1. Introduction
Active safety systems, such as Forward Collision Warning (FCW), Dynamic Brake Support (DBS), and Autonomous Emergency Braking (AEB), have been widely offered by many automobile companies in today’s new car. Active safety systems use radar, camera, or ultrasonic sensors to detect vehicles, pedestrians, and obstacles. Once an imminent collision is detected, these systems will alert drivers or intervene to avoid crashes. In the meantime, with the increasing ability in driving behavior data collection, there is an emerging possibility to take advantage of machine learning to identify aggressive drivers and prevent crash events. Aggressive drivers behave recklessly, including speeding, improper following, and risky lane-changing, and put people and property at risk. In recent years, many studies have worked on the method of driving pattern identification based on naturalist driving experiments [
1,
2,
3], in which experiment vehicles were equipped with cameras to capture driver motions and the surrounding environment [
4,
5], and with specialized sensors to collect vehicle operation data and vehicle trajectory data [
6,
7]. Some research adopted driving simulators to detect driving behavior in the designed driving environment [
8,
9]. Compared to naturalistic driving study and driving simulator, video surveillance deployed on the roadside can provide a large amount of traffic environment data and vehicle trajectory data at a relatively affordable expense [
10]. However, driving behavior extraction from the video can be time-consuming and computation-intensive [
11,
12,
13]. Therefore, it is very important to find effective features based on the data extracted from the video to aid in driving pattern recognition.
Features that were used to recognize driving patterns can be grouped into three types: (1) control data, (2) physiological data, and (3) vehicle trajectory data. The in-vehicle cameras and sensors could capture the control data such as throttle opening and pedal brake, and wheel steering [
2,
3]. The images of the driver’s face and eye movement were also recorded to analyze distracted driving [
3,
4]. Some researchers adopted physiological data to identify drowsy driving. For example, Khushaba et al. [
14] extracted drowsiness related data through electrocardiograph (ECG), electroencephalogram (EEG), and electrooculogram (EOG). Fu et al. [
15] put electrodes on the drivers’ skin to collect physiological data. The control data and physiological data of drivers require additional cameras and sensors installment in the vehicle, which limits their application in practice, while vehicle trajectory data can be extracted from video surveillance. The vehicle trajectory data consists of lateral and longitudinal data. Murphey et al. [
16] adopted longitudinal data, including speed, acceleration, and acceleration jerk, to classify drivers as aggressive, moderate, and calm. The lateral data, i.e., yaw rate, the distance from lane mark, the lateral acceleration, were also used to identify driving styles and driving patterns [
9,
17].
It is difficult to observe real traffic accident and target vehicle’s driving behavior before the accident. For example, Strategic Highway Research Program 2 (SHRP 2) Naturalistic Driving Study contains 41,478 records in total while there are only 102 crash records. Collision surrogate measurements are widely used to measure a vehicle’s risk level, such as Time to Collision (TTC), Headway, Deceleration Rate to Avoid Crash (DRAC), etc. [
18,
19]. Mahmud et al. [
20] discussed the advantages and disadvantages of many existing proximal surrogate indicators of rear-end collision. TTC cannot handle zero relative speed properly in car-following and assume constant speed for both leading and following vehicles. Margin to collision (MTC), first proposed by Kitajima et al. [
21], measures the crash potential in the case that both leading and following vehicles decelerate abruptly. Difference of Space distance and Stopping distance (DSS) [
22], and similarly Potential Index for Collision with Urgent Deceleration (PICUD) [
23] further considers the reaction time of deceleration for the following vehicle, and Time Integrated DSS (TIDSS) [
24] calculates the aggregated crash risk for a vehicle by integrating the gap between DSS and the dangerous threshold value over a certain period.
Behavior recognition methods, especially machine learning algorithms, have been studied in many previous works. Different types of neural network (NN) algorithms such as back-propagation neural network (BPNN), multilayer feed-forward neural network (MLP), and constructive probabilistic neural network (CPNN) were adopted to identify driving behaviors [
6,
25,
26]. Some studies proposed Hidden Markov Model (HMM) to detect dangerous driving behaviors [
27], which could be challenging with a large number of states to be estimated [
28]. SVM also has been widely applied to various kinds of pattern recognition problems, including voice identification, text categorization, and face detection [
29,
30].
Most machine learning algorithms were designed for balanced data, and class imbalance can impact the algorithm’s performance. Unfortunately, driving behavior data is usually imbalanced. The number of positive samples, for example, aggressive drivers are outnumbered by normal drivers in real-world traffic. Aggressive drivers as the minority in the dataset may be ignored by classification algorithms, which tend to focus on predicting normal drivers. Therefore, using imbalanced data in the training of machine learning algorithms may lead to biased results and bad performance on aggressive driver recognition. Two main solutions to imbalance classification problems are cost-sensitive learning and resampling. Cost-sensitive learning assumes that the misclassification costs of normal and aggressive drivers are different. Higher misclassification costs for the minority class can force the model to better predict aggressive drivers. Resampling methods oversample the minority samples or undersample the majority samples to make the training data more balanced. Existing research tried cost-sensitive learning, or different resampling methods as data preprocessing with no modification on the existing machine learning algorithms.
Different from existing studies, this paper implements imbalanced class boosting algorithms, such as SMOTEBoost [
31], RUSBoost [
32], and CUSBoost [
33], which have not been applied to recognition driving behavior or driving style. Imbalanced class boosting algorithms apply the resampling method to increase the number of minority class samples or decrease the number of majority class samples in each iteration of boosting. Imbalanced class boosting algorithms were tested on many datasets, and they give better results than using the resampling method only as data preprocessing [
31,
32,
33]. The recognition results of imbalanced class boosting algorithms are compared with cost-sensitive boosting and boosting with resampling.
In the paper, the Next Generation Simulation (NGSIM) vehicle trajectory data extracted from video surveillance is adopted to measure the rear-end collision risk for each driver. The advantage of video-extracted vehicle trajectory data is the huge number of vehicles that can be observed simultaneously with relatively low cost of video recording and video processing. A large sample of vehicle trajectory can help better train data-hungry machine learning models. Once the recognition model is well-trained, the identification of drivers can be done using any data source that provides vehicle trajectory information, including video-extracted data, in-vehicle sensor data, and cell-phone data. If the data used for training and identification are from different sources, then the multiple-source data should be calibrated to have consistent measurement accuracy.
Among many aggressive driving behaviors, improper following is the most common one in the NGSIM vehicle trajectory data and its severity can be quantified using the surrogate measurement of rear-end collision. In this paper, the driving aggressiveness is determined and labeled by a proposed surrogate measurement of rear-end collision, which can be calculated automatically using vehicle trajectory data and therefore is more efficient and objective than questionnaires and the subjective judgment of experts. Then different algorithms are applied to identify aggressive drivers with labeled and imbalanced data. The identification results are discussed based on performance indicators.
2. Materials and Methods
The methodology can be divided into two parts. The first part includes
Section 2.1. and
Section 2.2., which explains how we measure the collision risk of each vehicle and label aggressive drivers. In
Section 2.1., we propose a new measurement of rear-end collision risk. In
Section 2.2., we introduce three anomaly detection methods to determine the threshold of aggressive driving. The second part explains how to train a classification model once each driver has been labeled.
Section 2.3. covers the feature extraction with the Discrete Fourier Transform (DFT) method, which transforms a given time series to signal amplitude in the frequency domain, which can reveal driving characteristics hidden in vehicle trajectory data.
Section 2.4. introduces imbalanced class boosting algorithms and other algorithms tested in this paper. The last section shows the performance indicators used to measure the ability of boosting algorithms. The methodology framework is shown in
Figure 1. This research does not involve human participants and the studied data contains no sensitive and personally identifiable information.
2.1. Surrogate Measurement of Collision
As discussed in the Introduction section, there are many proximal surrogate indicators proposed to measure the collision risk or evaluate safety level. Among all, Time to Collision (TTC) is commonly used in the collision warning system. It assumes constant driving speed for both leading and following vehicles and ignores the scenario that the leading vehicle decelerates abruptly, which may underestimate the crash risk of the following vehicle in unsteady traffic flow. Margin to Collision (MTC) overcomes the disadvantage of TTC by assuming that both leading and following vehicles can decelerate abruptly at the same time. Difference of Space distance and stopping distance (DSS) considers the following vehicle’s reaction time to the leading vehicle’s deceleration. Time Integrated DSS (TIDSS) calculates the integrate DSS over a time period to show the aggregated crash risk of a given vehicle.
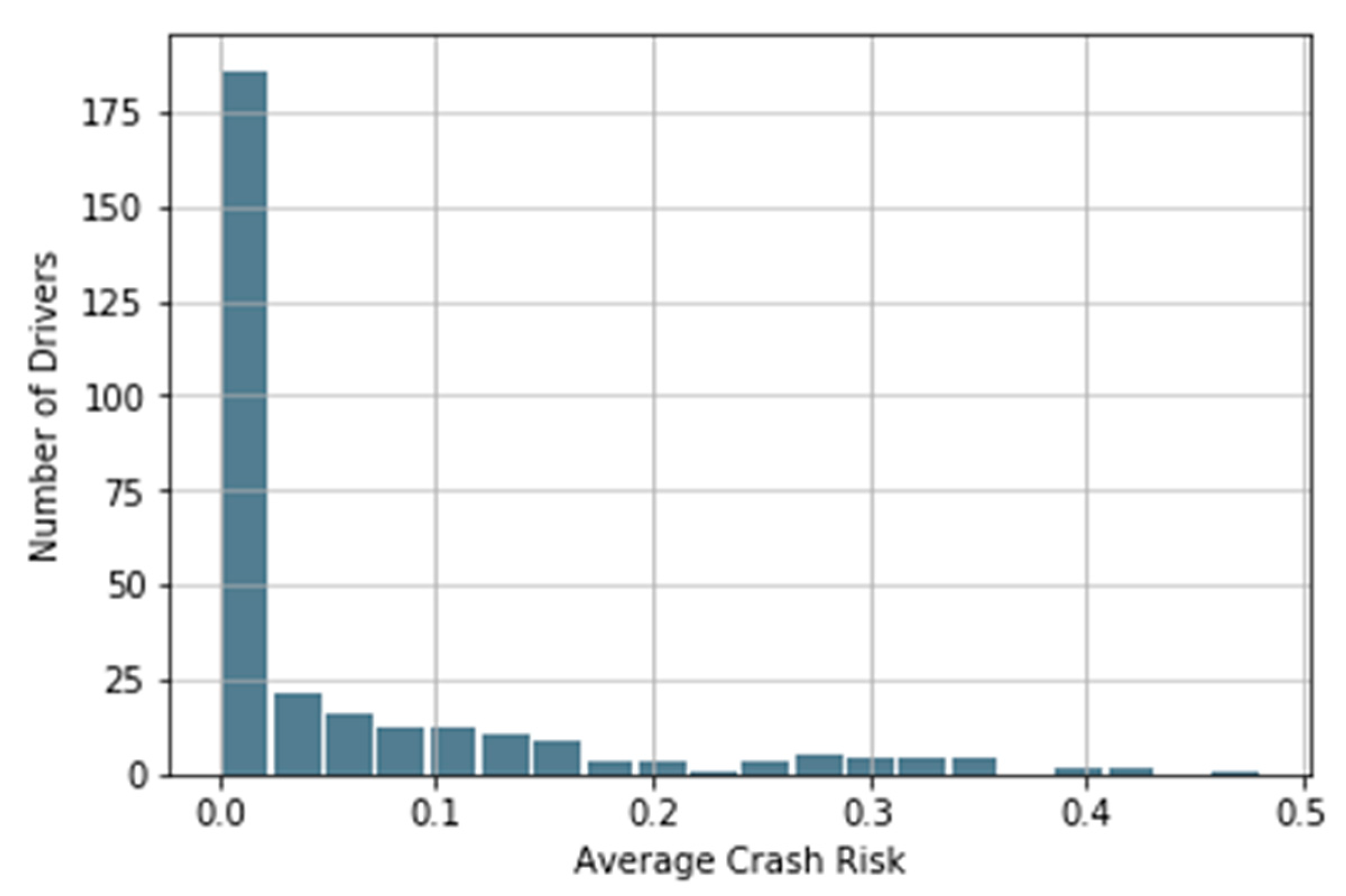
We propose a new surrogate indicator, Average Crash Risk (ACR), to measure a driver’s aggressiveness. For each vehicle, Crash Risk (CR) at time point t is calculated based on its DSS:
where
vl and
vf are the speed of the leading and following vehicles, respectively,
μ is the fraction rate, set to 0.7;
g is the acceleration of gravity, 9.8 m/s
2 (or 32.174 ft/s
2);
d is the gap between the leading and following vehicles;
τ is the reaction time of drivers. When the vehicle is accelerating,
τ is set to 1.5 s. When the vehicle is decelerating or idling,
τ is set to 0.7 s.
When DSS > 0, it means the following vehicle has enough time to decelerate and avoid a collision. Therefore, Crash Risk is 0. When DSS ≤ 0, the following vehicle has a potential crash risk, and the Crash Risk is measured as the absolute value of DSS divided by the speed of the following vehicle.
To measure the overall driving aggressiveness for each driver during the whole car-following process, we calculate the average crash risk as follows:
where T is the car-following duration; Δ
t is the sampling interval, 0.1 s.
2.2. Average Crash Risk (ACR) Threshold
Once each driver’s ACR is calculated based on how they interact with their preceding vehicle, aggressive drivers can be determined as their ACR exceeds a certain threshold. However, there is no empirical or theoretical threshold available in previous studies, and we apply three anomaly detection methods to find the boundary between normal drivers and aggressive drivers: K-means clustering, interquartile range rule, and Xth percentile.
2.2.1. K-means clustering
Given a set of observations (x
1, x
2, …, x
n), where each observation is a d-dimensional real vector, K-means clustering aims to partition the
n observations into
k groups = {C
1, C
2,…, C
k} to minimize the within-cluster sum of variance. The objective of K-means is:
where
is the mean vector within cluster Ci.
The K-means algorithm uses the squared Euclidean distance metric and a heuristic to find centroid seeds for k-means clustering. We use k-means to group 299 drivers into 2 clusters: normal and aggressive.
2.2.2. Interquartile Range Rule
The interquartile range rule is useful in detecting outliers that fall far away from the center of the data. We assume that an aggressive driver’s ACR is extremely apart from the average and use the following equation to calculate the threshold.
where Q
3 is the 75th percentile of the data; IQR is the difference between the 75th percentile and the 25th percentile of the data.
2.2.3. The Xth percentile
The Xth percentile method is straightforward. Using the Xth percentile of the data as the threshold is equivalent to assuming that (100−X)% of drivers on the road are aggressive. The proper value of X is vague and subjective. We take the 94th percentile of the ACR as the threshold and use it only as complementary to the other methods above.
2.3. Discrete Fourier Transform
Since every vehicle has a different length of trajectory data, the time series of gap, speed, and acceleration rate of each vehicle cannot be used directly to identify the driver’s driving aggressiveness. Discrete Fourier Transform (DFT) has been applied many times in driving behavior studies to convert time series of driving features to signal amplitude in the frequency domain.
The DFT of a given time series (x
1, x
2,…, x
N) is defined as a sequence of N complex numbers
:
where
i is the imaginary unit.
Time series data have temporal structures. The low/medium-frequency information shows the time series’ level, trend, and periodicity. The high-frequency part is noise. Through Discrete Fourier Transform, we keep the first 15 DFT coefficients of each time series as input and drop the rest part as noise.
2.4. Imbalanced Class Boosting Algorithms
In real traffic, the proportion of aggressive drivers is much smaller than the proportion of normal drivers. Therefore, the dataset is usually imbalanced with aggressive drivers as the minority class. A popular solution is to fully or partially balance the class distribution by resampling. For example, SMOTE (Synthetic Minority Oversampling Technique) [
34] balances the data by synthetically generating more instances of the minority class, and the classifiers can broaden their decision regions for the minority class. RUS (Random Under Sampling) removes examples from the majority class at random until the desired class distribution is achieved.
The first imbalanced class boosting algorithm SMOTEBoost was proposed by Chawla et al. [
31]. It combines the SMOTE and the standard boosting procedure. The standard boosting procedure gives equal weights to all misclassified examples, and sampling distributions in subsequent boosting iterations could have a larger composition of majority class cases. By introducing SMOTE in each round of boosting, SMOTEBoost algorithm gradually increases the number of minority class samples. The algorithm procedure of AdaBoost and imbalanced class boosting are shown in
Figure 2. Seiffert et al. [
32] proposed the RUSBoost algorithm that combines RUS and AdaBoost. In each iteration of boosting, RUS is used to balance class instead of SMOTE. CUSBoost [
33] is another imbalanced class boosting algorithm that combines under-sampling with AdaBoost. CUSBoost clusters majority class first, and then randomly removes majority samples based on their cluster.
Nine algorithms are tested in the paper (see
Table 1). The first group is cost-sensitive boosting, including AdaBoost and XGBoost, which does not resample the training data. Instead, a higher-class weight was set for the minority class to offset the imbalance. The second group is standard boosting with resampling. We tried two resampling methods: SMOTE and RUS. There are four algorithms in the second group. SMOTE + AdaBoost, for example, uses SMOTE first on the training data to oversample the minority class, and then train the AdaBoost model using the balanced training data. The third group is imbalanced class boosting, including SMOTEBoost, RUSBoost, and CUSBoost. Hyperparameter optimization for each machine learning model is achieved by Grid Search.
2.5. Performance Evaluation
The performance of the boosting algorithm depends on its power to identify aggressive drivers using vehicle trajectory data. This paper use four important performance indices: precision rate, recall rate, f1 score, and Area under the Precision-Recall Curve (AUPRC).
Precision rate is defined as follows:
where
TP is the number of aggressive drivers correctly identified;
FP is the number of normal drivers wrongly identified as aggressive drivers.
Recall rate is defined as follows:
where
FN is the number of aggressive drivers wrongly identified as normal drivers.
The F1 score is the harmonic average of the precision and recall. A high F1 score represents high values in both precision rate and recall rate.
A ROC curve (receiver operating characteristic curve) is a graph showing the false positive rate versus the true positive rate for different candidate threshold values between 0 and 1. Similarly, a precision-recall curve is a plot of the precision and the recall for different thresholds. Generally, ROC curves should be used when there are roughly equal numbers of observations for each class. When there is a class imbalance, Precision-Recall curves should be used, because the ROC curve with an imbalanced dataset might be deceptive and lead to incorrect interpretations of the model skill [
35]. Therefore, this paper uses AUPRC to compare algorithms’ performance, which measures the entire two-dimensional area underneath the entire Precision-Recall curve.
Stratified K-fold cross-validation is widely used to evaluate the classification algorithm’s performance, especially when the dataset is highly imbalanced. Since using all 299 drivers to train the model may cause an overfitting problem and exaggerate the accuracy of the trained model, we divided the 299 drivers randomly into five equal-sized subsets. At each time, four subsets are used for resampling and then training, and the left-out subset is used to assess the performance of the trained model. This process rotates through each subset, and the average accuracy, precision rate, and recall rate represent the performance of the algorithm. Stratified 5-fold cross-validation was repeated five times.
6. Discussion
6.1. ACR and Aggressiveness
There is one question we need to answer: is a high crash risk equivalent to aggressive driving? There are several external factors that may impact a vehicle’s crash risk. For example, frequent/abrupt acceleration and braking by the leading vehicle, either caused by unstable traffic flow or the leading vehicle’s reckless driving style, may lead to high crash risk for the following vehicle. If the following vehicle is not responsible, or not completely responsible for the high crash risk, then using ACR or any rear-end collision surrogate indicator to measure driving aggressiveness could be problematic.
To rule out the possibility that traffic condition and/or the leading vehicle’s driving style may impact the following vehicle’s crash risk, we calculated the correlation between the leader and follower’s ACRs based on simple logic. If traffic condition has an impact on vehicle’s ACR, then both leading and following vehicle in the same traffic flow should have similar crash risk level. If the leading vehicle’s reckless driving has an influence on the following vehicle, making whom more aggressive or more defensive, then the ACRs of two vehicles should also show some degree of correlation.
Among 299 leader-follower pairs (LVP), 264 leading vehicle’s driving aggressiveness are also determined since they are following vehicles in other LVP. Therefore, we are able to calculate the correlation of ACR for these 264 LVPs. The Pearson correlation coefficient between the leader and follower’s ACRs is −0.0137, which indicates that the leading vehicle’s crash risk is not delivered to its follower, and also implies that ACR can represent driving aggressiveness.
6.2. Algorithm Performance
Based on the results shown in
Table 3 to
Table 5, we find that imbalanced class boosting algorithms, SMOTEBoost and CUSBoost, generally outperform other boosting algorithms. XGBoost also performs well when the imbalance ratio of the dataset is moderate.
The advantage of the imbalanced class boosting algorithm is more obvious with a high imbalance ratio. For example, in Dataset 3, aggressive drivers account for 14.4% of all drivers, and the performance difference between XGBoost, which is the best cost-sensitive boosting algorithm, and CUSBoost is small (AUPRC: 0.938 vs. 0.935). By contrast, in Dataset 5, in which only 6.4% of drivers are aggressive, the AUPRC of XGBoost decreases from 0.938–0.871, while the AUPRC of CUSBoost only drops slightly from 0.935–0.924.
It is surprising to find that SMOTE + AdaBoost and RUS + AdaBoost give worse results than AdaBoost, and SMOTE + XGBoost and RUS + XGBoost give worse result than XGBoost. Several existing studies used SMOTE or other resampling methods before boosting, assuming that it will create better results for imbalanced data. It implies that apply the resampling method before boosting algorithms does not guarantee a better recognition result than cost-sensitive learning. One possible reason is that a one-time resampling in the training data before the boosting may skew the data distribution and later weaken the boosting algorithm’s power to recognize the test data because test data is not balanced by the resampling method.
6.3. Mode Input
We found that using the discrete Fourier coefficients of acceleration alone as the input was much worse than using other inputs. Due to acceleration’s poor ability to recognize aggressive drivers, its result is not included in this paper. It is a little surprising since some previous studies found that acceleration, pedal brake, or throttle opening have significant power in driving style classification. For example, Kluger et al. [
1] found a distinct difference in acceleration discrete Fourier coefficients between vehicles with safety-critical events and vehicles at baseline. There are several possible explanations. First, acceleration is the first-order derivative of speed, which implies that the information of acceleration has been included in the DFT coefficient of speed. Second, the trajectory data in the paper was recorded on a highway near night peak-hour, the acceleration pattern would be different from vehicles in free-flow traffic, local street traffic, or vehicle data generated from driving simulator with no traffic or light traffic. Third, the fidelity of acceleration in NGSIM, even after reconstruction by Montanino and Punzo [
34], is still the second-order derivative of vehicle position extracted from the video. Errors in vehicle position will be amplified and delivered to vehicle acceleration. The innate disadvantage of video-based trajectory data might be the reason for the indifference between normal and aggressive driver’s acceleration DFT coefficients.
7. Conclusions
The objectives of this research are mainly three things: find out how to label drivers using a new collision surrogate measurement, how to identify aggressive drivers using imbalanced class boosting, and what is the key feature.
This paper takes advantage of the reconstructed NGSIM trajectory data to explore the possibility of identifying aggressive drivers. To label each driver’s driving aggressiveness, we propose a surrogate measurement of collision risk, Average Crash Risk (ACR), which distinguishes aggressive drivers from others based on their response in the car-following process. Compared to other labeling methods, like experts’ subjective judgment, questionnaire, or clustering based on speed/acceleration/wheel steering, surrogate measurement is more suitable in real-world traffic. The correlation of collision risk between leading and following vehicles is tested. This paper found that the crash risk of the leading vehicle, measured by ACR proposed in this paper, has no impact on the following vehicle, and the driving aggressiveness of the two drivers are independent.
We found the gap between the leading and following vehicles is the key feature to recognize aggressive drivers. A vehicle’s speed and acceleration can be influenced by its leading vehicle, and we found using speed and acceleration alone cannot identify the driver’s aggressiveness with acceptable precision rate and recall rate. By contrast, using the gap alone as the input can train a model with precision rate and recall rate both at a 90% level.
Imbalanced class boosting algorithms show their ability to handle imbalanced driving data. The more imbalanced the data is, the more necessary it is to use an imbalanced class boosting algorithm rather than a standard classification algorithm. When using the discrete Fourier coefficients of the gap, speed, and acceleration as the input features, SMOTEBoost, RUSBoost, and CUSBoost outperform AdaBoost and XGBoost in the most imbalanced Dataset 5. Resampling imbalanced data before AdaBoost or XGBoost does not always improve the model’s recognition ability. Since SMOTEBoost, CUSBoost, and RUSBoost are modified AdaBoost with the resampling method, their performance can be further improved by replacing AdaBoost with more advanced boosting algorithms.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}