Shared Control of an Electric Wheelchair Considering Physical Functions and Driving Motivation

Abstract
:1. Introduction
2. Related Works
3. System Requirements Based on Target User
3.1. Operating Characteristics of Individuals with Severe Physical Impairments
- Limited input range. Individuals with extremely weak physical functions usually lack appropriate input devices. Although some devices have been developed with their physical functions in mind, during the development of their input devices, the user’s physical functions continue diminishing; thus, they cannot properly operate the designed devices after development.
- Delayed or advanced input signals. For individuals with the problems discussed above, their input only intuitively represents the intention of the subjects, although driving an EW in real environments corresponds to complicated behavior. More accurate and frequent input is necessary, especially for situations where fine steering skills are required, which is almost impossible for them.
3.2. Driving Environment Settings
3.3. System Requirements
- The system should assist users in reaching their destination.
- The complete driving process should be safe.
- The complete driving process should be comfortable.
- The system should gradually adapt to different users.
- The system should gradually adapt to different environments.
- The system should completely utilize the residual physical functions of individuals with disabilities.
- The system should consider the driving motivation of users.
4. Construction of the Shared Control System
4.1. Modeling an EW
- The slip between the wheels and the road can be neglected.
- The EW will not move in the pitch direction, which means that the casters will not leave the road.
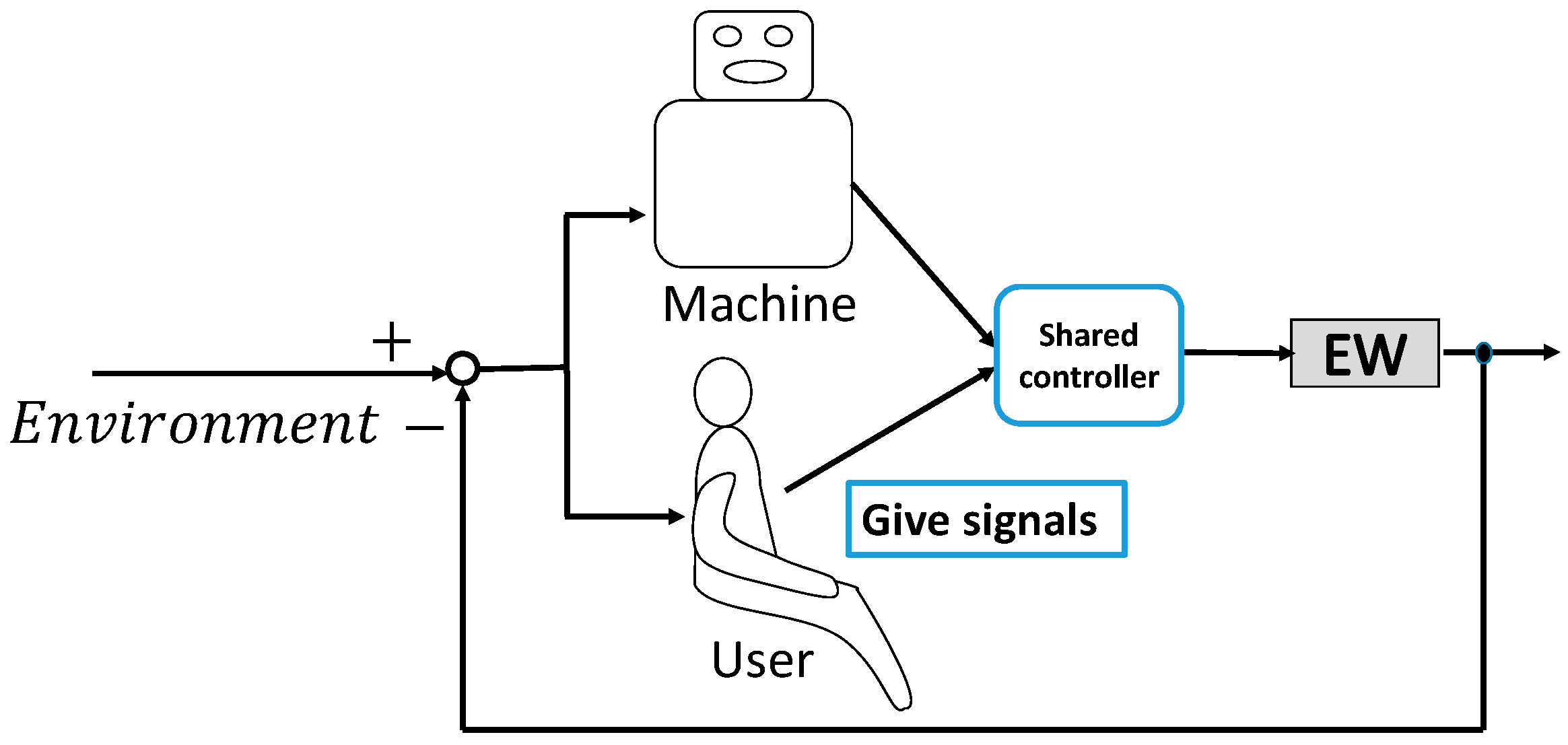
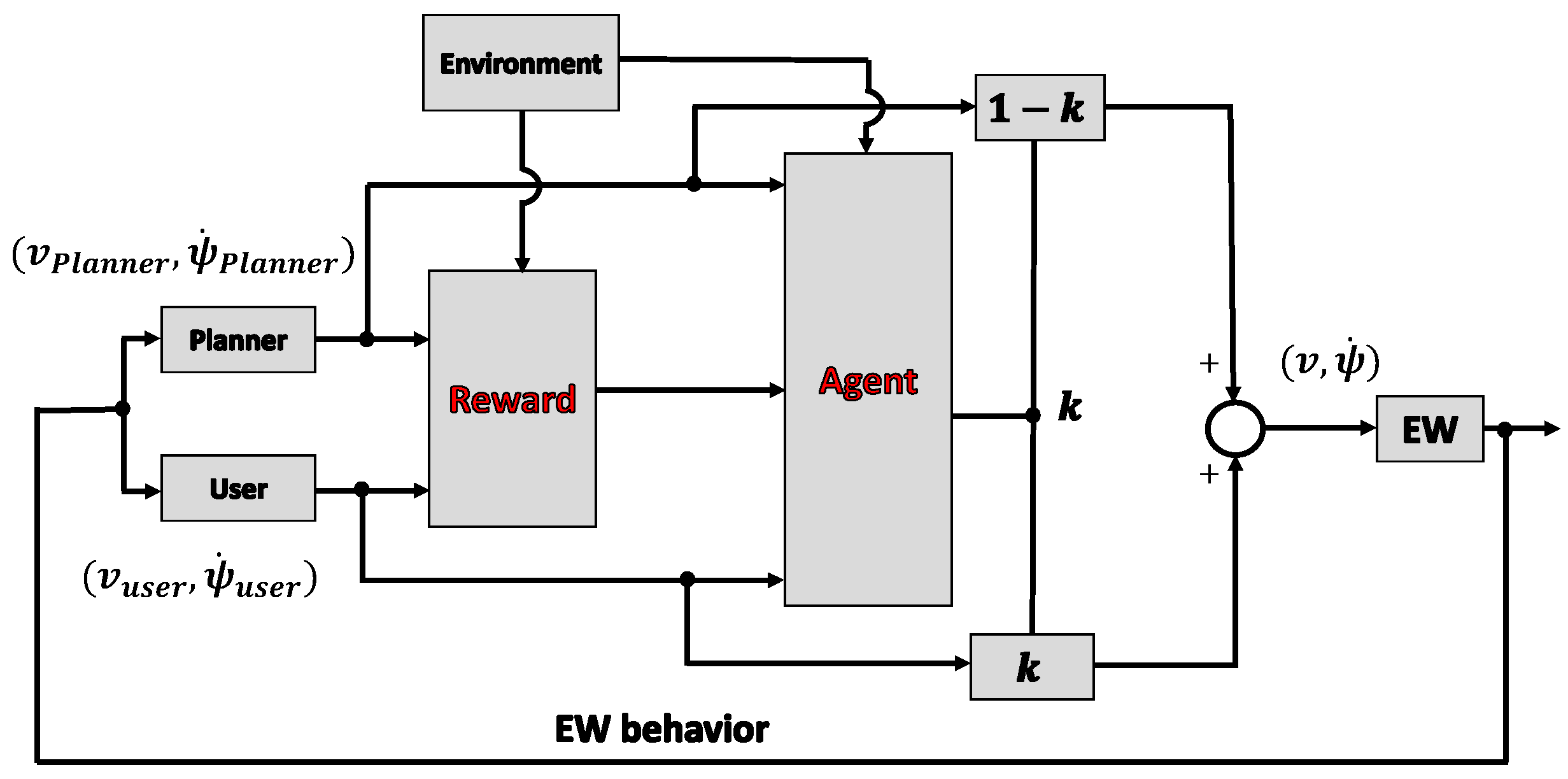
4.2. Concept of the Shared Control System
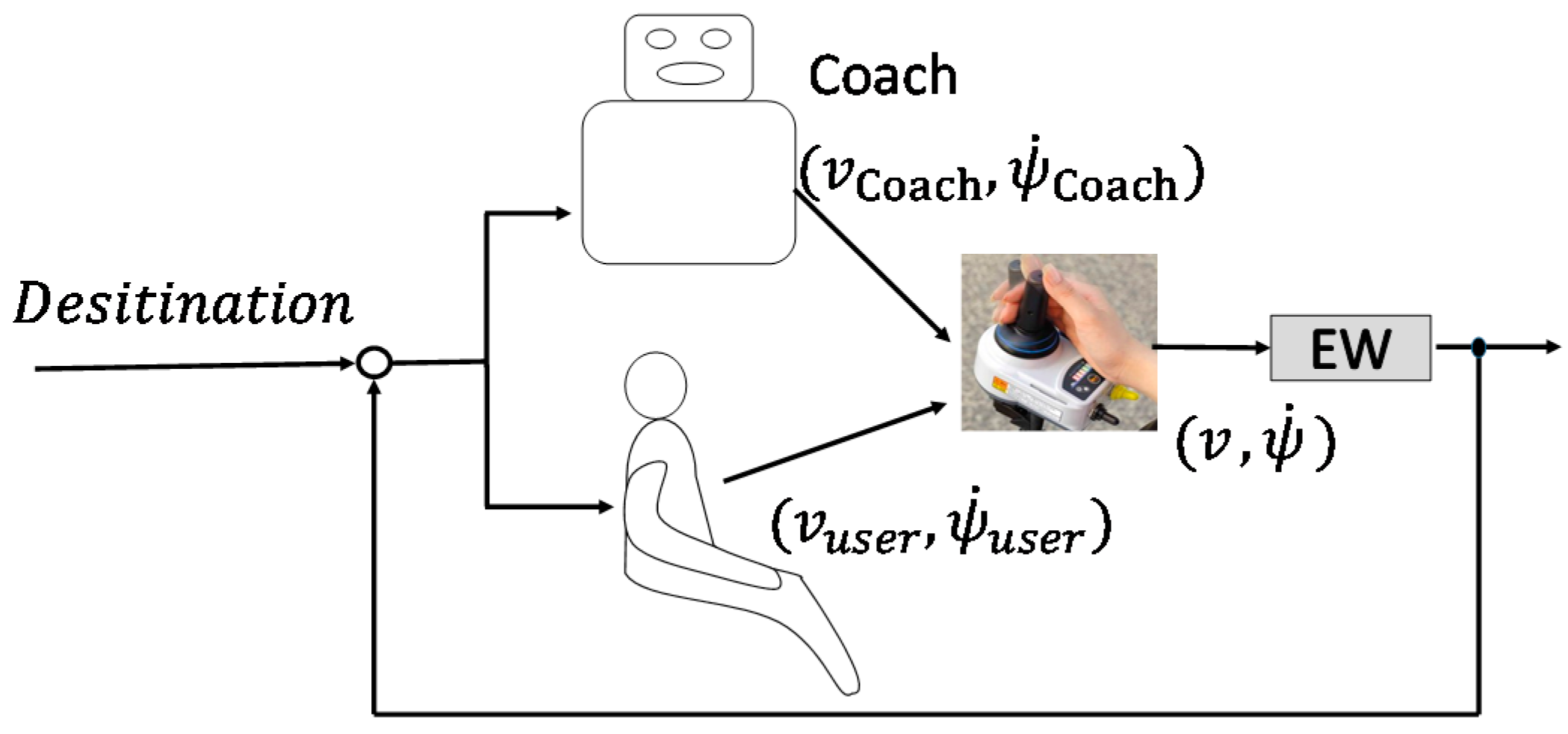
4.3. Framework of the Shared Control System
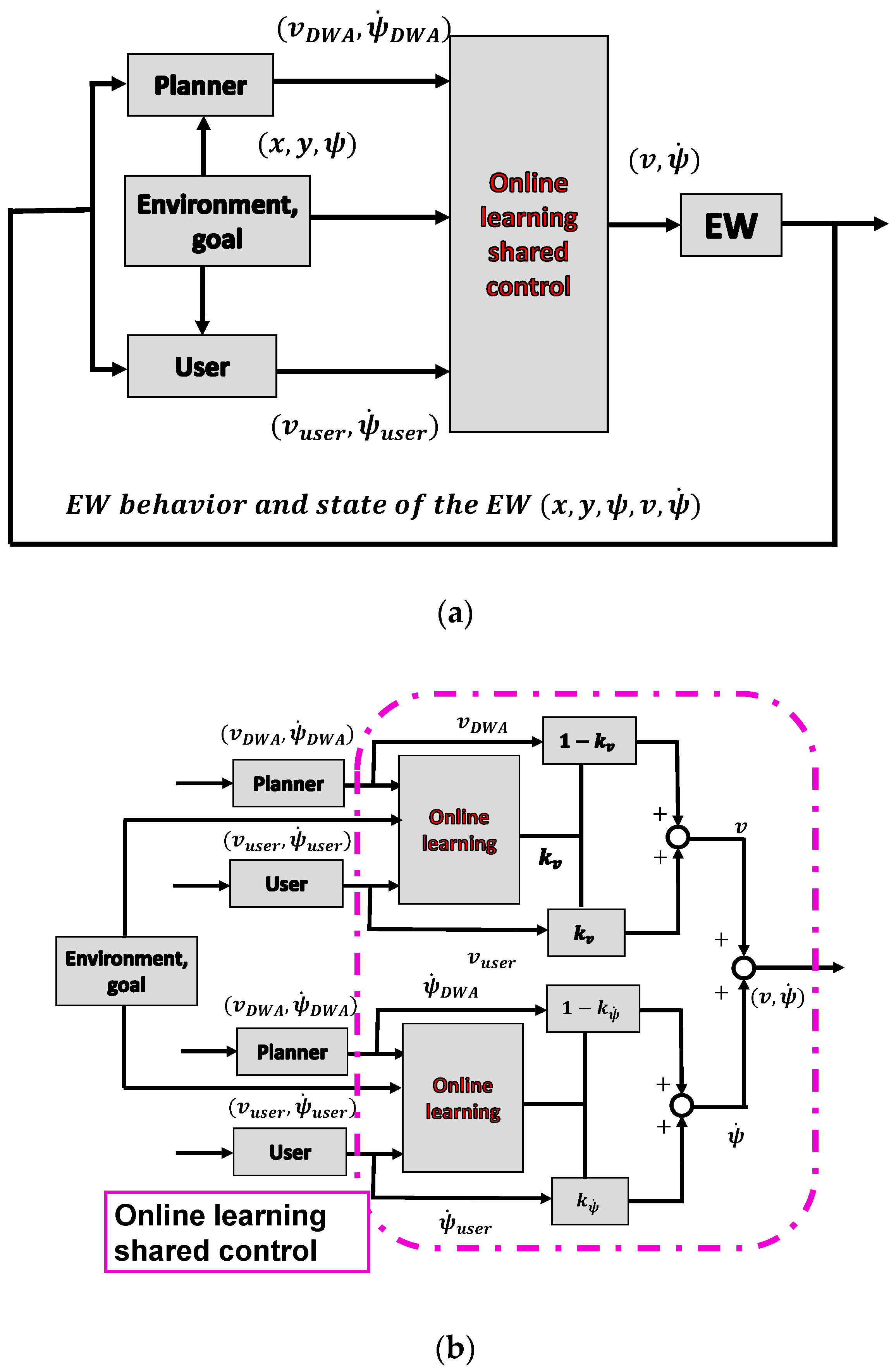
5. Online Learning System Design for the Shared Control System
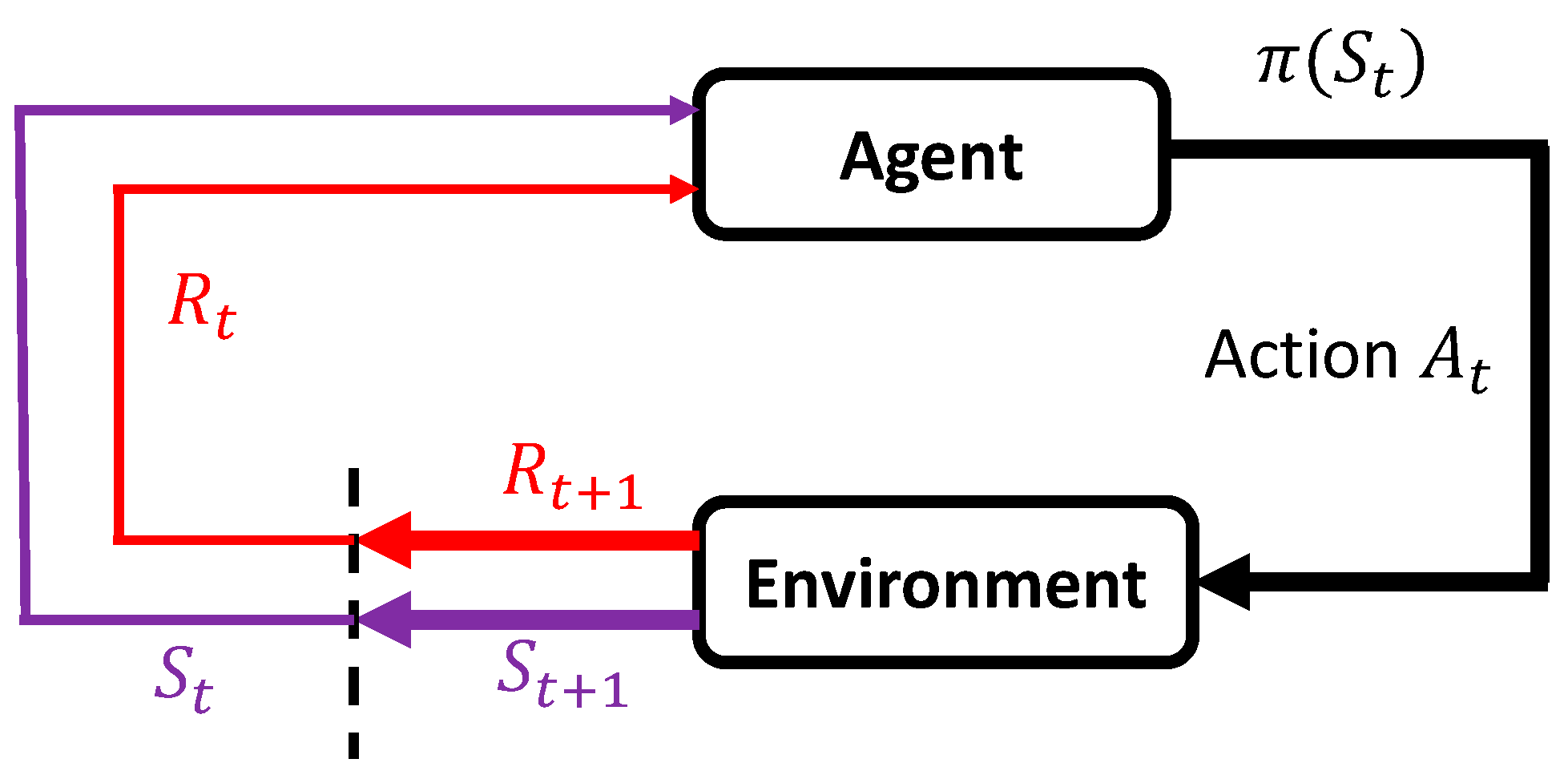
5.1. Definition of Reinforcement Learning
5.2. Reinforcement Learning for the Shared Control System to Determine the Control Weights
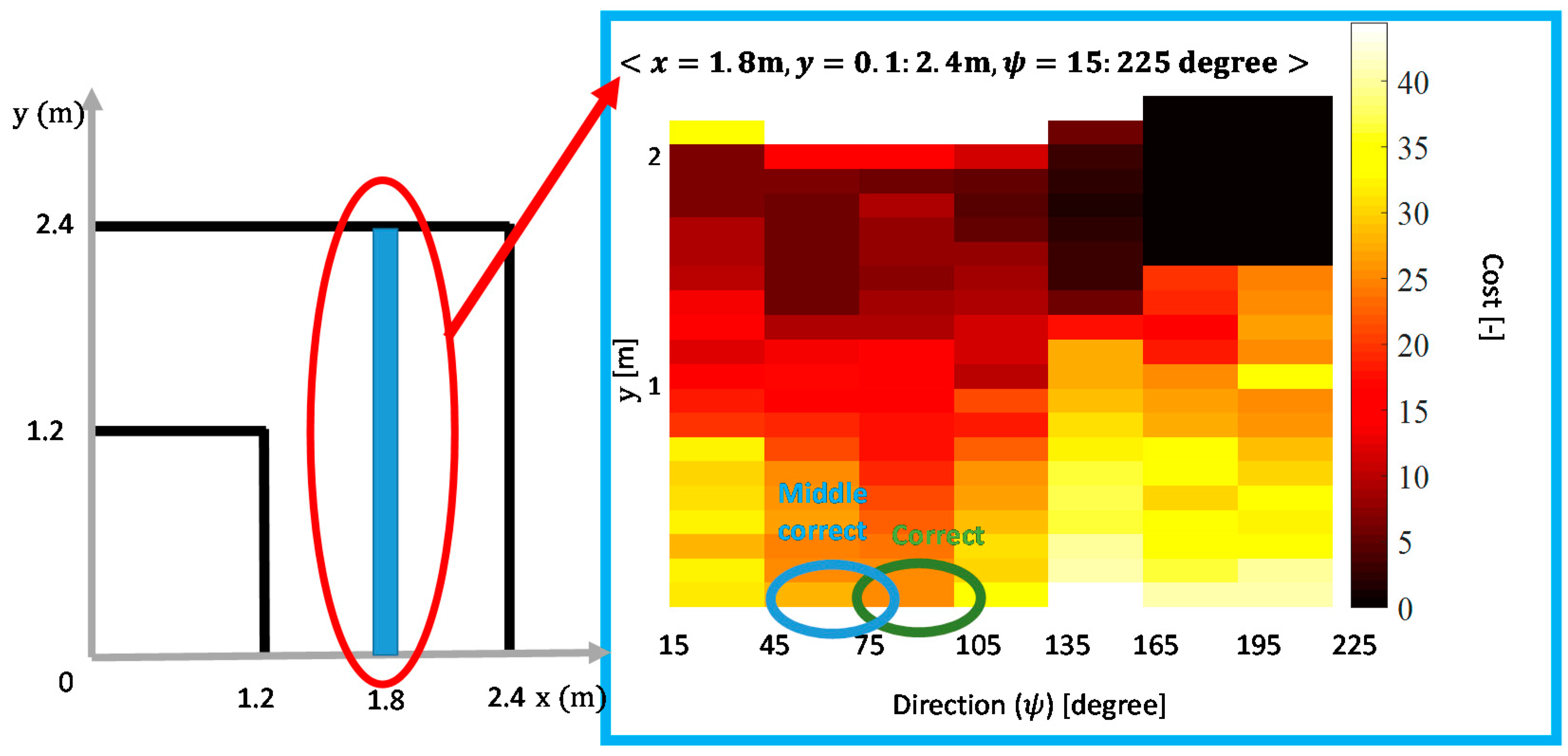
5.3. Reward Design for the Shared Control System
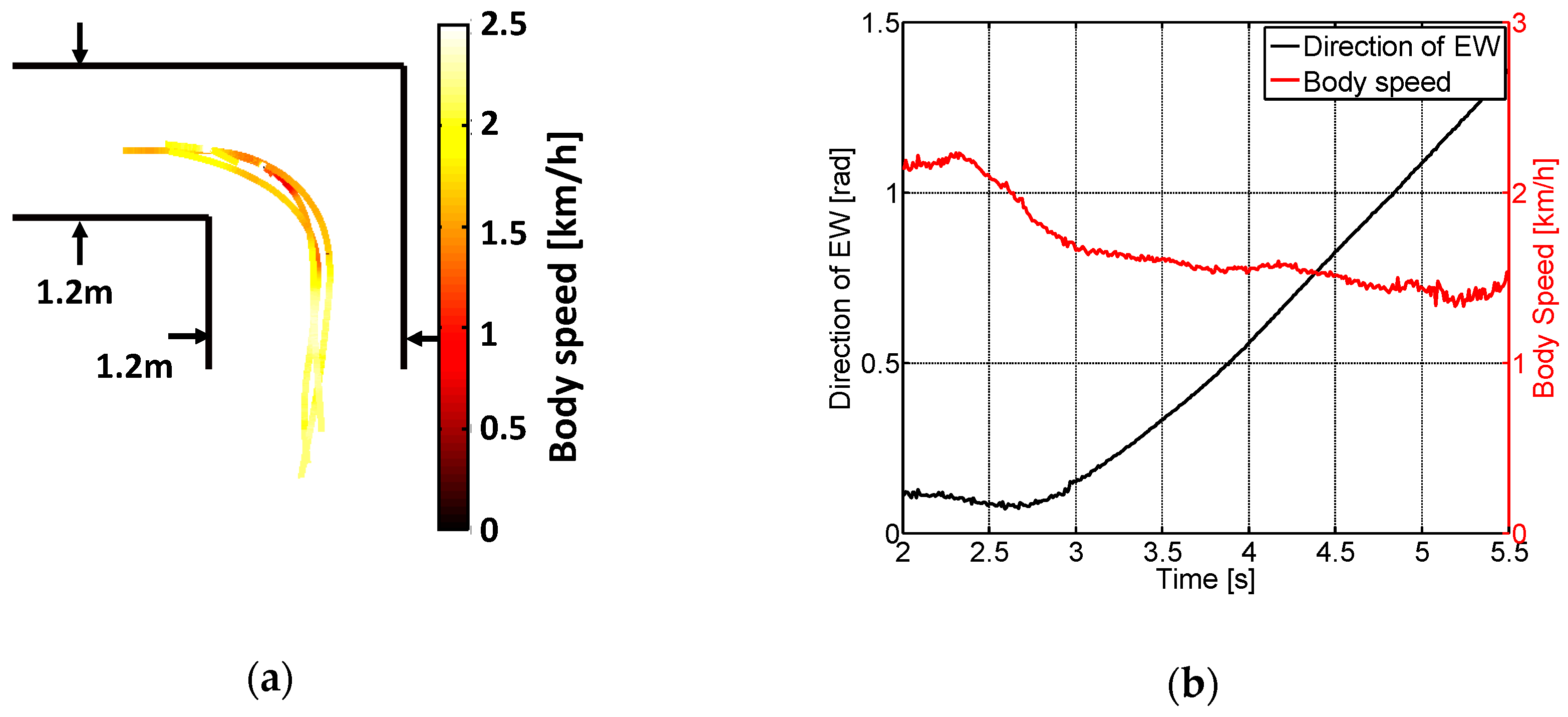
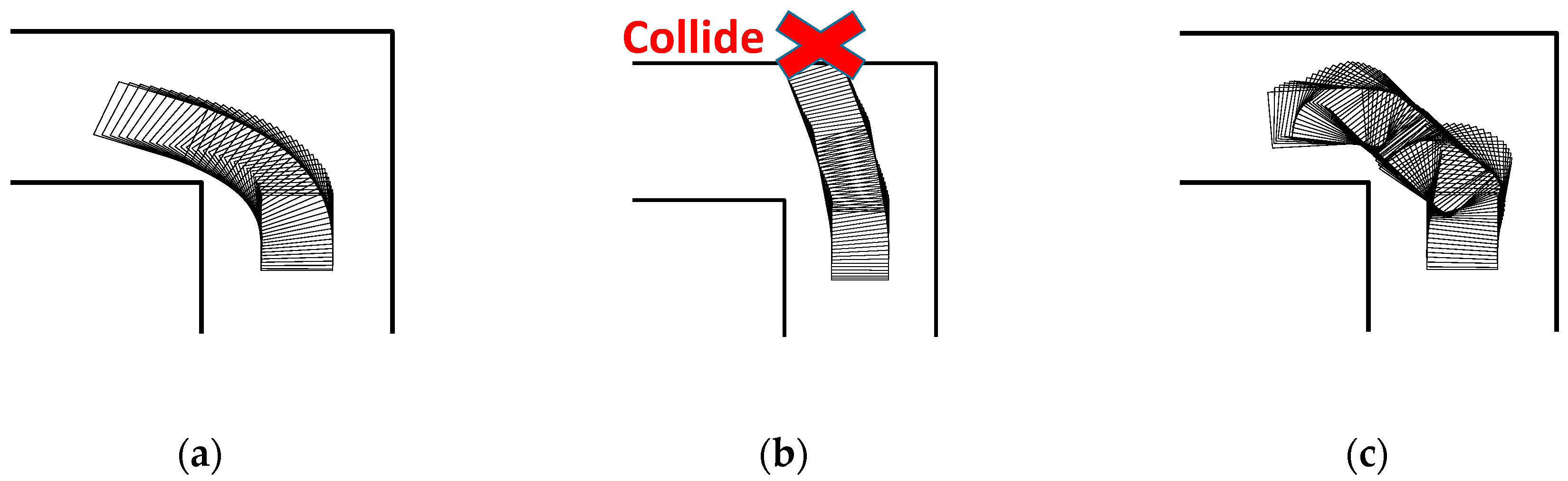
5.3.1. Driving Characteristics Investigation
5.3.2. Reward Design for the Shared Control System
5.4. States and Action Sets Design for the Shared Control System
5.5. Sarsa Learning Based Shared Control Algorithm
- Q (s,a) for each state only changes to a certain value.
- The rank Q (s,a) for each state only changes to a certain value.
- The latest trajectory does not include new states.
- Consecutive successes of the above condition.
- The number of training trials exceeds a certain number.
6. Experiments: System Effectiveness and User-Machine Interactions
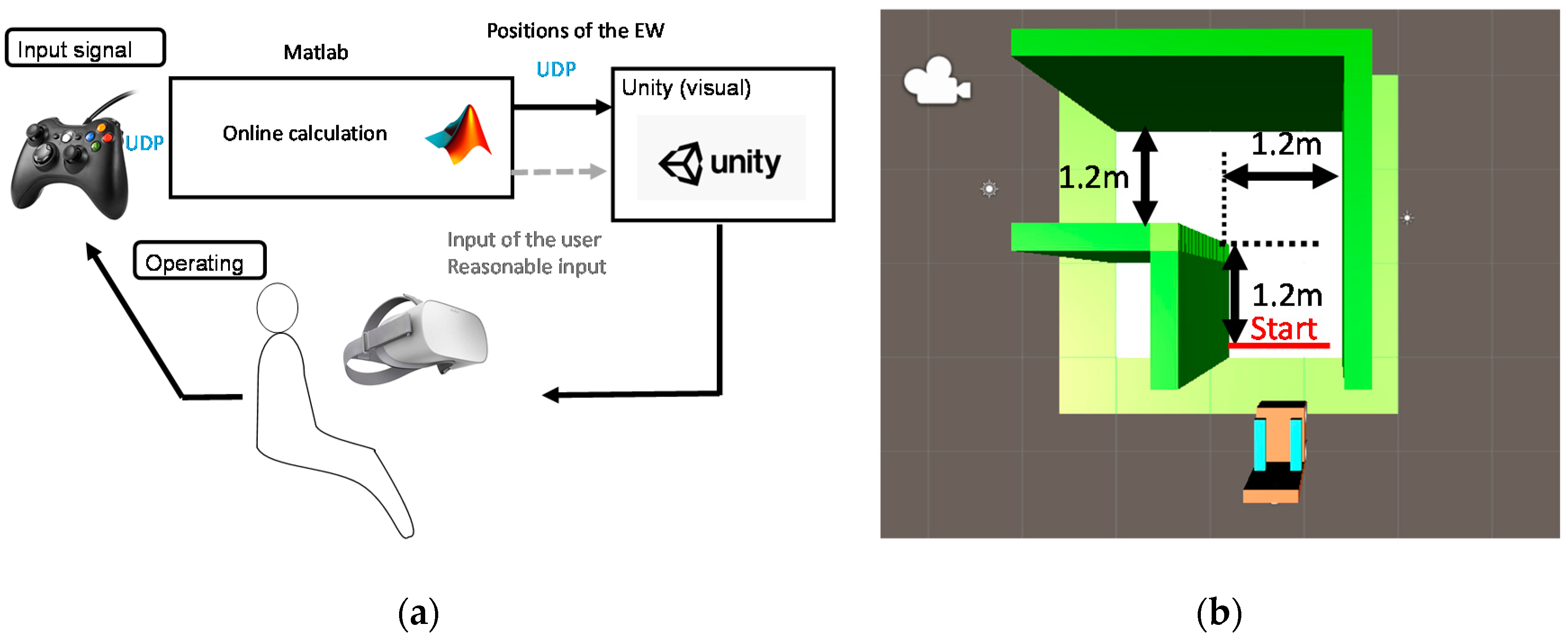
6.1. Experimental Setup
6.2. Experimental Method
- The control is easy.
- The control requires concentration.
- The control causes physical fatigue.
- The training duration is long.
- The EW is controlled by the user.
- The control is mostly satisfactory.
6.3. Experimental Results
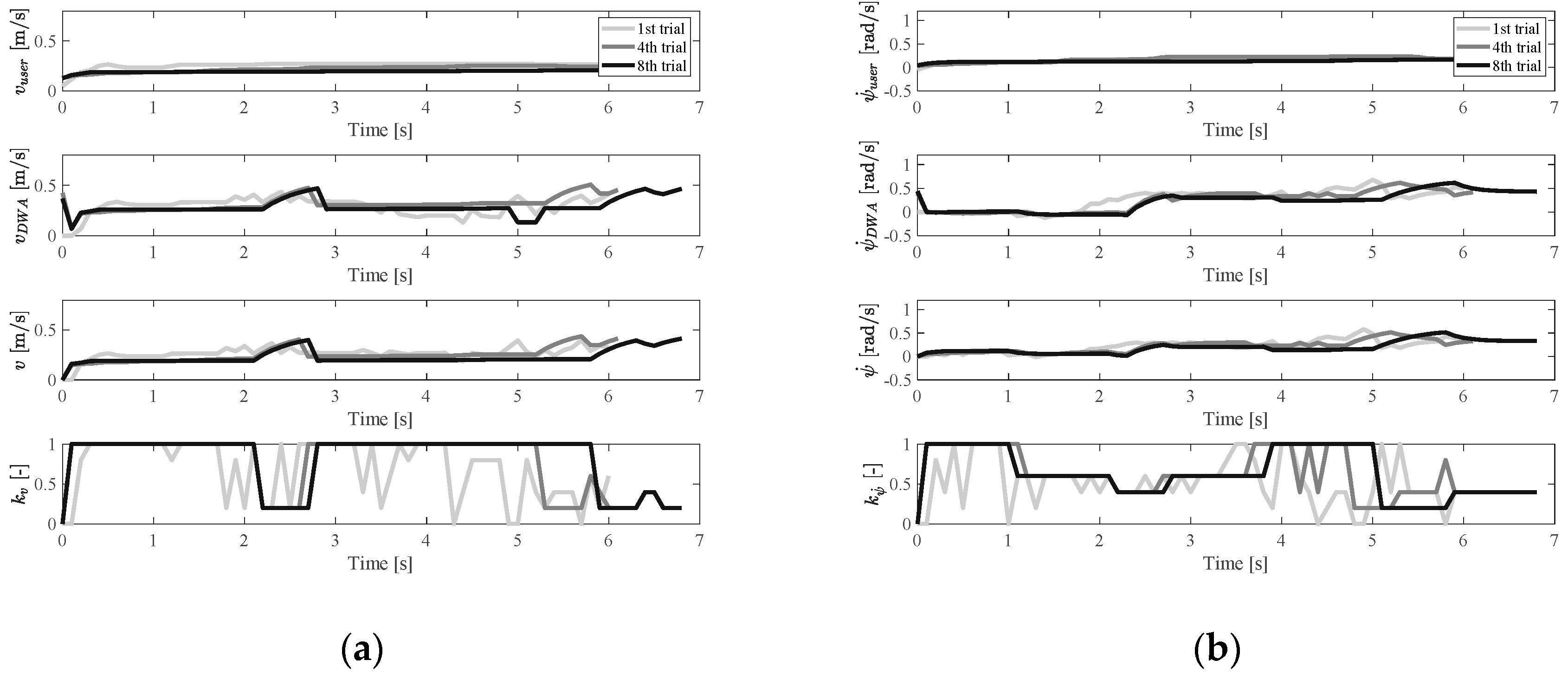
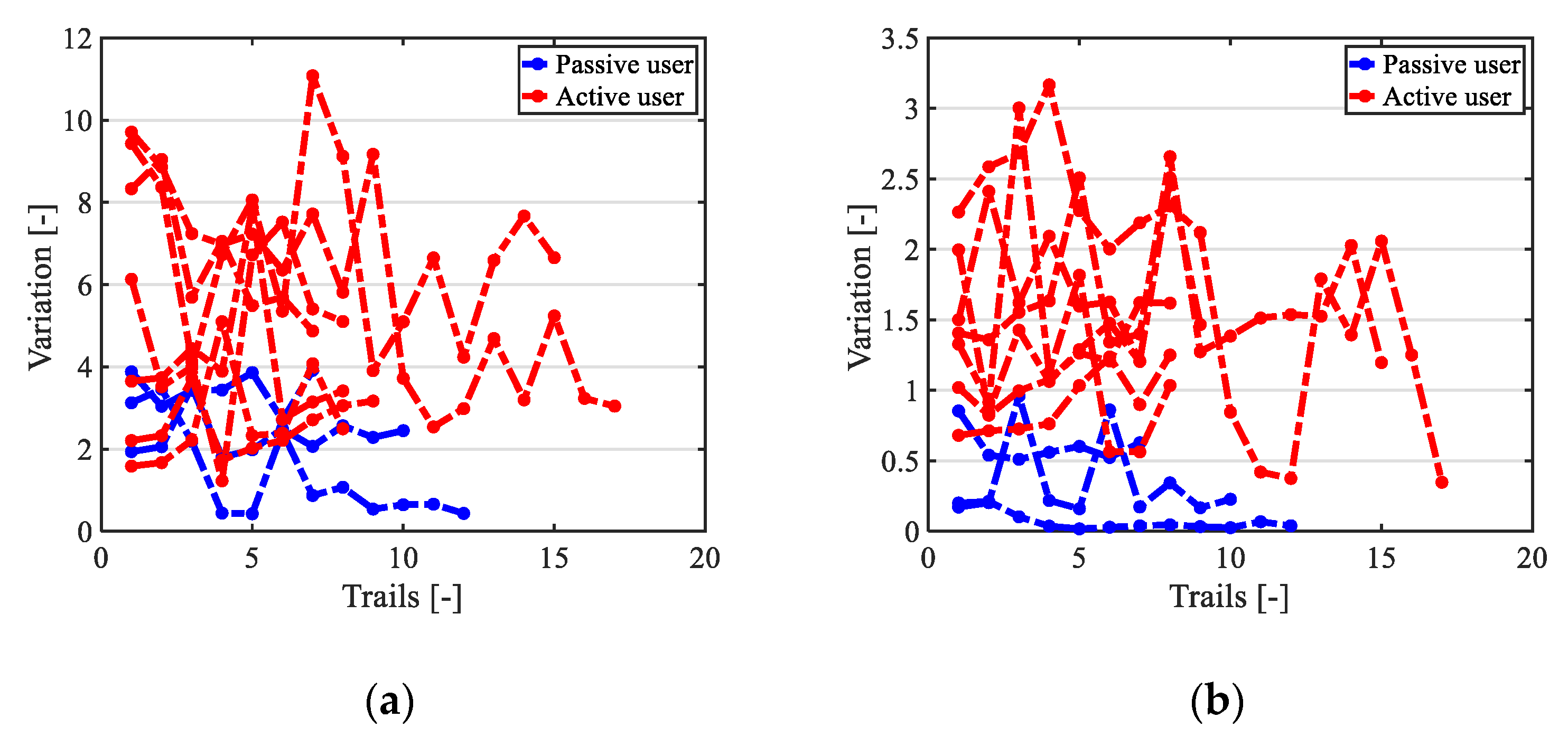
6.3.1. Objective Results
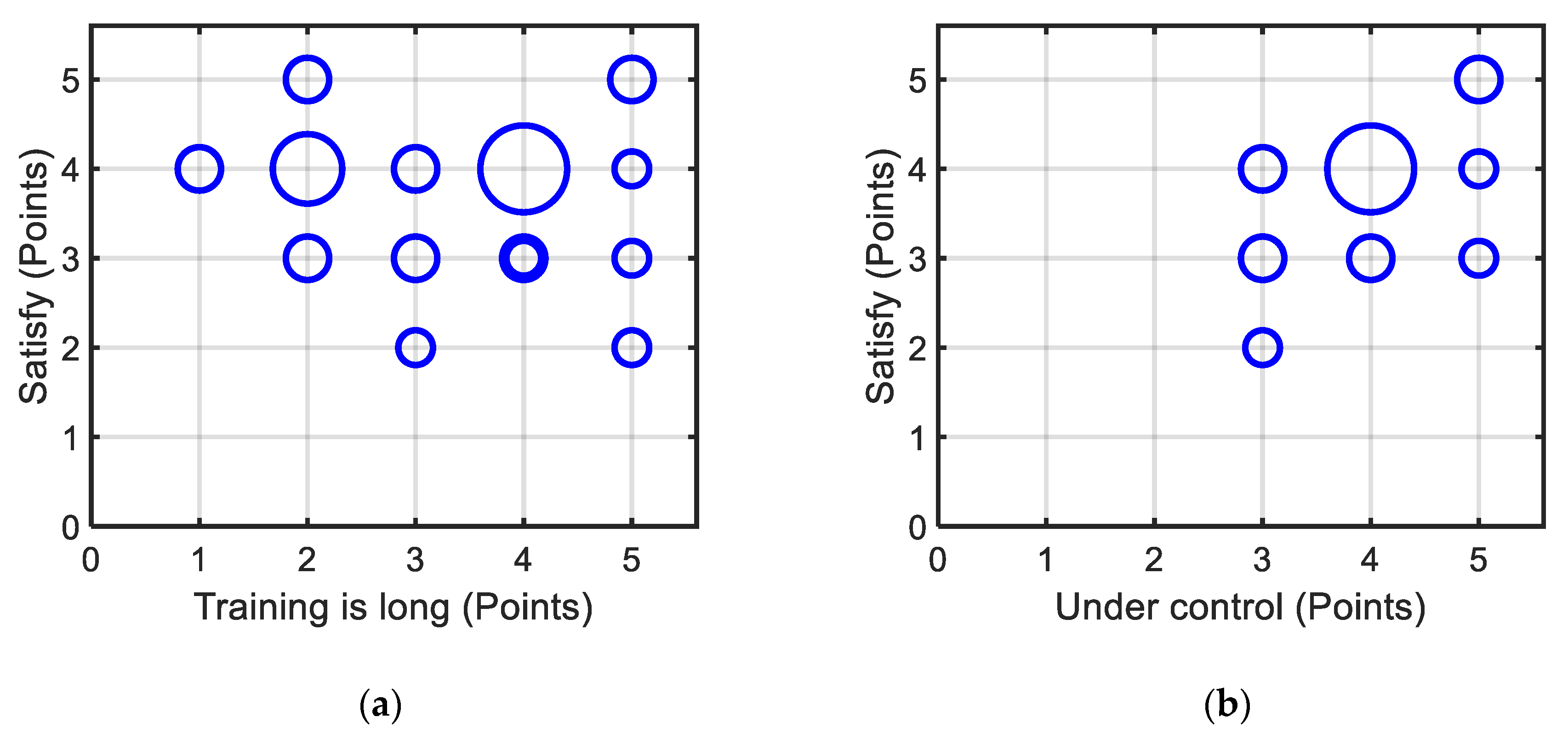
6.3.2. Subjective Results
6.4. Discussion
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Cabinet Office. Annual Report on Individuals of Disabilities. Available online: https://www8.cao.go.jp/shougai/whitepaper/h30hakusho/zenbun/siryo_02.html (accessed on 10 April 2020).
- Rosenbloom, S. The mobility needs of the elderly. In Transportation in an Aging Society, Improving Mobility and Safety for Older Persons; Transportation Research Board: Washington, DC, USA, 1988; Volume 2, pp. 21–71. [Google Scholar]
- Sasaki, T. Application of mechatronics to support of movement for the handicapped. J. Soc. Mech. Eng. 1998, 101, 57–61. [Google Scholar]
- Vanhooydonck, D.; Demeester, E.; Nuttin, M.; Van Brussel, H. Shared control for intelligent wheelchairs: An implicit estimation of the user intention. In Proceedings of the 1st International Workshop on Advances in Service Robotics, Bardolino, Italy, 13–15 March 2003. [Google Scholar]
- Zeng, Q.; Teo, C.L.; Rebsamen, B.; Burdet, E. Collaborative path planning for a robotic wheelchair. Disabil. Rehabil. Assist. Technol. 2008, 3, 315–324. [Google Scholar] [CrossRef] [PubMed]
- Urdiales, C.; Peula, J.M.; Fdez-Carmona, M.; Barrue, C.; Perez, E.J.; Sanchez-Tato, I.; Caltagirone, C. A new multi-criteria optimization strategy for shared control in wheelchair assisted navigation. Auton. Robot. 2011, 30, 179–197. [Google Scholar] [CrossRef]
- Simpson, R.; LoPresti, E.; Hayashi, S.; Guo, S.; Ding, D.; Ammer, W.; Cooper, R. A prototype power assist wheelchair that provides for obstacle detection and avoidance for those with visual impairments. J. Neuroeng. Rehabil. 2005, 2, 30. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Suzuki, M.; Takeyoshi, D. Mobility support robotics for the elderly (in Japanese). BME 1996, 10, 18–23. [Google Scholar]
- Aigner, P.; McCarragher, B. Shared control framework applied to a robotic aid for the blind. IEEE Control Syst. Mag. 1999, 19, 40–46. [Google Scholar]
- Vanhooydonck, D.; Demeester, E.; Huntemann, A.; Philips, J.; Vanacker, G.; Van Brussel, H.; Nuttin, M. Adaptable navigational assistance for intelligent wheelchairs by means of an implicit personalized user model. Rob. Auton. Syst. 2010, 58, 963–977. [Google Scholar] [CrossRef]
- Cooper, R.A. Intelligent control of power wheelchairs. IEEE Eng. Med. Biol. 1995, 14, 423–431. [Google Scholar] [CrossRef]
- Poncela, A.; Urdiales, C.; Perez, E.J.; Sandoval, F. A new efficiency-weighted strategy for continuous human/robot cooperation in navigation. IEEE Trans. Syst. Man Cybern. B Cybern. 2009, 39, 486–500. [Google Scholar] [CrossRef]
- Yanco, H.A. Shared User-Computer Control of a Robotic Wheelchair System. Ph.D. Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 2000. [Google Scholar]
- Fox, D.; Burgard, W.; Thrun, S. The dynamic window approach to collision avoidance. IEEE Robot Autom. Mag. 1997, 4, 23–33. [Google Scholar] [CrossRef] [Green Version]
- Simpson, R.C.; Levine, S.P.; Bell, D.A.; Jaros, L.A.; Koren, Y.; Borenstein, J. NavChair: An assistive wheelchair navigation system with automatic adaptation. In Assistive Technology and Artificial Intelligence; Springer Verlag GMBH: Berlin, Germany, 1998; pp. 235–255. [Google Scholar]
- Demeester, E.; Huntemann, A.; Vanhooydonck, D.; Vanacker, G.; Van Brussel, H.; Nuttin, M. User-adapted plan recognition and user-adapted shared control: A Bayesian approach to semi-autonomous wheelchair driving. Auton. Robot. 2008, 24, 193–211. [Google Scholar] [CrossRef]
- Shino, M.; Yamamoto, Y.; Mikata, T.; Inoue, T. Input device for electric wheelchairs considering physical functions of persons with severe Duchenne muscular dystrophy. Technol. Disabil. 2014, 26, 105–115. [Google Scholar] [CrossRef]
- Xi, L.; Yamamoto, Y.; Mikata, T.; Shino, M. One-dimensional input device of electric wheelchair for persons with severe Duchenne Muscular Dystrophy. Technol. Disabil. 2019, 31, 101–113. [Google Scholar] [CrossRef]
- Simpson, R.C.; LoPresti, E.F.; Cooper, R.A. How many people would benefit from a smart wheelchair? J. Rehabil. Res. Dev. 2008, 45, 53–71. [Google Scholar] [CrossRef] [PubMed]
- Furumasu, J.; Guerette, P.; Tefft, D. The development of a powered wheelchair mobility program for young children. Technol. Disabil. 1996, 5, 41–48. [Google Scholar] [CrossRef]
- Sim, J.; Shino, M.; Kamata, M. Analysis on the upper extremities to persons with Duchenne Muscular Dystrophy for the operation of electronic wheelchair. In Proceedings of the Society of Life Supporting Engineering, Osaka, Japan, 18–20 September 2010. [Google Scholar]
- Oh, S.; Hata, N.; Hori, Y. Integrated motion control of a wheelchair in the longitudinal, lateral, and pitch directions. IEEE Trans. Ind. Electron. 2008, 55, 1855–1862. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Finite Markov Decision Processes. In Reinforcement Learning: An Introduction, 2nd ed.; MIT Press: London, UK, 2014; pp. 53–82. [Google Scholar]
- Petereit, J.; Emter, T.; Frey, C.W.; Kopfstedt, T.; Beutel, A. Application of Hybrid A* to an autonomous mobile robot for path planning in unstructured outdoor environments. In Proceedings of the 7th German Conference on Robotics, Munich, Germany, 21–22 May 2012. [Google Scholar]
- Xu, W.; Huang, J.; Wang, Y.; Tao, C.; Cheng, L. Reinforcement learning-based shared control for walking-aid robot and its experimental verification. Adv. Robot. 2015, 29, 1463–1481. [Google Scholar] [CrossRef]
- Ramachandran, D.; Gupta, R. Smoothed sarsa: Reinforcement learning for robot delivery tasks. In Proceedings of the 2009 IEEE International Conference on Robotics and Automation, Kobe, Japan, 12–17 May 2009. [Google Scholar]
- Likert, R. A technique for the measurement of attitudes. Arch. Psychol. 1932, 22, 55. [Google Scholar]
- Komada, Y.; Shinohara, K.; Kimura, T.; Miura, T. The classification of drivers by their self-report driving behavior and accident risk. IATSS Rev. 2009, 34, 230–237. [Google Scholar]
- Ishibashi, M.; Okuwa, M.; Akamatsu, M. Development of driving style questionnaire and workload sensitivity questionnaire for driver’s characteristic identification. JSAE 2002, 55-02, 9–12. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Meaning of the Parameters |
|---|---|
| Angular velocity of the right (left) wheel | |
| Radius of the rear wheels | |
| Width of the EW | |
| Velocity of the straight (yaw) motion | |
| Position in world coordinate system | |
| COG | Center of gravity |
| COR | Center of rotation |
| Cost Items | Calculating Method |
|---|---|
| Approaching the goal | |
| Safety | |
| Magnitude of the input | |
| Input change | |
| Forward/backward change | |
| Backward |
| Algorithm: Sarsa Learning-Based Shared Control Algorithm |
|---|
| 1. calculated by reward function |
| 2. Recursively compute until the stop condition is met |
| 3. Recursively compute until reaching the goal |
| 4. Obtain current state |
| 5. Decide action by Sarsa learning |
| 6. Send to the system, calculate output |
| 7. Send output to the EW |
| 8. Calculate the next state |
| 9. Update the Q-table, Load |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xi, L.; Shino, M. Shared Control of an Electric Wheelchair Considering Physical Functions and Driving Motivation. Int. J. Environ. Res. Public Health 2020, 17, 5502. https://doi.org/10.3390/ijerph17155502
Xi L, Shino M. Shared Control of an Electric Wheelchair Considering Physical Functions and Driving Motivation. International Journal of Environmental Research and Public Health. 2020; 17(15):5502. https://doi.org/10.3390/ijerph17155502
Chicago/Turabian StyleXi, Lele, and Motoki Shino. 2020. "Shared Control of an Electric Wheelchair Considering Physical Functions and Driving Motivation" International Journal of Environmental Research and Public Health 17, no. 15: 5502. https://doi.org/10.3390/ijerph17155502