
Space-Time Cluster’s Detection and Geographical Weighted Regression Analysis of COVID-19 Mortality on Texas Counties



Abstract
:1. Introduction
2. Materials and Methods
2.1. Data
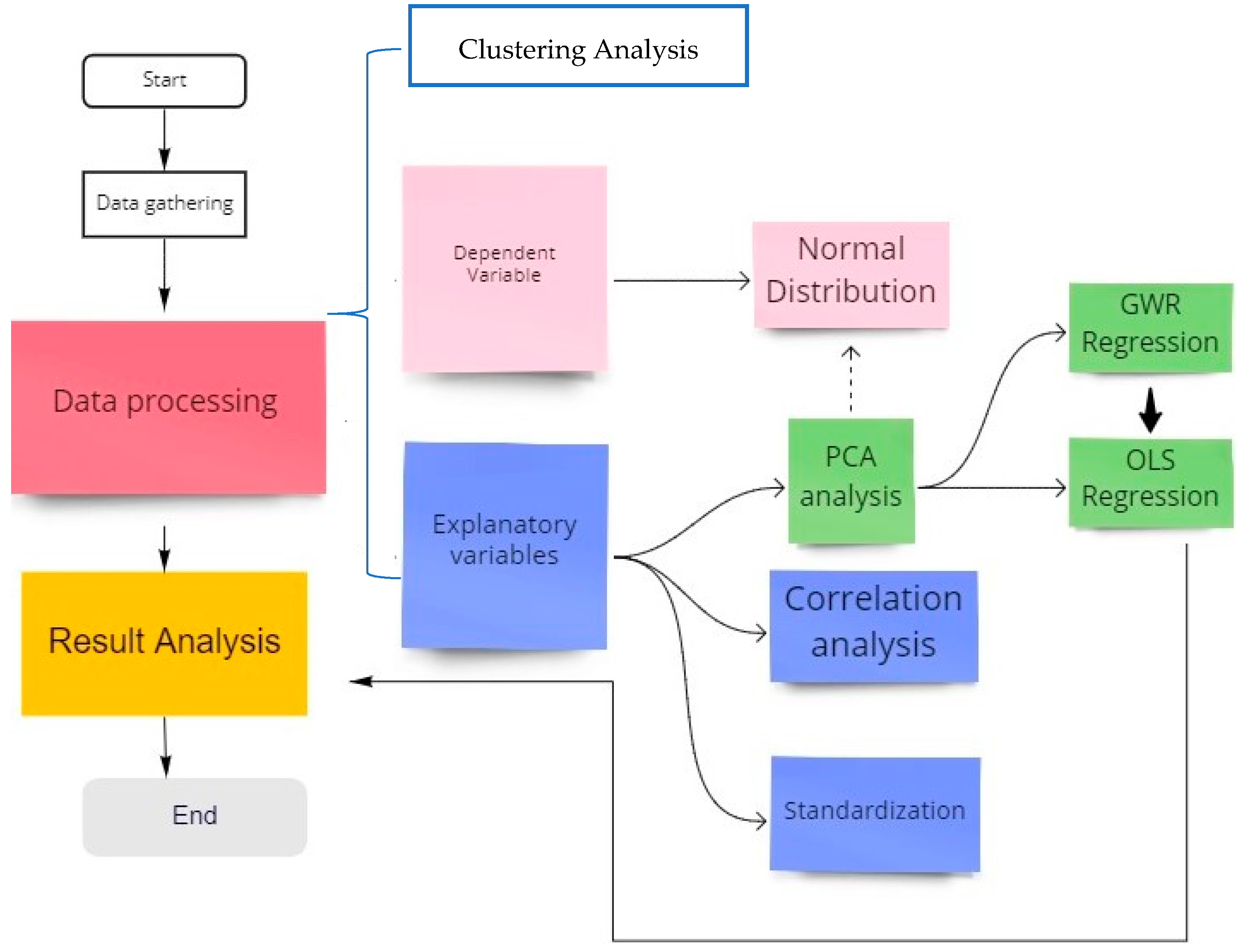
2.2. Study Framework
2.3. Space-Time Scan Statistics
2.4. Expectation-Maximization Clustering and Hierarchical Clustering Analysis
2.5. Selection of Explanatory Variables
2.6. Model Selection
2.7. GWR
3. Results
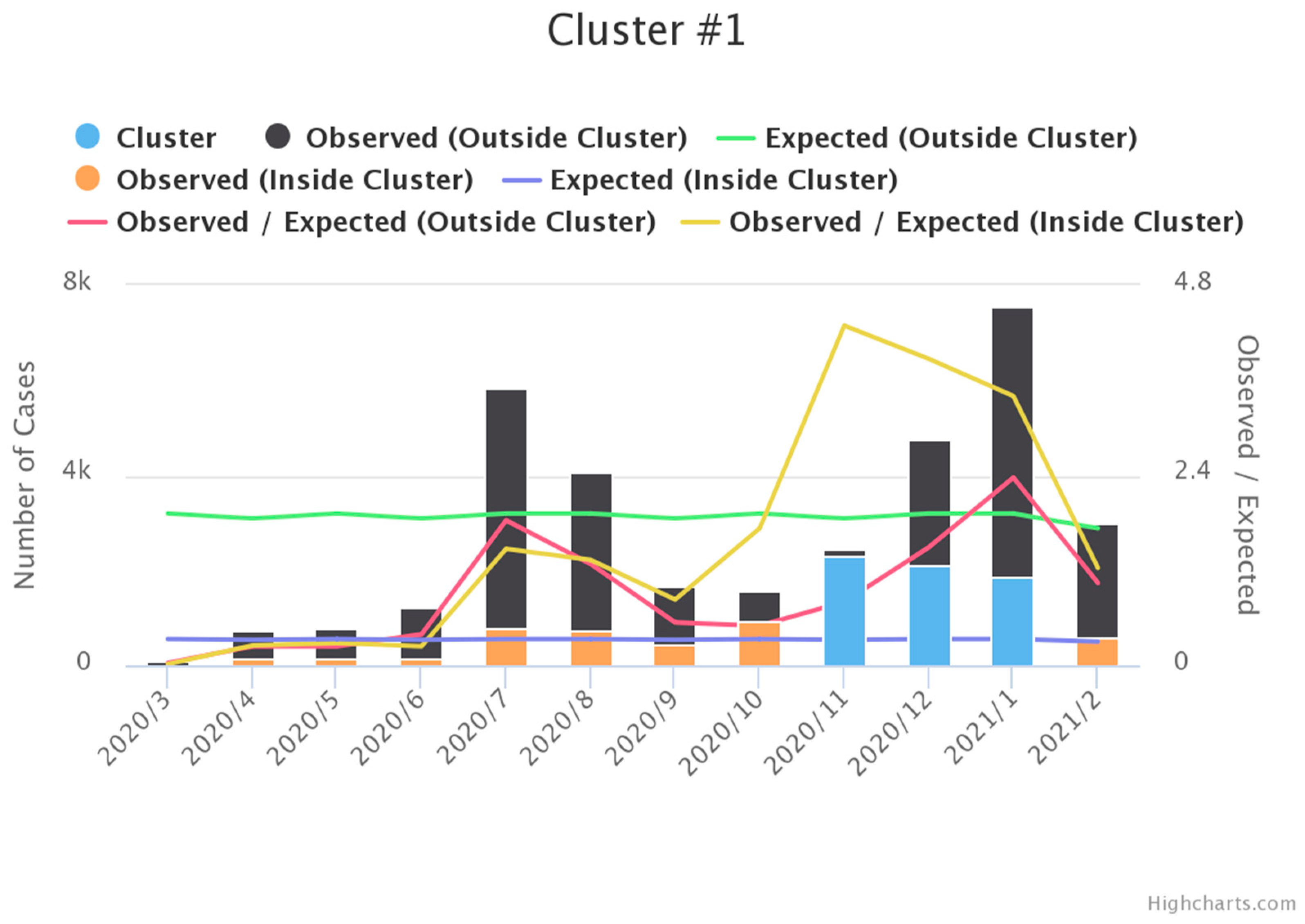
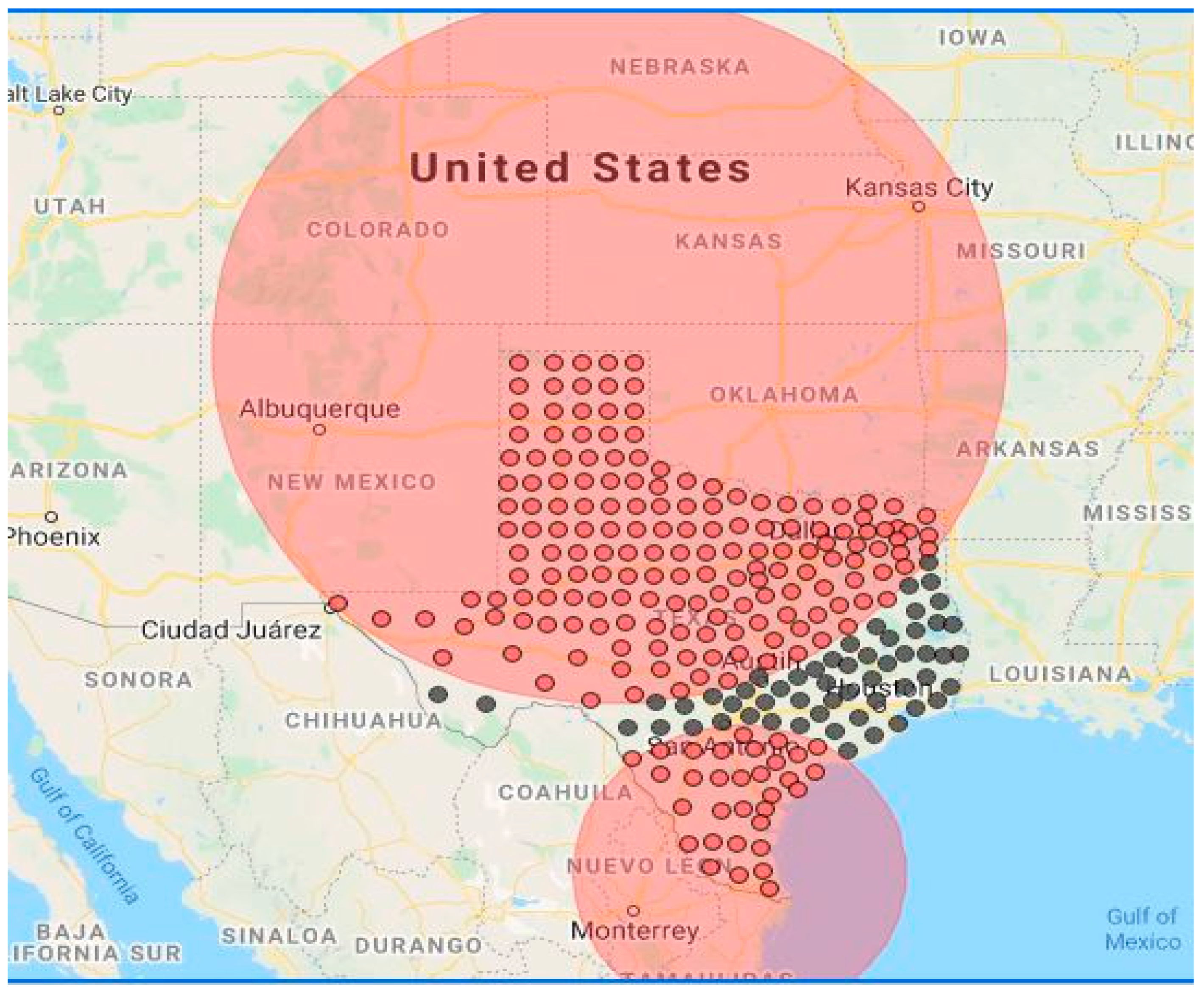
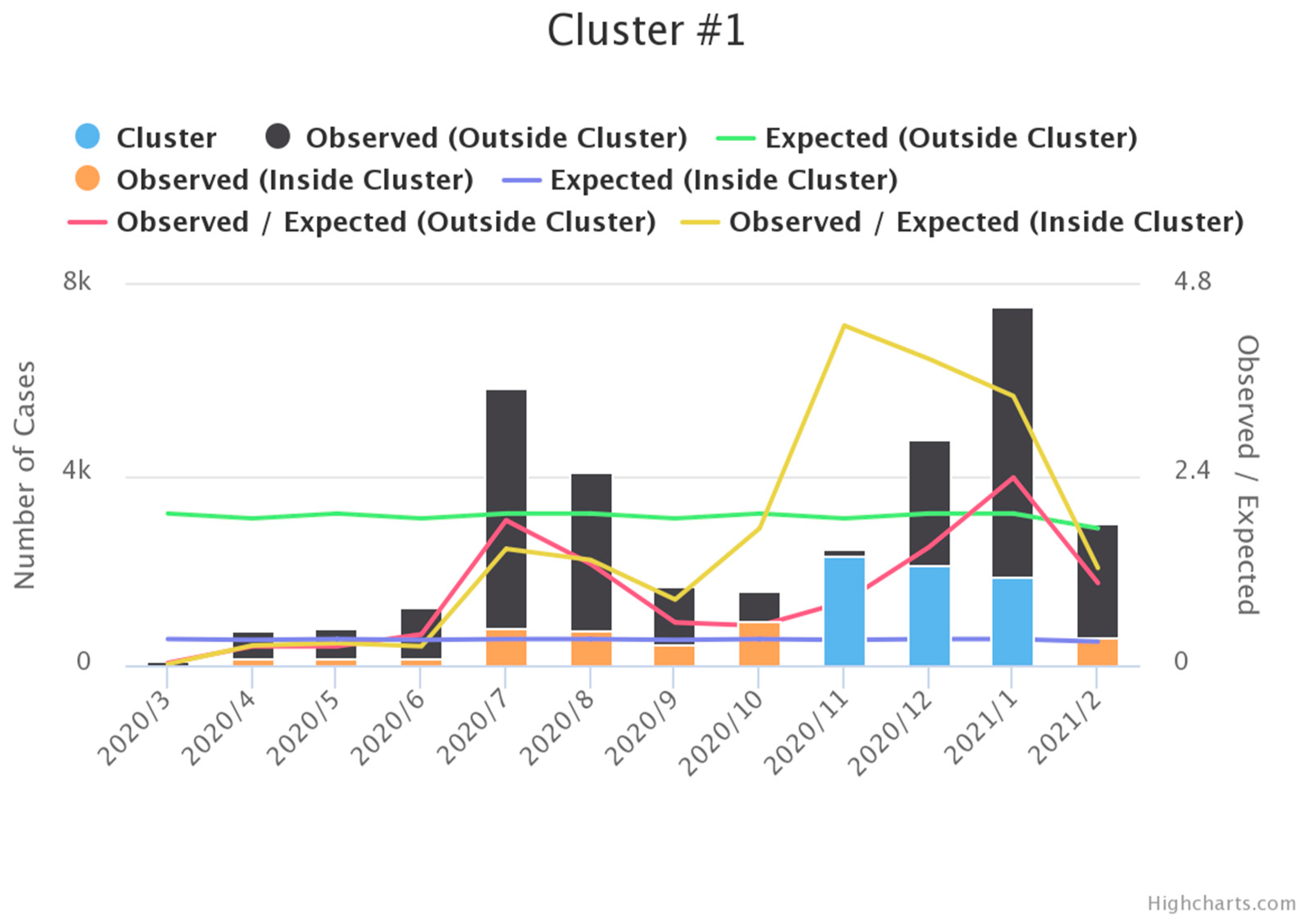
3.1. Space-Time Scan Statistics
3.2. EM Clustering and HC Clustering
3.3. Normal Distribution
3.4. Correlation
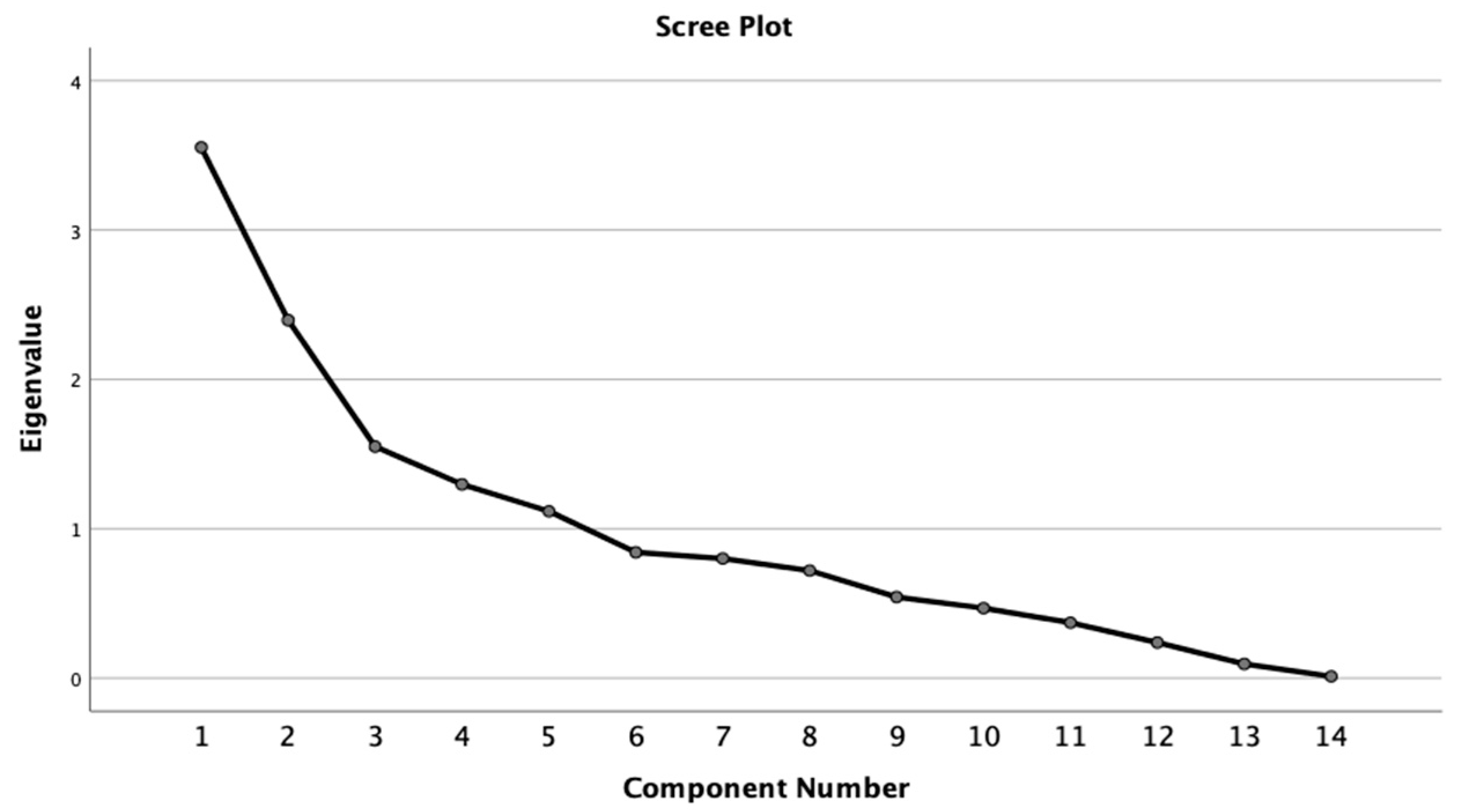
3.5. Factor Analysis
3.6. Comparison of Composite OLS and Composite GWR Models
3.7. GWR Result Analysis
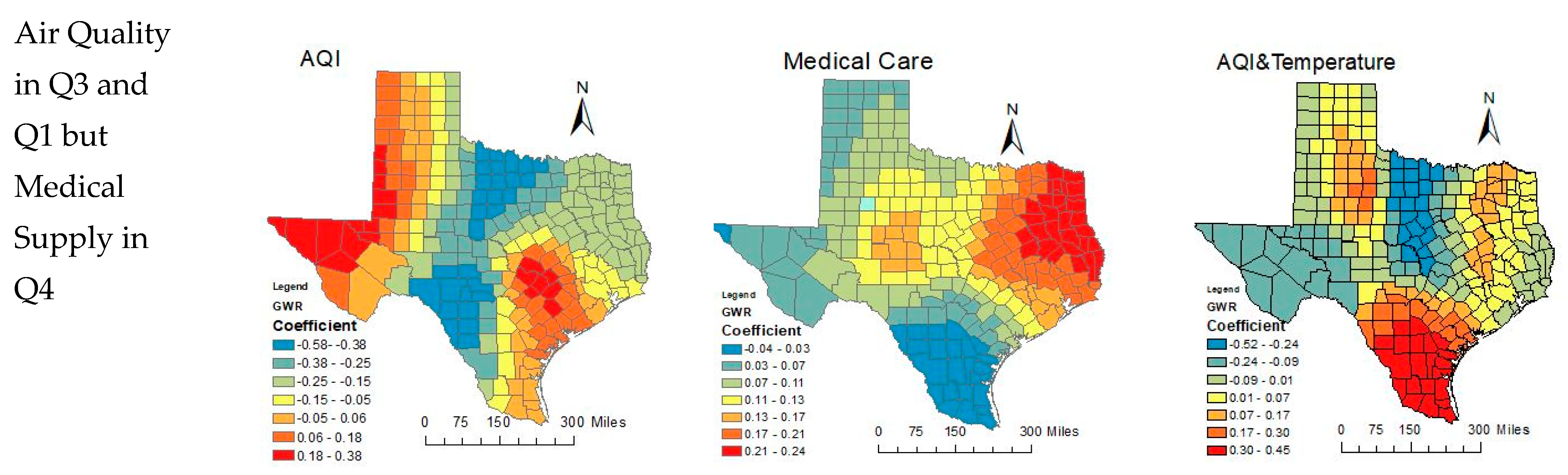
3.7.1. Spatial Change of MR Factors
3.7.2. Temporal Change of CC Factors
4. Discussion
5. Conclusions
5.1. Limitations
5.2. Implications
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Peker, Y.; Celik, Y.; Arbatli, S.; Isik, S.R.; Balcan, B.; Karataş, F.; Uzel, F.I.; Tabak, L.; Çetin, B.; Baygül, A.; et al. Effect of High-Risk Obstructive Sleep Apnea on Clinical Outcomes in Adults with Coronavirus Disease 2019: A Multicenter, Prospective, Observational Cohort Study. Ann. Am. Thorac. Soc. 2021. [Google Scholar] [CrossRef] [PubMed]
- Ahmar, A.S.; Boj, E. Will COVID-19 confirmed cases in the USA reach 3 million? A forecasting approach by using SutteARIMA Method. Curr. Res. Behav. Sci. 2020, 1. [Google Scholar] [CrossRef]
- Bashir, M.F.; Ma, B.; Shahzad, L. A brief review of socio-economic and environmental impact of Covid-19. Air Qual. Atmos. Health Int. J. 2020, 13, 1403. [Google Scholar] [CrossRef] [PubMed]
- Woolhandler, S.; Himmelstein, D.U.; Ahmed, S.; Bailey, Z.; Bassett, M.T.; Bird, M.; Bor, J.; Bor, D.; Carrasquillo, O.; Chowkwanyun, M.; et al. Public policy and health in the Trump era. Lancet 2021, 397, 705–753. [Google Scholar] [CrossRef]
- Center for Systems Science and Engineering, John Hopkins University. COVID-19 Data Repository. 2020. Available online: https://coronavirus.jhu.edu/map.html (accessed on 29 December 2020).
- Holshue, M.L.; DeBolt, C.; Lindquist, S.; Lofy, K.H.; Wiesman, J.; Bruce, H.; Spitters, C.; Ericson, K.; Wilkerson, S.; Tural, A.; et al. First Case of 2019 Novel Coronavirus in the United States. N. Engl. J. Med. 2020, 382, 929–936. [Google Scholar] [CrossRef]
- Kulldorff, M. A spatial scan statistic. Commun. Stat. Theory Methods 1997, 26, 1481–1496. [Google Scholar] [CrossRef]
- Desjardins, M.; Hohl, A.; Delmelle, E. Rapid surveillance of COVID-19 in the United States using a prospective space-time scan statistic: Detecting and evaluating emerging clusters. Appl. Geogr. 2020, 118. [Google Scholar] [CrossRef]
- Hohl, A.; Delmelle, E.M.; Desjardins, M.R.; Lan, Y. Daily surveillance of COVID-19 using the prospective space-time scan statistic in the United States. Spat. Spatio-Temporal Epidemiol. 2020, 34, 100354. [Google Scholar] [CrossRef]
- Amin, R.; Hall, T.; Church, J.; Schlierf, D.; Kulldorff, M. Geographical surveillance of COVID-19: Diagnosed cases and death in the United States. medRxiv 2020. [Google Scholar] [CrossRef]
- Rosenkrantz, L.; Schuurman, N.; Bell, N.; Amram, O. The need for GIScience in mapping COVID-19. Health Place 2021. [Google Scholar] [CrossRef]
- Smith, C.D.; Mennis, J. Incorporating Geographic Information Science and Technology in Response to the COVID-19 Pandemic. Prev. Chronic Dis. 2020, 17. [Google Scholar] [CrossRef] [PubMed]
- Sun, Y.; Hu, X.; Xie, J. Spatial inequalities of COVID-19 mortality rate in relation to socioeconomic and environmental factors across England. Sci. Total. Environ. 2021, 758. [Google Scholar] [CrossRef] [PubMed]
- Scarpone, C.; Brinkmann, S.T.; Große, T.; Sonnenwald, D.; Fuchs, M.; Walker, B.B. A multimethod approach for county-scale geospatial analysis of emerging infectious diseases: A cross-sectional case study of COVID-19 incidence in Germany. Int. J. Health Geogr. 2020, 19, 32. [Google Scholar] [CrossRef] [PubMed]
- Caraka, R.E.; Lee, Y.; Chen, R.C.; Toharudin, T.; Gio, P.U.; Kurniawan, R.; Pardamean, B. Cluster Around Latent Variable for Vulnerability Towards Natural Hazards, Non-Natural Hazards, Social Hazards in West Papua. IEEE Access 2021, 9, 1972–1986. [Google Scholar] [CrossRef]
- Tate, E.; Rahman, A.; Emrich, C.T.; Sampson, C.C. Flood exposure and social vulnerability in the United States. Nat. Hazards 2021, 106, 435–457. [Google Scholar] [CrossRef]
- Cumberbatch, J.; Drakes, C.; Mackey, T.; Nagdee, M.; Wood, J.; Degia, A.K.; Hinds, C. Social Vulnerability Index: Barbados—A Case Study. Coast. Manag. 2020, 48, 505–526. [Google Scholar] [CrossRef]
- Tiwari, A.; Dadhania, A.V.; Ragunathrao, V.A.B.; Oliveira, E.R.A. Using Machine Learning to Develop a Novel COVID-19 Vulnerability Index (C19VI). Sci. Total Environ. 2021, 773, 145650. [Google Scholar] [CrossRef]
- Kim, L.; Whitake, M.; O’Halloran, A.; Kambhampati, A.; Chai, S.J.; Reingold, A.; Armistead, I.; Kawasaki, B.; Meek, J.; Yousey-Hindes, K.; et al. Hospitalization Rates and Characteristics of Children Aged <18 Years Hospitalized with Laboratory-Confirmed COVID-19—COVID-NET, 14 States, 1 March–25 July 2020. MMWR Morb. Mortal. Wkly. Rep. 2020, 69, 1081–1088. [Google Scholar] [CrossRef]
- Bashir, A.; Malik, A.W.; Rahman, A.U.; Iqbal, S.; Cleary, P.R.; Ikram, A. MedCloud: Cloud-Based Disease Surveillance and Information Management System. IEEE Access 2020, 8, 81271–81282. [Google Scholar] [CrossRef]
- Sha, D.; Malarvizhi, A.S.; Liu, Q.; Tian, Y.; Zhou, Y.; Ruan, S.; Dong, R.; Carte, K.; Lan, H.; Wang, Z.; et al. A State-Level Socioeconomic Data Collection of the United States for COVID-19 Research. Data 2020, 5, 118. [Google Scholar] [CrossRef]
- Chakraborti, S.; Maiti, A.; Pramanik, S.; Sannigrahi, S.; Pilla, F.; Banerjee, A.; Das, D.N. Evaluating the plausible application of advanced machine learnings in exploring determinant factors of present pandemic: A case for continent specific COVID-19 analysis. Sci. Total. Environ. 2021, 765. [Google Scholar] [CrossRef] [PubMed]
- Rodriguez-Villamizar, L.A.; Belalcázar-Ceron, L.C.; Fernández-Niño, J.A.; Marín-Pineda, D.M.; Rojas-Sánchez, O.A.; Acuña-Merchán, L.A.; Ramírez-García, N.; Mangones-Matos, S.C.; Vargas-González, J.M.; Herrera-Torres, J.; et al. Air pollution, sociodemographic and health conditions effects on COVID-19 mortality in Colombia: An ecological study. Sci. Total. Environ. 2021, 756. [Google Scholar] [CrossRef] [PubMed]
- Perkin, M.R.; Heap, S.; Crerar-Gilbert, A.; Albuquerque, W.; Haywood, S.; Avila, Z.; Hartopp, R.; Ball, J.; Hutt, K.; Kennea, N. Deaths in people from Black, Asian and minority ethnic communities from both COVID-19 and non-COVID causes in the first weeks of the pandemic in London: A hospital case note review. BMJ Open 2020, 10, e040638. [Google Scholar] [CrossRef]
- Nguyen, L.H.; Drew, D.A.; Graham, M.S.; Joshi, A.D.; Guo, C.-G.; Ma, W.; Mehta, R.S.; Warner, E.T.; Sikavi, D.R.; Lo, C.-H.; et al. Risk of COVID-19 among front-line health-care workers and the general community: A prospective cohort study. Lancet Public Health 2020, 5, e475–e483. [Google Scholar] [CrossRef]
- Rothstein, A.; Oldridge, O.; Schwennesen, H.; Do, D.; Cucchiara, B.L. Acute Cerebrovascular Events in Hospitalized COVID-19 Patients. Stroke 2020, 51, e219–e222. [Google Scholar] [CrossRef]
- Caraballo, C.; McCullough, M.; Fuery, M.A.; Chouairi, F.; Keating, C.; Ravindra, N.G.; Miller, P.E.; Malinis, M.; Kashyap, N.; Hsiao, A.; et al. COVID-19 infections and outcomes in a live registry of heart failure patients across an integrated health care system. PLoS ONE 2020, 15, e0238829. [Google Scholar] [CrossRef]
- Majidi, S.; Fifi, J.T.; Ladner, T.R.; Lara-Reyna, J.; Yaeger, K.A.; Yim, B.; Dangayach, N.; Oxley, T.J.; Shigematsu, T.; Kummer, B.R.; et al. Emergent Large Vessel Occlusion Stroke During New York City’s COVID-19 Outbreak. Stroke 2020, 51, 2656–2663. [Google Scholar] [CrossRef]
- Lakhani, A. Which Melbourne Metropolitan Areas Are Vulnerable to COVID-19 Based on Age, Disability, and Access to Health Services? Using Spatial Analysis to Identify Service Gaps and Inform Delivery. J. Pain Symptom Manag. 2020, 60, e41–e44. [Google Scholar] [CrossRef] [PubMed]
- Bhayani, S.; Sengupta, R.; Markossian, T.; Tootooni, S.; Luke, A.; Shoham, D.; Cooper, R.; Kramer, H. Dialysis, COVID-19, Poverty, and Race in Greater Chicago: An Ecological Analysis. Kidney Med. 2020, 2, 552–558.e1. [Google Scholar] [CrossRef]
- Hawkins, D. Differential occupational risk for COVID-19 and other infection exposure according to race and ethnicity. Am. J. Ind. Med. 2020, 63, 817–820. [Google Scholar] [CrossRef] [PubMed]
- Patel, A.P.; Paranjpe, M.D.; Kathiresan, N.P.; Rivas, M.A.; Khera, A.V. Race, socioeconomic deprivation, and hospitalization for COVID-19 in English participants of a national biobank. Int. J. Equity Health 2020, 19. [Google Scholar] [CrossRef] [PubMed]
- Jones, J.; Sullivan, P.S.; Sanchez, T.H.; Guest, J.L.; Hall, E.W.; Luisi, N.; Zlotorzynska, M.; Wilde, G.; Bradley, H.; Siegler, A.J. Similarities and Differences in COVID-19 Awareness, Concern, and Symptoms by Race and Ethnicity in the United States: Cross-Sectional Survey. J. Med. Internet Res. 2020, 22, e20001. [Google Scholar] [CrossRef]
- Khazanchi, R.; Evans, C.T.; Marcelin, J.R. Racism, Not Race, Drives Inequity Across the COVID-19 Continuum. JAMA Netw. Open 2020, 3, e2019933. [Google Scholar] [CrossRef] [PubMed]
- Rentsch, C.T.; Kidwai-Khan, F.; Tate, J.P.; Park, L.S.; Jr, J.T.K.; Skanderson, M.; Hauser, R.G.; Schultze, A.; Jarvis, C.I.; Holodniy, M.; et al. Patterns of COVID-19 testing and mortality by race and ethnicity among United States veterans: A nationwide cohort study. PLoS Med. 2020, 17, e1003379. [Google Scholar] [CrossRef] [PubMed]
- Zeng, C.; Zhang, J.; Li, Z.; Sun, X.; Olatosi, B.; Weissman, S.; Li., X. Spatial-Temporal Relationship Between Population Mobility and COVID-19 Outbreaks in South Carolina: Time Series Forecasting Analysis. JMIR 2021, 23, e27045. [Google Scholar] [CrossRef]
- Hernandez, W.; Mendez, A.; Zalakeviciute, R.; Diaz-Marquez, A.M. Analysis of the Information Obtained From PM2.5 Concentration Measurements in an Urban Park. IEEE Trans. Instrum. Meas. 2020, 69, 6296–6311. [Google Scholar] [CrossRef]
- Zhang, H.-H.; Li, Z.; Liu, Y.; Xinag, P.; Cui, X.-Y.; Ye, H.; Hu, B.-L.; Lou, L.-P. Physical and chemical characteristics of PM2.5 and its toxicity to human bronchial cells BEAS-2B in the winter and summer*. J. Zhejiang Univ. Sci. B Biomed. Biotechnol. 2018, 19, 317. [Google Scholar] [CrossRef]
- Xu, Y.; Liu, H.; Duan, Z. A novel hybrid model for multi-step daily AQI forecasting driven by air pollution big data. Air Qual. Atmos. Health Int. J. 2020, 13, 197. [Google Scholar] [CrossRef]
- Wang, Z.; Chen, L.; Zhu, J.; Chen, H.; Yuan, H. Double decomposition and optimal combination ensemble learning approach for interval-valued AQI forecasting using streaming data. Environ. Sci. Pollut. Res. 2020, 27, 37802. [Google Scholar] [CrossRef]
- Zhang, X.-T.; Liu, X.-H.; Su, C.-W.; Umar, M. Does asymmetric persistence in convergence of the air quality index (AQI) exist in China? Environ. Sci. Pollut. Res. 2020, 27, 36541. [Google Scholar] [CrossRef] [PubMed]
- Wen, S.; Kedem, B. A semiparametric cluster detection method—A comprehensive power comparison with Kulldorff’s method. Int. J. Health Geogr. 2009, 8, 73–89. [Google Scholar] [CrossRef] [Green Version]
- Dwass, D. Modified randomization tests for nonparametric hypotheses. Annu. Math. Stat. 1957, 28, 181–187. [Google Scholar] [CrossRef]
- Turnbull, B.W.; Wano, E.J.; Burnett, W.S.; Howe, H.L.; Clark, L.C. Monitoring for clusters of disease: Application to leukemia incidence in upstate New York. Am. J. Epidemiology 1990, 132, 136–143. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yao, Z.; Tang, J.; Zhan, F.B. Detection of arbitrarily-shaped clusters using a neighbor-expanding approach: A case study on murine typhus in South Texas. Int. J. Health Geogr. 2011, 10. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wu, C.; Steinbauer, J.R.; Kuo, G.M. EM clustering analysis of diabetes patients basic diagnosis index. In Proceedings of the AMIA Annual Symposium Proceedings, American Medical Informatics Association, Washington, DC, USA, 22–26 October 2005; p. 1158. [Google Scholar]
- Gray, V. Principal Component Analysis: Methods, Applications, and Technology. Mathematics Research Developments; Nova Science Publishers, Inc.: Hauppauge, NY, USA, 2017. [Google Scholar]
- Bilginol, K.; Denli, H.H.; Şeker, D.Z. Ordinary Least Squares Regression Method Approach for Site Selection of Automated Teller Machines (ATMs). Procedia Environ. Sci. 2015, 26, 66–69. [Google Scholar] [CrossRef] [Green Version]
- Guidolin, M.; Pedio, M. Forecasting commodity futures returns with stepwise regressions: Do commodity-specific factors help? Ann. Oper. Res. 2020. [Google Scholar] [CrossRef]
- Kutela, B.; Novat, N.; Langa, N. Exploring geographical distribution of transportation research themes related to COVID-19 using text network approach. Sustain. Cities Soc. 2021, 67. [Google Scholar] [CrossRef] [PubMed]
- Smith, G. Step away from stepwise. J. Big Data 2018, 5, 32. [Google Scholar] [CrossRef]
- Wang, J.; Wang, S.; Li, S. Examining the spatially varying effects of factors on PM2.5 concentrations in Chinese cities using geographically weighted regression modeling. Environ. Pollut. 2019, 248, 792–803. [Google Scholar] [CrossRef]
- Das, S.; Avelar, R.; Dixon, K.; Sun, X. Investigation on the wrong way driving crash patterns using multiple correspondence analysis. Accid. Anal. Prev. 2018, 111, 43–55. [Google Scholar] [CrossRef]
- Tobler, W.R. A Computer Movie Simulating Urban Growth in the Detroit Region. Econ. Geogr. 1970, 46, 234–240. [Google Scholar] [CrossRef]
- Fotheringham, A.S.; Charlton, M.E.; Brunsdon, C. Geographically Weighted Regression: The Analysis of Spatially Varying Relationships; Wiley: New York, NY, USA, 2002. [Google Scholar]
- Nakaya, T. GWR4.09 User Manual; National Centre of Geocomputation, National University of Ireland: Dublin, Ireland, 2016; pp. 2–27. [Google Scholar]
- Liu, Q.; Sha, D.; Liu, W.; Houser, P.; Zhang, L.; Hou, R.; Lan, H.; Flynn, C.; Lu, M.; Hu, T.; et al. Spatiotemporal Patterns of COVID-19 Impact on Human Activities and Environment in Mainland China Using Nighttime Light and Air Quality Data. Remote Sens. 2020, 12, 1576. [Google Scholar] [CrossRef]
- Mollalo, A.; Vahedi, B.; Rivera, K.M. GIS-based spatial modeling of COVID-19 incidence rate in the continental United States. Sci. Total. Environ. 2020, 728. [Google Scholar] [CrossRef] [PubMed]
- Dockery, D.W.; Pope, C.A. Acute Respiratory Effects of Particulate Air Pollution. Annu. Rev. Public Health 1994, 15, 107–132. [Google Scholar] [CrossRef]
- Hu, J.; Zhang, Y.; Wang, W.; Tao, Z.; Tian, J.; Shao, N.; Liu, N.; Wei, H.; Huang, H. Clinical characteristics of 14 COVID-19 deaths in Tianmen, China: A single-center retrospective study. BMC Infect. Dis. 2021, 21. [Google Scholar] [CrossRef]
- Du, H.; Wang, D.W.; Chen, C. The potential effects of DPP-4 inhibitors on cardiovascular system in COVID-19 patients. J. Cell. Mol. Med. 2020, 24, 10274–10278. [Google Scholar] [CrossRef]
- Dyson, K. Conservative Liberalism in American and British Political Economy; Oxford University Press: Oxford, UK, 2021. [Google Scholar] [CrossRef]
- Anjaria, K. Phylogenetic analysis of some leguminous trees using CLUSTALW2 bioinformatics tool. In Proceedings of the 2012 IEEE International Conference on Bioinformatics and Biomedicine Workshops (BIBMW), Philadelphia, PA, USA, 4–7 October 2012; Volume 1, pp. 917–921. [Google Scholar]
- McNeil, L.M.; Kelso, T.S. Spatial Temporal Information Systems: An Ontological Approach Using STK®; CRC Press: Boca Raton, FL, USA, 2013. [Google Scholar]
- Luo, Y.; Yan, J.; McClure, S. Distribution of the environmental and socioeconomic risk factors on COVID-19 death rate across continental USA: A spatial nonlinear analysis. Environ. Sci. Pollut. Res. 2021, 28, 6587. [Google Scholar] [CrossRef]
- Gadicherla, S.; Krishnappa, L.; Madhuri, B.; Mitra, S.G.; Ramaprasad, A.; Seevan, R.; Sreeganga, S.D.; Thodika, N.K.; Mathew, S.; Suresh, V. Envisioning a learning surveFillance system for tuberculosis. PLoS ONE 2020, 15, e0243610. [Google Scholar] [CrossRef] [PubMed]
- Wu, X.; Zhang, J. Exploration of spatial-temporal varying impacts on COVID-19 cumulative case in Texas using geographically weighted regression (GWR). Environ. Sci. Pollut. Res. 2021, 1. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable Category | Variable Name | Acronym | Variable Description |
|---|---|---|---|
| Economic | Annual income | PCI | Median Household Income |
| Unemployment | UEM | Percent of residents who don’t have job | |
| Environmental | Precipitation | PCN | Mean precipitation per month |
| Temperature | TPE | Mean temperature per month | |
| PM2.5 | PM2.5 | Mean PM2.5 per day | |
| Air quality | AQI | Mean air quality per day | |
| Land Area | LA | Total land area per county | |
| Demographic | Population density | POD | Population density |
| Total population | TP | Total population | |
| Male population | PMP | Percent of residents who are male | |
| Black population | PBP | Percent of residents who are black | |
| Population between 20–59 | P59 | Percent of residents who are between 20–59 | |
| Population beyond 80 | P80 | Percent of residents who are beyond 80 | |
| Health | Total hospital beds | THB | Total hospital beds |
| Beds per capital | BPC | Incidents per 1000 residents | |
| Covid-19 | Fatalities | TF | Total death number |
| Mortality Rate | MR | Percent of fatalities case on total case |
| Items | Cluster 1 | Cluster 2 |
|---|---|---|
| Time frame | 6 November 2020 to 5 February 2021 | 6 July 2020 to 5 September 2020 |
| Population | 13,085,347 | 26,217,888 |
| Neighborhood | 172 counties | 27 counties |
| Log-likelihood Ratios | 4084.27 | 3072.54 |
| Number of cases | 12,761 | 3635 |
| Expected cases | 5147.24 | 695.01 |
| Observed/expected | 2.48 | 5.23 |
| Relative risk | 3.08 | 5.61 |
| p-value | <0.0001 | <0.0001 |
| Cluster | EM (Classes to Cluster Evaluation) | HC (Classes to Cluster Evaluation) | ||||||
|---|---|---|---|---|---|---|---|---|
| Quarter 3 | Quarter 4 | Quarter 3 | Quarter 4 | |||||
| County NO. | p-Value | County NO. | p-Value | County NO. | Probability | County NO. | Probability | |
| 0 | 11 | 0.36 | 10 | 0.27 | 4 | 55.01 | 8 | 62.78 |
| 1 | 11 | 0.1 | 8 | 0.14 | 4.15 | 3.1 | ||
| 2 | 10 | 0.1 | 8 | 0.07 | ||||
| 3 | 16 | 0.09 | 7 | 0.3 | ||||
| 4 | 4 | 0.09 | 6 | 0.03 | ||||
| 5 | 16 | 0.1 | 9 | 0.03 | ||||
| 6 | 8 | 0.07 | 4 | 0.02 | ||||
| 7 | 12 | 0.11 | 7 | 0.01 | ||||
| 8 | 6 | 0.04 | ||||||
| 9 | 5 | 0.04 | ||||||
| 10 | 8 | 0.04 | ||||||
| Log likelihood | −86.34 | −73.25 | ||||||
| Incorrectly Clustered instance | 251 | 98.04% | 247 | 96.48% | ||||
| Explanatory Variables | Quarter 3 Coe./Sig. | Quarter 4 Coe./Sig. |
|---|---|---|
| TPE | −0.265/0.000 ** | −2.11/0.001 ** |
| PCN | −0.251/0.000 ** | −0.166/0.008 ** |
| AQI | −0.121/0.054 | −0.062/0.325 |
| THB | −0.145/0.020 * | −0.176/0.005 ** |
| BPC | −0.007/0.908 | −0.018/0.781 |
| POD | −0.203/0.001 ** | −0.247/0.000 ** |
| LA | −0.074/0.241 | −0.092/0.146 |
| PCI | 0.147/0.019 * | −0.111/0.078 ** |
| TP | −0.176/0.005 ** | −0.215/0.001 ** |
| PBP | −0.191/0.002 ** | −0.082/0.194 |
| UEM | −0.106/0.093 | −0.046/0.471 |
| PMP | 0.011/0.857 | 0.020/0.746 |
| P59 | −0.300/0.000 ** | −0.250/0.000 ** |
| P80 | 0.243/0.000 ** | 0.183/0.00 3** |
| Items | The Third Quarter Component in 2020 | The Fourth Quarter Component in 2020 | The first Quarter Component in 2021 | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Extr. | 1 | 2 | 3 | 4 | 5 | Extr. | 1 | 2 | 3 | 4 | 5 | Extr. | 1 | 2 | 3 | 4 | 5 | |
| TPE | 0.80 | 0.14 | −0.06 | 0.48 | 0.32 | 0.66 | 0.62 | 0.15 | 0.55 | 0.21 | 0.03 | −0.50 | 0.83 | 0.15 | 0.11 | 0.82 | 0.01 | 0.35 |
| PCN | 0.81 | 0.12 | −0.12 | 0.65 | 0.37 | 0.48 | 0.77 | 0.10 | 0.37 | 0.77 | 0.06 | −0.16 | 0.78 | 0.13 | 0.85 | 0.06 | −0.08 | 0.19 |
| AQI | 0.63 | 0.29 | 0.02 | −0.19 | 0.03 | 0.71 | 0.50 | 0.18 | 0.55 | 0.24 | −0.02 | −0.33 | 0.83 | 0.05 | −0.31 | 0.85 | −0.02 | 0.08 |
| THB | 0.95 | 0.97 | 0.06 | 0.01 | −0.02 | −0.01 | 0.96 | 0.97 | 0.01 | 0.02 | 0.08 | 0.04 | 0.96 | 0.98 | 0.02 | −0.02 | 0.06 | −0.02 |
| BPC | 0.34 | 0.15 | 0.04 | 0.05 | 0.08 | −0.56 | 0.64 | 0.12 | 0.00 | 0.09 | −0.05 | 0.79 | 0.33 | 0.11 | −0.08 | −0.54 | 0.08 | 0.13 |
| POD | 0.93 | 0.95 | 0.12 | 0.10 | −0.06 | 0.07 | 0.93 | 0.94 | −0.01 | 0.12 | 0.15 | −0.04 | 0.93 | 0.94 | 0.13 | 0.03 | 0.12 | −0.06 |
| LA | 0.71 | 0.07 | 0.06 | −0.80 | 0.18 | 0.15 | 0.61 | 0.08 | 0.20 | −0.75 | 0.10 | 0.03 | 0.67 | 0.15 | −0.74 | 0.07 | 0.06 | 0.20 |
| PCI | 0.69 | 0.14 | 0.05 | 0.10 | −0.81 | 0.09 | 0.63 | 0.18 | −0.73 | 0.09 | 0.07 | −0.23 | 0.60 | 0.09 | 0.03 | 0.00 | 0.06 | −0.80 |
| TP | 0.97 | 0.98 | 0.08 | 0.02 | −0.03 | 0.06 | 0.97 | 0.98 | 0.01 | 0.03 | 0.11 | −0.02 | 0.97 | 0.98 | 0.03 | 0.02 | 0.09 | −0.03 |
| PBP | 0.59 | 0.29 | 0.27 | 0.51 | 0.31 | −0.26 | 0.71 | 0.23 | 0.26 | 0.70 | 0.23 | 0.22 | 0.69 | 0.26 | 0.65 | −0.18 | 0.25 | 0.31 |
| UEM | 0.68 | 0.03 | 0.00 | 0.13 | 0.80 | 0.14 | 0.66 | 0.00 | 0.81 | 0.07 | 0.01 | −0.06 | 0.68 | 0.03 | 0.12 | 0.20 | 0.01 | 0.79 |
| PMP | 0.36 | −0.14 | 0.53 | −0.16 | 0.01 | −0.17 | 0.45 | −0.16 | −0.02 | −0.08 | 0.46 | 0.46 | 0.39 | −0.16 | −0.16 | −0.23 | 0.54 | 0.04 |
| P59 | 0.79 | 0.19 | 0.84 | 0.20 | −0.10 | 0.08 | 0.78 | 0.17 | −0.08 | 0.17 | 0.84 | −0.03 | 0.79 | 0.18 | 0.18 | 0.09 | 0.84 | −0.12 |
| P80 | 0.65 | −0.21 | −0.77 | 0.05 | −0.03 | −0.02 | 0.69 | −0.19 | −0.03 | 0.05 | −0.81 | 0.03 | 0.64 | −0.21 | 0.03 | 0.01 | −0.77 | −0.02 |
| Study Period | Population and Hospitalization | Adult Population | Land Area | Economical Condition | Air Quality and Medical Care |
|---|---|---|---|---|---|
| 2020 Quarter 3 | Factor 1 | Factor 2 | Factor 3 | Factor 4 | Factor 5 |
| 2020 Quarter 4 | Factor 1 | Factor 4 | Factor 3 | Factor 2 | Factor 5 |
| 2021 Quarter1 | Factor 1 | Factor 4 | Factor 2 | Factor 5 | Factor 3 |
| Explanatory Variables | Cor./Sig. | Cor./Sig. | Cor./Sig. | Cor./Sig. | Cor./Sig. |
| THB | 0.97/0.00 | ||||
| POD | 0.95/0.00 | ||||
| TP | 0.98/0.00 | ||||
| PCN | |||||
| PBP | |||||
| P59 | 0.84/0.00 | ||||
| P80 | −0.77/0.00 | ||||
| TPE | |||||
| AQI | 0.71/0.00 | ||||
| PCI | −0.81/0.00 | ||||
| UEM | 0.801/0.00 | ||||
| BPC | 0.78/0.00 | ||||
| LA | −0.81/0.00 |
| Item | The Third Quarter of 2020 | The Fourth Quarter of 2020 | The First Quarter of 2021 | |||
|---|---|---|---|---|---|---|
| OLS | GWR | OLS | GWR | OLS | GWR | |
| AICc | 875.23 | 851.54 | 665.44 | 653.85 | 875.2 | 851.54 |
| R2 | 0.17 | 0.37 | 0.10 | 0.20 | 0.16 | 0.37 |
| Std. Deviation | 0.59 | 0.74 | 0.29 | 0.35 | 0.59 | 0.74 |
| Neighbors | 254 | 128 | 254 | 201 | 254 | 128 |
| Max_Value | −1.52 | −0.57 | −2.78 | −2.93 | −1.52 | −0.57 |
| Min_Value | −5.22 | −4.92 | −5.66 | −4.97 | −5.23 | −4.92 |
| Average | −3.18 | −3.14 | −2.78 | −3.80 | −3.18 | −3.14 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; Wu, X.; Chow, T.E. Space-Time Cluster’s Detection and Geographical Weighted Regression Analysis of COVID-19 Mortality on Texas Counties. Int. J. Environ. Res. Public Health 2021, 18, 5541. https://doi.org/10.3390/ijerph18115541
Zhang J, Wu X, Chow TE. Space-Time Cluster’s Detection and Geographical Weighted Regression Analysis of COVID-19 Mortality on Texas Counties. International Journal of Environmental Research and Public Health. 2021; 18(11):5541. https://doi.org/10.3390/ijerph18115541
Chicago/Turabian StyleZhang, Jinting, Xiu Wu, and T. Edwin Chow. 2021. "Space-Time Cluster’s Detection and Geographical Weighted Regression Analysis of COVID-19 Mortality on Texas Counties" International Journal of Environmental Research and Public Health 18, no. 11: 5541. https://doi.org/10.3390/ijerph18115541
APA StyleZhang, J., Wu, X., & Chow, T. E. (2021). Space-Time Cluster’s Detection and Geographical Weighted Regression Analysis of COVID-19 Mortality on Texas Counties. International Journal of Environmental Research and Public Health, 18(11), 5541. https://doi.org/10.3390/ijerph18115541