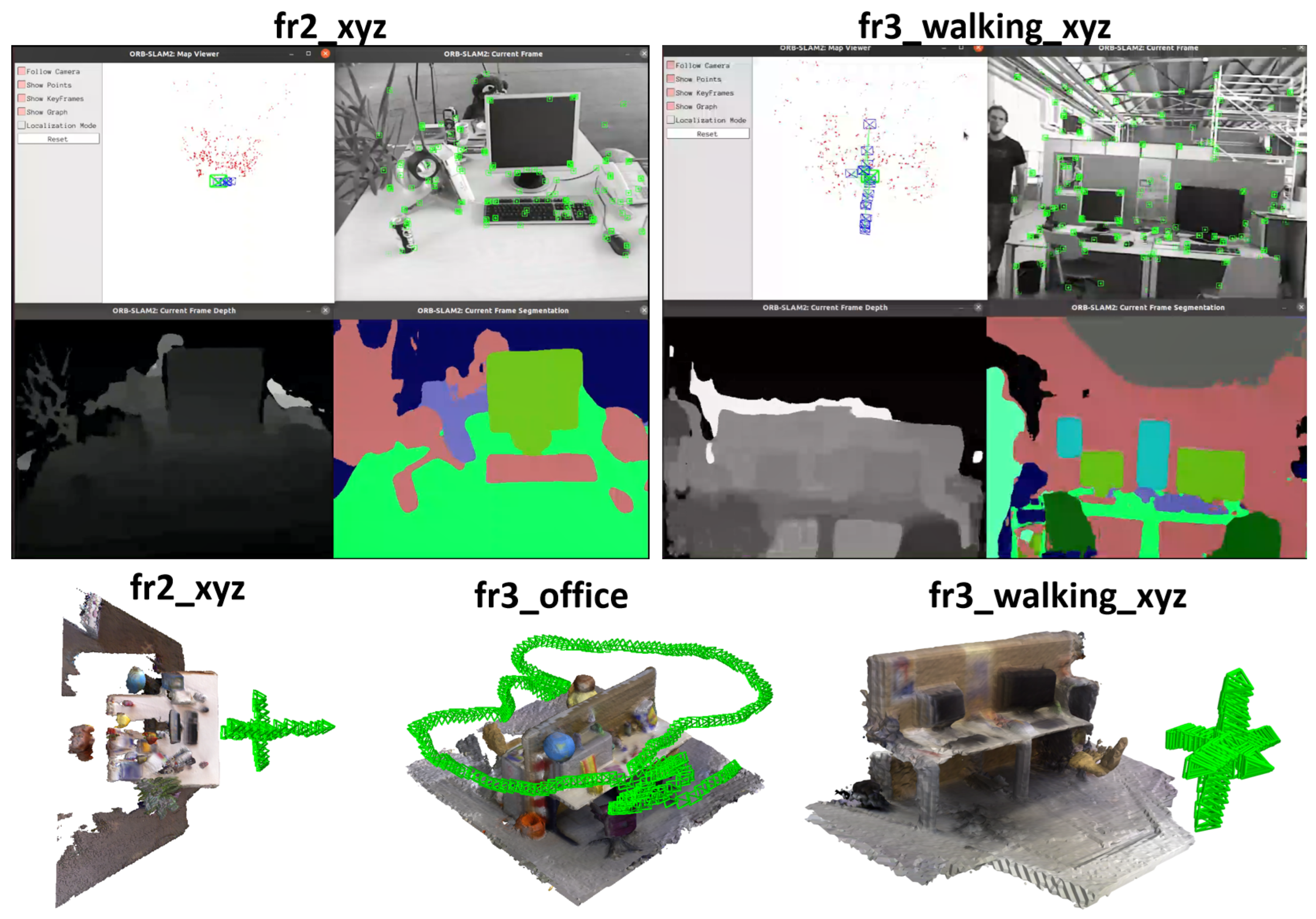
Visualization results. The top part of Figure 4 states the visualization results of depth and segmentation on TUM RGB-D. It is noticeable that TUM RGB-D does not contain the training semantic information. The results are obtained by training JSDNet on the whole of SUN RGB-D.
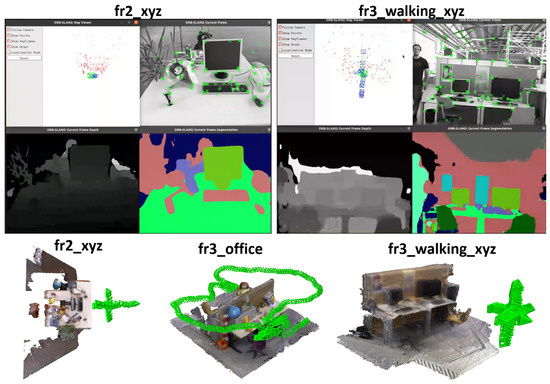
Figure 4.
Visualization of depth estimation, semantic segmentation, and predicted camera poses on TUM RGB-D dataset.
5.3. Object-Level SLAM Result
Static scenes. The quantitative results of localization accuracy on TUM RGB-D are shown in Table 3. In static scenes with monocular input, it is clearly seen that our SLAM system obtains less camera trajectory error compared with ORB-SLAM2 [17] and Luo et al. [9]. The localization improvements are , respectively, in the four experimental sequences compared with ORB-SLAM2, proving the effects of the estimated depth and semantic segmentation. When the input covers the additional depth information, our system also achieves better performance than ORB-SLAM2. The improvements show that the utilization of semantic information contributes to the more accurate localization results.
Table 3.
RMSE of absolute trajectory error (m) results on TUM RGB-D dataset.
Dynamic scenes. In dynamic scenes, we compare with ORB-SLAM2 [17], DS-SLAM [25], DynaSLAM [24], Refusion [47], LC-CRF SLAM [48], DGM-VINS [32], Wang et al. [49], and SG-SLAM [50] in Table 3. It is obvious that our SLAM system with RGB-D input achieves the best performance. Moreover, lines 1, 2, and 9 demonstrate that the monocular system outperforms ORB-SLAM2 and DS-SLAM. This is due to the depth estimation improvement with the fixed range.
Camera pose visualization. The bottom part of Figure 4 states the camera pose visualization results predicted by our SLAM result in both static (fr2_xyz, fr2_office) and dynamic scenes (fr3_walking_xyz). It is obvious that the pose sequences remain stable, which demonstrates localization robustness.
5.4. Ablation Studies
Discussion of outstanding performance. In the above experiments, the results demonstrate state-of-the-art performance on depth estimation, semantic segmentation, and camera localization. In our opinion, the reason for improvement lies in three aspects. Firstly, we design the feature fusion module for feature sharing jointly using depth estimation and semantic segmentation. Secondly, we propose the semantic consistency process to guarantee depth and semantics in different views, which not only improves the two tasks, but also contributes to feature matching in camera localization. Thirdly, we put forward object-level BA for camera pose and map optimization that combines hand-crafted features and predicted semantic object features. In the following, we conduct ablation experiments to prove the effect of these modules.
Ablation studies of feature fusion block and semantic consistency on depth estimation and semantic segmentation. To validate the effects of the feature fusion block and semantic consistency, we perform ablation studies on both segmentation and depth estimation, with the results shown in Table 4. In the settings S2 and S3 of Table 4, we remove feature fusion and semantic consistency, respectively. It is clear that both the RMSE and IoU metrics decrease, which proves the positive effect of the two modules. Moreover, we remove both the modules in the setting . It can be seen that the accuracy further decreases compared with and .
Table 4.
Ablation studies on the effects of feature fusion and semantic consistency on depth estimation (RMSE) and segmentation (IoU).
Ablation studies of feature fusion, semantic consistency, and object-level BA on localization. In S1–S8 of Table 5, we show the results of ablation studies on the impact of the three modules on localization. All the results in the table are obtained by using RGB-D as input. When there is no object-level BA process, we use the traditional BA defined in ORB-SLAM2 instead. Without feature fusion and semantic consistency, we also exploit the predicted depth and segmentation from the visual odometer.
Table 5.
Ablation studies on the effects of feature fusion, semantic consistency, and object-level BA on localization performance.
In settings and , we remove feature fusion, semantic consistency, and object-level BA, respectively. It can be see that the localization errors all increase compared with , proving the positive effect of the three modules. Moreover, the localization error order of these four settings is >>>. The results indicate that the feature fusion module has a small effect on localization ( to ), while the effects of semantic consistency and object-level BA are large ( to and ). The explanations are as follows. The feature fusion module mainly aims to improve depth estimation and segmentation, but this has little effect on localization. In contrast, semantic consistency not only improves the two tasks, but also contributes to feature matching in the visual odometer, hence generates a large effect on the localization results. In settings and , two modules are removed. From the result pairs and and and , the accuracy increase with feature fusion is further validated. Meanwhile, improvements with semantic consistency and object-level BA can also be proven. When we remove the three modules (), the localization generates the most increase, which sufficiently proves the positive effect of the three modules on localization.
6. Conclusions
In this paper, paying attention to localization robustness and accuracy of the monocular SLAM system, we study the object-level SLAM system design with the enhancement of joint depth estimation and semantic segmentation. We first propose a joint learning network called JSDNet that outputs both depth estimation and semantic segmentation. To improve the performance of JSDNet, a fusion block and semantic consistency modules are designed. Specifically, the feature fusion combines depth estimation features with segmentation features, with the aim of improving both tasks, while semantic consistency guarantees depth and segmentation consistency under different views. To train JSDNet, we design an appropriate loss function with learned weights to balance the two tasks. Based on the results of JSDNet, we define the object-level BA error with additional camera-object and object-point constraints to improve localization accuracy and robustness. Additionally, we design a scale recovery procedure to obtain a stable scale. To validate the performance, experiments of JSDNet and the proposed SLAM system are conducted. First, in terms of depth estimation and semantic segmentation on NYU depth v2, we achieve state-of-the-art performance compared with other methods while keeping real-time performance. Second, our object-level SLAM system obtains a lower RMSE error on both static and dynamic scenes of the TUM RGB-D dataset. Moreover, ablation experiments of the feature fusion, semantic consistency, and object-level BA are conducted, which sufficiently prove the positive effect of the three modules on depth prediction, semantic segmentation, and localization.
In this paper, we make a good attempt at embedding the predicted depth and segmentation into the SLAM system with visual odometer and optimization. For future work, it is recommended to investigate a method that combines semantics with multi-source data, such as RGB, depth, inertial measurement units, and so on. In our opinion, this may further improve the localization robustness.
Author Contributions
Conceptualization, R.G. and Y.Q.; methodology, R.G. and Y.Q.; software, R.G.; validation, R.G. and Y.Q.; formal analysis, R.G.; investigation, R.G.; resources, Y.Q.; data curation, Y.Q.; writing—original draft preparation, R.G.; writing—review and editing, Y.Q.; visualization, R.G.; supervision, Y.Q.; project administration, Y.Q.; funding acquisition, Y.Q. All authors have read and agreed to the published version of the manuscript.
Funding
This paper is supported by the National Natural Science Foundation of China (No. 62072020) and Leading Talents in Innovation and Entrepreneurship of Qingdao, China (19-3-2-21-zhc).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The original data presented in the study are openly available in [37,44].
Acknowledgments
We thank the anonymous reviewers for their valuable suggestions.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Wei, X.; Huang, J.; Ma, X. Real-time monocular visual slam by combining points and lines. In Proceedings of the IEEE International Conference on Multimedia and Expo, Shanghai, China, 8–12 July 2019; pp. 103–108. [Google Scholar]
- Wang, J.; Qi, Y. Scene-independent Localization by Learning Residual Coordinate Map with Cascaded Localizers. In Proceedings of the IEEE International Symposium on Mixed and Augmented Reality, Sydney, Australia, 16–20 October 2023; pp. 79–88. [Google Scholar]
- Hu, W.; Zhang, Y.; Liang, Y.; Yin, Y.; Georgescu, A.; Tran, A.; Kruppa, H.; Ng, S.K.; Zimmermann, R. Beyond geo-localization: Fine-grained orientation of street-view images by cross-view matching with satellite imagery. In Proceedings of the ACM International Conference on Multimedia, Lisboa, Portugal, 10–14 October 2022; pp. 6155–6164. [Google Scholar]
- Leng, K.; Yang, C.; Sui, W.; Liu, J.; Li, Z. Sitpose: A Siamese Convolutional Transformer for Relative Camera Pose Estimation. In Proceedings of the International Conference on Multimedia and Expo, Brisbane, Australia, 10–14 July 2023; pp. 1871–1876. [Google Scholar]
- Li, W.; Wang, Y.; Guo, Y.; Wang, S.; Shao, Y.; Bai, X.; Cai, X.; Ye, Q.; Li, D. ColSLAM: A Versatile Collaborative SLAM System for Mobile Phones Using Point-Line Features and Map Caching. In Proceedings of the ACM International Conference on Multimedia, Brisbane, Australia, 10–14 July 2023; pp. 9032–9041. [Google Scholar]
- Chang, Y.; Hu, J.; Xu, S. OTE-SLAM: An Object Tracking Enhanced Visual SLAM System for Dynamic Environments. Sensors 2023, 23, 7921. [Google Scholar] [CrossRef] [PubMed]
- Lin, B.H.; Shivanna, V.M.; Chen, J.S.; Guo, J.I. 360° Map Establishment and Real-Time Simultaneous Localization and Mapping Based on Equirectangular Projection for Autonomous Driving Vehicles. Sensors 2023, 23, 5560. [Google Scholar] [CrossRef] [PubMed]
- Vial, P.; Puig, V. Kinematic/Dynamic SLAM for Autonomous Vehicles Using the Linear Parameter Varying Approach. Sensors 2022, 22, 8211. [Google Scholar] [CrossRef] [PubMed]
- Luo, H.; Gao, Y.; Wu, Y.; Liao, C.; Yang, X.; Cheng, K. Real-Time Dense Monocular SLAM With Online Adapted Depth Prediction Network. IEEE Trans. Multimed. 2019, 21, 470–483. [Google Scholar]
- McCormac, J.; Handa, A.; Davison, A.; Leutenegger, S. SemanticFusion: Dense 3D semantic mapping with convolutional neural networks. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation, Singapore, 29 May–3 June 2017; pp. 4628–4635. [Google Scholar]
- Liang, H.J.; Sanket, N.J.; Fermüller, C.; Aloimonos, Y. Salientdso: Bringing attention to direct sparse odometry. IEEE Trans. Autom. Sci. Eng. 2019, 16, 1619–1626. [Google Scholar]
- Yang, S.; Scherer, S. Cubeslam: Monocular 3-D object slam. IEEE Trans. Robot. 2019, 35, 925–938. [Google Scholar]
- Wang, J.; Qi, Y. Simultaneous Scene-independent Camera Localization and Category-level Object Pose Estimation via Multi-level Feature Fusion. In Proceedings of the IEEE Conference Virtual Reality and 3D User Interfaces, Shanghai, China, 25–29 March 2023; pp. 254–264. [Google Scholar]
- Frost, D.; Prisacariu, V.; Murray, D. Recovering Stable Scale in Monocular SLAM Using Object-Supplemented Bundle Adjustment. IEEE Trans. Robot. 2018, 34, 736–747. [Google Scholar] [CrossRef]
- Jiao, J.; Cao, Y.; Song, Y.; Lau, R. Look deeper into depth: Monocular depth estimation with semantic booster and attention-driven loss. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 53–69. [Google Scholar]
- Nekrasov, V.; Dharmasiri, T.; Spek, A.; Drummond, T.; Shen, C.; Reid, I. Real-time joint semantic segmentation and depth estimation using asymmetric annotations. In Proceedings of the International Conference on Robotics and Automation, Montreal, QC, Canada, 20–24 May 2019; pp. 7101–7107. [Google Scholar]
- Mur-Artal, R.; Tardós, J.D. ORB-SLAM2: An Open-Source SLAM System for Monocular, Stereo, and RGB-D Cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar]
- Newcombe, R.A.; Lovegrove, S.J.; Davison, A.J. DTAM: Dense tracking and mapping in real-time. In Proceedings of the International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2320–2327. [Google Scholar]
- Mur-Artal, R.; Montiel, J.M.M.; Tardós, J.D. ORB-SLAM: A Versatile and Accurate Monocular SLAM System. IEEE Trans. Robot. 2015, 31, 1147–1163. [Google Scholar]
- Campos, C.; Elvira, R.; Rodríguez, J.J.G.; Montiel, J.M.; Tardós, J.D. Orb-slam3: An accurate open-source library for visual, visual–inertial, and multimap slam. IEEE Trans. Robot. 2021, 37, 1874–1890. [Google Scholar]
- Klein, G.; Murray, D. Parallel Tracking and Mapping for Small AR Workspaces. In Proceedings of the 2007 6th IEEE and ACM International Symposium on Mixed and Augmented Reality, Nara, Japan, 13–16 November 2007; pp. 225–234. [Google Scholar]
- Von Stumberg, L.; Cremers, D. DM-VIO: Delayed marginalization visual-inertial odometry. IEEE Robot. Autom. Lett. 2022, 7, 1408–1415. [Google Scholar] [CrossRef]
- Song, S.; Lim, H.; Lee, A.J.; Myung, H. DynaVINS: A visual-inertial SLAM for dynamic environments. IEEE Robot. Autom. Lett. 2022, 7, 11523–11530. [Google Scholar] [CrossRef]
- Bescos, B.; Fácil, J.M.; Civera, J.; Neira, J. DynaSLAM: Tracking, mapping, and inpainting in dynamic scenes. IEEE Robot. Autom. Lett. 2018, 3, 4076–4083. [Google Scholar] [CrossRef]
- Yu, C.; Liu, Z.; Liu, X.; Xie, F.; Yang, Y.; Wei, Q.; Fei, Q. DS-SLAM: A Semantic Visual SLAM towards Dynamic Environments. In Proceedings of the International Conference on Intelligent Robots and Systems, Madrid, Spain, 1–5 October 2018; pp. 1168–1174. [Google Scholar]
- Bescos, B.; Campos, C.; Tardós, J.D.; Neira, J. DynaSLAM II: Tightly-coupled multi-object tracking and SLAM. IEEE Robot. Autom. Lett. 2021, 6, 5191–5198. [Google Scholar] [CrossRef]
- Wang, J.; Qi, Y. Visual camera relocalization using both hand-crafted and learned features. Pattern Recognition 2024, 145, 109914. [Google Scholar] [CrossRef]
- Long, R.; Rauch, C.; Zhang, T.; Ivan, V.; Vijayakumar, S. Rigidfusion: Robot localisation and mapping in environments with large dynamic rigid objects. IEEE Robot. Autom. Lett. 2021, 6, 3703–3710. [Google Scholar] [CrossRef]
- Wu, W.; Guo, L.; Gao, H.; You, Z.; Liu, Y.; Chen, Z. YOLO-SLAM: A semantic SLAM system towards dynamic environment with geometric constraint. Neural Comput. Appl. 2022, 34, 6011–6026. [Google Scholar] [CrossRef]
- Qiu, K.; Qin, T.; Gao, W.; Shen, S. Tracking 3-D motion of dynamic objects using monocular visual-inertial sensing. IEEE Trans. Robot. 2019, 35, 799–816. [Google Scholar] [CrossRef]
- Xiao, L.; Wang, J.; Qiu, X.; Rong, Z.; Zou, X. Dynamic-SLAM: Semantic monocular visual localization and mapping based on deep learning in dynamic environment. Robot. Auton. Syst. 2019, 117, 1–16. [Google Scholar] [CrossRef]
- Song, B.; Yuan, X.; Ying, Z.; Yang, B.; Song, Y.; Zhou, F. DGM-VINS: Visual-Inertial SLAM for Complex Dynamic Environments with Joint Geometry Feature Extraction and Multiple Object Tracking. IEEE Trans. Instrum. Meas. 2023, 72, 8503711. [Google Scholar] [CrossRef]
- Zheng, Z.; Lin, S.; Yang, C. RLD-SLAM: A Robust Lightweight VI-SLAM for Dynamic Environments Leveraging Semantics and Motion Information. IEEE Trans. Ind. Electron. 2024, 71, 14328–14338. [Google Scholar]
- Mousavian, A.; Pirsiavash, H.; Košecká, J. Joint semantic segmentation and depth estimation with deep convolutional networks. In Proceedings of the International Conference on 3D Vision, Stanford, CA, USA, 25–28 October 2016; pp. 611–619. [Google Scholar]
- He, L.; Lu, J.; Wang, G.; Song, S.; Zhou, J. SOSD-Net: Joint semantic object segmentation and depth estimation from monocular images. Neurocomputing 2021, 440, 251–263. [Google Scholar]
- Gao, T.; Wei, W.; Cai, Z.; Fan, Z.; Xie, S.Q.; Wang, X.; Yu, Q. CI-Net: A joint depth estimation and semantic segmentation network using contextual information. Appl. Intell. 2022, 52, 18167–18186. [Google Scholar] [CrossRef]
- Silberman, N.; Hoiem, D.; Kohli, P.; Fergus, R. Indoor segmentation and support inference from rgbd images. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 746–760. [Google Scholar]
- Song, S.; Lichtenberg, S.P.; Xiao, J. Sun rgb-d: A rgb-d scene understanding benchmark suite. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 567–576. [Google Scholar]
- Eigen, D.; Fergus, R. Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2650–2658. [Google Scholar]
- Qi, X.; Liao, R.; Jia, J.; Fidler, S.; Urtasun, R. 3D Graph Neural Networks for RGBD Semantic Segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5209–5218. [Google Scholar]
- Song, S.; Yu, F.; Zeng, A.; Chang, A.X.; Savva, M.; Funkhouser, T. Semantic Scene Completion from a Single Depth Image. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 190–198. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for mobilenetv3. In Proceedings of the International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Kendall, A.; Cipolla, R. Geometric loss functions for camera pose regression with deep learning. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5974–5983. [Google Scholar]
- Sturm, J.; Engelhard, N.; Endres, F.; Burgard, W.; Cremers, D. A Benchmark for the Evaluation of RGB-D SLAM Systems. In Proceedings of the International Conference on Intelligent Robot Systems, Vilamoura-Algarve, Portugal, 7–12 October 2012. [Google Scholar]
- Hoyer, L.; Dai, D.; Chen, Y.; Koring, A.; Saha, S.; Van Gool, L. Three ways to improve semantic segmentation with self-supervised depth estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 11130–11140. [Google Scholar]
- Lopes, I.; Vu, T.H.; de Charette, R. Cross-task attention mechanism for dense multi-task learning. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–7 January 2023; pp. 2329–2338. [Google Scholar]
- Palazzolo, E.; Behley, J.; Lottes, P.; Giguere, P.; Stachniss, C. Refusion: 3D reconstruction in dynamic environments for rgb-d cameras exploiting residuals. In Proceedings of the International Conference on Intelligent Robots and Systems, Macau, China, 3–8 November 2019; pp. 7855–7862. [Google Scholar]
- Du, Z.J.; Huang, S.S.; Mu, T.J.; Zhao, Q.; Martin, R.R.; Xu, K. Accurate dynamic SLAM using CRF-based long-term consistency. IEEE Trans. Vis. Comput. Graph. 2020, 28, 1745–1757. [Google Scholar]
- Wang, K.; Yao, X.; Ma, N.; Jing, X. Real-time motion removal based on point correlations for RGB-D SLAM in indoor dynamic environments. Neural Comput. Appl. 2023, 35, 8707–8722. [Google Scholar] [CrossRef]
- Cheng, S.; Sun, C.; Zhang, S.; Zhang, D. SG-SLAM: A real-time RGB-D visual SLAM toward dynamic scenes with semantic and geometric information. IEEE Trans. Instrum. Meas. 2022, 72, 7501012. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).