4.1. Stress Sensitive Band Selection of Heavy Metal Pollution
This study carried out a correlation analysis between the content of heavy metal in soils and the spectral reflectance obtained after performing a first-order differential transformation, envelope elimination and inverse logarithmic transformation. Eight maximum correlated bands were selected as pollution stress sensitive bands for the heavy metals Cd, Cr, Cu, Pb and Zn.
Compared with the first-order differential transformation and envelope elimination, the correlation coefficient between the Cd content in the mine reclamation soil and the spectrum obtained after performing the inverse logarithmic transformation was significantly reduced, and no significant correlation to the selection of feature bands was found. The selection results of the five heavy metals’ stress sensitive spectral bands are shown in
Table 2.
4.2. Establishment of the MLR Estimation Model
According to the results of the stress sensitive band selection, the spectral reflectance values obtained through the spectral transformation of the sensitive band were defined as a set of independent variables , and the heavy metal content in the soil of the mining area was treated as dependent variable Y to establish the model.
The stress sensitive bands with a significant correlation were selected as related factors. The data for 6 sample points (12 soil samples, accounting for 60% of the total samples) from the fly-ash and coal gangue reclamation areas were used as the training data, and the remaining eight soil samples (accounting for 40% of the total samples) were used as the testing data. The regression coefficients of the MLR model were calculated, and the stability and forecast accuracy of the model was predicted. The MLR equations for the contents of the five heavy metals are as follows:
This paper evaluated the stability of the regression model with the coefficient of determination (
R2) and the accuracy with the root mean square error using the following formulas, respectively:
In Equations (22) and (23), and represent the measured and predicted values of the heavy metal content, respectively; represents the average of the measured values of the heavy metal contents; , and N represent the number of modeling samples, the number of forecast modeling samples and the number of total samples, respectively; and k represents the number of the independent variables in the model.
R2 indicates the stability of the model. The closer the value is to 1, the more stable the model is.
RMSE indicates the accuracy of the model. The smaller the value, the higher the accuracy of the model. The results for estimating the heavy metal contents in the soil samples of the mining area using the MLR model are shown in
Table 3.
As shown in
Table 3, the MLR model was used to estimate the heavy metal contents in the soil of the mining area. Among them, the Cr estimation result is the best, and the value of its
R2 reaches 0.5976. The estimated values of Cu and Cd are the second best, with
R2 values more than 0.5. The estimated values of Pb and Zn are the worst, with their
R2 values reaching 0.4851 and 0.4687, respectively.
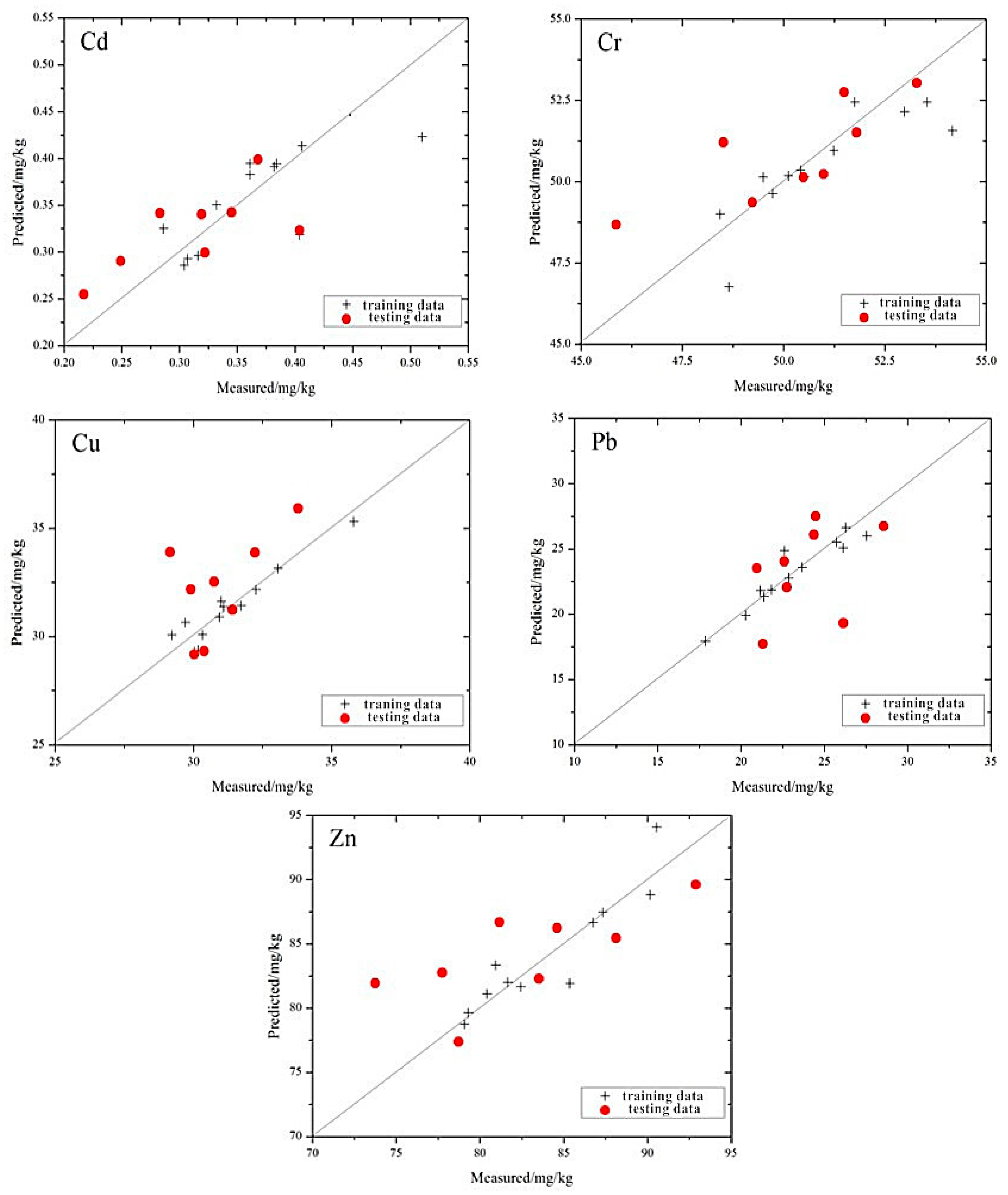
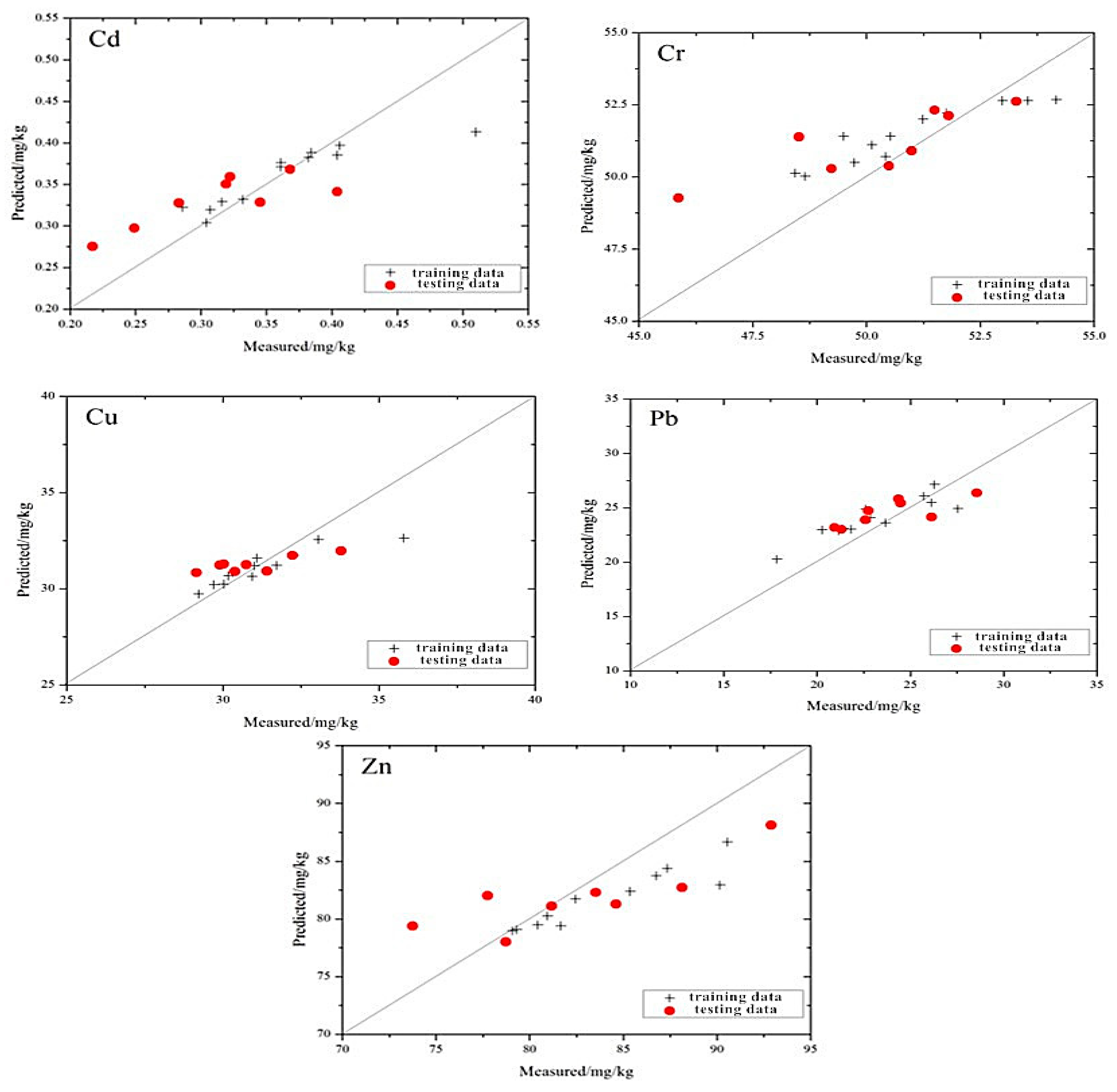
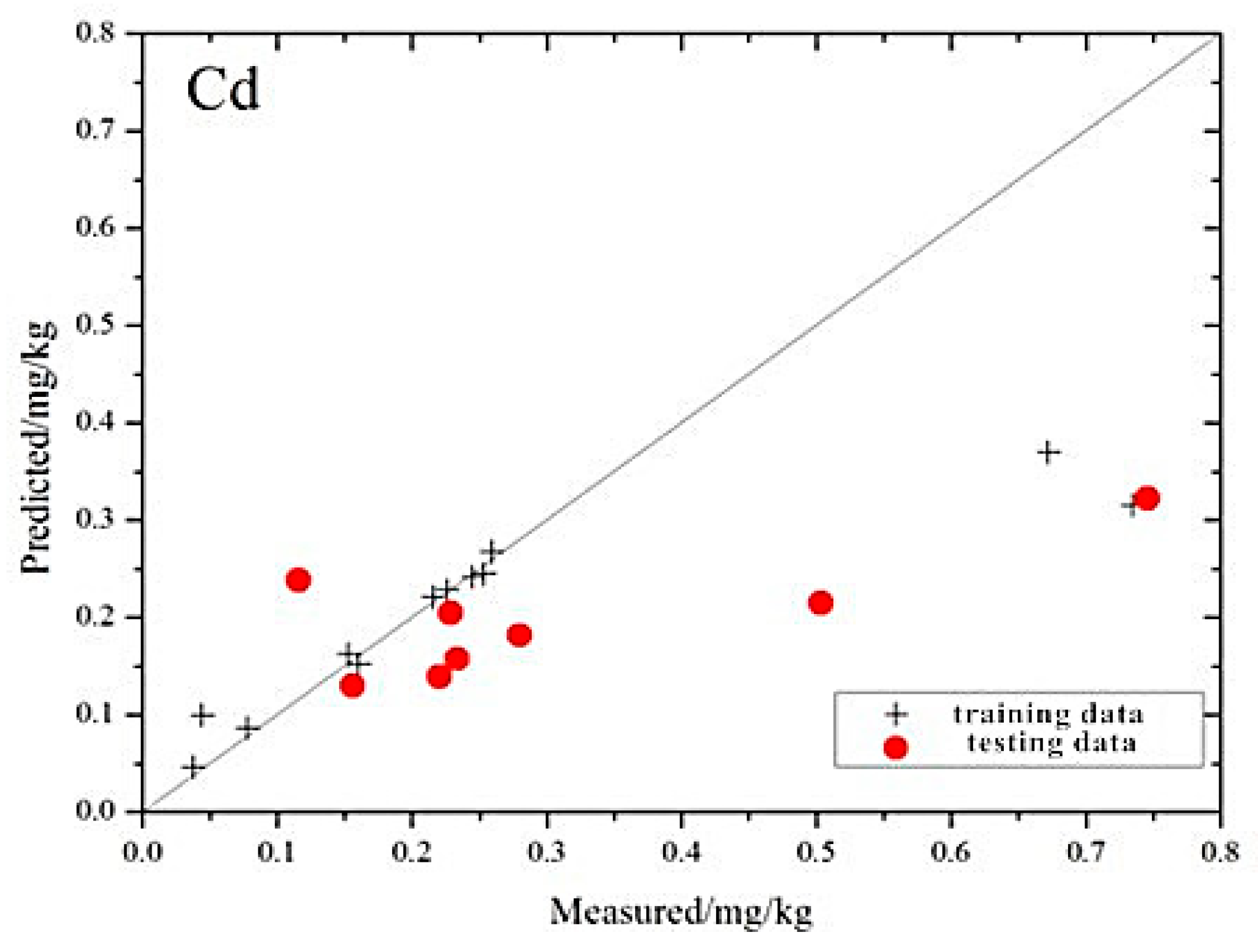
The distribution of the measured values and the estimated values based on the MLR model is shown in
Figure 3. Compared to the prediction efforts of a single element, the distribution of the five types of heavy metal elements is closer to the 1:1 line. Cd, Cr and Zn all have different degrees to which the maximum or minimum values deviate from the 1:1 line. Because the differences between these extreme values and the majority of the sample are great, there are insufficient training samples to support the modeling in the corresponding multi-dimensional space. As a result, the generalization ability of the model is weak, and the model performs unsatisfactorily when the model’s value is a maximum or minimum.
Among the five heavy metals, the distribution of Cr is the closest to the 1:1 line, and the trend is more consistent with the 1:1 line. Relative to Cr, the distributions of Cd and Cu appear to be loose in the vicinity of the 1:1 line, and the overall trend is consistent with the 1:1 line. The distribution of Pb and Zn show that the estimation of those two heavy metals are not very impressive using the model. These results indicate that the best prediction ability of the model is for Cr, followed by Cu and Cd, while the worst is for Pb and Zn.
4.3. Establishment of the GRNN Estimation Model
A smoothing factor
has a significant effect on the ability for the forecasting and generalization of the GRNN. Therefore, the emphasis rests on improving the accuracy of the network forecasting by selecting and using a suitable smoothing factor as the parameter in this network. The experiment adopted a cross validation approach to conduct the parameter optimization of smoothing factor
. The steps of the parameter optimization are given as follows:
- (1)
Set an initializing smoothing factor.
- (2)
Divide the modeling sample into four equal parts, with the first part as the modeling sample and the rest for establishing the GRNN.
- (3)
Use the network model established in step (2) to forecast the modeling sample and calculate the RMSE in this situation.
- (4)
Use the second, third and fourth parts to repeat steps (2) and (3), and calculate the average of the RMSE for the smoothing factor.
- (5)
Progressively increase and change the value of the smoothing factor in the proper order; repeat step (2–4); compare the RMSE of the network when the smoothing factor takes different values; and take the value of the smoothing factor when the RMSE has minimum value as the final value of the smoothing factor of the GRNN.
According to the selection results of the sensitive bands, the spectral reflectance values obtained through the spectral transformation of the sensitive bands were defined as the independent variables , and the heavy metal content in the soil of the mining area is treated as the dependent variable to establish the model.
The stress sensitive bands with a significant correlation were selected as the related factors. The data of six sample points (12 soil samples, accounting for 60% of the total samples) from the fly-ash and coal gangue filling sites were considered as the training data, and the remaining eight soil samples (accounting for 40% of the total samples) were considered as the testing data.
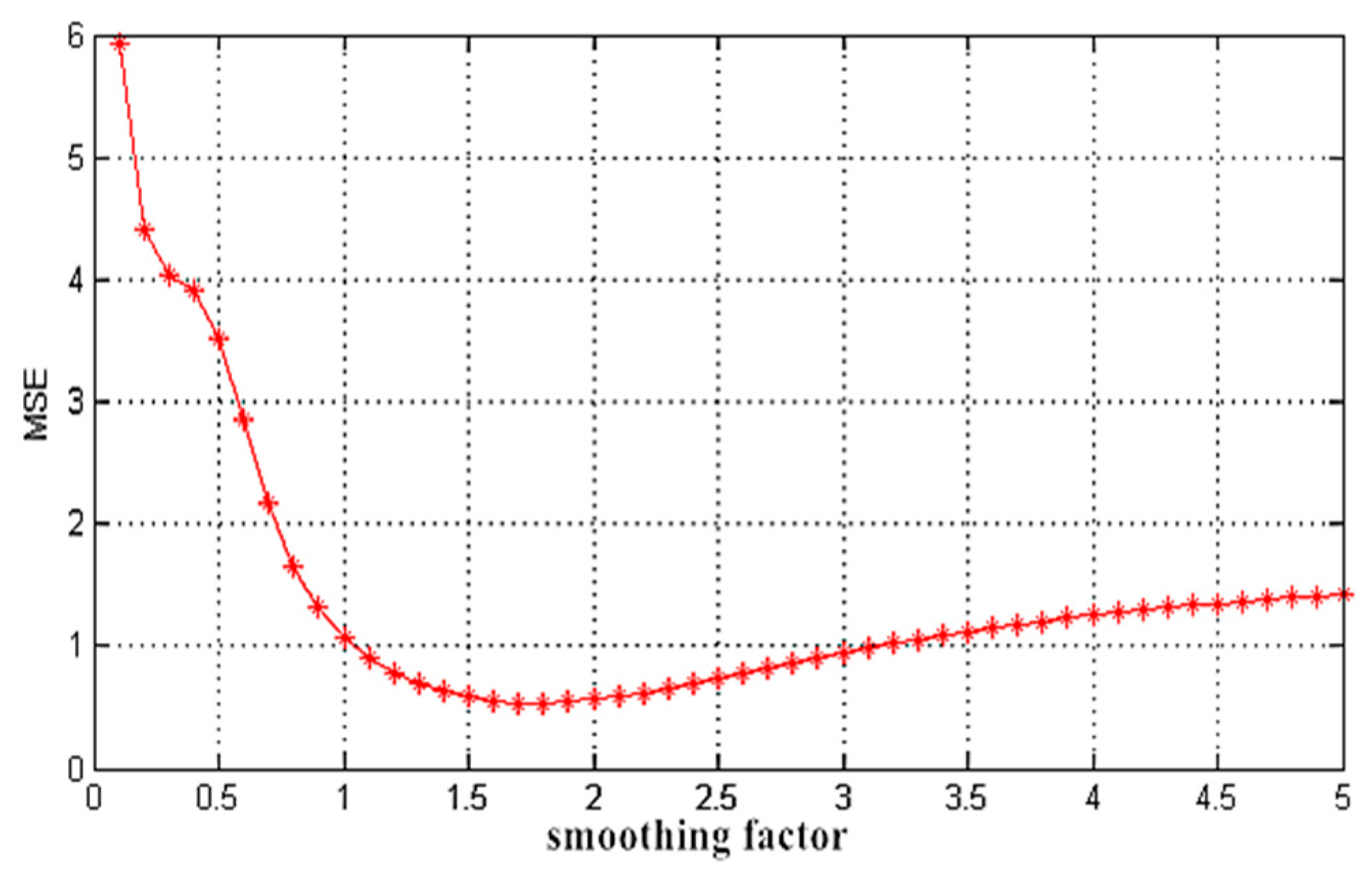
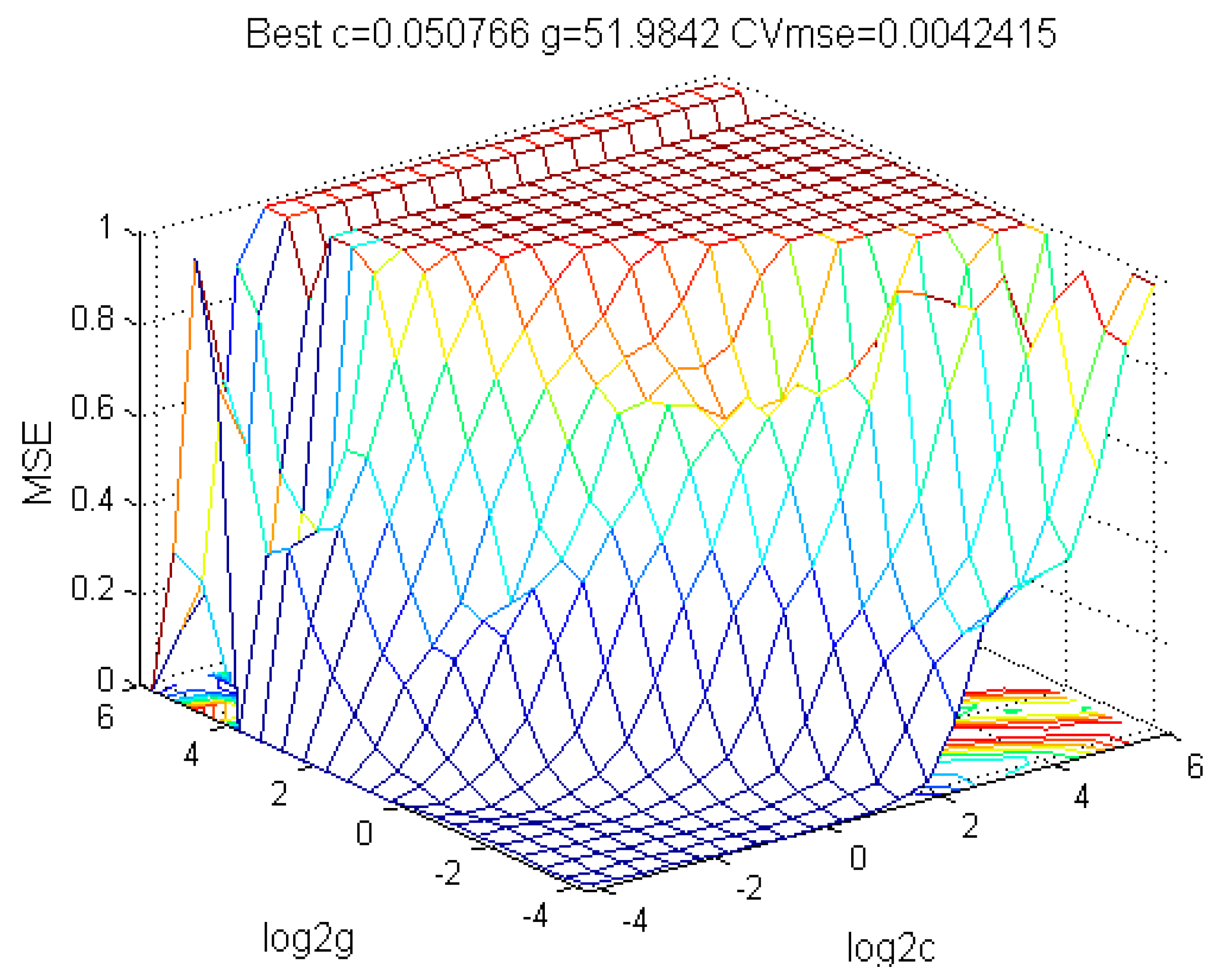
The parameter optimization of the smoothing factor
for Cr in the GRNN is shown in
Figure 4. When
is 1.7, the generalization ability of the network is the best and thus the parameter
participates in the subsequent process of the regression forecast. The optimization of the other parameters used the same method.
The results using the GRNN model for estimating the five types of heavy metal contents in the reclamation soil of the mining area are shown in
Table 4.
As shown in
Table 4, the GRNN model can successfully estimate the heavy metal contents of the mine reclamation soils. Among them, the estimated values of Cr and Cd are the best, and their
R2 values reach 0.7932 and 0.7843, respectively. The estimated values of Pb and Cu are the second best, with
R2 values greater than 0.7. The estimated value of Zn is the worst, but the
R2 value reaches 0.6990.
The distribution of the measured and the estimated values based on the GRNN model is shown in
Figure 5, which shows that the position relationship between the scatter point distribution of the five heavy metals and the 1:1 line is similar to the scatter point distribution of the MLR model. However, the scatter point distribution of the GRNN model is closer to the 1:1 line.
4.4. Establishment of SMO-SVM Estimation Model
This experiment selected the Radial Basis Function (RBF) as the kernel function of SMO-SVM. RBF has the characteristics of a good classification effect and easily adjustable parameters. The computational formula is as follows:
On selecting the SVM parameters when adopting RBF, the internationally commonly-used method confines the penalty parameter C and the kernel function parameter g to a certain range of values, uses cross validation to obtain the optimum parameters C and g, which have the highest accuracy of modeling and validation, and selects the two parameters to participle in the subsequent SVM model establishment. Due to the problem of two-parameter selection, there may be a situation in which there are multiple-unit combinations of C and g that correspond to the highest accuracy of the validation. Therefore, the strategy of selecting the combination of C and g can reach the highest validation accuracy when the parameter C is minimized. If g corresponding to the minimum C has several groups, the first g that was searched for as the optimal parameter is selected.
The stress sensitive bands with a significant correlation were selected as the related factors. The data of six sample points (12 soil samples, accounting for 60% of the total samples) from the fly-ash and coal gangue filling sites were used as the training data, and the remaining eight soil samples (accounting for 40% of the total samples) were used as the testing data.
The map of parameter optimization of the SVM network’s parameters
C and
g for Cr is shown in
Figure 6. When
and
, the generalization ability of the support vector machines is the best and thus the parameter combination participates in the subsequent process of the regression forecast. The optimization methods for the rest of the elements are the same.
The results of using the SMO-SVM model for estimating the five types of heavy metal contents in the reclamation soil of the mining area are shown in
Table 5.
As shown in
Table 5, the SMO-SVM model can successfully estimate the heavy metal contents of the mining area. Among them, the estimated values of Cr and Cd are the best, and their values of
R2 reach 0.8628 and 0.8532, respectively. The estimated values of Pb and Cu are the second best, with
R2 values greater than 0.79. The estimated values of Zn are the worst, but the value of
R2 reaches 0.7653.
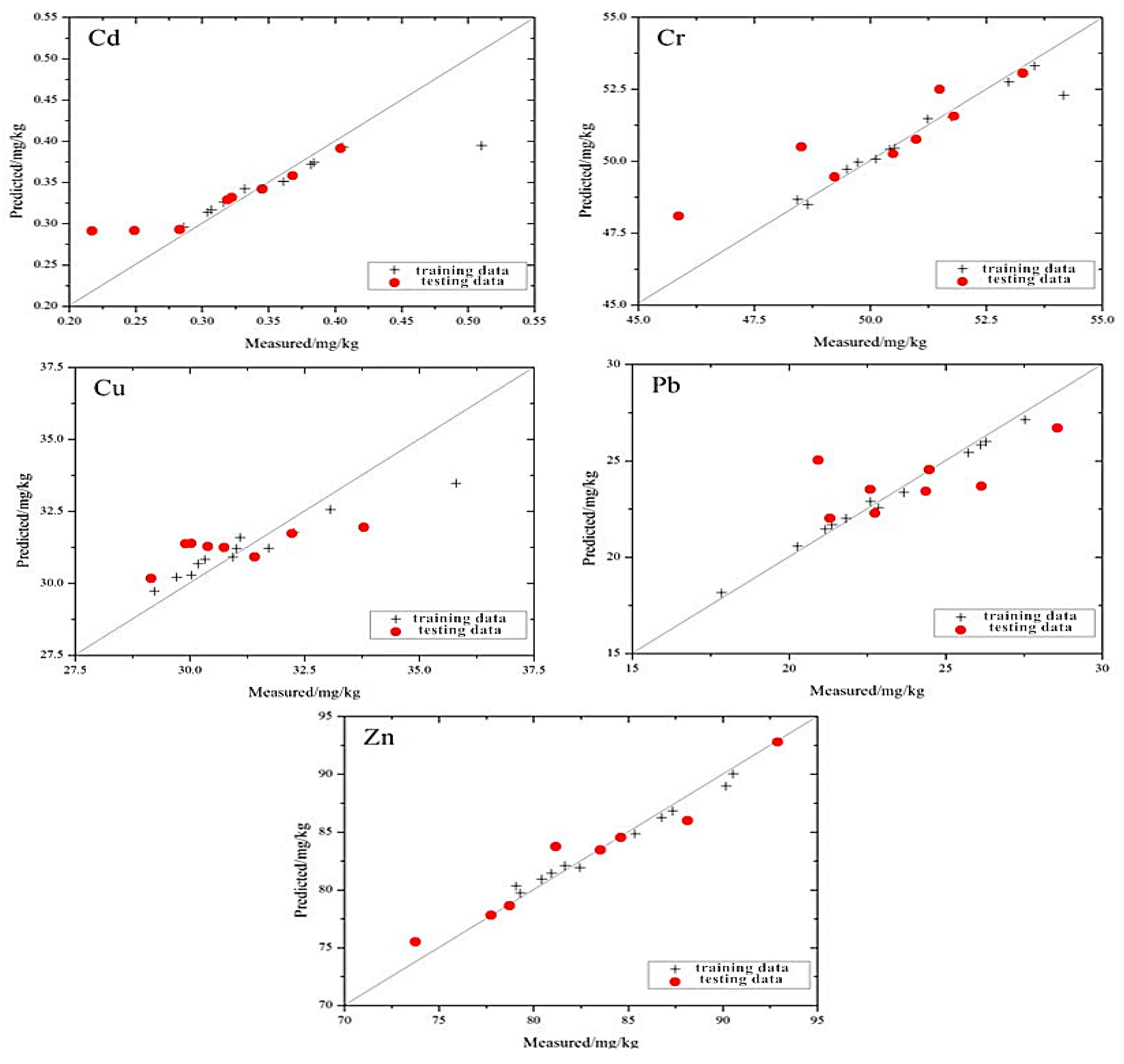
The distribution of the measured and the estimated values based on the SMO-SVM model is shown in
Figure 7, which shows that the position relationship between the scatter point distribution of the five elements and the 1:1 line is similar to the MLR and GRNN models. However, the scatter point distribution of the SMO-SVM model is closer to the 1:1 line.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}