

Machine Learning Techniques for Predicting Drug-Related Side Effects: A Scoping Review


Abstract

1. Introduction
2. Materials and Methods
2.1. Stage 1: Identifying Research Questions
- What were the machine learning techniques used for predicting drug-related side effects?
- What were the main features used for predicting drug-related side effects?
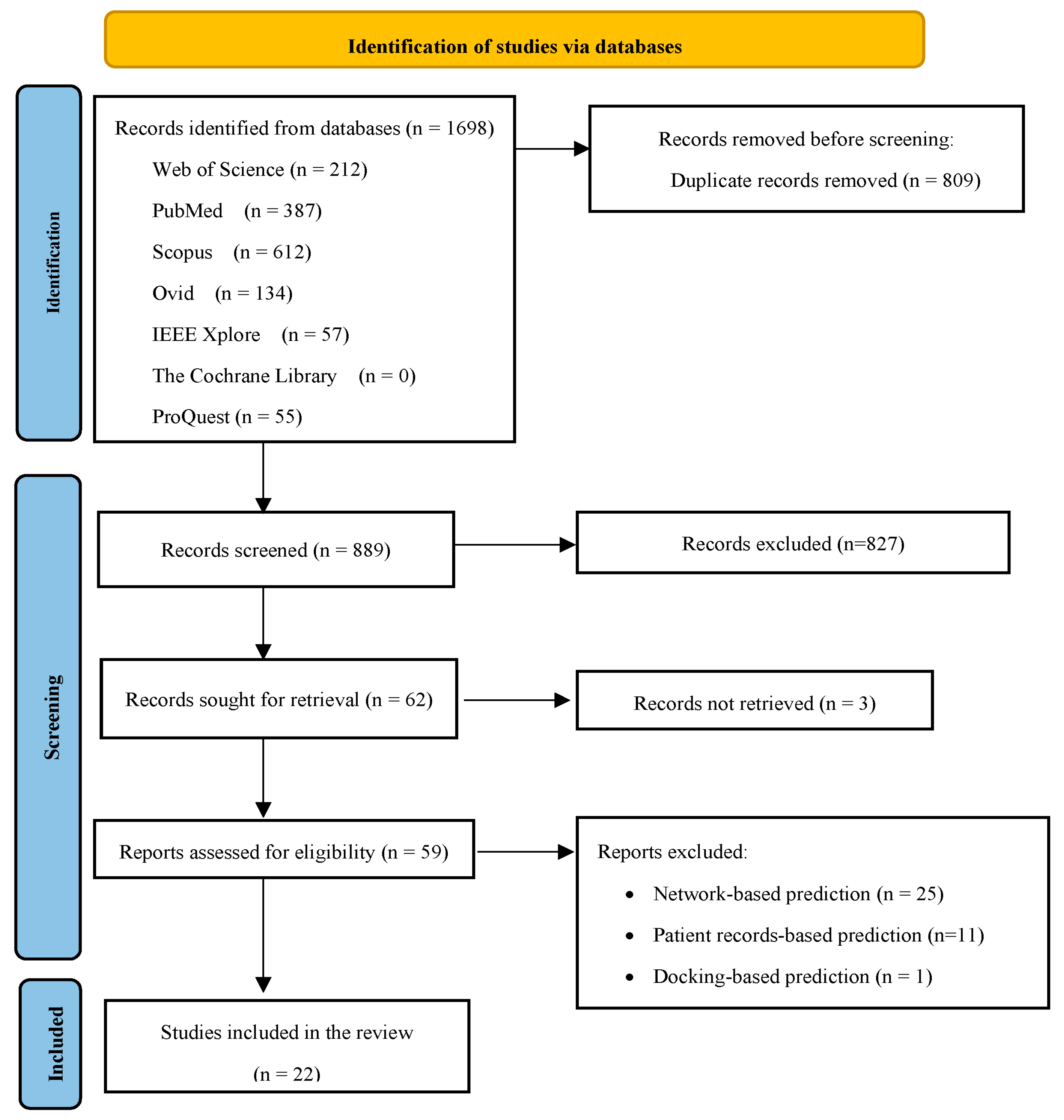
2.2. Stage 2: Identifying Relevant Studies
2.3. Stage 3: Study Selection
2.4. Stage 4: Charting the Data
3. Results
3.1. Characteristics of the Selected Studies
3.2. Selected Features and Data Sources
3.2.1. General Features
3.2.2. Chemical Features
3.2.3. Biological Features
3.2.4. Phenotypical Features
3.3. Algorithms and Evaluation Metrics
3.4. Comparison of Evaluation Metrics
4. Discussion
4.1. Principal Findings
4.2. Implication for Practice
4.3. Strengths and Limitations of the Study
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Das, P.; Mazumder, D.H. An extensive survey on the use of supervised machine learning techniques in the past two decades for prediction of drug side effects. Artif. Intell. Rev. 2023, 56, 9809–9836. [Google Scholar] [CrossRef] [PubMed]
- Downing, N.S.; Shah, N.D.; Aminawung, J.A.; Pease, A.M.; Zeitoun, J.-D.; Krumholz, H.M.; Ross, J.S. Postmarket safety events among novel therapeutics approved by the US food and drug administration between 2001 and 2010. JAMA 2017, 317, 1854–1863. [Google Scholar] [CrossRef]
- Craveiro, S.N.; Lopes, S.B.; Tomás, L.; Almeida, F.S. Drug withdrawal due to safety: A review of the data supporting withdrawal decision. Curr. Drug Saf. 2020, 15, 4–12. [Google Scholar] [CrossRef]
- Subbiah, V. The next generation of evidence-based medicine. Nat. Med. 2023, 29, 49–58. [Google Scholar] [CrossRef] [PubMed]
- Lavertu, A.; Vora, B.; Giacomini, K.M.; Altman, R.; Rensi, S. A new era in pharmacovigilance: Toward real-world data and digital monitoring. Clin. Pharmacol. Ther. 2021, 109, 1197–1202. [Google Scholar] [CrossRef] [PubMed]
- Vora, L.K.; Gholap, A.D.; Jetha, K.; Thakur, R.R.; Solanki, H.K.; Chavda, V.P. Artificial intelligence in pharmaceutical technology and drug delivery design. Pharmaceutics 2023, 15, 1916. [Google Scholar] [CrossRef]
- Yang, S.; Kar, S. Application of artificial intelligence and machine learning in early detection of adverse drug reactions (ADRs) and drug-induced toxicity. Artif. Intell. Chem. 2023, 1, 100011. [Google Scholar] [CrossRef]
- Biala, G.; Kedzierska, E.; Kruk-Slomka, M.; Orzelska-Gorka, J.; Hmaidan, S.; Skrok, A.; Kaminski, J.; Havrankova, E.; Nadaska, D.; Malik, I. Research in the field of drug design and development. Pharmaceuticals 2023, 16, 1283. [Google Scholar] [CrossRef] [PubMed]
- Han, R.; Yoon, H.; Kim, G.; Lee, H.; Lee, Y. Revolutionizing medicinal chemistry: The application of artificial intelligence (AI) in early drug discovery. Pharmaceuticals 2023, 16, 1259. [Google Scholar] [CrossRef]
- Johnson, K.B.; Wei, W.Q.; Weeraratne, D.; Frisse, M.E.; Misulis, K.; Rhee, K.; Zhao, J.; Snowdon, J.L. Precision medicine, AI, and the future of personalized health care. Clin. Transl. Sci. 2021, 14, 86–93. [Google Scholar] [CrossRef]
- Singh, S.; Kumar, R.; Payra, S.; Singh, S.K. Artificial intelligence and machine learning in pharmacological research: Bridging the gap between data and drug discovery. Cureus 2023, 15, e44359. [Google Scholar] [CrossRef] [PubMed]
- Alowais, S.A.; Alghamdi, S.S.; Alsuhebany, N.; Alqahtani, T.; Alshaya, A.I.; Almohareb, S.N.; Aldairem, A.; Alrashed, M.; Bin Saleh, K.; Badreldin, H.A.; et al. Revolutionizing healthcare: The role of artificial intelligence in clinical practice. BMC Med. Educ. 2023, 23, 689. [Google Scholar] [CrossRef] [PubMed]
- Sachdev, K.; Gupta, M.K. A comprehensive review of computational techniques for the prediction of drug side effects. Drug Dev. Res. 2020, 81, 650–670. [Google Scholar] [CrossRef] [PubMed]
- Ho, T.B.; Le, L.; Thai, D.T.; Taewijit, S. Data-driven approach to detect and predict adverse drug reactions. Curr. Pharm. Des. 2016, 22, 3498–3526. [Google Scholar] [CrossRef]
- Deimazar, G.; Sheikhtaheri, A. Machine learning models to detect and predict patient safety events using electronic health records: A systematic review. Int. J. Med. Inform. 2023, 180, 105246. [Google Scholar] [CrossRef] [PubMed]
- Rajpoot, K.; Desai, N.; Koppisetti, H.; Tekade, M.; Sharma, M.C.; Behera, S.K.; Tekade, R.K. In silico methods for the prediction of drug toxicity. In Pharmacokinetics and Toxicokinetic Considerations; Tekade, R.K., Ed.; Academic Press: New York, NY, USA, 2022; Volume 2, pp. 357–383. [Google Scholar]
- Liu, M.; Wu, Y.; Chen, Y.; Sun, J.; Zhao, Z.; Chen, X.W.; Matheny, M.E.; Xu, H. Large-scale prediction of adverse drug reactions using chemical, biological, and phenotypic properties of drugs. J. Am. Med. Inform. Assoc. JAMIA 2012, 19, e28–e35. [Google Scholar] [CrossRef] [PubMed]
- Pauwels, E.; Stoven, V.; Yamanishi, Y. Predicting drug side-effect profiles: A chemical fragment-based approach. BMC Bioinf. 2011, 12, 169. [Google Scholar] [CrossRef] [PubMed]
- Mizutani, S.; Pauwels, E.; Stoven, V.; Goto, S.; Yamanishi, Y. Relating drug-protein interaction network with drug side effects. Bioinformatics 2012, 28, i522–i528. [Google Scholar] [CrossRef] [PubMed]
- Amaro, R.E.; Mulholland, A.J. Multiscale methods in drug design bridge chemical and biological complexity in the search for cures. Nat. Rev. Chem. 2018, 2, 0148. [Google Scholar] [CrossRef]
- Duran-Frigola, M.; Aloy, P. Analysis of chemical and biological features yields mechanistic insights into drug side effects. Chem. Biol. 2013, 20, 594–603. [Google Scholar] [CrossRef]
- Boland, M.R.; Jacunski, A.; Lorberbaum, T.; Romano, J.D.; Moskovitch, R.; Tatonetti, N.P. Systems biology approaches for identifying adverse drug reactions and elucidating their underlying biological mechanisms. Wiley Interdiscip. Rev. Syst. Biol. Med. 2016, 8, 104–122. [Google Scholar] [CrossRef] [PubMed]
- Yoo, S.; Noh, K.; Shin, M.; Park, J.; Lee, K.-H.; Nam, H.; Lee, D. In silico profiling of systemic effects of drugs to predict unexpected interactions. Sci. Rep. 2018, 8, 1612. [Google Scholar] [CrossRef] [PubMed]
- Zitnik, M.; Nguyen, F.; Wang, B.; Leskovec, J.; Goldenberg, A.; Hoffman, M.M. Machine learning for integrating data in biology and medicine: Principles, practice, and opportunities. Int. J. Inf. Fusion 2019, 50, 71–91. [Google Scholar] [CrossRef] [PubMed]
- Marques, L.; Costa, B.; Pereira, M.; Silva, A.; Santos, J.; Saldanha, L.; Silva, I.; Magalhães, P.; Schmidt, S.; Vale, N. Advancing precision medicine: A review of innovative In Silico approaches for drug development, clinical pharmacology and personalized healthcare. Pharmaceutics 2024, 16, 332. [Google Scholar] [CrossRef]
- Arksey, H.; O’Malley, L. Scoping studies: Towards a methodological framework. Int. J. Soc. Res. Methodol. 2005, 8, 19–32. [Google Scholar] [CrossRef]
- Chen, T.; Liu, C.; Huang, M.; Cheng, X.; Zhou, L. Adverse drug reaction prediction and feature importance mining based on SIDER dataset. In Proceedings of the SPIE—The International Society for Optical Engineering, Shenyang, China, 25 May 2023; p. 1236360D. [Google Scholar]
- Wu, Z.; Chen, L. Similarity-based method with multiple-feature sampling for predicting drug side effects. Comput. Math. Methods Med. 2022, 2022, 9547317. [Google Scholar] [CrossRef] [PubMed]
- Güneş, S.S.; Yeşil, Ç.; Gurdal, E.E.; Korkmaz, E.E.; Yarım, M.; Aydın, A.; Sipahi, H. Primum non nocere: In Silico prediction of adverse drug reactions of antidepressant drugs. Comput. Toxicol. 2021, 18, 100165. [Google Scholar] [CrossRef]
- Zhou, H.Y.; Cao, H.N.; Matyunina, L.; Shelby, M.; Cassels, L.; McDonald, J.F.; Skolnick, J. MEDICASCY: A machine learning approach for predicting small-molecule drug side effects, indications, efficacy, and modes of action. Mol. Pharm. 2020, 17, 1558–1574. [Google Scholar] [CrossRef]
- Seo, S.; Lee, T.; Kim, M.H.; Yoon, Y. Prediction of side effects using comprehensive similarity measures. BioMed Res. Int. 2020, 2020, 1357630. [Google Scholar] [CrossRef]
- Jiang, H.; Qiu, Y.; Hou, W.; Cheng, X.; Yim, M.Y.; Ching, W.K. Drug side-effect profiles prediction: From empirical to structural risk minimization. IEEE/ACM Trans. Comput. Biol. Bioinform. 2020, 17, 402–410. [Google Scholar] [CrossRef]
- Galeano, D.; Li, S.; Gerstein, M.; Paccanaro, A. Predicting the frequencies of drug side effects. Nat. Commun. 2020, 11, 4575. [Google Scholar] [CrossRef]
- Afdhal, D.; Ananta, K.W.; Hartono, W.S. Adverse drug reactions prediction using multi-label linear discriminant analysis and multi-label learning. In Proceedings of the International Conference on Advanced Computer Science and Information Systems, ICACSIS, Depok, Indonesia, 17–18 October 2020; pp. 69–76. [Google Scholar]
- Muñoz, E.; Nováček, V.; Vandenbussche, P.Y. Facilitating prediction of adverse drug reactions by using knowledge graphs and multi-label learning models. Brief. Bioinform. 2019, 20, 190–202. [Google Scholar] [CrossRef]
- Jamal, S.; Ali, W.; Nagpal, P.; Grover, S.; Grover, A. Computational models for the prediction of adverse cardiovascular drug reactions. J. Transl. Med. 2019, 17, 171. [Google Scholar] [CrossRef] [PubMed]
- Zhao, X.; Chen, L.; Lu, J. A similarity-based method for prediction of drug side effects with heterogeneous information. Math. Biosci. 2018, 306, 136–144. [Google Scholar] [CrossRef] [PubMed]
- Zheng, Y.; Ghosh, S.; Li, j. An optimized drug similarity framework for side-effect prediction. In Proceedings of the 2017 Computing in Cardiology (CinC), Rennes, France, 24–27 September 2017; pp. 1–4. [Google Scholar]
- Sun, C.; Zheng, Y.; Jia, Y.; Gan, L. Drug side-effect prediction based on comprehensive drug similarity. In Proceedings of the 2016 International Forum on Mechanical, Control and Automation (IFMCA 2016); Atlantis Press: Paris, France, 2017; pp. 171–178. [Google Scholar]
- Niu, Y.Q.; Zhang, W. Quantitative prediction of drug side effects based on drug-related features. Interdiscip. Sci. Comput. Life Sci. 2017, 9, 434–444. [Google Scholar] [CrossRef]
- Lee, W.P.; Huang, J.Y.; Chang, H.H.; Lee, K.T.; Lai, C.T. Predicting drug side effects using data analytics and the integration of multiple data sources. IEEE Access 2017, 5, 20449–20462. [Google Scholar] [CrossRef]
- Jamal, S.; Goyal, S.; Shanker, A.; Grover, A. Predicting neurological adverse drug reactions based on biological, chemical and phenotypic properties of drugs using machine learning models. Sci. Rep. 2017, 7, 872. [Google Scholar] [CrossRef]
- Dimitri, G.M.; Lio, P. DrugClust: A machine learning approach for drugs side effects prediction. Comput. Biol. Chem. 2017, 68, 204–210. [Google Scholar] [CrossRef] [PubMed]
- Zhang, W.; Zou, H.; Luo, L.; Liu, Q.; Wu, W.; Xiao, W. Predicting potential side effects of drugs by recommender methods and ensemble learning. Neurocomputing 2016, 173, 979–987. [Google Scholar] [CrossRef]
- Zhang, W.; Yanlin, C.; Shikui, T.; Feng, L.; Qianlong, Q. Drug side effect prediction through linear neighborhoods and multiple data source integration. In Proceedings of the 2016 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Shenzhen, China, 15–18 December 2016; pp. 427–434. [Google Scholar]
- Zhang, W.; Liu, F.; Luo, L.; Zhang, J. Predicting drug side effects by multi-label learning and ensemble learning. BMC Bioinform. 2015, 16, 365. [Google Scholar] [CrossRef]
- Niu, S.-Y.; Xin, M.-Y.; Luo, J.; Liu, M.-Y.; Jiang, Z.-R. DSEP: A tool implementing novel method to predict side effects of drugs. J. Comput. Biol. 2015, 22, 1108–1117. [Google Scholar] [CrossRef] [PubMed]
- Jahid, M.J.; Ruan, J. An ensemble approach for drug side effect prediction. In Proceedings of the 2013 IEEE International Conference on Bioinformatics and Biomedicine, Shanghai, China, 18–21 December 2013; pp. 440–445. [Google Scholar]
- Tricco, A.C.; Lillie, E.; Zarin, W.; O’Brien, K.K.; Colquhoun, H.; Levac, D.; Moher, D.; Peters, M.D.J.; Horsley, T.; Weeks, L.; et al. PRISMA extension for scoping reviews (PRISMA-ScR): Checklist and explanation. Ann. Intern. Med. 2018, 169, 467–473. [Google Scholar] [CrossRef] [PubMed]
- Kuhn, M.; Letunic, I.; Jensen, L.J.; Bork, P. The SIDER database of drugs and side effects. Nucleic Acids Res. 2016, 44, D1075–D1079. [Google Scholar] [CrossRef] [PubMed]
- Kim, S.; Thiessen, P.A.; Bolton, E.E.; Chen, J.; Fu, G.; Gindulyte, A.; Han, L.; He, J.; He, S.; Shoemaker, B.A.; et al. PubChem substance and compound databases. Nucleic Acids Res. 2016, 44, D1202–D1213. [Google Scholar] [CrossRef] [PubMed]
- Yang, W.; Wang, S.; Hu, J.; Tao, X.; Li, Y. Feature extraction and learning approaches for cancellable biometrics: A survey. CAAI Trans. Intell. Technol. 2024, 9, 4–25. [Google Scholar] [CrossRef]
- Lotfi Shahreza, M.; Ghadiri, N.; Mousavi, S.R.; Varshosaz, J.; Green, J.R. A review of network-based approaches to drug repositioning. Brief. Bioinform. 2018, 19, 878–892. [Google Scholar] [CrossRef] [PubMed]
- Natsiavas, P.; Malousi, A.; Bousquet, C.; Jaulent, M.-C.; Koutkias, V. Computational advances in drug safety: Systematic and mapping review of knowledge engineering based approaches. Front. Pharmacol. 2019, 10, 415. [Google Scholar] [CrossRef] [PubMed]
- Alpay, B.A.; Gosink, M.; Aguiar, D. Evaluating molecular fingerprint-based models of drug side effects against a statistical control. Drug Discov. Today 2022, 27, 103364. [Google Scholar] [CrossRef] [PubMed]
- Wu, L.; Gao, J.; Zhang, Y.; Sui, B.; Wen, Y.; Wu, Q.; Liu, K.; He, S.; Bo, X. A hybrid deep forest-based method for predicting synergistic drug combinations. Cell Rep. Methods 2023, 3, 100411. [Google Scholar] [CrossRef]
- Ward, I.R.; Wang, L.; Lu, J.; Bennamoun, M.; Dwivedi, G.; Sanfilippo, F.M. Explainable artificial intelligence for pharmacovigilance: What features are important when predicting adverse outcomes? Comput. Methods Programs Biomed. 2021, 212, 106415. [Google Scholar] [CrossRef]
- Cavasotto, C.N.; Scardino, V. Machine learning toxicity prediction: Latest advances by toxicity end point. ACS Omega 2022, 7, 47536–47546. [Google Scholar] [CrossRef] [PubMed]
- Kim, H.R.; Sung, M.; Park, J.A.; Jeong, K.; Kim, H.H.; Lee, S.; Park, Y.R. Analyzing adverse drug reaction using statistical and machine learning methods: A systematic review. Medicine 2022, 101, e29387. [Google Scholar] [CrossRef] [PubMed]
- Zhao, J.; Henriksson, A.; Asker, L.; Boström, H. Predictive modeling of structured electronic health records for adverse drug event detection. BMC Med. Inform. Decis. Mak. 2015, 15, S1. [Google Scholar] [CrossRef] [PubMed]
- Ietswaart, R.; Arat, S.; Chen, A.X.; Farahmand, S.; Kim, B.; DuMouchel, W.; Armstrong, D.; Fekete, A.; Sutherland, J.J.; Urban, L. Machine learning guided association of adverse drug reactions with in vitro target-based pharmacology. EBioMedicine 2020, 57, 102837. [Google Scholar] [CrossRef] [PubMed]
- Yasrebi-de Kom, I.A.R.; Dongelmans, D.A.; de Keizer, N.F.; Jager, K.J.; Schut, M.C.; Abu-Hanna, A.; Klopotowska, J.E. Electronic health record-based prediction models for in-hospital adverse drug event diagnosis or prognosis: A systematic review. J. Am. Med. Inform. Assoc. JAMIA 2023, 30, 978–988. [Google Scholar] [CrossRef] [PubMed]
- La, M.K.; Sedykh, A.; Fourches, D.; Muratov, E.; Tropsha, A. Predicting adverse drug effects from literature- and database-mined assertions. Drug Saf. 2018, 41, 1059–1072. [Google Scholar] [CrossRef] [PubMed]
- Luque, A.; Carrasco, A.; Martín, A.; de las Heras, A. The impact of class imbalance in classification performance metrics based on the binary confusion matrix. Pattern Recognit. 2019, 91, 216–231. [Google Scholar] [CrossRef]
- Chalasani, S.H.; Syed, J.; Ramesh, M.; Patil, V.; Pramod Kumar, T.M. Artificial intelligence in the field of pharmacy practice: A literature review. Explor. Res. Clin. Soc. Pharm. 2023, 12, 100346. [Google Scholar] [CrossRef] [PubMed]
- Paul, D.; Sanap, G.; Shenoy, S.; Kalyane, D.; Kalia, K.; Tekade, R.K. Artificial intelligence in drug discovery and development. Drug Discov. Today 2021, 26, 80–93. [Google Scholar] [CrossRef]
- Ivanov, S.M.; Lagunin, A.A.; Poroikov, V.V. In silico assessment of adverse drug reactions and associated mechanisms. Drug Discov. Today 2016, 21, 58–71. [Google Scholar] [CrossRef]
- Xuan, P.; Xu, K.; Cui, H.; Nakaguchi, T.; Zhang, T. Graph generative and adversarial strategy-enhanced node feature learning and self-calibrated pairwise attribute encoding for prediction of drug-related side effects. Front. Pharmacol. 2023, 14, 1257842. [Google Scholar] [CrossRef] [PubMed]
- Yu, L.; Cheng, M.; Qiu, W.; Xiao, X.; Lin, W. idse-HE: Hybrid embedding graph neural network for drug side effects prediction. J. Biomed. Inform. 2022, 131, 104098. [Google Scholar] [CrossRef] [PubMed]
- Zhang, W.; Liu, X.; Chen, Y.; Wu, W.; Wang, W.; Li, X. Feature-derived graph regularized matrix factorization for predicting drug side effects. Neurocomputing 2018, 287, 154–162. [Google Scholar] [CrossRef]
- Zhao, B.-W.; Su, X.-R.; Hu, P.-W.; Huang, Y.-A.; You, Z.-H.; Hu, L. iGRLDTI: An improved graph representation learning method for predicting drug–target interactions over heterogeneous biological information network. Bioinformatics 2023, 39, btad451. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.; Chen, L.; Zhong, F.; Wang, D.; Jiang, J.; Zhang, S.; Jiang, H.; Zheng, M.; Li, X. Graph neural network approaches for drug-target interactions. Curr. Opin. Struct. Biol. 2022, 73, 102327. [Google Scholar] [CrossRef]
- Paul, S.G.; Saha, A.; Hasan, M.Z.; Noori, S.R.H.; Moustafa, A. A systematic review of graph neural network in healthcare-based applications: Recent advances, trends, and future directions. IEEE Access 2024, 12, 15145–15170. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
| No | Author, Year, and Country | Objective | Selected Features and Data Sources | Algorithm(s) | Evaluation Metrics | Main Results | |||
|---|---|---|---|---|---|---|---|---|---|
| General Features | Chemical Features | Biological Features | Phenotypical Features | ||||||
| 1 | Chen et al., 2023 [27], China | To predict adverse drug reactions and mining importance features based on the SIDER dataset | Drugs and drug–side effects Data source: SIDER, OFFSIDES | Drug fingerprint association Software: RDKit | _ | _ | Logistic regression, SVM, XGBoost, AdaBoost, single-layer stacking, multi-layer stacking | F1 score, AUC, recall, precision | Single-layer stacking, on average, had the highest AUC of 0/684 SVM, on average, had the highest recall of 0/92 Multi-layer stacking, on average, had the highest precision of 0/735 and F1 score of 0/696. |
| 2 | Wu and Chen., 2022 [28], China | To predict drug side effects using similarity-based multiple-feature sampling. |
|
| Drug target protein association Data source: DrugBank | _ | SVM, Adaboost, Random Forest, Bayesian network, naive Bayes, KNN, decision tree, PART, logistic regression, MLP, RIPPER | Recall, specificity, accuracy, MCC, F1 score, AUC, AUPR | Random Forest had the highest performance with MCC of 0.8661, AUC of 0.969, and AUPR of 0.977. |
| 3 | Güneş et al., 2021 [29], Turkey | To predict adverse drug reactions in a predictive model by integrating drug chemical structures and biological properties. |
| Chemical structure information Data sources: PubChem, Molecular Operating Environment | Biological properties (i.e., targets, enzymes, and transporters) Data source: DrugBank | _ | MLP | MCC, F1 score, AUC, NPV | MLP had a high performance with both chemical and biological features (AUC = 0.695) |
| 4 | Zhou et al., 2020 [30], USA | To use machine learning for predicting small molecule drug side effects, indications, efficacy, and mode of action. |
|
| Drug target protein association Data source: DrugBank | Cell culture Data source: National Cancer Institute/Division of Cancer Treatment and Diagnosis/Developmental Therapeutics Program | Random Forest | AUPR, AUC, recall, precision | Random Forest had a high performance (AUC = 0.902). |
| 5 | Seo et al., 2020 [31], Republic of Korea | To propose a machine learning approach to predict potential drug side effects. |
|
| Drug target protein interaction Data sources: DrugBank, Therapeutic Target Database | Single nucleotide polymorphism Data sources: Comparative Toxicogenomic Database, DisGeNET | Naive Bayes, logistic regression, Random Forest, XGBoost | Recall, precision, specificity, F1 score, AUC | Random Forest and XGBoost had the highest precision Random Forest had the highest performance with a specificity of 0.8126, precision of 0.8178, recall of 0.8473, and F1 score of 0.8294. |
| 6 | Jiang et al., 2020 [32], China | To propose a preliminary machine learning model for drug side-effects prediction |
| Chemical structure
| _ | _ | SVM, regularized regression, LNSM | AUC, AUPR, accuracy, hamming loss, ranking loss, one error, coverage, average precision | The KNN model has a higher average accuracy (95.37%) than other methods. SVM (WGTS kernel) had the highest performance with an AUC of 0.9052 The LNSM model had the highest performance with an AUPR of 0.4491 |
| 7 | Galeano et al., 2020 [33], USA | To propose a machine learning framework for drug side effect frequency prediction. |
| Drug fingerprint association
| Drug target protein interaction Data source: DrugBank | _ | Matrix decomposition model | RMSE, AUC | The drug side effect model predicted Semagacestat side effect frequencies in phases 2 and 3 with AUC values of 0.853 and 0.810. The model predicted drug-shared protein targets with 68.38% AUC action biology. |
| 8 | Afdhal et al., 2020 [34], Indonesia | To use multi-label linear discriminant analysis and learning for predicting adverse drug reactions |
| Chemical substructure
| Drug targets, transporters, enzymes Data sources: Liu’s dataset | Indications Data sources: Liu’s dataset | KNN, MLP | AUC, Hamming loss, F1 score, accuracy | KNN and MLP algorithms increase AUC by 1.56% and 6.53%, respectively. |
| 9 | Muñoz et al., 2019 [35], Ireland | To predict adverse drug reactions using knowledge graphs and multi-label learning models |
| Chemical substructure
| Drug targets, transporters, enzymes Data sources: Liu’s dataset, Bio2RDF v2, SIDER 4 | Indications Data sources: Liu’s dataset, Bio2RDF v2, SIDER 4 | KNN, decision tree, linear regression, MLP, Random Forest | Average precision, AUPR, AUC, ranking loss, one-error, coverage | According to average precision and AUPR metrics, Bio2RDF v2 performed slightly better with Liu’s dataset. MLP outperformed other models in AUC, ranking-loss, and one-error metrics. |
| 10 | Jamal et al., 2019 [36], India | To propose a machine learning-based exhaustive computational model for adverse cardiovascular drug reaction prediction. | Drugs (n = 965), side effects
| Chemical structure (n = 881)
| Drug targets (n = 1264), transporters (n = 86), enzymes (n = 182) Data source: DrugBank | Therapeutic indications (n = 1840), Other ADRs (n = 5497) Data source: SIDER | SMO, Random Forest | Recall, precision, accuracy, specificity, F1 score, AUC | Integrating biological, chemical, and phenotypic features increased random forest and SMO model AUC values. Phenotypical features increased accuracy values, demonstrating their potential to improve model predictiveness. |
| 11 | Zhao et al., 2018 [37], China | To propose a similarity-based method for drug side effects prediction with heterogeneous information. |
Drug ATC code |
| Drug target protein association Data source: DrugBank | _ | Random Forest | Recall, specificity, accuracy, MCC, F1 score | The model had an average sensitivity of 0.791, specificity of 0.759, accuracy of 0.775, precision of 0.766, and F1-measure 0.778. The model predicted drug side effects effectively with an MCC of 0.8492. |
| 12 | Zheng et al., 2017 [38], Australia | To improve side-effect prediction with an optimized drug similarity framework. | Drugs (n = 917), side effect (n = 500), drug–side effect pairs (n = 78,855) Data source: SIDER | Drug substituent, therapeutic, chemical structure similarity Data source: DrugBank | Drug target protein similarity Data source: EMBL-EBI website | _ | KNN, SVM, ELM, RBF | F1 score | SVM had the highest side-effect prediction performance improvement (18.4%), and KNN had the lowest (up to 2.5%) in F1 scores. |
| 13 | Sun et al., 2017 [39], China | To predict drug side effects using drug similarities and known side effects. | Drugs (n = 1134), side effect (n = 300), drug–side effect pairs (n = 75,578) Data source: DrugBank, DrugCom | Drug chemical formula similarity: Software: Tanimoto similarity tool from CDK v1.5.13 | _ | _ | KNN, SVM | Recall, precision, F1 score | The comprehensive similarity-based approach using KNN outperformed SVM-based methods with an average F1-Score of 70.91%, recall of 92.80%, and precision of 57.57%. |
| 14 | Niu and Zhang., 2017 [40], China | To quantitatively predict drug side effects using drug features. | Drugs (n = 888), side effects (n = 1385) Data sources: Pauwels’s dataset, Mizutani’s dataset, Liu’s dataset | Chemical substructure Data sources: Pauwels’s dataset, Mizutani’s dataset, Liu’s dataset | Drug targets, transporters, enzymes Data sources: Pauwels’s dataset, Mizutani’s dataset, Liu’s dataset | Indications Data sources: Liu’s dataset | Random Forest | AUPR, AUC, RMSE, R2 | In Pauwels’s, Mizutani’s, and Liu’s datasets, Random Forest algorithms had AUPR scores of 0.2509 to 0.4117, AUC scores of 0.9, RMSE values of 0.0390 to 0.0496, and R2 values of 0.0237 to 0.2893. |
| 15 | Lee et al., 2017 [41], Taiwan | To propose a hybrid machine learning approach to create side effect predictors using relevant data features. | Drugs (n = 1002), side effects (n = 3903) Data source: DrugBank, SIDER | Chemical substructure Data sources: DrugBank, PubChem Software: Open Babel | Drug targets, transporters, enzymes, carrier Data sources: DrugBank, UniProt | Indications Data sources: DrugBank, ND-FRT | Native Bayes, KNN, Random Forest | Recall, specificity, accuracy, AUC, F1 score | The Native Bayes algorithm had an AUC of 0.89 and an F1 score of 0.81, the KNN algorithm had 0.87 and 0.80, and the Random Forest algorithm had 0.90 and 0.85. |
| 16 | Jamal et al., 2017 [42], India | Use machine learning models based on drug biological, chemical, and phenotypic properties to predict neurological adverse drug reactions. | Drugs (n = 965), side effects Data source: SIDER | Chemical structure (n = 881) Data source: PubChem | Drug targets (n = 1264), transporters (n = 86), enzymes (n = 182) Data source: DrugBank | Therapeutic indications (n = 1840), Other ADRs (n = 5497) Data source: SIDER | SMO | Recall, precision, accuracy, F1 score, AUC | Chemical + phenotypic properties models predicted neurological adverse drug reactions better than models based on individual properties or their combinations, with the highest F1 score and AUC of 0.96. |
| 17 | Dimitri and Lió., 2017 [43], UK | To demonstrate a drug side effect prediction by machine learning algorithm. | Drugs (n = 888), side effects (n = 1385) Data sources: SIDER 4, Mizutani’s dataset, Liu’s dataset | Chemical substructure Data sources: SIDER 4, Mizutani’s dataset, Liu’s dataset | Drug targets, transporters, enzymes, pathway Data sources: SIDER 4, Mizutani’s dataset, Liu’s dataset | Indications Data sources: SIDER 4, Liu’s dataset | K-means, PAM, K-seeds | AUC, AUPR | AUC performance for protein targets, chemical substructure, and their combination is consistently higher for K-seeds than K-means and PAM across all three datasets. |
| 18 | Zhang et al., 2016 [44], China | Use approved drugs, side effect terms, and drug–side effect associations to create a recommender system for side effect prediction. | Drugs (n = 888), side effects (n = 1385) Data sources: Pauwels’s dataset, Mizutani’s dataset, Liu’s dataset | Chemical substructure Data sources: Pauwels’s dataset, Mizutani’s dataset, Liu’s dataset | Drug targets, transporters, enzymes, pathway Data sources: Pauwels’s dataset, Mizutani’s dataset, Liu’s dataset | Indications Data sources: Liu’s dataset | INBM, RBMBM | Recall, precision, accuracy, F1 score, AUC, AUPR | In all three datasets, RBMBM had higher AUC scores than INBM, suggesting it may be better at drug side effect prediction. INBM still had competitive AUC scores and may be a good alternative. |
| 19 | Zhang et al., 2016 [45], China | To predict drug side effects using linear neighborhoods and integrating multiple data sources. | Drugs (n = 888), side effects (n = 1385) Data sources: SIDER 4, Pauwels’s dataset, Mizutani’s dataset, Liu’s dataset | Chemical substructure Data sources: SIDER 4, Pauwels’s dataset, Mizutani’s dataset, Liu’s dataset | Drug targets, transporters, enzymes, pathway Data sources: SIDER 4, Pauwels’s dataset, Mizutani’s dataset, Liu’s dataset | Indications Data sources: SIDER 4, Liu’s dataset | LNSM | Average precision, AUPR, AUC, ranking loss, Hamming loss, one-error, coverage | The AUC values for the LNSM are 0.8941 for the SIDER 4 dataset, 0.8941 for Pauwels’s dataset, 0.8946 for Mizutani’s dataset, and 0.8850 for Liu’s dataset. |
| 20 | Zhang et al., 2015 [46], China | Drug side effect prediction using multi-label and ensemble learning. | Drugs (n = 888), side effects (n = 1385) Data sources: Pauwels’s dataset, Mizutani’s dataset, Liu’s dataset | Chemical substructure Data sources: Pauwels’s dataset, Mizutani’s dataset, Liu’s dataset | Drug targets, transporters, enzymes, pathway Data sources: Pauwels’s dataset, Mizutani’s dataset, Liu’s dataset | Indications Data sources: Liu’s dataset | FS-MLKNN, MLKNN | Average precision, AUPR, AUC, ranking loss, Hamming loss, one-error, coverage | FS-MLKNN outperformed MLKNN in all features tested, including chemical substructures, drug targets, transporters, enzymes, pathways, and indications. |
| 21 | Niu et al., 2015 [47], China | To develop a novel method to predict potential adverse drug reactions based on chemical substructures. | Drugs (n = 697), side effect (n = 2604), drug–side effect pairs (n = 74,343) Data source: SIDER | Chemical substructure Data source: Pauwels’s dataset | Drug targets and transporters Data source: Pauwels’s dataset | _ | MLP, SVM, kernel regression, sparse canonical correlation analysis | AUPR, AUC | The highest AUC score was 0.8927 for MLP, followed by SVM (0.7984), sparse canonical correlation analysis (0.8811), and kernel regression (0.8576). |
| 22 | Jahid and Ruan., 2013 [48], USA | To propose a chemical structure-based ensemble model to predict drug side effects. | Drugs (n = 888), side effects (n = 1385) Data source: Pauwels’s dataset | Chemical substructure Data source: Pauwels’s dataset | _ | _ | Multi-layer staking | AUC, accuracy | With an average AUC of 0.87, the model predicted 1032 out of 1385 side-effect terms for drug molecules with 0.77 accuracy. |
| Algorithm (Number of Studies) | Selected Features | Evaluation Metrics | Ref. | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Chemical | Biological | Phenotypical | Precision | Accuracy | Recall | F1 Score | AUC | AUPR | |||
| Ensemble methods | Random Forest (n = 8) | ✓ | 0.94 | 0.8875 | 0.97 | 0.95 | 0.52 | 0.95 | [36] | ||
| ✓ | ✓ | 0.8860 | 0.8944 | 0.8201 | 0.8514 | 0.969 | 0.977 | [28] | |||
| 0.94 | 0.9381 | 0.98 | 0.96 | 0.55 | 0.95 | [36] | |||||
| 0.766 | 0.775 | 0.791 | 0.788 | 0.8492 | [37] | ||||||
| 0.8897 | 0.4117 | [40] | |||||||||
| 0.59 | 0.916 | 0.673 | 0.629 | 0.97 | [41] | ||||||
| ✓ | ✓ | ✓ | 0.72 | 0.78 | 0.902 | [30] | |||||
| 0.8178 | 0.8473 | 0.8294 | 0.9018 | [31] | |||||||
| 0.4609 | 0.8357 | 0.4331 | [35] | ||||||||
| 0.94 | 0.9092 | 0.96 | 0.95 | 0.54 | 0.94 | [36] | |||||
| 0.8934 | 0.2509 | [40] | |||||||||
| 0.554 | 0.908 | 0.657 | 0.601 | 0.976 | [41] | ||||||
| AdaBoost (n = 2) | ✓ | 0.749 | 0.685 | 0.637 | 0.618 | [27] | |||||
| ✓ | ✓ | 0.9024 | 0.8963 | [28] | |||||||
| XGBoost (n = 2) | ✓ | 0.777 | 0.776 | 0.681 | 0.660 | [27] | |||||
| ✓ | ✓ | ✓ | 0.7154 | 0.8196 | 0.8175 | 0.8921 | [31] | ||||
| Single-layer stacking (n = 1) | ✓ | 0.795 | 0.822 | 0.699 | 0.685 | [27] | |||||
| Multi-layer stacking (n = 2) | ✓ | 0.793 | 0.837 | 0.696 | 0.680 | [27] | |||||
| 0.84 | [48] | ||||||||||
| SVM | SVM (n = 6) | ✓ | 0.746 | 0.92 | 0.656 | 0.639 | [27] | ||||
| 0.5078 | 0.9503 | 0.9052 | 0.4180 | [32] | |||||||
| 0.4917 | 0.7992 | 0.5712 | [39] | ||||||||
| ✓ | ✓ | 0.9152 | 0.9147 | [28] | |||||||
| 0.773 | [38] | ||||||||||
| 0.7814 | 0.3637 | [47] | |||||||||
| SMO (n = 2) | ✓ | ✓ | ✓ | 0.85 | 0.9361 | 0.89 | 0.87 | 0.44 | 0.93 | [36] | |
| 0.92 | 0.98 | 0.96 | 0.98 | 0.63 | [42] | ||||||
| Neighborhood-based methods | KNN (n = 7) | ✓ | 0.5757 | 0.928 | 0.7091 | [39] | |||||
| ✓ | ✓ | 0.9071 | 0.9054 | [28] | |||||||
| 0.719 | [38] | ||||||||||
| ✓ | ✓ | ✓ | 0.5083 | 0.8835 | 0.4341 | [35] | |||||
| 0.615 | 0.930 | 0.235 | 0.340 | 0.745 | [41] | ||||||
| 0.5008 | 0.8963 | 0.4557 | [46] | ||||||||
| 0.9149 | 0.5612 | 0.7362 | [34] | ||||||||
| LNSM (n = 2) | ✓ | 0.5126 | 0.8941 | 0.4491 | [32] | ||||||
| ✓ | ✓ | ✓ | 0.5329 | 0.9091 | 0.4909 | [45] | |||||
| INBM (n = 1) | ✓ | ✓ | ✓ | 0.606 | 0.959 | 0.607 | 0.606 | 0.934 | 0.641 | [44] | |
| Regression | Logistic (n = 3) | ✓ | 0.756 | 0.718 | 0.660 | 0.642 | [27] | ||||
| ✓ | ✓ | 0.9157 | 0.9115 | [28] | |||||||
| ✓ | ✓ | ✓ | 0.7933 | 0.8014 | 0.7973 | 0.9018 | [31] | ||||
| Linear (n = 1) | ✓ | ✓ | ✓ | 0.2854 | 0.6724 | 0.2595 | [35] | ||||
| Regularized (n = 1) | ✓ | 0.3607 | 0.9435 | 0.7506 | 0.3015 | [32] | |||||
| Neural network | MLP (n = 5) | ✓ | ✓ | 0.8616 | 0.8688 | [28] | |||||
| 0.7416 | 0.537 | 0.695 | [29] | ||||||||
| 0.8941 | 0.4165 | [47] | |||||||||
| ✓ | ✓ | ✓ | 0.9087 | 0.6031 | 0.7234 | [34] | |||||
| 0.5196 | 0.9003 | 0.4967 | [35] | ||||||||
| RBF (n = 1) | ✓ | ✓ | ✓ | 0.761 | [38] | ||||||
| RBMBM (n = 1) | ✓ | ✓ | ✓ | 0.581 | 0.957 | 0.608 | 0.594 | 0.941 | 0.616 | [44] | |
| ELM (n = 1) | ✓ | ✓ | ✓ | 0.699 | [38] | ||||||
| Bayes theorem | Naive Bayes (n = 3) | ✓ | ✓ | 0.8528 | 0.8296 | [28] | |||||
| ✓ | ✓ | ✓ | 0.7682 | 0.8240 | 0.7951 | 0.8713 | [31] | ||||
| 0.377 | 0.919 | 0.431 | 0.402 | 0.7 | [41] | ||||||
| Bayesian network (n = 1) | ✓ | ✓ | 0.8473 | 0.8225 | [28] | ||||||
| Clustering | K-means (n = 1) | ✓ | ✓ | ✓ | 0.895 | 0.404 | [43] | ||||
| K-seeds (n = 1) | ✓ | ✓ | ✓ | 0.894 | 0.404 | [43] | |||||
| PAM (n = 1) | ✓ | ✓ | ✓ | 0.895 | 0.399 | [43] | |||||
| Decision tree | Decision tree (n = 2) | ✓ | ✓ | 0.9170 | 0.9142 | [28] | |||||
| ✓ | ✓ | ✓ | 0.2252 | 0.6634 | 0.1989 | [35] | |||||
| PART (n = 1) | ✓ | ✓ | 0.9192 | 0.9166 | [28] | ||||||
| RIPPER (n = 1) | ✓ | ✓ | 0.9215 | 0.9181 | [28] | ||||||
| Other algorithms | Sparse canonical correlation analysis (n = 1) | ✓ | ✓ | 0.8230 | 0.3444 | [47] | |||||
| Matrix decomposition model (n = 1) | ✓ | ✓ | 0.920 | 0.59 | [33] | ||||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Toni, E.; Ayatollahi, H.; Abbaszadeh, R.; Fotuhi Siahpirani, A. Machine Learning Techniques for Predicting Drug-Related Side Effects: A Scoping Review. Pharmaceuticals 2024, 17, 795. https://doi.org/10.3390/ph17060795
Toni E, Ayatollahi H, Abbaszadeh R, Fotuhi Siahpirani A. Machine Learning Techniques for Predicting Drug-Related Side Effects: A Scoping Review. Pharmaceuticals. 2024; 17(6):795. https://doi.org/10.3390/ph17060795
Chicago/Turabian StyleToni, Esmaeel, Haleh Ayatollahi, Reza Abbaszadeh, and Alireza Fotuhi Siahpirani. 2024. "Machine Learning Techniques for Predicting Drug-Related Side Effects: A Scoping Review" Pharmaceuticals 17, no. 6: 795. https://doi.org/10.3390/ph17060795
APA StyleToni, E., Ayatollahi, H., Abbaszadeh, R., & Fotuhi Siahpirani, A. (2024). Machine Learning Techniques for Predicting Drug-Related Side Effects: A Scoping Review. Pharmaceuticals, 17(6), 795. https://doi.org/10.3390/ph17060795