1. Introduction
Air is one of the most basic elements for human survival and good air quality is necessary for human health. Unfortunately, air pollution has become a global problem, which has aroused widespread concern from scholars, governments and the public. Some studies have found that exposure to air pollutants is associated with the occurrence of many diseases such as respiratory disease, cardiovascular disease and even cancer, contributing to as many as 4–9 million human deaths per year globally [
1,
2]. The situation in China is also grim. With the rapid development of industrialization and urbanization, more and more fossil fuels are being burned, which results in increasing emissions of sulphur, nitrogen and particulate matter, causing deteriorating air quality and frequent hazy weather. As the “Capital Economic Circle” and future world-class urban agglomeration, influenced by adverse geographical and meteorological conditions along with industrial structure, the Jing-Jin-Ji region has become one of the most heavily polluted areas, with frequent long duration, wide range and severe degree regional pollution events. To solve this serious problem, researchers have done a lot of work, including air pollutant prediction and air quality evaluation.
Numerous forecasting models have been proposed, mainly for pollutant concentration. According to their principles, these forecasting models can be divided into three categories: statistic forecasting models, numerical forecasting models and machine learning models.
Statistic forecasting models have been widely used in air quality forecasting from the early days because of their simplicity and rapidity, and they still have value in application and research up to now. They can predict pollutant concentrations in the future only by studying the relationship between pollutant concentration and meteorological factors from past records without information about pollution sources. Common statistical models include the multiple linear regression model (MLR) [
3], autoregressive integrated moving average model (ARIMA) [
4], grey model (GM) and Markov model. For example, Elbayoumi et al. [
5] used MLR to predict the annual indoor concentrations of PM
2.5 and PM
10 by analyzing the meteorological variables (wind speed, temperature and relative humidity) collected from 12 natural ventilation systems. Jian et al. [
6] used ARIMA to study the effects of meteorological factors on the concentrations of ultrafine particles and PM
10 in Hangzhou under heavy traffic conditions. A first-order variable grey differential equation model was proposed by Pai et al. [
7] to predict the hourly PM concentration in Banqiao, Taiwan. A Hidden Markov Model (HMMS) was used to predict daily average PM
2.5 concentrations [
8]. Although these statistic forecasting models (linear method) have been widely used in PM concentration prediction (non-linear process), their accuracy is largely limited by their linear mapping ability. Most of the air pollutant time series in the real world are non-linear and irregular, so statistic forecasting model may not be suitable for these data.
Since the 1990s, with the development of computer technology and the abundance of air pollution data, numerical forecasting models have been greatly developed and are currently in the third generation. Based on the idea of “One Atmosphere”, they realize two-way coupling between atmospheric dynamics and atmospheric chemistry which can simulate atmospheric physical and chemical processes on different scales and therefore predict the concentrations of different air pollutants [
9]. Numerical forecasting model usually consist of meteorological modules, emission modules and chemical modules following this principle that weather or climate modules provide meteorological background fields which drive the chemical transport modules. At present, common numerical forecasting models include the U.S. Models-3 and WRF-Chem, Polyphemus from France as well as Nested Air Quality Prediction Modeling System (NAQPMS) from China [
10,
11,
12]. Although numerical forecasting models are helpful to reveal the mechanism of pollution processes, their accuracy, especially in severe air pollution incidents, is greatly limited by some difficulties such as inaccurate atmospheric boundary layer simulation schemes, insufficient emission inventory of pollution sources and limited knowledge of atmospheric physical and chemical process. Furthermore, they require a lot of computing time.
Machine learning belongs to the field of artificial intelligence. The arrival of the big data era has brought unprecedented opportunities for the development of machine learning. Machine learning has excellent performance in regression and classification problems, and it is usually recognized as one of the most powerful tools in pollutant prediction for its high robustness and fault tolerance. Therefore, there are increasingly studies on pollutant concentration prediction with machine learning models. For example, support vector machine (SVM) [
13] and artificial neural network (ANN) [
14] are commonly selected. Paschalidou et.al [
15] used a radial basis function (RBF) and multilayer perceptron (MLP) to predict hourly concentrations of PM
2.5 in Cyprus. Wu et al. [
16] acquired predictions of PM
10 concentrations using a general regression neural network (GRNN).
Pollutant concentration data are too abstract for the public to understand, and people are eager for simplified and intuitive information to quickly understand the state of ambient air, which means air quality evaluation is indispensable. When it comes to methods of air quality evaluation, the most commonly used method is the air quality index (AQI) originally proposed by the US Environmental Protection Agency (EPA). AQI is widely used worldwide, while the standards vary among countries. China’s standard comes from “Technical Regulation on Air Quality Index (on trial) (HJ 633-2012)” issued by the Ministry of Environmental Protection. It considers a variety of pollutants including PM
2.5, PM
10, NO
2, SO
2, CO, O
3. However, as with all environmental quality evaluations, there are ambiguities in air quality evaluation due to the vagueness of evaluation factors, criteria and objects, etc., which makes it difficult to justify the use of sharp boundaries in classification schemes, so the air quality index method has some limitations, for example, a slight increase or decrease of pollutant data near a boundary value will change the evaluation level. Such fuzziness has led many researchers to seek advanced evaluation methods [
17], for instance, fuzzy mathematics. Fuzzy mathematics is proved to be a useful tool for air quality evaluation [
18,
19], and many air quality indicators based on fuzziness [
20,
21,
22,
23] are proposed.
Individual prediction or evaluation is not enough to help us cope with air pollution, so an integrated and complete system is expected to play a greater value. Some early-warning systems including prediction and evaluation have been gradually proposed. The problem of air pollution in China has attracted increasing attention, but there are relatively few in-depth and targeted studies in air quality early warning based on artificial intelligence. Consideration of pollutants which affect air quality should be as comprehensive as possible, but some studies only focus on single pollutant, mainly PM. Although the selection of experimental sites is of importance, some scholars don’t give sufficient reasons such as purpose and significance for their choices. The selection of algorithms and pollutant concentration limits in air quality evaluation also remain to be discussed. Therefore, developing an accurate and robust air quality early-warning system has become an urgent need of society. It is hoped to provide not only air quality information comprehensively and objectively, but also necessary preventive measures for citizens to avoid hazards, and even help relevant departments to better control air pollution and minimize negative impacts.
Based on the above analyses, this paper proposes a novel air quality early-warning system composed of prediction and evaluation. The prediction part took advantage of advanced improved complete ensemble empirical mode decomposition with adaptive noise (ICEEMDAN) and combined whale optimization algorithm (WOA) with extreme learning machine (ELM). The three methods have been proved to be effective in air pollutant forecasting [
24,
25,
26]. Fuzzy comprehensive evaluation (FCE) based on fuzzy mathematics was conducted subsequently.
Generally speaking, the contributions of this paper are as follows:
A complete air quality early-warning system was established and achieved good results in the Jing-Jin-Ji region where air pollution problems are of great concern.
A novel hybrid prediction model ICEEMDAN-WOA-ELM was proposed for the main air pollutants in Beijing, Tianjin and Shijiazhuang. ICEEMDAN and WOA are confirmed to greatly improve the prediction ability of ELM through comparison.
The predictive results can be transformed into corresponding air quality levels by fuzzy comprehensive evaluation, which means citizens without professional knowledge of atmospheric science can easily understand the current air quality and get scientific advices to avoid air pollution.
The air quality early-warning system is feasible and practical in air pollution treatment, which can not only protect the public from air pollution but also offer services for government decision-making on environmental protection.
The rest of this paper is organized as follows:
Section 2 briefly introduces the methodologies adopted in this paper. Empirical research is given in
Section 3, along with the description of experiment sites, data, evaluation criteria and so forth.
Section 4 gives the conclusions.
2. Methodology
2.1. The Proposed Air Quality Early-Warning System
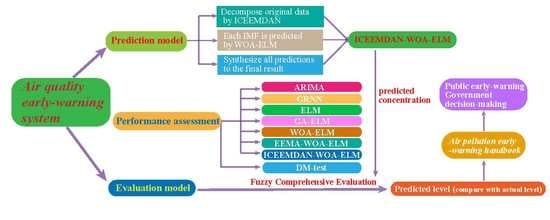
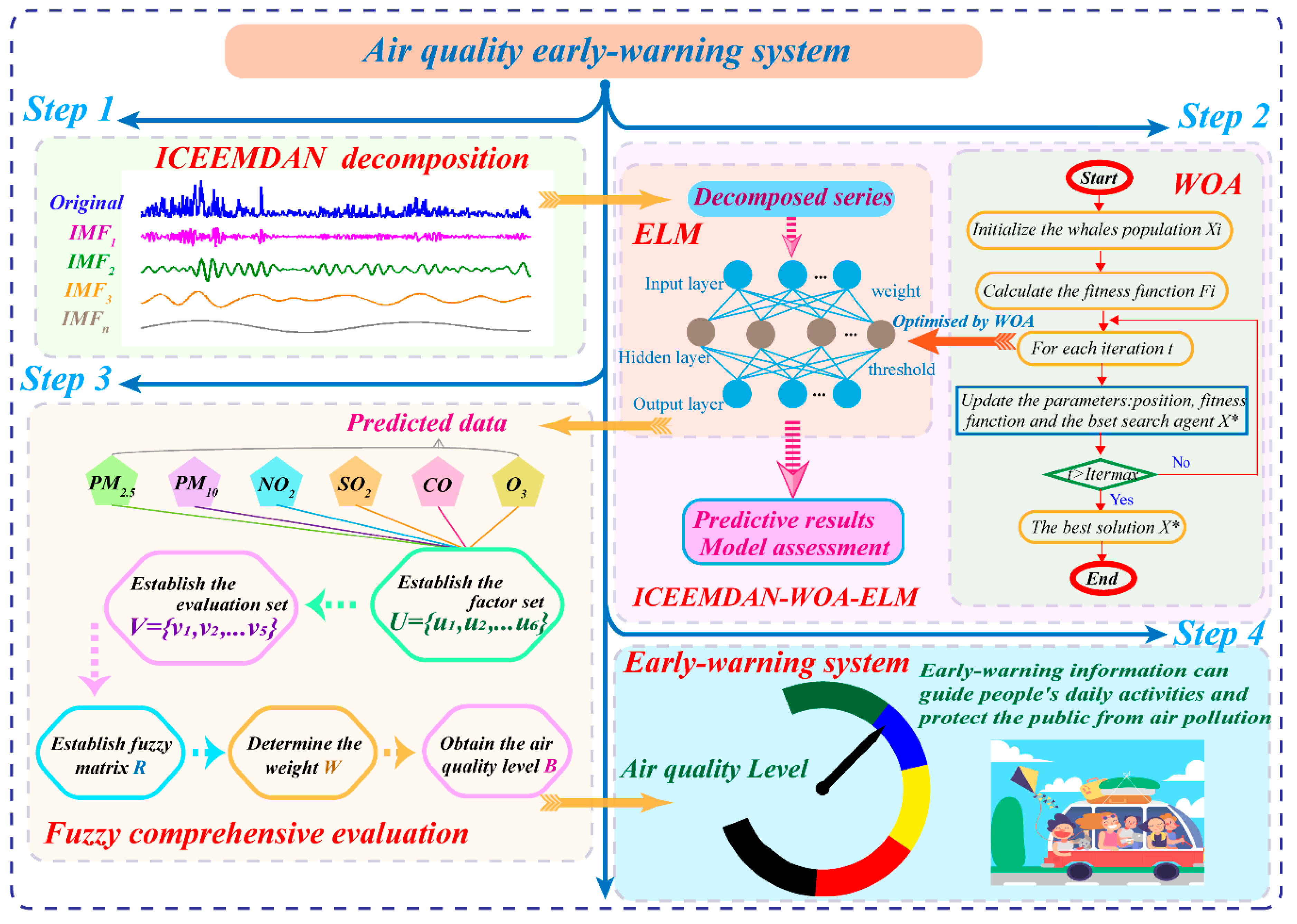
In this section, the air quality early-warning system whose core is the hybrid ICEEMDAN-WOA-ELM-FCE model is introduced in detail. The flow diagram consisted of four steps, presented in
Figure 1.
Step 1: Pollutant concentration data are usually chaotic time series, requiring denoising technology to eliminate the influences of outliers and improve the prediction accuracy. ICEEMDAN is used to process the original data into several IMFs from high frequency to low frequency, which contain different characteristics of the original data.
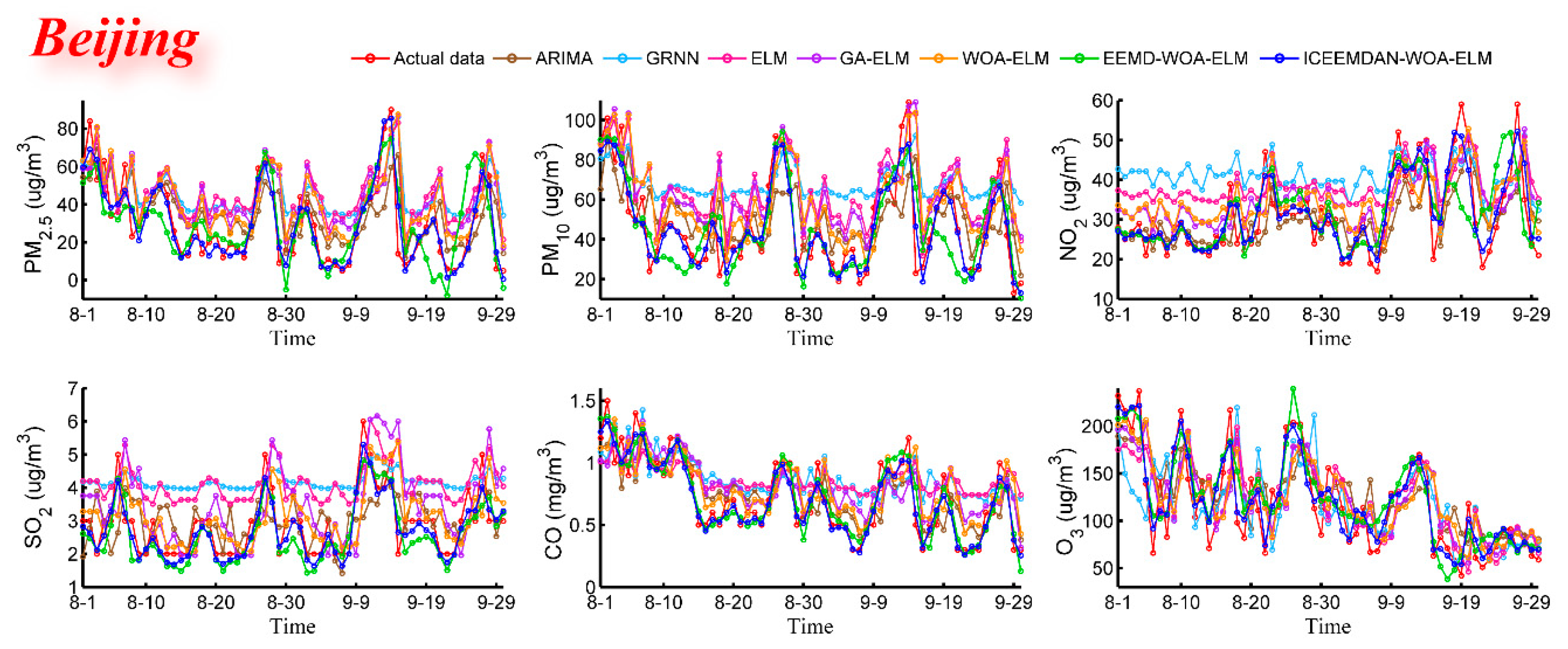
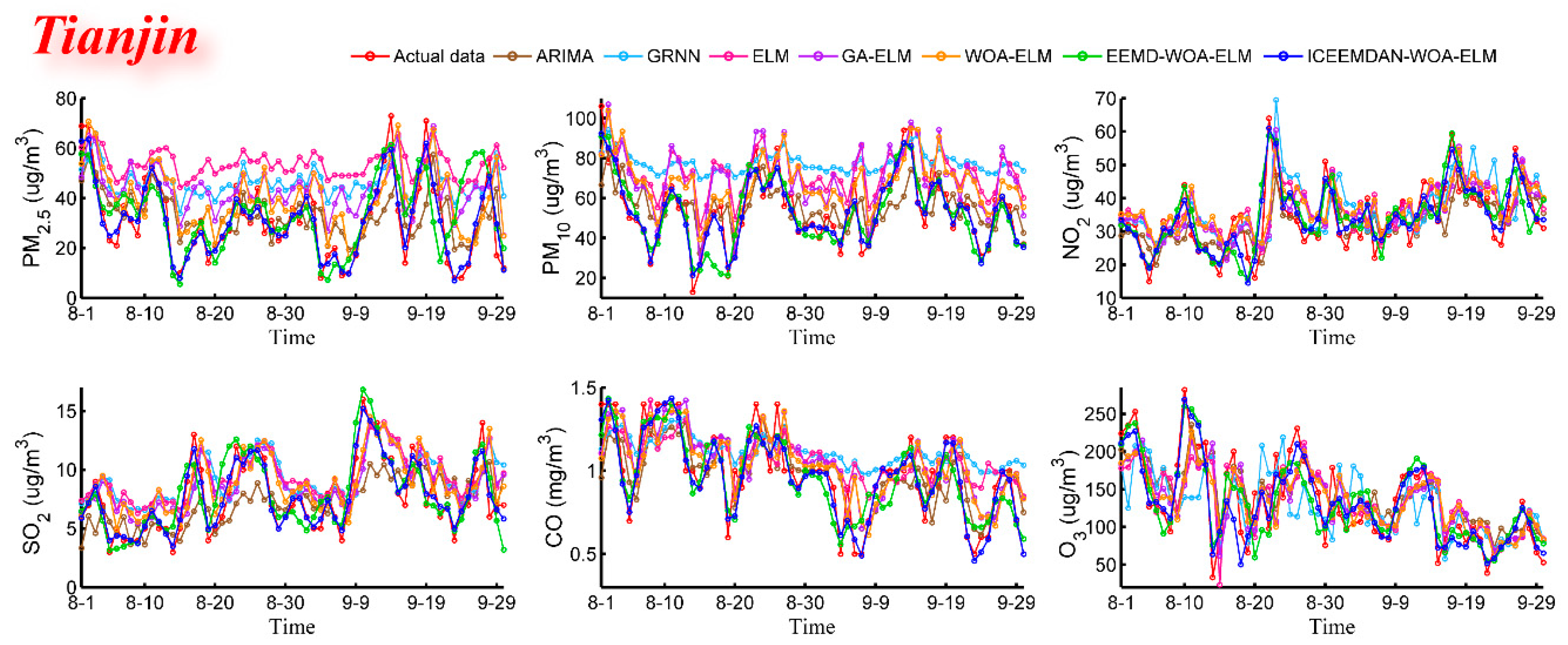
Step 2: The ELM optimized by WOA is applied to build a predictor for each IMF. The WOA algorithm is used to obtain the best parameters of ELM to establish a forecasting model which is not only fast but also accurate. All the predictive results of IMFs are synthesized and the final predictive result is obtained. The optimized ELM model is used to forecast the concentrations of six major air pollutants in Beijing, Tianjin and Shijiazhuang, which will be the key information for the evaluation model.
Step 3: Fuzzy comprehensive evaluation can convert the predictive results into air quality levels scientifically and objectively, providing crucial information for further research and analysis.
Step 4: The air quality information can be applied to guide people’s daily lives. Different colors are assigned to different levels, so air quality information can be easily understood. In addition, brief but practical guidance corresponding to levels can be offered to the public against air pollution. Scientific and precise results also serve the government decision-making on environmental protection. Generally, the proposed air quality early-warning system will play a key role in future air pollution prevention.
In this section, all individual methods belonging to the air quality early-warning system are described in detail, including ICEEMDAN, WOA, ELM and FCE.
2.2. Improved Complete Ensemble Empirical Mode Decomposition with Adaptive Noise (ICEEMDAN)
The empirical mode decomposition (EMD) [
27] is a widely used method to analyze non-linear and non-stationary data. Compared with the traditional decomposition algorithm, Fourier transform or wavelet transform which are more applicable to stationary and linear data, EMD is adaptive and highly efficient. Original data can be expressed as a sum of intrinsic mode functions (IMFs) and a final monotonic trend by EMD, but oscillations may be produced with different scales in one mode or with same scale in different modes which called “mode mixing”. The ensemble empirical mode decomposition (EEMD) [
28] is proposed to address this problem by adding Gaussian white noise to the original signal, but the added noise can’t be completely neutralized and different noisy copies of the signal may produce different number of modes. The complete ensemble empirical mode decomposition with adaptive noise (CEEMDAN) [
29] provides accurate reconstruction of the original signal, better spectral separation of the mode and computational efficiency, achieving huge improvements on EEMD. Furtherly, the ICEEMDAN [
30] improves some aspects of CEEMDAN involving residual noise, “spurious mode” and so forth, becoming the latest decomposition method of EMD family. In this study, considering the non-stationary and non-linear characteristics of pollutant concentration, ICEEEMDAN was used as a data preprocessing method to better dig out the rules behind the pollutant data and serve the prediction later. The main steps of ICCEMDAN are summarized as follows:
(1) Calculate local means of realizations by EMD to get the first residue , where is a realization of white Gaussian noise with zero mean unit variance, is the operator that produces the th mode obtained by EMD and is the operator that generates the local mean of the applied signal.
(2) Calculate the first mode at the first stage .
(3) Calculate the second residue as the average of local means of the realizations and define the second mode:
(4) For calculate the th residue .
(5) Calculate the th mode .
(6) Return to step 4 for next .
2.3. Whale Optimization Algorithm (WOA)
Inspired by the bubble-net hunting strategy which corresponds to the social behavior of humpback whales, a nature-inspired meta-heuristic optimization algorithm called WOA [
31] was proposed in 2016. Tested with 29 mathematical benchmark functions and six structural engineering problems in exploration, exploitation, local optima avoidance and convergence behavior, WOA was proved to be highly competitive compared to the state-of-art meta-heuristic algorithms as well as conventional methods. The mathematical model of WOA is illustrated as follows [
31].
2.3.1. Encircling Prey
Humpback whales can identify and encircle the location of their prey. After defining the best search agent, other search agents will try to move to the best location. This behavior is expressed by the following mathematical formulas:
where
is the current iteration,
is the best position,
denotes the position vector,
is an element-by element multiplication, and
and
are coefficient vectors which can be calculated by the following equations:
where
is a random vector between 0 and 1, and
is linearly reduced from 2 to 0 in the iteration process.
2.3.2. Bubble-Net Attacking Method (Exploitation Phase)
Humpback whales usually attack their prey using the bubble-net strategy and two approaches are designed:
(1) Shrinking encircling mechanism.
This behavior is realized by reducing the value of in Equation (3). Setting random values in [−1,1], the new position can be obtained between the original position and the current position of the best agent.
(2) Spiral updating position
A spiral equation is established between whales and prey to simulate the helix-shaped movements of humpback whales:
where
is the distance between the
th whale and the best position obtained so far,
is a constant to define the logarithmic spiral,
is a random number between −1 and 1, and
is an element-by-element multiplication. WOA assumes that there is a 50% probability of choosing shrinking encircling mechanism or the spiral model to update the position of whales in the optimization process. The algorithm is defined as follows:
where
is a random number between 0 and 1.
2.3.3. Search for Prey (Exploration Phase)
Humpback whales can randomly search for prey according to the position of each other. In the exploration phase, we can update the location of a search agent based on a randomly selected search agent, rather than the best search agent found so far. This mechanism emphasizes exploration, allowing the WOA algorithm to perform a global search. This mathematical model is expressed as follows:
where
is a random location vector selected from the current population.
The WOA algorithm (Algorithm 1) starts with a set of random solutions. In each iteration, the search agent updates its location based on the randomly selected search agent or the best solution obtained so far. A random search agent is selected when > 1, and the best solution is selected when < 1. According to value, WOA can switch between spiral and circular movement. The WOA algorithm is terminated when it satisfies the termination criterion. The pseudo code of the WOA algorithm is represented as follows:
| Algorithm 1 WOA |
| Input: Maximum number of iterations , Fitness function , Current iteration number t, |
| A random number between −1 and 1, A constant number . |
| 1: Initialize the whales population |
| 2: for each search agent do |
| 3: Calculate the fitness function |
| 4: end for |
| 5: the best search agent |
| 6: while do |
| 7: for each search agent do |
| 8: Update and |
| 9: if then |
| 10: if then |
| 11: Update the position of search agent using Eq(2); |
| 12: elseIf |
| 13: Select a random search agent ; |
| 14: Update position of search agent using Eq(8); |
| 15: end if |
| 16: elseIf |
| 17: Update the position with spiral Eq(5); |
| 18: end if |
| 19: end for |
| 20: Check if any search agent goes beyond the search space and amend it; |
| 21: for each search agent do |
| 22: Calculate the fitness function |
| 23: end for |
| 24: Update if there is a better solution; |
| 25: |
| 26: end while |
| 27: return |
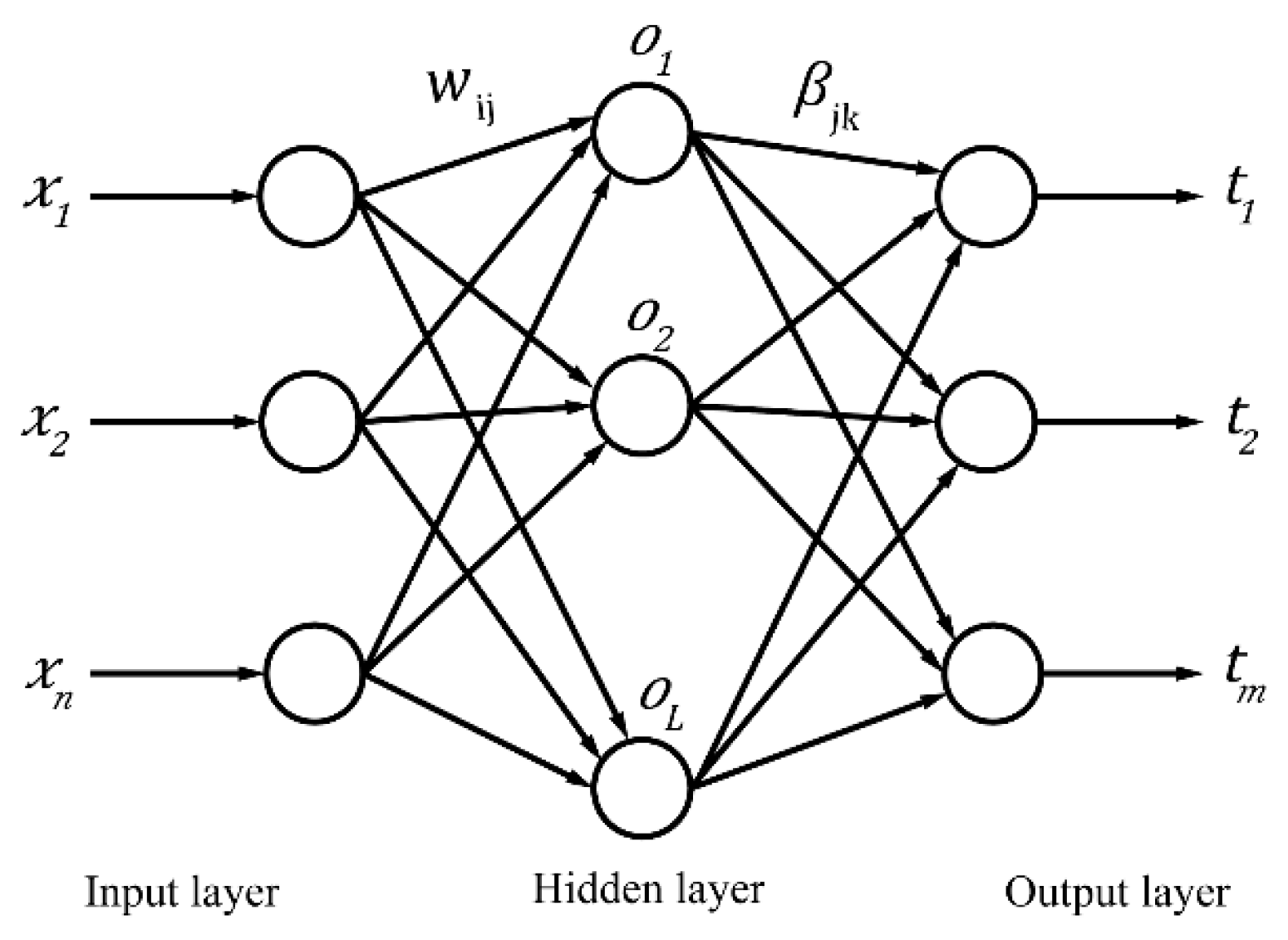
2.4. Extreme Learning Machine (ELM)
ELM [
32] is a simple and extremely fast learning algorithm of single-hidden layer feedforward neural networks (SLFN). ELM randomly assign input weights and hidden layer biases (thresholds) without adjustment in the training process, which leads to thousands of times faster than traditional feedforward network learning algorithms and better generalization performance in most artificial and real benchmark problems. The structure of single-hidden layer feedforward neural network is shown in
Figure 2.
For
independent samples
,
and
. SLFN can be expressed as [
32]:
where
is the weight vector between the input layer neurons and the
th hidden layer neuron,
is the threshold of the
th hidden layer neuron,
is the activation function, and
is the weight vector between the
th hidden layer neuron and the output layer neurons. Formula (9) can be expressed as:
where
is the output matrix of the hidden layer,
is the weight vector between the hidden layer neurons and the output layer neurons,
is the expected output of network, represented as follows [
32]:
The number of required hidden layer neurons
when activation function
is infinitely differentiable. Its solution is:
where
is the Moore-Penrose generalized inverse of
.
ELM can generate and randomly before training and calculate only by determining and . Generally, the ELM algorithm has the following steps:
(1) Determine the number of neurons in the hidden layer, and randomly set the connection weight between the input layer and the hidden layer and the threshold of hidden layer neurons.
(2) An infinitely differentiable function is selected as the activation function of the hidden layer neurons, and then the output matrix of the hidden layer is calculated.
(3) Calculate the weight of the output layer: .
2.5. Fuzzy Comprehensive Evaluation (FCE)
Environmental quality is a huge and ambiguous system with a large number of uncertain factors. Fuzzy mathematics [
18] can effectively solve the influences of ambiguity of evaluation boundary and monitoring error on evaluation. Using membership function to represent air quality level can eliminate subjective and artificial factors in classification, objectively reflecting regional air quality. The concrete steps of fuzzy comprehensive evaluation are as follows:
(1) Establish the factor set
A factor set is a set of elements that affect the evaluation object, usually represented by
. It is well known that different pollutants can cause different hazards to human health, so these parameters should be treated separately. Therefore, six main pollutants are selected as air quality parameters in this project:
(2) Set up the evaluation set
Because this research is carried out in China, air pollutant concentration limits from “Technical Regulation on Air Quality Index (on trial) (HJ 633-2012)” of China have a reference value. On account of the lack of values of O
3 (8 h) beyond the fifth level, we have a decision that the evaluation set comprises five levels:
and the corresponding air quality categories are “Excellent, Good, Moderate, Poor, Hazardous”. The air quality levels and corresponding concentration limits of different pollutants are given in
Table 1.
(1) Establish fuzzy matrix
The fuzzy matrix can be expressed by the matrix
, where
is the membership degree of factor
aiming at the comment
:
The membership function can calculate the membership degree of pollutant concentration to the evaluation grade. There are many membership functions such as halved trapezoidal distribution function, Gauss membership function, triangular membership function, etc. In this study, the halved trapezoidal distribution function [
33] which has often been used in air quality evaluation is selected and details are presented as follows:
(2) Determine the factor weights
The weight of a factor is an index to measure the relative degree of a pollutant impact on air quality. The multi-scale weighting method is commonly used in the fuzzy evaluation of environment quality, therefore the weight of pollution factor can be obtained by Equation (16):
(3) Evaluation result
By synthesizing the weight vector and the fuzzy matrix with the appropriate operator, the final result of the fuzzy comprehensive evaluation can be obtained. The Zadeh operator
is commonly used as a solution, therefore it is adopted here:
According to the principle of maximum membership degree, the maximum value of is the result of fuzzy comprehensive evaluation of air quality.
4. Conclusions
Air pollution is a long-standing problem that plagues the whole world, seriously harming human health, social development and natural environment. In order to solve this problem, a great deal of manpower and material resources have been invested, but unfortunately the results are not satisfactory enough. There is always a way and the rapid development of artificial intelligence in recent years has brought new hope for air pollution control. This proposed air quality early-warning system is hoped to play a key role in future for its accuracy and effectiveness. This system mainly consists of two parts: prediction model and evaluation model.
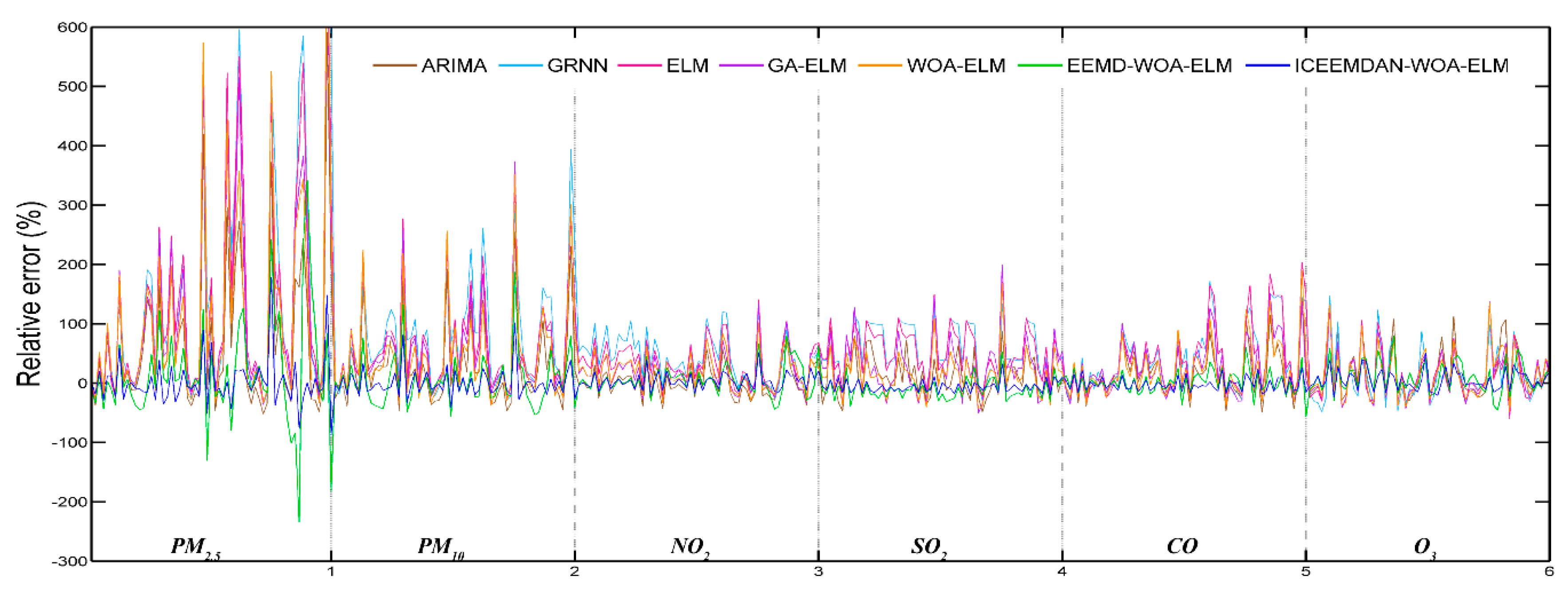
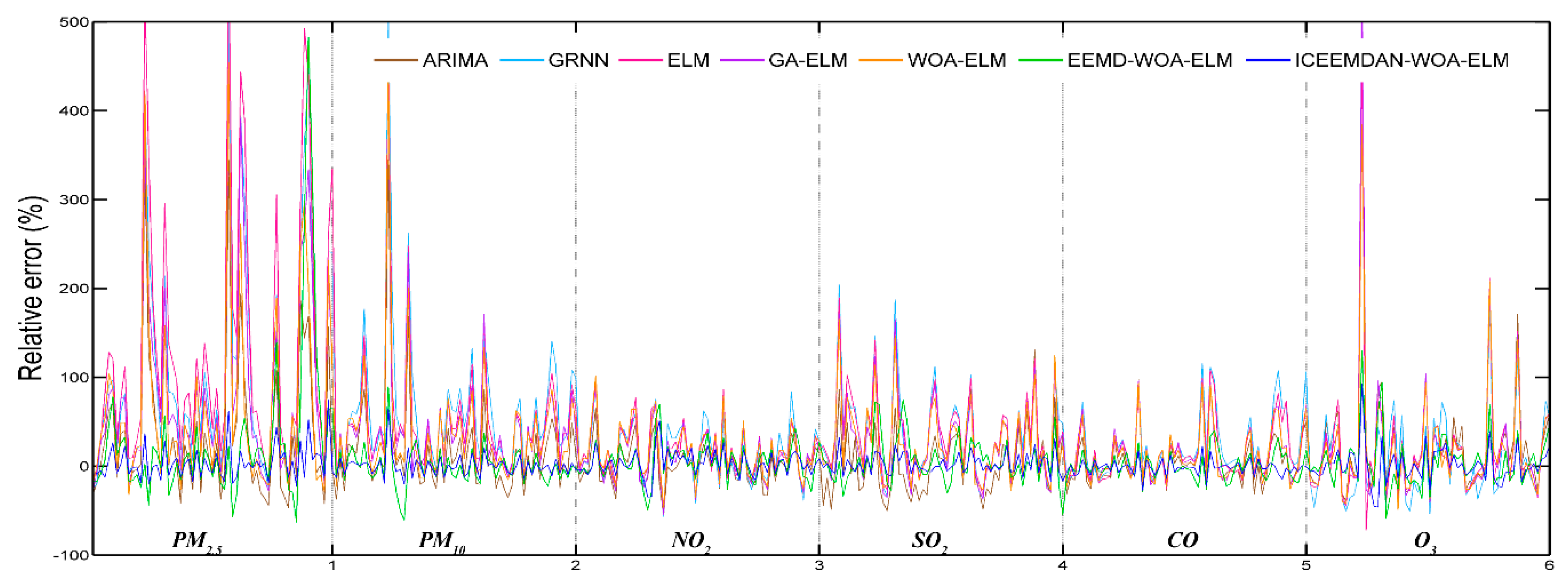
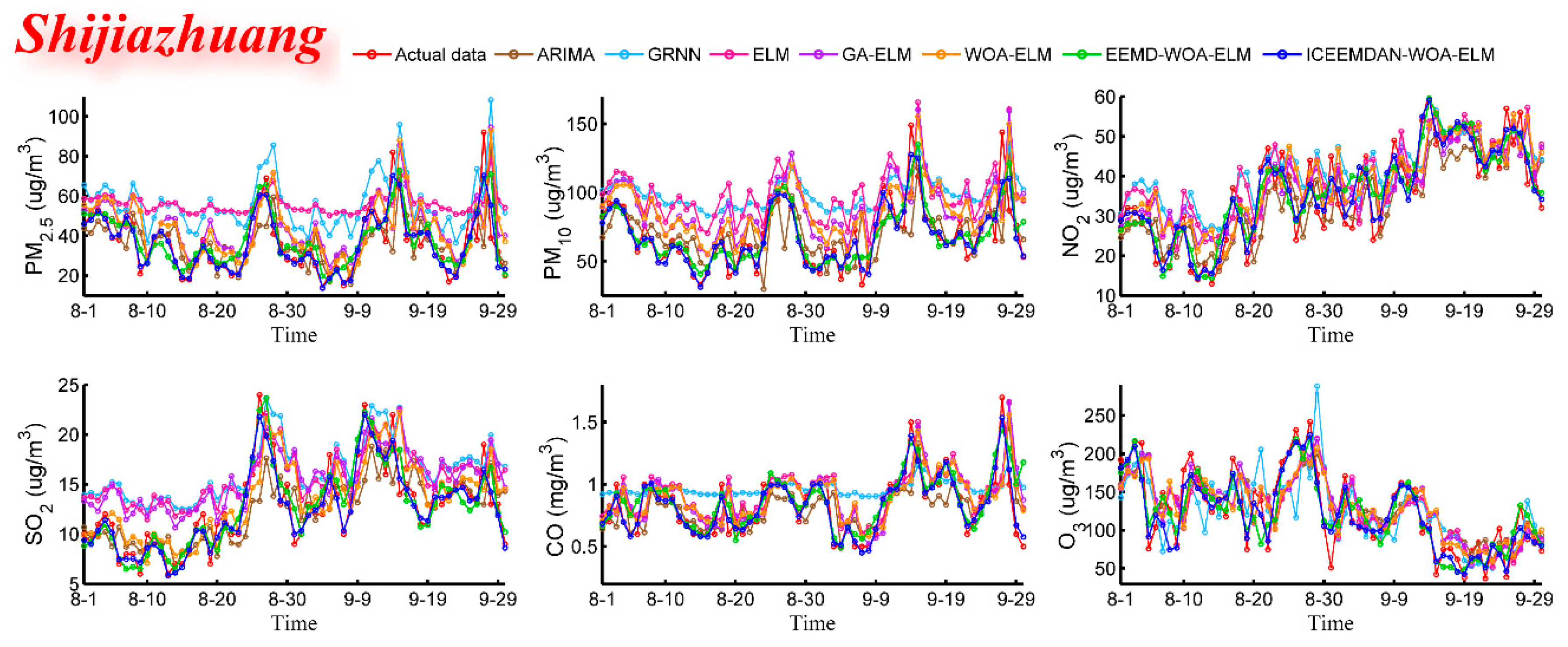
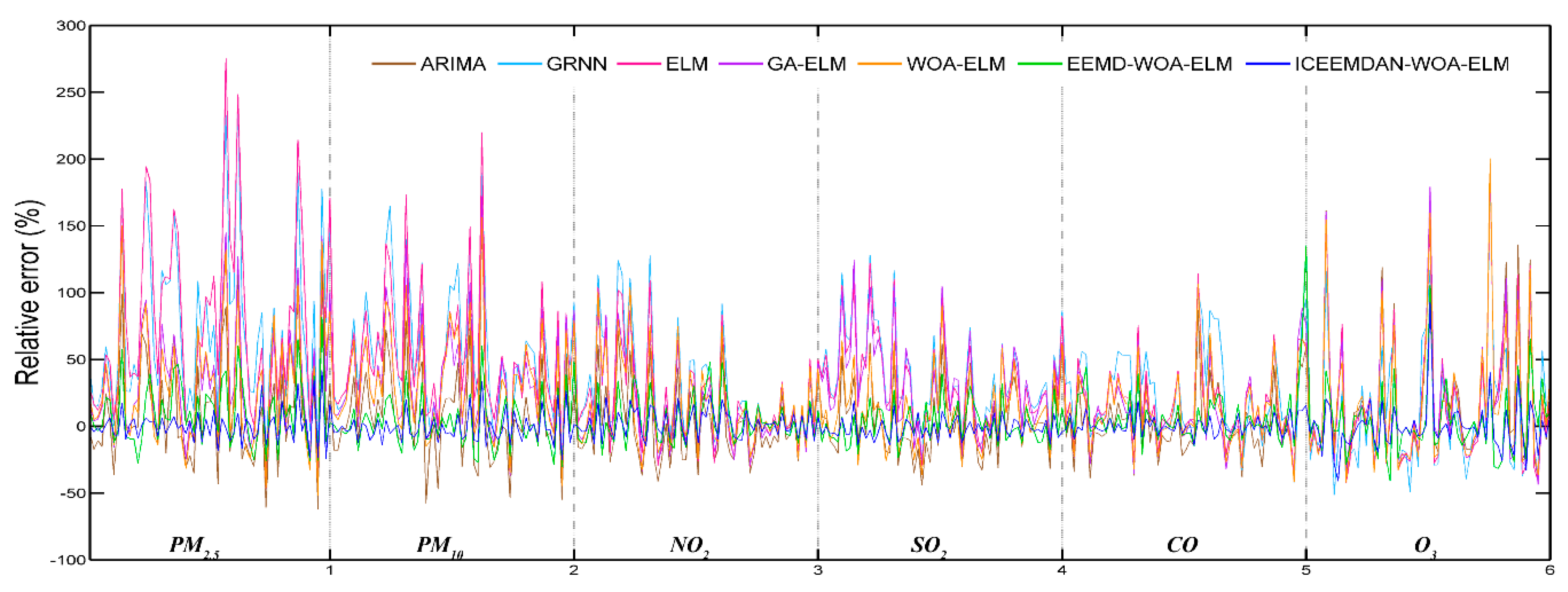
In order to establish the prediction model, ELM, which is famous for accuracy and robustness, was employed. Taking ELM as the core, a hybrid model ICEEMDAN-WOA-ELM was proposed. Firstly, according to the theory of “decomposition and integration”, the original time series of pollutant concentration were decomposed into IMFs by decomposition algorithm (ICEEMDAN). Secondly, the ELM optimized by WOA was used to predict each IMF. Finally, all the predictive results were combined to get the final predictive result. In this study, six main air pollutants PM2.5, PM10, NO2, SO2, CO and O3 in Beijing, Tianjin and Shijiazhuang were chosen. This proposed prediction model was used to predict air pollutant concentrations and compare with the six benchmark models including ARMA, GRNN, ELM, GA-ELM, WOA-ELM and EEMD-WOA-ELM. The simulation results showed that the proposed ICEEMDAN-WOA-ELM model was superior to other models and ICEEMDAN decomposition algorithm along with WOA optimization algorithm played important roles in improving the prediction accuracy of neural network.
In addition to prediction of air pollutant concentration, air quality evaluation was an indispensable part of the air early warning system. For the sake of understanding the future state of air, air quality was evaluated with the above predicted data by fuzzy comprehensive evaluation. The evaluation results were satisfactory enough compared with the actual status, which means our proposed evaluation model can meet the requirement of early warning. Furthermore, air pollution early-warning handbook was compiled to provide the public with intuitive air quality information and reasonable measures.
The combination of air pollutant prediction and air quality evaluation lays a solid foundation for the establishment and implementation of air quality early-warning system. The proposed system can offer us accurate air pollutant concentration prediction, correct air quality evaluation, reasonable countermeasures and scientific decision-making support, which means it will become a sharp weapon for air pollution control and even smart city construction in future.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}