This section presents the findings of the bibliometric analysis. It consists of three subsections. First, a general overview of the field of AI for drug discovery is given. The second subsection shows the results of our performance analysis. Finally, the last subsection contains a network analysis and a thematic overview.
2.1. General Overview
This section gives an overview of the research field of AI applied for drug discovery.
Table 1 shows an overview of key metrics of the identified publications. In total, 3884 different documents were identified that dealt with that topic. These documents were published in 1073 different journals or conferences. In total, 217,668 references were cited by the 3884 documents. In total, 6790 different author keywords were used. Apart from the author keywords, which are provided by the original authors of a document themselves, keywords plus are an additional way to analyze a document’s content. Keywords plus are automatically generated and are words or phrases that appear in the titles of an article’s references [
62,
63]. In summary, 19,326 different keywords plus were identified in our sample.
In total, 12,044 different researchers authored the 3884 articles dealing with AI-based drug discovery. A total of 19,011 authors appear in the publications, and this is equivalent to an average number of 4.89 authors per document. Only 261 documents are single-author papers, and this is equivalent to 6.7% of the articles. This might be an indicator of the topic’s high complexity, which makes it necessary to collaborate with other researchers. This assumption is underpinned by the high number of almost five researchers authoring one document on average. To analyze the cooperation among researchers, the collaboration index (CI) is an often-used variable. It is calculated by dividing the total number of authors of multi-authored documents by the total number of multi-authored articles [
64,
65]. For our sample, we received a collaboration index of 3.26. This is a high value compared to other bibliometric studies (see
Table 2 for a comparison).
Figure 1 shows the distribution of the identified publications among the different disciplines. The data for
Figure 1 were derived from Scopus, where the publications are assigned to disciplines based on the outlets they were published in. An outlet can be related to more than one discipline. Therefore, the total number of documents in
Figure 1 is higher than the number of identified documents.
In total, the 3884 identified documents cover 26 different disciplines. The fact that scholars from many different disciplines contributed to it shows the interdisciplinary nature of this research field and AI in general [
61]. We can see that most articles have been published within four disciplines. Three of these disciplines are directly related to medicine and topics related to drug development, namely “Biochemistry, Genetics, and Molecular Biology”, “Pharmacology, Toxicology, and Pharmaceuticals”, and “Chemistry”. The fact that “Computer Science” is the discipline with the second-highest number of publications is not surprising, since AI is a traditional topic within computer science. In comparison, “Biochemistry, Genetics, and Molecular Biology” and “Pharmacology, Toxicology, and Pharmaceuticals” are fields that are concerned with discovering and developing new drugs.
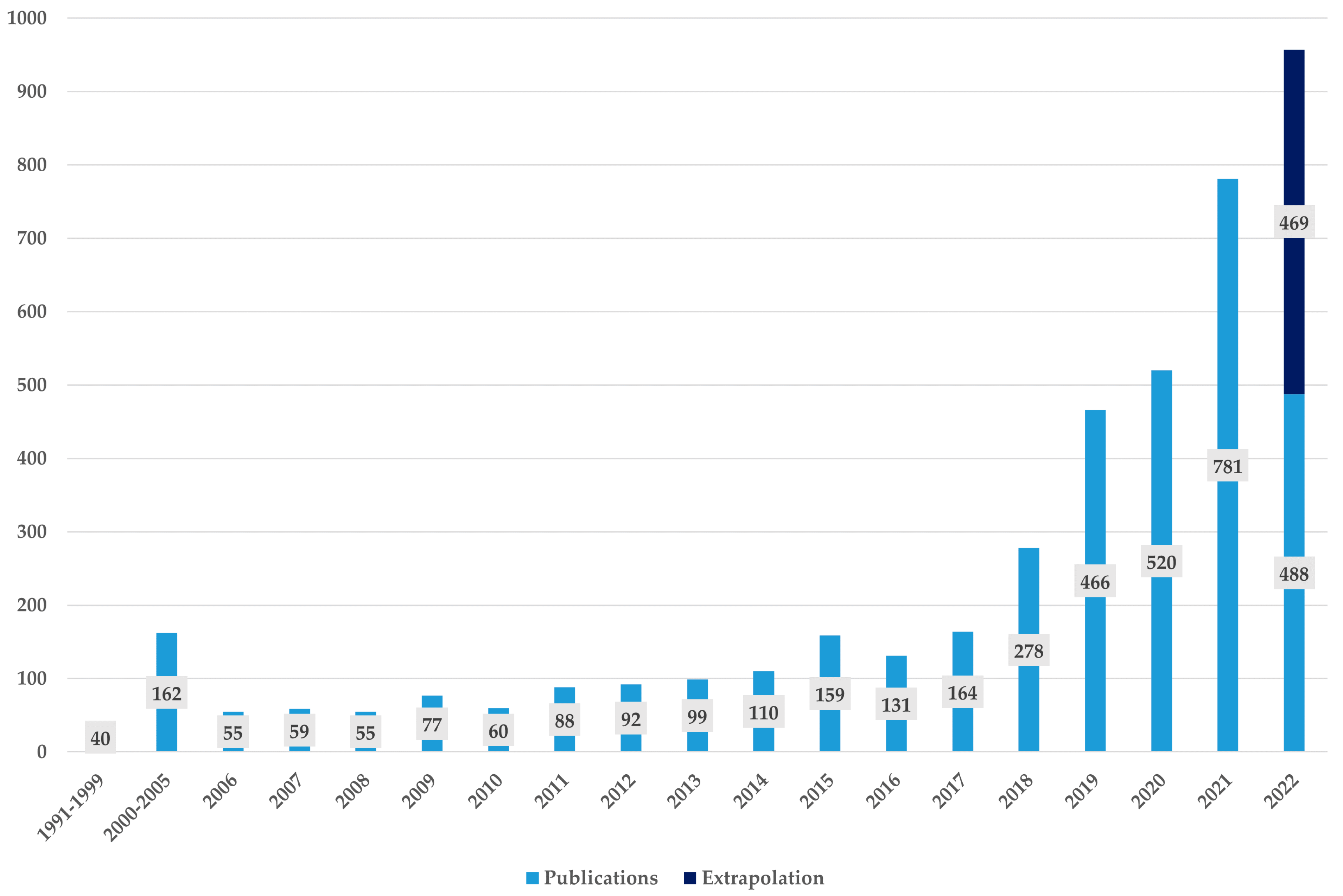
Figure 2 depicts the number of publications for every year. The first identified publication dealing with AI for drug discovery was published in 1991 [
70]. In this article, the authors present their preliminary results about the application of machine learning computer-aided molecular design. In this early work, the machine learning that is used is trained with a knowledge base of chemical properties. The goal of the model was to automatically identify relevant fragments in a molecule that are “responsible for activity in a set of inhibitors of thermolysin and, furthermore, to determine a generalized model for an optimal inhibitor” [
70].
In the next years, however, we observe only slow growth of research on AI for drug discovery. In total, only 40 articles were published between 1990 and 1999. From 2000 on, there was an increasing interest in the field of AI applied for drug discovery. From 2000 until 2005, four times as many articles were published than in the 10 years before. By the year 2006, the annual number of research is steadily increasing, with the exception of only three years (2008, 2010, and 2016). In the first eight months of 2022, 488 articles were published. We therefore can assume that the trend of an increase in publication numbers will be ongoing in 2022. Since, in previous years of our final sample, statistically more publications appear in the last months of the year, we extrapolated the total number of publications for 2022 to 957 in total.
In summary,
Figure 2 shows that the research interest in AI for drug discovery has increased significantly over the last few years. It has to be noted, however, that this development is not unique to AI applications for drug discovery. Instead, AI in general is a topic that has gained a lot of attention in the last years, notwithstanding the application.
2.2. Performance Analysis
This subsection presents the results of our performance analysis, while the previous subsection aimed to give a general overview. The 3884 publications that were included in our final sample were published in 1073 different sources. From these sources, 263 were conferences and 810 were journals.
Table 3 lists the outlets with the most publications on AI applied for drug discovery. The leading journal with the most articles (
n = 222) on this subject is the
Journal of Chemical Information and Modeling. This outlet is followed by the
Briefings in Bioinformatics,
Drug Discovery Today,
BMC Bioinformatics, and the
Journal of Cheminformatics. Among the 20 sources with the most publications, only one item referred to conference proceedings (
Lecture Notes in Computer Science on rank 10). The thematic focus of the sources reflects the strong dominance of computer science and biochemistry that was already outlined above (see
Figure 1).
AI for drug discovery is a topic of international and global interest. In total, researchers from 100 different countries have contributed to the studies that were identified. In
Table 4, the 20 countries with the most publications are listed. A publication is assigned to a country when its corresponding author is affiliated with an institution or company located in this nation. If the corresponding author was not clearly identifiable, an article was excluded from the analysis. In total, 3236 of the identified 3884 articles had a clearly defined corresponding author.
Authors from the United States have authored, by far, the most publications. In total, 850 of the 3236 publications have corresponding authors from institutions or companies in the United States, which is equal to more than 26%. The United States are followed by China, with 577 publications. In summary, authors from China and the United States corresponded to 44% of all publications dealing with AI for drug discovery. China and the United States are followed by India (216 publications) and the United Kingdom (207 publications). With 152 publications, Germany is the first country from the European Union to appear in our list, on the fifth rank.
The United States is also leading in terms of the total citation count. In summary, the articles with a corresponding author from the United States received 69,461 citations, which is equal to an average citation count of 81.72 per document. It is important to mention, however, that one single article, dealing with deep learning in general [
52] is responsible for 37,560 of the 69,461 citations of the United States, and this is equal to more than 54%. In terms of the total citation count, the United States is followed by China, the United Kingdom, Germany, Switzerland, and Canada. Additionally, it is interesting to observe that a high number of articles does not necessarily correlate with a high number of citations. When we focus on the average number of citations per document, the United States is followed by Canada, Switzerland, and Singapore.
Next, we take a look at the sponsors that funded most of the articles.
Table 5 shows an overview of the top 20 funding sponsors of all articles. Of the 3884 sources we identified, 2003 were supported by funding sponsors. Although the majority of the 2003 articles was funded by only one sponsor, several projects were supported by more than one institution. We can observe that funding sponsors from China, the United States, and the European Union are most often present on the list. Of the top 20 sponsors, 8 were from the United States, four from China, and three from the European Union. The National Natural Science Foundation of China funded the most articles of our sample (361 publications), followed by the National Institutes of Health (327 publications, United States), and the National Science Foundation (153 publications, United States). While most of the funding sponsors belong to one single country, three funding programs were from the European Union, namely the Horizon 2020 Framework Programme, the European Commission, and the Seventh Framework Programme.
The following
Table 6 shows the top 20 funding sponsors of the 100 most cited articles of our sample. With 13 funding sponsors, a majority of the 20 top funding sponsors originate from the United States. Furthermore, two funding sponsors from Switzerland are among the top 20, namely the Eidgenössische Technische Hochschule Zürich and the Schweizerischer Nationalfonds zur Förderung der Wissenschaftlichen Forschung. Switzerland is thus the only country in
Table 5, apart from the United States, that is represented more than once. The Horizon 2020 Framework Programme is ranked 6th and funded 3 of the 100 most cited articles on AI-supported drug discovery. The National Natural Science Foundation of China, which funded the most articles in total, funded four of the most cited articles.
Finally, our performance analysis consists of an overview of the most productive affiliations. To address this,
Table 7 shows an overview of the 20 most productive affiliations. In total, the 12,044 authors that contributed to the research about AI-based drug discovery came from 2970 different affiliations. With 138 authors, the University of California, in the United States, was most often represented in research about AI for drug discovery. The University of California is followed by the Zhejiang University, the Central South University (both located in China), and the University of Cambridge (United Kingdom). From ten affiliations, more than 100 authors contributed to research on AI for drug discovery. The Uppsala University from Sweden and the National University of Singapore are the two only affiliations that are not located in the United States, China, or the United Kingdom.
2.3. Science Mapping and Thematic Analysis
Next to the performance analysis that was presented in the last section, we conducted science mapping to obtain a better understanding of the topics and structure of the research field of AI in drug discovery. Together with performance analysis, science mapping is one of the two main categories of bibliometric tools [
22]. In contrast to performance analysis, which aims to measure performance, science mapping examines interactions and relationships of research constituents [
22,
71,
72]. Science mapping is a widely adopted set of methods that aims to shed light on a research field’s conceptual, social, and intellectual structure [
73,
74,
75]. By conducting science mapping and studying keywords and their frequency, this section aims to analyze the key topics addressed in research on using AI for drug discovery.
We begin our examination by looking at commonly used keywords that appeared in the title, abstract, or keywords. In
Table 8, we show the keywords that appeared most frequently throughout our sample. Many of the most frequently used terms are not surprising since they also occurred in the search string that was used for the literature collection (e.g., drug discovery, machine learning, artificial intelligence, deep learning, or artificial neural network). It is worth mentioning that “machine learning” is the technical term that appeared most frequently in our sample. This is not surprising, since “machine learning” is an umbrella term that often includes frequently used technologies such as decision trees and artificial neural networks [
76]. Deep learning is another concept that belongs to machine learning and is based on artificial neural networks [
77]. It is therefore hardly surprising that also deep learning is among the top 10 keywords, with 812 appearances of that term in total.
With 1651 and 1391 appearances, the terms “human” and “humans” are also among the top five keywords within our sample. This indicates that a high percentage of the identified research deals with drugs or proteins that are relevant for the human organism. Typical research contributions within this category are machine learning and AI approaches for predicting the interactions between SARS-CoV-2 and human proteins [
78], the investigation of human intestinal drug absorption for drug discovery [
79], or for the development of G-protein-coupled receptor (GPCR) agonists [
80].
Figure 3 and
Figure 4 show word clouds from different time periods. The bigger a word is, the more often it appeared throughout the keywords of the articles within that period. We divided our sample into four different periods (see
Table 9 for an overview).
Figure 3a shows the author keywords used most frequently from 1991 to 2007. This is the longest period of time, and it contains 316 articles in total. It is the earliest stage of research on AI for drug discovery. We see that “drug discovery” is by far the most dominant term. When we focus on technology-related terms (e.g., artificial intelligence, machine learning, random forest, etc.), it is interesting to see that there is no clear dominance of one single technology in that early phase.
While machine learning and deep learning seem to dominate the discussions in later periods, many technologies have an equal size in
Figure 3a. This shows that researchers were experimenting with different technologies in the early years. Already in the second period that consists of 580 articles published between 2008 and 2014, machine learning has become the technology most often used, followed by support vector machines.
Figure 4 shows the word clouds from the most recent periods.
Figure 4a contains 1197 articles published between 2015 and 2019. In the third period, machine learning is obviously the most often used author keyword and the most popular group of technologies for drug discovery within our sample. While support vector machines were still frequently applied in the second period (
Figure 3b), they lost a lot of attention from 2014 on. Furthermore, the third period is characterized by the rise of deep learning which is now appearing among the keywords for the first time. In 2015, the first three articles were published that suggested or investigated deep learning’s potential for drug discovery [
52,
81,
82]. From 2015 on, research containing deep learning grew continuously. In 2016, 10 more articles on deep learning for drug discovery were published, followed by 18 publications in 2017, 58 publications in 2018, and 138 publications in 2019.
Given that tremendous growth, it is not surprising that “deep learning” is among the top keywords in the latest period (
Figure 4b). In total, 644 publications containing “deep learning” as an author keyword were published between 2020 and 2022. Together with “machine learning” and the umbrella term “artificial intelligence”, “deep learning” is thus the most frequently applied technology for drug discovery in the last few years. Additionally, COVID-19 and SARS-CoV-2 are now frequently used author keywords. As recent studies show, machine learning or AI can be used for several for the discovery and development of drugs or antibodies against COVID-19 [
83]. For example, [
84] proposes a deep learning model for screening effective inhibitors against SARS-CoV-2, while [
85] presents D3AI-CoV, which is a platform that consists of three deep learning models that aim to support the discovery of drugs against COVID-19. These examples show that AI-based technologies can help to quickly understand new diseases and to find countermeasures against them.
Finally,
Figure 5 shows a graphical representation of the keyword co-occurrences. The underlying assumption of a co-word analysis is “that words that frequently appear together have a thematic relationship with one another” [
22] (p. 289). In
Figure 5, only keywords appear that were used at least 50 times in our sample. Similar to word clouds, terms that occur more frequently are represented with a bigger font size and circle. Terms that appear together are linked with lines. Following the same logic as the font and circle size, a line between two terms is thicker the more often these two terms appeared together in one publication. Additionally, words that are in the center of the network are linked to other words in different clusters. Keywords that are less linked and do not have many relations to other clusters are depicted at the edge of
Figure 5.
When we look at
Figure 5, we can see four different thematic clusters that are represented in different colors. First, the red cluster is the medical branch of the research that deals with AI for drug discovery. Keywords such as “human”, “nonhuman”, or “animal” indicate that the focus is on understanding drugs in relation to organisms. The abovementioned works that deal with the use of AI for the development of drugs to fight diseases such as COVID-19 [
83,
84,
85] are typical examples. Keywords such as “personalized medicine”, “precision medicine”, or “human cell” indicate that also the development of tailored drugs is part of this cluster, for example, to better fight cancer [
86,
87].
The green cluster consists of keywords such as “chemistry”, “drug design”, or “chemical structure”. While the green cluster is also about drug design, a keyword such as “chemical structure”, “molecular model”, or “molecular dynamics” indicates that the green cluster is more concerned with topics that belong to chemistry. Examples that belong to this cluster are the application of AI to understand molecular docking to discover and design marine drugs [
88] or the prediction of molecular properties [
89]. In most cases, the ultimate goal of these articles within the green cluster is still about developing drugs that can be used for treatment. However, the method and approach that underlies the green cluster’s articles are often different.
While the red and green clusters are driven by medicine and natural sciences, such as biology and chemistry, the yellow cluster is more technology oriented. In this cluster, many technologies, such as machine learning, learning systems, and deep neural networks, are among the keywords. Articles within this cluster often do investigate the potential of AI for drug discovery from a more technical point of view. Closely related to the yellow cluster is also the blue group of terms. The blue cluster is located most centrally, and its terms have several relationships to all the other thematic areas. It is therefore hard to identify the thematic core of the blue cluster and to distinguish it from the from the other ones. In essence, publications within the blue cluster investigate the topic of AI for drug discovery more theoretically. Typical examples that fall within the blue cluster are review articles, for example, on computational model development of drug–target interaction prediction [
90], molecular docking [
91], or how AI applications can be combined with other approaches for drug discovery [
92]. Overall, the keyword “co-occurrence network” in
Figure 5 underpins the multidisciplinary nature of AI in the context of drug discovery.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}