1. Introduction
Lead exposure has adverse health impacts on children’s mental and physical growth and development. Children under six years of age have the highest chance of exposure to lead hazard due to their behavior and other factors. Even low exposure will affect children’s nerve and brain system, causing low IQ, learning disabilities, and hearing problems [
1,
2]. Water, paint, soil, and dust are the common sources of environmental lead exposure. However, pediatric lead poisoning is completely preventable through an intervention such as proactively identifying the lead sources in the environment and educating parents and guardians on how to reduce exposure to these environmental sources [
3]. The local health departments started lead screening programs in the early 1990s to monitor the children’s blood lead levels. Later, in order to prevent pediatric lead poisoning, public health service agencies decided that it is important to shift from case identification and management to primary prevention. Thus, these service agencies are interested in developing analytical methods to identify high-risk areas of lead poisoning.
Statistical models are useful tools for assessing the risks of lead poisoning. They establish the relationships between the number of lead poisoning cases and socio-economic variables and/or environmental factors. These models then can be applied to identify and predict localized risks. Griffith et al. [
4] developed a spatially filtered logistic regression model to explain the empirical probabilities (i.e., the number of children with an elevated level of lead poisoning divided by the number of cases) from the blood lead surveillance records (1992 to 1994) [
4]. They found that population density, household rent/house value, and the percentage of African American people were significant risk factors for children’s lead poisoning [
4]. However, after 20 years of intervention implementation by the Onondaga county government, New York, the lead poisoning incidences have been reduced to approximately 4% and the disease has become rare. As a result, the outcome variable moved from a binomial frequency distribution to a Poisson frequency distribution [
5], because Poisson can be used to approximate a binomial distribution if the population size is sufficiently large and the probability of the event is sufficiently small. Therefore, it would be more appropriate to use Poisson regression to model the number of children with lead poisoning cases.
In epidemiological research, most public health data involve response variables of disease counts, proportions or rates rather than continuous variables [
6]. Generalized linear models (GLIM) provide a collection of modeling methodologies, extending from Gaussian distribution to a family of exponential distributions including the binomial and Poisson distributions [
7,
8]. GLIM consists of a random component defining the distribution of error terms, a systematic component defining the linear combination of explanatory variables, and a link function defining the relationship between the systematic and random components [
6]. For the cases of rare diseases, Poisson models are appropriate for modeling count data [
9,
10].
Spatial count data are more challenging for statistical modeling. This type of data commonly presents the problems of overdispersion and spatial effects (spatial autocorrelation and heterogeneity) [
11]. Overdispersion is concerned with the strict requirement of the Poisson distribution that the mean and variance of a count response variable be equal. For rare disease count data, the observed sample variance is usually much larger than the sample mean because zero counts tend to occur more often than a higher number of counts. This is particularly true for spatially clustered data such as the counts of events in a census tract due to spatial heterogeneity within and between small geographical areas. If the overdispersion in the count data is ignored, it results in underestimating the standard errors of regression coefficients and leading to biased hypothesis testing [
7,
8]. Spatial autocorrelation is concerned with the dependence of a response variable among adjacent neighboring units in a geographical area. Thus, one of the model assumptions, i.e., independent observations, is violated, which has a strong impact on the standard error estimation of regression coefficients. However, the impact is complicated depending on the sign and magnitude of spatial autocorrelation. Positive spatial autocorrelation causes the underestimation of the standard errors, while negative spatial autocorrelation leads to their overestimation [
12].
Agresti [
6] extended the generalized linear models (GLIM) to generalized linear mixed models (GLIMM) by including random effects, which can be used to handle overdispersion and clustered observations. Haining et al. [
11] proposed two modeling strategies to deal with spatial autocorrelation and overdispersion such as the conditional spatial autoregressive model (spatial CAR model) and a spatial filter model, which provided a robust approach for statistical inferences. Ma et al. [
13] applied a generalized linear mixed Poisson model to investigate the influence of the climate and land cover patterns of birds by taking spatial autocorrelation and heterogeneity into account.
Further, the overdispersion problem may become more difficult when the count data contain excessive zero counts. Such data are not uncommon in many public health applications, especially spatial count data due to the spatial partitioning of the study areas [
11,
14]. Given the restriction of equal mean and variance, a Poisson distribution may not be able to handle the count data with disproportionately too many zeros (a.k.a. zero-inflated count data). Other statistical models are more appropriate such as a negative binomial model, a Hurdle model, and a zero-inflated model [
15,
16]. The negative binomial model is a mixture of gamma distribution and Poisson model. It relaxes the assumption of equal mean and variance in a Poisson model by including a dispersion parameter to accommodate the unobserved heterogeneity in the count data [
7,
8]. Mullahy [
17] proposed Hurdle models in order to model the count data with excessive zeros. It has two-parts: the first part is a logistic regression to model the probability that a count is zero or a positive integer value, and the second part is a truncated-at-zero distribution to model the number of counts greater than zero (i.e., positive integer numbers). Although Mullahy [
17] limited his discussion to the case where both transition probabilities were from zero to one and the count variables were Poisson variates, the truncated distribution can be either a Poisson or a negative binomial. Later, Lambert [
18] proposed zero-inflated models which are a mixture of a logistic regression and either a Poisson or a negative binomial model. The logistic model is used to separate zeros from positive counts and the Poisson or negative binomial model is used to model the positive counts. Zero-inflated models are distinct from Hurdle models in their way of interpreting and analyzing zero counts. Zero-inflated models assume that zero observations have two different origins, namely “structural” and “sampling”, while Hurdle models assume that all zeros are from one “sampling” source [
7,
8,
19].
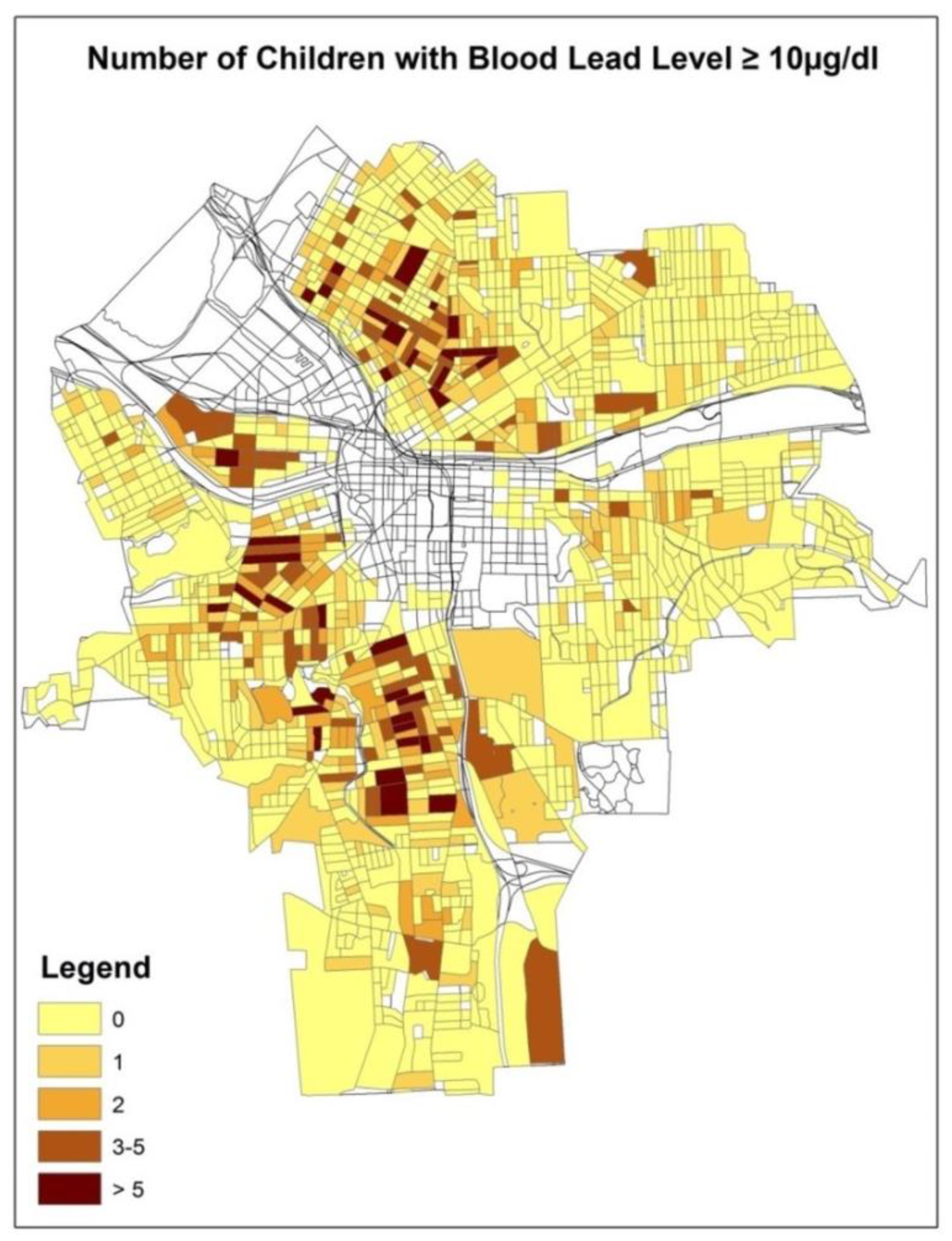
The objective of this study was to develop a model to predict the expected number of children with lead poisoning cases with an elevated blood lead level (≥10 µg/dL) in the inner city of Syracuse, New York, USA. The census block was chosen as the spatial resolution to identify the residential areas of children with lead poisoning. In our previous studies [
20], we assumed that the children with lead poisoning risk could be assessed through two perspectives, physical exposure to the environmental sources of lead hazard and socio-economic vulnerability. We explored a number of socio-economic statuses and environmental factors [
4,
21] and identified three important factors (i.e., soil lead concentration, building year and the town taxable value of the residential houses) as the predictors used in the regression models in this study. Because the number of children with lead poisoning has been greatly reduced after 20 years of lead poisoning prevention, the available count data were strongly skewed with excessive zero counts. Hence, we attempted to compare different statistical models to obtain an optimal model for the given empirical dataset and assess the model prediction performance by the jackknife resampling technique.
3. Results
In general, the soil lead concentration was negatively associated with the building year with a Pearson correlation coefficient of −0.54, meaning that the older the house, the higher the lead concentration in the soil. The Pearson correlation between the house building year and its town taxable value was 0.35, indicating that older houses had lower taxable values. The Pearson correlation coefficient between the town taxable value and soil lead concentration was −0.33. Given the relatively lower correlations between the three predictor variables, there was no multicollinearity problem in the modeling and prediction processes [
26].
The Poisson, negative binomial, Poisson Hurdle, and negative binomial Hurdle models were fitted to the children’s BLL data, respectively, with the census blocks as the random effects (RE) and the total number of BLL screening tests (Ni) in each census block as the offset variable (Equation (12)). The above four generalized linear mixed models with the random effects (i.e., the GLIMM models) fitted the data significantly better than the corresponding generalized linear models without the random effects (i.e., the GLIM models). For example, the AIC of the Poisson model without RE was 3009.7, while the AIC of the Poisson model with RE reduced to 2810.5. The AIC of the negative binomial model with RE was 2586.9, which was smaller than that (2637.9) of the negative binomial model without RE. In general, the magnitudes of the model coefficients of the GLIMM models were smaller than those of the GLIM models, but the standard errors of the model coefficients in the GLIMM models became slightly larger than those of the GLIM models, though all model coefficients remained statistically significant at the significance level of α = 0.05.
In this study, we used the census blocks as the random effects of the four regression models to deal with the spatial effects [
11]. We computed Moran’s I, one of the measures on spatial autocorrelation for the response variable [
12], as well as the model residuals in order to demonstrate the improvement of model fitting if the random effects (RE) were incorporated into the models. The results indicated that for the observed count response variable, the Moran’s I was 0.0529 (Z = 37.78 and
p < 0.0001), for the residuals of the Poisson model without RE the Moran’s I was 0.0204 (Z = 14.86 and
p < 0.0001), and for the residuals of the Poisson model with RE the Moran’s I was reduced to 0.00261 (Z = 1.33 and
p = 0.1832). The results clearly indicated that using the census blocks as RE would be able to significantly reduce the spatial autocorrelation in the model residuals.
The negative binomial model with RE fitted the children’s BLL data better than the Poisson model with RE (
Table 2). The estimated model coefficients were in a close range between the Poisson model and the negative binomial model, but the standard errors (SE) of the negative binomial model coefficients were much larger than those of the Poisson model (
Table 3). The dispersion parameter of the negative binomial model was estimated as κ = 1.1424, which was significantly different from zero. Thus, the negative binomial model allowed the variance of the response variable to be 2.1424 (= 1 + 1.1424, Equation (4), assuming linear variance function) times larger than the mean of the response variable so that it relaxed the rigorous assumption of equal mean and variance for the Poison model. The estimated coefficients of the negative binomial model were all statistically significant. The model coefficient for X
1 (building year) indicated that more recently built houses would have a lower likelihood of lead poisoning. The coefficient of X
2 (log of town taxable value) showed that the higher the average block town taxable value, the lower the chance of having lead poisoning. The estimated parameter of X
3 (log of soil lead concentration) implied that the children would have a higher chance to exposure to lead if the surrounding of the house had higher soil lead concentration (
Table 3).
The Hurdle models had two parts: (1) a logistic regression was used to predict the probability that the count response variable was zero or a positive integer, and (2) a truncated (Poisson or negative binomial) model was used to model the observed counts greater than zero (i.e., positive integers). The negative binomial Hurdle model fitted the children’s BLL data better than the Poisson Hurdle model (
Table 2). The model coefficients in both the Poisson and negative binomial Hurdle models were very similar for both logistic regression and truncated models (
Table 4). However, all model coefficients were statistically significant in the logistic regression models, while the model coefficients for the X
3 (log of soil lead concentration) in both truncated models became non-significant (
p-value > 0.11), indicating that the soil lead concentration was less important for predicting the positive cases of the children’s BLL.
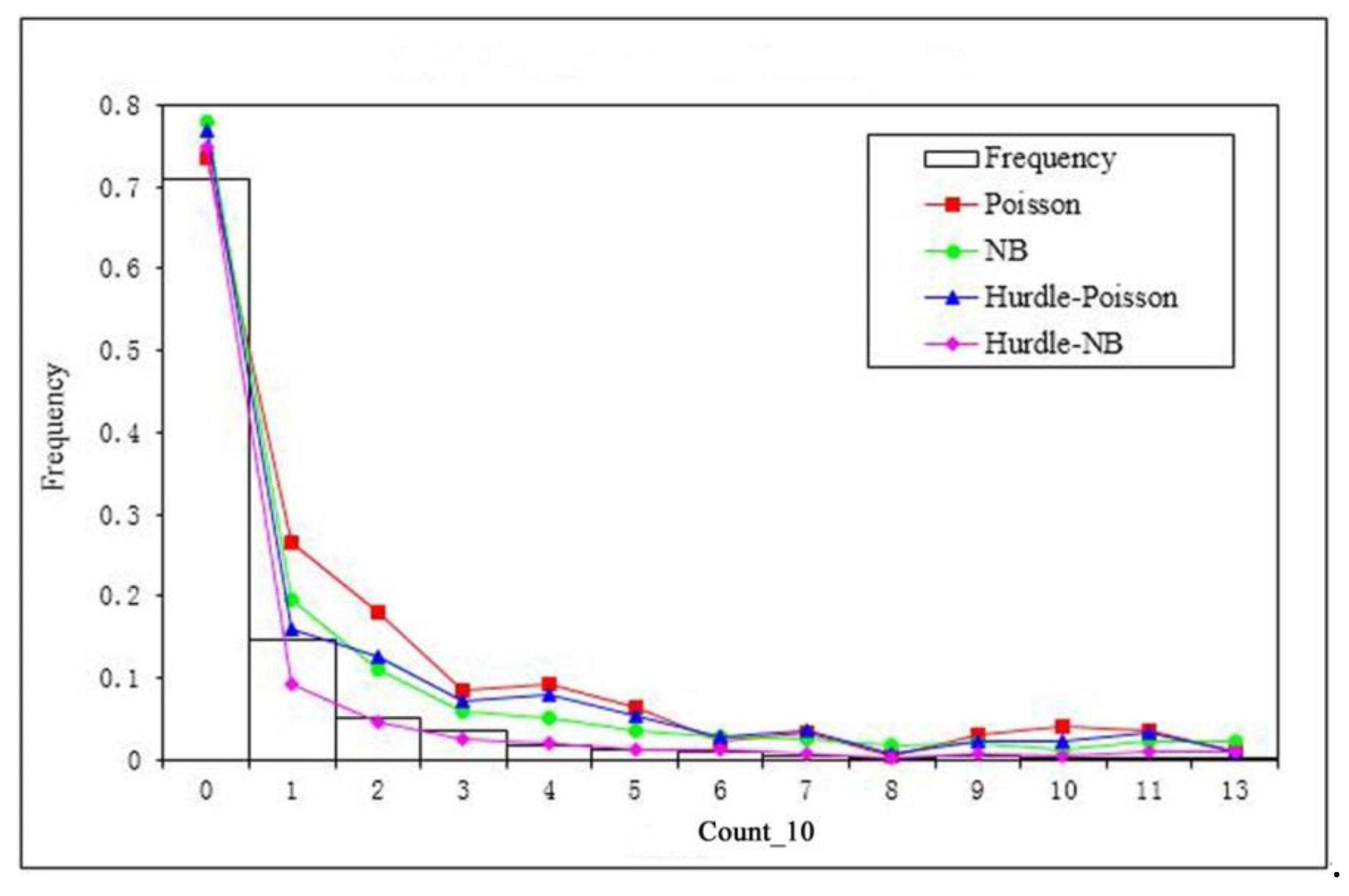
After the model fitting, the four models were used to produce the predictions of the expected numbers of children’s BLL ≥ 10 µg/dL at the census block level, and the Spearman correlation coefficients were computed between observed and predicted response variable. The results indicated that the Spearman correlation coefficient for the Poisson model was 0.53, negative binomial model 0.53, Poisson Hurdle model 0.44, and negative binomial Hurdle model 0.46. Then, the predicted numbers of children’s BLL ≥ 10 µg/dL at the census block level were aggregated to the frequencies of children’s BLL ≥ 10 µg/dL across the range of the count response variable (0 to 13 in this study).
Figure 3 shows the comparison between the observed and predicted frequencies of the response variable. It was evident that the Poisson, negative binomial, and Poisson Hurdle over-predicted the frequency at each count category, while the negative binomial Hurdle model provided the best model fitting (
Figure 3). The Pearson χ
2 statistic was calculated between observed and predicted frequencies for each model. The results showed that the Poisson model with RE had the largest deviance from the observed frequencies (χ
2 = 65.45), followed by the Poisson Hurdle model with RE (χ
2 = 26.50) and the negative binomial model with RE (χ
2 = 21.02). The negative binomial Hurdle model with RE (χ
2 = 6.62) had the smallest deviance from the observed frequencies. The results indicated that the negative binomial Hurdle model handled both issues of overdispersion and excessive zeros effectively and improved model fitting.
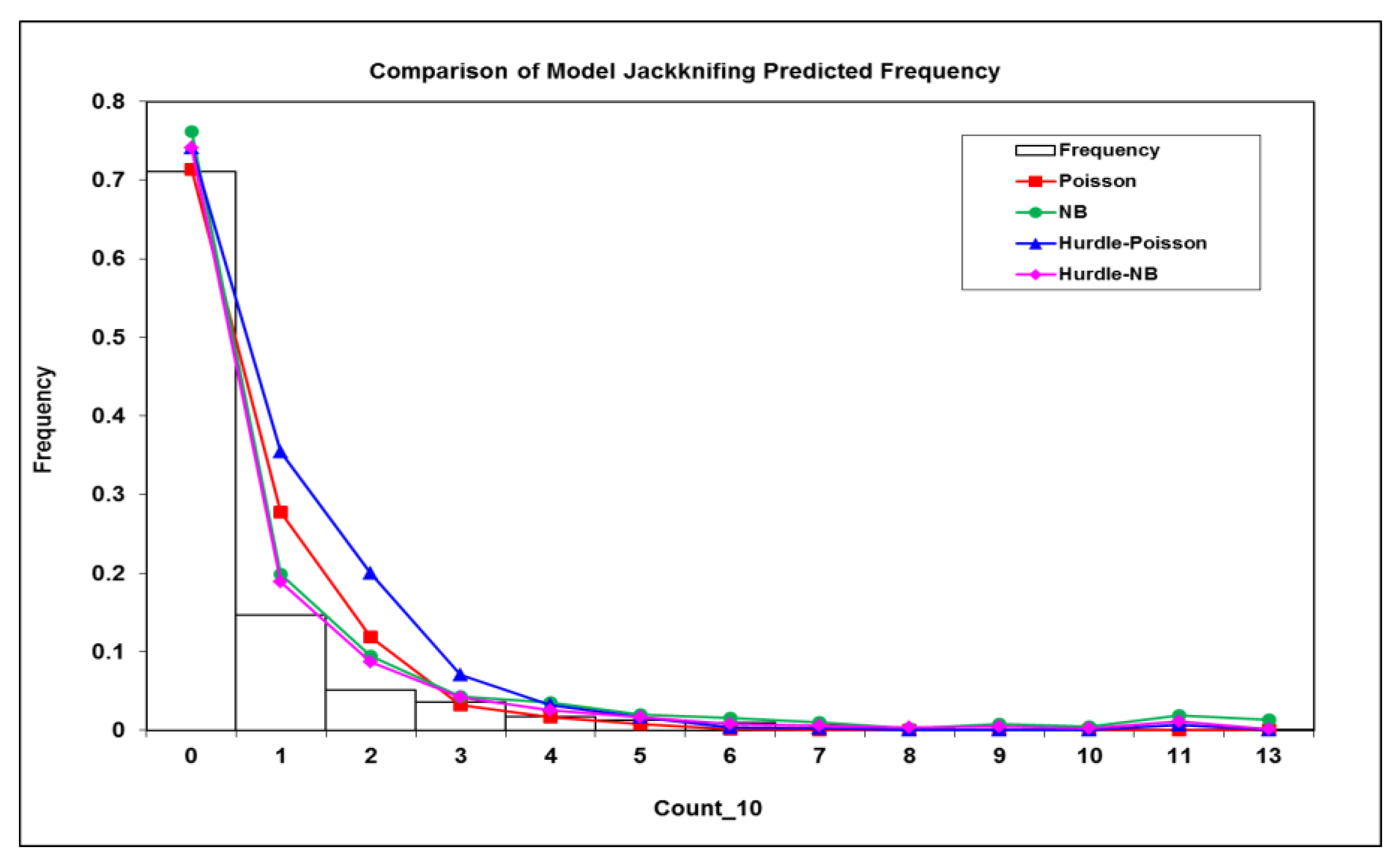
The jackknife resampling was used to validate the model performance or prediction for the four models. The mean prediction error (MPE) and mean absolute error (MAE) were calculated (
Table 5). It appeared that two negative binomial models produced a smaller MPE and MAE than two Poisson counterparts, indicating that negative binomial models were more suitable to deal with overdispersion better. Further, the model jackknifing predictions were summarized into count categories and compared with the observed frequency of the response variable (
Figure 4). It was evident that both the negative binomial and negative binomial Hurdle models performed much better than both Poisson and Poisson Hurdle models, which over-predicted the frequency at the count categories of 1, 2, and 3 (
Figure 4). The Pearson χ
2 statistic was then calculated between jackknifing predicted and the frequencies for each model were observed. The results showed that the negative binomial Hurdle model with RE had the smallest χ
2 deviance from the observed frequencies (
Table 5), which confirmed that the negative binomial Hurdle model handled both issues of overdispersion and excessive zeros effectively and improved both model fitting and prediction.
4. Discussion
Our results showed that the negative binomial Hurdle model with the random effects was the best model among the four GLIMM models applied in this study. Generally, the Poisson model was not a good candidate model for the count data with overdispersion due to its restricted assumption of equal mean and variance. In this case, the negative binomial model became a better alternative because it included a dispersion parameter to deal with the overdispersion. The Hurdle model, a mixture of logistic regression and truncated-at-zero model, is designed to treat the zero count and positive counts in two stages when there are excessive zero counts in the data. It was no surprise to find that the negative binomial Hurdle model was the best model for our children’s BLL data because it could account for the overdispersion from the excessive zeros. Other research results showed that the zero-inflated negative binomial model had a similar performance as the negative binomial Hurdle model, and both showed better model fitting and prediction over other candidate models for the vaccine adverse health outcomes modeling [
16]. In this study, however, the excessive zeros only came from one process (i.e., sampling zeros), which was the children’s BLL less than 10 µg/dL. Thus, the Hurdle model would be more appropriate to handle the excessive zeros. On the other hand, if the zero counts also included the children without BLL screening test, the zero-inflated negative binomial would be a good choice, which treats the zero counts generated by two different processes [
7,
8,
16]. It could be used to deal with complex spatial data of children with lead poisoning and may be generalized to other cities or conditions.
It was argued that the lead in soil was a major lead contamination source causing pediatric lead poisoning. Therefore, soil lead was considered as one of the covariates in this study. Among the four models, the soil lead concentration was statistically significant in the Poisson and negative binomial models. It was also significant in the logistic regression models of the two Hurdle models for predicting the probability of children having lead poisoning in a given census block. However, it became less significant in the truncated models for predicting the number of children at lead poisoning risk. Therefore, the soil lead concentration may play a different role in children’s lead poisoning. It may be more important for identifying the possibility of children’s lead poisoning, but it may not be strongly associated with high risks of lead poisoning. This result might indicate that relatively poor conditions of older houses with lower tax values may be a more important factors impacting the high risks of children’s lead poisoning, while the soil lead contamination may have a certain level of association with indoor dust but this pathway was influenced by latent factors, so we concluded that soil lead had an insubstantial link with the high risks of children with lead poisoning [
1,
2,
3].
Lead-contaminated dust and lead-based paint appeared to be the principal sources of exposure for young children. Water could be contaminated by the leaching of lead from lead pipes or lead-based solder at pipe joints. Lead abatement treatments and water pipe systems were expensive for a low-income household to implement and replace. Given these lead pathways, the children living in older, inner-city housing and low socioeconomic class are at higher risks for lead poisoning. Our models clearly showed that the building year of the houses is an important risk factor of children with lead poisoning because old houses are associated with lead-based paint as well as lead pipes or pipe joints in the water delivery system. Another important risk factor is the town taxable value of the houses which implies the ability to mitigate the lead hazard. Low-income households will not have been able to remodel and are more vulnerable to the lead hazard.
One of the limitations of this study was that the data sources were from different years, for example, the response variable was collected in 2007–2011, the socio-economic variables such as the building year and town taxable value were collected from the 2005 tax layer, and the soil lead concentration data were collected in 2003–2004. The timing mismatch of the data and variables may cause inaccuracies and imprecisions in the modeling process.






{kind=link}
{kind=link}
{kind=link}
{kind=link}