
Malicious Traffic Detection Method for Power Monitoring Systems Based on Multi-Model Fusion Stacking Ensemble Learning


Abstract
1. Introduction
2. Background
2.1. Application of Traffic Detection in Power Monitoring Systems
2.2. Overview of Malicious Traffic Detection Techniques
2.3. Overview of Ensemble Learning Methods
2.4. Overview of Relevant Model Principles
3. Malicious Traffic Detection Method Based on Stacking Ensemble Learning
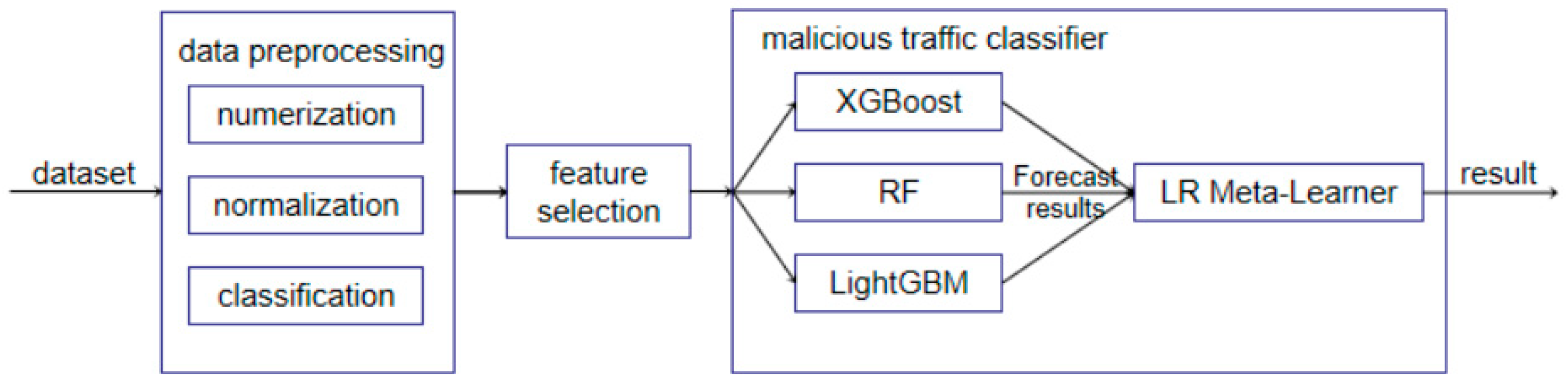
3.1. Malicious Traffic Detection Framework
3.2. Data Preprocessing and Feature Selection
3.2.1. Data Preprocessing
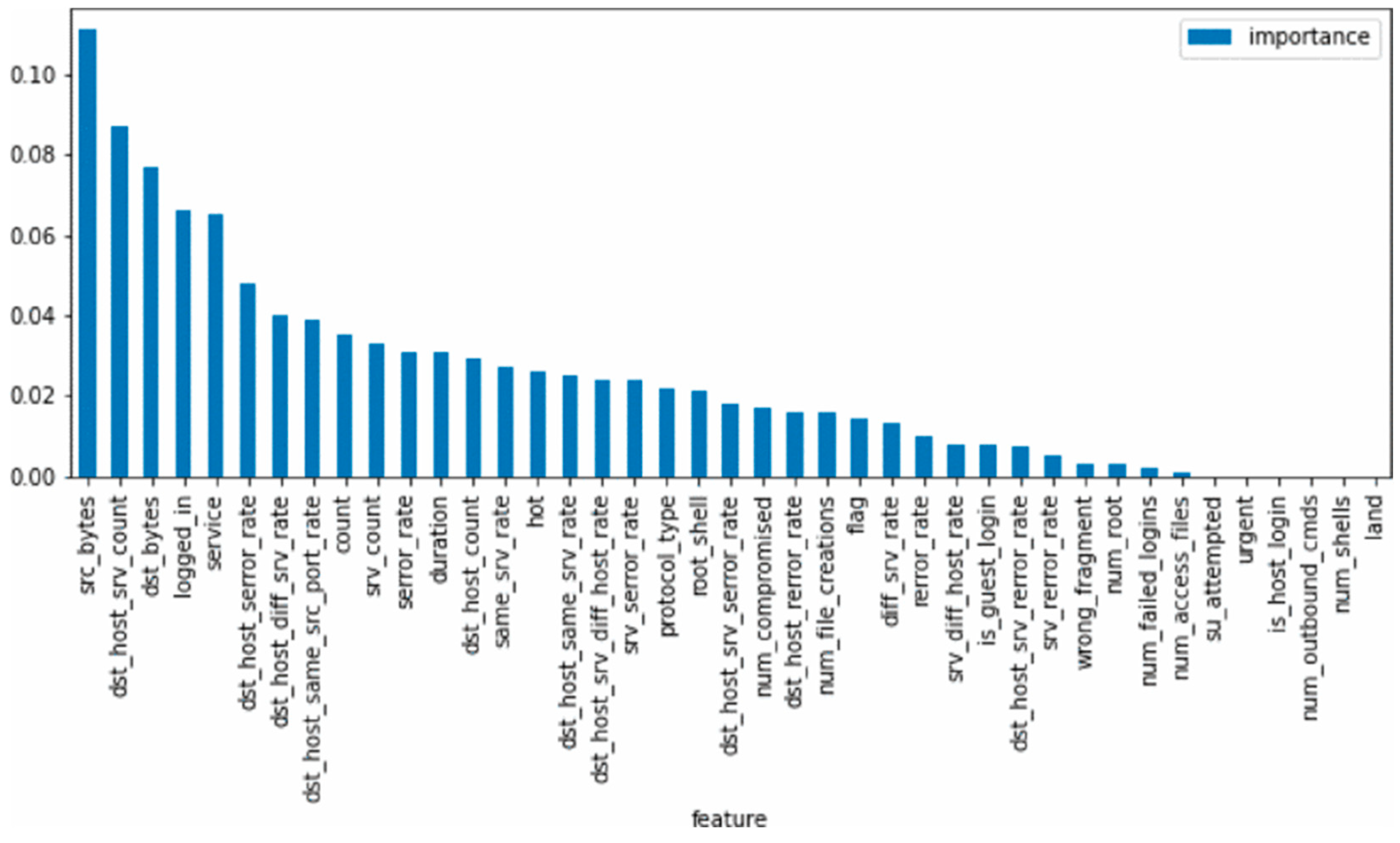
3.2.2. Feature Selection
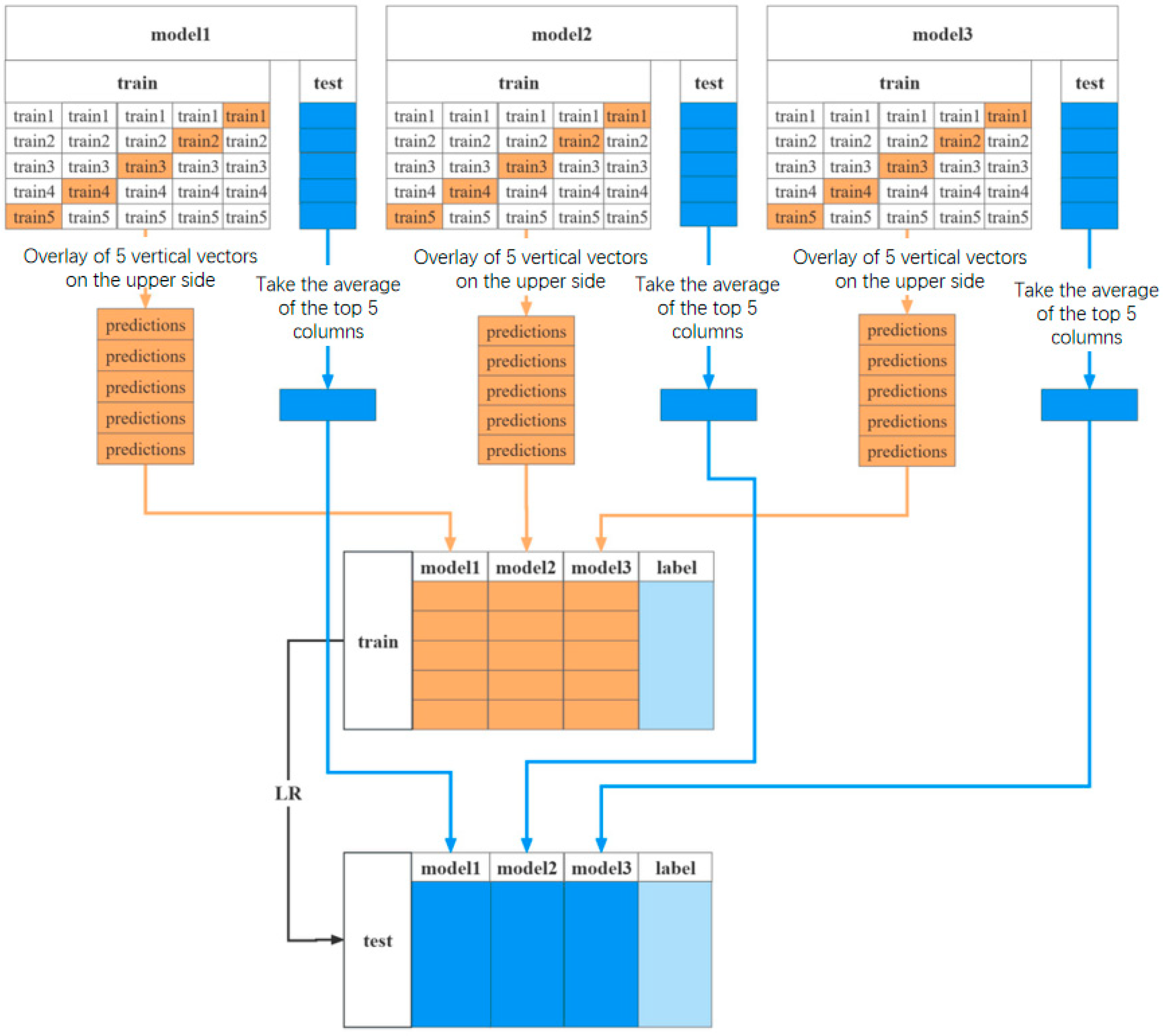
3.3. Stacking Multi-Model Fusion Strategy
| Algorithm 1: Multi-Model Fusion Detection Model Based on Stacking Strategy |
| Input: Training set , First-layer learners: M1, M2, …, ML Meta-learner: M Step 1: Train the first-layer learners on the complete training dataset D. For each first-layer learner Ml (l = 1, 2, 3, …, L), train on the complete training dataset D to obtain learning model . Step 2: Construct a new dataset. For each sample , use the first-layer learners to predict xi, generating prediction values . All predictions from the first-layer learners are combined as new features and combined with the original labels to construct a new training dataset . Step 3: Train the meta-learner M on the new training dataset to obtain the meta-learning model . Step 4: Final model prediction. The model output is: . Output: Stacking ensemble model . |
4. Stacking Ensemble Model Testing
4.1. Experimental Setup
4.2. Experimental Results and Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Subarna, S.; Lalitpur, N.; Smys, S. Anomalies Detection in Fog Computing Architectures Using Deep Learning. J. Trends Comput. Sci. Smart Technol. 2020, 2, 46–55. [Google Scholar]
- Griffin, K.; Schneider, S.; Hu, X.; Chiueh, T.C. Automatic generation of string signatures for malware detection. In Proceedings of the International Workshop on Recent Advances in Intrusion Detection, Saint-Malo, France, 23–25 September 2009; pp. 101–120. [Google Scholar]
- Bhuyan, M.; Bhattacharyya, D.; Kalita, J. Network anomaly detection: Methods, systems, and tools. IEEE Commun. Surv. Tutor. 2014, 16, 303–336. [Google Scholar] [CrossRef]
- Dong, B.; Wang, X. Comparison of deep learning methods to traditional methods for network intrusion detection. In Proceedings of the 2016 8th IEEE International Conference on Communication Software and Networks, Beijing, China, 4–6 June 2016; pp. 581–585. [Google Scholar]
- Halimaa, A.; Sundarakantham, K. Machine Learning-Based Intrusion Detection System. In Proceedings of the Third International Conference on Trends in Electronics and Informatics, Tirunelveli, India, 23–25 April 2019; pp. 916–920. [Google Scholar]
- Arijit, C.; Sunil, K.; Rajbala, S. Filter-based Attribute Selection Approach for Intrusion Detection using k-Means Clustering and Sequential Minimal Optimization Technique. In Proceedings of the Amity International Conference on Artificial Intelligence, Dubai, United Arab Emirates, 4–6 February 2019; pp. 740–745. [Google Scholar]
- Roshan, P.; Prabhat, P.; Arun, K. Anomaly-Based Intrusion Detection System using User Profile Generated from System Logs. Int. J. Sci. Res. Publ. 2019, 9, 244–248. [Google Scholar]
- Simone, A. Applying a Neural Network Ensemble to Intrusion Detection. J. Artif. Intell. Soft Comput. Res. 2019, 9, 177–188. [Google Scholar]
- Raihan, M.; Hossen, A. Network Intrusion Detection System Using Voting Ensemble Machine Learning. In Proceedings of the IEEE International Conference on Telecommunications and Photonics, Dhaka, Bangladesh, 28–30 December 2019; pp. 1–4. [Google Scholar]
- Huang, J.; Qu, L.; Jia, R.; Zhao, B. O2u-net: A simple noisy label detection approach for deep neural networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3326–3334. [Google Scholar]
- Smitha, R.; Poornima, P.; Katiganere, S. A Stacking Ensemble for Network Intrusion Detection Using Heterogeneous Datasets. Secur. Commun. Netw. 2020, 2020, 4586875. [Google Scholar]
- Cengiz, E.; Gök, M. Reinforcement Learning Applications in Cyber Security: A Review. Sak. Univ. J. Sci. 2023, 27, 481–503. [Google Scholar] [CrossRef]
- Chen, T.; Carlos, G. XGBoost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Peng, S.; Zhai, Y.; Liu, Z.; Zhang, L.; Wan, Z. A Hierarchical Intrusion Detection System Based on Machine Learning. In Proceedings of the 5th International Symposium on Big Data and Applied Statistics, Shanghai, China, 26–28 February 2022; Volume 2294, p. 012033. [Google Scholar]
- Zhou, L.; Li, J. Security Situation Awareness Model of Joint Network Based on Decision Tree Algorithm. Comput. Simul. 2021, 38, 264–268. [Google Scholar]
- Tang, M.; Zhang, Y.; Deng, G. An Efficient Non-Interactive Privacy-Preserving Logistic Regression Model. Comput. Eng. 2023, 49, 32–42, 51. [Google Scholar]
- Zhang, Z.; Li, J.; Manikopoulos, C.; Jorgenson, J.; Ucles, J. Hide: A hierarchical network intrusion detection system using statistical preprocessing and neural network classification. In Proceedings of the IEEE Workshop on Information Assurance and Security, New York, NY, USA, 5–6 June 2001; pp. 85–90. [Google Scholar]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. In Proceedings of the Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Yoav, F.; Robert, E. A Decision-Theoretic Generalization of On-Line Learning and an Application to Boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar]
- Tavallaee, M.; Bagheri, E.; Lu, W.; Ghorbani, A.A. A Detailed Analysis of the KDD CUP 99 Dataset. In Proceedings of the IEEE Symposium on Computational Intelligence for Security and Defense Applications, Ottawa, ON, Canada, 8–10 July 2009; pp. 1–6. [Google Scholar]
- Sasikala, T.; Rajesh, M.; Sreevidya, B. Performance of Academic Performance of Alcoholic Students Using Data Mining Techniques. Adv. Intell. Syst. Comput. 2020, 1040, 141–148. [Google Scholar]
- Sri, I.; Rasmitha, K.; Kavitha, C.; Sasikala, T. Data Mining Techniques used in the Recommendation of E-Commerce Services. In Proceedings of the 2nd International Conference on Electronics Communication and Aerospace Technology, Coimbatore, India, 29–31 March 2018; pp. 379–382. [Google Scholar]
- Fahad, A.; Tari, Z.; Khalil, I.; Habib, I.; Alnuweiri, H. Toward an Efficient and Scalable Feature Selection Approach for Internet Traffic Classification. Comput. Netw. 2013, 57, 2040–2057. [Google Scholar] [CrossRef]
- Panda, M.; Abraham, A.; Patra, M. Discriminative Multinomial Naive Bayes for Network Intrusion Detection. In Proceedings of the International Conference on Information Assurance and Security, Miyazaki, Japan, 23–25 June 2010; pp. 5–10. [Google Scholar]
- Lippmann, R.P.; Fried, D.J.; Graf, I.; Haines, J.W.; Kendall, K.R.; McClung, D.; Weber, D.; Webster, S.E.; Wyschogrod, D.; Cunningham, R.K.; et al. Evaluating Intrusion Detection Systems: The 1998 DARPA Off-line Intrusion Detection Evaluation. In Proceedings of the DARPA Information Survivability Conference and Exposition, DISCEX’00, Hilton Head, SC, USA, 25–27 January 2000; IEEE: Piscataway, NJ, USA, 2000; Volume 2, pp. 12–26. [Google Scholar]
- Zhu, D.; Chen, J.; Zhou, X.; Shang, W.; Hassan, A.E.; Grossklags, J. Vulnerabilities of data protection in vertical federated learning training and countermeasures. IEEE Trans. Inf. Forensics Secur. 2024, 19, 3674–3689. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Feature Name | No. | Feature Name |
|---|---|---|---|
| 1 | duration | 22 | is_guest_login |
| 2 | protocol_type | 23 | count |
| 3 | service | 24 | srv_count |
| 4 | flag | 25 | serror_rate |
| 5 | src_bytes | 26 | srv_serror_rate |
| 6 | dst_bytes | 27 | rerror_rate |
| 7 | land | 28 | srv_rerror_rate |
| 8 | wrong_fragment | 29 | same_srv_rate |
| 9 | urgent | 30 | diff_srv_rate |
| 10 | hot | 31 | srv_diff_host_rate |
| 11 | num_failed_logins | 32 | dst_host_count |
| 12 | logged_in | 33 | dst_host_srv_count |
| 13 | num_compromised | 34 | dst_host_same_srv_rate |
| 14 | root_shell | 35 | dst_host_diff_srv_rate |
| 15 | su_attempted | 36 | dst_host_same_src_port_rate |
| 16 | num_root | 37 | dst_host_srv_diff_host_rate |
| 17 | num_file_creations | 38 | dst_host_serror_rate |
| 18 | num_shells | 39 | dst_host_srv_serror_rate |
| 19 | num_access_files | 40 | dst_host_rerror_rate |
| 20 | num_outbound_cmds | 41 | dst_host_srv_rerror_rate |
| 21 | is_hot_login |
| Dataset | Normal | DoS | Probe | U2R | R2L | Total |
|---|---|---|---|---|---|---|
| Training | 67,343 (53%) | 45,927 (37%) | 11,656 (9.11%) | 52 (0.04%) | 995 (0.85%) | 125,973 |
| Testing | 9711 (43%) | 7458 (33%) | 2421 (11%) | 200 (0.92%) | 2754 (12.1%) | 22,544 |
| Attack Type | Specific Attacks |
|---|---|
| DoS | back, land, neptune, pod, smurf, teardrop, mailbomb, apache2, processtable, udpstorm |
| Probe | ipsweep, nmap, portsweep, satan, mscan, saint |
| R2L | ftp_write, guess_passwd, imap, multihop, phf, spy, warezclient, warezmaster, sendmail, named, snmpgetattack, snmpguess, xlock, xsnoop, worm |
| U2R | buffer_overflow, load-module, perl, rootkit, httptunnel, ps, sqlattack, xterm |
| No. | Feature | Description |
|---|---|---|
| 1 | src_bytes | Number of bytes sent from the source host to the destination host |
| 2 | dst_host_srv_count | Number of connections with the same destination host and service as the current one |
| 3 | dst_bytes | Number of bytes sent from the destination host to the source host |
| 4 | logged_in | 1 if login is successful, otherwise 0 |
| 5 | service | The network service type on the destination host |
| 6 | dst_host_serror_rate | Percentage of connections with SYN errors among those with the same destination host |
| 7 | dst_host_diff_srv_rate | Percentage of connections with different services among those with the same destination host |
| 8 | dst_host_same_src_port_rate | Percentage of connections with the same source port on the same destination host |
| 9 | count | Number of connections with the same destination host as the current one |
| 10 | srv_count | Number of connections with the same service as the current one |
| 11 | serror_rate | Percentage of connections with SYN errors among those with the same destination host |
| 12 | duration | Duration of the connection |
| 13 | dst_host_count | Number of connections with the same destination host |
| 14 | same_srv_rate | Percentage of connections with the same service as the current one at the same destination host |
| 15 | hot | Number of times sensitive system files or directories were accessed |
| 16 | dst_host_same_srv_rate | Percentage of connections with the same service at the same destination host |
| 17 | dst_host_srv_diff_host_rate | Percentage of connections from different source hosts with the same service at the same destination host |
| 18 | srv_serror_rate | Percentage of SYN error connections among those with the same service as the current one |
| 19 | protocol_type | Type of protocol used (e.g., TCP, UDP, ICMP) |
| 20 | root_shell | 1 if superuser privileges were gained, otherwise 0 |
| Algorithm | Accuracy | F1 |
|---|---|---|
| XGBoost | 92.3% | 92.4% |
| RF | 91.6% | 91.6% |
| DT | 87.7% | 87.8% |
| NB | 85.7% | 85.9% |
| LightGBM | 90.4% | 90.5% |
| AdaBoost | 89.1% | 89.2% |
| First-Layer Learners | Accuracy | F1 |
|---|---|---|
| XGBoost, RF, LightGBM | 96.5% | 96.6% |
| XGBoost, RF, AdaBoost | 96.2% | 96.3% |
| XGBoost, LightGBM, AdaBoost | 96.0% | 95.9% |
| RF, LightGBM, AdaBoost | 95.7% | 95.7% |
| RF, NB, XGBoost | 95.4% | 95.4% |
| Model | Accuracy | Precision | Recall | F1 | False-Positive Rate |
|---|---|---|---|---|---|
| Proposed Model | 96.5% | 97.1% | 96.2% | 96.6% | 1.8% |
| Model | XGBoost | RF | LightGBM | Proposed Model |
|---|---|---|---|---|
| Runtime, s | 269 | 240 | 108 | 517 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, H.; Liang, Y.; Li, Y.; Wang, S.; Gong, H.; Zhai, J.; Zhang, H. Malicious Traffic Detection Method for Power Monitoring Systems Based on Multi-Model Fusion Stacking Ensemble Learning. Sensors 2025, 25, 2614. https://doi.org/10.3390/s25082614
Zhang H, Liang Y, Li Y, Wang S, Gong H, Zhai J, Zhang H. Malicious Traffic Detection Method for Power Monitoring Systems Based on Multi-Model Fusion Stacking Ensemble Learning. Sensors. 2025; 25(8):2614. https://doi.org/10.3390/s25082614
Chicago/Turabian StyleZhang, Hao, Ye Liang, Yuanzhuo Li, Sihan Wang, Huimin Gong, Junkai Zhai, and Hua Zhang. 2025. "Malicious Traffic Detection Method for Power Monitoring Systems Based on Multi-Model Fusion Stacking Ensemble Learning" Sensors 25, no. 8: 2614. https://doi.org/10.3390/s25082614
APA StyleZhang, H., Liang, Y., Li, Y., Wang, S., Gong, H., Zhai, J., & Zhang, H. (2025). Malicious Traffic Detection Method for Power Monitoring Systems Based on Multi-Model Fusion Stacking Ensemble Learning. Sensors, 25(8), 2614. https://doi.org/10.3390/s25082614