1. Introduction
Community characteristics matter when it comes to individuals’ well-being, and that relationship is better understood now than ever before [
1]. Several studies have demonstrated this [
2,
3] and knowing how these community characteristics can influence holistic well-being brings a new opportunity for communities to intervene with policies and practices that broadly enhance well-being. Despite the important implications of such information, debates continue over the most appropriate measures of well-being.
Determining the appropriate spatial scales at which human well-being may be influenced by the built and social environment is another challenge facing researchers. It is important to consider, for example, how measures of access or opportunity may be appropriate for certain neighborhood characteristics (e.g., number of alcohol or tobacco retailers in a given geography, or availability of neighborhood parks), while measures of exposure are needed for others (e.g., amount of advertising for alcohol and tobacco products in a given geography, or distance to a green open space) [
4]. Additional challenges arise when considering the potential sorting of individuals into neighborhoods that might suit their preexisting behaviors or traits [
5]. In the case of well-being, the exact pathways linking person and place are not well understood, perhaps, in part due to our conceptualization and measurement of well-being.
While it is suggested that the measurement of well-being is multi-dimensional [
6], previous studies examining relations between well-being and neighborhood contexts have primarily used selections of well-being survey instruments, such as the Gallup-Sharecare Well-being Index (WBI), the 36-Item Short Form Survey (SF-36), or the General Social Survey (GSS) [
2,
7,
8,
9]. While other studies that have utilized the entirety of the survey instruments, they mostly focus on well-being as the overall global score of the instruments, overlooking the potential influence of the environment on the individual domains that comprise the overall scores.
While global measures of well-being encourage a conceptualization of human health that is broader than physical ability or illness-related dimensions, they do not offer much insight into exactly how well-being could be related to the neighborhood context. Psychological research has illustrated how multi-component measurement tools are needed to account for variation across individuals’ experiences of well-being and its three broad dimensions: [
10] 1) hedonic, which focuses on individuals’ happiness and enjoyment; 2) evaluative, which focuses on individuals’ satisfaction with their life; and 3) eudaimonic, which focuses on individuals’ sense of purpose and meaning [
11]. Yet, what is missing from such conceptualizations is how different elements of well-being may be linked to an individual’s neighborhood context.
The Stanford WELL for Life Initiative has created a more comprehensive measure of well-being, the Stanford WELL for Life Scale (SWLS) [
10], that measures ten constituent domains (described in
Section 2.1). These domains collectively address the above three dimensions of well-being and its pluralistic nature. The SWLS provides participants with ten separate domain scores that, when combined, provide an overall well-being score. Thus, the SWLS can provide a more nuanced look at how the many dimensions of well-being are associated with surrounding community characteristics at the neighborhood (in this case, ZIP-code) level.
In this study, we first compare the global SWLS measure, collected in a sample of U.S. adults who registered online for the WELL for Life Initiative, to a recent nationally-representative study (
n = 338,846) by Roy and colleagues [
8] that examined well-being as measured by the Gallup-Sharecare Well Being Index individual well-being score, or iWBS, and 77 county-level physical, social, and demographic factors. That study found independent and significant associations between well-being and twelve county-level indicators, some of which are used in generating scores for the well-known Robert Wood Johnson Foundation County Health Rankings [
12]. We draw upon the same data sources to carefully mirror the indicators used by Roy et al., but at a more fine-grained geographic unit, the ZIP code. Subsequently, we test for significant associations between the SWLS domain measures and these 12 indicators to further investigate relationships between place and well-being. In both parts of this investigation, we use ZIP-code level analogues to the county-level factors described in Roy et al.
2. Materials and Methods
2.1. Outcome Variables: Well-Being and Its Domains
The Stanford WELL for Life registry was started in May 2016 to accelerate the science of well-being and to improve and sustain health and well-being. Data collection is ongoing and for the purposes of this analysis, data were drawn on September 15, 2018, and the sample includes 3611 adult participants. To be eligible to participate in the registry, individuals had to be aged 18 years and older, residing in the United States, and able to complete the online survey in English, Spanish or simplified or traditional Chinese. Participants were recruited via existing research registries and email list serves within Stanford; on-line through social media, e-mail blasts and webpages; through existing community partnerships that assisted with targeted recruitment strategies aimed at populations of interest, for example, working with Asian community-based collaboratives to recruit Asian participants; and at community events such as health fairs.
The Stanford WELL for Life Scale (SWLS) was used to measure individual level well-being. This scale asks respondents to rate their well-being for the past two to four-week time period. The SWLS was developed from qualitative data gathered using a grounded narrative approach in which individuals described times of high and low well-being, with no priming regarding the definition of well-being [
10]. Ten domains of well-being were identified, as follows: social connectedness, lifestyle and daily practices (diet, physical activity, sleep, tobacco and alcohol use), experience of emotions, stress and resilience, physical health, purpose and meaning, sense of self, financial security and satisfaction, exploration and creativity, and spirituality and religiosity. To measure the ten domains of well-being identified during the qualitative data gathering and analysis, the quantitative SWLS was developed using previously validated questions where relevant and available, or questions created de novo by the research group to address gaps. Each of the ten domains is scored from 0–10, and an unweighted overall well-being score is calculated by summing each of the ten domain scores. The lifestyle and daily practices domain contains five sub-domains (diet, physical activity, sleep, tobacco, and alcohol use) which each contribute up to 2 points to the lifestyle and daily practices domain. For the purposes of this analysis, all well-being outcomes were treated as continuous variables.
All data preparation, transformation, and analyses were performed using R version 3.5.1 [
13].
2.2. Sociodemographic Covariates
Additional data gathered from participants included socio-demographic information (age, gender, education, household income, employment status, and marital status), household information (number of individuals living in the household, how many times individuals have moved in the past year, number of children, and where they live), and health history and status (access to healthcare, diagnosis of a variety of chronic, and acute conditions).
2.3. Exposure Variables: Neighborhood-Level Social and Environmental Features
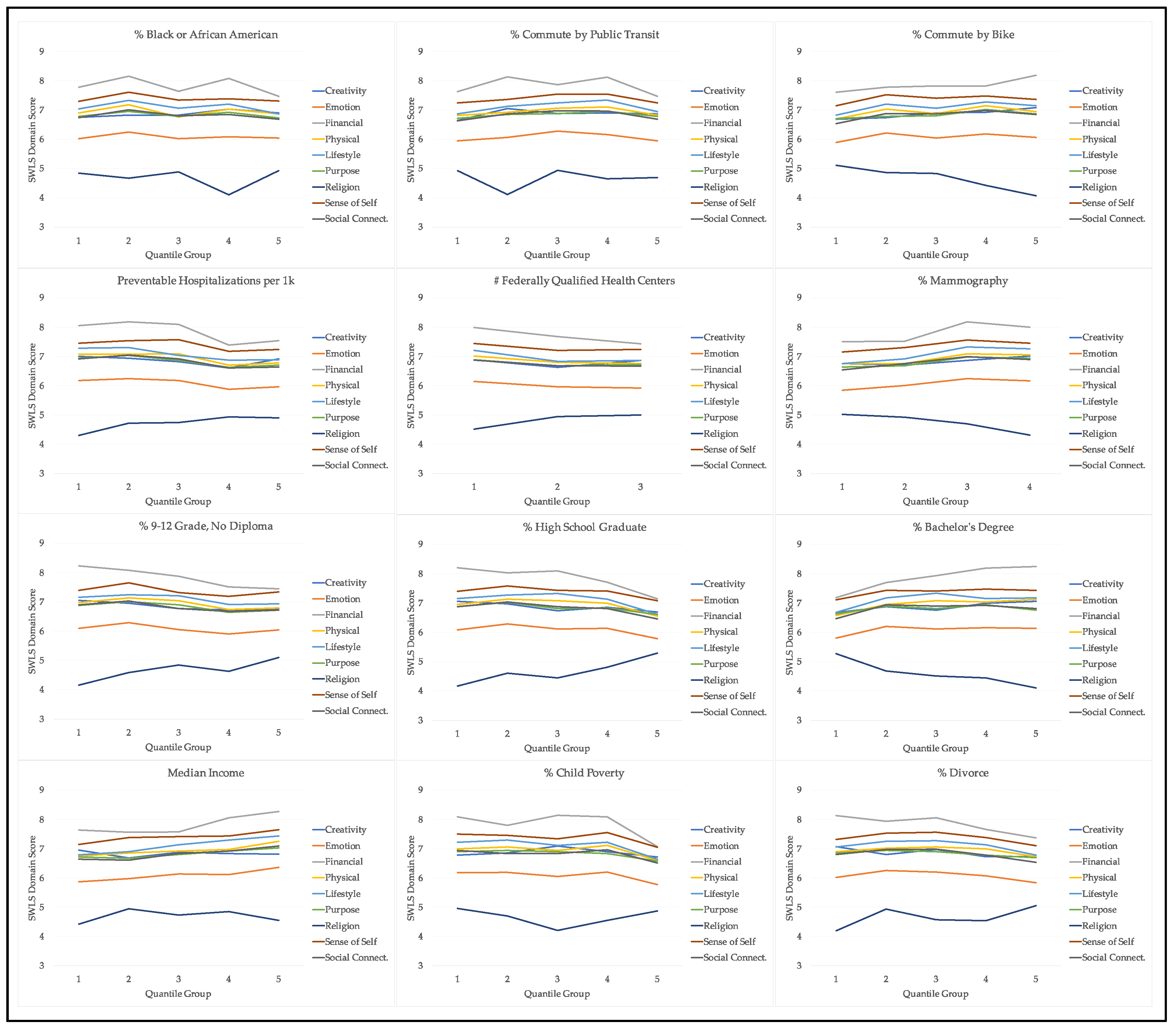
To be included in the Stanford Well for Life study participants had to provide a valid 5-digit ZIP-code, excluding post-office boxes. This geographic identifier was then used to assign neighborhood-level data to each participant. We selected 12 ZIP-level variables (see
Table 1) that were as similar as possible to the physical environment, social/economic, and demographic factors found to be significant in a recent empirical study of 77 potential county-level correlates of well-being [
8]. Five-year estimates of the 2013–2017 American Communities Survey were used for ZIP code-level demographic characteristics (percent Black or African American), educational attainment (three values: 9–12 grade without a diploma, high school diploma or equivalent, and bachelor’s degree), median household income, divorce rate, child poverty rate, unemployment rate, and commuter characteristics (percent commuting by public transit, percent commuting by bicycle). Similar to the County Health Rankings used by Roy et al. [
8,
12], we drew health care-related data from the 2015 Dartmouth Atlas of Health Care (DAHC) [
14]. These included the percent of women receiving mammograms and percentage of preventable hospital stays, which were summarized at the HSA (hospital service area) level and re-aggregated to ZIP codes based on an Atlas-provided crosswalk. ZIP codes having at least one Federally Qualified Health Center (FQHC) were identified from a US Health Resource and Services Administration (HRSA) database of health center service delivery sites [
15].
Table 1 provides a summary of neighborhood-level data used in this study.
2.4. Data Transformations
As an exploratory, hypothesis-generating exercise, this project sought to understand how relative (rather than absolute) differences in neighborhood factors correlated with well-being outcomes. To facilitate this, continuous neighborhood factor variables were transformed into roughly equal quantile groups, with the lowest quantile serving as the reference level in analyses, again following the method used in the comparison study by Roy and colleagues [
8]. Given the geographic distribution of participants across ZIP-codes, roughly equal quantile groups were not feasible for two variables (% mammography and # FQHCs); in these scenarios, alternative groupings were used. A summary of all quantile group characteristics is provided in
Appendix A Table A1.
Tukey’s Ladder of Powers transformations [
16] were applied to all well-being outcome variables using the “tranformTukey” function of the “rcompanion” R package [
17,
18], and the attendant lambda values were used to back-transform coefficient estimates and standard errors for reporting.
2.5. Statistical Models
Linear mixed models fit by maximum likelihood were generated to assess the relationship between well-being outcomes (the overall SWLS measure and ten domains) and the previously-mentioned 12 neighborhood and individual-level covariates [
19]. To account for spatial aggregation of neighborhood data, a ZIP-level grouping variable was incorporated as a random effect. For each model, participants with missing data were omitted and assumed to be missing at random. Spatial autocorrelation of the primary outcome variable was assessed at the level of participants (individual well-being scores) and using Morans’
I test statistic for spatial autocorrelation [
20,
21], which indicated significant geographic clustering of similar outcome values. To account for this spatial autocorrelation of the outcome variable, a Gaussian correlation structure was specified using latitude and longitude coordinates of ZIP code centroids. Spatial autocorrelation was then assessed with Moran’s I test for residuals from the full linear mixed model for the main well-being outcome. All linear mixed modeling was performed using the “lme” function from the “nlme” R package [
22,
23,
24,
25], and Moran’s I tests were performed using the “moran.test” function from the “spdep” R package [
26]. These spatial statistics and their attendant p-values are reported in Tables 5 and 6.
Two models were constructed for the overall SWLS well-being score and its ten constituent domains: a “partial” model only including neighborhood factors and a “full” model with neighborhood and individual-level covariates. Backward and forward stepwise model selection by Akaike Information Criterion (AIC) was performed using maximum likelihood parameter estimation to identify covariates for inclusion in final models, using the “stepAIC” function from the “MASS” R package [
27]. Prior to this procedure, outliers (defined as observations having a standardized residual distance greater than 2.5 from 0) were identified based on the initial partial and full model fits and removed [
28]. With the covariates identified in stepwise model selection, partial and full models were refit using restricted maximum likelihood parameter estimation, to partially account for the unbalanced nature of our higher-level groups (i.e., ZIPs). To assess the amount of variance explained by the ZIP code groupings, intra-class correlation coefficients were calculated, and marginal and conditional r-squared values were calculated to assess variance with and without the ZIP-level random effect [
29,
30,
31]. Finally, to identify significant differences in coefficient estimates between quantile groups of each neighborhood factor, type II sum of squares test for ANOVA effects were performed using the “car” R package’s built-in “Anova” function [
32].
4. Discussion
While using an independently-developed and unique measure of well-being, we found similar associations between five of the twelve county-level factors identified by a much larger, nationally-representative survey of well-being (iWBS) [
8]. Similar to iWBS, our SWLS measure of well-being was significantly associated with socio-economic indicators such as educational attainment and median household income, clinical characteristics; as measured by the percent of hospital stays classified as “preventable” and mammography rate, and physical environment characteristics, as defined by the commuting patterns of residents. The overall SWLS well-being measure was not significantly associated with six of the significant factors in the Roy et al. study—divorce rate, child poverty rate, mammography rate, number of FQHCs and commuting by bicycle—though of these, only the number of FQHCs did not exhibit any significant associations with the constituent SWLS domains.
Even when adjusting for major, well-studied individual-level characteristics, like gender, income, and employment and marital status (all of which exhibited significant effects on SWLS and its domains), statistically significant variation between quantile groups of the neighborhood factors remained. While the insights given by Roy and colleagues in their nationally-representative study provide an important focus on key neighborhood-level associations with well-being, this paper deepens that understanding by affirming many of their findings with an independently-derived well-being measure. Additionally, by further identifying associations with specific domains of well-being, we provide a basis for additional inquiries into the nature of these relationships between place, health, and well-being.
The results can set the stage for the development of interventions in the physical environment arena as a means for enhancing well-being, including health behaviors that can impact it [
8]. While “top-down” policy-level approaches to environmental change have often been targeted, an emerging area of “bottom-up” community engagement activities around changing local physical environments to support healthy living have shown increasing promise [
33]. Community-engaged research models such as the Our Voice global citizen science research initiative [
34] may provide fruitful methods for eliciting and identifying possible mechanisms, supports, and barriers to achieving the types of well-being outcomes targeted in this study [
35].
Strengths of this study include its multi-dimensional measure of well-being, as well as a more fine-grained treatment of place (i.e., at the ZIP level). By exploring relations of both a global well-being score and its component parts, we are able to develop hypotheses about which aspects of well-being are associated with different aspects of the built and social environment. For example, if it is possible that some domains of well-being are relatively insulated to the effects of neighborhood environment, while others are quite sensitive, or that individuals self-select into certain neighborhoods based on amenities that support their well-being (e.g., that can directly impact the SWLS domain of lifestyle and daily practices). By conducting our investigation at a smaller geographic level, we may better identify likely exposures to the kinds of environments that may be too aggregated at the level of counties and states. For example, participants residing in Santa Clara County, California, were spread across 55 separate ZIP codes, which ranged widely in neighborhood characteristics. Finally, by assessing differences across quantile groupings of neighborhood factors (as in Roy et al. [
8]), rather than seeking to draw more precise “dose-response” inferences, we allowed for the possibility that certain effects of neighborhood characteristics on well-being are non-linear (e.g., both extremely low and extremely high values exhibited a positive relationship with well-being, while mid-range values had a negative relationship).
This study also has several limitations. Several data assumptions were made that are important limitations. First, while SWLS domain scores are treated as continuous for the purpose of this exploratory study, some domains were generated from single questions, making them ordinal in nature, which may be more fully investigated in future studies. Second, we assume data to be missing at random, which may be a source of bias should significant patterns of omission exist. Future studies might incorporate weighting schemes based on participant non-response, which is not currently a feature of the SWLS dataset. The study’s cross-sectional design also precludes our ability to draw causal inferences based on the significant correlations we have described. Future research utilizing longitudinal cohort studies, including the Stanford WELL for Life registry, will enable additional investigations of these relations as both individual-level variables and neighborhood contexts change over time. Longitudinal studies may also track individuals who move from one neighborhood context to another, offering yet another opportunity to account for exposure. Another limitation of the study is the difficulty of dealing with self-selection bias. Common to neighborhood research, we are not able to rule out the possibility that individuals “sort” themselves into neighborhoods that reinforce pre-existing individual characteristics or traits, rather than the scenario suggested here, whereby neighborhood contextual factors may influence different aspects of an individual’s self-rated well-being. One final limitation is related to individual exposure to neighborhood contexts; for example, while each participant is assigned a summary score for a neighborhood characteristic, an individual’s unique exposure to, or experience with that factor, may be quite variable. Focusing our analysis at the sub-county level helps address this question to some degree, although it does not entirely control for the potentially confounding effects of this dynamic.




{kind=link}
