
Apolipoprotein E (APOE) Haplotypes in Healthy Subjects from Worldwide Macroareas: A Population Genetics Perspective for Cardiovascular Disease, Neurodegeneration, and Dementia


Abstract
1. Introduction
2. Materials and Methods
2.1. Data Recovery and Management
2.2. Dataset Quality Control and Linkage Estimation
2.3. Data Phasing and Haplotype Estimation
3. Results
3.1. Variant Summary Statistics
3.2. Variant Uniqueness and Genotype Distribution across Macroareas
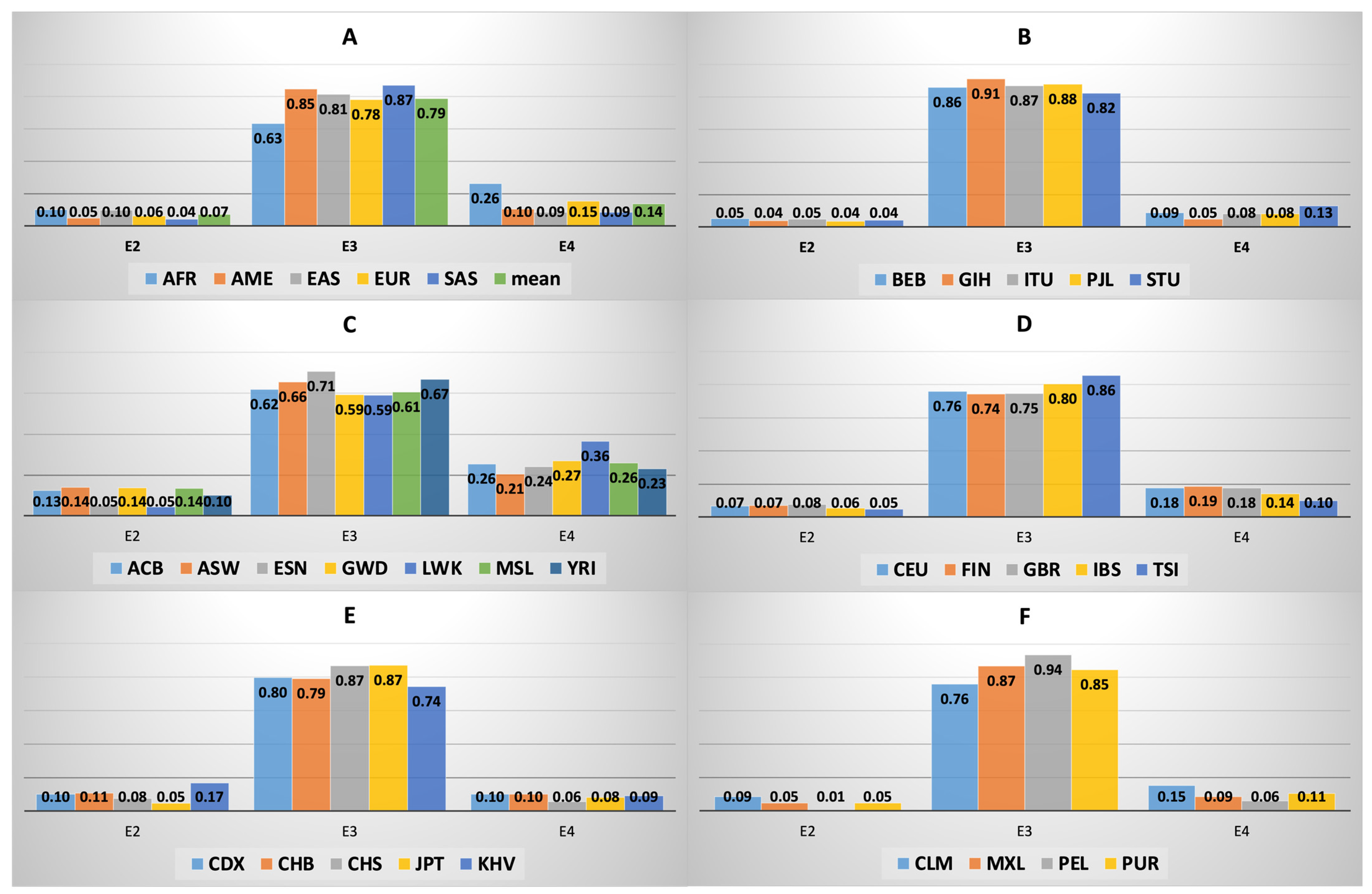
3.3. APOE Isoform Frequency across and within Macroareas
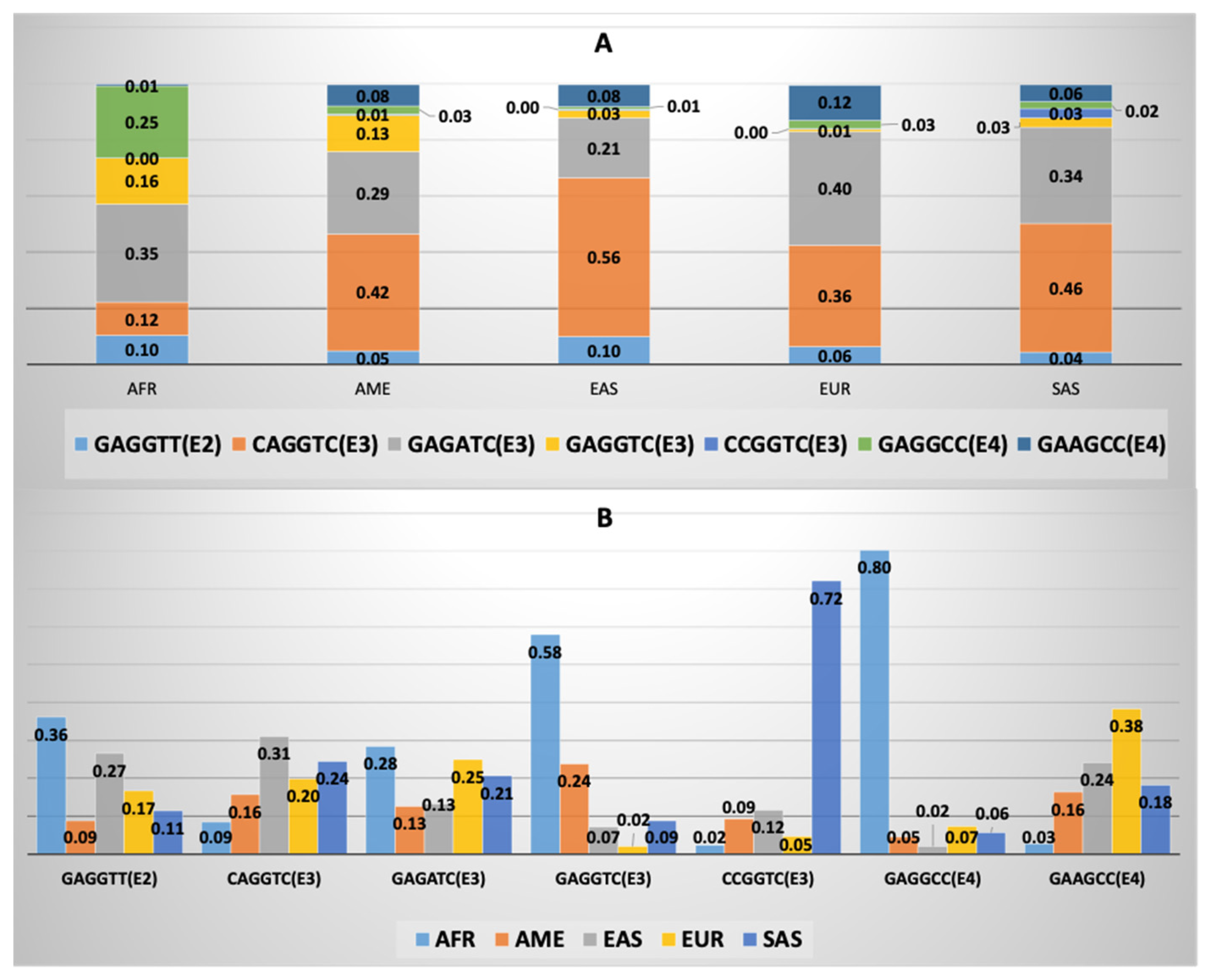
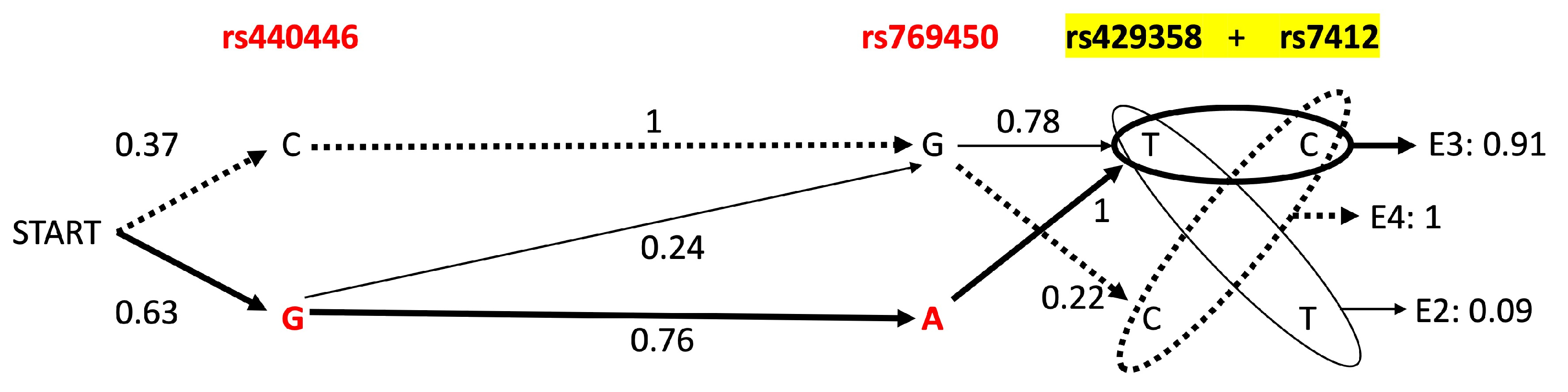
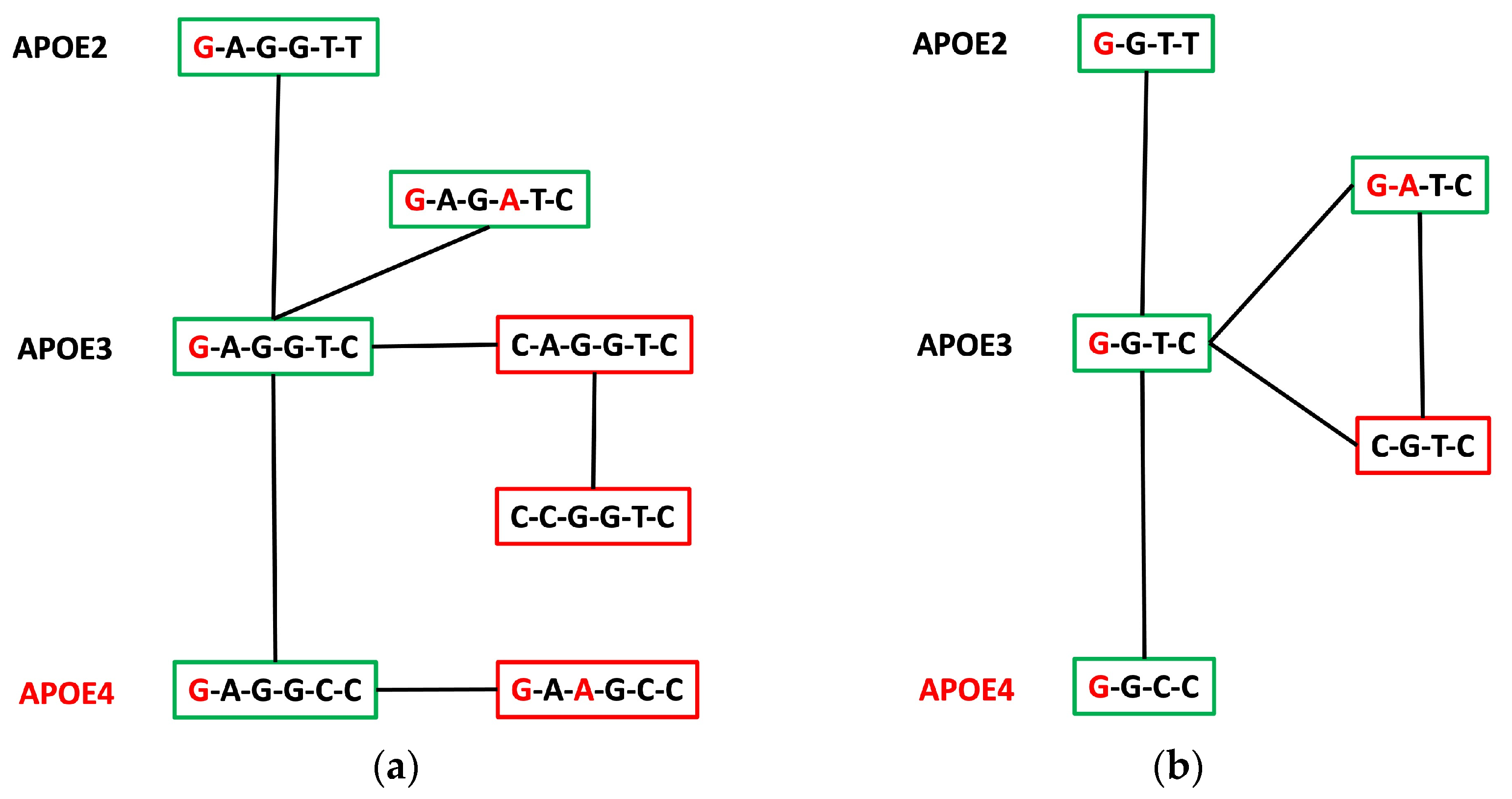
3.4. APOE Core Haplotype Characteristics
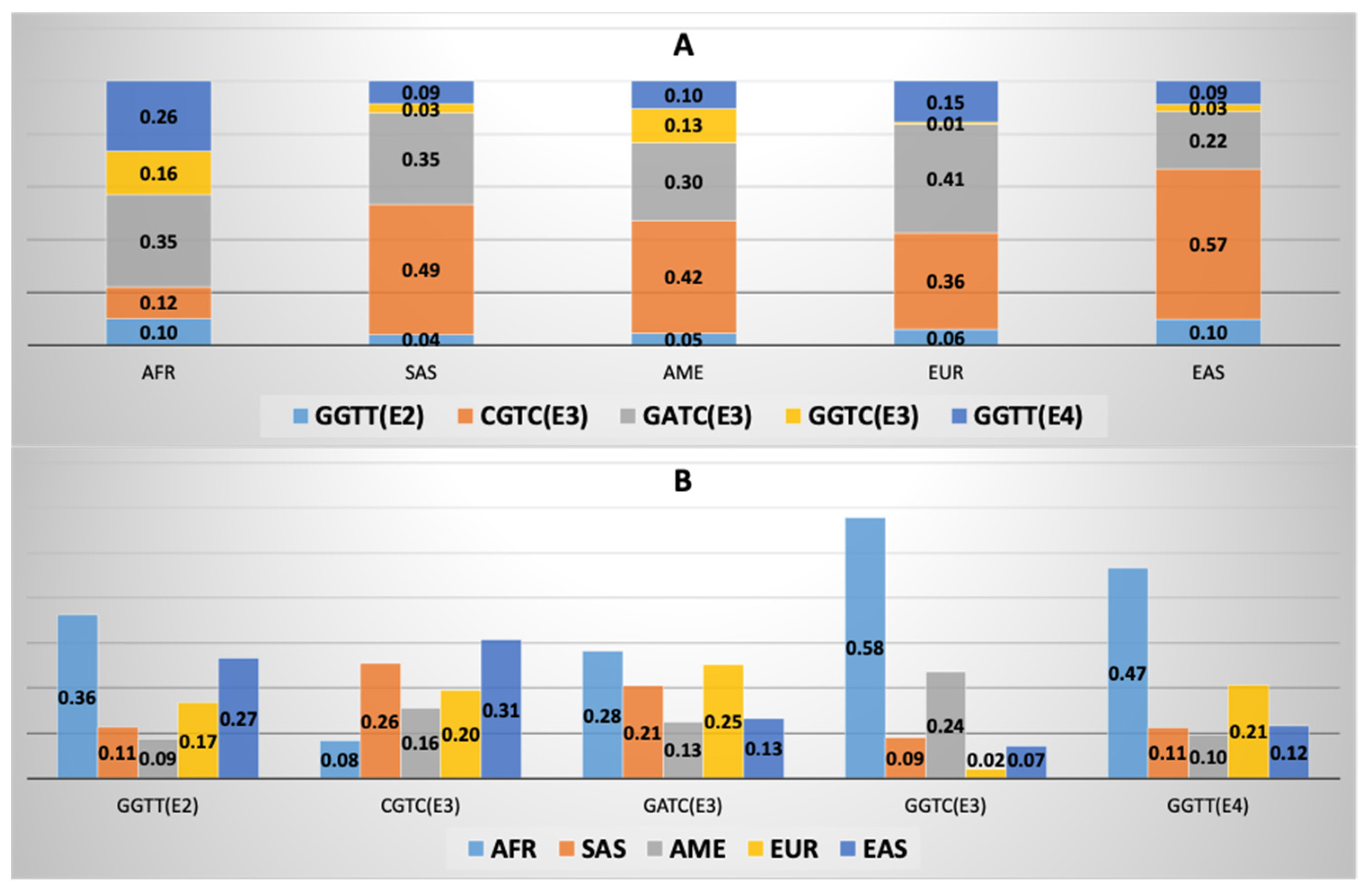
3.5. APOE Super-Core Haplotype Characteristics
3.6. APOE Macroarea-Specific Haplotypes
4. Discussion
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kockx, M.; Traini, M.; Kritharides, L. Cell-specific production, secretion, and function of apolipoprotein E. J. Mol. Med. 2018, 96, 361–371. [Google Scholar] [CrossRef] [PubMed]
- Chernick, D.; Ortiz-Valle, S.; Jeong, A.; Qu, W.; Li, L. Peripheral versus central nervous system APOE in Alzheimer’s disease: Interplay across the blood-brain barrier. Neurosci. Lett. 2019, 708, 134306. [Google Scholar] [CrossRef] [PubMed]
- Fernández-Calle, R.; Konings, S.C.; Frontiñán-Rubio, J.; García-Revilla, J.; Camprubí-Ferrer, L.; Svensson, M.; Martinson, I.; Boza-Serrano, A.; Venero, J.L.; Nielsen, H.M.; et al. APOE in the bullseye of neurodegenerative diseases: Impact of the APOE genotype in Alzheimer’s disease pathology and brain diseases. Mol. Neurodegener. 2022, 17, 62. [Google Scholar] [CrossRef] [PubMed]
- Mahley, R.W.; Weisgraber, K.H.; Huang, Y. Apolipoprotein E: Structure determines function, from atherosclerosis to Alzheimer’s disease to AIDS. J. Lipid Res. 2009, 50, S183–S188. [Google Scholar] [CrossRef]
- Chen, Y.; Strickland, M.R.; Soranno, A.; Holtzman, D.M. Apolipoprotein E: Structural Insights and Links to Alzheimer Disease Pathogenesis. Neuron 2021, 109, 205–221. [Google Scholar] [CrossRef] [PubMed]
- Chetty, P.S.; Mayne, L.; Lund-Katz, S.; Englander, S.W.; Phillips, M.C. Helical structure, stability, and dynamics in human apolipoprotein E3 and E4 by hydrogen exchange and mass spectrometry. Proc. Natl. Acad. Sci. USA 2017, 114, 968–973. [Google Scholar] [CrossRef]
- Tudorache, I.F.; Trusca, V.G.; Gafencu, A.V. Apolipoprotein E—A Multifunctional Protein with Implications in Various Pathologies as a Result of Its Structural Features. Comput. Struct. Biotechnol. J. 2017, 15, 359–365. [Google Scholar] [CrossRef]
- Alagarsamy, J.; Jaeschke, A.; Hui, D.Y. Apolipoprotein E in Cardiometabolic and Neurological Health and Diseases. Int. J. Mol. Sci. 2022, 23, 9892. [Google Scholar] [CrossRef]
- Huang, Y.; Mahley, R.W. Apolipoprotein E: Structure and function in lipid metabolism, neurobiology, and Alzheimer’s diseases. Neurobiol. Dis. 2014, 72 Pt A, 3–12. [Google Scholar] [CrossRef]
- Jiang, Y.; Ma, L.; Han, C.; Liu, Q.; Cong, X.; Xu, Y.; Zhao, T.; Li, P.; Cao, Y. Effects of Apolipoprotein E Isoforms in Diabetic Nephropathy of Chinese Type 2 Diabetic Patients. J. Diabetes Res. 2017, 2017, 3560920. [Google Scholar] [CrossRef]
- Wu, L.; Zhang, Y.; Zhao, H.; Rong, G.; Huang, P.; Wang, F.; Xu, T. Dissecting the Association of Apolipoprotein E Gene Polymorphisms With Type 2 Diabetes Mellitus and Coronary Artery Disease. Front. Endocrinol. 2022, 13, 838547. [Google Scholar] [CrossRef]
- Akinyemi, R.O.; Yaria, J.; Ojagbemi, A.; Guerchet, M.; Okubadejo, N.; Njamnshi, A.K.; Sarfo, F.S.; Akpalu, A.; Ogbole, G.; Ayantayo, T.; et al. Dementia in Africa: Current evidence, knowledge gaps, and future directions. Alzheimers Dement. 2022, 18, 790–809. [Google Scholar] [CrossRef] [PubMed]
- Abondio, P.; Sazzini, M.; Garagnani, P.; Boattini, A.; Monti, D.; Franceschi, C.; Luiselli, D.; Giuliani, C. The Genetic Variability of APOE in Different Human Populations and Its Implications for Longevity. Genes 2019, 10, 222. [Google Scholar] [CrossRef] [PubMed]
- Huebbe, P.; Dose, J.; Schloesser, A.; Campbell, G.; Glüer, C.-C.; Gupta, Y.; Ibrahim, S.; Minihane, A.-M.; Baines, J.F.; Nebel, A.; et al. Apolipoprotein E (APOE) genotype regulates body weight and fatty acid utilization-Studies in gene-targeted replacement mice. Mol. Nutr. Food Res. 2015, 59, 334–343. [Google Scholar] [CrossRef]
- Jones, N.S.; Watson, K.Q.; Rebeck, G.W. Metabolic Disturbances of a High-Fat Diet Are Dependent on APOE Genotype and Sex. eNeuro 2019, 6, ENEURO.0267-19.2019. [Google Scholar] [CrossRef]
- Angelopoulou, E.; Paudel, Y.N.; Papageorgiou, S.G.; Piperi, C. APOE Genotype and Alzheimer’s Disease: The Influence of Lifestyle and Environmental Factors. ACS Chem. Neurosci. 2021, 12, 2749–2764. [Google Scholar] [CrossRef] [PubMed]
- Rueter, J.; Rimbach, G.; Huebbe, P. Functional diversity of apolipoprotein E: From subcellular localization to mitochondrial function. Cell. Mol. Life Sci. 2022, 79, 499. [Google Scholar] [CrossRef]
- Qin, W.; Li, W.; Wang, Q.; Gong, M.; Li, T.; Shi, Y.; Song, Y.; Li, Y.; Li, F.; Jia, J. Race-Related Association between APOE Genotype and Alzheimer’s Disease: A Systematic Review and Meta-Analysis. J. Alzheimers Dis. 2021, 83, 897–906. [Google Scholar] [CrossRef]
- Mezlini, A.M.; Magdamo, C.; Merrill, E.; Chibnik, L.B.; Blacker, D.L.; Hyman, B.T.; Das, S. Characterizing Clinical and Neuropathological Traits of APOE Haplotypes in African Americans and Europeans. J. Alzheimers Dis. 2020, 78, 467–477. [Google Scholar] [CrossRef]
- The 1000 Genomes Project Consortium. A global reference for human genetic variation. Nature 2015, 526, 68–74. [Google Scholar] [CrossRef]
- Danecek, P.; Auton, A.; Abecasis, G.; Albers, C.A.; Banks, E.; DePristo, M.A.; Handsaker, R.E.; Lunter, G.; Marth, G.T.; Sherry, S.T.; et al. The variant call format and VCFtools. Bioinformatics 2011, 27, 2156–2158. [Google Scholar] [CrossRef] [PubMed]
- Newman, V.; Moore, B.; Sparrow, H.; Perry, E. The Ensembl Genome Browser: Strategies for Accessing Eukaryotic Genome Data. In Eukaryotic Genomic Databases; Methods in Molecular Biology; Humana Press: New York, NY, USA, 2018; Volume 1757, pp. 115–139. [Google Scholar] [CrossRef]
- Purcell, S.; Neale, B.; Todd-Brown, K.; Thomas, L.; Ferreira, M.A.R.; Bender, D.; Maller, J.; Sklar, P.; de Bakker, P.I.W.; Daly, M.J.; et al. PLINK: A Tool Set for Whole-Genome Association and Population-Based Linkage Analyses. Am. J. Hum. Genet. 2007, 81, 559–575. [Google Scholar] [CrossRef] [PubMed]
- Herrero, J.; Muffato, M.; Beal, K.; Fitzgerald, S.; Gordon, L.; Pignatelli, M.; Vilella, A.J.; Searle, S.M.J.; Amode, R.; Brent, S.; et al. Ensembl comparative genomics resources. Database 2016, 2016, bav096. [Google Scholar] [CrossRef] [PubMed]
- Delaneau, O.; Marchini, J.; Zagury, J.-F. A linear complexity phasing method for thousands of genomes. Nat. Methods 2012, 9, 179–181. [Google Scholar] [CrossRef] [PubMed]
- Delaneau, O.; Zagury, J.-F.; Marchini, J. Improved whole-chromosome phasing for disease and population genetic studies. Nat. Methods 2013, 10, 5–6. [Google Scholar] [CrossRef]
- Radwan, Z.H.; Wang, X.; Waqar, F.; Pirim, D.; Niemsiri, V.; Hokanson, J.E.; Hamman, R.F.; Bunker, C.H.; Barmada, M.M.; Demirci, F.Y.; et al. Comprehensive evaluation of the association of APOE genetic variation with plasma lipoprotein traits in U.S. whites and African blacks. PLoS ONE 2014, 9, e114618. [Google Scholar] [CrossRef]
- Pirim, D.; Radwan, Z.H.; Wang, X.; Niemsiri, V.; Hokanson, J.E.; Hamman, R.F.; Feingold, E.; Bunker, C.H.; Demirci, F.Y.; Kamboh, M.I. Apolipoprotein E-C1-C4-C2 gene cluster region and inter-individual variation in plasma lipoprotein levels: A comprehensive genetic association study in two ethnic groups. PLoS ONE 2019, 14, e0214060. [Google Scholar] [CrossRef]
- Hoffmann, T.J.; Theusch, E.; Haldar, T.; Ranatunga, D.K.; Jorgenson, E.; Medina, M.W.; Kvale, M.N.; Kwok, P.-Y.; Schaefer, C.; Krauss, R.M.; et al. A large electronic-health-record-based genome-wide study of serum lipids. Nat. Genet. 2018, 50, 401–413. [Google Scholar] [CrossRef] [PubMed]
- Wojcik, G.L.; Graff, M.; Nishimura, K.K.; Tao, R.; Haessler, J.; Gignoux, C.R.; Highland, H.M.; Patel, Y.M.; Sorokin, E.P.; Avery, C.L.; et al. Genetic analyses of diverse populations improves discovery for complex traits. Nature 2019, 570, 514–518. [Google Scholar] [CrossRef]
- Yee, A.; Tsui, N.B.Y.; Kwan, R.Y.C.; Leung, A.Y.M.; Lai, C.K.Y.; Chung, T.; Lau, J.Y.N.; Fok, M.; Dai, D.L.K.; Lau, L.-T. Apolipoprotein E Gene Revisited: Contribution of Rare Variants to Alzheimer’s Disease Susceptibility in Southern Chinese. Curr. Alzheimer Res. 2021, 18, 67–79. [Google Scholar] [CrossRef]
- Medway, C.W.; Abdul-Hay, S.; Mims, T.; Ma, L.; Bisceglio, G.; Zou, F.; Pankratz, S.; Sando, S.B.; Aasly, J.O.; Barcikowska, M.; et al. ApoE variant p.V236E is associated with markedly reduced risk of Alzheimer’s disease. Mol. Neurodegener. 2014, 9, 11. [Google Scholar] [CrossRef] [PubMed]
- Koopal, C.; Marais, A.D.; Westerink, J.; Visseren, F.L.J. Autosomal dominant familial dysbetalipoproteinemia: A pathophysiological framework and practical approach to diagnosis and therapy. J. Clin. Lipidol. 2017, 11, 12–23.e1. [Google Scholar] [CrossRef]
- Abondio, P.; Bruno, F.; Bruni, A.C.; Luiselli, D. Rare Amyloid Precursor Protein Point Mutations Recapitulate Worldwide Migration and Admixture in Healthy Individuals: Implications for the Study of Neurodegeneration. Int. J. Mol. Sci. 2022, 23, 15871. [Google Scholar] [CrossRef] [PubMed]
- Sazzini, M.; Abondio, P.; Sarno, S.; Gnecchi-Ruscone, G.A.; Ragno, M.; Giuliani, C.; De Fanti, S.; Ojeda-Granados, C.; Boattini, A.; Marquis, J.; et al. Genomic history of the Italian population recapitulates key evolutionary dynamics of both Continental and Southern Europeans. BMC Biol. 2020, 18, 51. [Google Scholar] [CrossRef] [PubMed]
- Marnetto, D.; Pankratov, V.; Mondal, M.; Montinaro, F.; Pärna, K.; Vallini, L.; Molinaro, L.; Saag, L.; Loog, L.; Montagnese, S.; et al. Ancestral genomic contributions to complex traits in contemporary Europeans. Curr. Biol. 2022, 32, 1412–1419.e3. [Google Scholar] [CrossRef] [PubMed]
- Rühli, F.J.; Henneberg, M. New perspectives on evolutionary medicine: The relevance of microevolution for human health and disease. BMC Med. 2013, 11, 115. [Google Scholar] [CrossRef] [PubMed]
- Šimčíková, D.; Heneberg, P. Refinement of evolutionary medicine predictions based on clinical evidence for the manifestations of Mendelian diseases. Sci. Rep. 2019, 9, 18577. [Google Scholar] [CrossRef]
- Fox, M. “Evolutionary medicine” perspectives on Alzheimer’s Disease: Review and new directions. Ageing Res. Rev. 2018, 47, 140–148. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| AFR | AME | EAS | EUR | SAS | Shared |
|---|---|---|---|---|---|
| rs72654467 | rs528229851 | rs373985746 2 | rs563571689 | rs555840707 | rs565782572 |
| rs1187843706 | rs538246559 | rs192348494 2 | rs769447 | rs555877419 | rs769450 2 |
| rs184686013 | rs539807928 | rs150375400 2 | rs769452 3 | rs550501196 | rs769449 2 |
| rs375741166 | rs535397097 | rs373651604 | rs186466504 | rs555914310 | rs440446 2 |
| rs189660912 | rs1227709957 | rs549553647 | rs121918393 2 | rs552962455 | rs7412 4 |
| rs564144591 | rs1313313298 | rs533904656 3 | rs530010303 1 | rs572713679 | rs429358 4 |
| rs148558158 | rs557715042 | rs140808909 1 | rs542186645 | ||
| rs1368528953 | rs190853081 3 | rs529662056 | |||
| rs577618688 | rs553874843 1 | rs563103121 | |||
| rs1018669382 1 | rs555222732 | ||||
| rs1181840153 | rs774452222 | ||||
| rs569017773 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abondio, P.; Bruno, F.; Luiselli, D. Apolipoprotein E (APOE) Haplotypes in Healthy Subjects from Worldwide Macroareas: A Population Genetics Perspective for Cardiovascular Disease, Neurodegeneration, and Dementia. Curr. Issues Mol. Biol. 2023, 45, 2817-2831. https://doi.org/10.3390/cimb45040184
Abondio P, Bruno F, Luiselli D. Apolipoprotein E (APOE) Haplotypes in Healthy Subjects from Worldwide Macroareas: A Population Genetics Perspective for Cardiovascular Disease, Neurodegeneration, and Dementia. Current Issues in Molecular Biology. 2023; 45(4):2817-2831. https://doi.org/10.3390/cimb45040184
Chicago/Turabian StyleAbondio, Paolo, Francesco Bruno, and Donata Luiselli. 2023. "Apolipoprotein E (APOE) Haplotypes in Healthy Subjects from Worldwide Macroareas: A Population Genetics Perspective for Cardiovascular Disease, Neurodegeneration, and Dementia" Current Issues in Molecular Biology 45, no. 4: 2817-2831. https://doi.org/10.3390/cimb45040184
APA StyleAbondio, P., Bruno, F., & Luiselli, D. (2023). Apolipoprotein E (APOE) Haplotypes in Healthy Subjects from Worldwide Macroareas: A Population Genetics Perspective for Cardiovascular Disease, Neurodegeneration, and Dementia. Current Issues in Molecular Biology, 45(4), 2817-2831. https://doi.org/10.3390/cimb45040184