
Pooling and Comparing Noise Annoyance Scores and “High Annoyance” (HA) Responses on the 5-Point and 11-Point Scales: Principles and Practical Advice



Abstract
:1. Introduction
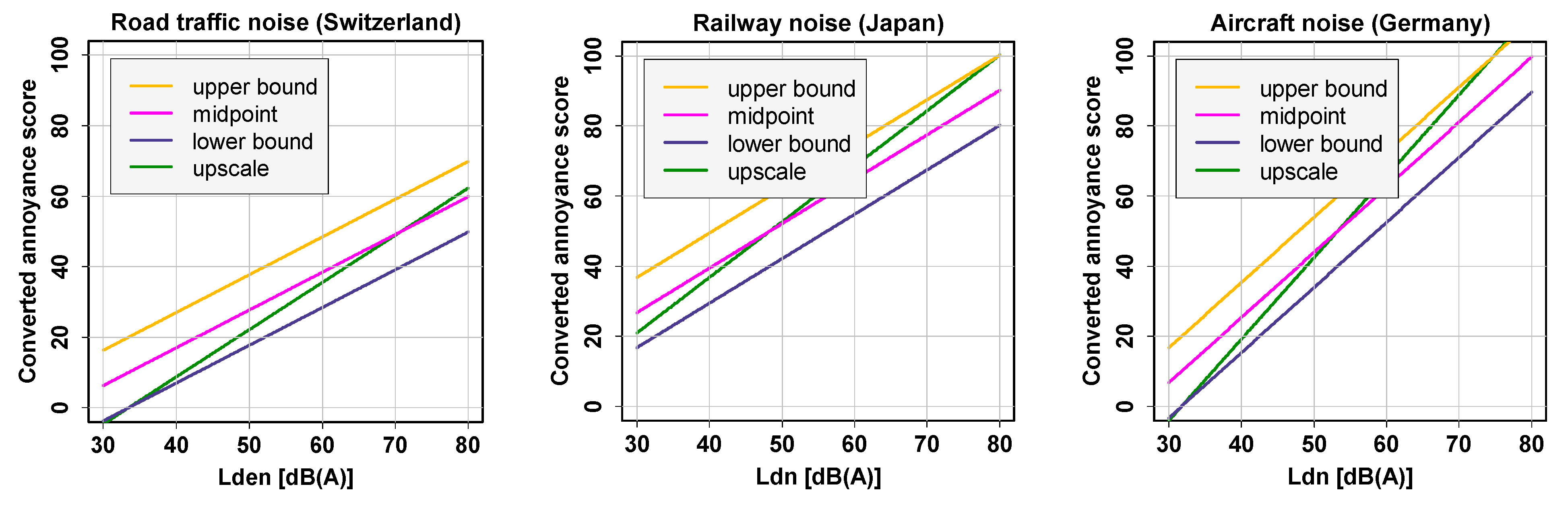
2. Linear Regression Context: Conversion of Equidistant Verbal and Numerical Annoyance Scales to a Common Scale
3. Logistic Regression Context: Simulating an Exposure–Response Relationship for the Percentage “Highly Annoyed” (HA) according to a Specified Cutoff Point
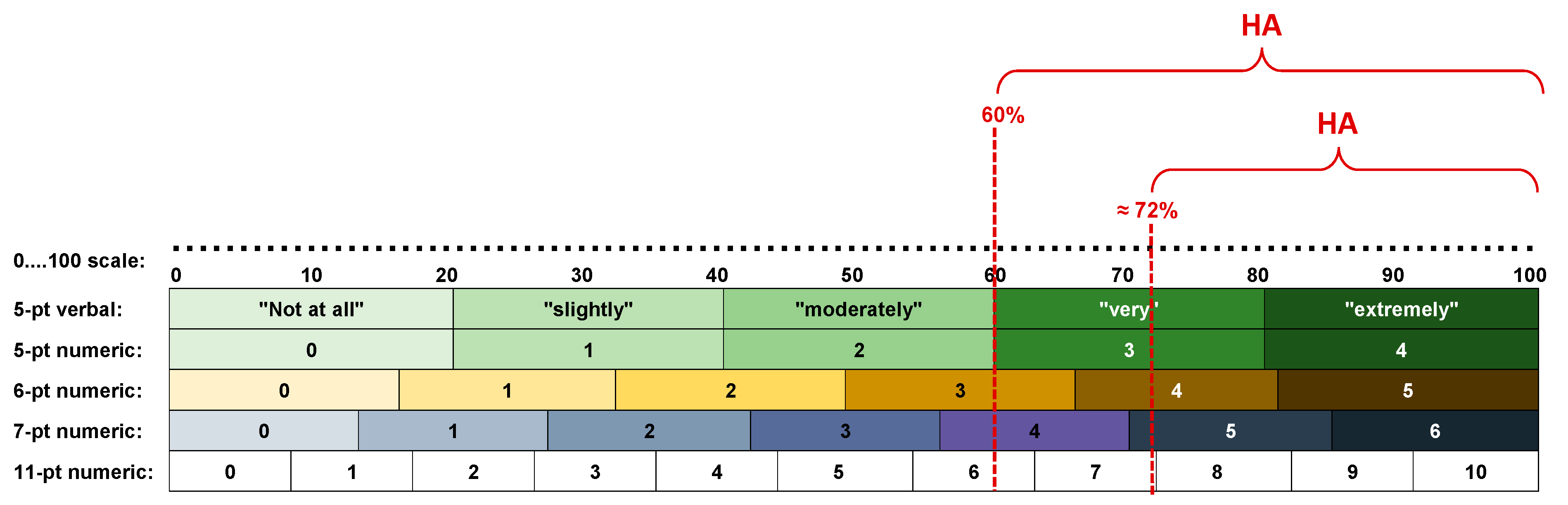
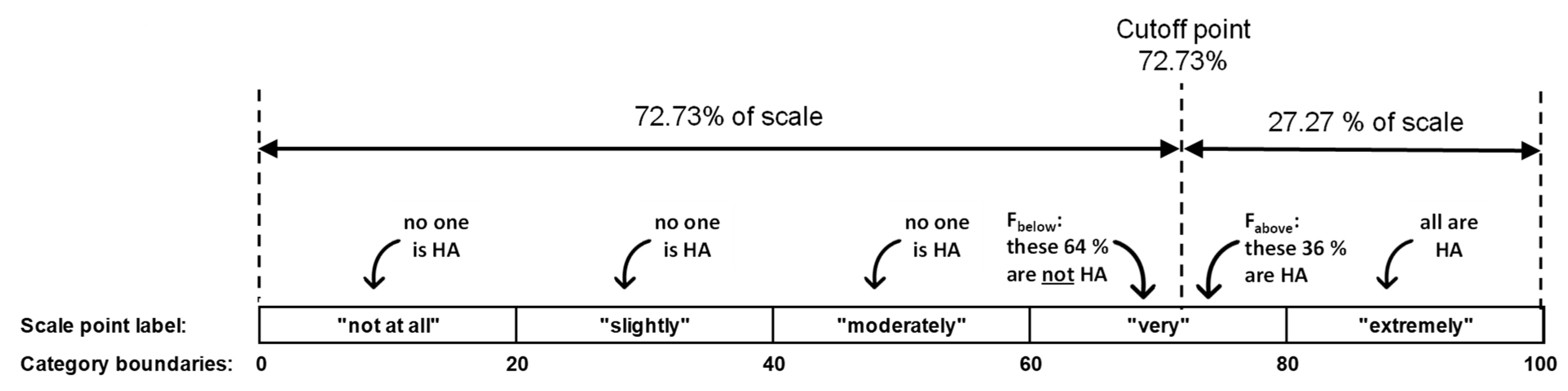
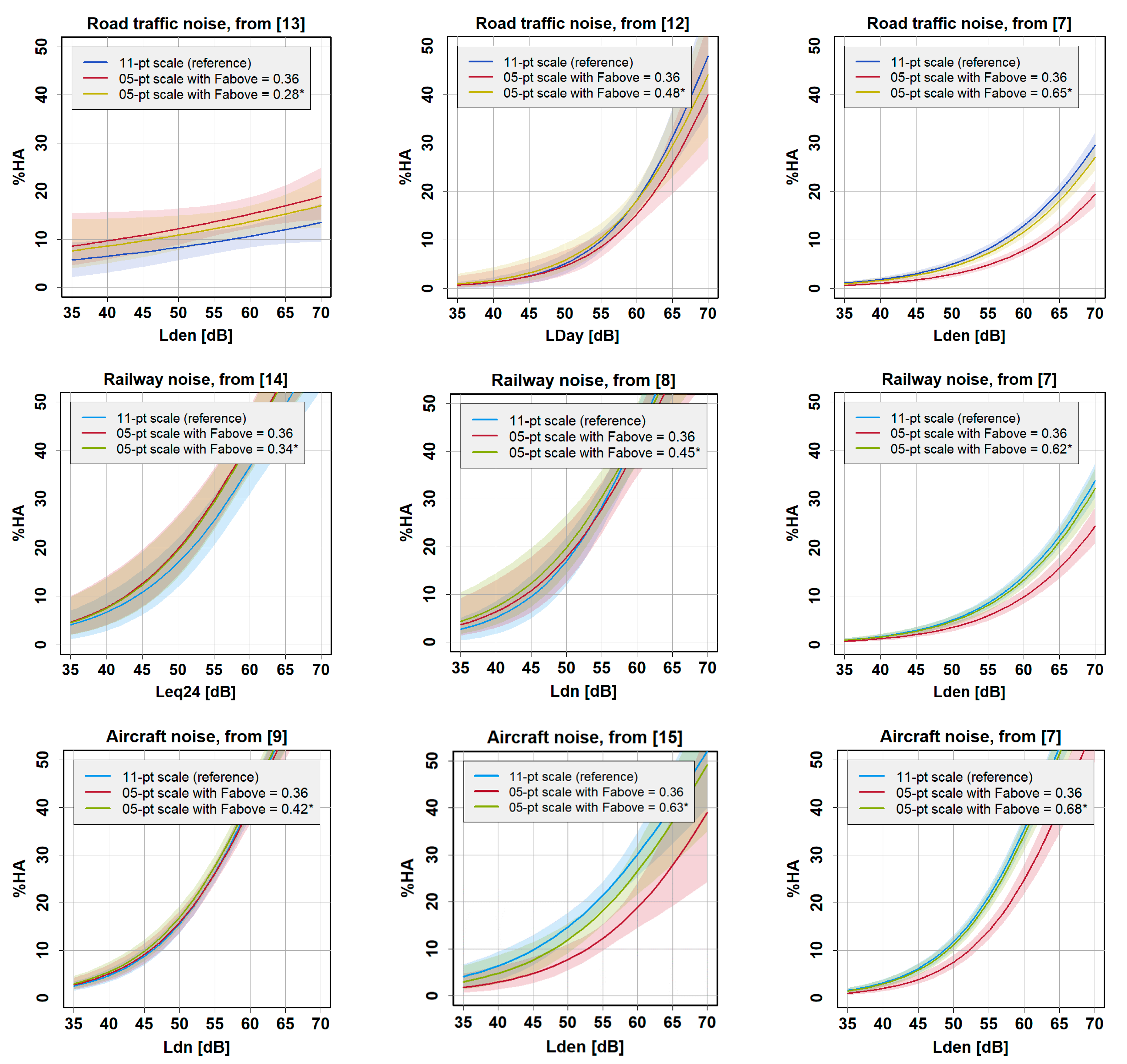
3.1. Choice of a Common Cutoff Point and Determination of the Fractions of Responses above That Cutoff Point
3.2. Determination of the Exposure–Response Relationship for %HA for an Arbitrary Cutoff Point
- From the data table containing exposure and response data from the 5-point scale, create a subtable with only those respondents that have values 0, 1, 2, or 4 on the 5-point verbal scale. Assign the binary value HA = 0 to the responses 0, 1, 2, and the value HA = 1 to response 4.
- Create a second subtable containing only the cases with value 3 (“very”) on the 5-point scale.
- Randomly sample a fraction of Fabove cases in that second subtable and assign these cases the binary value HA = 1, and the remaining cases a value of HA = 0.
- Combine the two subtables into a new table and run the logistic regression (with formula HA ~ exposure + additional predictors, if any) using the data of this new table.
- Save resulting model coefficients and variance-covariance matrix.
- Start over at Step 3 and repeat the procedure for a certain number of iterations, e.g., 500.
- After a sufficiently large number of iterations of the above steps, the average exposure-response relationship for a cutoff of 72.73% can be simply obtained from the means of the 500 resulting model coefficient sets; in addition, confidence intervals can be calculated from the saved variance-covariance matrices.
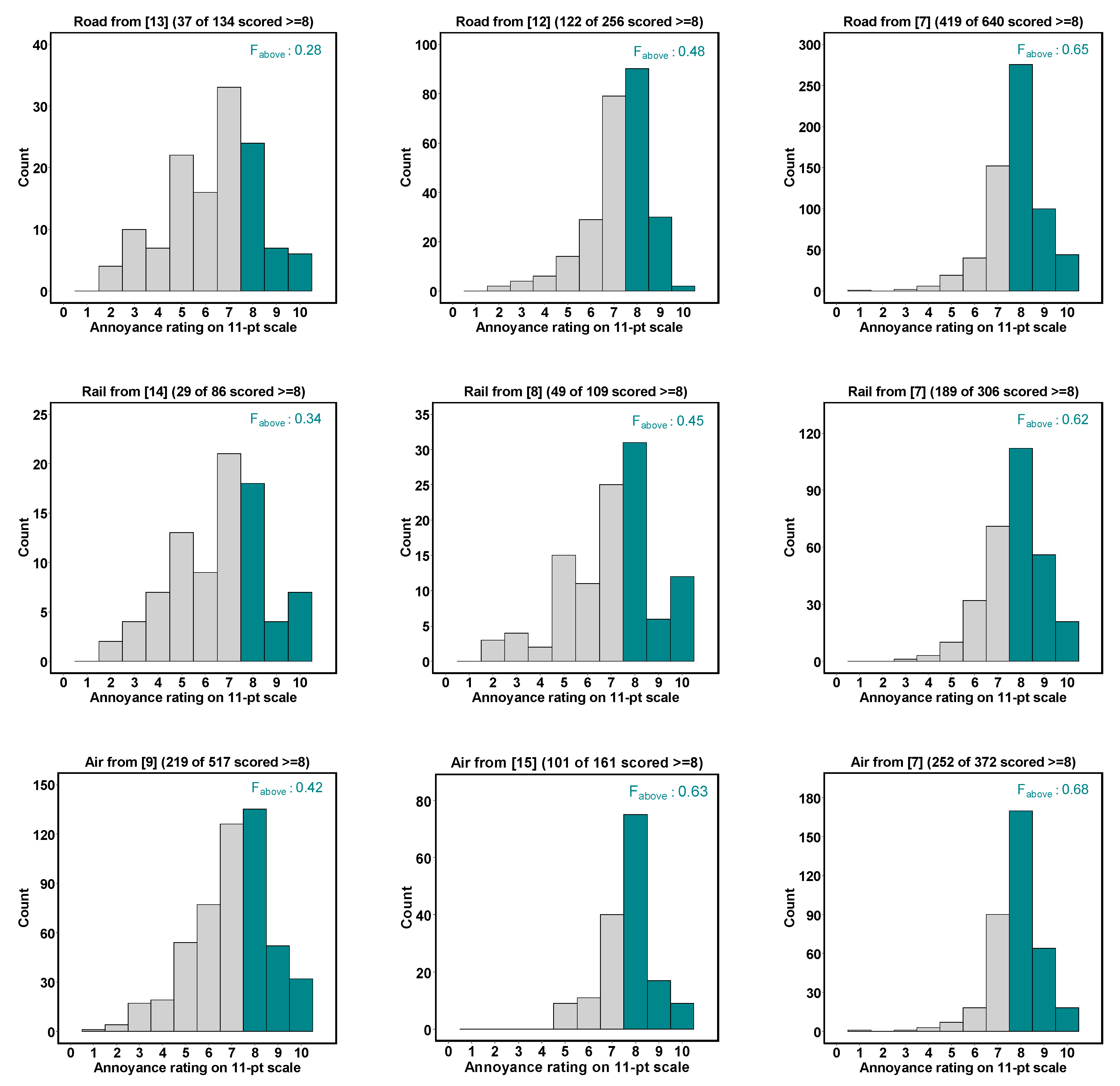
3.3. Which Value for Fabove Is the ‘True’ One?
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Guski, R.; Schreckenberg, D.; Schuemer, R. WHO Environmental Noise Guidelines for the European Region: A Systematic Review on Environmental Noise and Annoyance. Int. J. Environ. Res. Public Health 2017, 14, 1539. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fields, J.M.; De Jong, R.G.; Gjestland, T.; Flindell, I.H.; Job, R.F.S.; Kurra, S.; Lercher, P.; Vallet, M.; Yano, T.; Guski, R.; et al. Standardized general-purpose noise reaction questions for community noise surveys: Research and a recommendation. J. Sound Vib. 2001, 242, 641–679. [Google Scholar] [CrossRef] [Green Version]
- ISO/IEC, ISO/TS 15666:2021. Acoustics—Assessment of Noise Annoyance by Means of Social and Socio-Acoustic Surveys. 2021. Available online: https://www.iso.org/obp/ui#iso:std:iso:ts:15666:ed-2:v1:en (accessed on 6 June 2021).
- WHO Environmental Noise Guidelines for the European Region. Available online: http://www.euro.who.int/en/health-topics/environment-and-health/noise/publications/2018/environmental-noise-guidelines-for-the-european-region-2018 (accessed on 6 June 2021).
- Schultz, T.J. Synthesis of social surveys on noise annoyance. J. Acoust. Soc. Am. 1978, 64, 377–405. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Miedema, H.; Vos, H. Exposure-response relationships for transportation noise. J. Acoust. Soc. Am. 1998, 104, 3432–3445. [Google Scholar] [CrossRef] [PubMed]
- Brink, M.; Schäffer, B.; Vienneau, D.; Foraster, M.; Pieren, R.; Eze, I.C.; Cajochen, C.; Probst-Hensch, N.; Röösli, M.; Wunderli, J.-M. A survey on exposure-response relationships for road, rail, and aircraft noise annoyance: Differences between continuous and intermittent noise. Environ. Int. 2019, 125, 277–290. [Google Scholar] [CrossRef] [PubMed]
- Sato, T.; Yano, T.; Morihara, T.; Masden, K. Relationships between rating scales, question stem wording, and community responses to railway noise. J. Sound Vib. 2004, 277, 609–616. [Google Scholar] [CrossRef]
- Schreckenberg, D.; Meis, M. Belästigung durch Fluglärm im Umfeld des Frankfurter Flughafens [Endbericht; Langfassung]. Available online: https://www.umwelthaus.org/download/?file=belaestigungsstudie_langfassung.pdf (accessed on 6 June 2021).
- Brink, M.; Schreckenberg, D.; Vienneau, D.; Cajochen, C.; Wunderli, J.-M.; Probst-Hensch, N.; Roosli, M. Effects of Scale, Question Location, Order of Response Alternatives, and Season on Self-Reported Noise Annoyance Using ICBEN Scales: A Field Experiment. Int. J. Environ. Res. Public Health 2016, 13, 1163. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Miedema, H.; Oudshoorn, C. Annoyance from transportation noise: Relationships with exposure metrics DNL and DENL and their confidence intervals. Environ. Health Perspect. 2001, 109, 409–416. [Google Scholar] [CrossRef] [PubMed]
- Brink, M.; Mathieu, S.; Rüttener, S. Does noise abatement through speed reductions reduce annoyance of a city population? Results from a longitudinal intervention study in Zurich. In Proceedings of the ICBEN 2021, Stockholm/e-Congress, 14–17 June 2021; Available online: http://www.icben.org/Proceedings.html (accessed on 6 June 2021).
- Schreckenberg, D.; Guski, R. Lärmbelästigung Durch Straßen-und Schienenverkehr in Abhängigkeit von der Tageszeit. Schlussbericht zur Einzelaufgabe 2131 im BMBF-Forschungsnetzwerkes “Leiser Verkehr”; ZEUS GmbH: Hagen, Germany, 2004. [Google Scholar]
- Takeshita, S.; Kuroda, T.; Morihara, T.; Sato, T.; Furuya, H.; Yano, T. A Survey on Community Response to Railway Noise in Kyusyu. Archit. Res. Meet. 2003, 41, 65–68. (In Japanese) [Google Scholar]
- UMRESTTE-IFSTTAR DEBATS: Discussion sur les Effets du Bruit des Aéronefs Touchant la Santé. 2021. Available online: http://debats-avions.ifsttar.fr (accessed on 6 June 2021).
- European Commission Position Paper on Dose Response Relationships between Transportation Noise and Annoyance; Luxembourg: Office for Official Publications of the European Communities. 2002. Available online: http://www.noiseineu.eu/en/2928-a/homeindex/file?objectid=2705&objecttypeid=0 (accessed on 6 June 2021).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Noise Source | 11-Point Only | 5-Point Only | Both 11-Point and 5-Point | Other Scales | Sum |
|---|---|---|---|---|---|
| Road traffic | 8 | 3 | 7 | 7 a | 25 |
| Railway | 1 | 4 | 4 | 1 b | 10 |
| Aircraft | 9 | 1 | 5 | 15 | |
| Wind turbines | 0 | 0 | 1 | 1 c | 2 |
| Combined sources | 1 | 1 | 3 | 5 | |
| Totals | 19 | 9 | 20 | 9 | 57 |
| 4-Point Numerical Scale | |||||||||||
| Numeric value: | 0 | 1 | 2 | 3 | |||||||
| Upscaled value: | 0 | 33 | 67 | 100 | |||||||
| Lower bound: | 0.00 | 25.00 | 50.00 | 75.00 | |||||||
| Midpoint: | 12.50 | 37.50 | 62.50 | 87.50 | |||||||
| Upper bound: | 25.00 | 50.00 | 75.00 | 100.00 | |||||||
| 5-Point Verbal Scale (ICBEN Scale) | |||||||||||
| Scale point label: | “Not at all” | “Slightly” | “Moderately” | “Very” | “Extremely” | ||||||
| Numeric value: | 0 | 1 | 2 | 3 | 4 | ||||||
| Upscaled value: | 0 | 25 | 50 | 75 | 100 | ||||||
| Lower bound: | 0 | 20 | 40 | 60 | 80 | ||||||
| Midpoint: | 10 | 30 | 50 | 70 | 90 | ||||||
| Upper bound: | 20 | 40 | 60 | 80 | 100 | ||||||
| 6-Point Numerical Scale | |||||||||||
| Numeric value: | 0 | 1 | 2 | 3 | 4 | 5 | |||||
| Upscaled value: | 0 | 20 | 40 | 60 | 80 | 100 | |||||
| Lower bound: | 0.00 | 16.67 | 33.33 | 50.00 | 66.67 | 83.33 | |||||
| Midpoint: | 8.33 | 25.00 | 41.67 | 58.33 | 75.00 | 91.67 | |||||
| Upper bound: | 16.67 | 33.33 | 50.00 | 66.67 | 83.33 | 100.00 | |||||
| 7-Point Numerical Scale | |||||||||||
| Numerical value: | 0 | 1 | 2 | 3 | 4 | 5 | 6 | ||||
| Upscaled value: | 0 | 17 | 33 | 50 | 67 | 83 | 100 | ||||
| Lower bound: | 0.00 | 14.29 | 28.57 | 42.86 | 57.14 | 71.43 | 85.71 | ||||
| Midpoint: | 7.14 | 21.43 | 35.71 | 50.00 | 64.29 | 78.57 | 92.86 | ||||
| Upper bound: | 14.29 | 28.57 | 42.86 | 57.14 | 71.43 | 85.71 | 100.00 | ||||
| 11-Point Numerical Scale (ICBEN Scale) | |||||||||||
| Scale point label: | “Not at all” | “Extr.” | |||||||||
| Numeric value: | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| Upscaled value: | 0 | 10 | 20 | 30 | 40 | 50 | 60 | 70 | 80 | 90 | 100 |
| Lower bound: | 0.00 | 9.09 | 18.18 | 27.27 | 36.36 | 45.45 | 54.55 | 63.64 | 72.73 | 81.82 | 90.91 |
| Midpoint: | 4.55 | 13.64 | 22.73 | 31.82 | 40.90 | 50.00 | 59.09 | 68.18 | 77.27 | 86.36 | 95.50 |
| Upper bound: | 9.09 | 18.18 | 27.27 | 36.36 | 45.45 | 54.55 | 63.64 | 72.73 | 81.82 | 90.91 | 100.00 |
| Scale | Desired Cutoff Point | Cutoff Point is in Category | Fbelow | Fabove |
|---|---|---|---|---|
| 5-point | 60% | “very”/3 | 0.00 | 1.00 |
| 5-point | 72% | “very”/3 | 0.60 | 0.40 |
| 5-point | 72.73% | “very”/3 | 0.64 | 0.36 |
| 11-point | 60% | “6”/6 | 0.60 | 0.40 |
| 11-point | 72% | “7”/7 | 0.92 | 0.08 |
| 11-point | 72.73% | “8”/8 | 0.00 | 1.00 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Brink, M.; Giorgis-Allemand, L.; Schreckenberg, D.; Evrard, A.-S. Pooling and Comparing Noise Annoyance Scores and “High Annoyance” (HA) Responses on the 5-Point and 11-Point Scales: Principles and Practical Advice. Int. J. Environ. Res. Public Health 2021, 18, 7339. https://doi.org/10.3390/ijerph18147339
Brink M, Giorgis-Allemand L, Schreckenberg D, Evrard A-S. Pooling and Comparing Noise Annoyance Scores and “High Annoyance” (HA) Responses on the 5-Point and 11-Point Scales: Principles and Practical Advice. International Journal of Environmental Research and Public Health. 2021; 18(14):7339. https://doi.org/10.3390/ijerph18147339
Chicago/Turabian StyleBrink, Mark, Lise Giorgis-Allemand, Dirk Schreckenberg, and Anne-Sophie Evrard. 2021. "Pooling and Comparing Noise Annoyance Scores and “High Annoyance” (HA) Responses on the 5-Point and 11-Point Scales: Principles and Practical Advice" International Journal of Environmental Research and Public Health 18, no. 14: 7339. https://doi.org/10.3390/ijerph18147339
APA StyleBrink, M., Giorgis-Allemand, L., Schreckenberg, D., & Evrard, A.-S. (2021). Pooling and Comparing Noise Annoyance Scores and “High Annoyance” (HA) Responses on the 5-Point and 11-Point Scales: Principles and Practical Advice. International Journal of Environmental Research and Public Health, 18(14), 7339. https://doi.org/10.3390/ijerph18147339