
EST-SSR Markers’ Development Based on RNA-Sequencing and Their Application in Population Genetic Structure and Diversity Analysis of Eleusine indica in China
 , and
, and
Abstract
:1. Introduction
2. Materials and Methods
2.1. Transcriptome Data of E. indica
2.2. Plant Culture and DNA Extraction
2.3. EST-SSR Locus Screening and Primer Design
2.4. Primer Selection and Validation
2.5. PCR Amplification and Capillary Electrophoresis
2.6. Statistical Analyses
3. Results
3.1. Frequency and Distribution of EST-SSRs
3.2. Polymorphism Analysis of Selected SSR Markers
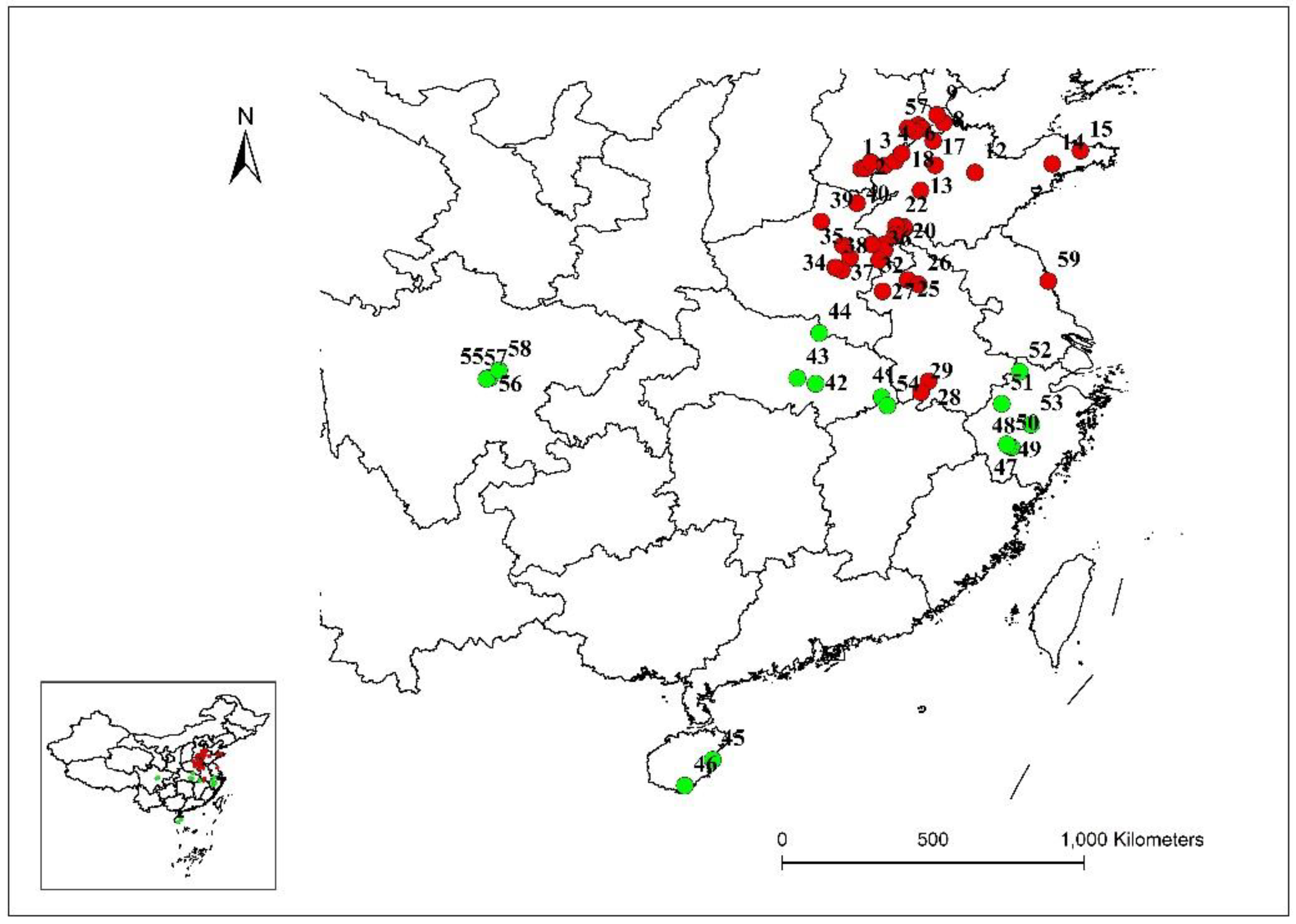
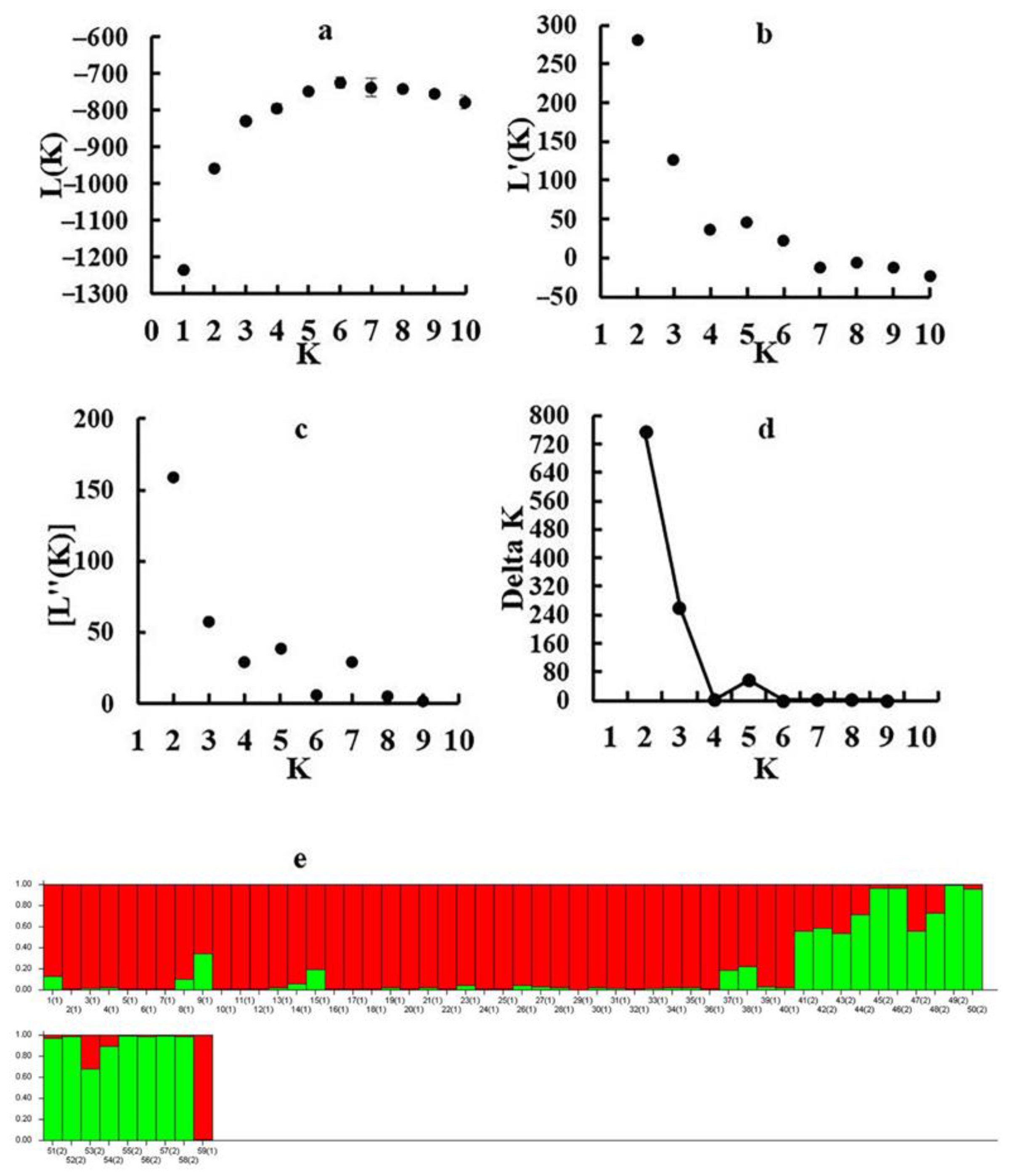
3.3. Genetic Structure and Principal Component Analysis
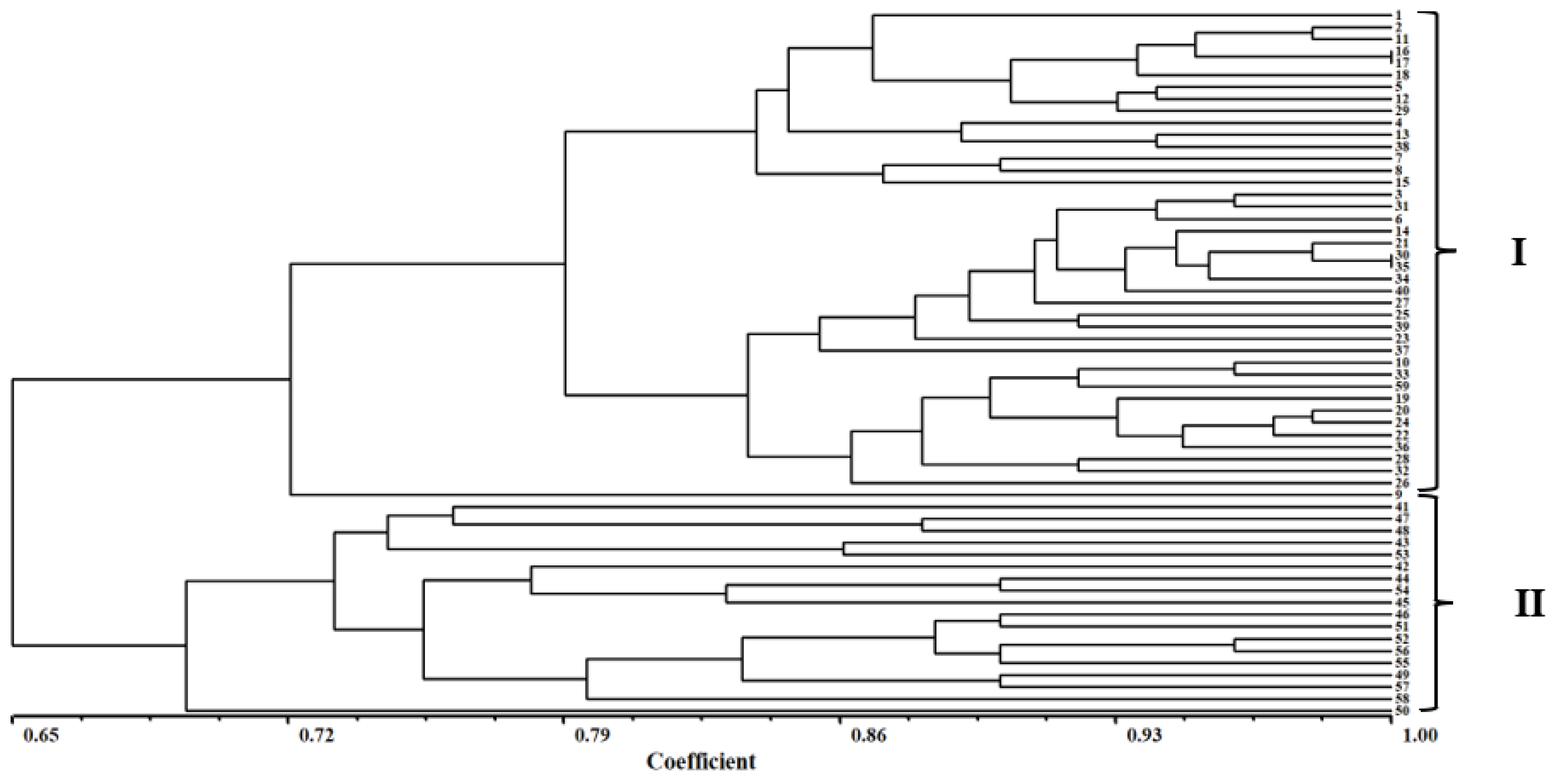
3.4. Cluster Analysis
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Holm, L.G.; Plucknett, D.L.; Pancho, J.V.; Herberger, J.P. The World’s Worst Weeds: Distribution and Biology; University Press of Hawaii: Honolulu, HI, USA, 1977; pp. 47–53. [Google Scholar]
- Chauhan, B.S.; Johnson, D.E. Germination ecology of goosegrass (Eleusine indica): An important grass weed of rainfed rice. Weed Sci. 2008, 56, 699–706. [Google Scholar] [CrossRef]
- Ma, X.; Wu, H.; Jiang, W.; Ma, Y. Goosegrass (Eleusine indica) density effects on cotton (Gossypium hirsutum). J. Integr. Agr. 2015, 14, 1778–1785. [Google Scholar] [CrossRef] [Green Version]
- Rao, A.; Johnson, D.; Sivaprasad, B.; Ladha, J.; Mortimer, A. Weed management in direct-seeded rice. Adv. Agron. 2007, 93, 153–255. [Google Scholar]
- Kong, H.; Wang, Z.; Guo, J.; Xia, Q.; Zhao, H.; Zhang, Y.; Guo, A.; Lu, B. Increases in genetic diversity of weedy rice associated with ambient temperatures and limited gene flow. Biology 2021, 10, 71. [Google Scholar] [CrossRef]
- Selkoe, K.A.; Toonen, R.J. Microsatellites for ecologists: A practical guide to using and evaluating microsatellite markers. Ecol. Lett. 2006, 9, 615–629. [Google Scholar] [CrossRef]
- Vieira, M.L.C.; Santini, L.; Diniz, A.L.; Munhoz, C.d.F. Microsatellite markers: What they mean and why they are so useful. Genet. Mol. Biol. 2016, 39, 312–328. [Google Scholar] [CrossRef] [Green Version]
- Wei, Z.; Sun, Z.; Cui, B.; Zhang, Q.; Xiong, M.; Wang, X.; Zhou, D. Transcriptome analysis of colored calla lily (Zantedeschia rehmannii Engl.) by Illumina sequencing: De novo assembly, annotation and EST-SSR marker development. PeerJ 2016, 4, e2378. [Google Scholar] [CrossRef] [Green Version]
- Lee, E.-J.; Nah, G.; Yook, M.-J.; Lim, S.-H.; Park, T.-S.; Lee, D.; Kim, D.-S. Phylogenetic relationship of Echinochloa species based on simple sequence repeat and phenotypic marker analyses. Weed Sci. 2016, 64, 441–454. [Google Scholar] [CrossRef]
- Yang, J.; Yu, H.; Li, X.; Dong, J. Genetic diversity and population structure of Commelina communis in China based on simple sequence repeat markers. J. Integr. Agr. 2018, 17, 2292–2301. [Google Scholar] [CrossRef] [Green Version]
- Csencsics, D.; Brodbeck, S.; Holderegger, R. Cost-effective, species-specific microsatellite development for the endangered dwarf bulrush (Typha minima) using next-generation sequencing technology. J. Hered. 2010, 101, 789–793. [Google Scholar] [CrossRef] [Green Version]
- Li, X.; Liu, X.; Wei, J.; Li, Y.; Tigabu, M.; Zhao, X. Development and transferability of EST-SSR markers for from cold-stressed transcriptome through Illumina sequencing. Genes 2020, 11, 500. [Google Scholar] [CrossRef] [PubMed]
- Taheri, S.; Abdullah, T.L.; Rafii, M.; Harikrishna, J.A.; Werbrouck, S.; Teo, C.H.; Sahebi, M.; Azizi, P. De novo assembly of transcriptomes, mining, and development of novel EST-SSR markers in Curcuma alismatifolia (Zingiberaceae family) through Illumina sequencing. Sci. Rep. 2019, 9, 3047. [Google Scholar] [CrossRef] [PubMed]
- Suliya, M.; Wenxuan, D.; Tong, L.; Yingmin, L. An RNA sequencing transcriptome analysis and development of EST-SSR markers in Chinese hawthorn through Illumina sequencing. Forests 2019, 10, 82. [Google Scholar]
- Yang, C.; Tian, X.; Feng, L.; Yue, M. Resistance of Eleusine indica Gaertn to glyphosate. Sci. Agric. Sin. 2012, 45, 2093–2098. [Google Scholar]
- Zhang, Z. Development of chemical weed control and integrated weed management in China. Weed Biol. Manag. 2003, 3, 197–203. [Google Scholar] [CrossRef]
- Takano, H.; Oliveira, R., Jr.; Constantin, J.; Silva, V.; Mendes, R. Chemical control of glyphosate-resistant goosegrass. Planta Daninha 2018, 36, e018176124. [Google Scholar] [CrossRef]
- The International Survey of Herbicide Resistant Weeds. Available online: www.weedscience.org (accessed on 11 November 2022).
- Silin Liu, Z.M.; Zhang, Y.; Chen, Z.; Du, X.; Mu, Y. Astragalus sinicus incorporated as green manure for weed control in corn. Front. Plant Sci. 2022, 13, 829421. [Google Scholar]
- Chen, J.; Huang, H.; Wei, S.; Huang, Z.; Xu, W.; Zhang, C. Investigating the mechanisms of glyphosate resistance in goosegrass (Eleusine indica (L.) Gaertn.) by RNA sequencing technology. Plant J. 2017, 89, 407–415. [Google Scholar] [CrossRef] [Green Version]
- Chen, J.; Huang, H.; Wei, S.; Zhang, C.; Huang, Z. Characterization of glyphosate-resistant goosegrass (Eleusine indica) populations in China. J. Integr. Agric. 2015, 14, 919–925. [Google Scholar] [CrossRef] [Green Version]
- Chen, J.; Jiang, C.; Huang, H.; Wei, S.; Huang, Z.; Wang, H.; Zhao, D.; Zhang, C. Characterization of Eleusine indica with gene mutation or amplification in EPSPS to glyphosate. Pestic. Biochem. Phys. 2017, 143, 201–206. [Google Scholar] [CrossRef]
- Beier, S.; Thiel, T.; Münch, T.; Scholz, U.; Mascher, M. MISA-web: A web server for microsatellite prediction. Bioinformatics 2017, 33, 2583–2585. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Untergasser, A.; Cutcutache, I.; Koressaar, T.; Ye, J.; Faircloth, B.C.; Remm, M.; Rozen, S.G. Primer3—New capabilities and interfaces. Nucleic Acids Res. 2012, 40, e115. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, C.; Chu, Y.; Ding, C.; Su, X.; Huang, Q. Genetic diversity and population structure of black cottonwood (Populus deltoides) revealed using simple sequence repeat markers. BMC Genet. 2020, 21, 2. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mei, L.; Xiaoming, Y.; Hang, L.; Shiying, S.; Hualin, Y.; Lijun, C.; Xiuxin, D. De novo transcriptome assembly of pummelo and molecular marker development. PLoS ONE 2015, 10, e0120615. [Google Scholar]
- Zhang, X.; Ye, Z.; Wang, T.; Xiong, H.; Yuan, X.; Zhang, Z.; Yuan, Y.; Liu, Z. Characterization of the global transcriptome for cotton (Gossypium hirsutum L.) anther and development of SSR marker. Genes 2014, 551, 206–213. [Google Scholar] [CrossRef] [PubMed]
- Zeng, J.; Chen, J.; Kou, Y.; Wang, Y. Application of EST-SSR markers developed from the transcriptome of (Taxaceae), a threatened nut-yielding conifer tree. PeerJ 2018, 6, e5606. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- D’esposito, D.; Orrù, L.; Dattolo, E.; Bernardo, L.; Lamontara, A.; Orsini, L.; Serra, I.A.; Mazzuca, S.; Procaccini, G. Transcriptome characterisation and simple sequence repeat marker discovery in the seagrass Posidonia oceanica. Sci. Data 2016, 3, 160115. [Google Scholar] [CrossRef] [PubMed]
- Varshney, R.K.; Thiel, T.; Stein, N.; Langridge, P.; Graner, A. In silico analysis on frequency and distribution of microsatellites in ESTs of some cereal species. Cell Mol. Biol. Lett. 2002, 7, 537–546. [Google Scholar] [PubMed]
- Cai, K.; Zhu, L.; Zhang, K.; Li, L.; Zhao, Z.; Zeng, W.; Lin, X. Development and characterization of EST-SSR markers from RNA-Seq data in Phyllostachys violascens. Front. Plant Sci. 2019, 10, 50. [Google Scholar] [CrossRef] [Green Version]
- Emami, A.; Shabanian, N.; Rahmani, M.-S.; Khadivi, A.; Mohammad-Panah, N. Genetic characterization of the Crataegus genus: Implications for in situ conservation. Sci. Hortic. 2018, 231, 56–65. [Google Scholar] [CrossRef]
- Yue, H.; Wang, L.; Liu, H.; Yue, W.; Du, X.; Song, W.; Nie, X. De novo assembly and characterization of the transcriptome of broomcorn millet (Panicum miliaceum L.) for gene discovery and marker development. Front. Plant Sci. 2016, 7, 1083. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gao, Z.; Wu, J.; Liu, Z.A.; Wang, L.; Ren, H.; Shu, Q. Rapid microsatellite development for tree peony and its implications. BMC Genom. 2013, 14, 886. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Weber, J.L. Informativeness of human (dC-dA) n·(dG-dT) n polymorphisms. Genomics 1990, 7, 524–530. [Google Scholar] [CrossRef] [PubMed]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Item | Parameters | Number |
|---|---|---|
| EST-SSR | Total number of sequences examined | 48852 |
| Total size of examined sequences (bp) | 41400899 | |
| Total number of identified SSRs | 8391 | |
| Number of SSR containing sequences | 6849 | |
| Number of sequences containing more than 1 SSR | 1206 | |
| Number of SSRs present in compound formation | 451 |
| Repeats | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16+ | Total | Percentage |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A/T | - | - | - | - | - | 1791 | 632 | 285 | 190 | 110 | 63 | 335 | 3406 | 40.59 |
| C/G | - | - | - | - | - | 43 | 38 | 26 | 9 | 14 | 14 | 41 | 185 | 2.20 |
| AC/GT | - | 93 | 36 | 39 | 23 | 22 | 24 | 3 | - | - | - | 1 | 241 | 2.87 |
| AG/CT | - | 283 | 174 | 149 | 147 | 214 | 80 | 5 | - | - | - | 1 | 1053 | 12.55 |
| AT/AT | - | 70 | 22 | 20 | 10 | 14 | 5 | 2 | - | - | - | 0 | 143 | 1.70 |
| CG/CG | - | 73 | 6 | 4 | - | - | - | - | - | - | - | 0 | 83 | 0.99 |
| AAC/GTT | 52 | 29 | 13 | 2 | - | - | - | - | - | - | - | 0 | 96 | 1.14 |
| AAG/CTT | 143 | 54 | 36 | 6 | - | - | - | - | - | - | - | 0 | 239 | 2.89 |
| AAT/ATT | 21 | 9 | 12 | 3 | - | - | - | - | - | - | 1 | 0 | 46 | 0.55 |
| ACC/GGT | 140 | 57 | 27 | 2 | - | - | - | - | - | - | - | 0 | 226 | 2.69 |
| ACG/CGT | 136 | 41 | 9 | 4 | - | - | - | - | - | - | - | 0 | 190 | 2.26 |
| ACT/AGT | 21 | 3 | 5 | - | - | - | - | - | - | - | 1 | 30 | 0.36 | |
| AGC/CTG | 257 | 96 | 27 | 2 | - | - | - | - | - | - | - | 0 | 382 | 4.55 |
| AGG/CCT | 334 | 151 | 78 | 6 | - | - | - | 1 | - | - | - | 0 | 570 | 6.79 |
| ATC/ATG | 90 | 30 | 19 | 3 | - | - | - | - | - | - | - | 0 | 142 | 1.69 |
| CCG/CGG | 896 | 264 | 76 | 5 | - | - | - | - | - | - | - | 0 | 1241 | 14.79 |
| Others | 98 | 15 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 118 | 1.41 |
| Total | 2188 | 1268 | 541 | 246 | 180 | 2085 | 779 | 322 | 199 | 124 | 79 | 380 | 8391 | 100 |
| Primer Name | Repeat | Primer Sequence (5′-3′) | TM (°C) | Na | Ne | Ho | He | I | PIC |
|---|---|---|---|---|---|---|---|---|---|
| SSR10 | (TTTG)5 | AACCAGTTCTTCCTCTGCCG GCCAGCACACCACTCATTTG | 60 | 2.00 | 1.68 | 0.95 | 0.40 | 0.59 | 0.44 |
| SSR12 | (ATCC)5 | TCCTCCTCCTCTGCCCTTTT GCATCCCACCGAACACACTA | 60 | 3.00 | 1.82 | 0.97 | 0.45 | 0.75 | 0.42 |
| SSR27 | (CGAT)5 | GGCTGCTGATGCTTAAACGG TCTAGCTGAGGCAGGACAGT | 60 | 2.00 | 1.83 | 0.95 | 0.45 | 0.65 | 0.40 |
| SSR104 | (GAG)5 | GGGCTCTAGGGACTACACCA GGCTTTCAGAAGGGCTGCTA | 60 | 3.00 | 1.07 | 0.98 | 0.07 | 0.17 | 0.07 |
| SSR105 | (CCG)5 | CGACCACGAGTTCTGCTTCT CCCGCCCTCCAATTTCTCTT | 60 | 3.00 | 1.23 | 0.86 | 0.19 | 0.40 | 0.05 |
| SSR137 | (ATGT)5 | CTGTCTCTGCCCTCCAACAG GGTAGCGTCCAGGATCATGC | 60 | 2.00 | 2.00 | 0.95 | 0.50 | 0.69 | 0.45 |
| SSR138 | (TATC)5 | TAACAGCGACCGCATCTACC AACCTCGCCGTTGTTCAGAG | 60 | 3.00 | 1.76 | 0.92 | 0.43 | 0.69 | 0.35 |
| SSR142 | (TTTC)5 | ACACTCACTCCCTGATCCCT CGGAGGCCCACGTTTCTTAT | 60 | 2.00 | 1.59 | 0.95 | 0.37 | 0.56 | 0.32 |
| SSR154 | (ATTT)5 | CGCGCGCATTTTCATCAGAT CTTGGGATGCTCGTAGCCAT | 60 | 2.00 | 1.96 | 0.95 | 0.49 | 0.68 | 0.44 |
| SSR186 | (ATGT)5 | CTGTCTCTGCCCTCCAACAG GGTAGCGTCCAGGATCATGC | 60 | 2.00 | 2.00 | 0.93 | 0.50 | 0.69 | 0.43 |
| SSR202 | (GAG)12 | CTCCACCATCTCCTTCCTCG CACAAGAAGATCCCCGTGCT | 60 | 4.00 | 1.38 | 0.92 | 0.28 | 0.51 | 0.19 |
| SSR204 | (TCTCTT)10 | GCAGCAAGCCCATGATCTTG TCAGCAGCTGAGCTTACTCC | 60 | 5.00 | 2.19 | 0.88 | 0.54 | 1.03 | 0.47 |
| SSR216 | (AT)12 | CGGTGCGTGACAGTCAAAAG GCCTCCCTGATCCGTTCATC | 60 | 11.00 | 4.53 | 0.33 | 0.78 | 1.78 | 0.48 |
| SSR224 | (TCAG)15 | TGGCTTACCAACAGGCACAA AACAAACAACGCGTCTTGGC | 60 | 5.00 | 2.20 | 0.97 | 0.55 | 1.09 | 0.56 |
| Mean | 3.50 | 1.94 | 0.89 | 0.43 | 0.74 | 0.36 | |||
| St. Dev | 2.41 | 0.82 | 0.17 | 0.17 | 0.38 | 0.15 | |||
| Source of Variation | d.f. | MS | SS | %Total | Est. Var. |
|---|---|---|---|---|---|
| Among groups | 1 | 82.427 | 82.427 | 40 | 1.568 |
| Among populations | 57 | 3.987 | 227.276 | 42 | 1.638 |
| Total | 58 | 351.703 | 82 | 3.205 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, J.; Cui, H.; Huang, H.; Wei, S.; Liu, Y.; Yu, H.; Ma, Y.; Li, X.; Ma, X. EST-SSR Markers’ Development Based on RNA-Sequencing and Their Application in Population Genetic Structure and Diversity Analysis of Eleusine indica in China. Curr. Issues Mol. Biol. 2023, 45, 141-150. https://doi.org/10.3390/cimb45010011
Chen J, Cui H, Huang H, Wei S, Liu Y, Yu H, Ma Y, Li X, Ma X. EST-SSR Markers’ Development Based on RNA-Sequencing and Their Application in Population Genetic Structure and Diversity Analysis of Eleusine indica in China. Current Issues in Molecular Biology. 2023; 45(1):141-150. https://doi.org/10.3390/cimb45010011
Chicago/Turabian StyleChen, Jingchao, Hailan Cui, Hongjuan Huang, Shouhui Wei, Yan Liu, Haiyan Yu, Yan Ma, Xiangju Li, and Xiaoyan Ma. 2023. "EST-SSR Markers’ Development Based on RNA-Sequencing and Their Application in Population Genetic Structure and Diversity Analysis of Eleusine indica in China" Current Issues in Molecular Biology 45, no. 1: 141-150. https://doi.org/10.3390/cimb45010011