1. Introduction
In the absence of a vaccination or effective medical treatment against the SARS-CoV-2, the global population must cohabitate with the virus. For succeeding in this task, different strategies to slow down the outbreak can be implemented, for example, encouraging social distancing, isolation of infected individuals, mobility restrictions, lockdowns, and contact tracing. The main objective is to guarantee that the number of infected individuals that develop critical forms of symptoms does not exceed the capacity of local health care systems. Nonetheless, most of the strategies to slow down the outbreak induce dramatic economical consequences, and thus, public health policies must be designed based on reliable predictions of the evolution of the pandemic to minimize undesired effects on the global economy. For doing so, estimating the values of variables such as the proportion of susceptible, infected and recovered individuals in the population, among other variables, is of paramount importance. This is due to the fact that such variables are the inputs of mathematical models that help to predict the evolution of the pandemic [
1,
2], and thus, impact public health policy-making. Reliable estimations of these variables can be achieved in part by testing the population. Nonetheless, diagnosing SARS-CoV-2 is a challenging task given that designing highly reliable tests for massive testing is still an open research problem, c.f., [
3,
4,
5].
In the general realm of epidemiology, the reliability of tests is measured in terms of two parameters: sensitivity and specificity. The former is the probability with which a test is able to correctly identify the presence of a condition, for example, a SARS-Cov-2 infection. Alternatively, the latter is the probability with which a test is able to correctly identify the absence of such condition. Within this context, the main contribution of this work is a mathematical formula for estimating the fraction of individuals that exhibit the condition in a population in which every individual has been tested once with identical unreliable tests. In the following, this fraction is referred to as the prevalence ratio [
2]. In these terms, the main result is Theorem 1 in
Section 4, which presents an estimator of the prevalence ratio in terms of the sensitivity, specificity and the fraction of positive test results. More importantly, the estimation error induced by such estimator is proved to decrease with the number of tests.
The novelty of this work with respect to existing methods for estimating the prevalence ratio, such as the method of multipliers, capture and recapture methods, among others [
2,
6], is that it takes into account the effects of both false positive and false negative probabilities. This consideration has already been discussed by several authors, c.f., [
7,
8,
9,
10]. Nonetheless, a simple general formula for estimating prevalence ratios in terms of the sensitivity, specificity, and the fraction of positive test results is not available in current literature. This said, the prevalence ratio estimation presented in this work is based exclusively on the results of data obtained through testing campaigns with unreliable binary tests. The main hypotheses adopted in this work are: (a) Individuals are tested once and test results are independent of each other; and (b) the prevalence ratio is assumed constant during the duration of the testing campaign. This breaks away from the studies based on mathematical regressions in which some assumptions on the proabability distribution of the random variables are adopted and whose correctness is often the ground of vivid discussions, c.f., [
11,
12,
13,
14].
The main conclusions of this work are:
- (i)
The number of positive tests might be drastically different than the number of infected individuals in a population depending on the sensitivity and specificity of the tests. Hence, the ratio between the number of positive tests and the total number of tested individuals is not a reliable estimation of the prevalence ratio;
- (ii)
Testing campaigns using tests for which the sum of the sensitivity and specificity is different than one, always allow a reliable estimation of the number of infected individuals when a sufficiently large number of individuals is tested in the population (Lemma 1 in
Section 4);
- (iii)
Testing campaigns using a test for which the sum of the sensitivity and the specificity is equal to one, lead to data from which it is impossible to estimate the prevalence ratio independently of the number of tested individuals (Lemma 7 in
Section 4); and
- (iv)
When the objective is to estimate the prevalence ratio in a population, the key parameter for reducing the estimation error is the number of tests (Lemma 5 in
Section 4). That is, as long as the sum of the sensitivity and specificity is different than one, and a large number of test results is available, the exact values of both sensitivity and specificity have very little impact on the estimation error.
The remaining sections of this paper are organized as follows:
Section 2 presents a brief overview of the tests for diagnosing SARS-CoV-2 and the reliability of the existing tests;
Section 3 formulates the problem of estimating the prevalence ratio taking into account the sensitivity and specificity of the tests;
Section 4 presents an estimator of the prevalence ratio using data obtained from unreliable tests, and the proofs of the main results;
Section 5 introduces some examples in which the impact of the sensitivity, specificity and number of tests on the estimation error is numerically analyzed;
Section 6 concludes this work.
2. Case Study: SARS-CoV-2
Tests for SARS-CoV-2 can be broadly divided into three groups: virological tests, serological tests, and tests based on medical imaging. Each of these groups provide information about different aspects of the infection and exhibit different reliability parameters.
2.1. Virological Tests
Virological tests inform about the presence of the SARS-CoV-2 virus genome in nasopharyngeal (nasal swab) or oropharyngeal swabs (oral swab), blood, anal swab, urine, stool, and sputum samples [
15]. Individuals with positive virological tests are declared capable of contaminating others, and thus, virological tests are central in decision-making and policy-making, c.f. [
3,
5].
The reliability of virological tests in terms of sensitivity and specificity depends on a variety of parameters. These parameters include the type of clinical specimen, the materials and methods used for obtaining the specimens, specimen transportation, viral density of patients, and human errors in data processing in laboratories. In the case of respiratory specimens, viral density appears to play a central role in the sensitivity and specificity of virological tests, c.f., [
16,
17]. This stems from the fact that during the first week after infection, the virus can be detected by nasopharyngeal or oropharyngeal swabs. During the second week and later, the virus might disappear in the upper parts of the respiratory system and migrate to the bronchial tube and the lungs. From the studies in [
16,
17], it appears that specimens from the lower respiratory track increase the sensitivity and specificity of virological tests.
Virological tests are based on several techniques: (a) Reverse transcription polymerase chain reaction (RT-PCR), c.f., [
18,
19]; and (b) Reverse transcription loop-mediated isothermal amplification (RT-LAMP), c.f., [
20,
21]; and (c) other techniques, c.f., [
19,
22,
23].
2.2. Serological Tests
Serological tests determine whether an individual has developed anti-bodies or antigens against the SARS-CoV-2 virus. Nonetheless, an individual produces anti-bodies against SARS-CoV-2 only several days after contracting the infection. Typically, the time between infection and the production of anti-bodies ranges from seven to fourteen days, c.f., [
24,
25,
26]. Serological tests are based on the enzyme linked immunosorbent assay (ELISA) and exhibit high specificity and sensitivity, after fourteen days of infections [
24]. This drastically limits the use of serological tests in the early detection of the infection and policy-making, c.f., [
3,
4]. In a nutshell, on the one hand, a serological test answers the question whether an individual is or has been infected. On the other hand, serological tests do not allow determining whether an individual has immunity to the SARS-CoV-2 virus or whether the individual is currently spreading the virus. Up to the day of publication of this paper, serological tests are not considered for massive testing in France, c.f., [
4].
2.3. Medical Imaging
Medical Imaging for detection of SARS-CoV-2 includes chest X-Ray and chest computed tomography (CT) scans, which reveal ground-glass opacities and consolidations in the periphery of the lungs of infected individuals [
27]. Nonetheless, the sensitivity and specificity of CT depends on the experience of radiologists to distinguish SARS-CoV-2 pneumonia from non-SARS-CoV-2 pneumonia [
28]. In [
29], it is reported that the sensitivity of CT is better than the one achieved by RT-PCR tests.
3. Prevalence Ratio and Unreliable Tests
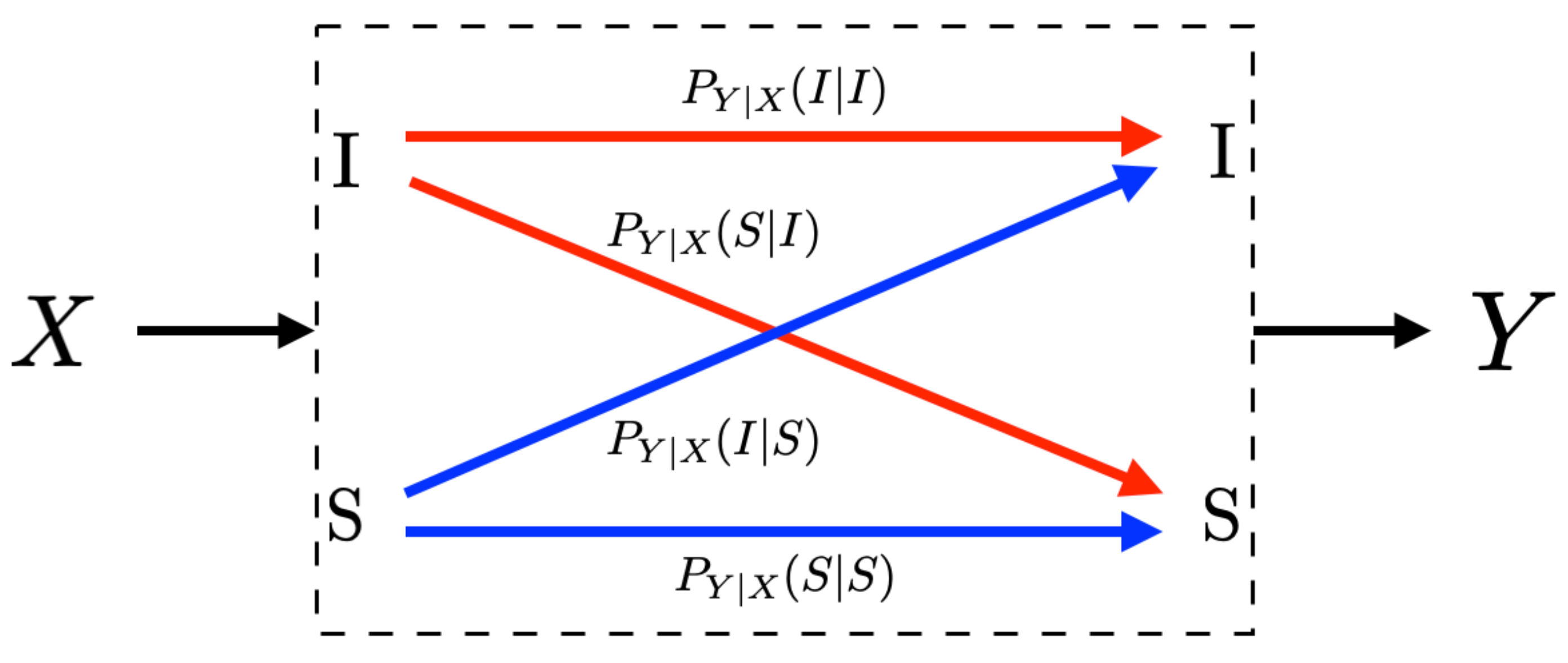
Consider a population subset of n individuals whose state is either susceptible (S) or infected (I) and assume that all individuals of this population subset are tested with the same type of test. Let the actual state of such n individuals be represented by the vector , , …, . That is, for all , it follows that is the true state of the individual t. The result of testing individual t is denoted by . Hence, the outcome of a testing campaign over such population is a vector , , …, . Due to the fact that tests possess strictly positive probabilities of false negatives and false positives, the vectors and might be different. That is, some individuals that are infected could have been declared susceptible and vice versa.
A central observation in this analysis is that a test for determining whether an individual is contaminated by SARS-CoV-2 can be modeled by a random transformation
for which the input and output sets are
. More specifically, if an individual whose state is
is tested, the result
is observed with probability
.
Figure 1 shows this binary-input binary-output model.
Using this notation, the sensitivity of the test is ; and the specificity of the test is . The probability of a false positive is ; and the probability of a false negative is . This said, a test is fully described by any of the following pairs of parameters:
The sensitivity and the specificity;
The sensitivity and the probability of a false positive;
The probability of a false negative and the specificity; or
The probability of a false negative and the probability of a false positive.
Let
X be random variable taking values in
and denote by
its probability distribution such that
is the actual fraction of infected individuals among the
n individuals. That is,
is the
prevalence ratio of SARS-Cov-2 in this population subset. For this reason, the probability distribution
is referred to as the
ground-truth input probability distribution. Let
Y be a second random variable taking values in
such that its joint probability distribution with
X is
and for all
,
where the conditional distribution
is the test. See, for instance,
Figure 1. Often, the probability distribution
is referred to as the
ground-truth output probability distribution and it is obtained as the marginal of
. That is, for all
,
The problem consists in using the data
obtained through a testing campaign with tests in which parameters are modeled by
to determine the fraction
of infected individuals in the population, i.e., the prevalence ratio. More formally, the problem can be stated as follows: Consider two random variables
X and
Y with the joint probability distribution
in (
1). The problem consists in estimating the probability distribution
based only on
n realizations
,
,
…,
of the random variable
Y, with
n a finite integer. This problem is reminiscent to the problem of
population recovery introduced in [
30] and further studied in [
31,
32].
4. Estimation of the Prevalence Ratio Using Unreliable Tests
Given the data
collected during a test campaign, the fraction of the population reporting positive and negative tests form an empirical distribution denoted by
on the set
such that,
where
is the indicator function. Essentially,
is a counting probability measure for which the values
and
represent the fraction of positive and negative test results. Hence,
. In the following, such probability measure is often referred to as the
output empirical distribution obtained from the data
.
Let
be a function representing the estimation of
based on the data
. The error induced by estimating
using
can be measured by the total variation, which is denoted by
and satisfies,
Note that in the case of binary tests, the total variation is simply the absolute difference between the actual prevalence ratio and the estimate .
4.1. Main Result
The following theorem presents the main result of this work.
Theorem 1. Consider a population of n individuals whose true ratio of infected (I) and susceptible (S) individuals is and , respectively, with . Assume that all individuals of such population are tested with a test that satisfies Let be the resulting output empirical probability distribution in (3) and assume that satisfies the following condition, Then, the estimator of , such that forms a probability measure that satisfies In a nutshell, Theorem 1 states that approximating the prevalence ratio
by
induces an error that vanishes when the number of tests
n increases. Nonetheless, despite the fact that
, it holds that for a small number of tests
n,
and
do not necessarily form a probability measure. That is, it might be observed that either
and
; or
and
. Later, in Lemma 4, it is shown that with a large number of test results, the fraction of positive results
satisfies the inequalities in (
7). Note also that the condition in (
7) is necessary and sufficient to observe that
in Theorem 1. This highlights the need for a sufficiently large number of tests in order to obtain a valid estimation of
using Theorem 1.
Finally, note that the formulas in (8) are given in terms of the sensitivity and specificity of the test. Nonetheless, it can be expressed in terms of the probabilities of a false positive and a false negative, or any combination of the parameters describing the test. The following corollary shows the formulas in (8) in terms of the probabilities of a false positive and a false negative .
Corollary 1. Consider a population of n individuals whose true ratio of infected (I) and susceptible (S) individuals is and , respectively, with . Assume that all individuals of such population are tested with a test that satisfies (6). Let be the resulting output empirical probability distribution in (3) and assume that satisfies condition (7). Then, the estimator of , such that forms a probability measure that satisfies (9). 4.2. Proof of Theorem 1
The proof of Theorem 1 leverages the following intuition: Under the assumption that
, which is obtained from the data
as in (3), is a valid estimation of the ground-truth output probability distribution
, i.e., it satisfies (
7), then a distribution
that satisfies
is a good estimation of the input probability distribution
. This intuition builds upon the observation that the output distribution
induced by the data, must be the marginal of a joint distribution consisting of the product of the conditional
and the input distribution. That is, for all
,
which is equivalent to the system in (
11).
With this intuition in mind, the proof proceeds as follows. First, it is shown that under the condition in (
6), there exists a unique pair
that satisfies the equality in (
11). This is essentially due to the fact that the equality in (
11) forms a linear system of two equations with two variables, and thus, if it is consistent, it has either a unique solution or infinitely many solutions.
Lemma 1. Consider the empirical output distribution in (3) obtained by a test described by the conditional probability distribtuion . Then, the following five statements are equivalent:
The system of equations in (11) has a unique solution; The sensitivity and specificity satisfy The sensitivity and the probability of a false positive satisfy The probability of a false negative and the specificity satisfy The probability of a false positive and the probability of a false negative satisfy
Proof. The proof of Lemma 1 follows from the fact that a unique solution to (
11) is observed if and only if the determinant of the matrix
is different than zero (Rouché–Fontené theorem [
33]). That is,
The proof is complete by verifying that the expression in (13) is equivalent to those in (12). ☐
Note that all conditions in (12) are equivalent to each other, and thus, they are equivalent to the condition in (
6).
The proof of Theorem 1 continues by showing that when such a unique solution exists, it is identical to the one shown in (8).
Lemma 2. Consider a test that satisfies at least one of the conditions in (12). Then, under the assumption that the empirical output distribution in (3) satisfies (7), the unique probability distribution that satisfies (11) is: Proof. The proof of Lemma 2 follows from solving the system of equations in (
11) and observing that
is a probability measure if and only if condition (
7) holds. ☐
The rest of the proof of Theorem 1 consists of showing that the error vanishes with the number of test results. This is shown in three steps. The first step consists of showing that the total variation between and , denoted by , is equivalent to the total variation between and , denoted by , up to a scaling factor.
Lemma 3. Consider a test that satisfies at least one of the conditions in (12). Then, under the assumption that the empirical output distribution in (3) satisfies (7), the estimation in (8) of satisfies where and are the input and output probability distributions in (1) and (2), respectively. Proof. The proof of Lemma 3 follows from the definition of total variation in (
4) and from equalities in (14). ☐
Note that Lemma 3 proves the intuition over which the proof of Theorem 1 is based on. That is, if is sufficiently close to , then must be sufficiently close to . The following lemma shows that the more test results are available, the closer and are in total variation.
Lemma 4. Consider a test that satisfies at least one of the conditions in (12). Then, the empirical output distribution in (3) satisfies where is the ground-truth output probability distribution in (2). Proof. The proof of Lemma 4 is a consequence of the Theorem of Glivenko and Cantelli [
34].
Finally, from Lemma 3 and Lemma 4, it holds that by increasing the number of tests, the error of approximating by in (14) can be made arbitrarily small. The following lemma leverages this observation.
Lemma 5. Consider a test that satisfies at least one of the conditions in (12). Then, under the assumption that the empirical output distribution in (3) satisfies (7), the input distribution and the estimation in (8) satisfy Proof. The proof of Lemma 5 is an immediate consequence of both Lemma 3 and Lemma 4. ☐
This completes the proof of Theorem 1.
4.3. Connections to Maximum Likelihood Estimation
In this section, it is shown that the estimator presented in Theorem 1 is also the
maximum likelihood estimator. For doing so, note that under the assumption that the prevalence ratio is
, the probability of observing
, as the result of testing any of the individuals of the population with a test described by the conditional probability distribution
is:
From this perspective, the probability of observing the vector
, as the result of a testing campaign over a population of
n individuals is
where
and
are defined in (3) and (18), respectively. Hence, the log-likelihood function
is for all
and
,
where
denotes the entropy of the probability distribution
; and
denotes the Kullback–Liebler divergence between the distributions
and
. Given that
, it follows that
where the equality holds if and only if
. That is, when both
and
are identical. This observation leads to the conclusion that the log-likelihood function is maximized when the assumed prevalence ratio
is such that
in (3) and
in (18) are identical, which is induces the system of equations in (
11) and in which the unique solution is formed by the equalities in (8). This proves that the estimator in Theorem (1) is the unique maximum likelihood estimator.
5. Final Remarks
This section highlights some of the conclusions drawn from Lemma 1–5 using a numerical analysis in particular examples. In the following examples, the data is artificially generated. That is, for a given prevalence ratio
, an
n-dimensional vector
,
,
…,
is generated such that for all
,
is a realization of a random variable
and represents the state of individual
t. Given a test
, an
n-dimensional vector
,
,
…,
is generated such that for all
,
is the realization of a random variable
and represents the result of the test of individual
t. Using the vector
, the fraction of positive tests
is calculated using (3); and the estimation
of the prevalence ratio
is calculated using (
8a).
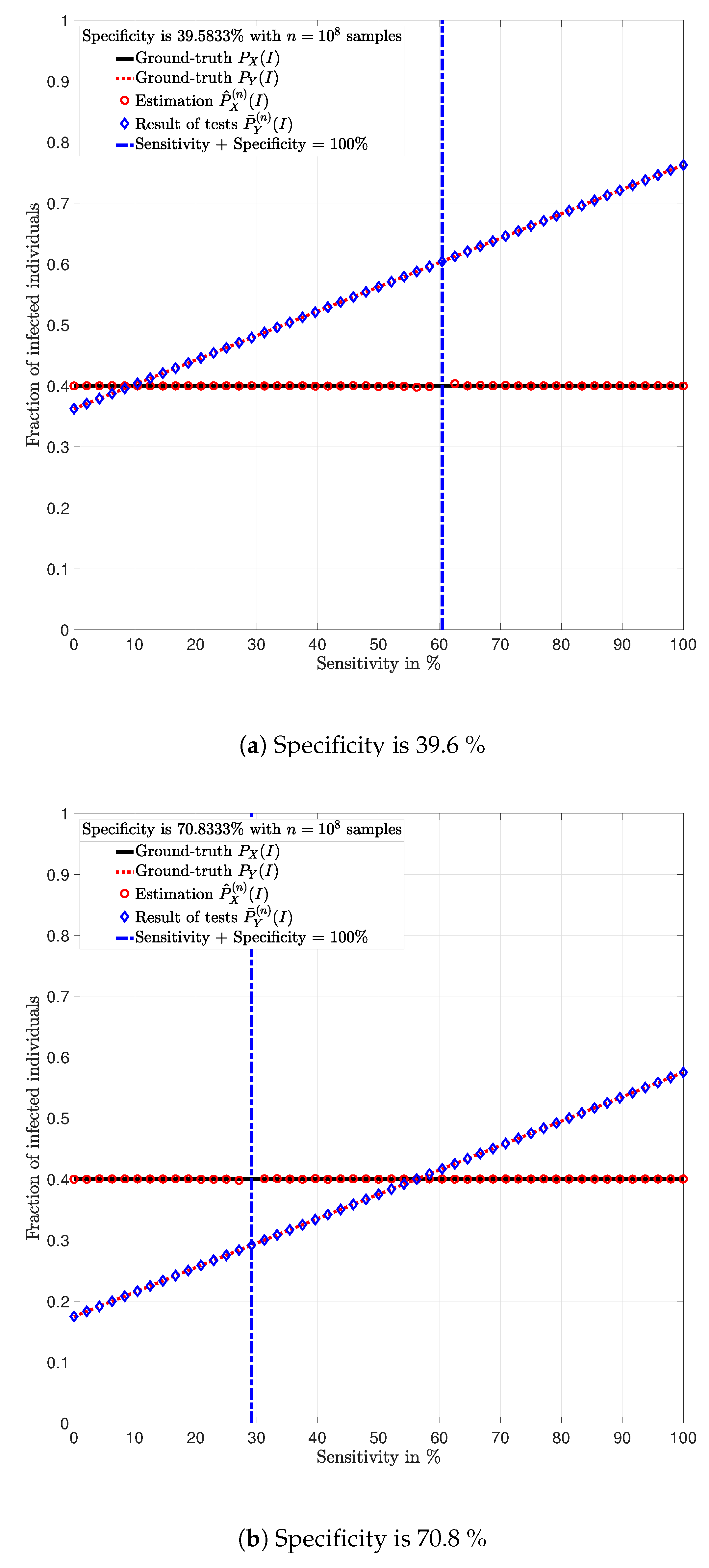
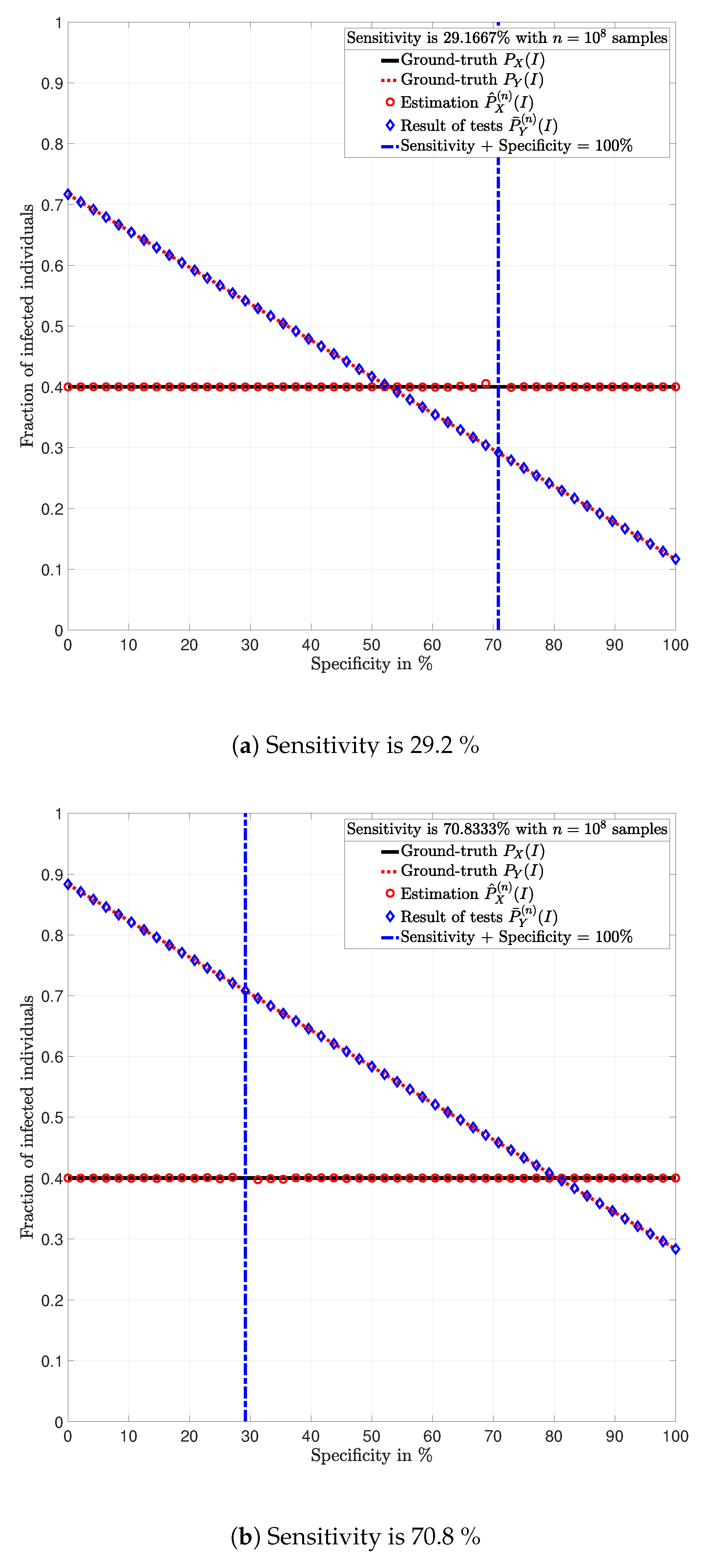
Figure 2 shows this procedure.
From this perspective, the analysis is based on simulated testing campaigns. Note that the use of simulated data allows knowing the actual prevalence ratio, which enables analyzing the estimation error. This is rarely possible with data from actual testing campaigns.
Example 1. Consider a population of individuals with prevalence . Assume that all individuals are tested with identical tests .
Example 2. Consider a population of individuals with prevalence . Assume that all individuals are tested with identical tests .
Example 3. Consider a population of individuals with prevalence . Assume that all individuals are tested with identical tests .
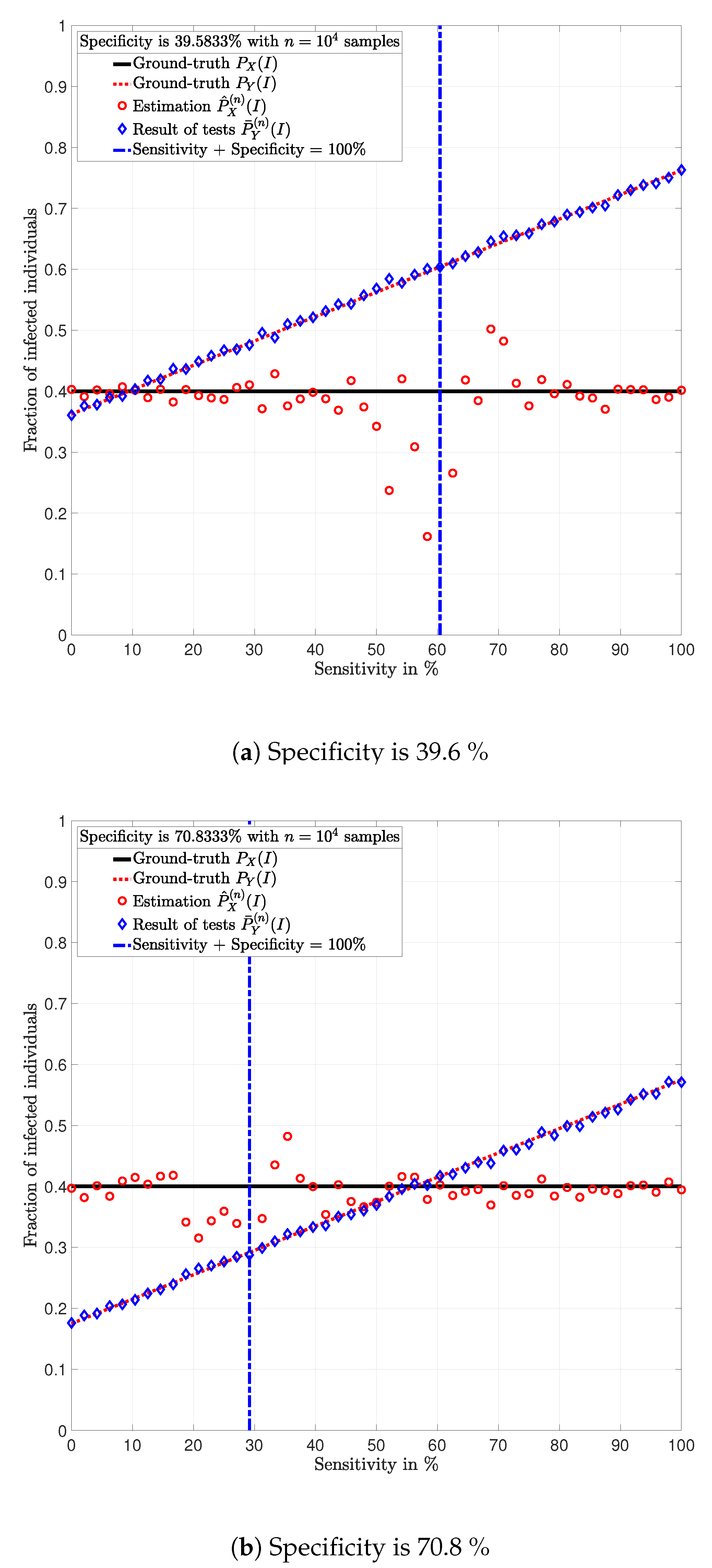
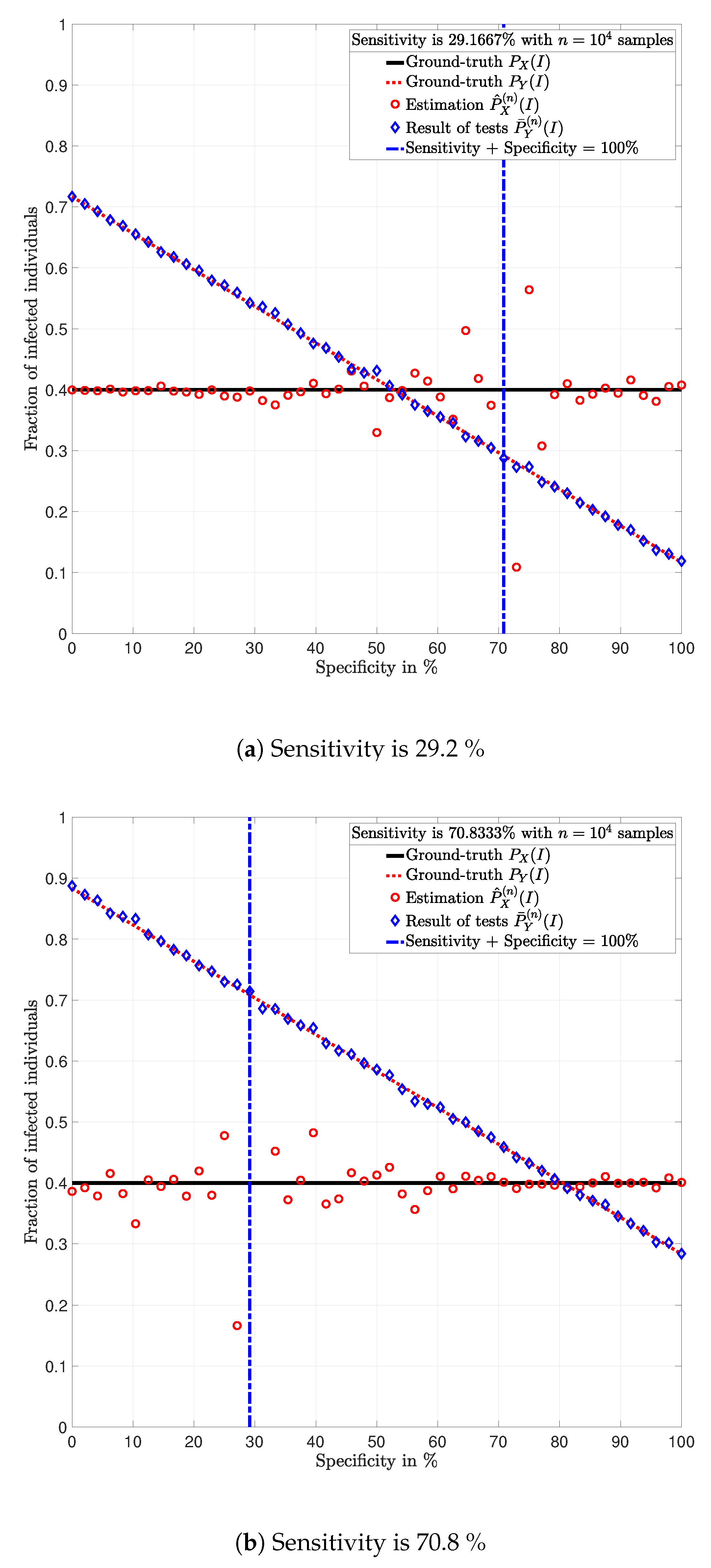
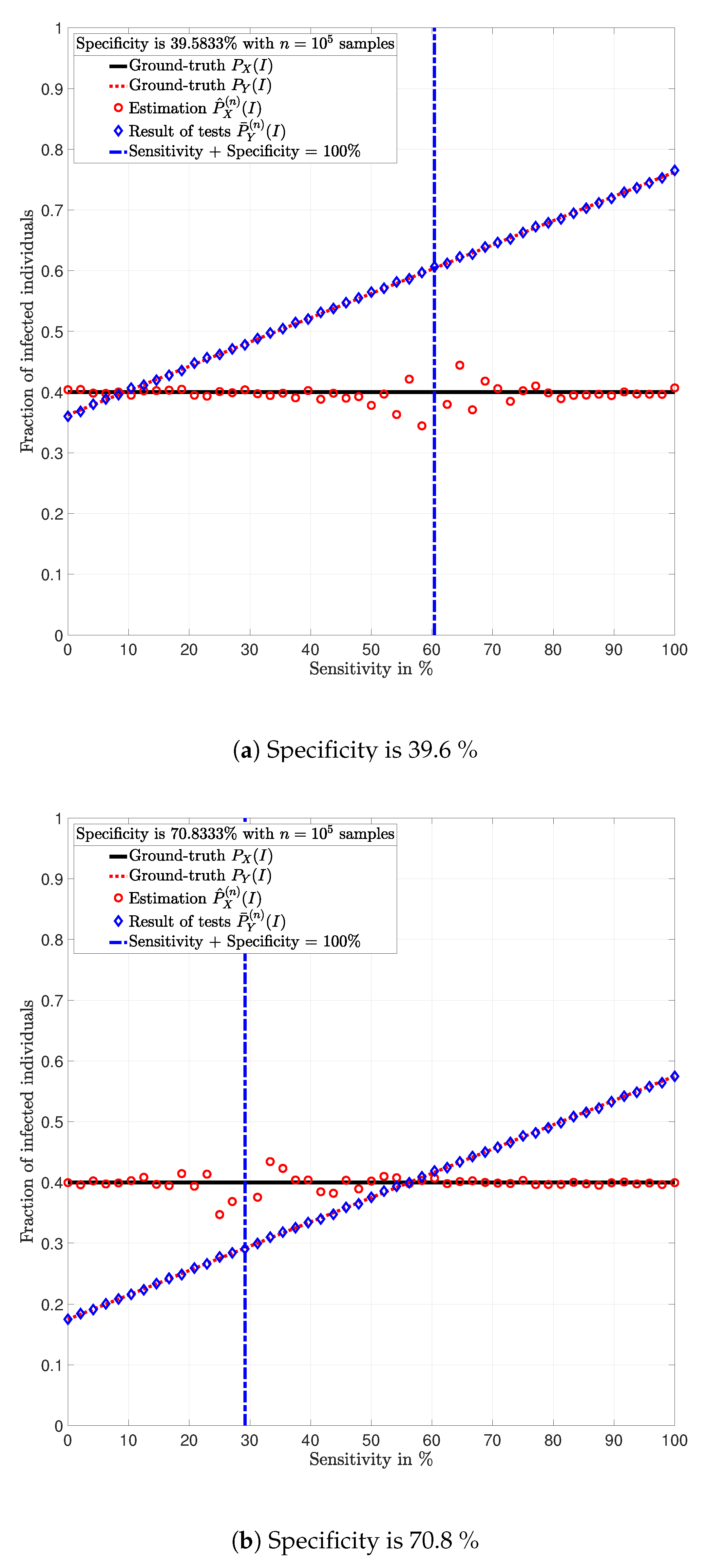
In
Figure 3,
Figure 4,
Figure 5,
Figure 6,
Figure 7 and
Figure 8, the actual prevalence ratio
is plotted with a straight black line; the estimation
of
is plotted with red circles; the fraction of positive tests
is plotted with blue diamonds; and the value of
in (
2) is plotted with a dashed red line. In
Figure 3,
Figure 5 and
Figure 7, these values are plotted as a function of the specificity
for a fixed sensitivity. Alternatively, in
Figure 4,
Figure 6 and
Figure 8, these values are plotted as a function of the sensitivity
for a fixed specificity. For each of the examples, one vector
is generated. In all figures,
Figure 3,
Figure 4,
Figure 5,
Figure 6,
Figure 7 and
Figure 8, each plotted point of
(blue diamonds) and
(red circles) is calculated using a single vector
generated by the same vector
, according to the corresponding values of sensitivity
and specificity
, as described above. In the following sections, some remarks based on these examples are presented.
5.1. Relevance of the Sensitivity and Specificity
One of the main observations to be highlighted from this numerical analysis is that there exists an important difference between the fraction of positive tests
and the actual prevalence ratio
due to the sensitivity and specificity of the tests. This difference is clearly depicted in
Figure 3,
Figure 4,
Figure 5,
Figure 6,
Figure 7 and
Figure 8, which together with the mathematical analysis presented before, highlights the conclusion that the fraction of positive tests should not be used as an estimation of the prevalence ratio in public health policy-making.
The following lemma determines the influence of the sensitivity and specificity on
. For doing so, note that from Lemma (2), it holds that the fraction of individuals reporting positive tests
satisfies:
Lemma 6. Consider a test that satisfies at least one of the conditions in (12). Then, given the empirical output distribution in (3) and assuming that it satisfies (7), the following statements hold: The fraction of positive tests linearly decreases with the specificity of the test ;
The fraction of positive tests linearly increases with the probability of a false positive of the test ;
The fraction of positive tests linearly increases with the sensitivity of the test ; and
The fraction of positive tests linearly decreases with the probability of a false negative of the test .
Proof. The proof of Lemma 6 consists in verifying that the derivative of in (26) with respect to is negative; with respect to is positive; with respect to is positive; and with respect to is negative.
The statements in Lemma 6 become evident in
Figure 3,
Figure 5 and
Figure 7. In these figures, it is shown that the fraction of positive tests increases with the sensitivity; where as in
Figure 4,
Figure 6 and
Figure 8, it is shown that the fraction of positive tests decreases with the specificity, c.f., Lemma 6. From this perspective, tests might lead to countings in which the fraction of individuals reporting positive testing results
is bigger than the actual prevalence ratio
, i.e.,
. Alternatively, tests might also lead to estimations in which the fraction of individuals reporting positive testing results
is smaller than the actual prevalence ratio
, i.e.,
. These observations highlight the relevance of using the estimation
of
for decision and policy making instead of
, which includes false positives and false negatives.
5.2. Tests whose Results are Useless
In
Figure 3,
Figure 4,
Figure 5,
Figure 6,
Figure 7 and
Figure 8, the value of the sensitivity
and specificity
that satisfy
are plotted with a blue dash-dot vertical line. Note that for these specific values of sensitivity and specificity, the estimation
of
is not plotted. The following lemmas shed some light into this singularity.
Lemma 7. Consider the empirical output distribution in (3) obtained by a test described by the conditional probability distribtuion . Then, the following five statements are equivalent:
The system of equations in (11) has infinitely many solutions; The sensitivity and specificity satisfy The sensitivity and the probability of a false positive satisfy The probability of a false negative and the specificity satisfy The probability of a false positive and the probability of a false negative satisfy
Proof. The proof of Lemma 7 follows from the theorem of Rouché and Fontené [
33] that states that when the system in (
11) is consistent, it has infinitely many solutions if the determinant of the matrix
is not full rank. When such a matrix is not full rank, its determinant is zero. That is,
The proof is completed by verifying that the expression in (28) is equivalent to those in (27). ☐
When at least one of the equalities in (27) is satisfied, nothing meaningful can be said about
based on the data. This is essentially because any probability distribution
satisfies the equality in (
11). The following lemma reinforces this statement in terms of information measures.
Lemma 8. Consider a test that satisfies at least one of the conditions in (27). Hence, the following statements are equivalent:
Given the output empirical distribution obtained from the data as in (3), any probability distribution on satisfies the equality in (11); Two random variables X and Y, in which the joint probability distribution satisfies (1), have zero mutual information; and Two random variables X and Y, in which the joint probability distribution satisfies (1), are independent.
Proof. The first statement is a consequence of Lemma 7; the second statement follows from the fact that under any of the assumptions in (27), the mutual information satisfies
where
,
, and
satisfy the equality in (
1). The third statement follows from the fact that two random variables are independent if and only if their mutual information is zero. ☐
Lemma 8 shows that when at least one of the conditions in (27) holds, the output probability distribution does not provide any information about the input probability distribution . That is, nothing can be said about based on the data .
Despite the singularity, the values of specificity and sensitivity in which the sum is close to one, i.e., around the singularity, are also worthy of discussion. Note that for some
, the absolute difference
is bigger when the sensibility and specificity satisfy
than when these parameters satisfy
. These observations are justified by the fact that the total variation
is equal to
up to a constant factor, as shown in Lemma 3. Such a factor is indeed
, and thus, larger errors are expected around the singularity for the same finite numbers of tests
n. This is evident in the numerical analysis. In Example 1, i.e.,
Figure 3 and
Figure 4, around the singularity, the estimations
of
appear more disperse than the estimations in Example 3, i.e.,
Figure 7 and
Figure 8.
5.3. Impact of the Number of Tests.
Figure 3,
Figure 4,
Figure 5,
Figure 6,
Figure 7 and
Figure 8 show that when the parameters of the test satisfy at least one of the conditions in (12) and there exist a sufficiently large number of test results, it is always possible to obtain an estimation
of the prevalence ratio
. This is independent of the exact values of the specificity and sensitivity as long as (12) holds. More importantly, the reliability of such estimation increases with the number of test results. For instance, compare the estimations in Examples 1 and 3. The implications of this observation are very important in practical terms. This shows that if the objective of a testing campaign against SARS-CoV-2 is to determine the prevalence ratio, the quality of the tests is not important. This is essentially because testing with low quality tests (low sensitivity and low specificity) or high quality tests (high sensitivity and high specificity) leads to identical results in terms of the estimation error, when a large number of tests is performed. Nonetheless, when a low number of tests is available, it is worth noting that when the sensitivity
and specificity
satisfy
, for some
, the smaller
, the smaller the estimation error of the prevalence ratio, c.f., Lemma 3. This observation is of paramount importance as it implies that smaller estimation errors are observed when the sum of the sensitivity and specificity is bounded away from one. This said, the key parameter for reducing the estimation error is the number of tests.
6. Conclusions
In this work, it has been shown that estimating the prevalence ratio of a condition, for example, a SARS-Cov-2 infection, by the ratio between the number of positive test results and the total number of tests leads to excessive estimation errors when tests are unreliable. This is simply due to the fact that unreliable tests, i.e., tests in which probabilities of false positives and false negatives are nonzero, lead to some individuals exhibiting the condition to observe negative test results (false negatives), and some individuals who do not exhibit the condition to observe positive results (false positives). From this perspective, an estimation of the prevalence ratio using data obtained from tests must take into account both the sensitivity and the specificity of the tests. Theorem 1 provides an estimation of the prevalence ratio with an estimation error that decreases with the number of tests.
Another important conclusion of this work is that testing campaigns using tests for which the sum of the sensitivity and specificity is different than one, always allow a reliable estimation of the prevalence ratio (Lemma 1 in
Section 4) subject to a sufficiently large number of individuals being tested. Alternatively, testing campaigns using tests for which the sum of the sensitivity and the specificity is equal to one, lead to data from which it is impossible to estimate the prevalence ratio even with infinitely many tests (Lemma 7 in
Section 4).
A final conclusion is that for estimating the prevalence ratio of a given condition, i.e., a SARS-CoV-2 infection, the key parameter for reducing the estimation error is the number of tests. Surprisingly, as long as the sum of the sensitivity and specificity of the tests is different than one, the exact values of both sensitivity and specificity have very little impact in the estimation when the number of tests is sufficiently large.
Author Contributions
Conceptualization, E.A., I.M., F.-Z.N. and S.M.P.; methodology, E.A., and S.M.P.; validation, I.M. and F.-Z.N.; formal analysis, E.A., I.M., F.-Z.N. and S.M.P.; writing–original draft preparation, S.M.P.; writing–review and editing, S.M.P. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding
Conflicts of Interest
The authors declare no conflict of interest.
References
- Brauer, F.; Castillo-Chávez, C.; Feng, Z. Mathematical Models in Epidemiology, 1st ed.; Springer: New York, NY, USA, 2019. [Google Scholar]
- Rothman, K.J.; Greenland, S. Modern Epidemiology, 3rd ed.; Lippincott Williams & Wilkins: Philadelphia, PA, USA, 2008. [Google Scholar]
- Vinh, D.B.; Zhao, X.; Kiong, K.L.; Guo, T.; Jozaghi, Y.; Yao, C.; Kelley, J.M.; Hanna, E. Overview of COVID-19 testing and implications for otolaryngologists. Head Neck 2020, 1–5. [Google Scholar] [CrossRef] [PubMed]
- Haute Autorité de Santé. Place des Tests Sérologiques Rapides (TDR, TROD, Autotests) dans la stratégie de Prise en Charge de la Maladie COVID—19; Technical Report; Haute Autorité de Santé (HAS): Saint-Denis La Plaine, France, 2020. [Google Scholar]
- Kelly, J.C.; Dombrowksi, M.; O’neil-Callahan, M.; Kernberg, A.S.; Frolova, A.I.; Stout, M.J. False-Negative COVID-19 Testing: Considerations in Obstetrical Care. Am. J. Obstet. Gynecol. MFM 2020, 100130. [Google Scholar] [CrossRef] [PubMed]
- Hickman, M.; Taylor, C. Indirect Methods to Estimate Prevalence. In Epidemiology of Drug Abuse; Sloboda, Z., Ed.; Springer: Boston, MA, USA, 2005; Chapter 8; pp. 113–131. [Google Scholar]
- Staquet, M.; Rozencweig, M.; Lee, Y.J.; Muggia, F.M. Methodology for the assessment of new dichotomous diagnostic tests. J. Chronic Dis. 1981, 34, 599–610. [Google Scholar] [CrossRef]
- Diggle, P. Estimating Prevalence Using an Imperfect Test. Epidemiol. Res. Int. 2011, 2011, 1–6. [Google Scholar] [CrossRef]
- Lachish, S.; Gopalaswamy, A.M.; Knowles, S.C.L.; Sheldon, B.C. Site-occupancy modelling as a novel framework for assessing test sensitivity and estimating wildlife disease prevalence from imperfect diagnostic tests. Methods Ecol. Evol. 2012, 3, 339–348. [Google Scholar] [CrossRef]
- Cannon, R.M. Sense and sensitivity–designing surveys based on an imperfect test. Prev. Vet. Med. 2001, 49, 141–163. [Google Scholar] [CrossRef]
- Skov, T.; Deddens, J.; Petersen, M.; Endahl, L. Prevalence proportion ratios: Estimation and hypothesis testing. Int. J. Epidemiol. 1998, 27, 91–95. [Google Scholar] [CrossRef]
- Penman, A.D.; Johnson, W.D. Complementary log-log regression for the estimation of covariate-adjusted prevalence ratios in the analysis of data from cross-sectional studies. Biom. J. 2009, 51, 433–442. [Google Scholar] [CrossRef]
- Chen, W.; Qian, L.; Shi, J.; Franklin, M. Comparing performance between log-binomial and robust Poisson regression models for estimating risk ratios under model misspecification. BMC Med Res. Methodol. 2018, 18, 1–12. [Google Scholar] [CrossRef]
- Petersen, M.R.; Deddens, J.A. A comparison of two methods for estimating prevalence ratios. BMC Med Res. Methodol. 2008, 8, 1–9. [Google Scholar] [CrossRef]
- Wang, W.; Xu, Y.; Gao, R.; Lu, R.; Han, K.; Wu, G.; Tan, W. Detection of SARS-CoV-2 in Different Types of Clinical Specimens. JAMA 2020, 323, 1843–1844. [Google Scholar] [CrossRef]
- Yang, Y.; Yang, M.; Shen, C.; Wang, F.; Yuan, J.; Li, J.; Zhang, M.; Wang, Z.; Xing, L.; Wei, J.; et al. Evaluating the accuracy of different respiratory specimens in the laboratory diagnosis and monitoring the viral shedding of 2019-nCoV infections. medRxiv 2020, 1–17. [Google Scholar] [CrossRef]
- Zou, L.; Ruan, F.; Huang, M.; Liang, L.; Huang, H.; Hong, Z.; Yu, J.; Kang, M.; Song, Y.; Xia, J.; et al. SARS-CoV-2 Viral Load in Upper Respiratory Specimens of Infected Patients. N. Engl. J. Med. 2020, 382, 1177–1179. [Google Scholar] [CrossRef] [PubMed]
- Van Kasteren, P.B.; Van der Veer, B.; Van den Brink, S.; Wijsman, L.; De Jonge, J.; Van den Brandt, A.; Molenkamp, R.; Reusken, C.B.; Meijer, A. Comparison of commercial RT-PCR diagnostic kits for COVID-19. J. Clin. Virol. 2020, 128, 104412. [Google Scholar] [CrossRef] [PubMed]
- Ishige, T.; Murata, S.; Taniguchi, T.; Miyabe, A.; Kitamura, K.; Kawasaki, K.; Nishimura, M.; Igari, H.; Matsushita, K. Highly sensitive detection of SARS-CoV-2 RNA by multiplex rRT-PCR for molecular diagnosis of COVID-19 by clinical laboratories. Clin. Chim. Acta 2020, 507, 139–1142. [Google Scholar] [CrossRef] [PubMed]
- Baek, Y.; Um, J.; Antigua, K.J.; Park, J.H.; Kim, Y.; Oh, S.; Kim, Y.i.; Choi, W.S.; Kim, S.; Jeong, J.; et al. Development of a reverse transcription-loop-mediated isothermal amplification as a rapid early-detection method for novel SARS-CoV-2. Emerg. Microbes Infect. 2020, 9, 1–31. [Google Scholar] [CrossRef]
- Yan, C.; Cui, J.; Huang, L.; Du, B.; Chen, L.; Xue, G.; Li, S.; Zhang, W.; Zhao, L.; Sun, Y.; et al. Rapid and visual detection of 2019 novel coronavirus (SARS-CoV-2) by a reverse transcription loop-mediated isothermal amplification assay. Clin. Microbiol. Infect. 2020, 26, 773–779. [Google Scholar] [CrossRef]
- Merindol, N.; Pépin, G.; Marchand, C.; Rheault, M.; Peterson, C.; Poirier, A.; Houle, C.; Germain, H.; Danylo, A. SARS-CoV-2 detection by direct rRT-PCR without RNA extraction. J. Clin. Virol. 2020, 128, 104423. [Google Scholar] [CrossRef]
- Esbin, M.N.; Whitney, O.N.S.C.; Maurer, A.; Darzacq, X.; Tjian, R. Overcoming the bottleneck to widespread testing: A rapid review of nucleic acid testing approaches for COVID-19 detection. RNA J. 2020, 1–20. [Google Scholar] [CrossRef]
- Xiang, F.; Wang, X.; He, X.; Peng, Z.; Yang, B.; Zhang, J.; Zhou, Q.; Ye, H.; Ma, Y.; Li, H.; et al. Antibody Detection and Dynamic Characteristics in Patients with COVID-19. Clin. Infect. Dis. 2020, 1–23. [Google Scholar] [CrossRef]
- Hoffman, T.; Nissen, K.; Krambrich, J.; Rönnberg, B.; Akaberi, D.; Esmaeilzadeh, M.; Salaneck, E.; Lindahl, J.; Lundkvist, A. Evaluation of a COVID-19 IgM and IgG rapid test: An efficient tool for assessment of past exposure to SARS-CoV-2. Infect. Ecol. Epidemiol. 2020, 10, 1754538. [Google Scholar] [PubMed]
- Zainol Rashid, Z.; Othman, S.N.; Abdul Samat, M.N.; Ali, U.K.; Wong, K.K. Diagnostic performance of COVID-19 serology assays. Malays J. Pathol. 2020, 42, 13–21. [Google Scholar] [PubMed]
- Chung, M.; Bernheim, A.; Mei, X.; Zhang, N.; Huang, M.; Zeng, X.; Cui, J.; Xu, W.; Yang, Y.; Fayad, Z.A.; et al. CT Imaging Features of 2019 Novel Coronavirus (2019-nCoV). Radiology 2020, 295, 202–207. [Google Scholar] [CrossRef] [PubMed]
- Bai, H.X.; Hsieh, B.; Xiong, Z.; Halsey, K.; Choi, J.W.; Tran, T.M.L.; Pan, I.; Shi, L.B.; Wang, D.C.; Mei, J.; et al. Performance of radiologists in differentiating COVID-19 from viral pneumonia on chest CT. Radiology 2020, 200823. [Google Scholar] [CrossRef]
- Ai, T.; Yang, Z.; Hou, H.; Zhan, C.; Chen, C.; Lv, W.; Tao, Q.; Sun, Z.; Xia, L. Correlation of Chest CT and RT-PCR Testing in Coronavirus Disease 2019 (COVID-19) in China: A Report of 1014 Cases. Radiology 2020, 200642. [Google Scholar] [CrossRef]
- Dvir, Z.; Rao, A.; Wigderson, A.; Yehudayoff, A. Restriction Access. In Proceedings of the 3rd Innovations in Theoretical Computer Science Conference, Cambridge, MA, USA, 8–10 January 2012; pp. 19–33. [Google Scholar]
- Lovett, S.; Zhang, J. Improved Noisy Population Recovery, and Reverse Bonami-Beckner Inequality for Sparse Functions. In Proceedings of the Forty-Seventh Annual ACM Symposium on Theory of Computing, Portland, OR, USA, 14–17 June 2015; pp. 137–142. [Google Scholar]
- De, A.; Saks, M.; Tang, S. Noisy Population Recovery in Polynomial Time. In Proceedings of the 57th Annual Symposium on Foundations of Computer Science (FOCS), New Brunswick, NJ, USA, 9–11 October 2016; pp. 675–684. [Google Scholar]
- Shafarevich, I.R.; Remizov, A.O. Linear Algebra and Geometry, 1st ed.; Springer: Berlin, Germany, 2012. [Google Scholar]
- Ash, R.B.; Doléans-Dade, C.A. Probability and Measure Theory, 2nd ed.; Harcourt/Academic Press: Burlington, MA, USA, 1999. [Google Scholar]
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







