A Hybrid Forecasting Approach to Air Quality Time Series Based on Endpoint Condition and Combined Forecasting Model

Abstract
1. Introduction
- Based on the decomposition and ensemble strategy, the endpoint condition method is utilized to sift IMFs and residues.
- A hybrid forecasting approach is proposed based on the varied weight combined forecasting model and EEMD.
- Some evaluation measures and model test are employed to estimate the forecasting performance of the developed hybrid approach.
- The developed hybrid approach significantly improves the forecasting accuracy of AQI.
2. Study Area and Dataset
3. Methodology
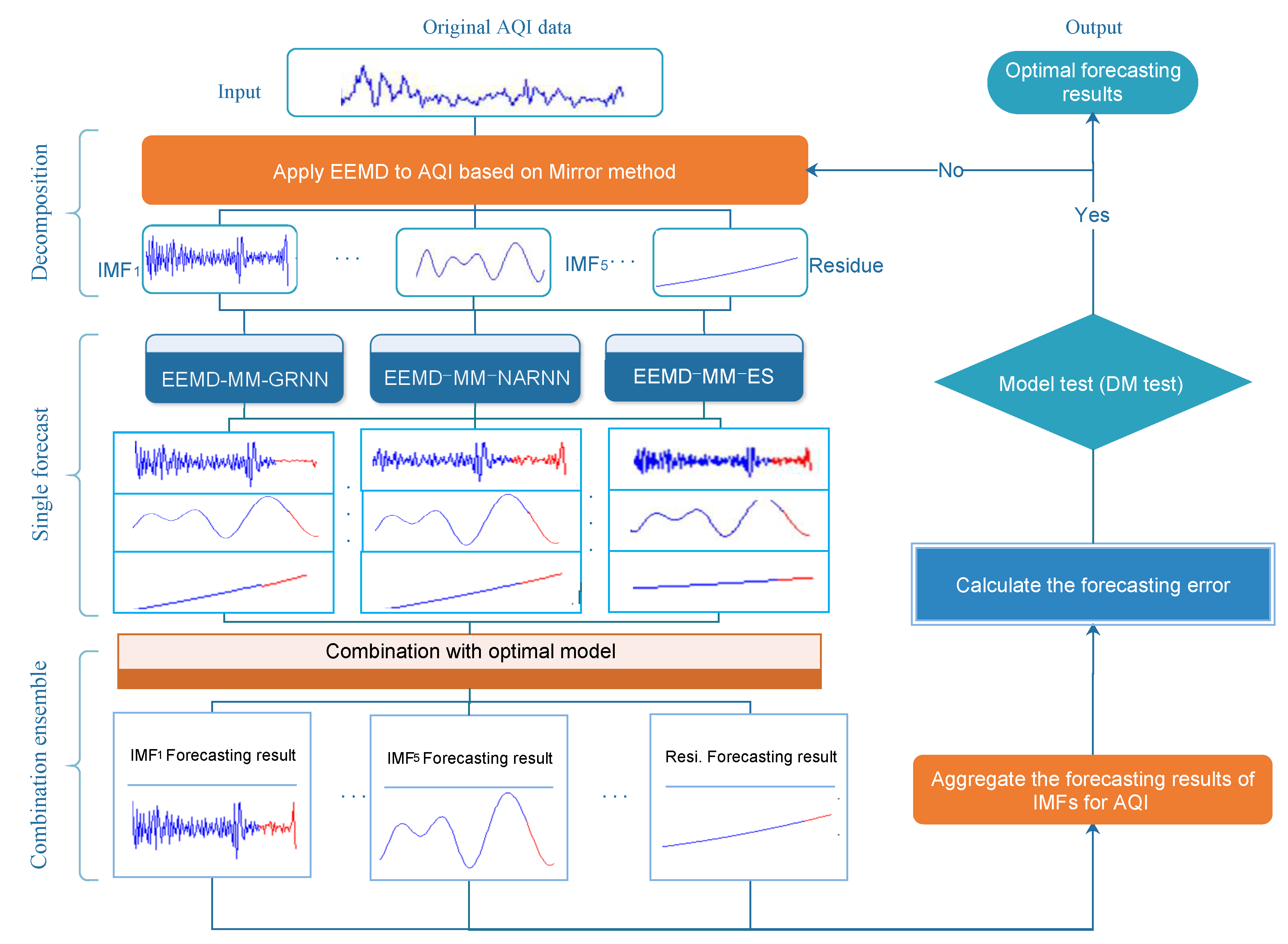
3.1. Overview of the Proposed Hybrid Methodology
3.2. EEMD with the Endpoint Condition Method
3.2.1. EEMD
- In the whole dataset, the number of zeros and the number of extreme crossings must either be equal or differ at most by one;
- At any point, the mean value of the envelope defined by the local maxima and local minima is zero.
- Step 1: In the original time series , random white noise obeying a normal distribution is added to generate the new time series .
- Step 2: Let , and calculate all of the local maxima and local minima.
- Step 3: Interpolate the local maxima by a cubic spline to obtain upper envelop , and the lower envelop can be obtained similarly.
- Step 4: Compute the mean envelop: .
- Step 5: Let , and judge whether meets the two conditions of IMFs. If it satisfies the two conditions, then is the i-th ; otherwise, let , and repeat Step 2–Step 5.
- Step 6: Repeat Step 2–Step 5 until the residue is a constant or trend time series.
- Step 7: Based on different random white noise, repeat Step 1–Step 6 times; is the number of ensemble members.
- Step 8: Find the ensemble and mean results from Step 7 to obtain the final result, i.e., the and the residue .
3.2.2. Endpoint Condition Method
| Algorithm 1 for data decomposition |
| 1: procedure . |
| 2: for do |
| 3: , |
| 4: , |
| 5: apply endpoint condition method to |
| 6: upper envelop of ; lower envelop of |
| 7: , |
| 8: while is a constant or trend do |
| 9: if satisfies the two conditions of IMFs, do |
| 10: is the i-th |
| 11: |
| 12: |
| 13: else |
| 14: |
| 15: end if |
| 16: , |
| 17: upper envelop of ; lower envelop of |
| 18: |
| 19: end while |
| 20: end for |
| 21: end procedure and |
3.3. Individual Forecasting Model
3.3.1. General Regression Neural Network Model
- (1)
- Input layer
- (2)
- Pattern layer
- (3)
- Summation layer
- (4)
- Output layer
3.3.2. Nonlinear Autoregressive Neural Network Model
3.3.3. Exponential Smoothing Method
3.4. Combined Forecasting Model
4. Empirical Study and Discussion
4.1. Statistical Measures for Forecasting Performance
4.2. Testing Method and Improvements of the Proposed Model
4.3. Empirical Results
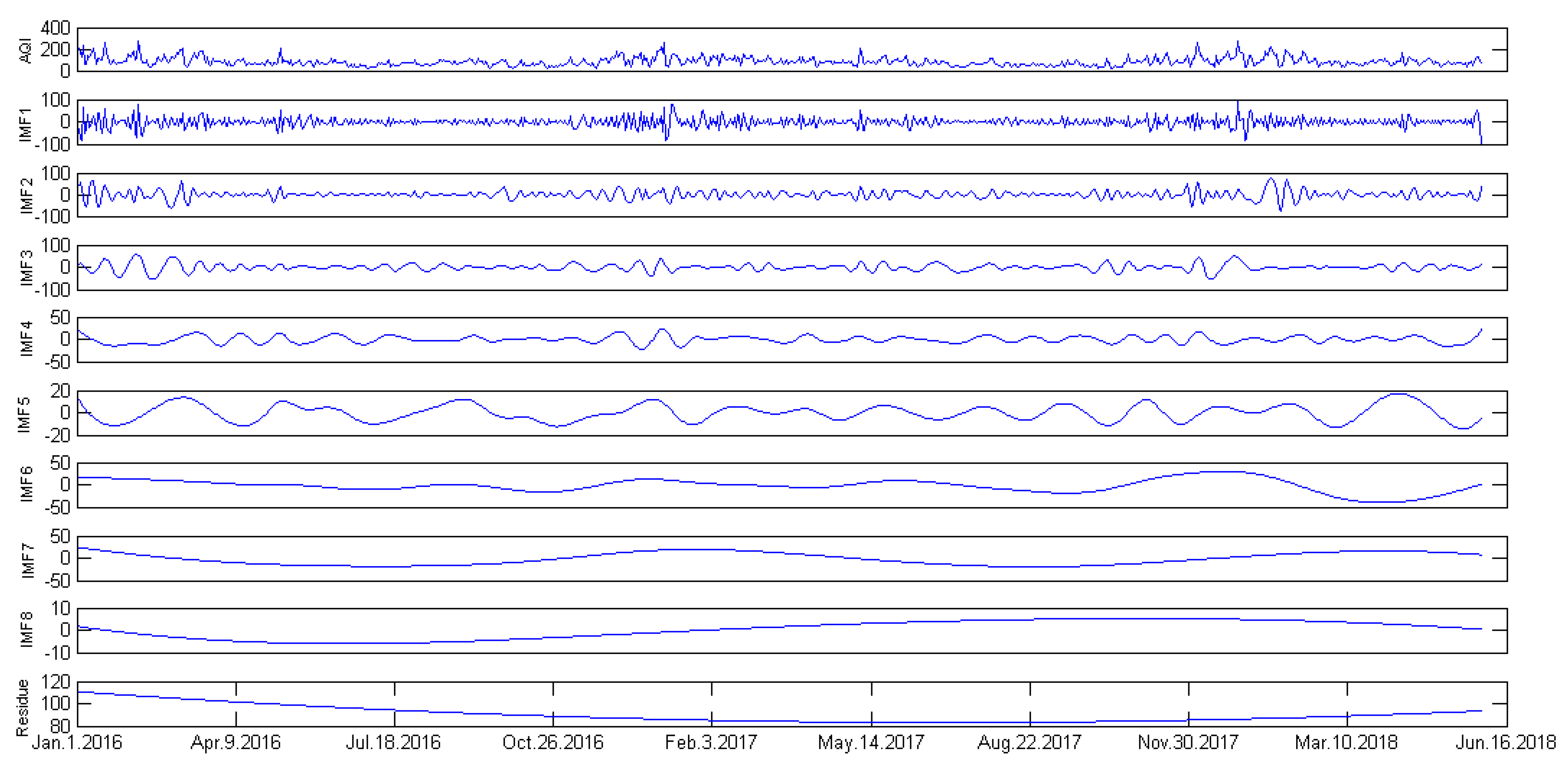
4.3.1. Data Decomposition
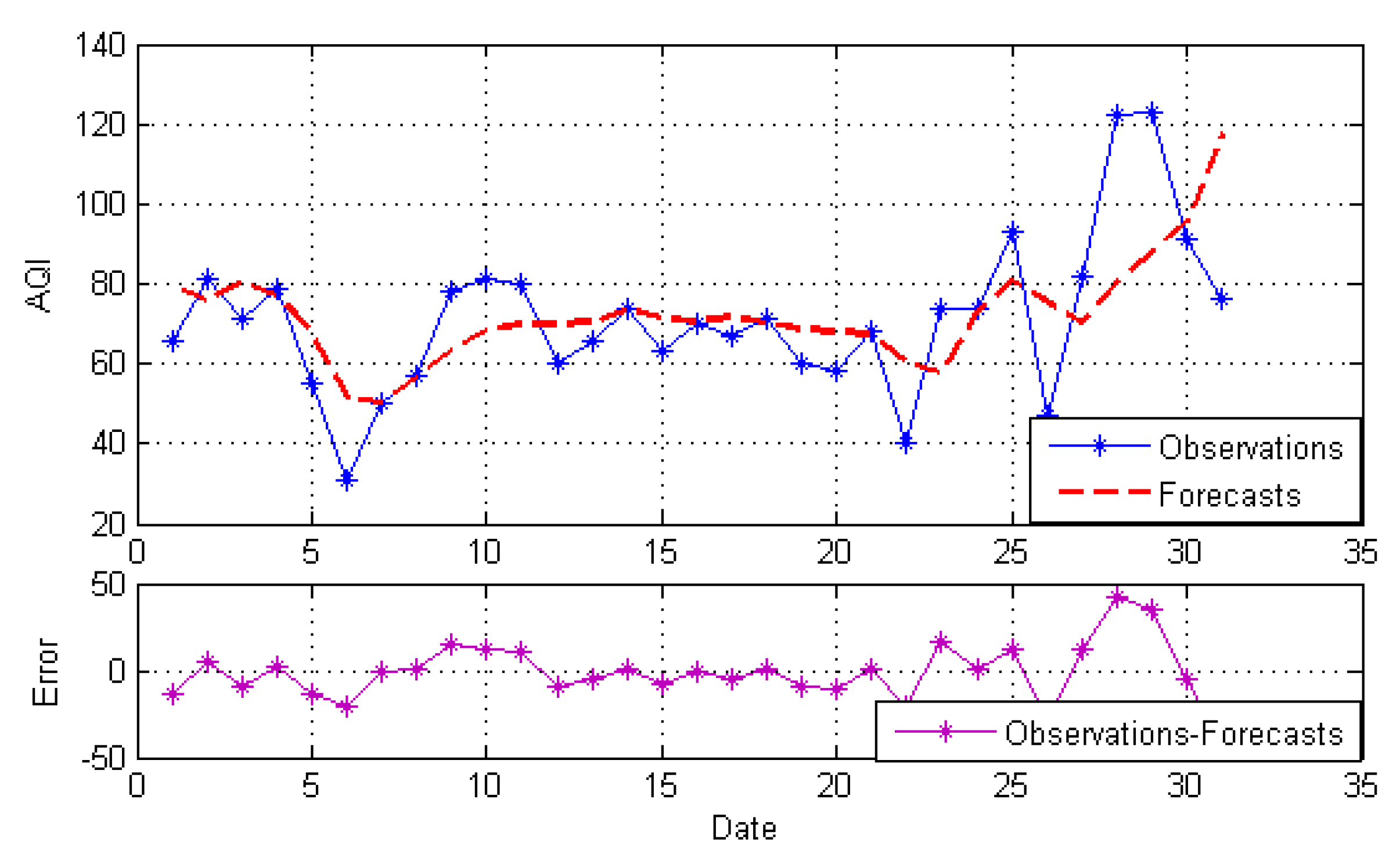
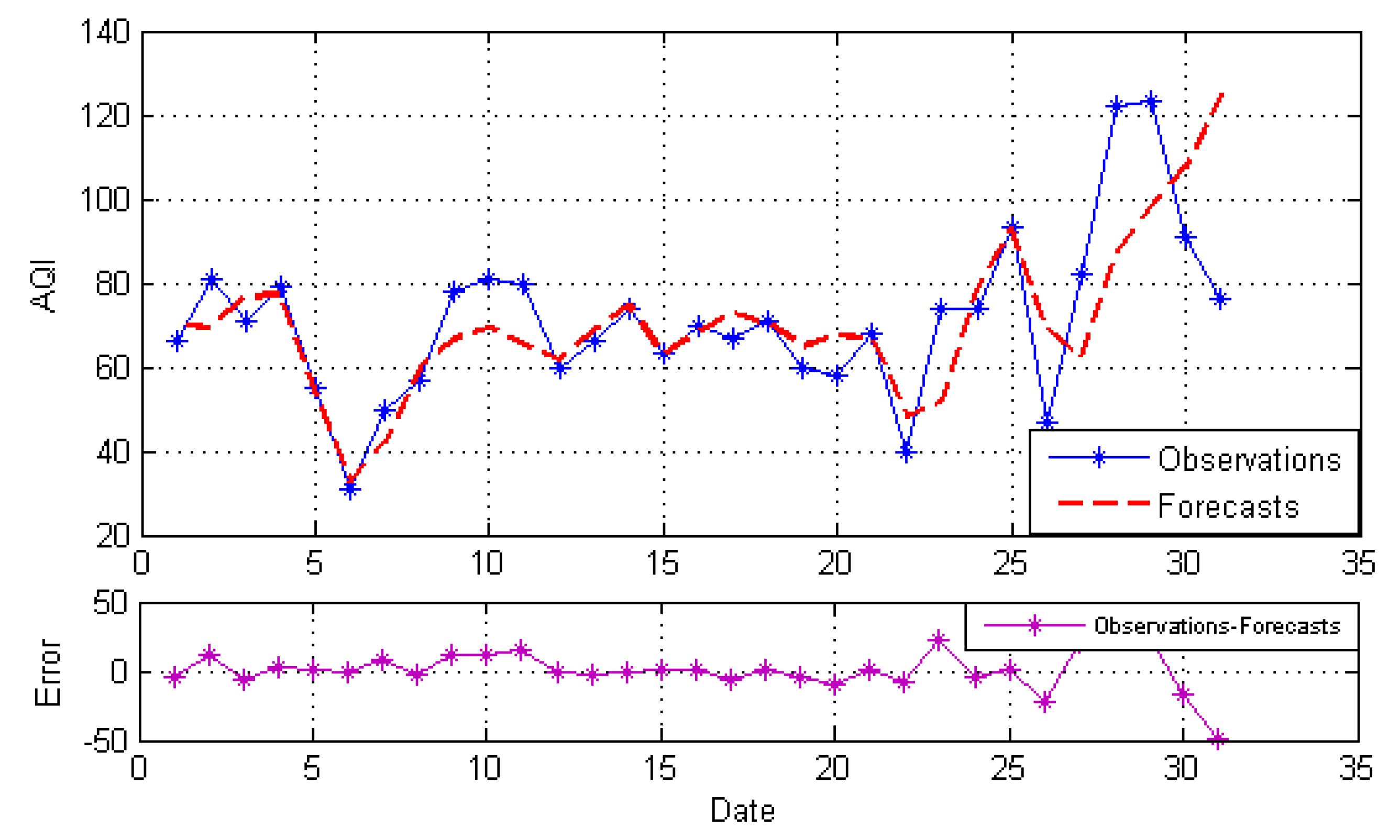
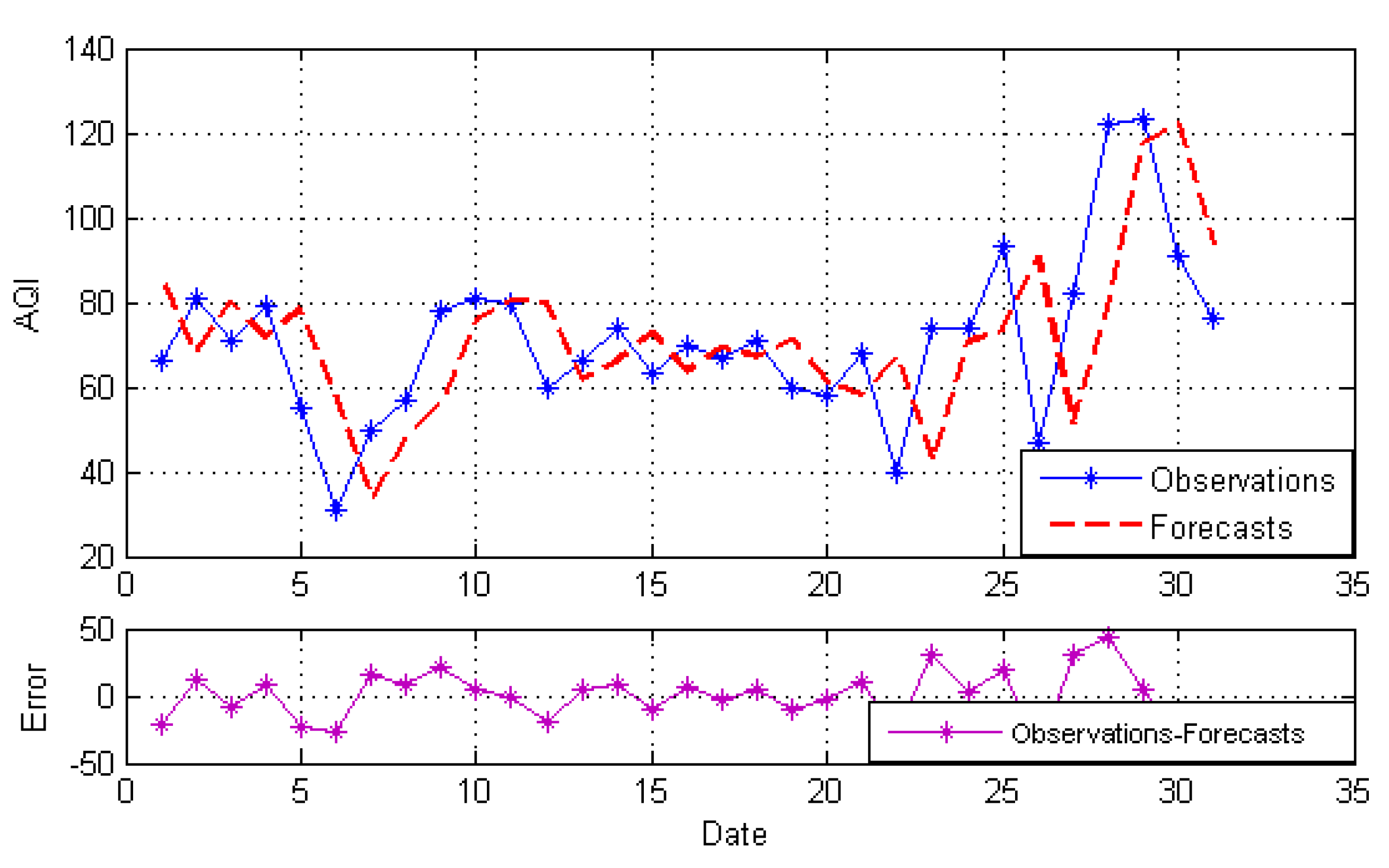
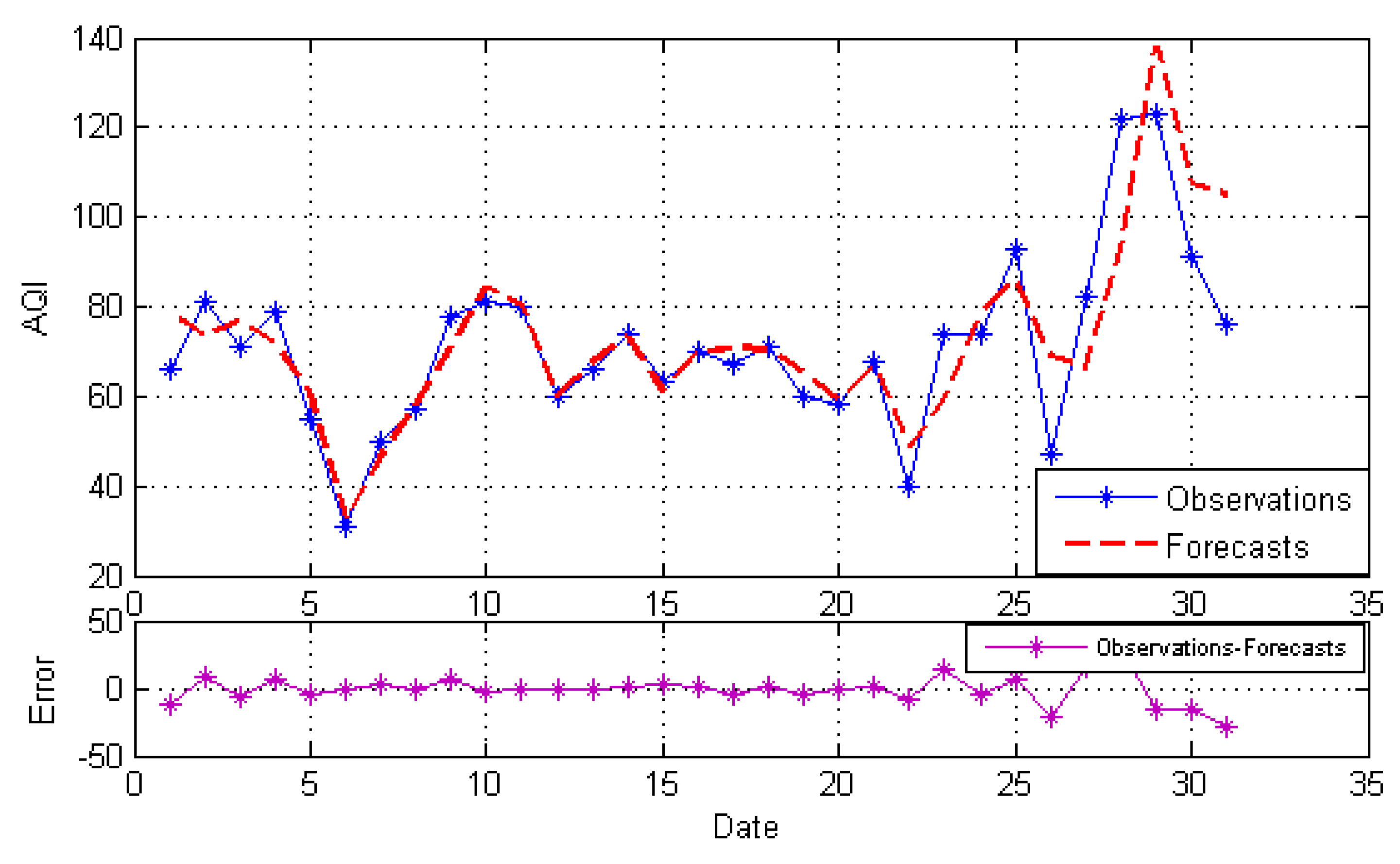
4.3.2. Forecasting Results
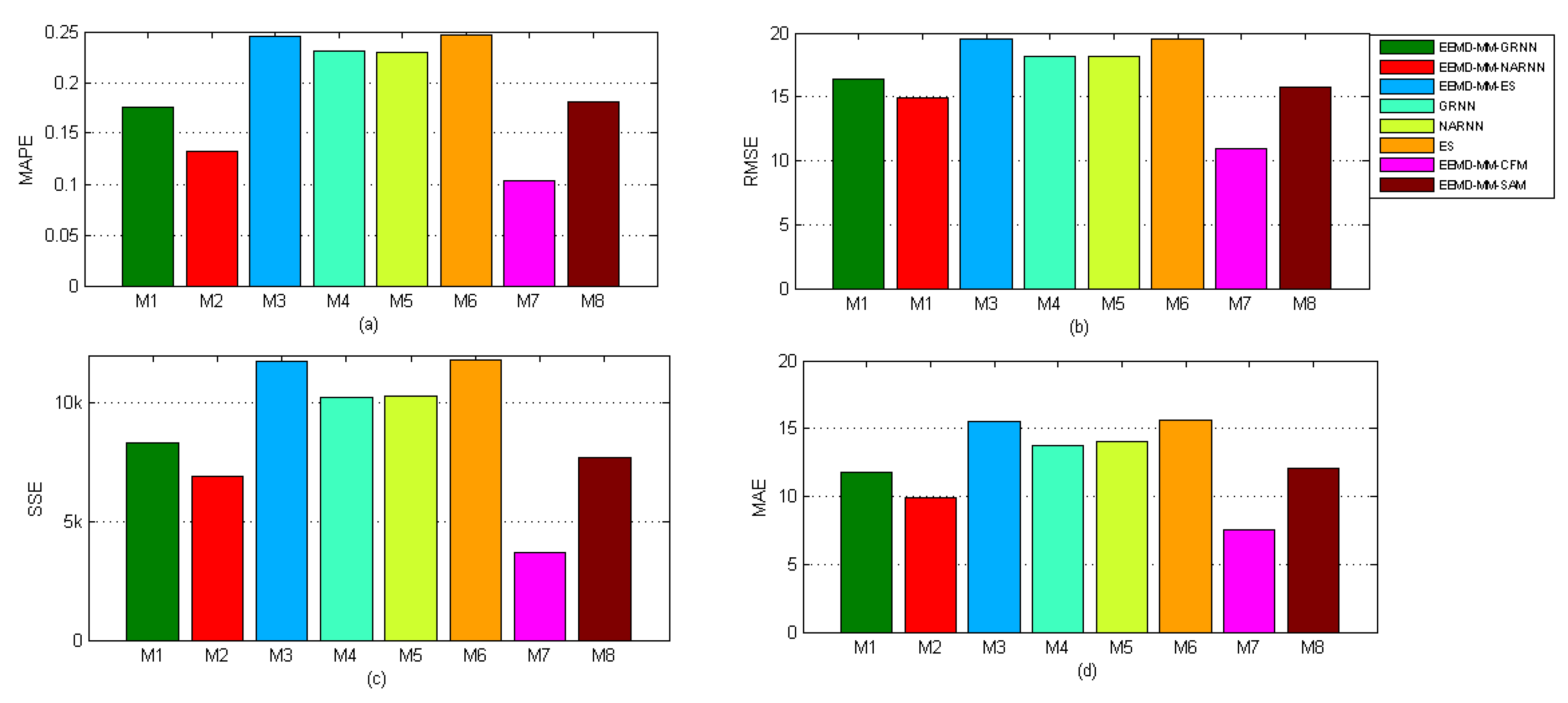
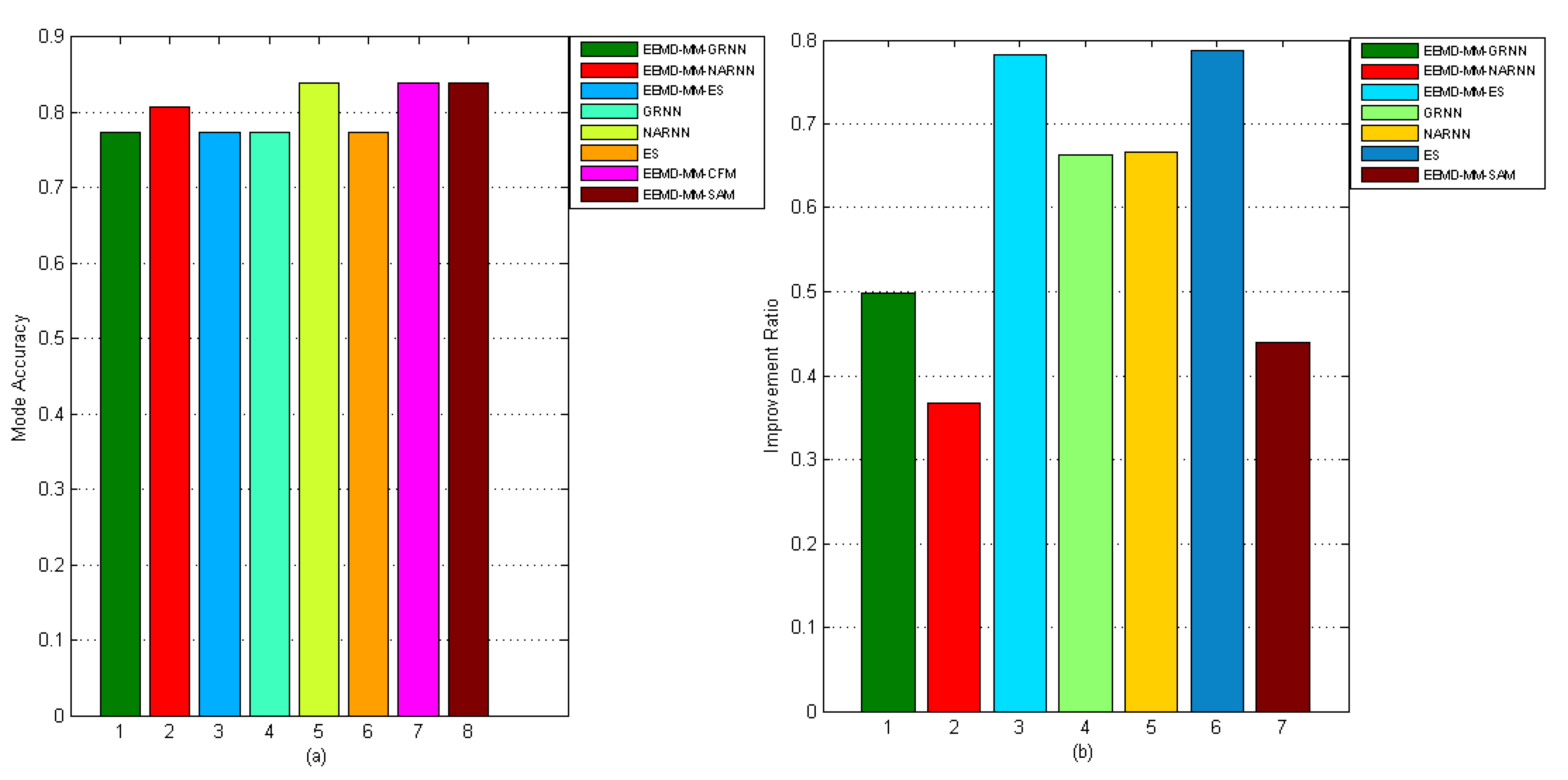
4.3.3. Forecasting Performance Comparisons
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| AQI | Air quality |
| EEMD | Ensemble empirical mode decomposition |
| IMF | Intrinsic mode function |
| ANN | Artificial neural networks |
| MLR | Multiple linear regression |
| PCR | Principal component regression |
| SVR | Support vector regression |
| GRNN | General regression neural network |
| IOWA | Induced ordered weighted averaging |
| NARNN | Nonlinear autoregressive neural network |
| ES | Exponential smoothing |
| MM | Mirror method |
| CFM | Combined forecasting model |
| MMA | Mean mode accuracy |
| DM test | Diebold–Mariano test |
| IR | Improvements of the proposed model |
| SSE | Sum of squared error |
| MAE | Mean absolute error |
| MAPE | Mean absolute percentage error |
| RMSE | Root mean squared error |
References
- Kumar, A.; Goyal, P. Forecasting of daily air quality index in Delhi. Sci. Total Environ. 2011, 409, 5517–5523. [Google Scholar] [CrossRef] [PubMed]
- Bhang, Y.; Bocquet, M.; Mallet, V.; Seigneur, C.; Baklanov, A. Real-time air quality forecasting, part I: History, techniques, and current status. Atmos. Environ. 2012, 60, 632–655. [Google Scholar]
- Liu, W.; Xu, Z.; Yang, T. Health Effects of Air Pollution in China. Int. J. Environ. Res. Public Health 2018, 15. [Google Scholar] [CrossRef] [PubMed]
- Sheng, N.; Tang, U. The first official city ranking by air quality in China-a review and analysis. Cities 2016, 51, 139–149. [Google Scholar] [CrossRef]
- Di, Q.; Koutrakis, P.; Schwartz, J. A hybrid prediction model for PM2.5 mass and components using a chemical transport model and land use regression. Atmos. Environ. 2016, 131, 390–399. [Google Scholar] [CrossRef]
- Brandt, J.; Silver, J.; Frohn, L.; Geels, C.; Gross, A. An integrated model study for Europe and North America using the Danish Eulerian Hemispheric Model with focus on intercontinental transport of air pollution. Atmos. Environ. 2012, 53, 156–176. [Google Scholar] [CrossRef]
- Reikard, G. Forecasting volcanic air pollution in Hawaii: Tests of time series models. Atmos. Environ. 2012, 60, 593–600. [Google Scholar] [CrossRef]
- Slini, T.; Karatzas, K.; Moussiopoulos, N. Statistical analysis of environmental data as the basis of forecasting: An air quality application. Sci. Total Environ. 2012, 288, 227–237. [Google Scholar] [CrossRef]
- Neal, L.; Agnew, P.; Moseley, S.; Ordóñez, C.; Savage, N.; Tilbee, M. Application of a statistical post-processing technique to a gridded, operational, air quality forecast. Atmos. Environ. 2014, 98, 385–393. [Google Scholar] [CrossRef]
- Silibello, C.; D’Allura, A.; Finardi, S.; Bolignano, A.; Sozzi, R. Application of bias adjustment techniques to improve air quality forecasts. Atmos. Pollut. Res. 2015, 6, 928–938. [Google Scholar] [CrossRef]
- Goyal, P.; Chan, A.T.; Jaiswal, N. Statistical models for the prediction of respirable suspended particulate matter in urban cities. Atmos. Environ. 2006, 40, 2068–2077. [Google Scholar] [CrossRef]
- Kumar, A.; Goyal, P. Forecasting of air quality in Delhi using principal component regression technique. Atmos. Pollut. Res. 2011, 2, 436–444. [Google Scholar] [CrossRef]
- Donnelly, A.; Misstear, B.; Broderick, B. Real time air quality forecasting using integrated parametric and non-parametric regression techniques. Atmos. Environ. 2015, 103, 53–65. [Google Scholar] [CrossRef]
- Jiang, D.; Zhang, Y.; Hu, X.; Zeng, Y.; Tan, J.; Shao, D. Progress in developing an ANN model for air pollution index forecast. Atmos. Environ. 2004, 38, 7055–7064. [Google Scholar] [CrossRef]
- Hooyberghs, J.; Mensink, C.; Dumont, G.; Fierens, F.; Brasseur, O. A neural network forecast for daily average PM10 concentrations in Belgium. Atmos. Environ. 2005, 39, 3279–3289. [Google Scholar] [CrossRef]
- Ordieres, J.; Vergara, E.; Capuz, R.; Salazar, R. Neural network prediction model for fine particulate matter (PM2.5) on the US–Mexico border in El Paso (Texas) and Ciudad Juárez (Chihuahua). Environ. Modell. Softw. 2005, 20, 547–559. [Google Scholar] [CrossRef]
- Voukantsis, D.; Karatzas, K.; Kukkonen, J.; Räsänen, T.; Karppinen, A.; Kolehmainen, M. Intercomparison of air quality data using principal component analysis, and forecasting of PM10 and PM2.5 concentrations using artificial neural networks, in Thessaloniki and Helsinki. Sci. Total Environ. 2011, 409, 1266–1276. [Google Scholar] [CrossRef] [PubMed]
- Elangasinghe, M.; Singhal, N.; Dirks, K.; Salmond, J.; Samarasinghe, S. Complex time series analysis of PM10 and PM2.5 for a coastal site using artificial neural network modelling and k-means clustering. Atmos. Environ. 2014, 94, 106–116. [Google Scholar] [CrossRef]
- Feng, X.; Li, Q.; Zhu, Y.; Hou, J.; Jin, L.; Wang, J. Artificial neural networks forecasting of PM2.5 pollution using air mass trajectory based geographic model and wavelet transformation. Atmos. Environ. 2015, 107, 118–128. [Google Scholar] [CrossRef]
- Ortiz-García, E.; Salcedo-Sanz, S.; Pérez-Bellido, Á.; Portilla-Figueras, J.; Prieto, L. Prediction of hourly O3 concentrations using support vector regression algorithms. Atmos. Environ. 2010, 44, 4481–4488. [Google Scholar] [CrossRef]
- Yeganeh, B.; Motlagh, M.; Rashidi, Y.; Kamalan, H. Prediction of CO concentrations based on a hybrid Partial Least Square and Support Vector Machine model. Atmos. Environ. 2012, 55, 357–365. [Google Scholar] [CrossRef]
- Wang, J.; Niu, T.; Wang, R. Research and application of an air quality early warning system based on a modified least squares support vector machine and a cloud model. Int. J. Environ. Res. Public Health 2017, 14, 249. [Google Scholar] [CrossRef] [PubMed]
- Wu, Z.; Huang, N. Ensemble empirical mode decomposition: A noise-assisted data analysis method. Adv. Adaptive Data Anal. 2009, 1, 1–41. [Google Scholar] [CrossRef]
- Yu, L.; Wang, Z.; Tang, L. A decomposition-ensemble model with data-characteristic-driven reconstruction for crude oil price forecasting. Appl. Energy 2015, 156, 251–267. [Google Scholar] [CrossRef]
- Tang, L.; Dai, W.; Yu, L.; Wang, S. A novel CEEMD-based EELM ensemble learning paradigm for crude oil price forecasting. Int. J. Inf. Technol. Decis. Mak. 2015, 14, 141–169. [Google Scholar] [CrossRef]
- He, K.; Yu, L.; Lai, K. Crude oil price analysis and forecasting using wavelet decomposed ensemble model. Energy 2012, 46, 564–574. [Google Scholar] [CrossRef]
- Song, J.; Wang, J.; Lu, H. A novel combined model based on advanced optimization algorithm for short-term wind speed forecasting. Appl. Energy 2018, 215, 643–658. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, J. A novel decomposition-ensemble model for forecasting short-term load-time series with multiple seasonal patterns. Appl. Soft Comput. 2018, 65, 478–494. [Google Scholar] [CrossRef]
- Che, J.; Wang, J. Short-term load forecasting using a kernel-based support vector regression combination model. Appl. Energy 2014, 132, 602–609. [Google Scholar] [CrossRef]
- Zhu, S.; Lian, X.; Liu, H.; Hu, J.; Wang, Y.; Che, J. Daily air quality index forecasting with hybrid models: A case in China. Environ. Pollut. 2017, 231, 1232–1244. [Google Scholar] [CrossRef] [PubMed]
- Niu, M.; Wang, Y.; Sun, S.; Li, Y. A novel hybrid decomposition-and-ensemble model based on CEEMD and GWO for short-term PM2.5 concentration forecasting. Atmos. Environ. 2016, 134, 168–180. [Google Scholar] [CrossRef]
- Zhou, Q.; Jiang, H.; Wang, J.; Zhou, J. A hybrid model for PM2.5 forecasting based on ensemble empirical mode decomposition and a general regression neural network. Sci. Total Environ. 2014, 496, 264–274. [Google Scholar] [CrossRef] [PubMed]
- Xiong, T.; Bao, Y.; Hu, Z. Does restraining end effect matter in EMD-based modeling framework for time series prediction? Some experimental evidences. Neurocomputing 2014, 123, 174–184. [Google Scholar] [CrossRef]
- Wu, F.; Qu, L. An improved method for restraining the end effect in empirical mode decomposition and its applications to the fault diagnosis of large rotating machinery. J. Sound Vib. 2008, 314, 586–602. [Google Scholar] [CrossRef]
- Bates, J.; Granger, C. Combination of forecasts. Oper. Res. 1969, 20, 451–468. [Google Scholar] [CrossRef]
- Chen, H. Validity Principle Theory of Combination Forecasting and Its Application; Science Press: Beijing, China, 2008. [Google Scholar]
- Chen, H.; Jin, L.; Li, X.; Yao, M. The optimal interval combination forecasting model based on closeness degree and IOWHA operator under the uncertain environment. Grey Syst. Theory A 2011, 1, 250–260. [Google Scholar] [CrossRef]
- Huang, N.; Shen, Z.; Long, S.; Wu, M.; Shih, H.; Zheng, Q.; Yen, N.-C.; Tung, C.C.; Liu, H.H. The empirical mode decomposition and the Hilbert spectrum for nonlinear and non-stationary time series analysis. Proc. R. Soc. Lond. A 1998, 454, 903–995. [Google Scholar] [CrossRef]
- Specht, D. A general regression neural network. IEEE Trans. Neural Netw. 1991, 2, 568–576. [Google Scholar] [CrossRef] [PubMed]
- Ahmed, A.; Khalid, M. Multi-step Ahead Wind Forecasting Using Nonlinear Autoregressive Neural Networks. Energy Procedia 2017, 134, 192–204. [Google Scholar] [CrossRef]
- Holt, C. Forecasting trends and seasonal by exponentially weighted averages. Int. J. Forecast. 1957, 20, 5–10. [Google Scholar] [CrossRef]
- Diebold, F.; Mariano, R. Comparing predictive accuracy. J. Business Econ. Stat. 1995, 13, 253–263. [Google Scholar]
- Che, J. Optimal sub-models selection algorithm for combination forecasting model. Neurocomputing 2015, 151, 364–375. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| AQI | AQI Classes | Health Impact | Suggestions |
|---|---|---|---|
| 0∼50 | Excellent | The air quality is satisfactory | It is suitable for normal actions for various people. |
| 51∼100 | Good | Have weak health effects on extremely sensitive people | Extremely sensitive people should reduce outdoor activities. |
| 101∼150 | Light pollution | Healthy people show signs of irritation | Children, the elderly and patients with heart disease should reduce outdoor activities. |
| 151∼200 | Moderate pollution | It may affect the heart and respiratory systems of healthy people | Even healthy people should reduce outdoor sports activities. |
| 201∼300 | Serious pollution | The symptoms of heart disease and lung disease increased significantly | Children, the elderly and patients with heart disease should stop outdoor activities. |
| 201∼300 | Heavy pollution | Healthy people have obvious strong symptoms | Healthy people should avoid outdoor activities. |
| Model | ES | NARNN | GRNN | EEMD-MM-SAM |
| Correlation Coefficient | 0.4553 | 0.4663 | 0.4163 | 0.5988 |
| Model | EEMD-MM-ES | EEMD-MM-NARNN | EEMD-MM-GRNN | EEMD-MM-CFM |
| Correlation Coefficient | 0.4563 | 0.6754 | 0.5335 | 0.8404 |
| Target Model | Benchmark | |||||
|---|---|---|---|---|---|---|
| EEMD-MM-GRNN | EEMD-MM-NARNN | EEMD-MM-ES | GRNN | NARNN | ES | |
| EEMD-MM-CFM | −2.059 | −1.972 | −3.027 | −4.057 | −2.972 | −3.027 |
| (0.039) | (0.046) | (0.002) | (0.000) | (0.003) | (0.002) | |
| EEMD-MM-GRNN | 2.788 | −1.455 | −0.886 | −0.681 | −1.479 | |
| (0.005) | (0.148) | (0.376) | (0.496) | (0.139) | ||
| EEMD-MM-NARNN | −1.617 | −1.325 | −0.979 | −1.641 | ||
| (0.106) | (0.185) | (0.328) | (0.100) | |||
| EEMD-MM-ES | 1.042 | 1.238 | −1.884 | |||
| (0.297) | (0.216) | (0.050) | ||||
| GRNN | −0.052 | −1.064 | ||||
| (0.958) | (0.287) | |||||
| NARNN | −1.246 | |||||
| (0.213) | ||||||
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, J.; Wu, P.; Chen, H.; Zhou, L.; Tao, Z. A Hybrid Forecasting Approach to Air Quality Time Series Based on Endpoint Condition and Combined Forecasting Model. Int. J. Environ. Res. Public Health 2018, 15, 1941. https://doi.org/10.3390/ijerph15091941
Zhu J, Wu P, Chen H, Zhou L, Tao Z. A Hybrid Forecasting Approach to Air Quality Time Series Based on Endpoint Condition and Combined Forecasting Model. International Journal of Environmental Research and Public Health. 2018; 15(9):1941. https://doi.org/10.3390/ijerph15091941
Chicago/Turabian StyleZhu, Jiaming, Peng Wu, Huayou Chen, Ligang Zhou, and Zhifu Tao. 2018. "A Hybrid Forecasting Approach to Air Quality Time Series Based on Endpoint Condition and Combined Forecasting Model" International Journal of Environmental Research and Public Health 15, no. 9: 1941. https://doi.org/10.3390/ijerph15091941
APA StyleZhu, J., Wu, P., Chen, H., Zhou, L., & Tao, Z. (2018). A Hybrid Forecasting Approach to Air Quality Time Series Based on Endpoint Condition and Combined Forecasting Model. International Journal of Environmental Research and Public Health, 15(9), 1941. https://doi.org/10.3390/ijerph15091941