
An Innovative Small-Target Detection Approach Against Information Attenuation: Fusing Enhanced Programmable Gradient Information and a Novel Mamba Module


Abstract
1. Introduction
- 2.
- 3.
2. Related Work
2.1. Mamba and Vision Mamba
2.2. YOLOv9 and Programmable Gradient Information (PGI)
3. Method and Principle
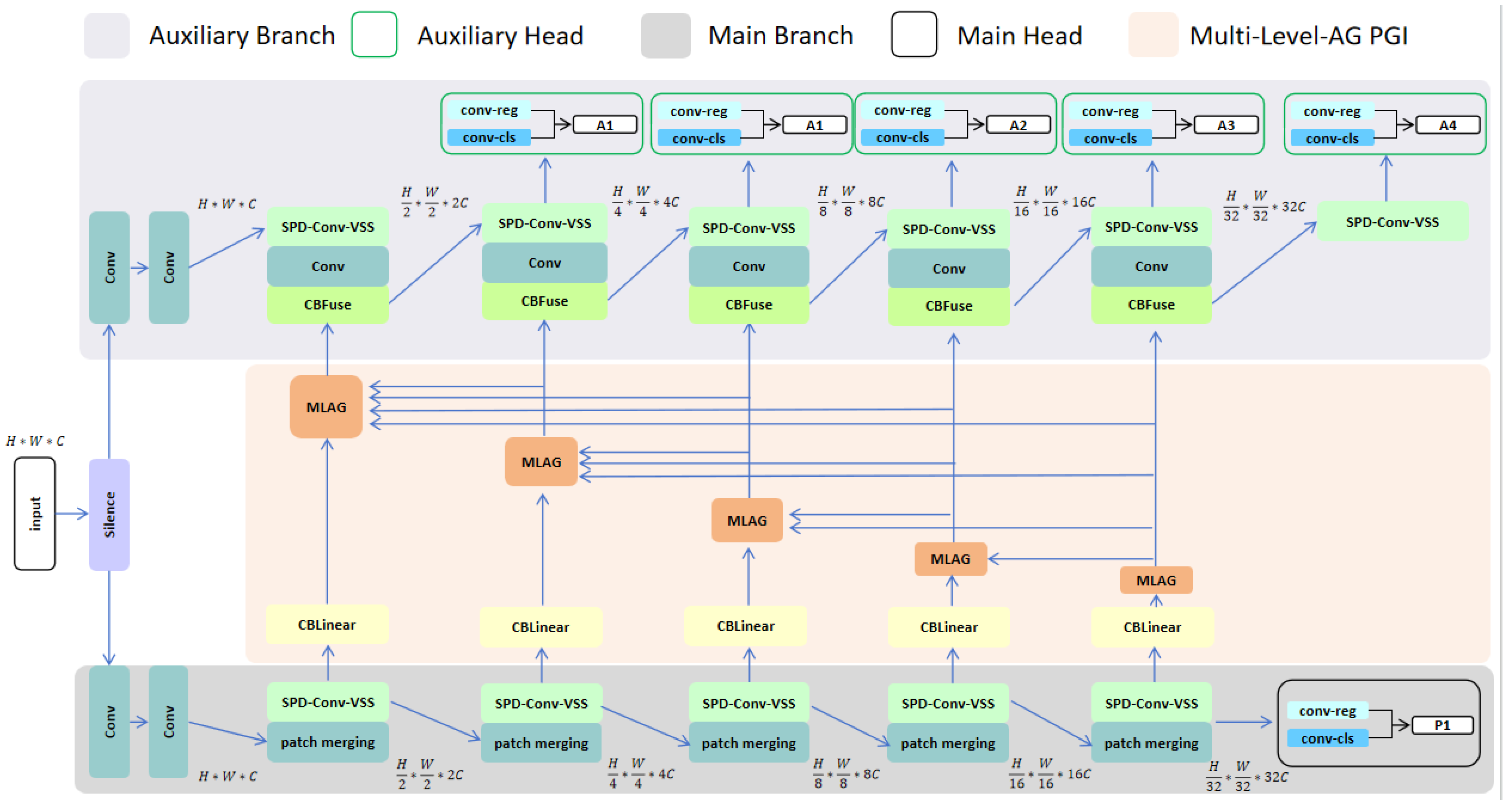
3.1. Architecture Overview
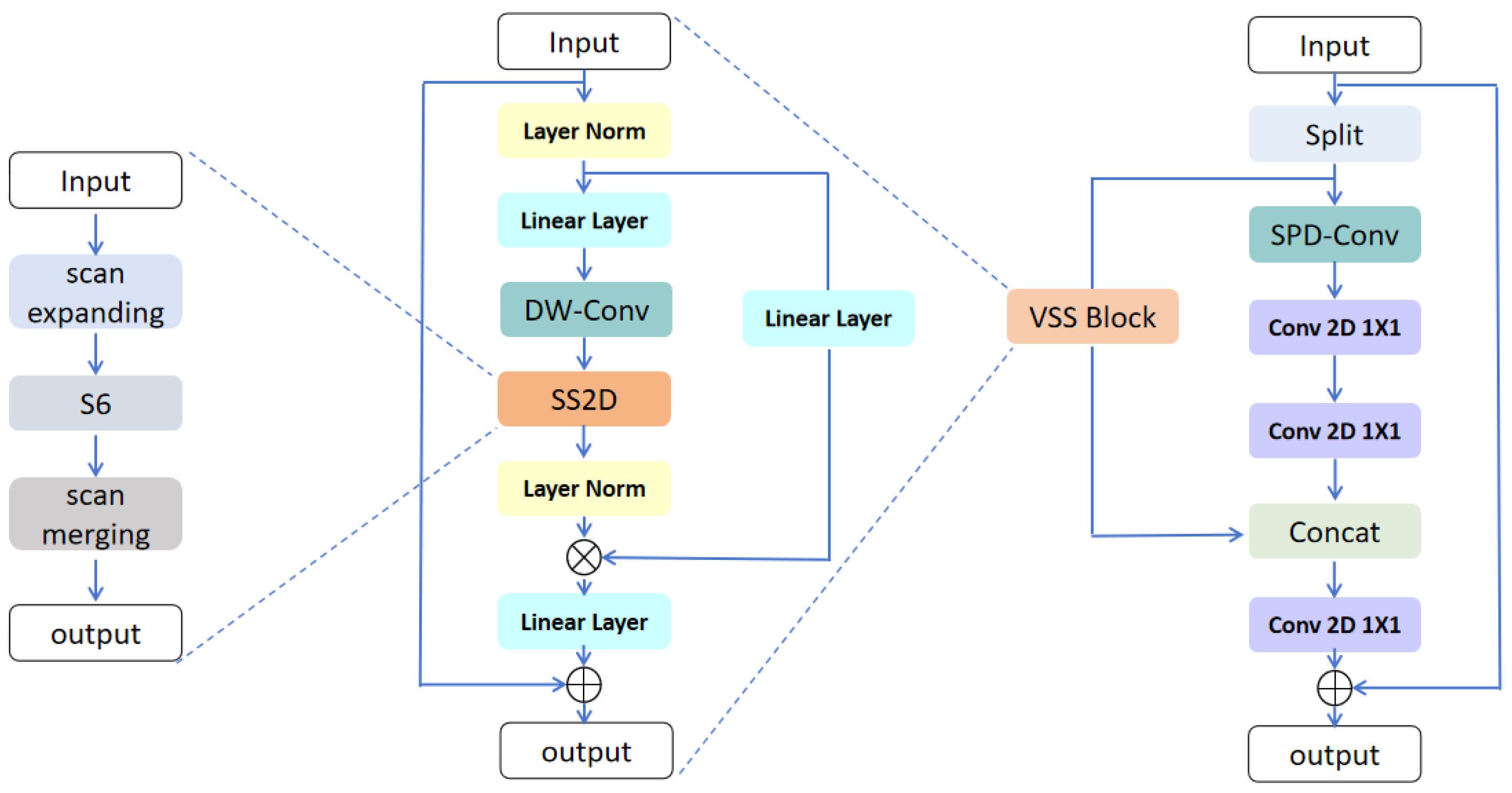
3.2. SPD-Conv-VSS Module
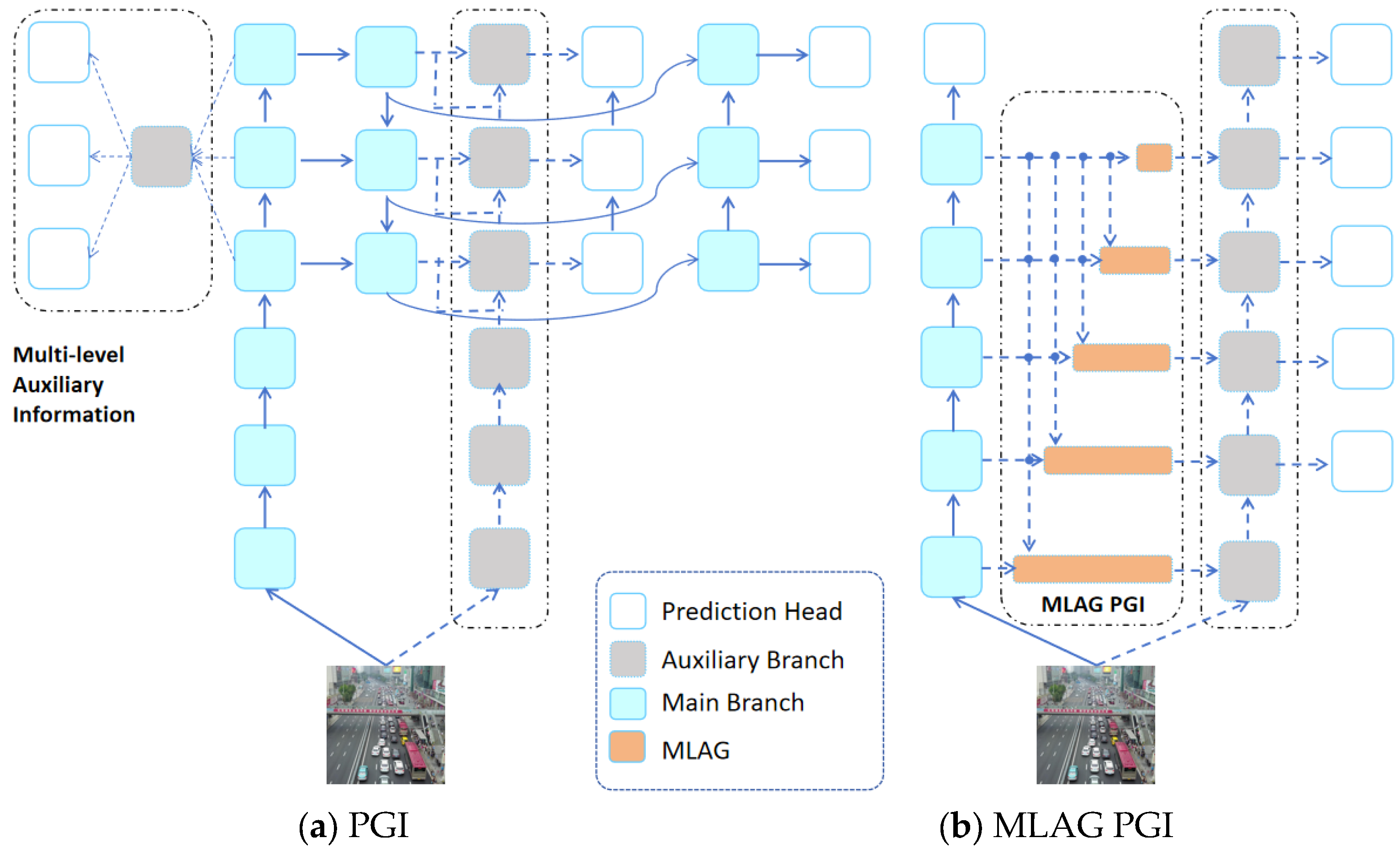
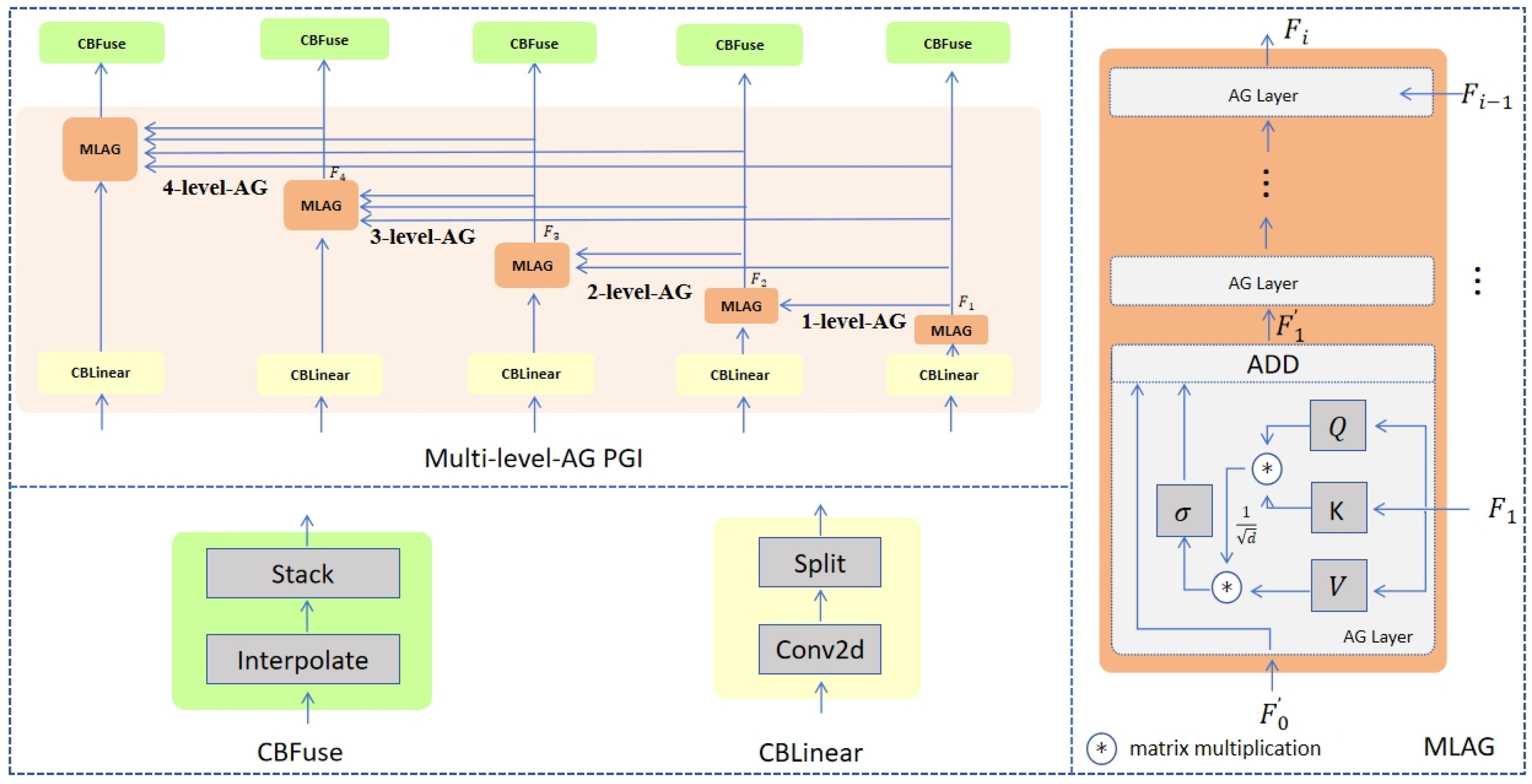
3.3. Multi-Level Attention-Gated PGI (MLAG PGI)
4. Experiments
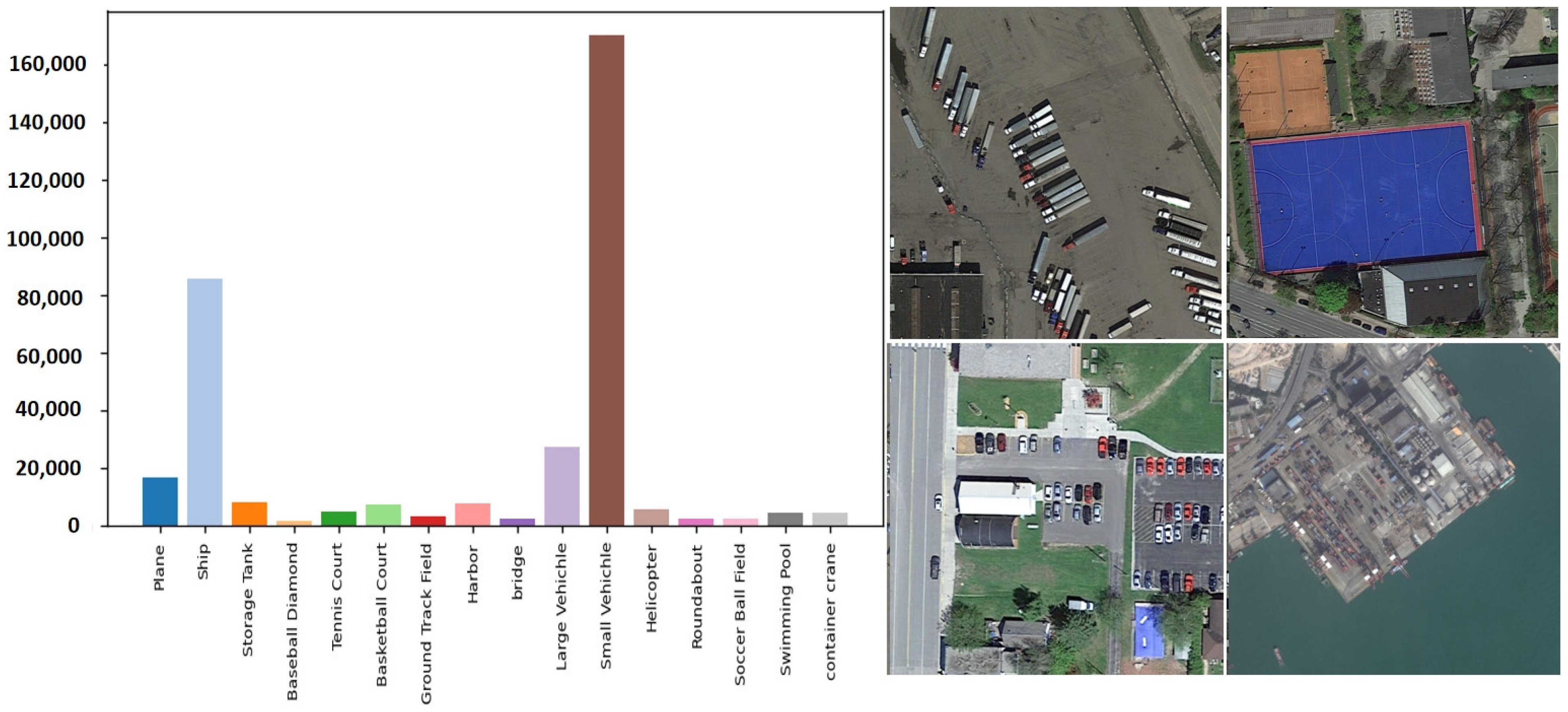
4.1. Datasets
4.2. Experimental Details
4.3. Comparison Results
4.3.1. Comparison with State-of-the-Art Methods
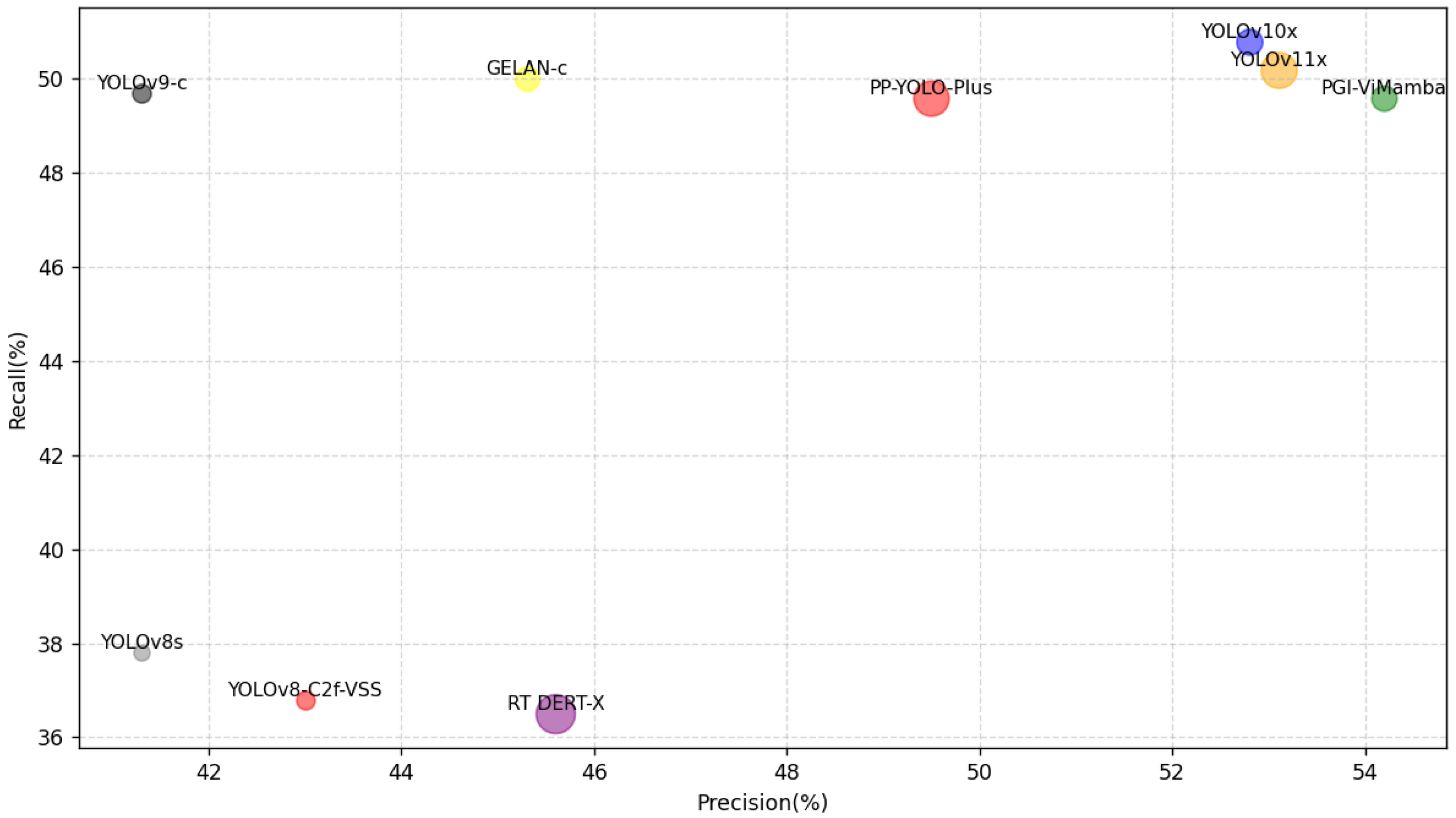
4.3.2. Comparison of Precision and Recall Rate of Different Models
4.3.3. Comparison of Precision and Recall of Different Objects
5. Ablation Study
5.1. Comparison of Different Levels of MLAG PGI
5.2. Comparison of Different Information Extraction Backbone Networks
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lin, T.-Y.; Dollár, P.; Girshick, R.B.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- He, H.; Bai, Y.; Garcia, E.A.; Li, S. ADASYN: Adaptive Synthetic Sampling Approach for Imbalanced Learning. In Proceedings of the IEEE International Joint Conference on Neural Networks (IJCNN), Hong Kong, China, 1–8 June 2008; pp. 1322–1328. [Google Scholar]
- Han, H.; Wang, W.-Y.; Mao, B.-H. Borderline-SMOTE: A New Over-Sampling Method in Imbalanced Data Sets Learning. In Proceedings of the International Conference on Intelligent Computing (ICIC), Hefei, China, 23–26 August 2005; pp. 878–887. [Google Scholar]
- Chawla, N.V.; Japkowicz, N.; Kotcz, A. SMOTE for Learning from Imbalanced Data: Progress and Challenges. J. Artif. Intell. Res. 2004, 21, 1–16. [Google Scholar]
- Yang, T.; Zhang, X.; Li, Z.; Zhang, W.; Sun, J. MetaAnchor: Learning to Detect Objects with Customized Anchors. arXiv 2018, arXiv:1807.00980. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.B.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Zhu, L.; Liao, B.; Zhang, Q.; Wang, X.; Liu, W.; Wang, X. Vision Mamba: Efficient Visual Representation Learning with Bidirectional State Space Model. arXiv 2024, arXiv:2401.09417. [Google Scholar]
- Wang, C.; Yeh, I.; Liao, H. YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information. arXiv 2024, arXiv:2402.13616. [Google Scholar]
- Gu, A.; Dao, T. Mamba: Linear-time sequence modeling with selective state spaces. arXiv 2023, arXiv:2312.00752. [Google Scholar]
- Gu, A.; Johnson, I.; Goel, K.; Saab, K.; Dao, T.; Rudra, A.; Ré, C. Combining Recurrent, Convolutional, and Continuous-time Models with Linear State-Space Layers. arXiv 2021, arXiv:2110.13985. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Redmon, J.; Divvala, S.K.; Girshick, R.B.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.; Liao, H.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Wang, C.; Bochkovskiy, A.; Liao, H.M. Scaled-YOLOv4: Scaling Cross Stage Partial Network. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13024–13033. [Google Scholar]
- Ge, Z.; Liu, S.T.; Wang, F.; Li, Z.M.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Li, Y.; Chen, X.; Wang, Z.; Liu, Y. SPD-Conv: A New Convolutional Layer for Improving CNN Performance on Low-Resolution Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 12345–12354. [Google Scholar]
- Gu, A.; Goel, K.; Ré, C. Efficiently Modeling Long Sequences with Structured State Spaces. arXiv 2021, arXiv:2111.00396. [Google Scholar]
- Liu, Y.; Tian, Y.; Zhao, Y.; Yu, H.; Xie, L.; Wang, Y.; Ye, Q.; Liu, Y. VMamba: Visual State Space Model. arXiv 2024, arXiv:2401.10166. [Google Scholar]
- Zhu, P.; Wen, L.; Du, D.; Bian, X.; Fan, H.; Hu, Q.; Ling, H. Detection and Tracking Meet Drones Challenge. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 7380–7399. [Google Scholar] [PubMed]
- Xia, G.-S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A large-scale dataset for object detection in aerial images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 3974–3983. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Param. (M) | FLOPs (G) | P (%) | R (%) | mAP50 (%) | FPS |
|---|---|---|---|---|---|---|
| YOLOv8s | 11.2 | 28.6 | 41.3/60.1 * | 37.8/58.3 | 22.1/25.6 | 188 |
| YOLOv8-C2f-VSS | 14.9 | 35.9 | 43.0/63.8 | 36.8/57.8 | 35.9/38.9 | 164 |
| YOLOv9-c | 25.3 | 102.1 | 41.3/61.3 | 49.7/63.4 | 41.3/42.5 | 150 |
| YOLOv10x | 29.5 | 160.4 | 52.8/70.1 | 50.8/66.7 | 40.8/43.6 | 84 |
| YOLOv11x | 56.9 | 194.9 | 53.1/72.0 | 50.2/65.4 | 41.6/44.8 | 92 |
| GELAN-c | 25.5 | 102.8 | 45.3/63.2 | 50.0/66.2 | 38.3/41.6 | 160 |
| PP-YOLO-Plus | 54.6 | 115.8 | 49.5/68.2 | 49.6/53.3 | 42.1/43.8 | 150 |
| RT DERT-X | 67.0 | 234.1 | 45.6/61.8 | 36.5/50.3 | 42.5/43.6 | 148 |
| PGI-ViMamba | 27.8 | 209.0 | 54.2/74.1 | 49.6/66.3 | 43.5/45.3 | 153 |
| Category | YOLOv8 | YOLOv8-C2f-VSS | YOLOv9-c | YOLOv10x | YOLOv11x | GELAN-c | PP-YOLO-Plus | RT DERT-X | PGI-ViMamba |
|---|---|---|---|---|---|---|---|---|---|
| Bicycle | 26.3/26.4 | 27.3/26.3 | 26.6/30.9 | 30.6/33.8 | 31.5/30.5 | 27.2/28.2 | 30.6/31.3 | 27.9/24.9 | 32.1/30.1 |
| People | 23.5/25.5 | 25.2/23.2 | 23.1/33.9 | 38.9/38.5 | 39.7/38.7 | 30.1/37.1 | 35.1/32.9 | 30.8/27.8 | 39.9/36.2 |
| Pedestrian | 33.9/33.9 | 34.1/28.1 | 33.1/33.9 | 43.8/43.7 | 42.4/40.4 | 36.2/36.2 | 40.2/42.3 | 36.3/30.3 | 45.1/33.1 |
| Motor | 35.2/35.4 | 35.2/30.2 | 34.2/35.5 | 35.7/35.6 | 36.9/36.6 | 32.1/37.1 | 35.7/34.7 | 32.5/30.5 | 37.7/36.2 |
| Bus | 62.3/52.3 | 67.3/51.3 | 61.3/79.3 | 86.8/81.2 | 87.6/77.6 | 81.1/88.1 | 86.9/86.1 | 81.9/59.2 | 87.7/83.1 |
| Awning-tricycle | 31.1/31.9 | 35.1/33.1 | 31.3/40.3 | 40.9/40.8 | 40.2/39.2 | 34.1/38.1 | 39.1/37.1 | 34.1/30.1 | 41.7/35.1 |
| Tricycle | 40.2/32.2 | 41.2/34.2 | 38.8/41.8 | 40.8/40.7 | 41.1/40.1 | 35.2/38.2 | 38.8/38.1 | 35.2/32.2 | 43.2/36.2 |
| Car | 77.4/62.7 | 78.2/64.4 | 77.4/85.4 | 91.4/83.4 | 90.9/81.3 | 80.4/85.4 | 85.6/85.4 | 80.4/65.4 | 91.5/86.5 |
| Van | 30.1/30.9 | 33.2/28.2 | 32.2/55.9 | 55.6/55.1 | 54.8/54.8 | 48.1/54.1 | 51.6/54.6 | 48.6/32.1 | 56.8/55.2 |
| Truck | 53.1/46.7 | 53.1/49.1 | 52.9/60.4 | 63.5/55.1 | 65.9/62.9 | 48.5/57.5 | 51.5/53.5 | 48.5/32.5 | 66.4/64.3 |
| Avg * | 41.3/37.8 | 43.0/36.8 | 41.3/49.7 | 52.8/50.8 | 53.1/50.2 | 45.3/50.0 | 49.5/49.6 | 45.6/36.5 | 54.2/49.6 |
| n-Level-PGI | P (%) | R (%) | mAP50 (%) | mAP50:95 (%) |
|---|---|---|---|---|
| 0-level-PGI 1 | 20.3 | 31.8 | 20.1 | 14.1 |
| 1-level-PGI | 21.9 | 37.8 | 28.9 | 23.2 |
| 2-level-PGI | 29.3 | 40.9 | 35.3 | 25.5 |
| 3-level-PGI | 45.3 | 41.7 | 38.3 | 28.6 |
| 4-level-PGI | 54.2 | 49.6 | 43.5 | 32.3 |
| 5-level-PGI | 41.5 | 41.8 | 34.1 | 20.3 |
| Model | BackBone | MLAG 1 | P (%) | R (%) | mAP50 (%) | mAP50:95 (%) |
|---|---|---|---|---|---|---|
| PGI-ViMamba | EfficientNet | X | 20.3 | 10.8 | 10.1 | 10.1 |
| PGI-ViMamba | EfficientNet | √ | 38.5 | 39.3 | 31.9 | 19.2 |
| PGI-ViMamba | ResNet-50 | X | 20.3 | 17.9 | 19.3 | 5.5 |
| PGI-ViMamba | ResNet-50 | √ | 35.3 | 38.1 | 33.3 | 18.6 |
| PGI-ViMamba | VGG-16 | X | 21.5 | 20.6 | 26.1 | 17.3 |
| PGI-ViMamba | VGG-16 | √ | 49.5 | 33.9 | 39.5 | 30.5 |
| PGI-ViMamba | SPD-Conv-VSS | X | 25.3 | 31.8 | 27.1 | 19.3 |
| PGI-ViMamba | SPD-Conv-VSS | √ | 54.2 | 49.6 | 43.5 | 33.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Y.; Ji, Y.; Ren, Q.; Shi, B.; Liu, N.; Lu, M.; Wu, N. An Innovative Small-Target Detection Approach Against Information Attenuation: Fusing Enhanced Programmable Gradient Information and a Novel Mamba Module. Sensors 2025, 25, 2117. https://doi.org/10.3390/s25072117
Liu Y, Ji Y, Ren Q, Shi B, Liu N, Lu M, Wu N. An Innovative Small-Target Detection Approach Against Information Attenuation: Fusing Enhanced Programmable Gradient Information and a Novel Mamba Module. Sensors. 2025; 25(7):2117. https://doi.org/10.3390/s25072117
Chicago/Turabian StyleLiu, Yang, Yatu Ji, Qingdaoerji Ren, Bao Shi, Na Liu, Min Lu, and Nier Wu. 2025. "An Innovative Small-Target Detection Approach Against Information Attenuation: Fusing Enhanced Programmable Gradient Information and a Novel Mamba Module" Sensors 25, no. 7: 2117. https://doi.org/10.3390/s25072117
APA StyleLiu, Y., Ji, Y., Ren, Q., Shi, B., Liu, N., Lu, M., & Wu, N. (2025). An Innovative Small-Target Detection Approach Against Information Attenuation: Fusing Enhanced Programmable Gradient Information and a Novel Mamba Module. Sensors, 25(7), 2117. https://doi.org/10.3390/s25072117